Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- RayNbow
- Registratie: Maart 2003
- Laatst online: 17:27
Kirika <3
/u/81985/crop566b00b43645a.png?f=community)
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
/u/243953/crop56f55a7bcf291.png?f=community)
Je bedoelt het OS wat door vele windows gebruikers nou niet echt goed ontvangen is?
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
/u/142011/crop65b383c6c6c2f_cropped.png?f=community)
Tja, je kan er veel over zeggen, maar zaken zeggen als "Hoe moeilijk is het nou..." en wat ik ook wel eens hoor "*** Microsoft kan weer eens iets niet goed" kan vaak al niet meer na Windows 8.1, omdat het juist daar is opgelost.Gropah schreef op zaterdag 17 mei 2014 @ 12:16:
[...]
Je bedoelt het OS wat door vele windows gebruikers nou niet echt goed ontvangen is?
[ Voor 4% gewijzigd door Caelorum op 17-05-2014 12:17 ]
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
User interface optie's voor mensen die niet willen overstappen? Virtual desktops?Caelorum schreef op zaterdag 17 mei 2014 @ 12:17:
[...]
Tja, je kan er veel over zeggen, maar zaken zeggen als "Hoe moeilijk is het nou..." en wat ik ook wel eens hoor "*** Microsoft kan weer eens iets niet goed" kan vaak al niet meer na Windows 8.1, omdat het juist daar is opgelost.
Sorry hoor, maar dit zijn 2 dingen waar ik mij redelijk aan stoor. Ik vind windows 8 metro gewoon knudde. Gnome3 is een stuk beter, voornamelijk omdat het menu daar een overzicht geeft van wat draait met een zoekoptie. Als ze die optie zouden geven dan was ik waarschijnlijk om geweest. Zoals het nu is, vind ik het gewoon niet lekker werken. Daarnaast hadden ze ook prima er voor kunnen zorgen dat mensen helemaal niets met metro hoeven. Tegenwoordig is dat al (bijna) mogelijk, maar goed.
Persoonlijk hecht ik ook veel waarde aan virtual desktops. Het geeft mij een stuk meer overzicht en het maakt het organiseren van windows zoveel makkelijker (als je er eenmaal aan gewend bent). Unix heeft dit al vele jaren, maar bij windows zijn er alleen nog maar (imo) brakke 3rd party implementatie's.
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
Ik zeg ook veel niet allesGropah schreef op zaterdag 17 mei 2014 @ 12:24:
[...]
User interface optie's voor mensen die niet willen overstappen? Virtual desktops?[...]
Vind zelf GNOME ook wel lekker werken hoor! Mijn plan is ook om over te gaan zodra Visual Studio of waarschijnlijker die nieuwe c++ editor van jetbrains er is voor linux.
- RayNbow
- Registratie: Maart 2003
- Laatst online: 17:27
Kirika <3
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows NT\CurrentVersion\WinLogon\Shell?Gropah schreef op zaterdag 17 mei 2014 @ 12:24:
[...] User interface optie's [...]
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- mrc4nl
- Registratie: September 2010
- Laatst online: 14:51
Procrastinatie expert
:strip_icc():strip_exif()/u/373647/b1aa8209a437bf987cf066823c044f0a.jpeg?f=community)
ik zat net te denken, PEBKAC is meestal niet van toepassing bij laptop gebruikers

ora et labora
Was het DPI probleem maar opgelost. Leuk die slider, maar dat zat volgens mij in XP er al in (alleen dan wat dieper weggestopt). Het werkt alleen bij aardig wat applicaties niet (met name bij Java bagger heb je een vergrootglas nodig) en het gebeurd regelmatig dat ik hem meerdere keren per dag handmatig aan moet passen en daarna uitloggen omdat dat het blijkbaar o zo lastig is om dat dynamisch om te kunnen schakelen.Caelorum schreef op zaterdag 17 mei 2014 @ 12:17:
[...]
Tja, je kan er veel over zeggen, maar zaken zeggen als "Hoe moeilijk is het nou..." en wat ik ook wel eens hoor "*** Microsoft kan weer eens iets niet goed" kan vaak al niet meer na Windows 8.1, omdat het juist daar is opgelost.
Ik overweeg serieus om maar weer terug te gaan naar Windows 7. Werkt het ook niet goed in, maar heb je tenminste die Metro ellende niet. Ik heb nog geen enkel voordeel aan Windows 8 kunnen ontdekken.
- incaz
- Registratie: Augustus 2012
- Laatst online: 15-11-2022
/u/470671/elephant.png?f=community)
'between keyboard and couch'? 
Overigens, ik zoek nog wel iets om comfortabel te typen als je ligt Iemand ideetjes voor de allerlazy'ste houding?
Iemand ideetjes voor de allerlazy'ste houding?
@StM, maar Java tekent altijd z'n eigen zut - dat is windows niet per se te verwijten toch?
Voordeel windows8: hmm, integratie met mijn phone denk ik. Verder geen voordelen, maar ook nauwelijks nadelen, zeker niet nu ik de edges heb uitgezet Geen metro te zien.
Overigens, ik zoek nog wel iets om comfortabel te typen als je ligt
@StM, maar Java tekent altijd z'n eigen zut - dat is windows niet per se te verwijten toch?
Voordeel windows8: hmm, integratie met mijn phone denk ik. Verder geen voordelen, maar ook nauwelijks nadelen, zeker niet nu ik de edges heb uitgezet
Never explain with stupidity where malice is a better explanation
Java onder OSX werkt het wel goed mee, wiens schuld het is kan mij vrij weinig interesseren 
En als Windows gewoon zoals onder OSX automatisch de DPI en resolutie instellingen goed zou zetten zou dat al enorm veel frustatie schelen.
En als Windows gewoon zoals onder OSX automatisch de DPI en resolutie instellingen goed zou zetten zou dat al enorm veel frustatie schelen.
- RayNbow
- Registratie: Maart 2003
- Laatst online: 17:27
Kirika <3
Het gaat niet om de slider, het gaat om de checkbox die is toegevoegd. DPI settings zitten al sinds Win9x erin.StM schreef op zaterdag 17 mei 2014 @ 14:11:
[...]
Was het DPI probleem maar opgelost. Leuk die slider, maar dat zat volgens mij in XP er al in (alleen dan wat dieper weggestopt).
En wat is het probleem met Metro?Ik overweeg serieus om maar weer terug te gaan naar Windows 7. Werkt het ook niet goed in, maar heb je tenminste die Metro ellende niet. Ik heb nog geen enkel voordeel aan Windows 8 kunnen ontdekken.
Het werkt alleen bij aardig wat applicaties niet (met name bij Java bagger heb je een vergrootglas nodig) en het gebeurd regelmatig dat ik hem meerdere keren per dag handmatig aan moet passen en daarna uitloggen omdat dat het blijkbaar o zo lastig is om dat dynamisch om te kunnen schakelen.
De schuld ligt bij incompetente applicatieontwikkelaars omdat dit probleem al speelt sinds Win9x. "Oh, het ziet er goed uit op mijn eigen pc? Ship it!"StM schreef op zaterdag 17 mei 2014 @ 14:25:
Java onder OSX werkt het wel goed mee, wiens schuld het is kan mij vrij weinig interesseren
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
Tja of ligt de schuld bij de framework ontwikkelaar die blijkbaar er voor gezorgd heeft dat de ontwikkelaar er over na moet denken?
Die checkbox werkt volgens mij niet omdat het externe scherm voor Windows het enige scherm is geworden en het voor Windows gewoon een single monitor setup is. Ik zal er binnenkort weer naar kijken, maar ik heb weinig zin om daar nu speciaal voor te gaan rebooten.
Die checkbox werkt volgens mij niet omdat het externe scherm voor Windows het enige scherm is geworden en het voor Windows gewoon een single monitor setup is. Ik zal er binnenkort weer naar kijken, maar ik heb weinig zin om daar nu speciaal voor te gaan rebooten.
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
Schuld ligt bij java onder windows ja ^^StM schreef op zaterdag 17 mei 2014 @ 14:37:
Tja of ligt de schuld bij de framework ontwikkelaar die blijkbaar er voor gezorgd heeft dat de ontwikkelaar er over na moet denken?[...]
Maar even zonder gekheid. Als ik de artikelen op deze pagina lees kan ik niet anders dan tot de conclusie komen dat het de ontwikkelaar is die blijkbaar geen rekening heeft gehouden met DPI scaling. Er zijn genoeg handles om er op in te haken en alles juist te renderen. Als je dat als programmeur niet wil/kan moet je maar een fatsoenlijk framework gebruiken zoals bijv. Qt of anders gewoon stoppen met (GUI-applicaties) ontwikkelen.
Is ook wel allemaal wereld op zijn kop zeg maar. Als iemand complete sites bouwt met fixed sized elementen is de programmeur slecht, maar als hij een vergelijkbaar iets doet bij het bouwen van GUI applicaties dan is het de schuld van de framework bouwer?
[ Voor 14% gewijzigd door Caelorum op 17-05-2014 14:56 . Reden: beter voorbeeld ]
- BikkelZ
- Registratie: Januari 2000
- Laatst online: 28-03 23:19
CMD+Z
/u/1695/jumpman60.png?f=community)
Retina schermen hebben exact de dubbele resolutie van de voorgaande generatie, dat is veel makkelijker dan allerlei tussenopties ondersteunen zoals 125% en 150%.StM schreef op zaterdag 17 mei 2014 @ 14:25:
Java onder OSX werkt het wel goed mee, wiens schuld het is kan mij vrij weinig interesseren
En als Windows gewoon zoals onder OSX automatisch de DPI en resolutie instellingen goed zou zetten zou dat al enorm veel frustatie schelen.
Onder OS X gebruikt bijna iedereen de Cocoa widgets van Apple, maar je ziet af en toe nog wel eens software die gewoon x2 gedaan wordt (FileZilla bijvoorbeeld). Wat dat betreft doet Apple het wel goed t.o.v. van ontwikkelaars, niet een miljoen verschillende hardware soorten maar makkelijk schaalbare oplossingen.
Onder Android zie je ook dat het lastiger is om over alle soorten DPI en schermgroottes een consistente GUI op te bouwen. Dat is het nadeel van keuze hebben, de software en hardware is minder gestroomlijnd met elkaar en vaak wacht de software op de hardware terwijl de hardware op de software wacht.
iOS developer
- incaz
- Registratie: Augustus 2012
- Laatst online: 15-11-2022
Ik weet niet hoe dat bij dpi en dergelijke zit. Maar als ik zie hoeveel moeite mensen in oudere applicaties (9x) hebben gedaan om alle normale manieren van Windows om een schaalbare applicatie te maken (dus naast 800x600 ook de belachelijke resolutie van 768x1024) te verkloten verbaas ik me nergens meer overStM schreef op zaterdag 17 mei 2014 @ 14:37:
Tja of ligt de schuld bij de framework ontwikkelaar die blijkbaar er voor gezorgd heeft dat de ontwikkelaar er over na moet denken?
(Nog steeds trouwens. Nu weer met de mediaqueries die op basis van de breedte van je scherm aannames doen over hoeveel verticale ruimte ze kunnen bechikken...)
Maar het zou heel goed kunnen dat windows daarin ook behoorlijk fout zit - zoals gezegd, dat weet ik niet.
Never explain with stupidity where malice is a better explanation
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
/u/373849/cowava2.png?f=community)
Sinds versie 29 van Firefox, kan ze niet meer overweg met headers groter dan 12kb lijkt het wel 

Seriously?
Seriously?
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
Denk niet dat Windows er erg makkelijk in is, maar onmogelijk nou ook weer niet. Er zijn zat applicaties die wel gewoon goed schalen me verschillende dpi settings.incaz schreef op zaterdag 17 mei 2014 @ 15:14:
[...]
Maar het zou heel goed kunnen dat windows daarin ook behoorlijk fout zit - zoals gezegd, dat weet ik niet.
- RayNbow
- Registratie: Maart 2003
- Laatst online: 17:27
Kirika <3
Op het laagste niveau moet je met pixels werken. CreateWindow(Ex) uit de Win32 API wil bijv. graag dat je de grootte van je vensters in pixels opgeeft. Als je dus hiermee werkt, moet je dus handmatig de DPI uitvogelen.incaz schreef op zaterdag 17 mei 2014 @ 15:14:
Maar het zou heel goed kunnen dat windows daarin ook behoorlijk fout zit - zoals gezegd, dat weet ik niet.
De oplossing is simpel. Doe niet aan low-level programming, maar pak gewoon VB6 die standaard twips als eenheid gebruikt.
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
Gelukkig kan je in Windows 8.1 aangeven dat je applicatie niet DPI aware is (== default) zodat DPI virtualization wordt aangezet (bij dpi >= 125%) voor die applicatie. Dat zorgt ervoor dat vanuit de applicatie het lijkt alsof DPI scaling 100% is en een 800x600 resolutie desktop hebt. Dan gaat vervolgens Windows wel het 1 en ander schalen voor je. Is wel een beetje lelijk, want kan mij goed voorstellen dat dit ervoor zorgt dat het een en ander wazig wordt.
Daarnaast kan je heel makkelijk zelf de DPI opvragen en dus die pixels omrekenen met GetDpiForMonitor(...)
*edit*
Ik heb er nog nooit eerder naar gekeken, maar zelfs ik als win32-n00b zie al hoe ik dpi aware applicaties zou moeten maken als ik direct tegen die windows meuk aan ga lopen praten. Zie dan dus ook niet hoe die de fout van MS zou moeten zijn. Dit is gewoon weer eens een goed voorbeeld van een stel apen die proberen applicaties te ontwikkelen, maar beter buiten in de tuin kunnen gaan spelen.
Daarnaast kan je heel makkelijk zelf de DPI opvragen en dus die pixels omrekenen met GetDpiForMonitor(...)
*edit*
Ik heb er nog nooit eerder naar gekeken, maar zelfs ik als win32-n00b zie al hoe ik dpi aware applicaties zou moeten maken als ik direct tegen die windows meuk aan ga lopen praten. Zie dan dus ook niet hoe die de fout van MS zou moeten zijn. Dit is gewoon weer eens een goed voorbeeld van een stel apen die proberen applicaties te ontwikkelen, maar beter buiten in de tuin kunnen gaan spelen.
[ Voor 25% gewijzigd door Caelorum op 17-05-2014 16:18 ]
- Gamebuster
- Registratie: Juli 2007
- Laatst online: 18:00
:strip_icc():strip_exif()/u/226826/aardblij-60.jpg?f=community)
Aan het werk in de tuin met enkel een korte broek aan. (en ondergoed)
0 minuten spijt gehad van mijn keuze om zelfstandig te gaan. Kan lekker werken hoe, waar en wanneer ik dat wil.
0 minuten spijt gehad van mijn keuze om zelfstandig te gaan. Kan lekker werken hoe, waar en wanneer ik dat wil.
[ Voor 26% gewijzigd door Gamebuster op 17-05-2014 16:16 ]
Let op: Mijn post bevat meningen, aannames of onwaarheden
Op je laptop zeker?Gamebuster schreef op zaterdag 17 mei 2014 @ 16:15:
Aan het werk in de tuin met enkel een korte broek aan. (en ondergoed)
0 minuten spijt gehad van mijn keuze om zelfstandig te gaan. Kan lekker werken hoe, waar en wanneer ik dat wil.
- Gamebuster
- Registratie: Juli 2007
- Laatst online: 18:00
Met een laptop ja. Met desktop in de tuin is niet zo praktisch. Kan mn tekst prima lezen ondanks dat ik in het zonnetje zit.
[ Voor 13% gewijzigd door Gamebuster op 17-05-2014 16:16 ]
Let op: Mijn post bevat meningen, aannames of onwaarheden
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
Haha, eerste waar ik aan dacht was dat je Farmville aan het spelen was ^^
Maar je bedoelt echt werken en dus niet de tuin doen? Dat heb ik gisteren namelijk gedaan, omdat ik compleet inspiratieloos was.
Maar je bedoelt echt werken en dus niet de tuin doen? Dat heb ik gisteren namelijk gedaan, omdat ik compleet inspiratieloos was.
- Gamebuster
- Registratie: Juli 2007
- Laatst online: 18:00
Ik bedoel letterlijk programmeren met laptop terwijl ik in de tuin zit 
Ik snap nu pas dat mijn zin open voor een alternatieve interpretatie was. Ik heb nog geen groene vingers, wil het wel een keer gaan doen. Heb zelf geen tuin, maar ga wel binnenkort verhuizen naar een woning met tuin.
Ik snap nu pas dat mijn zin open voor een alternatieve interpretatie was. Ik heb nog geen groene vingers, wil het wel een keer gaan doen. Heb zelf geen tuin, maar ga wel binnenkort verhuizen naar een woning met tuin.
Let op: Mijn post bevat meningen, aannames of onwaarheden
Dus je zit nu in andermans tuin?Gamebuster schreef op zaterdag 17 mei 2014 @ 16:19:
Ik bedoel letterlijk programmeren met laptop terwijl ik in de tuin zit
Ik snap nu pas dat mijn zin open voor een alternatieve interpretatie was. Ik heb nog geen groene vingers, wil het wel een keer gaan doen. Heb zelf geen tuin, maar ga wel binnenkort verhuizen naar een woning met tuin.
- mrc4nl
- Registratie: September 2010
- Laatst online: 14:51
Procrastinatie expert
ora et labora
- BikkelZ
- Registratie: Januari 2000
- Laatst online: 28-03 23:19
CMD+Z
Mensen zien in nieuwe Windows-versies gewoon niet de verbeteringen die doorgevoerd worden maar ze willen het liefste stug bij het oude blijven. Windows 8 applicaties zien er fantastisch uit op HDPI schermen, WPF biedt al jaren mogelijkheden (niet perfect maar het is al veel beter) maar blijkbaar is een GPU-geaccellereerde vector based DPI onafhankelijke interface nog een brug te ver voor veel ontwikkelaars.
"Works on my screen"
"Works on my screen"
iOS developer
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
Ik vind zelf WPF echt heerlijk om mee te werken en om bijna dezelfde redenen ook Qt (al moet ik nog naar Qt Quick kijken), maar ik ben dan ook een "programmeur" die is begonnen met AS1, toen AS3, java, C# (silverlight -> WPF) en nu C++. Ik lijk dus alles verkeerd om mee gekregen te hebben (volgens sommigen verkeerd). Ik zoek dus telkens de fatsoenlijke no-nonsense frameworks op die mij werk uit handen nemen, in tegenstelling tot sommige mensen die blijkbaar telkens het wiel, de spaken, het hout opnieuw (maar dan verkeerd) willen uitvinden.BikkelZ schreef op zaterdag 17 mei 2014 @ 16:24:
[...] WPF biedt al jaren mogelijkheden (niet perfect maar het is al veel beter) maar blijkbaar is een GPU-geaccellereerde vector based DPI onafhankelijke interface nog een brug te ver voor veel ontwikkelaars.
"Works on my screen"
[ Voor 16% gewijzigd door Caelorum op 17-05-2014 16:30 ]
- incaz
- Registratie: Augustus 2012
- Laatst online: 15-11-2022
Ik zou nog wel een e-ink scherm voor buiten willen hebben Mijn ideeen over werken op terrasjes en balkons stranden helaas toch op het niet goed genoeg leesbaar zijn voor mij.
Never explain with stupidity where malice is a better explanation
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
incaz, dan moet je een fatsoenlijk scherm kopen. Ben echt helemaal weg van mijn anti-glare scherm in mijn HP elitebook. Geweldige schermen dat om mee buiten te werken. Totaal geen weerkaatsing en met de brightness op redelijk hoog is alles perfect te lezen.
* WernerL is dit weekend begonnen met de cursus Functional Programming Principles in Scala op coursera. Voor de opgaven van week 1 was ik helaas telaat. Week 2 en 3 beide iets hoger dan een 9 gescoord. Hoewel week 3 nu een 10/10 zou moeten zijn, dat weet ik over 10 minuten.
Scala begint steeds leuker te worden nu ik het weer iets beter begin te begrijpen
//edit
Ja hij staat nu op 10/10 Er zat een foutje in mijn mostRetweeted functie.
Er zat een foutje in mijn mostRetweeted functie.
Scala begint steeds leuker te worden nu ik het weer iets beter begin te begrijpen
//edit
Ja hij staat nu op 10/10
[ Voor 10% gewijzigd door WernerL op 17-05-2014 18:32 ]
Roses are red, violets are blue, unexpected '{' on line 32.
:strip_icc():strip_exif()/u/246777/crop5665347035c66.jpeg?f=community)
Ik zou wel mee willen doen, alleen ik loop al 2 weken achter. En daarnaast niet echt tijd ervoorWernerL schreef op zaterdag 17 mei 2014 @ 18:31:
* WernerL is dit weekend begonnen met de cursus Functional Programming Principles in Scala op coursera.
- mrc4nl
- Registratie: September 2010
- Laatst online: 14:51
Procrastinatie expert
faalmeneer aan het werk bij de website van postnl
Bij deze dropdown kan ik kiezen tussen "je leefttijd" en "ouder dan 23"
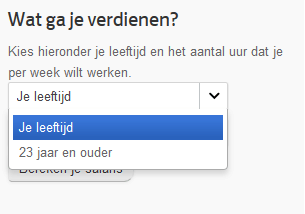
Bij deze dropdown kan ik kiezen tussen "je leefttijd" en "ouder dan 23"
ora et labora
- tommieonos
- Registratie: Oktober 2011
- Laatst online: 14:28
Strikvraag. Er staat vrij duidelijk kies "je leeftijd"mrc4nl schreef op zaterdag 17 mei 2014 @ 19:55:
faalmeneer aan het werk bij de website van postnl
Bij deze dropdown kan ik kiezen tussen "je leefttijd" en "ouder dan 23"
[afbeelding]
:strip_icc():strip_exif()/u/5964/crop56503163e97a5.jpeg?f=community)
tommieonos schreef op zaterdag 17 mei 2014 @ 20:29:
[...]
Strikvraag. Er staat vrij duidelijk kies "je leeftijd"
Vandaag dagje extra thuis gewerkt nog (ja, in het mooie weer..."chris come outside!") en morgenavond/nacht een update van een platform live gooien. Opzich spannend maar wel leuk, altijd wel n sfeertje zulk soort dingen.
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
Potentiele date. Altijd leuk natuurlijk.
Maar...
Ze vind Star Wars niet leuk, want "het is Science Fiction".
Moet ik m'n gevoel of m'n verstand volgen in dit geval?
Maar...
Ze vind Star Wars niet leuk, want "het is Science Fiction".
Moet ik m'n gevoel of m'n verstand volgen in dit geval?
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
:strip_exif()/u/294184/20150204_SITE_GIF_VALKUIL-resized.gif?f=community)
- Douweegbertje
- Registratie: Mei 2008
- Laatst online: 19-03 04:46
Wat kinderachtig.. godverdomme
/u/262310/ava.png?f=community)
Wees nou maar blij. Handig als iemand eerlijk is, ipv dat je hoort "ja leuk" om vervolgens na x-aantal films gezeik aan te horen dat ze het eigenlijk niets vind en dat je haar niet snapt en dat je niets om der geeft.Firesphere schreef op zaterdag 17 mei 2014 @ 21:20:
Potentiele date. Altijd leuk natuurlijk.
Maar...
Ze vind Star Wars niet leuk, want "het is Science Fiction".
Moet ik m'n gevoel of m'n verstand volgen in dit geval?
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
Eerlijk is natuurlijk wel een dingetje. Maar kom op, niet eens Star Wars leuk vinden? What's next, niet leuk vinden dat ik Dropkick Murphys een toffe band vind?!Douweegbertje schreef op zaterdag 17 mei 2014 @ 21:26:
[...]
Wees nou maar blij. Handig als iemand eerlijk is, ipv dat je hoort "ja leuk" om vervolgens na x-aantal films gezeik aan te horen dat ze het eigenlijk niets vind en dat je haar niet snapt en dat je niets om der geeft.
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
En wat van Harry Potter en/of Lord of the Rings?Firesphere schreef op zaterdag 17 mei 2014 @ 21:34:
[...]
Eerlijk is natuurlijk wel een dingetje. Maar kom op, niet eens Star Wars leuk vinden? What's next, niet leuk vinden dat ik Dropkick Murphys een toffe band vind?!
Als ze dat ook niks vind, dan serieus dumpen!
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
* Firesphere vind Harry Plotter maar een zinloze grafiek eigenlijk....Ryur schreef op zaterdag 17 mei 2014 @ 21:36:
[...]
En wat van Harry Potter en/of Lord of the Rings?
Als ze dat ook niks vind, dan serieus dumpen!
LOTR weet ik niet, nog niet gevraagd. Maar als Breaking Bad niet werkt, dan ben ik er wel klaar mee hoor!
[ Voor 15% gewijzigd door Firesphere op 17-05-2014 21:37 ]
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- Rutix
- Registratie: Augustus 2009
- Laatst online: 14-03 17:10
:strip_icc():strip_exif()/u/315253/boy-tweakers.jpg?f=community)
Breaking Bad is wel een geval apart hoor. Ik ken mensen die het echt een overrated serie vindenFiresphere schreef op zaterdag 17 mei 2014 @ 21:37:
[...]
* Firesphere vind Harry Plotter maar een zinloze grafiek eigenlijk....
LOTR weet ik niet, nog niet gevraagd. Maar als Breaking Bad niet werkt, dan ben ik er wel klaar mee hoor!
Nothing to see here!
- Gamebuster
- Registratie: Juli 2007
- Laatst online: 18:00
Met 3 jaar rails ervaring zeg ik bij deze het framework gedag. Rails is niet langer mijn framework-to-go en ik zal dan ook mijn projecten langzamerhand loskoppelen van Rails.
Wel blijf ik voorlopig programmeren met Ruby. Ik zal gaan werken met de Entity, Boundary, Control pattern. Persistance doe ik met de Repository pattern. Als guideline gebruik ik de clean coders boek en video's voor het ontwikkelen van de applicatie.
Ik stap af van Rails i.v.m. de beperkte testbaarheid, de grote blackbox gehalte van Rails en de afwijkende standpunten van mr. DHH.
Het zal even werk zijn om voor bepaalde dingen alternatieven te zoeken. Voorlopig zal ik ook bepaalde componenten uit Rails blijven gebruiken, maar ik hoop volledig geïsoleerd te zijn spoedig.
Wel blijf ik voorlopig programmeren met Ruby. Ik zal gaan werken met de Entity, Boundary, Control pattern. Persistance doe ik met de Repository pattern. Als guideline gebruik ik de clean coders boek en video's voor het ontwikkelen van de applicatie.
Ik stap af van Rails i.v.m. de beperkte testbaarheid, de grote blackbox gehalte van Rails en de afwijkende standpunten van mr. DHH.
Het zal even werk zijn om voor bepaalde dingen alternatieven te zoeken. Voorlopig zal ik ook bepaalde componenten uit Rails blijven gebruiken, maar ik hoop volledig geïsoleerd te zijn spoedig.
Let op: Mijn post bevat meningen, aannames of onwaarheden
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
:strip_exif()/u/306933/ezgif.com-optimize.gif?f=community)
Ik vind SciFi anders ook niet leuk hoor. Ook nooit gezien.
HP ook nooit gelezen/gezien.
Doe mij maar TBBT, House of Cards, Borgen, of Person of Interest. Veel leuker.
HP ook nooit gelezen/gezien.
Doe mij maar TBBT, House of Cards, Borgen, of Person of Interest. Veel leuker.
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
Zou jij hierover kunnen bloggen ofzo?Gamebuster schreef op zaterdag 17 mei 2014 @ 21:50:
Met 3 jaar rails ervaring zeg ik bij deze het framework gedag. Rails is niet langer mijn framework-to-go en ik zal dan ook mijn projecten langzamerhand loskoppelen van Rails.
Ik ben heel benieuwd naar je ervaringen!
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
Er is een reden dat jij compleet kansloos bent om mijn vriendin te zijn.F.West98 schreef op zaterdag 17 mei 2014 @ 21:54:
Ik vind SciFi anders ook niet leuk hoor. Ook nooit gezien.
HP ook nooit gelezen/gezien.
Doe mij maar TBBT, House of Cards, Borgen, of Person of Interest. Veel leuker.
En deze argumenten staan redelijk niet bovenaan de lijst...
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Ik bedoelde meer dat dat dus echt niets zegt over de persoon.
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Ardana
- Registratie: Januari 2003
- Laatst online: 29-03 17:28
Mens
:strip_icc():strip_exif()/u/76503/chuchu%252070x70.jpg?f=community)
West, slim weer: hoe de f... kun je weten dat je iets niet leuk vind als je het nooit gezien hebt? Overigens vind ik PoI ook redelijk SF-gehalte hebben. Of denk je dat dit werkelijk mogelijk is?
[ Voor 32% gewijzigd door Ardana op 17-05-2014 22:26 ]
Investeer in een nieuwe vorm van anti-conceptie: Choice!
- Gamebuster
- Registratie: Juli 2007
- Laatst online: 18:00
Ik heb een tweakblogs waar ik soms wat rants plaats. Ik zal proberen mijn ontwikkelingen te delen.Ryur schreef op zaterdag 17 mei 2014 @ 22:12:
[...]
Zou jij hierover kunnen bloggen ofzo?
Ik ben heel benieuwd naar je ervaringen!
Let op: Mijn post bevat meningen, aannames of onwaarheden
Verwijderd
Hoe weet je nou of je iets niet leuk vindt als je het nog nooit hebt gezienF.West98 schreef op zaterdag 17 mei 2014 @ 21:54:
Ik vind SciFi anders ook niet leuk hoor. Ook nooit gezien.
spuit11....
[ Voor 4% gewijzigd door Verwijderd op 17-05-2014 22:27 ]
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Hahaha ok.
Ik heb één HP gezien, en gepoogd deel 1 te lezen, ik vond het vreselijk.
Ik heb wel eens delen van Star Wars e.d. meegekregen, totaal niet mijn smaak. Ook The Matrix, mijn vader keek dat laatst, totaal niet aan mij besteed.
PoI is realistischer dan alles hierboven
Ik heb één HP gezien, en gepoogd deel 1 te lezen, ik vond het vreselijk.
Ik heb wel eens delen van Star Wars e.d. meegekregen, totaal niet mijn smaak. Ook The Matrix, mijn vader keek dat laatst, totaal niet aan mij besteed.
PoI is realistischer dan alles hierboven
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
Ik denk dat het in de nabije toekomst wel mogelijk zou worden, zodra ze genoeg processing power ter beschikking hebben. Natuurlijk gaat het dan niet door een enkeling ontwikkeld worden, maar bij de NSA ziten er genoeg knappe koppen + budget ervoor. Ik zie dat dus nog gebeuren, ja.Ardana schreef op zaterdag 17 mei 2014 @ 22:25:
West, slim weer: hoe de f... kun je weten dat je iets niet leuk vind als je het nooit gezien hebt? Overigens vind ik PoI ook redelijk SF-gehalte hebben. Of denk je dat dit werkelijk mogelijk is?
- .oisyn
- Registratie: September 2000
- Laatst online: 11:08
:strip_icc():strip_exif()/u/12461/crop65b195553d948.jpg?f=community)
Alsof je dat nodig hebt om het leuk met elkaar te hebbenFiresphere schreef op zaterdag 17 mei 2014 @ 21:20:
Potentiele date. Altijd leuk natuurlijk.
Maar...
Ze vind Star Wars niet leuk, want "het is Science Fiction".
Moet ik m'n gevoel of m'n verstand volgen in dit geval?
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
Ik had hier een bordje "sarcasme" bij moeten plaatsen. Natuurlijk, dit is de devschuur..oisyn schreef op zaterdag 17 mei 2014 @ 23:24:
[...]
Alsof je dat nodig hebt om het leuk met elkaar te hebben
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- Rutix
- Registratie: Augustus 2009
- Laatst online: 14-03 17:10
Nu zak je nog verder op mijn lijstjeF.West98 schreef op zaterdag 17 mei 2014 @ 21:54:
Ik vind SciFi anders ook niet leuk hoor. Ook nooit gezien.
HP ook nooit gelezen/gezien.
Doe mij maar TBBT, House of Cards, Borgen, of Person of Interest. Veel leuker.
Nothing to see here!
- BikkelZ
- Registratie: Januari 2000
- Laatst online: 28-03 23:19
CMD+Z
Nou ik ben anders wel heel blij als ik rustig met iemand een "moeilijke", "rare" of science fiction film kan kijken. Anders kom je al heel gauw bij een avondje bioscoop bij Ben Stiller, Ben Stiller of Ben Stiller uit.
Laatst deze zitten kijken met zijn tweeën:
http://vimeo.com/63167099
Heb er echt geen tijd voor als ik alle films die ik wil zien in de tijd moet kijken die ik toevallig net voor mezelf in mijn eentje heb zonder dat ik hoef te werken. Dat is vijf uur per jaar of zo.
Laatst deze zitten kijken met zijn tweeën:
http://vimeo.com/63167099
Heb er echt geen tijd voor als ik alle films die ik wil zien in de tijd moet kijken die ik toevallig net voor mezelf in mijn eentje heb zonder dat ik hoef te werken. Dat is vijf uur per jaar of zo.
[ Voor 40% gewijzigd door BikkelZ op 17-05-2014 23:53 ]
iOS developer
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Stond ik al laag?Rutix schreef op zaterdag 17 mei 2014 @ 23:51:
[...]
Nu zak je nog verder op mijn lijstjestraks ga je ook nog zeggen dat GoT kut is en LOTR ook maar stom is


Die twee heb ik niet gezien/gelezen, maar van wat ik er van gehoord heb is het niet mijn smaak.
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
Tja, veel verder kun je niet zakken in ieder geval.F.West98 schreef op zondag 18 mei 2014 @ 00:53:
[...]
Stond ik al laag?
Die twee heb ik niet gezien/gelezen, maar van wat ik er van gehoord heb is het niet mijn smaak.
Tenzij je PHP gaaf vindt en Basic helemaal jouw ding is natuurlijk.
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Encoding issues...
En nu alweer
En nu alweer
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
Ow ja, als je niet snapt hoe UTF8 encryptie werkt, zak je natuurlijk nog wat verder weg.
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Huh, wat? Is UTF8 encryptie?! 
Dat verklaart alles!
Dat verklaart alles!
spoiler:
Ik snap niet dat als .NET UTF8 stuurt naar de client, met utf8 in de header, met juiste weergave in de debugger, en dat het dan TOCH misgaat
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
Zelfs KPN versleuteld UTF8 man.F.West98 schreef op zondag 18 mei 2014 @ 01:28:
Huh, wat? Is UTF8 encryptie?!
Dat verklaart alles!
spoiler:Ik snap niet dat als .NET UTF8 stuurt naar de client, met utf8 in de header, met juiste weergave in de debugger, en dat het dan TOCH misgaat
https://twitter.com/KPNwebcare/status/168371471675174913
Kom eens in de huidige tijd en doe wat je moet doen!
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Jeej, encoding gefixt.
Maar @KPN: 
Maar @KPN:
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
/u/126369/Daos2.png?f=community)
Kan je niet naar de ruwe bytes kijken? Een raar teken heeft in utf8 een andere code/byte dan hetzelfde teken in win-xyz.F.West98 schreef op zondag 18 mei 2014 @ 01:28:
Huh, wat? Is UTF8 encryptie?!
Dat verklaart alles!
spoiler:Ik snap niet dat als .NET UTF8 stuurt naar de client, met utf8 in de header, met juiste weergave in de debugger, en dat het dan TOCH misgaat
En helpt het als je utf8 een bom geeft?
- Caelorum
- Registratie: April 2005
- Laatst online: 17:06
Van die weergave in de debugger moet je toch al niet uitgaan want die geeft niet altijd weer wat de daadwerkelijke data is
- Rutix
- Registratie: Augustus 2009
- Laatst online: 14-03 17:10
F.West98 schreef op zondag 18 mei 2014 @ 00:53:
[...]
Stond ik al laag?
Die twee heb ik niet gezien/gelezen, maar van wat ik er van gehoord heb is het niet mijn smaak.
Jup! Nu sta je bijna onderaan
Oh een artikel over hoe MS software maakt
[ Voor 17% gewijzigd door Rutix op 18-05-2014 09:56 ]
Nothing to see here!
- .oisyn
- Registratie: September 2000
- Laatst online: 11:08
3 uur per dag hierBikkelZ schreef op zaterdag 17 mei 2014 @ 23:52:
Heb er echt geen tijd voor als ik alle films die ik wil zien in de tijd moet kijken die ik toevallig net voor mezelf in mijn eentje heb zonder dat ik hoef te werken. Dat is vijf uur per jaar of zo.
Maar je vriendin/vrouw gaat verder ook nooit uit ofzo zonder dat jij meegaat (of andersom natuurlijk maar dan kun je die film niet kijken)?
[ Voor 17% gewijzigd door .oisyn op 18-05-2014 13:52 ]
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Het was al gefixt. Ik deed:Daos schreef op zondag 18 mei 2014 @ 08:08:
[...]
Kan je niet naar de ruwe bytes kijken? Een raar teken heeft in utf8 een andere code/byte dan hetzelfde teken in win-xyz.
En helpt het als je utf8 een bom geeft?
C#:
1
2
| Stream stream = response.GetResponseStream(); string result = (new StreamReader(stream)).ReadToEnd(); |
En dan heb je UTF8 encoding, maar het bleek dus win1252 te zijn. Nu is het dit:
C#:
1
2
3
4
5
6
| Stream stream = response.GetResponseStream(); var ms = new MemoryStream(); stream.CopyTo(ms); byte[] win1252bytes = ms.ToArray(); byte[] utf8bytes = Encoding.Convert(Encoding.GetEncoding(1252), Encoding.UTF8, win1252bytes); string result = Encoding.UTF8.GetString(utf8bytes); |
Kan vast mooier, maar het voldoet.
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Robbiedobbie
- Registratie: Augustus 2009
- Laatst online: 16:33
verdorie, harde waren heeft mijn topic gesloten ^^
http://gathering.tweakers...message/42249089#42249089
http://gathering.tweakers...message/42249089#42249089
- .oisyn
- Registratie: September 2000
- Laatst online: 11:08
Waarom ga je nou eerst naar UTF-8 als je doel is om er gewoon een String van te krijgenF.West98 schreef op zondag 18 mei 2014 @ 14:02:
[...]
Het was al gefixt. Ik deed:
C#:
En dan heb je UTF8 encoding, maar het bleek dus win1252 te zijn. Nu is het dit:
C#:
Kan vast mooier, maar het voldoet.
Encoding.GetEncoding(1252).GetString(win1252bytes)
[ Voor 3% gewijzigd door .oisyn op 18-05-2014 14:17 ]
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
Het is tenminste niet naar de TC, je mag daar (voorlopig) nog blij mee zijnRobbiedobbie schreef op zondag 18 mei 2014 @ 14:09:
verdorie, harde waren heeft mijn topic gesloten ^^
http://gathering.tweakers...message/42249089#42249089
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Omdat ik UTF8 teruggeef naar de client......oisyn schreef op zondag 18 mei 2014 @ 14:15:
[...]
Waarom ga je nou eerst naar UTF-8 als je doel is om er gewoon een String van te krijgen
Encoding.GetEncoding(1252).GetString(win1252bytes)
Of wacht..
Stom SODD
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Robbiedobbie
- Registratie: Augustus 2009
- Laatst online: 16:33
Het is in ieder geval terecht gekomen waar velen hookers bij vonden passenwsitedesign schreef op zondag 18 mei 2014 @ 14:22:
[...]
Het is tenminste niet naar de TC, je mag daar (voorlopig) nog blij mee zijn
Robbiedobbie schreef op zondag 18 mei 2014 @ 14:26:
[...]
Het is in ieder geval terecht gekomen waar velen hookers bij vonden passen
Die klopt wel redelijk
- Biersteker
- Registratie: Juni 2009
- Laatst online: 15:07
Hmz....netbeans what the fuck have you done?
Netbeans heeft sinds 8.0 bij mij de neiging zichzelf at random dicht te gooien. (Win8.1).
ElementaryOS heeft ook een mooie bug met netbeans. (Als netbeans maximized draait, kan je ineens geen folder meer collapsen)
Dus nu maar in een VM van Mavericks in netbeans aan het werk
Of terug naar 7.4
Netbeans heeft sinds 8.0 bij mij de neiging zichzelf at random dicht te gooien. (Win8.1).
ElementaryOS heeft ook een mooie bug met netbeans. (Als netbeans maximized draait, kan je ineens geen folder meer collapsen)
Dus nu maar in een VM van Mavericks in netbeans aan het werk
Of terug naar 7.4
[ Voor 26% gewijzigd door Biersteker op 18-05-2014 14:41 ]
Originally, a hacker was someone who makes furniture with an axe.
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Volgens mij had ik hier eerder gevraagd, maar de brakke tweakers-search kan het niet meer vinden.
Ik zoek een vervangende mailoplossing voor mijn moeder. Ik zoek MS Exchange, en ik moet mijn eigen domein kunnen koppelen. Redelijk veel opslag is ook wenselijk, en eventuele uitbreiding.
Ik zoek een vervangende mailoplossing voor mijn moeder. Ik zoek MS Exchange, en ik moet mijn eigen domein kunnen koppelen. Redelijk veel opslag is ook wenselijk, en eventuele uitbreiding.
[ Voor 70% gewijzigd door F.West98 op 18-05-2014 14:50 ]
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Robbiedobbie
- Registratie: Augustus 2009
- Laatst online: 16:33
Wat heb je gevraagd?F.West98 schreef op zondag 18 mei 2014 @ 14:49:
Volgens mij had ik hier eerder gevraagd, maar de brakke tweakers-search kan het niet meer vinden.
...
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Dat ging dus een beetje mis, ik deed te vroeg tab-enter
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
:strip_icc():strip_exif()/u/6143/rincewind.jpg?f=community)
Ja of je geeft de streamreader gewoon de juiste encoding meeF.West98 schreef op zondag 18 mei 2014 @ 14:02:
[...]
Het was al gefixt. Ik deed:
C#:
En dan heb je UTF8 encoding, maar het bleek dus win1252 te zijn. Nu is het dit:
C#:
Kan vast mooier, maar het voldoet.
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Bedankt!
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- BikkelZ
- Registratie: Januari 2000
- Laatst online: 28-03 23:19
CMD+Z
Ja ik ga toch wel eens een SF film pakken met vrienden maar ik zit in ieder geval niet thuis iedere keer stompzinnige films te kijken.oisyn schreef op zondag 18 mei 2014 @ 13:50:
[...]
3 uur per dag hier
Maar je vriendin/vrouw gaat verder ook nooit uit ofzo zonder dat jij meegaat (of andersom natuurlijk maar dan kun je die film niet kijken)?
iOS developer
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Oh great, visualstudio.com is offline....
edit: Oh no, it's Ziggo....
edit: Oh no, it's Ziggo....
[ Voor 26% gewijzigd door F.West98 op 18-05-2014 15:24 ]
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
FFFFFFFFFFFFUUUUUUUUUUUUUUUUU!!!!!!!!!!!!!!!
Ik was in m'n controlpanel van m'n primaire VPS, status bekijken en gedachtenloos beetje de opties langs hoveren.
Door een twitch in m'n vinger wordt m'n primaire VPS nu naar de originele installatie-image gereset
Had daar niet EVEN een bevestigingsdialoogje tussen kunnen zitten?!
Dat wordt een half uur wachten, dan de image van vannacht restoren (weer een half uur wachten) en hopen dat alles weer werkt naar behoren.
Ik was in m'n controlpanel van m'n primaire VPS, status bekijken en gedachtenloos beetje de opties langs hoveren.
Door een twitch in m'n vinger wordt m'n primaire VPS nu naar de originele installatie-image gereset
Had daar niet EVEN een bevestigingsdialoogje tussen kunnen zitten?!
Dat wordt een half uur wachten, dan de image van vannacht restoren (weer een half uur wachten) en hopen dat alles weer werkt naar behoren.
[ Voor 17% gewijzigd door Firesphere op 18-05-2014 15:33 ]
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- Alex)
- Registratie: Juni 2003
- Laatst online: 12-12-2025
Office 365?F.West98 schreef op zondag 18 mei 2014 @ 14:49:
Volgens mij had ik hier eerder gevraagd, maar de brakke tweakers-search kan het niet meer vinden.
Ik zoek een vervangende mailoplossing voor mijn moeder. Ik zoek MS Exchange, en ik moet mijn eigen domein kunnen koppelen. Redelijk veel opslag is ook wenselijk, en eventuele uitbreiding.
We are shaping the future
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Ze wil niet bij MS of Google, en ze zoekt nu een alternatief omdat de uni over gaat naar Google Apps.
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- Firesphere
- Registratie: September 2010
- Laatst online: 11:30
Yoshis before Hoshis
Zo, na de herstelprocedure, meteen maar even de favicon van codingplayground aangepast 
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- Gamebuster
- Registratie: Juli 2007
- Laatst online: 18:00
ElementaryOS heeft wel meer dan 1 mooie bug... #rantBiersteker schreef op zondag 18 mei 2014 @ 14:34:
ElementaryOS heeft ook een mooie bug
Let op: Mijn post bevat meningen, aannames of onwaarheden
Je kan er vanuit gaan dat als veel mensen iets nodig hebben, Microsoft wel iets handigs in C# of .Net heeft gestopt. En encoding is iets dat veel mensen nodig hebben.
Verder lijkt het erop dat je niet volledig begrijpt hoe alles werkt. Net zolang prutsen totdat alles werkt is niet de juiste methode. Zorg eerst dat je de documentatie volledig begrijpt en pas die toe. Bij een fout/bug probeer die te begrijpen en lees je eventueel de documentatie beter. Pas als je alles goed denkt te weten fix je de bug.
Over de encoding:
Characters zijn dingen die wij zien. Om deze op te slaan en weer terug te toveren is er een mapping nodig van character naar bitjes/bytes. Deze mapping is de encoding (waarvan ascii wel de bekendste is).
In C# is er een speciaal datatype voor een character: char (een string is een reeks van chars). Het is het makkelijkste als je intern hier mee werkt. Dat de encoding UTF16 is doet er vrijwel nooit toe.
Tekst buiten C# is vaak in verschillende/andere encodings. Wat je dus nodig hebt is 1 conversie naar string bij binnenkomst en 1 conversie van string bij vertrek. Omdat conversie zo algemeen is kan het vaak tegelijk in de ontvang- of verzendfunctie uit een library. Is dit niet mogelijk, dan heb je **1** regel extra code nodig (uitlezen/ontvangen geeft byte[] en ene regel conversie maakt daarvan een string).
- incaz
- Registratie: Augustus 2012
- Laatst online: 15-11-2022
Ergens vind ik dat echt heel grappig. Noem mij 1 bedrijf waar dat zo gaatDaos schreef op zondag 18 mei 2014 @ 17:42:
[...]
Net zolang prutsen totdat alles werkt is niet de juiste methode. Zorg eerst dat je de documentatie volledig begrijpt en pas die toe. Bij een fout/bug probeer die te begrijpen en lees je eventueel de documentatie beter. Pas als je alles goed denkt te weten fix je de bug.
Never explain with stupidity where malice is a better explanation
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Mijn methode is meestal: net zo lang prutsen tot ik het begrijp, waarna het werkt
En nu snap ik die encoding, precies zoals jij het uitlegt
Dat het ook nog in één regel bleek te kunnen ipv in twee zoals ik uiteindelijk had is niet een kwestie van niet begrijpen, maar niet goed kijken naar de constructors
En nu snap ik die encoding, precies zoals jij het uitlegt
Dat het ook nog in één regel bleek te kunnen ipv in twee zoals ik uiteindelijk had is niet een kwestie van niet begrijpen, maar niet goed kijken naar de constructors
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
Wat ik probeerde duidelijk te maken is dat je pas als je vrij zeker weet wat iets doet het gaat typen/fixen. Is dat niet juist, dan sta je even stil met de vraag: waarom is dit niet juist? Zomaar wat proberen en als dat niet werkt zomaar wat anders proberen noem ik prutsen. Zo fix je vaak 1 bug en krijg je er weer nieuwe voor in de plaats.incaz schreef op zondag 18 mei 2014 @ 17:54:
[...]
Ergens vind ik dat echt heel grappig. Noem mij 1 bedrijf waar dat zo gaat
F.West98 is al jaren (ik overdrijf niet) met encoding bezig. Dit zou max een paar dagen moeten duren en de rest van zijn leven nooit meer fout moeten gaan. Noem mij 1 bedrijf die hier blij mee zou zijn
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Daos, nou overdrijf je.
Ik heb die quick-quote feature 1x geschreven, toen zat die fout erin. Toen maanden later een middag naar gekeken, maar hé, AJAX + Tweakers wil in dit geval niet samen. Dus toen heb ik die hele feature gedisabled.
Dat ik nu in een los geval toevallig één keer een probleempje had wat ik in een uurtje had gefixed straat daar totaal los van. Overigens probeer ik niet zomaar wat, ik google wat enzo, maar op de verkeerde termen waardoor ik verkeerde dingen tegenkom. Dankzij jullie is het nu wel goed en daar ben ik blij om, ook weer wat geleerd.
Nee ik ben niet boos
Ik heb die quick-quote feature 1x geschreven, toen zat die fout erin. Toen maanden later een middag naar gekeken, maar hé, AJAX + Tweakers wil in dit geval niet samen. Dus toen heb ik die hele feature gedisabled.
Dat ik nu in een los geval toevallig één keer een probleempje had wat ik in een uurtje had gefixed straat daar totaal los van. Overigens probeer ik niet zomaar wat, ik google wat enzo, maar op de verkeerde termen waardoor ik verkeerde dingen tegenkom. Dankzij jullie is het nu wel goed en daar ben ik blij om, ook weer wat geleerd.
Nee ik ben niet boos
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
Wat ik mij kan herinneren is dat je steeds weer encoding-problemen had met die quick-quote en dat je het steeds ging fixen. Nu had je weeeeer problemen met encoding.
Poll: F.West98 loopt/liep te prutsen met encoding
• Ja, dit lijkt prutsen
• Nee, dit is normaal/goed
• Geen mening
Tussenstand:

Ook een poll maken? Klik hier
Poll: F.West98 loopt/liep te prutsen met encoding
• Ja, dit lijkt prutsen
• Nee, dit is normaal/goed
• Geen mening
Tussenstand:
Ook een poll maken? Klik hier
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Het was niet steeds weer, maar steeds hetzelfde, ik heb het gewoon nooit gefixt, twee keer een middag geprobeerd.
En nu was ik ervan uitgegaan dat het utf8 was, maar dat bleek niet zo (andere testplekken hadden wel utf8, dus kwam ik nu pas tegen).
En nu was ik ervan uitgegaan dat het utf8 was, maar dat bleek niet zo (andere testplekken hadden wel utf8, dus kwam ik nu pas tegen).
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
- mrc4nl
- Registratie: September 2010
- Laatst online: 14:51
Procrastinatie expert
bij mij is het prutsen net zolang tot het werkt, daarna begrijp ik het.F.West98 schreef op zondag 18 mei 2014 @ 18:05:
Mijn methode is meestal: net zo lang prutsen tot ik het begrijp, waarna het werkt
ora et labora
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Het is trouwens inderdaad prutsen, maar dat is toch niet negatief?
Het is pas slecht als je iets braks gaat leveren naar klanten, dan is het prutswerk.
Het is pas slecht als je iets braks gaat leveren naar klanten, dan is het prutswerk.
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
/u/310810/tnetimage2.png?f=community)
Ben blij dat het niet de trashcan in verdwenen isRobbiedobbie schreef op zondag 18 mei 2014 @ 14:09:
verdorie, harde waren heeft mijn topic gesloten ^^
http://gathering.tweakers...message/42249089#42249089
Rare vogel in spe
- Robbiedobbie
- Registratie: Augustus 2009
- Laatst online: 16:33
Nu ben ik daar blij mee jaXesxen schreef op zondag 18 mei 2014 @ 19:38:
[...]
Ben blij dat het niet de trashcan in verdwenen is
Maar als ik over bijv. 1 jaar wordt gegoogled door een eventueel werkgever, denk ik dat ik er minder blij mee zal zijn
Jawel en prutswerk (wat meestal ook nog veels te laat af is) is het resultaat.F.West98 schreef op zondag 18 mei 2014 @ 19:31:
Het is trouwens inderdaad prutsen, maar dat is toch niet negatief?
Het is pas slecht als je iets braks gaat leveren naar klanten, dan is het prutswerk.
Denk ook eens aan (toekomstige) collega's. Bij ons lopen er een paar rotte appels rond en ik kan dan steeds na een tijdje hun puinhoop opruimen. Zelf iets maken is veel leuker dan dat en bovenal ik moet dan ook alles zien te begrijpen om het te kunnen fixen. Het kost mij dan net zoveel tijd/energie (misschien zelfs meer) als dat ik het helemaal zelf had gedaan. En dan krijg je ook vaak excuusjes/smoesjes/leugens te horen. Zoiets maakt mij echt heel kwaad en verpest mijn hele dag.
- F.West98
- Registratie: Juni 2009
- Laatst online: 02:13
Alweer 17 jaar hier
Ik ken twee opvattingen van prutsen:
- je werk niet kunnen, wat doen, en prutswerk opleveren
- lekker wat kloten tot het wel werkt, niet per sé negatief. ik pruts ook altijd wat in een nieuw programma om het te leren kennen.
Jij denk ik alleen maar de bovenste. Ik heb het over de onderste, dat doe ik.
- je werk niet kunnen, wat doen, en prutswerk opleveren
- lekker wat kloten tot het wel werkt, niet per sé negatief. ik pruts ook altijd wat in een nieuw programma om het te leren kennen.
Jij denk ik alleen maar de bovenste. Ik heb het over de onderste, dat doe ik.
2x ViewSonic VP-27885K | R9 7950X | 128GB RAM | 980 Pro 2TB x2 | RTX2070 Super
.oisyn: Windows is net zo slecht in commandline als Linux in GUI
![]() Dit topic is gesloten.
Dit topic is gesloten.
![]()
Let op:
Dit topic is niet de plaats om te lopen helpdesken. De Coffee Corner is primair bedoeld als uitlaatklep voor iedereen in de Devschuur® en niet als vraagbaak.
Dit topic is niet de plaats om te lopen helpdesken. De Coffee Corner is primair bedoeld als uitlaatklep voor iedereen in de Devschuur® en niet als vraagbaak.