:strip_icc():strip_exif()/u/181149/crop676521c5b6d54_cropped.jpg?f=community)
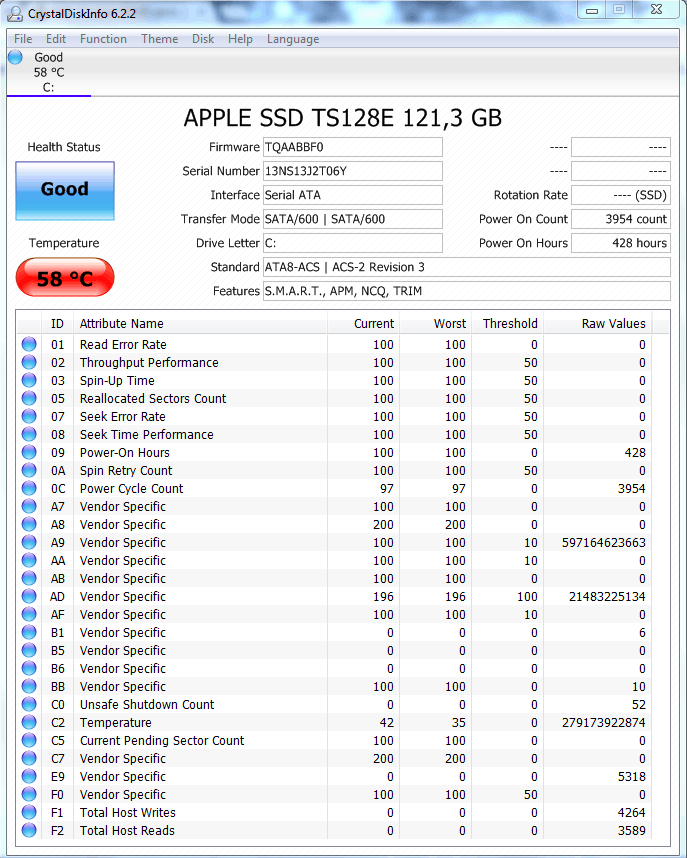
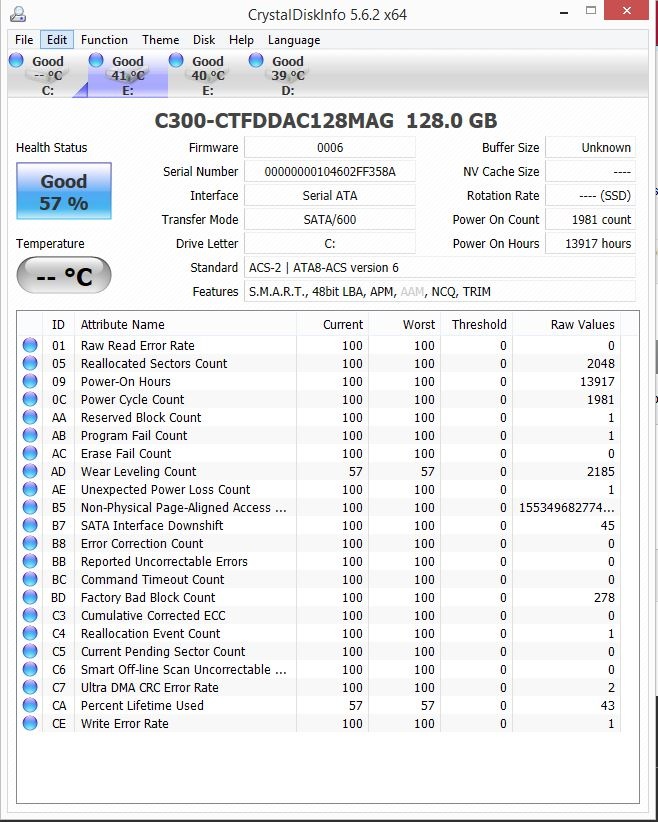
er viel mij zojuist iets vreemds op. niet dat m'n smart er slecht uitziet maar de hoeveelheid data die gelezen en geschreven is. er staat een datum bij van 19-04-2014.
Ik heb de schijf al een jaar of 3 in gebruik. mogelijk is dit de datum van zijn laatste firmware upgrade. klopt dit? en mag een fabrikant dat doen? het wist dan een heel stuk geschiedenis van de drive.

Ik heb de schijf al een jaar of 3 in gebruik. mogelijk is dit de datum van zijn laatste firmware upgrade. klopt dit? en mag een fabrikant dat doen? het wist dan een heel stuk geschiedenis van de drive.

[ Voor 7% gewijzigd door dezejongeman op 23-12-2014 19:17 ]
/u/502133/crop63230156ad849_cropped.png?f=community)


/u/409447/ico_tw_team.png?f=community)

:strip_icc():strip_exif()/u/146731/crop562615a0aa64c.jpeg?f=community)
:strip_exif()/u/34969/flusherr.gif?f=community)
/u/125506/link-8bit.png?f=community)
:strip_icc():strip_exif()/u/242941/crop5a0ecbff49196_cropped.jpeg?f=community)

:strip_icc():strip_exif()/u/369469/crop56fcfa2fc45b2_cropped.jpeg?f=community)
/u/5360/crop65d3c045ca48f_cropped.png?f=community)




/u/238501/crop5e2f0f8a11c1f_cropped.png?f=community)





/u/200133/artemis_square_e_60-60.png?f=community)
:strip_icc():strip_exif()/u/135404/crop586e284093763_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/158536/850RGot.jpg?f=community)









/u/351515/crop6897f6e5d19a1_cropped.png?f=community)

:strip_icc():strip_exif()/u/251875/crop5bfed18b3d7a2_cropped.jpeg?f=community)







:strip_icc():strip_exif()/u/334861/crop5fe3838ae0c5c_cropped.jpeg?f=community)



:strip_exif()/u/142133/crop5757eebf3fe4f_cropped.gif?f=community)




:strip_icc():strip_exif()/u/340506/crop618ed3082ef20.jpg?f=community)





:strip_icc():strip_exif()/u/212073/crop5790930e15fe8_cropped.jpeg?f=community)




/u/363003/firewall.png?f=community)


:strip_icc():strip_exif()/u/184432/crop5666ef06248fb_cropped.jpeg?f=community)
/u/379733/crop5b8587125ef6d_cropped.png?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}