Ik heb zelf een beetje een raar geval aan m'n handen denk ik.
Ik zit met een ARECA ARC-1230 SATA raid kaart met 8* 2TB'ers in RAID-5 van WD. (WD Greens, ja, ik weet het, ik had meer onderzoek moeten doen en het was gevaarlijk voor deze op een HW RAID HBA te draaien.).
Deze setup draait ongeveer vanaf ~2010.
In de loop van 2012 heb ik 2 disken vervangen omdat ze opeens vrij gestaag hun reserved sectors aan het verliezen waren.
Ik heb wel vaker "miserie" gehad met deze setup, voornamelijk door de TLER waardoor de adapter hem uit de RAID smijt en ik mag gaan rebuilden. Vaak was dit enkel maar met 2 specifieke disks die verder geen enkele fouten gaven dus ik denk dat het grotendeels misschien slecht contact zou kunnen zijn.
Echter merk ik sinds een week dat random I/O opeens wel heel traag gaat.
Een ~15GB file unrarren bijvoorbeeld gaat tussen de 7 a 15MB/s.
Hierna de originele files&folder verwijderen gaat ook nogal traag.
Copy/pasten van een random file op de RAID zelf gaat nog wel min of meer degelijk.
Met een file van 1.5GB begint tegen 30MB/s en eindigt het tegen de 100MB/s net voor de file klaar is.
Een andere test die ik dan deed was "dd if=/dev/zero of=test.file bs=32M count=512", en die daarna omgekeerd naar /dev/null voor uit te lezen. Deze tests gingen wel nog goed tegen de 300 a 400MB/s.
Het gaat om een ext4 partitie onder Linux. Ik ben dan eens gaan kijken in de event log wat er mis zou kunnen zijn. Ik zie een paar keer deze lijn voorbij komen :
code:
1
| IDE Channel 3 Reading Error |
Deze disk ga ik dus morgen (of ASAP) vervangen. Echter als ik voort kijk in de logs die m'n HBA me gestuurd heeft, is dit al letterlijk meer dan een jaar aan de gang. Dit terwijl de kaart zegt dat de HDD zelf "A-OK" is.
Enkele voorbeelden :
code:
1
2
3
4
| 2017-04-18 04:37:51 IDE Channel 3 : Reading Error
2016-11-20 16:13:22 IDE Channel 3 : Reading Error
2016-07-15 13:51:38 IDE Channel 3 : Reading Error
2016-03-07 22:51:08 IDE Channel 3 : Reading Error |
Het is dus al even aan de gang, echter was het meer "under the radar" omdat hij verder niet zat te klagen, en de performance nog goed was.
Na een scrub te draaien had die disk in minder dan een kwartier al in 1 ruk ~75 read errors dus dat was volgens mij wel duidelijk en de scrub dus gestopt.
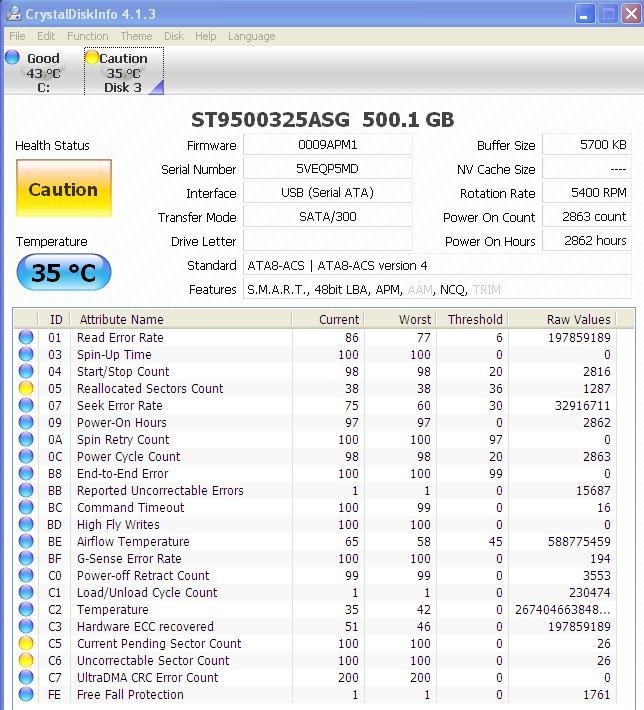
Het rare is dan weer wel dat er 0 reallocated sectors zijn, hij heeft z'n volle 200 dus nog.
Ik had dan een short self-test laten lopen en dit kwam er dus ook naar boven bij de self test.
code:
1
2
3
| SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed: read failure 90% 55664 4292810503 |
Ter vervollediging ook de SMART details voor ik de test liet lopen
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.9.12-aufs] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar Green (AF)
Device Model: WDC WD20EARS-00S8B1
Serial Number: WD-WCAVY5042988
LU WWN Device Id: 5 0014ee 25a1d1704
Firmware Version: 80.00A80
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 2.6, 3.0 Gb/s
Local Time is: Sun May 7 18:54:38 2017 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (41880) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 477) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x3031) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 152 137 021 Pre-fail Always - 9391
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 710
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 024 024 000 Old_age Always - 55664
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 697
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 688
193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 1528962
194 Temperature_Celsius 0x0022 113 088 000 Old_age Always - 39
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 59
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 15
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 16
200 Multi_Zone_Error_Rate 0x0008 200 199 000 Old_age Offline - 23
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay. |
Het is dus wel duidelijk dat die disk vrij op z'n laatste benen aan het lopen is, maar ik vind het raar dat volgens de HBA gewoon nog A-OK is, nog nooit uit de RAID geschopt is geweest whatsoever. Ook niet na al die read errors.
Terwijl als een disk door TLER of wat dan ook wat lang over z'n reply doet hij instantly uit de RAID geschopt werd.
Mijn vraag na dit alles is dus eigenlijk of zo 1 disk ervoor kan zorgen dat de hele RAID random I/O zo traag is, of ik nog verder moet gaan zoeken? Het heeft lang geduurd voor ik dit vond net omdat de algehele performance nog in orde was tot ongeveer een week terug en ik ging uitzoeken waarom dit was.
Geld om de hele RAID te vervangen met non-green disks heb ik momenteel niet dus is ook geen goede aanbeveling. Laat staan dat ik plaats heb om alles tijdelijk ergens anders te dumpen mid-transfer

.
De "rotte" disk word sowieso dus wel vervangen komende week.



/u/238501/crop5e2f0f8a11c1f_cropped.png?f=community)
:strip_icc():strip_exif()/u/64029/crop5b4e6ed3481f4_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/219593/lamas_60x60icon.jpg?f=community)
:strip_icc():strip_exif()/u/25914/crop57f6364541cd7_cropped.jpeg?f=community)


/u/398257/crop64e1f99128b1b_cropped.png?f=community)

:strip_exif()/u/6897/IGKIPU.gif?f=community)
:strip_icc():strip_exif()/u/363314/avator3.jpg?f=community)
:strip_icc():strip_exif()/u/177828/crop5db1af9701f4c_cropped.jpeg?f=community)

/u/175520/crop636e2cf4962f2_cropped.png?f=community)
:strip_exif()/u/128173/crop59a1592e54731_cropped.gif?f=community)
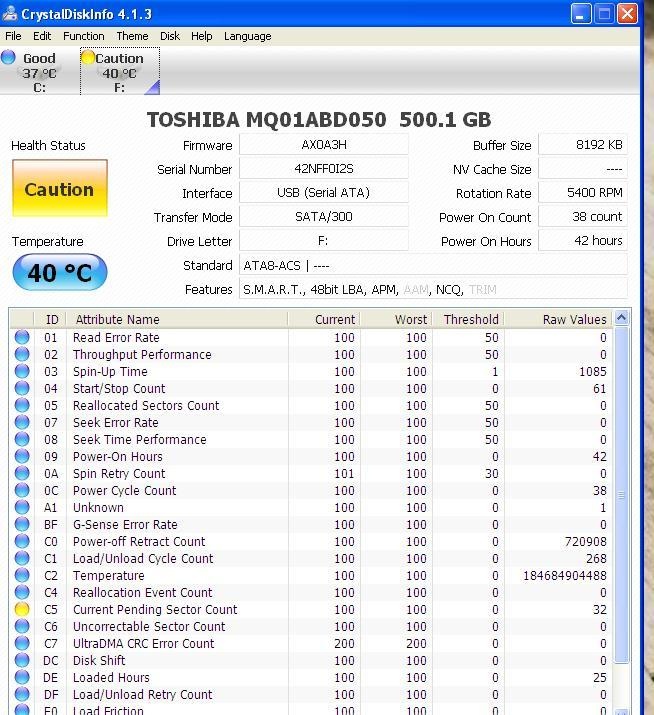
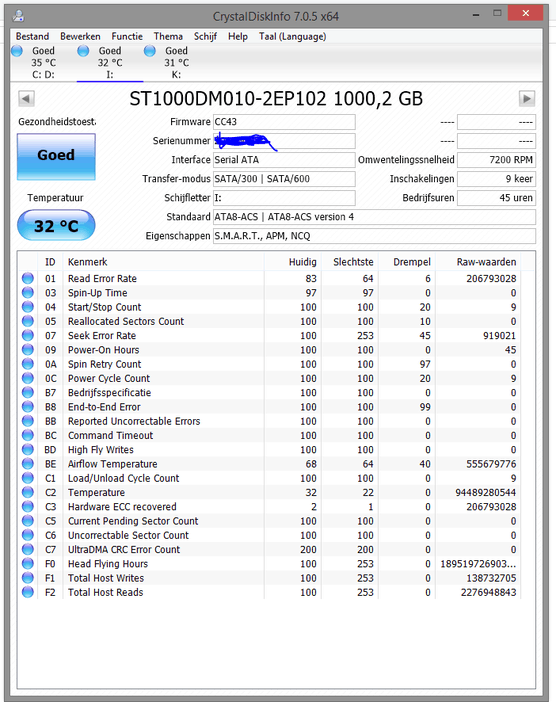
 De Load/Unload Retry Count waarde lijkt stabiel te blijven.
De Load/Unload Retry Count waarde lijkt stabiel te blijven.



:strip_icc():strip_exif()/u/138740/bugz-ju-bugs-g70.jpg?f=community)


/u/24434/crop5ef589f361611_cropped.png?f=community)

:strip_exif()/u/574651/crop5b78563680eb2.gif?f=community)





:strip_icc():strip_exif()/u/295343/crop635f8fc8a6e32_cropped.jpg?f=community)


:strip_icc():strip_exif()/u/665698/crop5aed7074eb8e3_cropped.jpeg?f=community)


:strip_icc():strip_exif()/u/256010/crop60dd2b71ceafb_cropped.jpg?f=community)

:strip_icc():strip_exif()/u/517178/crop5e8dca00a16b9.jpeg?f=community)

:strip_icc():strip_exif()/u/631112/crop5a62131cdb6ad_cropped.jpeg?f=community)

/u/223246/abduction_android_game_small.png?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}