:strip_icc():strip_exif()/u/648947/crop5658ba3c481e3_cropped.jpeg?f=community)
Helemaal top, thanks!PilatuS schreef op donderdag 09 juni 2016 @ 22:25:
[...]
Je hebt maar 1 pending bad sector, heel normaal voor een grote wat oudere schijf. Data er af halen en een volledige format geven lost het op.
:strip_icc():strip_exif()/u/65843/chef60x60.jpg?f=community)
Het lijkt er op dat je hier een goed punt had: elke keer als ik m'n laptop dichtklapte en hij standby ging werd die unsafe-shutdown-counter opgehoogd. Ofwel, goede kans op dataverlies bij elke standby-actie.Reepje schreef op zondag 05 juni 2016 @ 18:50:
Bij eventuele vervanging moet je ook goed beseffen, dat er misschien ergens een foutje zit in de laptop. 2229 unsafe shutdowns is geen kattepis, en zou een verklaring kunnen zijn waarom de ssd beschadigd is geraakt. Het kan door de specifieke combinatie plextor-jouw laptop komen, of er is iets anders aan de hand. Maar ik zou die waarde toch in de gaten houden als je er een nieuwe ssd in zet.
Nu maar een nieuwe Samsung 850-EVO SSD er in gezet, vooralsnog geen issues mee, maar helaas heeft deze Samsung daar (volgens mij) in de SMART geen indicatie voor - dus kan alleen maar hopen dat het de combinatie plextor-laptop is waar het bij fout gaat.
- Reepje
- Registratie: Juni 2010
- Niet online
:strip_icc():strip_exif()/u/363314/avator3.jpg?f=community)
PORvanaalten schreef op vrijdag 10 juni 2016 @ 16:18:
[...]
Nu maar een nieuwe Samsung 850-EVO SSD er in gezet, vooralsnog geen issues mee, maar helaas heeft deze Samsung daar (volgens mij) in de SMART geen indicatie voor
ID # 235 Power Recovery Count
A count of the number of sudden power off cases. If there is a sudden power off, the firmware must recover all of the mapping and user data during the next power on. This is a count of the number of times this has happened.
Dank! Totaal over die waarde heen gekeken. 
Die staat - na enkele keren standby gegaan te zijn - in elk geval nog steeds op nul. Ofwel
Asus N56VM + Plextor PX-256M2P = bad combination;
Asus N56VM + Samsung 850-EVO = good combination (nou ja, voor de eerste zes dagen dag...)
Die staat - na enkele keren standby gegaan te zijn - in elk geval nog steeds op nul. Ofwel
Asus N56VM + Plextor PX-256M2P = bad combination;
Asus N56VM + Samsung 850-EVO = good combination (nou ja, voor de eerste zes dagen dag...)
- jorr1986
- Registratie: Juli 2014
- Laatst online: 28-12-2025
:strip_exif()/u/607462/crop58df82592cc15_cropped.gif?f=community)
Heb deze schijf liggen.
Zelf gebruik ik eigenlijk altijd HDtune en niet CrystalDisk.
Welke van de 2 programma's geeft nou het juiste aantal power on hours aan?
Zit aardig verschil tussen en wie heeft er meer power on hours dan mij.
 ]
]
Zelf gebruik ik eigenlijk altijd HDtune en niet CrystalDisk.
Welke van de 2 programma's geeft nou het juiste aantal power on hours aan?
Zit aardig verschil tussen en wie heeft er meer power on hours dan mij.
 ]
]
[ Voor 28% gewijzigd door jorr1986 op 14-06-2016 12:10 ]
- Reepje
- Registratie: Juni 2010
- Niet online
Geen van de twee. Deze programmas lezen overigens alleen de smart data uit zoals door de schijf geleverd, en daar zit overduidelijk een storing.jorr1986 schreef op dinsdag 14 juni 2016 @ 12:07:
Heb deze schijf liggen.
Zelf gebruik ik eigenlijk altijd HDtune en niet CrystalDisk.
Welke van de 2 programma's geeft nou het juiste aantal power on hours aan?
[afbeelding]]
Volgens crystaldiskinfo is de waarde 304A93 hex, dat komt overeen met 3164819 uur, ongeveer wat hd tune ook uitleest (3164826), dat komt dus aardig overeen. Echter is het natuurlijk een onzin getal. Dat zouden dan 361 jaar draaiuren zijn.
- jorr1986
- Registratie: Juli 2014
- Laatst online: 28-12-2025
Haha, I know. 
Hij telt de minuten ipv de uren. Heel apart. 3164819 / 60 minuten = 52747 uur.
Hij telt de minuten ipv de uren. Heel apart. 3164819 / 60 minuten = 52747 uur.
- McFastFood
- Registratie: Oktober 2013
- Laatst online: 01-06 19:12
Beste mede tweakers,
Onlangs heb ik de laptop van mijn kennis gekregen met de klacht dat die vreselijk traag is, slecht afsluiten etc. Het klopt dat het opstarten erg traag gaat en lang duurt. Ik heb de smart gecheckt met HDtune en met crystal disk info. HDtune geeft wel een foutmelding aan en crystal disk info geeft aan dat de hdd in orde is.
Heb even gegoogeld naar de fout die hd tune aangeeft en de meeste beweren dit: 'f you have the possibility to simply return the drive/exchange it for a new one you should change it. Just in case.
The Error itself points to a mechanical problem of the drive. This could be a one time issue, but could get worse over time.
If the store you bought it from does not have a fair return policy, you could try to stress it a little bit to see if things get worse and than exchange it via warranty.'
Graag zou ik jullie mening/advies ook even ontvangen.
Afbeeldingen:


Onlangs heb ik de laptop van mijn kennis gekregen met de klacht dat die vreselijk traag is, slecht afsluiten etc. Het klopt dat het opstarten erg traag gaat en lang duurt. Ik heb de smart gecheckt met HDtune en met crystal disk info. HDtune geeft wel een foutmelding aan en crystal disk info geeft aan dat de hdd in orde is.
Heb even gegoogeld naar de fout die hd tune aangeeft en de meeste beweren dit: 'f you have the possibility to simply return the drive/exchange it for a new one you should change it. Just in case.
The Error itself points to a mechanical problem of the drive. This could be a one time issue, but could get worse over time.
If the store you bought it from does not have a fair return policy, you could try to stress it a little bit to see if things get worse and than exchange it via warranty.'
Graag zou ik jullie mening/advies ook even ontvangen.
Afbeeldingen:
- Reepje
- Registratie: Juni 2010
- Niet online
Ik zou me er niet direct druk om maken. Als die nu op 5000 zou staan of zo....
En hoe krijg je de laptop weer wat sneller? Juist: windows er eens vers op te zetten. Mooi moment om over te stappen naar win10?
En hoe krijg je de laptop weer wat sneller? Juist: windows er eens vers op te zetten. Mooi moment om over te stappen naar win10?
- McFastFood
- Registratie: Oktober 2013
- Laatst online: 01-06 19:12
Ik was ook van plan om Windows 10 er opnieuw op te zetten maar wou eerst even de smart van de hdd checken. Dus ik hoef me geen zorgen te maken . Bestaat de kans ook niet dat de waarde op gaat lopen? Dat ik hem bijv. Over een paar weken weer heb met dezelfde klacht?Reepje schreef op vrijdag 17 juni 2016 @ 19:54:
Ik zou me er niet direct druk om maken. Als die nu op 5000 zou staan of zo....
En hoe krijg je de laptop weer wat sneller? Juist: windows er eens vers op te zetten. Mooi moment om over te stappen naar win10?
- Reepje
- Registratie: Juni 2010
- Niet online
Ik heb alleen gekeken naar calibration retry count (niets om je zorgen te maken). Ik zie echter nu ook een write error rate. En ik weet niet hoe die te interpreteren. Misschien weet iemand anders wat die te betekenen heeft.
- Zorian
- Registratie: Maart 2010
- Laatst online: 03:04
What the fox?
/u/351515/crop6897f6e5d19a1_cropped.png?f=community)
Raw read error rate, G sense error rate, write error rate... Ik zou het er persoonlijk niet meer op gokken en hem vervangen door een SSD of een nieuwe HDD.
- dcm360
- Registratie: December 2006
- Niet online
/u/200133/artemis_square_e_60-60.png?f=community)
Kan je ook nog uitleggen waarom? Of is het meer 'ze zijn niet 0'? Dat laatste is een onzinreden om de schijf te vervangen.Zorian schreef op vrijdag 17 juni 2016 @ 20:20:
Raw read error rate, G sense error rate, write error rate... Ik zou het er persoonlijk niet meer op gokken en hem vervangen door een SSD of een nieuwe HDD.
- Zorian
- Registratie: Maart 2010
- Laatst online: 03:04
What the fox?
Toch is dat wel ergens de reden. Noem me paranoïde, maar als de errors beginnen op te lopen (en al helemaal als het diverse zijn) dan is mijn vertrouwen in een schijf weg. Die errors komen niet uit de lucht vallen, dus er is *iets* mis mee. Vandaar dat ik ook zei: Persoonlijk.dcm360 schreef op vrijdag 17 juni 2016 @ 20:32:
[...]
Kan je ook nog uitleggen waarom? Of is het meer 'ze zijn niet 0'? Dat laatste is een onzinreden om de schijf te vervangen.
- Tortelli
- Registratie: Juli 2004
- Laatst online: 02-07 14:57
mixing gas and haulin ass
:strip_exif()/u/117880/911_gt3rs_60.gif?f=community)
Laatst 2 oude Seagate desktop schijven uit mijn oude DIY Windows "NAS" gehaald en een SHR volume gemaakt in mijn Synology. Vertrouwde de schijven al niet (ze staan zeer slecht bekend) en had er een los volume mee gemaakt waar niets op stond wat ik niet kon missen (hoofd data op 4*4TB staan)
Nadat ik volume uitgebreid had (en eea aan data erop stond) crashte een van de schijven 2 of 3 dagen later . Nog een volledige wipe en check gedraaid met HD tune maar deze is echt overleden;
. Nog een volledige wipe en check gedraaid met HD tune maar deze is echt overleden;

Hij heeft gister het boormachine treadment gehad; snelste methode om HDD's definitief onbruikbaar te maken volgens mi (paar gaten door platter boren).
2e hdd gisteravond aan gezet en die lijkt er beter aan toe te zijn;

SMART:

Heb weinig kennis van SMART status, maar dit ziet er niet gek uit volgens mij?. Zit te denken om heb of als 2e disc (stripe) te laten draaien naast een 3e 3TB seagate die ik in mijn desktop pc heb, of bij mijn vader in zijn Synology te stoppen als backup locatie (hij zal amper draaiuren maken dan).
Nadat ik volume uitgebreid had (en eea aan data erop stond) crashte een van de schijven 2 of 3 dagen later
Hij heeft gister het boormachine treadment gehad; snelste methode om HDD's definitief onbruikbaar te maken volgens mi (paar gaten door platter boren).
2e hdd gisteravond aan gezet en die lijkt er beter aan toe te zijn;
SMART:
Heb weinig kennis van SMART status, maar dit ziet er niet gek uit volgens mij?. Zit te denken om heb of als 2e disc (stripe) te laten draaien naast een 3e 3TB seagate die ik in mijn desktop pc heb, of bij mijn vader in zijn Synology te stoppen als backup locatie (hij zal amper draaiuren maken dan).
[ Voor 8% gewijzigd door Tortelli op 17-06-2016 21:15 ]
- McFastFood
- Registratie: Oktober 2013
- Laatst online: 01-06 19:12
Allen bedankt voor de reacties.
De meningen zijn dus nog even verdeeld als ik het zo zie. Een voorwaarde is wel dat de hdd nog wel betrouwbaar moet zijn en niet dat ik hem over een paar weken weer terug heb met dezelfde klacht en dat de hdd dan defect is
De meningen zijn dus nog even verdeeld als ik het zo zie. Een voorwaarde is wel dat de hdd nog wel betrouwbaar moet zijn en niet dat ik hem over een paar weken weer terug heb met dezelfde klacht en dat de hdd dan defect is
:strip_icc():strip_exif()/u/64029/crop5b4e6ed3481f4_cropped.jpeg?f=community)
Ben het met je eens. Je kan deze schijf niet meer als betrouwbaar zien. Voor die paar tientjes zou ik de schijf lekker vervangen. Het zou mij ook niets verbazen als deze laptop een keer helemaal niet meer wil booten gezien de klachten die er nu zijn.Zorian schreef op vrijdag 17 juni 2016 @ 20:33:
[...]
Toch is dat wel ergens de reden. Noem me paranoïde, maar als de errors beginnen op te lopen (en al helemaal als het diverse zijn) dan is mijn vertrouwen in een schijf weg. Die errors komen niet uit de lucht vallen, dus er is *iets* mis mee. Vandaar dat ik ook zei: Persoonlijk.
- McFastFood
- Registratie: Oktober 2013
- Laatst online: 01-06 19:12
Duidelijk antwoord bedankt voor de genomen tijd en moeitePilatuS schreef op vrijdag 17 juni 2016 @ 21:30:
[...]
Ben het met je eens. Je kan deze schijf niet meer als betrouwbaar zien. Voor die paar tientjes zou ik de schijf lekker vervangen. Het zou mij ook niets verbazen als deze laptop een keer helemaal niet meer wil booten gezien de klachten die er nu zijn.
- Borromini
- Registratie: Januari 2003
- Niet online
Mislukt misantroop
:strip_icc():strip_exif()/u/75828/sid.jpg?f=community)
Ik wou even polsen of deze schijf nog OK is of aan vervanging toe is.
Mijn broer z'n server meldde onlangs deze foutmelding:
Als ik de SMART status zelf check krijg ik dit:
en de output van smartctl -a:
Ik vermoed dat de schijf gewoon aan het verslijten is, aangezien er bij heel veel waarden 'Old_age' staat (ook bij 'Offline_Uncorrectable'). Is dit te fiksen of is de schijf gewoon aan vervanging toe?
Mijn broer z'n server meldde onlangs deze foutmelding:
Syslog zegt dit:Van: "root" <root@blabla
Datum: 18 jun. 2016 12:00 a.m.
Onderwerp: SMART error (OfflineUncorrectableSector) detected on host: prometheus
Aan: <bla@bla>
Cc:
This message was generated by the smartd daemon running on:
host name: prometheus
DNS domain: [Empty]
The following warning/error was logged by the smartd daemon:
Device: /dev/sda [SAT], 234 Offline uncorrectable sectors
Device info:
SAMSUNG HD203WI, S/N:S1UYJ1YZ500946, WWN:5-0024e9-003964a9a, FW:1AN10003, 2.00 TB
For details see host's SYSLOG.
[...]
# grep -i sda /var/log/syslog Jun 18 08:00:48 prometheus smartd[698]: Device: /dev/sda [SAT], 250 Currently unreadable (pending) sectors Jun 18 08:00:48 prometheus smartd[698]: Device: /dev/sda [SAT], 234 Offline uncorrectable sectors Jun 18 10:00:48 prometheus smartd[698]: Device: /dev/sda [SAT], 250 Currently unreadable (pending) sectors Jun 18 10:00:48 prometheus smartd[698]: Device: /dev/sda [SAT], 234 Offline uncorrectable sectors Jun 18 12:00:48 prometheus smartd[698]: Device: /dev/sda [SAT], 250 Currently unreadable (pending) sectors Jun 18 12:00:48 prometheus smartd[698]: Device: /dev/sda [SAT], 234 Offline uncorrectable sectors Jun 18 14:00:48 prometheus smartd[698]: Device: /dev/sda [SAT], 250 Currently unreadable (pending) sectors Jun 18 14:00:48 prometheus smartd[698]: Device: /dev/sda [SAT], 234 Offline uncorrectable sectors
Als ik de SMART status zelf check krijg ik dit:
# smartctl -H /dev/sda smartctl 6.4 2014-10-07 r4002 [x86_64-linux-3.16.0-4-amd64] (local build) Copyright (C) 2002-14, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED
en de output van smartctl -a:
SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x002f 100 100 051 Pre-fail Always - 612 2 Throughput_Performance 0x0026 055 055 000 Old_age Always - 24767 3 Spin_Up_Time 0x0023 060 059 025 Pre-fail Always - 12295 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 795 5 Reallocated_Sector_Ct 0x0033 252 252 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x002e 252 252 051 Old_age Always - 0 8 Seek_Time_Performance 0x0024 252 252 015 Old_age Offline - 0 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 9313 10 Spin_Retry_Count 0x0032 252 252 051 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 252 252 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 633 191 G-Sense_Error_Rate 0x0022 098 098 000 Old_age Always - 24236 192 Power-Off_Retract_Count 0x0022 252 252 000 Old_age Always - 0 194 Temperature_Celsius 0x0002 058 048 000 Old_age Always - 42 (Min/Max 14/52) 195 Hardware_ECC_Recovered 0x003a 100 100 000 Old_age Always - 0 196 Reallocated_Event_Count 0x0032 252 252 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 099 099 000 Old_age Always - 250 198 Offline_Uncorrectable 0x0030 099 099 000 Old_age Offline - 234 199 UDMA_CRC_Error_Count 0x0036 100 100 000 Old_age Always - 7 200 Multi_Zone_Error_Rate 0x002a 100 100 000 Old_age Always - 2236 223 Load_Retry_Count 0x0032 252 252 000 Old_age Always - 0 225 Load_Cycle_Count 0x0032 098 098 000 Old_age Always - 27594
Ik vermoed dat de schijf gewoon aan het verslijten is, aangezien er bij heel veel waarden 'Old_age' staat (ook bij 'Offline_Uncorrectable'). Is dit te fiksen of is de schijf gewoon aan vervanging toe?
Got Leenucks? | Debian Bookworm x86_64 / ARM | OpenWrt: Empower your router | Blogje
250 pending bad sectors is nogal slecht. Een stuk of 5 maakt niet uit, die zijn na een lange format weg. Maar bij 250 stuks zullen er snel weer nieuwe bijkomen.Borromini schreef op zaterdag 18 juni 2016 @ 15:21:
Ik wou even polsen of deze schijf nog OK is of aan vervanging toe is.
- Reepje
- Registratie: Juni 2010
- Niet online
Geef even voor elke schijf aan wat precies de problemen ermee zijn, dat ben je helemaal vergeten !.fabianruben schreef op maandag 20 juni 2016 @ 12:52:
Zouden jullie nog naar mijn waardes willen kijken fabianruben in "Check je SMART".
Alvast bedankt.
- OgWok
- Registratie: Augustus 2001
- Laatst online: 10:55
U.N.C.L.E.
/u/32016/NSOLO.JPG?f=community)
Heb een Seagate 1TB HD en daar is in de Smart error ID 184 End to End opgedoken. Kan er geen sluitende info over vinden. Heb wel het idee dat de schijf trager is omdat het probleem zich in de cache van de HD afspeelt. Op site van Seagate is niets te vinden.
Ernstig of niet? (Heb nog 6 maanden garantie op de HD)
Ernstig of niet? (Heb nog 6 maanden garantie op de HD)
MacPro Core i5 750, Mac Mini, hier en daar een verdwaalde pc.....
Ik hoop dat het zo duidelijker is (fabianruben in "Check je SMART").
- Reepje
- Registratie: Juni 2010
- Niet online
Ik zie niets raars.fabianruben schreef op maandag 20 juni 2016 @ 13:56:
Ik hoop dat het zo duidelijker is (fabianruben in "Check je SMART").
Ok, dankjewel!
Zou jij (of iemand anders) mij kunnen uitleggen hoe je de S.M.A.R.T. waardes van een SSD diagnosticeert/interpreteert?
Dan hoef ik dit in het vervolg niet te vragen.
Alvast bedankt.
Zou jij (of iemand anders) mij kunnen uitleggen hoe je de S.M.A.R.T. waardes van een SSD diagnosticeert/interpreteert?
Dan hoef ik dit in het vervolg niet te vragen.
Alvast bedankt.
- dcm360
- Registratie: December 2006
- Niet online
Naast dat de schijf zoals PilatuS al aangeeft best wel aan vervanging toe is, nog wel even een opmerking over het 'Old_age'. 'Old_age' geeft aan wat de (waarschijnlijke) oorzaak is als een bepaalde waarde niet meer in orde is. Dat er overal 'old_age' staat zegt dus dat het gaat om waarden die met de veroudering van de schijf te maken hebben, en het geeft niet aan dat de schijf oud is.Borromini schreef op zaterdag 18 juni 2016 @ 15:21:
Ik vermoed dat de schijf gewoon aan het verslijten is, aangezien er bij heel veel waarden 'Old_age' staat (ook bij 'Offline_Uncorrectable'). Is dit te fiksen of is de schijf gewoon aan vervanging toe?
Verwijderd
De laatste tijd geeft de pc bij opstarten aan: "SMART status bad, back up and replace drive" oid.
Lukt mij niet om een screen van de smart status te posten, maar crystaldiskinfo geeft het volgende aan:
Gezondheidstoestand: slecht
En verder 1 rood bolletje bij Reallocated sectors count geeft hij de volgende waarde:
- huidige: 1
- Slechtste: 1
- Drempel: 5
- RAW-waarden: 2005.
Schijf: Hitachi HDS721010DLE630 - 1000,2 MB
Wordt t misschien tijd voor een nieuwe HD?
Alvast bedankt voor de hulp.
Lukt mij niet om een screen van de smart status te posten, maar crystaldiskinfo geeft het volgende aan:
Gezondheidstoestand: slecht
En verder 1 rood bolletje bij Reallocated sectors count geeft hij de volgende waarde:
- huidige: 1
- Slechtste: 1
- Drempel: 5
- RAW-waarden: 2005.
Schijf: Hitachi HDS721010DLE630 - 1000,2 MB
Wordt t misschien tijd voor een nieuwe HD?
Alvast bedankt voor de hulp.
- Weijlander
- Registratie: December 2011
- Laatst online: 08-06-2025
:strip_icc():strip_exif()/u/437973/crop5e0f08c099694_cropped.jpeg?f=community)
Ik heb een WD3200BEKT in mijn laptop hangen welke (subjectief) niet snel leest waardoor Windows ook erg langzaam reageert en opstart. Ook eventuele kleine spelletjes of programma's doen er lang over om op te starten. Nu had ik hierover al een vraag gesteld in een ander topic. Daar werd ik hier naartoe verwezen werd. Ik vroeg me af of iemand hier nog enig advies heeft over mijn HDD.

- OgWok
- Registratie: Augustus 2001
- Laatst online: 10:55
U.N.C.L.E.
Misschien eens een HD benchmark draaien en hier posten. Heb, zelf, wel eens een 2,5" HD meegemaakt die op zich in orde was, maar erg, erg traag werd.Weijlander schreef op zaterdag 25 juni 2016 @ 00:16:
Ik heb een WD3200BEKT in mijn laptop hangen welke (subjectief) niet snel leest waardoor Windows ook erg langzaam reageert en opstart. Ook eventuele kleine spelletjes of programma's doen er lang over om op te starten. Nu had ik hierover al een vraag gesteld in een ander topic. Daar werd ik hier naartoe verwezen werd. Ik vroeg me af of iemand hier nog enig advies heeft over mijn HDD.
[afbeelding]
MacPro Core i5 750, Mac Mini, hier en daar een verdwaalde pc.....
- chim0
- Registratie: Mei 2000
- Laatst online: 30-06 22:23
:strip_exif()/u/6897/IGKIPU.gif?f=community)
Die vlieger gaat niet altijd op. Kijk maar naar mijn schijf.PilatuS schreef op donderdag 09 juni 2016 @ 22:25:
[...]
Je hebt maar 1 pending bad sector, heel normaal voor een grote wat oudere schijf.

Inmiddels 6 jaar oud en helemaal grijs ge-torrent, maar geeft geen kick en draait nog steeds als een zonnetje. Het is ook mijn enige schijf waar Windows ook nog op draait (gaat binnenkort wel vervangen worden door een SSD en dienen als dataschijf). Maar vergelijk zijn inschakelingen/bedrijfsuren eens met die van mij. Dubbele bedrijfsuren tegen een fractie van inschakelingen, omdat mijn PC altijd aan staat. Ik heb altijd geleerd dat het constant in- en uitschakelen van een mechanische schijf, niet echt bevorderlijk is voor de levensduur van het ding, maar ik weet niet of daar ook bad sectors van kunnen komen.
Klopt, onlangs nog meegemaakt.Data er af halen en een volledige format geven lost het op.
Voor format:

Na format:

Natuurlijk niet. Er zijn genoeg schijven die geen bad sectors krijgen. Ik zeg alleen dat het normaal is dat het wel zo is, niet dat het altijd zo is.chim0 schreef op zaterdag 25 juni 2016 @ 08:04:
[...]
Die vlieger gaat niet altijd op. Kijk maar naar mijn schijf.
In veel gevallen zijn er wel bad sectors - onleesbare sectoren. Ze worden alleen niet ontdekt omdat het daarvoor nodig is om sectoren te lezen. Veel sectoren worden lange tijd nooit gelezen omdat ze niet in gebruik zijn. Als ze in gebruik worden genomen worden ze overschreven. Als ze - door lange tijd niet beschreven te zijn geweest - onleesbaar worden na lange tijd, blijft dit onopgemerkt voor de schijf zelf. De schijf heeft dan wel degelijk 'bad sectors' maar ze worden nooit ontdekt. Bij het overschrijven van een dergelijke sector wordt de data ververst en verdwijnt het probleem dus ook automatisch.
Dat gezegd, er bestaat veel fluctuatie tussen samples voor wat betreft uBER bad sectors - dus zonder fysieke schade. Dus je kunt schijven hebben die vele jaren lang nooit (zichtbare) bad sectors hebben, en schijven die dat al in de eerste paar maanden hebben. Beide zijn prima bruikbaar met de juiste software.
Dat gezegd, er bestaat veel fluctuatie tussen samples voor wat betreft uBER bad sectors - dus zonder fysieke schade. Dus je kunt schijven hebben die vele jaren lang nooit (zichtbare) bad sectors hebben, en schijven die dat al in de eerste paar maanden hebben. Beide zijn prima bruikbaar met de juiste software.
- Weijlander
- Registratie: December 2011
- Laatst online: 08-06-2025
Hey OgWok, bedankt voor je reactie. Bij deze ook een benchmark gedaan met CrystalDiskMark.

Je hardeschijf functioneert zeer waarschijnlijk correct, maar je hebt hem best vol gestopt (60%) en waarschijnlijk heb je je Windows-installatie behoorlijk vervuild. Hierdoor moet de schijf continu seeken en dat gaat tegen minder dan 0,4 MB/s. Een SSD voor je C-schijf is natuurlijk aan te bevelen. Als je het met een HDD moet doen, is het zaak je Windows-installatie zo schoon mogelijk te houden.
In jouw geval kun je je probleem oplossen door:
In jouw geval kun je je probleem oplossen door:
- Een SSD aan te schaffen en alles te migreren naar je SSD door (vaak bijgevelerde) cloning software.
- Een nieuwe installatie uit te voeren; dus alles te backuppen en je hardeschijf tijdens de installatie van Windows te formatteren; cq. door de hardeschijf te resetten naar fabrieksinstellingen middels de 'recoverypartitie'.
- Alles te backuppen en Windows helemaal te strippen, daarna een defragmentatie uit te voeren. Deze optie is minder effectief dan bovenstaande twee opties.
- sdk1985
- Registratie: Januari 2005
- Laatst online: 01:48
Moet ik mij hier zorgen om maken? Volgens windows wel. Ik heb in ieder geval de spindown time even op never gezet en ben wat dingen aan het kopiëren.
edit: Hier staat dat het mogelijk een firmware probleem is. Ding is echter al jaren oud en hij draait al iets van een maand op Win10: Verwijderd in "Samsung Spinpoint F4 geeft Spin up time error"
edit: Hier staat dat het mogelijk een firmware probleem is. Ding is echter al jaren oud en hij draait al iets van een maand op Win10: Verwijderd in "Samsung Spinpoint F4 geeft Spin up time error"
[ Voor 32% gewijzigd door sdk1985 op 28-06-2016 20:55 ]
Hostdeko webhosting: Sneller dan de concurrentie, CO2 neutraal en klantgericht.
De slechte score van Spin-Up Time houdt in dat tenminste één keer het opspinnen 57851msec oftewel 57,9 seconden heeft geduurd. Dit is natuurlijk extreem lang. Dit kan komen door een probleem met de stroomvoorziening, een probleem met de firmware of een echt groot probleem: problemen met de motor. Dat laatste kan een teken zijn dat de schijf wel eens kan falen. Als dat gebeurt, is het waarschijnlijk over en uit voor de schijf, aangezien hij niet meer (goed) kan opspinnen en in zo'n geval kun je alleen met datarecovery aan de slag.
Beschouw de schijf dus zeker als minder betrouwbaar en maak extra goede backups zolang je de schijf in gebruik hebt. Controleer ook de SMART wat vaker en let in het bijzonder of je 'Huidig' (Current) waarde van dit attribuut weer boven de grenswaarde van 25 ziet stijgen. De 'Slechtste' (Worst) waarde zal altijd op 1 blijven staan. Een normale waarde voor dit attribuut is tussen de 4000 en 8000 (4 tot 8 seconden spinup tijd). Jij zit daar dus 10 keer boven en dat is zeker abnormaal.
Beschouw de schijf dus zeker als minder betrouwbaar en maak extra goede backups zolang je de schijf in gebruik hebt. Controleer ook de SMART wat vaker en let in het bijzonder of je 'Huidig' (Current) waarde van dit attribuut weer boven de grenswaarde van 25 ziet stijgen. De 'Slechtste' (Worst) waarde zal altijd op 1 blijven staan. Een normale waarde voor dit attribuut is tussen de 4000 en 8000 (4 tot 8 seconden spinup tijd). Jij zit daar dus 10 keer boven en dat is zeker abnormaal.
- sdk1985
- Registratie: Januari 2005
- Laatst online: 01:48
Een minuut is wel erg lang. Ik heb gisteren disk spindown naar never gezet, daarbij vergeten dat het systeem in geheel wel in suspend to ram zou gaan. De waarde is nu 67.
Normaal zou ik de schijf direct weggooien. Echter het verhaal van JJHH211 is wel verdacht. Hij heeft precies dezelfde value en dezelfde firmware. Op Linux kwam ik er vorig jaar al achter dat ik een rare schijf er tussen heb zitten die niet normaal reageert op hdparm, maar omgekeerd. Dat was een Samsung disk, ik ben alleen vergeten welke. Heb namelijk ook nog een hd103SJ.
Dus ik weet nu niet of het een Win8/10 kernel probleem is gerelateerd aan standby of dat er daadwerkelijk iets met de motor is. Dat is wel vervelend.
Verder is de timing irritant want ik ben me juist aan het oriënteren op herziening van mijn NAS maar ik zit nu nog in het " ik zie door de bomen het bos niet meer" stadium. Dat was meer iets voor volgende maand!
Normaal zou ik de schijf direct weggooien. Echter het verhaal van JJHH211 is wel verdacht. Hij heeft precies dezelfde value en dezelfde firmware. Op Linux kwam ik er vorig jaar al achter dat ik een rare schijf er tussen heb zitten die niet normaal reageert op hdparm, maar omgekeerd. Dat was een Samsung disk, ik ben alleen vergeten welke. Heb namelijk ook nog een hd103SJ.
Dus ik weet nu niet of het een Win8/10 kernel probleem is gerelateerd aan standby of dat er daadwerkelijk iets met de motor is. Dat is wel vervelend.
Verder is de timing irritant want ik ben me juist aan het oriënteren op herziening van mijn NAS maar ik zit nu nog in het " ik zie door de bomen het bos niet meer" stadium. Dat was meer iets voor volgende maand!
[ Voor 10% gewijzigd door sdk1985 op 29-06-2016 18:21 . Reden: edit: de waarde is nu 67 ]
Hostdeko webhosting: Sneller dan de concurrentie, CO2 neutraal en klantgericht.
- geenwindows
- Registratie: November 2015
- Niet online
het betreft een Seagate Archive HDD v2 8TB hdd, ding gebruik ik als offline backup disk voor mijn server,
Laatste was ie wel erg traag en zag dat de ecc error recovered en seek error rate vrij hoog waren. Na wat te hebben gespeurd op het web voor antwoorden ben ik er niet heel zeker van en die hier ff een poging wagen..
Laatste was ie wel erg traag en zag dat de ecc error recovered en seek error rate vrij hoog waren. Na wat te hebben gespeurd op het web voor antwoorden ben ik er niet heel zeker van en die hier ff een poging wagen..
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| === START OF INFORMATION SECTION === Device Model: ST8000AS0002-1NA17Z Firmware Version: AR13 User Capacity: 8,001,563,222,016 bytes [8.00 TB] Sector Sizes: 512 bytes logical, 4096 bytes physical Rotation Rate: 5980 rpm Device is: Not in smartctl database [for details use: -P showall] ATA Version is: ACS-2, ACS-3 T13/2161-D revision 3b SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s) Local Time is: Tue Jun 14 21:53:16 2016 CEST SMART support is: Available - device has SMART capability. SMART support is: Enabled SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 119 100 006 Pre-fail Always - 218799360 3 Spin_Up_Time 0x0003 091 091 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 58 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 071 060 030 Pre-fail Always - 8616751940 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 182 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 40 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 099 000 Old_age Always - 12885098500 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 066 061 045 Old_age Always - 34 (Min/Max 28/38) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 14 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 64 194 Temperature_Celsius 0x0022 034 040 000 Old_age Always - 34 (0 18 0 0 0) 195 Hardware_ECC_Recovered 0x001a 119 100 000 Old_age Always - 218799360 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 221538708095147 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 21602898377 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 8055662042 SMART Error Log Version: 1 No Errors Logged |
Fan van: Unraid, ProxMox, Pi-hole, PlexMediaServer, OPNsense. Meer een gluurder dan een reaguurder.
Dat is binary encoded; niet het absoluut aantal errors. Met 'Rate' wordt ook bedoeld de verhouding; het exact aantal zegt weinig. Het gaat om de verhouding tussen totale I/O's en hoe vaak een seek error of read error voorkomt. Zonder ECC kan je hardeschijf weinig informatie foutloos lezen. ECC is dus continu nodig.
Kortom, dit is volstrekt normaal. Alleen de genormaliseerde waarden zeggen iets concreets en die zijn bij jou prima.
Kortom, dit is volstrekt normaal. Alleen de genormaliseerde waarden zeggen iets concreets en die zijn bij jou prima.
- geenwindows
- Registratie: November 2015
- Niet online
dankje, top!Verwijderd schreef op woensdag 29 juni 2016 @ 19:44:
Dat is binary encoded; niet het absoluut aantal errors. Met 'Rate' wordt ook bedoeld de verhouding; het exact aantal zegt weinig. Het gaat om de verhouding tussen totale I/O's en hoe vaak een seek error of read error voorkomt. Zonder ECC kan je hardeschijf weinig informatie foutloos lezen. ECC is dus continu nodig.
Kortom, dit is volstrekt normaal. Alleen de genormaliseerde waarden zeggen iets concreets en die zijn bij jou prima.
had al zo'n vermoede dat er niks aan de hand was, was ff aan het twijfelen (het is tenslotte de Backup disk
Fan van: Unraid, ProxMox, Pi-hole, PlexMediaServer, OPNsense. Meer een gluurder dan een reaguurder.
- chim0
- Registratie: Mei 2000
- Laatst online: 30-06 22:23
Het leven kan soms ook mooi zijn! Zomaar uit het niets krijg je opeens twee van deze schatjes in je schoot geworpen > pricewatch: Seagate Barracuda 7200.10 ST3320620AS, 320GB


Hebben in een oude PC bij een vereniging gedraaid als twee aparte schijven en zoals je ziet super weinig bedrijfsuren en foutloos. Ik ga ze in RAID-0 zetten als systeemschijf en dan kan eindelijk m'n huidige schijf als dataschijf fungeren want die heeft het aardig te verduren gehad de afgelopen 5 jaar, maar hij houdt nog steeds stand Dit, tot ik een SSD kan betalen.
Dit, tot ik een SSD kan betalen.
Sorry jongens, wilde m'n enthousiasme even delen. Als je jarenlang ellende hebt gehad, is het ook weleens leuk als er iets leuks op je pad komt. Ben oprecht dankbaar!
PS: Die laatste staat op SATA-150, omdat ik de jumper was vergeten weg te halen voor de screenshot. Oh ja, en ik zal ook een nieuwe voeding moeten hebben want ik heb niet genoeg aansluitingen.
Die dingen worden wel loeiheet, zoals ook anderen ervaren. Bijna 50 graden.
Fannetje ervoor en niks aan de hand.
Hebben in een oude PC bij een vereniging gedraaid als twee aparte schijven en zoals je ziet super weinig bedrijfsuren en foutloos. Ik ga ze in RAID-0 zetten als systeemschijf en dan kan eindelijk m'n huidige schijf als dataschijf fungeren want die heeft het aardig te verduren gehad de afgelopen 5 jaar, maar hij houdt nog steeds stand
Sorry jongens, wilde m'n enthousiasme even delen. Als je jarenlang ellende hebt gehad, is het ook weleens leuk als er iets leuks op je pad komt. Ben oprecht dankbaar!
PS: Die laatste staat op SATA-150, omdat ik de jumper was vergeten weg te halen voor de screenshot. Oh ja, en ik zal ook een nieuwe voeding moeten hebben want ik heb niet genoeg aansluitingen.
Die dingen worden wel loeiheet, zoals ook anderen ervaren. Bijna 50 graden.
Fannetje ervoor en niks aan de hand.
[ Voor 4% gewijzigd door chim0 op 19-07-2016 04:16 ]
- Pittie
- Registratie: Maart 2002
- Laatst online: 02-07 19:29
Ik heb ook een schijfje waarbij ik mij afvraag, is deze nog te vertrouwen?

[ Voor 25% gewijzigd door Pittie op 07-07-2016 22:29 ]
Post anders even een screenshot van CrystalDiskInfo. Nu heb ik geen idee wat die Unknown is.Pittie schreef op donderdag 07 juli 2016 @ 22:29:
Ik heb ook een schijfje waarbij ik mij afvraag, is deze nog te vertrouwen?
[afbeelding]
- Pittie
- Registratie: Maart 2002
- Laatst online: 02-07 19:29
Bij deze. Het heeft even geduurd, want het is niet mijn computer.PilatuS schreef op donderdag 07 juli 2016 @ 22:55:
[...]
Post anders even een screenshot van CrystalDiskInfo. Nu heb ik geen idee wat die Unknown is.

CDI leest in ieder geval de boel uit zoals het hoort. Als je het mij vraagt ziet het er goed uit.Pittie schreef op vrijdag 08 juli 2016 @ 20:18:
[...]
Bij deze. Het heeft even geduurd, want het is niet mijn computer.
[afbeelding]
- Pittie
- Registratie: Maart 2002
- Laatst online: 02-07 19:29
Ik schrok eigenlijk zelf vooral van de hoge waarde van de Read Error Rate en de Seek Error Rate.PilatuS schreef op vrijdag 08 juli 2016 @ 20:22:
[...]
CDI leest in ieder geval de boel uit zoals het hoort. Als je het mij vraagt ziet het er goed uit.
Maar dat is dan normaal?
Voor een schijf met zoveel uren vind ik het niet zo heel vreemd.Pittie schreef op vrijdag 08 juli 2016 @ 20:31:
[...]
Ik schrok eigenlijk zelf vooral van de hoge waarde van de Read Error Rate en de Seek Error Rate.
Maar dat is dan normaal?
Edit: Wanneer je pending bad sectors krijgt is de data op de schijf in gevaar, dat is nu gelukkig niet zo. Dat is 1 van de meeste voorkomende problemen en daarvan word alles ook enorm langzaam. De schijf die je hebt is wat ouder aan het worden, maar ik zou niet gelijk zeggen dat ie onbetrouwbaar is.
[ Voor 33% gewijzigd door PilatuS op 08-07-2016 20:51 ]
- Reepje
- Registratie: Juni 2010
- Niet online
Het gaat om een rate (verhouding). De eerste 16 bits *( =vier waardes) geven het aantal read erros en seek errors aan. Als je even kijkt zijn deze voor beide 0000.Pittie schreef op vrijdag 08 juli 2016 @ 20:31:
[...]
Ik schrok eigenlijk zelf vooral van de hoge waarde van de Read Error Rate en de Seek Error Rate.
Maar dat is dan normaal?
0 fouten dus.
- Reepje
- Registratie: Juni 2010
- Niet online
Is juist verkeerd als het "getal" niet bestaat, maar de binaire code uit verschillende variabelen bestaat.
Neem bijv temperatuur: HEX 000024170024.
De uitgelezen temperatuur is 36.
Zet ik m echter op DEC, dan wordt de waarde voor temperatuur: 605487140.
Nietszeggend dus, omdat je hier weer een samengestelde variable hebt, de laatste 16 bits waarschijnlijk de temperatuur: HEX 0024 = DEC 36
- ThinkPad
- Registratie: Juni 2005
- Laatst online: 10:45
:strip_icc():strip_exif()/u/146731/crop562615a0aa64c.jpeg?f=community)
Ik wilde even een image maken (Macrium Reflect Free) van de laptop van m'n schoonvader omdat ik de laptop wil upgraden naar W10.
Ik kreeg echter foutmeldingen in Macrium ("Gegevensfout (cyclische redundantiecontrole)").
CrystalDiskInfo geeft een waarschuwing en toont deze waarden.

Ik weet van een eerdere post van mij in dit topic dat de Load Cycle Count wel aardig hoog is.
Volgens mij kan ik de schijf beter vervangen?
Misschien een mooi moment voor hem om te upgraden naar een 128GB SSDtje (hij heeft er nog geen 5GB aan persoonlijke data op staan).
Ik kreeg echter foutmeldingen in Macrium ("Gegevensfout (cyclische redundantiecontrole)").
CrystalDiskInfo geeft een waarschuwing en toont deze waarden.
Ik weet van een eerdere post van mij in dit topic dat de Load Cycle Count wel aardig hoog is.
Volgens mij kan ik de schijf beter vervangen?
Misschien een mooi moment voor hem om te upgraden naar een 128GB SSDtje (hij heeft er nog geen 5GB aan persoonlijke data op staan).
[ Voor 11% gewijzigd door ThinkPad op 17-07-2016 18:20 ]
- SkullboX
- Registratie: September 2004
- Laatst online: 28-05 10:06
Ik probeer op verzoek een oude externe HDD van een huisgenoot leeg te trekken. Windows herkent de schijf, maar laat mij hem niet openen zonder te formatten. CHKDSK herkent de schijf niet. De tool HDDScan doet dat wel en ik run op dit moment een scan van de gehele HDD.
Bij de scan gaat het na ongeveer 24000 sectoren flink fout en vindt een hoop trage en bad sectors bij elkaar en de scan stop nagenoeg. Na een paar minuten komt de scan hier echter toch langs en gaat vervolgens op volle snelheid door de rest van de schijf heen (tot nog toe), dus ik neem aan dat de schijf zelf nog werkt en dat het weigeren van het lezen hier iets mee te maken heeft.
Hier is het SMART report:

Is er een manier deze data eraf te halen door eventueel die bad sectors te skippen? Ik vermoed dat deze de reden zijn dat ik geen toegang heb tot de schijf via windows en er geen data af kan halen, maar ik heb erg weinig ervaring met data recovery.
Alvast bedankt!
Bij de scan gaat het na ongeveer 24000 sectoren flink fout en vindt een hoop trage en bad sectors bij elkaar en de scan stop nagenoeg. Na een paar minuten komt de scan hier echter toch langs en gaat vervolgens op volle snelheid door de rest van de schijf heen (tot nog toe), dus ik neem aan dat de schijf zelf nog werkt en dat het weigeren van het lezen hier iets mee te maken heeft.
Hier is het SMART report:
Is er een manier deze data eraf te halen door eventueel die bad sectors te skippen? Ik vermoed dat deze de reden zijn dat ik geen toegang heb tot de schijf via windows en er geen data af kan halen, maar ik heb erg weinig ervaring met data recovery.
Alvast bedankt!
Ga eens aan de slag met een recoverytool, bijvoorbeeld: GetDataBack.SkullboX schreef op maandag 18 juli 2016 @ 19:12:
Is er een manier deze data eraf te halen door eventueel die bad sectors te skippen? Ik vermoed dat deze de reden zijn dat ik geen toegang heb tot de schijf via windows en er geen data af kan halen, maar ik heb erg weinig ervaring met data recovery.
Alvast bedankt!
- SkullboX
- Registratie: September 2004
- Laatst online: 28-05 10:06
DANK! Dit werkt geweldig.PilatuS schreef op maandag 18 juli 2016 @ 19:28:
[...]
Ga eens aan de slag met een recoverytool, bijvoorbeeld: GetDataBack.
Sommige mappen komt hij inderdaad nauwelijks doorheen. De bestanden hieruit - vooral leuk te zien bij de foto's - zijn flink corrupt. De rest kopieert als een trein.
Data die zit in beschadigde sectoren krijg je er niet meer terug, maar de rest gelukkig wel. Meestal komt 95+% zonder problemen terug. Het kan een paar uur duren of een paar dagen, maar meestal lukt het welSkullboX schreef op maandag 18 juli 2016 @ 21:18:
[...]
DANK! Dit werkt geweldig.
Sommige mappen komt hij inderdaad nauwelijks doorheen. De bestanden hieruit - vooral leuk te zien bij de foto's - zijn flink corrupt. De rest kopieert als een trein.
Verwijderd
Hallo allemaal,
mijn laptop werkt de laatste tijd waardeloos, foutmeldingen, vast lopen etc dus ik heb een SMART rapport gemaakt maar ik heb geen idee hoe je zoiets leest en wat ik er daarna aan kan doen. Hopelijk kunnen jullie me helpen, bij voorbaat heel veel dank!
mijn laptop werkt de laatste tijd waardeloos, foutmeldingen, vast lopen etc dus ik heb een SMART rapport gemaakt maar ik heb geen idee hoe je zoiets leest en wat ik er daarna aan kan doen. Hopelijk kunnen jullie me helpen, bij voorbaat heel veel dank!
- EricJH
- Registratie: November 2003
- Laatst online: 05:45
/u/97665/Opera1_t.png?f=community)
Uhm..... je bent geloof ik vergeten het plaatje te posten. 
/u/189604/crop62f3f8c952ebc_cropped.png?f=community)
{kind=link}
Ik heb een klein servertje draaien met daarin 4 x Western Digital WD20EARS Caviar Green 2TB schijven (RAID5). De schijven zijn aangeschaft op 20-08-2010 en draaien dus al bijna 6 jaar. De eerste jaren draaide de server (bijna) 24/7 en sinds een aantal jaren gaat de server in slaapstand als ik niet thuis ben.
Hoewel ik de back-up goed geregeld heb, staat op de server toch mijn data staat. Daarom ben ik benieuwd wat jullie aan de hand van de SMART status kunnen vertellen over de schijven. Kunnen deze nog even mee of moet ik deze zekerheidshalve binnenkort gaan vervangen?
Schijf 1:
Schijf 2:
Schijf 3:
Schijf 4:
Thx alvast
Hoewel ik de back-up goed geregeld heb, staat op de server toch mijn data staat. Daarom ben ik benieuwd wat jullie aan de hand van de SMART status kunnen vertellen over de schijven. Kunnen deze nog even mee of moet ik deze zekerheidshalve binnenkort gaan vervangen?
Schijf 1:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| === START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar Green (AF)
Device Model: WDC WD20EARS-00J2GB0
Serial Number: WD-WCAYY0167996
LU WWN Device Id: 5 0014ee 204c6c85e
Firmware Version: 80.00A80
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 2.6, 3.0 Gb/s
Local Time is: Wed Jul 20 00:33:56 2016 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (40260) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 459) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x3031) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 161 148 021 Pre-fail Always - 8941
4 Start_Stop_Count 0x0032 099 099 000 Old_age Always - 1150
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 075 075 000 Old_age Always - 18379
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 1148
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 109
193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 1681725
194 Temperature_Celsius 0x0022 114 073 000 Old_age Always - 38
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Schijf 2:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| === START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar Green (AF)
Device Model: WDC WD20EARS-00J2GB0
Serial Number: WD-WCAYY0186755
LU WWN Device Id: 5 0014ee 2af71a839
Firmware Version: 80.00A80
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 2.6, 3.0 Gb/s
Local Time is: Wed Jul 20 00:35:11 2016 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (41100) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 468) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x3031) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 162 153 021 Pre-fail Always - 8866
4 Start_Stop_Count 0x0032 099 099 000 Old_age Always - 1162
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 067 067 000 Old_age Always - 24806
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 1160
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 116
193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 1860356
194 Temperature_Celsius 0x0022 115 082 000 Old_age Always - 37
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Schijf 3:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| === START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar Green (AF)
Device Model: WDC WD20EARS-00J2GB0
Serial Number: WD-WCAYY0187603
LU WWN Device Id: 5 0014ee 2af71aaba
Firmware Version: 80.00A80
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 2.6, 3.0 Gb/s
Local Time is: Wed Jul 20 00:35:04 2016 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (41100) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 468) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x3031) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 163 150 021 Pre-fail Always - 8816
4 Start_Stop_Count 0x0032 099 099 000 Old_age Always - 1166
5 Reallocated_Sector_Ct 0x0033 199 199 140 Pre-fail Always - 1
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 066 066 000 Old_age Always - 24831
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 1164
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 113
193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 1792547
194 Temperature_Celsius 0x0022 114 072 000 Old_age Always - 38
196 Reallocated_Event_Count 0x0032 199 199 000 Old_age Always - 1
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Schijf 4:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| === START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar Green (AF)
Device Model: WDC WD20EARS-00J2GB0
Serial Number: WD-WCAYY0191701
LU WWN Device Id: 5 0014ee 204c6c3e5
Firmware Version: 80.00A80
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 2.6, 3.0 Gb/s
Local Time is: Wed Jul 20 00:34:56 2016 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (39600) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 451) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x3031) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 162 154 021 Pre-fail Always - 8858
4 Start_Stop_Count 0x0032 099 099 000 Old_age Always - 1167
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 066 066 000 Old_age Always - 24839
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 1165
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 115
193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 1796001
194 Temperature_Celsius 0x0022 114 080 000 Old_age Always - 38
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Thx alvast
- tdm850ed
- Registratie: Januari 2008
- Laatst online: 02-07 16:06
Schijf 3:
Deze schijf heeft momenteel 1 re-allocated sector, de andere schijven zien er nog goed uit.
1 sector kan nog niet echt kwaad, ik raad je wel aan om te monitoren of het erger word als dat het geval is schijfje swappen en raid rebuilden.
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| === START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar Green (AF)
Device Model: WDC WD20EARS-00J2GB0
Serial Number: WD-WCAYY0187603
LU WWN Device Id: 5 0014ee 2af71aaba
Firmware Version: 80.00A80
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 2.6, 3.0 Gb/s
Local Time is: Wed Jul 20 00:35:04 2016 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x84) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (41100) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 468) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x3031) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 163 150 021 Pre-fail Always - 8816
4 Start_Stop_Count 0x0032 099 099 000 Old_age Always - 1166
[b]5 Reallocated_Sector_Ct 0x0033 199 199 140 Pre-fail Always - 1[/b]
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 066 066 000 Old_age Always - 24831
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 1164
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 113
193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 1792547
194 Temperature_Celsius 0x0022 114 072 000 Old_age Always - 38
196 Reallocated_Event_Count 0x0032 199 199 000 Old_age Always - 1
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Deze schijf heeft momenteel 1 re-allocated sector, de andere schijven zien er nog goed uit.
1 sector kan nog niet echt kwaad, ik raad je wel aan om te monitoren of het erger word als dat het geval is schijfje swappen en raid rebuilden.
Verwijderd
hallo iedereen,
ik heb sins een weekje een apart probleem met mijn computer. op een ochtend startte ik hem op en alles leek normaal tot dat ik google(chrome) opende en alles was erg traag ik keek in de windows task manager en ik kwam er achter dat hij uit en niets 100% geheugen gebruikt. dus ik besloot mijn computer te resetten.
nu ik dat heb gedaan dacht ik van het probleem af te zijn. maar dat is dus niet zo. alles is nog erg traag en ik heb besloten een HDDScan te doen daar uit kwam dat ik 2 errors heb:
error 1: 199 UltraDMA CRC Errors 200 197 0000000006-E93A 000
error 2: 197 Current Pending Errors Count 200 200 0000000000-0013 000
ik had hier een topic over gemaakt en hun verwezen mij hier heen
hier is de screenshot van mijn crystaldiskinfo:
https://gyazo.com/9c9b46a169ce0525dd108f51089c65c8
gr johnybrick
ik heb sins een weekje een apart probleem met mijn computer. op een ochtend startte ik hem op en alles leek normaal tot dat ik google(chrome) opende en alles was erg traag ik keek in de windows task manager en ik kwam er achter dat hij uit en niets 100% geheugen gebruikt. dus ik besloot mijn computer te resetten.
nu ik dat heb gedaan dacht ik van het probleem af te zijn. maar dat is dus niet zo. alles is nog erg traag en ik heb besloten een HDDScan te doen daar uit kwam dat ik 2 errors heb:
error 1: 199 UltraDMA CRC Errors 200 197 0000000006-E93A 000
error 2: 197 Current Pending Errors Count 200 200 0000000000-0013 000
ik had hier een topic over gemaakt en hun verwezen mij hier heen
hier is de screenshot van mijn crystaldiskinfo:
https://gyazo.com/9c9b46a169ce0525dd108f51089c65c8
gr johnybrick
- Nat-Water
- Registratie: December 2013
- Laatst online: 11:18
/u/564823/crop57076ba347bf1.png?f=community)
Hi,
Ik heb een laptop met de volgende SMART-waarden:
(ja, een foto en geen screenshot, de laptop is niet van mij en dit was even de snelste manier)

Eigenaar van de laptop heeft daadwerkelijk last van dit probleem. Windows is gevoelsmatig langzaam, zelfs voor een HDD, en er verdwijnen blijkbaar gegevens van de schijf.
Na een beetje bijgelezen te hebben begrijp ik dat een goeie format dit probleem zou verhelpen. Nadeel is dat dit de C schijf is, dus dat wordt Windows opnieuw installeren.
Is er binnen Windows zelf ook een mogelijkheid om de pending sectors etc. weer naar 0 te brengen?
Ik weet dat de beste optie gewoon is om een verse SSD erin te gooien, maar dat kost -helaas- geld.
Wat extra informatie: Windows is traag omdat hij 100% disk usage heeft (surprise,surprise). Wat me opviel toen ik de laptop in handen had is dat hij erg veel met de shadow copy bezig is.
Ik heb een laptop met de volgende SMART-waarden:
(ja, een foto en geen screenshot, de laptop is niet van mij en dit was even de snelste manier)
Eigenaar van de laptop heeft daadwerkelijk last van dit probleem. Windows is gevoelsmatig langzaam, zelfs voor een HDD, en er verdwijnen blijkbaar gegevens van de schijf.
Na een beetje bijgelezen te hebben begrijp ik dat een goeie format dit probleem zou verhelpen. Nadeel is dat dit de C schijf is, dus dat wordt Windows opnieuw installeren.
Is er binnen Windows zelf ook een mogelijkheid om de pending sectors etc. weer naar 0 te brengen?
Ik weet dat de beste optie gewoon is om een verse SSD erin te gooien, maar dat kost -helaas- geld.
Wat extra informatie: Windows is traag omdat hij 100% disk usage heeft (surprise,surprise). Wat me opviel toen ik de laptop in handen had is dat hij erg veel met de shadow copy bezig is.
[ Voor 12% gewijzigd door Nat-Water op 29-07-2016 14:35 ]
Balls have got to be one of the oldest toys. They've been round for a long time.
Gloria patri furnituribus In nomine IKEA!
- DoingK
- Registratie: Juli 2003
- Laatst online: 31-08-2024
i just wanna be friends.......
:strip_icc():strip_exif()/u/88827/GoT.jpg?f=community)
Naar aanleiding van problemen met een hangende schijf werd geadviseerd om hier een SMART screenshot te plaatsen voor analyse, graag hoor ik dan ook of er iets mis is met mijn schijf of dat het toch software is.
Meer informatie vind je in het topic:
Harddisk 'hangt' soms na Windows anniversary update
CrystalDiskInfo:

Meer informatie vind je in het topic:
Harddisk 'hangt' soms na Windows anniversary update
CrystalDiskInfo:
Je gebruikt denk ik spindown. Daardoor is het aantal start-stop-cycli erg hoog (1402) en tijdens het opspinnen hangt al je I/O. Dus dat is aardig conform de symptonen die je noemt:
Verder heb je één kabelfout (UDMA CRC Error) maar dat mag geen naam hebben.
Kortom, ik zie niet dat er iets mis is met je schijf; enkel dat je veel start-stop cycli hebt.
Behalve dan dat het geen 30 seconden hoort te duren maar minder dan 10 seconden. Het kan ook zijn dat er iets met de stroomvoorziening is. Echter, ik zie slechts 55 keer een power-off retract, waarbij de leesknop automatisch wordt geparkeerd wanneer de hardeschijf onverwacht stroom verliest. Zolang deze waarde niet sterk oploopt mag dat je probleem van 30 seconden hangende I/O niet veroorzaken.Wanneer de schijf blijft hangen zie ik bij taakbeheer>prestaties dat de harde schijf voor 100% actief is met een lees en schrijf snelheid van 0,0. Na ongeveer 30 seconden gaat alles weer verder waar het gebleven was.
Verder heb je één kabelfout (UDMA CRC Error) maar dat mag geen naam hebben.
Kortom, ik zie niet dat er iets mis is met je schijf; enkel dat je veel start-stop cycli hebt.
- DoingK
- Registratie: Juli 2003
- Laatst online: 31-08-2024
i just wanna be friends.......
Bij de energie instellingen staat het al ingesteld dat de harde schijf nooit uit gaat, dat zou spindown moeten voorkomen toch?Verwijderd schreef op zaterdag 06 augustus 2016 @ 17:53:
Je gebruikt denk ik spindown. Daardoor is het aantal start-stop-cycli erg hoog (1402) en tijdens het opspinnen hangt al je I/O. Dus dat is aardig conform de symptonen die je noemt:
[...]
Behalve dan dat het geen 30 seconden hoort te duren maar minder dan 10 seconden. Het kan ook zijn dat er iets met de stroomvoorziening is. Echter, ik zie slechts 55 keer een power-off retract, waarbij de leesknop automatisch wordt geparkeerd wanneer de hardeschijf onverwacht stroom verliest. Zolang deze waarde niet sterk oploopt mag dat je probleem van 30 seconden hangende I/O niet veroorzaken.
Verder heb je één kabelfout (UDMA CRC Error) maar dat mag geen naam hebben.
Kortom, ik zie niet dat er iets mis is met je schijf; enkel dat je veel start-stop cycli hebt.
Verder is de power loss te wijten aan een probleem wat ik enige tijd geleden had, waarbij mijn toetsenbord en muis na het opstarten niet werkten. Hierdoor heb ik vele malen een harde reset moeten uitvoeren omdat ik zonder toetsenbord niet kan aanmelden. Dit probleem is overigens opgelost maar ik vermoed dat daar die power fails van komen.
- hcQd
- Registratie: September 2009
- Laatst online: 02-07 20:30
De power-cycle-count is ook 1402, het lijkt me niet dat de drive tussendoor de schijf stillegt.Verwijderd schreef op zaterdag 06 augustus 2016 @ 17:53:
Je gebruikt denk ik spindown. Daardoor is het aantal start-stop-cycli erg hoog (1402)
- artie16
- Registratie: Augustus 2007
- Laatst online: 01-07 17:14
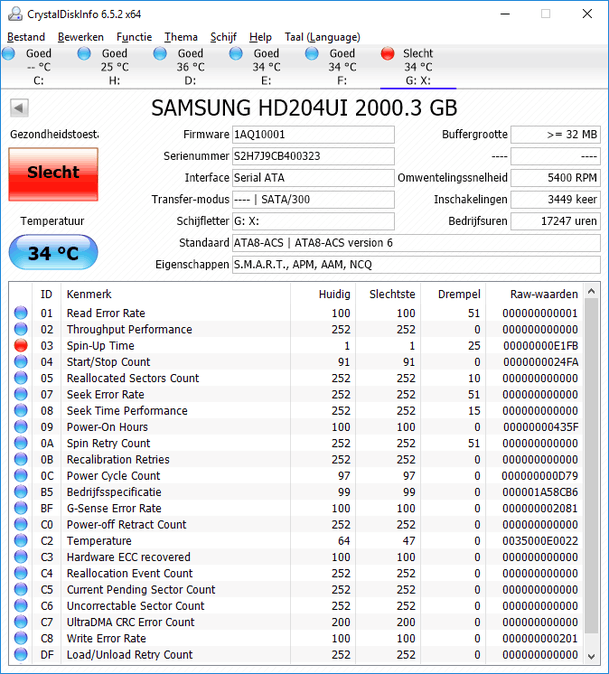
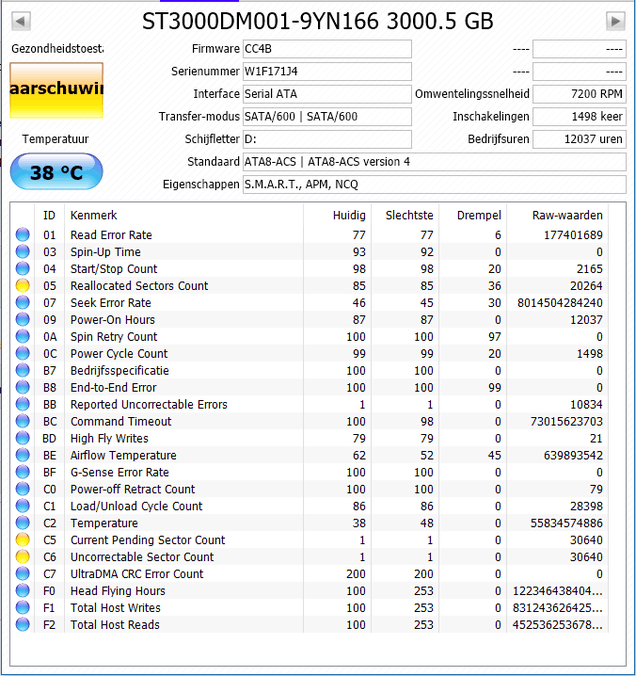
Ik denk dat een van mijn schijven het gaat begeven. De schijf hangt vaak en als ik dan in taskmanager kijk is de schijf 100% actief.
CrystalDiskInfo geeft ook een waarschuwing:
Ik had ook al CHKDSK gedraaid overnacht
En daar krijg ik de volgende meldingen:
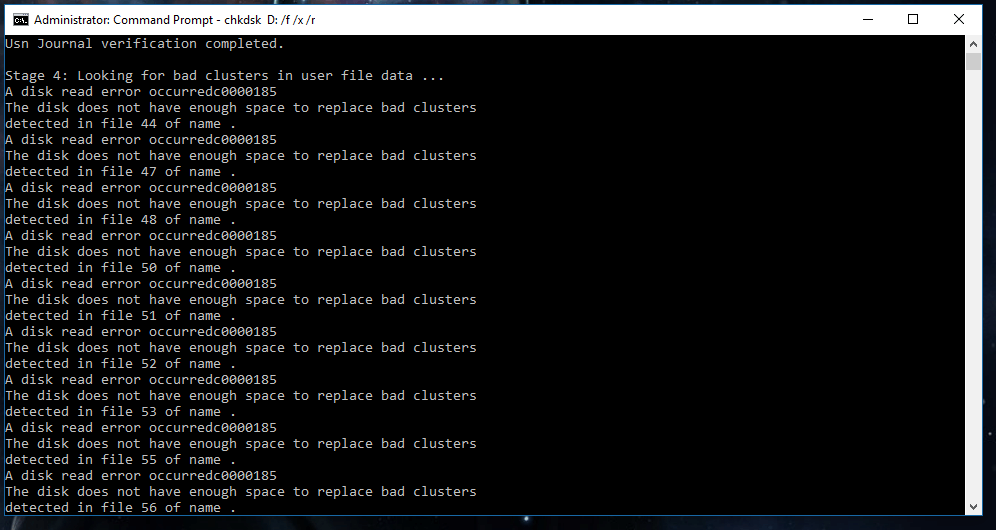
Nu heb ik al een nieuwe schijf gekocht en die komt vanmiddag binnen. Mij vraag is wat is de beste manier om de data van mijn oude schijf naar mijn nieuwe schijf over te zetten?
CrystalDiskInfo geeft ook een waarschuwing:
Ik had ook al CHKDSK gedraaid overnacht
chkdsk D: /f /r /x
En daar krijg ik de volgende meldingen:
Nu heb ik al een nieuwe schijf gekocht en die komt vanmiddag binnen. Mij vraag is wat is de beste manier om de data van mijn oude schijf naar mijn nieuwe schijf over te zetten?
Dat zijn wel heel erg veel bad sectors. Sowieso ga je niet alle data terug krijgen. Heb je ergens een backup van of helemaal niet ? Je kan kijken wat je over kan zetten door gewoon data over te zetten naar de nieuwe schijf. Anders kan GetDataBack misschien nog wat voor je doen.artie16 schreef op zaterdag 13 augustus 2016 @ 09:22:
Ik denk dat een van mijn schijven het gaat begeven. De schijf hangt vaak en als ik dan in taskmanager kijk is de schijf 100% actief.
CrystalDiskInfo geeft ook een waarschuwing:
[afbeelding]
Ik had ook al CHKDSK gedraaid overnacht
chkdsk D: /f /r /x
En daar krijg ik de volgende meldingen:
[afbeelding]
Nu heb ik al een nieuwe schijf gekocht en die komt vanmiddag binnen. Mij vraag is wat is de beste manier om de data van mijn oude schijf naar mijn nieuwe schijf over te zetten?
- artie16
- Registratie: Augustus 2007
- Laatst online: 01-07 17:14
Helaas heb ik geen back-up van de schijf. Is het dan beter om per map naar de nieuwe schijf te kopieren, zodat ik meer inzicht heb waar het mis gaat of alles in een keer?PilatuS schreef op zaterdag 13 augustus 2016 @ 14:01:
[...]
Dat zijn wel heel erg veel bad sectors. Sowieso ga je niet alle data terug krijgen. Heb je ergens een backup van of helemaal niet ? Je kan kijken wat je over kan zetten door gewoon data over te zetten naar de nieuwe schijf. Anders kan GetDataBack misschien nog wat voor je doen.
Ik zou losse bestanden doen. Sowieso hoe groter het bestand hoe groter de kans dat het niet goed gaat. Dingen als onbelangrijke films zou ik lekker laten zitten. Begin met de belangrijke bestanden en daarna kijken wat er nog meer te redden valt.artie16 schreef op zaterdag 13 augustus 2016 @ 14:33:
[...]
Helaas heb ik geen back-up van de schijf. Is het dan beter om per map naar de nieuwe schijf te kopieren, zodat ik meer inzicht heb waar het mis gaat of alles in een keer?
20 of 100 pending bad sectors is nog niet zo heel erg, meer dan 30.000 is wel een groot probleem.
- artie16
- Registratie: Augustus 2007
- Laatst online: 01-07 17:14
Het zijn voornamelijk series dus zo super belangrijk is het niet. In ieder geval bedankt voor de hulp!PilatuS schreef op zaterdag 13 augustus 2016 @ 14:40:
[...]
Ik zou losse bestanden doen. Sowieso hoe groter het bestand hoe groter de kans dat het niet goed gaat. Dingen als onbelangrijke films zou ik lekker laten zitten. Begin met de belangrijke bestanden en daarna kijken wat er nog meer te redden valt.
20 of 100 pending bad sectors is nog niet zo heel erg, meer dan 30.000 is wel een groot probleem.
Dat scheelt weer. Tip voor de volgende keer, even los van een backup maken, hou de SMART in de gaten. Deze schijf heeft waarschijnlijk al maanden bad sectors en het worden er steeds meer. Door 1x per week of maand naar de SMART te kijken zie je dit aankomen en kan je alles optijd redden.artie16 schreef op zaterdag 13 augustus 2016 @ 15:29:
[...]
Het zijn voornamelijk series dus zo super belangrijk is het niet. In ieder geval bedankt voor de hulp!
Wat kan ik hier nog aan doen?
Wat ik niet snap is dat de CPS niet worden vervangen, ik ben al daaagen een badblock -wsv scan aan het laten lopen incl. op voorhand enkel SMART long tests...
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| === START OF INFORMATION SECTION === Model Family: Seagate Desktop HDD.15 Device Model: ST4000DM000-1F2168 Serial Number: W300HXBH LU WWN Device Id: 5 000c50 069c37ab5 Firmware Version: CC52 User Capacity: 4,000,787,030,016 bytes [4.00 TB] Sector Sizes: 512 bytes logical, 4096 bytes physical Rotation Rate: 5900 rpm Form Factor: 3.5 inches Device is: In smartctl database [for details use: -P show] ATA Version is: ATA8-ACS T13/1699-D revision 4 SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s) Local Time is: Sat Aug 13 19:34:25 2016 CEST SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 117 074 006 Pre-fail Always - 146970904 3 Spin_Up_Time 0x0003 092 091 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 140 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 072 060 030 Pre-fail Always - 60408004466 9 Power_On_Hours 0x0032 071 071 000 Old_age Always - 25682 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 75 183 Runtime_Bad_Block 0x0032 098 098 000 Old_age Always - 2 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 001 001 000 Old_age Always - 19718 188 Command_Timeout 0x0032 100 088 000 Old_age Always - 5 5 29 189 High_Fly_Writes 0x003a 094 094 000 Old_age Always - 6 190 Airflow_Temperature_Cel 0x0022 060 046 045 Old_age Always - 40 (Min/Max 33/42) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 54 193 Load_Cycle_Count 0x0032 080 080 000 Old_age Always - 40173 194 Temperature_Celsius 0x0022 040 054 000 Old_age Always - 40 (0 16 0 0 0) 197 Current_Pending_Sector 0x0012 001 001 000 Old_age Always - 31760 198 Offline_Uncorrectable 0x0010 001 001 000 Old_age Offline - 31760 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 2 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 25105h+32m+11.096s 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 82620153746 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 385882815281 |
Wat ik niet snap is dat de CPS niet worden vervangen, ik ben al daaagen een badblock -wsv scan aan het laten lopen incl. op voorhand enkel SMART long tests...
- Deze advertentie is geblokkeerd door Pi-Hole -
Ik ben erg benieuwd naar hoe het met mijn schijf staat, ik ervaar geen problemen met de schijf maar de NAS geeft bij disk 1 bij: "Telling herverbinding schijf: 1" aan, ik weet niet wat het precies zegt maar merk er nu nog niks van.
Disk 2 heb ik helemaal geen problemen mee maar toch wel benieuwd of er toch iets mis mee is en ik op bepaalde dingen moet gaan letten.
Disk 1:

Disk 2:

Ook al staat er bij alles de status: "OK" kun je dit niet altijd 100% vertrouwen neem ik aan? Of zolang er niks staat is de schijf gewoon 100% in orde?
Disk 2 heb ik helemaal geen problemen mee maar toch wel benieuwd of er toch iets mis mee is en ik op bepaalde dingen moet gaan letten.
Disk 1:
Disk 2:
Ook al staat er bij alles de status: "OK" kun je dit niet altijd 100% vertrouwen neem ik aan? Of zolang er niks staat is de schijf gewoon 100% in orde?
Nee, dat "OK" zegt bijzonder weinig. Dit is de officiële SMART failure threshold, in jouw screenshot 'Drempel' genoemd. Als de 'Waarde' (value) lager komt dan de 'Drempel' (threshold) dan geldt dat attribuut als FAILED en dus niet 'OK'.
Maar je attribuut kan dus prima 'OK' zijn terwijl je hardeschijf grote problemen heeft. Sterker nog, veel van de attributen hebben 000 als drempel, wat betekent dat ze altijd 'OK' zullen zijn omdat 'Waarde' nooit negatief kan worden en dus ook nooit lager dan 0.
Zie ook de posts onder de startpost voor meer informatie over hoe SMART werkt. Jouw twee schijven zijn verder prima; disk1 heeft één keer een kabelfoutje gehad, mag geen naam hebben.
Maar je attribuut kan dus prima 'OK' zijn terwijl je hardeschijf grote problemen heeft. Sterker nog, veel van de attributen hebben 000 als drempel, wat betekent dat ze altijd 'OK' zullen zijn omdat 'Waarde' nooit negatief kan worden en dus ook nooit lager dan 0.
Zie ook de posts onder de startpost voor meer informatie over hoe SMART werkt. Jouw twee schijven zijn verder prima; disk1 heeft één keer een kabelfoutje gehad, mag geen naam hebben.
- wannez1
- Registratie: Januari 2014
- Laatst online: 20-01-2025
Pas geleden kon ik mijn harde E; schijf in niet in en gaf windows hem ook niet weer.
Ik weet niet zeker of ik ook niet in de D; schijf kon. Dit zijn beide oudere Samsung schijven en windows 8.1 staat op SSD schijf.
Helaas had ik al CHKDSK gedaan voor ik deze topic vond


Ik weet niet zeker of ik ook niet in de D; schijf kon. Dit zijn beide oudere Samsung schijven en windows 8.1 staat op SSD schijf.
Helaas had ik al CHKDSK gedaan voor ik deze topic vond
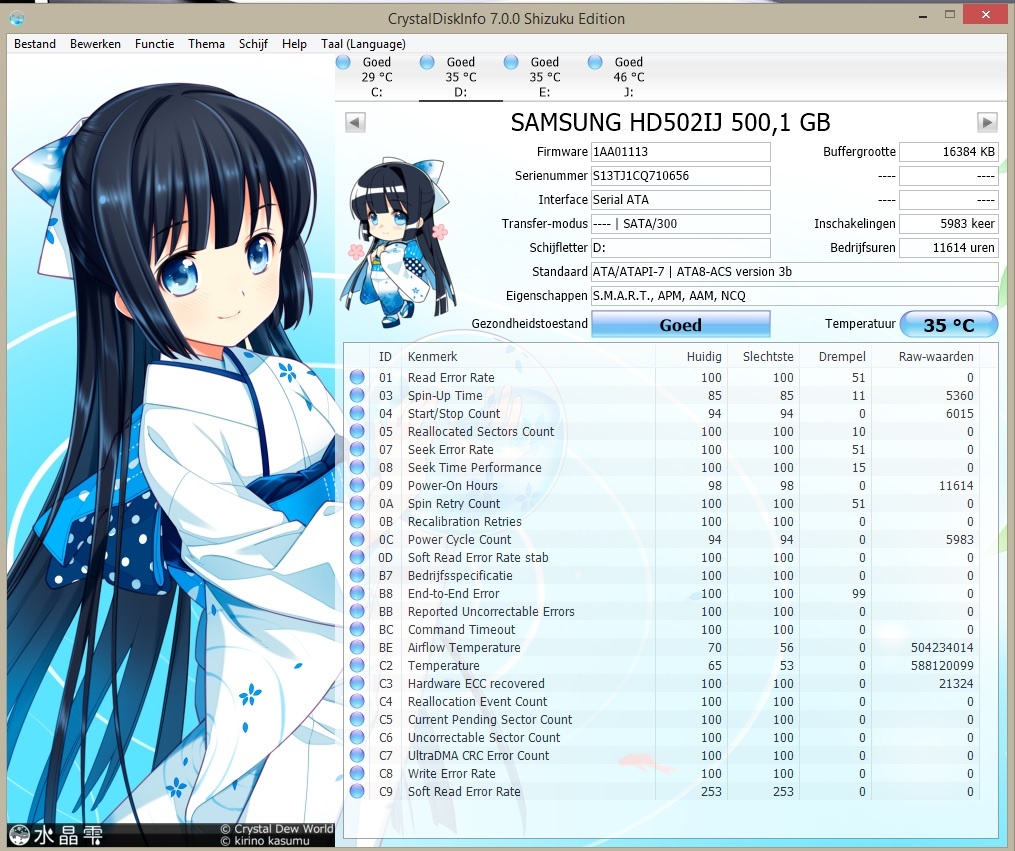
- dcm360
- Registratie: December 2006
- Niet online
UltraDMA CRC Error Count is bij jouw bovenste schijf wel erg hoog. Meestal komt dit doordat de SATA-kabel niet goed is of niet goed is aangesloten. Controleren of de kabel goed vast zit of anders de kabel vervangen lost problemen hiermee vaak op.
- JeroenFM
- Registratie: September 2005
- Laatst online: 02-07 19:59
Gisteravond liep mijn Windows install volledig vast, en sindsdien start hij niet meer op met een melding dat hij de boot sector (of iets in die trant, weet de exacte error niet meer) niet kan vinden. Nu heb ik op ditzelfde systeem (op een andere drive) ook Linux geïnstalleerd, en daar met smartctl even de SMART van de Windows schijf uitgelezen:
Nu lijkt het mij (gezien het feit dat Windows zichzelf van kant gemaakt heeft) dat de SSD aan zijn einde is (dingetje is ook al iets van 5 of 6 jaar oud), maar wellicht kunnen jullie op basis van deze SMART properties meer zeggen.
Die Retired_Block_Count ziet er niet goed uit toch?
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-- 118 106 050 - 0/176831437
5 Retired_Block_Count PO--CK 074 074 003 - 6720
9 Power_On_Hours_and_Msec -O--CK 100 100 000 - 4953h+07m+32.140s
12 Power_Cycle_Count -O--CK 099 099 000 - 1609
171 Program_Fail_Count ------ 000 000 000 - 0
172 Erase_Fail_Count ------ 000 000 000 - 0
174 Unexpect_Power_Loss_Ct ----CK 000 000 000 - 24
177 Wear_Range_Delta ------ 000 000 --- - 0
181 Program_Fail_Count ------ 000 000 000 - 0
182 Erase_Fail_Count ------ 000 000 000 - 0
187 Reported_Uncorrect -O--CK 100 100 000 - 0
194 Temperature_Celsius -O---K 029 037 000 - 29 (Min/Max 0/37)
195 ECC_Uncorr_Error_Count --SRC- 118 106 000 - 0/176831437
196 Reallocated_Event_Count PO--CK 100 100 003 - 0
231 SSD_Life_Left PO--C- 062 062 010 - 1
233 SandForce_Internal ------ 000 000 000 - 1536
234 SandForce_Internal ------ 000 000 000 - 2048
241 Lifetime_Writes_GiB -O--CK 000 000 000 - 2048
242 Lifetime_Reads_GiB -O--CK 000 000 000 - 5184
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning |
Nu lijkt het mij (gezien het feit dat Windows zichzelf van kant gemaakt heeft) dat de SSD aan zijn einde is (dingetje is ook al iets van 5 of 6 jaar oud), maar wellicht kunnen jullie op basis van deze SMART properties meer zeggen.
Die Retired_Block_Count ziet er niet goed uit toch?
[ Voor 21% gewijzigd door JeroenFM op 19-08-2016 14:33 ]
- SmiGueL
- Registratie: September 2005
- Laatst online: 02-07 22:47
:strip_exif()/u/154471/crop5e09176a82484.gif?f=community)
Ik kwam er afgelopen vrijdag achter dat het LEZEN van de serverschijf op ons bedrijf extreem traag ging (800 kB/s), terwijl het schrijven nog met de volle 110+ MB/s gaat (Gbit LAN snelheid)
Getest vanaf meerdere pc's, en vanaf meerdere mappen, maar het probleem leek toch echt bij de server te liggen.
Een CrystalDiskMark zit (uiteraard sequentieel) zowel qua read als write op 150+ MB/s, waardoor de schijf in dat opzicht het probleem niet leek.
Totdat ik zojuist de SMART data er even bij haalde, en ik denk dat het probleem wel is gevonden.
Bij openen SMART data:
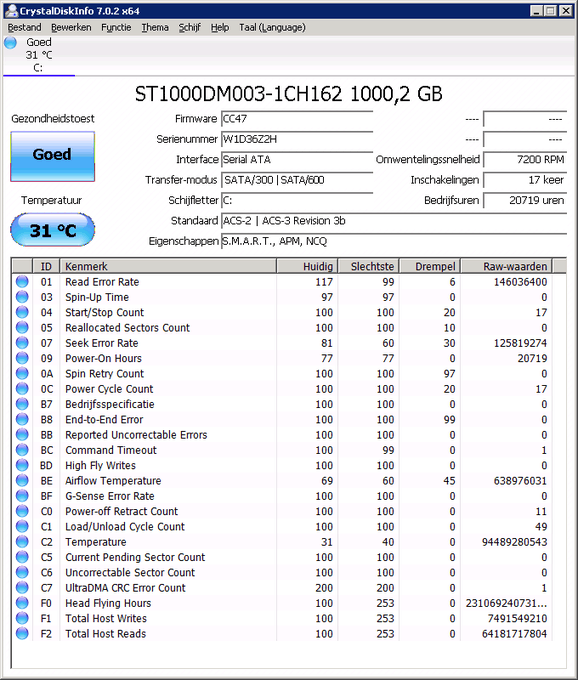
SMART data 5 minuten later:
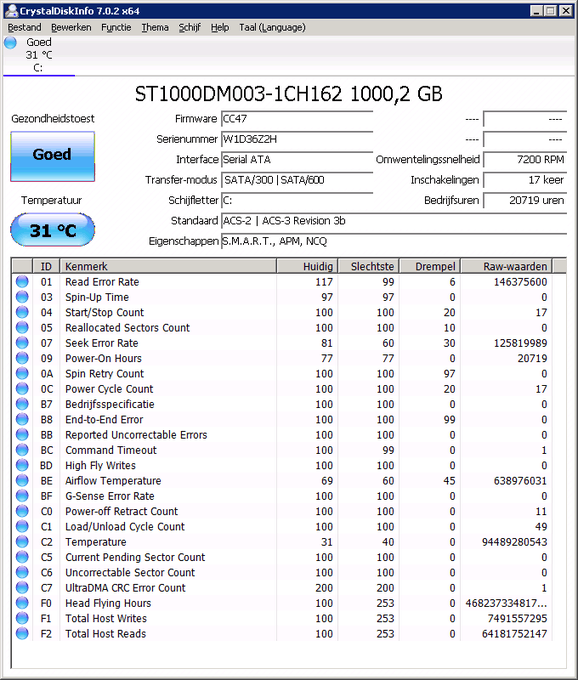
Extreme groei van de Read Error Rate en Seek Error Rate dus.
Deze maar z.s.m. vervangen? (Zal me hier morgen even wat inlezen, maar gok toch wel dat ik het bij de HDD moet zoeken i.p.v. een netwerkinstelling)
(Zal me hier morgen even wat inlezen, maar gok toch wel dat ik het bij de HDD moet zoeken i.p.v. een netwerkinstelling)
De Current Pending Sector Count en/of Reallocated Sector Count blijven overigens keurig op 0 staan, dus twijfel of dit het wel is..
Getest vanaf meerdere pc's, en vanaf meerdere mappen, maar het probleem leek toch echt bij de server te liggen.
Een CrystalDiskMark zit (uiteraard sequentieel) zowel qua read als write op 150+ MB/s, waardoor de schijf in dat opzicht het probleem niet leek.
Totdat ik zojuist de SMART data er even bij haalde, en ik denk dat het probleem wel is gevonden.
Bij openen SMART data:
SMART data 5 minuten later:
Extreme groei van de Read Error Rate en Seek Error Rate dus.
Deze maar z.s.m. vervangen?
De Current Pending Sector Count en/of Reallocated Sector Count blijven overigens keurig op 0 staan, dus twijfel of dit het wel is..
[ Voor 7% gewijzigd door SmiGueL op 22-08-2016 10:58 ]
Delidded 4770K 4.7GHz @ H220 || Gigabyte Z87X-UD4H || 16GB @ 2400MHz || Gigabyte GTX 760 || 2x128GB Samsung 830 @ RAID-0 & WD 3 TB || Iiyama XB2483HSU-B1 || Synology DS916+ 3x6TB + 120GB SSD Cache || Synology DS213+ 6TB backup
- Reepje
- Registratie: Juni 2010
- Niet online
De aanduiding is rate, dus niet number. Dus niet Seek error number, maar seek error rate. Het is een verhoudingsgetal, en dat kan je beter in HEX afbeelden omdat het een verhouding is van 2 getallen variabelen: geen fouten, dan zijn de eerste 5 nullen (de eerste 16 bits), daarachter staan dan de seeks.
Je zal dus even in hex moeten kijken, niet naar raw values.
Je zal dus even in hex moeten kijken, niet naar raw values.
- SmiGueL
- Registratie: September 2005
- Laatst online: 02-07 22:47
Thanks, was wat laat om dat zo snel uit te zoeken, maar de schijf lijkt dan dus niet het probleem te zijn.Reepje schreef op maandag 22 augustus 2016 @ 09:44:
De aanduiding is rate, dus niet number. Dus niet Seek error number, maar seek error rate. Het is een verhoudingsgetal, en dat kan je beter in HEX afbeelden omdat het een verhouding is van 2 getallen variabelen: geen fouten, dan zijn de eerste 5 nullen (de eerste 16 bits), daarachter staan dan de seeks.
Je zal dus even in hex moeten kijken, niet naar raw values.
De HDD zelf is toch wel het eerste waar je aan denkt gezien de read performance zeer slecht is en toevallig ook de read error teller vrij hard oploopt
Waarom proppen ze die 2 getallen in 1 HEX waarde i.p.v. er gewoon 2 losse getallen van maken, dat maakt het toch veel overzichtelijker.
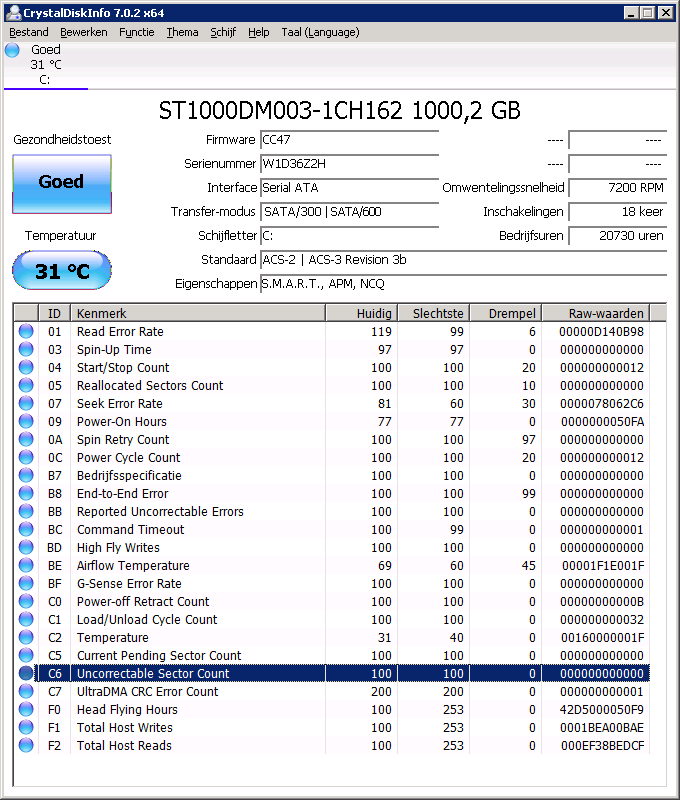
Nu uitzoeken wat het wel is.
[ Voor 21% gewijzigd door SmiGueL op 22-08-2016 13:21 ]
Delidded 4770K 4.7GHz @ H220 || Gigabyte Z87X-UD4H || 16GB @ 2400MHz || Gigabyte GTX 760 || 2x128GB Samsung 830 @ RAID-0 & WD 3 TB || Iiyama XB2483HSU-B1 || Synology DS916+ 3x6TB + 120GB SSD Cache || Synology DS213+ 6TB backup
- revengeyo
- Registratie: December 2007
- Laatst online: 01-07 04:04
:strip_exif()/u/246532/crop6218d2843a5de_cropped.gif?f=community)
Kan iemand mij vertellen of dit resultaat erg is?
Ik heb een CHCKDSK /R gedaan vanwege blauwe schermen, en na enkele uren was hij klaar.
Daarna Crystal Disk uitgevoerd en dit is het resultaat:

Ik heb een CHCKDSK /R gedaan vanwege blauwe schermen, en na enkele uren was hij klaar.
Daarna Crystal Disk uitgevoerd en dit is het resultaat:
- Patrick_6369
- Registratie: April 2010
- Laatst online: 29-06 11:56
:strip_icc():strip_exif()/u/353533/crop5e78bebddb940_cropped.jpeg?f=community)
Een gelijksoortig rapport als mijn voorganger (zelfde vakje is geel), alleen beetje warmer Het probleem met mijn harde schijf (de secundaire waar mijn data op staan) is dat hij soms wegvalt, met name als mijn computer zware bewerkingen uitvoert zoals films recoderen naar DVD. Hij is ook al 5 jaar oud. Zouden het vele reallocated sectors zijn?
Hieronder de toestand van de schijf terwijl ik de schijf backup naar mijn externe harddrive. Zou de temperatuur de oorzaak kunnen zijn? En is het dan de HDD die het probleem is, of de rest van de laptop? De Dell Studio 1749 staat er om bekend dat hij nogal warm wordt.

Hieronder de toestand van de schijf terwijl ik de schijf backup naar mijn externe harddrive. Zou de temperatuur de oorzaak kunnen zijn? En is het dan de HDD die het probleem is, of de rest van de laptop? De Dell Studio 1749 staat er om bekend dat hij nogal warm wordt.
Hier zou een handtekening kunnen staan.
@revengeyo, ja met 653 omgewisselde sectoren heeft jouw schijf best wat schade, en dien je hem op zijn best als minder betrouwbaar te beschouwen. Vervangen indien je garantie hebt. Je kunt de schijf alleen gebruiken voor minder belangrijke dingen of data waar je echt goede up-to-date backups van hebt.
@Patrick_6369, je schijf is te warm geweest daarom zie je een rood bolletje. Daarnaast heb je 23 omgewisselde sectoren, iets om in de gaten te houden, dit mag niet teveel stijgen. Daarnaast moet je echt wat doen aan de temperatuur, want dit is te hoog. Je schijf is zelfs 69 graden geweest in het verleden. Dat zijn vrij extreme waarden. Juist mechanische hardeschijven wil je op een continu middelmatige temperatuur houden die niet te sterk fluctueert. Als je de schijf uitschakelt en hij afkoelt, geeft dit te veel temperatuurschommeling als de schijf enorm heet was. Dit zorgt voor metaaluitzetting en -krimping wat mogelijk kan bijdragen aan problemen en voortijdig uitval.
Kortom, zorg goed voor je schijfje.
@Patrick_6369, je schijf is te warm geweest daarom zie je een rood bolletje. Daarnaast heb je 23 omgewisselde sectoren, iets om in de gaten te houden, dit mag niet teveel stijgen. Daarnaast moet je echt wat doen aan de temperatuur, want dit is te hoog. Je schijf is zelfs 69 graden geweest in het verleden. Dat zijn vrij extreme waarden. Juist mechanische hardeschijven wil je op een continu middelmatige temperatuur houden die niet te sterk fluctueert. Als je de schijf uitschakelt en hij afkoelt, geeft dit te veel temperatuurschommeling als de schijf enorm heet was. Dit zorgt voor metaaluitzetting en -krimping wat mogelijk kan bijdragen aan problemen en voortijdig uitval.
Kortom, zorg goed voor je schijfje.
Verwijderd
Zojuist is mijn server vast gelopen en ik ben bang dat 1 van mijn drives de oorzaak was, na een reset lijkt alles weet te werken, aangezien ik dit topic al een tijdje volg, gewoon mooi om te zien hoe sommige drives het uit houden, toch maar even mijn eigen drives plaatsen.
De drives staan in RAID, maar draaien 24/7 voor camera opnames (beveiliging), drives moeten dus goed 100% goed zijn, in de tijd voor "WD Purple" gekozen omdat eeeh... tja?
Terwijl ik dit aan het typen ben schoot "reallocated sectors count" van 4 naar 5, kan ik er vanuit gaan dat deze drives aan het overlijden is?


Graag advies of ik de drive moet vervangen voor een vers exemplaar.
De drives staan in RAID, maar draaien 24/7 voor camera opnames (beveiliging), drives moeten dus goed 100% goed zijn, in de tijd voor "WD Purple" gekozen omdat eeeh... tja?
Terwijl ik dit aan het typen ben schoot "reallocated sectors count" van 4 naar 5, kan ik er vanuit gaan dat deze drives aan het overlijden is?
Graag advies of ik de drive moet vervangen voor een vers exemplaar.
5 weggeschreven slechte sectoren is niet echt een probleem bij een 4TB HDD. Even in de gaten houden of er niet snel weer nieuwe bijkomen is genoeg. Van 4 naar 5 stelt ook niet echt wat voor. Zodra het van 40 naar 50 gaat in korte tijd is het een ander verhaal.
- Falcon Heavy
- Registratie: Juli 2003
- Laatst online: 09:09
:strip_icc():strip_exif()/u/88171/crop6311d1fd636f2_cropped.jpg?f=community)
Vorige week een RAID5 degraded DISC2 was niet goed, bij het rebuilden DISC1 die eruit vloog. Complete RAID verdwenen hierdoor.
Nu heb ik mijn RAID gelukkig terug op 3 nieuwe schijven met dank aan de THECUS support afdeling , WD RED in dit geval maar gekozen.
Ik vraag me alleen af of mijn oude schijven nog bruikbaar zijn:
[EDIT]
Nieuwe HDD 2 geeft nu ook error. Zie DISC4 onder aan deze pagina.
Disc 1

Disc 2

Disc 3

[EDIT]
Ik heb een nieuwe HDD in mijn RAID systeem zitten, na het backuppen van deze data gaf deze ook een RAID error. Zie onderstaande screenshot
Disc 4

Nu heb ik mijn RAID gelukkig terug op 3 nieuwe schijven met dank aan de THECUS support afdeling
Ik vraag me alleen af of mijn oude schijven nog bruikbaar zijn:
[EDIT]
Nieuwe HDD 2 geeft nu ook error. Zie DISC4 onder aan deze pagina.
Disc 1
Disc 2
Disc 3
[EDIT]
Ik heb een nieuwe HDD in mijn RAID systeem zitten, na het backuppen van deze data gaf deze ook een RAID error. Zie onderstaande screenshot
Disc 4
[ Voor 27% gewijzigd door Falcon Heavy op 04-09-2016 09:28 ]
- Falcon Heavy
- Registratie: Juli 2003
- Laatst online: 09:09
Even een schopje.
Hoop dat iemand antwoord kan geven op mijn SMART status van DISC 1 2 en 4
Hoop dat iemand antwoord kan geven op mijn SMART status van DISC 1 2 en 4
Schijf1: Heeft een lange format nodig om de 32 pending sectors te laten verwdijnen, dan is ie weer te gebruiken.Frank J. schreef op zondag 04 september 2016 @ 09:29:
Even een schopje.
Hoop dat iemand antwoord kan geven op mijn SMART status van DISC 1 2 en 4
Schijf2: Heeft zoveel pending bad sectors dat ie vervangen moet worden.
Schijf4: Zelfde verhaal als schijf 1.
Helaas staat deze serie HDD's er bekend om niet erg betrouwbaar te zijn. Als je een lange format doet en de schijven blijft gebruiken even goed in de gaten houden of er niet snel weer nieuwe slechte secotoren bijkomen. Persoonlijk zou ik ze allemaal vervangen door iets wat betrouwbaarder is. De kans dat het na de lange format goed blijft gaan is helaas denk ik niet erg groot.
[ Voor 10% gewijzigd door PilatuS op 04-09-2016 10:49 ]
- Falcon Heavy
- Registratie: Juli 2003
- Laatst online: 09:09
Ik zal deze eens onderwerpen aan een format en in de gaten houden.
Disc 4 is een nieuwe WD red (1 van de 3 nieuwe schijven waar thecus mijn raid op had hersteld, en ik nu weer kwijt ben) , beter om deze retour te sturen ivm garantie en een nieuwe vragen, of is zelfs de WD red serie niet te vertrouwen?
Disc 4 is een nieuwe WD red (1 van de 3 nieuwe schijven waar thecus mijn raid op had hersteld, en ik nu weer kwijt ben) , beter om deze retour te sturen ivm garantie en een nieuwe vragen, of is zelfs de WD red serie niet te vertrouwen?
[ Voor 30% gewijzigd door Falcon Heavy op 04-09-2016 10:56 ]
1 pending bad sectors is geen probleem en opzich vrij normaal. Na 123 uur is aan de andere kant wel weer heel snel. Ik zou de schijf een volledige format geven en het even in de gaten houden. Mocht er binnen een paar 100 uur weer een nieuwe slechte sector komen zou ik de schijf laten vervangen.Frank J. schreef op zondag 04 september 2016 @ 10:54:
Ik zal deze eens onderwerpen aan een format en in de gaten houden.
Disc 4 is een nieuwe WD red, beter om deze retour te sturen ivm garantie en een nieuwe vragen?
- Falcon Heavy
- Registratie: Juli 2003
- Laatst online: 09:09
Ok.
Vervelende is dat de WD dus een degraded versie van mijn raid draaiden (thecus support had dit gefixt voor me) om alle data eerst te back-uppen. Nu is mijn 2e degraded raid dus damaged tijdens back-uppen haha
Vervelende is dat de WD dus een degraded versie van mijn raid draaiden (thecus support had dit gefixt voor me) om alle data eerst te back-uppen. Nu is mijn 2e degraded raid dus damaged tijdens back-uppen haha
Probleem: hangende laptop, sloom, crashes
Verdenking: HDD
SMART uitlees: alles in de clear behalve Current Pending Sector count deze is volgens de RAW 58.
Vraag: Laptop is slechts 4 maanden oud. Kan dit? Anders breng ik deze gewoon terug.
Kan nu geen screentje plaatsen want ding is bezig herinstallatie maar goed
Verdenking: HDD
SMART uitlees: alles in de clear behalve Current Pending Sector count deze is volgens de RAW 58.
Vraag: Laptop is slechts 4 maanden oud. Kan dit? Anders breng ik deze gewoon terug.
Kan nu geen screentje plaatsen want ding is bezig herinstallatie maar goed
- Reepje
- Registratie: Juni 2010
- Niet online
Het kan wel, maar het mag niet. Ik zou deze dus terugbrengen.
Dit topic is echt bedoeld om je SMART gegevens te posten. Maar een Current Pending Sector van 58 is zeker niet goed. Als je hardeschijf (of gehele laptop) slechts enkele maanden oud is, lijkt het me goed deze onder garantie om te laten wisselen.
Inmiddels is Windows 10 opnieuw geinstalleerd en de broodnodige dingen zoals AV en drivers:Verwijderd schreef op maandag 05 september 2016 @ 10:30:
Dit topic is echt bedoeld om je SMART gegevens te posten. Maar een Current Pending Sector van 58 is zeker niet goed. Als je hardeschijf (of gehele laptop) slechts enkele maanden oud is, lijkt het me goed deze onder garantie om te laten wisselen.

Je hebt 88 bad sectors, niet 58. Je hebt de weergave niet op decimaal ingesteld zoals in de startpost als tip staat vermeld. Dit betekent dat je moet omrekenen. 0x58 hex komt overeen met 88 dus 88 bad sectors. Dat is best een aantal. Als je garantie hebt zou ik die gebruiken. Met minder dan 1000 draaiuren lijkt me dat wel.
![]() Dit topic is gesloten.
Dit topic is gesloten.
![]()