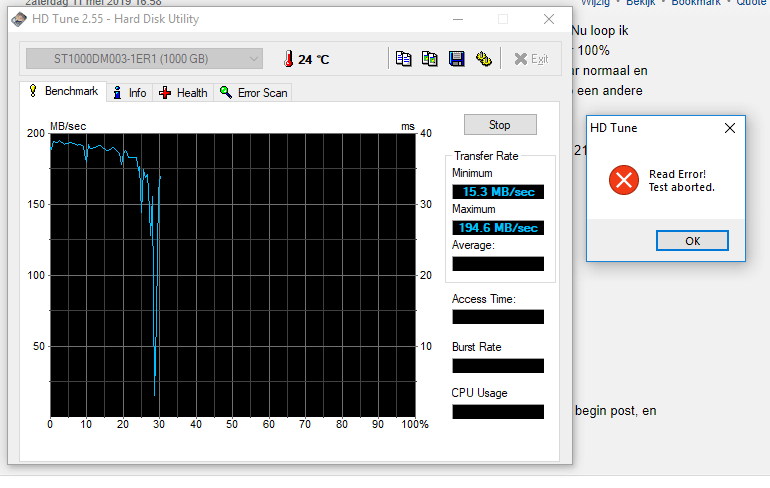
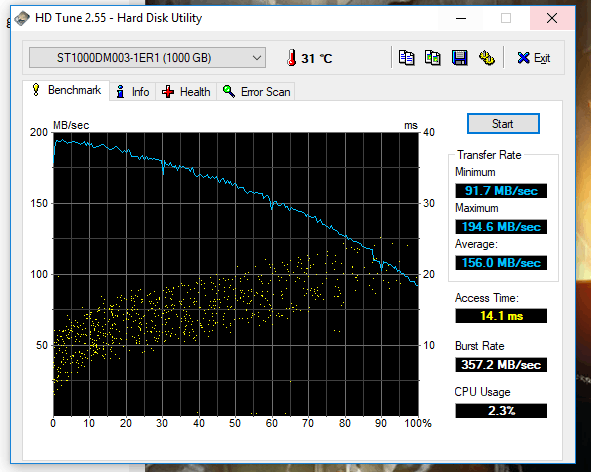
De gezondheid van mijn Toshiba A100 loopt terug. In hd sentinel nu 81%
Hieronder een print van cristal disk info
----------------------------------------------------------------------------
CrystalDiskInfo 8.0.0 (C) 2008-2018 hiyohiyo
Crystal Dew World :
https://crystalmark.info/
----------------------------------------------------------------------------
OS : Windows 10 Enterprise [10.0 Build 18362] (x64)
Date : 2019/05/31 17:21:22
-- Controller Map ----------------------------------------------------------
+ Standaard Dual Channel PCI IDE Controller [ATA]
- ATA Channel 0 (0)
- ATA Channel 1 (1)
+ Standaard Dual Channel PCI IDE Controller [ATA]
- ATA Channel 0 (0)
- ATA Channel 1 (1)
+ Standaard Dual Channel PCI IDE Controller [ATA]
+ ATA Channel 0 (0)
- WDC WD20EFRX-68EUZN0 ATA Device
- ST2000DM006-2DM164 ATA Device
- TOSHIBA A100 ATA Device
+ ATA Channel 1 (1)
- WDC WD20EZRZ-00Z5HB0 ATA Device
- ST32000542AS ATA Device
- WDC WD20EARS-00MVWB0 ATA Device
- ASUS DVD-E616A ATA Device
- PLEXTOR DVDR PX-860A ATA Device
- Controlefunctie voor opslagruimten van Microsoft [SCSI]
-- Disk List ---------------------------------------------------------------
(1) TOSHIBA A100 : 240,0 GB [0/2/0, pd1] - to
(2) ST2000DM006-2DM164 : 2000,3 GB [1/2/1, pd1] - st
(3) WDC WD20EARS-00MVWB0 : 2000,3 GB [2/3/0, pd1] - wd
(4) ST32000542AS : 2000,3 GB [3/3/1, pd1] - st
(5) WDC WD20EFRX-68EUZN0 : 2000,3 GB [4/4/0, pd1] - wd
(6) WDC WD20EZRZ-00Z5HB0 : 2000,3 GB [5/5/0, pd1] - wd
----------------------------------------------------------------------------
(1) TOSHIBA A100
----------------------------------------------------------------------------
Model : TOSHIBA A100
Firmware : SBFA10.3
Serial Number : 87OB61POKQ8U
Disk Size : 240,0 GB (8,4/137,4/240,0/240,0)
Buffer Size : onbekend
Queue Depth : 32
# of Sectors : 468862128
Rotation Rate : ---- (SSD)
Interface : Serial ATA
Major Version :
Minor Version : ----
Transfer Mode : SATA/300 | SATA/600
Power On Hours : 1468 uren
Power On Count : 626 keer
Temperature : 37 C (98 F)
Health Status : Goed
Features : S.M.A.R.T., 48bit LBA, NCQ, TRIM, DevSleep
APM Level : ----
AAM Level : ----
Drive Letter : C:
-- S.M.A.R.T. --------------------------------------------------------------
ID Cur Wor Thr RawValues(6) Attribute Name
09 100 100 __0 0000000005BC Bedrijfs Uren
0C 100 100 __0 000000000272 Inschakelingen
A7 100 100 __0 000000000000 SSD Bescherming Modus
A8 100 100 __0 000000000000 SATA PHY Fouten
A9 100 100 _10 000000000000 Totaal Slechte Block's
AD 187 187 __0 000000000000 Erase Count
C0 100 100 __0 000000000009 Onverwachte Power Onderbrekingen
C2 _63 _57 _20 002B00110025 Temperatuur
-

:strip_icc():strip_exif()/u/990805/crop5e20ca3d75443_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/324574/crop5664287011016_cropped.jpeg?f=community)

:strip_exif()/u/3008/superkoe1.gif?f=community)
/u/200133/artemis_square_e_60-60.png?f=community)
:strip_exif()/u/53522/crop583d477015a24.gif?f=community)
:strip_icc():strip_exif()/u/424743/crop5684595a3e5fd_cropped.jpeg?f=community)
:strip_exif()/u/6897/IGKIPU.gif?f=community)


/u/103308/crop676a6fdba00da_cropped.png?f=community)


/u/97665/Opera1_t.png?f=community)

:strip_icc():strip_exif()/u/21971/crop5b5ae9fcba7bc_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/454512/crop56da14dba10bd_cropped.jpeg?f=community)


:strip_icc():strip_exif()/u/645063/crop5fc68baa33f41_cropped.jpeg?f=community)




/u/175520/crop636e2cf4962f2_cropped.png?f=community)
:strip_exif()/u/574651/crop5b78563680eb2.gif?f=community)




:strip_exif()/u/106005/animated%2520garfield.gif?f=community)
/u/380961/crop591d348f69cd9_cropped.png?f=community)





/u/238501/crop5e2f0f8a11c1f_cropped.png?f=community)
/u/157530/mandrakeTM2.png?f=community)

:strip_icc():strip_exif()/u/32590/Meteora60.jpg?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}