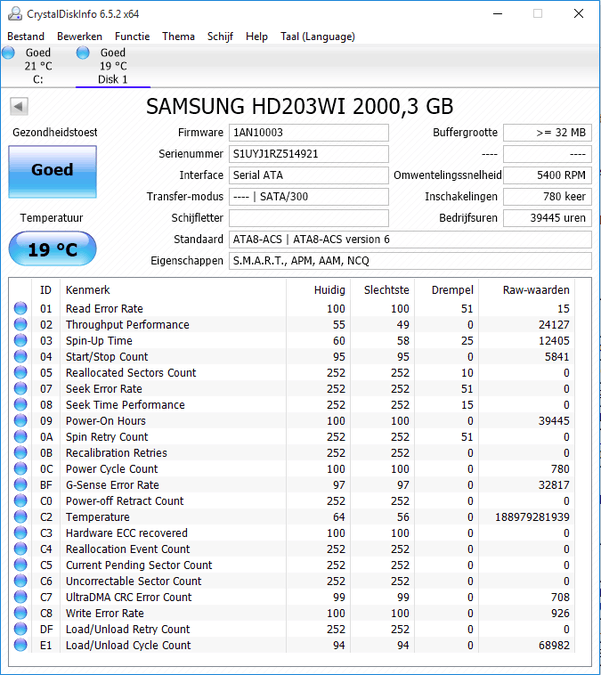
23 actieve bad sectors (0x17 = 23) - zie ook de topicstart en de post daaronder daar wordt alles uitgelegd. 
Wat je moet doen:
1. Alles backuppen van de schijf op ALLE partities
2. Formatteer alle partities zonder 'quick format' aangevinkt te hebben, dus een lange format op alle partities.
Dit overschrijft alle sectoren met nulletjes en dat zal ook de 23 bad sectors overschrijven. Na deze procedure hoort Current Pending Sector weer op 0 te staan (raw value) en dan is je probleem voorlopig verholpen. Controleer wekelijks of de Current Pending Sector op 0 blijft. Als deze regelmatig stijgt is dit een slecht teken en is de schijf onbetrouwbaar.
Wat je moet doen:
1. Alles backuppen van de schijf op ALLE partities
2. Formatteer alle partities zonder 'quick format' aangevinkt te hebben, dus een lange format op alle partities.
Dit overschrijft alle sectoren met nulletjes en dat zal ook de 23 bad sectors overschrijven. Na deze procedure hoort Current Pending Sector weer op 0 te staan (raw value) en dan is je probleem voorlopig verholpen. Controleer wekelijks of de Current Pending Sector op 0 blijft. Als deze regelmatig stijgt is dit een slecht teken en is de schijf onbetrouwbaar.
/u/97665/Opera1_t.png?f=community)






:strip_icc():strip_exif()/u/146731/crop562615a0aa64c.jpeg?f=community)


/u/238501/crop5e2f0f8a11c1f_cropped.png?f=community)
:strip_exif()/u/574651/crop5b78563680eb2.gif?f=community)

:strip_icc():strip_exif()/u/64465/crop5db09addab56c_cropped.jpeg?f=community)



:strip_exif()/u/154471/crop5e09176a82484.gif?f=community)













:strip_icc():strip_exif()/u/602798/rubik-cube-game-clip-art_424221.jpg?f=community)


:strip_icc():strip_exif()/u/52072/crop5de51ebf91960_cropped.jpeg?f=community)





/u/101204/n8.png?f=community)

:strip_exif()/u/142133/crop5757eebf3fe4f_cropped.gif?f=community)


:strip_icc():strip_exif()/u/605437/crop5bd227179ea01_cropped.jpeg?f=community)


/u/381013/rsz_title560481555.png?f=community)





/u/286506/KiefAD.png?f=community)


:strip_icc():strip_exif()/u/363314/avator3.jpg?f=community)
:strip_icc():strip_exif()/u/272160/PUNT.jpg?f=community)

{kind=link}
{kind=link}