Oh dat zeg ik ook niet, de feature levels waren zeker een verbetering over de cap bits. Neemt niet weg dat D3D10 voor de rest gewoon bar weinig had, zeker als je het vergelijkt met 11 (of 9 t.o.v. 8 toen dat uitkwam). Dat is waarom devs er niet aan gingen, terwijl ze wel heel snel op D3D11 hapten. Wat wil je ook, als D3D11 multithreaded rendering, compute shaders, betere texture compressie, tessellation enzovoort heeft; en een deel hiervan werkte gewoon op 9.0/10.0 class kaarten, in tegenstelling tot bij 10.0, waar niets werkte op 9.0 kaarten

Omdat, 8 maanden na Windows 10, de eerste game is pas net uit is (die opvallend genoeg totaal niet op AMD hardware draait).
Heb je het over GeoW?
Prachtig hoe dat broodje aap verhaal in het rond vliegt, iedereen laat het klinken alsof het alleen op AMD ruk draait. Het draait net zo ruk op Nvidia. Sterker nog, een 970 draait soepeler dan een 980 Ti (net zoals een 290X zich blijkbaar ineens met een Fury X kan meten); alleen heb je dan iets meer texture pop-in. Dat is wel beter te behapstukken dan de framedrops op een 980 Ti.
GeoW is ontzettend slecht gebouwd en veel van D3D12 gebruikt het niet. En dat het zo slecht draait ligt niet aan AMD en ook niet aan Nvidia
Daarnaast geeft Nvidia aan dat Async compute nog niet driver enabled is. Ze zouden dus het gat nog wat kunnen dichten.
Ze kunnen er bij Nvidia wel wat van qua software, maar ik betwijfel of ze het helemaal kunnen af vangen. Want wat ze bedoelen is dat ze hun AC implementatie nog niet genoeg getweaked hebben; vergeet niet dat AMD hun AC scheduling in hardware doet, Nvidia moet het in de driver doen omdat ze de hardware simpelweg niet hebben.
RobinHood schreef op donderdag 03 maart 2016 @ 21:25:
AMD haalt gewoon telkens even goede performance in de prijsklasse, maar verliest het telkens in watt/performance. Soms enorm, zoals bij de R9 390 en GTX970, maar bij nieuwere kaarten is het verschil al veel kleiner.
Natuurlijk, meer DX11 performance is altijd welkom, en dat zal de watt/performance zeker verbeteren, en dat is zeker bij de 390 echt nodig, maar AMD is echt niet totaal gedoemd in DX11
Frametimes zijn bij Nvidia nog steeds stabieler. En met name Fiji wordt waarschijnlijk maar voor 75% benut met al die driver overhead van ze
Muurtje over Async Compute voor de liefhebber, want ik heb nog niet in zo veel woorden dit verhaal uitgelegd gezien hier onder ons Tweakers (we hebben alleen naar verschillende posts gelinked)

Floor plans voor het onderstaande:
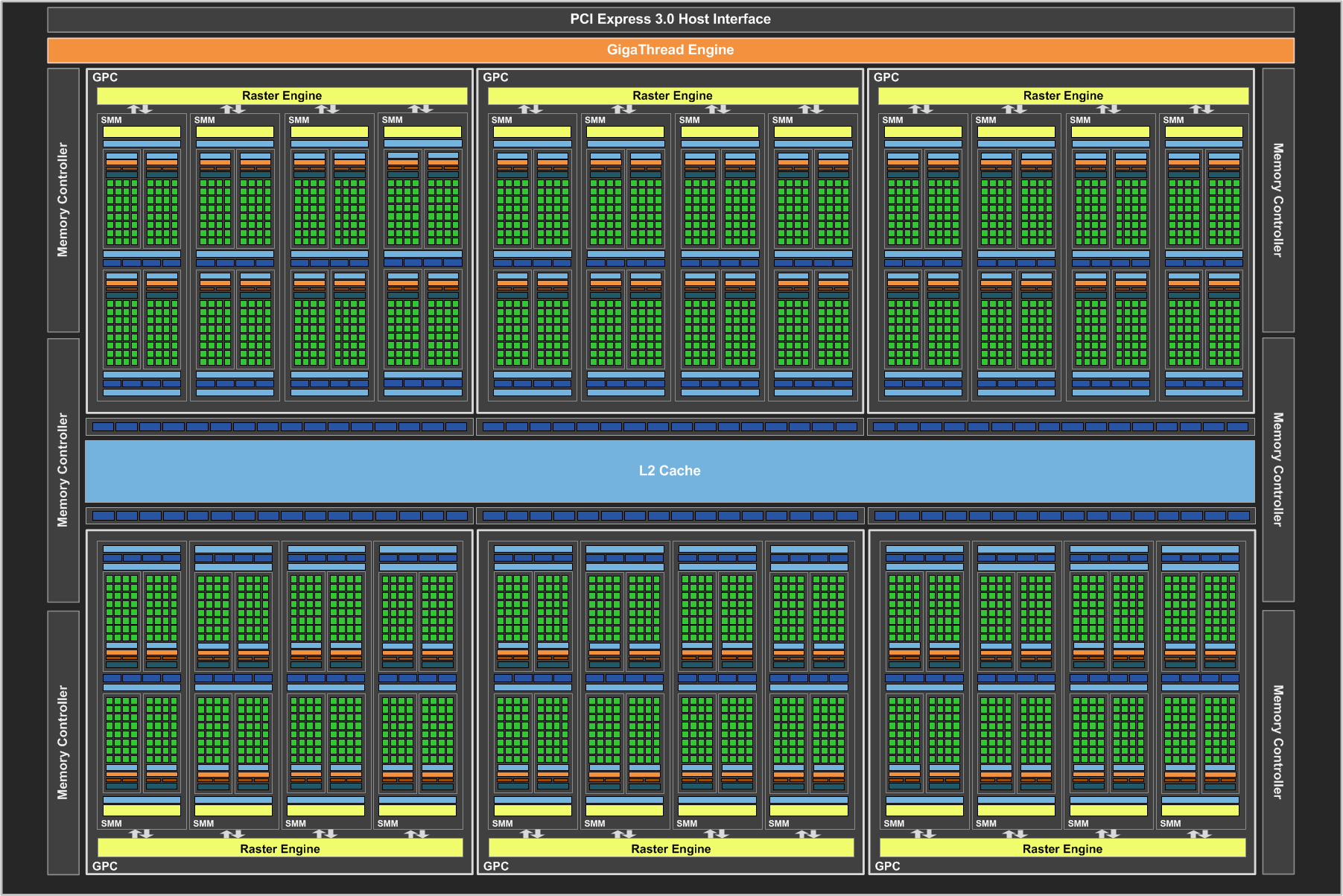
- GM200-400:
http://images.anandtech.c...X_Block_Diagram_FINAL.png
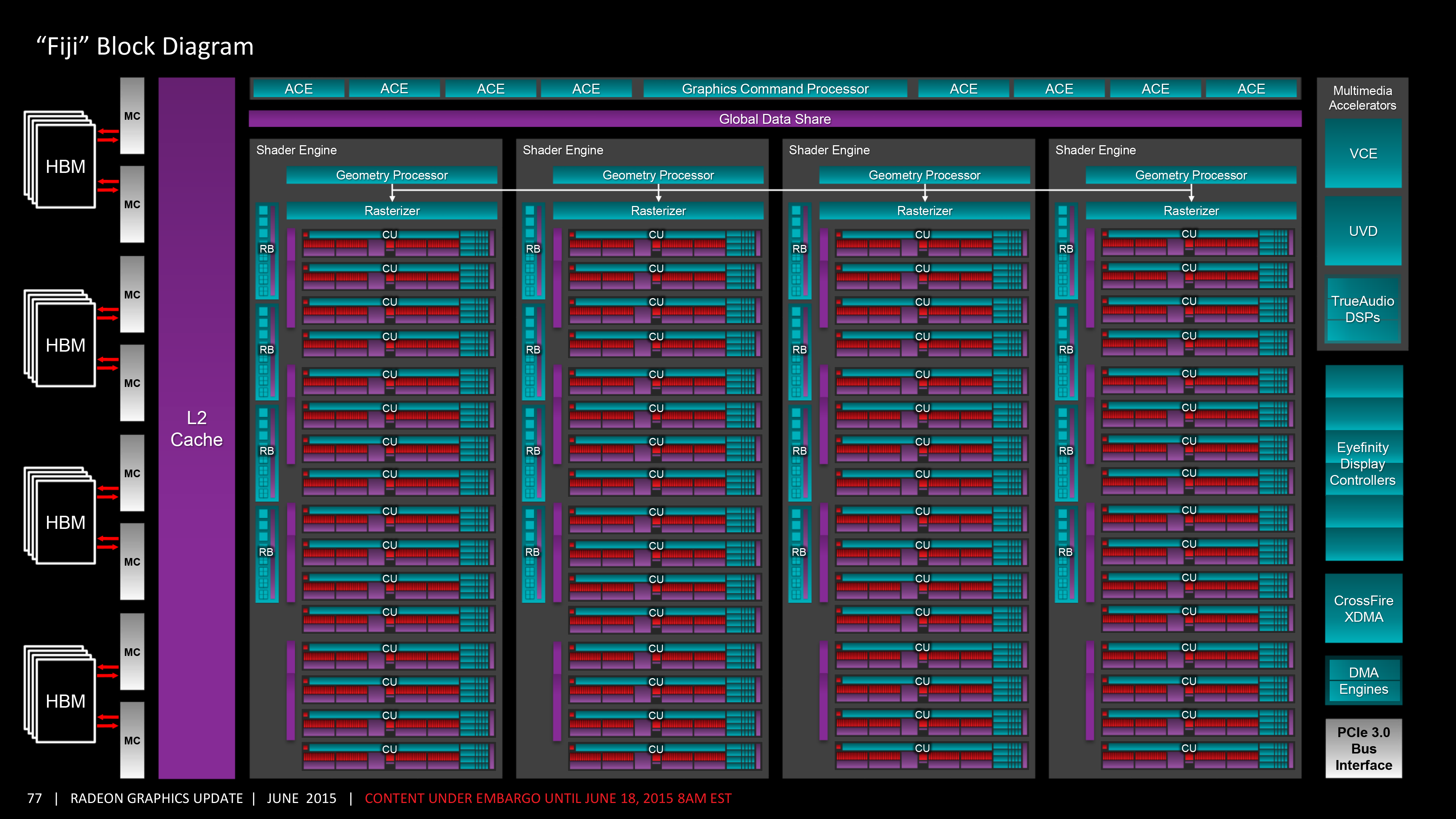
- Fiji XT:
http://images.anandtech.com/doci/9390/FijiBlockDiagram.png
AMD heeft in GCN zogenaamde ACE's:
Asynchronous Compute Engine. Deze staan
buiten de shader clusters (CU's) en hebben elk 8 queues voor opdrachten (in het geval van Hawaii en Fiji heb je dus 64 queues verdeeld over 8 ACE's). Naast deze ACE's is er ook een graphics command queue. Deze ACE's zijn verantwoordelijk voor het verdelen van non-render opdrachten richting de CU's en Geometry Engines (die overigens óók buiten de CU's zitten en dus los aangestuurd kunnen worden). Elke ACE kan eender welke CU of GE aansturen: in het geval van Fiji betekent dat elk van de 64 queues in theorie iets kan doen met 1 van de 64 CU's of 1 van de 4 GE's. Elke CU heeft z'n eigen cache en bestaat uit 64 Shader Processor (4096 totaal dus).
Nvidia heeft dat niet. Punt. Nvidia heeft namelijk besloten dit in software af te vangen met HyperQ. Op papier is HyperQ gewoon een hele dikke ACE met 32 queues (in het geval van GM204 en GM200 in elk geval
). Hier heb je echter al hint/probleem #1: dit gebeurt in software, op de CPU en dus zit er extra latency omdat de driver moet wachten op de GPU alvoor hij iets doet. Want omdat Nvidia geen aparte scheduler in hardware heeft, stuurt HyperQ de SMMs (vrijwel) direct aan (niet helemaal direct natuurlijk, maar het zit er zo dicht bij als mogelijk is met de hardware). Een SMM is hier een shader cluster. Nu gaan we richting probleem nummer twee en ik zal hier op GM200-400 (Titan Z) focussen, omdat deze nog het krachtigste is (en omdat dat overeen komt met Fiji hierboven
). Een SMM bestaat uit een Polymorph Engine (hun tegenhanger van een GE) en 128 SP's; GM200 heeft er 24, dus daar heb je die 3072 SP's in totaal. Dat is ook meteen het probleem: de hele chip kan dus maar per 1/24e aangestuurd worden. En je raakt niet alleen 1/24e van de shaders kwijt, maar ook een hele PE. Binnen die SMM zit dan ook nog eens aan vierdeling, waar TMU's gedeeld worden tussen de partities en SMMs moeten ook een deel van het cache geheugen delen...enfin, efficiënt is anders.
Waarom? Dit is nu dat context switch verhaal. Een CU of SMM moet zich aan andere regels houden afhankelijk van of het render taken of compute taken zijn. Denk aan bijvoorbeeld geheugen toegang. Nvidia moet dus telkens 1/24e van hun GPU context laten switchen voordat ze die aan kunnen sturen; bij AMD is dat slechts 1/64e. Erger nog, Nvidia moet wáchten tot dit gebeurd is voordat HyperQ daadwerkelijk shit kan sturen, terwijl een ACE acuut "weet" wanneer dat gebeurd is. Dit lossen ze op met "preemption" - ofwel de toekomst voorspellen. Door slim queues te groeperen en min of meer te voorspellen wanneer ze resources vrij hebben, kunnen ze de latency zo min mogelijk houden. Maar die latency is er en blijft er.
Vergeet niet dat ik het nu over GM200-400 heb; op een 980 Ti heb je het al over 1/22e, GM204 zakt naar 1/16e en het blijft maar zakken. GK104 is in verhouding nog relatief flexibel met 1/8e, maar die chip heeft andere beperkingen
En om je een idee te geven wat "compute" betekent voor een GPU: een copy operation valt al onder compute. Texture asynchroon laden? Hoppa, 1/24e van je shaders kwijt - en nog veel erger, die 128 zijn er in verhouding veel te veel. Geometry werk te doen? Cluster kwijt; AMD doet dat los van de clusters.
Dit is wat ik bedoel als ik zeg dat GCN een bijzonder indrukwekkende en flexibele architectuur is - het zit allemaal gewoon heel elegant in elkaar. Is wat Nvidia doet nou zo slecht dan? Nee, want met hun aanpak kunnen ze seriële workloads (DX11) juist heel makkelijk plannen en verwerken, terwijl AMD daar iets meer werk voor moet verzetten. Feit is ook dat Nvidia het dus kan verprutsen in de DX12 driver, terwijl AMD zich daar met DX12 juist geen zorgen over hoeft te maken (momenteel). Sterker nog, het preemption verhaal is waar ze nu mee bezig zijn bij Nvidia en dat zullen ze waarschijnlijk op de <DX12 manier op aan het lossen zijn: per game bepalen wat wanneer en waar geplanned wordt. AMD en Nvidia hebben nu in hun drivers talloze hacks om maar te zorgen dat bepaalde games lekker lopen.
Sommige dingen hierboven zijn uiteraard iets te kort door de bocht (Nvidia's driver stuurt helemaal niet 100% direct de SMM's aan en AMD's ACE's kunnen natuurlijk niet zomaar een CU claimen
), maar het laat wel heel duidelijk zien waar de verschillen vandaan komen. Nvidia's pipeline is gewoon heel geschikt voor een bruteforce aanpak in DX11, terwijl AMD voor DX12 juist geen reet hoeft te doen. Verschil is echter dat AMD hun DX11 wél kan oplossen, maar andersom zijn de mogelijkheden erg beperkt.
EDIT: dit is trouwens uiteraard slechts hoe ik en wat anderen de informatie van AMD, Nvidia en verschillende gasten op Beyond3D begrijpen. Kan best dat we volledig fout zitten
[
Voor 14% gewijzigd door
Werelds op 04-03-2016 01:22
]
:strip_icc():strip_exif()/u/324515/crop627103b05ba2e_cropped.jpg?f=community)
/u/48525/EgyptEyes.JPG?f=community)
:strip_exif()/u/17028/ico_sphere.gif?f=community)

:strip_exif()/u/417802/crop563540b38fe2f_cropped.gif?f=community)
:strip_icc():strip_exif()/u/486359/crop5679254888b42_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/53639/iconstar.jpg?f=community)
:strip_exif()/u/211274/bestabstractwallpapers5.gif?f=community)
:strip_exif()/u/327460/cowboy.gif?f=community)
/u/400/defember100.png?f=community)
:strip_exif()/u/306122/TNJ_P38.gif?f=community)
/u/34200/crop6554f56fe2075_cropped.png?f=community)
:strip_icc():strip_exif()/u/83337/countess6-nice.jpg?f=community)
/u/267848/crop6148de8bb8292_cropped.png?f=community)
:strip_icc():strip_exif()/u/7205/duke3.jpg?f=community)



/u/343341/crop6095457d39560_cropped.png?f=community)
{kind=link}
{kind=link}
{kind=link}