:strip_exif()/i/2007025992.png?f=thumbmini)
:strip_exif()/i/2004983538.png?f=thumbmini)
:strip_exif()/i/2005553786.png?f=thumbmini)
:fill(white):strip_exif()/i/2005466442.jpeg?f=thumbmini)
:strip_exif()/i/2006261514.webp?f=thumbmini)
:fill(white):strip_exif()/i/2003937722.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/2003937724.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/2003532750.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/2006752498.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/2005322060.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/2006752500.jpeg?f=thumbmini)
:strip_exif()/i/2001936103.png?f=thumbmini)
:fill(white):strip_exif()/i/2001904109.jpeg?f=thumbmini)
:strip_exif()/i/2001936109.png?f=thumbmini)
:fill(white):strip_exif()/i/2004307982.jpeg?f=thumbmini)
:strip_exif()/i/2001766419.png?f=thumbmini)
:strip_exif()/i/2001936107.png?f=thumbmini)
:strip_exif()/i/2001936105.png?f=thumbmini)
:fill(white):strip_exif()/i/2002872184.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/2001429879.jpeg?f=thumbmini)
:strip_exif()/i/2001457441.png?f=thumbmini)
:fill(white):strip_exif()/i/2001415763.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/2002872196.jpeg?f=thumbmini)
:strip_exif()/i/2002209673.png?f=thumbmini)
:fill(white):strip_exif()/i/2001583647.jpeg?f=thumbmini)
:fill(white):strip_exif()/i/2001583645.jpeg?f=thumbmini)
:strip_exif()/i/2001457443.png?f=thumbmini)
:strip_exif()/i/2001469737.png?f=thumbmini)
:strip_icc():strip_exif()/u/109773/ziltoid_fetid_70px.jpg?f=community)
Of:sunsmountain schreef op donderdag 5 januari 2023 @ 21:20:
YouTube: AMD Provides More Ryzen 9 7950X3D Details
2 different CCD's, each has 8 cores.
"...one of the CCD's stacked with extra 64 MB L3 cache. when you playing games, you got all that cache available. When doing something bursty, you want all 5,7 Ghz? You do that on the non-stacked"
Dus:Best slim. 7800X3D zal wel $499 worden, 7900X3D $649 en 7950X3D $799. Gewoon $100 erbij, klaar.
- 7800X3D = 5 GHz max (8 cores) met 64 MB L3 cache
- 7900X3D = 5,6 GHz max (6 cores) èn 5 GHz max (6 cores) met 64 MB L3 cache
- 7950X3D = 5,7 GHz max (8 cores) èn 5 GHz max (8 cores) met 64 MB L3 cache
- 7800X3D = 5 GHz max (8 cores) met 96MB L3 cache
- 7900X3D = 5,6 GHz max (6 cores) 32MB L3 èn 5 GHz max (6 cores) met 96MB L3 cache
- 7950X3D = 5,7 GHz max (8 cores) 32MB L3 èn 5 GHz max (8 cores) met 96MB L3 cache
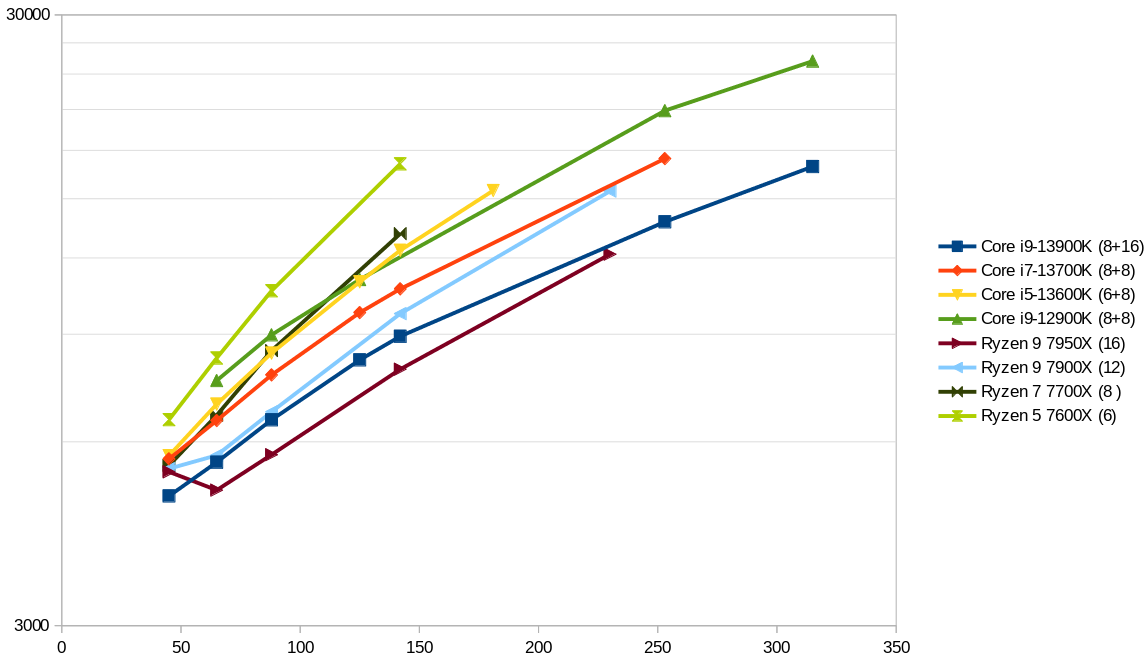
Of het effect van meer L3 al gesatureerd heeft bij 12MB gaan we nog zien. Wellicht dat de 12-core nog wat verrasingen kan laten zien, maar het kan ook zo zijn dat omdat games vaak niet meer dan 4-6 cores gebruken, dat het geen effect heeft. Immers als er 1 core actief is, heeft die in princiepe al beschikking tot de gehele 96MB L3.
AFAIK is het live "delen" van data in L3 bij Ryzen niet mogelijk, omdat het een victim cache is. Voor L1 en L2 bestaan er copies van cache lines in beide caches, en worden deze adhv tags en state bits bijgehouden waar ze mee gekoppeld zijn. Denk aan het belang om geschreven data netjes (uiteindelijk) terug het werkgeheugen in te schrijven. L2 en L3 hebben daardoor ook (shadow) tags om bij te houden waar de meest recente data te vinden is zodat alle cores netjes synchroon over dezelfde (beschreven) data beschikking hebben.
Ik kan niet zo gauw vinden wat er met de L3 entry gebeurd als die opnieuw wordt benaderd; maar ik vermoed dat wordt gedeactiveerd omdat de L3 een 'victim' cache is en geen referenties heeft waar die data op dat moment in gebruik is. Dit hoeft niet erg te zijn, want dit is vanaf Zen 1 al zo, en Intel is sinds paar jaar ook overgestapt van inclusive naar victim (sinds Cascade Lake).
Ik denk niet dat we [voorlopig] geen cache dies op de I/O die gaan zien. Vanaf afstandje zou het een logische stap zijn, maar eigenlijk spreek je dan over L4 cache. Echter Huidige L3 caches hebben bandbreedtes van 0.5+TB/s, dus puur die bandbreedte over IF zou al een zware bottleneck zijn.
Intel heeft redelijk recentelijk op een paar CPUs L4 cache gehad, maar dit waren vooral mobile SoCs voor betere iGPU prestaties. IMO was dat gewoon extra blokje werkgeheugen (~64-128MB) zodat de geheugenbus niet supersnel geheugen hoeft te bevatten, omdat de iGPU daar nogal gevoellig voor is.
:strip_icc():strip_exif()/u/19522/crop6124d729ee8a5_cropped.jpg?f=community)
/u/400/defember100.png?f=community)
:strip_exif()/u/211274/bestabstractwallpapers5.gif?f=community)
:strip_icc():strip_exif()/u/218864/crop5db0c8ff43fff_cropped.jpeg?f=community)
/u/145971/logotnet.png?f=community)
:strip_exif()/u/153057/kolibrietattoo.gif?f=community)
:strip_icc():strip_exif()/u/85228/crop63ed297d1762f.jpg?f=community)
/u/324913/crop56a24cce05cd3_cropped.png?f=community)
:strip_icc():strip_exif()/u/92491/crop64a1593f33a7b_cropped.jpg?f=community)
/u/286895/icon1.png?f=community)
/u/46804/crop5f989efcbb253.png?f=community)
/u/4639/crop5f68bdea0f2fd_cropped.png?f=community)
:strip_icc():strip_exif()/u/78438/klein.jpg?f=community)
/u/351975/28008.png?f=community)
:strip_icc():strip_exif()/u/695850/crop5a1869add3d89_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/534186/crop5fde83f85a409.jpeg?f=community)
:strip_icc():strip_exif()/u/180657/texacoiq2.jpg?f=community)
:fill(white):strip_exif()/f/image/qmLgKNXinXNspEuJ7cVwLBYR.png?f=user_large)
:strip_icc():strip_exif()/u/715918/crop6270f596785bb_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/59472/crop63ded6dc1b6d4_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/272138/crop686071dac3de4_cropped.jpg?f=community)
:strip_exif()/u/109452/AMD.gif?f=community)
:fill(white):strip_exif()/f/image/6yjkva00YN3rVlE73RdfDZT1.png?f=user_large){kind=link}
{kind=link}