Nou, ik niet eerlijk gezegd. Een groot deel van je OS en apps zijn statische data en gaan niet snel veranderen. Als daar niet aan gedacht is, dan kunnen fabrikanten geen 3 jaar garantie geven op die dingen.
[...]
Net zoals het voorgaande: geen idee of dat zo is. Jij hebt blijkbaar een bron - waar ik erg nieuwsgierig naar ben - waar dat staat.
Voor mij staat nl. niet vast dat per block of whatever apart een tellertje wordt bijgehouden (bij elke write weer een extra write!). Of dat er een wat grover algorithme werkzaam is. Ik kan meerdere mechanisme bedenken.
Nou ja, het is meer common sense. Ik heb geen bron waar dat letterlijk in staat nee, maar ik heb wel ervaring met het ontwerpen van embedded systems.
Het is aan te nemen dat de controllers een deel van het flash gereserveerd hebben voor het opslaan van tabellen en andere data betreffende de staat van het flash. Als je 80GB flash hebt, kun je best 32MB reserveren voor system data. Dat hoeft dan ook niet gewist te worden bij een firmware flash of full erase. Mocht er geen wear data per block worden bijgehouden (wat ik me wel kan voorstellen, reken maar eens uit hoeveel data dat kost) dan zou je nog altijd de kwaliteit van het flash kunnen meten door de voltage drop te meten per cell in een block. Ik weet niet in hoeverre dat ook te doen is, dat ligt mede aan de flashchips denk ik.
Dat vind ik het irritante aan het hele SSD gebeuren. Hoe het écht precies werkt kan ik niet vinden.
Bijv. waarom het Intel algorithme blijkbaar wel zo slim is om een wipertooltje minder nodig te maken.
Hoe die garbagecollection werkt. Etc, etc.
Er is een pool aan stellingen die regelmatig herhaald worden ("intel heeft minder schrijfperformancedegradatie"). Maar ik wil eigenlijk veel meer de diepte informatie. En die vind ik nergens. Die SSD's zijn nog veel te veel black-box naar mijn zin

Dus diepte-info: ik hou me aanbevolen!
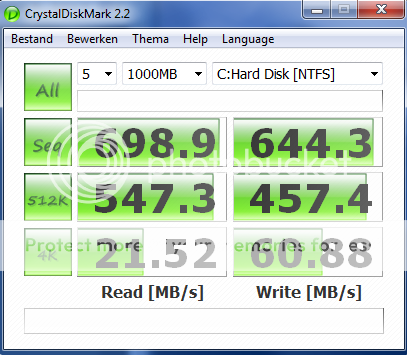
Bij de Vertex valt enige prformance drop meteen op doordat deze geen cap op de sustained write heeft. De Intel MLC's hebben een cap van 70-90MB/s sustained, deze zul je dus ook niet zo snel in zien zakken omdat ze altijd wat achter de hand hebben.
De garbage collector zal waarschijnlijk de schijf aflopen en kijken welke flash blocks maar gedeeltelijk aan LBA adressen gelinkt zijn, en de nog lege pages vullen met data uit andere half gevulde flash blocks. Elke compleet invalid gemarkeerde block is er weer 1 waar full speed naar geschreven kan worden. Omdat er nogal wat flash blocks op een schijf zitten, kan dit proces aardig wat tijd kosten. Er kan vast wel wat gestoeid worden met intelligende algoritmes en de LBA -> flash link tabel om het compleet scrubben van de SSD overbodig te maken.
Als een SSD een aardig stuk flash achter de hand heeft als scratch buffer, dan zal met een goede garbage collector de TRIM functie nagenoeg overbodig zijn. Heb je geen scratch buffer, dan holt de performance achteruit zoveelte voller de schijf is. Dan is TRIM gewoon een must. Elke LBA sector die als leeg gemarkeerd wordt door een TRIM commando is beschikbaar als scratch buffer namelijk.
Intel heeft waarschijnlijk al ver van tevoren aan zien komen dat SSD's op een dag betaalbaar zouden zijn, en het zou me ook niets verbazen als ze een jaar of 4-5 terug al zijn begonnen met de eerste ontwerpen voor wat nu de postville controller is. Daarom verbaast het me niets dat ze een betere garbage collector hebben, dit is iets wat je pas later in het ontwikkelstadium toe voegt. De Barefoot was nog lang niet feature complete toen OCZ ze op de makrt bracht, en dat hebben we allemaal kunnen zien door de datacorruptie verhalen her en der.
Black boxes zullen het altijd wel blijven, het is tenslotte geen open source...
:fill(white):strip_exif()/i/1247037448.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1246967936.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1241185239.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1249459372.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1232614472.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1247650207.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1247650252.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1251113681.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1240403610.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1240403635.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1255338452.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1240403617.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1240403629.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1240941674.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1232524116.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1240941034.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1232523812.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1245668492.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1245670290.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1249973574.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1257766708.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1244112654.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1244101280.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1251358807.jpeg?f=thumbmini)
:strip_exif()/i/1214992167.jpg?f=thumbmini)
:fill(white):strip_exif()/i/1226678888.jpg?f=thumbmini)
:fill(white):strip_exif()/i/1231942259.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1231942188.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1231942054.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1231668863.jpg?f=thumbmini)
:fill(white):strip_exif()/i/1228900016.jpg?f=thumbmini)
:fill(white):strip_exif()/i/1240299435.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1240299352.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/1239184343.jpeg?f=thumbmini)
:strip_icc():strip_exif()/u/199641/albundy23.jpg?f=community)

/u/400/defember100.png?f=community)


:strip_icc():strip_exif()/u/64465/crop5db09addab56c_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/308274/crop6020103c77862_cropped.jpeg?f=community)
:strip_exif()/u/49483/mandarin_sm.gif?f=community)
:strip_icc():strip_exif()/u/97973/crop689da1cf6ac35.jpg?f=community)
:strip_exif()/u/96401/konijntjebovennognogkleiner.gif?f=community)
:strip_icc():strip_exif()/u/184256/QinXava2.jpg?f=community)




/u/4501/crop5bdb35c450e89.png?f=community)
:strip_exif()/u/128173/crop59a1592e54731_cropped.gif?f=community)
:strip_icc():strip_exif()/u/58156/fan54a.jpg?f=community)

:strip_icc():strip_exif()/u/89655/crop598723fb7c8a7_cropped.jpeg?f=community)
/u/246939/pingu.png?f=community)
:strip_icc():strip_exif()/u/102237/jcash.jpg?f=community)
:strip_icc():strip_exif()/u/297796/Cryptum60.jpg?f=community)

:strip_icc():strip_exif()/u/4547/crop60281945ae3f4_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/56984/crop5d55aa406bb59.jpeg?f=community)
:strip_exif()/u/21590/icon4.gif?f=community)

/u/1/femme.png?f=community)
/u/260593/charlie_small.JPG?f=community)

/u/136816/Home.png?f=community)

:strip_icc():strip_exif()/u/145979/7613.jpg?f=community)



:strip_icc():strip_exif()/u/57550/crop6246ebeb6bed3_cropped.jpg?f=community)
/u/33916/crop5d4d5b00c4c16_cropped.png?f=community)
:strip_exif()/u/11443/217096.gif?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}