:strip_icc():strip_exif()/u/85118/smoker.jpg?f=community)
"I believe that forgiving them is God's function. Our job is simply to arrange the meeting."
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
:strip_exif()/u/17028/ico_sphere.gif?f=community)
Niet met GTX ervoor nee, maar wel Geforce: Wikipedia: GeForce
Van de Geforce FX5000 series tot de Geforce 9000-series.
Van de Geforce FX5000 series tot de Geforce 9000-series.
- Indy91
- Registratie: Oktober 2005
- Laatst online: 13-04 21:10
:strip_exif()/u/158601/prmm3.gif?f=community)
@Phuncz:
Zelfs vanaf de GeForce 4000 series: Ti4200, Ti4400 en de Ti4600.
Zelfs vanaf de GeForce 4000 series: Ti4200, Ti4400 en de Ti4600.
offtopic:
Een heerlijke kaartje was dat, de GeForce Ti4200… mijn voorgaande kaart was de Matrox Millenium G400, dus qua 3D performance ging ik met een sprong vooruit.
Een heerlijke kaartje was dat, de GeForce Ti4200… mijn voorgaande kaart was de Matrox Millenium G400, dus qua 3D performance ging ik met een sprong vooruit.
[ Voor 53% gewijzigd door Indy91 op 16-09-2015 14:13 ]
AMD CPU FX-8350@4,4GHz | Scythe Fuma | Scythe Kaze Master II | Asus M5A97 Rev.2 | Sapphire RX 480 Nitro OC+ | 16GB Geil Black Dragon DDR1600 | 480 Sandisk Ultra II SSD | Corsair GamingSeries 800Watt | Creative Tactic 3D Alpha | Corsair Gaming M65
Verwijderd
Ik heb weer een nieuwe dx 12 demo draaien van Zelda maar waarom geeft fraps of MSI afterburner geen fps weer? Is daar een ander programma voor want wil de framerate testen al is het zonder te benchen. Dit is trouwens een mooiere demo dan die andere Unreal dx 12 demo's deze is meer foto realistisch
- Xtr3me4me
- Registratie: Juli 2009
- Laatst online: 27-08-2024
Saiyajin Godlike Tweaker
:strip_icc():strip_exif()/u/309946/crop57082da2bca91.jpeg?f=community)
Ken gij die delen?Verwijderd schreef op donderdag 17 september 2015 @ 11:22:
Ik heb weer een nieuwe dx 12 demo draaien van Zelda maar waarom geeft fraps of MSI afterburner geen fps weer? Is daar een ander programma voor want wil de framerate testen al is het zonder te benchen. Dit is trouwens een mooiere demo dan die andere Unreal dx 12 demo's deze is meer foto realistisch
-- My Gaming Rig Power -- -- <SG> Diabolic --
Verwijderd
Bij deze video staat gelijk de link
YouTube: Unreal Engine 4 \[4.9] Zelda OOT : Dark Young Link DX12 + Download link
De demo draait vloeiend maar meer kan ik er ook niet van zeggen.
Enige wat ik nu wel werkende heb om te zien in beeld is Physx over de cpu.
YouTube: Unreal Engine 4 \[4.9] Zelda OOT : Dark Young Link DX12 + Download link
De demo draait vloeiend maar meer kan ik er ook niet van zeggen.
Enige wat ik nu wel werkende heb om te zien in beeld is Physx over de cpu.
[ Voor 25% gewijzigd door Verwijderd op 17-09-2015 11:34 ]
Verwijderd
Nog geen ondersteuning voor DX12 dan.Verwijderd schreef op donderdag 17 september 2015 @ 11:22:
Ik heb weer een nieuwe dx 12 demo draaien van Zelda maar waarom geeft fraps of MSI afterburner geen fps weer?
- haarbal
- Registratie: Januari 2010
- Laatst online: 20:04
Werkt shadowplay met dx12?
Mechwarrior Online: Flapdrol
Verwijderd
Ja alleen opname en niet de fraps teller die andere demo's lieten wel de fps zien met afterburnerhaarbal schreef op donderdag 17 september 2015 @ 11:40:
Werkt shadowplay met dx12?
[ Voor 13% gewijzigd door Verwijderd op 17-09-2015 11:51 ]
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
:strip_exif()/u/211274/bestabstractwallpapers5.gif?f=community)
Moet nog wel wat gebeuren aan die demo, link flikkert behoorlijk in het begin stuk. Er wordt gigantisch veel DOF/Bokeh gebruikt waardoor je helaas de rest van de wereld mist, maar dit is misschien een kwestie van smaak. Het lijkt in mijn ogen haast meer op de hitte die je ziet in een woestijnVerwijderd schreef op donderdag 17 september 2015 @ 11:32:
Bij deze video staat gelijk de link
YouTube: Unreal Engine 4 \[4.9] Zelda OOT : Dark Young Link DX12 + Download link
De demo draait vloeiend maar meer kan ik er ook niet van zeggen.
Enige wat ik nu wel werkende heb om te zien in beeld is Physx over de cpu.
Kan je Shadowplay ook laten opnemen met een oneindig aantal fps? Je kan op die manier als hack je fps zien indien je videoplayer het kan uitlezen
Verwijderd
Helaas gaat Shadowplay maar tot 60 fps en in de andere dx 12 demo's zat ik daar al ver boven.
Verwijderd
Nvidia Pascal GP100 GPUs spotted in transit from TSMC
En word een batch getest bij Nvidia als ik het goed begrijp?
Hoe lang kan het dan nog duren voor deze nieuwe videokaart uit komt?
http://hexus.net/tech/new...pus-spotted-transit-tsmc/
En word een batch getest bij Nvidia als ik het goed begrijp?
Hoe lang kan het dan nog duren voor deze nieuwe videokaart uit komt?
http://hexus.net/tech/new...pus-spotted-transit-tsmc/
Verwijderd
Begin juni, eind mei dit jaar was waarschijnlijk de eerste tapeout van de GP100 GPU. Wat je nu allemaal ziet zijn nog allemaal testchips, daarom zijn het er ook zo weinig. Zou zo maar nog een jaar kunnen duren voor de launch, sowieso zou het het niet voor de zomer van volgend jaar verwachten.
- LongBowNL
- Registratie: Juni 2009
- Laatst online: 15-07 14:43
Precies, ik zocht even naar de Fiji chip van AMD. Die werd op 7 november 2014 gespot in shipping notices. Release was zomer 2015. Dus het kan nog even duren.
- madmaxnl
- Registratie: November 2009
- Laatst online: 09-08-2022
:strip_exif()/u/327460/cowboy.gif?f=community)
Vergeet wel niet dat Fiji nog niet echt geweldig beschikbaar is... Dus release zegt op zichzelf ook nog niks.
Hoe staat AMD er met zij Artic Islands ervoor m.b.t. tapeout enzovoort?
Hoe staat AMD er met zij Artic Islands ervoor m.b.t. tapeout enzovoort?
[ Voor 51% gewijzigd door madmaxnl op 22-09-2015 17:06 ]
- XanderDrake
- Registratie: November 2004
- Laatst online: 14:41
Build the future!
Pascal was toch gepland voor Q1 2016, of in ieder geval H1 2016?
Iemand eerder in het topic had het uitgerekend vanaf de tapout, die kwam aan begin 2016.
Iemand eerder in het topic had het uitgerekend vanaf de tapout, die kwam aan begin 2016.
Hephaestus: Xeon 2680 v2 - 64GB ECC Quad - WD Blue 3D 1TB
Virtualis: Ryzen 3700X - 16GB DDR4 - Gigabyte 1080 Ti OC - Sandisk 2TB - Valve Index
Agon:Valve Steam Deck 64GB
Non scholae sed vitae discimus Seneca
Verwijderd
Ook rond deze tijd, tenminste een FinFET product, kan eventueel ook een APU of CPU zijn.madmaxnl schreef op dinsdag 22 september 2015 @ 17:00:
Hoe staat AMD er met zij Artic Islands ervoor m.b.t. tapeout enzovoort?
http://www.kitguru.net/co...ur-first-finfet-products/
http://www.kitguru.net/co...and-baffin-and-ellesmere/
Valt weinig aan uit te rekenen als je ook afhankelijk van andere bedrijven bent (TSMC), het gaat over een nieuw productieprocess, met een nieuwe GPU architectuur en nieuw geheugen in de vorm van HBM2.XanderDrake schreef op dinsdag 22 september 2015 @ 17:03:
Pascal was toch gepland voor Q1 2016, of in ieder geval H1 2016?
Iemand eerder in het topic had het uitgerekend vanaf de tapout, die kwam aan begin 2016.
- JayJay
- Registratie: September 2009
- Laatst online: 17-06-2024
:strip_icc():strip_exif()/u/317261/crop566fe8e7746f5_cropped.jpeg?f=community)
Ik wil graag  Aankoopadvies vragen mag weer.. (maar lees eerst dit!)
Aankoopadvies vragen mag weer.. (maar lees eerst dit!)
[ Voor 69% gewijzigd door br00ky op 23-09-2015 20:06 ]
- haarbal
- Registratie: Januari 2010
- Laatst online: 20:04
Mjah, met hyper Q kan je meerdere compute taken tegelijk uitvoeren.
Maar niet graphics en compute tegelijk.
Maar niet graphics en compute tegelijk.
Mechwarrior Online: Flapdrol
Verwijderd
Mmm lijkt me een goede toevoeging voor voor games zo lang het maar performance winst geeft of dat de gpu meer draw calls uit kunt voeren zonder dat het een extreme hit geeft op de performance.
- Werelds
- Registratie: Juli 2007
- Laatst online: 08-07 13:40
haarbal schreef op woensdag 23 september 2015 @ 13:15:
Mjah, met hyper Q kan je meerdere compute taken tegelijk uitvoeren.
Maar niet graphics en compute tegelijk.
HyperQ is al actief. Het is een feature die er vanaf Kepler in zit, 2012 dus. Het is een hybride scheduler, die het merendeel op de CPU plant. Zie http://www.overclock.net/...wd-sourcing#post_24385652 en mijn eerdere post.Verwijderd schreef op woensdag 23 september 2015 @ 13:29:
Mmm lijkt me een goede toevoeging voor voor games zo lang het maar performance winst geeft of dat de gpu meer draw calls uit kunt voeren zonder dat het een extreme hit geeft op de performance.
Verwijderd
Maar niet in games actief voor dx 12 wat Nvidia wil gaan doen voor geforce kaarten zodat er als nog performance winst te behalen is zoals AMD dat ook doet via hardware alleen gaat dat bij nvidia dan over de cuda cores. Dus dat werk ook niet alleen maar softwarematig?
[ Voor 69% gewijzigd door Verwijderd op 23-09-2015 17:56 ]
- Jeroenneman
- Registratie: December 2009
- Laatst online: 03-05-2024
Pre-order/Early Acces: Nee!
/u/331213/crop56ef13408ff38_cropped.png?f=community)
Ehm wat?Verwijderd schreef op woensdag 23 september 2015 @ 17:49:
Maar niet in games actief voor dx 12 wat Nvidia wil gaan doen voor geforce kaarten zodat er als nog performance winst te behalen is zoals AMD dat ook doet via hardware alleen gaat dat bij nvidia dan over de cuda cores.
Nvidia zal wel weer iets verzinnen met Pascal. Zolang ze maar lekker stil en krachtig zijn zal het me verroesten hoe ze dat bereiken.
| Old Faithful | i7 920 @ (3,3Ghz) / X58 UD4P / GTX960 (1,550Mhz) / CM 690 | NOVA | i5 6600K (4,4Ghz) / Z170 Pro Gaming / GTX 960 (1,500Mhz) / NZXT S340
- XanderDrake
- Registratie: November 2004
- Laatst online: 14:41
Build the future!
OK. In dit bericht van een paar dagen geleden, zegt Fudzilla dat productie start in Q1 2016. Daarmee kan het natuurlijk begin januari zijn of eind maart, maar het duurt daarna niet zo lang meer toch? Paar maanden?Verwijderd schreef op dinsdag 22 september 2015 @ 18:02:
Valt weinig aan uit te rekenen als je ook afhankelijk van andere bedrijven bent (TSMC), het gaat over een nieuw productieprocess, met een nieuwe GPU architectuur en nieuw geheugen in de vorm van HBM2.
Hephaestus: Xeon 2680 v2 - 64GB ECC Quad - WD Blue 3D 1TB
Virtualis: Ryzen 3700X - 16GB DDR4 - Gigabyte 1080 Ti OC - Sandisk 2TB - Valve Index
Agon:Valve Steam Deck 64GB
Non scholae sed vitae discimus Seneca
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
Welke DX12 games bedoel je ?Verwijderd schreef op woensdag 23 september 2015 @ 17:49:
Maar niet in games actief voor dx 12 wat Nvidia wil gaan doen voor geforce kaarten zodat er als nog performance winst te behalen is zoals AMD dat ook doet via hardware alleen gaat dat bij nvidia dan over de cuda cores. Dus dat werk ook niet alleen maar softwarematig?
- Help!!!!
- Registratie: Juli 1999
- Niet online
/u/400/defember100.png?f=community)
Lijkt me dan inderdaad niet langer dan paar maanden te duren voordat er voldoende voorraad is opgebouwd. Ervan uitgaande dat massaproductie smooth loopt. Maar ja, wie durft daar zijn hand voor in het vuur te steken.XanderDrake schreef op woensdag 23 september 2015 @ 20:33:
[...]
OK. In dit bericht van een paar dagen geleden, zegt Fudzilla dat productie start in Q1 2016. Daarmee kan het natuurlijk begin januari zijn of eind maart, maar het duurt daarna niet zo lang meer toch? Paar maanden?
Mijn glazen bol zegt dat ze niet eerder dan april komen en waarschijnlijk pas juni/aug.
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- Werelds
- Registratie: Juli 2007
- Laatst online: 08-07 13:40
Nee, dat gaat niet "over de CUDA cores". Ik zal de afbeelding van de oc.net post er bij nemen en uit leggen.Verwijderd schreef op woensdag 23 september 2015 @ 17:49:
Maar niet in games actief voor dx 12 wat Nvidia wil gaan doen voor geforce kaarten zodat er als nog performance winst te behalen is zoals AMD dat ook doet via hardware alleen gaat dat bij nvidia dan over de cuda cores. Dus dat werk ook niet alleen maar softwarematig?

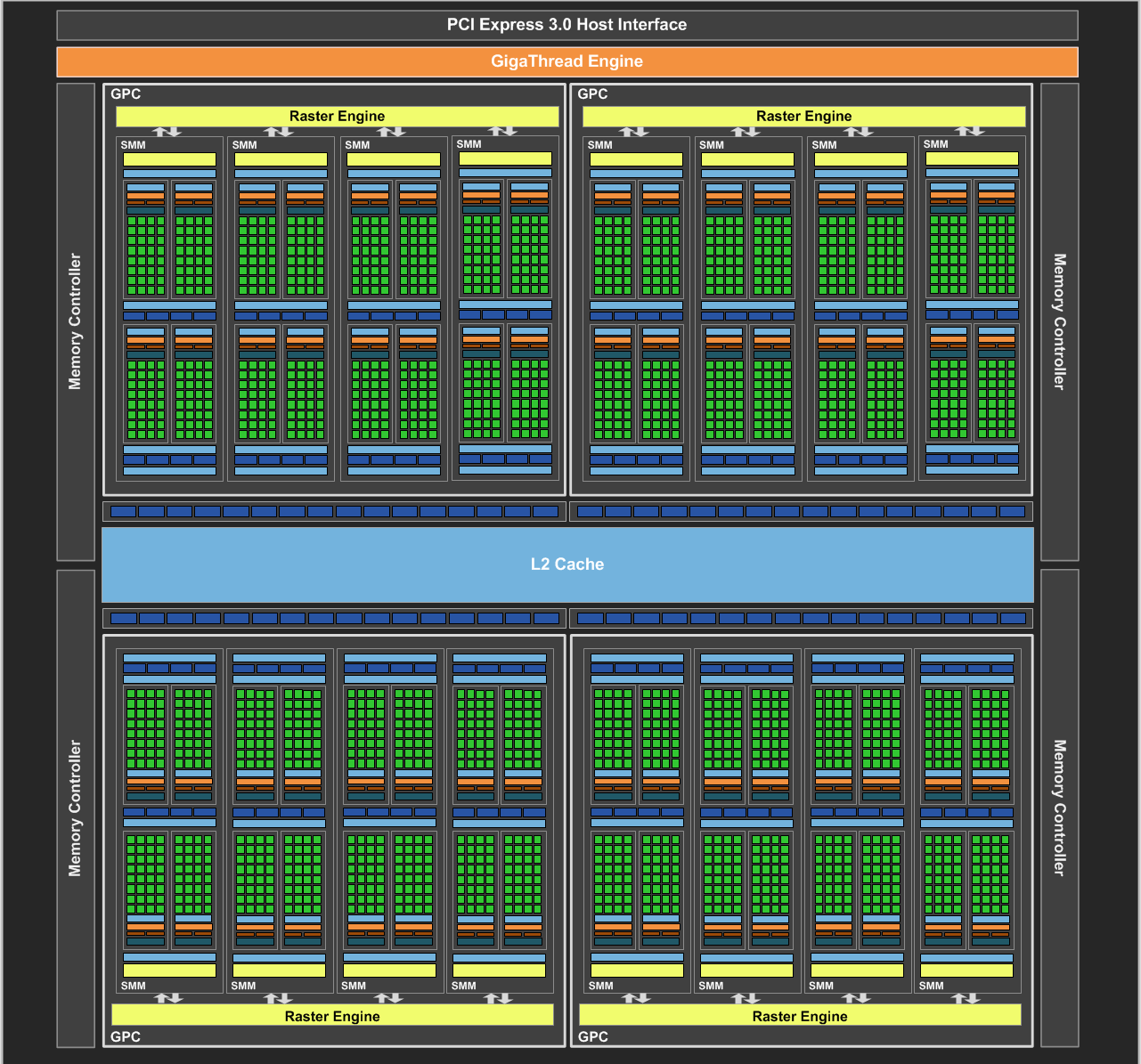
Alles in dit diagram zit in software op de CPU - behalve die SMX'en onderaan, dat is het enige stukje GPU hier. In elke SMX/SMM (cluster van Shader Processors...of "CUDA Core" in Nvidia marketing termen) zit een Asynchronous Warp Scheduler. Die laatste is degene die weet welke SP bezet is in "zijn" cluster en welke niet. Het werk is dan echter al verdeeld. En elk van die AWS'en heeft geen flauw benul hoe druk de andere clusters zijn. Het gevolg is dat die Grid Management Unit regelmatig moet wachten tot hij antwoord van de GPU krijgt, anders weet hij niet of er al resources vrij zijn; en waar. Dat brengt latency met zich mee en zorgt er voor dat je alsnog korte resource barriers hebt.
Bekijk nu de volgende diagrammen eens (deze doe ik als platte links, zijn iets te groot
http://images.anandtech.c...0_Block_Diagram_FINAL.png
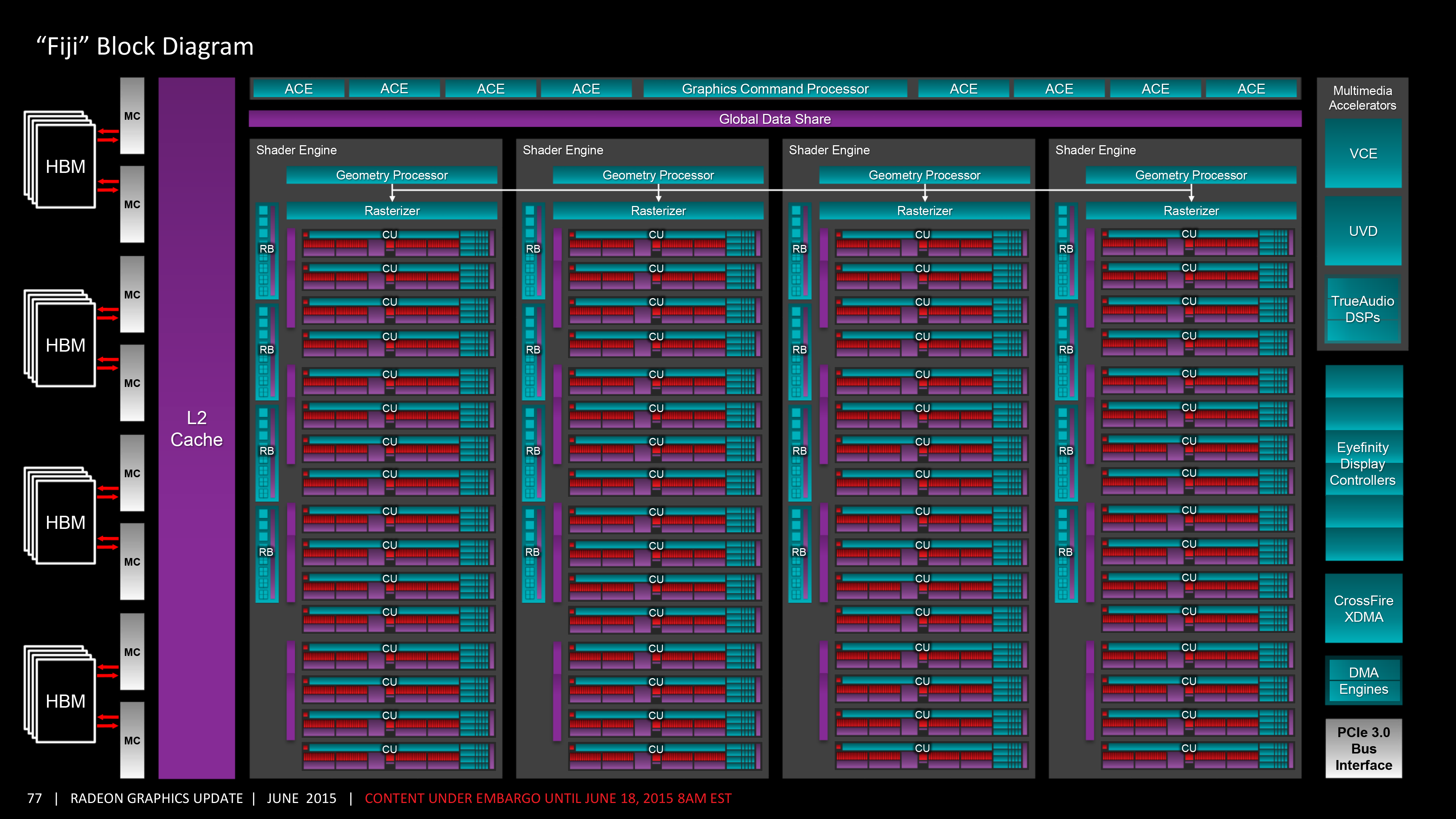
http://images.anandtech.com/doci/9390/FijiBlockDiagram.png
Bij AMD zitten de queues in de GPU, maar vóór de cluster groepen (ACE bovenin). De ACE's kunnen ook elke CU aansturen en weten welke CUs bezig zijn. Zij kunnen dus heel nauwkeurig het werk verdelen, ongeacht hoe en waar het binnen komt. Nog veel belangrijker, ze weten ook van tevoren waar er binnenkort ruimte is (dat is dat preemption verhaal). Dat is wat Nvidia mist. Zij moeten aan de software kant al een hoop werk verdelen. Dat verdelen brengt wachttijd met zich mee, omdat ze niets naar de GPU kunnen sturen voordat ze weten of daar ruimte voor is.
Poging tot een analogie (bear with me
Bij AMD gaat iedereen fijn in een van de 64 rijen (queues) staan en zijn er per 8 rijen 1 verkeersagent (ACE). Die verkeersagenten zien op een live kaart precies welke uitvalswegen en uitgangen het drukst zijn en dirigeren op basis daar van. Klaar.
Bij Nvidia staat er midden op de parkeerplaats een enkele verkeersagent (GMU). Die heeft een walkietalkie waarmee hij met de gasten bij de uitgangen communiceert. Pas als hij van hen hoort dat er ruimte is, laat hij auto's door. Vervolgens komen die bij de uitgangen, maar wordt er dan pas gekeken welke uitvalswegen het rustigste zijn en waar ze precies terecht komen. Die agent in het midden probeert wel zo slim mogelijk auto's te verdelen, maar hij is toch afhankelijk van die andere gasten.
Je moet overigens wellicht eens Anandtech's oudere artikelen lezen. Ik ben wellicht een mierenneuker, maar termen als "CUDA Core" zijn grote onzin. Het klinkt mooi, maar als puntje bij paaltje komt is dat gewoon een Shader Processor en kan Nvidia daar niet meer mee dan AMD met die van hen kan. Als je een beetje door de oudere artikelen heen gaat zie je hoe de GPU's zich ontwikkelen en zul je ook iets abstracter gaan denken. Ik denk dat je dan ook beter begrijpt waar de "grenzen" zitten.
- XanderDrake
- Registratie: November 2004
- Laatst online: 14:41
Build the future!
Vind ik erg laat. Ik ga voor april/mei.Help!!!! schreef op woensdag 23 september 2015 @ 20:45:
Mijn glazen bol zegt dat ze niet eerder dan april komen en waarschijnlijk pas juni/aug.
Hephaestus: Xeon 2680 v2 - 64GB ECC Quad - WD Blue 3D 1TB
Virtualis: Ryzen 3700X - 16GB DDR4 - Gigabyte 1080 Ti OC - Sandisk 2TB - Valve Index
Agon:Valve Steam Deck 64GB
Non scholae sed vitae discimus Seneca
Vergeet niet dat, zoals eerder gezegd, het om een nieuwe architectuur op een nieuw procede met een nieuwe techniek (HBM/Interposer) gaat. Het kan maar zo een Fermi-achtige chip worden. Zeker gezien TSMC nou niet echt bekend staat om hoge yields op een nieuw proces.XanderDrake schreef op woensdag 23 september 2015 @ 21:41:
[...]
Vind ik erg laat. Ik ga voor april/mei.
Maar voor hetzelfde geld heb je gelijk hoor
- Help!!!!
- Registratie: Juli 1999
- Niet online
Wanneer precies is afhankelijk van zoveel variabelen die nog niet bekend zijn, ook niet voor nVidia, dat het het enige zinvolle wat je er volgensmij over kunt zeggen dat het waarschijnlijk in het April / November 2016 timeframe zal zijn.
Rekening houdend met nieuw procede, nieuw geheugen en nieuw chipontwerp lijkt een enigszins conservatieve verwachting me aannemelijker. Maar wie ben ik.
Rekening houdend met nieuw procede, nieuw geheugen en nieuw chipontwerp lijkt een enigszins conservatieve verwachting me aannemelijker. Maar wie ben ik.
[ Voor 3% gewijzigd door Help!!!! op 24-09-2015 20:31 ]
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
Verwijderd
Ik denk dat Nvidia zelf de betere bron is voor de uitlegWerelds schreef op woensdag 23 september 2015 @ 21:09:
[...]
Nee, dat gaat niet "over de CUDA cores". Ik zal de afbeelding van de oc.net post er bij nemen en uit leggen.
Je moet overigens wellicht eens Anandtech's oudere artikelen lezen. Ik ben wellicht een mierenneuker, maar termen als "CUDA Core" zijn grote onzin. Het klinkt mooi, maar als puntje bij paaltje komt is dat gewoon een Shader Processor en kan Nvidia daar niet meer mee dan AMD met die van hen kan. Als je een beetje door de oudere artikelen heen gaat zie je hoe de GPU's zich ontwikkelen en zul je ook iets abstracter gaan denken. Ik denk dat je dan ook beter begrijpt waar de "grenzen" zitten.
http://blogs.nvidia.com/b...des-with-keplers-hyper-q/
How Hyper-Q Works A GPU consists of multiple CUDA cores grouped into streaming multiprocessors operating in parallel. A hardware unit called the CUDA Work Distributor (CWD) is responsible for assigning work to the individual multiprocessors. - See more at: http://blogs.nvidia.com/b...r-q/#sthash.AvaHBTBH.dpuf

Unreal games enzv en op steam komen honderden Indie's daar op uit.
[ Voor 54% gewijzigd door Verwijderd op 24-09-2015 11:21 ]
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Hoe is dit anders dan de uitleg die Werelds geeft? CUDA core is gewoon een marketing term die Nvidia heeft bedacht. Ze mogen hoog of laag springen maar dat zal nooit veranderen dat het in feite gewoon een shader processor is.Verwijderd schreef op donderdag 24 september 2015 @ 11:12:
[...]
Ik denk dat Nvidia zelf de betere bron is voor de uitleg
http://blogs.nvidia.com/b...des-with-keplers-hyper-q/
How Hyper-Q Works A GPU consists of multiple CUDA cores grouped into streaming multiprocessors operating in parallel. A hardware unit called the CUDA Work Distributor (CWD) is responsible for assigning work to the individual multiprocessors. - See more at: http://blogs.nvidia.com/b...r-q/#sthash.AvaHBTBH.dpuf
[afbeelding]
[...]
Ga er maar van uit dat meer dan 75% van de indie devs DX12 gewoon links laten liggen. De meeste kunnen prima af met DX9-11 (en dan vraag ik me sterk af of er veel indie devs gebruik maken van DX10 en DX11). De meeste spellen die indie devs maken lopen nog lang niet tegen dezelfde performance limieten aan die de AAA games hebben.Unreal games enzv en op steam komen honderden Indie's daar op uit.
Denk dat indie devs de laatste groep zijn die zullen overstappen om eerlijk te zijn. Ze hebben in ieder geval niet de inhouse resources om die stap net zo snel te maken als de grote studios.
Zelf kijk ik nog even de kat uit de boom, ik weet wat voor moois DX12 kan maar ik ben op het moment totaal niet gelimiteerd door de mogelijkheden die de oudere DX versies bieden en ik heb op het moment geen zin om mij te verdiepen in DX12
Die DX12 demo's die je van de UE4 ziet zijn vooral leuke showcases zonder enige gameplay elementen (dit zeg ik met die Link demo in het achterhoofd).
Verwijderd
Ik weet dat er heel wat unreal 4 games in de planning staan bij indie game ontwikkelaars. Ik vermoed dus dat er vooral veel dx 11 en dx 12 gebruikt gaat worden en het is voor de ontwikkelaar juist een hele makkelijke engine om games op te bouwen. In Zelda zitten overigens wel gameplay elementen al is het alleen maar lopen en springen. Ik vraag me af hoe ze met unreal 4 dx 12 links willen laten liggen het zit in de core.
[ Voor 11% gewijzigd door Verwijderd op 24-09-2015 12:54 ]
- tomcatha
- Registratie: Oktober 2006
- Laatst online: 21-05-2022
:strip_icc():strip_exif()/u/192627/av70.jpg?f=community)
zo ver ik weet is de halve indie dev bohemia wel bezig met dx12 voor hun games. Natuurlijk is DX12 juist iets waar een game zoals arma heel veel aan heeft.
- Help!!!!
- Registratie: Juli 1999
- Niet online
Nvidia Pascal GPU's krijgen 'mixed precision' en 16 GB HBM2
http://wccftech.com/nvidi...-feature-16-gb-hbm2-vram/
http://wccftech.com/nvidi...-feature-16-gb-hbm2-vram/
[ Voor 27% gewijzigd door Help!!!! op 24-09-2015 15:48 ]
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
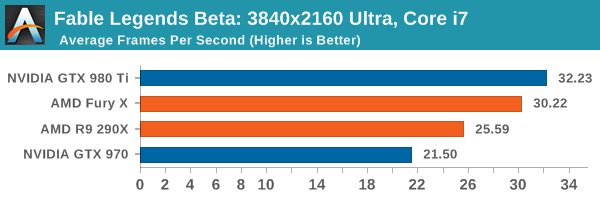
Fable Legends Early Preview: DirectX 12 Benchmark Analysis
Leuk om te zien wat DX12 zowel gaat brengen. Resultaten zijn best in lijn met de Ashes of the Singularity benchmark.
Leuk om te zien wat DX12 zowel gaat brengen. Resultaten zijn best in lijn met de Ashes of the Singularity benchmark.
- madmaxnl
- Registratie: November 2009
- Laatst online: 09-08-2022
Wel grappig om te zien dat de Fury nu op lagere resoluties juist sneller is dan de 980Ti. Is er iemand die dat kan verklaren? Kan alleen aan een geheugen hoeveelheid te kort voor de Fury als oorzaak denken wat mij tevens doet vermoeden dat deze benchmark/engine geheugen hoeveelheid intensiever is als wat we tot nu toe gezien hebben? Of is het een fenomeen dat veroorzaakt wordt door het gebruik van DX12?
[ Voor 64% gewijzigd door madmaxnl op 24-09-2015 16:01 ]
- haarbal
- Registratie: Januari 2010
- Laatst online: 20:04
Zitten sowieso wat wonderlijke dingen bij. Bij de frametime percentiles zie je bijvoorbeeld dat i5's het beter doen wat betreft minimum framerates. Zet de hyperthreading maar weer uit voor dx12 jongens...
Mechwarrior Online: Flapdrol
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Inderdaadhaarbal schreef op donderdag 24 september 2015 @ 16:31:
Zitten sowieso wat wonderlijke dingen bij. Bij de frametime percentiles zie je bijvoorbeeld dat i5's het beter doen wat betreft minimum framerates. Zet de hyperthreading maar weer uit voor dx12 jongens...
Link van wccftech geeft meer/betere informatie. De nieuwe kaarten van de Pascal generatie gaan tot maximaal 16GB HBM2 krijgen, de traagste varianten krijgen 2GB. Als ik het tabelletje op de website mag geloven dan hebben de nieuwe AMD kaarten (Arctic Islands) minimaal 4GB tot maximaal 16GB HBM2 geheugen.
- madmaxnl
- Registratie: November 2009
- Laatst online: 09-08-2022
Ik denk dat die 16GB in de categorie wetenschappelijke toepassingen alleen terug gezien zal worden? Lijkt me dat ze hiervoor ook nog wel een 32GB variant introduceren. Ook al brengt dit problemen met zich mee m.b.t. de productie van de hiervoor benodigde geheugenstacks. Immers hoeven ze er toch niet heel erg veel van te produceren, maar die wat gelukt zijn brengen aanzienlijk meer geld op binnen de sectoren waarvoor het bedoelt is.
Mits het de kosten niet dusdanig hoog oplopen dat de prijs/prestatie t.o.v. een 16GB model nergens meer overgaat.
Mits het de kosten niet dusdanig hoog oplopen dat de prijs/prestatie t.o.v. een 16GB model nergens meer overgaat.
[ Voor 5% gewijzigd door madmaxnl op 24-09-2015 17:35 ]
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
Ze hebben bij Nvidia nu al kaarten met 6GB en 12GB dus zo bizar is dat niet. Aangezien HBM toelaat lager geclocked geheugen te gebruiken, zou het me niet verwonderen dat ze met stacking uiteindelijk meer GB kunnen voorzien voor een relatief lagere prijs.
Verwijderd
Ik vind de resultaten juist meer in lijn met deze review.Sp3ci3s8472 schreef op donderdag 24 september 2015 @ 15:47:
Fable Legends Early Preview: DirectX 12 Benchmark Analysis
Leuk om te zien wat DX12 zowel gaat brengen. Resultaten zijn best in lijn met de Ashes of the Singularity benchmark.
https://www.extremetech.c...test-directx-12-benchmark
Hier komt de gtx 980 ti in eens niet zo goed uit de verf en de Fury x juist wel weer.
Verkeerde link net.
[ Voor 8% gewijzigd door Verwijderd op 24-09-2015 19:15 ]
- madmaxnl
- Registratie: November 2009
- Laatst online: 09-08-2022
Hij heeft het over dezelfde review???
[ Voor 16% gewijzigd door madmaxnl op 24-09-2015 18:55 ]
Verwijderd
Ik had de verkeerde linkt te pakken.
Hier nog een review en let dan vooral op de frametimes van de Fury x
http://www.pcper.com/revi...ontinues/Results-4K-Ultra
Hier nog een review en let dan vooral op de frametimes van de Fury x
http://www.pcper.com/revi...ontinues/Results-4K-Ultra
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Appart dat hij het daar ineens een stukje beter doet en sneller is als een GTX980Ti. Het lijkt haast wel alsof de andere reviews de normale Fury hebben gepakt. Want de Fury scored net zo hoog als de Fury X in de andere reviews (of ik zie iets over het hoofd).Verwijderd schreef op donderdag 24 september 2015 @ 18:12:
[...]
Ik vind de resultaten juist meer in lijn met deze review.
https://www.extremetech.c...test-directx-12-benchmark
Hier komt de gtx 980 ti in eens niet zo goed uit de verf en de Fury x juist wel weer.
Verkeerde link net.
Het zou ook kunnen komen doordat ze een andere cpu gebruiken, helaas melden ze niet welke ze gebruiken. AMD lijkt minder cpu overhead te hebben en dat kan ze misschien net de edge geven die ze nodig hebben met dat test systeem?
- haarbal
- Registratie: Januari 2010
- Laatst online: 20:04
Niet alle sites testen met dezelfde cpu. Verder testen sommige sites met reference modellen en andere met kaarten die daadwerkelijk verkocht worden.
Mechwarrior Online: Flapdrol
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Door enchion in het AMD CJ topic:
Uit de test van Extremetech
The next thing to check was power management — and this is where we found our smoking gun. We tested Windows 10 in its “Balanced” power configuration, which is our standard method of testing all hardware. While we sometimes increase to “High Performance” in corner cases or to measure its impact on power consumption, Windows can generally be counted on to handle power settings, and there’s normally no performance penalty for using this mode.
The benchmark is actively running in the screenshot above, with power conservation mode and clock speed visible at the same time. And while CPU clock speed isn’t the determining factor in most titles, clocking down to 1.17GHz is guaranteed to have an impact on overall frame rates. Switching to “High Performance” pegged the CPU clock between 3.2 and 3.3GHz — exactly where we’d expect it to be. It’s not clear what caused this problem — it’s either a BIOS issue with the Asus X99-Deluxe or an odd driver bug in Windows 10, but we’ve retested both GPUs in High Performance mode.
Grote kans is dat dit de reden is dat de scores zo uiteenlopen.enchion schreef op donderdag 24 september 2015 @ 22:08:
[...]
Dit is wel erg slecht van MS en gooit gelijk een zak zout/zoutmijn naar alle vorige benchmarks die we gezien hebben.
btw Powermanagement moet helemaal uitschakelbaar gemaakt worden op windows, wat het niet is, met betrekking op performance is power management niks anders dan een virus.
Kan me ook niet aan het idee onttrekken dat het invloed heeft op dingen als microstutter.
Verwijderd
Nog een benchmark van GTX 980 ti is duidelijk sneller dan de fury x op 1 site na. Word ook wel uitgelegd bij PCPER. De benchmark is meer GPU afhankelijk vergeleken met AOS
http://www.pcgameshardwar...Spiele-Benchmark-1172196/
http://techreport.com/rev...12-performance-revealed/2
http://www.pcgameshardwar...Spiele-Benchmark-1172196/
http://techreport.com/rev...12-performance-revealed/2
[ Voor 77% gewijzigd door Verwijderd op 25-09-2015 07:05 ]
- SG
- Registratie: Januari 2001
- Laatst online: 15-07 06:40
Ik vermoed dat kwa rauwe power kwa shader TMU Rops en testalation de 980Ti al stuk beter kan presteren dat met hogere dan standaard klokken.
Maar deze power isue geeft ook aan dat ACE zorgt dat de GPU stuk minder afhankelijk is van CPU. Nou gebruiken de meeste gamers niet top CPU en kan AMD toch de betere keus zijn.
Tenzij je dikke dure CPU hebt en zwaar OC'ed CPU en GPU.
Alleen op deze gen en procede behaalde resultaten van derde refresh is geen garantie voor de toekomst. Dus veel grotere kans dat Pascal de volgende moeizame Fermi wordt.
En procedes worden al morizamer HBM vergroot problemen ook al.
Denk toch dat ik mijn 5870 vervang voor tonga en ben bang dat next gen toch wel een jaar op zich laat wachten. En zuiniger zal het niet zijn. Want nvidia moet de snelste zijn dus is geneigd om maximale er uit te halen en dat geeft veel meer rauwe performance maar is ook minder zuiniger.
De zuinigheid komt met de refreshes als ze bigchip niet nog bigger maken.
Maar deze power isue geeft ook aan dat ACE zorgt dat de GPU stuk minder afhankelijk is van CPU. Nou gebruiken de meeste gamers niet top CPU en kan AMD toch de betere keus zijn.
Tenzij je dikke dure CPU hebt en zwaar OC'ed CPU en GPU.
Alleen op deze gen en procede behaalde resultaten van derde refresh is geen garantie voor de toekomst. Dus veel grotere kans dat Pascal de volgende moeizame Fermi wordt.
En procedes worden al morizamer HBM vergroot problemen ook al.
Denk toch dat ik mijn 5870 vervang voor tonga en ben bang dat next gen toch wel een jaar op zich laat wachten. En zuiniger zal het niet zijn. Want nvidia moet de snelste zijn dus is geneigd om maximale er uit te halen en dat geeft veel meer rauwe performance maar is ook minder zuiniger.
De zuinigheid komt met de refreshes als ze bigchip niet nog bigger maken.
X399 Taichi; ThreadRipper 1950X; 32GB; VEGA 56; BenQ 32" 1440P | Gigbyte; Phenom X4 965; 8GB; Samsung 120hz 3D 27" | W2012SER2; i5 quadcore | Mac mini 2014 | ATV 4g | ATV 4K
- Jeroenneman
- Registratie: December 2009
- Laatst online: 03-05-2024
Pre-order/Early Acces: Nee!
Dat had net zo goed Chinees kunnen zijn.SG schreef op vrijdag 25 september 2015 @ 07:37:
Ik vermoed dat kwa rauwe power kwa shader TMU Rops en testalation de 980Ti al stuk beter kan presteren dat met hogere dan standaard klokken.
Maar deze power isue geeft ook aan dat ACE zorgt dat de GPU stuk minder afhankelijk is van CPU. Nou gebruiken de meeste gamers niet top CPU en kan AMD toch de betere keus zijn.
Tenzij je dikke dure CPU hebt en zwaar OC'ed CPU en GPU.
Alleen op deze gen en procede behaalde resultaten van derde refresh is geen garantie voor de toekomst. Dus veel grotere kans dat Pascal de volgende moeizame Fermi wordt.
En procedes worden al morizamer HBM vergroot problemen ook al.
Denk toch dat ik mijn 5870 vervang voor tonga en ben bang dat next gen toch wel een jaar op zich laat wachten. En zuiniger zal het niet zijn. Want nvidia moet de snelste zijn dus is geneigd om maximale er uit te halen en dat geeft veel meer rauwe performance maar is ook minder zuiniger.
De zuinigheid komt met de refreshes als ze bigchip niet nog bigger maken.
| Old Faithful | i7 920 @ (3,3Ghz) / X58 UD4P / GTX960 (1,550Mhz) / CM 690 | NOVA | i5 6600K (4,4Ghz) / Z170 Pro Gaming / GTX 960 (1,500Mhz) / NZXT S340
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Een aantal sites gebruiken een non reference GTX980 Ti, dit kan meespelen in het grote verschil. Laat niet weg dat een GTX980 Ti zich makkelijk laat overclocken. Maar dan ben ik nog steeds van mening dat als je een benchmark doet dat je dan appels met appels moet vergelijkenVerwijderd schreef op vrijdag 25 september 2015 @ 06:27:
Nog een benchmark van GTX 980 ti is duidelijk sneller dan de fury x op 1 site na. Word ook wel uitgelegd bij PCPER. De benchmark is meer GPU afhankelijk vergeleken met AOS
http://www.pcgameshardwar...Spiele-Benchmark-1172196/
http://techreport.com/rev...12-performance-revealed/2
Waarbij je er bij kan vermelden dat een GTX980 Ti zich beter laat overclocken.
Bijv techreport, dat is een 20% OC:
Asus Strix GTX 980 Ti GeForce 355.82 1216 1317 1800 6144
Dat is dus ook de reden dat je bij extremetech ziet dat de Fury x het wint net zoals de 390 het wint van een stock 980.
[ Voor 16% gewijzigd door Sp3ci3s8472 op 25-09-2015 16:56 ]
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Wat bedoel je precies? Zover ik kan zien gebruikt Anandtech een groot aantal stock kaarten met een uitzondering, die resultaten komen dus ook veel beter overeen met die van extremetech.
PCPER geeft het niet echt aan wat ze gebruiken.
PCPER geeft het niet echt aan wat ze gebruiken.
- Jeroenneman
- Registratie: December 2009
- Laatst online: 03-05-2024
Pre-order/Early Acces: Nee!
Maar uiteindelijk kopen de meeste consumenten ook een non reference kaart. Dus eigenlijk kun je beter de verschillende non-reference vergelijken, dan dat je alles moet gaan downclocken. Eventueel zou je ook nog overclocked VS overclocked kunnen vergelijken, aangezien dat tegenwoordig weinig meer is dan een slider in Afterburner.Sp3ci3s8472 schreef op vrijdag 25 september 2015 @ 16:43:
[...]
Een aantal sites gebruiken een non reference GTX980 Ti, dit kan meespelen in het grote verschil. Laat niet weg dat een GTX980 Ti zich makkelijk laat overclocken. Maar dan ben ik nog steeds van mening dat als je een benchmark doet dat je dan appels met appels moet vergelijken.
Waarbij je er bij kan vermelden dat een GTX980 Ti zich beter laat overclocken.
Bijv techreport, dat is een 20% OC:
Asus Strix GTX 980 Ti GeForce 355.82 1216 1317 1800 6144
Dat is dus ook de reden dat je bij extremetech ziet dat de Fury x het wint net zoals de 390 het wint van een stock 980.
| Old Faithful | i7 920 @ (3,3Ghz) / X58 UD4P / GTX960 (1,550Mhz) / CM 690 | NOVA | i5 6600K (4,4Ghz) / Z170 Pro Gaming / GTX 960 (1,500Mhz) / NZXT S340
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Geen idee hoeveel mensen een non-reference kaart koopt (ik heb zelf vooral reference kaarten). Maar wat jij zegt is het in een test beter om een reference kaart te nemen en eentje met een oc. Dan is het voor mensen ook duidelijk hoeveel winst er gehaalt kan worden en dan kunnen ze de afweging maken of ze meer willen betalen voor een non-reference kaart aangezien die meestal duurder zijn.Jeroenneman schreef op vrijdag 25 september 2015 @ 18:44:
[...]
Maar uiteindelijk kopen de meeste consumenten ook een non reference kaart. Dus eigenlijk kun je beter de verschillende non-reference vergelijken, dan dat je alles moet gaan downclocken. Eventueel zou je ook nog overclocked VS overclocked kunnen vergelijken, aangezien dat tegenwoordig weinig meer is dan een slider in Afterburner.
- Jeroenneman
- Registratie: December 2009
- Laatst online: 03-05-2024
Pre-order/Early Acces: Nee!
Hmm, in mijn beleving zijn de enige mensen die een reference kaart kopen, de Tweakers die een waterblok willen installeren. En die zullen echt niet op referentie snelheden gaan draaien. Voor de rest koopt het grote deel toch MSI, ASUS of Gigabyte. En die verkopen volgens mij alleen aangepaste producten.Sp3ci3s8472 schreef op vrijdag 25 september 2015 @ 19:03:
[...]
Geen idee hoeveel mensen een non-reference kaart koopt (ik heb zelf vooral reference kaarten). Maar wat jij zegt is het in een test beter om een reference kaart te nemen en eentje met een oc. Dan is het voor mensen ook duidelijk hoeveel winst er gehaalt kan worden en dan kunnen ze de afweging maken of ze meer willen betalen voor een non-reference kaart aangezien die meestal duurder zijn.
| Old Faithful | i7 920 @ (3,3Ghz) / X58 UD4P / GTX960 (1,550Mhz) / CM 690 | NOVA | i5 6600K (4,4Ghz) / Z170 Pro Gaming / GTX 960 (1,500Mhz) / NZXT S340
- haarbal
- Registratie: Januari 2010
- Laatst online: 20:04
Als ik bij tweakers pricewatch op videokaarten klik zie ik weinig reference kaarten, amper te krijgen. De 300 serie van amd heeft zelfs geen referencekaarten meer.
En de 980Ti van techreport is ook geen 20% OC, de turbo clocks gaan niet met dat percentage mee omhoog. Hij draait wel iets harder dan de meesten, ~50 MHz?
En de 980Ti van techreport is ook geen 20% OC, de turbo clocks gaan niet met dat percentage mee omhoog. Hij draait wel iets harder dan de meesten, ~50 MHz?
Mechwarrior Online: Flapdrol
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Dat klopt, maar die kaarten zijn al een behoorlijke tijd uit. Reference kaarten zijn meestal alleen in het begin te koop, de "early adopters" zullen dus best vaak een reference kaart hebben. Mensen die later een kaart kopen zullen dus haast gegarandeert een non-reference kaart hebben.haarbal schreef op vrijdag 25 september 2015 @ 19:10:
Als ik bij tweakers pricewatch op videokaarten klik zie ik weinig reference kaarten, amper te krijgen. De 300 serie van amd heeft zelfs geen referencekaarten meer.
http://www.geforce.com/ha...gtx-980-ti/specificationsEn de 980Ti van techreport is ook geen 20% OC, de turbo clocks gaan niet met dat percentage mee omhoog. Hij draait wel iets harder dan de meesten, ~50 MHz?
Base clock van 1000 -> 1.2* 1000 = 1200
Boost clock van 1075 -> 1.2* 1075 = 1290
Asus Strix GTX 980 Ti
Base clock van 1216
Boost clock van 1317
Dus ik moet inderdaad terugkomen om mijn vorige berekening
- haarbal
- Registratie: Januari 2010
- Laatst online: 20:04
Die boostclock is niet de max boostclock, de referencekaart gaat al naar 1200 Mhz. Dan zouden de factory OC kaarten naar 1440 moeten. Dat komt aardig in de buurt van de maximum haalbare snelheden. Zouden ze dat met factory overclocks aandurven? Ik denk niet dat elke chip dat haalt.
Mechwarrior Online: Flapdrol
Verwijderd
Niet iedereen stelt zijn PC zelf samen uit losse onderdelen. De meeste mensen halen een kant en klare PC en daar komen reference kaarten veel vaker voor. In de retailmarkt bij de meeste videokaarten alleen in het begin, waarna de fabrikanten als Gigabyte, Asus, MSI, etc. met hun eigen ontwerpen komen.Jeroenneman schreef op vrijdag 25 september 2015 @ 19:05:
[...]
Hmm, in mijn beleving zijn de enige mensen die een reference kaart kopen, de Tweakers die een waterblok willen installeren. En die zullen echt niet op referentie snelheden gaan draaien. Voor de rest koopt het grote deel toch MSI, ASUS of Gigabyte. En die verkopen volgens mij alleen aangepaste producten.
- Jeroenneman
- Registratie: December 2009
- Laatst online: 03-05-2024
Pre-order/Early Acces: Nee!
Hehe, en hoeveel OEM PC's hebben een GTX960 of hoger aan boord? Alienware en consorten zijn maar minuscuul vergeleken met een Dell, HP of Packard. En die gooien niks hogers dan een 750 erin.Verwijderd schreef op vrijdag 25 september 2015 @ 19:42:
[...]
Niet iedereen stelt zijn PC zelf samen uit losse onderdelen. De meeste mensen halen een kant en klare PC en daar komen reference kaarten veel vaker voor. In de retailmarkt bij de meeste videokaarten alleen in het begin, waarna de fabrikanten als Gigabyte, Asus, MSI, etc. met hun eigen ontwerpen komen.
| Old Faithful | i7 920 @ (3,3Ghz) / X58 UD4P / GTX960 (1,550Mhz) / CM 690 | NOVA | i5 6600K (4,4Ghz) / Z170 Pro Gaming / GTX 960 (1,500Mhz) / NZXT S340
- sdk1985
- Registratie: Januari 2005
- Laatst online: 18:27
Toch zijn er onder de tientallen miljoenen Steam gebruikers erg veel luxe kaarten te vinden. Het lijkt vooral een IGP te zijn OF een luxere kaart. De goedkope GT serie is er wel maar staat toch flink op achterstand...
http://store.steampowered.com/hwsurvey/videocard/
http://store.steampowered.com/hwsurvey/videocard/
Hostdeko webhosting: Sneller dan de concurrentie, CO2 neutraal en klantgericht.
Verwijderd
Het is ook niet de OC want dat is te weinig voor zo veel winst. Ik krijg er ook maar amper 5 fps meer uit met 100mhz meer op de core.
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
In dit geval dus wel, pak maar eens de resultaten van Anandtech. Daar haalt de GTX980 Ti 33fps, vermedigvuldig dat met ~1.2 en je krijgt de verwachte 39fps.
Je krijgt inderdaad niet altijd meer fps omdat dit van meerdere factoren afhangt zoals geheugen/geheugenbandbreedte/cpu, alleen zijn de resultaten in dit geval redelelijk obvious.
Je krijgt inderdaad niet altijd meer fps omdat dit van meerdere factoren afhangt zoals geheugen/geheugenbandbreedte/cpu, alleen zijn de resultaten in dit geval redelelijk obvious.
Verwijderd
Maar anandtech gebruikt stock en is alsnog sneller dan bij Extremetech die laatste klopt dus voor geen meter vergeleken met de rest. Ook die P state problemen kloppen niet dus die hele benchmark kun je wegschuiven.
[ Voor 53% gewijzigd door Verwijderd op 26-09-2015 15:10 ]
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Serieus?Verwijderd schreef op zaterdag 26 september 2015 @ 15:09:
Maar anandtech gebruikt stock en is alsnog sneller dan bij Extremetech die laatste klopt dus voor geen meter vergeleken met de rest. Ook die P state problemen kloppen niet dus die hele benchmark kun je wegschuiven.
We praten over een verschil van +/- 1.5 fps op 4k en jij vind dat dan niet kloppen? Dat valt heel goed weg te schrijven naar het gebruiken van een ander systeem. Kijk zelf maar eens naar de tweakers review van een aantal moederborden je ziet dat die qua performance allemaal aan elkaar gewaagd zitten en 1-3% meer of minder presteren. Dan kan ook nog cpu/ram anders zijn enzovoort.
Ze hebben de benchmark opnieuw gedaan, dus ik heb geen idee waarom je de benchmark zou willen wegschrijven. Ze geven zelfs netjes aan waarom de resultaten iets anders zijn dan andere websites, ze gebruiken namelijk de reference kaart.
Loze posts.....
Verwijderd
Je mag het loos vinden maar vergelijk maar eens met soortgelijke systemen die presteren veel beter met stock kaart gtx 980 ti's waarom zou deze ene review dan kloppen die totaal andere resultaten laat zien Anandtech en die andere naam kwijt. Maar goed maakt ook niet uit Ti is sneller in deze benchmark tot nu toe.
[ Voor 21% gewijzigd door Verwijderd op 26-09-2015 17:17 ]
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Zowel Anandtech als Extremetech laten vergelijkbare resultaten zien want ze gebruiken allebij de stock variant. Als je een review doet dan is het gewoon gebruikelijk om een stock kaart te gebruiken en daarnaast nog eventueel een andere (hier mag je het oneens mee zijn want het is mijn mening).Verwijderd schreef op zaterdag 26 september 2015 @ 17:14:
Je mag het loos vinden maar vergelijk maar eens met soortgelijke systemen die presteren veel beter met stock kaart gtx 980 ti's waarom zou deze ene review dan kloppen die totaal andere resultaten laat zien Anandtech en die andere naam kwijt. Maar goed maakt ook niet uit Ti is sneller in deze benchmark tot nu toe.
Zowel pcgameshardware.de en techreport.com gebruiken een kaart die een overclock heeft, respectievelijk 10% en 20%.
Als je die resultaten met die van Anandtech en Extremetech vergelijkt dan zie je dat je gewoon de fps kan pakken en die keer 1.1 of 1.2 kan doen en dan kom je op vergelijkbare cijfers uit. Als je de fps dan vergelijkt dan zie je dat pcgameshardware, techreport, extremetech en anandtech allemaal ongeveer dezelfde resultaten hebben.
Met loos bedoel ik dat ik liever zie dat je eerst eens goed alle dingen bekijkt voordat je onzin post.
Het verschil is dat ik probeer te onderzoeken waarom de scores anders lijken te zijn. Jou zal dat een worst zijn, jij wil alleen maar zien dat de (/jouw) 980 Ti sneller is. Wat mij een worst zal zijn.
Waar zie je mij beweren dat de Fury X sneller is dan een stock 980 Ti?
De enige kaart die ik zwart maak in mijn posts (in het CJ topic) is de standaard 980 (en 970) omdat ik niet echt onder de indruk ben van hun prestaties.
Maar goed dit is mierenneuken en voegt verder niks toe aan de discussie.
Ik ben klaar met onderzoeken, vandaar de einde discussie... Geen mooi tabelletje want ik ga er van uit dat iedereen die de resultaten naast elkaar legt het sommetje wel kan maken.
[ Voor 4% gewijzigd door Sp3ci3s8472 op 26-09-2015 18:53 ]
Verwijderd
Ik wil helemaal niet zien dat de TI sneller is vooroordelen is niet nodig en alles is ook geen onzin. Maar als je nog onderzoek er naar doet prima dan ik wacht af tot je er mee klaar bent.
Je cijfers kloppen ook van een kan want bij Anandtech is de gtx stock refenrence sneller dan de fury x en bij Extremetech juist het omgekeerde met de zelfde kaarten en niet een beetje ook
Je cijfers kloppen ook van een kan want bij Anandtech is de gtx stock refenrence sneller dan de fury x en bij Extremetech juist het omgekeerde met de zelfde kaarten en niet een beetje ook
[ Voor 34% gewijzigd door Verwijderd op 26-09-2015 19:59 ]
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
http://wccftech.com/nvidi...-meeting-press-york-city/
GTX 990 aankondiging incoming ?
GTX 990 aankondiging incoming ?
[ Voor 11% gewijzigd door Phuncz op 26-09-2015 22:45 ]
- Xtr3me4me
- Registratie: Juli 2009
- Laatst online: 27-08-2024
Saiyajin Godlike Tweaker
Denk een soort GTX980Tix2 met 2 gpu's van hetzelfde type. Pascal is nog veelste vroeg ervoor.Phuncz schreef op zaterdag 26 september 2015 @ 22:44:
http://wccftech.com/nvidi...-meeting-press-york-city/
GTX 990 aankondiging incoming ?
-- My Gaming Rig Power -- -- <SG> Diabolic --
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
GTX 990 als in een dual GPU, zoals de GTX 690. Twee GTX 980 Ti's op één kaart is insane, alleen al om te koelen.
:strip_icc():strip_exif()/u/91627/crop6479f5b3c63ee_cropped.jpg?f=community)
dual 980 zou beetje nutteloos zijn. Een stevig gekietelde 980ti komt redelijk in de buurt van een 980sli combo. dual 980ti zou wel te koelen zijn door een hybride oplossing. Denk dat het wel mogelijk moet zijn om ze sub 75 graden te houden.
R7 5800X3D // Dark Rock rock 4 // MSI B450 Tomahawk Max // 32Gb Corsair Vengeance // BeQuiet Pure Base 500FX // RX9070 Hellhound
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
1. Twee GTX 980's kunnen ook overgeklokt worden, aldus ook zo'n kaart
2. Een enkele kaart vs twee kaarten (Mogelijk op ITX, minder ruimte nodig, geen SLI bridge, etc.)
3. Dual GTX 980 Ti's zouden het totaalplaatje te complex en te duur maken
2. Een enkele kaart vs twee kaarten (Mogelijk op ITX, minder ruimte nodig, geen SLI bridge, etc.)
3. Dual GTX 980 Ti's zouden het totaalplaatje te complex en te duur maken
/u/4501/crop5bdb35c450e89.png?f=community)
{kind=link}
{kind=link}
{kind=link}
Op zich hebben ze ook de Titan Z gemaakt, dus waarom niet? Jammer dat die een 3 laags koeler had. Wel nog steeds een leuke kaart om veel compute per slot te krijgen, jammer dat hij zo duur was. In een 8 slot mobo kun je er met waterkoeling wel 8 kwijt, dus 16 gpu's
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
Helaas niet, de Titan Z heeft een DVI connector op de "2de slot" hoogte:

- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Verwijderd schreef op zaterdag 26 september 2015 @ 18:40:
Je cijfers kloppen ook van een kan want bij Anandtech is de gtx stock refenrence sneller dan de fury x en bij Extremetech juist het omgekeerde met de zelfde kaarten en niet een beetje ook


Waar dan?
Of bedoel je die halve fps?
Die meet resultaten vallen prima binnen de margin of error. Niet elke website gebruikt hetzelfde moederbord/cpu en niet elke website heeft de cpu op dezelfde clocks. Als jij hiermee websites zwart wilt gaan maken dan hou ik je niet tegen, het is alleen niet erg slim.

Hier een +/- 20% overclock.
Doe eens voor de grap 31 fps (gemiddelde tussen extremetech en anandtech) * 1.2? Goh dat lijkt wel op 37 fps, zelfs al zou je de testresultaten van anandtech *1.2 doen dan kom je op een vergelijkbaar getal namelijk 39 fps uit.
http://www.pcgameshardwar...Spiele-Benchmark-1172196/
Van pcgameshardware +/- 10% overclock:
EVGA GTX 980 Ti Superclocked/6G 34 fps
Verrek dat lijkt wel erg op 31fps * 1.1.
Ik zie hier op elke website de Fury +/- 30fps halen, op elke website als je de overclock weghaalt haalt de GTX980 Ti tussen de 31 en 32.5 fps. Het is haast belachelijk hoe consistent de Fury X scored bij elke website.
Dus leg mij maar uit waar mijn resultaten niet kloppen. Als je dat niet kan post dan niks, want deze discussie gaat al veels te lang door.
[ Voor 3% gewijzigd door Sp3ci3s8472 op 27-09-2015 17:10 . Reden: pcgameshardware link ]
1. Vraag me af of met de huidige TDP designs nog wel kan maar zeker een valide punt.Phuncz schreef op zondag 27 september 2015 @ 16:14:
1. Twee GTX 980's kunnen ook overgeklokt worden, aldus ook zo'n kaart
2. Een enkele kaart vs twee kaarten (Mogelijk op ITX, minder ruimte nodig, geen SLI bridge, etc.)
3. Dual GTX 980 Ti's zouden het totaalplaatje te complex en te duur maken
2. Eveneens sterk punt, had ik niet bij nagedacht.
3. Dit weet ik nog net zo niet. Ze houden de ti kunstmatig redelijk hoog qua prijs. We moeten de geruchten maar again afwachten
R7 5800X3D // Dark Rock rock 4 // MSI B450 Tomahawk Max // 32Gb Corsair Vengeance // BeQuiet Pure Base 500FX // RX9070 Hellhound
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
Ik zie eigenlijk niet wat ze in 2015 nog zouden kunnen lanceren. Een GTX 960 Ti ? Een GTX 970 Ti ? Het lijkt me dat daar de hype niet voor nodig is en een GTX 990 geeft de toekomstige Radeon Fury X2 tegenvuur.
[ Voor 8% gewijzigd door Phuncz op 27-09-2015 17:21 ]
- madmaxnl
- Registratie: November 2009
- Laatst online: 09-08-2022
Een dual GTX980Ti lijkt me prima mogelijk. Immers ligt het verbruik van de GTX980Ti (non-OC a.k.a. reference) lager dan dat van een Fury X. AMD heeft nog een Fury X2 opkomst dus waarom zou nVidia dit niet lukken met twee GM200 GPUs? Er zal een complexere PCB voor nodig zijn als bij de Fury X2. Daarnaast is nog op te merken dat AMD met de Nano wel heeft laten zien dat de kaart aanzienlijk efficiënter kan.
Een volledig functionele GM200 met 6GB geheugen en iets lagere en efficiëntere kloksnelheden en daarbij behorend voltage. Mwah, dat moet toch we lukken om er twee op één PCB geplaatst te krijgen zonder dat het koeler ervan een probleem vormt. Let wel, hiervoor is waarschijnlijk een AIO waterkoeling wel te verwachten net als bij de R9 295X2, Fury X en Fury X2.
Een R9 295X2 kan makkelijk meer dan 500 watt verbruiken. Een GTX980Ti (non-OC) verbruikt doorgaans minder dan de helft.
Bron
Ik denk wel dat een GTX990 zoals hierboven genoemd het af gaat leggen tegen een Fury X gebaseerd op de resultaten die we hebben gezien van de Fury X CF vs GTX980Ti SLI. Zeker op het gebied van frame tijden laat AMD heel erg goed resultaat zien.
Bron
Een volledig functionele GM200 met 6GB geheugen en iets lagere en efficiëntere kloksnelheden en daarbij behorend voltage. Mwah, dat moet toch we lukken om er twee op één PCB geplaatst te krijgen zonder dat het koeler ervan een probleem vormt. Let wel, hiervoor is waarschijnlijk een AIO waterkoeling wel te verwachten net als bij de R9 295X2, Fury X en Fury X2.
Een R9 295X2 kan makkelijk meer dan 500 watt verbruiken. Een GTX980Ti (non-OC) verbruikt doorgaans minder dan de helft.
Bron
Ik denk wel dat een GTX990 zoals hierboven genoemd het af gaat leggen tegen een Fury X gebaseerd op de resultaten die we hebben gezien van de Fury X CF vs GTX980Ti SLI. Zeker op het gebied van frame tijden laat AMD heel erg goed resultaat zien.
Bron
[ Voor 26% gewijzigd door madmaxnl op 27-09-2015 17:37 ]
- Phuncz
- Registratie: December 2000
- Niet online
ico_sphere by Matthew Divito
Ja hoor: http://wccftech.com/nvidi...al-gpu-flagship-graphics/Phuncz schreef op zaterdag 26 september 2015 @ 22:44:
http://wccftech.com/nvidi...-meeting-press-york-city/
GTX 990 aankondiging incoming ?
Nu is het wel vrijwel zeker
Blijkbaar zat ik fout, men verwacht toch een dual GTX 980 Ti.
Ben benieuwd  . Dit is natuurlijk wel een indicatie dat de volgende generatie nog wel ff op zich laat wachten.
. Dit is natuurlijk wel een indicatie dat de volgende generatie nog wel ff op zich laat wachten.
- madmaxnl
- Registratie: November 2009
- Laatst online: 09-08-2022
Dat was het van te voren ook al. Eind 2016 wordt al een gesuggereerd. De 380X en Fury X2 moeten ook nog uitkomen.
[ Voor 30% gewijzigd door madmaxnl op 27-09-2015 23:41 ]
Verwijderd
Hier met reference 0% overklock met een i7 en die verschillen zijn veel groter dan die jij aan haalt ook met langzamere cpu's zoals de i3 dus ik vind alle websites helemaal niet over een komen zeker niet op de lagere resoluties.Sp3ci3s8472 schreef op zondag 27 september 2015 @ 17:09:
[...]
[afbeelding]
[afbeelding]
Waar dan?
Of bedoel je die halve fps?
Die meet resultaten vallen prima binnen de margin of error. Niet elke website gebruikt hetzelfde moederbord/cpu en niet elke website heeft de cpu op dezelfde clocks. Als jij hiermee websites zwart wilt gaan maken dan hou ik je niet tegen, het is alleen niet erg slim.
[afbeelding]
Hier een +/- 20% overclock.
Doe eens voor de grap 31 fps (gemiddelde tussen extremetech en anandtech) * 1.2? Goh dat lijkt wel op 37 fps, zelfs al zou je de testresultaten van anandtech *1.2 doen dan kom je op een vergelijkbaar getal namelijk 39 fps uit.
http://www.pcgameshardwar...Spiele-Benchmark-1172196/
Van pcgameshardware +/- 10% overclock:
EVGA GTX 980 Ti Superclocked/6G 34 fps
Verrek dat lijkt wel erg op 31fps * 1.1.
Ik zie hier op elke website de Fury +/- 30fps halen, op elke website als je de overclock weghaalt haalt de GTX980 Ti tussen de 31 en 32.5 fps. Het is haast belachelijk hoe consistent de Fury X scored bij elke website.
Dus leg mij maar uit waar mijn resultaten niet kloppen. Als je dat niet kan post dan niks, want deze discussie gaat al veels te lang door.
{kind=link}
{kind=link}
{kind=link}


VS
Ik respecteer je moeite wel en vind dit zelf ook meer zeuren.
[ Voor 3% gewijzigd door Verwijderd op 28-09-2015 11:06 ]
- Sp3ci3s8472
- Registratie: Maart 2007
- Laatst online: 18-04 16:32
Volgens mij is dit meer een discussie van wat je/we acceptabel vind(en) als afwijkings fout tussen verschillende testsystemen. Ik denk dat jij een van de weinige bent die er grote verschillen tussen ziet (jouw goed recht natuurlijk).Verwijderd schreef op maandag 28 september 2015 @ 11:03:
[...]
Hier met reference 0% overklock met een i7 en die verschillen zijn veel groter dan die jij aan haalt ook met langzamere cpu's zoals de i3 dus ik vind alle websites helemaal niet over een komen zeker niet op de lagere resoluties.
[afbeelding]
[afbeelding]
VS
[afbeelding]
Ik respecteer je moeite wel en vind dit zelf ook meer zeuren.
{kind=link}
{kind=link}
Maar wat wil je bereiken met deze post? Ik zie 3 plaatjes van benchmarks van verschillende sites zonder enige beargumentatie en duidelijke toelichting, leg mij maar uit waar jij de grote verschillen ziet.
Als je het nu eens goed kan beargumenteren dan ben ik echt niet zo slecht om toe te geven dat ik iets over het hoofd zie of dat ik fout zit.
Om deze post toch wat toegevoegde waarde te geven
Als je tegenwoordig een benchmark doet dan is je score afhankelijk van veel factoren, meer dan vroeger omdat je tegenwoordig kaarten hebt die een boost snelheid hebben. Om er een aantal factoren op te noemen (ik vergeet er vast wat):
- CPU
- Moederbord (PCI-E bus clock enzovoort)
- Geheugen (hoeveelheid en snelheid)
- Omgevingstemperatuur (ivm het halen van een boost snelheid)
- Warmen de testers de kaarten (eigenlijk de koelelementen) goed op voordat ze gaan testen zodat er realworld resultaten worden behaalt.
- Wordt de benchmark meerdere keren gedraait om daarna een gemiddelde te nemen.
- Drivers die gebruikt worden
- Windows patches
- Windows power scheme
Verwijderd
Vreemd waarom dat er hier dan ook altijd zo vaak tussen verschillende reviews word vergeleken en dan komen jullie zelf ook tot conclusies en nu kloppen conclusies die niet meer omdat er verschil in hardware is. Kortom je eigen conclusies kloppen dan ook voor geen kant en is dit deze hele discussie voor niets geweest bij deze zet ik er dan ook een punt achter en ga ik voor het echte nieuws.
[ Voor 54% gewijzigd door Verwijderd op 01-10-2015 10:30 ]
- Racing_Reporter
- Registratie: Januari 2012
- Laatst online: 16-07 22:48
Contentmaker
Er is altijd wel een globale lijn te vinden. Alleen de reviews die echt afwijken, worden niet serieusgenomen.
Als je dit leest, heb je teveel tijd.
- batumulia
- Registratie: Mei 2007
- Laatst online: 16:22
/u/219127/avaof2.png?f=community)
Na 1,5 jaar plezierig spelen op mijn 780ti heeft hij gisteravond de geest gegeven. Ik heb er nog garantie opzitten bij de winkel, maar neem aan dat ze geen 780ti op voorraad meer hebben (Alternate). Weet iemand welke ik daarvoor terug zou krijgen? Een 980?
Steam/Origin/Uplay: Batumulia | Star Citizen GoT organisation / Referral code | Gamerig
- Racing_Reporter
- Registratie: Januari 2012
- Laatst online: 16-07 22:48
Contentmaker
Sorry maar je zit totaal in het verkeerde topic.batumulia schreef op vrijdag 02 oktober 2015 @ 11:31:
Na 1,5 jaar plezierig spelen op mijn 780ti heeft hij gisteravond de geest gegeven. Ik heb er nog garantie opzitten bij de winkel, maar neem aan dat ze geen 780ti op voorraad meer hebben (Alternate). Weet iemand welke ik daarvoor terug zou krijgen? Een 980?
Als je dit leest, heb je teveel tijd.
- batumulia
- Registratie: Mei 2007
- Laatst online: 16:22
Ik zie het inderdaad, excuus. Dacht dat ik het ervaringen topic te pakken had.
Steam/Origin/Uplay: Batumulia | Star Citizen GoT organisation / Referral code | Gamerig
- Help!!!!
- Registratie: Juli 1999
- Niet online
PC Specs
Asus ROG Strix B650E-E | AMD 9800X3D |TR Phantom Spirit 120 SE | G-Skill 32GB DDR5 6000C30 M-die | 4090 FE | LG 3840*1600p 160Hz | Corsair RM1000x Shift
Ik heb al een 3 jaar een GTX 680, maar nu begint die rare keuren te vertonen.
Tijdens het gamen clockt de GPU zichzelf terug omdat de temperatuur oploopt, vervolgens begint de fan op 100% te draaien voor een paar seconden. Vervolgens is de GPU weer op normale temperatuur om vervolgens zodra die weer te warm wordt weer terug te clocken etc. Je snapt het al dit is gigantisch storend en zorgt ook voor een aantal framedrops in het spel iRacing wat ik speel. Iemand enig idee wat het probleem zou kunnen zijn? Ik heb al een keer het koelblok eraf gehaald en ontdoen van stof maar dat mag het probleem helaas niet oplossen. Hieronder een kleine log uit GPU-Z.

Tijdens het gamen clockt de GPU zichzelf terug omdat de temperatuur oploopt, vervolgens begint de fan op 100% te draaien voor een paar seconden. Vervolgens is de GPU weer op normale temperatuur om vervolgens zodra die weer te warm wordt weer terug te clocken etc. Je snapt het al dit is gigantisch storend en zorgt ook voor een aantal framedrops in het spel iRacing wat ik speel. Iemand enig idee wat het probleem zou kunnen zijn? Ik heb al een keer het koelblok eraf gehaald en ontdoen van stof maar dat mag het probleem helaas niet oplossen. Hieronder een kleine log uit GPU-Z.
- madmaxnl
- Registratie: November 2009
- Laatst online: 09-08-2022
Verkeerde topic.
offtopic:
Geen garantie zeker? Duw hem maar in de oven.
Geen garantie zeker? Duw hem maar in de oven.
Hoezo verkeerd topic? In de TS staat "Dit is een discussietopic. Hierin is de bedoeling dat je hier discussieerd over alles wat gerelateerd is aan de grafische kaarten van nVidia."madmaxnl schreef op zondag 11 oktober 2015 @ 20:35:
Verkeerde topic.
offtopic:
Geen garantie zeker? Duw hem maar in de oven.
Nee de garantie is verlopen, wat is een goede opvolger van deze kaart zonder de hoofdprijs te moeten betalen. Na de aankoop van de GTX 680 nooit meer verdiept in nieuwe kaarten
- Xtr3me4me
- Registratie: Juli 2009
- Laatst online: 27-08-2024
Saiyajin Godlike Tweaker
Ik had ook de GTX680, maar merkte met nieuwe AAA games me kaart behoorlijk zat te zweten. Nu heb ik de GTX980Ti en is zekers een super kaart als opvolger.FabiandJ schreef op zondag 11 oktober 2015 @ 22:21:
[...]
Hoezo verkeerd topic? In de TS staat "Dit is een discussietopic. Hierin is de bedoeling dat je hier discussieerd over alles wat gerelateerd is aan de grafische kaarten van nVidia."
Nee de garantie is verlopen, wat is een goede opvolger van deze kaart zonder de hoofdprijs te moeten betalen. Na de aankoop van de GTX 680 nooit meer verdiept in nieuwe kaarten
Ja het is een prijzige maar weet dat deze kaart me de volgende 3 jaar zekers zal mee gaan.
Heb geen enkel moment spijt ervan.
-- My Gaming Rig Power -- -- <SG> Diabolic --
€700 euro voor een GPU is me iets teveel van het goedeXtr3me4me schreef op zondag 11 oktober 2015 @ 22:48:
[...]
Ik had ook de GTX680, maar merkte met nieuwe AAA games me kaart behoorlijk zat te zweten. Nu heb ik de GTX980Ti en is zekers een super kaart als opvolger.
Ja het is een prijzige maar weet dat deze kaart me de volgende 3 jaar zekers zal mee gaan.
Heb geen enkel moment spijt ervan.
Let op:
Dit topic is bedoeld om de nieuwste ontwikkelingen op het gebied van nVidia GPU's te bespreken. Dit topic is dus uitdrukkelijk niet bedoeld voor persoonlijk aankoopadvies of troubleshooting!
Voor discussies over de nieuwste serie, klik aub door naar [NVIDIA GeForce RTX 40XX] Levertijden & Prijzen zodat dit topic over nieuws blijft gaan.
Zware videokaarten trekken een zware last op de voeding van een PC. Dit is niet de plek voor discussies over voedingen, dat kan in Voeding advies en informatie topic - Deel 34 - en lees daar sowieso de topicstart voordat je post, grote kans dat je vraag al behandeld is.
Dit topic is bedoeld om de nieuwste ontwikkelingen op het gebied van nVidia GPU's te bespreken. Dit topic is dus uitdrukkelijk niet bedoeld voor persoonlijk aankoopadvies of troubleshooting!
Voor discussies over de nieuwste serie, klik aub door naar [NVIDIA GeForce RTX 40XX] Levertijden & Prijzen zodat dit topic over nieuws blijft gaan.
Zware videokaarten trekken een zware last op de voeding van een PC. Dit is niet de plek voor discussies over voedingen, dat kan in Voeding advies en informatie topic - Deel 34 - en lees daar sowieso de topicstart voordat je post, grote kans dat je vraag al behandeld is.