@The-dragon
Aan beide schijven is geen spoor van falen te zien.
Ze hebben al wel behoorlijk wat draai-uren meegemaakt ...
Aan beide schijven is geen spoor van falen te zien.
Ze hebben al wel behoorlijk wat draai-uren meegemaakt ...
Dit topic is onderdeel van een reeks. Ga naar het meest recente topic in deze reeks.
Ten eersten beide bedankt voor de hulp.TweetCu schreef op zaterdag 25 januari 2020 @ 03:41:
[...]
Hoi, het zou handig zijn als je even de BSOD error met ons kan delen en de dump bestand.
Je kan in de logboek kijken of BlueScreenView van Nirsoft downloaden om de errorcode te vinden.
Het is meestal een code als bijvoorbeeld '0x0000007e' of 'SYSTEM THREAD EXCEPTION NOT HANDLED'.
Het crash dump bestand bevindt zich gewoonlijk op 'C:\Windows\memory\memory.dump'.
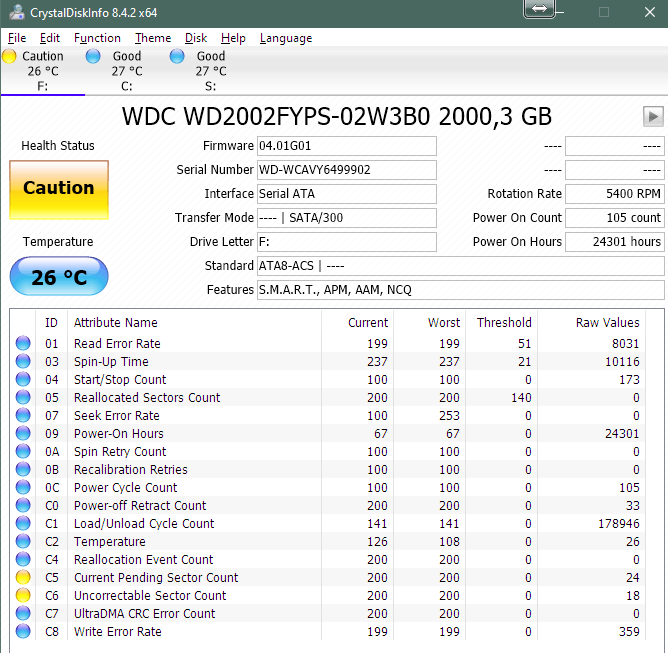
Je SMART gegevens zien er in ieder geval goed uit, dit betekent natuurlijk niet dat er niets aan de hand is, er kan bijvoorbeeld een corruptie op je partitie of een bad sector die niet was gelogd.
je kan HDAT2 (https://www.hdat2.com/) runnen met 'Device tests menu'>'Detect and fix bad sectors menu'>'Verify Write Verify' scan, maar zorg eerst even voor een goede backup van je gegevens voor als er wat misgaat, of gewoon sowieso (En ondanks de naam van de menu's, gaat dit programma niet een kapotte schijf repareren, gebruik het alleen om te kijken of je bad sectors hebt en of deze wel geschreven kunnen worden, als je ze hebt), en 'chkdsk /r C:' in CMD met administrator om je partitie te scannen op fouten.
Btw een bad sector betekent niet gelijk dat je HDD kapot is, het kan dat dit alleen een slechte sector is die gewoon corrupt was, niet schade, maar is wel handig als je oplet over de maanden of deze meer worden en als het er duizenden zijn of de schijf loopt vast of veel tikt tijdens scan wanneer iets gevonden is of sectoren kunnen niet overschreven worden, is allemaal niet erg goed.
Het kan ook mogelijk een driver probleem met een apparaat wat je aansloot of Videokaart driver die een bug heeft of een recente Windows Update op je PC of je RAMDisk die een programma een probleem gaf (kleine kans), maar de werking van de RAMDisk zou 'mogelijk' wel een probleem zijn, alleen heb je maar mondjes maat aan informatie gegeven waar wij moeten raden.
Het kan heel goed dat het klik geluid betekent dat je schijf aan het einde van zijn leven is, maar voor de zekerheid is goed om niet gelijk de conclusie maken dat je HDD gelijk kapot is een BSOD kan ook vele andere redenen hebben, maar wij weten alleen maar dat je eén BSOD/error kreeg?
Oja, je zou ook je RAM kunnen testen op fouten met Memtest86 (Windows heeft Windows Memory Diagnostics, maar Ik vindt persoonlijk Memtest86 fijner), draai het een paar uur met een aantal passen/rondes (minstens meer dan 1) en kijk of het errors weergeeft.
https://www.memtest86.com/
Sowieso moet je altijd backups maken, liefst met incremental geschiedenis en ook een backup naar off site zodat als een van de 3 eraan gaan of de plek afbrand, je nog een kopie van je gegevens hebt.
Btw, kijk of die RAMDisk je wel sowieso >merkbare< snelheid verschil geeft, Ik gebruikte vroeger ook RAMDisk's met ImDisk (http://www.ltr-data.se/opencode.html/), maar toen Ik een SSD nam merkte Ik zeer weinig prestatie verschil, terwijl Ik wel een deel van mijn RAM kwijt was eraan.
Voor mappen waar zeer veel geschreven wordt zoals de Firefox cache kan je wel eventueel de cache naar RAM optie inschakelen met een optie in de officiele config van Firefox, kan de levensduur ietsje verlengen ook (alhoewel dat wel meevalt sinds SSD's al best wat aankunnen).
De Temp map in je gebruiker zou opzich ook logisch zijn om op RAMDisk te zetten (kan met junctions (https://schinagl.priv.at/...t/linkshellextension.html en https://docs.microsoft.co.../hard-links-and-junctions) of de Temp USER variable aanpassen), maar ....bestanden die daar komen kunnen bij elkaar je RAMDisk al erg snel vol maken en daardoor errors of crashes creëren in programma's, dus kan het niet echt aanraden.
Hoi, Ik heb even rond gekeken voor jouw fout, en lijkt inderdaad op een driverfout wat vrijwel nooit door hardware fouten veroorzaakt wordt, Ik heb vele forums bekeken voor mensen die deze fout hadden opgelost en de meeste Kwamen uit op een driver bestand genaamd 'HpqKbFiltr.sys' (wat gebruikt lijkt te worden door HP Quick Launch Buttons) en deze te hernoemen of verwijderen.mlormans schreef op zondag 2 februari 2020 @ 15:50:
[...]
Ten eersten beide bedankt voor de hulp.
Het betreft de WDF_violation BSOD,
Ik ga zometeen dus eerst even de drie methodes uit proberen
Verder kan ik de memory.dump niet terugvinden, niet op de SSD of HDD,
Zojuist een clone van de 1TB HDD gemaakt en zal de diverse programma's eens gaan proberen/draaien.
Bij een falende schijf kan, is het eea dus weer makkelijk teruggezet/gered.
De reden om de documentmappen op de HDD te zetten is om ruimte op de SSD te bewaren.
Dit heeft de afgelopen jaren perfect gewerkt en in het verleden ook op mijn macbook gedaan dus bevalt mij verder prima.
[ Voor 21% gewijzigd door TweetCu op 03-02-2020 05:33 ]
[ Voor 20% gewijzigd door Tieske op 05-02-2020 19:17 ]
Wij zullen doorgaan...
Ik heb zojuist bericht van Seagate gehad:Renault schreef op maandag 27 januari 2020 @ 18:55:
@mark de man
Ben wel benieuwd op welke manier die reageren, we hopen er het beste van.
Nou, over dat advies, een schijf kan inderdaad functioneren met slechte sectoren, fisiek of virtueel, maar dan moet deze sector wel als niet gebruiken gezet zijn door de controller van de schijf, wat bijna altijd gebeurd, anders kun je beter je partitie verkleinen zodat de sector er niet in zit, maar als de slechte sectoren verdeelt zitten over de hele schijf, is dat wat vervelender.mark de man schreef op donderdag 13 februari 2020 @ 10:11:
[...]
Ik heb zojuist bericht van Seagate gehad:
De schijven kunnen nog goed functioneren met meer dan 1000 slechte sectoren, wij raden u aan om Seatools te downloaden en de korte en lange test uit te voeren. Indien de schijf deze slaagt hoeft u zich geen zorgen te maken. Buiten dit om raden we altijd de mensen aan om een backup te hebben van hun data.
Ik hoop dat de winkel meer voor mij kan betekenen en anders vrees ik dat ik het toch moet gaan proberen om de schijf naar Seagate te gaan sturen.
:strip_exif()/u/6897/IGKIPU.gif?f=community)


/u/216161/crop5daf72732a011.png?f=community)
Dat geldt voor fabrieksgarantie.Renault schreef op donderdag 13 februari 2020 @ 19:23:
- RMA kan in de praktjk alléén als je de tool van de fabrikant er overheen haalt: als er een foutcode uit komt en je zit binnen de RMA-termijn heb je recht op RMA, anders in principe niet.
Nee, ik doelde op de wettelijke garantie bij consumentenkoop.Renault schreef op zondag 1 maart 2020 @ 15:53:
Wat ik er van weet:
Haal je hier niet twee dingen door elkaar?
De verkoper kan natuurlijk allerlei niet-goed-geld-terug voorwaarden maken, maar dat is altijd een toevoeging aan de wet.Bij de wet op de consumentenkoop heb je het over je relatie met de verkoper: binnen een bepaalde redelijke termijn (enkele dagen, zie de aankoopvoorwaarden) kan je (alles natuurlijk met aankoopbon) vaak de koop ontbinden (zeker bij online aangekoop) als het product niet aan je verwachtingen voldoet.
RMA bestaat niet in de wet. Niemand hoeft geautoriseerd te worden om een gekocht product te retourneren als daar iets mee mis is voor wettelijke garantie. De term is over komen waaien uit de VS, maar het heeft geen wettelijke basis.Daarná zal de verkoper terughoudender zijn en je vragen om "bewijzen" van wat er aan het product mankeert. Als het product vervolgens nog gewoon werkt zonder mankementen (zoals in het voorliggende geval, de volle capaciteit is gewoon bruikbaar voor opslag) heb je m.i. slechte kaarten. In dit stadium is er nog helemaal geen sprake van RMA.
De wettelijke garantietermijn in Nederland is niet vastgelegd. Meestal is het ten minste 2 a 3 jaar voor computeronderdelen die niet sneller zouden moeten slijten bij normaal gebruik. De bewijslast ligt bij de verkoper, niet bij de consument. Een uitlezing via een tool van derden is geldig bewijs. De fabrikant kan het alleen daar niet mee eens zijn als ze kunnen aantonen dat die tool verkeerde informatie levert.Na je aankoop-garantietermijn kan je tevens zelf online kijken of de harddisk fabrikant garantie biedt op het door hem aan een andere partij (je verkoper) geleverde product. Als dat zo is:
In dit stadium zul je moeten aantonen dat er wat mis is met het product en dat doe je normaal gesproken via een specifiek door de fabrikant daarvoor aangewezen analysetooltje. Als dit tooltje uiteindelijk een foutcode oplevert, kan je RMA aanvragen en krijg je een gerfurbished ander maar functioneel gelijkwaardig product terug.
Als consument heb je te maken met de verkoper. Die heeft de plicht wettelijke garantie af te handelen. In de praktijk zie je soms dat er verwezen wordt naar een fabrikant, maar dat kan alleen een toevoeging zijn, geen vervanging. De koper stelt dus de verkoper aansprakelijk, en die kan op zijn beurt de groothandel of de fabrikant aansprakelijk stellen. Dat heet ketenaansprakelijkheid.Bij een RMA-aanvraag gaat in principe voor de gebruiker alle data op de gegevensdrager verloren (voor zover het tooltje daar al niet voor zorgt) en is het ook onduidelijk wat er verder met die data gebeurt (als die data vertrouwelijk zou zijn).
Inschakelingen: 97 keerFormatting 2,7 TB
The media being formatted has been removed or has become invalid.
Format aborted.
258 bad sectors were encountered during the format. These sectors
cannot be guaranteed to have been cleaned.
Format failed.
[ Voor 3% gewijzigd door zekerpixels op 01-03-2020 18:41 ]
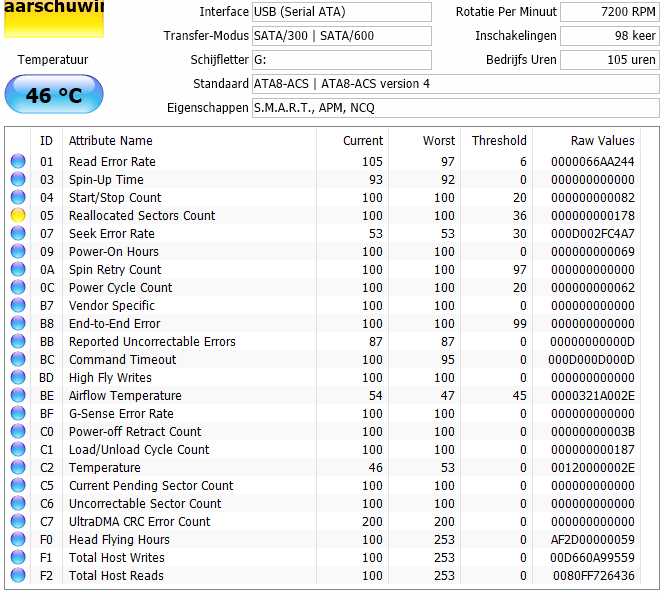
[ Voor 10% gewijzigd door zekerpixels op 02-03-2020 00:01 ]
Klopt, PC staat vaak lang aan. Gaat ook vaak in slaapstand, maar staat ook lang aan als ie aan staat.Renault schreef op zondag 1 maart 2020 @ 13:25:
De total bytes written (ruim 4TB) valt mee.
Ik zie ook niets raars in de tabellen staan.
Wel heb je een fors aantal bedrijfsuren, wellicht dat de afname van de gezondheidsstatus daarmee te maken heeft.
En 2% afname in gezondheidsstatus stelt sowieso niets voor.
Bij gebruik van de slaapstand wordt telkens de actuele geheugeninhoud op SSD gezet, dus een deel van die ruimt 4 TB zal daar vandaan komen.
Maar ik zie geen enkele reden om daarvoor iets in je gedrag te veranderen.
500GB drive: 180TB Total Bytes Written (TBW), equal to 98GB per day for 5 yearsAls je het precies wil weten: zoek zelf eens in de specs van jouw SSD op wat het verwachte max bytes written voor jouw SSD is en deel die ruim 4 TB daar eens op. Waarschijnlijk kom je dan op 2 % .....
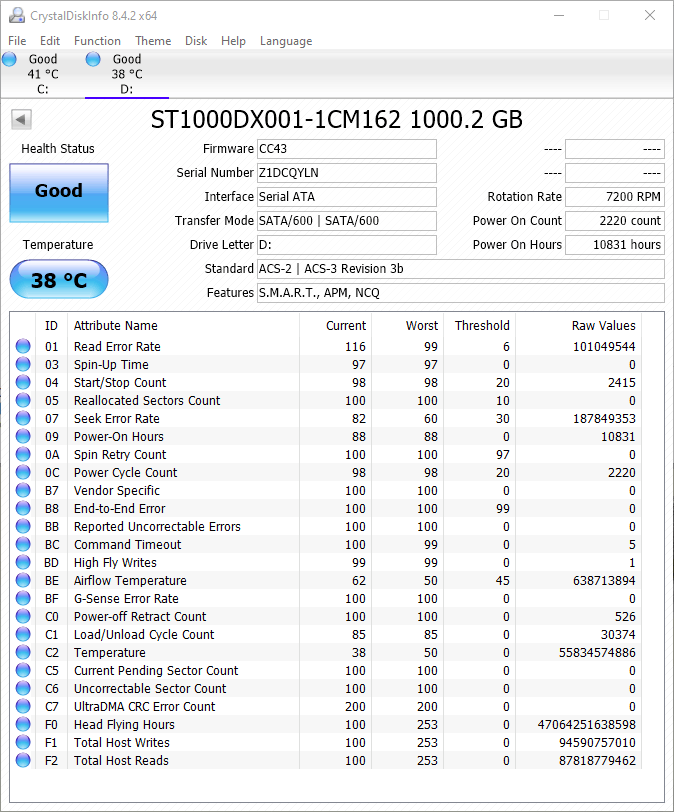

[ Voor 34% gewijzigd door Renault op 17-03-2020 17:16 ]
Verwijderd

/u/170728/owl.png?f=community)
1
2
3
4
5
| ------------------------------------------------------------------------------------------------------------------- | Dev | Model | Serial Number | GB | Firmware | Temp | Hours | PS | RS | RSE | CRC | ------------------------------------------------------------------------------------------------------------------- | sdl | ST4000DM000-1F2168 | xxxxxxxx | 4000 | CC52 | 48 | 54558 | 8600 | 42960 | ? | 0 | ------------------------------------------------------------------------------------------------------------------- |
Verwijderd
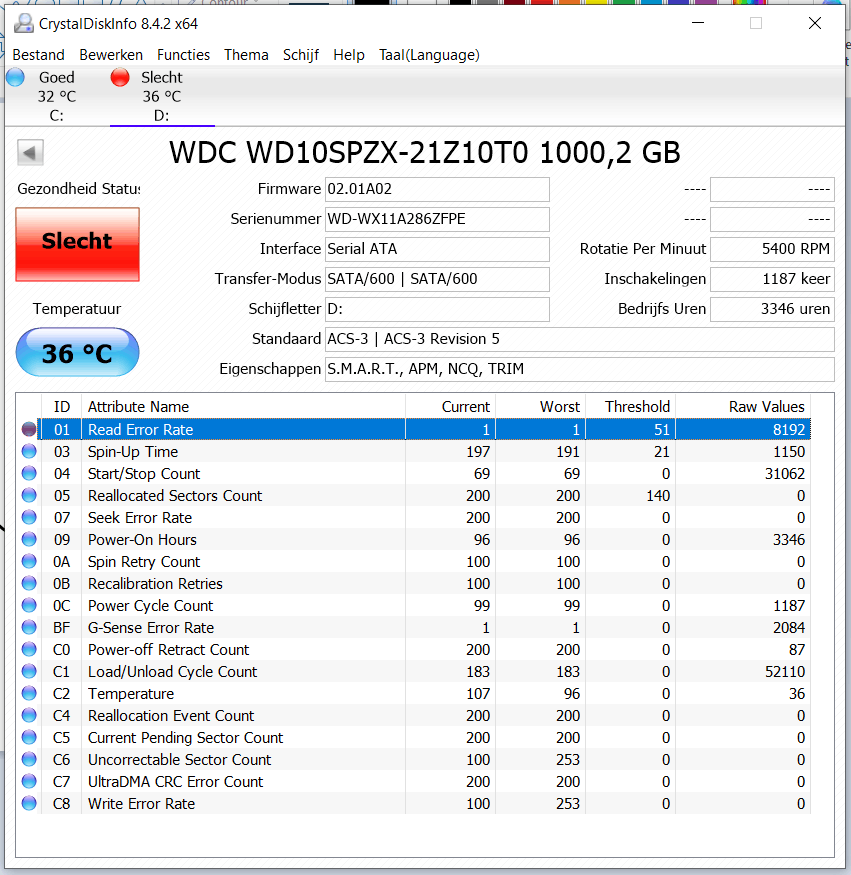
Het gaat denk ik om een harde schijf in een laptop, klopt dat?Verwijderd schreef op woensdag 25 maart 2020 @ 00:04:
Een goedenavond/-ochtend/-middag,
Ik heb sinds vandaag problemen met mijn harde schijf, en geeft een waarschuwing aan van een SMART gebuertenis(?) Ik heb jullie instructies opgevolgd en krijg dan dit te zien. (zie screenshot van SMART waarden)
In het kort is mijn vraag: moet ik me zorgen gaan maken? En hoe kan ik het verhelpen?
Alvast hartelijk bedankt.
Wij zullen doorgaan...
Even een update. Vandaag heb ik toch gelukkig kosteloos een nieuwe schijf ontvangen. Ik had hem geformatteerd en naar de winkel gebracht en zij hebben hem naar de fabrikant gestuurd en ik heb via de winkel weer een nieuwe ontvangen. Hopelijk blijft deze wel goed werkenRenault schreef op donderdag 13 februari 2020 @ 19:23:
Daarom zei ik het ook zo voorzichtig:
- direct na aankoop kan je omruilen als het product niet werkt.
Jouw product werkt wel, maar met kanttekeningen.
Inmiddels is de omruiltermijn wel verstreken.
- RMA kan in de praktjk alléén als je de tool van de fabrikant er overheen haalt: als er een foutcode uit komt en je zit binnen de RMA-termijn heb je recht op RMA, anders in principe niet.
- de tool van de fabrikant eroverheen halen betekent meestal dat je alle data op de schijf kwijt bent.
Jij had geen concrete foutcode, dus dan wordt het altijd een lastig verhaal.
Langharig tuig
:strip_icc():strip_exif()/u/513333/crop58b92df12af71_cropped.jpeg?f=community)


When life throws you a curve, lean into it and have faith!
Langharig tuig
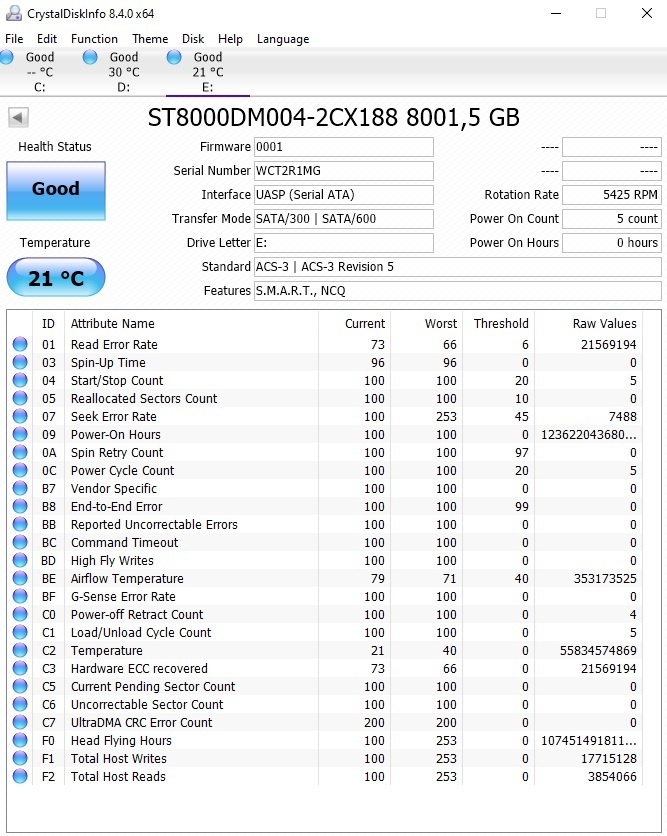
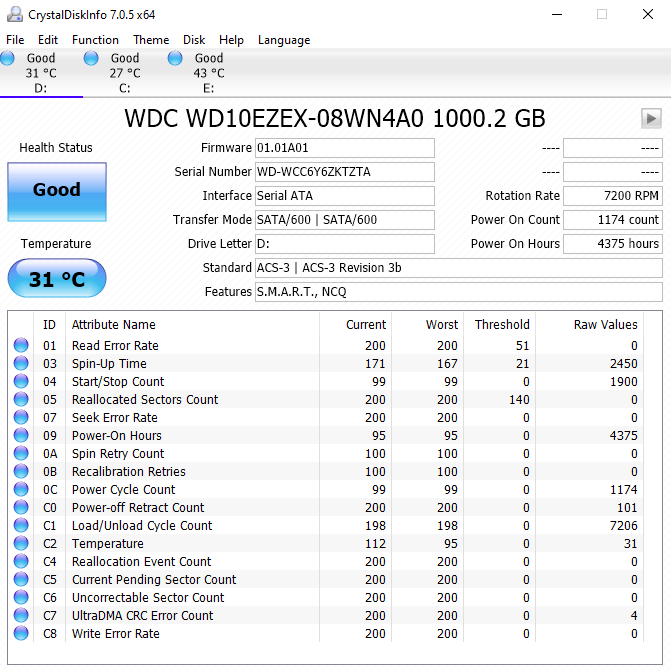
Fijn om te horen. Zal C7 in de gaten houdenRenault schreef op donderdag 2 april 2020 @ 17:34:
Je 1 TB harddisk heeft ooit 4 communicatie errors gehad met het moederbord. Als C7 niet meer oploopt is er niets mis nu.
Voor de rest geen rare dingen zichtbaar.
When life throws you a curve, lean into it and have faith!
Langharig tuig



[ Voor 18% gewijzigd door LankHoar op 05-04-2020 23:34 ]
When life throws you a curve, lean into it and have faith!
:strip_icc():strip_exif()/u/146157/crop6360cc32931c5_cropped.jpg?f=community)

Samsung 65QN93B | Denon AVR-X1700H DAB | Monitor Audio Silver RX6 | BK XXLS 400 FF | PS5 Pro | BMW 330i G21 LCI2 xDrive
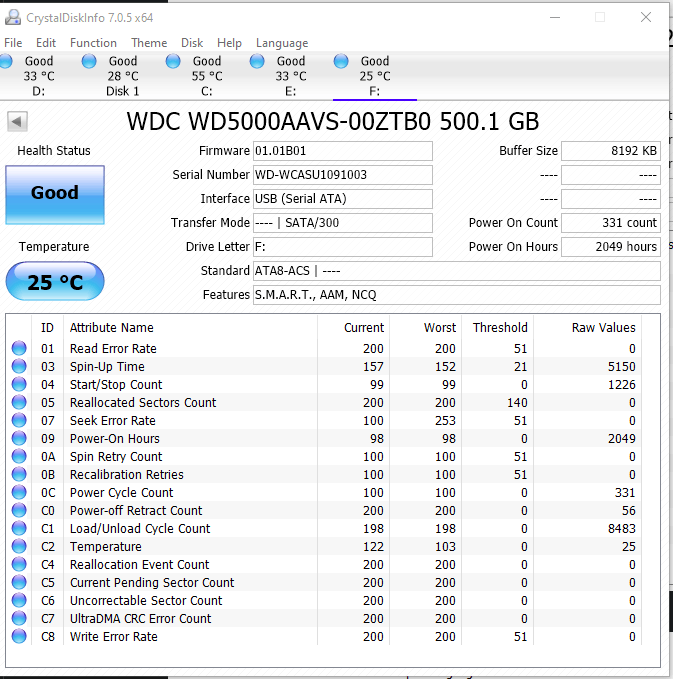
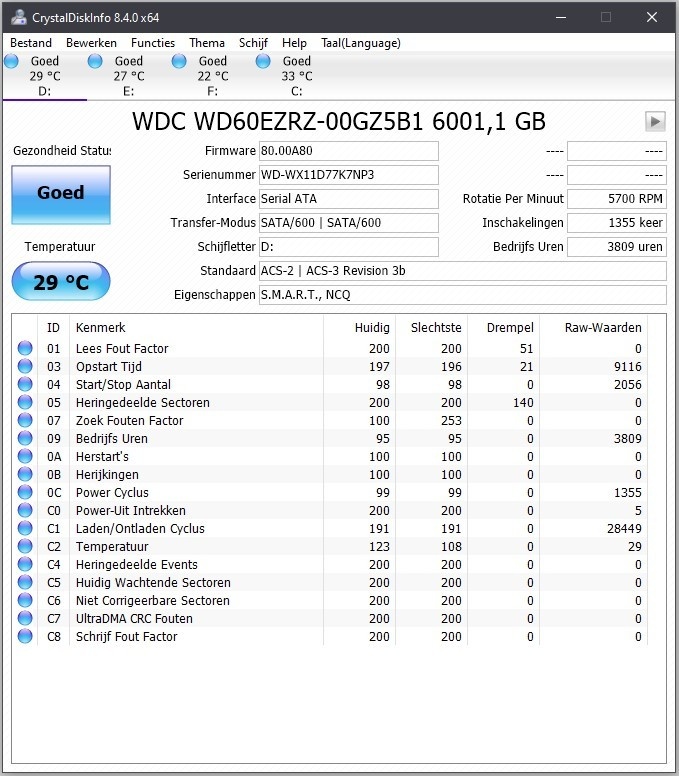
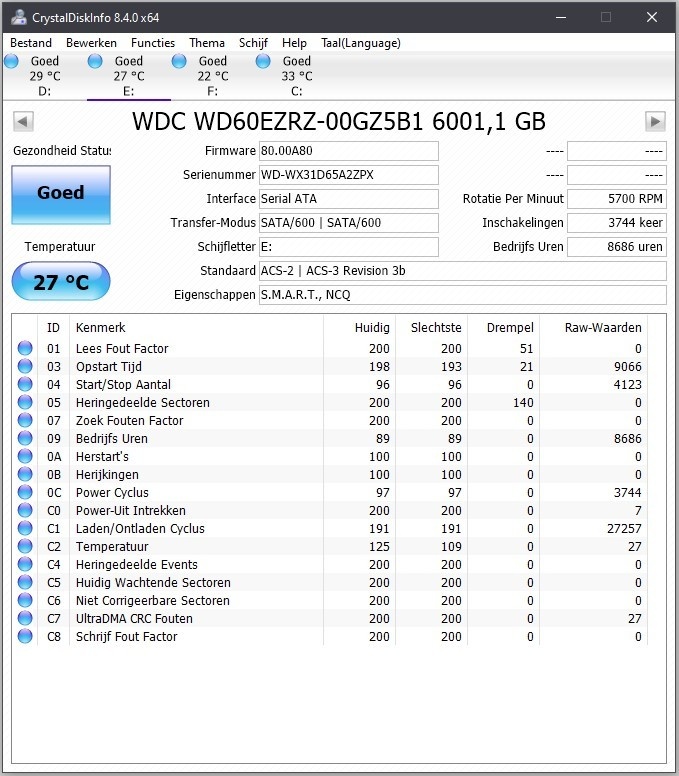
De 3 HDD's zijn degene die ik overgezet heb van mijn vorige pc bij het bouwen van de huidige. Ik heb idd 2 nieuwe bijgeleverde sata kabeltjes gebruikt en 1 van de oude pc. Kan dit dan kwaad?mrmrmr schreef op maandag 6 april 2020 @ 10:41:
@ikbenben Er staan UltraDMA CRC fouten bij de laatste 2 drives. Heb je daar ooit een ander type/merk kabel voor gebruikt dan voor de 2e drive?
Je kan overwegen die kabels te vervangen door kabels van betere kwaliteit. Bijvoorbeeld van een merk als Akasa. Bij een goed merk kun je ervan uit gaan dat er kwaliteitscontrole is.
Je kunt ook wachten en kijken of het aantal fouten oploopt na verloop van tijd.
CRC is een checksum, een berekening over een hoeveelheid data. Als de data is gewijzigd tussen verzender en ontvanger klopt de checksum meestal niet meer. Zodoende weet de ontvanger dat er een probleem is.
[ Voor 0% gewijzigd door ikbenben op 06-04-2020 10:55 . Reden: typo ]
Samsung 65QN93B | Denon AVR-X1700H DAB | Monitor Audio Silver RX6 | BK XXLS 400 FF | PS5 Pro | BMW 330i G21 LCI2 xDrive
Maar CrystalDiskInfo geeft toch geen Gezondheid Status waarschuwing, hoef ik mij dan wel zorgen te maken?mrmrmr schreef op maandag 6 april 2020 @ 10:53:
De vraag is waar de problemen zijn ontstaan, bij de oude of de nieuwe kabels. Je kan in de gaten houden of het aantal CRC fouten oplopen. Als ze oplopen zou ik de kabels vervangen van de laatste 2 drives.
Natuurlijk moeten de stekkers goed zijn aangesloten, dat spreekt vanzelf.
Samsung 65QN93B | Denon AVR-X1700H DAB | Monitor Audio Silver RX6 | BK XXLS 400 FF | PS5 Pro | BMW 330i G21 LCI2 xDrive
Langharig tuig
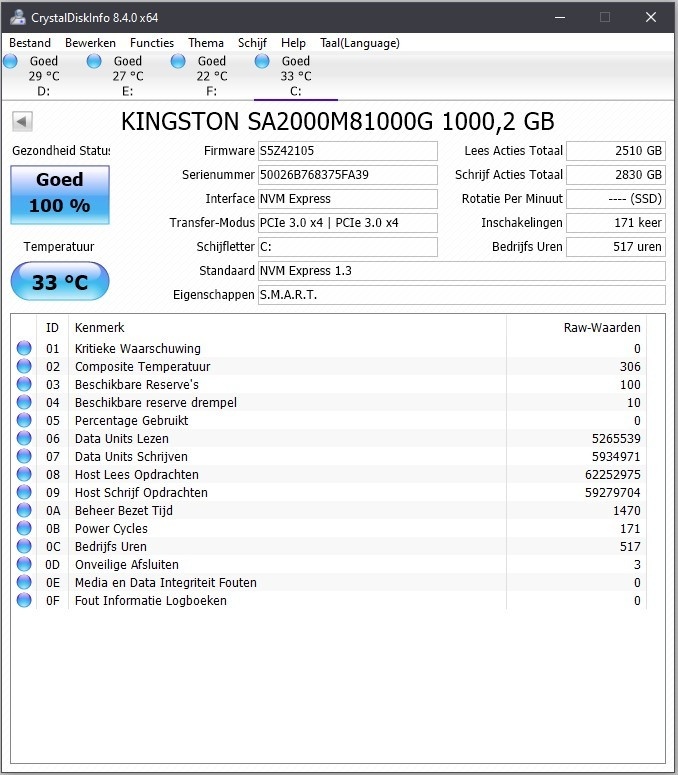
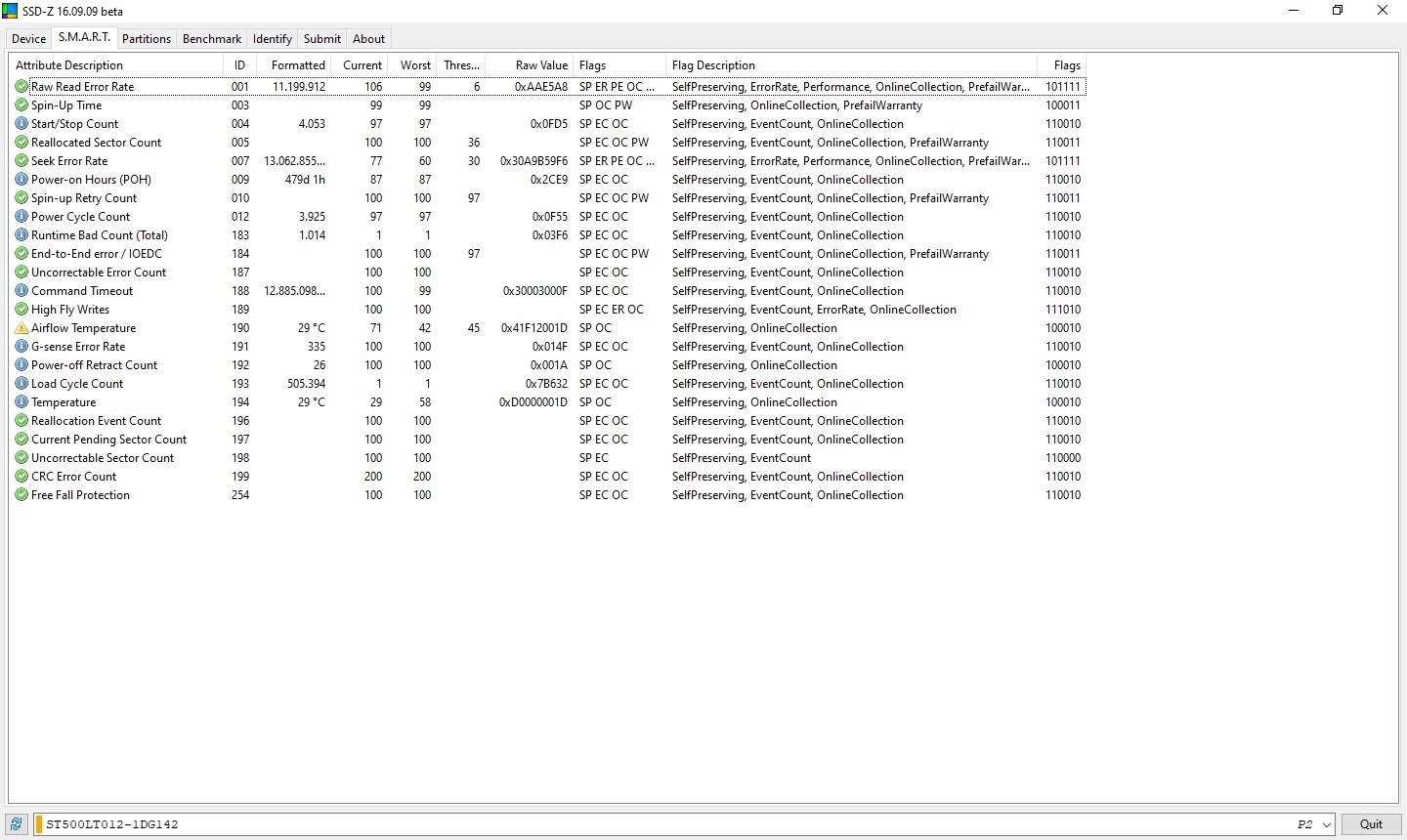
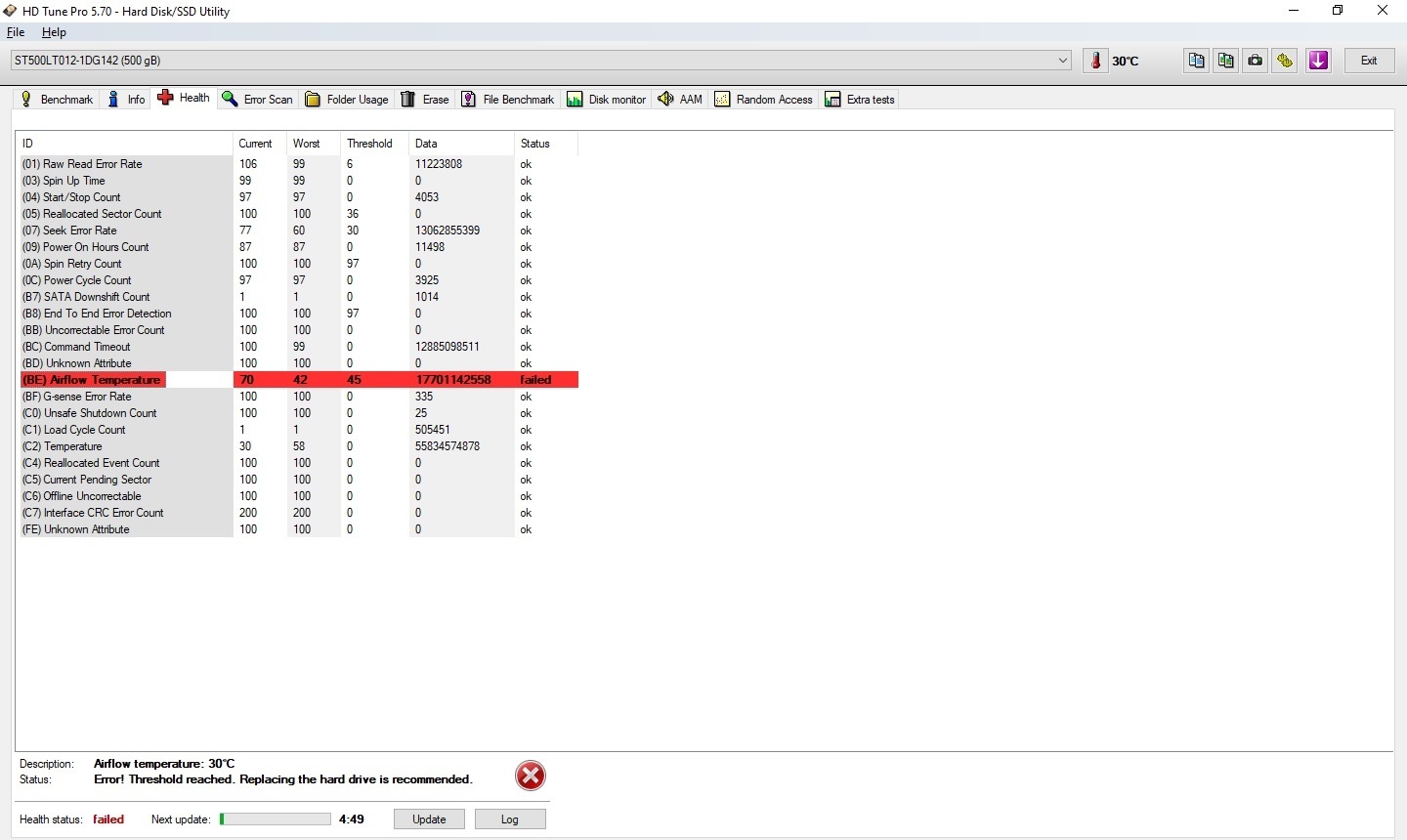
Aha, dus 55 graden is nog niet problematisch? Gelukkig maar; mijn moederbord heeft het M.2 slot een beetje op een idiote plaats, namelijk precies onder mijn GPU. Ik kan me voorstellen dat daar best wat warmte afkomt wanneer ik game, en zo kan ik er helaas ook geen fan o.i.d. op plaatsenchim0 schreef op maandag 6 april 2020 @ 04:48:
@LankHoar Volgens mij is dat een instelling in CrystalDiskInfo wanneer ie moet waarschuwen. Als je op die knop met 55 klikt, krijg je een menuutje waar je met een schuifje de waarschuwingstemperatuur kan instellen.
Maar 55 graden is volgens mij niet zo erg voor een m.2 drive, al zou je er wel een fan tegenaan kunnen zetten om hem iets koeler te houden. Zie ook deze review > https://www.techpowerup.c...ial-mx500-m-2-1-tb/7.html
De interne 500 GB schijf heeft altijd in een laptop gezeten, die zal dus nog wel eens een tikje gehad hebben (laptop op schoot en verplaatsen terwijl deze aan staat e.d.). De andere is mijn backup drive, en die heb ik inderdaad 1x laten vallen terwijl deze aan stondRenault schreef op maandag 6 april 2020 @ 09:53:
@LankHoar
Let je er wel op dat bij twee van de disks de waarde BF niet op nul staat? Beide disks hebben ergens in hun levensduur dus een mechanische tik meegemaakt. Is niet erg, wel iets om te voorkomen.
When life throws you a curve, lean into it and have faith!
Warmte van de videokaart gaat volgens mij omhoog (fan staat ook op blazen) dus daar zou je weinig hinder van moeten ondervinden. Bij de meeste moederborden zit het m.2 slot meestal tussen het PCI-e slot en de CPU waar het veel warmer zou moeten zijn. Anders een gat frasen in het zijpaneel en een fan monteren.LankHoar schreef op maandag 6 april 2020 @ 11:17:
[...]
Aha, dus 55 graden is nog niet problematisch? Gelukkig maar; mijn moederbord heeft het M.2 slot een beetje op een idiote plaats, namelijk precies onder mijn GPU. Ik kan me voorstellen dat daar best wat warmte afkomt wanneer ik game, en zo kan ik er helaas ook geen fan o.i.d. op plaatsen
Doel je op die BF waarde of de temperatuur? De temperatuur is volgens mij een instelling in het programma zelf d.m.v. een schuifbalkje, maar ik zit daar nooit aan.mrmrmr schreef op maandag 6 april 2020 @ 11:19:
CrystalDiskInfo geeft niet altijd een waarschuwing. Het leest de SMART waarden uit, maar de interpretatie ervan wordt overgelaten aan de toolgebruikers.
Het was een reactie op bericht van @ikbenben.chim0 schreef op maandag 6 april 2020 @ 12:21:
Doel je op die BF waarde of de temperatuur? De temperatuur is volgens mij een instelling in het programma zelf d.m.v. een schuifbalkje, maar ik zit daar nooit aan.
Ik ga het alvast in de gaten houden en kijken of de waardes nog (veel) stijgen of niet. Is het wel zo dan zal ik eens proberen met nieuwe sata kabeltjes te plaatsen.mrmrmr schreef op maandag 6 april 2020 @ 12:37:
[...]
Het was een reactie op bericht van @ikbenben.
Ik bedoel de tool als geheel. Sommige tools geven bijvoorbeeld een waarschuwing bij BF hoger dan 0, dat doet CrystalDiskInfo niet. Als CrystalDiskInfo geen waarschuwing geeft betekent het niet dat er niets aan de hand is. Je moet het zelf interpreteren of zoals hier, om hulp vragen.
Samsung 65QN93B | Denon AVR-X1700H DAB | Monitor Audio Silver RX6 | BK XXLS 400 FF | PS5 Pro | BMW 330i G21 LCI2 xDrive
Klopt! HD Tune Pro geeft bijvoorbeeld weer een waarschuwing op m'n 1TB schijf, waar CrystalDiskInfo en SSD-Z dat niet doen, dus het verschilt inderdaad per programma.mrmrmr schreef op maandag 6 april 2020 @ 12:37:
[...]
Ik bedoel de tool als geheel. Sommige tools geven bijvoorbeeld een waarschuwing bij BF hoger dan 0, dat doet CrystalDiskInfo niet. Als CrystalDiskInfo geen waarschuwing geeft betekent het niet dat er niets aan de hand is. Je moet het zelf interpreteren of zoals hier, om hulp vragen.

[ Voor 17% gewijzigd door chim0 op 06-04-2020 13:19 ]
Ondertussen al x-aantal GB's bijgekomen op beide schijven en de CRC fouten blijven op dezelfde waardes staan. Het probleem zal dan waarschijnlijk nog voortkomen uit de vorige pc.mrmrmr schreef op maandag 6 april 2020 @ 10:53:
De vraag is waar de problemen zijn ontstaan, bij de oude of de nieuwe kabels. Je kan in de gaten houden of het aantal CRC fouten oplopen. Als ze oplopen zou ik de kabels vervangen van de laatste 2 drives.
Natuurlijk moeten de stekkers goed zijn aangesloten, dat spreekt vanzelf.
Samsung 65QN93B | Denon AVR-X1700H DAB | Monitor Audio Silver RX6 | BK XXLS 400 FF | PS5 Pro | BMW 330i G21 LCI2 xDrive
:strip_icc():strip_exif()/u/239611/Vuur%2520en%2520Vlam%2520icon.jpg?f=community)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| NAS# smartctl -a /dev/ada3 smartctl 7.0 2018-12-30 r4883 [FreeBSD 11.3-RELEASE-p7 amd64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate Barracuda 7200.14 (AF)
Device Model: ST2000DM001-1CH164
Serial Number: Z1E4JCG7
LU WWN Device Id: 5 000c50 06396aa66
Firmware Version: CC44
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 4
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Sat Apr 11 17:15:04 2020 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 118 099 006 Pre-fail Always - 196767104
3 Spin_Up_Time 0x0003 095 094 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 73
5 Reallocated_Sector_Ct 0x0033 099 099 010 Pre-fail Always - 1168
7 Seek_Error_Rate 0x000f 065 060 030 Pre-fail Always - 3250676
9 Power_On_Hours 0x0032 047 047 000 Old_age Always - 46686
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 71
183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0
184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 0 0
189 High_Fly_Writes 0x003a 099 099 000 Old_age Always - 1
190 Airflow_Temperature_Cel 0x0022 067 058 045 Old_age Always - 33 (Min/Max 27/33)
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 48
193 Load_Cycle_Count 0x0032 093 093 000 Old_age Always - 14869
194 Temperature_Celsius 0x0022 033 042 000 Old_age Always - 33 (0 11 0 0 0)
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 48
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 48
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 1820h+45m+51.614s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 1268158375
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51649260371
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Self-test routine in progress 20% 46686 -
# 2 Extended offline Completed without error 00% 46681 -
# 3 Extended offline Completed without error 00% 46668 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| NAS# smartctl -a /dev/ada5 smartctl 7.0 2018-12-30 r4883 [FreeBSD 11.3-RELEASE-p7 amd64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate Barracuda 7200.14 (AF)
Device Model: ST2000DM001-1CH164
Serial Number: Z1E4JCAY
LU WWN Device Id: 5 000c50 06396a6db
Firmware Version: CC44
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 4
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Sat Apr 11 17:16:23 2020 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 118 100 006 Pre-fail Always - 169598512
3 Spin_Up_Time 0x0003 095 094 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 84
5 Reallocated_Sector_Ct 0x0033 099 099 010 Pre-fail Always - 1808
7 Seek_Error_Rate 0x000f 062 058 030 Pre-fail Always - 8593186176
9 Power_On_Hours 0x0032 046 046 000 Old_age Always - 48168
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 71
183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0
184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 0 0
189 High_Fly_Writes 0x003a 097 097 000 Old_age Always - 3
190 Airflow_Temperature_Cel 0x0022 066 059 045 Old_age Always - 34 (Min/Max 27/34)
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 49
193 Load_Cycle_Count 0x0032 092 092 000 Old_age Always - 17457
194 Temperature_Celsius 0x0022 034 041 000 Old_age Always - 34 (0 11 0 0 0)
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 40
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 40
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 1963h+30m+04.423s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 1265781687
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 53356582434
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed: read failure 50% 48168 2751056640
# 2 Extended offline Completed: read failure 90% 48165 2752568656
# 3 Extended offline Completed: read failure 40% 48161 2752972360
# 4 Extended offline Completed without error 00% 48150 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
[ Voor 124% gewijzigd door ykaenS op 11-04-2020 17:24 ]
Alle data staat ook in de cloud.mrmrmr schreef op zaterdag 11 april 2020 @ 20:09:
@ykaenS Kort antwoord: ja het is verstandig hier iets aan te doen, vooral de tweede disk met de read failures. Ik zou eerst een backup maken om de aanwezige data veilig te stellen. Daarna per disk fix tools draaien en proberen aanwezige fouten te herstellen. Let op dat je de juiste tool+parameters kiest om dat te doen als de disks in RAID-achtige configuratie zitten.
De disks draaien ruim 5 jaar en het is min of meer tijd voor vervanging wegens ouderdom en gebruik.
Er zijn bij de tweede disk bijna 41x meer LBA's gelezen dan geschreven. De eerste disk 42x. Weet je waarom dat zo is?
| # | Category | Product | Prijs | Subtotaal |
| 1 | Interne harde schijven | Seagate IronWolf, 2TB | € 75,90 | € 75,90 |
| 1 | Interne harde schijven | WD Red (256MB cache), 2TB | € 74,43 | € 74,43 |
| Bekijk collectie Importeer producten | Totaal | € 150,33 | ||
:fill(white):strip_exif()/f/image/HY3mndd844ZApOZj4aR3Oqcu.png?f=user_large)
[ Voor 8% gewijzigd door ParaDroid2 op 14-04-2020 15:09 ]
Ligt eraan of die nog oploopt. Ik heb een disk met UDMA_CRC_Error_Count: 1706. Daar is de kabel natuurlijk van vervangen, maar die count gaat dan niet magisch naar 0.mrmrmr schreef op dinsdag 14 april 2020 @ 16:45:
2. Kabel vervangen wegens de CRC errors door een kwalitatief goede en moderne SATA-600 kabel.
Voor het gemak ging ik er van uit dat altijd dezelfde kabel is gebruikt. De kabel vervangen is wat ik zou doen. Als de teller verder niet oploopt met de nieuwe kabel kan het probleem als opgelost worden beschouwd.Groentjuh schreef op dinsdag 14 april 2020 @ 17:06:
[...]
Ligt eraan of die nog oploopt. Ik heb een disk met UDMA_CRC_Error_Count: 1706. Daar is de kabel natuurlijk van vervangen, maar die count gaat dan niet magisch naar 0.
:fill(white):strip_exif()/f/image/vyXvvURtVELzklsFkT37Kk2B.png?f=user_large)
:fill(white):strip_exif()/f/image/T5wcTDZwyuodyaDLvk3FdnzH.png?f=user_large)
:fill(white):strip_exif()/f/image/saH8cIrr5BSFQszGfljOJ8ge.png?f=user_large)
:fill(white):strip_exif()/f/image/LSIBIgR6W1wwG632A3M1fFmM.png?f=user_large)
Als hardeschijven een SMART-waarschuwing gaan geven dan is het zaak om garantie te gaan claimen, en niet zelf te gaan kloten. Oh, en backups hebben, dan wel maken, natuurlijk.pcc schreef op maandag 27 april 2020 @ 22:21:
Afgelopen nacht heeft er één van mijn 5 Seagate 5TB schijven de geest gegeven na amper 5 maanden. Voor de zekerheid heb ik de SMART status van de andere 4 schijven opgevraagd en allemaal geven ze SMART warnings op de Load Cycle Count, deze staan tussen de 603749 en 651859.
Voor amper 5 maanden oud te zijn, zijn deze waarden veel te hoog. Na even te luisteren hoor ik effectief op 2 seconden tijd de schijven in slaap gaan en terug opspinnen.
Volgende zaken heb ik al aangepast maar geven geen verbetering: Link State Power Management op Off gezet en Turn off hard disk after: 3 min.
De andere waarden lijken mij ook enorm hoog. Afbeelding van één schijf toegevoegd, de SMART data is bij de andere schijven zo goed als hetzelfde.
OS is Windows 10, moederbord D3644-B.
Heeft er iemand een idee hoe ik dit probleem kan oplossen?
[Afbeelding]
[Afbeelding]
The devil is in the details.
Het instellen van spindown timings is normaal gesproken een eigen handeling. De vraag is dus eerst hoe het komt dat er zoveel stopgezet en gestart wordt. Ligt dat aan de Windows instelling, toegangsvraag uit software, of aan RAID software? Als dat is uitgesloten zou je kunnen denken aan een fout van de hard disk zelf. Maar dat lijkt mij minder waarschijnlijk dan een instellings- of gebruiksprobleem.
[ Voor 11% gewijzigd door mrmrmr op 28-04-2020 08:08 ]
/u/97665/Opera1_t.png?f=community)
:fill(white):strip_exif()/f/image/z7n87KQ0ZUYZRkLG75MEh1yC.png?f=user_large)
Het zijn 5 schijven die het probleem geven, ik betwijfel of de schijven het probleem zijn. Voordat ik er nieuwe schijven insteek moet het probleem zijn opgelost.Hahn schreef op maandag 27 april 2020 @ 22:42:
[...]
Als hardeschijven een SMART-waarschuwing gaan geven dan is het zaak om garantie te gaan claimen, en niet zelf te gaan kloten. Oh, en backups hebben, dan wel maken, natuurlijk.
Is het een oud systeem? Gebruik je MBR of GPT indeling?EricJH schreef op dinsdag 28 april 2020 @ 06:02:
Zouden jullie eens naar de SMART van deze SSD willen kijken: [Afbeelding]
Hij zit in een systeem dat problemen geeft dat soms kan niet booten. Het stopt dan met een zwart scherm met linksboven een knipperende cursor. Windows start pas op na diverse pogingen op te starten. Het probleem kan optreden bij koude en warme start en als de pc inactief is (Fast Startup en slaapstand zijn uitgeschakeld).
Voor nu ben ik benieuwd of de SMART reden tot zorg laat zien of dat de SSD in goede conditie is.
/u/37667/Gundam1.png?f=community)
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/JLOg247uuREQYRzR57wuRh4v.jpg?f=user_large)
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/k8YjYQXSsvQGvZPqUvkY0zyT.jpg?f=user_large)
Niet geschoten is altijd mis
:strip_exif()/u/574651/crop5b78563680eb2.gif?f=community)
:fill(white):strip_exif()/f/image/Y009GpiOlGLuwfOFnzfQEYod.png?f=user_large)
:fill(white):strip_exif()/f/image/NwuLBXweXvKVmTSRycKY2I4M.png?f=user_large)
[ Voor 53% gewijzigd door MedionAkoya op 05-05-2020 15:50 ]
Trein?
:strip_exif()/u/106005/animated%2520garfield.gif?f=community)
1 reallocated sector is niet per se een probleem maar ik zou het wel in de gaten houden. Als deze teller oploopt dan kan het zijn dat er toch een probleem ontstaat. Zorg er sowieso voor dat je backups hebt van je belangrijke data maar dat advies geldt ook bij een drive die geen SMART waarschuwingen geeftD-Three schreef op dinsdag 28 april 2020 @ 22:32:
De laatste dagen reageert de laptop soms nogal traag en dus ben ik op zoek naar de oorzaak. Met Samsung Magician heb ik de SSD bekeken maar die lijkt nog OK. Echter geeft die tool wel fails bij twee S.M.A.R.T. attributes van de HDD.
[Afbeelding]
Daarom heb ik ook de waarden met CrystalDiskInfo bekeken en ik krijg een 'Caution'. Al zijn de waarden waar Samsung Magician over valt voor CrystalDiskInfo wel OK, de waarschuwing komt nu van Reallocated Sectors Count.
[Afbeelding]
Volgens de topicstart zou er geen probleem mogen zijn maar wat denken jullie?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
| smartctl 7.0 2018-12-30 r4883 [FreeBSD 11.3-RELEASE-p7 amd64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Toshiba 3.5" DT01ACA... Desktop HDD
Device Model: TOSHIBA DT01ACA300
Firmware Version: MX6OABB0
User Capacity: 3,000,592,982,016 bytes [3.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 4
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue May 5 21:39:58 2020 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (22222) seconds.
Offline data collection
capabilities: (0x5b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 371) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 016 Pre-fail Always - 0
2 Throughput_Performance 0x0005 140 140 054 Pre-fail Offline - 69
3 Spin_Up_Time 0x0007 139 139 024 Pre-fail Always - 411 (Average 415)
4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 77
5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 0
7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always - 0
8 Seek_Time_Performance 0x0005 124 124 020 Pre-fail Offline - 33
9 Power_On_Hours 0x0012 098 098 000 Old_age Always - 20469
10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 77
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 682
193 Load_Cycle_Count 0x0012 100 100 000 Old_age Always - 682
194 Temperature_Celsius 0x0002 176 176 000 Old_age Always - 34 (Min/Max 14/52)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 32
198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 3
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 20441 -
# 2 Short offline Completed without error 00% 20399 -
# 3 Short offline Completed without error 00% 20231 -
# 4 Short offline Completed without error 00% 20064 -
# 5 Short offline Completed without error 00% 19896 -
# 6 Short offline Completed without error 00% 19728 -
# 7 Short offline Completed without error 00% 19560 -
# 8 Short offline Completed without error 00% 19393 -
# 9 Short offline Completed without error 00% 19225 -
#10 Short offline Completed without error 00% 19060 -
#11 Short offline Completed without error 00% 18891 -
#12 Short offline Completed without error 00% 18724 -
#13 Short offline Completed without error 00% 12446 -
#14 Short offline Completed without error 00% 12278 -
#15 Short offline Completed without error 00% 12110 -
#16 Short offline Completed without error 00% 11942 -
#17 Short offline Completed without error 00% 11774 -
#18 Short offline Completed without error 00% 11606 -
#19 Short offline Completed without error 00% 11438 -
#20 Short offline Completed without error 00% 11271 -
#21 Short offline Completed without error 00% 9133 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Webshop heeft dit gecheckt helaas out of warranty.Renault schreef op woensdag 6 mei 2020 @ 00:08:
Sowieso kan je de harddisk proberen in te voeren op de site van Toshiba om te kijken of ook op deze schijf nog garantie zit.
(Diverse fabrikanten geven tot 5 jaar garantie op hun disks, onafhankelijk van waar je die hebt gekocht.)
Niet geschoten is altijd mis
:fill(white):strip_exif()/f/image/ZZjleBvTdjt9kKzZcdkd8ald.png?f=user_large) L]
L]
[ Voor 55% gewijzigd door MedionAkoya op 08-05-2020 22:56 ]
Trein?
Hier is geen soep van te koken, omdat de labels niet betrouwbaar zijn te interpreteren.
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/zxliawH0WEbFbkk9CuabZQXL.jpg?f=user_large)
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/23TyPwQ0Y1yfzXGxVcEhy7fh.jpg?f=user_large)
Livin' the good life
:strip_exif()/u/91205/avator_pavo.gif?f=community)
:fill(white):strip_exif()/f/image/WdbPuTFBNPbfNnTaJUMR9dui.png?f=user_large)
[ Voor 11% gewijzigd door DeluxZ op 13-05-2020 14:38 ]
/u/175520/crop636e2cf4962f2_cropped.png?f=community)
Livin' the good life
Geen idee of die is opgelopen. Was eigenlijk de eerste keer dat ik deze SMART check heb gedaan. Laptop nooit open gehad dus of de SSD goed is aangesloten? ¯\_(ツ)_/¯Acid Vendetta schreef op woensdag 13 mei 2020 @ 15:23:
Loopt de (BC) Command Timeout count ook op na zo'n freeze? Zit de SSD goed aangesloten?
De SSD heeft ook tamelijk veel (AE) Unexpected Powwer Loss Count ten op zichte van de inschakelingen.
[ Voor 8% gewijzigd door DeluxZ op 13-05-2020 15:26 ]
Livin' the good life
Hmmm... ok.Renault schreef op woensdag 13 mei 2020 @ 18:46:
SMART ziet er goed uit.
Ik vermoed dat de SSD niet de oorzaak is van je traagheid.
Uitzondering op die regel:
- voer eens een schijfcontrole uit om zeker te zijn dat je bestandssysteem in orde is
- hoeveel vrije ruimte heb je nog op de SSD? Bij te weinig (echte) vrije ruimte kakt de performance in.
Zet eens Taakbeheer open als de PC traag is en sorteer dan op CPU-gebruik: de grootste CPU-verbruiker is vaak de bron van de traagheid. En dan kan je zelf wel bedenken wat dan de verdere actie is.
:fill(white):strip_exif()/f/image/Gacl3c19uPj2laJGfSb2iYOb.png?f=user_large)
[ Voor 6% gewijzigd door DeluxZ op 14-05-2020 08:30 ]
[☼☼] [:::][:::] [☼☼]
:strip_exif()/u/26131/Calvin.gif?f=community)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
| smartctl 7.0 2018-12-30 r4883 [x86_64-linux-5.0.0-38-generic] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate Barracuda 7200.14 (AF)
Device Model: ST2000DM001-1ER164
Serial Number: Z5605PSF
LU WWN Device Id: 5 000c50 091d7800e
Firmware Version: CC26
User Capacity: 2.000.398.934.016 bytes [2,00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2, ACS-3 T13/2161-D revision 3b
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Fri May 15 22:31:26 2020 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
See vendor-specific Attribute list for marginal Attributes.
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 80) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 210) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x1085) SCT Status supported.
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 118 099 006 Pre-fail Always - 188555888
3 Spin_Up_Time 0x0003 095 095 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 097 097 020 Old_age Always - 4091
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 080 060 030 Pre-fail Always - 105928696
9 Power_On_Hours 0x0032 078 078 000 Old_age Always - 19958
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 48
183 Runtime_Bad_Block 0x0032 095 095 000 Old_age Always - 5
184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 097 097 000 Old_age Always - 3
188 Command_Timeout 0x0032 100 096 000 Old_age Always - 7 7 7
189 High_Fly_Writes 0x003a 090 090 000 Old_age Always - 10
190 Airflow_Temperature_Cel 0x0022 065 038 045 Old_age Always In_the_past 35 (5 154 36 21 0)
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 3
193 Load_Cycle_Count 0x0032 040 040 000 Old_age Always - 121763
194 Temperature_Celsius 0x0022 035 062 000 Old_age Always - 35 (0 17 0 0 0)
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 001 000 Old_age Always - 1942
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 9973h+49m+34.612s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 60792895937
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 166368139242
SMART Error Log Version: 1
ATA Error Count: 3
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 3 occurred at disk power-on lifetime: 19838 hours (826 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 48 48 65 ac 4b 00 5d+14:27:38.648 READ FPDMA QUEUED
60 00 38 f0 02 00 40 00 5d+14:27:38.648 READ FPDMA QUEUED
60 00 a0 ff ff ff 4f 00 5d+14:27:38.648 READ FPDMA QUEUED
60 00 88 ff ff ff 4f 00 5d+14:27:38.648 READ FPDMA QUEUED
60 00 28 ff ff ff 4f 00 5d+14:27:38.648 READ FPDMA QUEUED
Error 2 occurred at disk power-on lifetime: 19838 hours (826 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 5d+14:27:34.712 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 5d+14:27:34.712 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 5d+14:27:34.712 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 5d+14:27:34.712 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 5d+14:27:34.712 READ FPDMA QUEUED
Error 1 occurred at disk power-on lifetime: 19838 hours (826 days + 14 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 51 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 5d+14:27:25.423 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 5d+14:27:25.392 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 5d+14:27:25.391 READ FPDMA QUEUED
60 00 10 ff ff ff 4f 00 5d+14:27:25.387 READ FPDMA QUEUED
60 00 10 ff ff ff 4f 00 5d+14:27:25.386 READ FPDMA QUEUED
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 19954 -
# 2 Extended offline Completed: read failure 10% 19935 3890473296
# 3 Short offline Completed without error 00% 19887 -
# 4 Short offline Completed without error 00% 19719 -
# 5 Extended offline Completed without error 00% 19651 -
# 6 Short offline Completed without error 00% 19551 -
# 7 Short offline Completed without error 00% 19383 -
# 8 Short offline Completed without error 00% 19215 -
# 9 Short offline Completed without error 00% 19047 -
#10 Extended offline Completed without error 00% 18907 -
#11 Short offline Completed without error 00% 18879 -
#12 Short offline Completed without error 00% 18711 -
#13 Short offline Completed without error 00% 18543 -
#14 Short offline Completed without error 00% 18376 -
#15 Short offline Completed without error 00% 18208 -
#16 Extended offline Completed without error 00% 18164 -
#17 Short offline Completed without error 00% 18040 -
#18 Short offline Completed without error 00% 17872 -
#19 Short offline Completed without error 00% 17707 -
#20 Short offline Completed without error 00% 17539 -
#21 Extended offline Completed without error 00% 17446 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Waarschuwing, opperprutser aan het werk... en als je een opmerking van mij niet snapt, klik dan hier
[☼☼] [:::][:::] [☼☼]
Deze schijf komt uit een NAS, vandaar het hoge aantal uren dat hij al gedraaid heeft. Hij kwam uit een set van de 2, de andere staat inmiddels op 1234 dagen onlineRenault schreef op zaterdag 16 mei 2020 @ 11:13:
Tabelwaarden 5 en 197 zijn nul, dus er zijn nog geen problemen met de magnetische laag van de platters geconstateerd.
De harddisk functioneert nog goed, maar hij heeft wel enorm veel uren gehad. Een actuele backup van je data is dus altijd handig.
Wat wel zorgen baart is tabelwaarde 199: ergens in de levensduur van de harddisk heeft hij flinke communicatieproblemen gehad met het moederbord van de NAS. Je kunt uit deze tabel niet opmaken wanneer dat is geweest. Daarom zou ik een evt. losse SATA-datakabel vernieuwen en tabelwaarde 199 periodiek in de gaten houden: zolang die niet hoger wordt is alles in orde (afnemen kan die waarde niet meer, alleen oplopen).
Waarschuwing, opperprutser aan het werk... en als je een opmerking van mij niet snapt, klik dan hier
![]() Dit topic is gesloten.
Dit topic is gesloten.
![]()
:strip_icc():strip_exif()/u/32590/Meteora60.jpg?f=community)
/u/679847/crop67445da09d4ed_cropped.png?f=community)
![[Afbeelding]](https://tweakers.net/i/gSfZRUK7Xvfby_T5LwA3-jUB7_o=/full-fit-in/4000x4000/filters:no_upscale():fill(white):strip_exif()/f/image/WIEo2gV2D4D85KWKVIlRNSQy.png?f=user_large){kind=link}
{kind=link}