Verwijderd schreef op woensdag 2 september 2020 @ 19:52:
[...]
DLSS gaat absoluut niet weg, het is gewoon de beste manier van upscalen. Ik zie niet in hoe die kwaliteit ooit gehaald gaat worden zonder neural network. Het enige wat ik zie gebeuren is dat in nieuwere game engines gebouwd gaat worden waardoor elke gpu het getrainde neural network kan draaien. Alleen AMD loopt nogal wat achter als het op AI aankomt. NVIDIA heeft daar gewoon veel te veel ervaring mee ondertussen. Als je met AI werkt, dan werk je met NVIDIA.
Dit klinkt mij heel erg als PhysX is de toekomst van GPU based physics. Was een decennium lang een gimmick totdat het in 2018 eindelijk open source is gemaakt. Of natuurlijk GameWorks dat gelukkig een stille dood gestorven lijkt te zijn. Je kon gewoon een lijst pakken van totale trainwreck games op de PC die totaal niet draaide en die naast de lijst met GameWorks titels leggen. Opvallend vaak waren het dezelfde games.

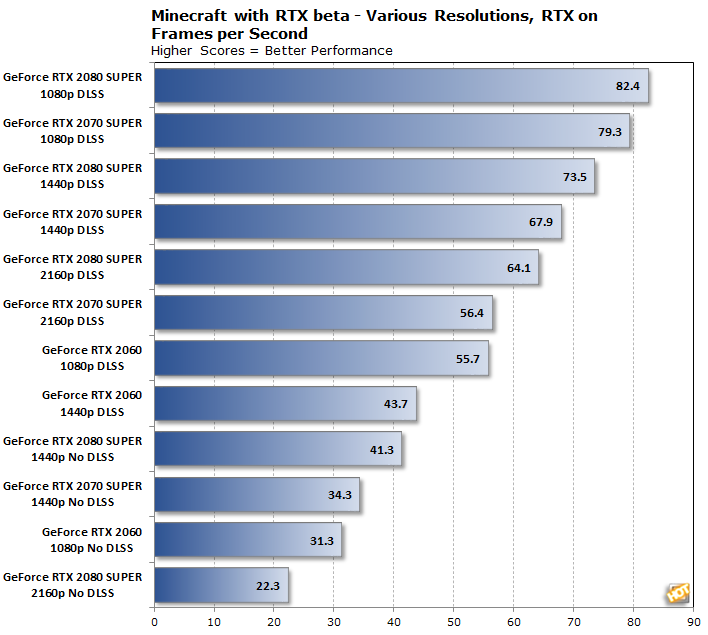
Nu heb je DLSS wat heel leuk is, als de game het überhaupt ondersteunt, totdat je een videokaart hebt die gewoon native de gewenste resolutie kan draaien met een acceptabele framerate. En toen kwam er opeens een lijn met videokaarten die waarschijnlijk ruim 60% sneller zijn dan de voorgaande generatie en waarschijnlijk vrijwel alles gewoon native kan draaien. Waarom heb ik dan precies DLSS nodig in een paar games? Wat is er beter aan dan native resolutie dat voor elke game werkt?
Er zijn ook zeker nieuwe game engines gebouwd de afgelopen tijd. Dat is alleen niet gebeurd omdat Nvidia met DLSS kwam. Nee, dat is gebeurd omdat er nieuwe consoles aan zitten te komen. Consoles die draaien op RDNA2. Dat is namelijk de realiteit in de gaming industrie. Het zijn Sony en al helemaal Microsoft die grotendeels bepalen wat voor software features standaard worden. Die kozen wederom voor AMD hardware met als resultaat dat RDNA2 de standaard gaat zijn de komende jaren. Immers zijn de meeste games gewoon geport van console.
Dennism schreef op woensdag 2 september 2020 @ 19:52:
Dat zou natuurlijk mooi zijn, maar ook iets dat je minimaal mag verwachten. RDNA2's RT moet imho gewoon op het niveau van Ampere liggen (zowel qua performance als support), misschien zelfs hoger. Zoals je zelf al aangeeft heeft AMD in principe alle tools om een beter product neer te zetten, laat ze hopelijk minimaal gelijkwaardig zijn (m.u.v. het Halo product mogelijkerwijs).
AMD moet uiteraard zeker kijken naar de eigen sterktes en daar de features op baseren. Ik bedoel echter meer dat je niet een situatie krijgt waarbij AMD bijvoorbeeld een kaart neerzet gelijk aan de 3080 qua performance en in een zelfde prijsklasse. Maar dat dan alsnog Nvidia veel beter verkoopt juist omdat ze wel DLSS, Die webcam applicatie en andere software foeftjes hebben.
Maar kijk ook bijv. naar een game als Cyberpunk, die vrijwel zeker heel wat kaarten gaat verkopen. Daar moet je gewoon als AMD zijne zorgen dat je kaarten op tijd zijn maar ook dat ze 'toe to toe' kunnen met Nvidia in die game.
Maar ook bijvoorbeeld, meer persoonlijk en lang niet voor iedereen belangrijk, World of Warcraft krijgt ook RT support. Als bijvoorbeeld een AMD daar achterblijft is de kans toch groot dat ik bijvoorbeeld dan voor Nvidia kies, puur omdat dit een game is die ik veel speel en graag in de beste kwaliteit wil draaien (ook al is het een cartoony game en totaal niet realistisch).
Ik ben dan eigenlijk ook niet heel erg onder de indruk van Ampere RT. Quake II RTX was niet eens 100% sneller dan de RTX2080. Dat is dan een volledig pathtraced game, geen shaders. Een purere benchmark ga je waarschijnlijk niet vinden. Maar reken de implicaties door. Turing RTX betekende in de regel een halvering van je framerate. Nu lijkt het erop dat er RT is die in staat is om je frame rate bij te houden, als je een Turing had. Je hebt alleen een Ampere die veel sneller is. Ik verwacht nog steeds dat je zo een kwart van je framerate zal verliezen.
Komt nog eens bij dat zowel de RTX3070 als RTX3080 niet de volle chips zijn en RT op een per SM basis plaatsvind en op een per clock basis. Het helpt simpelweg niet als een flink aantal SM's zijn uitgeschakeld en de clock speed verbetering over Turing ook niet veel is. Ik heb laatst nog uitgetypt wat het zeer waarschijnlijk is, maar dat lijkt compleet ondergesneeuwd te zijn.
DaniëlWW2 in "CJ's AMD Radeon Info & Nieuwsdiscussietopic - Deel 144"
Maar het lijkt erop dat RDNA2 heel veel rays kan casten, ook meer dan Ampere. Als ik zie dat Nvidia 2x ray/triangle intersection claimt en de Titan RTX 11G/sec aan ray triangle intersections kan doen, tja dan denk ik dat zelfs een kleinere Navi 2x hier makkelijk overheen zal gaan. Immers zou de XSX met 52CU's al 95G/sec ray-triangle calculations doen met een relatief lage clockspeed van 1825MHz. Een 80CU Navi 21 op 1825MHz doet dan al 146G/sec en @2000MHz zit je op 160G/sec. Een RTX3080 zal met 2x ten opzichte van Turing, rond de 16G/sec zitten. Het probleem is alleen dat ik bijvoorbeeld al geen idee heb hoe ik de RTX denoising moet inschatten.
Maar de formule voor RDNA2, afgeleid van de XSX haar GPU zou als volgt moeten zijn:
RT is per CU en voor triangles is het 1G/sec x 1825MHz x 52. Dat is dus 94,9G/sec voor de hele chip. Maal vier is dan 379,6G/sec. Zo kom je er dus achter dat het 4G/sec is per CU voor BVH. Je kan ook 379,6G/sec : 52CU en dan gedeeld door 4 doen. Zo kom je op 1825MHz. Of 379,6G/sec : 52CU : 1,825GHz = 4G/sec.
Je rekent immers Gigarays per seconde voor de hele chip om naar Gigarays per clock, per CU.
Omdat het dus maximaal 1G/sec is per CU per clock cycle, is het rekenen vrij makkelijk.

Ik ben opzettelijk zeer voorzichtig met uitspraken over RT. Ik sluit alleen helemaal niks uit.

XWB schreef op woensdag 2 september 2020 @ 21:43:
[...]
Dat efficiëntie argument zie ik wel vaker voorbij komen maar Fury en Vega hebben nooit zoden aan de dijk gezet, ondanks dat deze videokaarten met HBM uitgerust zijn. Ik denk dat HBM erg nuttig kan zijn voor bijvoorbeeld een APU, maar een high-end videokaart loopt wellicht eerder tegen andere bottlenecks aan dan de efficiëntie tussen GDDR6 en HMB2.
HBM heeft Fiji en Vega anders aardig gered van nog veel slechter zijn en nog meer te verbruiken.
Het gaat ook niet om GB/s hier. Het gaat om verbruik wat simpelweg veel lager is met HBM2(E). Dat kan je gebruiken voor een goedkoper PCB of koeloplossing of hogere clock speeds van de GPU zonder dat je de TBP te hoog maakt.

Never argue with an idiot. He will drag you down to his own level and beat you with experience.
:strip_icc():strip_exif()/u/7205/duke3.jpg?f=community)

/u/34200/crop6554f56fe2075_cropped.png?f=community)
/u/331666/crop581e2c93efc13.png?f=community)
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/Cs8Wm6BqCTKNjKUTBKcHA2Zh.jpg?f=user_large)
/u/400/defember100.png?f=community)
/u/324913/crop56a24cce05cd3_cropped.png?f=community)
/u/46804/crop5f989efcbb253.png?f=community)
/u/233413/crop574768220d598_cropped.png?f=community)
:strip_icc():strip_exif()/u/18872/crop643c23a7a7810_cropped.jpg?f=community)
:strip_exif()/f/image/2QCBxguaaJ3mBlV3OSduooRZ.png?f=user_large)
:strip_exif()/u/211274/bestabstractwallpapers5.gif?f=community)
/u/75044/crop5fb7030b0d077.png?f=community)

:strip_icc():strip_exif()/u/86827/sm_3037399.jpg?f=community)
:strip_icc():strip_exif()/u/291146/crop5d31533862205_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/145751/check-in-minion-small2.jpg?f=community)
:strip_icc():strip_exif()/u/5169/sbod.jpg?f=community)
:strip_icc():strip_exif()/u/99201/21.jpg?f=community)

:no_upscale():strip_icc():fill(white):strip_exif()/f/image/tpBRjlHRVE3PU3naxqjWbNDY.jpg?f=user_large)
:no_upscale():strip_icc():fill(white):strip_exif()/f/image/XGdajKjBUM8BAHziVc6EELRe.jpg?f=user_large)

{kind=link}