Ik zie geen plaatje ...Verwijderd schreef op donderdag 6 september 2018 @ 20:42:
[Afbeelding] Reden: Tikken van hdd tijdens het downloaden. Moet nog testen of het tikken ook aanhoudt buiten de kast
/u/24735/crop6112615003fcf_cropped.png?f=community)
Vaag hé?FireDrunk schreef op woensdag 29 augustus 2018 @ 08:11:
Ik zie inderdaad niks mis met de waardes. Heb je ook een geschedulede test? Misschien dat FreeNAS zelf ook een long-test probeert te draaien terwijl er al 1 draait, en de huidige onderbroken wordt ofzo?
Ik heb zojuist ad-hoc een short test gestart. Precies hetzelfde resultaat.. Dus dit was de enige SMART test die liep.
Is het gevaarlijk om een full test te doen? Heb al nieuwe schijven in bestelling staan (zo'n beetje).
[EDIT]
Ik vind dat een scrub tijd van 16 uur ook wel fors voor 3.8 TB. Ik kan me herinneren dat dit voorheen (okay wel met minder data) iets van 4 uur duurde ofzo.
[ Voor 13% gewijzigd door Wasp op 13-09-2018 16:47 ]
Ryzen 9 5900X, MSI Tomahawk MAX, 32GB RAM, Nvidia RTX 4070 Ti | Mijn livesets
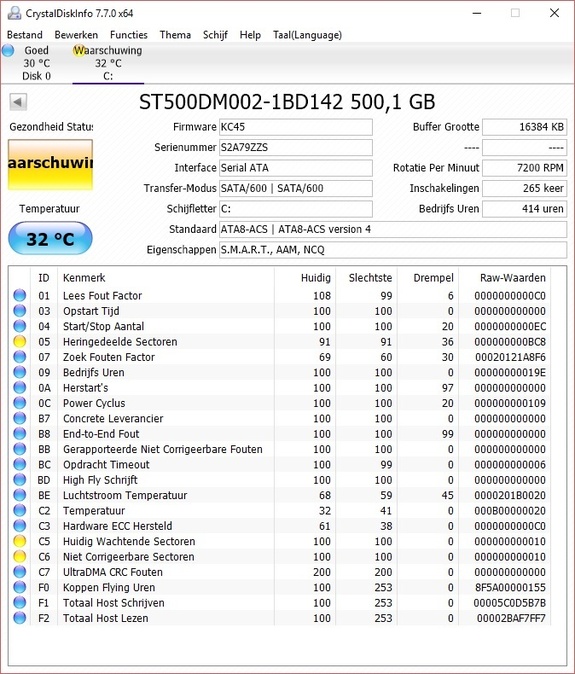
Hallo,
Binnenkort ga ik een nieuwe pc bouwen. Hiervoor ben ik aan het kijken wat ik nog mee kan nemen van mijn huidige build van 7 jaar oud.
Mijn vraag gaat over mijn Seagate hdd. Deze wil ik gaan gebruiken om foto's en video's e.d. op te slaan. Dus niet om programma's e.d. te installeren. Als ik de Smart waardes check valt het me op dat bij Hardware ECC recovered een hele hoge raw value staat. Is dit erg? Of kan ik deze schijf gewoon mee nemen naar de nieuwe pc?

Binnenkort ga ik een nieuwe pc bouwen. Hiervoor ben ik aan het kijken wat ik nog mee kan nemen van mijn huidige build van 7 jaar oud.
Mijn vraag gaat over mijn Seagate hdd. Deze wil ik gaan gebruiken om foto's en video's e.d. op te slaan. Dus niet om programma's e.d. te installeren. Als ik de Smart waardes check valt het me op dat bij Hardware ECC recovered een hele hoge raw value staat. Is dit erg? Of kan ik deze schijf gewoon mee nemen naar de nieuwe pc?
- EricJH
- Registratie: November 2003
- Laatst online: 01:45
/u/97665/Opera1_t.png?f=community)
Volgens de Acronis database:
De schijf is al ouder. Ik weet niet hoe belangrijk de foto's en video's zijn. Als ze belangrijk zijn is het verstandig om te overwegen een nieuwe schijf te kopen.Although this parameter is not considered critical by the most hardware vendors, degradation of this parameter may indicate electromechanical problems of the disk. Regular backup is recommended. If no other (critical) parameters report a problem, hardware replacement is recommended on mission critical systems only.
- Acid Vendetta
- Registratie: Mei 2006
- Laatst online: 10:33
/u/175520/crop636e2cf4962f2_cropped.png?f=community)
Een goed werkende schijf preventief vervangen? Het moet niet gekker worden.EricJH schreef op donderdag 13 september 2018 @ 18:05:
Volgens de Acronis database:
[...]
De schijf is al ouder. Ik weet niet hoe belangrijk de foto's en video's zijn. Als ze belangrijk zijn is het verstandig om te overwegen een nieuwe schijf te kopen.
Alleen de "critical SMART attributes" zijn bij afwijkende waarden een reden tot vervanging. Tenzij je problemen merkt bij een goede SMART zou verder gekeken kunnen worden naar de andere attributes.
Voor opslag van belangrijke data:
Opslag draaiende HDD + dagelijkse/wekelijkse/whatever offline backup synchroniseren. Veiliger is er niet. Op cloud diensten kun je niet 100% vertrouwen (daarnaast privacy).
Er is een grafiek van percentage uitval HDD'S met leeftijd. Hoe ouder hoe groter de kans, maar bij een offline backup kun je de draaiende schijf blijven gebruiken totdat hij op is. Elke paar jaar preventief vervangen kost alleen maar geld. Tenzij je dat niet erg vindt.
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Ik zou deze schijf gewoon meenemen naar je nieuwe PC, maar let dan wel even op C7: dat duidt op communicatie fouten (ooit) tussen de harddisk en het moederbord. Neem dan dus veiligheidshalve een nieuwe SATA-kabel voor deze harddisk in gebruik.RMark schreef op donderdag 13 september 2018 @ 17:19:
Hallo,
Binnenkort ga ik een nieuwe pc bouwen. Hiervoor ben ik aan het kijken wat ik nog mee kan nemen van mijn huidige build van 7 jaar oud.
Mijn vraag gaat over mijn Seagate hdd. Deze wil ik gaan gebruiken om foto's en video's e.d. op te slaan. Dus niet om programma's e.d. te installeren. Als ik de Smart waardes check valt het me op dat bij Hardware ECC recovered een hele hoge raw value staat. Is dit erg? Of kan ik deze schijf gewoon mee nemen naar de nieuwe pc?
[Afbeelding]
Die hardware ECC recovered heeft blijkbaar niet geleid tot fouten in de opslag, maar beide verschijnselen (C3 en C7) verklaren wellicht wel BC (Command Timeout).
Hou in de nieuwe PC vooral 05, C5 en C7 maandelijks in de gaten: die mogen niet hoger worden dan de huidige waarden.
- icecreamfarmer
- Registratie: Januari 2003
- Laatst online: 27-06 13:29
en het is
:strip_icc():strip_exif()/u/75578/crop5935346597d2a_cropped.jpeg?f=community)
Mijn idee ook niet toch gaf windows die dag ervoor veel foutmeldingen over de schijf.Renault schreef op donderdag 13 september 2018 @ 10:14:
[...]
Met die schijf is volgens deze cijfers niets mis.
ik zie ik zie wat jij niet ziet
- icecreamfarmer
- Registratie: Januari 2003
- Laatst online: 27-06 13:29
en het is
Vandaag wilde windows weer niet opstarten.Renault schreef op donderdag 13 september 2018 @ 10:14:
[...]
Met die schijf is volgens deze cijfers niets mis.
nu krijg ik dit:

BTW ook een behoorlijke windows update gehad vandaag.
ik zie ik zie wat jij niet ziet
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
De vraag is hoe je komt aan zo'n enorm aantal leesfouten zonder CRC's enz..
Wellicht weten anderen dat?
Dan zou ik als workaround toch gaan voor een nieuwe harddisk: als er geen communicatiefouten zijn (CRC = 0) en magnetisch is er niets mis (geen wachtende of uncorrrectable sectoren), zou je denken dat het ligt aan de printplaat (aansturing leesarm) of de leeskop. En daar doe je niets tegen.
Wellicht weten anderen dat?
Dan zou ik als workaround toch gaan voor een nieuwe harddisk: als er geen communicatiefouten zijn (CRC = 0) en magnetisch is er niets mis (geen wachtende of uncorrrectable sectoren), zou je denken dat het ligt aan de printplaat (aansturing leesarm) of de leeskop. En daar doe je niets tegen.
[ Voor 15% gewijzigd door Renault op 16-09-2018 13:46 ]
- EricJH
- Registratie: November 2003
- Laatst online: 01:45
De Acronis KB zegt hetzelfde als Renault:
Read Error Rate S.M.A.R.T. parameter indicates the rate of hardware read errors that occurred when reading data from a disk surface. Any value differing from zero means there is a problem with the disk surface, read/write heads (including crack on a head, broken head, head contamination, head resonance, bad connection to electronics module, handling damage). The higher parameter’s value is, the more the hard disk failure is possible.
Recommendations
This is a critical parameter. Degradation of this parameter may indicate imminent drive failure. Urgent data backup and hardware replacement is recommended.
- icecreamfarmer
- Registratie: Januari 2003
- Laatst online: 27-06 13:29
en het is
Wat ik niet snap is dat ik dezelfde melding een paar weken geleden had maar na een herstart was de smart weer goed.Renault schreef op zondag 16 september 2018 @ 13:44:
De vraag is hoe je komt aan zo'n enorm aantal leesfouten zonder CRC's enz..
Wellicht weten anderen dat?
Dan zou ik als workaround toch gaan voor een nieuwe harddisk: als er geen communicatiefouten zijn (CRC = 0) en magnetisch is er niets mis (geen wachtende of uncorrrectable sectoren), zou je denken dat het ligt aan de printplaat (aansturing leesarm) of de leeskop. En daar doe je niets tegen.
Maar ik zal eens een nieuwe HDD bestellen. Nog tips voor een 1 of 2tb schijf?
ik zie ik zie wat jij niet ziet
- Giesber
- Registratie: Juni 2005
- Laatst online: 02-07 11:42
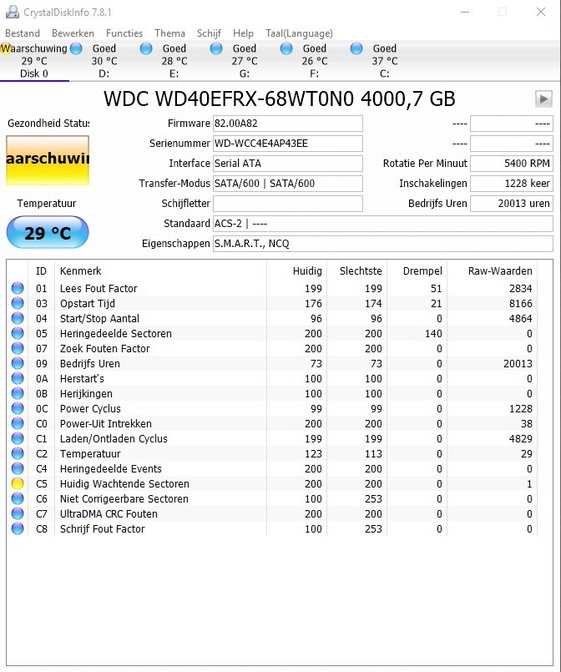
Ik kreeg wat rare fouten op mijn Freenas server (met een verwijzing naar een ATA Device), maar alles lijkt op het eerste zicht normaal te zijn.
Toch maar even de SMART data bekeken, maar die ziet er op het eerste zicht goed uit?
Toch maar even de SMART data bekeken, maar die ziet er op het eerste zicht goed uit?
=== START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 237 3 Spin_Up_Time 0x0027 172 170 021 Pre-fail Always - 8366 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 37 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 9 Power_On_Hours 0x0032 079 079 000 Old_age Always - 15848 10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 37 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 16 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 284 194 Temperature_Celsius 0x0022 120 110 000 Old_age Always - 32 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 14
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Nee.
Hoewel ik mijn twijfels heb bij de samenstelling van deze tabel (de getoonde cijfers komen niet helemaal overeen met wat je verwacht onder Value/Worstt/Threshold), denk ik dat 140 de actual waarde is bij Reallocated Sector Count (5). Hoewel de Currrent Pending Sector (197) op nul lijkt te staan (dus momenteel in totaal geen onbetrouwbare sectoren), is de waarde voor de Reallocated Sector Count (5) (= voor reservesectoren omgewisselde sectoren) te hoog voor een (Free-)NAS functionaliteit. De kans dat het fout gaat is aanwezig. Je kunt met deze schijf doorgaan, als je vaak backups ervan maakt.
E.e.a. ligt m.n. aan of dit de enige disk is in je NAS, en de mate waarin je de NAS inzet voor availability van de data óf de veilige opslag van de data en dat is aan jou ter beoordeling.
Hoewel ik mijn twijfels heb bij de samenstelling van deze tabel (de getoonde cijfers komen niet helemaal overeen met wat je verwacht onder Value/Worstt/Threshold), denk ik dat 140 de actual waarde is bij Reallocated Sector Count (5). Hoewel de Currrent Pending Sector (197) op nul lijkt te staan (dus momenteel in totaal geen onbetrouwbare sectoren), is de waarde voor de Reallocated Sector Count (5) (= voor reservesectoren omgewisselde sectoren) te hoog voor een (Free-)NAS functionaliteit. De kans dat het fout gaat is aanwezig. Je kunt met deze schijf doorgaan, als je vaak backups ervan maakt.
E.e.a. ligt m.n. aan of dit de enige disk is in je NAS, en de mate waarin je de NAS inzet voor availability van de data óf de veilige opslag van de data en dat is aan jou ter beoordeling.
- Giesber
- Registratie: Juni 2005
- Laatst online: 02-07 11:42
Bedankt voor de input. Is de Reallocated Sector Count niet gewoon 0?Renault schreef op maandag 24 september 2018 @ 13:03:
Nee.
Hoewel ik mijn twijfels heb bij de samenstelling van deze tabel (de getoonde cijfers komen niet helemaal overeen met wat je verwacht onder Value/Worstt/Threshold), denk ik dat 140 de actual waarde is bij Reallocated Sector Count (5). Hoewel de Currrent Pending Sector (197) op nul lijkt te staan (dus momenteel in totaal geen onbetrouwbare sectoren), is de waarde voor de Reallocated Sector Count (5) (= voor reservesectoren omgewisselde sectoren) te hoog voor een (Free-)NAS functionaliteit. De kans dat het fout gaat is aanwezig. Je kunt met deze schijf doorgaan, als je vaak backups ervan maakt.
E.e.a. ligt m.n. aan of dit de enige disk is in je NAS, en de mate waarin je de NAS inzet voor availability van de data óf de veilige opslag van de data en dat is aan jou ter beoordeling.
Ik heb overigens nog eens naar de andere WD schijven in dezelfde setup gekeken, en die hebben dezelfde cijfers, buiten de Raw_Read_Error_Rate (1) en Multi_Zone_Error_Rate (200). Die staan voor de andere 2 WD schijven op 0. De rest van de waardes zijn hetzelfde, met soms wat kleine logische afwijkeingen (voor bv de spin up time).
Ik weet dus nog niet echt wat ik ermee moet aanvangen, misschien dat ik eens een long self-test zal doen om te kijken of daar problemen boven water komen.
Verder is het een RAIDZ2 (met 6 schijven), dus een kapotte schijf kan ie wel hebben, en staan er voornamelijk backups op (waarbij de belangrijkste data nog eens een cloud backup heeft), maar van de andere kant hoort het backup systeem gewoon betrouwbaar te zijn. Voor € 120 ga ik daar niet op beknibbelen.
Ik zal een lange SMART self-test draaien, en daarna verder beoordelen.
- EricJH
- Registratie: November 2003
- Laatst online: 01:45
Post eens een screenshot van CrystalDiskInfo. Ik ben benieuwd naar de Reallocated Sector Count die CDI rapporteert.
[ Voor 1% gewijzigd door EricJH op 25-09-2018 16:27 . Reden: Taalfout ]
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
... en doe dat uitlezen met CDI vóórdat je tests draait, want tests resetten sommige waarden ...
[ Voor 23% gewijzigd door Renault op 25-09-2018 22:12 ]
- Giesber
- Registratie: Juni 2005
- Laatst online: 02-07 11:42
CrystalDiskInfo is een Windows tool dacht ik? De schijf zit in een Freenas bak.
- chim0
- Registratie: Mei 2000
- Laatst online: 07-07 04:27
:strip_exif()/u/6897/IGKIPU.gif?f=community)
Schijf van een kennis. Klaagde over traag opstarten van de PC dus had een bedrag over voor het upgraden van de PC dus ik heb hem vervangen door een SSD en een snellere processor. Is een jaar of 7 geleden aangeschaft en zoals je ziet heel weinig gebruikt.
Heb die PC toen zelf samengesteld en gewoon een willekeurige schijf gepakt, maar verder niet gelet op het type ofzo, maar nu lees ik bij de gebruikersreviews veel uiteenlopende reacties bij deze schijf zoals uitvallen en kapotte sectoren dus achteraf gezien misschien toch niet zo'n goede keuze geweest of ik heb gewoon domme pech gehad.
Hoe dan ook, dit was voor en na een lange format. Is ie nog betrouwbaar denken jullie? Heb hem nu als opslag schijf in de PC hangen en er staat wat data op en hij doet het verder ook prima maar wat zeggen jullie? Blijven gebruiken of in de kliko ermee?
Heb die PC toen zelf samengesteld en gewoon een willekeurige schijf gepakt, maar verder niet gelet op het type ofzo, maar nu lees ik bij de gebruikersreviews veel uiteenlopende reacties bij deze schijf zoals uitvallen en kapotte sectoren dus achteraf gezien misschien toch niet zo'n goede keuze geweest of ik heb gewoon domme pech gehad.
Hoe dan ook, dit was voor en na een lange format. Is ie nog betrouwbaar denken jullie? Heb hem nu als opslag schijf in de PC hangen en er staat wat data op en hij doet het verder ook prima maar wat zeggen jullie? Blijven gebruiken of in de kliko ermee?
- Cpt.Morgan
- Registratie: Februari 2001
- Laatst online: 23-11-2025
:strip_icc():strip_exif()/u/21971/crop5b5ae9fcba7bc_cropped.jpeg?f=community)
Deze schijf heeft sowieso wat problemen. De kans dat er opnieuw foute sectoren bijkomen is aanwezig. De schijf is 7 jaar oud en niet van jezelf maar van een kennis waar je deze PC voor hebt gemaakt. Als je hem nu aflevert wil je dus gewoon dat die PC weer werkt en niet dat die kennis over enige tijd mogelijk weer problemen heeft...chim0 schreef op zaterdag 6 oktober 2018 @ 02:50:
Schijf van een kennis.
...
Is een jaar of 7 geleden aangeschaft en zoals je ziet heel weinig gebruikt.
...
Blijven gebruiken of in de kliko ermee?
Voor minder dan 50 euro heb je een 1 TB schijf tegenwoordig: pricewatch: Seagate Desktop HDD, 1TB
Vervangen dus.
- chim0
- Registratie: Mei 2000
- Laatst online: 07-07 04:27
Klopt, maar zoals ik zei hadden ze een bepaald bedrag over voor een upgrade en dat is nu allemaal opgegaan dus er kan sowieso niks meer extra worden uitgegeven. Het is ook niet nodig want in principe hoeft er niks te worden opgeslagen op die PC want ze werken in de cloud en hij wordt voornamelijk gebruikt om te internetten en extern in te loggen op het werk. Het ging er puur om dat de PC super traag was en ze hem sneller wilden maken. Opslag gebeurt dus in de cloud of op een externe schijf/USB stick. Dat ik die schijf erin laat, is puur een principe van mezelf, omdat ie gewoon van hun is, maar natuurlijk niet als ie defect is.Cpt.Morgan schreef op zaterdag 6 oktober 2018 @ 08:08:
[...]
Deze schijf heeft sowieso wat problemen. De kans dat er opnieuw foute sectoren bijkomen is aanwezig. De schijf is 7 jaar oud en niet van jezelf maar van een kennis waar je deze PC voor hebt gemaakt. Als je hem nu aflevert wil je dus gewoon dat die PC weer werkt en niet dat die kennis over enige tijd mogelijk weer problemen heeft...
Voor minder dan 50 euro heb je een 1 TB schijf tegenwoordig: pricewatch: Seagate Desktop HDD, 1TB
Vervangen dus.
Maar goed, hen kennende zullen ze waarschijnlijk zeggen dat ik hem mag houden omdat ie defect is.
Verwijderd
Meer dan 3000 vervangen sectoren, dat zijn er nogal veel. Dan lijkt het mij beter om hem gewoon los te koppelen als die niet meer gebruikt wordt. Kan de HDD ook geen problemen meer veroorzaken. En kunnen ze er ook niet per ongeluk data opzetten.
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Deze schijf is niet betrouwbaar genoeg meer voor normaal gebruik.
Wat je uit kostenoogpunt verantwoord zou kunnen overwegen is het volgende:
- ik zie ook CRC-fouten (C7): vervang de kabel tussen de harddisk en het moederbord, want dit zijn communicatiefouten met onbekende gevolgen.
- start die PC op en laat hem een halve dag actief in de BIOS staan: in die tijd wordt de harddisk niet gebruikt en krijgt de schijf de tijd om de wachtende sectoren (C5) weg te werken.
- ga daarmee in elk geval door totdat de wachtende sectoren (C5) nul zijn.
- als daarna het aantal niet corrigeerbare sectoren (C6) nog steeds nul is, kan je de schijf gewoon verder gebruiken, MITS:
- er regelmatig databackups worden gemaakt
- de SMART gegevens regelmatig worden bekeken !ZONDER tests te draaien! (alleen kijken) en C6 nul blijft.
Het is geen echt goede oplossing voor data die beslist niet verloren mag gaan, maar in bepaalde omstandigheden (budget, enz) toch verantwoord is.
Wat je uit kostenoogpunt verantwoord zou kunnen overwegen is het volgende:
- ik zie ook CRC-fouten (C7): vervang de kabel tussen de harddisk en het moederbord, want dit zijn communicatiefouten met onbekende gevolgen.
- start die PC op en laat hem een halve dag actief in de BIOS staan: in die tijd wordt de harddisk niet gebruikt en krijgt de schijf de tijd om de wachtende sectoren (C5) weg te werken.
- ga daarmee in elk geval door totdat de wachtende sectoren (C5) nul zijn.
- als daarna het aantal niet corrigeerbare sectoren (C6) nog steeds nul is, kan je de schijf gewoon verder gebruiken, MITS:
- er regelmatig databackups worden gemaakt
- de SMART gegevens regelmatig worden bekeken !ZONDER tests te draaien! (alleen kijken) en C6 nul blijft.
Het is geen echt goede oplossing voor data die beslist niet verloren mag gaan, maar in bepaalde omstandigheden (budget, enz) toch verantwoord is.
- EricJH
- Registratie: November 2003
- Laatst online: 01:45
Als Current Pending Sector Count (C5) terug naar nul is duurt het meerdere dagen voordat Uncorrectable Sector Count volgt (C6). Dat is in het geval als je harde schijft gebruikt. Ik weet niet hoe dat vertaalt naar de situatie waarin de PC een halve dag actief in de BIOS is.
- chim0
- Registratie: Mei 2000
- Laatst online: 07-07 04:27
Bedankt voor de tips! De schijf is inmiddels losgekoppeld en niet meer in gebruik. Jammer! Ding was amper gebruikt.

Heb een snelle vraag,
geen klachten,
zouden jullie deze schijf nog gebruiken voor opslag, backup in externe case?
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Ja hoor, is nog niets mis mee.
De vraag is natuurlijk wel of je zo'n klein schijfje nog verantwoord in kan/wil zetten als een nieuwe (dus met minder risico want nieuw) externe USB3 schijf in een case al voor pakweg 50 Euro te krijgen is ...
De vraag is natuurlijk wel of je zo'n klein schijfje nog verantwoord in kan/wil zetten als een nieuwe (dus met minder risico want nieuw) externe USB3 schijf in een case al voor pakweg 50 Euro te krijgen is ...
- Giesber
- Registratie: Juni 2005
- Laatst online: 02-07 11:42
Ik zal hier even het vervolg van het verhaal zetten.Giesber schreef op dinsdag 25 september 2018 @ 13:43:
[...]
Bedankt voor de input. Is de Reallocated Sector Count niet gewoon 0?
Ik heb overigens nog eens naar de andere WD schijven in dezelfde setup gekeken, en die hebben dezelfde cijfers, buiten de Raw_Read_Error_Rate (1) en Multi_Zone_Error_Rate (200). Die staan voor de andere 2 WD schijven op 0. De rest van de waardes zijn hetzelfde, met soms wat kleine logische afwijkeingen (voor bv de spin up time).
Ik weet dus nog niet echt wat ik ermee moet aanvangen, misschien dat ik eens een long self-test zal doen om te kijken of daar problemen boven water komen.
Verder is het een RAIDZ2 (met 6 schijven), dus een kapotte schijf kan ie wel hebben, en staan er voornamelijk backups op (waarbij de belangrijkste data nog eens een cloud backup heeft), maar van de andere kant hoort het backup systeem gewoon betrouwbaar te zijn. Voor € 120 ga ik daar niet op beknibbelen.
Ik zal een lange SMART self-test draaien, en daarna verder beoordelen.
De SMART testen draaiden dus niet goed omwille van een leesfout. Maar meteen een nieuwe schijf besteld en ingebouwd, en intussen ook de oude schijf in mijn desktop gestoken om uit te vogelen wat er aan de hand is.
Hier is nog de gevraagde output van CrystalDiskInfo:
https://imgur.com/X99u7ba
En na een uitgebreide chkdsk sessie had de disk plots in de gaten dat ie ziek is:
https://imgur.com/gpb7NVd
Moest iemand geïnteresseerd zijn in de chkdsk resultaten:
https://imgur.com/8HJbLW9
Ik veronderstel dat dat genoeg is voor een retour naar WD? Weet iemand hoe de support van WD is? Als die echt om te huilen is probeer ik het wel via de webwinkel te regelen (de schijf is zakelijk aangekocht, dus van consumentenrechten is hier niet echt sprake lijkt me).
- Acid Vendetta
- Registratie: Mei 2006
- Laatst online: 10:33
Laatste keer dat ik er gebruik van gemaakt heb prima (rechtstreeks via WD). Was een 1TB WD Black waarvoor ik binnen vrij korte tijd een 2TB exemplaar terug kreeg. Als vervanging worden soms "certified repaired" schijven gebruikt.Giesber schreef op donderdag 18 oktober 2018 @ 16:20:
[...]
Ik veronderstel dat dat genoeg is voor een retour naar WD? Weet iemand hoe de support van WD is? Als die echt om te huilen is probeer ik het wel via de webwinkel te regelen (de schijf is zakelijk aangekocht, dus van consumentenrechten is hier niet echt sprake lijkt me).
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Waarschijnlijk moet je voordat je een RMA doet, de software van WD zelf draaien, waaruit een resultaatcode komt. Met die code zal het een stuk soepeler verlopen bij de winkel (je hebt bij hen gekocht en je hebt garantie), of (als dat niet soepel loopt) bij de fabrikant.
Verwijderd
Mijn Samsung SM951 van net geen drie jaar oud rapporteert in Linux (4.18.14-arch1-1-ARCH) een SMART "Attribute 173" Pre-fail conditie:
(Veel schijven schijnen dat attribuut overigens als "Wear Level Count" te rapporteren.)
Echter komt dat niet overeen met mijn verwachting en met de waarde van de Total_LBA's_Written: die rapporteert slechts 1,04TB (raw value van 33334 met een sector-size van 512 bytes, dus 33334 * 65536 * 512 = 1118503436288 bytes), terwijl de Total Bytes Written specificatie 75TB bedraagt!
Moet ik me zorgen maken?
code:
1
| 173 Unknown_Attribute 0x0033 001 001 005 Pre-fail Always FAILING_NOW 3291 |
(Veel schijven schijnen dat attribuut overigens als "Wear Level Count" te rapporteren.)
Echter komt dat niet overeen met mijn verwachting en met de waarde van de Total_LBA's_Written: die rapporteert slechts 1,04TB (raw value van 33334 met een sector-size van 512 bytes, dus 33334 * 65536 * 512 = 1118503436288 bytes), terwijl de Total Bytes Written specificatie 75TB bedraagt!
Moet ik me zorgen maken?
- JaimeJeter
- Registratie: September 2015
- Laatst online: 18-07-2025
Hi all,
Ik heb een gek probleem. Ik heb niet een, maar twee schijven (beide HGST Ultrastar 7K4000 4TB) met dezelfde waarschuwing voor Spin Retry Count. Ze zaten beiden in dezelfde externe dock (Sharkoon QuickPort XT Duo Clone).
Dat dock hangt aan een seedbox die min of meer 24/7 aan staat. Op een ochtend ontdekte ik dat de pc de verbinding met het dock verloren was. Een herstart van het hele systeem zorgde dat de boel het weer deed, maar error-checking was nodig en 10% van de inhoud van schijf Y is verdwenen. Ugh. Uit voorzorg de boel afgesloten. De onderstaande SMART-waardes uitgelezen door de schijven in mijn desktop te bouwen. Nu liggen ze even aan de zijlijn tot ik weet wat wijsheid is.
Hoor graag wat een handige volgende stap is.
Thanks!


Ik heb een gek probleem. Ik heb niet een, maar twee schijven (beide HGST Ultrastar 7K4000 4TB) met dezelfde waarschuwing voor Spin Retry Count. Ze zaten beiden in dezelfde externe dock (Sharkoon QuickPort XT Duo Clone).
Dat dock hangt aan een seedbox die min of meer 24/7 aan staat. Op een ochtend ontdekte ik dat de pc de verbinding met het dock verloren was. Een herstart van het hele systeem zorgde dat de boel het weer deed, maar error-checking was nodig en 10% van de inhoud van schijf Y is verdwenen. Ugh. Uit voorzorg de boel afgesloten. De onderstaande SMART-waardes uitgelezen door de schijven in mijn desktop te bouwen. Nu liggen ze even aan de zijlijn tot ik weet wat wijsheid is.
Hoor graag wat een handige volgende stap is.
Thanks!
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
@JaimeJeter
Niet alleen de Spin Retry Count valt op, ook de CRC Count!
Ik zou de voeding waar beide harddisks hun spanning van krijgen, als eerste verdenken en die vervangen door een wat steviger/beter modelletje.
Niet alleen de Spin Retry Count valt op, ook de CRC Count!
Ik zou de voeding waar beide harddisks hun spanning van krijgen, als eerste verdenken en die vervangen door een wat steviger/beter modelletje.
[ Voor 4% gewijzigd door Renault op 29-10-2018 20:14 ]
- JaimeJeter
- Registratie: September 2015
- Laatst online: 18-07-2025
Dank @Renault! Ik vermoedde al zoiets. In de specsheet van de schijf lees ik startup current (A, max): 1.2 (5V), 2.0 (12V). Eigenlijk moet ik dus een adapter hebben die 2,4A op 5V en 4A op 12V kan leveren, niet? Gewoon dubbel wat de schijf max kan willen trekken. Misschien nog ietsjes meer dan dat, voor de zekerheid. Hoor graag of dit hout snijdt of dat ik de plank juist missla.Renault schreef op maandag 29 oktober 2018 @ 20:13:
@JaimeJeter
Niet alleen de Spin Retry Count valt op, ook de CRC Count!
Ik zou de voeding waar beide harddisks hun spanning van krijgen, als eerste verdenken en die vervangen door een wat steviger/beter modelletje.
Hopelijk is dat het dan, want ik geloof dat die adapter-stekkertjes ook niet allemaal uniek zijn en je een adapter zonder al te veel moeite kan vervangen.
Edit: overigens staat er op de adapter van de Sharkoon alleen output: 12V 4A. Hoe zit het met 5V dan?
[ Voor 10% gewijzigd door JaimeJeter op 01-11-2018 00:05 ]
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Ik denk dat een steviger voeding inderdaad hout snijdt.
Bij die Sharkoon adapter moet je even kijken hoeveel pinnentjes die heeft: vaak levert de adapter alleen 12 Volt en wordt van de 12 Volt intern de 5 Volt "gemaakt". Als dat zo is, voldoet die adapter niet om deze harddisks te voeden, omdat hij neit genoeg energie kan leveren aan de 12V én 5 Volt lijnen tegelijkertijd.
Ik weet niet of die Sharkoon adapter een geschakelde voeding is: geschakelde voedingen kan je meestal wel parallel gebruiken als ze helemaal identiek zijn. Twee stuks is dan de dubbele capaciteit.
(Als ze niet identiek zijn, zou ik het niet doen.)
Bij die Sharkoon adapter moet je even kijken hoeveel pinnentjes die heeft: vaak levert de adapter alleen 12 Volt en wordt van de 12 Volt intern de 5 Volt "gemaakt". Als dat zo is, voldoet die adapter niet om deze harddisks te voeden, omdat hij neit genoeg energie kan leveren aan de 12V én 5 Volt lijnen tegelijkertijd.
Ik weet niet of die Sharkoon adapter een geschakelde voeding is: geschakelde voedingen kan je meestal wel parallel gebruiken als ze helemaal identiek zijn. Twee stuks is dan de dubbele capaciteit.
(Als ze niet identiek zijn, zou ik het niet doen.)
- JaimeJeter
- Registratie: September 2015
- Laatst online: 18-07-2025
@Renault

Ik heb 'm even uitgegraven. Volgens mij zie ik twee contactpuntjes aan de zijkant. Dat zijn dan vermoedelijk 12V en Ground? Dus dat zou niet goed genoeg zijn.
Ik kan niet zien of het een geschakelde voeding is. Voor wat het waard is, dit ding weegt helemaal niets, bijna.

Ik zie ook bij universele adapters in webshops slechts een enkele output-voltage staan. Is er wel iets dat ik kan kopen om deze situatie werkbaar te maken? Ik zit te denken aan twee sata-power-verlengkabels en twee lange sata-kabels halen en de boel gewoon aansturen alsof het interne schijven zijn. Ze hoeven er nooit af maar passen er ook niet in (Fractal Node 202).
Ik heb 'm even uitgegraven. Volgens mij zie ik twee contactpuntjes aan de zijkant. Dat zijn dan vermoedelijk 12V en Ground? Dus dat zou niet goed genoeg zijn.
Ik kan niet zien of het een geschakelde voeding is. Voor wat het waard is, dit ding weegt helemaal niets, bijna.
Ik zie ook bij universele adapters in webshops slechts een enkele output-voltage staan. Is er wel iets dat ik kan kopen om deze situatie werkbaar te maken? Ik zit te denken aan twee sata-power-verlengkabels en twee lange sata-kabels halen en de boel gewoon aansturen alsof het interne schijven zijn. Ze hoeven er nooit af maar passen er ook niet in (Fractal Node 202).
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Ja, dat is een geschakelde voeding van 12 Volt, 4 Ampère.
Dat kan net te weinig zijn voor twee 3,5" harddisks die opgegeven hebben dat ze ieder 2 A nodig hebben.
Het kan niet anders dan dat intern in je harddisk-behuizing de 5 Volt lijn wordt betrokken van de 12 Volt lijn, dus ja, de voeding is veel te krap voor jouw harddisks.
Je kunt er een 12 Volt 2A voeding (bv. van een oude laptop) aan parallel zetten, mits je de plussen en de minnen ieder aan elkaar maakt.
Wellicht gaat het dan wel goed.
Dat kan net te weinig zijn voor twee 3,5" harddisks die opgegeven hebben dat ze ieder 2 A nodig hebben.
Het kan niet anders dan dat intern in je harddisk-behuizing de 5 Volt lijn wordt betrokken van de 12 Volt lijn, dus ja, de voeding is veel te krap voor jouw harddisks.
Je kunt er een 12 Volt 2A voeding (bv. van een oude laptop) aan parallel zetten, mits je de plussen en de minnen ieder aan elkaar maakt.
Wellicht gaat het dan wel goed.
[ Voor 91% gewijzigd door Renault op 05-11-2018 17:09 ]
Ik denk dat die van mij op overlijden staat ??
Advies aub

Advies aub
[ Voor 15% gewijzigd door roymo op 05-11-2018 19:18 ]
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Ik weet niet wat voor jouw SSD wordt opgegeven aan total bytes written, maar inmiddels ongeveer 94 TB is al aardig wat.
Dat gezegd hebbende: hij is volgens de cijfers nu nog niet aan het instorten.
Als je je goed houdt aan een backupstramien van je belangrijke data, hoef je hem nog niet buiten gebruik te stellen.
Maar zijn beste periode heeft hij wel achter de rug.
Dat gezegd hebbende: hij is volgens de cijfers nu nog niet aan het instorten.
Als je je goed houdt aan een backupstramien van je belangrijke data, hoef je hem nog niet buiten gebruik te stellen.
Maar zijn beste periode heeft hij wel achter de rug.
- JaimeJeter
- Registratie: September 2015
- Laatst online: 18-07-2025
Hmm, twee voedingen parallel aan deze dock hangen betekent dus wel draden knippen en verbinden, niet? Ik denk dat met mijn beperkte (lees: geen) ervaring met elektro-doe-het-zelven dat het wellicht een makkelijker idee is om een tweede dock te regelen zodat iedere disk zijn eigen heeft. Voor een enkele drive moet deze immers genoeg zijn, niet?Renault schreef op maandag 5 november 2018 @ 12:52:
Ja, dat is een geschakelde voeding van 12 Volt, 4 Ampère.
Dat kan net te weinig zijn voor twee 3,5" harddisks die opgegeven hebben dat ze ieder 2 A nodig hebben.
Het kan niet anders dan dat intern in je harddisk-behuizing de 5 Volt lijn wordt betrokken van de 12 Volt lijn, dus ja, de voeding is veel te krap voor jouw harddisks.
Je kunt er een 12 Volt 2A voeding (bv. van een oude laptop) aan parallel zetten, mits je de plussen en de minnen ieder aan elkaar maakt.
Wellicht gaat het dan wel goed.
Dank voor alle adviezen. Wordt zeer gewaardeerd!
Edit: nee, dan extra lange sata-power-extension en sata-data. Heb je voor weinig, zie ik.
[ Voor 4% gewijzigd door JaimeJeter op 06-11-2018 23:20 ]
- Slenger
- Registratie: April 2008
- Laatst online: 29-06 13:25
Ik zit met in mijn ogen een complex probleem.
In een laptop zit een Toshiba THNSNK SSD, dit is de enige schijf in de laptop. Als de laptop lang achter elkaar aanstaat (8-10 uur.) start de laptop opnieuw op en geeft de BIOS aan dat er geen bootable device is aangetroffen. Ook in de BIOS is de SSD niet meer te vinden. Als ik de laptop helemaal uitzet en 10 minuten wacht start hij wel gewoon op. Echter begint het riedeltje daarna opnieuw.
Eerst dacht ik dat het in de BIOS zat, echter heb ik deze geupdate en hebben andere laptops van hetzelfde merk en type dit probleem niet.
Daarom heb ik toch maar een S.M.A.R.T. uitdraai via CrystalDiskInfo gemaakt en hoop ik dat iemand hem wil uitlezen.

In een laptop zit een Toshiba THNSNK SSD, dit is de enige schijf in de laptop. Als de laptop lang achter elkaar aanstaat (8-10 uur.) start de laptop opnieuw op en geeft de BIOS aan dat er geen bootable device is aangetroffen. Ook in de BIOS is de SSD niet meer te vinden. Als ik de laptop helemaal uitzet en 10 minuten wacht start hij wel gewoon op. Echter begint het riedeltje daarna opnieuw.
Eerst dacht ik dat het in de BIOS zat, echter heb ik deze geupdate en hebben andere laptops van hetzelfde merk en type dit probleem niet.
Daarom heb ik toch maar een S.M.A.R.T. uitdraai via CrystalDiskInfo gemaakt en hoop ik dat iemand hem wil uitlezen.
/u/407403/WAhack.png?f=community)
@Slenger Als ik het goed lees is de schijf 69 graden? Dat ziet er uit alsof de schijf wel heel erg warm wordt, hoe is de koeling in de laptop? (En hoe stoffig?) En zit er iets naast dat misschien erg warm wordt?
Afhankelijk van het model kan het dat als hij boven de 70 a 75 graden komt best wel eens zichzelf kan uitschakelen ja. Samsung SSD's hebben volgens mij 70 als treshold en die van intel zo'n 70 a 75. (Eerst worden ze veel trager overigens, schakelen niet direct uit.) Als dat het gemiddelde is dan zit jij daar met 69 graden wel heel dik tegenaan te hikken.
Afhankelijk van het model kan het dat als hij boven de 70 a 75 graden komt best wel eens zichzelf kan uitschakelen ja. Samsung SSD's hebben volgens mij 70 als treshold en die van intel zo'n 70 a 75. (Eerst worden ze veel trager overigens, schakelen niet direct uit.) Als dat het gemiddelde is dan zit jij daar met 69 graden wel heel dik tegenaan te hikken.
[ Voor 46% gewijzigd door WhatsappHack op 08-11-2018 12:33 ]
Geen quote of mention @WhatsappHack? Dan niet raar opkijken als je geen reactie krijgt. ;)
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
En over de rest van de SMART-waarden:
- C0 (Unexpected Power Loss) is erg hoog op een overigens "bijna nieuwe" SSD (157 uren bedrijfstijd) en nog géén 1 TB Bytes written.
Sterker nog: van de 276 keer inschakelen van je SSD had hij 162 x een Unexpected Power Loss!
Ga eens kritisch na hoe jij je laptop uitzet en schakel evt. eens tijdelijk je slaapstand uit om er via de (niet) oplopende SMART C0 waarde achter te komen welke status van je laptop leidt tot een Unexpected Power Loss.
- je 05-waarde (Reallocated Sectors Count) vertrouw ik niet helemaal gezien het grote aantal waarden "vendor specific" wat net als deze waarde precies op 100 staat.
Dus onderzoek hoe je de Unexpectes Power Loss waarden kunt beperken (slaapstand? / temperatuur?) en ga lekker verder met deze SSD.
Maak anders met behulp van Youtube of iFixedit instructies je laptop open (als je handig bent en voorzichtig/zorgvuldig kan werken) en ontdoe die van stof.
(Je maakt toch wel backups van je data he? SSD's zijn net als USB-sticks en harddisks niet betrouwbaar genoeg als enige datadrager)
- C0 (Unexpected Power Loss) is erg hoog op een overigens "bijna nieuwe" SSD (157 uren bedrijfstijd) en nog géén 1 TB Bytes written.
Sterker nog: van de 276 keer inschakelen van je SSD had hij 162 x een Unexpected Power Loss!
Ga eens kritisch na hoe jij je laptop uitzet en schakel evt. eens tijdelijk je slaapstand uit om er via de (niet) oplopende SMART C0 waarde achter te komen welke status van je laptop leidt tot een Unexpected Power Loss.
- je 05-waarde (Reallocated Sectors Count) vertrouw ik niet helemaal gezien het grote aantal waarden "vendor specific" wat net als deze waarde precies op 100 staat.
Dus onderzoek hoe je de Unexpectes Power Loss waarden kunt beperken (slaapstand? / temperatuur?) en ga lekker verder met deze SSD.
Maak anders met behulp van Youtube of iFixedit instructies je laptop open (als je handig bent en voorzichtig/zorgvuldig kan werken) en ontdoe die van stof.
(Je maakt toch wel backups van je data he? SSD's zijn net als USB-sticks en harddisks niet betrouwbaar genoeg als enige datadrager)
[ Voor 9% gewijzigd door Renault op 08-11-2018 20:59 ]
:strip_exif()/u/2227/rattle_snake.gif?f=community)
Hing mijn amper gebruikte externe backup disk weer even aan mijn pc.
Ik merkte dat toen ik voor de eerste keer een file wou openen dit heel lang duurde. Dus gelijk maar even mijn smart waarden bekeken. Ik zie heel veel seek en read errors.. Is deze disk rijp voor de sloop?
Op dit moment reageerd de HD nog?/ Weer? normaal.

Ik merkte dat toen ik voor de eerste keer een file wou openen dit heel lang duurde. Dus gelijk maar even mijn smart waarden bekeken. Ik zie heel veel seek en read errors.. Is deze disk rijp voor de sloop?
Op dit moment reageerd de HD nog?/ Weer? normaal.
[ Voor 28% gewijzigd door snakeye op 09-11-2018 09:05 ]
Atari 2600 @ 1,1 Hz, 1 Bits speaker, 16 Kb mem, 8 kleuren..
- McFastFood
- Registratie: Oktober 2013
- Laatst online: 01-06 19:12
Beste mede tweakers,
Graag jullie advies over het volgende.
Ik heb een laptop van mijn kennis voor een APK'tje en zoals altijd controleer ik de S.M.A.R.T. status daarvan met Crystaldiskinfo. Deze was niet uit te lezen met Crystadiskinfo waarop ik besloot het met HDtune uit te lezen. Hiermee, kreeg ik de S.M.A.R.T. status ook niet te zien maar. heb ik wel een error scan gedaan met het volgende resultaat:
1: Quick scan (stopte halverwege)

2: full Scan (stopte nog geen 15 blokjes verder)

WD lifeguard:

Daarnaast, ook nog een scan gedaan met Data lifeguard van WD en Seatools for Windows op beide programma's de short test en long test gedraaid, geen problemen daarmee.
Is de SSD die tevens op het moederbord vast gesoldeerd zit (dus ook niet te vervangen). dus ook de laptop afgeschreven?
Ik denk het persoonlijk wel want, toen ik HDtune en Seatools tegelijk opende BSOD. Maar, weet simpelweg niet van welke informatie ik moet uitgaan . Je zou logischerwijs zeggen dat Seatools e.a. programma anders dan HDtune ook bad sectors zouden moeten aangeven
. Je zou logischerwijs zeggen dat Seatools e.a. programma anders dan HDtune ook bad sectors zouden moeten aangeven  . Vandaar, dat ik jullie om advies vraag
. Vandaar, dat ik jullie om advies vraag 
Graag jullie advies over het volgende.
Ik heb een laptop van mijn kennis voor een APK'tje en zoals altijd controleer ik de S.M.A.R.T. status daarvan met Crystaldiskinfo. Deze was niet uit te lezen met Crystadiskinfo waarop ik besloot het met HDtune uit te lezen. Hiermee, kreeg ik de S.M.A.R.T. status ook niet te zien maar. heb ik wel een error scan gedaan met het volgende resultaat:
1: Quick scan (stopte halverwege)
2: full Scan (stopte nog geen 15 blokjes verder)
WD lifeguard:
Daarnaast, ook nog een scan gedaan met Data lifeguard van WD en Seatools for Windows op beide programma's de short test en long test gedraaid, geen problemen daarmee.
Is de SSD die tevens op het moederbord vast gesoldeerd zit (dus ook niet te vervangen). dus ook de laptop afgeschreven?
Ik denk het persoonlijk wel want, toen ik HDtune en Seatools tegelijk opende BSOD. Maar, weet simpelweg niet van welke informatie ik moet uitgaan
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
@snakeye :
Volgens mij is er helemaal niets mis met die disk, ik zie geen belangrijke foute waarden staan.
Volgens mij is er helemaal niets mis met die disk, ik zie geen belangrijke foute waarden staan.
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
@McFastFood :
Het kan zijn dat de laptop incompatible is geworden met SMART door de truukjes van de fabrikant.
Wat zegt Windows zelf als je een lange scandisk uitvoert?
Die resultaten zou ik als uitgangspunt nemen als maat voor de betrouwbaarheid van de SSD.
Het kan zijn dat de laptop incompatible is geworden met SMART door de truukjes van de fabrikant.
Wat zegt Windows zelf als je een lange scandisk uitvoert?
Die resultaten zou ik als uitgangspunt nemen als maat voor de betrouwbaarheid van de SSD.
Verwijderd
Beste tweakers een pc lovers,
Zouden jullie even naar mijn SMART checks kunnen kijken.
Volgens mij einde verhaal?
C: volgens mij niet veel problemen mee?
https://imgur.com/a/4LckdwL
En hier het probleem kindje geloof ik.
D:
https://imgur.com/a/r0HgcFJ
Wat raden jullie aan? nieuwe kopen of valt er nog wat te redden?
Alvast bedankt
PS, het lukt me niet om afbeelding te plaatsen
Zouden jullie even naar mijn SMART checks kunnen kijken.
Volgens mij einde verhaal?
C: volgens mij niet veel problemen mee?
https://imgur.com/a/4LckdwL
En hier het probleem kindje geloof ik.
D:
https://imgur.com/a/r0HgcFJ
Wat raden jullie aan? nieuwe kopen of valt er nog wat te redden?
Alvast bedankt
PS, het lukt me niet om afbeelding te plaatsen
[ Voor 18% gewijzigd door Verwijderd op 20-11-2018 14:37 ]
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
C: lijkt op basis van de waarden in orde, al zou ik niet blij zijn met de waarde voor Onverwachte Power Onderbrekingen (bij een SSD ...).
D: zou ik niet meer vertrouwen, het lijkt gewoon exit te zijn.
D: zou ik niet meer vertrouwen, het lijkt gewoon exit te zijn.
- FireDrunk
- Registratie: November 2002
- Laatst online: 06-07 18:04
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
Volledig eens met Renault, die D: schijf moet je in de vuilnisbak gooien.
Even niets...
Verwijderd
Top bedankt voor jullie snelle reactie.
Nieuwe kopen dan maar. wel jammer pas 3800uur gedraaid.
bijna 3 jaar oud. Dus dan ga ik maar afscheid nemen.
Nieuwe kopen dan maar. wel jammer pas 3800uur gedraaid.
bijna 3 jaar oud. Dus dan ga ik maar afscheid nemen.
[ Voor 12% gewijzigd door Verwijderd op 20-11-2018 19:25 ]
- chim0
- Registratie: Mei 2000
- Laatst online: 07-07 04:27
Klopt het dat bij een IDE schijf de temperatuur niet wordt weergegeven of is hier iets anders aan de hand?


- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
@chim0
Dit is een al wat oudere harddisk, die blijkbaar de temperatuur niet als uitleesbare parameter opslaat.
Dat heeft niets te maken met de IDE interface, maar alles met de printplaat/firmware op de harddisk die deze faciliteit toen blijkbaar nog niet bood.
(Ik heb IDE harddisks gezien met de temperatuur wel als uitleesbare parameter.)
Dit is een al wat oudere harddisk, die blijkbaar de temperatuur niet als uitleesbare parameter opslaat.
Dat heeft niets te maken met de IDE interface, maar alles met de printplaat/firmware op de harddisk die deze faciliteit toen blijkbaar nog niet bood.
(Ik heb IDE harddisks gezien met de temperatuur wel als uitleesbare parameter.)
- FireDrunk
- Registratie: November 2002
- Laatst online: 06-07 18:04
@Hamazaki Staat er super veel data op? Je zou de schijf eens door een long format heen kunnen halen. Die Pending Sectors zouden dan weg moeten gaan en omgezet moeten worden naar Reallocated Sectors.
Als het aantal Reallocated Sectors daarna stabiel blijft, kan je de schijf in principe nog wel gebruiken.
Reallocated Sectors zijn een teken van slijtage, en heel veel van die sectoren, geeft aan dat de schijf aan het einde van zijn levensduur is.
Blijft het dus stabiel, kan het een 'vuiltje' of een slechte sector op de disk zijn, die verder niet hoeft te betekenen dat de schijf niet nog een paar jaar mee kan.
Als het aantal Reallocated Sectors daarna stabiel blijft, kan je de schijf in principe nog wel gebruiken.
Reallocated Sectors zijn een teken van slijtage, en heel veel van die sectoren, geeft aan dat de schijf aan het einde van zijn levensduur is.
Blijft het dus stabiel, kan het een 'vuiltje' of een slechte sector op de disk zijn, die verder niet hoeft te betekenen dat de schijf niet nog een paar jaar mee kan.
Even niets...
- chim0
- Registratie: Mei 2000
- Laatst online: 07-07 04:27
Duidelijk! Komt uit een oude PC en voor de rest doet ie het nog prima. Heb hem te koop gezet, maar als niemand hem wil, haal ik er zo'n IDE naar SATA converter voor en gebruik ik hem als extra opslag.Renault schreef op woensdag 21 november 2018 @ 10:01:
@chim0
Dit is een al wat oudere harddisk, die blijkbaar de temperatuur niet als uitleesbare parameter opslaat.
Dat heeft niets te maken met de IDE interface, maar alles met de printplaat/firmware op de harddisk die deze faciliteit toen blijkbaar nog niet bood.
(Ik heb IDE harddisks gezien met de temperatuur wel als uitleesbare parameter.)
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
@Hamazaki
Eigenlijk valt het allemaal wel mee met jouw harddisk; hij heeft veel draai-uren, maar de rest valt wel mee.
Je kunt als alternatief die Current Pending Sectoren ook kwijtraken als je de PC enkele uren in het BIOS-scherm laat staan: dan kan de harddisk ongestoord verder met uitlees pogingen.
Daarna kijk je of de C5 waarde naar nul is gegaan. Zo niet: nogmaals in de BIOS zetten en wachten. C5 moet nul worden.
Daarna blijf je de harddisk verder gebruiken, maar hou je een aantal weken de 05 en C5 waarde in de gaten: die mogen daarna niet oplopen. Als ze niet oplopen is er niets aan de hand.
En backups maken deed je toch al?
Eigenlijk valt het allemaal wel mee met jouw harddisk; hij heeft veel draai-uren, maar de rest valt wel mee.
Je kunt als alternatief die Current Pending Sectoren ook kwijtraken als je de PC enkele uren in het BIOS-scherm laat staan: dan kan de harddisk ongestoord verder met uitlees pogingen.
Daarna kijk je of de C5 waarde naar nul is gegaan. Zo niet: nogmaals in de BIOS zetten en wachten. C5 moet nul worden.
Daarna blijf je de harddisk verder gebruiken, maar hou je een aantal weken de 05 en C5 waarde in de gaten: die mogen daarna niet oplopen. Als ze niet oplopen is er niets aan de hand.
En backups maken deed je toch al?
- wc2wc
- Registratie: December 2002
- Laatst online: 27-06 15:44
Mijn Synology Nas gaf een waarschuwing op 1 schijf .
Geen raid gewoon 2 eenvoudige volumes met muziek en films
Dit lees ik uit met Crystal disk info
moet ik deze al vervangen of ?
Geen raid gewoon 2 eenvoudige volumes met muziek en films
Dit lees ik uit met Crystal disk info
moet ik deze al vervangen of ?
- FireDrunk
- Registratie: November 2002
- Laatst online: 06-07 18:04
Mwoh, niet direct. Geen primaire data meer op zetten. Maar kan prima in een raid engine of voor secundaire data.
Even niets...
- wc2wc
- Registratie: December 2002
- Laatst online: 27-06 15:44
welke waarde moet ik in de gaten houden ? : c5 en 05 en 01 ?
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
C5 zou na enige tijd vanzelf moeten verdwijnen: de printplaat moet al zijn uitlees-pogingen afwerken om die sector uit te lezen. Als dat is afgerond wordt waarschijnlijk 05 eentje hoger.
Hou verder periodiek in de gaten of C5 en 05 oplopen.
En backups zijn altijd handig, vooral die van vóór het verschijnen van die "1" bij C5. die backup zou ik niet meer weggooien maar bewaren.
Hou verder periodiek in de gaten of C5 en 05 oplopen.
En backups zijn altijd handig, vooral die van vóór het verschijnen van die "1" bij C5. die backup zou ik niet meer weggooien maar bewaren.
- wc2wc
- Registratie: December 2002
- Laatst online: 27-06 15:44
Bedankt FireDrunk en Renault ,
er staan geen belangrijke dingen op, alleen films en series .
Begrijp ik goed dat bv een volledige format geen zin heeft, omdat dan alleen de smart waardes weer op 0 worden gezet, maar geen fysieke disk fouten worden hersteld.
er staan geen belangrijke dingen op, alleen films en series .
Begrijp ik goed dat bv een volledige format geen zin heeft, omdat dan alleen de smart waardes weer op 0 worden gezet, maar geen fysieke disk fouten worden hersteld.
- Cpt.Morgan
- Registratie: Februari 2001
- Laatst online: 23-11-2025
Om gerealloceerd te worden, moet die foutieve sector benaderd worden. Nu is het wachten tot dat gebeurd, bij een volledige format forceer je dat. Zoals hierboven gezegd, deze waarde kan gebeuren en zal verdwijnen, maar mocht hij oplopen, dan is dat wel reden tot zorg.wc2wc schreef op zondag 25 november 2018 @ 20:21:
Begrijp ik goed dat bv een volledige format geen zin heeft, omdat dan alleen de smart waardes weer op 0 worden gezet, maar geen fysieke disk fouten worden hersteld.
- Rieverst
- Registratie: Januari 2010
- Laatst online: 12:40
Ik heb onderstaande smartlisting en ik snap het niet helemaal. status is goed, maar een aantal waarden zijn dan vreemd.
ook staan er in de eventviewer van Windows melding over beschadigde blocken op de disk.
Lees ik het nu verkeerd en is de smart wel goed. Ik dacht dat je naar de raw-waarden moest kijken....

ook staan er in de eventviewer van Windows melding over beschadigde blocken op de disk.
Lees ik het nu verkeerd en is de smart wel goed. Ik dacht dat je naar de raw-waarden moest kijken....
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
De waarden voor 05 en A0 geven aan dat je data niet veilig is op deze SSD.
Maar als je goede backups maakt/hebt kan je hem nog wel gebruiken.
Mijn mening:
Als het mijn SSD was, mikte ik hem bij de huidige prijzen weg en kocht ik een nieuwe: de ellende van je missende bestanden en de moeite die je ervoor moet doen om e.e.a. tijdig te detecteren en backuppen/restoren zou ik er niet voor over hebben.
Maar als je goede backups maakt/hebt kan je hem nog wel gebruiken.
Mijn mening:
Als het mijn SSD was, mikte ik hem bij de huidige prijzen weg en kocht ik een nieuwe: de ellende van je missende bestanden en de moeite die je ervoor moet doen om e.e.a. tijdig te detecteren en backuppen/restoren zou ik er niet voor over hebben.
- Killsko
- Registratie: Februari 2017
- Laatst online: 14-06 12:06
:strip_icc():strip_exif()/u/884807/crop5aaf95748d181_cropped.jpeg?f=community)
Ook ik heb een waarschuwing bij mijn current pending sectors.

Is het echt nodig om hem compleet te formatteren? Helpt het niet om de free space te wipen?
Ik heb maar 2 schijven, waarvan 1 kleine SSD voor mijn OS en wat programma's en deze harde schijf voor mijn data...
Is het echt nodig om hem compleet te formatteren? Helpt het niet om de free space te wipen?
Ik heb maar 2 schijven, waarvan 1 kleine SSD voor mijn OS en wat programma's en deze harde schijf voor mijn data...
[ Voor 4% gewijzigd door Killsko op 24-12-2018 12:46 ]
Verwijderd
NeeKillsko schreef op maandag 24 december 2018 @ 12:46:
Is het echt nodig om hem compleet te formatteren?
Dat helpt alleen als de current pending sectors ook op de free space zitten.Helpt het niet om de free space te wipen?
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Heb je gezien dat er (C7) communicatiefouten zijn tussen de chip op je moederbord en die op je harddisk?
Geef de harddisk eerst eens een andere/nieuwe SATA-kabel op een andere SATA-poort.
Laat je PC daarna eens enkele uren in het BIOS-scherm staan, dan krijgt de harddisk tijd om via herhaald uitlezen te kijken wat er met de pending sectoren moet gebeuren.
Daarna kijk je wat er met C5 en C6 gebeurt om te bepalen wat je verder nog met deze harddisk kan.
En zorg voor actuele backups van je data.
In een programma als HD-Tune kan je uiteindelijk op het laatste tabblad zien of de slechte sectoren op één plaats geclusterd zitten (= mogelijk een uitbreidend defect in de magnetische laag op een platter) of verspreid.
edit: Na verder inlezen: kijk in de post van The_Mask voor de juiste oplossing. Ik zit er in de doorgehaalde tekst naast.
Geef de harddisk eerst eens een andere/nieuwe SATA-kabel op een andere SATA-poort.
Laat je PC daarna eens enkele uren in het BIOS-scherm staan, dan krijgt de harddisk tijd om via herhaald uitlezen te kijken wat er met de pending sectoren moet gebeuren.
Daarna kijk je wat er met C5 en C6 gebeurt om te bepalen wat je verder nog met deze harddisk kan.
En zorg voor actuele backups van je data.
In een programma als HD-Tune kan je uiteindelijk op het laatste tabblad zien of de slechte sectoren op één plaats geclusterd zitten (= mogelijk een uitbreidend defect in de magnetische laag op een platter) of verspreid.
edit: Na verder inlezen: kijk in de post van The_Mask voor de juiste oplossing. Ik zit er in de doorgehaalde tekst naast.
[ Voor 26% gewijzigd door Renault op 24-12-2018 20:46 ]
Verwijderd
In de meer dan 10000 uren dat de hardeschijf actief is geweest hebben maar drie communicatiefouten opgetreden, dat is niet noemenswaardig.Renault schreef op maandag 24 december 2018 @ 15:25:
Heb je gezien dat er (C7) communicatiefouten zijn tussen de chip op je moederbord en die op je harddisk?
Geef de harddisk eerst eens een andere/nieuwe SATA-kabel op een andere SATA-poort.
Dan gebeurt er niks, zoals al vaker aangegeven.Laat je PC daarna eens enkele uren in het BIOS-scherm staan, dan krijgt de harddisk tijd om via herhaald uitlezen te kijken wat er met de pending sectoren moet gebeuren.
- bvk
- Registratie: Maart 2002
- Laatst online: 13:21
Het gaat nooit snel genoeg!
:strip_icc():strip_exif()/u/52100/DSC00966voorGoT-60x60.jpg?f=community)
Ik had vannacht tijdens het gamen ineens een BSOD.... Bij proberen opnieuw te starten de melding dat er geen bootrecord gevonden kon worden. Systeem uitgezet en na opnieuw starten meteen de UEFI ingedoken waar ik inderdaad mijn SSD niet meer zag staan. De default waarden geladen en opnieuw geboot waarna de problemen opgelost waren en alles weer werkte.
Nu moet ik dus gaan troubleshooten en wil ik jullie vragen eens naar de waardes te kijken die ChrystaldiskInfo geeft:

Dit ziet er voor mij goed uit en moet ik de oorzaak ergens anders gaan zoeken, maar wellicht zit er toch iets (die ene procent?) fout?
Nu moet ik dus gaan troubleshooten en wil ik jullie vragen eens naar de waardes te kijken die ChrystaldiskInfo geeft:
Dit ziet er voor mij goed uit en moet ik de oorzaak ergens anders gaan zoeken, maar wellicht zit er toch iets (die ene procent?) fout?
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
- er is 1 bad sector omgewisseld voor een reservesector (o5 en B3).
Maar dat geeft niets als het hierna niet oploopt.
- wat minder goed is dat je behoorlijk wat CRC-fouten hebt (C7), dat duidt op communicatiefouten (ooit) tussen je moederbord en je SSD.
Wat je daaraan veiligheidshalve kunt doen, is je SSD een nieuwe SATA-kabel gunnen en die aansluiten op een andere SATA-poort van je moederbord.
En goede, actuele backups zijn nooit verkeerd.
Maar dat geeft niets als het hierna niet oploopt.
- wat minder goed is dat je behoorlijk wat CRC-fouten hebt (C7), dat duidt op communicatiefouten (ooit) tussen je moederbord en je SSD.
Wat je daaraan veiligheidshalve kunt doen, is je SSD een nieuwe SATA-kabel gunnen en die aansluiten op een andere SATA-poort van je moederbord.
En goede, actuele backups zijn nooit verkeerd.
- bvk
- Registratie: Maart 2002
- Laatst online: 13:21
Het gaat nooit snel genoeg!
Dank voor je analyse! Een nieuwe Sata kabel monteren is wel een goed idee, misschien is die inderdaad niet helemaal lekker meer waardoor het mobo ook ineens de SSD niet meer zag.Renault schreef op zaterdag 29 december 2018 @ 23:23:
- er is 1 bad sector omgewisseld voor een reservesector (o5 en B3).
Maar dat geeft niets als het hierna niet oploopt.
- wat minder goed is dat je behoorlijk wat CRC-fouten hebt (C7), dat duidt op communicatiefouten (ooit) tussen je moederbord en je SSD.
Wat je daaraan veiligheidshalve kunt doen, is je SSD een nieuwe SATA-kabel gunnen en die aansluiten op een andere SATA-poort van je moederbord.
En goede, actuele backups zijn nooit verkeerd.
- CH4OS
- Registratie: April 2002
- Niet online
It's a kind of magic
:strip_exif()/u/53522/crop583d477015a24.gif?f=community)
 Dit is een HDD van mij, die het voor het oog prima doet. Toch geeft CrystalDiskInfo een waarschuwing. Moet ik mij terecht zorgen gaan maken en de disk voortijdig vervangen?
Dit is een HDD van mij, die het voor het oog prima doet. Toch geeft CrystalDiskInfo een waarschuwing. Moet ik mij terecht zorgen gaan maken en de disk voortijdig vervangen? Backups zal ik in elk geval gaan maken, just in case.
[ Voor 8% gewijzigd door CH4OS op 31-12-2018 00:49 ]
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Zo te zien aan de getallen (het is nog erger dan je denkt want de waarden zijn in het hexadecimale stelsel weergegeven) is je schijf magnetisch aan het falen.
In jouw plaats zou ik het serienummer invoeren op de site van de fabrikant om te kijken of er nog fabrieksgarantie op zit (ben te lui om het aantal bedrijfsuren om te rekenen).
Zo ja: tooltje van de fabrikant er overheen halen en insturen voor RMA.
Zo nee: backup maken, wegmikken en nieuwe kopen en daar je data op zetten.
In jouw plaats zou ik het serienummer invoeren op de site van de fabrikant om te kijken of er nog fabrieksgarantie op zit (ben te lui om het aantal bedrijfsuren om te rekenen).
Zo ja: tooltje van de fabrikant er overheen halen en insturen voor RMA.
Zo nee: backup maken, wegmikken en nieuwe kopen en daar je data op zetten.
- jan99999
- Registratie: Augustus 2005
- Laatst online: 05:46
Je hebt 64616 sectoren uitgewisseld, erg veel, dus schijf weggooien.Backups zal ik in elk geval gaan maken, just in case.
- Randfiguur
- Registratie: Juli 2007
- Laatst online: 07-07 13:51

Current Pending Sector Count, Uncorrectable Sector Count en Write Error Rate kregen 3 weken geleden een raw value van 1 en zijn sindsdien stabiel.
Vandaag voerde ik een backup uit met backupsoftware en het viel me op dat de Read Error Rate met 9 klom naar 34. De backupsoftware bleef even 'hangen' bij een specifieke file, dus ik gok dat daar de bad sector zit. In Windows Event Viewer zag ik 9 disk-fouten, die ik interpreteer als 9 leespogingen.
Waarom heeft Windows of chkdsk deze bad sector niet al geflagd, m.a.w., waarom blijft Windows proberen om hem te lezen? Voorkomt een handmatige scan zoals chkdsk E: /f /r /x dat de Read Error Rate verder stijgt?
Alvast bedankt!
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Wellicht eens de lange scan van HD-Tune eroverheen laten lopen?
Nog beter is een full ("lange") format en de data terug erop zetten.
En dan de cijfers periodiek in de gaten houden.
Nog beter is een full ("lange") format en de data terug erop zetten.
En dan de cijfers periodiek in de gaten houden.
- Moppersmurf51
- Registratie: Juli 2016
- Laatst online: 30-05 11:23
:strip_icc():strip_exif()/u/797535/crop62c3362e4ab9f_cropped.jpg?f=community)
Ik heb een Synology NAS 4 bay DS416PLAY. Heb gisteren 2 WD RED 4TB schijven bijgezet (zaten al twee WD RED 4TB in). Nu is de NAS al hele tijd bezig met pariteitsconsistentie controle. Ik krijg nu de melding dat 1 van de oudere RED's al 390 beschadigde sectoren heeft. Als hij klaar is met het toevoegen van de nieuwe RED's aan de pool wil ik een SMART test draaien (even uitzoeken hoe ik dat moet doen). De oude vallen nog net onder de garantie. Zal de SMART hier posten met het verzoek voor advies.
Valt dit onder de garantie? En heb nog een vraag, als ik 1 schijf retourneer, kan men dan aan de hand van deze schijf mijn systeem en alles wat er op staat herbouwen? Staat nogal wat privé informatie op. Heb SHR, btrfs (1 schijf reparatie).
Valt dit onder de garantie? En heb nog een vraag, als ik 1 schijf retourneer, kan men dan aan de hand van deze schijf mijn systeem en alles wat er op staat herbouwen? Staat nogal wat privé informatie op. Heb SHR, btrfs (1 schijf reparatie).
Sinds 2012 1880 WP op Z.
- jan99999
- Registratie: Augustus 2005
- Laatst online: 05:46
Schijf zelf leeg maken en dan retour sturen! lijkt me logisch.Moppersmurf51 schreef op dinsdag 1 januari 2019 @ 22:20:
Ik heb een Synology NAS 4 bay DS416PLAY. Heb gisteren 2 WD RED 4TB schijven bijgezet (zaten al twee WD RED 4TB in). Nu is de NAS al hele tijd bezig met pariteitsconsistentie controle. Ik krijg nu de melding dat 1 van de oudere RED's al 390 beschadigde sectoren heeft. Als hij klaar is met het toevoegen van de nieuwe RED's aan de pool wil ik een SMART test draaien (even uitzoeken hoe ik dat moet doen). De oude vallen nog net onder de garantie. Zal de SMART hier posten met het verzoek voor advies.
Valt dit onder de garantie? En heb nog een vraag, als ik 1 schijf retourneer, kan men dan aan de hand van deze schijf mijn systeem en alles wat er op staat herbouwen? Staat nogal wat privé informatie op. Heb SHR, btrfs (1 schijf reparatie).
En in je nas instellen, dat je bij 20 sectoren een alarm/foutmelding krijgt, via mail, dan had je geweten dat er al fouten waren. En natuurlijk voordat je de schijven zou toevoegen , eerst de smart uitlezen.
- jan99999
- Registratie: Augustus 2005
- Laatst online: 05:46
chkdsk niet draaien , deze vernietigd de file als deze niet te lezen is.Randfiguur schreef op dinsdag 1 januari 2019 @ 15:10:
[Afbeelding]
Current Pending Sector Count, Uncorrectable Sector Count en Write Error Rate kregen 3 weken geleden een raw value van 1 en zijn sindsdien stabiel.
Vandaag voerde ik een backup uit met backupsoftware en het viel me op dat de Read Error Rate met 9 klom naar 34. De backupsoftware bleef even 'hangen' bij een specifieke file, dus ik gok dat daar de bad sector zit. In Windows Event Viewer zag ik 9 disk-fouten, die ik interpreteer als 9 leespogingen.
Waarom heeft Windows of chkdsk deze bad sector niet al geflagd, m.a.w., waarom blijft Windows proberen om hem te lezen? Voorkomt een handmatige scan zoals chkdsk E: /f /r /x dat de Read Error Rate verder stijgt?
Alvast bedankt!
9 -32 leesfouten, is dat de sector vaker gelezen wordt, om daar de data eraf te halen, dus sector is wel nog leesbaar, maar blijkbaar slecht.
Als je de schijf leeg kunt maken, zou ik de schijf meerdere keren volledig, elke sector meerdere keren herschrijven, zodat je kunt zien of de schijf slechter wordt.
In linux met badblocks(hier goede handleiding zoeken, dus herschrijven van elke sector doen), kun je elke sector flink overschrijven, dan kan smart zijn werkt doen, of betaal software spinrite is een hele mooie software om sectoren te testen, deze kun je ook gebruiken om harde schijven te verversen als deze als backup dienen(en bijna nooit gebruikt worden).
- Moppersmurf51
- Registratie: Juli 2016
- Laatst online: 30-05 11:23
Hallo Jan,jan99999 schreef op dinsdag 1 januari 2019 @ 22:26:
[...]
Schijf zelf leeg maken en dan retour sturen! lijkt me logisch.
En in je nas instellen, dat je bij 20 sectoren een alarm/foutmelding krijgt, via mail, dan had je geweten dat er al fouten waren. En natuurlijk voordat je de schijven zou toevoegen , eerst de smart uitlezen.
Leegmaken via de pc neem ik aan, formatteren of andere tool gebruiken?
Had dit inderdaad niet aan staan. Op een oudere DS214PLAY wel, staat op 50.
Heb er dus niet aan gedacht dat er iets mis mee kon zijn.
Sinds 2012 1880 WP op Z.
- jan99999
- Registratie: Augustus 2005
- Laatst online: 05:46
Leeg maken via een pc, google hier op, je hebt bootable cd/usb sticks om dit te doen.Moppersmurf51 schreef op dinsdag 1 januari 2019 @ 22:33:
[...]
Hallo Jan,
Leegmaken via de pc neem ik aan, formatteren of andere tool gebruiken?
Had dit inderdaad niet aan staan. Op een oudere DS214PLAY wel, staat op 50.
Heb er dus niet aan gedacht dat er iets mis mee kon zijn.
En vooral de goede manier doen, zodat alle data weg is,
DBAN is een goede.
Zelf had ik de aantal sectoren in de nas op 1 gezet, dus bij 1 fout gooi de nas de hd er direct uit, daarom op 20 zetten, of een beetje hoger, maar bij 20 zou ik deze gaan vervangen.
- jaspov
- Registratie: Januari 2000
- Laatst online: 02-07 19:39
:strip_exif()/u/2393/Tie-Fighter-Pilot3.gif?f=community)
Goedemorgen, ik heb een Synology DS214Play met twee keer een WD Red 4GB disk. Disk 1 staat op 0 bad sectors en Disk 2 al een jaar op 2 bad sectors, heel stabiel. Alles groen/normal volgens de Synology
Vorige week voor het eerst een I/O error op disk 1, SMART gaf nog steeds 0 bad sectors en toen een extended SMART scan gedraaid die bleef hangen op 90% (drie dagen). Na reboot opnieuw een extended SMART scan gedraaid. Tijdens die scan gaf de synology meerdere foutmeldingen aan "Bad sector was found on disk 1", de scan voltooide nu wel en geeft 0 bad sectors. Hierdoor in verwarring door deze (voor mij) tegenstrijdige meldingen.
Synology: rechts de bad sector meldingen (die kwamen tijdens het uitvoeren van de extended SMART scan, en nu links de summary: 0 bad sectors

SMART gegevens (na de extended SMART scan, daarvoor stonden de bad sectors ook al op 0)

Graag advies, is de NAS verstrooid of gaat de disk toch zijn einde naderen. Dacht dat een SMART scan zelf niets aanpaste (itt een tool van de fabrikant)
Vorige week voor het eerst een I/O error op disk 1, SMART gaf nog steeds 0 bad sectors en toen een extended SMART scan gedraaid die bleef hangen op 90% (drie dagen). Na reboot opnieuw een extended SMART scan gedraaid. Tijdens die scan gaf de synology meerdere foutmeldingen aan "Bad sector was found on disk 1", de scan voltooide nu wel en geeft 0 bad sectors. Hierdoor in verwarring door deze (voor mij) tegenstrijdige meldingen.
Synology: rechts de bad sector meldingen (die kwamen tijdens het uitvoeren van de extended SMART scan, en nu links de summary: 0 bad sectors
SMART gegevens (na de extended SMART scan, daarvoor stonden de bad sectors ook al op 0)
Graag advies, is de NAS verstrooid of gaat de disk toch zijn einde naderen. Dacht dat een SMART scan zelf niets aanpaste (itt een tool van de fabrikant)
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Voor het antwoord is het nogal belangrijk hoe de disks in je NAS zitten (RAID1 of iets anders zoals RAID0 / JBOD) en of je recente backups hebt van al je data. En waarvoor je je NAS gebruikt (voor beschikbaar houden van de gegevens of als backupmedium).
Daarnaast is het belangrijk om te weten dat SMART een statistische verzameling gegevens over het wel en wee van de harddisk is. Het geeft dus geen absolute toestand aan, het geeft hoogstens herleidbare indicaties daarover. Daarnaast gaan die gegevens over wat er heeft plaatsgevonden: als er plaatsen zijn op de harddisk die slecht zijn en die al tijden lang niet meer zijn geraadpleegd, zul je dat niet terug zien in de SMART gegevens tenzij je die gegevens alsnog benaderd (bv. middels benadering van die gegevens middels een scanopdracht). Dat verklaart waarom je bij een nadere controle meer nog verschjinselen ontdekt.
Als je data absoluut veilig staat buiten je NAS, zou ik overwegen om Disk 1 te vervangen. De data staat er niet meer betrouwbaar genoeg op. Maar dat hangt ook af van hoe die disken zijn geconfigureerd en wat het gebruiksdoel is. Als je nu in RAID1 draait, zou je Disk 1 gewoon eruit kunnen halen en doordraaien met Disk 2.
Als je data niet absoluut veilig staat buiten je NAS (dus geen goede originelen/backups beschikbaar), en de disks staan niet in RAID1, zou ik direct de NAS offline halen en "een recovery uitvoeren" op Disk 1: eerst de SMART scan herstarten en uit laten lopen tot 100 % en dan alle data eraf halen die nog intact is. Zie Thematopic: Datarecovery.
Of je daarna nog recht op RMA hebt kan je uitzoeken door het serienummer in te voeren op de website van de fabrikant. En kijk bij RMA of je de disk vooraf goed wiped of niet.
Daarna zette ik er een nieuwe harddisk in, zette de data erop terug en draaide verder.
Overweeg dan m.b.t. deze ervaringen of je iets anders doet m.b.t. RAID en/of actuele backups. En wellicht kan je op jouw NAS ook een alarm met actie zetten m.b.t. read-errors?
Daarnaast is het belangrijk om te weten dat SMART een statistische verzameling gegevens over het wel en wee van de harddisk is. Het geeft dus geen absolute toestand aan, het geeft hoogstens herleidbare indicaties daarover. Daarnaast gaan die gegevens over wat er heeft plaatsgevonden: als er plaatsen zijn op de harddisk die slecht zijn en die al tijden lang niet meer zijn geraadpleegd, zul je dat niet terug zien in de SMART gegevens tenzij je die gegevens alsnog benaderd (bv. middels benadering van die gegevens middels een scanopdracht). Dat verklaart waarom je bij een nadere controle meer nog verschjinselen ontdekt.
Als je data absoluut veilig staat buiten je NAS, zou ik overwegen om Disk 1 te vervangen. De data staat er niet meer betrouwbaar genoeg op. Maar dat hangt ook af van hoe die disken zijn geconfigureerd en wat het gebruiksdoel is. Als je nu in RAID1 draait, zou je Disk 1 gewoon eruit kunnen halen en doordraaien met Disk 2.
Als je data niet absoluut veilig staat buiten je NAS (dus geen goede originelen/backups beschikbaar), en de disks staan niet in RAID1, zou ik direct de NAS offline halen en "een recovery uitvoeren" op Disk 1: eerst de SMART scan herstarten en uit laten lopen tot 100 % en dan alle data eraf halen die nog intact is. Zie Thematopic: Datarecovery.
Of je daarna nog recht op RMA hebt kan je uitzoeken door het serienummer in te voeren op de website van de fabrikant. En kijk bij RMA of je de disk vooraf goed wiped of niet.
Daarna zette ik er een nieuwe harddisk in, zette de data erop terug en draaide verder.
Overweeg dan m.b.t. deze ervaringen of je iets anders doet m.b.t. RAID en/of actuele backups. En wellicht kan je op jouw NAS ook een alarm met actie zetten m.b.t. read-errors?
- jaspov
- Registratie: Januari 2000
- Laatst online: 02-07 19:39
Dank voor de reactie, de schijven staan in RAID0 (Mirror). Van de belangrijkste data heb ik ook een cloud backup. Schijven zijn voor 3TB gevuld van de 4TB.Renault schreef op woensdag 2 januari 2019 @ 10:39:
Voor het antwoord is het nogal belangrijk hoe de disks in je NAS zitten (RAID1 of iets anders zoals RAID0 / JBOD) en of je recente backups hebt van al je data. En waarvoor je je NAS gebruikt (voor beschikbaar houden van de gegevens of als backupmedium).
Daarnaast is het belangrijk om te weten dat SMART een statistische verzameling gegevens over het wel en wee van de harddisk is. Het geeft dus geen absolute toestand aan, het geeft hoogstens herleidbare indicaties daarover. Daarnaast gaan die gegevens over wat er heeft plaatsgevonden: als er plaatsen zijn op de harddisk die slecht zijn en die al tijden lang niet meer zijn geraadpleegd, zul je dat niet terug zien in de SMART gegevens tenzij je die gegevens alsnog benaderd (bv. middels benadering van die gegevens middels een scanopdracht). Dat verklaart waarom je bij een nadere controle meer nog verschjinselen ontdekt.
Schijf wordt voornamelijk gebruikt voor documenten, eigen foto's etc. Die staan allemaal ook gebackupped in de cloud.
Ik wil vooral op dat ding kunnen vertrouwen en dat is nu een beetje weg. Gisteren al bijna een nieuwe harddisk besteld om disk 1 te vervangen maar was vanochtend verward door de melding 0 bad sectors na een (eindelijk gelukte) extended scan. Het liefst bestel ik dus gelijk een nieuwe schijf, zou het alleen zonde vinden als de NAS hier de boosdoener is van de vreemde meldingen.
Had de extended scan niet op zijn minst iets moeten vinden (als er bad sectors zijn?). Ik dacht dat die extended scan echt de hele schijf tracht te lezen, ook de stukken die je niet of zelden gebruikt.
Een SMART Scan stond al maandelijks gepland. Nu ook een extended SMART scan alleen twijfel ik dus of die me helpt aangezien die met 0 bad sectors komt. 0 Bad sectors maar toch een slechte schijf.
Anders gezegd: ik haal het liefst vanmiddag een nieuwe schijf, maar als die ook in een smart extended scan 0 bad sectors geeft dan heb ik daar op grond van deze ervaring niet veel vertrouwen in dat zo'n scan me iets zegt over de gezondheid van een disk.
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
RAID0 <> mirror!!
Ik denk dat dit een typevaut van je is. Ik ga ervan uit dat je RAID1 hebt (mirror).
Als je scant, wordt structureel elke sector gelezen. Daarbij leest hij de sector consistent uit of inconsistent.
In het laatste geval wordt de sector tijdelijk gemarkeerd en start een sequentie van herhaalde uitleespogingen. Als de data er uiteindelijk goed vanaf komt is het goed. Als de sector niet betrouwbaar meer blijkt te zijn, wordt hij gemarkeerd en niet meer gebruikt waarbij de capaciteit wordt hersteld door het in gebruik nemen van een reservesector".
Zoals het er nu uit ziet is alles weer in orde. Voer wat vaker scans uit en hou de SMART parameters in de gaten. Zet er evt. een alarm op.
Je gebruikt de schijf alleen voor het beschikbaar stellen van data terwijl je een goede actuele backup hebt. Geen paniek dus.
Ik denk dat dit een typevaut van je is. Ik ga ervan uit dat je RAID1 hebt (mirror).
Als je scant, wordt structureel elke sector gelezen. Daarbij leest hij de sector consistent uit of inconsistent.
In het laatste geval wordt de sector tijdelijk gemarkeerd en start een sequentie van herhaalde uitleespogingen. Als de data er uiteindelijk goed vanaf komt is het goed. Als de sector niet betrouwbaar meer blijkt te zijn, wordt hij gemarkeerd en niet meer gebruikt waarbij de capaciteit wordt hersteld door het in gebruik nemen van een reservesector".
Zoals het er nu uit ziet is alles weer in orde. Voer wat vaker scans uit en hou de SMART parameters in de gaten. Zet er evt. een alarm op.
Je gebruikt de schijf alleen voor het beschikbaar stellen van data terwijl je een goede actuele backup hebt. Geen paniek dus.
- jaspov
- Registratie: Januari 2000
- Laatst online: 02-07 19:39
Oeps ja Raid1 inderdaad.
Dank, ik zal wat vaker scannen. Met de tweede schijf en kritieke data in de cloud op zich safe. Op zich ook niet heel veel draai-uren nog (voor een NAS schijf). Kijken of ik deze week foutloos doorkom en einde van de week nog een scan.
Dank, ik zal wat vaker scannen. Met de tweede schijf en kritieke data in de cloud op zich safe. Op zich ook niet heel veel draai-uren nog (voor een NAS schijf). Kijken of ik deze week foutloos doorkom en einde van de week nog een scan.
- Killsko
- Registratie: Februari 2017
- Laatst online: 14-06 12:06
Okee, ik heb inmiddels de free space gewiped maar dat heeft het probleem niet opgelost.Verwijderd schreef op maandag 24 december 2018 @ 13:26:
[...]
Nee
[...]
Dat helpt alleen als de current pending sectors ook op de free space zitten.
Hoe ernstig is dit probleem en wat kan ik er nog meer aan doen?
- Giesber
- Registratie: Juni 2005
- Laatst online: 02-07 11:42
Je kan eens een long/extended SMART test doen, die zou elke sector moeten lezen en schrijven (zonder data verlies). Dan heb je ook meteen een compleet beeld van het aantal slechte sectoren.Killsko schreef op woensdag 2 januari 2019 @ 16:05:
[...]
Okee, ik heb inmiddels de free space gewiped maar dat heeft het probleem niet opgelost.
Hoe ernstig is dit probleem en wat kan ik er nog meer aan doen?
- chim0
- Registratie: Mei 2000
- Laatst online: 07-07 04:27
Verrek, door de post @Killsko zie ik nu pas die C8 waarde. Ik heb dezelfde schijf en ook bij mij staat er een waarde. Al die jaren nooit op gelet eigenlijk. Heb het even opgezocht en kwam hierop uit > https://kb.acronis.com/content/9136
Als ik het goed begrijp, is het dus een proprietary attribuut en zijn het dus fouten die voorkomen als er data geschreven wordt door problemen met het schijfoppervlak of leeskop? En die problemen komen waarschijnlijk door slijtage van de schijf door de leeftijd van de schijf. Dat kan wel kloppen, want deze schijf heb ik in eerste instantie als systeemschijf gebruikt, maar al heel snel werd het een opslagschijf en heb ik hem helemaal grijs geschreven. Plus het is natuurlijk een oud beestje. Valt me nog mee dat ie geen kapotte of beschadigde sectoren heeft. Bijna 55.000 bedrijfsuren and still going strong behalve die write errors dan.
Dat zou misschien ook mijn corrupte mp3's probleem kunnen verklaren.
Als ik het goed begrijp, is het dus een proprietary attribuut en zijn het dus fouten die voorkomen als er data geschreven wordt door problemen met het schijfoppervlak of leeskop? En die problemen komen waarschijnlijk door slijtage van de schijf door de leeftijd van de schijf. Dat kan wel kloppen, want deze schijf heb ik in eerste instantie als systeemschijf gebruikt, maar al heel snel werd het een opslagschijf en heb ik hem helemaal grijs geschreven. Plus het is natuurlijk een oud beestje. Valt me nog mee dat ie geen kapotte of beschadigde sectoren heeft. Bijna 55.000 bedrijfsuren and still going strong behalve die write errors dan.
Dat zou misschien ook mijn corrupte mp3's probleem kunnen verklaren.
[ Voor 16% gewijzigd door chim0 op 03-01-2019 06:58 ]
- Moppersmurf51
- Registratie: Juli 2016
- Laatst online: 30-05 11:23
Bij toevoegen van 2 extra HD in 4bay (zie eerdere posting) liep ik tegen 390 errors aan op schijf 2.
Na toevoegen schijven aan de pool smart test uitgebreid gedaan maar die bleef hangen op 90%.
Vervolgens gestopt.

In smart info zie ik:

Mijn logboek gaf dit aan:

De WD RED 4TB valt nog onder de garantie. Zou ik een RMA aanmaken? Valt dit onder de garantie?
Na toevoegen schijven aan de pool smart test uitgebreid gedaan maar die bleef hangen op 90%.
Vervolgens gestopt.
In smart info zie ik:
Mijn logboek gaf dit aan:
De WD RED 4TB valt nog onder de garantie. Zou ik een RMA aanmaken? Valt dit onder de garantie?
[ Voor 6% gewijzigd door Moppersmurf51 op 03-01-2019 17:56 ]
Sinds 2012 1880 WP op Z.
- jaspov
- Registratie: Januari 2000
- Laatst online: 02-07 19:39
Garantie weet ik niet maar 1 van mijn WD RED 4TB schijven kwam ook niet verder dan 90%. NAS gereboot en opnieuw geprobeerd en toen lukte het wel (wellicht hebben andere taken op de NAS ook invloed, dus kan mogelijk helpen om even niet teveel te doen als je taken kan uitstellen. Vandaag ging hij van 50% naar 10% terug wellicht doordat er teveel was veranderd oid, ik was druk in de weer op de NAS).Moppersmurf51 schreef op donderdag 3 januari 2019 @ 14:41:
Bij toevoegen van 2 extra HD in 4bay (zie eerdere posting) liep ik tegen 390 errors aan op schijf 2.
Na toevoegen schijven aan de pool smart test uitgebreid gedaan maar die bleef hangen op 90%.
Vervolgens gestopt.
De WD RED 4TB valt nog onder de garantie. Zou ik een RMA aanmaken? Valt dit onder de garantie?
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
Waarom zolang je garantie nog niet is afgelopen, niet even afwachten en voorlopig even met korte intervallen een uitgebreide SMART check doen en kijken of e.e.a. stabiel blijft?
Of (als je zeker bent van je data) deze disk wipen en opnieuw toevoegen in de NAS en in goed in de gaten houden?
En evt. sowieso de tool van de fabrikant er overheen laten lopen om te kijken of er een code uitkomt?
Zonder foutcode heeft RMA weinig zin, dan krijg je je eigen disk mogelijk ongewijzigd terug.
Als je RMA doet met directe vervangende disk leverantie, weet je namelijk niet wat voor disk je terug krijgt in termen van betrouwbaarheid en dan moet je die óók toevoegen aan je NAS met hetzelfde nadeel (terug opbouwen van je data).
Of (als je zeker bent van je data) deze disk wipen en opnieuw toevoegen in de NAS en in goed in de gaten houden?
En evt. sowieso de tool van de fabrikant er overheen laten lopen om te kijken of er een code uitkomt?
Zonder foutcode heeft RMA weinig zin, dan krijg je je eigen disk mogelijk ongewijzigd terug.
Als je RMA doet met directe vervangende disk leverantie, weet je namelijk niet wat voor disk je terug krijgt in termen van betrouwbaarheid en dan moet je die óók toevoegen aan je NAS met hetzelfde nadeel (terug opbouwen van je data).
- jaspov
- Registratie: Januari 2000
- Laatst online: 02-07 19:39
Update (2x WD Red 4TB in Synology DS214Play). Disk 1 had na de extended SMART scan 0 bad sectors.
Gisteravond in de Synology interface 5 meldingen "Bad sector was found on disk [1]" en 1 melding "Read abnormality (UNC error) is detected on disk 1 on DS214play connected to DS214Play".
Storage manager gaf op dat moment 1 bad sector aan op die Disk 1. Gelijk een extended scan aangezet. Nu in de ochtend staat die op 90% en storage manager geeft weer aan: Bad sectors: 0
Ga toch een nieuwe disk bestellen, heb hier geen goed gevoel bij. Zit me vooral niet lekker dat het wat wispelturig is allemaal.
Gisteravond in de Synology interface 5 meldingen "Bad sector was found on disk [1]" en 1 melding "Read abnormality (UNC error) is detected on disk 1 on DS214play connected to DS214Play".
Storage manager gaf op dat moment 1 bad sector aan op die Disk 1. Gelijk een extended scan aangezet. Nu in de ochtend staat die op 90% en storage manager geeft weer aan: Bad sectors: 0
Ga toch een nieuwe disk bestellen, heb hier geen goed gevoel bij. Zit me vooral niet lekker dat het wat wispelturig is allemaal.
- JaimeJeter
- Registratie: September 2015
- Laatst online: 18-07-2025
Om hier nog even op terug te komen, ik heb het uiteindelijk opgelost door de schijven als intern aan te sluiten (op de voeding van de pc), maar met zodanig lange kabels, dat de schijven alsnog buiten de behuizing staan. Prima voor mijn doeleinden.Renault schreef op maandag 5 november 2018 @ 12:52:
Ja, dat is een geschakelde voeding van 12 Volt, 4 Ampère.
Dat kan net te weinig zijn voor twee 3,5" harddisks die opgegeven hebben dat ze ieder 2 A nodig hebben.
Het kan niet anders dan dat intern in je harddisk-behuizing de 5 Volt lijn wordt betrokken van de 12 Volt lijn, dus ja, de voeding is veel te krap voor jouw harddisks.
Je kunt er een 12 Volt 2A voeding (bv. van een oude laptop) aan parallel zetten, mits je de plussen en de minnen ieder aan elkaar maakt.
Wellicht gaat het dan wel goed.
Moest nog een Y-splitter voor sata power kopen aangezien de voeding niet genoeg aansluitingen heeft van zichzelf. Niet de bedoeling, maar ik waag het erop aangezien 1 van de 3 schijven een ssd is, er geen discrete gpu aan hangt en de cpu de zwakste is van zijn generatie.
Anyway, alle waarden worden door het systeem weer als 'GOOD' bestempeld en ik heb geen enkel probleem meer gehad!
Hartelijk dank @Renault!
- KennieNL
- Registratie: Mei 2007
- Laatst online: 01-07 18:50
Hmm ik zit te twijfelen over de betrouwbaarheid van een schijf in mijn Synology NAS.
Ik heb een Synology met een 4TB WD Red en 4TB WD Black (deze had ik nog liggen).
Vannacht mailtje gekregen dat het aantal bad sectors overschreven was van de WD Black.
SMART gecontroleerd en inderdaad, current pending sector in de SMART waarden stond op 1.
Vervolgens een SMART test vanuit DSM gedraaid en na voltooien staat de current pending sectors count weer op 0...
Ik zou verwachten dat mijn reallocated sector count dan op 1 zou staan, maar deze is alsnog 0.
Buiten dat een SMART test normaal hiermee niets gaat doen...
Iemand dit ooit meegemaakt?
De rede overigens dat ik over de schijf twijfel is omdat deze al ooit kapot is geweest en onder RMA terug, ik krijg gewoon een naar onderbuik gevoel van dit type
Ik heb een Synology met een 4TB WD Red en 4TB WD Black (deze had ik nog liggen).
Vannacht mailtje gekregen dat het aantal bad sectors overschreven was van de WD Black.
SMART gecontroleerd en inderdaad, current pending sector in de SMART waarden stond op 1.
Vervolgens een SMART test vanuit DSM gedraaid en na voltooien staat de current pending sectors count weer op 0...
Ik zou verwachten dat mijn reallocated sector count dan op 1 zou staan, maar deze is alsnog 0.
Buiten dat een SMART test normaal hiermee niets gaat doen...
Iemand dit ooit meegemaakt?
De rede overigens dat ik over de schijf twijfel is omdat deze al ooit kapot is geweest en onder RMA terug, ik krijg gewoon een naar onderbuik gevoel van dit type
- jaspov
- Registratie: Januari 2000
- Laatst online: 02-07 19:39
Zie mijn posts hierboven met de WD RED. Eerst bad sectors die daarna weer verdwijnen. Zit me ook niet lekker. Juist dat ze weer verdwijnen om direct daarna weer terug te komen.KennieNL schreef op zaterdag 5 januari 2019 @ 11:27:
Hmm ik zit te twijfelen over de betrouwbaarheid van een schijf in mijn Synology NAS.
Ik heb een Synology met een 4TB WD Red en 4TB WD Black (deze had ik nog liggen).
Vannacht mailtje gekregen dat het aantal bad sectors overschreven was van de WD Black.
SMART gecontroleerd en inderdaad, current pending sector in de SMART waarden stond op 1.
Vervolgens een SMART test vanuit DSM gedraaid en na voltooien staat de current pending sectors count weer op 0...
Ik zou verwachten dat mijn reallocated sector count dan op 1 zou staan, maar deze is alsnog 0.
Buiten dat een SMART test normaal hiermee niets gaat doen...
Iemand dit ooit meegemaakt?
De rede overigens dat ik over de schijf twijfel is omdat deze al ooit kapot is geweest en onder RMA terug, ik krijg gewoon een naar onderbuik gevoel van dit type

{kind=link}
{kind=link}
- Renault
- Registratie: Januari 2014
- Laatst online: 12:26
@KennieNL
Het kan zijn dat zo'n sector niet direct goed kon worden uitgelezen, maar dat na een aantal pogingen (dat doet de print op de harddisk geheel zelfstandig) dat wel is gelukt. En dan staan zowel het aantal wachtende als vervangen sectoren op nul.
Je zou (als je die mogelijkheid hebt) eens een lange smart-test aan kunnen zetten (van het type zoals HD-Tune dat doet, dus zonder gegevensverlies elke sector uittesten of verse gegevens goed terugkomen na opslag op die sector) om te kijken wat je qua betrouwbaarheid kunt verwachten van deze disks.
En als je goede actuele backups hebt, gebruik je de NAS alleen voor de beschikbaarheid van je gegevens en is er weinig zorg voor dataverlies.
Het kan zijn dat zo'n sector niet direct goed kon worden uitgelezen, maar dat na een aantal pogingen (dat doet de print op de harddisk geheel zelfstandig) dat wel is gelukt. En dan staan zowel het aantal wachtende als vervangen sectoren op nul.
Je zou (als je die mogelijkheid hebt) eens een lange smart-test aan kunnen zetten (van het type zoals HD-Tune dat doet, dus zonder gegevensverlies elke sector uittesten of verse gegevens goed terugkomen na opslag op die sector) om te kijken wat je qua betrouwbaarheid kunt verwachten van deze disks.
En als je goede actuele backups hebt, gebruik je de NAS alleen voor de beschikbaarheid van je gegevens en is er weinig zorg voor dataverlies.
![]() Dit topic is gesloten.
Dit topic is gesloten.
![]()