

There are 11 kind of people in the world, ones that can read binary, ones that can't and ones that complain about my signature
PC Specs | Mo Murda Squad Clan
- Oet
- Registratie: Mei 2000
- Laatst online: 13-07 17:57
[DPC]TG & MoMurdaSquad AYBABTU
- Cheetah
- Registratie: Oktober 2000
- Laatst online: 26-06-2022
:strip_exif()/u/14387/Animation-2.gif?f=community)
Veel X1800's in de V&A plotseling 

ASUS Max IV GENE-Z, Core i7 3770k, 16GB Kingston HyperX DDR3-1600, EVGA GTX970 FTW
Crucial M550 512GB SSD, 2TB WD HDD, LG GGW-H20L Blu/HD, Panasonic 40" AX630 UHD
Full Specz
- edward2
- Registratie: Mei 2000
- Laatst online: 31-01 01:56
Schieten op de beesten
:strip_icc():strip_exif()/u/7205/duke3.jpg?f=community)
Dat mag je niet zeggen johOet schreef op woensdag 25 januari 2006 @ 00:30:
Ik zie net prijzen van de Sapphire x1900XT en de XTX bij mijn NL distributeur staan:
€433,20 en €499,80 resp. (inkoop ex btw) worden vandaag binnenverwacht. Geeft mij iig een goed teken dat de beschikbaarheid prima is @ launch!
Niet op voorraad.
- Oet
- Registratie: Mei 2000
- Laatst online: 13-07 17:57
[DPC]TG & MoMurdaSquad AYBABTU
Zolang ik de naam niet laat vallen is het geen probleemedward2 schreef op woensdag 25 januari 2006 @ 00:51:
[...]
Dat mag je niet zeggen johMaar bedankt, ik weet nu bij welke prijs toe te slaan. (Die marges zijn echt dun bij enkelen)
offtopic:
Weet iemand trouwens wanneer SocketM2 nou gaat komen, wanneer er RD580 bordjes voor M2 komen en de procs ervoor komen?? Heb zitten speuren op t.net en GoT maar kom niets noemenswaardigs tegen
Weet iemand trouwens wanneer SocketM2 nou gaat komen, wanneer er RD580 bordjes voor M2 komen en de procs ervoor komen?? Heb zitten speuren op t.net en GoT maar kom niets noemenswaardigs tegen
There are 11 kind of people in the world, ones that can read binary, ones that can't and ones that complain about my signature
PC Specs | Mo Murda Squad Clan
- CJ
- Registratie: Augustus 2000
- Niet online
:strip_icc():strip_exif()/u/10014/assassin.jpg?f=community)
Ok, wat weten we nu zeker...The Source schreef op dinsdag 24 januari 2006 @ 22:53:
[...]
Puzzelen moet leuk blijven he
G70 -> 24-48-24-48 CATZ
G71 -> 24-48-24-48 CATZ
G73 -> 8-24-12-16 CATZ
G74 -> 2-8-4-4 CATZ
G72 -> 2-8-4-4 CATZ
Succes
Uiteraard kan dit veranderen he... roadmaps zijn er om te veranderen, en deze info is van begin december ofzo.
G72 -> 2 ROPs (dus 2 Colour Ops) , 8 ALUs totaal (2 per pipe, totaal 4 Pipes), 4 Texture Units, 4 Z Samples per clock.
G70 -> 16 ROPs (dus 16 Colour Ops), 48 ALUs totaal (2 per pipe, totaal 24 pipes), 24 Texture Units, 32 Z Samples per clock
Van G73 dacht ik het volgende... 8 ROPs - 16 ALUs - 8 Texture Units - 16 Z Samples. Maar als ik de G72 lijn door trek dan is het 8 ROPs - 24 ALUs (a la RV530), 12 Texture Units (ook losgekoppeld), 16 Z/Stencils (komt weer overeen met 8 ROPs met dubbele Z output)
Maar dit klopt dan weer niet met G70, want daar kan ik de tweede 48 niet echt plaatsen en de eerste 24...
Als ik dus uit ga van dit rijtje... dan:
G73 -> 8 ROPs, maar geen 24 ALUs (tenzij nVidia het ook verdriedubbeld heeft...), 12 Texture Units, 16 Z/Stencils.
Volgens nVidia heeft de 7300GS een MSRP van $99. Voor dat geld koop je ook een X1300Pro. En zelfs tegen een X1300LE heeft de 7300GS moeite kon je zien in wat recente reviews.The Source schreef op dinsdag 24 januari 2006 @ 23:05:
[...]
Vergis je niet.. 7300GS wordt vaak ten onrechte met de X1300PRO vergeleken, terwijl hij tov de X1300LE of X1300 gepositioneerd dient te worden. De 7300GT (G73 core gok ik) zal zo'n 3000 3dmarks doen en qua performance kunnen vergelijken met een 6600. Daarom denk ik dat de G72 vooral afgeknepen wordt door de 64bit bus.
En G73 is toch GF7600? Want de GF7600Go is gebaseerd op de G73.G72 = GF7300 (en GF7300Go en GF7400Go). G74 is toch de 80nm versie van de GF72?
Hmm. even kijken of het gemakkelijk kan worden uitgelegd. Om te beginnen... het vind allemaal plaats in de ROP...Astennu schreef op dinsdag 24 januari 2006 @ 22:58:
CJ zou je kunnen vertellen wat die Z/Stencils doen ? en hoeveel van die dingen er in de R580 zitten ? Ik zie het namelijk niet in de topic start staan.
En eigenlijk moet je daarvoor Z & Stencil Buffers uitleggen. Dit zijn stukjes geheugen waarin data wordt opgeslagen over pixels. Bij Z Buffers worden er diepte waardes (depth value) van alle gerenderde pixels. Dit gebeurt om te kijken of een pixel wel of niet gerenderd moet worden (bv objecten die voor elkaar staan die dus niet allemaal helemaal gerenderd hoeven te worden). Bij Stencil Buffers lijkt het veel op Z-Buffers. Ook hier wordt informatie opgeslagen, maar de developer mag nu zelf weten wat voor informatie hij/zij hier op slaat. Het is een soort van kladblokje. Het meeste gebruikt wordt stencilbuffers bij realtime schaduweffecten zoals in Doom3. In de stencilbuffer wordt dan bijgehouden op welke objecten schaduwen vallen door met lichtbronnen (ook bewegende) te werken.
Dit kost veel rekenkracht en nVidia heeft al sinds de FX de mogelijkheid om een ROP op dubbele snelheid te laten werken wanneer er gewerkt werd met Z Stencils. In een nV ROP zit een zogenaamde Z Compare unit en een C(olour) Compare unit. Die C Compare Unit kan zowel Z-Compares doen als C Compares. Dus wanneer er niet gewerkt hoeft te worden met kleurwaardes (C-Compare), dan houdt die unit zich ook bezig met Z-compares en kan-ie een Z/Stencil waarde per clockcycle outputten naast de Z/Stencil waarde van de Z-Compare unit.
1 ROP: 1 kleur + z/stencil per clockcycle OF 2 z/stencils per clockcycle
16 ROPs: 16 kleur + z/stencil per clockcycle OF (maximaal) 32 z/stencils per clockcycle
Zoals je ziet heeft een NV kaart dus veel voordeel bij games als Doom3. Maar er zit ook 1 nadeel aan het geheel bij NV. De maximale MSAA mode is daardoor op dit moment maar 4x, maar daar ga ik nu maar niet op in. Bij ATi heeft alleen de RV530 een verdubbelde Z/Stencil, dus 4 ROPs, maar 8 Z/Stencils per clockcycle.
Technical PR Officer @ MSI Europe. My thoughts and opinions may not reflect the ones of my employer.
- CJ
- Registratie: Augustus 2000
- Niet online
Even een nieuwe post omdat het anders zo'n lang verhaal wordt als ik edit. 
Ik durf wel te zeggen dat ATi eerst verwacht had dat ze op 110nm hogere snelheden konden halen, vooral gezien het feit dat op de eerste X800XL cores "X800Pro" gedrukt stond. Maar ze haalden die 475 niet met 160M transistoren, dus laat staan dat ze 520-540Mhz haalden voor de X850 serie.
Het feit is dat 80nm zowel kleiner (en dus goedkoper is) EN low-k heeft (en dus niets aan snelheid hoeft in te boeten en zelfs hoger te klokken is). TSMC hoeft weinig te veranderen aan het proces, omdat de libraries hetzelfde zijn. Het is gewoon een optisch verkleiningsproces van de bestaande techniek. Het enige waar rekening mee moet worden gehouden is de kleinere transistors en verbindingsdraadjes, maar dat is doorgaans geen probleem bij dieshrinks.
Wat zou jij doen als je op een gegeven moment (bv begin lente) op eenzelfde yieldrate zat als de R580, maar dit ook nog eens hoger kon klokken door het kleinere proces en dan ook nog eens 20% goedkoper uit was dan een R580? Zou je dit puur als kostenbesparend middel gebruiken of zou je dit proces dan ook nog eens gebruiken om het onderste uit de kan te halen om een G71 te verslaan?
Is trouwens iemand dit ook opgevallen...

Ik geloof dat FireFoxAG ooit eens zei dat HDR performance van een X1800 in SS2 'dramatisch' was. Valt op zich best mee als ik dit zo bekijk... Drivers en gamepatch hebben dus blijkbaar toch veel kunnen fixen.... En de extra pixelshader engines in de R580 zorgen hier natuurlijk weer voor een flinke boost aangezien het FP16 HDR is.
Geen low-k op 110nm is juist de reden waarom X850 niet uit is gekomen op dit proces. X850 moest op 520-540Mhz draaien. ATi had er niet echt veel tijd in gestopt om op dit proces te optimaliseren. R430 was bv dan ook niets meer dan een regelrechte copy van R423 op een kleiner proces puur om kosten te besparen.Verwijderd schreef op dinsdag 24 januari 2006 @ 23:52:
[...]
De reden om naar 80nm te gaan lijkt me eerder te gaan om kostenbesparing, dan om de snelheid. We hebben de X850 serie ook niet op 110 nm gezien (het niet low-k zijn van dit proces, daargelaten. Het leek mij niet onwaarschnijnlijk om daar toen ook voor low-k te kiezen). Lijkt me eerder handig om X1300/1600/1700 in 80nm uit te voeren. Die zullen ook en masse verkocht worden (hopelijk)
De vraag is misschien of het rendabel is om design voor 80 nm aan te passen, voor die paar maandjes tot de R600 en afgeleiden.
Ik durf wel te zeggen dat ATi eerst verwacht had dat ze op 110nm hogere snelheden konden halen, vooral gezien het feit dat op de eerste X800XL cores "X800Pro" gedrukt stond. Maar ze haalden die 475 niet met 160M transistoren, dus laat staan dat ze 520-540Mhz haalden voor de X850 serie.
Het feit is dat 80nm zowel kleiner (en dus goedkoper is) EN low-k heeft (en dus niets aan snelheid hoeft in te boeten en zelfs hoger te klokken is). TSMC hoeft weinig te veranderen aan het proces, omdat de libraries hetzelfde zijn. Het is gewoon een optisch verkleiningsproces van de bestaande techniek. Het enige waar rekening mee moet worden gehouden is de kleinere transistors en verbindingsdraadjes, maar dat is doorgaans geen probleem bij dieshrinks.
Wat zou jij doen als je op een gegeven moment (bv begin lente) op eenzelfde yieldrate zat als de R580, maar dit ook nog eens hoger kon klokken door het kleinere proces en dan ook nog eens 20% goedkoper uit was dan een R580? Zou je dit puur als kostenbesparend middel gebruiken of zou je dit proces dan ook nog eens gebruiken om het onderste uit de kan te halen om een G71 te verslaan?
B&W2 is nou niet echt een denderend voorbeeld... Er zit een bug in waardoor een X1800XT net zo goed of zelfs minder goed presteert als een X850XT op het SM2.0 pad. ATi en Lionhead zijn de bug op het spoor en Lionhead zal hopelijk zeer snel een patch voor de game uit brengen. Dit zorgt er dus ook voor dat CrossFire modes langzamer zijn dan singlecard scores.Oet schreef op woensdag 25 januari 2006 @ 00:30:
[...]
Hier wil ik eigelijk ook wel graag een antwoord op zien
Wat is dit btw:
[afbeelding]
[afbeelding]
Zie: Tom's HardWare Review
XTX single en XTX CF en 0.0 aan verbetering (sterker nog, ik zie een drop!)... Dit riekt naar een software/configuratieprobleem. Maarja goed logisch ook, ze gebruiken nog een bèta driver...
Edit2:
Ik zie net prijzen van de Sapphire x1900XT en de XTX bij mijn NL distributeur staan:
€433,20 en €499,80 resp. (inkoop ex btw) worden vandaag binnenverwacht. Geeft mij iig een goed teken dat de beschikbaarheid prima is @ launch!
Is trouwens iemand dit ook opgevallen...
Ik geloof dat FireFoxAG ooit eens zei dat HDR performance van een X1800 in SS2 'dramatisch' was. Valt op zich best mee als ik dit zo bekijk... Drivers en gamepatch hebben dus blijkbaar toch veel kunnen fixen.... En de extra pixelshader engines in de R580 zorgen hier natuurlijk weer voor een flinke boost aangezien het FP16 HDR is.
Technical PR Officer @ MSI Europe. My thoughts and opinions may not reflect the ones of my employer.
- Cheetah
- Registratie: Oktober 2000
- Laatst online: 26-06-2022
Tja... SS2 level1 (Jungle)... zeg jij 't maar...CJ schreef op woensdag 25 januari 2006 @ 03:20:
Is trouwens iemand dit ook opgevallen...
[afbeelding]
Ik geloof dat FireFoxAG ooit eens zei dat HDR performance van een X1800 in SS2 'dramatisch' was. Valt op zich best mee als ik dit zo bekijk... Drivers en gamepatch hebben dus blijkbaar toch veel kunnen fixen.... En de extra pixelshader engines in de R580 zorgen hier natuurlijk weer voor een flinke boost aangezien het FP16 HDR is.
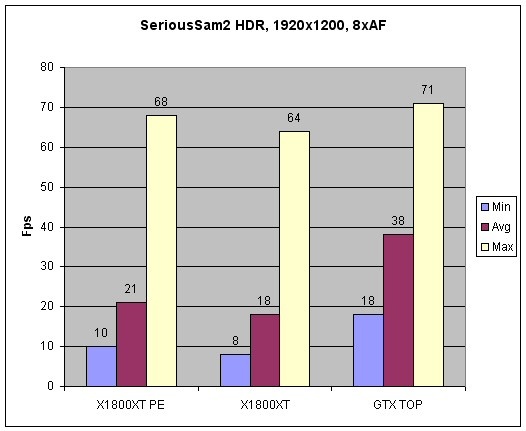
Catalyst 5.13. Manier van testen:
Serious Sam II HDR (v.2.066a)
SS2 patch 2.066a bevat de fix voor gebruik van HDR op de Radeon X1xxx serie videokaarten. Deze patch lost de artifacts op bij gebruik van HDR op de X1xxx serie, maar brengt (helaas) geen merkbare performanceverbeteringen met zich mee.
Alle ingame grafische settings stonden maximaal (Bloom: Glaring), met HDR ingeschakeld. Gezien SS2 – net als Far Cry – FP16 HDR gebruikt is AA op de 7800GTX wederom niet mogelijk in combinatie hiermee. Zodoende is er ook in deze game niet met AA getest.
Het geteste SS2 level betreft het eerste level (Jungle – M’Digbo), van het begin tot en met het verslaan van Kronk (de holbewoner met de bijl
Ik heb het al eerder gezegd, maar zolang men niet duidelijk aangeeft hoe en met welke settings er is getest kan ik geen brood bakken van dat soort grafiekjes
Ik heb geen X1800XT meer, maar misschien dat iemand met zo'n kaart een een A64 ~@2.7Ghz het even kan nakijken?
[ Voor 20% gewijzigd door Cheetah op 25-01-2006 04:04 ]
ASUS Max IV GENE-Z, Core i7 3770k, 16GB Kingston HyperX DDR3-1600, EVGA GTX970 FTW
Crucial M550 512GB SSD, 2TB WD HDD, LG GGW-H20L Blu/HD, Panasonic 40" AX630 UHD
Full Specz
- Bever!
- Registratie: Maart 2004
- Laatst online: 16-07 23:12
3
:strip_icc():strip_exif()/u/109762/crop63cfada0dde8a_cropped.jpg?f=community)
ze hadden bij firingsquad deze driver getest met de ati kaarten:
Driver version sample_8-203-3-060104a-029367E
Maar tis een curieus iets het verschil tussen firefox en firingsquad dat zeker
Driver version sample_8-203-3-060104a-029367E
Maar tis een curieus iets het verschil tussen firefox en firingsquad dat zeker
- CJ
- Registratie: Augustus 2000
- Niet online
Dat is de 6.2beta en die zorgt voor een leuke boost op alle X1900XT kaarten in vergelijking met de drivers die bij de kaarten zelf wordt meegeleverd. En ook de gelekte previews maken geen gebruik van Cat 6.2b en die gaven dus een lichtelijk vertekend beeld van de performance. Ik geloof dat Cat 6.2b ook op de X1800 serie een leuke boost gaf en veel bugs verholpen heeft, dus waarschijnlijk is SS2 HDR ook gefixed.
Maar aan de andere kant meldt HardOCP nog steeds dat je beter zonder HDR in SS2 kan spelen op de X1800XT terwijl ze zelfs HDR + HQ AF + 4xAA aanraden op 1600x1200 op een X1900XT. En Guru3D laat ook weer betere SS2 + HDR scores zien.
Maar aan de andere kant meldt HardOCP nog steeds dat je beter zonder HDR in SS2 kan spelen op de X1800XT terwijl ze zelfs HDR + HQ AF + 4xAA aanraden op 1600x1200 op een X1900XT. En Guru3D laat ook weer betere SS2 + HDR scores zien.
Technical PR Officer @ MSI Europe. My thoughts and opinions may not reflect the ones of my employer.
Verwijderd
Ben even op zoek geweest naar meer SS2 HDR cijfers. Ze zijn schaars, maar hier hebben we nog wat.
http://www.tbreak.com/rev...=grfx&id=430&pagenumber=9
Ook hier is de X1800XT sneller als de 7800GTX/256...
http://www.tbreak.com/rev...=grfx&id=430&pagenumber=9
Ook hier is de X1800XT sneller als de 7800GTX/256...
[ Voor 20% gewijzigd door Verwijderd op 25-01-2006 05:01 ]
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
/u/34200/crop6554f56fe2075_cropped.png?f=community)
Nu is het allemaal een stuk duidelijker. Maar wordt er nu veel gebruik gemaakt van die Z-Stencils ? of alleen Doom 3 en quake 4 waar er echt veel gebruik wordt gemaakt ? Want ATi heeft toch gekozen om er 16 te gebruiken in de R520/R580 en wel 8 in de RV530.CJ schreef op woensdag 25 januari 2006 @ 02:24:
[...]
Ok, wat weten we nu zeker...
G72 -> 2 ROPs (dus 2 Colour Ops) , 8 ALUs totaal (2 per pipe, totaal 4 Pipes), 4 Texture Units, 4 Z Samples per clock.
G70 -> 16 ROPs (dus 16 Colour Ops), 48 ALUs totaal (2 per pipe, totaal 24 pipes), 24 Texture Units, 32 Z Samples per clock
Van G73 dacht ik het volgende... 8 ROPs - 16 ALUs - 8 Texture Units - 16 Z Samples. Maar als ik de G72 lijn door trek dan is het 8 ROPs - 24 ALUs (a la RV530), 12 Texture Units (ook losgekoppeld), 16 Z/Stencils (komt weer overeen met 8 ROPs met dubbele Z output)
Maar dit klopt dan weer niet met G70, want daar kan ik de tweede 48 niet echt plaatsen en de eerste 24...
Als ik dus uit ga van dit rijtje... dan:
G73 -> 8 ROPs, maar geen 24 ALUs (tenzij nVidia het ook verdriedubbeld heeft...), 12 Texture Units, 16 Z/Stencils.
[...]
Volgens nVidia heeft de 7300GS een MSRP van $99. Voor dat geld koop je ook een X1300Pro. En zelfs tegen een X1300LE heeft de 7300GS moeite kon je zien in wat recente reviews.
En G73 is toch GF7600? Want de GF7600Go is gebaseerd op de G73.G72 = GF7300 (en GF7300Go en GF7400Go). G74 is toch de 80nm versie van de GF72?
[...]
Hmm. even kijken of het gemakkelijk kan worden uitgelegd. Om te beginnen... het vind allemaal plaats in de ROP...
En eigenlijk moet je daarvoor Z & Stencil Buffers uitleggen. Dit zijn stukjes geheugen waarin data wordt opgeslagen over pixels. Bij Z Buffers worden er diepte waardes (depth value) van alle gerenderde pixels. Dit gebeurt om te kijken of een pixel wel of niet gerenderd moet worden (bv objecten die voor elkaar staan die dus niet allemaal helemaal gerenderd hoeven te worden). Bij Stencil Buffers lijkt het veel op Z-Buffers. Ook hier wordt informatie opgeslagen, maar de developer mag nu zelf weten wat voor informatie hij/zij hier op slaat. Het is een soort van kladblokje. Het meeste gebruikt wordt stencilbuffers bij realtime schaduweffecten zoals in Doom3. In de stencilbuffer wordt dan bijgehouden op welke objecten schaduwen vallen door met lichtbronnen (ook bewegende) te werken.
Dit kost veel rekenkracht en nVidia heeft al sinds de FX de mogelijkheid om een ROP op dubbele snelheid te laten werken wanneer er gewerkt werd met Z Stencils. In een nV ROP zit een zogenaamde Z Compare unit en een C(olour) Compare unit. Die C Compare Unit kan zowel Z-Compares doen als C Compares. Dus wanneer er niet gewerkt hoeft te worden met kleurwaardes (C-Compare), dan houdt die unit zich ook bezig met Z-compares en kan-ie een Z/Stencil waarde per clockcycle outputten naast de Z/Stencil waarde van de Z-Compare unit.
1 ROP: 1 kleur + z/stencil per clockcycle OF 2 z/stencils per clockcycle
16 ROPs: 16 kleur + z/stencil per clockcycle OF (maximaal) 32 z/stencils per clockcycle
Zoals je ziet heeft een NV kaart dus veel voordeel bij games als Doom3. Maar er zit ook 1 nadeel aan het geheel bij NV. De maximale MSAA mode is daardoor op dit moment maar 4x, maar daar ga ik nu maar niet op in. Bij ATi heeft alleen de RV530 een verdubbelde Z/Stencil, dus 4 ROPs, maar 8 Z/Stencils per clockcycle.
Edit:
En CJ. ATi kaarten hebben toch ook 2 Alu's per shader pipe ? Een kan ADD/MULL/MADD De 2e kan alleen ADD doen En ze hebben een Vector en een Scale alu.. Nvidia heeft er dan 2 die alles kunnen. Alleen wat dat ADD/MULL/MADD doet weet ik nog niet daar ga ik me vanmiddag maar eens in verdiepen. Ook hoe nvidia de pixelpipes opbouwd. Maar tot nu toe herb ik nog niet zo'n mooi overzicht van de G70 kunnen vinden @ anandtech. Voor de ATi staat wel de gehle opbouw er in. En wat de ALU's kunnen. Bij de G70 review niet. Het lijkt wel of nvidia dat voorzigzelf wil houden.
[ Voor 11% gewijzigd door Astennu op 25-01-2006 09:16 ]
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- Cheetah
- Registratie: Oktober 2000
- Laatst online: 26-06-2022
Mja, dit is natuulijk erg snel te testen mocht jij (of iemand anders) ook SS2 hebben liggen...Verwijderd schreef op woensdag 25 januari 2006 @ 04:46:
Ben even op zoek geweest naar meer SS2 HDR cijfers. Ze zijn schaars, maar hier hebben we nog wat.
http://www.tbreak.com/rev...=grfx&id=430&pagenumber=9
Ook hier is de X1800XT sneller als de 7800GTX/256...
Ff fraps downloaden, en opstarten.
SS2 opstarten, liefst 1920x1200 (FullScreen + WideScreen) - alternatief 1600x1200 - kiezen; alle graphicsopties op maximum (ook in Advanced Options); AF 8x; Bloom op "Glaring"; HDR aan.
Start "New Game" en speel het eerste stuk tot de holbewoner uit de grot...
Maar goed, naar wat ik heb gemeten/gezien heb je FRAPS niet eens nodig om vast te stellen dat het onspeelbaar is... Van 1600x1200 ben ik niet 100% zeker, maar bij 1920x1200 weet ik echt wel wat ik heb gezien/gemeten. Ik heb zelfs de FRAPS files nog liggen.
[ Voor 13% gewijzigd door Cheetah op 25-01-2006 11:03 ]
ASUS Max IV GENE-Z, Core i7 3770k, 16GB Kingston HyperX DDR3-1600, EVGA GTX970 FTW
Crucial M550 512GB SSD, 2TB WD HDD, LG GGW-H20L Blu/HD, Panasonic 40" AX630 UHD
Full Specz
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Ik zal donderdag eens kijken hoe het op me X1800 XL en de X1900 XT loopt. Moet alleen die patch gaan downloaden. Maar ik had idd al eerder gezien dat met HDR de FPS wel vaak op 8 kwam in grote battles. En ik zagh blokjes in de rook. Die had ik met de X850 niet.FirefoxAG schreef op woensdag 25 januari 2006 @ 10:36:
[...]
Mja, dit is natuulijk erg snel te testen mocht jij (of iemand anders) ook SS2 hebben liggen...
Ff fraps downloaden, en opstarten.
SS2 opstarten, liefst 1920x1200 (FullScreen + WideScreen) - alternatief 1600x1200 - kiezen; alle graphicsopties op maximum (ook in Advanced Options); AF 8x; Bloom op "Glaring"; HDR aan.
Start "New Game" en speel het eerste stuk tot de holbewoner uit de grot...
Maar goed, naar wat ik heb gemeten/gezien heb je FRAPS niet eens nodig om vast te stellen dat het onspeelbaar is...
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
/u/139379/format-c.png?f=community)
Ik heb toch maar een X1900XT besteld want potverdorie wat is dat ding snel! Hij owned een GTX 512 gewoon...
Dan overklok ik hem zelf wel naar XTX speeds. Ik neem aan dat dat geen enkel probleem oplevert?
Dan overklok ik hem zelf wel naar XTX speeds. Ik neem aan dat dat geen enkel probleem oplevert?
[ Voor 8% gewijzigd door Format-C op 25-01-2006 10:48 ]
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- estorino
- Registratie: Maart 2000
- Laatst online: 07-05 20:04
:strip_icc():strip_exif()/u/3716/palm.jpg?f=community)
Goh, de x1900xt en xtx zijn zowaar ook al meteen leverbaar, ik zag dat komplett ze op voorraad heeft. Niet dat ik er een ga kopen, helaas heb ik daar geen centen voor.
https://www.strava.com/athletes/10490675
- PassieWassie
- Registratie: Mei 2004
- Laatst online: 30-03-2025
:strip_icc():strip_exif()/u/114851/0a4.jpg?f=community)
Heeft er iemand een linkje naar de 6.2 beta drivers?
Ik wil wel even een benchmark draaien in serious sam op een x1800xt PE. CPU is een winchester op 2,71 ghz. Even ter referentie met de boven geplaatste benchmarks.
Ik wil wel even een benchmark draaien in serious sam op een x1800xt PE. CPU is een winchester op 2,71 ghz. Even ter referentie met de boven geplaatste benchmarks.
Specs: http://specs.tweak.to/14936= Nieuwe Spekjes mensen !
- Help!!!!
- Registratie: Juli 1999
- Niet online
/u/400/defember100.png?f=community)
Ben je van je geloof gevallen....RappieRappie schreef op woensdag 25 januari 2006 @ 10:48:
Ik heb toch maar een X1900XT besteld want potverdorie wat is dat ding snel! Hij owned een GTX 512 gewoon...
Dan overklok ik hem zelf wel naar XTX speeds. Ik neem aan dat dat geen enkel probleem oplevert?
Denk dat het een goede keus is. Zeker als je de prijs vergelijkt met de 7800gtx512....
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Dat denk ik ook. We kunnen nog niet vergelijken met de G71. Maar echt tegenvallen zal het denk ik niet. Mischien is die 7900 GTX 10-20% sneller. En mischien is het in nieuwe games wel ongeveer gelijk of ook 20% winst voor de 7900.Help!!!! schreef op woensdag 25 januari 2006 @ 11:21:
[...]
Ben je van je geloof gevallen....
Denk dat het een goede keus is. Zeker als je de prijs vergelijkt met de 7800gtx512....
Maar ik krijg em als het goed is mrogen binnen
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
:strip_icc():strip_exif()/u/68155/crop6a1481c865d9f_cropped.jpg?f=community)
Same here, net de sapphire x1900xt besteld voor 529€RappieRappie schreef op woensdag 25 januari 2006 @ 10:48:
Ik heb toch maar een X1900XT besteld want potverdorie wat is dat ding snel! Hij owned een GTX 512 gewoon...
Dan overklok ik hem zelf wel naar XTX speeds. Ik neem aan dat dat geen enkel probleem oplevert?
Overclocken naar XTX speeds zal ff afwachten worden. Elke kaart is toch weer uniek. Maar we zien wel, hopelijk is ie iig snel binnen
- Cheetah
- Registratie: Oktober 2000
- Laatst online: 26-06-2022
Ik heb zelf 5.13 gebruikt. Vergelijk die twee anders eventhabazzman schreef op woensdag 25 januari 2006 @ 11:13:
Heeft er iemand een linkje naar de 6.2 beta drivers?
Ik wil wel even een benchmark draaien in serious sam op een x1800xt PE. CPU is een winchester op 2,71 ghz. Even ter referentie met de boven geplaatste benchmarks.
ASUS Max IV GENE-Z, Core i7 3770k, 16GB Kingston HyperX DDR3-1600, EVGA GTX970 FTW
Crucial M550 512GB SSD, 2TB WD HDD, LG GGW-H20L Blu/HD, Panasonic 40" AX630 UHD
Full Specz
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Waar heb je em voor 529 gehaald ? en was i ook op vooraad ?CHeeCH schreef op woensdag 25 januari 2006 @ 11:30:
[...]
Same here, net de sapphire x1900xt besteld voor 529€
Overclocken naar XTX speeds zal ff afwachten worden. Elke kaart is toch weer uniek. Maar we zien wel, hopelijk is ie iig snel binnen
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- winwiz
- Registratie: September 2000
- Laatst online: 15:32
:strip_icc():strip_exif()/u/12169/crop5f6b926faa837_cropped.jpeg?f=community)
Hoera
Ik kreeg een mailtje dat ik mijn 1900 XT kan afhalen in vlaardingen! Het is wel erg snel deze wisseling van een 1800 XL naar een 1900 XT, maar wel noodzakelijk om mijn 24 " Dell optimaal te gebruiken...
Ik stop vandaag maar iets eerder met werken.... belangrijkere zaken....... toch???
Ik kreeg een mailtje dat ik mijn 1900 XT kan afhalen in vlaardingen! Het is wel erg snel deze wisseling van een 1800 XL naar een 1900 XT, maar wel noodzakelijk om mijn 24 " Dell optimaal te gebruiken...
Ik stop vandaag maar iets eerder met werken.... belangrijkere zaken....... toch???
Ryzen 5950x + 32GB GSKILL @3600 op Rog Strix Gaming E x570 + Asrock Phantom Gaming 6800XT+ Gigabyte Aorus FV43U Zwart + DS1621+ + DS414 + MacbookPro 16" 2021 + Mac Mini M4 Pro + Tesla MY RWD 2023 BYD
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Ghehe thats the spirrit !!. Ik kreeg ook een mailtje dat me bestelling klaar is. Zal vandaag wel wordt verstuurd. Oook een sapphire toevallig ? ik mog nog voor zo'n dell gaan kijken maar zit te twijfelen of ik niet op de 2407 moet wachten.winwiz schreef op woensdag 25 januari 2006 @ 12:08:
Hoera
Ik kreeg een mailtje dat ik mijn 1900 XT kan afhalen in vlaardingen! Het is wel erg snel deze wisseling van een 1800 XL naar een 1900 XT, maar wel noodzakelijk om mijn 24 " Dell optimaal te gebruiken...
Ik stop vandaag maar iets eerder met werken.... belangrijkere zaken....... toch???
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- PassieWassie
- Registratie: Mei 2004
- Laatst online: 30-03-2025
Prima, alleen kan mijn TFT geen 1920 reso aan. Missschien even 1280 doen ?FirefoxAG schreef op woensdag 25 januari 2006 @ 11:35:
[...]
Ik heb zelf 5.13 gebruikt. Vergelijk die twee anders even
BTW ik zal vanavond wat tabelletjes in elkaar flansen met de results.
Pascal
Specs: http://specs.tweak.to/14936= Nieuwe Spekjes mensen !
- winwiz
- Registratie: September 2000
- Laatst online: 15:32
2405 bevalt mij in ieder geval uitstekend maar wel ontzettend verslavend. Wat is een 20" in één keer klein dan zegAstennu schreef op woensdag 25 januari 2006 @ 12:13:
[...]
Ghehe thats the spirrit !!. Ik kreeg ook een mailtje dat me bestelling klaar is. Zal vandaag wel wordt verstuurd. Oook een sapphire toevallig ? ik mog nog voor zo'n dell gaan kijken maar zit te twijfelen of ik niet op de 2407 moet wachten.
Als je in de gelegenheid bent..... doen!!! en er ontzettend van genieten, zeker met zo'n Saphire X1900 XT
Ik kan dan wel zeggen "the way it's ment to be played" of kwan die spreuk uit een groen kamp
Ryzen 5950x + 32GB GSKILL @3600 op Rog Strix Gaming E x570 + Asrock Phantom Gaming 6800XT+ Gigabyte Aorus FV43U Zwart + DS1621+ + DS414 + MacbookPro 16" 2021 + Mac Mini M4 Pro + Tesla MY RWD 2023 BYD
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Neeh okeey ik wil er ook zekers een hebbenwinwiz schreef op woensdag 25 januari 2006 @ 12:40:
[...]
2405 bevalt mij in ieder geval uitstekend maar wel ontzettend verslavend. Wat is een 20" in één keer klein dan zeg
Als je in de gelegenheid bent..... doen!!! en er ontzettend van genieten, zeker met zo'n Saphire X1900 XT
Ik kan dan wel zeggen "the way it's ment to be played" of kwan die spreuk uit een groen kamp
Ik zag bij B3D dat er nog wel meer in verandert aan de R580 dat een een grotere Z buffer heeft gekregen en nog wat extra's om die pixel shaders aan het werk te kunnen houden.
Ik kwam dit tegen maar snap het nog niet helemaal:
PS ALU 1 --- 48 ADDs --- 1 --- 4 --- 192
PS ALU 2 --- 48 MADDs --- 2 --- 4 --- 384
VS ALU --- 8 MADDs --- 2 --- 5 --- 80
Volgorde van links naar rechts: Processor>Instruction>FLOPs>Components> FLOPs.
Nu vraag ik me af hoe ziet dit er bij de G70 uit.
Dan is het volgens mij zo dat de ALU 1 ook MADD's doet. Anadtech had het er over dat de 2e alu toch meer zou kunnen dan de eerst ( Bij de G70 dan ) en dat Nvidia vond dat je meer MADD's moest kunnen doen omdat die veel gebruikt worden. ATi kiest voor extra ADD's. maar wat is nu het grote verschil.
CJ kun je mischien een handje helpen ?? kijkt heel lief
[ Voor 44% gewijzigd door Astennu op 25-01-2006 12:53 ]
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- winwiz
- Registratie: September 2000
- Laatst online: 15:32
780 Euro is een mooie prijs vooral als je een maatje hebt die er ook 1 wil hebben.... Van ghosting heb ik in ieder geval geen last.
Ik denk dat ik maar eens stop met werken. Gelukkig is de gladheid redelijk voorbij en kunnen we zo'n mooi doosje gaan ophalen..
Ik denk dat ik maar eens stop met werken. Gelukkig is de gladheid redelijk voorbij en kunnen we zo'n mooi doosje gaan ophalen..
Ryzen 5950x + 32GB GSKILL @3600 op Rog Strix Gaming E x570 + Asrock Phantom Gaming 6800XT+ Gigabyte Aorus FV43U Zwart + DS1621+ + DS414 + MacbookPro 16" 2021 + Mac Mini M4 Pro + Tesla MY RWD 2023 BYD
- Cheetah
- Registratie: Oktober 2000
- Laatst online: 26-06-2022
Mja, dat valt moeilijk te vergelijken natuurlijk... bij 1920x1200 heb je ~88% meer pixels te verwerken dan bij 1280x960, en 76% meer dan bij 1280x1024.thabazzman schreef op woensdag 25 januari 2006 @ 12:25:
Prima, alleen kan mijn TFT geen 1920 reso aan. Missschien even 1280 doen ?
BTW ik zal vanavond wat tabelletjes in elkaar flansen met de results.
Maar goed, post maar misschien dat we toch een trend kunnen ontdekken ofzo
ASUS Max IV GENE-Z, Core i7 3770k, 16GB Kingston HyperX DDR3-1600, EVGA GTX970 FTW
Crucial M550 512GB SSD, 2TB WD HDD, LG GGW-H20L Blu/HD, Panasonic 40" AX630 UHD
Full Specz
- Joepi
- Registratie: December 1999
- Laatst online: 06-07 13:54
:strip_exif()/u/1258/lemmings40.gif?f=community)
CJ, wat zeg je hiervan: die russen hebben wel door hoe het werkt in the bizz
kan nog spannend worden ...
http://www.digit-life.com/articles2/video/r580-part2.html#p5As we can see, advantage of the R580 over the R520 has practically no effect as performance is limited by texture units, 16 in both cases. Thus NVIDIA formally looks like a winner in this case. But as it's still a tad faster in the first scenario with computations (in a procedural test) and slightly slower in the second scenario (in a parallax mapping test), programmers will most likely prefer the first shader modifications and not create two different shaders for different cards. ATI will win in this situation, unless programmers decide for some reason (I wonder why?) to create a texture-priority shader in order to equalize G70 and R580. In this case ATI has implemented all the 32 new pixel processors for nothing. It's an interesting situation – too much depends on a context and programmers' preferences. We'll see what ways they will choose in their applications. But don't forget about a possible situation when the choice is already made – for example, the game is already released. Then the case may go against the R580. Just because programmers didn't know about its features and high performance in computing rather than texture sampling.
kan nog spannend worden ...
- Help!!!!
- Registratie: Juli 1999
- Niet online
é Astennu, raadt ns wat hier op mijn bureau ligt......
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- waterking
- Registratie: Juli 2005
- Laatst online: 10-03 12:52
een koffiemolen
klik hier voor de specs van m'n systeem || ook al is INTEL nog zo snel AMD achterhaalt hem wel
- Help!!!!
- Registratie: Juli 1999
- Niet online
Ik wil niet teveel slowchat doen hier maar: Ja, gedeeltelijk is het ook een koffiemolen qua geluid heb ik gehoord....
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Grrr niet liefHelp!!!! schreef op woensdag 25 januari 2006 @ 13:44:
é Astennu, raadt ns wat hier op mijn bureau ligt......
Dit is inderdaat een probleem. Alleen je ziet wel dat Texture units steeds minder belangrijk worden. Voor ATi is het hopen dat dit zo door gaat. Voor Nvidia juist weer niet. In denk wel dat we steeds meer naar shaders toe gaan. Dat zie je ook bij FEAR. Unreal III zal ook veel shaders gaan gebruiken maar hoe belangrijk testure units daar zullen zijn weet ik niet. Ik vraag me nu ook af hoeveel Texture units de R500 Xenos heeft. Die werkt ook al met 48 ALu's die Vertex en Pixels kunnen doen. Maar daar zit natuurlijk ook nog wat voor.Joepi schreef op woensdag 25 januari 2006 @ 13:33:
CJ, wat zeg je hiervan: die russen hebben wel door hoe het werkt in the bizz
[...]
http://www.digit-life.com/articles2/video/r580-part2.html#p5
kan nog spannend worden ...
Hoeveel robs heeft die ? en Z/Stincels ? en hoeveel texture units ? want naar zo iets zullen we wel gaan met de R600. Alleen die heeft mischien 64 ALU's.
Nja mijn X850 was best erg maar ik heb gehoord dat de X1800 een stuk stiller was. Alleen de X1900 wordt wat warmer. Mijn X850 draaide @ stock eigenlijk altijd op 5 of 10% en dan hoor je em niet. Ik weet niet hoe dit met de X1900 is maar dat ga ik morgen wel merkenHelp!!!! schreef op woensdag 25 januari 2006 @ 13:55:
[...]
Ik wil niet teveel slowchat doen hier maar: Ja, gedeeltelijk is het ook een koffiemolen qua geluid heb ik gehoord....
Het is BTW wel erg er staan 5 X1800 's te koop
[ Voor 24% gewijzigd door Astennu op 25-01-2006 14:39 ]
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- SgtStrider
- Registratie: Juli 2003
- Laatst online: 02-12-2025
Fractal Switchover!
:strip_icc():strip_exif()/u/87986/fractal.jpg?f=community)
Is het mogelijk dat je ook ff temperatuur benched @ jouw systeem? Bijv. met ATi tool ofzo, en dan load/idle temps.Astennu schreef op woensdag 25 januari 2006 @ 14:32:
[...]
Grrr niet lief
[...]
Dit is inderdaat een probleem. Alleen je ziet wel dat Texture units steeds minder belangrijk worden. Voor ATi is het hopen dat dit zo door gaat. Voor Nvidia juist weer niet. In denk wel dat we steeds meer naar shaders toe gaan. Dat zie je ook bij FEAR. Unreal III zal ook veel shaders gaan gebruiken maar hoe belangrijk testure units daar zullen zijn weet ik niet. Ik vraag me nu ook af hoeveel Texture units de R500 Xenos heeft. Die werkt ook al met 48 ALu's die Vertex en Pixels kunnen doen. Maar daar zit natuurlijk ook nog wat voor.
Hoeveel robs heeft die ? en Z/Stincels ? en hoeveel texture units ? want naar zo iets zullen we wel gaan met de R600. Alleen die heeft mischien 64 ALU's.
[...]
Nja mijn X850 was best erg maar ik heb gehoord dat de X1800 een stuk stiller was. Alleen de X1900 wordt wat warmer. Mijn X850 draaide @ stock eigenlijk altijd op 5 of 10% en dan hoor je em niet. Ik weet niet hoe dit met de X1900 is maar dat ga ik morgen wel merken
Het is BTW wel erg er staan 5 X1800 's te koop
CM NR200P | Gigabyte B550i Aorus Pro AX | 5600X | AMD Radeon 6900XT | Crucial P2 1TB | Ballistix 2x16GB 3600CL16 | BQ DarkRock TF | Corsair SF600
Ik heb 'm hier besteld: https://www.empc.nl/index.php?page=64&sub=&Cat=174Astennu schreef op woensdag 25 januari 2006 @ 11:58:
[...]
Waar heb je em voor 529 gehaald ? en was i ook op vooraad ?
Gisteren hadden ze nog voorraad maar daar zijn ze nu blijkbaar doorheen.
529€ was trouwens inclusief verzending/verzekering. Op de site zelf staat ie voor 516,70incl.
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Sure morgen zal ik dat wel even testen. Ik test die stressed temp wel ff met een leuke HDR DemoSgtStrider schreef op woensdag 25 januari 2006 @ 14:47:
[...]
Is het mogelijk dat je ook ff temperatuur benched @ jouw systeem? Bijv. met ATi tool ofzo, en dan load/idle temps.
Uhmm okeey want dat is wel 20-30 euro minder dan wat ik er voor heb betaald alleen ik krijg em wel morgen binnen.CHeeCH schreef op woensdag 25 januari 2006 @ 14:57:
[...]
Ik heb 'm hier besteld: https://www.empc.nl/index.php?page=64&sub=&Cat=174
Gisteren hadden ze nog voorraad maar daar zijn ze nu blijkbaar doorheen.
529€ was trouwens inclusief verzending/verzekering. Op de site zelf staat ie voor 516,70incl.
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
Ik heb hem ook bij EMPC besteld; hij zou binnen 3 dagen binnen zijn zeiden ze. 
Bij mij thuis dus.
Bij mij thuis dus.
[ Voor 14% gewijzigd door Format-C op 25-01-2006 15:10 ]
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- Joepi
- Registratie: December 1999
- Laatst online: 06-07 13:54
Die Russen toch, echt een aanwinst!
Anton Shilov op z'n best!
http://www.xbitlabs.com/a...play/radeon-x1900xtx.html
hier hebben ze voor de gijn de cores van G70, R520, en R580 vergeleken

Anton Shilov op z'n best!
http://www.xbitlabs.com/a...play/radeon-x1900xtx.html
hier hebben ze voor de gijn de cores van G70, R520, en R580 vergeleken
- winwiz
- Registratie: September 2000
- Laatst online: 15:32
Zo.... hebbes........ en nu gaan we dus ff schroeven
Ben dus ff uit de lucht. Aardige lui daar in Vlaardingen, kopje koffie erbij... erg relaxt. Er lag trouwens achteloos een 1900 XTX op de toonbank, en die heeft een veel grotere doos Bijna dus de "verkeerde " meegenomen
Bijna dus de "verkeerde " meegenomen 
Ben dus ff uit de lucht. Aardige lui daar in Vlaardingen, kopje koffie erbij... erg relaxt. Er lag trouwens achteloos een 1900 XTX op de toonbank, en die heeft een veel grotere doos
Ryzen 5950x + 32GB GSKILL @3600 op Rog Strix Gaming E x570 + Asrock Phantom Gaming 6800XT+ Gigabyte Aorus FV43U Zwart + DS1621+ + DS414 + MacbookPro 16" 2021 + Mac Mini M4 Pro + Tesla MY RWD 2023 BYD

- CJ
- Registratie: Augustus 2000
- Niet online
Veel games met real time schaduwen maken gebruik van Z/Stencils, maar Doom3 was natuurlijk een erg extreem geval. ATi heeft trouwens wel een verdubbelde Z/Stencil rate wanneer er 2xMSAA gebruikt wordt. Je ziet hier dat de Z Fillrate niet veel zakt in vergelijking tot de No AA Z Fillrate.Astennu schreef op woensdag 25 januari 2006 @ 08:02:
[...]
Nu is het allemaal een stuk duidelijker. Maar wordt er nu veel gebruik gemaakt van die Z-Stencils ? of alleen Doom 3 en quake 4 waar er echt veel gebruik wordt gemaakt ? Want ATi heeft toch gekozen om er 16 te gebruiken in de R520/R580 en wel 8 in de RV530.
ATi heeft in de R520 1 pixelshaderengine per fragmentpipe. Dus totaal:En CJ. ATi kaarten hebben toch ook 2 Alu's per shader pipe ? Een kan ADD/MULL/MADD De 2e kan alleen ADD doen En ze hebben een Vector en een Scale alu.. Nvidia heeft er dan 2 die alles kunnen. Alleen wat dat ADD/MULL/MADD doet weet ik nog niet daar ga ik me vanmiddag maar eens in verdiepen. Ook hoe nvidia de pixelpipes opbouwd. Maar tot nu toe herb ik nog niet zo'n mooi overzicht van de G70 kunnen vinden @ anandtech. Voor de ATi staat wel de gehle opbouw er in. En wat de ALU's kunnen. Bij de G70 review niet. Het lijkt wel of nvidia dat voorzigzelf wil houden.
- 16 Vector MADD/ADD/MUL ALUs
- 16 Vector ADD ALUs
- 16 Branch Execution Units
R580 heeft totaal 3 pixelshaderengines per fragment pipe. Dus totaal
- 48 Vector MADD/ADD/MUL ALUs
- 48 Vector ADD ALUs
- 48 Branch Execution Units
Dus 48 volledige ALUs en 48 'halve' ALUs.
nVidia heeft 2 ALUs per fragment pipe bij G70, dus in totaal:
- 48 Vector MADD/ADD/MUL ALUs
Maar... per 2 ALUs per fragment pipe, houdt eentje zich ook bezig met texture processing instructions. Dus alleen in weinig voorkomende gevallen kan G70 beschikken over de volledige maximale ALU power. ATi heeft hier geen last van want die heeft dedicated texture processing units.
Voor de volledigheid, R500/Xenos heeft 16 Texture Fetch Units (en ook 16 Vertex Fetch Units). Alle games die dus ontwikkeld worden op de Xbox360 zijn hiervoor geoptimaliseerd. En ook bevat de Xbox360 alle flexibele HDR vormen die de R5x0 serie ook kan inclusief AA en natuurlijk 3Dc. Eventuele ports van de Xbox360 zullen zich dus zeer thuisvoelen op de R580/R520 (Halo3?).
Wat betreft Z/Stencils is het moeilijk te vergelijken. Ik geloof dat de R500/Xenos er 64 Z/Stencil operations per clockcycle aan kan. Maar dit gebeurt allemaal in de speciale eDRAM daughterdie (net zoals AA, alpha blending) en niet meer in de parent-die. Daarnaast is het geoptimaliseerd voor HDTV resoluties.
Het aantal ROPs staat ongeveer gelijk aan 8 (er wordt gesproken van 192 processing elements in de eDRAM daughterdie, maar de output staat ongeveer gelijk aan 8 pixel writes per cycle) en die hebben allemaal de mogelijkheid om 2x zo veel pixels te outputten wanneer er geen colour operations hoeven worden uitgevoerd (dus dubbel Z ratenet zoals RV530 en de meeste NV kaarten). Dus 16 pixels in dat laatste geval.
Doordat het eDRAM een interne bandbreedte heeft van 256GB/s, een interne buffer van 10MB (en met Tile Rendering werkt in die buffer), kan de Xbox360 dus zonder al te veel performanceverlies 4xMSAA doen (maximaal ong 4-5% performancedrop) en 2xMSAA zelfs helemaal zonder performancehit. Als pixeldata dus bewerkt is door de unified shaders, gaat het richting de daughterdie (eDRAM module) die zorgt voor de rest (blending, HDR, AA).
Je moet ook even de rest er bij pakken net niet alleen naar de oude PS2.0 texture intensieve tests. Je ziet dat een G70 nog steeds profijt heeft van het terugvallen naar partial precision (FP16), terwijl ATi's full precision (FP32) ongeveer net zo snel is als hun FP16. Belachelijk toch eigenlijk?Joepi schreef op woensdag 25 januari 2006 @ 13:33:
CJ, wat zeg je hiervan: die russen hebben wel door hoe het werkt in the bizz
[...]http://www.digit-life.com/articles2/video/r580-part2.html#p5
kan nog spannend worden ...
Daarnaast heeft ATi al maanden (half jaartje ongeveer?) aan gamedevelopers voornamelijk de X1600XT gegeven, zodat ze hun games konden optimaliseren/uitbalanseren voor een 3:1 ALU:TEX ratio voorzover ze dat nog niet gedaan hadden, want de meeste games gaan toch al richting ALU power.
Wat ik er van denk is dat nVidia ook dezelfde kant op gaat als ATi, dus het verhogen van de ALUs. Omdat nVidia tot nu toe de texture units niet heeft losgekoppeld van de rest van de pipeline, zoals ATi dat heeft gedaan, zal dit dus meeschalen met het aantal fragment pipes.
Gaan we uit van G71 met 32 fragment pipes met 2 ALUs per fragment pipe, dan is het totaal dus:
- 64 Vector MADD/ADD/MUL ALUs
Hiervan houden 32 zich ook bezig met texture operations, maar toch is het wel een vergroting in ALU power van 33%. De verwachting is dus dat nVidia ook uiteindelijk de texture units gaat loskoppelen van de fragmentpipes, want textures vreten veel bandbreedte (en shaders niet) en het omhoog gooien van het aantal texture units vereist veel meer van de bandbreedte (vandaar misschien dat GTX512 zo veel beter presteert dankzij veel meer bandbreedte en waarom er geruchten gaan dat G71 enorm veel bandbreedte heeft?). En die bandbreedte heb je ook nodig voor het vullen van die 16 ROPs voor zaken als HDR en MSAA (24 ROPs zou ofwel een 512-bit memory interface vereisen of supersnel GDDR4).
Je moet kiezen voor snelheid in oude games of in nieuwe games. Nieuwere games/engines gaan duidelijk voor meer shaderpower. Zie F.E.A.R., SC:CT, B&W2, HL2, Oblivion, UE3, Cry Engine 2. Oudere games gaan meer voor hoge texture fillrates. Veel games gebaseerd op de Q3 engine zijn zeer blij met veel TMUs. Maar hoeveel games komen er nog uit met een Q3 engine? En is de R520/R580 niet snel genoeg voor dat soort games die er al zijn? En zelfs D3 is bv een game met een technisch gezien 'oudere' engine die meer neigt naar OGL1.5 (vergelijkbaar met DX8.1 met af en toe wat PS2.0 achtige effecten)) en je ziet dat die generatie games meer profiteren van meer texture units. Maar hoe meer shaders er worden gebruikt, des te efficienter is een ATi kaart.
De conclusie van Digit Life is beter om te quoten:
Dus toekomstige games = meer ALUs is beter. Zelfs nVidia ziet dit, maar zoals het er nu naar uit ziet gaan ze dus voor brute kracht. Als hun pixelshaderengines niet zo goed zijn in dynamic branching en de vertexshaders niet snel zijn met vertex texturing, dan gooien we er gewoon meer van in op een veeeeeeeeeeel hogere snelheid, zodat het minder opvalt dat ze niet zo efficient zijn. Dit is natuurlijk absoluut niet verkeerd en zal z'n voordelen hebben in zowel oudere games als ook in nieuwere games, maar persoonlijk vind ik R580 een elegantere oplossing.What concerns the expedience of the new 3:1 formula accepted in Toronto (computing:texturing) - we have grounds to expect it bear some fruit. We can see that the newer the games, the more requirements they pose to shader computations. And vice versa, the older the game, the paler the efficiency of the X1900 XTX. It's obviously foolish to buy such a card for playing Quake3 or Serious Sam 1.
I also want to note that the efficiency of Shaders 3.0 in terms of (dynamic) branching is manifold higher in the X1900 XTX than in the competitor from NVIDIA, which may also have a positive effect in future games. But there is still one question remaining: how well will SM 3.0 be used in the light of the nearest appearance of DX Next (MS Vista), when games and engines have to be developed in a totally different way. Low dynamic branching performance in Shaders 3.0 in NVIDIA, as the main and only recent owner of these technologies, led to reluctant introduction of SM 3.0 into games. Even despite the texturing features in vertex pipelines, which are not available in the X1xxx. The time will show who was right.
Klopt, dat komt doordat er ook 48 branching units in zitten. Maar als je 1 R520 pixelshaderengine vergelijkt met 1 R580 pixelshaderengine, dan is de efficientie omlaag gegaan. Overigens heeft ATi er ook over nagedacht om R520 een 16-1-2-1 (dus 2 pixelshaderengines per fragment pipe) te geven.Verwijderd schreef op woensdag 25 januari 2006 @ 15:55:
DB is behoorlijk vooruit gegaan:
[afbeelding]
http://www.beyond3d.com/reviews/ati/r580/int/index.php?p=03Quote by Eric Deemers
When we designed the R520, we were already starting the design of the R580. The R580 (X1900) was designed to be both the next high end after R520, but was also designed to be more balanced overall for the newest applications. We designed the R520 first with a Spring 05 introduction target, and it was a reasonable design for that time, that introduced many new technologies. We might of done a 2x ALU, but there was already so much new technology in R520, that we decided against that. But it ended up being delayed, and so lost some of its steam due to that. I feel that for the current newest applications today, R580 is a better balanced part (given that it often doubles the performance of R520, I think that's reasonable). But in Spring 05, R520 would have rocked :-)
[ Voor 9% gewijzigd door CJ op 25-01-2006 16:03 ]
Technical PR Officer @ MSI Europe. My thoughts and opinions may not reflect the ones of my employer.
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Die G70 scoort goed in deze test. DE X1900 vaak wat beter. Maar ik verbaas me er over dat de G70 meer vertex power heeft dan bijde ATi kaarten. En die vertex shaders van ATi lopen op een hogere clocksnelheid.Verwijderd schreef op woensdag 25 januari 2006 @ 15:55:
DB is behoorlijk vooruit gegaan:
[afbeelding]
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- CJ
- Registratie: Augustus 2000
- Niet online
Waar zie jij in dat plaatje dat de G70 meer vertexpower heeft?Astennu schreef op woensdag 25 januari 2006 @ 16:00:
[...]
Die G70 scoort goed in deze test. DE X1900 vaak wat beter. Maar ik verbaas me er over dat de G70 meer vertex power heeft dan bijde ATi kaarten. En die vertex shaders van ATi lopen op een hogere clocksnelheid.
Dat is een test van Pixelshaderpower in PS2 en PS3 en heeft verder niets te maken met VS3... tenzij je Vertex Noise bedoeld?
Technical PR Officer @ MSI Europe. My thoughts and opinions may not reflect the ones of my employer.
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Jah die laatste bedoelde ik. Ik denk dat ik iets te veel op het woordje vertex heb geletCJ schreef op woensdag 25 januari 2006 @ 16:04:
[...]
Waar zie jij in dat plaatje dat de G70 meer vertexpower heeft?
Dat is een test van Pixelshaderpower in PS2 en PS3 en heeft verder niets te maken met VS3... tenzij je Vertex Noise bedoeld?
Kun je michien kort uit leggen wat:
ADD
MADD
MULL
bewerkingen doen ?
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- winwiz
- Registratie: September 2000
- Laatst online: 15:32
1e snelle bench met alles op stock 2005 = 10700.... In CCC staat alles op gebalanceerd. Temp idle = 51 en direct na 2005 was hij 69 graden. Ventilator sloeg nauwelijks hoorbaar aan.
Ryzen 5950x + 32GB GSKILL @3600 op Rog Strix Gaming E x570 + Asrock Phantom Gaming 6800XT+ Gigabyte Aorus FV43U Zwart + DS1621+ + DS414 + MacbookPro 16" 2021 + Mac Mini M4 Pro + Tesla MY RWD 2023 BYD
- Joepi
- Registratie: December 1999
- Laatst online: 06-07 13:54
Tja, we gaan hard op unified shaders, he en ati heeft ondertussen kostbare routine en is erdoor close inside R/D (Xenos!).
Vreemd dus, dat een spel als AoE3, dat nota bene van MS zelf is, dus DX9c puur, de R520 zo op het verkeerde ben heeft gezet!?
Dat hebben ze natuurlijk meteen gezien en zo is de keuze voor een super shader (3x meer) logies.
Moet er nu wel nog een R600 komen?
Welk spel zou dat dan wel moeten hebben?
Ik zie maar een, en die gebruikt stikkum D3D10!
We krijgen een situatie waar echt alles door elkaar begint te lopen, wat is nog dx9 en wat dx10 en wat ervan D3D10!?
Vreemd dus, dat een spel als AoE3, dat nota bene van MS zelf is, dus DX9c puur, de R520 zo op het verkeerde ben heeft gezet!?
Dat hebben ze natuurlijk meteen gezien en zo is de keuze voor een super shader (3x meer) logies.
Moet er nu wel nog een R600 komen?
Welk spel zou dat dan wel moeten hebben?
Ik zie maar een, en die gebruikt stikkum D3D10!
We krijgen een situatie waar echt alles door elkaar begint te lopen, wat is nog dx9 en wat dx10 en wat ervan D3D10!?
Verwijderd
Omg !  I switched sides. Ik had vanaf 9 December al een XFX 7800GTX 512 kaart op bestelling staan ; vandaag maar de order laten veranderen omdat de kaart nog zeker een maand vaporware is.
I switched sides. Ik had vanaf 9 December al een XFX 7800GTX 512 kaart op bestelling staan ; vandaag maar de order laten veranderen omdat de kaart nog zeker een maand vaporware is.
Dus de Asus X1900XTX wordt m'n eerste Ati kaart
Dus de Asus X1900XTX wordt m'n eerste Ati kaart
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
CongratsVerwijderd schreef op woensdag 25 januari 2006 @ 16:59:
Omg !
Dus de Asus X1900XTX wordt m'n eerste Ati kaart
Maar in veel Titels presteerd de X1K serie niet goed:
AoE 3
B&W 2
SS 2
Dawn of War
Pasific fighters
Zo maar een paar opgenoemd. Dus ik vraag me af waardoor dit is. Of het gaat bijna gelijk op of je ziet echt gigantiese verschillen zoals in de bovenstaande games. Dus het lijkt op een bug die mischien in alle games zit.
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
Verwijderd
Addition, Multiply and Addtion, Multiply?Astennu schreef op woensdag 25 januari 2006 @ 16:11:
[...]
Jah die laatste bedoelde ik. Ik denk dat ik iets te veel op het woordje vertex heb gelet
Kun je michien kort uit leggen wat:
ADD
MADD
MULL
bewerkingen doen ?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Verwijderd
lol juist de nieuwste kaarten in belgie gevonden (verkrijgbaar en de prijzen)
XFX 1900XTX 750 euro
XFX 1900XT 700 euro
belachelijk veel dus in vergelijking met nederland denk ik dan
om effe de vergelijking beter te maken hier de nvid kaartne
7800GTX 512mb 675 euro
7800GTX 256mb 493.50 euro
prijzen van tones.be toch wel gekend in belgie als een van de goedkopere
schandalig niet, kzou wel zo'n nieuw kaartje willen hebben , maar 30.000 BEF (om het oud uit te drukken) is toch wel wat veel van het goede
XFX 1900XTX 750 euro
XFX 1900XT 700 euro
belachelijk veel dus in vergelijking met nederland denk ik dan
om effe de vergelijking beter te maken hier de nvid kaartne
7800GTX 512mb 675 euro
7800GTX 256mb 493.50 euro
prijzen van tones.be toch wel gekend in belgie als een van de goedkopere
schandalig niet, kzou wel zo'n nieuw kaartje willen hebben , maar 30.000 BEF (om het oud uit te drukken) is toch wel wat veel van het goede
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Bestel je ze toch in NL ? voor 5 tot 15 euro meer bezorgen ze ook in het buitenlandVerwijderd schreef op woensdag 25 januari 2006 @ 17:43:
lol juist de nieuwste kaarten in belgie gevonden (verkrijgbaar en de prijzen)
XFX 1900XTX 750 euro
XFX 1900XT 700 euro
belachelijk veel dus in vergelijking met nederland denk ik dan
om effe de vergelijking beter te maken hier de nvid kaartne
7800GTX 512mb 675 euro
7800GTX 256mb 493.50 euro
prijzen van tones.be toch wel gekend in belgie als een van de goedkopere
schandalig niet, kzou wel zo'n nieuw kaartje willen hebben , maar 30.000 BEF (om het oud uit te drukken) is toch wel wat veel van het goede
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
Verwijderd
Ach ja.... ik had € 715 neergelegd voor de XFX 512xxx op 9 Dec. Icomputers krijgt morgen de Asus X1900XTX binnen tegen een lagere prijs. Games die ik graag speel ; SC Chaos Theory en binnenkort SC Double Agent en dit jaar Alan Wake etc ; dat zijn toch denk ik wel shader intensieve games.Astennu schreef op woensdag 25 januari 2006 @ 17:13:
[...]
Congrats
Maar in veel Titels presteerd de X1K serie niet goed:
AoE 3
B&W 2
SS 2
Dawn of War
Pasific fighters
HDR en AA tegelijkertijd ; eindelijk !
- CJ
- Registratie: Augustus 2000
- Niet online
Als je reviews leest, dan wordt vaak ook genoemd waarom dit is.Astennu schreef op woensdag 25 januari 2006 @ 17:13:
[...]
Congrats
Maar in veel Titels presteerd de X1K serie niet goed:
AoE 3
B&W 2
SS 2
Dawn of War
Pasific fighters
Zo maar een paar opgenoemd. Dus ik vraag me af waardoor dit is. Of het gaat bijna gelijk op of je ziet echt gigantiese verschillen zoals in de bovenstaande games. Dus het lijkt op een bug die mischien in alle games zit.
AoE3 (TWIMTPB game) maakt veel gebruik van FP16 HDR. Van FP16 HDR is nu bekend dat het mee schaalt met het aantal pixelshader units (G70 dus 24, R520 dus 16 en R580 dus 48). Hoe meer pixelshaderunits des te hoger de performance.
Pacific Fighters... OpenGL game. Need I say more? Tevens enigste (TWIMTBP) game die met een patch Vertex Texture Fetch gebruikt voor het water (en het daarmee gelijk haast onspeelbaar wordt).
B&W 2... gamebugs, Lionhead is al met een patch bezig ism ATi (zou Hexus of Driverheavendie gebruikt hebben?).
SS 2 - valt schijnbaar ook weer mee met de laatste patch + drivers, tevens ook TWIMTBP game met oa HDR gefinetuned voor de GF6/7 (zie bv de FP Filtering bug die er pas met de laatste patch uit is gehaald).
Warhammer 40000: Dawn of War.... maakt gebruik van een zwaar aangepaste Impossible Creatures engine... en die engine is een custom engine gemaakt voor de TNT/TNT2 generatie in de tijd dat het aantal TMUs nog een belangrijke rol speelde. Aan de engine toegevoegd zijn Hardware T&L en maakt verder gebruik van DX8.1 en stencil buffering voor schaduwen. Aan het begin is het ontwikkeld op GeForce3 kaarten en later op GeForce6 kaarten. En dan kijk je er vreemd van op dat het op een G70 met 24 Texture Units en 24 fragment pipes sneller is?
[ Voor 3% gewijzigd door CJ op 25-01-2006 18:12 ]
Technical PR Officer @ MSI Europe. My thoughts and opinions may not reflect the ones of my employer.
Verwijderd
ik vertrouw internet versturen, mijn oom werkt bij de post, ik vond niet leuk wat ik van hem hoorde, en zou er zo in prive verzend bedrijven ook zo aan toe gaanAstennu schreef op woensdag 25 januari 2006 @ 17:45:
[...]
Bestel je ze toch in NL ? voor 5 tot 15 euro meer bezorgen ze ook in het buitenland
(me is oldschool en gaat nog altijd naar de winkel om iets te kopen)
- m277755
- Registratie: Februari 2004
- Laatst online: 24-01-2022
leest meer dan hij typt
Geen idee dat die engine al zo oud was zeg, ziet er allemaal prima uit. Hij draait hier trouwens op mijn x1800xl stock op 1600x1200 met alle opties aan (zonder aa) meestal 60 fps en in de grote gevechten min 40 fps, dus dan maakt het allemaal niet zoveel meer uitCJ schreef op woensdag 25 januari 2006 @ 18:11:
[...]
Warhammer 40000: Dawn of War.... maakt gebruik van een zwaar aangepaste Impossible Creatures engine... en die engine is een custom engine gemaakt voor de TNT/TNT2 generatie in de tijd dat het aantal TMUs nog een belangrijke rol speelde. Aan de engine toegevoegd zijn Hardware T&L en maakt verder gebruik van DX8.1 en stencil buffering voor schaduwen. Aan het begin is het ontwikkeld op GeForce3 kaarten en later op GeForce6 kaarten. En dan kijk je er vreemd van op dat het op een G70 met 24 Texture Units en 24 fragment pipes sneller is?
Verwijderd
Heb ook de Asus XTX besteld. Alleen jammer dat Asus te lui is om de cooler van een eigenVerwijderd schreef op woensdag 25 januari 2006 @ 16:59:
Dus de Asus X1900XTX wordt m'n eerste Ati kaart
fancy plaatje te voorzien, Ruby staat er op.
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Het verbaast mij ook. Ik vind de game super maar ik heb de slechte peformance wel gemerkt vooral omdat ik ook AA en AF gebruikm277755 schreef op woensdag 25 januari 2006 @ 18:21:
[...]
Geen idee dat die engine al zo oud was zeg, ziet er allemaal prima uit. Hij draait hier trouwens op mijn x1800xl stock op 1600x1200 met alle opties aan (zonder aa) meestal 60 fps en in de grote gevechten min 40 fps, dus dan maakt het allemaal niet zoveel meer uit
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- Cheetah
- Registratie: Oktober 2000
- Laatst online: 26-06-2022
Alleen jammer dat Asus te lui is om die hele cooler te vervangen door iets stillersVerwijderd schreef op woensdag 25 januari 2006 @ 18:39:
Heb ook de Asus XTX besteld. Alleen jammer dat Asus te lui is om de cooler van een eigen
fancy plaatje te voorzien, Ruby staat er op.
Anders was ik voor ~540 voor de X1900XT nu al overstag geweest. Ik baal er van dat je bij montage van een aftermarket cooler problemen kunt krijgen met garantie
ASUS Max IV GENE-Z, Core i7 3770k, 16GB Kingston HyperX DDR3-1600, EVGA GTX970 FTW
Crucial M550 512GB SSD, 2TB WD HDD, LG GGW-H20L Blu/HD, Panasonic 40" AX630 UHD
Full Specz
- Oet
- Registratie: Mei 2000
- Laatst online: 13-07 17:57
[DPC]TG & MoMurdaSquad AYBABTU
Gun het even wat tijd, in het begin zul je altijd kaarten krijgen die BBA zijn, daarna komen pas de kaarten die door de verschillende producenten aangepast zijn naar hun smaak/visie.. Dat was bij mijn 9800pro 256mb van gigabyte ook..FirefoxAG schreef op woensdag 25 januari 2006 @ 19:05:
[...]
Alleen jammer dat Asus te lui is om die hele cooler te vervangen door iets stillers
Anders was ik voor ~540 voor de X1900XT nu al overstag geweest. Ik baal er van dat je bij montage van een aftermarket cooler problemen kunt krijgen met garantie
There are 11 kind of people in the world, ones that can read binary, ones that can't and ones that complain about my signature
PC Specs | Mo Murda Squad Clan
Verwijderd
Gewoon originele koeler bewaren voor het geval het mis gaat. Een goede schroevendraaier gebruiken zodat je de schroefjes niet beschadigt is voldoende om je garantie niet te verliezen. (oftewel, ze zien niet dat je de cooler vervangen had)FirefoxAG schreef op woensdag 25 januari 2006 @ 19:05:
[...]
Alleen jammer dat Asus te lui is om die hele cooler te vervangen door iets stillers
Anders was ik voor ~540 voor de X1900XT nu al overstag geweest. Ik baal er van dat je bij montage van een aftermarket cooler problemen kunt krijgen met garantie
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
Ik snap niet echt dat er mensen zijn die €100-150 MEER uitgeven voor een 1900XTX tov een XT.
Dus 25MHz core meer, en 50 mem tov de XT. Dat kan je er toch makkelijk zelf bijklokken?
Dus 25MHz core meer, en 50 mem tov de XT. Dat kan je er toch makkelijk zelf bijklokken?
[ Voor 10% gewijzigd door Format-C op 25-01-2006 19:22 ]
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
Verwijderd
Tja maar een XTX klokt dan natuurlijk ook weer verder dan een XT Je hebt altijd baas boven baas.
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
Zou het?
We zullen zien.
Alleen denk ik dat we met stock cooling niet ver komen. Als ik de reviews lees is het een aardige heethoofd die R580.
We zullen zien.
Alleen denk ik dat we met stock cooling niet ver komen. Als ik de reviews lees is het een aardige heethoofd die R580.
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- dennisvank
- Registratie: Mei 2005
- Laatst online: 27-06 16:49
Zijn er al aftermarket koelers voor de 1900 serie? Of passen de koelers van de 1800 serie ook op de 1900?
- winwiz
- Registratie: September 2000
- Laatst online: 15:32
Klopt, is hier geen enkel probleem. Het verschil is echter zeer klein en dat blijkt uit eigen ervaring en uit de reviews. De XTX die ik gezien heb ( stond toch nog ff te twijfelen ) had wel een veel grotere doos. Alle gekheid op een stokkie, er zit misschien meer potentieel in maar of dat ongeveer 20% prijsverschil waard isRappieRappie schreef op woensdag 25 januari 2006 @ 19:21:
Ik snap niet echt dat er mensen zijn die €100-150 MEER uitgeven voor een 1900XTX tov een XT.
Dus 25MHz core meer, en 50 mem tov de XT. Dat kan je er toch makkelijk zelf bijklokken?
[ Voor 20% gewijzigd door winwiz op 25-01-2006 19:43 ]
Ryzen 5950x + 32GB GSKILL @3600 op Rog Strix Gaming E x570 + Asrock Phantom Gaming 6800XT+ Gigabyte Aorus FV43U Zwart + DS1621+ + DS414 + MacbookPro 16" 2021 + Mac Mini M4 Pro + Tesla MY RWD 2023 BYD
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
Wat zijn jouw scores in 3DMark 03, 05 en 06? En wat zijn de load temperaturen? (Kan je opnemen met Rivatuner )
Daar ben ik eigenlijk wel HEEL nieuwschierig naar.
Daar ben ik eigenlijk wel HEEL nieuwschierig naar.
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- Biff
- Registratie: December 2000
- Laatst online: 30-01-2025
waar zijn de visjes
:strip_icc():strip_exif()/u/18572/heron1.jpg?f=community)
Mailtje winkelier: Asus ATI EAX1900XT bestelling verzonden
Ben benieuwd!
Na de 9800 Pro, die ik indertijd na een paar frustrerende dagen heb omgeruild voor een Nvidia, toch maar weer eens een ATI gokje gewaagd.
Ben benieuwd!
Na de 9800 Pro, die ik indertijd na een paar frustrerende dagen heb omgeruild voor een Nvidia, toch maar weer eens een ATI gokje gewaagd.
Yeah well. The Dude abides.
Verwijderd
Het geheugen van een XTX zal toch wel een stuk beter overclockbaar zijn dan van een XT. Er zit toch 1.1 geheugen op een XTX.
Alleen vreemd dat ze het geheugen dan niet meteen op 800 - 900 Mhz laten draaien. Blijkbaar is het voor ATI even duur of zelfs nog goedkoper om een hele zooi 1.1 geheugen te kopen ipv 1.1 en 1.2 voor de XTX. Of zit het anders?
Alleen vreemd dat ze het geheugen dan niet meteen op 800 - 900 Mhz laten draaien. Blijkbaar is het voor ATI even duur of zelfs nog goedkoper om een hele zooi 1.1 geheugen te kopen ipv 1.1 en 1.2 voor de XTX. Of zit het anders?
- Pubbert
- Registratie: Juni 2002
- Laatst online: 14:07
random gestoord
:strip_icc():strip_exif()/u/57026/drag0nico.jpg?f=community)
Bij 4Launch de goedkoopste X1900XTX, 525E voor de Sapphire, en op voorraad.
╔╗╔═╦╗
║╚╣║║╚╗
╚═╩═╩═╝
- Aight!
- Registratie: Juli 2004
- Laatst online: 17:21
'A toy robot...'
:strip_icc():strip_exif()/u/118853/Nintendo_Player_t-shirt_lin.jpg?f=community)
Die cooler van Artcic die nieuwe.dennisvank schreef op woensdag 25 januari 2006 @ 19:39:
Zijn er al aftermarket koelers voor de 1900 serie? Of passen de koelers van de 1800 serie ook op de 1900?
- Bever!
- Registratie: Maart 2004
- Laatst online: 16-07 23:12
3
wow die hanteren een kleine marge zeg, hulde!Thund3r schreef op woensdag 25 januari 2006 @ 19:58:
Bij 4Launch de goedkoopste X1900XTX, 525E voor de Sapphire, en op voorraad.
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
Dat is een XT . En geen XTX.Thund3r schreef op woensdag 25 januari 2006 @ 19:58:
Bij 4Launch de goedkoopste X1900XTX, 525E voor de Sapphire, en op voorraad.
[ Voor 3% gewijzigd door Format-C op 25-01-2006 20:06 ]
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- SAiN ONeZ
- Registratie: April 2004
- Laatst online: 12:00
Ⅎnll-Ԁɹooɟǝp Ⅎool
:strip_icc():strip_exif()/u/112011/crop64ec918860c01_cropped.jpg?f=community)
XT, degelijk verschil met 'jouw' XTXThund3r schreef op woensdag 25 januari 2006 @ 19:58:
Bij 4Launch de goedkoopste X1900XTX, 525E voor de Sapphire, en op voorraad.
edit:
[ Voor 6% gewijzigd door SAiN ONeZ op 25-01-2006 20:10 ]
N47h4N|The secret to creativity is knowing how to hide your sources| Dyslexic atheists don't believe in doG! | ˙ʞuɐlq ʇɟǝl ʎllɐuoᴉʇuǝʇuᴉ sɐʍ ǝɔɐds sᴉɥ┴ ®
- The Source
- Registratie: April 2000
- Laatst online: 11-07 21:45
:strip_exif()/u/5079/tweak.gif?f=community)
Het blijven belgen he.... XFX is nVidia only, en ze zouden willen dat ze ATI zouden verkopen, maar dan springt nVidia uit haar vel. Bovenstaande is dus BSVerwijderd schreef op woensdag 25 januari 2006 @ 17:43:
lol juist de nieuwste kaarten in belgie gevonden (verkrijgbaar en de prijzen)
XFX 1900XTX 750 euro
XFX 1900XT 700 euro
Anna FilatovaJoepi schreef op woensdag 25 januari 2006 @ 15:16:
Die Russen toch, echt een aanwinst!
Anton Shilov op z'n best!
http://www.xbitlabs.com/a...play/radeon-x1900xtx.html
Zal pas Q2 zijn.Oet schreef op woensdag 25 januari 2006 @ 01:01:
[...]
offtopic:
Weet iemand trouwens wanneer SocketM2 nou gaat komen, wanneer er RD580 bordjes voor M2 komen en de procs ervoor komen?? Heb zitten speuren op t.net en GoT maar kom niets noemenswaardigs tegen
[ Voor 48% gewijzigd door The Source op 25-01-2006 20:37 ]
- Help!!!!
- Registratie: Juli 1999
- Niet online
Heb net ff die kaart geinstalled maar nu geeft ie als ik 6.1 probeer te installeren: "INF Error. Video Driver Not Found".
Misschien toch nog resten van nVidia of Catalyst 6.1 ondersteunt X1900XT nog niet????
mmz Ik ga nog ns verder zoeken op Inet of heeft iemand hier een linkje naar de 6.2 ?
Misschien toch nog resten van nVidia of Catalyst 6.1 ondersteunt X1900XT nog niet????
mmz Ik ga nog ns verder zoeken op Inet of heeft iemand hier een linkje naar de 6.2 ?
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- edward2
- Registratie: Mei 2000
- Laatst online: 31-01 01:56
Schieten op de beesten
Volgens mij ondersteund de 6.1 idd de X1900 niet, je moet 5.13 of 6.2 (nog niet off uit) hebben.Help!!!! schreef op woensdag 25 januari 2006 @ 20:58:
Heb net ff die kaart geinstalled maar nu geeft ie als ik 6.1 probeer te installeren: "INF Error. Video Driver Not Found".
Misschien toch nog resten van nVidia of Catalyst 6.1 ondersteunt X1900XT nog niet????
mmz Ik ga nog ns verder zoeken op Inet of heeft iemand hier een linkje naar de 6.2 ?
Niet op voorraad.
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
Misschien een beetje offtopic: maar ik heb me laatst een beetje ge-ergerd aan CCC. Wat waren ook alweer de drivers zónder CCC?
Over een paar dagen heb ik hem hopelijk binnen, en dan wil ik niet dat geheugenslurpende CCC op mijn PC hebben staan.
Zodoende.
Edit: @ Edward: had je "hem" nog gevonden in de doos?
Over een paar dagen heb ik hem hopelijk binnen, en dan wil ik niet dat geheugenslurpende CCC op mijn PC hebben staan.
Zodoende.
Edit: @ Edward: had je "hem" nog gevonden in de doos?
[ Voor 13% gewijzigd door Format-C op 25-01-2006 21:06 ]
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- Help!!!!
- Registratie: Juli 1999
- Niet online
de CD met 5.13??? pakt ie idd wel! Maar ben een beetje gaar van het werk vandaag dus weet niet of ik nog veel ga testen.edward2 schreef op woensdag 25 januari 2006 @ 21:00:
[...]
Volgens mij ondersteund de 6.1 idd de X1900 niet, je moet 5.13 of 6.2 (nog niet off uit) hebben.
T is me wat moois, doen ze eindelijk een hard launch, zijn de bijbehorende drivers (6.2) nog niet af......
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Bij ATi zelf kun je drivers vinden met een Control Pannel. Maar die heeft niet alles opties. Die van Omega wel: www.omegadrivers.net.RappieRappie schreef op woensdag 25 januari 2006 @ 21:03:
Misschien een beetje offtopic: maar ik heb me laatst een beetje ge-ergerd aan CCC. Wat waren ook alweer de drivers zónder CCC?
Over een paar dagen heb ik hem hopelijk binnen, en dan wil ik niet dat geheugenslurpende CCC op mijn PC hebben staan.
Zodoende.
Edit: @ Edward: had je "hem" nog gevonden in de doos?
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- edward2
- Registratie: Mei 2000
- Laatst online: 31-01 01:56
Schieten op de beesten
RappieRappie schreef op woensdag 25 januari 2006 @ 21:03:
Misschien een beetje offtopic: maar ik heb me laatst een beetje ge-ergerd aan CCC. Wat waren ook alweer de drivers zónder CCC?
Over een paar dagen heb ik hem hopelijk binnen, en dan wil ik niet dat geheugenslurpende CCC op mijn PC hebben staan.
Zodoende.
Edit: @ Edward: had je "hem" nog gevonden in de doos?
offtopic:
Yep, alles gevonden.
Yep, alles gevonden.
Niet op voorraad.
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
En die drivers zijn net zo goed of beter?Astennu schreef op woensdag 25 januari 2006 @ 21:46:
[...]
Bij ATi zelf kun je drivers vinden met een Control Pannel. Maar die heeft niet alles opties. Die van Omega wel: www.omegadrivers.net.
En hoe zit het met de tweaked/ modified drivers van ATi dan? Maken ze die ook bij Tweaks R us? Ik zie daar wel X-G Warcat drivers staan nl. En ik zie op google nog DNA drivers en NGO?
Iemand daar nog ervaringen mee?
(Misschien niet het goeie topic hiervoor, zeg het dan maar even Dan hou ik erover op
@ Edward: gelukkig.
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Nja al die andere vind ik maar niets. Ik gebruik liever omega's en anders de orginele. Ik krijg me X1800 XL maar niet verkochtRappieRappie schreef op woensdag 25 januari 2006 @ 21:56:
[...]
En die drivers zijn net zo goed of beter?
En hoe zit het met de tweaked/ modified drivers van ATi dan? Maken ze die ook bij Tweaks R us? Ik zie daar wel X-G Warcat drivers staan nl. En ik zie op google nog DNA drivers en NGO?
Iemand daar nog ervaringen mee?
(Misschien niet het goeie topic hiervoor, zeg het dan maar even Dan hou ik erover op
@ Edward: gelukkig.
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
Had ik geluk dat ik een GTX had. Ik heb hem vanmiddag te koop gezet; na 2 uur was ik hem kwijt.
Maar goed,
bedankt Astennu;
dan zal ik die omega's proberen zodra ik mijn kaart binnen heb.
Mijn PC gebruikt nu, met een Nv kaart, idle in Windows, 158MB geheugen.
Met CCC gebruikte hij 240MB. Ik vind bijna 100MB voor wat drivers wel heel erg veel, zodoende.
EDIT:
Zijn er al mensen met REAL-life benches? Ik zag dat wat mensen de X1900 al hadden, maar ik zie nog steeds geen resultaten.
Maar goed,
bedankt Astennu;
dan zal ik die omega's proberen zodra ik mijn kaart binnen heb.
Mijn PC gebruikt nu, met een Nv kaart, idle in Windows, 158MB geheugen.
Met CCC gebruikte hij 240MB. Ik vind bijna 100MB voor wat drivers wel heel erg veel, zodoende.
EDIT:
Zijn er al mensen met REAL-life benches? Ik zag dat wat mensen de X1900 al hadden, maar ik zie nog steeds geen resultaten.
[ Voor 20% gewijzigd door Format-C op 25-01-2006 22:15 ]
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Nja voor de omega's moet je wel 5.13 pakken of wachten op de 6.2 drivers. Andere ondersteunen de X1900 niet.RappieRappie schreef op woensdag 25 januari 2006 @ 22:12:
Had ik geluk dat ik een GTX had. Ik heb hem vanmiddag te koop gezet; na 2 uur was ik hem kwijt.
Maar goed,
bedankt Astennu;
dan zal ik die omega's proberen zodra ik mijn kaart binnen heb.
Mijn PC gebruikt nu, met een Nv kaart, idle in Windows, 158MB geheugen.
Met CCC gebruikte hij 240MB. Ik vind bijna 100MB voor wat drivers wel heel erg veel, zodoende.
EDIT:
Zijn er al mensen met REAL-life benches? Ik zag dat wat mensen de X1900 al hadden, maar ik zie nog steeds geen resultaten.
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- edward2
- Registratie: Mei 2000
- Laatst online: 31-01 01:56
Schieten op de beesten
Ik ook. Maar moet eerst een goed bod vangen op m'n 7800GTX 512 mb extreme, want die gaat niet zomaar weg.Verwijderd schreef op woensdag 25 januari 2006 @ 22:37:
mm, ik zit nog te dubben tussen de xt en de xtx, hebben beiden nou het 1.1ns geheugen?
Anderzijds, ik heb geen haast, de X1900 kan z'n krachten nog niet goed kwijt in het huidige gameaanbod (COD2 en FEAR springen er het meest uit) Oblivion volgt? voor die laatste game alleen al zou ik het doen als er idd veel verschil inzit.
Niet op voorraad.
- Aight!
- Registratie: Juli 2004
- Laatst online: 17:21
'A toy robot...'
Die GTX 512 gaat ook nog goed mee in de huidige games, dus jij bent nog wel eventjes zoet.
Ik ben alleen bang dat ik mijn X850XT niet meer kwijt kan, alleen voor 200 euro of zo, maak ik er nog verlies op balen.
Ik ben alleen bang dat ik mijn X850XT niet meer kwijt kan, alleen voor 200 euro of zo, maak ik er nog verlies op balen.
- Bull
- Registratie: December 2000
- Laatst online: 16-07 19:57
:strip_icc():strip_exif()/u/18583/Dragon%2520Age%252060x60.jpg?f=community)
Vergeet Gothic 3 nietIk ook. Maar moet eerst een goed bod vangen op m'n 7800GTX 512 mb extreme, want die gaat niet zomaar weg.
Anderzijds, ik heb geen haast, de X1900 kan z'n krachten nog niet goed kwijt in het huidige gameaanbod (COD2 en FEAR springen er het meest uit) Oblivion volgt? voor die laatste game alleen al zou ik het doen als er idd veel verschil inzit.
- Joepi
- Registratie: December 1999
- Laatst online: 06-07 13:54
http://www.beyond3d.com/reviews/ati/r580/int/index.php?p=04In an effort to dig further into ATI's thinking behind the design of R580 and gain a greater understanding of the decisions that have lead to this process we decided to put some questions to them. In replay we have answers from Eric Demers, from ATI's Desktop Graphics Engineering group, as well as a few comments from Richard Huddy, who brings in the perspective from their ISV relations group, which has a front line role to play with developers and who plays an important part in shaping future hardware.
The Source:
klopt! sorry dat ik haar vergeten ben :Anna S. Filatova, Editor in Chief

http://www.xbitlabs.com/misc/about.html
[ Voor 15% gewijzigd door Joepi op 26-01-2006 00:54 ]
- Help!!!!
- Registratie: Juli 1999
- Niet online
Heb gisteravond nog even twee 3Dmark06 runs kunnen doen.
CPU std op 2400mhz (200*12): 4485
CPU oc op 2605mhz (217*12): 4594
Is maar 100 puntjes verschil.
De gedownloade 5.13 pakt ie bij mij niet. De enige driver die wel pakt is de bijgeleverde CD, dit is dan ook voor het eerst dat ik zo'n CD gebruik.... In driverproperties staat er "Driver Version: 8.203.0.0"
Iemand enig idee welke versie dit is
En wanneer komt 6.2 ongeveer uit?
Ook mooi is dat ik binnenkort eindelijk ATI tray tools weer kan gebruiken.
CPU std op 2400mhz (200*12): 4485
CPU oc op 2605mhz (217*12): 4594
Is maar 100 puntjes verschil.
De gedownloade 5.13 pakt ie bij mij niet. De enige driver die wel pakt is de bijgeleverde CD, dit is dan ook voor het eerst dat ik zo'n CD gebruik....
Iemand enig idee welke versie dit is
En wanneer komt 6.2 ongeveer uit?
Ook mooi is dat ik binnenkort eindelijk ATI tray tools weer kan gebruiken.
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- Format-C
- Registratie: Maart 2005
- Laatst online: 16:49
Wat haal je in '05 dan?
[ Voor 48% gewijzigd door Format-C op 26-01-2006 08:20 ]
Ducati 899 Panigale / CM MB511/ 7800X3D @ ML360R/ RTX5090 Phantom/ Gbyte B650 GAMING PLUS/ 32GB G.Skill Z5 6000 CL30 A-Die/ Team M2 1TB/ 990Pro M2 1TB/ MX500 1TB/ 5TB SATA / Gbyte WBAX200/ Corsair 1000w/ Scarlett Solo / AOC AG493UCX/ LG 65" OLED TV
- Help!!!!
- Registratie: Juli 1999
- Niet online
Heb helaas geen tijd om 05 nu te installeren en draaien. Moet helaas werken..... Vanavond kan ik wel wat meer benchen
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
Verwijderd
ik moet snel zon X1900 zien te bemachtigen mja de XTX is nerges leverbaar en wil toch wel 1.1ns geheuge
mja nog ma ff w8te dan
mja nog ma ff w8te dan
- Help!!!!
- Registratie: Juli 1999
- Niet online
Iemand was anders bij een shop waar ze er gewoon 1 hadden liggen..Verwijderd schreef op donderdag 26 januari 2006 @ 08:30:
ik moet snel zon X1900 zien te bemachtigen
mja nog ma ff w8te dan
...... gevonden:
Moet je even aan hem vragen welke shop dit waswinwiz schreef op woensdag 25 januari 2006 @ 15:34:
Zo.... hebbes........ en nu gaan we dus ff schroeven
Ben dus ff uit de lucht. Aardige lui daar in Vlaardingen, kopje koffie erbij... erg relaxt. Er lag trouwens achteloos een 1900 XTX op de toonbank, en die heeft een veel grotere doos
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
Lol de XT's zouden ook 1.1 ns hebbenVerwijderd schreef op donderdag 26 januari 2006 @ 08:30:
ik moet snel zon X1900 zien te bemachtigen
mja nog ma ff w8te dan
En vlaardingen = iComputers daar komt mijn X1900 XT ook vandaan die hadden er best wat binnen gekregen.
[ Voor 11% gewijzigd door Astennu op 26-01-2006 09:07 ]
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
- CJ
- Registratie: Augustus 2000
- Niet online
6.2 komt begin februari uit en zal wat leuke boosts hebben voor de X1900 zeker als je het vergelijkt met de bijgeleverde drivers of 5.13. Eric Deemers heeft aangegeven dat ze dus begin februari uit komen, maar dat er misschien nog wel "andere manieren" waren om er aan te komen (waarmee hij impliciet naar gelekte versies hintte).Help!!!! schreef op donderdag 26 januari 2006 @ 08:15:
En wanneer komt 6.2 ongeveer uit?
Ook mooi is dat ik binnenkort eindelijk ATI tray tools weer kan gebruiken.
Technical PR Officer @ MSI Europe. My thoughts and opinions may not reflect the ones of my employer.
- Astennu
- Registratie: September 2001
- Laatst online: 24-04 12:13
100% zeker weet ik het nog niet he !. Maar de revieuw sites zijden ook dat dat zo was. Dan hun XT's ook 1.1 hadden en ze dus niet goed begrepen wat de meerwaarde van een X1900 XTX was.
Ik zal het vanmiddag testen/Nakijken of het echt zo is.
LET OP!!! dyslectisch Dus spelling kan verkeerd zijn!!! -- RIP CJ, The ATi Topic wont be the same without you.....
![]() Dit topic is gesloten.
Dit topic is gesloten.
![]()