pixeled schreef op zondag 18 oktober 2020 @ 19:34:
[...]
Dat lijkt gezien je houding in dit topic tot nu toe een behoorlijke ommezwaai, ben wel nieuwsgierig waar dat zo ineens vandaan komt? Vind jouw uitspraken/inzichten in dit topic over het algemeen realistisch en nuchter. Is dat vanwege de hier vermelde tweets? Patrick Schur? _rogame? Die namen zeggen me niks, dus ik hang er niet zoveel waarde aan

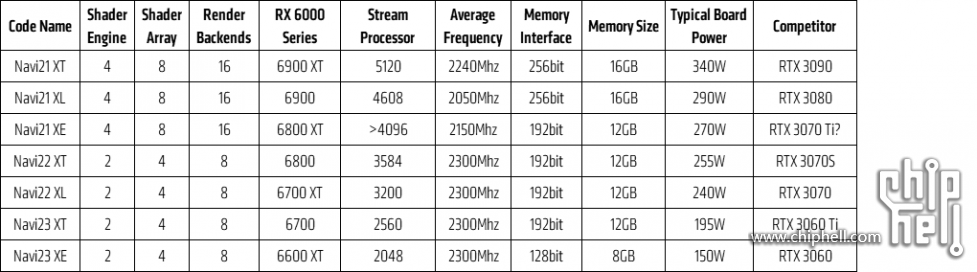
Omdat zelfs de "Navi 21 XT" serieus hoge effectieve clock speeds zou hebben. Dat Navi 21 waarschijnlijk hogere effectieve clock speeds zou hebben dan GA102, wist ik eigenlijk in augustus al. 2400MHz had ik echt niet gedacht. Ik had 2100MHz al heel wat gevonden. Dat lijkt nog steeds een mogelijkheid te zijn, maar hoger lijkt ook goed te kunnen. We weten ook dat Ampere eigenlijk nauwelijks verschilt van Turing. Al het gedoe over verbruik, node en de meeste van Nvidia claims zijn eigenlijk irrelevant. Het is puur de mogelijkheid om maximaal 2x floating point instructies uit te voeren onder bepaalde omstandigheden die het verschil zullen maken in bijna alle games. Het lijkt gemiddeld ongeveer 25% op te leveren op 4K over de RTX2080Ti die dezelfde basis 4352 ALU's deelt. Gemiddeld, want voor een compute zware game zoals BF5, is het beduidend minder dan 25% en voor een toch wat verouderde game zoals the Witcher 3 is het meer dan 25%. Dat is de basislijn waarmee je kan rekenen. Met de door Nvidia geclaimde resultaten voor de RTX3070, denk ik niet dat je op meer dan 25% hoeft te rekenen voor andere Ampere chips.
We weten dat Turing en RDNA1 zeer vergelijkbaar zijn op een per FP32 ALU basis met vergelijkbare clock speeds. Turing heeft alleen stiekem tweemaal zoveel ALU's, waar het tweede deel exclusief INT doet. RDNA1 zal efficiënter zijn in haar ALU's benutten, immers vergelijkbaar presterend met de helft aan ALU's die zowel FP als INT moeten doen. Ampere lijkt circa 25% efficiënter te zijn in haar ALU's benutten dan Turing en dan weet je dat je eigenlijk een forse stap in clock speed nodig hebt voor RDNA2 met een vergelijkbaar aantal ALU's, tenzij ze nog iets echt serieus verbergen bij AMD.
Als ik dan de Navi 21 XT neem die ik inschat op 72CU's/4608 ALU's en op 2400MHz i.p.v. circa 1900MHz voor de RTX3080, tja dan zou je het gat overbrugt moeten hebben. De volle Navi 21 is alleen 80CU's. Komt nog eens bij dat AMD in hun stupide marketing manieren, wel iets gezegd lijkt te hebben over Navi 21. Die "RX6000" van hun, tja ze kozen twee games uit waar Turing eigenlijk beter was dan RDNA1. Dat waren Borderlands 3 en Gears 5. Ze leken redelijk te matchen met de RTX3080 in hun eigen test. Dat moet met wat nuance want eigen benchmarks en ze lijken er de Ryzen 5900X voor gebruikt te hebben, maar het geeft aan dat er tenminste een Navi 21 variant lijkt te zijn die zeer dicht in de buurt van de RTX3080 komt. Ik begin alleen te betwijfelen of het de volle chip was als de Navi 21 XT al zulke clock speeds kan halen. In theorie zou 72CU's @2400MHz afdoende moeten kunnen zijn. 68CU's/4352ALU's zou ook afdoende kunnen zijn als dit de Navi 21 XT is.
Er komt dus een punt om iets minder voorzichtig te zijn. Ik zeg alleen nog steeds niet dat de RTX3090 verslagen gaat worden, maar de RTX3080 verslaan is denk ik een redelijk realistisch inschatting als dit allemaal klopt. Met zulke clock speeds, de GPU van data voorzien zal een uitdaging worden en dat is denk ik het enige waar het denk ik nog mis kan gaan. Qua de normale weg van waves met instructies samenstelling, tja die zullen op dezelfde clock speed worden aangemaakt als de rest van de GPU op loopt. Je zal wel een CPU nodig hebben die flink wat draw calls kan aanleveren om een GPU van dit formaat bezig te houden. Ik denk dat DX12 en/of Vulkan misschien geen overbodige luxe meer zullen zijn. Die twee API's kunnen namelijk draw calls produceren vanaf meerdere threads. Gelukkig kan je niet meer om DX12 heen als je ook DXR wil gebruiken. Onder DX11 kan het misschien nog wel eens ietwat gaan tegenvallen met bepaalde games en lage resoluties.
Als het om instructies berekenen die informatie uit eerdere berekeningen vragen gaat, tja het externe geheugen loopt niet synchroon met alles in de GPU zelf. Daar zou een enorme L2 cache kunnen helpen om die ALU's aan het werk te houden. Immers kost data vanuit VRAM relatief meer clock cycles naarmate de GPU sneller clockt. Extern VRAM is gewoon relatief langzaam en kan snelheden binnen een GPU simpelweg niet bijhouden en dat probleem word alleen maar groter met hogere clock speeds. Je gaat gewoon meer clock cycles missen en dat lijkt de reden te zijn dat met name Fiji en Vega nog wel eens reageerde op relatief geringe geheugen overclocking. Die chips hadden toch al weinig cache en lijken eigenlijk aardig data starved te zijn. De vermoede enorme L2 cache kan dit beter omdat dit ook aan de GPU clock zal hangen.
SG schreef op zondag 18 oktober 2020 @ 19:30:
Er is kans dat volgens geruchten AMD de RX6000 referentie laag inzet. Maar dat AIB vrij zijn om all out te gaan. Volgens de referentie is AMD stuk zuiniger. Maar de top Custom Halo kaarten gaan voor de 3090 en zullen dan ook niet zo zuinig zijn. Kan marketing strategie optie zijn.
Dat zou goed kunnen, maar.

Ik denk dat als AMD de RTX3080 kan pakken en alsnog een fors lager verbruik heeft, ze dat doen. Idem als ze de RTX3090 kunnen matchen. Daarvoor zie ik ze ook wel ruim over de 300W gaan als het echt moet. Dan kan je de partners loslaten om er nog wat beters van te maken, maar ik zou het echt niet begrijpen als ze de referentiemodellen nu heel erg tam afstellen en de perceptie ontstaat dat ze de Nvidia tegenhangers niet aankunnen, terwijl de partnermodellen het wel kunnen. Dat zou zelfs voor RTG standaarden, vrij stupide zijn.
[
Voor 8% gewijzigd door
DaniëlWW2 op 18-10-2020 22:03
]
Never argue with an idiot. He will drag you down to his own level and beat you with experience.
/u/233413/crop574768220d598_cropped.png?f=community)
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/wwTXxrxjDaCDYHBc7MPunK5a.jpg?f=user_large)
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/Iip0a35iz5LdzDdZtun24CF3.jpg?f=user_large)
/u/141745/1295159.png?f=community)
:strip_icc():strip_exif()/u/218864/crop5db0c8ff43fff_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/145751/check-in-minion-small2.jpg?f=community)
/u/324913/crop56a24cce05cd3_cropped.png?f=community)
:strip_icc():strip_exif()/u/122768/crop5dd928114717e.jpeg?f=community)
:strip_icc():strip_exif()/u/94045/crop66c1b4250e8a2_cropped.jpg?f=community)

:no_upscale():strip_icc():fill(white):strip_exif()/f/image/ADGvvbip6SII4MtnyLnwvKrk.jpg?f=user_large)

:fill(white):strip_exif()/f/image/DeRCBD62QNyhkDqF7MiQJ04K.png?f=user_large)
:strip_icc():strip_exif()/u/45765/3dfx2.jpg?f=community)
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/wzPCj2gF799urjjot4cg5zvG.jpg?f=user_large)
/u/400/defember100.png?f=community)
:strip_icc():strip_exif()/u/1460872/crop5f92b5f697c31_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/92491/crop64a1593f33a7b_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/280016/crop58a99242b659f_cropped.jpeg?f=community)
:strip_exif()/u/211274/bestabstractwallpapers5.gif?f=community)
{kind=link}
{kind=link}