
If at first you don’t succeed, call an airstrike.
/u/238501/crop5e2f0f8a11c1f_cropped.png?f=community)
Niets mis mee, wellicht even een kleine powerdip (voeding?). Of kwam je schijf misschien uit slaapstand?
AMD Ryzen 7 5900x | Custom WC | ASUS ROG Strix X570-E Gaming | 32GB Corsair DDR4-3600MHz | Samsung 970 nvme 1TB | Samsung 860 EVO 2TB | AMD RX 6900XT 16GB | 1x Asus RoG XG27AQDMG | 1x LG UltraGear 27GL850
- Tornado1.0
- Registratie: April 2011
- Laatst online: 16:56
Work in progress
/u/404954/dsotm.png?f=community)
Nee pc stond toen al een aantal uren constant aan. Voeding zou kunnen eventueel, is daar nog een manier om achter te komen?rikadoo schreef op dinsdag 14 juli 2015 @ 23:01:
Niets mis mee, wellicht even een kleine powerdip (voeding?). Of kwam je schijf misschien uit slaapstand?
If at first you don’t succeed, call an airstrike.
Die schijven kunnen software matig via windows in slaapstand gebracht worden als ze niet gebruikt worden. Testen van de voeding word lastig, je kan de kabels doormeten met een multimeter meer kan je denk ik niet doen. De schijf heeft er niet veel hinder van gehad, als het een spin error was dan was de spin retry error wel omhoog gegooid maar dat is niet het geval.Tornado1.0 schreef op dinsdag 14 juli 2015 @ 23:03:
[...]
Nee pc stond toen al een aantal uren constant aan. Voeding zou kunnen eventueel, is daar nog een manier om achter te komen?
AMD Ryzen 7 5900x | Custom WC | ASUS ROG Strix X570-E Gaming | 32GB Corsair DDR4-3600MHz | Samsung 970 nvme 1TB | Samsung 860 EVO 2TB | AMD RX 6900XT 16GB | 1x Asus RoG XG27AQDMG | 1x LG UltraGear 27GL850
- Koldur
- Registratie: Juni 2003
- Laatst online: 17-06 20:32
:strip_icc():strip_exif()/u/86810/display.jpg?f=community)
Net via V&A een Crucial M4 gekocht, de SMART geeft aardig wat Erase Fail Count aan wat in de verkoper zijn SMART statuutje (ook CrystalDisk) niet weergegeven wordt. Iemand enig idee hoe dit kan verschillen?
Mijn SMART readout:

SMART readout van de medetweaker:

Is er iets aan de hand of klopt het gewoon?
EDIT:
Dit komt door een secure erase, dan flagged de SSD blijkbaar iets verkeerd in de SMART, niets aan de hand dus!
Mijn SMART readout:
SMART readout van de medetweaker:
Is er iets aan de hand of klopt het gewoon?
EDIT:
Dit komt door een secure erase, dan flagged de SSD blijkbaar iets verkeerd in de SMART, niets aan de hand dus!
[ Voor 16% gewijzigd door Koldur op 19-07-2015 16:29 ]
i7 12700K,GB WindForce RTX4090,32GB KF436C16RB1K2/32,Gigabyte Z690 UD DDR4,Corsair RM1000x,WD Black SN850 2TB,Phanteks Eclipse P360A,Quest 3 VR Headset,Corsair iCUE H100i RGB Pro XT 240mm
Mijn harde schijven bleken in orde te zijn, ook het ramgeheugen zorgde niet voor dit probleem, (het uitvallen van het systeem).
Het bleek de voeding. De waardes van de voeding waren daarentegen niet zoals het hoorde. De waarde -5, gaf -8.
Er is is besloten om de voeding te vervangen. Het lijkt erop dat dit het probleem heeft opgelost.
Excuus, dat ik de eerder geplaatste post heb weggehaald.
Het bleek de voeding. De waardes van de voeding waren daarentegen niet zoals het hoorde. De waarde -5, gaf -8.
Er is is besloten om de voeding te vervangen. Het lijkt erop dat dit het probleem heeft opgelost.
Excuus, dat ik de eerder geplaatste post heb weggehaald.
[ Voor 216% gewijzigd door xtaix op 18-07-2015 15:26 ]
Verwijderd
Klacht: PC wordt steeds langzamer, niet alleen bij games maar ook bij basisfuncties als opstarten en internet (youtube). laatst ben ik erachter gekomen dat in het taakbeheer te zien is dat mijn schijf een alarmerend groot deel van de tijd op 100% staat.
het gaat om een HITACHI dekstar van ongeveer 5 jaar.
is deze hd dood, of is dit softwarematig en hoe kan ik dit oplossen?
screenshot van de SMART gegevens

het gaat om een HITACHI dekstar van ongeveer 5 jaar.
is deze hd dood, of is dit softwarematig en hoe kan ik dit oplossen?
screenshot van de SMART gegevens
[ Voor 18% gewijzigd door Verwijderd op 17-07-2015 23:48 ]
Bijna een half miljoen omgewisselde sectoren. Dat is extreem veel - zoveel heb ik nog nooit gezien. Nog best goed dat hij zo lang stand heeft gehouden.
De schijf is nog niet stuk, maar waarschijnlijk maakt hij continu onleesbare sectoren aan, en dat is extreem gevaarlijk in termen van corruptie/dataconsistentie en zorgt inderdaad ook voor hangende applicaties en kan ook voor blauwe schermen / plotse resets zorgen.
Dus je kunt hem afschrijven. Je kunt nog wel even controleren of je er misschien 5 jaar garantie op hebt en dit nog binnen de termijn valt. Dit kun je doen op de site van de fabrikant. Hiervoor heb je je serienummer nodig en partnumber.
De schijf is nog niet stuk, maar waarschijnlijk maakt hij continu onleesbare sectoren aan, en dat is extreem gevaarlijk in termen van corruptie/dataconsistentie en zorgt inderdaad ook voor hangende applicaties en kan ook voor blauwe schermen / plotse resets zorgen.
Dus je kunt hem afschrijven. Je kunt nog wel even controleren of je er misschien 5 jaar garantie op hebt en dit nog binnen de termijn valt. Dit kun je doen op de site van de fabrikant. Hiervoor heb je je serienummer nodig en partnumber.
Verwijderd
oke dan ga ik zeerzeker voor een nieuwe, maar hoe viable is deze schijf nog als extra/2e schijf? of hou ik dan een deel van de problemen?Verwijderd schreef op zaterdag 18 juli 2015 @ 00:21:
Bijna een half miljoen omgewisselde sectoren. Dat is extreem veel - zoveel heb ik nog nooit gezien. Nog best goed dat hij zo lang stand heeft gehouden.
De schijf is nog niet stuk, maar waarschijnlijk maakt hij continu onleesbare sectoren aan, en dat is extreem gevaarlijk in termen van corruptie/dataconsistentie en zorgt inderdaad ook voor hangende applicaties en kan ook voor blauwe schermen / plotse resets zorgen.
Dus je kunt hem afschrijven. Je kunt nog wel even controleren of je er misschien 5 jaar garantie op hebt en dit nog binnen de termijn valt. Dit kun je doen op de site van de fabrikant. Hiervoor heb je je serienummer nodig en partnumber.
- McKaamos
- Registratie: Maart 2002
- Niet online
Master of the Edit-button
Die schijf kan je het beste markeren als zeer onbetrouwbaar.Verwijderd schreef op zaterdag 18 juli 2015 @ 01:14:
[...]
oke dan ga ik zeerzeker voor een nieuwe, maar hoe viable is deze schijf nog als extra/2e schijf? of hou ik dan een deel van de problemen?
Niet gebruiken voor operationele doeleinden, backups of cruciale data, maar kan mogelijk nog dienst doen als externe schijf om even gauw wat onbelangrijke data te transporteren.
Verwijderd
en dan mijn laatste vraag: had ik dit kunnen voorkomen?McKaamos schreef op zaterdag 18 juli 2015 @ 01:20:
[...]
Die schijf kan je het beste markeren als zeer onbetrouwbaar.
Niet gebruiken voor operationele doeleinden, backups of cruciale data, maar kan mogelijk nog dienst doen als externe schijf om even gauw wat onbelangrijke data te transporteren.
- McKaamos
- Registratie: Maart 2002
- Niet online
Master of the Edit-button
Nee.Verwijderd schreef op zaterdag 18 juli 2015 @ 11:19:
[...]
en dan mijn laatste vraag: had ik dit kunnen voorkomen?
Elke hardeschijf verslijt. Sterker nog, elk opslagmedium verslijt. SSD, flashkaartjes, CD/DVD, diskette, harddisks, etc.
Een hardeschijf heeft gelukkig wel een ingebouwd mechanisme om versleten plekken te markeren en daarbij een stuk ruimte waar je normaal niet bij kan. Die ruimte wordt gebruikt om de versleten plekken tijdelijk op te vangen.
Die extra ruimte is ooit een keer op, en jouw schijf is hard onderweg naar het compleet opgebruiken van die ruimte. Als dat moment aanbreekt, zal je onherstelbare schade aan je data gaan merken.
Daarom is het dus slim om regelmatig de SMART status te controleren om te zien of er nog geen 're-allocated sector count' is.
Zodra die teller begint op te lopen, moet je al gaan zorgen voor een nieuwe harddisk.
- ThinkPad
- Registratie: Juni 2005
- Laatst online: 17:57
:strip_icc():strip_exif()/u/146731/crop562615a0aa64c.jpeg?f=community)
Heb voor m'n pa een Intel NUC gebouwd met onderdelen her en der verzameld. Nu is het ding sowieso baggertraag naar mijn idee. Maar hij doet ook een beetje raar, zo had ik hem vannacht Windows (7) updates laten installeren. Toen ik vanochtend bij de PC keek stond hij op een zwart scherm met de tekst "A bootable device has not been detected". NUC hard uitgezet en weer aan en bij het booten de melding "Windows is niet goed afgesloten". Dit heb ik nu al een aantal keer gehad (moest flink wat updates installeren, dus telkens 's nachts laten doen).
Nu weet ik niet of ik het in het RAM-geheugen moet zoeken of de SSD. Geheugen is nieuw en gaf na een uurtje Memtest (zal nog een keer een hele nacht laten draaien) geen errors. SSD is tweedehands, maar lijkt er goed uit te zien.
Ziet iemand iets 'geks' aan onderstaande waarden?
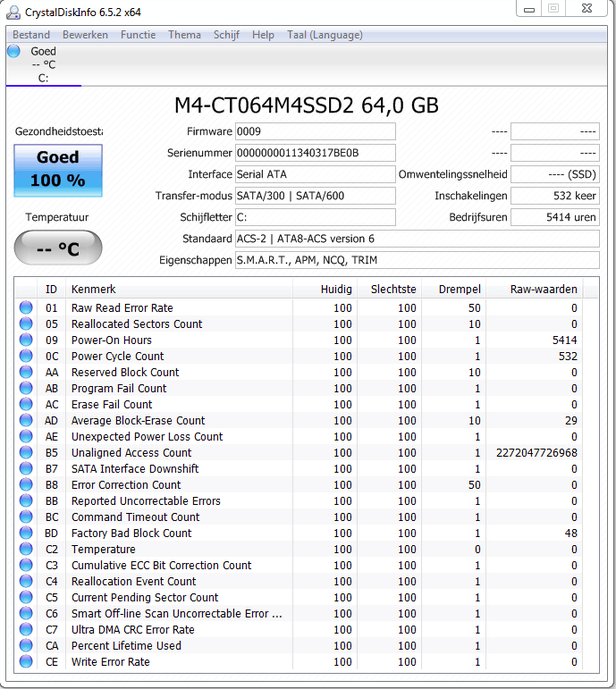
Nu weet ik niet of ik het in het RAM-geheugen moet zoeken of de SSD. Geheugen is nieuw en gaf na een uurtje Memtest (zal nog een keer een hele nacht laten draaien) geen errors. SSD is tweedehands, maar lijkt er goed uit te zien.
Ziet iemand iets 'geks' aan onderstaande waarden?
[ Voor 6% gewijzigd door ThinkPad op 18-07-2015 13:14 ]
SMART ziet er prima uit. Crucial M4 is een onbeveiligde SSD, maar met stabiele firmware wel een stabiele SSD die lang mee kan gaan.
MemTest86+ zou inderdaad de goede vervolgstap zijn. Anders zou drivers nog iets zijn wat ik zou verdenken, mits de instabiliteit/problemen zich enkel voordoen onder Windows.
MemTest86+ zou inderdaad de goede vervolgstap zijn. Anders zou drivers nog iets zijn wat ik zou verdenken, mits de instabiliteit/problemen zich enkel voordoen onder Windows.
- ThinkPad
- Registratie: Juni 2005
- Laatst online: 17:57
Ik heb net sowieso even de firmware geupdate 0009 > 070H. Zag namelijk dat er met die nieuwste firmware ook het issue gefixed is dat na harde poweroff soms de SSD niet werd gevonden. Dat heb ik eerder gezien met een M4 128GB, maar deze 64GB deed het dus ook, gezien de "A bootable device has not been detected".
Zal nu eerst eens een nacht memtest laten draaien dan.
Thanks iig voor de respons, nu ik weet dat de schijf an sich goed is heb ik in dit topic niks meer te zoeken
Zal nu eerst eens een nacht memtest laten draaien dan.
Thanks iig voor de respons, nu ik weet dat de schijf an sich goed is heb ik in dit topic niks meer te zoeken


- Orion
- Registratie: Januari 2004
- Laatst online: 26-06 23:04
:strip_icc():strip_exif()/u/104531/orion.jpg?f=community)
Ik heb een harde schijf die al geruime tijd niet helemaal fris meer is. Meerdere slechte sectoren. Als ik data eraf wil halen komt er een soms een mooi blauw scherm en wordt windows herstart. Is deze schijf nog te redden dmv een herstelprogramma. Indien dit niet het geval is hoe kan ik dan de data eraf halen zonder crash?

ddrescue, maar daarvoor heb je een nieuwe/verse/tijdelijke schijf nodig van minimaal dezelfde capaciteit. Dan kun je alles - minus de bad sectors - overzetten op een andere schijf en die vervolgens door Windows laten controleren (chkdsk). Dat is niet zo heel moeilijk, ook al draait ddrescue onder linux. Dat kun je prima doen met een LiveCD.
- MerlijnD
- Registratie: Januari 2011
- Laatst online: 24-06 14:50
:strip_icc():strip_exif()/u/390150/fdsa.jpg?f=community)
Volgens mij is alles nog in orde bij mij?
RAID 0


RAID 0


RAID 0
RAID 0
Niets mis mee.MerlijnD schreef op zaterdag 18 juli 2015 @ 23:11:
Volgens mij is alles nog in orde bij mij?
RAID 0
[afbeelding]
[afbeelding]
RAID 0
[afbeelding]
[afbeelding]
Ook niets mis mee.willy1986 schreef op zaterdag 18 juli 2015 @ 19:24:
Wat vinden jullie hiervan?
[afbeelding]
[afbeelding]
AMD Ryzen 7 5900x | Custom WC | ASUS ROG Strix X570-E Gaming | 32GB Corsair DDR4-3600MHz | Samsung 970 nvme 1TB | Samsung 860 EVO 2TB | AMD RX 6900XT 16GB | 1x Asus RoG XG27AQDMG | 1x LG UltraGear 27GL850
- Havermans
- Registratie: April 2014
- Laatst online: 24-09-2025
http://drive.google.com/open?id=0B8NeISa8bpY9OXVsU0RzR2hnUEU[img]
Ik heb sindskort een probleem met deze WD 1 TB harde schijf. Soms disconnect hij uit zijn eigen, als hij dit niet doet is de schrijfsnelheid heel onregelmatig. Zo valt hij geregeld stil en kan ik 20 minuten wachten voor hij weer begint te kopieren.
Ik heb sindskort een probleem met deze WD 1 TB harde schijf. Soms disconnect hij uit zijn eigen, als hij dit niet doet is de schrijfsnelheid heel onregelmatig. Zo valt hij geregeld stil en kan ik 20 minuten wachten voor hij weer begint te kopieren.
- henkbert
- Registratie: December 2013
- Laatst online: 13:42
:strip_icc():strip_exif()/u/562642/crop647e4e51aa8c9_cropped.jpg?f=community)
http://gyazo.com/a0307e4ebc12ecebf4dc7016d2644438
Het gaat hier om een Seagate ST1000DM003
Ik vraag me af of deze schijf nog goed is aangezien de schijf elke paar seconde verdwijnt in windows en even later weer verschijnt
Alvast Bedankt!
Het gaat hier om een Seagate ST1000DM003
Ik vraag me af of deze schijf nog goed is aangezien de schijf elke paar seconde verdwijnt in windows en even later weer verschijnt
Alvast Bedankt!
- ResuCigam
- Registratie: Maart 2005
- Laatst online: 16:26
BOFH
Ik heb hier een SSD met hoge gelijke waardes in de 4 geselecteerde regels, wat is hier aan de hand?

We do what we must because we can.
@havermans: prima
@henkbert: zoals gezegd, kun je het beste even met CrystalDiskInfo de SMART opvragen en daar een screenshot van maken. Uit het screenshot wat jij hebt gepost heb ik al gezien dat er geen vreemde dingen op staan. CDI zou nog beter zijn.
@ResuCigam: niets aan de hand. Genormaliseerde waarde ligt ver boven de Threshold (drempel).
@henkbert: zoals gezegd, kun je het beste even met CrystalDiskInfo de SMART opvragen en daar een screenshot van maken. Uit het screenshot wat jij hebt gepost heb ik al gezien dat er geen vreemde dingen op staan. CDI zou nog beter zijn.
@ResuCigam: niets aan de hand. Genormaliseerde waarde ligt ver boven de Threshold (drempel).
- Down Under
- Registratie: Augustus 2000
- Laatst online: 06:34
:strip_icc():strip_exif()/u/10610/51a.jpg?f=community)
Nu begint crystaldiskinfo ook een waarschuwing te geven. Ik kreeg een beetje het idee dat de schijf veel activiteit begon te vertonen met als gevolg dat soms programma's even een moment van freeze hadden.

Einde oefening nu?
[ Voor 23% gewijzigd door Down Under op 22-07-2015 13:18 ]
- henkbert
- Registratie: December 2013
- Laatst online: 13:42

Ik weet niet of hier nog iets opmerkelijks te zien is?
[ Voor 9% gewijzigd door henkbert op 22-07-2015 13:21 ]
@Down Under: Nee. Alleen is je schijf wel failed officiëel omdat de Current-waarde onder de Threshold komt. 15 is lager dan 17, en dus is dat attribuut rood.
Maar dit is waarschijnlijk gewoon een eigenaardigheid van deze SSD. Want de SSD bepaalt zelf of hij failed is. De SSD bepaalt de CurrentWorst/Threshold en de SMART programma's nemen dat klakkeloos over.
Kortom, ik denk dat je de SSD prima kunt gebruiken. Het is niet de beste SSD - voortaan zou ik een betere aanschaffen - maar je kunt hem waarschijnlijk nog wel lang gebruiken.
@henkbert: ziet er ook prima uit.
Maar dit is waarschijnlijk gewoon een eigenaardigheid van deze SSD. Want de SSD bepaalt zelf of hij failed is. De SSD bepaalt de CurrentWorst/Threshold en de SMART programma's nemen dat klakkeloos over.
Kortom, ik denk dat je de SSD prima kunt gebruiken. Het is niet de beste SSD - voortaan zou ik een betere aanschaffen - maar je kunt hem waarschijnlijk nog wel lang gebruiken.
@henkbert: ziet er ook prima uit.
- henkbert
- Registratie: December 2013
- Laatst online: 13:42
Vreemd, ik ga wel proberen of het wisselen van kabels wat doet en anders ligt het aan de voeding denk ik?
Heb je al gekeken of je een voedingsconversiestekker gebruikt? Want dat kan een mogelijke oorzaak zijn.
- henkbert
- Registratie: December 2013
- Laatst online: 13:42
Nee die gebruik ik niet, dus dat kan het niet zijn.
Dus je gebruikt een SATA-powerstekker direct geleverd door de voeding? Heb je de voedingsstekker stevig aangedrukt?
Heb je nu nog last van het probleem? Wanneer is de laatste keer dat je het probleem ondervond?
Heb je nu nog last van het probleem? Wanneer is de laatste keer dat je het probleem ondervond?
- henkbert
- Registratie: December 2013
- Laatst online: 13:42
ik heb de harde schijf de afgelopen dagen losgekoppeld aangezien windows telkens even freezed als de schijf wegvalt, de stekkers zaten goed aangeduwd en elke keer als de schijf wel aangesloten zit ondervind ik dit probleem
- Geert de Graaf
- Registratie: April 2005
- Laatst online: 14:38
:strip_exif()/u/142133/crop5757eebf3fe4f_cropped.gif?f=community)
Wat is jullie advies voor deze schijf?

Nog wat minder leuke foto's van twee ST2000DM001 schijven:
http://imgur.com/a/7dIil
http://imgur.com/a/QHpUZ
Nog wat minder leuke foto's van twee ST2000DM001 schijven:
http://imgur.com/a/7dIil
http://imgur.com/a/QHpUZ
Geert
- SanderH_
- Registratie: Juni 2010
- Laatst online: 13-06 18:28
Iets gelijkaardig aan de hand met mijn externe harde schijf. Niet echt het moment aangezien ik alle data van mijn oude NAS terug aan het plaatsen ben op mijn nieuwe systeem (meerdere TB..):

Temps zijn wel vrij hoog, maar niet abnormaal voor een externe harde schijf denk ik. Het grote dilemma is nu of ik de schijf zo weinig mogelijk aanraak en eerst uitpluis wat er precies aan de hand is, of anderzijds zoveel mogelijk data overpomp moest hij plots het loodje leggen..
Temps zijn wel vrij hoog, maar niet abnormaal voor een externe harde schijf denk ik. Het grote dilemma is nu of ik de schijf zo weinig mogelijk aanraak en eerst uitpluis wat er precies aan de hand is, of anderzijds zoveel mogelijk data overpomp moest hij plots het loodje leggen..
[ Voor 45% gewijzigd door SanderH_ op 27-07-2015 14:46 ]
@Geert de Graaf: bad sectors dus lang formatteren en daarna opnieuw gebruiken.
@SanderH_: tot 50 graden moet de schijf kunnen verdragen. Koeler is natuurlijk wel beter. Samsung Seagate doet aan BGMS (background scanning) en dat kan de re den zijn van het hogere verbruik en dus temperatuur.
Maar net als je bovenbuurman heb je 8 bad sectors en dat is het kritieke punt. Je kunt daar niet heel veel mee; probeer te backuppen wat je kunt en een aantal bestanden (of directories) kunnen onleesbaar zijn. Om die reden wil je ZFS en niets anders...
@SanderH_: tot 50 graden moet de schijf kunnen verdragen. Koeler is natuurlijk wel beter. Samsung Seagate doet aan BGMS (background scanning) en dat kan de re den zijn van het hogere verbruik en dus temperatuur.
Maar net als je bovenbuurman heb je 8 bad sectors en dat is het kritieke punt. Je kunt daar niet heel veel mee; probeer te backuppen wat je kunt en een aantal bestanden (of directories) kunnen onleesbaar zijn. Om die reden wil je ZFS en niets anders...
- SanderH_
- Registratie: Juni 2010
- Laatst online: 13-06 18:28
Verwijderd schreef op maandag 27 juli 2015 @ 14:50:
@SanderH_: tot 50 graden moet de schijf kunnen verdragen. Koeler is natuurlijk wel beter. Samsung doet aan BGMS (background scanning) en dat kan de re den zijn van het hogere verbruik en dus temperatuur.
Maar net als je bovenbuurman heb je 8 bad sectors en dat is het kritieke punt. Je kunt daar niet heel veel mee; probeer te backuppen wat je kunt en een aantal bestanden (of directories) kunnen onleesbaar zijn. Om die reden wil je ZFS en niets anders...
Dus redden wat er te redden valt? Het is trouwens mijn backup schijf die ik om de zoveel tijd syncte met mijn NAS via Total Commander. Dat wordt een namiddagje alles overpompen...
Als je een tijdelijke schijf hebt van minimaal dezelfde grootte kun je ddrescue gebruiken. Die zet alles over exclusief de bad sectors. Je kunt vervolgens chkdsk gebruiken op de nieuwe disk die geen bad sectors meer heeft maar gewoon corrupte data (nulletjes) op de plekken waar de bad sectors zaten. Dan kun je vervolgens alles kopiëren van die schijf naar een andere. Iets omslachtiger maar hiermee heb je wel de beste kans op recovery.
- dcm360
- Registratie: December 2006
- Niet online
/u/200133/artemis_square_e_60-60.png?f=community)
Want ZFS gaat je helpen met beschadigde sectoren op een externe harddisk...Verwijderd schreef op maandag 27 juli 2015 @ 14:50:
Maar net als je bovenbuurman heb je 8 bad sectors en dat is het kritieke punt. Je kunt daar niet heel veel mee; probeer te backuppen wat je kunt en een aantal bestanden (of directories) kunnen onleesbaar zijn. Om die reden wil je ZFS en niets anders...
Inderdaad. ZFS heeft standaard al ditto blocks voor de metadata, dus je filesystem zelf kan nooit onderuit door een bad sector. Ook niet op een enkele disk zonder redundantie, want ditto blocks werkt naast en onafhankelijk van de redundantie.
Daarnaast kun je met copies=2 ook de data van extra bescherming voorzien; en dit kun je per filesystem regelen. Dus tank/movies kan copies=1 krijgen en tank/importantdocuments krijgt copies=2. Bovendien heb je met snapshots ook historie waardoor een oudere versie van het bestand beschikbaar kan zijn.
Mochten alle errorcorrectie-mechanismen falen, dan heb je nog altijd errordetectie - je kunt exact zien welk bestand corrupt en dus ontoegankelijk is.
Vergelijk dit met een legacy filesystem waar corruptie doodleuk ongedetecteerd naar je backups kan stromen, en bij een bad sector er hele delen van het filesystem kunnen wegvallen als in die sector belangrijke metadata was opgeslagen. Dat zijn toch enorme verschillen met het moderne ZFS filesystem wat je data waardigheid geeft; terwijl filesystems van de 2e generatie je gewoon in de put laten zakken.
Daarnaast kun je met copies=2 ook de data van extra bescherming voorzien; en dit kun je per filesystem regelen. Dus tank/movies kan copies=1 krijgen en tank/importantdocuments krijgt copies=2. Bovendien heb je met snapshots ook historie waardoor een oudere versie van het bestand beschikbaar kan zijn.
Mochten alle errorcorrectie-mechanismen falen, dan heb je nog altijd errordetectie - je kunt exact zien welk bestand corrupt en dus ontoegankelijk is.
Vergelijk dit met een legacy filesystem waar corruptie doodleuk ongedetecteerd naar je backups kan stromen, en bij een bad sector er hele delen van het filesystem kunnen wegvallen als in die sector belangrijke metadata was opgeslagen. Dat zijn toch enorme verschillen met het moderne ZFS filesystem wat je data waardigheid geeft; terwijl filesystems van de 2e generatie je gewoon in de put laten zakken.
Verwijderd
http://imgur.com/gallery/2WjguNP/new
Kan ik hier meer door?
Weet niet hoe ik deze afbeelding gelijktoon
Kan ik hier meer door?
Weet niet hoe ik deze afbeelding gelijktoon
[ Voor 221% gewijzigd door Verwijderd op 27-07-2015 20:06 ]
Valt niets bijzonders op te zien. Maar weet dat dit een onveilige OCZ SSD is die regelmatig corruptie kan vertonen. De SSD is in feite onbruikbaar behalve voor systemen waarop je accepteert dat er af en toe gekke dingen op gebeuren. Als je vage klachten hebt waar je niet direct iets kan aanwijzen, is de SSD een mogelijke oorzaak.
De D schijf heeft overigens wel een warning, kan je hier eens een screen van posten?Verwijderd schreef op maandag 27 juli 2015 @ 20:01:
http://imgur.com/gallery/2WjguNP/new
Kan ik hier meer door?
Weet niet hoe ik deze afbeelding gelijktoon
AMD Ryzen 7 5900x | Custom WC | ASUS ROG Strix X570-E Gaming | 32GB Corsair DDR4-3600MHz | Samsung 970 nvme 1TB | Samsung 860 EVO 2TB | AMD RX 6900XT 16GB | 1x Asus RoG XG27AQDMG | 1x LG UltraGear 27GL850
- SanderH_
- Registratie: Juni 2010
- Laatst online: 13-06 18:28
Heb ondertussen alles kunnen overzetten zonder problemen. Misschien 3-4 keer een melding gehad van 1 bestand die hij niet kon vinden. Maar voor de rest heeft hij alles gewoon mooi overgezet.Verwijderd schreef op maandag 27 juli 2015 @ 15:05:
Als je een tijdelijke schijf hebt van minimaal dezelfde grootte kun je ddrescue gebruiken. Die zet alles over exclusief de bad sectors. Je kunt vervolgens chkdsk gebruiken op de nieuwe disk die geen bad sectors meer heeft maar gewoon corrupte data (nulletjes) op de plekken waar de bad sectors zaten. Dan kun je vervolgens alles kopiëren van die schijf naar een andere. Iets omslachtiger maar hiermee heb je wel de beste kans op recovery.
Klopt het dat als ik nu chkdesk runt hij automatisch de bad sectors flagt en ze in het vervolg niet meer worden gebruikt. Ik zou namelijk de schijf nog gewoon graag gebruiken, of is dat een verschrikkelijk slecht idee?
Dat bad sectors 'flaggen' in de $BadSect$ file is iets van voor de oorlog. Vanaf dat hardeschijven groter dan 400 megabyte zijn, worden sectoren intern omgewisseld. Het enige wat je moet doen om bad sectors weg te krijgen, is ze overschrijven. Dus een lange format in Windows doet wonderen - alleen Windows XP en Vista RTM werkt dit niet omdat die alleen alle sectoren lezen bij het formatteren ipv ze te overschrijven met nullen.
- SanderH_
- Registratie: Juni 2010
- Laatst online: 13-06 18:28
Die Quick format optie staat er inderdaad echt niet voor de lol... De complete format heeft ongeveer 10 uur geduurd (4TB schijf).
Current Pending Sector Count en Uncorrectable Sector Count staat inderdaad van beiden netjes terug op 0. Het hitteprobleem blijft echter, daarnet even gecheckt en zat al boven de 50 °C dus heb ik er terug een ventilator mogen op los laten. Toch maar even dat ding openmaken.
EDIT: nog een 500GB schijfje uit een oude PC kunnen recupereren met volgende SMART waardes:

Enkel de Read Error Rate geeft dus problemen, maar ziet er voor de rest prima uit volgens mij aangezien ik geen bad sectors spot. Ik zou deze schijf willen gebruik als backup voor wat minder belangrijke data.
Current Pending Sector Count en Uncorrectable Sector Count staat inderdaad van beiden netjes terug op 0. Het hitteprobleem blijft echter, daarnet even gecheckt en zat al boven de 50 °C dus heb ik er terug een ventilator mogen op los laten. Toch maar even dat ding openmaken.
EDIT: nog een 500GB schijfje uit een oude PC kunnen recupereren met volgende SMART waardes:

Enkel de Read Error Rate geeft dus problemen, maar ziet er voor de rest prima uit volgens mij aangezien ik geen bad sectors spot. Ik zou deze schijf willen gebruik als backup voor wat minder belangrijke data.
[ Voor 33% gewijzigd door SanderH_ op 31-07-2015 11:22 ]
:strip_exif()/u/294184/20150204_SITE_GIF_VALKUIL-resized.gif?f=community)
Deze zal af te schrijven zijn zeker?
Kan hem nog een format geven en zien of er iets verbeterd, maar hij reageert echt niet goed meer... Zou gelukkig nog ruim in garantie moeten zitten, heb hem in oktober gekocht...
Die schijf heeft geen kabelfouten en geen actieve bad sectors, dus zou perfect moeten werken. De omgewisselde sectoren kunnen namelijk geen problemen meer veroorzaken. Wel kan het zijn dat er nog meer zwakke sectoren zijn die omgewisseld zullen worden. Zeker als je nog garantie hebt, zou ik wel proberen de schijf om te wisselen voor een nieuwe/refurbished.
Het is een externe HD, en op dit moment lijkt hij totaal niet meer te reageren op een format... Er staat gelukkig geen data meer op (en er heeft gedurende al de tijd amper iets opgestaan). Garantie loopt volgens WD nog tot 10/2017, dus ik ga zeker een RMA procedure opstarten als het vanavond nog steeds zo slecht gaat (vastlopers tijdens kopiëren, kopiëren met 10 mb/s waar hij eerder 100 mb/s haalde)...Verwijderd schreef op vrijdag 31 juli 2015 @ 12:51:
Die schijf heeft geen kabelfouten en geen actieve bad sectors, dus zou perfect moeten werken. De omgewisselde sectoren kunnen namelijk geen problemen meer veroorzaken. Wel kan het zijn dat er nog meer zwakke sectoren zijn die omgewisseld zullen worden. Zeker als je nog garantie hebt, zou ik wel proberen de schijf om te wisselen voor een nieuwe/refurbished.
Bedankt voor de info in elk geval
Verwijderd
Sowieso RMA, zoveel verwisselde sectoren in nog maar 81 draaiuren is echt veel. Dan is er of iets goed mis mee of het ding heeft eens een beste stuiter gemaakt. 
Heb hem 1 maal uitgeleend, en verder een aantal keer gebruikt. Ik weet dat ik er altijd heel voorzichtig mee ben omgesprongen (heeft 95% van de tijd sinds aankoop hier op de bureau gelegen...). Tja, niet meer uitlenen zeker om die oorzaak uit te sluiten?Verwijderd schreef op vrijdag 31 juli 2015 @ 12:58:
Sowieso RMA, zoveel verwisselde sectoren in nog maar 81 draaiuren is echt veel. Dan is er of iets goed mis mee of het ding heeft eens een beste stuiter gemaakt.
- Brad Pitt
- Registratie: Oktober 2005
- Laatst online: 30-06 18:26
:strip_icc():strip_exif()/u/158536/850RGot.jpg?f=community)
Heeft deze SSD nog zin om proberen te fixen?

Gebruik hem al tijden met een Smart status die Bad is en het volgende Windows scherm dat om de zoveel minuten tevoorschijn komt maar merk eigenlijk vrij weinig van rare dingen.

Op het geheel vast slaan van de computer na (waarna je de power van de drive af moet halen om hem weer te laten werken) maar da's volgens mij geen resultaat van de Bad Smart
Vind het toch zonde om hem weg te gooien eigenlijk
Gebruik hem al tijden met een Smart status die Bad is en het volgende Windows scherm dat om de zoveel minuten tevoorschijn komt maar merk eigenlijk vrij weinig van rare dingen.
Op het geheel vast slaan van de computer na (waarna je de power van de drive af moet halen om hem weer te laten werken) maar da's volgens mij geen resultaat van de Bad Smart
Vind het toch zonde om hem weg te gooien eigenlijk
Nickname does not reflect reality
- Gino-1993
- Registratie: Juli 2015
- Laatst online: 16-03-2024
Hey,
ik had mijn gegevens eerder al gepost maar ben voor hulp hiernaar doorverwezen.
In mijn PC zit een
- WD 1TB WD1002FAEX BLACK
Dit zijn mijn smart gegevens:

Overigens is dit de melding bij taakbeheer van de gemiddelde reactietijd waardoor ik me af begon te vragen of het wel kon kloppen:

Alvast bedankt!
ik had mijn gegevens eerder al gepost maar ben voor hulp hiernaar doorverwezen.
In mijn PC zit een
- WD 1TB WD1002FAEX BLACK
Dit zijn mijn smart gegevens:
Overigens is dit de melding bij taakbeheer van de gemiddelde reactietijd waardoor ik me af begon te vragen of het wel kon kloppen:
Alvast bedankt!
[ Voor 5% gewijzigd door Gino-1993 op 01-08-2015 11:01 ]
Je schijf is waarschijnlijk prima, maar je gebruikt hem als C:-schijf en hebt hem waarschijnlijk ook een beetje vol zitten. Je schijf moet nu seeken als een gek en dat zorgt ervoor dat je systeem aanvoelt als in het jaar 2000.
Dus een SSD voor het OS en je HDD formatteren en enkel als dataopslag gebruiken, zou een oplossing zijn.
Dus een SSD voor het OS en je HDD formatteren en enkel als dataopslag gebruiken, zou een oplossing zijn.
/u/299055/crop660d40949f8ca_cropped.png?f=community)
Ik heb 2 schijven in mijn ZFS Z1 pool waar ik me een beetje zorgen over maak:
De eerste schijf heeft pending sectors die maar niet vervangen willen worden. Ook na een scub blijven ze gewoon bestaan.
<WDC WD30EZRX-00MMMB0 80.00A80> ATA-8 SATA 3.x device
De 2e heeft een groot aantal reallocated sectors. Maar is wel al zeker een half jaar stabiel.
<ST3000DM001-1CH166 CC43> ATA-8 SATA 3.x device
Het is een zfs Z1 pool, dus ik kan me eigenlijk maar 1 faild disk veroorloven. Wat denken jullie. Vervangen, of kunnen ze nog een tijdje mee?
De eerste schijf heeft pending sectors die maar niet vervangen willen worden. Ook na een scub blijven ze gewoon bestaan.
<WDC WD30EZRX-00MMMB0 80.00A80> ATA-8 SATA 3.x device
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # SMART attribute Flag Current Worst Threshold Failed RAW value 1 Raw_Read_Error_Rate 0x002f 200 196 051 - 0 3 Spin_Up_Time 0x0027 146 144 021 - 9691 4 Start_Stop_Count 0x0032 099 099 000 - 1075 5 Reallocated_Sector_Ct 0x0033 200 200 140 - 0 7 Seek_Error_Rate 0x002e 200 200 000 - 0 9 Power_On_Hours 0x0032 070 070 000 - 22275 10 Spin_Retry_Count 0x0032 100 100 000 - 0 11 Calibration_Retry_Count 0x0032 100 253 000 - 0 12 Power_Cycle_Count 0x0032 100 100 000 - 58 192 Power-Off_Retract_Count 0x0032 200 200 000 - 41 193 Load_Cycle_Count 0x0032 138 138 000 - 186690 194 Temperature_Celsius 0x0022 111 102 000 - 41 196 Reallocated_Event_Count 0x0032 200 200 000 - 0 197 Current_Pending_Sector 0x0032 200 200 000 - 6 198 Offline_Uncorrectable 0x0030 200 200 000 - 5 199 UDMA_CRC_Error_Count 0x0032 200 200 000 - 0 200 Multi_Zone_Error_Rate 0x0008 200 200 000 - 6 |
De 2e heeft een groot aantal reallocated sectors. Maar is wel al zeker een half jaar stabiel.
<ST3000DM001-1CH166 CC43> ATA-8 SATA 3.x device
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # SMART attribute Flag Current Worst Threshold Failed RAW value 1 Raw_Read_Error_Rate 0x000f 118 099 006 - 201077440 3 Spin_Up_Time 0x0003 092 090 000 - 0 4 Start_Stop_Count 0x0032 099 099 020 - 1103 5 Reallocated_Sector_Ct 0x0033 100 100 036 - 520 7 Seek_Error_Rate 0x000f 071 055 030 - 94793820252 9 Power_On_Hours 0x0032 075 075 000 - 22650 10 Spin_Retry_Count 0x0013 100 100 097 - 0 12 Power_Cycle_Count 0x0032 100 100 020 - 54 183 Runtime_Bad_Block 0x0032 100 100 000 - 0 184 End-to-End_Error 0x0032 100 100 099 - 0 187 Reported_Uncorrect 0x0032 100 100 000 - 0 188 Command_Timeout 0x0032 100 100 000 - 0 0 0 189 High_Fly_Writes 0x003a 093 093 000 - 7 190 Airflow_Temperature_Cel 0x0022 063 052 045 - 37 (Min/Max 31/48) 191 G-Sense_Error_Rate 0x0032 100 100 000 - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 - 44 193 Load_Cycle_Count 0x0032 100 100 000 - 1103 194 Temperature_Celsius 0x0022 037 048 000 - 37 (0 14 0 0 0) 197 Current_Pending_Sector 0x0012 100 100 000 - 0 198 Offline_Uncorrectable 0x0010 100 100 000 - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 - 0 240 Head_Flying_Hours 0x0000 100 253 000 - 19141h+27m+27.795s 241 Total_LBAs_Written 0x0000 100 253 000 - 15442036400 242 Total_LBAs_Read 0x0000 100 253 000 - 45339075345 |
Het is een zfs Z1 pool, dus ik kan me eigenlijk maar 1 faild disk veroorloven. Wat denken jullie. Vervangen, of kunnen ze nog een tijdje mee?
Dit komt omdat de bad sectors zich bevinden in ongebruikte sectoren - die ZFS dus niet in gebruik heeft. Dergelijke sectoren lopen extra risico om onleesbaar te worden omdat ze mogelijk lange tijd niet worden geschreven en wellicht een keer worden gelezen - pas dan komt de schijf erachter dat deze sector is gedegradeerd en de data niet meer foutloos uitgelezen kan worden. In de meeste gevallen komt de schijf er op tijd achter dat de sector veel ECC nodig heeft ('weak sector') en wordt deze automatisch opnieuw geschreven zodat hij weer vers is en voorkomen wordt dat het een onleesbare sector wordt.Johnnygo schreef op woensdag 05 augustus 2015 @ 15:46:
Ik heb 2 schijven in mijn ZFS Z1 pool waar ik me een beetje zorgen over maak:
De eerste schijf heeft pending sectors die maar niet vervangen willen worden. Ook na een scub blijven ze gewoon bestaan.
Je hoeft voor deze schijf niets te doen; je kunt de pending sectoren lekker laten zitten. Een ZFS systeem voor familie had binnen enkele maanden bad sectors op de helft van de disks (WD30EARX uit mijn hoofd) en dat is nog steeds zo. Mocht ZFS een bad sector tegenkomen dan zal je pool tijdelijk vertragen (hangende audio-streams) afhankelijk van je OS instellingen, maar alles wordt automatisch gerepareerd indien mogelijk.
Ook zonder RAID-Z ben je deels beschermd omdat de metadata ditto blocks bescherming heeft. Dus een bad sector zou in het ergste geval op een degraded RAID-Z een bestand kunnen doden; en je ziet dan ook precies welk bestand in de zpool status -v output. Je filesystem kan niet onderuit gaan, zoals wel bij alle filesystems van de 1e en 2e generatie (FAT, NTFS, Ext2/3/4, HFS, UFS, JFS, XFS).
Een paar bad sectors zegt helemaal NIETS of een schijf gaat falen. Falen betekent mechanisch falen: de schijf spint niet meer op, of je hoort de leeskop achter elkaar klikjes geven omdat hij niet meer kan kalibreren (weet niet meer op welke plek de leeskop zich bevindt). Dan is je schijf kapot, en dat heeft dus met de mechanische gesteldheid te maken.De 2e heeft een groot aantal reallocated sectors. Maar is wel al zeker een half jaar stabiel.
Het is een zfs Z1 pool, dus ik kan me eigenlijk maar 1 faild disk veroorloven. Wat denken jullie. Vervangen, of kunnen ze nog een tijdje mee?
Een schijf met bad sectors kan onbruikbaar worden voor legacy filesystems, maar voor ZFS en andere 3e generatie bestandssystemen zijn die prima bruikbaar. Daar heb je nou ZFS voor, dat alles niet gelijk op zijn bek gaat als je hardeschijf een paar kleine plekjes niet kan lezen. Gewoon lekker blijven gebruik je schijven, maar houd de SMART wel in de gaten; bij voorkeur regelmatig de SMART opslaan zodat je later kunt zien wat de trend is.
Voorspellen of een schijf mechanisch gaat falen is moeilijk, dan kun je nog het beste letten op vage klikjes en piepjes en andere geluiden.
- PaulHendrix
- Registratie: Maart 2010
- Laatst online: 19-04 08:35
back! met goed en slecht nieuws, slechte is dat ondanks een compleet nieuwe en andere versie van windows7 hij nog steeds met die "harde schijf gaat kapot" mededeling komt, morgen 10 er op zetten, kijken of 'ie het dan nog zegt, het goede is dat het OS ondanks die ""fout" toch gewoon installeert.(zit toch ernstig aan zo'n SSD te denken, maar ben er wat huiverig voor, want iedere nacht gaat pc uit met hibernate niet met gewoon "uit", want wake-on-Lan werkt alleen met hibernate)
- Erw
- Registratie: December 1999
- Laatst online: 27-06 23:47

Zo, mn harde schijf tikt als een Zwitsers uurwerk, is er nog wat aan te doen?
Eagles may soar, but weasels don't get sucked into jet engines
- Erw
- Registratie: December 1999
- Laatst online: 27-06 23:47
Ja hij is echt aan het overlijden, klik klik tik, klik klik tik....Verwijderd schreef op vrijdag 07 augustus 2015 @ 18:52:
Vervangen, tikkende HDD zie je ook niet terug in de S.M.A.R.T. status.
Gelukkig van alles op tijd een back up kunnen maken
Eagles may soar, but weasels don't get sucked into jet engines
- Brad Pitt
- Registratie: Oktober 2005
- Laatst online: 30-06 18:26
Hier nog tips voor dan? Of in de dustbin ermee en forget about it?
Nickname does not reflect reality
Windows en CDI zegt dat er een probleem is, omdat de Current-waarde onder de Threshold ligt. Maar je SSD is nog niet dood; hij is alleen flink gebruikt. Je kunt hem gewoon blijven gebruiken, hij is alleen iets minder betrouwbaar. Met name retentie is een punt; dus ga de SSD niet offline op de plank laten liggen en dan verwachten dat je data foutloos uitgelezen kan worden. Maar gebruik je hem op normale manier bij een systeem dat regelmatig aan gaat, dan denk ik dat je prima nog een tijd kunt doen met de SSD.Brad Pitt schreef op zaterdag 08 augustus 2015 @ 11:33:
Hier nog tips voor dan? Of in de dustbin ermee en forget about it?
Enige is wel dat Windows aan je kop gaat zeuren. Maar dat is puur omdat de SSD zelf aangeeft Current = 7 en Threshold = 10 dus dan denkt ieder SMART programma dat die schijf/SSD aan het falen is; immers geeft de SSD dit zelf aan.
In het verleden is er vaker SMART erg strict geprogrammeerd. Zoals een hardeschijf die bij het (tijdelijk) bereiken van 55 graden ook al als failed werd gerekend; omdat de Current/Threshold zo waren ingesteld. Dat is natuurlijk wel erg overdreven. In jouw geval is je SSD gewoon flink gebruikt en tegen het einde aan; maar dat kan nog prima 20 jaar duren als je hem nu rustig in een 2e/3e systeem propt en nog vele jaren gebruikt. Niet weggooien dus.
- Brad Pitt
- Registratie: Oktober 2005
- Laatst online: 30-06 18:26
Had hem, uiteraard tegen beter weten in, als Usenet download disk gebruikt. Vond het super snelle (en stille) parren en unrarren een verademing. Nu dit weer HD-based is is dat toch een heel ander verhaalVerwijderd schreef op zaterdag 08 augustus 2015 @ 21:29:
Windows en CDI zegt dat er een probleem is, omdat de Current-waarde onder de Threshold ligt. Maar je SSD is nog niet dood; hij is alleen flink gebruikt.
Snap ik! Gebruikte hem ook gewoon als bootdisk en er is nog nooit iets mis gegaan qua verlies van data of zo. Ding doet het gewoon prima. Op sporadisch dus geheel vastslaan, hetgeen wel vreselijk irritant is.Je kunt hem gewoon blijven gebruiken, hij is alleen iets minder betrouwbaar. Met name retentie is een punt; dus ga de SSD niet offline op de plank laten liggen en dan verwachten dat je data foutloos uitgelezen kan worden.
Ja, in de Bios uit moeten zetten omdat de PC anders niet eens wil booten maar die melding van Windows zelf is ook irritant. Komt om de zoveel tijd opzetten. Enige remedie is dat windowtje helemaal naar de rand van je scherm slepen zodat je er nog maar een paar pixels van kunt zien. Niet bijzonder profiEnige is wel dat Windows aan je kop gaat zeuren. Maar dat is puur omdat de SSD zelf aangeeft Current = 7 en Threshold = 10 dus dan denkt ieder SMART programma dat die schijf/SSD aan het falen is; immers geeft de SSD dit zelf aan.
Okay! Heb hem nu een keer gewiped (door met nullen te vullen) en een full format gedaan. Meer kan je niet doen toch? Ga hem eerst bij een vriendin even tijdelijk in haar laptop zetten om aan te tonen wát een SSD doet (ze gelooft niet dat het zó'n verschil maakt) en daarna wellicht weer gewoon als download monster gebruiken tot 'ie echt helemaal op is. Thanks!In jouw geval is je SSD gewoon flink gebruikt en tegen het einde aan; maar dat kan nog prima 20 jaar duren als je hem nu rustig in een 2e/3e systeem propt en nog vele jaren gebruikt. Niet weggooien dus.
Nickname does not reflect reality
- dcm360
- Registratie: December 2006
- Niet online
Beiden zijn eigenlijk een best wel slecht om op een SSD uit te voeren. Door een SSD vol te schrijven met allemaal nullen zit de schijf daadwerkelijk 'vol', wat slecht is voor de prestaties en het kost niet alleen een volledige schijfactie op alle cellen, maar ook de volgende schijfacties krijgen een hoge amplification doordat er geen vrije ruimte is. Een full format is zo ongeveer hetzelfde...Brad Pitt schreef op zondag 09 augustus 2015 @ 09:55:
[...]
Okay! Heb hem nu een keer gewiped (door met nullen te vullen) en een full format gedaan. Meer kan je niet doen toch?
De manier om een SSD te wissen is door het uitvoeren van een Secure Erase. Hiermee geeft de SSD alle cellen 'vrij' (en de cellen zullen daadwerkelijk geleegd worden door de controller).
Een TRIM erase is vrijwel hetzelfde als secure erase; en dat is ook wat gebeurt bij een Quick Format en volgens mij ook Full Format in recente Windows-versies. Dus uiteindelijk is de SSD na de format juist helemaal leeg. Hetzelfde doen sommige andere operating systems en filesystems (ZFS).
- Paul Hewson
- Registratie: Maart 2003
- Laatst online: 18:47
:strip_exif()/u/82099/Image1.gif?f=community)
Sinds een upgrade van mijn computer waarbij ik onderstaande oude harde schijf heb hergebruikt krijg ik meldingen van Windows dat er een probleem is met de schijf. Daarnaast valt deze af en toe spontaan weg, ook niet meer te zien in Device Manager bijvoorbeeld.

Het heeft een keer 37.3 seconden gekost om de schijf op te spinnen; daarom zegt hij nu failed. Dit kan inderdaad een heel duidelijk voorteken zijn dat je schijf niet meer gaat opspinnen binnenkort. Het kan ook zijn dat de schijf een keer wat instabiele stroom heeft gekregen en het opspinnen een paar keer is onderbroken. Dan kun je ook een zeer hoge spinup time krijgen, maar dit zou dan tijdelijk moeten zijn.
Zou je je systeem uitzetten en weer aan, dan kan het zijn dat de Current waarde van 1 terug is naar een waarde boven de 25. Dan werkt het voorlopig wel goed. Worst zal op 1 blijven staan en dat zal ook nooit meer weggaan. Je zult altijd een SMART fout/melding blijven houden op deze schijf.
Zou je je systeem uitzetten en weer aan, dan kan het zijn dat de Current waarde van 1 terug is naar een waarde boven de 25. Dan werkt het voorlopig wel goed. Worst zal op 1 blijven staan en dat zal ook nooit meer weggaan. Je zult altijd een SMART fout/melding blijven houden op deze schijf.
- PaulHendrix
- Registratie: Maart 2010
- Laatst online: 19-04 08:35
vraagje: ik wil me toch aan een SSD wagen, maar ik zet de pc altijd met "hibernate" uit omdat dat de enige manier blijkt waarin 'ie reageert op een wake-on-lan packet (weird)(om hem vanuit bed via app op telefoon aan te zetten, is namelijk tevens mijn radio). Nu zegt "men" dat het constante wegschrijven van grote bestanden (wat gebeurt bij "hibernate") niet echt goed is voor SSD, maar als het in plaats van tien acht jaar mee gaat, vind ik dat ook prima, any thoughts?
- Xudonax
- Registratie: November 2010
- Laatst online: 18-05 20:33
Aangezien de gemiddelde SSD ruim 100TB wegschrijven voordat deze readonly word. Samsung claimt bijvoorbeeld 150TB voor de Samsung 850 Evo. Het lijkt me dat je hier ruimschoots 15 jaar mee moet kunnen doen, zelfs inclusief je hibernate
[ Voor 20% gewijzigd door Xudonax op 11-08-2015 18:10 ]
- PaulHendrix
- Registratie: Maart 2010
- Laatst online: 19-04 08:35
ok, thanks. Cipher (SSD-guru;) nog opmerkingen?
[ Voor 7% gewijzigd door PaulHendrix op 12-08-2015 07:44 ]
Hallo Experts,
Ook hier een waarschuwing met Smart. Als een van jullie tijd heeft kan dit even bekeken worden met advies?
Bij voorbaat Hartelijk Dank.

PS voor alle zekerheid ga ik nu een nieuwe backup maken (dat duurt wel even )
Ook hier een waarschuwing met Smart. Als een van jullie tijd heeft kan dit even bekeken worden met advies?
Bij voorbaat Hartelijk Dank.
PS voor alle zekerheid ga ik nu een nieuwe backup maken (dat duurt wel even )
[ Voor 16% gewijzigd door Emphyr op 12-08-2015 17:56 ]
- rjmno1
- Registratie: Oktober 2013
- Laatst online: 18-06 01:12
Vroeger had je gewoon een progamaatje bij je harde schijf of je kon het downloaden via de website van de harddisk fabriekant.
Je kon je harde schijf low level formateren (zoals die in de fabriek werd gedaan).
En daarna dus met windows quickformat of full format doen.
Maar als je die schijf dus low level geformateerd was stond er ECHT HELEMAAL NIKS MEER OP JE SCHIJF.
Tegenwoordig doen ze dat dus met enen en nullen schrijven op de hd, maar ik weet niet of dat een waterdichte methode is om de schijf dus helemaal leeg te maken.
Ik heb het dus over de magneet-schijven ,en dus niet die modernere ssd harde schijven.
Ik heb trouwens dezelfde test gedaan en mijn schijf kwam goed uit de bus maar is pas 2,5 jaar oud
Mijn desktop medion akoya intel i7 (3770) 16gb infeon windows 10 x 64 pro met oem hd 1tb.
Je kon je harde schijf low level formateren (zoals die in de fabriek werd gedaan).
En daarna dus met windows quickformat of full format doen.
Maar als je die schijf dus low level geformateerd was stond er ECHT HELEMAAL NIKS MEER OP JE SCHIJF.
Tegenwoordig doen ze dat dus met enen en nullen schrijven op de hd, maar ik weet niet of dat een waterdichte methode is om de schijf dus helemaal leeg te maken.
Ik heb het dus over de magneet-schijven ,en dus niet die modernere ssd harde schijven.
Ik heb trouwens dezelfde test gedaan en mijn schijf kwam goed uit de bus maar is pas 2,5 jaar oud
Mijn desktop medion akoya intel i7 (3770) 16gb infeon windows 10 x 64 pro met oem hd 1tb.
[ Voor 13% gewijzigd door rjmno1 op 12-08-2015 23:45 ]
- DeRooney
- Registratie: Oktober 2002
- Laatst online: 20-02 14:59
mijn samsung hdd geeft al een poosje problemen (hij is ook al aardig oud).
Op de hdd zijn 3 partities gemaakt waaronder 1 partitie waarop linux is geinstalleerd. Linux wil nu niet meer booten en regelmatig verschijnt de hdd niet in de lijst met ide devices tijdens het bootscreen.
Nu heb ik met crystaldiskinfo de hdd even uitgelezen. hieronder staat het resultaat:
Heeft het nog zin om moeite te doen voor deze schijf? alles dat erop staat is al gebackupt op een andere schijf, externe schijf.
ik heb al gelezen dat een lange format de current pending sector count op 0 zet, maar is dat nog de moeite waarde of kan de schijf beter de kliko* in (na die low level format)?
*kliko = naar de rova brengen.
Edit: de schijf heb ik los gemaakt en aangesloten met de stekkers/connectors waarmee mijn dvd drive aangesloten zat. Nu kon ik probleemloos linux opstarten.
Van daaruit wil ik alle bestanden op de hdd "even"** backuppen. Maar met andere stekkers aansluiten helpt blijkbaar al in dit geval.
**"Even" duurt inmiddels al 8 uur en er staat dat er nog 9 uur resterend is (voor in totaal 121gb). Oorspronkelijke geschatte tijd was 11 uur.
Hij schrijft weg naar een externe usb met 1,9mb/seconde.
Op de hdd zijn 3 partities gemaakt waaronder 1 partitie waarop linux is geinstalleerd. Linux wil nu niet meer booten en regelmatig verschijnt de hdd niet in de lijst met ide devices tijdens het bootscreen.
Nu heb ik met crystaldiskinfo de hdd even uitgelezen. hieronder staat het resultaat:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| -- S.M.A.R.T. -------------------------------------------------------------- ID Cur Wor Thr RawValues(6) Attribute Name 01 253 100 _51 000000000000 Read Error Rate 03 100 100 _25 000000001600 Spin-Up Time 04 _97 _97 __0 000000000D56 Start/Stop Count 05 253 253 _10 000000000000 Reallocated Sectors Count 07 253 253 _51 000000000000 Seek Error Rate 08 253 253 _15 000000000000 Seek Time Performance 09 100 100 __0 00000000097C Power-On Hours 0A 253 253 _51 000000000000 Spin Retry Count 0B 253 253 __0 000000000000 Recalibration Retries 0C _99 _99 __0 0000000007D6 Power Cycle Count BB _85 _85 __0 000000020010 Reported Uncorrectable Errors BE 139 109 __0 000000000021 Airflow Temperature C2 139 109 __0 000000000021 Temperature C3 100 100 __0 000000001AD5 Hardware ECC recovered C4 253 253 __0 000000000000 Reallocation Event Count C5 100 100 __0 000000000001 Current Pending Sector Count C6 253 253 __0 000000000000 Uncorrectable Sector Count C7 200 189 __0 000000000005 UltraDMA CRC Error Count C8 253 100 __0 000000000000 Write Error Rate C9 253 100 __0 000000000000 Soft Read Error Rate |
Heeft het nog zin om moeite te doen voor deze schijf? alles dat erop staat is al gebackupt op een andere schijf, externe schijf.
ik heb al gelezen dat een lange format de current pending sector count op 0 zet, maar is dat nog de moeite waarde of kan de schijf beter de kliko* in (na die low level format)?
*kliko = naar de rova brengen.
Edit: de schijf heb ik los gemaakt en aangesloten met de stekkers/connectors waarmee mijn dvd drive aangesloten zat. Nu kon ik probleemloos linux opstarten.
Van daaruit wil ik alle bestanden op de hdd "even"** backuppen. Maar met andere stekkers aansluiten helpt blijkbaar al in dit geval.
**"Even" duurt inmiddels al 8 uur en er staat dat er nog 9 uur resterend is (voor in totaal 121gb). Oorspronkelijke geschatte tijd was 11 uur.
Hij schrijft weg naar een externe usb met 1,9mb/seconde.
[ Voor 107% gewijzigd door Verwijderd op 31-08-2015 18:39 . Reden: Alleen de SMART informatie posten, niet alle andere rotzooi. ]
- Tijntje
- Registratie: Februari 2000
- Laatst online: 24-06 13:46
Hello?!
:strip_icc():strip_exif()/u/2761/crop5d863c57a7d5d.jpeg?f=community)
Het lijkt er op dat één van mijn disk SMART errors begint te geven.
Moet ik hier bang van worden?

Moet ik hier bang van worden?
Als het niet gaat zoals het moet, dan moet het maar zoals het gaat.
/u/169999/crop57175bd319db1_cropped.png?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Deze laptop is af en toe ontzettend traag en dat terwijl er net sinds kort een clean install is gedaan.

@Gait
Fysieke bad sectors en pending sectors, zeker opsturen voor garantie als je dat nog hebt. Zo niet, is deze schijf minder betrouwbaar geworden en kun je deze niet meer gebruiken met ouderwetse bestandssystemen zoals Windows thans gebruikt.
@Tijntje
Bad sectors zonder fysieke schade: formatteer je hardeschijf (lang) nadat je alle data die je wilt behouden eraf hebt gehaald. Controleer daarna of de Current Pending Sector een raw value van 0 heeft. Dan kun je de schijf weer gebruiken.
Fysieke bad sectors en pending sectors, zeker opsturen voor garantie als je dat nog hebt. Zo niet, is deze schijf minder betrouwbaar geworden en kun je deze niet meer gebruiken met ouderwetse bestandssystemen zoals Windows thans gebruikt.
@Tijntje
Bad sectors zonder fysieke schade: formatteer je hardeschijf (lang) nadat je alle data die je wilt behouden eraf hebt gehaald. Controleer daarna of de Current Pending Sector een raw value van 0 heeft. Dan kun je de schijf weer gebruiken.
[ Voor 35% gewijzigd door Verwijderd op 31-08-2015 18:40 ]
- Electromonkey
- Registratie: Augustus 2006
- Laatst online: 30-06 23:20
/u/183749/crop581c6e4a1d696_cropped.png?f=community)
Sinds afgelopen week deze status vanaf DSM doorgekregen (214+), draait RAID 1.

Voor mijn huis/tuin/keuken/game pc zou ik me hier geen zorgen om maken. De NAS wordt echter gebruikt voor zakelijke toepassing. Raden jullie aan om gelijk de schijf te vervangen? Het belangrijkste is betrouwbaarheid.
Voor mijn huis/tuin/keuken/game pc zou ik me hier geen zorgen om maken. De NAS wordt echter gebruikt voor zakelijke toepassing. Raden jullie aan om gelijk de schijf te vervangen? Het belangrijkste is betrouwbaarheid.
[ Voor 14% gewijzigd door Electromonkey op 03-09-2015 12:10 ]
Drie omgewisselde sectoren. Niet zo heel spannend. Je draait RAID1, dus je hebt een vorm van bescherming. Zorg uiteraard voor goede (dus ook up-to-date) backups. Maar een paar bad sectors zorgt mijns inziens niet voor een hogere kans op falen. Want falen is echt mechanisch falen. Een bad sector zorgt er niet voor dat de motor het opeens gaat begeven, ofzo. Dus in die zin denk ik niet dat je met een hogere kans op falen te maken hebt.
Wel in de gaten houden. Oplopende bad sectors is een minder goed teken zeker als dit blijft doorgaan. Maar drie bad sectors is echt niets spannends. Zou erg zonde zijn als de schijf om die reden wordt afgedankt. Maar er zijn bedrijven die geen enkele scheet of kuch accepteren. Maar dan kun je beter aan High Availability denken al dan in combinatie met goede redundancy (zes disks in een mirror; dus 6x een kopie van alle data).
Wel in de gaten houden. Oplopende bad sectors is een minder goed teken zeker als dit blijft doorgaan. Maar drie bad sectors is echt niets spannends. Zou erg zonde zijn als de schijf om die reden wordt afgedankt. Maar er zijn bedrijven die geen enkele scheet of kuch accepteren. Maar dan kun je beter aan High Availability denken al dan in combinatie met goede redundancy (zes disks in een mirror; dus 6x een kopie van alle data).
- Electromonkey
- Registratie: Augustus 2006
- Laatst online: 30-06 23:20
Thx voor je snelle en duidelijke uitleg! De schijven hebben er nu bijna 15.000 uur opzitten, daarin zijn ze 1 of 2 opnieuw gestart maar verder niet. Is de error icm de uren een signaal dat het wel op zn einde gaat lopen? Binnen een x aantal maanden?Verwijderd schreef op donderdag 03 september 2015 @ 12:36:
..... Maar dan kun je beter aan High Availability denken al dan in combinatie met goede redundancy (zes disks in een mirror; dus 6x een kopie van alle data).
Nee. Als een schijf gaat falen, dus echt STUK, dan is dat mechanisch falen. Zoals: de motor start niet meer op, of de leeskop kan niet meer goed kalibreren (weet niet meer waar hij zit - dan hoor je klikjes achter elkaar).
Als een hardeschijf rare geluiden gaat maken, dan kan dit wel een voorteken zijn van falen, veelal zijn dit soort failures juist NIET in de SMART te zien. De SMART kun je juist wel zien hoe goed je medium-oppervlakte is, dus of je schijf aan amnesie lijdt. Ook kun je zaken als temperatuur, kabelfouten, stroomissues, seek-performance, enzovoorts aflezen.
Maar je schijf kan zomaar opeens TJANGGGG-klik-klik-klik-klik zeggen, of niet meer opspinnen. Dat soort falen kun je doorgaans niet zien aankomen. Dat jouw schijf oud is, is opzich juist een goed teken: al die tijd heeft de schijf robuust gefunctioneerd. In die zin zou je kunnen zeggen dat de schijf juist mogelijk betrouwbaarder is dan een nieuw exemplaar waarvan je niet weet of die binnen x maanden stuk gaat - iets wat vrij regelmatig voorkomt (bathtub). Wel zegt onderzoek dat hele oude schijven (5+ jaar) een hogere kans op falen hebben. Dus op een gegeven moment wordt ouderdom wel een ding.
Maar in jouw geval zit je nog niet aan 2 jaar, dus lekker gebruiken die schijf. Als je meer zekeheid wilt, zou ik zeggen doe wat aan je redundancy; 3 disks in een mirror. Kunnen er twee disks falen zonder dat je alles kwijt bent. Maar ik zou de schijf niet vervangen - de nieuwe schijf komt dan als extra naast de huidige twee te draaien. Niet alle RAID-implementaties ondersteunen triple mirrors overigens.
Als een hardeschijf rare geluiden gaat maken, dan kan dit wel een voorteken zijn van falen, veelal zijn dit soort failures juist NIET in de SMART te zien. De SMART kun je juist wel zien hoe goed je medium-oppervlakte is, dus of je schijf aan amnesie lijdt. Ook kun je zaken als temperatuur, kabelfouten, stroomissues, seek-performance, enzovoorts aflezen.
Maar je schijf kan zomaar opeens TJANGGGG-klik-klik-klik-klik zeggen, of niet meer opspinnen. Dat soort falen kun je doorgaans niet zien aankomen. Dat jouw schijf oud is, is opzich juist een goed teken: al die tijd heeft de schijf robuust gefunctioneerd. In die zin zou je kunnen zeggen dat de schijf juist mogelijk betrouwbaarder is dan een nieuw exemplaar waarvan je niet weet of die binnen x maanden stuk gaat - iets wat vrij regelmatig voorkomt (bathtub). Wel zegt onderzoek dat hele oude schijven (5+ jaar) een hogere kans op falen hebben. Dus op een gegeven moment wordt ouderdom wel een ding.
Maar in jouw geval zit je nog niet aan 2 jaar, dus lekker gebruiken die schijf. Als je meer zekeheid wilt, zou ik zeggen doe wat aan je redundancy; 3 disks in een mirror. Kunnen er twee disks falen zonder dat je alles kwijt bent. Maar ik zou de schijf niet vervangen - de nieuwe schijf komt dan als extra naast de huidige twee te draaien. Niet alle RAID-implementaties ondersteunen triple mirrors overigens.
Verwijderd

Was wel benieuwd hier naar. Heeft enorm veel draaiuren (37872 uur
[ Voor 13% gewijzigd door Verwijderd op 04-09-2015 01:02 ]
Verwijderd
Was je post net aan het doornemen idd. Maar wel een reassurance, misschien dat er andere waarden waren die er niet zo goed uit zagen. ThanksVerwijderd schreef op vrijdag 04 september 2015 @ 01:05:
SMART ziet er perfect uit voor zo'n oude schijf - zie verhaal hierboven.
- Electromonkey
- Registratie: Augustus 2006
- Laatst online: 30-06 23:20
Aan de hand hiervan had ik gisteren besloten om de schijf nog lekker even te blijven gebruiken en de backups iets scherper te zetten. Krijg ik vanmorgen het nieuwe SMART rapport:Verwijderd schreef op donderdag 03 september 2015 @ 15:59:
Nee. Als een schijf gaat falen, dus echt STUK, dan is dat mechanisch falen. Zoals: de motor start niet meer op, of de leeskop kan niet meer goed kalibreren (weet niet meer waar hij zit - dan hoor je klikjes achter elkaar).
Niet alle RAID-implementaties ondersteunen triple mirrors overigens.
- Reallocated Sector Count van 3 naar 4 (lijkt me ook geen ramp)
- Multi Zone Error Rate van 0 naar 42
Ik heb hier helemaal geen kaas van gegeten dus ik zie zo'n waarde stijging als "code rood"
Een extra bad sector moet je zeker in de gaten houden; maar lees eerst alle sectoren van je schijf. Kortom, doe een surface scan. Loopt het getal dan flink op, dan is dat wél een teken dat de platter kwaliteit aan het afnemen is. Of bijvoorbeeld dat er stofdeeltjes zijn vrijgekomen die sectoren beschadigen - iets wat zal blijven toenemen gedurende het gebruik. In dat geval is je schijf wél minder betrouwbaar. Echter: ook met tienduizend bad sectors heeft dit geen invloed op de mechanische kwaliteit van je schijf, zoals de motor en de leeskoop die moet weten waar hij zit. Dat is wat je schijf echt STUK kan maken. Bad sectors zorgen er hooguit voor dat plekjes op de schijf niet gelezen kunnen worden. Aangezien deze worden omgewisseld, is er geen accuut gevaar. Het is 'Current Pending Sector' waar je bang voor moet zijn. De raw-value hiervan moet altijd 0 zijn.
Jouw Multi Zone Error Rate kun je de raw value niet van interpreteren - kijk naar de genormaliseerde waarde. In jouw screenshot was deze 200 - de best mogelijke waarde. Kijk welke waarde deze nu heeft, en ook naar Worst. Als beide nog steeds 200 zijn of dichtbij de 200, dan is er niets aan de hand.
Bedenk: voor genormaliseerde waarde (Current/Worst) geldt: hoe HOGER hoe beter. Het is een 8-bit waarde van 0 tot 255 die dus aftelt naar 0 toe. 0 is de slechts mogelijke waarde. Als de waarde ONDER de Threshold (grenswaarde) komt, dan geldt de schijf als failed.
Jouw Multi Zone Error Rate kun je de raw value niet van interpreteren - kijk naar de genormaliseerde waarde. In jouw screenshot was deze 200 - de best mogelijke waarde. Kijk welke waarde deze nu heeft, en ook naar Worst. Als beide nog steeds 200 zijn of dichtbij de 200, dan is er niets aan de hand.
Bedenk: voor genormaliseerde waarde (Current/Worst) geldt: hoe HOGER hoe beter. Het is een 8-bit waarde van 0 tot 255 die dus aftelt naar 0 toe. 0 is de slechts mogelijke waarde. Als de waarde ONDER de Threshold (grenswaarde) komt, dan geldt de schijf als failed.
- 129383_
- Registratie: Oktober 2013
- Laatst online: 01-04 10:39
/u/544397/crop5efeeba79f4d4_cropped.png?f=community)
Ik heb mijn headless server al een tijdje aanstaan en dacht dat het een goed moment is om te kijken hoe mijn harde schijf er voor staat.
(output van smartctl)

Ik zie hier alleen maar "old_age" en "pre-fail" staan en ook de hoeveelheid reallocated sectors baart mij zorgen.
Betekent dit dat mijn harde schijf op z'n laatste benen loopt en direct vervangen moet worden of kan deze nog een paar maanden mee?
Ik heb verder geen problemen ondervonden met mijn schijf en smartctl zegt zelf ook dat ie "passed" is.
(output van smartctl)
Ik zie hier alleen maar "old_age" en "pre-fail" staan en ook de hoeveelheid reallocated sectors baart mij zorgen.
Betekent dit dat mijn harde schijf op z'n laatste benen loopt en direct vervangen moet worden of kan deze nog een paar maanden mee?
Ik heb verder geen problemen ondervonden met mijn schijf en smartctl zegt zelf ook dat ie "passed" is.
77 duizend start-stop cycli, dat is veel (spindown gebruikt lange tijd?). 2,25 miljoen headparks... ouch! 300.000 is de opgegeven max.
218 fysieke bad sectors die zijn omgewisseld; mwaa kan nog prima voor zo'n oudje. Die ene Current Pending Sector is nog het meest kritieke.
Ook heeft je schijf flinke schokken gehad (G-Sense Error Rate).
old_age betekent dat het opgegeven attribuut een indicatie is van ouderdom, zoals het aantal draaiuren - pre-fail betekent dat het attribuut zou aangeven wanneer de schijf acuut aan het falen is. Dit is gewoon het TYPE attribuut, je moet het niet interpreteren dat je schijf op sterven staat. Elk SMART attribuut is OF pre-fail OF old-age. Dat laatste houdt in dat het attribuut eigenlijk niet kan falen. Pre-fail wel, let meer eens op de Threshold, die is alleen aanwezig voor pre-fail attributen. Met de Threshold op 0 betekent dat dit attribuut nooit kan falen. Dus een triljard draaiuren of een triljard headparks (Load Cycle Count) betekent nog niet een gefaalde schijf. Maar tig bad sectors wel. 218 valt echt nog mee.
Je schijf is zeker een oudje! Maar kan nog prima mee. Wel kun je verwachten dat hij mechanisch slijtage heeft ondervonden van de vele headparks en start-stop cycli. Dus het is geen nieuwe schijf meer.
218 fysieke bad sectors die zijn omgewisseld; mwaa kan nog prima voor zo'n oudje. Die ene Current Pending Sector is nog het meest kritieke.
Ook heeft je schijf flinke schokken gehad (G-Sense Error Rate).
old_age betekent dat het opgegeven attribuut een indicatie is van ouderdom, zoals het aantal draaiuren - pre-fail betekent dat het attribuut zou aangeven wanneer de schijf acuut aan het falen is. Dit is gewoon het TYPE attribuut, je moet het niet interpreteren dat je schijf op sterven staat. Elk SMART attribuut is OF pre-fail OF old-age. Dat laatste houdt in dat het attribuut eigenlijk niet kan falen. Pre-fail wel, let meer eens op de Threshold, die is alleen aanwezig voor pre-fail attributen. Met de Threshold op 0 betekent dat dit attribuut nooit kan falen. Dus een triljard draaiuren of een triljard headparks (Load Cycle Count) betekent nog niet een gefaalde schijf. Maar tig bad sectors wel. 218 valt echt nog mee.
Je schijf is zeker een oudje! Maar kan nog prima mee. Wel kun je verwachten dat hij mechanisch slijtage heeft ondervonden van de vele headparks en start-stop cycli. Dus het is geen nieuwe schijf meer.
- 129383_
- Registratie: Oktober 2013
- Laatst online: 01-04 10:39
Bedankt voor je uitleg, het kan wel kloppen dat de schijf flinke schokken heeft gehad. Het heeft immers in een netbook gezeten!
Ik hou de harde schijf voortaan beter in de gaten, kijken of de waarden exponentieel groeien en dan gaat ie er gelijk uit.
Ik hou de harde schijf voortaan beter in de gaten, kijken of de waarden exponentieel groeien en dan gaat ie er gelijk uit.
Wat zeggen jullie over deze schijf?
Is een 250GB oudje, kan deze nog verkocht worden?

Is een 250GB oudje, kan deze nog verkocht worden?
[ Voor 23% gewijzigd door Pittie op 08-09-2015 20:46 ]
Lijkt mij prima. Hoeveel fysiek oud, heeft hij ook niet heel veel draaiuren gemaakt. Ziet er prima uit verder.
Hallo Cypher,
12 augustus om 17.55 heb ik een smart gepost met 2 errors.
Ik vermoed dat u door de vakantietijd mijn post niet hebt gezien.
Zou u als het uitkomt alsnog even willen kijken en mij advies kunnen geven of ik de schijf moet vervangen ?
Bij voorbaat hartelijk dank.
12 augustus om 17.55 heb ik een smart gepost met 2 errors.
Ik vermoed dat u door de vakantietijd mijn post niet hebt gezien.
Zou u als het uitkomt alsnog even willen kijken en mij advies kunnen geven of ik de schijf moet vervangen ?
Bij voorbaat hartelijk dank.
Dankjewel!Verwijderd schreef op dinsdag 08 september 2015 @ 21:55:
Lijkt mij prima. Hoeveel fysiek oud, heeft hij ook niet heel veel draaiuren gemaakt. Ziet er prima uit verder.
@Emphyr: deze post bedoel je denk ik: Emphyr in "Check je SMART".
SMART ziet er goed uit verder, maar je hebt wel één bad sector. Dat kan al problemen geven met een bepaald bestand, of zorgen voor 'hangende applicaties' als juist die ene sector wordt gelezen, wat dan mislukt.
Indien mogelijk: backup alle bestanden op de schijf en formatteer deze. Geen quick format, dus een lange format die 3+ uur duurt. Dan worden alle sectoren overschreven, dus ook die ene bad sector. Als je daarna de SMART weer controleert, zul je Current Pending Sector met een raw value van 0 zien, ipv 1. Dan is dat probleem opgelost. Verder om de maand de SMART in de gaten houden. Maar de rest van de SMART ziet er netjes uit. Bad sectors zijn 'normaal' mits ze beperkt voorkomen. Maar ze kunnen wel grote problemen veroorzaken in combinatie met oudere bestandssystemen, waaronder NTFS wat vrijwel iedereen gebruikt op het Windows-platform. Microsoft loopt van alle operating systems achter op het gebied van bestandssystemen.
SMART ziet er goed uit verder, maar je hebt wel één bad sector. Dat kan al problemen geven met een bepaald bestand, of zorgen voor 'hangende applicaties' als juist die ene sector wordt gelezen, wat dan mislukt.
Indien mogelijk: backup alle bestanden op de schijf en formatteer deze. Geen quick format, dus een lange format die 3+ uur duurt. Dan worden alle sectoren overschreven, dus ook die ene bad sector. Als je daarna de SMART weer controleert, zul je Current Pending Sector met een raw value van 0 zien, ipv 1. Dan is dat probleem opgelost. Verder om de maand de SMART in de gaten houden. Maar de rest van de SMART ziet er netjes uit. Bad sectors zijn 'normaal' mits ze beperkt voorkomen. Maar ze kunnen wel grote problemen veroorzaken in combinatie met oudere bestandssystemen, waaronder NTFS wat vrijwel iedereen gebruikt op het Windows-platform. Microsoft loopt van alle operating systems achter op het gebied van bestandssystemen.
Cypher,Verwijderd schreef op woensdag 09 september 2015 @ 09:39:
@Emphyr: deze post bedoel je denk ik: Emphyr in "Check je SMART".
SMART ziet er goed uit verder, maar je hebt wel één bad sector. Dat kan al problemen geven met een bepaald bestand, of zorgen voor 'hangende applicaties' als juist die ene sector wordt gelezen, wat dan mislukt.
-knip_
Hartelijk Bedankt!
Van het weekend evenuitgebreid uw advies opvolgen,
fijne avond.
- klaasvd79
- Registratie: April 2005
- Laatst online: 24-12-2025
Hallo,
Een computer heeft wat vage klachten, blijft soms hangen en muis/toetsenbord valt uit(bedraad). Soms ook problemen met opstarten(in de zin wil niet). Zelf dacht ik aan problemen met voeding, maar deze kan ik niet goed uitlezen op één of andere manier(dell vostro). Toch ook nog even de zelfcheck gedaan en kreeg een foutmelding over HDD, vandaar dat ik de SMART hier even wil laten bekijken of deze schijf daadwerkelijk slecht is of dit meevalt.
-- S.M.A.R.T. --------------------------------------------------------------
ID Cur Wor Thr RawValues(6) Attribute Name
01 200 200 _51 00000000028D Read Error Rate
03 134 132 _21 0000000010BB Spin-Up Time
04 _99 _99 __0 0000000006B4 Start/Stop Count
05 200 200 140 000000000000 Reallocated Sectors Count
07 100 253 __0 000000000000 Seek Error Rate
09 _92 _92 __0 000000001757 Power-On Hours
0A 100 100 __0 000000000000 Spin Retry Count
0B 100 100 __0 000000000000 Recalibration Retries
0C _99 _99 __0 0000000006AB Power Cycle Count
C0 200 200 __0 000000000025 Power-off Retract Count
C1 200 200 __0 00000000068E Load/Unload Cycle Count
C2 107 100 __0 000000000024 Temperature
C4 200 200 __0 000000000000 Reallocation Event Count
C5 200 200 __0 000000000001 Current Pending Sector Count
C6 200 200 __0 000000000001 Uncorrectable Sector Count
C7 200 200 __0 000000000000 UltraDMA CRC Error Count
C8 200 200 __0 000000000001 Write Error Rate
F0 _93 _93 __0 0000000015D9 Head Flying Hours
F1 200 200 __0 00021BBF927E Total Host Writes
F2 200 200 __0 0002363F35FF Total Host Reads
Een computer heeft wat vage klachten, blijft soms hangen en muis/toetsenbord valt uit(bedraad). Soms ook problemen met opstarten(in de zin wil niet). Zelf dacht ik aan problemen met voeding, maar deze kan ik niet goed uitlezen op één of andere manier(dell vostro). Toch ook nog even de zelfcheck gedaan en kreeg een foutmelding over HDD, vandaar dat ik de SMART hier even wil laten bekijken of deze schijf daadwerkelijk slecht is of dit meevalt.
-- S.M.A.R.T. --------------------------------------------------------------
ID Cur Wor Thr RawValues(6) Attribute Name
01 200 200 _51 00000000028D Read Error Rate
03 134 132 _21 0000000010BB Spin-Up Time
04 _99 _99 __0 0000000006B4 Start/Stop Count
05 200 200 140 000000000000 Reallocated Sectors Count
07 100 253 __0 000000000000 Seek Error Rate
09 _92 _92 __0 000000001757 Power-On Hours
0A 100 100 __0 000000000000 Spin Retry Count
0B 100 100 __0 000000000000 Recalibration Retries
0C _99 _99 __0 0000000006AB Power Cycle Count
C0 200 200 __0 000000000025 Power-off Retract Count
C1 200 200 __0 00000000068E Load/Unload Cycle Count
C2 107 100 __0 000000000024 Temperature
C4 200 200 __0 000000000000 Reallocation Event Count
C5 200 200 __0 000000000001 Current Pending Sector Count
C6 200 200 __0 000000000001 Uncorrectable Sector Count
C7 200 200 __0 000000000000 UltraDMA CRC Error Count
C8 200 200 __0 000000000001 Write Error Rate
F0 _93 _93 __0 0000000015D9 Head Flying Hours
F1 200 200 __0 00021BBF927E Total Host Writes
F2 200 200 __0 0002363F35FF Total Host Reads
[ Voor 34% gewijzigd door klaasvd79 op 10-09-2015 15:42 ]
Je hebt 1 current pending sector, zou alles backuppen en de schijf een volledige (geen quick) format geven in windows, nu zal de Current pending sector naar 0 zijn veranderd als deze nog goed blijkt te zijn, of de reallocated sector count is 1 omhoog gegaan, dan is die omgewisseld.klaasvd79 schreef op donderdag 10 september 2015 @ 15:42:
Hallo,
Een computer heeft wat vage klachten, blijft soms hangen en muis/toetsenbord valt uit(bedraad). Soms ook problemen met opstarten(in de zin wil niet). Zelf dacht ik aan problemen met voeding, maar deze kan ik niet goed uitlezen op één of andere manier(dell vostro). Toch ook nog even de zelfcheck gedaan en kreeg een foutmelding over HDD, vandaar dat ik de SMART hier even wil laten bekijken of deze schijf daadwerkelijk slecht is of dit meevalt.
-- S.M.A.R.T. --------------------------------------------------------------
ID Cur Wor Thr RawValues(6) Attribute Name
01 200 200 _51 00000000028D Read Error Rate
03 134 132 _21 0000000010BB Spin-Up Time
04 _99 _99 __0 0000000006B4 Start/Stop Count
05 200 200 140 000000000000 Reallocated Sectors Count
07 100 253 __0 000000000000 Seek Error Rate
09 _92 _92 __0 000000001757 Power-On Hours
0A 100 100 __0 000000000000 Spin Retry Count
0B 100 100 __0 000000000000 Recalibration Retries
0C _99 _99 __0 0000000006AB Power Cycle Count
C0 200 200 __0 000000000025 Power-off Retract Count
C1 200 200 __0 00000000068E Load/Unload Cycle Count
C2 107 100 __0 000000000024 Temperature
C4 200 200 __0 000000000000 Reallocation Event Count
C5 200 200 __0 000000000001 Current Pending Sector Count
C6 200 200 __0 000000000001 Uncorrectable Sector Count
C7 200 200 __0 000000000000 UltraDMA CRC Error Count
C8 200 200 __0 000000000001 Write Error Rate
F0 _93 _93 __0 0000000015D9 Head Flying Hours
F1 200 200 __0 00021BBF927E Total Host Writes
F2 200 200 __0 0002363F35FF Total Host Reads
AMD Ryzen 7 5900x | Custom WC | ASUS ROG Strix X570-E Gaming | 32GB Corsair DDR4-3600MHz | Samsung 970 nvme 1TB | Samsung 860 EVO 2TB | AMD RX 6900XT 16GB | 1x Asus RoG XG27AQDMG | 1x LG UltraGear 27GL850
- ThinkPad
- Registratie: Juni 2005
- Laatst online: 17:57
Twee schijven gekocht om in m'n NAS te plaatsen (heb nu één schijf, wil graag naar 2TB in RAID1).
Heb met verkoper afgesproken dat ik ze dit weekend even zou testen en als ze niet goed waren mocht omruilen.
Hieronder de waarden:
schijf 1: http://i.imgur.com/Bd5VVYN.png
schijf 2: http://i.imgur.com/JdeJkKn.png
Hebben wel flink wat draaiuren (~3,5 jaar), maar dat moet opzich niet uitmaken toch?
Kan iemand zeggen of deze OK zijn?
En welk programma is aan te raden zodat ik zelf de schijven nog even goed kan testen? Gewoon de software van WD ("Data LifeGuard Diagnostics") en dan een uitgebreide scan draaien? Of zijn er betere programma's voor?
Heb met verkoper afgesproken dat ik ze dit weekend even zou testen en als ze niet goed waren mocht omruilen.
Hieronder de waarden:
schijf 1: http://i.imgur.com/Bd5VVYN.png
{kind=link}
schijf 2: http://i.imgur.com/JdeJkKn.png
{kind=link}
Hebben wel flink wat draaiuren (~3,5 jaar), maar dat moet opzich niet uitmaken toch?
Kan iemand zeggen of deze OK zijn?
En welk programma is aan te raden zodat ik zelf de schijven nog even goed kan testen? Gewoon de software van WD ("Data LifeGuard Diagnostics") en dan een uitgebreide scan draaien? Of zijn er betere programma's voor?
[ Voor 13% gewijzigd door ThinkPad op 11-09-2015 18:02 ]
Verwijderd
LCC (Load Cycle Count) zit voor beide schijven ruim boven het aantal dat door WD wordt gegarandeerd (300.000): specificaties voor WD20EARS: http://www.wdc.com/wdprod...Sheet/NLD/2879-800026.pdf.
[ Voor 5% gewijzigd door Verwijderd op 11-09-2015 18:58 . Reden: Per ongeluk verkeerde link. ]
- ThinkPad
- Registratie: Juni 2005
- Laatst online: 17:57
Dus conclusie: schijven zijn versleten, terug ermee?Verwijderd schreef op vrijdag 11 september 2015 @ 18:08:
LCC (Load Cycle Count) zit voor beide schijven ruim boven het aantal dat door WD wordt gegarandeerd (300.000): specificaties voor WD20EARS: http://www.wdc.com/wdprod...Sheet/NLD/2879-800026.pdf.
Je document noemt overigens de WD20EARS niet, dit document wel. Ook daar de 300.000 LCC
Ik weet genoeg en ga ze terugbrengen, bedankt voor je snelle reactie. Toch maar wat geld bijleggen en nieuwe schijven kopen.
[ Voor 39% gewijzigd door ThinkPad op 11-09-2015 18:23 ]
Verwijderd
Excuus voor de verkeerde link, zag ook pas daarnet dat de WD20EARS daar niet in stond, maar had die domweg weggehaald van de pagina waarop de WD20EARS onder de hoofdproductlijn WD Green stond. Ik had verder moeten zoeken en bij WD Caviar Green moeten uitkomen.
Gelukkig vond je al snel de juiste.
Als de schijven in mijn NAS zaten, zou ik ze blijven gebruiken, maar wel met een goede backup en een bewaking door een regelmatige S.M.A.R.T.-rapportage. Maar ik heb er persoonlijk geen cent voor over (behoudens schrootwaarde ).
).
Gelukkig vond je al snel de juiste.
Als de schijven in mijn NAS zaten, zou ik ze blijven gebruiken, maar wel met een goede backup en een bewaking door een regelmatige S.M.A.R.T.-rapportage. Maar ik heb er persoonlijk geen cent voor over (behoudens schrootwaarde
[ Voor 6% gewijzigd door Verwijderd op 11-09-2015 18:34 ]
- EricJH
- Registratie: November 2003
- Laatst online: 18:57
/u/97665/Opera1_t.png?f=community)
Een van mijn hard drives geeft problemen. Het gaat om een WD 6400 AAKS. Western Digital Data LifeGuard Diagnostics geeft de volgende fout:
Mijn vraag is of jullie mij de CrystalDiskInfo informatie kunnen duiden? Ik weet dat Reallocated Sector Count, Current Pending Sector Count en Uncorrectable Sector Count de relevante indicatoren zijn maar ik weet niet of ik ze juist interpreteer. Als ik het goed begrijp zijn nog geen sectoren verplaatst. Hoe moet ik de Current Pending Sector Count en Uncorrectable Sector Count duiden?
Ik de relevante data overgezet en ik wil nog wat met deze harde schijf stoeien. Is het mogelijk met chkdsk /r of zero write de problematische sectoren te laten vervangen door spare sectors?

Een Google zoektocht leert dat er dan sprake van bad sector(s). Een uitgebreide scan met Western Digital Data LifeGuard Diagnostics rapporteert dat het de bad sectoren niet kan repareren.Test Result: FAIL
Test Error Code: 06-Quick Test on drive 1 did not complete! Status code = 07 (Failed read test element), Failure Checkpoint = 97 (Unknown Test) SMART self-test did not complete on drive 1!
Mijn vraag is of jullie mij de CrystalDiskInfo informatie kunnen duiden? Ik weet dat Reallocated Sector Count, Current Pending Sector Count en Uncorrectable Sector Count de relevante indicatoren zijn maar ik weet niet of ik ze juist interpreteer. Als ik het goed begrijp zijn nog geen sectoren verplaatst. Hoe moet ik de Current Pending Sector Count en Uncorrectable Sector Count duiden?
Ik de relevante data overgezet en ik wil nog wat met deze harde schijf stoeien. Is het mogelijk met chkdsk /r of zero write de problematische sectoren te laten vervangen door spare sectors?
![]() Dit topic is gesloten.
Dit topic is gesloten.
![]()