:no_upscale():strip_icc():fill(white):strip_exif()/f/image/9FCcvWpGLMeYTcoQ5gxg6EhX.jpg?f=user_large)
- knip -
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Gewoon doen!deepbass909 schreef op zaterdag 16 mei 2020 @ 14:58:
[...]
Deze schijf komt uit een NAS, vandaar het hoge aantal uren dat hij al gedraaid heeft. Hij kwam uit een set van de 2, de andere staat inmiddels op 1234 dagen online(en z'n vervanger, een Ironwolf-uitvoering) alweer 434 dagen.
Ik heb deze ooit vervangen omdat de NAS (een QNAP) SMART-fouten rapporteerde en de data op die NAS mij iets teveel waard is.
Data staat er nu niet meer op (gisteren heb ik alle partities eraf gegooid, hij lag inmiddels al ruim een jaar buiten de NAS op de plank). Maar ik wil hem nu eventueel inzetten voor non-critical data in m'n desktop (tussentijdse opslag voor videobewerking met bron en doelbestanden op een betrouwbare plek, spellen) want me chronisch ruimtegebrek is het zonde om een 2TB schijf werkeloos te laten liggen als hij nog wel bruikbaar is.
Mijn opmerkingen waren bedoeld om de huidige conditie van de schijf (goed) af te zetten tegen het hoge aantal draai-uren e.d. ..
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Tja, als de schijf kwalitatief goed is en zich happy voelt in zijn omgeving (temperatuur, trillingen, vochtigheid enz.) kan dat gewoon ...Raymond P schreef op zaterdag 16 mei 2020 @ 23:29:
20k is dat enorm veel?
Ik heb vandaag een op dode firecuda sshd uit m'n thuisserverkast mogen trekken. Oorzaak onbekend.
Toch even de rest handmatig nagelopen en daar kwam ik een Thaise watersnoodschijf uit 2011 tegen (wd30ezrx) met het drievoudige aan uurtjes.
[Afbeelding]
- Raymond P
- Registratie: September 2006
- Laatst online: 18:43
/u/189310/crop571f5b38cbd6b_cropped.png?f=community)
De firecuda sshd is permanent dood, wordt niet meer herkend. Helaas dus ook geen SMART status.
Jammer, en ook best snel na amper twee jaar.
Bovenstaande schijf ga ik wel alvast een vervanger voor klaarleggen.
Jammer, en ook best snel na amper twee jaar.
Bovenstaande schijf ga ik wel alvast een vervanger voor klaarleggen.
- knip -
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Permanent dood ineens?
Je zou eens kunnen kijken/meten op de printplaat of daar een onderdeeltje het heeft begeven (een beveiliigings diode of zo) ..
Je zou eens kunnen kijken/meten op de printplaat of daar een onderdeeltje het heeft begeven (een beveiliigings diode of zo) ..
- Raymond P
- Registratie: September 2006
- Laatst online: 18:43
@Renault Yep, na nog geen 2 jaar dienst.
Ik heb doorgemeten wat ik kon, en zie geen visuele gebreken.
Het praktische nut van zo'n sshd was ook laag in mijn setup dus ik vind het wel best.
Ik heb doorgemeten wat ik kon, en zie geen visuele gebreken.
Het praktische nut van zo'n sshd was ook laag in mijn setup dus ik vind het wel best.
- knip -
- Raymond P
- Registratie: September 2006
- Laatst online: 18:43
De fabrieksgarantie is inderdaad 5 jaar.
Ik ben niet zo happig op schijven met data erop inleveren.
Ik ben niet zo happig op schijven met data erop inleveren.
- knip -
- ari2asem
- Registratie: November 2002
- Laatst online: 29-06 10:52
graag even jullie mening hierover
https://imgur.com/a/Qayh5aR
screenshots van 2 verschillende programma's: crystal disk info en gsmartcontr (= gui van smartmontools).
bij crystal is duidelijk alles prima, maar bij gsmart zie in tab 3 (STATISTICS) toch wel een error, terwijl in hetzelfde gsmart op tab 2 (ATTRIBUTES) geen error aangegeven wordt. gsmart gebruikt de laatste beta van smartmontools (r5053, https://builds.smartmontools.org/).
deze schijf wordt gebruikt als CONTENT-schijf in Snapraid. er wordt geen data erop opgeslagen. dus 1 file van ongveer 8-9 GB groot.
moet ik me zorgen maken? belangrijk detail....dat roze van gsmart is al misschien wel 2 jaar zo. dus al 2 jaar lang staat die error op 2.
2e vraag: kan iemand mij uitleggen wat die roze 2 betekent, terwijl nergens anders in gsmart verder errors aangegeven worden??
alvast bedankt voor jullie tijd en moeite
https://imgur.com/a/Qayh5aR
screenshots van 2 verschillende programma's: crystal disk info en gsmartcontr (= gui van smartmontools).
bij crystal is duidelijk alles prima, maar bij gsmart zie in tab 3 (STATISTICS) toch wel een error, terwijl in hetzelfde gsmart op tab 2 (ATTRIBUTES) geen error aangegeven wordt. gsmart gebruikt de laatste beta van smartmontools (r5053, https://builds.smartmontools.org/).
deze schijf wordt gebruikt als CONTENT-schijf in Snapraid. er wordt geen data erop opgeslagen. dus 1 file van ongveer 8-9 GB groot.
moet ik me zorgen maken? belangrijk detail....dat roze van gsmart is al misschien wel 2 jaar zo. dus al 2 jaar lang staat die error op 2.
2e vraag: kan iemand mij uitleggen wat die roze 2 betekent, terwijl nergens anders in gsmart verder errors aangegeven worden??
alvast bedankt voor jullie tijd en moeite
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Geen zorgen maken, in de bovenste SMART tabel is alles goed.
Hoe hij aan die waarde "2" komt weet ik niet, want die komt in de bovenste tabel niet voor.
Het zou zelfs een interpretatiefout van gsmart kunnen zijn ...
Hoe hij aan die waarde "2" komt weet ik niet, want die komt in de bovenste tabel niet voor.
Het zou zelfs een interpretatiefout van gsmart kunnen zijn ...
Verwijderd
Beste helper,
Ik weet veel van dingen op de computer maar niet van veel dingen in de computer. Ik heb de laatste tijd een SMART waarschuwing gekregen(?) en heb besloten u te raadplegen voor hulp. Hieronderstaand is de crystaldiskinfo analyse geplaatst... kunt u zo snel mogelijk helpen, het ziet er namelijk niet al te best uit!
:fill(white):strip_exif()/f/image/Tp00rxHgXAKyCFWxthkrMqLd.png?f=user_large)
Ik weet veel van dingen op de computer maar niet van veel dingen in de computer. Ik heb de laatste tijd een SMART waarschuwing gekregen(?) en heb besloten u te raadplegen voor hulp. Hieronderstaand is de crystaldiskinfo analyse geplaatst... kunt u zo snel mogelijk helpen, het ziet er namelijk niet al te best uit!
- dcm360
- Registratie: December 2006
- Niet online
/u/200133/artemis_square_e_60-60.png?f=community)
@Verwijderd Die SSD begint aan het einde van zijn levensduur te raken wat betreft het aantal schrijfacties dat het geheugen volgens de specificaties kan afhandelen. Dat hoeft niet per se te betekenen dat de SSD er mee gaat ophouden, maar vervangen is wel aan te raden.
Verwijderd
Kan dit tot gevolg hebben dat mijn computer langzamer wordt?dcm360 schreef op woensdag 20 mei 2020 @ 12:17:
@Verwijderd Die SSD begint aan het einde van zijn levensduur te raken wat betreft het aantal schrijfacties dat het geheugen volgens de specificaties kan afhandelen. Dat hoeft niet per se te betekenen dat de SSD er mee gaat ophouden, maar vervangen is wel aan te raden.
- dcm360
- Registratie: December 2006
- Niet online
Mogelijk, maar misschien ook niet. Een interessantere vraag is of de schijf blijft werken na het verstrijken van de levensduur. Sommige schijven gaan gewoon door tot op het punt dat ze niet meer betrouwbaar data kunnen opslaan, anderen weigeren om nog data weg te schijven.Verwijderd schreef op woensdag 20 mei 2020 @ 13:00:
[...]
Kan dit tot gevolg hebben dat mijn computer langzamer wordt?
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Als je geen problemen wil, vervang je deze SSD door een nieuwe: ze zijn momenteel erg goedkoop.
Kijk meteen naar je huidige vrije ruimte, de praktijk leert dat een maatje groter vaak op zijn plaats is.
Zoek dan naar een 2,5" SATA SSD, bv. pricewatch: Crucial BX500 480GB
Bij het vervangen kan je Windows opnieuw installeren en je data mee overnemen, óf de huidige SSD Clonen naar de nieuwe SSD: dat laatste is gratis met de software van de SSD-leverancier en duurt nog geen 10 minuten.
Als je praat over "langzamer worden" zou je met de huidige SSD de benchmark "AS-SSD" kunnen draaien: als je na opstarten van AS-SSD meteen al twee van de vier regeltjes linksboven in de benchmark in de kleur groen ziet, staat AHCI aan en is de SSD-alignment in orde: de SSD loopt dan op de goede snelheid in jouw PC.
Kijk meteen naar je huidige vrije ruimte, de praktijk leert dat een maatje groter vaak op zijn plaats is.
Zoek dan naar een 2,5" SATA SSD, bv. pricewatch: Crucial BX500 480GB
Bij het vervangen kan je Windows opnieuw installeren en je data mee overnemen, óf de huidige SSD Clonen naar de nieuwe SSD: dat laatste is gratis met de software van de SSD-leverancier en duurt nog geen 10 minuten.
Als je praat over "langzamer worden" zou je met de huidige SSD de benchmark "AS-SSD" kunnen draaien: als je na opstarten van AS-SSD meteen al twee van de vier regeltjes linksboven in de benchmark in de kleur groen ziet, staat AHCI aan en is de SSD-alignment in orde: de SSD loopt dan op de goede snelheid in jouw PC.
- Megasyb
- Registratie: Oktober 2019
- Laatst online: 28-06 08:38
:strip_icc():strip_exif()/u/1267020/crop5dc4fb909b216_cropped.jpeg?f=community)
Beste allemaal,
Gisteren heb ik een jonge tweedehands WD Black 4TB ontvangen en dus wilde ik kijken hoe gezond deze schijf is. Ik heb al wat gezocht op het web, maar tot nu toe heb ik geen inzicht gekregen in de ernst van de waarschuwingen en fails. De schijf bevat nog data van een eerdere eigenaar (bedankt voor de 11 seizoenen Baantjer ) en is nog geen jaar oud. Tijd voor een RMA? Of moet ik eerst formatteren en dan nog eens kijken?
) en is nog geen jaar oud. Tijd voor een RMA? Of moet ik eerst formatteren en dan nog eens kijken?
Alvast bedankt!
Gisteren heb ik een jonge tweedehands WD Black 4TB ontvangen en dus wilde ik kijken hoe gezond deze schijf is. Ik heb al wat gezocht op het web, maar tot nu toe heb ik geen inzicht gekregen in de ernst van de waarschuwingen en fails. De schijf bevat nog data van een eerdere eigenaar (bedankt voor de 11 seizoenen Baantjer
Alvast bedankt!
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/p0rrB1VDtFuYUojclMyHlNX1.jpg?f=user_large) | :no_upscale():strip_icc():fill(white):strip_exif()/f/image/UnAtalgJckeFQ7dYpaKsu11d.jpg?f=user_large) |
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Ik weet niet hoeveel je hebt betaald, maar dit is een riskante aankoop geweest: de waarden bij C5 en C6 geven aan dat er al problemen zijn bij met de magnetische laag bij het uitlezen van sectoren.
Je kunt verschillende dingen doen:
1. de koop terugdraaien en gaan voor een nieuwe harddisk, ze zijn momenteel relatief goedkoop
2. RMA? Ik denk het niet. Waarom:
- de disk heeft nog garantie. Eerste aanspreekpunt is de winkel waar de harddisk is gekocht. Dit is typisch iets voor degene die de aankoop heeft gedaan, mét de originele aankoopbon en de SMART-uitdraai als bewijs.
De disk wordt dan vervangen door een nieuwe harddisk.
- pas als de garantie is afgelopen, heb je recht op RMA, mits de fabrikant dat ondersteunt voor jouw harddisk.
Voorwaarde voor RMA is dat de RMA-software van de fabrikant (downloaden en laten draaien) een foutcode genereert. Met die foutcode kan je RMA aanvragen en je ontvangt géén nieuwe disk, maar een tweedehands disk die geen foutcode genereert.
Let op: de RMA-tool verwijdert je data, een backup maken is dus evident.
3. berusten in de aankoop en er het beste van maken:
- je maakt (gecontroleerde) backups van al je data
- je voert een low level format uit (dus "een lange format") van je 4 TB harddisk en neemt hem weer in gebruik. Hierdoor wordt C5 nul.
- je blijft backups maken van de nieuwe data en je houdt elke maand via SMART in de gaten of C5 en C6 oplopen: als dat zo is heb je pech gehad en verlies je data op die harddisk.
Ik hoop dat je nu meer duidelijkheid hebt mbt de opties zodat je de voor jou gevoelsmatig juiste beslissing kunt maken.
Je kunt verschillende dingen doen:
1. de koop terugdraaien en gaan voor een nieuwe harddisk, ze zijn momenteel relatief goedkoop
2. RMA? Ik denk het niet. Waarom:
- de disk heeft nog garantie. Eerste aanspreekpunt is de winkel waar de harddisk is gekocht. Dit is typisch iets voor degene die de aankoop heeft gedaan, mét de originele aankoopbon en de SMART-uitdraai als bewijs.
De disk wordt dan vervangen door een nieuwe harddisk.
- pas als de garantie is afgelopen, heb je recht op RMA, mits de fabrikant dat ondersteunt voor jouw harddisk.
Voorwaarde voor RMA is dat de RMA-software van de fabrikant (downloaden en laten draaien) een foutcode genereert. Met die foutcode kan je RMA aanvragen en je ontvangt géén nieuwe disk, maar een tweedehands disk die geen foutcode genereert.
Let op: de RMA-tool verwijdert je data, een backup maken is dus evident.
3. berusten in de aankoop en er het beste van maken:
- je maakt (gecontroleerde) backups van al je data
- je voert een low level format uit (dus "een lange format") van je 4 TB harddisk en neemt hem weer in gebruik. Hierdoor wordt C5 nul.
- je blijft backups maken van de nieuwe data en je houdt elke maand via SMART in de gaten of C5 en C6 oplopen: als dat zo is heb je pech gehad en verlies je data op die harddisk.
Ik hoop dat je nu meer duidelijkheid hebt mbt de opties zodat je de voor jou gevoelsmatig juiste beslissing kunt maken.
- Megasyb
- Registratie: Oktober 2019
- Laatst online: 28-06 08:38
Hartelijk dank voor de uitgebreide reactie. Helaas heb ik geen aankoopbon, dus voorlopig zal ik het dan houden op formatteren en monitoren.
- Admiral Freebee
- Registratie: Februari 2004
- Niet online
:strip_exif()/u/106005/animated%2520garfield.gif?f=community)
@Renault @Megasyb de schijf aanbieden voor fabrieksgarantie is niet per definitie onmogelijk tijdens de wettelijke garantietermijn. De fabrikant mag zelf zijn voorwaarden stellen voor fabrieksgarantie en die mogen afwijken van de voorwaarden voor wettelijke garantie.
Het kan dus lonen om even de voorwaarden te lezen op de site van western digital.
Edit:
Ik heb het even opgezocht op de website van Western Digital en de fabrieksgarantie sluit tweedehands goederen uit:
https://support-en.wd.com/app/Warranty_Policy
In praktijk kan je vaak wel fabrieksgarantie claimen met enkel het serienummer maar in principe sluiten hun eigen voorwaarden tweedehands goederen uit.
Het kan dus lonen om even de voorwaarden te lezen op de site van western digital.
Edit:
Ik heb het even opgezocht op de website van Western Digital en de fabrieksgarantie sluit tweedehands goederen uit:
Je kan het nog even nalezen op:Your Use of the Product
WD will have no liability for any Product returned if WD determines that:
The product was stolen from WD.
The asserted defect:
is not present,
cannot reasonably be fixed because of damage occurring when the Product is in the possession of someone other than WD, or
is attributable to misuse, improper installation, alteration (including removing or obliterating labels and opening or removing external covers (unless authorized to do so by Western Digital or an authorized Service Center)), accident or mishandling while in the possession of someone other than WD.
The Product was not sold to you as new.
The product was not used in accordance with Western Digital specifications and instructions.
The product was not used for its intended function (for example, desktop drives used in an Enterprise environment).
https://support-en.wd.com/app/Warranty_Policy
In praktijk kan je vaak wel fabrieksgarantie claimen met enkel het serienummer maar in principe sluiten hun eigen voorwaarden tweedehands goederen uit.
[ Voor 63% gewijzigd door Admiral Freebee op 22-05-2020 09:57 ]
- Tadsz
- Registratie: Augustus 2013
- Laatst online: 27-06 11:36
Ik heb net iets meer dan 2 weken geleden (4 mei) een HDD aangeschaft (WD Red 8TB) en deze is uiteindelijk op 9 mei geleverd. Nu ik 'm even heb draaien valt op dat de temperatuur enorm oploopt. Hij lijkt verder goed te functioneren, maar ik snap bepaalde uitslagen uit de SMART check niet. De overige schijven die er naast liggen hebben ook een relatief hoge temperatuur maar blijven 'keurig' rond de 50 graden. Alleen de WD Red komt na een uur altijd tegen de 58C aan.
En wat betekent het dat dat de spin-up time zo'n grote waarde aangeeft?
Kan ik de schijf op basis hiervan omruilen?
/f/image/ijUax5YhttVSs7DfOMaHrQVq.png?f=fotoalbum_large)
En wat betekent het dat dat de spin-up time zo'n grote waarde aangeeft?
Kan ik de schijf op basis hiervan omruilen?
:fill(white):strip_exif()/f/image/ijUax5YhttVSs7DfOMaHrQVq.png?f=user_large)
- Q
- Registratie: November 1999
- Nu online
/u/1176/crop635f8931b2b68_cropped.png?f=community)
Ik denk dat er niets mis is met je schijf. Echter ik noem 50 graden niet 'keurig', zelfs niet tussen quotes. Alhoewel het waarschijnlijk binnen de specs valt heb jij een probleem met de koeling van je schijven en ik adviseer je om daar wat aan te doen.Tadsz schreef op zaterdag 23 mei 2020 @ 00:08:
Ik heb net iets meer dan 2 weken geleden (4 mei) een HDD aangeschaft (WD Red 8TB) en deze is uiteindelijk op 9 mei geleverd. Nu ik 'm even heb draaien valt op dat de temperatuur enorm oploopt. Hij lijkt verder goed te functioneren, maar ik snap bepaalde uitslagen uit de SMART check niet. De overige schijven die er naast liggen hebben ook een relatief hoge temperatuur maar blijven 'keurig' rond de 50 graden. Alleen de WD Red komt na een uur altijd tegen de 58C aan.
En wat betekent het dat dat de spin-up time zo'n grote waarde aangeeft?
Kan ik de schijf op basis hiervan omruilen?
[Afbeelding]
Ik probeer zelf onder de 40 graden te blijven met mijn schijven.
Als je kijkt naar de raw temperatuur waarde en ook naar screenshots van andere mensen dan zal je opvallen dat je wel vaker van die hele rare grote getallen ziet. Ik weet niet precies hoe die waarden gedecodeerd worden, maar ik denk dat jouw schijf het prima doet.
[ Voor 5% gewijzigd door Q op 23-05-2020 00:38 ]
- Tadsz
- Registratie: Augustus 2013
- Laatst online: 27-06 11:36
Thanks voor de snelle respons! Ik denk dat de case waar ze in zitten ook zeker niet geschikt is voor 4 schijven ookal is het mogelijk. Betreft de SMR dacht ik dat het de WD Red uit deze serie alleen trof als ze 2TB tm 6TB waren, dus hopen dat er niet later alsnog een statement komt met dat de 8TB er toch ook onder viel.Q schreef op zaterdag 23 mei 2020 @ 00:35:
[...]
Ik denk dat er niets mis is met je schijf. Echter ik noem 50 graden niet 'keurig', zelfs niet tussen quotes. Alhoewel het waarschijnlijk binnen de specs valt heb jij een probleem met de koeling van je schijven en ik adviseer je om daar wat aan te doen.
Ik probeer zelf onder de 40 graden te blijven met mijn schijven.
Als je kijkt naar de raw temperatuur waarde en ook naar screenshots van andere mensen dan zal je opvallen dat je wel vaker van die hele rare grote getallen ziet. Ik weet niet precies hoe die waarden gedecodeerd worden, maar ik denk dat jouw schijf het prima doet.
Ik ga deze schijf in een synology DS920+ plaatsen wanneer die beschikbaar komt, maar hoop ze voor die tijd nog in leven te houden.
- edwinwel
- Registratie: Mei 2020
- Laatst online: 09-03-2022
ik heb een synology nas 916+. hier heb ik drie hdd's van 8tb in. een seagate archive 8 tb en twee seagates ironwolf 8 tb. nou geeft hij op mijn oudste hdd, de seagate archive (wel type voor een nas) steeds foutmeldingen aan. i/o fouten en bad sector fouten. de schijf is van 28 juni 2016 en heeft 29054 uren gedraaid.
nou had ik al even op het synology forum omgestruind en daar staat dat het aan de hdd kan liggen maar ook aan de hdd sleuf waar de schijf in zit. de i/o fouten zouden hier op kunnen wijzen. nou is dit al de derde keer in een maand dat ik deze fouten krijg. de eerste keer heb ik een uitgebreide smart test laten doen en daar kwam uit naar voren dat er niks aan de hand was. de tweede keer heeft de nas uit zichzelf weer een test gedaan. wederom niks gevonden. nou las ik al een beetje op dit forum dat als ik mijn smart data wil delen, ik dat eigenlijk moet doen voor de smart test omdat sommige waarden anders gereset kunnen worden. dus bij deze mijn smart data voor de test.
ik ben redelijk handig met computers maar de smart data is nog wel even een dingetje . een nieuwe hdd kost ongeveer 300 euro. als het moet dan komt die er ook gewoon maar ik wil eigenlijk voor ik dat doe wel zeker weten dat het ook aan die schijf ligt dan.
. een nieuwe hdd kost ongeveer 300 euro. als het moet dan komt die er ook gewoon maar ik wil eigenlijk voor ik dat doe wel zeker weten dat het ook aan die schijf ligt dan.
alvast hartstikke bedankt dat jullie naar mijn data willen kijken
Groetjes, Edwin
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/BsiBPfTOM7YmH6moD9xZyADO.jpg?f=user_large)
nou had ik al even op het synology forum omgestruind en daar staat dat het aan de hdd kan liggen maar ook aan de hdd sleuf waar de schijf in zit. de i/o fouten zouden hier op kunnen wijzen. nou is dit al de derde keer in een maand dat ik deze fouten krijg. de eerste keer heb ik een uitgebreide smart test laten doen en daar kwam uit naar voren dat er niks aan de hand was. de tweede keer heeft de nas uit zichzelf weer een test gedaan. wederom niks gevonden. nou las ik al een beetje op dit forum dat als ik mijn smart data wil delen, ik dat eigenlijk moet doen voor de smart test omdat sommige waarden anders gereset kunnen worden. dus bij deze mijn smart data voor de test.
ik ben redelijk handig met computers maar de smart data is nog wel even een dingetje
alvast hartstikke bedankt dat jullie naar mijn data willen kijken
Groetjes, Edwin
[ Voor 5% gewijzigd door edwinwel op 23-05-2020 01:26 ]
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
@edwinwel
Wat opvalt:
- niet de temperatuur (190) en (194)
- wel dat je ooit in de levensduur van deze disk 3 x een communicatiefout (199) hebt gehad tussen de harddisk en de interface op het moederbord: als deze waarde 3 blijft, is het nu goed. (Hij wordt nooit meer nul.)
- maar erger: 197: er zijn 8 sectoren die momenteel met moeite worden uitgelezen, maar waarvan nog niet is bepaald of ze worden gemarkeerd als onbruikbaar en vervangen (5, nu nog nul vervangen sectoren) door daarvoor gereserveerde reservesectoren: zolang (5) nul blijft ben je waarschijnlijk nog geen data kwijt op deze disk (want de data-checksum klopte uiteindelijk).
Wel is uit de historie (steeds foutmeldingen) en (197) op te maken dat er iets is met de magnetische laag van de harddisk, op minimaal 1 plek.
Hoe nu verder met deze disk?
- een NAS kan deel uitmaken van een backupregime, maar is dat op zichzelf nooit: RAID is bedacht voor data-beschikbaarheid, niet voor datazekerheid (zoals in "een backup vervangend").
Voorbeeld: je hebt een Synology equivalent van RAID5 met drie disks. Eén disk faalt en je vervangt deze.
Een rebuild van je RAID kan uren/dagen (weken?) duren en in die tijd heb je geen data beschikbaar (of heel traag).
Als een tweede disk faalt, heb je geen data meer omdat de rebuild faalt. In dat geval moet je een full backup hebben (die uit een full backup met incrementals kan zijn opgebouwd).
Hoe zit dat bij jou? Heb je een full backup tot op vandaag van alle cruciale data? Neem dit mee in je verdere beslissingen.
- als je backupregime goed is uitgevoerd/gecontroleerd, kan je gewoon verder met deze harddisk. Ik hoop dat hij onderdeel is van RAID1 (Mirror of Synology-gelijkwaardig), want je risico is nu wat hoger geworden.
- als je niet zeker bent van de actualiteit van je backups, koop je (als die nog nieuw leverbaar is) een ironwolf bij (ironwolf puur omdat je daar nog geen fouten mee hebt gevonden nu, dus die lijkt betrouwbaar te werken in jouw NAS) en zet je bovenstaande schijf in als externe schijf om backups van je data op te maken. Dat is niet gek, want dataversie 1 staat na rebuild met de nieuwe disk op de NAS, versie 2 staat op deze backupschijf en je maakt vast nog wel ergens incremental backups, zodat je dan 3 versies van je data hebt. Kijk hierbij ook naar je backupregime, of dit daarin past. En start vóór de inzet van deze schijf met een full ("lange") format, omdat dan elke sector wordt getest.
- vertrouw met dit soort grote schijven niet teveel op RAID-vormen, want fouten op disks worden pas zichtbaar bij raadpleging van de sectoren waarop de data staat: bij een rebuild kan dus zomaar de hele RAID-set corrupt raken en alle data ontoegankelijk worden. Oftewel: dat beide ironwolfs in SMART geen fouten aangeven, wil niet zeggen dat er geen foute sectoren op zitten: die worden pas opgenomen in de SMART-statistieken als de sector wordt geraadpleegd. Een full format is wat dat betreft zekerder, maar kost je de data op de disk.
Vandaar het belang van een goed uitgevoerd backupregime.
Wat opvalt:
- niet de temperatuur (190) en (194)
- wel dat je ooit in de levensduur van deze disk 3 x een communicatiefout (199) hebt gehad tussen de harddisk en de interface op het moederbord: als deze waarde 3 blijft, is het nu goed. (Hij wordt nooit meer nul.)
- maar erger: 197: er zijn 8 sectoren die momenteel met moeite worden uitgelezen, maar waarvan nog niet is bepaald of ze worden gemarkeerd als onbruikbaar en vervangen (5, nu nog nul vervangen sectoren) door daarvoor gereserveerde reservesectoren: zolang (5) nul blijft ben je waarschijnlijk nog geen data kwijt op deze disk (want de data-checksum klopte uiteindelijk).
Wel is uit de historie (steeds foutmeldingen) en (197) op te maken dat er iets is met de magnetische laag van de harddisk, op minimaal 1 plek.
Hoe nu verder met deze disk?
- een NAS kan deel uitmaken van een backupregime, maar is dat op zichzelf nooit: RAID is bedacht voor data-beschikbaarheid, niet voor datazekerheid (zoals in "een backup vervangend").
Voorbeeld: je hebt een Synology equivalent van RAID5 met drie disks. Eén disk faalt en je vervangt deze.
Een rebuild van je RAID kan uren/dagen (weken?) duren en in die tijd heb je geen data beschikbaar (of heel traag).
Als een tweede disk faalt, heb je geen data meer omdat de rebuild faalt. In dat geval moet je een full backup hebben (die uit een full backup met incrementals kan zijn opgebouwd).
Hoe zit dat bij jou? Heb je een full backup tot op vandaag van alle cruciale data? Neem dit mee in je verdere beslissingen.
- als je backupregime goed is uitgevoerd/gecontroleerd, kan je gewoon verder met deze harddisk. Ik hoop dat hij onderdeel is van RAID1 (Mirror of Synology-gelijkwaardig), want je risico is nu wat hoger geworden.
- als je niet zeker bent van de actualiteit van je backups, koop je (als die nog nieuw leverbaar is) een ironwolf bij (ironwolf puur omdat je daar nog geen fouten mee hebt gevonden nu, dus die lijkt betrouwbaar te werken in jouw NAS) en zet je bovenstaande schijf in als externe schijf om backups van je data op te maken. Dat is niet gek, want dataversie 1 staat na rebuild met de nieuwe disk op de NAS, versie 2 staat op deze backupschijf en je maakt vast nog wel ergens incremental backups, zodat je dan 3 versies van je data hebt. Kijk hierbij ook naar je backupregime, of dit daarin past. En start vóór de inzet van deze schijf met een full ("lange") format, omdat dan elke sector wordt getest.
- vertrouw met dit soort grote schijven niet teveel op RAID-vormen, want fouten op disks worden pas zichtbaar bij raadpleging van de sectoren waarop de data staat: bij een rebuild kan dus zomaar de hele RAID-set corrupt raken en alle data ontoegankelijk worden. Oftewel: dat beide ironwolfs in SMART geen fouten aangeven, wil niet zeggen dat er geen foute sectoren op zitten: die worden pas opgenomen in de SMART-statistieken als de sector wordt geraadpleegd. Een full format is wat dat betreft zekerder, maar kost je de data op de disk.
Vandaar het belang van een goed uitgevoerd backupregime.
- edwinwel
- Registratie: Mei 2020
- Laatst online: 09-03-2022
hartstikke bedankt voor je vlotte reactie. aan de hand van je verhaal heb ik nog een aantal vragen / opmerkingen:
die drie communicatiefouten zijn denk ik allemaal deze maand gebeurd. de schijf heeft nu drie of vier keer fouten aangegeven bij mijn nas.
ik heb in principe alleen de raid configuratie zoals die is als backup. de raid versie die ik gebruik is de standaard synology raid met 1 hdd als backup. had synology ook al een bericht gestuurd of ik niet in slot vier een schijf toe kan voegen. alles kopieren. en dan schijf drie verwijderen maar dit kan niet. dus bij een nieuwe schijf moet hij de kapotte rebuilden (al doet de schijf het voor nu nog wel).
ik heb dus geen andere backups of iets dergelijks. de rebuild gaat denk ik wel een maandje ofzo duren. toen ik mijn volume uitbreidde van 2 naar 3 schijven duurde het ook zo lang.
mijn schijven worden elke maand minimaal 1 keer uitgebreid getest op smart. mag ik dan aannemen dat als daar helemaal niks uitkomt en het aantal fouten op 0 staat, dat het aantal fouten dan ook echt 0 is? want bij de uitgebreidde smart test spreekt hij alle sectoren toch juist aan lijkt mij (logischerwijs)
de schijf geeft nu 16 fouten aan en vijf herverbindingen. echter de eerste keer dat ik storingen kreeg had ik ook een aantal fouten en herverbindingen maar na de smart controle was opeens alles weer weg en op nul en bij smart controle kwamen geen fouten aan het licht en gaf hij aan schijf is normaal.
maar om een lang verhaal kort te maken? is het zeker dat de communicatiefout door de hdd komt en niet door de hdd sleuf waar de schijf in zit?? de i/o fout van de nas zelf zou hier op kunnen wijzen en ook die fouten tussen de hdd en moederbord misschien?? en het feit dat alle fouten na een check opeens weer weg waren
als het wel de hdd is dan is advies dus wel vervangen?? en dan deze als backup te houden. ik heb op de nas heel veel films en series en ook al mijn persoonlijke bestanden zoals fotos en documenten. deze laatste zijn het belangrijkste dus dan zou ik die bijvoorbeeld als backup op de schijf kunnen zetten.
hoe lang heeft deze schijf nog ongeveer dan voor hij er helemaal mee ophoudt. dagen? maanden? en hoe betrouwbaar zou hij dan zijn als backup??
groetjes Edwin
die drie communicatiefouten zijn denk ik allemaal deze maand gebeurd. de schijf heeft nu drie of vier keer fouten aangegeven bij mijn nas.
ik heb in principe alleen de raid configuratie zoals die is als backup. de raid versie die ik gebruik is de standaard synology raid met 1 hdd als backup. had synology ook al een bericht gestuurd of ik niet in slot vier een schijf toe kan voegen. alles kopieren. en dan schijf drie verwijderen maar dit kan niet. dus bij een nieuwe schijf moet hij de kapotte rebuilden (al doet de schijf het voor nu nog wel).
ik heb dus geen andere backups of iets dergelijks. de rebuild gaat denk ik wel een maandje ofzo duren. toen ik mijn volume uitbreidde van 2 naar 3 schijven duurde het ook zo lang.
mijn schijven worden elke maand minimaal 1 keer uitgebreid getest op smart. mag ik dan aannemen dat als daar helemaal niks uitkomt en het aantal fouten op 0 staat, dat het aantal fouten dan ook echt 0 is? want bij de uitgebreidde smart test spreekt hij alle sectoren toch juist aan lijkt mij (logischerwijs)
de schijf geeft nu 16 fouten aan en vijf herverbindingen. echter de eerste keer dat ik storingen kreeg had ik ook een aantal fouten en herverbindingen maar na de smart controle was opeens alles weer weg en op nul en bij smart controle kwamen geen fouten aan het licht en gaf hij aan schijf is normaal.
maar om een lang verhaal kort te maken? is het zeker dat de communicatiefout door de hdd komt en niet door de hdd sleuf waar de schijf in zit?? de i/o fout van de nas zelf zou hier op kunnen wijzen en ook die fouten tussen de hdd en moederbord misschien?? en het feit dat alle fouten na een check opeens weer weg waren
als het wel de hdd is dan is advies dus wel vervangen?? en dan deze als backup te houden. ik heb op de nas heel veel films en series en ook al mijn persoonlijke bestanden zoals fotos en documenten. deze laatste zijn het belangrijkste dus dan zou ik die bijvoorbeeld als backup op de schijf kunnen zetten.
hoe lang heeft deze schijf nog ongeveer dan voor hij er helemaal mee ophoudt. dagen? maanden? en hoe betrouwbaar zou hij dan zijn als backup??
groetjes Edwin
[ Voor 25% gewijzigd door edwinwel op 23-05-2020 10:52 ]
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Dat zijn veel vragen, ik probeer ze te beantwoorden.
- als de door de Synology uitgevoerde SMART-controle echt een job is die een hele tijd duurt, zal hij waarschijnlijk elke sector testen en de onbetrouwbare sectoren markeren. Maar dit is een aanname van mij, ik weet niet precies hoe Synology dit doet.
- de communicatiefouten worden geregistreerd door de harddisk als resultaat van communicatiepogingen tussen de harddisk-controller en de communicatie controller van de NAS. Alles wat daartussen zit aan connectoren, kabels en backplanes, kan veroorzaker van de communicatiefouten zijn. Praktijk: als het een kabel betreft vervang je die nu, als het een connector betreft berust je erin en kijk je of de waarde niet meer oploopt.
Na een geregistreerde communicatiefout wordt het betreffende deel van de communicatie genegeerd en opnieuw gestart. Communicatiefouten leiden dus in principe niet tot dataverlies, wel tot performanceproblemen.
En drie is een waarde waar je je in principe geen zorgen over hoeft te maken.
- betrouwbaarheid van de harddisk: het lijkt erop dat de software in de NAS dat goed bewaakt: voor beschikbaarheid van je data is dat voldoende.
- iets anders is dat je geen backups van je essentiële data hebt: dat is een riskant scenario, waarvoor RAID géén oplossing is: wat doe je als je NAS wordt gestolen? Of als hij wordt opgevreten door een cryptolocker? Of vernietigd bij brand? Ik heb bv. kinderen en wat er ook gebeurt, hun kinder-video's en foto's wil ik koste wat kost bewaren en dat doe ik middels backups op harddisks die elk kwartaal (half jaar) worden gecontroleerd en bewaard thuis (niet bij mijn PC) en op mijn werk in mijn locker. Wellicht heb jij ook data die je niet meer kunt downloaden en die je niet kwijt wil, beschermen? Dan zou ik daarvan toch backups gaan maken en die periodiek controleren. Maar daar hint je ook al op.
Wat nu?
- of je de harddisk wil vervangen moet je zelf weten, dat hangt van jouw situatie en wensen af.
- je zou eerst kunnen rebuilden en daarna als dat is gelukt, je essentiële data kunnen kopiëren naar een externe harddisk. 3 maanden later doe je dat naar een andere externe harddisk, Die bewaar je op een andere locatie (niet thuis). Vóórdat je een nieuwe backup maakt controleer je het bestandssysteem op de disk en de SMART cijfers ervan. Daarna maak je pas een nieuwe backup.
Je hebt dan alleen nog het probleem van de dagelijkse incrementals: die zou je automatisch op een clouddienst kunnen maken als aanvulling op je kwartaalbackups.
- ik zou raad vragen in het Synology topic m.b.t. de betrouwbaarheid van deze disk: dat hangt er mede vanaf hoe goed de Synology software is in dit soort gevallen. Op zich loop je met rebuilden van RAID met 8 TB disks wel een behoorlijk risico ...
- als backup disk is hij betrouwbaar genoeg: als één van de datasets (NAS + op 2 externe harddisks) faalt, heb je de andere set nog steeds naast het origineel.
- als de door de Synology uitgevoerde SMART-controle echt een job is die een hele tijd duurt, zal hij waarschijnlijk elke sector testen en de onbetrouwbare sectoren markeren. Maar dit is een aanname van mij, ik weet niet precies hoe Synology dit doet.
- de communicatiefouten worden geregistreerd door de harddisk als resultaat van communicatiepogingen tussen de harddisk-controller en de communicatie controller van de NAS. Alles wat daartussen zit aan connectoren, kabels en backplanes, kan veroorzaker van de communicatiefouten zijn. Praktijk: als het een kabel betreft vervang je die nu, als het een connector betreft berust je erin en kijk je of de waarde niet meer oploopt.
Na een geregistreerde communicatiefout wordt het betreffende deel van de communicatie genegeerd en opnieuw gestart. Communicatiefouten leiden dus in principe niet tot dataverlies, wel tot performanceproblemen.
En drie is een waarde waar je je in principe geen zorgen over hoeft te maken.
- betrouwbaarheid van de harddisk: het lijkt erop dat de software in de NAS dat goed bewaakt: voor beschikbaarheid van je data is dat voldoende.
- iets anders is dat je geen backups van je essentiële data hebt: dat is een riskant scenario, waarvoor RAID géén oplossing is: wat doe je als je NAS wordt gestolen? Of als hij wordt opgevreten door een cryptolocker? Of vernietigd bij brand? Ik heb bv. kinderen en wat er ook gebeurt, hun kinder-video's en foto's wil ik koste wat kost bewaren en dat doe ik middels backups op harddisks die elk kwartaal (half jaar) worden gecontroleerd en bewaard thuis (niet bij mijn PC) en op mijn werk in mijn locker. Wellicht heb jij ook data die je niet meer kunt downloaden en die je niet kwijt wil, beschermen? Dan zou ik daarvan toch backups gaan maken en die periodiek controleren. Maar daar hint je ook al op.
Wat nu?
- of je de harddisk wil vervangen moet je zelf weten, dat hangt van jouw situatie en wensen af.
- je zou eerst kunnen rebuilden en daarna als dat is gelukt, je essentiële data kunnen kopiëren naar een externe harddisk. 3 maanden later doe je dat naar een andere externe harddisk, Die bewaar je op een andere locatie (niet thuis). Vóórdat je een nieuwe backup maakt controleer je het bestandssysteem op de disk en de SMART cijfers ervan. Daarna maak je pas een nieuwe backup.
Je hebt dan alleen nog het probleem van de dagelijkse incrementals: die zou je automatisch op een clouddienst kunnen maken als aanvulling op je kwartaalbackups.
- ik zou raad vragen in het Synology topic m.b.t. de betrouwbaarheid van deze disk: dat hangt er mede vanaf hoe goed de Synology software is in dit soort gevallen. Op zich loop je met rebuilden van RAID met 8 TB disks wel een behoorlijk risico ...
- als backup disk is hij betrouwbaar genoeg: als één van de datasets (NAS + op 2 externe harddisks) faalt, heb je de andere set nog steeds naast het origineel.
- WorstCaseOfZen
- Registratie: Mei 2016
- Laatst online: 04-07 08:01
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/Yw4vTnXvWTisl1ydSXumz1Lv.jpg?f=user_large)
Hi allen, Ik ervaar sinds een paar weken problemen met mijn (nog niet bejaarde) HDD.
Wat ik merk is dat de schrijfsnelheid bij gebruik rap afneemt.
Zo gebruik ik deze schijf o.a. voor een plex server en dat werkt (vooralsnog) ok.
Maar als ik op dezelfde schijf een spel wil installeren via Steam, dan duurt dit enorm lang. Ook andere schrijfopdrachten kunnen gerust uren duren, ondanks de beperkte grootte.
Ik heb nog niet de mogelijkheid gehad om de schijf in een andere pc te hangen, wel heb ik momenteel 3 x ssd + 3 x Hdd in mijn systeem hangen. (* 1 x hdd extern)
Ik heb reeds alle schijven reeds een keer losgekoppeld en opnieuw teruggeplaatst (niet 100% zeker dat deze nu met dezelfde kabel in dezelfde slot hangt)
Is er vanuit de Smart data meer info te achterhalen?
Alvast mijn dank!
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Ja.
De schijf zelf lijkt helemaal in orde te zijn, maar de waarde van C7 wijkt af: in de levensduur van je harddisk heb je honderden communicatiefouten opgelopen (162 hexadecimaal is uit mijn hoofd 354 decimaal).
Dat betekent dat ergens tussen het moederbord en je harddisk-printplaat een slecht contact zit.
Normaal gesproken vervang je dan je SATA-kabel door een nieuwe en gebruik je een andere, vrije SATA-aansluiting op je moederbord.
Het tijdstip waarop deze communicatiefouten ontstonden is niet te achterhalen, maar je bent er snel achter of je er nu nog last van hebt: als je in de komende tijd waarde C7 ziet oplopen, heb je er nu nog last van en is reparerende actie dringend geboden.
Als je communicatiefouten hebt, kan de haperende communicatie met de harddisk performanceproblemen geven. Nog even voor de zekerheid: als de SATA-connector zo te zien/voelen goed op de harddisk-printplaat vastzit en je hebt zo te zien geen haarscheurtjes en/of slechte solderingen op de printplaat, is de harddisk zelf helemaal in orde! Ga daar nu voorlopig maar vanuit (dus de harddisk is in orde), vervang de SATA-kabel en gebruik een andere SATA-aansluiting op het moederbord.
Wel zou ik na het verhelpen van de oorzaak een schijfcontrole uitvoeren op alle Windows & data-partities die op de harddisk staan, want het bestandssysteem op die partities kan hierdoor een defect hebben opgelopen.
Als je op zeker wil spelen, doe je "Bestand Uitvoeren als admin" (na rechter muisknop op Start) en dan een "sfc /scannow" (dus zonder aanhalingstekens en met één spatie voor de /), zodat je zeker weet dat Windows 10 integer is.
De schijf zelf lijkt helemaal in orde te zijn, maar de waarde van C7 wijkt af: in de levensduur van je harddisk heb je honderden communicatiefouten opgelopen (162 hexadecimaal is uit mijn hoofd 354 decimaal).
Dat betekent dat ergens tussen het moederbord en je harddisk-printplaat een slecht contact zit.
Normaal gesproken vervang je dan je SATA-kabel door een nieuwe en gebruik je een andere, vrije SATA-aansluiting op je moederbord.
Het tijdstip waarop deze communicatiefouten ontstonden is niet te achterhalen, maar je bent er snel achter of je er nu nog last van hebt: als je in de komende tijd waarde C7 ziet oplopen, heb je er nu nog last van en is reparerende actie dringend geboden.
Als je communicatiefouten hebt, kan de haperende communicatie met de harddisk performanceproblemen geven. Nog even voor de zekerheid: als de SATA-connector zo te zien/voelen goed op de harddisk-printplaat vastzit en je hebt zo te zien geen haarscheurtjes en/of slechte solderingen op de printplaat, is de harddisk zelf helemaal in orde! Ga daar nu voorlopig maar vanuit (dus de harddisk is in orde), vervang de SATA-kabel en gebruik een andere SATA-aansluiting op het moederbord.
Wel zou ik na het verhelpen van de oorzaak een schijfcontrole uitvoeren op alle Windows & data-partities die op de harddisk staan, want het bestandssysteem op die partities kan hierdoor een defect hebben opgelopen.
Als je op zeker wil spelen, doe je "Bestand Uitvoeren als admin" (na rechter muisknop op Start) en dan een "sfc /scannow" (dus zonder aanhalingstekens en met één spatie voor de /), zodat je zeker weet dat Windows 10 integer is.
- vanpeers
- Registratie: Februari 2010
- Laatst online: 23:18
:strip_icc():strip_exif()/u/345735/ross.jpg?f=community)
Hallo medeforumleden!
Ik heb al een tijdje last van mijn Synology die traag loopt, hierop heb ik al verschillende dingen getest die normaal blijken te zijn.
Nu begin in te denken dat het aan mijn harde schijven zelf zou kunnen liggen het probleem.
Beide schijven gaan al een hele tijd mee.
De software van Synology zelf zegt dat beide schijven nog goed zijn en dat de smart gegevens ook goed zijn.
Met wat op te zoeken hoe ik dit interpreteer kwam ik dit topic tegen.
Zou iemand deze gegevens willen bekijken?
:strip_exif()/f/image/TRQsiQwXIILotX614e65GBXL.jpg?f=fotoalbum_large)
Ik heb al een tijdje last van mijn Synology die traag loopt, hierop heb ik al verschillende dingen getest die normaal blijken te zijn.
Nu begin in te denken dat het aan mijn harde schijven zelf zou kunnen liggen het probleem.
Beide schijven gaan al een hele tijd mee.
De software van Synology zelf zegt dat beide schijven nog goed zijn en dat de smart gegevens ook goed zijn.
Met wat op te zoeken hoe ik dit interpreteer kwam ik dit topic tegen.
Zou iemand deze gegevens willen bekijken?
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/TRQsiQwXIILotX614e65GBXL.jpg?f=user_large)
.BE / Marstek Venus 5,12kWh / 8400Wp panelen / energie negatieve woning / ENG
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Beide harddisks laten geen enkele aanleiding tot falen zien, gewoon verder gebruiken.
Je ervaren traagheid zou ergens anders aan moeten liggen ....
Fragmentatie?
Wellicht heeft Synology daar standaard al wat voor beschikbaar?
Je ervaren traagheid zou ergens anders aan moeten liggen ....
Fragmentatie?
Wellicht heeft Synology daar standaard al wat voor beschikbaar?
[ Voor 21% gewijzigd door Renault op 31-05-2020 10:43 ]
Ik heb sinds 1,5 jaar een Samsung X5 Thunderbolt 3 NVME SSD, die sinds een paar dagen er geen zin meer in heeft.
Ik gebruik de schijf als primaire schijf op mijn iMac 2017.
Na een update van MacOS Mojave kon ik niet meer opstarten.
Ik dacht dat het aan de update lag, maar nu blijkt de schijf defect.
De schijf is nu read only en ik kan er niets meer mee.
Ondertussen een nieuwe schijf gekocht en die werkt na het terugzetten van de laatste reservekopie prima.
De Samsung X5 ls nu alleen bruikbaar als read only apparaat.
Op een Windows laptop de schijf aangesloten en Crystaldiskinfo gedraaid met het onderstaande resultaat.
Is hij kapot en moet hij naar Samsung?
:strip_exif()/f/image/N8tN3zhga61RXPpfumbpaa5f.jpg?f=fotoalbum_large)
Ik gebruik de schijf als primaire schijf op mijn iMac 2017.
Na een update van MacOS Mojave kon ik niet meer opstarten.
Ik dacht dat het aan de update lag, maar nu blijkt de schijf defect.
De schijf is nu read only en ik kan er niets meer mee.
Ondertussen een nieuwe schijf gekocht en die werkt na het terugzetten van de laatste reservekopie prima.
De Samsung X5 ls nu alleen bruikbaar als read only apparaat.
Op een Windows laptop de schijf aangesloten en Crystaldiskinfo gedraaid met het onderstaande resultaat.
Is hij kapot en moet hij naar Samsung?
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/N8tN3zhga61RXPpfumbpaa5f.jpg?f=user_large)
- vanpeers
- Registratie: Februari 2010
- Laatst online: 23:18
Bedankt Renault!Renault schreef op zaterdag 30 mei 2020 @ 18:02:
Beide harddisks laten geen enkele aanleiding tot falen zien, gewoon verder gebruiken.
Je ervaren traagheid zou ergens anders aan moeten liggen ....
Fragmentatie?
Wellicht heeft Synology daar standaard al wat voor beschikbaar?
Ja misschien moet ik dat eens bekijken, of hier standaard defragmentatie in zit.
.BE / Marstek Venus 5,12kWh / 8400Wp panelen / energie negatieve woning / ENG
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
@sssensss:
Heb je nog garantie?
En is de data die erop staat niet vertrouwelijk?
Als beide vragen "ja" zijn, kan je voor garantie gaan.
En breng nu eerst je data in veiligheid nu je de SSD nog kunt lezen.
Het read-only worden van SSD's is meestal een teken dat er een kritieke fout is opgetreden.
In de door jou geposte tabel herkent Crystaldiskinfo enkele parameters niet correct, dus de waarden zijn daardoor slecht interpretabel.
Lees de SMART-tabel eens uit met de (gratis) Samsung Magician software: daar worden parameters veel beter voorzien van commentaar en wellicht zit daar ook iets van "Revert to original" of zoiets tussen om de hele SSD te wipen en zo het read-only eraf te krijgen. Probeer alle menuopties maar eens uit, je kunt er niet op achteruit gaan.
Heb je nog garantie?
En is de data die erop staat niet vertrouwelijk?
Als beide vragen "ja" zijn, kan je voor garantie gaan.
En breng nu eerst je data in veiligheid nu je de SSD nog kunt lezen.
Het read-only worden van SSD's is meestal een teken dat er een kritieke fout is opgetreden.
In de door jou geposte tabel herkent Crystaldiskinfo enkele parameters niet correct, dus de waarden zijn daardoor slecht interpretabel.
Lees de SMART-tabel eens uit met de (gratis) Samsung Magician software: daar worden parameters veel beter voorzien van commentaar en wellicht zit daar ook iets van "Revert to original" of zoiets tussen om de hele SSD te wipen en zo het read-only eraf te krijgen. Probeer alle menuopties maar eens uit, je kunt er niet op achteruit gaan.
Ik heb nog garantie en de data die er op staat is wel vertrouwelijk, dus opsturen voor garantie is niet echt een optie.
De data had ik gelukkig al goed geback-upt en staat al weer op die nieuwe schijf te draaien.
Ik heb de defecte drive zojuist even aangesloten op de laptop met Win10 en gekeken wat er met Samsung Magician mogelijk is, maar bij alle opties staat “the selected drive does not support thuis feature”
Er staat in het programma ook aangegeven dat ik Samsung Portable SSD Software moet downloaden.
Dat heb ik gedaan, maar ook dit programma kan niets met de schijf.
hieronder de SMART waarden vanuit Samsung Magician
/f/image/wTyrHbHJ1h4X1FSfbLT2yGKn.png?f=fotoalbum_large)
De data had ik gelukkig al goed geback-upt en staat al weer op die nieuwe schijf te draaien.
Ik heb de defecte drive zojuist even aangesloten op de laptop met Win10 en gekeken wat er met Samsung Magician mogelijk is, maar bij alle opties staat “the selected drive does not support thuis feature”
Er staat in het programma ook aangegeven dat ik Samsung Portable SSD Software moet downloaden.
Dat heb ik gedaan, maar ook dit programma kan niets met de schijf.
hieronder de SMART waarden vanuit Samsung Magician
:fill(white):strip_exif()/f/image/wTyrHbHJ1h4X1FSfbLT2yGKn.png?f=user_large)
[ Voor 25% gewijzigd door sssensss op 01-06-2020 19:18 ]
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Helaas, dat gaat ook niet goed dus.
Nou hebben veel fabikanten een eigen tool om harddisks te analyseren voordat een RMA wordt aangevraagd.
Die tool vernietigt meesal tijdens de test alle aanwezige data en die tool is meestal gewoon te downloaden wanneer je doet alsof je RMA gaat aanvragen.
Misschien kan je dat eens proberen met als resultaat een lege SSD?
En als dat niet lukt:
Wellicht kan je je probleem eens voorleggen aan de Samsung helpdesk, m.n. dat je een manier zoekt om je data te vernietigen vóórdat je garantie claimt, op een inmiddels read-only geworden SSD?
Nou hebben veel fabikanten een eigen tool om harddisks te analyseren voordat een RMA wordt aangevraagd.
Die tool vernietigt meesal tijdens de test alle aanwezige data en die tool is meestal gewoon te downloaden wanneer je doet alsof je RMA gaat aanvragen.
Misschien kan je dat eens proberen met als resultaat een lege SSD?
En als dat niet lukt:
Wellicht kan je je probleem eens voorleggen aan de Samsung helpdesk, m.n. dat je een manier zoekt om je data te vernietigen vóórdat je garantie claimt, op een inmiddels read-only geworden SSD?
Ja, ik ga contact opnemen met Samsung om te kijken of er i.d.d. een manier is om de data voor het verzenden te verwijderen.
Hartelijk bedankt voor het meedenken!
Hartelijk bedankt voor het meedenken!
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/kK3pvsClrya4y6e6u9bWivJz.jpg?f=user_large)
De tweede dit jaar, wat een brakke schijven zijn dit zeg.
- EricJH
- Registratie: November 2003
- Laatst online: 22:16
/u/97665/Opera1_t.png?f=community)
Hoe oud is deze schijf? Hij valt mogelijk nog in de garantieperiode. Mocht je overwegen de schijf te formatteren doe dat niet voor het geval je garantie wilt claimen.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
In elk geval nu je SMART-data opslaan en dan maandelijks in de gaten houden ....
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Deze was van maart dit jaar, de vorige was van december 2019 en is toen vervangen door deze. Nu maar vast een nieuwe WD schijf besteld en even kijken hoe deze Seagate zich verder gaat ontwikkelen. Ben bang dat deze reeks gewoon veel slechte schijven bevat als ik hem weer laat vervangen.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Kan je eens wat meer vertellen over waar die harddisks zich in bevinden? Misschien is er sprake van een omgevingsfactor die dit type harddisk niet leuk vind?
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Ja het is een externe harde schijf, deze:
pricewatch: Seagate Backup Plus Hub 8TB Zwart
Misschien zijn deze er gewoon niet op gemaakt om een paar uur per dag te draaien. Al had ik daar met andere externe harde schijven nooit probleem mee gehad. Er staat verder niks opgestapeld, al is de ventilatie in zo'n plastic doos nooit ideaal, maar begin dit jaar was het uiteraard niet warm toen de eerste fouten begon te geven.
pricewatch: Seagate Backup Plus Hub 8TB Zwart
Misschien zijn deze er gewoon niet op gemaakt om een paar uur per dag te draaien. Al had ik daar met andere externe harde schijven nooit probleem mee gehad. Er staat verder niks opgestapeld, al is de ventilatie in zo'n plastic doos nooit ideaal, maar begin dit jaar was het uiteraard niet warm toen de eerste fouten begon te geven.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Tja, dat is redelijk standaard, dat zou geen probleem moeten geven.
En hij is altijd in dezelfde stand (horizontaal/verticaal) gebruikt?
En hij is altijd in dezelfde stand (horizontaal/verticaal) gebruikt?
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Ja ik heb hem altijd plat neergelegd met de bovenkant van de schijf ook naar boven toe, ik ben er zelf geen fan van om ze zo rechtop neer te zetten net als op de productfoto, heb dan altijd het idee dat ze erg instabiel staan en makkelijk kunnen wiebelen, al zal het in de praktijk waarschijnlijk wel meevallen.
Zou het ook kunnen zijn dat de meegeleverde usb kabel bij deze schijven misschien niet helemaal perfect is?
Zou het ook kunnen zijn dat de meegeleverde usb kabel bij deze schijven misschien niet helemaal perfect is?
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Dat is in elk geval niet geregistreerd: C7 = aantal geregistreerde communicatiefouten tussen de SATA-comtroller op je moederbord en de SATA-controller op je harddisk = 0 ....
Dus ik denk het niet.
Gevalletje pech hebben?
Monitor de ontwikkeling van je SMART-gegevens en onderneem op tijd actie richting garantie (bij de winkel waar je hem hebt gekocht, met bon en schermprint van de SMART-data).
Dus ik denk het niet.
Gevalletje pech hebben?
Monitor de ontwikkeling van je SMART-gegevens en onderneem op tijd actie richting garantie (bij de winkel waar je hem hebt gekocht, met bon en schermprint van de SMART-data).
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Ahh oke bedankt, ik zal dan weer richting de winkel gaan straks
- Q
- Registratie: November 1999
- Nu online
@mark de man
Niet dat ik hier ook een discussie over temperatuur wil starten maar 48 graden voor een schijf is ook niet alles denk ik dan.
Niet dat ik hier ook een discussie over temperatuur wil starten maar 48 graden voor een schijf is ook niet alles denk ik dan.
[ Voor 6% gewijzigd door Q op 03-06-2020 19:09 ]
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Dat klopt, ik kan nog wel een rechthoekige heatsink van een pentium 2 erop leggenQ schreef op woensdag 3 juni 2020 @ 19:02:
@mark de man
Niet dat ik hier ook een discussie over temperatuur wil starten maar 48 graden voor een schijf is ook niet alles denk ik dan.
Mijn externe WD tikt regelmatig de 55 graden en draait al jaren zonder enkele fout. Ik vrees dat ik er niet veel aan kan doen om de externe schijf koeler te krijgen, behalve de behuizing eraf halen.
- Q
- Registratie: November 1999
- Nu online
Tja, als je hier in dit topic een beetje naar de smart-waarden kijkt dan is dit wel een 'outlier'. Het mag wel van de specs, hij werkt bij die temperatuur, maar wat het doet voor de levensduur is vraag twee.
Zelf weten hoor.
Zelf weten hoor.
- Q
- Registratie: November 1999
- Nu online
- Scrape tweakers 'post je smart topic' met selenium
- Filter alle image urls er uit
- download alle images
- Doe ORC OCR over de images met python + tesseract
- Beetje grep en cut om de temps er uit te halen
- Gooi het in excel voor een leuk plaatje
Het is geen steekproef van de hele populatie.
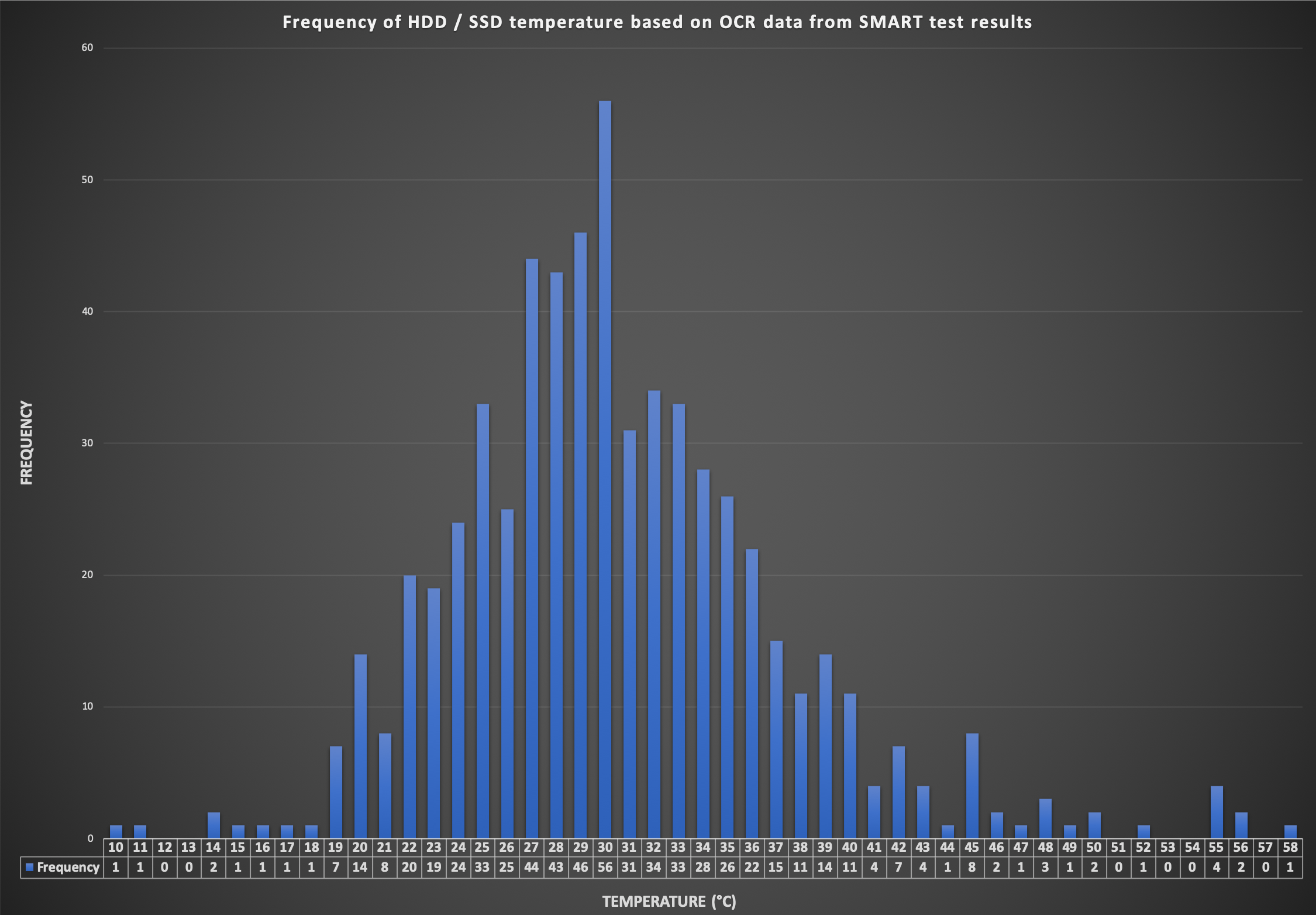
De overgrote meerderheid heeft de harde schijven / SSDs tussen de 20 - 40 graden Celsius.
[ Voor 7% gewijzigd door Q op 04-06-2020 19:34 ]
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Ja klopt. Ik zelf vraag me ook af of die temperatuur van de schijf wel helemaal klopt. De behuizing wordt ook veel minder warm dan die van andere schijven. Ik kan wel kijken of het veel uitmaakt als ik de schijf anders positioneer, maar helaas is het geen behuizing die zonder schade makkelijk open kan worden gemaakt.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Tijd voor een proefje met een ventilator op de buitenkant en dan kijken wat de harddisk temperatuur dan doet bij dezelfde belasting?
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Ja ik zal even een aantal verschillende dingen testen, alhoewel hij nu 46 graden is, maar het is dan ook een aantal graden koeler binnen. Inmiddels ook een WD80EDAZ van 8TB binnen, die volgens sommige bronnen ook erg warm wordt. Even kijken of er veel verschil tussen die 2 is, ook bij verschillende posities. Al lijkt de behuizing van die WD wel beter lucht door te laten en is er in de behuizing ook meer lege ruimte rondom de schijf.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Ik heb zelf dit om aan harddisks te sleutelen: pricewatch: Sharkoon QuickPort XT Duo Clone Zwart
(Backups maak ik op externe harddisks van max 4 TB, gewoon omdat dat toen de betaalbare max size was, en zonder hitteproblemen.)
Je zou bijna aan zoiets gaan denken voor jou (prima koeling!), MITS de harddisks een SATA interface op de printplaat hebben en geen USBxx ...
(Backups maak ik op externe harddisks van max 4 TB, gewoon omdat dat toen de betaalbare max size was, en zonder hitteproblemen.)
Je zou bijna aan zoiets gaan denken voor jou (prima koeling!), MITS de harddisks een SATA interface op de printplaat hebben en geen USBxx ...
- Q
- Registratie: November 1999
- Nu online
Mijn ervaring met wat oudere schijven is dat schijven door een gebrek aan airflow ook erg warm worden. Ooit had ik zo'n quickport met een fan, maar die is stuk gegaan.Renault schreef op donderdag 4 juni 2020 @ 22:44:
Ik heb zelf dit om aan harddisks te sleutelen: pricewatch: Sharkoon QuickPort XT Duo Clone Zwart
(Backups maak ik op externe harddisks van max 4 TB, gewoon omdat dat toen de betaalbare max size was, en zonder hitteproblemen.)
Je zou bijna aan zoiets gaan denken voor jou (prima koeling!), MITS de harddisks een SATA interface op de printplaat hebben en geen USBxx ...
Ik heb nu een quickport duo (ewent) gemod door er zelf een 80mm fan op te monteren + solderen. Niet super mooi maar als schijven zo warm worden dat je ze niet aan kunt raken....
Als harde schijven maar een klein beetje airflow hebben is het al goed. Of een goede heatsink / metalen case.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Ik heb er een losse 13 cm fan op een zelf gemaakte voet naast staan (zo'n ouderwetse fan, die nog echt wind met herrie produceert ) die "tussen de disks door" blaast, maar die heb ik eigenlijk nog nooit nodig gehad omdat ik voornamelijk checks doe, wat full formats en bij gelegenheid wat clone/backups maak.
Voor reguliere backups gebruik ik dit niet omdat me dan het risico te groot is i.v.m. vallen e.d. (mijn gezin komt daar ook).
Voor reguliere backups gebruik ik dit niet omdat me dan het risico te groot is i.v.m. vallen e.d. (mijn gezin komt daar ook).
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Ik ben nu tussen de twee schijven wat bestanden aan het kopiëren, allebei in dezelfde positie en zonder koeling. De Seagate is nu 49 graden en de WD 60  Bij nader inzien misschien toch beter om de Seagate als daily schijf te gebruiken en de WD voor cold storage.
Bij nader inzien misschien toch beter om de Seagate als daily schijf te gebruiken en de WD voor cold storage.
Ik zal zometeen een 80mm fan voor de ventilatiegaten zetten en kijken wat het verschil is.
Met een fan ervoor dalen ze allebei naar ongeveer 43 graden. Bij de Seagate is er slechts aan één kant een kleine ventilatieopening, terwijl bij de WD je door de voor en achterkant heen blaast. Ik zal straks ook kijken of het verschil uitmaakt door de schijven toch verticaal rechtop neer te zetten. In principe zijn dan de onder en bovenkant van de schijven vrij, alhoewel de ventilatieopening bij de Seagate dan afgesloten is door het bureau en bij de WD 1 kant ook.
Edit: bij de Seagate inmiddels ook weer 1 BB Reported Uncorrectable Error.
Ik zal zometeen een 80mm fan voor de ventilatiegaten zetten en kijken wat het verschil is.
Met een fan ervoor dalen ze allebei naar ongeveer 43 graden. Bij de Seagate is er slechts aan één kant een kleine ventilatieopening, terwijl bij de WD je door de voor en achterkant heen blaast. Ik zal straks ook kijken of het verschil uitmaakt door de schijven toch verticaal rechtop neer te zetten. In principe zijn dan de onder en bovenkant van de schijven vrij, alhoewel de ventilatieopening bij de Seagate dan afgesloten is door het bureau en bij de WD 1 kant ook.
Edit: bij de Seagate inmiddels ook weer 1 BB Reported Uncorrectable Error.
[ Voor 43% gewijzigd door mark de man op 05-06-2020 15:56 ]
- Q
- Registratie: November 1999
- Nu online
Gevalletje RMA denk ikmark de man schreef op vrijdag 5 juni 2020 @ 10:51:
Edit: bij de Seagate inmiddels ook weer 1 BB Reported Uncorrectable Error.
- mark de man
- Registratie: November 2005
- Laatst online: 05-07 20:20
Wij zullen doorgaan...
Ja ik denk het wel, BB staat nu op 3.
Ik denk dat ik de behuizing van de WD wel open ga maken, dat schijnt wel mogelijk te zijn zonder hem te slopen.
YouTube: WD My Book (Fall 2016) - Disassembly with card, without broken tabs.
Ik hoop dat die dan wel iets koeler blijft en dat ik die elke dag kan gaan gebruiken.
Ik denk dat ik de behuizing van de WD wel open ga maken, dat schijnt wel mogelijk te zijn zonder hem te slopen.
YouTube: WD My Book (Fall 2016) - Disassembly with card, without broken tabs.
Ik hoop dat die dan wel iets koeler blijft en dat ik die elke dag kan gaan gebruiken.
- Pyramiden
- Registratie: Maart 2012
- Laatst online: 02-07 09:46
:strip_icc():strip_exif()/u/452092/Tweakers.jpg?f=community)
Heeft iemand ervaring met wat een "Media wearout indicator" is, en wat hier exact mee bedoeld wordt?
Ik heb een oude Toshiba OEM SSD met 8000 power on hours welke nu als externe schrijf gebruikt wordt.
Bij HDD Sentinel krijg ik de melding:
173 media Wearout Indicator: Threshold 100 | Value 74 Pre-Failure: Data loss predicted
Ik neem aan dat dit betekend dat de SSD binnenkort niet meer onder ons is?
CrystalDiskInfo noemt het een "Erase count" met dezelfde waarde.
Ik heb een oude Toshiba OEM SSD met 8000 power on hours welke nu als externe schrijf gebruikt wordt.
Bij HDD Sentinel krijg ik de melding:
173 media Wearout Indicator: Threshold 100 | Value 74 Pre-Failure: Data loss predicted
Ik neem aan dat dit betekend dat de SSD binnenkort niet meer onder ons is?
CrystalDiskInfo noemt het een "Erase count" met dezelfde waarde.
- Giesber
- Registratie: Juni 2005
- Laatst online: 02-07 11:42
Het staat hier uitgelegd in de 3e rij vanonder in de tabel. Het is dus een waarde die weergeeft hoeveel (waarschijnlijk write) cycles de chips in de SSD al gedaan hebben.Pyramiden schreef op zondag 14 juni 2020 @ 17:55:
Heeft iemand ervaring met wat een "Media wearout indicator" is, en wat hier exact mee bedoeld wordt?
Ik heb een oude Toshiba OEM SSD met 8000 power on hours welke nu als externe schrijf gebruikt wordt.
Bij HDD Sentinel krijg ik de melding:
173 media Wearout Indicator: Threshold 100 | Value 74 Pre-Failure: Data loss predicted
Ik neem aan dat dit betekend dat de SSD binnenkort niet meer onder ons is?
CrystalDiskInfo noemt het een "Erase count" met dezelfde waarde.
Mijn gok is als die waarde gemaximaliseerd is, dat je dan aan de fabrikant opgegeven levensduur gaat zitten. Een SSD kan waarschijnlijk nog veel langer meegaan, maar zonder backups kan het wel tricky worden.
Ik zou je voorlopig niet te veel zorgen maken, maar stilletjes plannen om een opvolger te zoeken als het nodig is.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
... en nu steeds zorgen voor goede (incremental) backups van je data op die SSD!
- d22wth
- Registratie: Juni 2015
- Laatst online: 12-06 14:05
... 𝗁𝖾𝗍 𝗁𝗈𝖾𝖿𝗍 𝗇𝗂𝖾𝗍 𝗉𝖾𝗋𝖿𝖾𝖼𝗍
:strip_icc():strip_exif()/u/679038/crop67db5e698a133_cropped.jpg?f=community)
Heb mijn PC net aangezet, vind deze temps toch wat aan de hoge kant... Ook nog maar 1178u gedraaid en nu al 94% 
:fill(white):strip_exif()/f/image/VDGHbzWFVuBnrtQtsq1J9LjZ.png?f=user_large)
Vanmiddag was ie:
:fill(white):strip_exif()/f/image/6xUtKY6DDCC9V45SBwtr8FQu.png?f=user_large)
Mijn HDD blijft netjes 27/29 graden...
:fill(white):strip_exif()/f/image/tjXfs3tpFBqxR8SpPqcYnnIJ.png?f=user_large)
SSD voelt aan de behuizing ook niet zo overdreven warm aan...
Vanmiddag was ie:
Mijn HDD blijft netjes 27/29 graden...
SSD voelt aan de behuizing ook niet zo overdreven warm aan...
𝚒𝙿𝚑𝚘𝚗𝚎 16 𝙿𝚛𝚘 - 𝖱7 5800𝖷3𝖣 - 𝖷63 - 𝖬𝖲𝖨 𝖱𝖳𝖷2070𝖲 - 32𝖦𝖡-3800 - 2𝖳𝖡 𝖲𝖲𝖣 - 𝖧510 𝖤𝗅𝗂𝗍𝖾
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
- temps: Tja, wij kunnen niet zien waar en hoe jij die SSD hebt ingebouwd in je PC en hoeveel koeling die krijgt.
Deze temperatuur kan hij gemakkelijk hebben.
- 94%: dat wordt berekend als de verhouding van het aantal geschreven bytes tot nu toe t.o.v. het max aantal bytes voor die (waarschijnlijk OS?) SSD. Je PC staat per inschakeling gemiddeld ruim 1 uur aan. Dat betekent dat per uur gebruik het hele opstart/shutdown proces wordt doorlopen, met alle Windows bestanden die daarbij horen. Dan kom je vrij snel aan een behoorlijk aantal bytes ...
Maareh, maak je je niet beter zorgen om de (ooit) geconstateerde communicatiefouten tussen de SSD en het moederbord (C7)?
Deze temperatuur kan hij gemakkelijk hebben.
- 94%: dat wordt berekend als de verhouding van het aantal geschreven bytes tot nu toe t.o.v. het max aantal bytes voor die (waarschijnlijk OS?) SSD. Je PC staat per inschakeling gemiddeld ruim 1 uur aan. Dat betekent dat per uur gebruik het hele opstart/shutdown proces wordt doorlopen, met alle Windows bestanden die daarbij horen. Dan kom je vrij snel aan een behoorlijk aantal bytes ...
Maareh, maak je je niet beter zorgen om de (ooit) geconstateerde communicatiefouten tussen de SSD en het moederbord (C7)?
- chim0
- Registratie: Mei 2000
- Laatst online: 05-07 05:51
:strip_exif()/u/6897/IGKIPU.gif?f=community)
Van wanneer is de jouwe? Of het ligt aan mij, maar ik begin nu toch een patroon te zien bij die MX500. De mijne is van februari 2019 en zit nu op 97%. Het is de C: schijf en er draait alleen Windows op en wordt amper beschreven. Mijn PC gaat heel vaak in stand-by en dan weer aan. Ook wordt hij vrij warm (40 graden) terwijl ie "los" in de kast hangt onderin aan de voorkant. Nu is mijn kast niet de best ingedeelde (alles hangt met vlieg en kunstwerk aan elkaar) maar toch. M'n kast staat op de grond en het zijpaneel is eraf en ons huis is niet geïsoleerd dus in de winter is alles super koel en in de zomer bloedheet.d22wth schreef op woensdag 17 juni 2020 @ 00:08:
Heb mijn PC net aangezet, vind deze temps toch wat aan de hoge kant... Ook nog maar 1178u gedraaid en nu al 94%
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/0tWIxyRdqeqMc6qVKh3mMDAt.jpg?f=user_large)
Hier nog iemand met een MX500 250GB, die op 98% zit. Eronder zijn 840 EVO, die veel ouder is en veel meer heeft gedraaid en nog op 100% zit. Moet je het verschil zien tussen de gedraaide uren en het aantal geschreven bytes bij beide SSD's. Conclusie: puur toeval of toch het verschil in kwaliteit tussen een A-merk en een net niet A-merk?
Shoprevieuw in "Random crashes PC - Windows 10"
- Admiral Freebee
- Registratie: Februari 2004
- Niet online
@d22wth @chim0 Een mx500 500gb is gerate op 180TB aan writes. Het percentage dat weergegeven wordt lijkt me voor deze schijven niets anders te zijn dan een indicatie van hoeveel schrijfacties er nog over zijn voor je aan die rating komt. Dit wil niet zeggen dat de ssd stopt met werken als je aan 0% komt.
De evo 840 gebruikt smart attribute 177 wear leveling count om een percentage weer te geven. Dit kan best op een andere berekening gebaseerd zijn dan simpelweg de hoeveelheid data die al geschreven is. Mogelijk kijkt Samsung naar de hoeveelheid defecte sectoren.
De evo 840 gebruikt smart attribute 177 wear leveling count om een percentage weer te geven. Dit kan best op een andere berekening gebaseerd zijn dan simpelweg de hoeveelheid data die al geschreven is. Mogelijk kijkt Samsung naar de hoeveelheid defecte sectoren.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Gewoon geen zorgen over maken: dat hebben we over harddisks immers ook niet gedaan in het tijdperk dat daar geen "resterende levensduur indicator" op zat.
En zolang de temperaturen van een SSD binnen de toegestane marges vallen (die marges kan je opzoeken), is er niets aan de hand.
Degenen die daar anders over denken stellen de SSD beter op (vrij, in de koelluchtstroom) en/of zetten er een extra fan op.
En zolang de temperaturen van een SSD binnen de toegestane marges vallen (die marges kan je opzoeken), is er niets aan de hand.
Degenen die daar anders over denken stellen de SSD beter op (vrij, in de koelluchtstroom) en/of zetten er een extra fan op.
- d22wth
- Registratie: Juni 2015
- Laatst online: 12-06 14:05
... 𝗁𝖾𝗍 𝗁𝗈𝖾𝖿𝗍 𝗇𝗂𝖾𝗍 𝗉𝖾𝗋𝖿𝖾𝖼𝗍
Hij krijgt weinig koeling, aangezien het een Define S is en dus aan de achterkant gemonteerd is. Dit is idd m'n OS drive, vind t ook niet gek.Renault schreef op woensdag 17 juni 2020 @ 00:48:
- temps: Tja, wij kunnen niet zien waar en hoe jij die SSD hebt ingebouwd in je PC en hoeveel koeling die krijgt.
Deze temperatuur kan hij gemakkelijk hebben.
- 94%: dat wordt berekend als de verhouding van het aantal geschreven bytes tot nu toe t.o.v. het max aantal bytes voor die (waarschijnlijk OS?) SSD. Je PC staat per inschakeling gemiddeld ruim 1 uur aan. Dat betekent dat per uur gebruik het hele opstart/shutdown proces wordt doorlopen, met alle Windows bestanden die daarbij horen. Dan kom je vrij snel aan een behoorlijk aantal bytes ...
Maareh, maak je je niet beter zorgen om de (ooit) geconstateerde communicatiefouten tussen de SSD en het moederbord (C7)?
De C7 zou kunnen komen door een eerdere SATA kabel met een 'moeie' clip, die is vervangen.
Dus de berekening van Crucial werkt weer anders dan die van Samsung? Ipv aangeven via health% komen er dus andere factoren nog bij kijken...Admiral Freebee schreef op woensdag 17 juni 2020 @ 05:15:
@d22wth @chim0 Een mx500 500gb is gerate op 180TB aan writes. Het percentage dat weergegeven wordt lijkt me voor deze schijven niets anders te zijn dan een indicatie van hoeveel schrijfacties er nog over zijn voor je aan die rating komt. Dit wil niet zeggen dat de ssd stopt met werken als je aan 0% komt.
De evo 840 gebruikt smart attribute 177 wear leveling count om een percentage weer te geven. Dit kan best op een andere berekening gebaseerd zijn dan simpelweg de hoeveelheid data die al geschreven is. Mogelijk kijkt Samsung naar de hoeveelheid defecte sectoren.
Ik maak mij geen zorgen, ga toch binnenkort een nieuw systeem aanschaffen (en stap dan over op nvmeRenault schreef op woensdag 17 juni 2020 @ 09:33:
Gewoon geen zorgen over maken: dat hebben we over harddisks immers ook niet gedaan in het tijdperk dat daar geen "resterende levensduur indicator" op zat.
En zolang de temperaturen van een SSD binnen de toegestane marges vallen (die marges kan je opzoeken), is er niets aan de hand.
Degenen die daar anders over denken stellen de SSD beter op (vrij, in de koelluchtstroom) en/of zetten er een extra fan op.
Anyway, thanks voor de antwoorden. Heb ik weer wat geleerd.
𝚒𝙿𝚑𝚘𝚗𝚎 16 𝙿𝚛𝚘 - 𝖱7 5800𝖷3𝖣 - 𝖷63 - 𝖬𝖲𝖨 𝖱𝖳𝖷2070𝖲 - 32𝖦𝖡-3800 - 2𝖳𝖡 𝖲𝖲𝖣 - 𝖧510 𝖤𝗅𝗂𝗍𝖾
- Admiral Freebee
- Registratie: Februari 2004
- Niet online
De fabrikant kiest zelf hoe ze deze waarde opvullen. Bij de MX500 lijkt het simpelweg te zijn hoeveel writes er nog overblijven maar in principe kan de fabrikant ook andere factoren mee in rekening nemen.d22wth schreef op woensdag 17 juni 2020 @ 10:13:
Dus de berekening van Crucial werkt weer anders dan die van Samsung? Ipv aangeven via health% komen er dus andere factoren nog bij kijken...
- sirmike
- Registratie: December 2013
- Laatst online: 30-05-2022
:fill(white):strip_exif()/f/image/ECLMMmKv7Pmcx57nzFCngkyo.png?f=user_large)
Regelmatig, maar niet altijd, heb ik dat tijdens het opstarten en het gigabyte scherm in zicht komt dat de computer een soort herstelproces uitvoert met het 'fixen van de c schijf'. Soms heb ik dat de computer tijdens opstarten niet eens voorbij het gigabyte scherm komt, waarna met een simpele herstart dit wel gebeurd.
Heeft men hier ervaringen mee waar dit op zou kunnen duiden en hoe dit mogelijk te verhelpen is?
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Ik raad je aan om de Samsung Magician software te installeren, dat op te starten, kijken of je SSD de laatste firmware heeft (zoniet: meteen met de Magician updaten, dat geeft geen dataverlies) en daarna de SMART tabel uit de Magician hier neer te zetten.
De Cristaldiskinfo geeft namelijk zoveel geïnterpreteerde/vertaalde termen weer, dat interpretatie van de getoonde waarden lastig is.
Op grond van bovenstaand getoonde waarden zie ik niets verkeerds staan.
Het herstelproces wat je beschrijft zegt ook niets over de SSD, maar wel iets over het bestandssysteem dat daarop staat: dat raakt blijkbaar periodiek beschadigd en dat behoeft dan reparatie door Windows.
Dat zou er op kunnen duiden dat de oorzaak in de SSD zit, maar even goed in iets anders (slecht geheugen of zo). Je zou een complete hardwaretest kunnen uitvoeren inclusief MEMtest, om achter de oorzaak te komen.
Als je je geheugen verdenkt zou je ook de helft van je intern geheugen tijdelijk kunnen verwijderen en kijken of dan de verschijnselen wegblijven. En daarna testen met de andere helft.
De SSD is dus een mogelijke oorzaak, maar niet persé DE oorzaak.
De Cristaldiskinfo geeft namelijk zoveel geïnterpreteerde/vertaalde termen weer, dat interpretatie van de getoonde waarden lastig is.
Op grond van bovenstaand getoonde waarden zie ik niets verkeerds staan.
Het herstelproces wat je beschrijft zegt ook niets over de SSD, maar wel iets over het bestandssysteem dat daarop staat: dat raakt blijkbaar periodiek beschadigd en dat behoeft dan reparatie door Windows.
Dat zou er op kunnen duiden dat de oorzaak in de SSD zit, maar even goed in iets anders (slecht geheugen of zo). Je zou een complete hardwaretest kunnen uitvoeren inclusief MEMtest, om achter de oorzaak te komen.
Als je je geheugen verdenkt zou je ook de helft van je intern geheugen tijdelijk kunnen verwijderen en kijken of dan de verschijnselen wegblijven. En daarna testen met de andere helft.
De SSD is dus een mogelijke oorzaak, maar niet persé DE oorzaak.
- sirmike
- Registratie: December 2013
- Laatst online: 30-05-2022
Dank. Ik heb de firmware kunnen updaten. Ik kon helaas geen smart gegevens exporteren. Dan slaat het programma vast. Hierbij dan maar even screenshots ervan.Renault schreef op maandag 22 juni 2020 @ 23:54:
Ik raad je aan om de Samsung Magician software te installeren, dat op te starten, kijken of je SSD de laatste firmware heeft (zoniet: meteen met de Magician updaten, dat geeft geen dataverlies) en daarna de SMART tabel uit de Magician hier neer te zetten.
De Cristaldiskinfo geeft namelijk zoveel geïnterpreteerde/vertaalde termen weer, dat interpretatie van de getoonde waarden lastig is.
Op grond van bovenstaand getoonde waarden zie ik niets verkeerds staan.
Het herstelproces wat je beschrijft zegt ook niets over de SSD, maar wel iets over het bestandssysteem dat daarop staat: dat raakt blijkbaar periodiek beschadigd en dat behoeft dan reparatie door Windows.
Dat zou er op kunnen duiden dat de oorzaak in de SSD zit, maar even goed in iets anders (slecht geheugen of zo). Je zou een complete hardwaretest kunnen uitvoeren inclusief MEMtest, om achter de oorzaak te komen.
Als je je geheugen verdenkt zou je ook de helft van je intern geheugen tijdelijk kunnen verwijderen en kijken of dan de verschijnselen wegblijven. En daarna testen met de andere helft.
De SSD is dus een mogelijke oorzaak, maar niet persé DE oorzaak.
https://imgur.com/a/5fqqf4l
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Dankjewel voor de genomen moeite: deze versie geeft helaas ook niet meer inzicht in de mogelijke foutoorzaak.
Maar mij lijkt het sterk dat de oorzaak in de SSD is te vinden.
Kijk ook eens of het met de nieuwe firmware wel goed blijft gaan.
Wellicht is er iets te vinden in je Windows logfiles (als je zover wil gaan)?
Maar mij lijkt het sterk dat de oorzaak in de SSD is te vinden.
Kijk ook eens of het met de nieuwe firmware wel goed blijft gaan.
Wellicht is er iets te vinden in je Windows logfiles (als je zover wil gaan)?
- sirmike
- Registratie: December 2013
- Laatst online: 30-05-2022
ik kijk het even aan, ik heb (voorlopig) geen problemen ondervonden.
- masuary
- Registratie: December 2010
- Laatst online: 27-03 10:30
Heb van een mede tweaker een HDD tweedehands gekocht.
Had al aardig wat draai uren maar na het versturen en de HDD in de PC geinstalleerd te hebben is de Spin-up time ineens slecht.
:fill(white):strip_exif()/f/image/R7hy2So3o5BvtMZc07BVqvNe.png?f=user_large)
Kan dit kwaad ? wou hem gaan gebruik als schijfje voor al mijn downloads.
Dit waren de gegevens voordat HDD was opgestuurd:
:fill(white):strip_exif()/f/image/Kv79YLR1wVRv5WQfCZcGZmZM.png?f=user_large)
Had al aardig wat draai uren maar na het versturen en de HDD in de PC geinstalleerd te hebben is de Spin-up time ineens slecht.
Kan dit kwaad ? wou hem gaan gebruik als schijfje voor al mijn downloads.
Dit waren de gegevens voordat HDD was opgestuurd:
[ Voor 21% gewijzigd door masuary op 30-06-2020 21:53 ]
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Op de spinup time na lijkt de schijf nog gezond na 30.000 uur gebruik. Ik zie dat de start/stop count relatief laag is, wat waarschijnlijk betekent dat de schijf een groot deel van die 30.000 uur heeft gedraaid. De lagers zullen dat waarschijnlijk niet fijn vinden en die zullen behoorlijk ge/versleten zijn: uit die hoek komt de melding over trage spinup.
Ook bij de vorige eigenaar is die waarde al relatief hoog.
Als je die schijf gebruikt voor backups, zal de start/stop count niet veel toenemen en zou je gewoon kunnen proberen hoe de schijf zich houdt. Hat kan wel handig zijn om bij de vorige eigenaar na te vragen hoe de schijf is gebruikt, vlak of rechtop staand en in welke stand van de aansluitingen-kant dat is geweest: als de schijf bij de vorige eigenaar plat heeft gelegen en jij gebruikt hem nu rechtop staand in een SATA-dock, zou dat de waarde kunnen verklaren.
Maar het blijft giswerk.
Ook bij de vorige eigenaar is die waarde al relatief hoog.
Als je die schijf gebruikt voor backups, zal de start/stop count niet veel toenemen en zou je gewoon kunnen proberen hoe de schijf zich houdt. Hat kan wel handig zijn om bij de vorige eigenaar na te vragen hoe de schijf is gebruikt, vlak of rechtop staand en in welke stand van de aansluitingen-kant dat is geweest: als de schijf bij de vorige eigenaar plat heeft gelegen en jij gebruikt hem nu rechtop staand in een SATA-dock, zou dat de waarde kunnen verklaren.
Maar het blijft giswerk.

- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
- Als je goede (incremental) backups hebt van al je bestanden mik je deze disk weg en verspil je je tijd niet.
- Als je geen goede backup hebt laat je dit lekker uitrazen en dan kijk je welke bestanden je nog over hebt: max 1424 bestanden kwijt op een hele harddisk wil zeggen dat er ook nog goede bestanden bij staan, wellicht nét de meest recente databestanden ...
- Als je geen goede backup hebt laat je dit lekker uitrazen en dan kijk je welke bestanden je nog over hebt: max 1424 bestanden kwijt op een hele harddisk wil zeggen dat er ook nog goede bestanden bij staan, wellicht nét de meest recente databestanden ...
[ Voor 4% gewijzigd door Renault op 04-07-2020 09:55 ]
- marigo
- Registratie: Juni 2006
- Laatst online: 05-07 15:58
:strip_icc():strip_exif()/u/180482/crop5adf2e9557c32_cropped.jpeg?f=community)
Ik gebruik een Crucial MX500 (1TB) als video opslag voor beveiligings camera beelden. De SSD is nog niet zo oud (7 maanden) en heeft ook nog maar 8,35TB weggeschreven. Echter zie ik dat er twee attributen een "pre-fail" status hebben.
Ik heb gezocht op attribuut "180", welke nu een waarde heeft van 42, en zodra deze "0" wordt gaat de disk op "read-only". Ik zou echt niet meer weten wat de oorspronkelijke waarde was van dit attribuut, maar die zou volgens Crucial ergens in de 1000+ moeten liggen.
Iemand een idee waarom deze schijf nu eigenlijk al vervangen moet worden?
code:
1
2
| 1 Raw_Read_Error_Rate 0x002f 100 100 000 Pre-fail 180 Unused_Reserve_NAND_Blk 0x0033 000 000 000 Pre-fail |
Ik heb gezocht op attribuut "180", welke nu een waarde heeft van 42, en zodra deze "0" wordt gaat de disk op "read-only". Ik zou echt niet meer weten wat de oorspronkelijke waarde was van dit attribuut, maar die zou volgens Crucial ergens in de 1000+ moeten liggen.
Iemand een idee waarom deze schijf nu eigenlijk al vervangen moet worden?
- Admiral Freebee
- Registratie: Februari 2004
- Niet online
Ik zou denken dat een ssd wel langer moet meegaan dan dat met die hoeveelheid aan geschreven data maar ik vraag me wel af waarom je een ssd gebruikt voor een continue(?) videostream op te slaan. Een harde schijf lijkt me hier veel geschikter voor.
- mrmrmr
- Registratie: April 2007
- Niet online
/u/216161/crop5daf72732a011.png?f=community)
@marigo Als je geen recente backup hebt, dat is zou ik die meteen maken.
0x33 hexadecimaal is 52 decimaal. Als je meteen daarna al op waarde 42 decimaal zit, dan daalt het snel. Als er geen reserve meer is kan de drive geen bestanden meer redden wegens NAND geheugen falen. Dan raak je data kwijt. Crucial adviseert vervanging bij een waarde van 100. Je zit nu al op nog maar 42.
Bron: https://www.crucial.com/s...q-ssd/ssds-and-smart-data
0x33 hexadecimaal is 52 decimaal. Als je meteen daarna al op waarde 42 decimaal zit, dan daalt het snel. Als er geen reserve meer is kan de drive geen bestanden meer redden wegens NAND geheugen falen. Dan raak je data kwijt. Crucial adviseert vervanging bij een waarde van 100. Je zit nu al op nog maar 42.
| Attribute 180: Unused Reserved Block Count (Available Spare Blocks on PCIe SSDs) Again, as the name implies, this is the count of extra blocks available to be used in case bad blocks need to be retired. This number varies based on the underlying NAND architecture, the firmware architecture, and the user capacity of the drive, but it usually starts in the thousands. This number decreases as the number of retired blocks increases. When Attribute 180 reaches 0, the firmware will place the SSD in read-only mode. The SSD will not be usable as a normal drive, but the user should be able to retrieve stored data and transfer to a new device. It is strongly advised that if this number should get below 100 or so, the drive should be replaced. |
- marigo
- Registratie: Juni 2006
- Laatst online: 05-07 15:58
Het is geen continu opname; alleen als er beweging is.
Ik heb voor een SSD gekozen juist vanwege de duurzaamheid, maar misschien moet ik het maar heroverwegen om de beelden toch maar op te slaan op een traditionele HD.
@mrmrmr Ja, dat had ik ook gevonden. Maar ik snap er eigenlijk niks van waarom dit zo snel degradeert.
Misschien is dit toch iets Crucial-achtig, want hiervoor deed ik precies hetzelfde op een Samsung 860 en zag ik dit niet zo snel achteruitlopen.
Dank jullie voor de reactie. Ik ga Crucial maar even spammen.
EDIT:
Er zit ook een Samsung 970 evo in mijn systeem die 7,99TB heeft geschreven en de "wearout of Percentage used" staat hier nog op "0".
Ik kan misschien wel eens een maandagochtend model hebben gekregen.
Ik heb voor een SSD gekozen juist vanwege de duurzaamheid, maar misschien moet ik het maar heroverwegen om de beelden toch maar op te slaan op een traditionele HD.
@mrmrmr Ja, dat had ik ook gevonden. Maar ik snap er eigenlijk niks van waarom dit zo snel degradeert.
Misschien is dit toch iets Crucial-achtig, want hiervoor deed ik precies hetzelfde op een Samsung 860 en zag ik dit niet zo snel achteruitlopen.
Dank jullie voor de reactie. Ik ga Crucial maar even spammen.
EDIT:
Er zit ook een Samsung 970 evo in mijn systeem die 7,99TB heeft geschreven en de "wearout of Percentage used" staat hier nog op "0".
Ik kan misschien wel eens een maandagochtend model hebben gekregen.
[ Voor 16% gewijzigd door marigo op 05-07-2020 10:03 ]
- mrmrmr
- Registratie: April 2007
- Niet online
De reden is dat er slechte stukken NAND geheugen zijn. Zodra je die stukken geheugen gebruikt en er zijn checksumfouten zal de drive die proberen te redden.
Daarom zou ik meteen stoppen met het gebruik van die drive. Eerst een backup maken van waardevolle bestanden. Vervolgens de drive wissen middels een quick format. Daarna overschrijven met bestanden (h2testw). Zodoende bereid je de drive voor op terugsturen naar de leverancier.
Als de drive eenmaal in read only mode gaat dat is het wissen van bestanden ook onmogelijk geworden. Dan heb je mogelijk privacyproblemen als je de SSD terugstuurt. De drive is hoe dan ook total loss en moet worden vervangen.
Samsung is over het algemeen betere kwaliteit. Ze maken alles zelf: NAND, controller. Zij tellen andersom, die 970 heeft dus nog geen slechte stukken aangetroffen.
Daarom zou ik meteen stoppen met het gebruik van die drive. Eerst een backup maken van waardevolle bestanden. Vervolgens de drive wissen middels een quick format. Daarna overschrijven met bestanden (h2testw). Zodoende bereid je de drive voor op terugsturen naar de leverancier.
Als de drive eenmaal in read only mode gaat dat is het wissen van bestanden ook onmogelijk geworden. Dan heb je mogelijk privacyproblemen als je de SSD terugstuurt. De drive is hoe dan ook total loss en moet worden vervangen.
Samsung is over het algemeen betere kwaliteit. Ze maken alles zelf: NAND, controller. Zij tellen andersom, die 970 heeft dus nog geen slechte stukken aangetroffen.
[ Voor 10% gewijzigd door mrmrmr op 05-07-2020 10:14 ]
- marigo
- Registratie: Juni 2006
- Laatst online: 05-07 15:58
Check, dank voor de verheldering.
Ik ga de schijf idd niet meer gebruiken en bedankt voor de tip mbt het herschrijven van de data.
Ik denk dat de schijf ook niet helemaal okselfris is, want de power-on hours staat op 2429 wat zou neerkomen op 102 dagen terwijl de schijf al ruim 7 maanden actief is.
Ik ga de schijf idd niet meer gebruiken en bedankt voor de tip mbt het herschrijven van de data.
Ik denk dat de schijf ook niet helemaal okselfris is, want de power-on hours staat op 2429 wat zou neerkomen op 102 dagen terwijl de schijf al ruim 7 maanden actief is.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
@marigo :
Mag ik een afwijkende mening hebben, zuiver op wat je hier schrijft?
- Ik heb in diverse SMART-reports gezien dat de categorie van een parameter "Pre-fail" is.
Dat je "Pre-Fail" ziet staan, is dus geen teken dat de Fail er aan zit te komen, maar het duidt aan dat de score vanaf nul wordt bijgehouden zodat je bij problemen kunt zien of deze parameter daaraan evt. bijdraagt.
- het aantal "unused reserve NAND" is nog volledig beschikbaar, want de count hiervoor staat volgens mij op "000".
Dit zou betekenen dat er nog geen enkele sector is vervangen door een reservesector.
Helaas heb je de tabel onvolledig afgebeeld (geen kolomkoppen, geen rest van de waarden), zodat we hiernaar slechts kunnen gissen.
- in hoeverre komen de Power On Hours niet overeen met 7 maanden (pakweg 210 dagen)? Dat ligt aan de wijze van gebruik (alleen "On" als iets wordt geschreven?). Je conclusie zou ik niet zonder meer durven trekken.
- met 8,35 TB written is de SSD nog "helemaal nieuw". Je kunt je resterende levensduur zelf uitrekenen als je het "Max bytes Written" even opzoekt in je specs. Waarschijnlijk is de resterende levensduur iets van 99,95 %.
Daarom het verzoek om de hele SMART-tabel hier neer te zetten, want ik heb het ernstige vermoeden dat er helemaal niets met deze SSD aan de hand is. En dat zou fijn zijn voor je.
Mag ik een afwijkende mening hebben, zuiver op wat je hier schrijft?
- Ik heb in diverse SMART-reports gezien dat de categorie van een parameter "Pre-fail" is.
Dat je "Pre-Fail" ziet staan, is dus geen teken dat de Fail er aan zit te komen, maar het duidt aan dat de score vanaf nul wordt bijgehouden zodat je bij problemen kunt zien of deze parameter daaraan evt. bijdraagt.
- het aantal "unused reserve NAND" is nog volledig beschikbaar, want de count hiervoor staat volgens mij op "000".
Dit zou betekenen dat er nog geen enkele sector is vervangen door een reservesector.
Helaas heb je de tabel onvolledig afgebeeld (geen kolomkoppen, geen rest van de waarden), zodat we hiernaar slechts kunnen gissen.
- in hoeverre komen de Power On Hours niet overeen met 7 maanden (pakweg 210 dagen)? Dat ligt aan de wijze van gebruik (alleen "On" als iets wordt geschreven?). Je conclusie zou ik niet zonder meer durven trekken.
- met 8,35 TB written is de SSD nog "helemaal nieuw". Je kunt je resterende levensduur zelf uitrekenen als je het "Max bytes Written" even opzoekt in je specs. Waarschijnlijk is de resterende levensduur iets van 99,95 %.
Daarom het verzoek om de hele SMART-tabel hier neer te zetten, want ik heb het ernstige vermoeden dat er helemaal niets met deze SSD aan de hand is. En dat zou fijn zijn voor je.
- marigo
- Registratie: Juni 2006
- Laatst online: 05-07 15:58
@Renault
Hierbij de output van het smartctl commando:
Ik dacht toch altijd dat het "power-on hours" hoe lang de schijf al draait, maar blijkbaar is er nu ook maar een "uurtje" bij gekomen terwijl ik deze net heb uitgelezen en dat was 3 uur geleden en nu is er maar één extra uur bijgekomen.
Hierbij de output van het smartctl commando:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
| smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.41-1-pve] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Crucial/Micron MX500 SSDs
Device Model: CT1000MX500SSD1
Serial Number: 1940E22xxxxxx
LU WWN Device Id: 5 00a075 1e2228225
Firmware Version: M3CR023
User Capacity: 1,000,204,886,016 bytes [1.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: Solid State Device
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.3, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Sun Jul 5 13:43:42 2020 CEST
==> WARNING: This firmware returns bogus raw values in attribute 197
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x80) Offline data collection activity
was never started.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 0) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 30) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x0031) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 100 100 000 Pre-fail Always - 0
5 Reallocate_NAND_Blk_Cnt 0x0032 100 100 010 Old_age Always - 0
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 2430
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 10
171 Program_Fail_Count 0x0032 100 100 000 Old_age Always - 0
172 Erase_Fail_Count 0x0032 100 100 000 Old_age Always - 0
173 Ave_Block-Erase_Count 0x0032 094 094 000 Old_age Always - 91
174 Unexpect_Power_Loss_Ct 0x0032 100 100 000 Old_age Always - 1
180 Unused_Reserve_NAND_Blk 0x0033 000 000 000 Pre-fail Always - 42
183 SATA_Interfac_Downshift 0x0032 100 100 000 Old_age Always - 0
184 Error_Correction_Count 0x0032 100 100 000 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
194 Temperature_Celsius 0x0022 049 035 000 Old_age Always - 51 (Min/Max 0/65)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
197 Bogus_Current_Pend_Sect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 100 100 000 Old_age Always - 0
202 Percent_Lifetime_Remain 0x0030 094 094 001 Old_age Offline - 6
206 Write_Error_Rate 0x000e 100 100 000 Old_age Always - 0
210 Success_RAIN_Recov_Cnt 0x0032 100 100 000 Old_age Always - 0
246 Total_LBAs_Written 0x0032 100 100 000 Old_age Always - 17953885570
247 Host_Program_Page_Count 0x0032 100 100 000 Old_age Always - 315469839
248 FTL_Program_Page_Count 0x0032 100 100 000 Old_age Always - 2286053657
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Completed [00% left] (0-65535)
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Ik dacht toch altijd dat het "power-on hours" hoe lang de schijf al draait, maar blijkbaar is er nu ook maar een "uurtje" bij gekomen terwijl ik deze net heb uitgelezen en dat was 3 uur geleden en nu is er maar één extra uur bijgekomen.
- Admiral Freebee
- Registratie: Februari 2004
- Niet online
Wellicht gaat de ssd in een slaapmodus net zoals een harde schijf kan downspinnen?
- marigo
- Registratie: Juni 2006
- Laatst online: 05-07 15:58
Ja, zoiets. Dat zou dan de "power-on hours" verklaren.
Er zit ook nog een andere ssd in de computer die zou dezelfde waarden moeten hebben want ze zijn er tegelijk in gekomen, maar die geeft ook minder "power-on-hours" aan.
Mijn verkeerde interpretatie van het gegeven....
Er zit ook nog een andere ssd in de computer die zou dezelfde waarden moeten hebben want ze zijn er tegelijk in gekomen, maar die geeft ook minder "power-on-hours" aan.
Mijn verkeerde interpretatie van het gegeven....
- mrmrmr
- Registratie: April 2007
- Niet online
@marigo @Renault
Unused_Reserve_NAND_Blk betekent het aantal ongebruikte reserveblokken NAND geheugen. 0 is read-only waarde volgens Crucial zelf. Dat wil zeggen dat er dan geen ruimte meer is. De raw value (scroll naar rechts) staat nu inderdaad op 42, niet op 0. Als er 42 blokken in totaal zouden zijn in een ongebruikte drive, is dat perfect. Als er origineel 100 blokken beschikbaar waren, dan is er een afname van 58 geweest. De vraag is dus hoeveel reserveblokken er zijn als de drive ongebruikt is. De indicatie die Crucial zelf geeft is de drempelwaarde van 100. Bij een waarde onder 100 moet de drive worden vervangen (zie de Crucial tekst).
Bij mijn redelijk nieuwe BX500 480GB SATA drive zijn er 219 blokken beschikbaar, volgens SMART. Dus ik denk dat jouw drive er misschien ook zoveel had of misschien 2 keer meer vanwege de grotere opslagcapaciteit.
Het aantal power on hours lijkt inderdaad het aantal actieve uren bij Crucial. Bij mij is het ook lager dan verwacht.
0x33 is een flag, dat is geen waarde.
Unused_Reserve_NAND_Blk betekent het aantal ongebruikte reserveblokken NAND geheugen. 0 is read-only waarde volgens Crucial zelf. Dat wil zeggen dat er dan geen ruimte meer is. De raw value (scroll naar rechts) staat nu inderdaad op 42, niet op 0. Als er 42 blokken in totaal zouden zijn in een ongebruikte drive, is dat perfect. Als er origineel 100 blokken beschikbaar waren, dan is er een afname van 58 geweest. De vraag is dus hoeveel reserveblokken er zijn als de drive ongebruikt is. De indicatie die Crucial zelf geeft is de drempelwaarde van 100. Bij een waarde onder 100 moet de drive worden vervangen (zie de Crucial tekst).
Bij mijn redelijk nieuwe BX500 480GB SATA drive zijn er 219 blokken beschikbaar, volgens SMART. Dus ik denk dat jouw drive er misschien ook zoveel had of misschien 2 keer meer vanwege de grotere opslagcapaciteit.
Het aantal power on hours lijkt inderdaad het aantal actieve uren bij Crucial. Bij mij is het ook lager dan verwacht.
0x33 is een flag, dat is geen waarde.
- marigo
- Registratie: Juni 2006
- Laatst online: 05-07 15:58
Ik heb het bij Crucial neergelegd en ben al heen en weer aan het mailen. Nu maar even afwachten hoe goed de service is daar.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Volgens mij mankeert er (na nalezen van de tabel) nog steeds niets aan je SSD.
Wel zie ik dat het # Bytes Written hoger ligt dan je eerst opgaf, wat leidt tot een nu resterende theoretische levensduur van 94% op basis van het aantal bytes written.
Als je zit met een ongemakkelijk gevoel over dit verschil van meningen: dat hoeft niet: een goed uitgevoerd backupregime kan elke angst voor dataverlies wegnemen.
Wel zie ik dat het # Bytes Written hoger ligt dan je eerst opgaf, wat leidt tot een nu resterende theoretische levensduur van 94% op basis van het aantal bytes written.
Als je zit met een ongemakkelijk gevoel over dit verschil van meningen: dat hoeft niet: een goed uitgevoerd backupregime kan elke angst voor dataverlies wegnemen.
[ Voor 25% gewijzigd door Renault op 05-07-2020 22:32 ]
- mrmrmr
- Registratie: April 2007
- Niet online
TN-FD-22: Client SATA SSD SMART Attribute Reference
SMART ID 180 (B4h): Unused Reserve (Spare) NAND Blocks
Current Value
This value is hard-coded to zero (00h).
Worst Value
This value is hard-coded to zero (00h).
Raw Data
This value is calculated as:
URBC = BT - BG
Where:
URBC = Total unused reserved block count.
BT = Total number of spare blocks when the drive left the factory. The spare block count represents the number of grown bad blocks the drive can handle in the field before it enters write protect.
BG = Total number of grown bad blocks.
Dit is uit een pdf uit 2018 over onder andere MX300 en M500, MX500 wordt niet genoemd. Maar ik zou verwachten dat het voor die drive ook geldt.
Wat vreemd is, is dat Reallocate_NAND_Blk_Cnt op nul staat. Ik zou verwachten dat die oploopt als het aantal reserve blocks afloopt. Of: er zou nog een reden kunnen zijn voor het gebruik van reserve blocks dan alleen bij het verplaatsen van blocks.
Crucial/Micron mag hier duidelijkheid scheppen.
SMART ID 180 (B4h): Unused Reserve (Spare) NAND Blocks
Current Value
This value is hard-coded to zero (00h).
Worst Value
This value is hard-coded to zero (00h).
Raw Data
This value is calculated as:
URBC = BT - BG
Where:
URBC = Total unused reserved block count.
BT = Total number of spare blocks when the drive left the factory. The spare block count represents the number of grown bad blocks the drive can handle in the field before it enters write protect.
BG = Total number of grown bad blocks.
Dit is uit een pdf uit 2018 over onder andere MX300 en M500, MX500 wordt niet genoemd. Maar ik zou verwachten dat het voor die drive ook geldt.
Wat vreemd is, is dat Reallocate_NAND_Blk_Cnt op nul staat. Ik zou verwachten dat die oploopt als het aantal reserve blocks afloopt. Of: er zou nog een reden kunnen zijn voor het gebruik van reserve blocks dan alleen bij het verplaatsen van blocks.
Crucial/Micron mag hier duidelijkheid scheppen.
- marigo
- Registratie: Juni 2006
- Laatst online: 05-07 15:58
Antwoord van Crucial na het checken van de SMART gegevens: de SSD mag teruggestuurd worden:
Thank you for reaching out to us.
We have checked the SMART information of SSD. We see that Attribute 180: Unused Reserved Block Count is 42 on your SSD. This number varies based on the underlying NAND architecture, the firmware architecture, and the user capacity of the drive, but it usually starts in the thousands.
This number decreases as the number of retired blocks increases. When Attribute 180 reaches 0, the firmware will place the SSD in read-only mode. The SSD will not be usable as a normal drive, but the user should be able to retrieve stored data and transfer to a new device. It is strongly advised that if this number should get below 100 or so, the drive should be replaced.
You can request warranty replacement on our website from below link.
https://eu.crucial.com/returns
EDIT: Ik ga de data weer opslaan op een 860 schijf. Daar had ik goede ervaring mee mbt de hoeveelheid I/O waar de disk mee te maken krijgt.
EDIT2: Ik heb nog een latop waar een zelfde schijf (500GB) in zit en deze even gecheckt met Crystal disk info en deze rapporteert het volgende:
Dit zou betekenen dat deze schijf "iets" beter is, maar ook vervangen moet worden. Deze heeft pas 167 uur aan bedrijfsuren. Ik begin sterk te twijfelen of er nu echt iets mis is. Crucial heeft de SMART gegevens ook gecheckt. Je mag er toch vanuit gaan dat zij de experts zijn...
EDIT3: Crucial gaat dit bij hun research afdeling neerleggen. Het lijkt op een firmware fout. Meerdere SMART outputs die ik heb gezien van een MX500 hangt allemaal rond de 40. De SSD is retour.
EDIT4: Ik heb een splinternieuwe SSD gekregen met een nog slechtere 'niet gebruikte NAND blocks van '30'. Dit is dus zeker een firmware fout.
EDIT5: Nog een reactie ontvangen van Crucial:
This email is regarding your query.
If the number gets below 100 or so, the drive should be replaced" is outdated, due to us changing from blocks to superblocks (made up of many individual blocks) on most of our SSDs, which means this value can start below 100 on a brand new SSD. We have already escalate this issue and soon this will be updated on SMART data .There is no issue with your SSD.
Dus...lekker bezig support!!!
@Renault Had je toch gelijk.
Thank you for reaching out to us.
We have checked the SMART information of SSD. We see that Attribute 180: Unused Reserved Block Count is 42 on your SSD. This number varies based on the underlying NAND architecture, the firmware architecture, and the user capacity of the drive, but it usually starts in the thousands.
This number decreases as the number of retired blocks increases. When Attribute 180 reaches 0, the firmware will place the SSD in read-only mode. The SSD will not be usable as a normal drive, but the user should be able to retrieve stored data and transfer to a new device. It is strongly advised that if this number should get below 100 or so, the drive should be replaced.
You can request warranty replacement on our website from below link.
https://eu.crucial.com/returns
EDIT: Ik ga de data weer opslaan op een 860 schijf. Daar had ik goede ervaring mee mbt de hoeveelheid I/O waar de disk mee te maken krijgt.
EDIT2: Ik heb nog een latop waar een zelfde schijf (500GB) in zit en deze even gecheckt met Crystal disk info en deze rapporteert het volgende:
code:
1
2
| ID Kenmerk Huidig Slechtste Drempel RAW B4 Niet gebruikte NAND blocks 0 0 0 00000000002E |
Dit zou betekenen dat deze schijf "iets" beter is, maar ook vervangen moet worden. Deze heeft pas 167 uur aan bedrijfsuren. Ik begin sterk te twijfelen of er nu echt iets mis is. Crucial heeft de SMART gegevens ook gecheckt. Je mag er toch vanuit gaan dat zij de experts zijn...
EDIT3: Crucial gaat dit bij hun research afdeling neerleggen. Het lijkt op een firmware fout. Meerdere SMART outputs die ik heb gezien van een MX500 hangt allemaal rond de 40. De SSD is retour.
EDIT4: Ik heb een splinternieuwe SSD gekregen met een nog slechtere 'niet gebruikte NAND blocks van '30'
EDIT5: Nog een reactie ontvangen van Crucial:
This email is regarding your query.
If the number gets below 100 or so, the drive should be replaced" is outdated, due to us changing from blocks to superblocks (made up of many individual blocks) on most of our SSDs, which means this value can start below 100 on a brand new SSD. We have already escalate this issue and soon this will be updated on SMART data .There is no issue with your SSD.
Dus...lekker bezig support!!!
@Renault Had je toch gelijk.
[ Voor 47% gewijzigd door marigo op 29-07-2020 11:11 ]
- thijsjek
- Registratie: Juni 2010
- Laatst online: 25-02-2025
Hallo,
Mijn wd green 2tb geeft een vage ata error in freenas ondertusssen al 77x, na telkens 283u. Er word elke zondag (na ca. 168u) een short test gedaan. de smart waardes zien er netjes uit voor een 3 jaar power on.
Ik heb even gezocht hier in het forum maar niet echt een vergelijkbaar geval gevonden.
Ik heb tevens een zelfde WDC WD20EARX-00PASB0 die deze errors niet geeft (in mirror pool)
Mijn wd green 2tb geeft een vage ata error in freenas ondertusssen al 77x, na telkens 283u. Er word elke zondag (na ca. 168u) een short test gedaan. de smart waardes zien er netjes uit voor een 3 jaar power on.
Ik heb even gezocht hier in het forum maar niet echt een vergelijkbaar geval gevonden.
Ik heb tevens een zelfde WDC WD20EARX-00PASB0 die deze errors niet geeft (in mirror pool)
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
| === START OF INFORMATION SECTION ===
Model Family: Western Digital Green
Device Model: WDC WD20EARX-00PASB0
Serial Number: WD-WCAZA7669852
LU WWN Device Id: 5 0014ee 2b08feda4
Firmware Version: 51.0AB51
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Fri Jul 24 20:44:48 2020 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 174 162 021 Pre-fail Always - 6291
4 Start_Stop_Count 0x0032 097 097 000 Old_age Always - 3754
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 064 064 000 Old_age Always - 26889
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 1284
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 367
193 Load_Cycle_Count 0x0032 101 101 000 Old_age Always - 298490
194 Temperature_Celsius 0x0022 117 088 000 Old_age Always - 33
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 8
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
ATA Error Count: 77 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 77 occurred at disk power-on lifetime: 283 hours (11 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
04 51 01 00 00 00 a0 Error: ABRT
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
b0 d6 01 e0 4f c2 a0 00 00:30:01.652 SMART WRITE LOG
ec 00 00 00 00 00 a0 00 00:30:01.648 IDENTIFY DEVICE
c6 00 10 00 00 00 a0 00 00:29:58.910 SET MULTIPLE MODE
ef 03 46 00 00 00 a0 00 00:29:58.910 SET FEATURES [Set transfer mode]
ef 03 0c 00 00 00 a0 00 00:29:58.910 SET FEATURES [Set transfer mode]
Error 76 occurred at disk power-on lifetime: 283 hours (11 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
04 51 01 00 00 00 a0 Error: ABRT
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
b0 d6 01 e0 4f c2 a0 00 00:27:27.757 SMART WRITE LOG
ec 00 00 00 00 00 a0 00 00:27:27.753 IDENTIFY DEVICE
c6 00 10 00 00 00 a0 00 00:27:25.054 SET MULTIPLE MODE
ef 03 46 00 00 00 a0 00 00:27:25.054 SET FEATURES [Set transfer mode]
ef 03 0c 00 00 00 a0 00 00:27:25.054 SET FEATURES [Set transfer mode]
Error 75 occurred at disk power-on lifetime: 283 hours (11 days + 19 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
04 51 01 00 00 00 a0 Error: ABRT
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
b0 d6 01 e0 4f c2 a0 00 00:27:24.711 SMART WRITE LOG
ec 00 00 00 00 00 a0 00 00:27:24.707 IDENTIFY DEVICE
c6 00 10 00 00 00 a0 00 00:27:21.819 SET MULTIPLE MODE
ef 03 46 00 00 00 a0 00 00:27:21.819 SET FEATURES [Set transfer mode]
ef 03 0c 00 00 00 a0 00 00:27:21.819 SET FEATURES [Set transfer mode] |
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Er is maar één afwijkende waarde: 199: je hebt communicatiefouten tussen de harddisk en de controller.
Ik weet niet of hij via een SATA-kabel is aangesloten, maar dan zou ik eerst die kabel vernieuwen.
Ik weet niet of hij via een SATA-kabel is aangesloten, maar dan zou ik eerst die kabel vernieuwen.
Verwijderd
Ik heb een externe hd en na meer dan 10 jaar gaat hij de geest geven volgens mij.
Disconnecten, tikken en vreselijk langzaam. Gelukkig op tijd om het meeste eraf te halen.
:fill(white):strip_exif()/f/image/ErqO0GvnNsMb5lcXc1XXJzxi.png?f=user_large)
Disconnecten, tikken en vreselijk langzaam. Gelukkig op tijd om het meeste eraf te halen.
- Renault
- Registratie: Januari 2014
- Laatst online: 21:36
Tja, die heeft na bijna 100.000 uren zijn betrouwbaarste / beste tijd wel gehad.
Toch doet hij het nog steeds goed: volgens de cijfers ben je nog steeds geen data kwijt.
Maar ik zou hem toch vervangen of zorgen dat je backups op orde zijn.
Als je hem een keer een extra full backup geeft, dan low level formatteert (let op: dan gaat je data verloren) en de backup terugzet, weet je meteen (aan de hand van de meldingen bij de format) hoe de schijf er momenteel aan toe is.
Toch doet hij het nog steeds goed: volgens de cijfers ben je nog steeds geen data kwijt.
Maar ik zou hem toch vervangen of zorgen dat je backups op orde zijn.
Als je hem een keer een extra full backup geeft, dan low level formatteert (let op: dan gaat je data verloren) en de backup terugzet, weet je meteen (aan de hand van de meldingen bij de format) hoe de schijf er momenteel aan toe is.
- Q
- Registratie: November 1999
- Nu online
Als die 301 een hexadecimale waarde is dan heb je 769 rotte sectoren op je schijf. Ik zou de schijf afschrijven.
Een full format kan helpen maar vertrouw je de schijf nog?
P.s. @Verwijderd waarom zoveel moeite om die data er nog af te halen? Blijkbaar had je geen backup van die data dus was die data niet belangrijk.
Een full format kan helpen maar vertrouw je de schijf nog?
P.s. @Verwijderd waarom zoveel moeite om die data er nog af te halen? Blijkbaar had je geen backup van die data dus was die data niet belangrijk.
[ Voor 5% gewijzigd door Q op 30-07-2020 11:43 ]
![]() Dit topic is gesloten.
Dit topic is gesloten.
![]()