Even niets...
- Patatjemet
- Registratie: Mei 2008
- Laatst online: 11-07 13:22
Ok. Dus de snelheid van de array is niet de beperkende factor in deze. Jammer dat ik niet een grotere ssd heb om de invloed daarvan ook uit te kunnen sluiten.
- raid does not fix stupid -
- Patatjemet
- Registratie: Mei 2008
- Laatst online: 11-07 13:22
Het was meer het begin van een excuus naar mijzelf om een grotere ssd aan te schaffen..  Ik zal van het weekend even kijken naar het aanmaken van een ramdisk.
Ik zal van het weekend even kijken naar het aanmaken van een ramdisk.
- raid does not fix stupid -
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
:strip_icc():strip_exif()/u/48499/IMAGE_120.jpg?f=community)
Ben ook al een tijd deze en ZFS-gerelateerde topics aan het volgen en wil nu met een collega een SAN gaan bouwen voor op ons werk (hebben groen licht gekregen van onze IT manager).
We hadden het idee om onze 2 NASsen te voorzien van 4 TB schijven (zodoende zou de netto opslagcapaciteit ervan te verdubbelen naar 18 TB) en om de vrijgekomen 12 stuks 2 TB schijven in een SAN te plaatsen. Als we die in een RAIDZ2 opstelling plaatsen, zouden we ongeveer 16/ 17 TB opslag in de SAN krijgen. Daarnaast blijven we ook de 2 TB in de server zelf gebruiken. Dit zou ons voorlopig weer even moeten helpen om voldoende opslagruimte te hebben.
Onze SAN willen we inrichten met een 12 disk RAIDZ2 array. De 2 NASsen die we nu 2,5 jaar in gebruik hebben, hebben recent 2 schijven verloren (elk 1). Daarom willen we in onze 12 disk array in ieder geval 2 schijven kwijt kunnen zijn zonder dat de array verloren is. Bij RAID10 bestaat (theoretisch) de kans dat je 2 schijven van 1 mirror kwijt raakt en zodoende je array om zeep is. Ook halveert RAID10 de opslagcapaciteit van je array en komt RAIDZ2 daar ook gunstiger naar voren. Ook is het performance voordeel van RAID10 boven RAIDZ2 volgens dit artikel ook gering.
De 14 stuks 4TB schijven zullen in de NASsen gebruikt worden, waarbij we zelf 2 cold spares willen aanhouden. De 12 vrijkomende schijven uit de NASsen willen we gebruiken in onze SAN.
Wat is volgens jullie het beste idee om de storage beschikbaar te maken in het netwerk?
We hadden het idee om onze 2 NASsen te voorzien van 4 TB schijven (zodoende zou de netto opslagcapaciteit ervan te verdubbelen naar 18 TB) en om de vrijgekomen 12 stuks 2 TB schijven in een SAN te plaatsen. Als we die in een RAIDZ2 opstelling plaatsen, zouden we ongeveer 16/ 17 TB opslag in de SAN krijgen. Daarnaast blijven we ook de 2 TB in de server zelf gebruiken. Dit zou ons voorlopig weer even moeten helpen om voldoende opslagruimte te hebben.
Onze SAN willen we inrichten met een 12 disk RAIDZ2 array. De 2 NASsen die we nu 2,5 jaar in gebruik hebben, hebben recent 2 schijven verloren (elk 1). Daarom willen we in onze 12 disk array in ieder geval 2 schijven kwijt kunnen zijn zonder dat de array verloren is. Bij RAID10 bestaat (theoretisch) de kans dat je 2 schijven van 1 mirror kwijt raakt en zodoende je array om zeep is. Ook halveert RAID10 de opslagcapaciteit van je array en komt RAIDZ2 daar ook gunstiger naar voren. Ook is het performance voordeel van RAID10 boven RAIDZ2 volgens dit artikel ook gering.
- Is dit ook jullie mening? Of performt een RAID10 array echt veel beter dan een RAIDZ2 array?
| # | Product | Prijs | Subtotaal |
| 1 | Intel Xeon E5-2609 v2 Boxed | € 257,73 | € 257,73 |
| 1 | Supermicro Supermicro X9SRH-7TF | € 499,21 | € 499,21 |
| 14 | HGST Deskstar NAS, 4TB | € 153,60 | € 2.150,40 |
| 1 | Supermicro SC846 E16-R1200B | € 1.199,26 | € 1.199,26 |
| 2 | 3Ware 3Ware Multi-lane SATA cable CBL-SFF8087OCF-05M | € 12,75 | € 25,50 |
| 1 | Intel Ethernet Converged Network Adapter X540-T2 | € 447,80 | € 447,80 |
| 1 | Netgear XS708E | € 704,- | € 704,- |
| 2 | Icydock 2.5" to 3.5" SSD & SATA Hard Drive Converter | € 18,- | € 36,- |
| 1 | Kingston ValueRAM KVR13LR9D4K4/64 | € 543,- | € 543,- |
| 1 | IBM ServeRAID M1015 SAS/SATA Controller for System x | € 130,63 | € 130,63 |
| 2 | Plextor PX-128M5S 128GB | € 77,- | € 154,- |
| Bekijk collectie Importeer producten | Totaal | € 6.147,53 | |
De 14 stuks 4TB schijven zullen in de NASsen gebruikt worden, waarbij we zelf 2 cold spares willen aanhouden. De 12 vrijkomende schijven uit de NASsen willen we gebruiken in onze SAN.
- Moeten we nog iets met die schijven doen ivm TLER oid voordat we ze kunnen gebruiken icm ZFS?
- Wat is hierin de beste verbindingsoptie? Teamen van de 2 aansluitingen? En zo ja in welke vorm levert dit de beste en meest betrouwbare performance? Of allebei in een apart subnet gooien en apart gebruiken? Is dan MPIO mogelijk?
- Verder zag ik in een vrij recente post van CiPHER nog dat een crosslink kabel tegenwoordig (>1Gbit) niet meer nodig is om 2 devices zonder switch aan elkaar te hangen. Zou dit impliceren dat we onze SAN zonder swicth met 2 UTP kabels aan onze server kunnen hangen? Is dit betrouwbaar en performt dit goed? Of is het toch beter om er een switch tussen te hangen?
Wat is volgens jullie het beste idee om de storage beschikbaar te maken in het netwerk?
- op de host een grote schijf maken (iSCSI) en daar netwerkshares op zetten?
- vanuit een VM netwerkshares delen?
- op de host 1 grote schijf maken, waarop middels verschillende VHD files weer virtuele schijven op gemaakt worden die via de VMs op het netwerk gedeeld kunnen worden?
Lenovo Thinkpad Yoga X380
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
Ik vind 1200 euro voor kast voor een server van 6000 euro best veel...
En waarom Plextor's en niet Intel DC's?
En waarom Plextor's en niet Intel DC's?
Even niets...
- Jormungandr
- Registratie: Oktober 2006
- Laatst online: 08-07 14:13
Redundant en 1 switch is niet redundant. In een SAN gebruikt men neestal 2 of meerdere HBA's die dan elk naar andere switches gaan. Wanneer 1 switch eruit knalt heb je nog een tweede pad naar je storage. Met maar 1 switch heeft dit geen nut.
Weet je de IOPS vereisten van je omgeving? 14x4TB is leuk vele opslag, maar IOPS gewijs een heel stuk minder spannend.
Weet je de IOPS vereisten van je omgeving? 14x4TB is leuk vele opslag, maar IOPS gewijs een heel stuk minder spannend.
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
Die behuizing is inderdaad best prijzig, maar ik kan maar weinig andere behuizingen vinden met 24 hot swappable 3,5" drive trays die goedkoper zijn. Mocht je een voorstel hebben, hoor ik het graag. Waarom 24 bays? Als we nu starten zijn er al 14 bays in gebruik (er vanuit gaande dat we de 2 SSDs in brackets ook in de hotswap bays hangen. Dan hebben we dus nog 10 bays over om later de SAN nog 'simpel' uit te breiden.
De keuze voor Plextors ipv Intel DC's? De keuze op de Plextor's gevallen vanwege huidige ervaringen en de grootte vanuit CiPHERs voorbeeld in het grote ZFS topic. Verder zit daar weinig achter. Ik moet eerlijk zeggen dat ik hier niet veel diepgaand onderzoek naar had gedaan.
Enkele dingen die me opvallen als ik de 2 vergelijk:
Met een dubbele lijn over een enkele switch gaan is inderdaad niet redundant. Daar heb je helemaal gelijk in. De vraag moest eigenlijk zijn hoe de dubbeluitgevoerde 10Gb aansluitingen op de Intel kaart en op het Supermicro moederbord het best benut kunnen worden.
De 14 stuks 4TB schijven worden 2x6 stuks in een RAID 5 array in de 2 NASsen gebruikt voor backup doeleinden (2 schijven blijven op de plank liggen). IOPS is hierin dus niet zo heel spannend tot nu toe, eigenlijk heb je de IOPS van 5 schijven (6 in RAID5 array - 1 parity schijf) - overhead voor RAID5 pariteitsberekeningen als ik het goed inschat. De 2 NASsen worden gemirrord gebruikt, dus ik ga er vanuit dat hierdoor de IOPS niet echt verbeteren?
De 12 schijven die uit de NASsen vrijkomen, willen we in 1 RAIDZ2 array in de SAN stoppen, dit zal als het goed is dan beter performen dan de 2 backup NASsen. Ook hierbij moet ik de kanttekening maken dat ik nog niet echt onderzocht heb wat we hier minimaal nodig hebben.
Hoe bepaal ik dat overigens? Zijn daar tools voor om de huidige IOPS van een pc of server te bekijken? Of wordt dit een inschatting op basis van vuistregels? Ik heb eerlijk gezegd geen flauw idee hoe ik dit moet uitrekenen of inschatten. Alle hulp hierin (of zetje in de richting) is zeer welkom.
De keuze voor Plextors ipv Intel DC's? De keuze op de Plextor's gevallen vanwege huidige ervaringen en de grootte vanuit CiPHERs voorbeeld in het grote ZFS topic. Verder zit daar weinig achter. Ik moet eerlijk zeggen dat ik hier niet veel diepgaand onderzoek naar had gedaan.
Enkele dingen die me opvallen als ik de 2 vergelijk:
- De Intel heeft stroomverliesbescherming, daar heb ik volgens mij al weleens meer over gelezen. Dat zou inderdaad wel belangrijke optie zijn om voor de Intel te kiezen. Nu zie ik trouwens ook dat die tot meest betrouwbare wordt verkozen door CiPHER.
- De Plextor zou veel hogere random write IOPS hebben, klopt dit eigenlijk wel, het verschil met de Intel lijkt me zo groot? En ga ik dat merken of maakt dat geen ruk uit in real life performance?
- De paar tientjes prijsverschil doen er in mijn ogen niet toe, wat dat betreft zou hier de keuze gewoon voor de beste optie gaan.
Met een dubbele lijn over een enkele switch gaan is inderdaad niet redundant. Daar heb je helemaal gelijk in. De vraag moest eigenlijk zijn hoe de dubbeluitgevoerde 10Gb aansluitingen op de Intel kaart en op het Supermicro moederbord het best benut kunnen worden.
De 14 stuks 4TB schijven worden 2x6 stuks in een RAID 5 array in de 2 NASsen gebruikt voor backup doeleinden (2 schijven blijven op de plank liggen). IOPS is hierin dus niet zo heel spannend tot nu toe, eigenlijk heb je de IOPS van 5 schijven (6 in RAID5 array - 1 parity schijf) - overhead voor RAID5 pariteitsberekeningen als ik het goed inschat. De 2 NASsen worden gemirrord gebruikt, dus ik ga er vanuit dat hierdoor de IOPS niet echt verbeteren?
De 12 schijven die uit de NASsen vrijkomen, willen we in 1 RAIDZ2 array in de SAN stoppen, dit zal als het goed is dan beter performen dan de 2 backup NASsen. Ook hierbij moet ik de kanttekening maken dat ik nog niet echt onderzocht heb wat we hier minimaal nodig hebben.
Hoe bepaal ik dat overigens? Zijn daar tools voor om de huidige IOPS van een pc of server te bekijken? Of wordt dit een inschatting op basis van vuistregels? Ik heb eerlijk gezegd geen flauw idee hoe ik dit moet uitrekenen of inschatten. Alle hulp hierin (of zetje in de richting) is zeer welkom.
[ Voor 30% gewijzigd door dreku88000 op 08-03-2014 14:45 . Reden: Jormungandr heeft inmiddels ook gereageerd ]
Lenovo Thinkpad Yoga X380
- Q
- Registratie: November 1999
- Laatst online: 09:01
/u/1176/crop635f8931b2b68_cropped.png?f=community)
dreku88000, ik ben zelf een voorstander van ZFS enzovoort, maar als het om bedrijfstoepassingen gaat, waar meerdere gezinnen van moeten eten, zou ik zelf liever mijn geld inzetten op een 'echte' SAN met support van HP, Dell, Netapp, etc.
Het hangt natuurlijk allemaal af van de requirements, maar wat als jouw zelfbouw hatseflats SAN opeens raar doet? Zijn jullie in staat om het ding helemaal te supporten? Heb je twee machines, voor failover?
Al eerder heeft iemand op dit forum uiteindelijk toch besloten niet de eigen ballen (of eierstokken) op het hakblok te leggen en een HP MSA G3 P2000 (heb ik toevallig ervaring mee) of iets soortgelijks te kopen. Ook betaalbaar, geen ZFS, maar de vraag is welk probleem je wilt oplossen.
Als je dan toch aan de zelfbouw gaat en geld is blijkbaar een issue, dan kun je erg veel winst halen door te bezuinigen op het moederbord en de kast, dat kan je zo duizend euro schelen. Ik heb zelf een kast bij ri-vier.eu gekocht (Geen reclame) of kijk eens naar Norco kasten (RPC-4224)
Kijk eens naar het artikel in mijn signature over hardware voor ZFS NAS. Dat bordje doet 'maar' 32 GB RAM, dus dat kan wel een deal breaker zijn. Maar je kosten komen fors lager uit en performance zal nog steeds erg knap zijn.
Een grote kostenpost is 10 Gbit networking voor storage. De kans is groot dat je niets met die bandbreedte gaat doen.
Wat is eigenlijk de reden dat je dit wil bouwen? ESXi? Virtual Machines? Dan is 1 Gbit waarschijnlijk goed genoeg omdat je toch met random IO te maken hebt. Bandbreedte naar clients? 1 Gbit is meestal zat.
Waarom wil je een SAN? Waarom wil je dit ding?
Laatste puntje: ZFS kent optimum aantallen voor je VDEVs dus 12 disk RAID6 is niet verstandig. De regel is 2^x+redundancy, dus 2^3 = 8, + 2 (RAIDZ2) = 10 disks. De eerst volgende stap is dus 2^4+2=18 disks.
RAIDZ2 vs. RAID10 --> RAID10 = shitload meer IOPS, met name WRITE IOPS. Bandbreedte boeit niet.
1 VDEV heeft altijd de random IO van 1 disk. RAID10 met ZFS is in feite 24 disks, dus 12 vdevs van 2 disks. Dus 12 x random IO performance van een RAIDZ2.
Het hangt natuurlijk allemaal af van de requirements, maar wat als jouw zelfbouw hatseflats SAN opeens raar doet? Zijn jullie in staat om het ding helemaal te supporten? Heb je twee machines, voor failover?
Al eerder heeft iemand op dit forum uiteindelijk toch besloten niet de eigen ballen (of eierstokken) op het hakblok te leggen en een HP MSA G3 P2000 (heb ik toevallig ervaring mee) of iets soortgelijks te kopen. Ook betaalbaar, geen ZFS, maar de vraag is welk probleem je wilt oplossen.
Als je dan toch aan de zelfbouw gaat en geld is blijkbaar een issue, dan kun je erg veel winst halen door te bezuinigen op het moederbord en de kast, dat kan je zo duizend euro schelen. Ik heb zelf een kast bij ri-vier.eu gekocht (Geen reclame) of kijk eens naar Norco kasten (RPC-4224)
Kijk eens naar het artikel in mijn signature over hardware voor ZFS NAS. Dat bordje doet 'maar' 32 GB RAM, dus dat kan wel een deal breaker zijn. Maar je kosten komen fors lager uit en performance zal nog steeds erg knap zijn.
Een grote kostenpost is 10 Gbit networking voor storage. De kans is groot dat je niets met die bandbreedte gaat doen.
Wat is eigenlijk de reden dat je dit wil bouwen? ESXi? Virtual Machines? Dan is 1 Gbit waarschijnlijk goed genoeg omdat je toch met random IO te maken hebt. Bandbreedte naar clients? 1 Gbit is meestal zat.
Waarom wil je een SAN? Waarom wil je dit ding?
Laatste puntje: ZFS kent optimum aantallen voor je VDEVs dus 12 disk RAID6 is niet verstandig. De regel is 2^x+redundancy, dus 2^3 = 8, + 2 (RAIDZ2) = 10 disks. De eerst volgende stap is dus 2^4+2=18 disks.
RAIDZ2 vs. RAID10 --> RAID10 = shitload meer IOPS, met name WRITE IOPS. Bandbreedte boeit niet.
1 VDEV heeft altijd de random IO van 1 disk. RAID10 met ZFS is in feite 24 disks, dus 12 vdevs van 2 disks. Dus 12 x random IO performance van een RAIDZ2.
[ Voor 12% gewijzigd door Q op 08-03-2014 15:15 ]
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
:strip_icc():strip_exif()/u/200296/arch-dsotm_small.jpg?f=community)
Kan je bij benadering berekenen wat de stroomkosten van een server zijn die 24/7 draait?
Ik heb bv een i7 3770 met 32GB geheugen (4 bankjes) en 11 harddisks, waarvan 2 of 3 green. Geen monitor, geen aparte GPU (geintegreerd) en Samsung 820 SSDtje.
Wat verbruikt dat ongeveer als het staat te idlen? 100 watt? 150 watt?
Klopt dit bijvoorbeeld een beetje:
2920 uren per jaar laag tarief: 0.2283 per kwh = 100 euro
5840 uren per jaar hoog tarief: 02479 per kwh = 217 euro
Totaal bij 150 watt zou dan 317 euro zijn.
Klopt dat een beetje? Ik hoef het niet op de cent nauwkeurig te weten maar als ik dan m'n voorschot met 25 euro verhoog dan kom ik niet voor verrassingen te staan volgend jaar .
.
Ik heb bv een i7 3770 met 32GB geheugen (4 bankjes) en 11 harddisks, waarvan 2 of 3 green. Geen monitor, geen aparte GPU (geintegreerd) en Samsung 820 SSDtje.
Wat verbruikt dat ongeveer als het staat te idlen? 100 watt? 150 watt?
Klopt dit bijvoorbeeld een beetje:
2920 uren per jaar laag tarief: 0.2283 per kwh = 100 euro
5840 uren per jaar hoog tarief: 02479 per kwh = 217 euro
Totaal bij 150 watt zou dan 317 euro zijn.
Klopt dat een beetje? Ik hoef het niet op de cent nauwkeurig te weten maar als ik dan m'n voorschot met 25 euro verhoog dan kom ik niet voor verrassingen te staan volgend jaar
Neem een ander moederbord. Dit ding heeft twee PCI-sloten. Tenzij je een faxmodem uit 1998 wilt gebruiken zou ik een X9slr-f nemen. Verder is alles wel genoemd door de mensen hierboven. Wat is de bedoeling van het apparaat en wat is het verschil met die twee Netgear nassen?dreku88000 schreef op zaterdag 08 maart 2014 @ 12:59:
Jullie feedback wordt zeer gewaardeerd.
- BartNL
- Registratie: Maart 2001
- Laatst online: 07-07 22:47
:strip_exif()/u/24321/motor1.gif?f=community)
een verbruiksmeter lenen/kopen en meten wat het verbruik van je server is?InflatableMouse schreef op zaterdag 08 maart 2014 @ 16:55:Kan je bij benadering berekenen wat de stroomkosten van een server zijn die 24/7 draait?
Kosten zijn dan inderdaad zoals je berekend ongeveer €2,- per watt die 24/7 en 365 dagen per jaar verbruikt wordt.
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Dank je, mijn berekening klopt dan wel dus?
Ik snap dat ik zo'n ding kan kopen en dat is leuk als ik het precies wil weten elk moment van de dag enzo, maar dat wil ik niet. Ik weet nu al dat ik dat ding dan 5 minuten gebruik en vervolgens verdwijnt tie in een hoekje en als ik dat dan volgend jaar nog es nodig heb kan ik em niet vinden.
Er zijn genoeg mensen die een vergelijkbaar systeem hebben en het wel hebben gemeten. Reken vervolgens 6 watt per disk tel dat er bij op en ik dan weet ik het bij benadering. Dat is alles wat ik wil, bij benadering. Verder maakt het me niet veel uit als ik eind van het jaar maar niet ineens 600 euro moet bijbetalen snap je? Daar ging het me om.
Ik snap dat ik zo'n ding kan kopen en dat is leuk als ik het precies wil weten elk moment van de dag enzo, maar dat wil ik niet. Ik weet nu al dat ik dat ding dan 5 minuten gebruik en vervolgens verdwijnt tie in een hoekje en als ik dat dan volgend jaar nog es nodig heb kan ik em niet vinden
Er zijn genoeg mensen die een vergelijkbaar systeem hebben en het wel hebben gemeten. Reken vervolgens 6 watt per disk tel dat er bij op en ik dan weet ik het bij benadering. Dat is alles wat ik wil, bij benadering. Verder maakt het me niet veel uit als ik eind van het jaar maar niet ineens 600 euro moet bijbetalen snap je? Daar ging het me om.
- GioStyle
- Registratie: Januari 2010
- Laatst online: 09:50
:strip_exif()/u/340453/crop67a669ce4f1f4_cropped.webp?f=community)
Typisch een geval van meten = weten. Als je het bij benadering wil weten zal je van alle componenten de specificaties moeten opzoeken en totaal uitrekenen wat het verbruik daarvan is.
- BartNL
- Registratie: Maart 2001
- Laatst online: 07-07 22:47
ja, ik denk dat je inschatting ook wel redelijk is maar verbruik ligt er nog wel aan of je server ook 24/7 voluit moet draaien of dat hij grotendeels staat te idlen.InflatableMouse schreef op zaterdag 08 maart 2014 @ 18:24:Dank je, mijn berekening klopt dan wel dus?
Om verrassing bij de jaarafrekening te voorkomen zou ook je af en toe in de meterkast de meterstanden kunnen controleren, dan weet je zeker wat je gaat betalen.
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ja, precies dat doe ik af en toe ook wel. Ik monitor en controleer de server regelmatig en de belasting is over het algemeen een paar %.
Ik ben aan het experimenteren met spindown, een daemon om de disks in slaap te gooien maar dat werkt nog niet helemaal lekker.
Bedankt in ieder geval!
Ik ben aan het experimenteren met spindown, een daemon om de disks in slaap te gooien maar dat werkt nog niet helemaal lekker.
Bedankt in ieder geval!
- Xudonax
- Registratie: November 2010
- Laatst online: 08:47
Ik weet niet of deze vraag echt hier thuis hoort, maar...
Ik heb de installatie van Office 2013 op mijn ZFS NAS gezet zodat ik deze bij de hand heb als ik 'em nog eens nodig heb, maar nu verteld Windows 8 me (over SMB3) dat het alles bij elkaar 2MB aan ruimte in neemt o.O
Ik heb met ls gekeken, en die zegt dit:
Okay, dus het is voor het gemak 926KB (ik rond de serial.txt even flink naar boven af), en on disk gebruikt het zelfs maar 609KB vanwege compressie. YaY! En ook als ik du --human --total loslaat in de map, dan krijg ik te zien dat er 657K gebruikt word om alles op te slaan. Err...
Wat nu dus mijn vraag is:
Waarom krijg ik van 3 verschillende programma's 3 verschillende hoeveelheden van in gebruik zijnde ruimte terug?
Het verschil tussen du en ls is klein genoeg, daar maak ik me weinig druk om. Maar hoe komt Windows op het bizarre idee dat er 2MB ruimte voor in gebruik is on-disk? Geeft Samba dat terug in 1MB blokken ofzo?
Ik moet wel zeggen dat ik een RAID-Z2 van 6 4K schijven draai, dus enige overhead/verspilling van ruimte is logisch en accepteer ik natuurlijk ook. Maar ik vind dit een beetje raar

Ik heb de installatie van Office 2013 op mijn ZFS NAS gezet zodat ik deze bij de hand heb als ik 'em nog eens nodig heb, maar nu verteld Windows 8 me (over SMB3) dat het alles bij elkaar 2MB aan ruimte in neemt o.O
Ik heb met ls gekeken, en die zegt dit:
code:
1
2
3
4
| $ ls -hl totaal 609K -rwxr--r--. 1 patrick patrick 29 9 mrt 13:09 serial.txt -rwxr--r--. 1 patrick patrick 925K 9 mrt 13:05 Setup.x86.nl-NL_HomeStudentRetail_<KEY>.exe |
Okay, dus het is voor het gemak 926KB (ik rond de serial.txt even flink naar boven af), en on disk gebruikt het zelfs maar 609KB vanwege compressie. YaY! En ook als ik du --human --total loslaat in de map, dan krijg ik te zien dat er 657K gebruikt word om alles op te slaan. Err...
Wat nu dus mijn vraag is:
Waarom krijg ik van 3 verschillende programma's 3 verschillende hoeveelheden van in gebruik zijnde ruimte terug?
Het verschil tussen du en ls is klein genoeg, daar maak ik me weinig druk om. Maar hoe komt Windows op het bizarre idee dat er 2MB ruimte voor in gebruik is on-disk? Geeft Samba dat terug in 1MB blokken ofzo?
Ik moet wel zeggen dat ik een RAID-Z2 van 6 4K schijven draai, dus enige overhead/verspilling van ruimte is logisch en accepteer ik natuurlijk ook. Maar ik vind dit een beetje raar
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
Het punt is dat je wilt dat je data altijd beschikbaar is en blijft. Hierbij is de zekerheid/ betrouwbaarheid afhankelijk van wat je ervoor over hebt (financieel of effort). Volgens mij zijn er 2 opties, de ene is een (in mijn ogen overprized) systeem implementeren wat dan goed ondersteund wordt, maar voor hetzelfde geld had je er nog een systeem naast kunnen zetten als failover of live spare. Zo’n offerte hebben we liggen (1 systeem, next business day support): € 17.000,00 voor een SAN van 10 TB (12 schijven à 1 TB). De andere optie is volgens mij net zo goed mogelijk, maar vereist meer inspanning/ effort (bovengenoemd idee, € 5.330,00 voor SAN van 16TB). Ohja, bedrijfsmatig gebruik, dus prijzen die ik noem zijn exclusief BTW.Q schreef op zaterdag 08 maart 2014 @ 15:10:
dreku88000, ik ben zelf een voorstander van ZFS enzovoort, maar als het om bedrijfstoepassingen gaat, waar meerdere gezinnen van moeten eten, zou ik zelf liever mijn geld inzetten op een 'echte' SAN met support van HP, Dell, Netapp, etc.
Het is maar net wat je wilt. Aangezien mijn collega en ik dit ook deels als hobby zien, is effort voor ons geen probleem. Omdat onze functie (en ons bedrijf) aan het groeien is, dringt onze IT manager er voldoende op aan dat wij alles netjes documenteren, zodat een andere ITer ook snapt hoe de vork in de steel zit. Die failover uitvoering heeft me wel aan het denken gezet, later meer hierover.Q schreef op zaterdag 08 maart 2014 @ 15:10:
Het hangt natuurlijk allemaal af van de requirements, maar wat als jouw zelfbouw hatseflats SAN opeens raar doet? Zijn jullie in staat om het ding helemaal te supporten? Heb je twee machines, voor failover?
Daarnaast is onze ervaring met ‘professionele’ partijen ook niet zo geweldig, ik zal dit met 2 voorbeelden proberen toe te lichten.
De migratie van SBS2003 naar SBS2011 met Premium Add-on en virtualisatie duurde meer dan 2 weken in plaats van (de door onze IT pro geplande) 3 dagen. Windows 2008R2 standard licentie wordt gebruikt als host en wordt 1x virtueel gedraaid als SQL server (Premium Addon van SBS2011), de SBS2011 licentie wordt enkel virtueel gebruikt. Toen we vragen hadden, konden we bij Microsoft al niet terecht; dit werd telefonisch al niet als ondersteunde optie bevestigd, terwijl dit toch echt op hun eigen TechNet blog werd geopperd als installatiemogelijkheid (http://social.technet.mic...overview-of-sbs-2011.aspx) . Na 2 weken rommelen liep het nog niet en hebben we zelf de shit op mogen lossen, wat uiteindelijk nog een maand duurde. Een groot drama dus.
Vervolgens hadden een andere collega en ik vorige week een consultant over de vloer (Microsoft Gold partner met alle papieren op het gebied van MS Project), die ons kwam vertellen dat ze ons eigenlijk maar weinig meer kon leren over MS Project Pro 2013 en dat de punten waar wij tegenaan lopen meer een gebrek van Project zijn dan gebrek aan kennis van ons. Beter dan het zelf in VBA geknutselde stuk export software kon zij het dus ook niet maken. Wat ze wel aan kon dragen was overstappen naar Project Server i.c.m. Sharepoint. Tuurlijk, dat betekend weer € 10.000 - € 15.000 aan licenties. Dit schept wat mij betreft weinig vertrouwen in de ‘pro’s’.
Het doel van onze SAN is simpel: meer opslagruimte voor netwerkgebruikers. Data die hier op komt bestaat onder andere uit FEM/ FEA analyses, digitale röntgenfoto’s, ‘gewone’ digitale foto’s, documenten, etc. onze backup strategie nu is als volgt: alle netwerkdata staat op de D schijf van de server (host), dit is een RAID5 array van 450GB SAS schijven. Hier zijn er inmiddels binnen 2 jaar al 3 van vervangen. Toegegeven, de support is, next businessday een nieuwe schijf binnen (we hebben er altijd 1 als cold spare liggen, maar goed).
Vervolgens wordt die D schijf dagelijks gebackupped naar een B schijf die bestaat uit een mirror van 2 luns op de 2 aparte nassen. 1x per week wordt er een backup van de hele server naar een externe schijf gemaakt. Hiervoor gebruiken wij 2 schijven die om en om gebruikt worden.
Volgens mij werkt dit redelijk goed en tot nu toe hebben we 3 server schijven vervangen en inmiddels ook 2 schijven uit de nassen, zonder dataverlies. Zelfs als er 1 nas compleet uitvalt, blijft de mirror in tact op de host en de backupruimte beschikbaar. Afgezien van wat bugs in het iSCSI verhaal vanuit Windows Server 2008R2, werkt alles prima.
Q schreef op zaterdag 08 maart 2014 @ 15:10:
Waarom wil je een SAN? Waarom wil je dit ding?
Het doel van de SAN is het uitbreiden van de opslagruimte, die nu alleen uit ruimte op de D schijf van de host bestaat. De backup willen we op dezelfde manier blijven uitvoeren, zodat ook alle data op de SAN dagelijks wordt gebackupped naar een mirror van 2 luns op de 2 nassen. Als we meer dan 4 TB moeten gaan backuppen naar een externe schijf, moeten we dat gaan opdelen, maar dat lijkt me ook geen probleem. Los hiervan krijgen we binnen een half jaar glasvezel en wordt ook backuppen naar een externe nas (of 2) mogelijk. Dit zal wel andere vragen oproepen en is nu verder niet aan de orde.jadjong schreef op zaterdag 08 maart 2014 @ 18:16:
[...]
Wat is de bedoeling van het apparaat en wat is het verschil met die twee Netgear nassen?
Q schreef op zaterdag 08 maart 2014 @ 15:10:
... Heb je twee machines, voor failover?
Als je dan toch aan de zelfbouw gaat en geld is blijkbaar een issue, dan kun je erg veel winst halen door te bezuinigen op het moederbord en de kast, dat kan je zo duizend euro schelen. Ik heb zelf een kast bij ri-vier.eu gekocht (Geen reclame) of kijk eens naar Norco kasten (RPC-4224)
Een grote kostenpost is 10 Gbit networking voor storage.
Laatste puntje: ZFS kent optimum aantallen voor je VDEVs dus 12 disk RAID6 is niet verstandig. De regel is 2^x+redundancy, dus 2^3 = 8, + 2 (RAIDZ2) = 10 disks. De eerst volgende stap is dus 2^4+2=18 disks.
Het moederbord was gekozen vanwege de 2 stuks 10GE aansluitingen. De PCI sloten interesseren me vrij weinig (waren me ook niet opgevallen). Waarschijnlijk komen er hooguit 2 PCI 2.0 8x kaarten in (de IBM’s) and that’s it. Die zouden gepast hebben in de 16x en de 8x PCI 3.0 sloten die erop zaten.jadjong schreef op zaterdag 08 maart 2014 @ 18:16:
[...]
Neem een ander moederbord. Dit ding heeft twee PCI-sloten. Tenzij je een faxmodem uit 1998 wilt gebruiken zou ik een X9slr-f nemen...
Bedankt voor de tips in ieder geval, ik heb wat andere spullen in de lijst gezet. Ook heb ik voor dit moment 10Gb lan even gelaten voor wat het is.
Dan kom ik nu op de volgende lijst:
| # | Product | Prijs | Subtotaal |
| 2 | Intel Xeon E3-1230V2 Boxed | € 196,90 | € 393,80 |
| 2 | Asus P8C WS | € 174,13 | € 348,26 |
| 14 | HGST Deskstar NAS, 4TB | € 153,60 | € 2.150,40 |
| 8 | WD Black SATA 6 Gb/s WD2002FAEX, 2TB | € 127,11 | € 1.016,88 |
| 4 | 3Ware 3Ware Multi-lane SATA cable CBL-SFF8087OCF-05M | € 12,75 | € 51,- |
| 2 | Norcotek RPC-4224 | € 487,03 | € 974,06 |
| 4 | Icydock 2.5" to 3.5" SSD & SATA Hard Drive Converter | € 18,- | € 72,- |
| 2 | Kingston ValueRAM KVR16R11S4K4/32 | € 293,- | € 586,- |
| 2 | IBM ServeRAID M1015 SAS/SATA Controller for System x | € 130,63 | € 261,26 |
| 2 | Seasonic S12II-Bronze 520W | € 46,94 | € 93,88 |
| 4 | Intel DC S3500 (2,5") 120GB | € 116,55 | € 466,20 |
| Bekijk collectie Importeer producten | Totaal | € 6.413,74 | |
Enkele opmerkingen bij deze lijst:
De behuizing is gewijzigd naar een Norcotek met 24 bays. Daar is wel een voeding bijgekomen, die hier standaard niet in zit.
10GE is voorlopig in de koelkast gezet, omdat we niet met zekerheid kunnen zeggen of we die bandbreedte vereisen. Voorlopig doen we het dus met LACP en 802.3ad link aggregation op 1GE. Dit resulteert erin dat we geen 10GE switch en netwerkkaart voor de huidige server nodig hebben en we ook met een goedkoper moederbord uit de voeten kunnen. Wijziging van moederbord brengt ook een andere Xeon mee, vanwege socket 1155. Scheelt ook weer 80 euro.
Wat is toegevoegd is failover van het hele spul, dus de hele SAN wordt 2x uitgevoerd. Omdat we al 12 schijven beschikbaar hebben en we 10 schijven in de SAN gaan stoppen, hebben we dus nog 8 schijven nodig om de 2e SAN ook van 10 stuks te voorzien.
Uiteindelijk wordt het hele spul dan slechts € 270,- duurder. Dit levert dan een dubbel uitgevoerde SAN met 14,4 TB storage. Lijkt me op zich, ook al wordt het zelfbouw, een redelijk betrouwbare setup.
Wederom bedankt voor jullie reacties
Lenovo Thinkpad Yoga X380
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Geen Black's gebruiken in combinatie met ZFS, blijf liever bij die Hitachi's. De snelheid weegt niet op tegen de nadelen (TLER=0, die schijven doen nooit aan recovery).
Die voeding is volgens mij al een wat oudere serie, liever de nieuwere Seasonic G-Series.
Neem ook echt liever een SuperMicro bord. Die zijn zoveel beter getest en stabieler dan die Asus borden. Bovendien heb je IPMI, en kan je dus remote supporten mocht het nodig zijn...
Zoiets dus: pricewatch: Supermicro X10SLH-F
En neem ECC UDIMM geheugen, ECC RDIMM werkt niet op socket 1150.
Die voeding is volgens mij al een wat oudere serie, liever de nieuwere Seasonic G-Series.
Neem ook echt liever een SuperMicro bord. Die zijn zoveel beter getest en stabieler dan die Asus borden. Bovendien heb je IPMI, en kan je dus remote supporten mocht het nodig zijn...
Zoiets dus: pricewatch: Supermicro X10SLH-F
En neem ECC UDIMM geheugen, ECC RDIMM werkt niet op socket 1150.
[ Voor 49% gewijzigd door FireDrunk op 10-03-2014 07:48 ]
Even niets...
Verwijderd
Stabieler lijkt mij de verkeerde bewoording, een onstabiel moederbord is stuk of verkeerd ingesteld normaal gesproken.
Qua voeding is de Seasonic G series idd een beter idee, hoger rendement, dus lagere stroomkosten en stabielere spanning. De S12II Bronze serie beschikt namelijk over group regulation van de 12, 5 en 3,3V en met een niet standaard load wat deze computer gaat generen gaan de spanningen wat afwijken van hun ideale waarde.
Een raid kaart met staggered spin-up is ook wel handig, kan het vermogen van de voeding de helft lager zijn. pricewatch: Seasonic G-Serie 360Watt zou met staggered spin-up bijvoorbeeld wel tot zo'n 20 HDD's van stroom kunnen voorzien samen met de rest van de computer.
Qua voeding is de Seasonic G series idd een beter idee, hoger rendement, dus lagere stroomkosten en stabielere spanning. De S12II Bronze serie beschikt namelijk over group regulation van de 12, 5 en 3,3V en met een niet standaard load wat deze computer gaat generen gaan de spanningen wat afwijken van hun ideale waarde.
Een raid kaart met staggered spin-up is ook wel handig, kan het vermogen van de voeding de helft lager zijn. pricewatch: Seasonic G-Serie 360Watt zou met staggered spin-up bijvoorbeeld wel tot zo'n 20 HDD's van stroom kunnen voorzien samen met de rest van de computer.
- jacovn
- Registratie: Augustus 2001
- Laatst online: 08:08
Wellicht ook maar geen Norcotek kopen ?
Ik heb 2 stuks 4220 units, beide hadden een defecte backplane. Wel keurig door ri-vier opgelost overigens met 2 nieuwe. Resultaat is helaas 4 hdds met wat rode waarschuwingen aan over gehouden.. Ze doen het prima omdat het niet hdd, maar backplane errors zijn.
De Ri-vier eigen kasten schijnen beter te zijn..
Ik heb 2 stuks 4220 units, beide hadden een defecte backplane. Wel keurig door ri-vier opgelost overigens met 2 nieuwe. Resultaat is helaas 4 hdds met wat rode waarschuwingen aan over gehouden.. Ze doen het prima omdat het niet hdd, maar backplane errors zijn.
De Ri-vier eigen kasten schijnen beter te zijn..
8x330 NO12.5°, 8x330 ZW12.5°, 8x350 ZW60°, 8x325 NO10°, SE8K, P500. 6x410 ZW10° Enphase
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
Die WD disks had ik gekozen omdat er nu al 12 van in gebruik zijn in onze 2 nassen. Die willen we vervangen door 4TB schijven en de vrijkomende WD RE4's willen we inzettenin de SAN. Om de 2e SAN te vullen, dacht ik simpel dezelfde schijven te pakken.FireDrunk schreef op maandag 10 maart 2014 @ 07:45:
Geen Black's gebruiken in combinatie met ZFS, blijf liever bij die Hitachi's. De snelheid weegt niet op tegen de nadelen (TLER=0, die schijven doen nooit aan recovery).
Die voeding is volgens mij al een wat oudere serie, liever de nieuwere Seasonic G-Series.
Neem ook echt liever een SuperMicro bord. Die zijn zoveel beter getest en stabieler dan die Asus borden. Bovendien heb je IPMI, en kan je dus remote supporten mocht het nodig zijn...
Zoiets dus: pricewatch: Supermicro X10SLH-F
En neem ECC UDIMM geheugen, ECC RDIMM werkt niet op socket 1150.
Ik heb even kort gezocht, maar het lijkt minder simpel dan gedacht om de drives te flashen of om de firmware aan te passen zodanig dat TLER wordt uitgezet. Ook lijkt er een tool te zijn die op nieuwere schijven niet meer werkt(WDTLER)? Of is dit alleen als je TLER aan wilt zetten op schijven die dit native niet aan hebben staan? Iemand hier die er ervaringen mee heeft? We hebben deze schijven net iets meer dan 2 jaar in gebruik en er zit 5 jaar garantie op, beetje jammer als we ze niet zouden kunnen gebruiken. Een doorgewinterde lezer heeft begrepen dat wij veel teveel betaald hebben voor die schijven vanwege wateroverlast in Taiwan
Verder zal ik inderdaad nog eens opnieuw kijken naar een Supermicro bord. Ik heb ook gelezen van die IPMI interface en wat video's gezien, lijkt inderdaad mooi te functioneren.
En bedankt ook voor de tips over de voeding en RAM, zal ik ook nog eens opnieuw naar kijken.
Thanks for the input!
Lenovo Thinkpad Yoga X380
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
TLER is niet erg icm ZFS, je wil alleen een korte TLER implementatie. (Dus niet de WD Green implementatie van 60 seconden ofzo). WD Black's doen voor zover ik weet helemaal niet aan TLER.
Als je dat niet erg vind (en je hebt echt goede backups) dan kan je het laten voor wat het is, en kan je ze gebruiken. Wil je ze naast bijvoorbeeld schijven zetten met wel TLER zou ik dat niet doen. Je kiest of helemaal niet voor TLER of voor een korte TLER. Iets er tussenin zou ik nooit doen.
Als je die schijven koopt om in een ander systeem te zetten, maak dan alsjeblieft RML lijstjes met de hardware waar je daadwerkelijk mee gaat werken, want het is voor mij (omdat ik hier de hele dag zit) veel te moeilijk om al die lijstjes uit elkaar te houden, en te onthouden wat iedereen met zijn build wil. Ik kijk gewoon naar die lijsten, en baseer daar mijn tips op
Als je dat niet erg vind (en je hebt echt goede backups) dan kan je het laten voor wat het is, en kan je ze gebruiken. Wil je ze naast bijvoorbeeld schijven zetten met wel TLER zou ik dat niet doen. Je kiest of helemaal niet voor TLER of voor een korte TLER. Iets er tussenin zou ik nooit doen.
Als je die schijven koopt om in een ander systeem te zetten, maak dan alsjeblieft RML lijstjes met de hardware waar je daadwerkelijk mee gaat werken, want het is voor mij (omdat ik hier de hele dag zit) veel te moeilijk om al die lijstjes uit elkaar te houden, en te onthouden wat iedereen met zijn build wil. Ik kijk gewoon naar die lijsten, en baseer daar mijn tips op
Even niets...
- wreckdicilous
- Registratie: Januari 2010
- Laatst online: 21-02-2024
Iemand al ervaring met : pricewatch: MyDigitalSSD SuperSSpeed SSD 64GB
http://www.tweaktown.com/...drive_review/index14.html
Ik zit er aan te denken om deze te gaan gebruiken voor ZIL.
Drives voor het ZIL mogen toch gewoon in een mirror gebruikt worden?
Regelen Freenas/Nas4free/ZFSguru de spindown voor een harddisk? Of is dat in te stellen?
Ik heb nog wat Green editions liggen maar deze spinnen ontzetten snel down. Nou kan ik dat natuurlijk wel uitzetten via het tooltje van WD, maar het zou mooier zijn als "spin down tijd" in te stellen is in de NAS software.
Thx
http://www.tweaktown.com/...drive_review/index14.html
Ik zit er aan te denken om deze te gaan gebruiken voor ZIL.
Drives voor het ZIL mogen toch gewoon in een mirror gebruikt worden?
Regelen Freenas/Nas4free/ZFSguru de spindown voor een harddisk? Of is dat in te stellen?
Ik heb nog wat Green editions liggen maar deze spinnen ontzetten snel down. Nou kan ik dat natuurlijk wel uitzetten via het tooltje van WD, maar het zou mooier zijn als "spin down tijd" in te stellen is in de NAS software.
Thx
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Hmm, in-drive UPS, en er is een 60GB model.. Klinkt wel goed. Enige wat ik jammer vind, is dat er een SandForce controller in zit... Maar op zich is het best een goede kandidaat!
http://www.tweaktown.com/..._drive_review/index8.html
Hier zie je dat met 4K QD=1 hij wel redelijke resultaten neer zet. Niet extreem goed, maar gewoon prima.
http://www.tweaktown.com/..._drive_review/index8.html
Hier zie je dat met 4K QD=1 hij wel redelijke resultaten neer zet. Niet extreem goed, maar gewoon prima.
[ Voor 38% gewijzigd door FireDrunk op 10-03-2014 12:53 ]
Even niets...
Verwijderd
Hallo dreku88000,
We hebben nu prachtige 24 bay server case voor slechts 275 EUR excl VAt.
Kijk hier eens naar:
https://ri-vier.eu/rivier...6a-p-352.html?cPath=1_3_7
Mvrgr, Richard.
We hebben nu prachtige 24 bay server case voor slechts 275 EUR excl VAt.
Kijk hier eens naar:
https://ri-vier.eu/rivier...6a-p-352.html?cPath=1_3_7
Mvrgr, Richard.
- Paul
- Registratie: September 2000
- Laatst online: 13-07 22:05
/u/11437/wandcontactdoos.png?f=community)
Hoeveel schijven (initieel) in één enclosure? Liefst maak je namelijk arrays van een macht van 2 aan dataschijven. Voor een RIADZ2 is dat dus met 4, 6 of 10 schijven. Ik zie 12 schijven in de huidige NAS en 8 nieuwe 2TB-schijven. Dan kom ik samen op 20 stuks, of 10 per enclosure / server. Waarom die hoeveelheid?dreku88000 schreef op maandag 10 maart 2014 @ 12:07:
Die WD disks had ik gekozen omdat er nu al 12 van in gebruik zijn in onze 2 nassen. Die willen we vervangen door 4TB schijven en de vrijkomende WD RE4's willen we inzettenin de SAN.
Bij 24 schijven kom ik op de volgende verdeling:
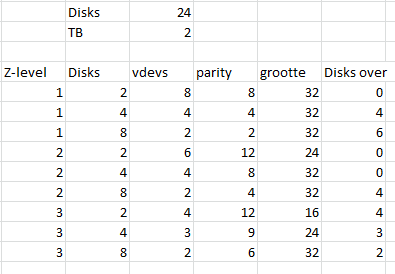 , daar kun je dus het beste RAIDZ1 met 2 schijven of RAIDZ2 met 4 schijven te nemen (of een andere verdeling en de resterende schijven in een andere array zetten). Met 10 schijven zijn die twee niet de meest optimale oplossing, dan heb je 12 of 8 TB en ongebruikte schijven. ZFS haalt IOPs uit vdevs, niet uit aantallen schijven, dus meer vdevs is sneller, en je wilt geen arrays die te groot zijn om de kans op errors tijdens het resilveren / rebuilden te verkleinen. Nu heb je natuurlijk wel de 2e server in mirror dus daar zit wel extra redundancy
, daar kun je dus het beste RAIDZ1 met 2 schijven of RAIDZ2 met 4 schijven te nemen (of een andere verdeling en de resterende schijven in een andere array zetten). Met 10 schijven zijn die twee niet de meest optimale oplossing, dan heb je 12 of 8 TB en ongebruikte schijven. ZFS haalt IOPs uit vdevs, niet uit aantallen schijven, dus meer vdevs is sneller, en je wilt geen arrays die te groot zijn om de kans op errors tijdens het resilveren / rebuilden te verkleinen. Nu heb je natuurlijk wel de 2e server in mirror dus daar zit wel extra redundancyHet werkt inderdaad heel mooiVerder zal ik inderdaad nog eens opnieuw kijken naar een Supermicro bord. Ik heb ook gelezen van die IPMI interface en wat video's gezien, lijkt inderdaad mooi te functioneren.
"Your life is yours alone. Rise up and live it." - Richard Rahl
Rhàshan - Aditu Sunlock
- Goshimaplonker298
- Registratie: Juni 2002
- Laatst online: 07-01 18:30
BOFH Wannabee
:strip_icc():strip_exif()/u/57319/BoFhphone.jpg?f=community)
Eerst stond er een supermicro 846E16 chassis in de lijst. deze heeft een ingebouwde sas expander op de backplane. Nu staat er 2x een Norco/Rivier/X-case 24 bay kast op met 2x een IBM Controller.
Je zal er vast al rekening mee gehouden hebben dat je meerdere controllers nodig gaat hebben in de kast om van alle 24 disk slots gebruik te maken. Dat of een losse sas expander.
- jacovn
- Registratie: Augustus 2001
- Laatst online: 08:08
ik draai met 2 x RaidZ2 van 10 hdd's per stuk.
Supermicro X9 serie moederbord met 2 x IBM M1015. dan heb je 4 aansluitingen van je mainbord nodig, en 16 van de 2 M1015 controllers. Werkt prima met ZFSguru.
Heb ook een 3e M1015 geprobeerd, dat werkte ook prima, maar zit dan in een x4 PCI-E slot (x8 mechanish)
10 GE van Intel werkt ook prima in een x4 PCI-E slot (x8 mechanisch nodig)
Voor backup tussen de nassen wellich interessant m.b.t snelheidswinst.
Supermicro X9 serie moederbord met 2 x IBM M1015. dan heb je 4 aansluitingen van je mainbord nodig, en 16 van de 2 M1015 controllers. Werkt prima met ZFSguru.
Heb ook een 3e M1015 geprobeerd, dat werkte ook prima, maar zit dan in een x4 PCI-E slot (x8 mechanish)
10 GE van Intel werkt ook prima in een x4 PCI-E slot (x8 mechanisch nodig)
Voor backup tussen de nassen wellich interessant m.b.t snelheidswinst.
8x330 NO12.5°, 8x330 ZW12.5°, 8x350 ZW60°, 8x325 NO10°, SE8K, P500. 6x410 ZW10° Enphase
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
Voor zover ik thuis ervaren heb met FreeNAS is dit in te stellen naar je eigen smaak, tot en met geen spin down.wreckdicilous schreef op maandag 10 maart 2014 @ 12:36:
...
Regelen Freenas/Nas4free/ZFSguru de spindown voor een harddisk? Of is dat in te stellen?
Ik heb nog wat Green editions liggen maar deze spinnen ontzetten snel down. Nou kan ik dat natuurlijk wel uitzetten via het tooltje van WD, maar het zou mooier zijn als "spin down tijd" in te stellen is in de NAS software.
Thx
Ik heb jullie opmerkingen als het goed is verwerkt in een nieuwe RML die enkel de spullen voor de SAN laat zien (@FireDrunk, ik snap de verwarring). De 14 Hitachi’s waren 2x6 + 2 cold spare bedoeld als nieuwe schijven in onze 2 6 bay nassen, deze zijn nu weggelaten in onderstaand overzicht ter verduidelijking.
| # | Product | Prijs | Subtotaal |
| 2 | Intel Xeon E3-1220 V3 Boxed | € 178,81 | € 357,62 |
| 2 | Supermicro X10SLH-F | € 189,15 | € 378,30 |
| 12 | Seagate Barracuda 7200.14 ST3000DM001, 3TB | € 93,85 | € 1.126,20 |
| 12 | WD Black SATA 6 Gb/s WD2002FAEX, 2TB | € 127,11 | € 1.525,32 |
| 4 | 3Ware 3Ware Multi-lane SATA cable CBL-SFF8087OCF-05M | € 12,75 | € 51,- |
| 4 | Icydock 2.5" to 3.5" SSD & SATA Hard Drive Converter | € 18,- | € 72,- |
| 2 | Kingston ValueRAM KVR16E11K4/32 | € 299,50 | € 599,- |
| 2 | IBM ServeRAID M1015 SAS/SATA Controller for System x | € 130,63 | € 261,26 |
| 2 | Seasonic G-Serie 550Watt | € 79,95 | € 159,90 |
| 4 | Intel DC S3500 (2,5") 120GB | € 116,55 | € 466,20 |
| Bekijk collectie Importeer producten | Totaal | € 4.996,80 | |
Moederbord is gewijzigd naar Supermicro vanwege IPMI en (blijkbaar) goede ondersteuning. Verder is de Seasonic voeding gewijzigd naar een G series. Daarnaast heb ik nu als het goed is ook het juiste geheugen gekozen. Verder heb ik de Norcotec behuizing eruit gehaald om te vervangen door een Ri-vier RVS4-06A. Deze staat alleen nog niet in de Pricewatch en ontbreekt derhalve in bovenstaande lijst.
We hebben momenteel 2 nassen van 6 bays in gebruik. Daar komen de 12 2TB schijven vandaan die we in een SAN willen stoppen. De NAS schijven vervangen we door 4TB exemplaren. We wilden (op basis van eerdere adviezen) 10 disks in een RAIDZ2 array in de SAN stoppen. Omdat we nu 2 SANs gaan mirroren, heb ik dit idee gewoon overgenomen zonder verder te kijken; 2^3 =8 array disks + 2 parity disks = 10 stuks. Omdat er 12 uit de nassen komen, moeten we er dus voor 2 SANs nog 8 toevoegen om er 2x 10 toe te kunnen passen.Paul schreef op maandag 10 maart 2014 @ 13:48:
[...]
Hoeveel schijven (initieel) in één enclosure? Liefst maak je namelijk arrays van een macht van 2 aan dataschijven. Voor een RIADZ2 is dat dus met 4, 6 of 10 schijven. Ik zie 12 schijven in de huidige NAS en 8 nieuwe 2TB-schijven. Dan kom ik samen op 20 stuks, of 10 per enclosure / server. Waarom die hoeveelheid?
...
[...]
Het werkt inderdaad heel mooi
Toen ik alles terug las, begreep ik je vraag pas. Het heeft inderdaad weinig zin om een grote RAIDZ2 array te maken van 8+2 schijven en hiervoor extra (dure) RE4 schijven aan te schaffen. Je kunt inderdaad beter kleinere vdevs in een pool stoppen (qua IOPS) en dit uitbreiden met interessantere schijven (€/GB). De 12 schijven die beschikbaar komen, kunnen als 2x 2 disk RAIDZ1 of 1x 4 disk RAIDZ2 in elke SAN gebruikt worden. Daarnaast kunnen er bijvoorbeeld 6 stuks 3 TB schijven worden toegevoegd aan elke SAN die in RAIDZ2 of 2x RAIDZ1 gebruikt kunnen worden. Dit zou in beide gevallen moeten leiden tot ongeveer 17 TB gemirrorde storage.
Thanks again allemaal voor jullie gewaardeerde input!
Lenovo Thinkpad Yoga X380
- Q
- Registratie: November 1999
- Laatst online: 09:01
Tja, dat scheelt weer 100 euro per uur consultancy kosten
- Nu bouw je twee systemen, maar ik mis nog - wat in server land erg gangbaar is - de dubbele voeding.
Kan weer downtime schelen.
Als je zelf twee servers bouwt, alleen al de hardware bouw + software installatie x je uur tarief voor de organisatie = ook een bedrag.
Verder, als ik het zo lees ga je er in ieder geval erg bewust mee om, de tijd gaat het leren wat het op gaat leveren.
Ik vraag me af of je manager de situatie Zelfbouw vs HP aan hoger management heeft voorgelegd, met bijbehorende voor/nadelen en budget impacts. Het zou me verbazen als de business / organisatie zich er echt lekker bij zou voelen en niet gewoon 30K wil neer tellen voor een vendor oplossing.
Ik heb hier ook een ZFS server draaien hoor en als ik morgen weg ben dan kan de organisatie daar niets mee. De kennis is gewoon niet in huis en ik kan het wel 20x documenteren, maar daar hebben ze toch geen donder aan., ik kan niet al mijn kenns op papier zetten.
Dat ding is dus voor test en niet productie. Productie is vendor spul. En ondanks wat spannende ervaringen zou ik het toch niet anders doen.
Het HP renew programma kan je aan apparatuur helpen die forst goedkoper is, toch 100% supported door HP met alle garantie die je wilt. Ik denk dat je voor ~20K al 2x MSA P2000 G3 iSCSI + 10 x 1 TB kunt hebben. Helaas geen SSD acceleratie maar is dat nodig?
Ik denk dat als je wat offertes opvraagt bij meerdere partijen je best een goede deal kunt krijgen, een stuk beter dan die belachelijke 17K voor 10 TB.
Hier, chassis voor 5K ex btw:
http://www.buyitdirect.co...ray_system/bk831b/1415060
http://www.buyitdirect.co...dl_hdd/605835-b21/1015308
12 disks is ~5000 euro, dus 10K per storage unit, met expantie naar 24 disks voor de toekomst.
Dus voor 20K bespaar je jezelf een hoop gedonder.
- Nu bouw je twee systemen, maar ik mis nog - wat in server land erg gangbaar is - de dubbele voeding.
Kan weer downtime schelen.
Als je zelf twee servers bouwt, alleen al de hardware bouw + software installatie x je uur tarief voor de organisatie = ook een bedrag.
Verder, als ik het zo lees ga je er in ieder geval erg bewust mee om, de tijd gaat het leren wat het op gaat leveren.
Ik vraag me af of je manager de situatie Zelfbouw vs HP aan hoger management heeft voorgelegd, met bijbehorende voor/nadelen en budget impacts. Het zou me verbazen als de business / organisatie zich er echt lekker bij zou voelen en niet gewoon 30K wil neer tellen voor een vendor oplossing.
Ik heb hier ook een ZFS server draaien hoor en als ik morgen weg ben dan kan de organisatie daar niets mee. De kennis is gewoon niet in huis en ik kan het wel 20x documenteren, maar daar hebben ze toch geen donder aan., ik kan niet al mijn kenns op papier zetten.
Dat ding is dus voor test en niet productie. Productie is vendor spul. En ondanks wat spannende ervaringen zou ik het toch niet anders doen.
Het HP renew programma kan je aan apparatuur helpen die forst goedkoper is, toch 100% supported door HP met alle garantie die je wilt. Ik denk dat je voor ~20K al 2x MSA P2000 G3 iSCSI + 10 x 1 TB kunt hebben. Helaas geen SSD acceleratie maar is dat nodig?
Ik denk dat als je wat offertes opvraagt bij meerdere partijen je best een goede deal kunt krijgen, een stuk beter dan die belachelijke 17K voor 10 TB.
Hier, chassis voor 5K ex btw:
http://www.buyitdirect.co...ray_system/bk831b/1415060
http://www.buyitdirect.co...dl_hdd/605835-b21/1015308
12 disks is ~5000 euro, dus 10K per storage unit, met expantie naar 24 disks voor de toekomst.
Dus voor 20K bespaar je jezelf een hoop gedonder.
[ Voor 48% gewijzigd door Q op 10-03-2014 17:49 ]
Verwijderd
Dual-psu lijkt mij vrij nutteloos, de kans dat een goede voeding zoals de gekozen Seasonic ermee ophoudt is heel erg klein, misschien maar zo'n 0,1%, als je externe oorzaken niet mee telt. Tegen externe problemen gaat een dual PSU setup ook niet helpen, dus dat zal het percentage ook niet verlagen. Een UPS is dan misschien wel handig, zorgt ervoor dat de PC niet uitvalt als de stroom wegvalt, dus kans op dataloss zal minder zijn. En filtert ook spanningspieken weg, wat ook één van de oorzaken is van een kapotte voeding door extern probleem.
- Q
- Registratie: November 1999
- Laatst online: 09:01
Een server zonder dual-psu is een onbelangrijke server.
Een dual-psu vs single psu is peanuts qua extra kosten maar availability kan weldegelijk uitmaken, ik heb meerdere servervoedingen in mijn carriere zien sterven, nota bene een van ons SAN!!! Het duurde nog weken voordat we een vervangende PSU van HP kregen, dat was nog wel even spannend.
Na disks is de PSU het eerste wat zo'n beetje stuk gaat.
Een UPS is verplicht, het is niet eens een discussiepunt, het is vanzelfsprekend dat je die hebt. Als je je servers niet beschermt met een UPS of andere noodstroom oplossing, dan ben je blijkbaar niets belangrijks aan het doen, zet dan de servers meteen ook maar uit, scheelt weer stroomkosten.
Een dual-psu vs single psu is peanuts qua extra kosten maar availability kan weldegelijk uitmaken, ik heb meerdere servervoedingen in mijn carriere zien sterven, nota bene een van ons SAN!!! Het duurde nog weken voordat we een vervangende PSU van HP kregen, dat was nog wel even spannend.
Na disks is de PSU het eerste wat zo'n beetje stuk gaat.
Een UPS is verplicht, het is niet eens een discussiepunt, het is vanzelfsprekend dat je die hebt. Als je je servers niet beschermt met een UPS of andere noodstroom oplossing, dan ben je blijkbaar niets belangrijks aan het doen, zet dan de servers meteen ook maar uit, scheelt weer stroomkosten.
[ Voor 26% gewijzigd door Q op 10-03-2014 18:05 ]
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
* FireDrunk pakt popcorn 
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
En daar ging de volgende Failgate ...
code:
1
2
3
| replacing-4 UNAVAIL 0 0 0
ata-ST2000DM001-9YN164_W1E0HYEX UNAVAIL 0 0 0
ata-WDC_WD20EARS-00MVWB0_WD-WCAZAA800271 ONLINE 0 0 0 (resilvering) |
Verwijderd
Van de duizenden voedingen die ik door mijn handen heb gehad waren degenen met problemen allemaal van slechte kwaliteit. Ik heb zelf nog nooit een kapotte voeding gezien die van erg goede kwaliteit was. Nu weet ik ook wel dat een goede voeding net zo goed stuk kan gaan. Maar de kans hierop is veel kleiner dan een kapot mobo, geheugen, de kans op een aantal defecte HDD's is nog groter. Daarnaast helpt een dual PSU ook niet tegen externe problemen zoals een spanningspiek. Ook "moet" je de dual PSU op twee verschillende stroombronnen aansluiten en ik denk ook niet dat die dat heeft.
Wat betreft de voeding van je SAN, daar heb je vast geen type van? Of foto's, interne zijn nog beter maar dat zal je denk ik toch niet hebben. Overigens zijn veel redundante voedingen ook niet perse beter, veel zijn maar erg dun en hebben 40mm fans. Niet echt goed voor de warmte afvoer en dus levensduur. Ander probleem, waar vind je een goede redundante voeding, als je dus al een extra stroombron hebt. Die dingen liggen niet voor het oprapen en hoe weet je of ze echt goed zijn? Reviews of interne foto's kan je wel vergeten.
Wat betreft de voeding van je SAN, daar heb je vast geen type van? Of foto's, interne zijn nog beter maar dat zal je denk ik toch niet hebben. Overigens zijn veel redundante voedingen ook niet perse beter, veel zijn maar erg dun en hebben 40mm fans. Niet echt goed voor de warmte afvoer en dus levensduur. Ander probleem, waar vind je een goede redundante voeding, als je dus al een extra stroombron hebt. Die dingen liggen niet voor het oprapen en hoe weet je of ze echt goed zijn? Reviews of interne foto's kan je wel vergeten.
- TrsvK
- Registratie: September 2006
- Laatst online: 12-07 09:09
HAHA
fantastisch deze overstatement
Een UPS is een relatief kleine investering op een server van 20k, maar om nou volledig het bestaansrecht van alles zonder noodvoeding in twijfel te trekken gaat wat ver..Als je je servers niet beschermt met een UPS of andere noodstroom oplossing, dan ben je blijkbaar niets belangrijks aan het doen, zet dan de servers meteen ook maar uit, scheelt weer stroomkosten.
Vorig jaar heeft een klant van ons een overspannings piek gehad. Bijna alles wat niet achter een UPS hing is defect gegaan. Incl de ups'en...TrsvK schreef op maandag 10 maart 2014 @ 19:24:
[...]
HAHAKomt ie dan

fantastisch deze overstatement
[...]
Een UPS is een relatief kleine investering op een server van 20k, maar om nou volledig het bestaansrecht van alles zonder noodvoeding in twijfel te trekken gaat wat ver..
- Deze advertentie is geblokkeerd door Pi-Hole -
Verwijderd
In een beetje fatsoenlijke voeding en een UPS zit een MOV die spanningspieken weg filtert en zich bij grote spanningspieken opoffert (doorbrand) ter bescherming van de rest van de elektronica.
- mphilipp
- Registratie: Juni 2003
- Laatst online: 09:31
Romanes eunt domus
/u/85941/crop61dd9b39bb021_cropped.png?f=community)
Niet het bestaansrecht, maar hoe belangrijk het voor je is. Als je niets kritieks aan het doen bent, waar een x-aantal mensen van afhankelijk zijn voor inkomsten/omzet is het misschien niet zo erg. Een gameserver voor een besloten groepje kan best een paar uurtjes zonder spelletje.TrsvK schreef op maandag 10 maart 2014 @ 19:24:
[...]
Een UPS is een relatief kleine investering op een server van 20k, maar om nou volledig het bestaansrecht van alles zonder noodvoeding in twijfel te trekken gaat wat ver..
Maar welk DC heeft nou geen UPS? En als je in een (serieus) bedrijf bezig bent, kan ik me niet voorstellen dat een geen UPS in de computerruimte staat. Je wilt op zijn minst dat dat ding fatsoenlijk down gaat als de stroom uitvalt. Al gok je op een uurtje stroomstoring per jaar en is dat overkomelijk, is het beveiligen van je server toch wel erg handig. Tenzij je écht niets belangrijks doet natuurlijk...
Tip: blijf heeeeel ver weg van die goedkope dingen van Trust. Ik wist wel dat Trust niet te vertrouwen was, maar heb me toch laten verleiden en ze zijn köt. Trek de poeplat verder open en koop een echte.
[ Voor 9% gewijzigd door mphilipp op 10-03-2014 19:41 ]
Mac Mini M4Pro | MS Surface Pro 9 | Canon 1Dx III | Bambu Lab H2C | BMW K1600 GTL
- mux
- Registratie: Januari 2007
- Laatst online: 14-06 19:03
/u/203831/ts2.PNG?f=community)
Het is toch leuk om hier op één pagina alle ouderwetse mythes over betrouwbaarheid en alle angst/management-ingegeven ontwerpkeuzes langs te zien komen. Overal eindeloos redundantie in smijten! Alles aan de UPS! Meer geld betekent meer uptime!

- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Kom jij dan ipv met een satire eens met constructieve feedback dan!
Even niets...
Verwijderd
Ik zou in elke SAN een triple redundante voeding zetten aangesloten op drie verschillende stroombronnen. Eén zet je op het net, de andere op je ze eigen gestookte kolencentrale en de derde op je miniatuur kerncentrale, veiliger kan niet!!!!11
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
* FireDrunk pakt nog meer popcorn
Even niets...
Allesinds, ze hebben hem vervangenVerwijderd schreef op maandag 10 maart 2014 @ 19:39:
In een beetje fatsoenlijke voeding en een UPS zit een MOV die spanningspieken weg filtert en zich bij grote spanningspieken opoffert (doorbrand) ter bescherming van de rest van de elektronica.
Dubbele voedingen zijn vooral handig wanneer je onderhoud moet uitvoeren aan de UPS :-)
[ Voor 11% gewijzigd door A1AD op 10-03-2014 20:30 ]
- Deze advertentie is geblokkeerd door Pi-Hole -
Ook voedingen welke continue 24/7 aan 60-70% belasting gebruikt waren?Verwijderd schreef op maandag 10 maart 2014 @ 19:21:
Van de duizenden voedingen die ik door mijn handen heb gehad waren degenen met problemen allemaal van slechte kwaliteit. Ik heb zelf nog nooit een kapotte voeding gezien die van erg goede kwaliteit was.
Verwijderd
Zoveel kom ik er daar niet van tegen. Kapotte voedingen die ik tegenkom werden vaak minder zwaar belast. In 90% van de gevallen waren het ook condensators die het begeven hadden en dan waren het in veel gevallen ook nog van die gare CapXon's die je in be quiet, FSP, goedkopere Delta's tegenkomt. In andere gevallen waren het vaak de lagers van de fans die het begaven, dat waren dan goedkope sleeve bearing fans.kluyze schreef op maandag 10 maart 2014 @ 20:31:
[...]
Ook voedingen welke continue 24/7 aan 60-70% belasting gebruikt waren?
Een voeding zoals de Seasonic G series 550W is gemaakt voor 5 jaar 24/7 op 100% load.
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Wij hebben onze servers met dubbele voedingen op nobreak systemen met een diesel generator er achter in een datacenter. Dat datacenter is indentiek dubbel uitgevoerd op een andere lokatie. Maar daar staan geen zelfbouw NASjes in.
Wacht even, waar hadden we het nou over?
/me Pakt en gaat naast Firedrunk zitten
en gaat naast Firedrunk zitten
Wacht even, waar hadden we het nou over?
/me Pakt
Verwijderd
Het is gewoon een stukje risicoanalyse. Hoeveel downtijd kun je als bedrijf accepteren, en hoe erg is dataverlies.
Dat bepaalt welke tegenmaatregelen je neemt, tegen welke prijs.
Ik denk dat twee identieke systemen die elkaar kunnen opvangen bij een storing al een aardige uptime kunnen halen. Met of zonder dubbele voeding. Zeker als het niet erg is dat het bedrijf een keertje een uur stil ligt.
Dat bepaalt welke tegenmaatregelen je neemt, tegen welke prijs.
Ik denk dat twee identieke systemen die elkaar kunnen opvangen bij een storing al een aardige uptime kunnen halen. Met of zonder dubbele voeding. Zeker als het niet erg is dat het bedrijf een keertje een uur stil ligt.
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
Wat dat betreft kunnen we nog best wat verschillende kanten op. Onze HP server (met redundante voeding op 2 aparte UPSen) blijft voorzien van 2TB opslagruimte. Hier zullen we voorts de meest kritische aan data opzetten. De uitbreiding willen we gebruiken voor overige netwerkdata die best eens een uurtje down mag zijn. De 2 SANs kunnen ook nog wel op deze 2 UPSen aangesloten worden, ze hebben nu ruim voldoende capaciteit om alles 30 minuten up te houden bij stroomuitval. Dat mag best 10 minuten minder worden als er een SAN extra bij hangt. Ook de 2 NASsen hangen elk aan een UPS en blijven bij stroomuitval ook 20 minuten draaien. Alle UPSen zijn van APC btw en werken (tot nu toe) perfect.
Nog even ter beeldvorming, we werken met ongeveer 40 man in een MKB bedrijf, waar de ICT manager tevens adjunct directeur is. Veel mensen hebben (part time) dubbele functies en we zijn nog niet op een punt aangekomen waar men bereid is om 20K neer te leggen voor 10TB opslagruimte, vandaar dat wij het met wat creativiteit toch redelijk betrouwbaar proberen op te zetten.
En wat betreft onze inspanning x uurloon = ook kosten -> zoals ik zei is het bij ons beiden ook een hobby om hier mee bezig te zijn en hoeft dus niet elk uur onder werktijd te vallen.
Nog even ter beeldvorming, we werken met ongeveer 40 man in een MKB bedrijf, waar de ICT manager tevens adjunct directeur is. Veel mensen hebben (part time) dubbele functies en we zijn nog niet op een punt aangekomen waar men bereid is om 20K neer te leggen voor 10TB opslagruimte, vandaar dat wij het met wat creativiteit toch redelijk betrouwbaar proberen op te zetten.
En wat betreft onze inspanning x uurloon = ook kosten -> zoals ik zei is het bij ons beiden ook een hobby om hier mee bezig te zijn en hoeft dus niet elk uur onder werktijd te vallen.
Lenovo Thinkpad Yoga X380
- Q
- Registratie: November 1999
- Laatst online: 09:01
Geef mij eens een handje?
Voor thuis gebruik zijn mijn uitspraken niet relevant, laten we wel wezen. Maar deze saaie uitspraak zal ik even compenseren.
Iedereen die betaalt krijgt om IT infrastructuur in de lucht te houden waar gezinnen van moeten eten en die geen redundancy toepast, verdient zijn/haar salaris niet.
Als je management niet aan het verstand kunt peuteren dat dit nodig is, dan heb je ofwel slechte communicatie skills, ben je gewoon onverstandig bezig, of is het management niet zo bij de pinken.
More?
Ik snap heel goed het dillema. Net te groot voor een goedkope oplossing, maar net te klein voor budget voor wat groters. <patspraatje weggehaald, boeit niet>.dreku88000 schreef op maandag 10 maart 2014 @ 21:42:
Wat dat betreft kunnen we nog best wat verschillende kanten op. Onze HP server (met redundante voeding op 2 aparte UPSen) blijft voorzien van 2TB opslagruimte. Hier zullen we voorts de meest kritische aan data opzetten. De uitbreiding willen we gebruiken voor overige netwerkdata die best eens een uurtje down mag zijn. De 2 SANs kunnen ook nog wel op deze 2 UPSen aangesloten worden, ze hebben nu ruim voldoende capaciteit om alles 30 minuten up te houden bij stroomuitval. Dat mag best 10 minuten minder worden als er een SAN extra bij hangt. Ook de 2 NASsen hangen elk aan een UPS en blijven bij stroomuitval ook 20 minuten draaien. Alle UPSen zijn van APC btw en werken (tot nu toe) perfect.
Nog even ter beeldvorming, we werken met ongeveer 40 man in een MKB bedrijf, waar de ICT manager tevens adjunct directeur is. Veel mensen hebben (part time) dubbele functies en we zijn nog niet op een punt aangekomen waar men bereid is om 20K neer te leggen voor 10TB opslagruimte, vandaar dat wij het met wat creativiteit toch redelijk betrouwbaar proberen op te zetten.
En wat betreft onze inspanning x uurloon = ook kosten -> zoals ik zei is het bij ons beiden ook een hobby om hier mee bezig te zijn en hoeft dus niet elk uur onder werktijd te vallen.
Met 40 man haal je wel een paar mijoen omzet per jaar, kun je dan geen 20K over 3 jaar afschrijven? ~7 k per jaar? Het is hoe je het verkoopt. En wat kost het bedrijf als jullie een paar dagen plat liggen?
[ Voor 61% gewijzigd door Q op 10-03-2014 21:45 ]
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Of je management wil gewoon voor een duppie op de eerste rij zitten
Even niets...
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
Dat ookFireDrunk schreef op maandag 10 maart 2014 @ 21:43:
Of je management wil gewoon voor een duppie op de eerste rij zitten
Lenovo Thinkpad Yoga X380
- Q
- Registratie: November 1999
- Laatst online: 09:01
Voor ons als mens is 20K veel geld, maar voor een beetje bedrijf is 20K gewoon peanuts, het valt weg achter de comma.FireDrunk schreef op maandag 10 maart 2014 @ 21:43:
Of je management wil gewoon voor een duppie op de eerste rij zitten
Ik wil niet stoken (dat wil ik wel
Maar eigenlijk fuck dat: gewoon hup 20K en je bent klaar. Geen gezeik. kun je zelf ook met een gerust hart verder Reddit browsen, fuck ZFS.
[ Voor 38% gewijzigd door Q op 10-03-2014 21:51 ]
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Ik denk dat je je vergist hoeveel kleine bedrijfjes er zijn waarvoor dat wel veel geld is...
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 09:01
Tja, zoals voor iedereen geldt: ik kan niet in je portemonnee kijken. Maar waar het denk ik wel om gaat is dat je heel eerlijk bent over de risico's die het bedrijf loopt met eigen gemaakt spul en hoeveel centjes je daar 'echt' mee bespaart. Misschien is dat bangmakerij van mijn kant.FireDrunk schreef op maandag 10 maart 2014 @ 21:50:
Ik denk dat je je vergist hoeveel kleine bedrijfjes er zijn waarvoor dat wel veel geld is...
@dreku88000, ik heb wel de indruk dat je weet wat je doet en je attude is ok, dus als het geld er echt niet is, go for it en have fun. En ik hoop dat je over 3 jaar een mooie successtory hebt.
En toch, 20K is in 1x wel veel geld, maar over een afschrijftermijn van 5 jaar? 4K per jaar? Seriously?
Ok, 5 jaar support kom je wel op 25K, dus 5K per jaar. Is dat nu zoveel geld voor de ruggengraat van je bedrijf?
[ Voor 14% gewijzigd door Q op 10-03-2014 22:02 ]
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
Thanks Q
We proberen met de juiste redundantie en met kwalitatief goed spul een zo betrouwbaar mogelijk (voor 5 a 6 k€) systeem op te zetten. De inschatting van benodigde ruimte komt nu uit op ongeveer 12 TB om weer 4 à 5 jaar door te kunnen, maar onze laatste schatting van 2 TB zat er ook al 2 jaar naast. Dus wellicht dat we over 2 jaar al weer zo zijn gegroeid dat we een nieuwe oplossing moeten zoeken. Dan zal het budget en ons personeelsbestand wellicht ook anders zijn en zal er waarschijnlijk wel een vendor oplossing gekozen worden.
Voor nu ben ik er toch redelijk van overtuigd dat we het wel aandurven met onze zelfbouw SANs.
We proberen met de juiste redundantie en met kwalitatief goed spul een zo betrouwbaar mogelijk (voor 5 a 6 k€) systeem op te zetten. De inschatting van benodigde ruimte komt nu uit op ongeveer 12 TB om weer 4 à 5 jaar door te kunnen, maar onze laatste schatting van 2 TB zat er ook al 2 jaar naast. Dus wellicht dat we over 2 jaar al weer zo zijn gegroeid dat we een nieuwe oplossing moeten zoeken. Dan zal het budget en ons personeelsbestand wellicht ook anders zijn en zal er waarschijnlijk wel een vendor oplossing gekozen worden.
Voor nu ben ik er toch redelijk van overtuigd dat we het wel aandurven met onze zelfbouw SANs.
Lenovo Thinkpad Yoga X380
Verwijderd
De kans dat een voeding zoals de Seasonic G-series 550W het begeeft acher een UPS binnen 5 jaar schat ik kleiner dan 1%, dreku88000 wil twee systemen nemen en die gaan mirrorren. De kans dat beide voedingen het tegelijkertijd begeven is wel zo verschrikkelijk klein, dat ik geen enkele reden zie om voor een redundante voeding te gaan. Er zijn zoveel andere die mis kunnen gaan welke zoveel vaker kunnen voorkomen dat een redundante voeding gewoon de kans op downtime niet zal verkleinen. Mocht toevallig toch één van de voedingen het begeven dan heb je de voeding in twee/drie dagen al vervangen, heb je die twee dagen wel even geen mirror maar de kans dat het nodig is is ook erg klein. En anders koop je nog gewoon een voeding extra als reserve, heb je hooguit een klein uur downtime voor het vervangen van de voeding. Al zou ik dat eerder voor andere componenten doen waarvan het uitval percentage hoger is.
[ Voor 5% gewijzigd door Verwijderd op 10-03-2014 23:32 ]
- Midas.e
- Registratie: Juni 2008
- Laatst online: 08-07 22:26
Is handig met dinges
:strip_exif()/u/264081/crop56d6d27c03d80_cropped.gif?f=community)
Redundancy kan je op meer manieren oplossen Q, of door 1 machine zwaar uit te voeren of door meer machines dezelfde taken uit te laten voeren.
Voor mn werk krijg ik nu een 3 tal 1U machines met 40TB aan opslag, ze zijn niet redundant uitgevoerd, de enige redundancy erin is ZFS. Ze zitten wel allemaal achter dezelfde namespace en replicaten constant met elkaar, Heb ik nu 3 redundant voedingen op 2 verschillende locaties op 4 verschillende stroomaansluitingen? Ja. Is het de beste oplossing? Vast niet, maar het is een stuk goedkoper dan 1 SAN neer te hangen als backup systeem waar storage te duur is en je nogsteeds legacy raid gebruikt.
Voor mn werk krijg ik nu een 3 tal 1U machines met 40TB aan opslag, ze zijn niet redundant uitgevoerd, de enige redundancy erin is ZFS. Ze zitten wel allemaal achter dezelfde namespace en replicaten constant met elkaar, Heb ik nu 3 redundant voedingen op 2 verschillende locaties op 4 verschillende stroomaansluitingen? Ja. Is het de beste oplossing? Vast niet, maar het is een stuk goedkoper dan 1 SAN neer te hangen als backup systeem waar storage te duur is en je nogsteeds legacy raid gebruikt.
- mphilipp
- Registratie: Juni 2003
- Laatst online: 09:31
Romanes eunt domus
Je moet dat ook nuanceren. Als je een UPS van 20k nodig hebt, ben je geen klein bedrijf meer, en dan is het inderdaad peanuts, of je rekent verkeerd. Pennywise, poundfoolish.FireDrunk schreef op maandag 10 maart 2014 @ 21:50:
Ik denk dat je je vergist hoeveel kleine bedrijfjes er zijn waarvoor dat wel veel geld is...
Als je die bakker op de hoek bent met een PC voor de administratie en een klein Qnapje....tsjaa...dan is een UPS een beetje overkill. Zolang je maar elke dag de boel backupped ben je hooguit een dag werk kwijt. Dat lijkt me geen probleem. Maar als je een hele vracht machines in een grote computerruimte hebt staan, moet je niet piepen over de kosten van een UPS, want dan werken er waarschijnlijk meerdere mensen op zo'n ding en dan is het potentieel dataverlies iets erger.
Natuurlijk kunnen die mensen op het moment van de stroomuitval zelf niet meer verder werken, maar je server kan iig geval netjes down gaan. Zo ben je naderhand tenminste niet extra tijd kwijt met backups restoren omdat je database niet helemaal lekker wakker wil worden.
Risicoanalyse klinkt leuk, maar als je bedrijfsmatig bezig bent, is het een kwestie van plannen. En de kosten vooraf incalculeren. En de juiste adviseur.
Mac Mini M4Pro | MS Surface Pro 9 | Canon 1Dx III | Bambu Lab H2C | BMW K1600 GTL

- Q
- Registratie: November 1999
- Laatst online: 09:01
Redundancy kun je ook bereiken door gewoon met meerdere goedkope servers te werken, helemaal waar. Zo kun je de service gewoon blijven aanbieden via een ander doosje als het oorspronkelijke doosje uitvalt.Midas.e schreef op maandag 10 maart 2014 @ 22:33:
Redundancy kan je op meer manieren oplossen Q, of door 1 machine zwaar uit te voeren of door meer machines dezelfde taken uit te laten voeren.
Voor mn werk krijg ik nu een 3 tal 1U machines met 40TB aan opslag, ze zijn niet redundant uitgevoerd, de enige redundancy erin is ZFS. Ze zitten wel allemaal achter dezelfde namespace en replicaten constant met elkaar, Heb ik nu 3 redundant voedingen op 2 verschillende locaties op 4 verschillende stroomaansluitingen? Ja. Is het de beste oplossing? Vast niet, maar het is een stuk goedkoper dan 1 SAN neer te hangen als backup systeem waar storage te duur is en je nogsteeds legacy raid gebruikt.
Ik zou dit prefereren boven 1 SAN. Popcorn er weer even bij: EEN SAN = GEEN SAN. SANs gaan ook stuk. Trust me.
Afhankelijk hoe belangrijk een service is en wat down-time ongeveer kost kun je een inschatting maken of het loont om toch RAID / Dual PSU toe te passen. Als dat betekent, dure nieuwe servers kopen in plaats van spul hergebruiken van wat je nu hebt, en het geld is een obstakel: tja, keuzes. Dat is niet zozeer goed/fout. Zolang het maar een eerlijke en bewuste keuze is en de business weet waarvoor ze kiest.
Wat dat aangaat is het soms wel lekker om bij een iets groter bedrijf te werken, daar is geld met een goede sales pitch geen enkel issue, zelfs in slechtere tijden. Maar dan nog, ik zou ook best wat ZFS doosjes willen bouwen hoor, lijkt me ook lachen, zolang ze de risico's maar accepteren.
Persoonlijk wil ik echter zoveel mogelijk voorkomen dat ik tijd van mijn leven verlies aan brandjes blussen waarvan ik weet dat ze makkelijk voorkomen kunnen worden. En helaas slaag ik daar niet altijd in.
[ Voor 13% gewijzigd door Q op 10-03-2014 23:51 ]
- Q
- Registratie: November 1999
- Laatst online: 09:01
Popcorn: 70 euro (UPS voor bakker) voor een dag werk? Is niet zoveel. UPS is bijna nooit overkill. Als je bedrijfsmatig je server-side IT zooi niet aan de UPS hangt ook al ben je een bakker (alsof dat uitmaakt) dan zit er popcorn in je hoofd.mphilipp schreef op maandag 10 maart 2014 @ 23:15:
[...]
Je moet dat ook nuanceren. Als je een UPS van 20k nodig hebt, ben je geen klein bedrijf meer, en dan is het inderdaad peanuts, of je rekent verkeerd. Pennywise, poundfoolish.
Als je die bakker op de hoek bent met een PC voor de administratie en een klein Qnapje....tsjaa...dan is een UPS een beetje overkill. Zolang je maar elke dag de boel backupped ben je hooguit een dag werk kwijt. Dat lijkt me geen probleem.
Fuck nuance.
En daar gaat het om. Gaat je 10 TB file server plat door gekloot, ben je NET te laat om op spatie te drukken tijdens het booten om die file system check (chkdsk) af te breken zodat je die op een beter moment kunt draaien.Natuurlijk kunnen die mensen op het moment van de stroomuitval zelf niet meer verder werken, maar je server kan iig geval netjes down gaan. Zo ben je naderhand tenminste niet extra tijd kwijt met backups restoren omdat je database niet helemaal lekker wakker wil worden.
Ik hap wel (popcorn is lekker). Klinkt heel stoer zo'n uitspraak, maar hij is een beetje hol en leeg zonder jezelf toe te lichten. Over wat soort ouderwetse mythes hebben we het? Ik vraag me af of je tegen een stroman schopt.mux schreef op maandag 10 maart 2014 @ 19:58:
Het is toch leuk om hier op één pagina alle ouderwetse mythes over betrouwbaarheid en alle angst/management-ingegeven ontwerpkeuzes langs te zien komen. Overal eindeloos redundantie in smijten! Alles aan de UPS! Meer geld betekent meer uptime!
[ Voor 42% gewijzigd door Q op 10-03-2014 23:56 ]
- mphilipp
- Registratie: Juni 2003
- Laatst online: 09:31
Romanes eunt domus
Bijna nooit. Fuck nuance.Q schreef op maandag 10 maart 2014 @ 23:34:
[...]
Popcorn: 70 euro (UPS voor bakker) voor een dag werk? Is niet zoveel. UPS is bijna nooit overkill. Als je bedrijfsmatig je server-side IT zooi niet aan de UPS hangt ook al ben je een bakker (alsof dat uitmaakt) dan zit er popcorn in je hoofd.
Vergeet alleen niet de accu's tijdig te vervangen...
Mac Mini M4Pro | MS Surface Pro 9 | Canon 1Dx III | Bambu Lab H2C | BMW K1600 GTL
- Q
- Registratie: November 1999
- Laatst online: 09:01
Ik dacht ook aan een UPS voor je NAS in die context, niet voor een desktop. Oh ik heb wel de UPSsen gezien met zo'n rood waarschuwingslampje aan en onder de spinnenwebben
- mux
- Registratie: Januari 2007
- Laatst online: 14-06 19:03
Omdat ik me toch een klein beetje verantwoordelijk voel zal ik toch maar antwoorden... Voor de duidelijkheid: ik betrek deze dingen voornamelijk op grotere servers/datacenters/etc., maar het is gedeeltelijk net zo relevant voor thuisservers en small business servers.Q schreef op maandag 10 maart 2014 @ 23:34:
Ik hap wel (popcorn is lekker). Klinkt heel stoer zo'n uitspraak, maar hij is een beetje hol en leeg zonder jezelf toe te lichten. Over wat soort ouderwetse mythes hebben we het? Ik vraag me af of je tegen een stroman schopt.
Er zijn nogal wat mythes en overdreven gegeneraliseerde best practices die zó hard ingebakken zijn dat er niet eens meer over wordt nagedacht. In orde van mythe-heid:
- Overal moet ECC in
- Alles moet redundant
- Alles moet aan een UPS/noodstroomvoorziening
- Servers moeten allemaal aan een cold/hot chamber op 25 +/- 5 graden, 80% RH gehouden worden
- Een server die niet 100% load draait is overgedimensioneerd
- Virtualiseer alles!
- density, density, density!
De meeste van deze mythes zijn soort van gedeeltelijk gebaseerd op logica, maar een hoop ook niet. Om eerst maar alle algemene argumenten weg te vegen: Aanschafkosten en verbruik zijn wél significant tov je licentiekosten, uptime is níet vitaal en mensen moeten wél in staat zijn om bij je servers te komen. Goed, nu alles apart:
Zowat de enige twee definitieve eigenschappen van een server zijn (1) wat voor RAM erin gaat en (2) support voor SMP. Alle andere eigenschappen die misschien toe te schrijven zijn aan een server zijn inmiddels ook verkrijgbaar in consumentenspul. Servers kunnen registered en ECC RAM huisvesten, wat betekent dat je er zo goed als oneindig veel geheugen in kunt smijten. Serverkeuzes worden meestal puur gemaakt op basis van geheugen - kan hier wel mijn VEREISTE 384GB in? Dan komt ook meteen de vraag: goh, wat nou als er een bitflip gebeurt in het geheugen, DAN CRASHT ALLES OMFG!!! En ja, bitflips gebeuren regelmatig. Meermalen per dag in een modern serversysteem, soms zelfs meermalen per uur. Maar de daadwerkelijke impact op je systeem? Reken maar dat softwarebugs en niet-robuuste exception handling de significantie van ECC heftig overstijgt. Bovendien schalen geheugenfouten niet met de hoeveelheid geheugen in een systeem, maar met writes naar geheugen, zeker als je het over serversystemen zonder self-refresh geheugen hebt. Dus... en dit is iets wat steeds vaker wordt gedaan: zelfs op kritieke systemen is ECC in geheugen vrijwel altijd géén belangrijke factor. Alleen bij zéér langdurige HPC-taken waar zowel heftig op geheugenbandbreedte als op iteratieve berekeningen op dezelfde dataset wordt geleund is ECC absoluut noodzakelijk. Voor een Oracle of LAMP-rack is het nutteloos.Overal moet ECC in
De enige andere reden om een serversysteem te nemen, afgezien van de form factor, is de hoeveelheid geheugen die je erin kunt proppen. Guess what, zelden maken mensen daadwerkelijk nuttig gebruik van hun geheugen. Er wordt vaak gewoon voor gekozen om het geheugen te sizen naar de maximale databasegrootte en de hele database dan maar op een RAM-disk te plempen, zelfs als een sparse database makkelijk in 4GB zou passen. En zelfs wanneer alles in geheugen staat zijn de programma's die over de data itereren vaak zo slecht ontworpen dat een SSD een véél kosteneffectievere oplossing zou zijn. We hebben het bijvoorbeeld over MSSQL dat niet eens 1GB/s haalt op een vrijwel sequentiële database-leesactie over DDR3L-2133 (17GB/s raw datarate).gerelateerd: OMG ik heb te weinig geheugen!
Stel je voor: een servermobo (€1500) met twee procs (€4000) en 256GB geheugen (€3000) vervangen door een consumersetje met 64GB geheugen (sub-€1500). Voor veel toepassingen kan het. Doordat consumerborden véél efficiënter met energie omgaan en zoveel goedkoper in aanschaf zijn kun je er zelfs een cold spare naast hangen zonder erover na te denken.
En ja, er zijn toepassingen waar het hangen van veel geheugen aan één processor inderdaad nuttig is of zelfs vereist. Maar dat is een kleine subset van de servers die er nu zo uitzien. Geheugen is 'goedkoop', maar niet zó goedkoop. Op de aanschaf van een server die toch al 10k+ kost is het een relatief kleine extra kostenpost, maar veel bedrijven realiseren zichzelf niet eens dat je met minimale concessies ook kunt downscalen naar workstation-level hardware en daarmee alleen al in aanschaf (laat staan licentie- en servicekosten) een hoop kunt besparen.
Hoe verbeter je je uptime? Fail safe. Als er iets stukgaat moet er direct overgeschakeld kunnen worden naar een hot spare. Dat is het denken van een hoop mensen, en dit is voor 100% availability-systemen een onontkoombare werkelijkheid. Maar dat wil niet zeggen dat élk systeem in élk aspect redundant moet worden uitgevoerd. Je hoeft niet elke voeding en elke harde schijf dubbel uit te voeren. Het lot gaat je namelijk tegenwerken als je dat doet. 1:1 redundantie betekent dat je een 2 keer zo hoge kans (in de praktijk zelfs nog wat meer - dit heet de failure growth factor) hebt dat er *iets* misgaat. Als je verschillende systemen redundant uitvoert die van elkaar afhangen is het effect zelfs nog veel sterker - een hogere failurerate van redundante harde schijven veroorzaakt bijvoorbeeld een hogere failurerate van anders prima functionerende voedingen. Sommige harde schijven falen namelijk op een manier die de voeding overbelast.Alles moet redundant
Redundantie in een ideale wereld werkt als n + 1, dat wil zeggen: als je n systemen met een identieke functie hebt hang je daar 1 hot spare naast die de functie kan overnemen als één van de systemen in de array het begeeft. Je zorgt er dan voor dat de software of load balancer zo is ontworpen dat dit kan. Je moet kunnen abstraheren naar een n + 1-model. In veruit de meeste toepassingen leidt dit tot de beste uptime; je hebt de kleinst mogelijke kans op failures zonder redundantie te verliezen. Echter, wat doe je als n = 1? Hoe ga je om met redundantie als je maar één systeem hebt?
Dat is een beetje een probleem. Aan de ene kant is het aantrekkelijk om te zeggen: nou, dan doe je volledige 1:1 redundantie. Maar in de praktijk kost je dat alleen maar veel teveel geld en tijd; je hebt (gemiddeld) ongeveer 3 keer zoveel servicekosten vanwege de hogere failure rate, twee keer zoveel aanschafkosten en twee keer zoveel verbruikskosten. Afschuwelijk slechte kostenefficiëntie. De beste oplossing hier is waarschijnlijk ofwel een cold spare (en dus <100% uptime), ofwel een heterogeen redundant systeem, dat wil zeggen een veel goedkopere, simpelere doos die de belangrijkste taken overneemt terwijl het primaire systeem wordt geservicet. Maar de laatste keuze moet wel zijn om een homogeen redundant systeem neer te zetten.
Uptime, uptime, uptime. Als de stroom uitvalt moeten alle computers verder werken! Overal power conditioning inbouwen zodat overspanning en brownouts ondervangen kunnen worden! In theorie klinkt dit geweldig, maar er zijn drie hele, hele, hele grote problemen met dit idee:Alles aan een UPS
1) Als de stroom in je datacenter uitvalt, valt waarschijnlijk de stroom uit in een veel grotere omgeving
2) Veruit de meeste power failures worden veroorzaakt door noodstroomvoorzieningen
3) Noodstroomvoorzieningen werken maar ongeveer 70% van de tijd naar behoren. Zelfs in kritieke omgevingen zoals ziekenhuizen.
Wederom heb je hier te maken met een soort wrangen kosten/batenanalyse. Alles moet aan de noodstroomvoorzieningen, maar goh dit kost best een hoop geld, dus gezien de stroom nooit uitvalt kunnen we net zo goed wel bezuinigen op deze dieselgeneratoren en even wachten met het tanken tot de dieselprijzen omlaag gaan. Dit is serieus hoe een hoop datacenters erover nadenken. Om niet te spreken van de gedrochten van UPS'en die men in serverracks propt. Underpowered, niet-transparant (OS denkt dat alles prima is en doet niet eens een poging om af te sluiten, om dan plots zonder stroom te zitten en in een deteriorated state terecht te komen)...
Dus met deze gedachte dat noodstroomvoorzieningen niet bepaald 100% betrouwbaar zijn is het een stuk moeilijker goed te praten om er veel geld aan uit te geven. Is 100% power-uptime nodig als statistisch de meeste stroomuitval gepaard gaat met zeer grote netwerkuitvallen? Of dat ze alleen gebeuren als het hele datacenter toch onder water staat en niet kan werken? Is het niet een veel beter idee om al dat geld te steken in lokale infrastructuur? Of in diversificatie van je serverpark met een aparte DNS-server/loadbalancer die traffic kan switchen?
Wederom, er is absoluut een niche voor UPS'en en grotere noodstroomvoorziening, maar die is kleiner dan je denkt. Uptime wordt maar in een relatief klein percentage van de datacenters gedomineerd door power availability, en je introduceert weer een extra schakel in je reliability-keten die stuk kan gaan (en daarbij alles meeneemt in je rack als het stukgaat).
Nee.Temperatuur en luchtvochtigheid moeten perfect gereguleerd zijn! Hitte doodt alle computers!
Geweldig staaltje van omgekeerde wereld. Het is blijkbaar geen probleem om 90k aan een licentie uit te geven voor Oracle op een paar racks, of om 10k per server uit te geven. Maar wee degene die zijn server overdimensioneert! Die 200 euro extra voor de net wat snellere processor-skew is het niet waard!Een server die niet op 100% load draait is overgedimensioneerd
Datacenters vragen vrij idiote prijzen voor energie. In Duitsland zijn een aantal regio's nu de 25ct/kWh gepasseerd. Het is daarom nuttig om na te denken over de meest efficiënte server in termen van joule/taak in plaats van 'wat is de kleinst/goedkoopst mogelijke server die deze taak kan doen'. En er zitten vrij grote verschillen tussen servers! En ga niet af op marketing; vraag samples aan en draai je eigen software er een dagje op. Bovendien: een server die constant op 100% load draait is een bottleneck die de efficiëntie van de rest van je infrastructuur nadelig beïnvloedt.
Om eerlijk te zijn is dit niet echt meer iets dat zo heel veel gezegd wordt. Ik zal er niet te lang over doorgaan
Hah, leuke grap. Voorbeeld: Cofely. Virtualiseert 24 desktops op één server en claimt meer dan 50% energiewinst. Wat hebben ze daadwerkelijk gedaan? Ze hadden Pentium 4 desktops staan als workstations (~90W gemiddeld verbruik) en hebben dit vervangen door een hele sloot nieuwe netwerkhardware en een 2-processor Sandy Bridge-server van ruim 8000 euro (hardware) + VMWare ESXi (€20k + client licenses) met in totaal minder dan 25% van de resources van de voorgaande 24 systemen. Op iedereens tafel staat alleen nog een thin client met een verbruik iets onder de 20W. Server verbruikt gemiddeld zo'n 350W. Netwerkapparatuur wordt niet meegenomen in het verbruik.Virtualiseer alles! Dat is beter!
Niemand hier hoeft je te vertellen dat je voor €1000 per werkplek de meest monsterlijke computer neer kunt zetten die níet constant netwerkbelasting veroorzaakt en idle onder de 20W zit. Ja, er is energie bespaard ten opzichte van de voorgaande situatie, maar er is niet nagedacht over de béste oplossing. Er is alleen iemand van VMWare Enterprise langsgekomen die hun rekensommetje heeft voorgedaan.
Bovendien had de alternatieve oplossing een véél betere user experience dan in het geval van massa-virtualisatie. Ja, het heeft deployment en administratie-voordelen, maar het heeft net zozeer ook nadelen. Eén server down en 24 mensen hoeven niet naar hun werk te komen. De kans dat 24 individuele workstations het in één keer begeven is een stuk kleiner.
Dit is maar één (extreem) voorbeeld waar virtualisatie obviously niet de beste oplossing was, maar virtualisatie is een buzzword dat veel management aanspreekt, waar het in veel gevallen níet de beste oplossing is.
En vervolgens is 90% van het rack leeg omdat je over de maximum toegestane stroomlimiet gaat. Dichtheid is niet meer een issue vandaag de dag. Je kunt meer computerkracht dan ooit in één doos stoppen. Ik begrijp niet meer waarom dit nog een issue is, we zijn inmiddels vér over de hoeveelheid watts per vierkante meter die een datacenter aan jouw colo kan geven.Meer computers in minder ruimte! Alles op blades!
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Ik moet spugen... Denk dat ik teveel popcorn heb gegeten
Even niets...
- TrsvK
- Registratie: September 2006
- Laatst online: 12-07 09:09
[irrelevant]
kan ik trouwens geen posts van mezelf deleten?
kan ik trouwens geen posts van mezelf deleten?
[ Voor 199% gewijzigd door TrsvK op 11-03-2014 11:38 ]
- Q
- Registratie: November 1999
- Laatst online: 09:01
Mijn vermoeden klopt, Mux schopt 100% tegen een stroman.
- mux
- Registratie: Januari 2007
- Laatst online: 14-06 19:03
Dan doe ik eens mijn best om het niveau van het topic op te krikken... Ik kruip wel weer terug in mn hol
- Q
- Registratie: November 1999
- Laatst online: 09:01
No offence, ik zal mijn opmerking toelichten buiten werktijd.
/u/8830/crop5df8eadcd55ca_cropped.png?f=community)
mux: Op zich allemaal valide punten, behalve de UPS: die gebruik je voornamelijk voor het FILTEREN van pieken/dalen en het netjes afsluiten van de machine als de power weg is... niet voor uptime.
En blades zijn trouwens lachen als de backplate stuk gaat en de leverancier deze niet op voorraad heeft
En blades zijn trouwens lachen als de backplate stuk gaat en de leverancier deze niet op voorraad heeft
[ Voor 21% gewijzigd door BCC op 11-03-2014 16:57 ]
Na betaling van een licentievergoeding van €1.000 verkrijgen bedrijven het recht om deze post te gebruiken voor het trainen van artificiële intelligentiesystemen.
- Q
- Registratie: November 1999
- Laatst online: 09:01
Backplates gaan nooit stuk. Ik heb 5000 backplates door mijn handen gehad, die stuk gingen, dat was allemaal slechte kwaliteit. euh.
Blade enclosure heb je natuurlijk dubbel uitgevoerd. Dus een backplate meer of minder, mwah
Blade enclosure heb je natuurlijk dubbel uitgevoerd. Dus een backplate meer of minder, mwah
- Paul
- Registratie: September 2000
- Laatst online: 13-07 22:05
Stuk misschien niet, maar als je een HP c7000 van het eerste uur hebt en er dan 8GBit FC of 10 GBit ethernet in zet dan gaat het in de hoeken mis  Daar zijn ze niet op berekend. Latere versies van het midplane kunnen dat wel, maar wij hebben dus van één enclosure al een swap gehad en moeten er nog één.
Daar zijn ze niet op berekend. Latere versies van het midplane kunnen dat wel, maar wij hebben dus van één enclosure al een swap gehad en moeten er nog één.
"Your life is yours alone. Rise up and live it." - Richard Rahl
Rhàshan - Aditu Sunlock
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ik wil iets proberen en als het bevalt mischien wel permanent maken. Dit idee wil ik graag even tegen jullie aanhouden om te zien of ik wat over het hoofd zie en of het uberhaubt gaat werken.
Ik heb een Asrock bordje, H77 Pro/MVP met een i7 3770 (non-K variant), 32GB geheugen. De geintegreerde netwerkkaart is niet gesupport door ESXi (5.5.0) dus ik denk dat ik sowieso een andere NIC moet kopen.
Er zit een IBM M1015 IT flashed in, totaal 11 disks in 2 ZFS pools.
OS is Debian 7, 64-bit. OS staat op een Samsung 830 SSD.
Ik wil proberen of ik ESXi kan draaien, bv vanaf een USB stickje en m'n Debian als raw disk aan een VM koppelen. Ook moet dan uiteraard de M1015 aan die VM "gegeven" worden, zodat m'n pools blijven werken.
Als dit kan en goed werkt, wil ik mischien ESXi permanent draaien maar ik wil het graag eerst even uitproberen.
Kan dat op deze manier? VOlgens mij heeft Debian gewoon de drivers aanwezig om als VM te starten (ik heb welles m'n systeem gerestored (tar backupje) onder een VM, dat werkte gewoon. Ik vermoed dat dit ook wel moet kunnen dan.
Zie ik dingen over het hoofd? Ideeen hierover?
Alvast bedankt!
Ik heb een Asrock bordje, H77 Pro/MVP met een i7 3770 (non-K variant), 32GB geheugen. De geintegreerde netwerkkaart is niet gesupport door ESXi (5.5.0) dus ik denk dat ik sowieso een andere NIC moet kopen.
Er zit een IBM M1015 IT flashed in, totaal 11 disks in 2 ZFS pools.
OS is Debian 7, 64-bit. OS staat op een Samsung 830 SSD.
Ik wil proberen of ik ESXi kan draaien, bv vanaf een USB stickje en m'n Debian als raw disk aan een VM koppelen. Ook moet dan uiteraard de M1015 aan die VM "gegeven" worden, zodat m'n pools blijven werken.
Als dit kan en goed werkt, wil ik mischien ESXi permanent draaien maar ik wil het graag eerst even uitproberen.
Kan dat op deze manier? VOlgens mij heeft Debian gewoon de drivers aanwezig om als VM te starten (ik heb welles m'n systeem gerestored (tar backupje) onder een VM, dat werkte gewoon. Ik vermoed dat dit ook wel moet kunnen dan.
Zie ik dingen over het hoofd? Ideeen hierover?
Alvast bedankt!
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Ja dat kan, maar je moet wel 1 datastore overhouden waar de VM zelf op staat en ook een bootdisk op heeft.
Een VM kan namelijk niet van een controller booten welke via VT-d doorgegeven is. (dat kan KVM wel )
Een VM kan namelijk niet van een controller booten welke via VT-d doorgegeven is. (dat kan KVM wel
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ik heb KVM geprobeert icm met OpenQRM maar alleen maar problemen.
Ik zou KVM ook best vinden, volgens mij kan ik dat dan gewoon op m'n Debian draaien, maar het probleem is ik heb geen zin om dat via de command line te beheren. Ik doe in principe alles al via de cmdline maar zoiets als vm's aanmaken, beheren etc moet gewoon via een GUI, vind ik. Maar dat moet wel goed werken.
Als je goed werkende (en vooral minder complexe) alternatieven hebt daar voor vind ik het ook best.
Ik zou KVM ook best vinden, volgens mij kan ik dat dan gewoon op m'n Debian draaien, maar het probleem is ik heb geen zin om dat via de command line te beheren. Ik doe in principe alles al via de cmdline maar zoiets als vm's aanmaken, beheren etc moet gewoon via een GUI, vind ik. Maar dat moet wel goed werken.
Als je goed werkende (en vooral minder complexe) alternatieven hebt daar voor vind ik het ook best.
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
virt-manager via remote X.
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Maar dan moet ik m'n server gaan vervuilen met xorg enzo, toch? Dat is in principe toch niet wat je wilt op een headless server?
- Q
- Registratie: November 1999
- Laatst online: 09:01
Op dit vlak kunnen we elkaar wel vinden: het is belangrijk dat je goed nadenkt over wat je doet. Niet slechts 'regeltjes' uitvoeren uit een boekje.mux schreef op dinsdag 11 maart 2014 @ 10:39:
[...]
Omdat ik me toch een klein beetje verantwoordelijk voel zal ik toch maar antwoorden... Voor de duidelijkheid: ik betrek deze dingen voornamelijk op grotere servers/datacenters/etc., maar het is gedeeltelijk net zo relevant voor thuisservers en small business servers.
Er zijn nogal wat mythes en overdreven gegeneraliseerde best practices die zó hard ingebakken zijn dat er niet eens meer over wordt nagedacht. In orde van mythe-heid:
In al mijn scenario's ga ik er vanuit dat het gaat om belangrijke applicaties / services voor een bedrijf waar mensen hun brood mee verdienen.
Servers: ja.- Overal moet ECC in
Server 2x uitgevoerd, beiden redundant. Qua voeding, disk etc. Redundantie in een server kost bijna niets.- Alles moet redundant
Uit fiancieel oogpunt is er geen reden om het niet te doen, en geeft je alleen maar extra veiligheid.
EEN SERVER = GEEN SERVER
Ja.- Alles moet aan een UPS/noodstroomvoorziening
Nee, servers kunnen beter tegen warmte dan wij dat kunnen. Niet nodig, eens denk ik.- Servers moeten allemaal aan een cold/hot chamber op 25 +/- 5 graden, 80% RH gehouden worden
Lijkt me totale onzin, bovendien moet je pieken kunnen opvangen, mee eens dus?- Een server die niet 100% load draait is overgedimensioneerd
Absoluut, als het half kan doen.- Virtualiseer alles!
Lijkt me niet zo boeiend, behalve voor mensen met ruimte gebrek.- density, density, density!
Dit topic gaat over consumenten spul, maar de popcorn discussie niet. Dus consumentenspul, ik wil het er niet over hebben.Zowat de enige twee definitieve eigenschappen van een server zijn (1) wat voor RAM erin gaat en (2) support voor SMP. Alle andere eigenschappen die misschien toe te schrijven zijn aan een server zijn inmiddels ook verkrijgbaar in consumentenspul.
Alles wat hier staat is gewoon fout. Zo vaak flippen bits ook niet, maar vaak genoeg dat je er last van hebt.Dan komt ook meteen de vraag: goh, wat nou als er een bitflip gebeurt in het geheugen, DAN CRASHT ALLES OMFG!!! En ja, bitflips gebeuren regelmatig. Meermalen per dag in een modern serversysteem, soms zelfs meermalen per uur. Maar de daadwerkelijke impact op je systeem? Reken maar dat softwarebugs en niet-robuuste exception handling de significantie van ECC heftig overstijgt.
applicatiefouten laten niet een hele esxi host vastlopen met 50+ VMs.
Het is eerder de vraag waarom wij het accepteren in consumenten spul dat daar GEEN ecc geheugen in zit. (antwoord: geld en onwetendheid).
Maar adviseer alle sever vendors maar om servers zonder ECC geheugen te introduceren, blijkbaar weten ze niet zo goed wat ze doen.
Totaal gelul. 1 bitflip en de boel raakt corrupt of crashed. ECC is voor iedereen relevant en daarom verkopen de vendors ook geen servers zonder ECC geheugen.Bovendien schalen geheugenfouten niet met de hoeveelheid geheugen in een systeem, maar met writes naar geheugen, zeker als je het over serversystemen zonder self-refresh geheugen hebt. Dus... en dit is iets wat steeds vaker wordt gedaan: zelfs op kritieke systemen is ECC in geheugen vrijwel altijd géén belangrijke factor. Alleen bij zéér langdurige HPC-taken waar zowel heftig op geheugenbandbreedte als op iteratieve berekeningen op dezelfde dataset wordt geleund is ECC absoluut noodzakelijk. Voor een Oracle of LAMP-rack is het nutteloos.
Wie dat doet moet als de sodemieter gecontroleerd worden op drugsgebruik (database op ramdisk).De enige andere reden om een serversysteem te nemen, afgezien van de form factor, is de hoeveelheid geheugen die je erin kunt proppen. Guess what, zelden maken mensen daadwerkelijk nuttig gebruik van hun geheugen. Er wordt vaak gewoon voor gekozen om het geheugen te sizen naar de maximale databasegrootte en de hele database dan maar op een RAM-disk te plempen, zelfs als een sparse database makkelijk in 4GB zou passen.
Je schetst nu scenario's van mensen die niet weten wat ze aan het doen zijn. Dat is niet zo interessant.
What de fuck? Slechte programma's over SSD draaien ipv RAM?En zelfs wanneer alles in geheugen staat zijn de programma's die over de data itereren vaak zo slecht ontworpen dat een SSD een véél kosteneffectievere oplossing zou zijn. We hebben het bijvoorbeeld over MSSQL dat niet eens 1GB/s haalt op een vrijwel sequentiële database-leesactie over DDR3L-2133 (17GB/s raw datarate).
Are you nuts?
Ga lekker ESXi draaien op consumenten spul zonder ECC en max 64GB per host. Maar volgens mij wil je van virtualisatie af.Stel je voor: een servermobo (€1500) met twee procs (€4000) en 256GB geheugen (€3000) vervangen
door een consumersetje met 64GB geheugen (sub-€1500). Voor veel toepassingen kan het. Doordat consumerborden véél efficiënter met energie omgaan en zoveel goedkoper in aanschaf zijn kun je er zelfs een cold spare naast hangen zonder erover na te denken.
Volgens mij wil je geen virtualisatie, maar gewoon alles op goedkope consumenten hardware draaien google-style zodat je gewoon redundancy over servers realiseerd en niet binnen servers.En ja, er zijn toepassingen waar het hangen van veel geheugen aan één processor inderdaad nuttig is of zelfs vereist. Maar dat is een kleine subset van de servers die er nu zo uitzien. Geheugen is 'goedkoop', maar niet zó goedkoop. Op de aanschaf van een server die toch al 10k+ kost is het een relatief kleine extra kostenpost, maar veel bedrijven realiseren zichzelf niet eens dat je met minimale concessies ook kunt downscalen naar workstation-level hardware en daarmee alleen al in aanschaf (laat staan licentie- en servicekosten) een hoop kunt besparen.
Dat kan best een OK aanpak zijn voor web schaal achtige zaken, met goeie provisioning. Maar ook daar zou ik voor availability absoluut geen non-ECC hardware gebruiken. Wat denk je dat Google en Amazon doen?
Maar voor de meeste bedrijven die intern KA en allemaal interne apps draaien, is dit totaal onrealistisch.
Daar is virtualisatie vrijwel altijd de redelijkste oplossing.
Je failover oplossing moet redelijk los staan van je productie, true. Maar dat heeft niets te maken met redundancy van je componenten. En zoveel kost dat laatste allemaal niet.Hoe verbeter je je uptime? Fail safe. Als er iets stukgaat moet er direct overgeschakeld kunnen worden naar een hot spare. Dat is het denken van een hoop mensen, en dit is voor 100% availability-systemen een onontkoombare werkelijkheid. Maar dat wil niet zeggen dat élk systeem in élk aspect redundant moet worden uitgevoerd. Je hoeft niet elke voeding en elke harde schijf dubbel uit te voeren. Het lot gaat je namelijk tegenwerken als je dat doet. 1:1 redundantie betekent dat je een 2 keer zo hoge kans (in de praktijk zelfs nog wat meer - dit heet de failure growth factor) hebt dat er *iets* misgaat. Als je verschillende systemen redundant uitvoert die van elkaar afhangen is het effect zelfs nog veel sterker - een hogere failurerate van redundante harde schijven veroorzaakt bijvoorbeeld een hogere failurerate van anders prima functionerende voedingen. Sommige harde schijven falen namelijk op een manier die de voeding overbelast.
Zoals ik ook schreef: 1 san is geen san. 1 server is geen server. Inderdaad, zul je veel dubbel moeten uitvoeren, maar het hoeft niet 1 op 1. Je kunt met VMware een licentie pakket kopen voor 3 hosts, waarbij je nummer 3 dus op een andere physieke locatie zet, als dat kan binnen je bedrijf (of in dc) en als je die wat over provisioned met ram, kun je op nummer 3 alles draaien van 1 en 2. Niet met gelijke performance, maar dat is dan de trade off. Tuurlijk, SAN moet wel 1:1 maar ook daar kun je kiezen om die niet zo bruut uit te voeren qua 15K 10K SSD disks en wat meer met 7200 rpm te werken. Kost performance, kan gedonder geven, maar dat moet je gewoon testen.
In de praktijk los je dit op met virtualisatie, die hosts zijn vaak wel 'duur', maar bedenk je wat echte hardware had gekost. Echte hardware schaalt niet qua beheerslast, ruimte, etc. Het gaat niet om alleen de aanschafprijs en stroomkosten. Hardware is evil, moet je zo weinig mogelijk van hebben.Redundantie in een ideale wereld werkt als n + 1, dat wil zeggen: als je n systemen met een identieke functie hebt hang je daar 1 hot spare naast die de functie kan overnemen als één van de systemen in de array het begeeft. Je zorgt er dan voor dat de software of load balancer zo is ontworpen dat dit kan. Je moet kunnen abstraheren naar een n + 1-model. In veruit de meeste toepassingen leidt dit tot de beste uptime; je hebt de kleinst mogelijke kans op failures zonder redundantie te verliezen. Echter, wat doe je als n = 1? Hoe ga je om met redundantie als je maar één systeem hebt?
Dat is een beetje een probleem. Aan de ene kant is het aantrekkelijk om te zeggen: nou, dan doe je volledige 1:1 redundantie. Maar in de praktijk kost je dat alleen maar veel teveel geld en tijd; je hebt (gemiddeld) ongeveer 3 keer zoveel servicekosten vanwege de hogere failure rate, twee keer zoveel aanschafkosten en twee keer zoveel verbruikskosten. Afschuwelijk slechte kostenefficiëntie. De beste oplossing hier is waarschijnlijk ofwel een cold spare (en dus <100% uptime), ofwel een heterogeen redundant systeem, dat wil zeggen een veel goedkopere, simpelere doos die de belangrijkste taken overneemt terwijl het primaire systeem wordt geservicet. Maar de laatste keuze moet wel zijn om een homogeen redundant systeem neer te zetten.
Ik geloof daar geen hout van (2)(3), maar misschien heb je goede bronnen die me overtuigen?Uptime, uptime, uptime. Als de stroom uitvalt moeten alle computers verder werken! Overal power conditioning inbouwen zodat overspanning en brownouts ondervangen kunnen worden! In theorie klinkt dit geweldig, maar er zijn drie hele, hele, hele grote problemen met dit idee:
1) Als de stroom in je datacenter uitvalt, valt waarschijnlijk de stroom uit in een veel grotere omgeving
2) Veruit de meeste power failures worden veroorzaakt door noodstroomvoorzieningen
3) Noodstroomvoorzieningen werken maar ongeveer 70% van de tijd naar behoren. Zelfs in kritieke omgevingen zoals ziekenhuizen.
Tegen drugsgebruikers is niets opgewassen.Wederom heb je hier te maken met een soort wrangen kosten/batenanalyse. Alles moet aan de noodstroomvoorzieningen, maar goh dit kost best een hoop geld, dus gezien de stroom nooit uitvalt kunnen we net zo goed wel bezuinigen op deze dieselgeneratoren en even wachten met het tanken tot de dieselprijzen omlaag gaan. Dit is serieus hoe een hoop datacenters erover nadenken.
Je schetst nu een veel te negatief beeld wat niet strookt met de werkelijkheid om het maar af te zeiken.
Je wilt iets van noodstroom al is het maar om de servers en met name (SAN) storage niet te laten crashen.Dus met deze gedachte dat noodstroomvoorzieningen niet bepaald 100% betrouwbaar zijn is het een stuk moeilijker goed te praten om er veel geld aan uit te geven. Is 100% power-uptime nodig als statistisch de meeste stroomuitval gepaard gaat met zeer grote netwerkuitvallen?
Ik weet wat je gaat zeggen over ZFS maar kom gerust daarna weer terug naar de echte wereld.
Dat het wel eens mis gaat wil niet zeggen dat je het dan maar niet moet doen. Ja het kost geld, en ja je moet goed kosten/baten afwegen. Waarom doe je iets?
Redundanctie over datacenters, dus datacenters 1:1. of 1:0.5 en dan wat minder performance of niet alle services beschikbaar. Dat is geen gek idee.Of dat ze alleen gebeuren als het hele datacenter toch onder water staat en niet kan werken? Is het niet een veel beter idee om al dat geld te steken in lokale infrastructuur? Of in diversificatie van je serverpark
met een aparte DNS-server/loadbalancer die traffic kan switchen?
Dus twee datacenters, ver uit elkaar, geen geld in noodstroom dus goedkoop. Datacenter 1 valt uit, alles dood, servers en storage klappen uit, hele omgeving naar de kloten, hardare stuk, data corruptie, en service outage. Failover naar dc 2 en terwijl je op dc2 draait kun je weken aan de slag om de puin in dc 1 op te ruimen, om dan een fail back te doen.
Ik denk dat je dit beter kunt voorkomen.
Er schiet mij te binnen dat google servers met een accu uitrust zodat ze geen gecentraliseerde noodstroomWederom, er is absoluut een niche voor UPS'en en grotere noodstroomvoorziening, maar die is kleiner dan je denkt. Uptime wordt maar in een relatief klein percentage van de datacenters gedomineerd door power availability, en je introduceert weer een extra schakel in je reliability-keten die stuk kan gaan (en daarbij alles meeneemt in je rack als het stukgaat).
hoeven te regelen. Maar de meeste bedrijven kunnen dat niet zomaar regelen.
http://gigaom.com/2009/04...ackup-battery-per-server/
Op dit vlak zitten we meer op 1 lijn: ook hier geld dat je het gewoon goed moet narekenen en zelf moet nadenken en nooit op verkoop praatjes af moet gaan. Gelden de voordelen voor jouw situatie en wordt alles wel meegerekend?Hah, leuke grap. Voorbeeld: Cofely. Virtualiseert 24 desktops op één server en claimt meer dan 50% energiewinst. Wat hebben ze daadwerkelijk gedaan? Ze hadden Pentium 4 desktops staan als workstations (~90W gemiddeld verbruik) en hebben dit vervangen door een hele sloot nieuwe netwerkhardware en een 2-processor Sandy Bridge-server van ruim 8000 euro (hardware) + VMWare ESXi (€20k + client licenses) met in totaal minder dan 25% van de resources van de voorgaande 24 systemen. Op iedereens tafel staat alleen nog een thin client met een verbruik iets onder de 20W. Server verbruikt gemiddeld zo'n 350W. Netwerkapparatuur wordt niet meegenomen in het verbruik.
Niemand hier hoeft je te vertellen dat je voor €1000 per werkplek de meest monsterlijke computer neer kunt zetten die níet constant netwerkbelasting veroorzaakt en idle onder de 20W zit. Ja, er is energie bespaard ten opzichte van de voorgaande situatie, maar er is niet nagedacht over de béste oplossing. Er is alleen iemand van VMWare Enterprise langsgekomen die hun rekensommetje heeft voorgedaan.
1 server down merk je niet want je hebt N+1 redundancy op zijn minst.Bovendien had de alternatieve oplossing een véél betere user experience dan in het geval van massa-virtualisatie. Ja, het heeft deployment en administratie-voordelen, maar het heeft net zozeer ook nadelen. Eén server down en 24 mensen hoeven niet naar hun werk te komen. De kans dat 24 individuele workstations het in één keer begeven is een stuk kleiner.
Wat desktop virtualisatie betreft, daar heb ik zelf ook vraagtekens bij, als ik de horror verhalen lees over je SAN requirements.
Ik hoop dat iedereen van zijn/haar popcorn geniet. Leuke rant van Mux, daar hou ik wel van. Er wordt tenminste nagedacht over wat we eigenlijk aan het doen zijn. Neem eens een stap terug en denk na.
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Xorg is niet een complete draaiende X omgeving. Linux is wat dat betreft wel makkelijk, je kan de grafische libraries installeren en nooit 1 grafische toepassing lokaal draaien. Dat is het mooie van X(11-Forwarding).InflatableMouse schreef op dinsdag 11 maart 2014 @ 19:26:
Maar dan moet ik m'n server gaan vervuilen met xorg enzo, toch? Dat is in principe toch niet wat je wilt op een headless server?
Bovendien heb je alleen xorg-server, en niet compleet Gnome of KDE met bijbehorende applicaties.
Een kale X installatie is misschien 100-150 MB ofzo.
EDIT: Nou vooruit, 190MB
root@NAS:~# apt-get install virt-manager Reading package lists... Done Building dependency tree Reading state information... Done The following extra packages will be installed: *knip* Suggested packages: *knip* The following NEW packages will be installed: *knip* 0 upgraded, 217 newly installed, 0 to remove and 0 not upgraded. Need to get 50.6 MB of archives. After this operation, 190 MB of additional disk space will be used.
[ Voor 160% gewijzigd door FireDrunk op 11-03-2014 20:48 ]
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ja, dat wist ik op zich wel, ik kan het eigenlijk niet uitleggen, ik vond het geen goed idee maar waarom precies weet ik ook niet.
Dus maar gedaan, en met het betere pruts en klungelwerk draait het ineens. Ik staar nu naar een Windows 8 installatie scherm in een remote X VMetje.
Best cool eigenlijk zo. Hoop dat het beetje stabiel draait.
Tx man!
Dus maar gedaan, en met het betere pruts en klungelwerk draait het ineens
Best cool eigenlijk zo. Hoop dat het beetje stabiel draait
Tx man!
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
NP
VirtIO gebruiken trouwens! Dat is echt bruut snel (nog veel sneller dan pvscsi onder ESXi)
VirtIO gebruiken trouwens! Dat is echt bruut snel (nog veel sneller dan pvscsi onder ESXi)
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ja kom ik achter. Het ziet m'n disk niet eens, zegt dat tie driver mist. Heb nu die ISO als 2de CDROM aan m'n VM gehangen zodat ik daar naar kan wijzen zo tijdens de installatie.
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
Je kan ook gewoon tijdens de install wisselen
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ik snap het niet ... wat voor controller moet ik kiezen? Heb SATA en SCSI geprobeert maar hij blijft mekkeren dat tie geen storage ziet. Ik heb die laatste Fedora ISO met VirtIO signed WHQL drivers voor Windows 8.
Edit: Ah denk dat ik em heb, moet natuurlijk Virtio kiezen.
Sorry voor de vervuiling ... zal geen rare KVM vragen meer stellen
Edit: Ah denk dat ik em heb, moet natuurlijk Virtio kiezen.
Sorry voor de vervuiling ... zal geen rare KVM vragen meer stellen
[ Voor 24% gewijzigd door InflatableMouse op 11-03-2014 21:19 ]
- FireDrunk
- Registratie: November 2002
- Laatst online: 13-07 17:42
VirtIO is echt een controller type.
Even niets...
Het grote probleem daarbij is dat mensen vanuit de verkeerde hoek denken. Ze proberen koste wat het kost uitval te voorkomen terwijl uitval evident is. Iemand die goed nadenkt over de materie richt zich dan ook op wat hij moet doen bij uitval. Het is niet risicoanalyse, het is schadebeperking. Die andere manier van denken zorgt er ook voor dat je binnen het gestelde budget kunt blijven en heel goed weet waar de zwakke plekken zitten.Q schreef op dinsdag 11 maart 2014 @ 20:24:
Op dit vlak kunnen we elkaar wel vinden: het is belangrijk dat je goed nadenkt over wat je doet. Niet slechts 'regeltjes' uitvoeren uit een boekje.
Een goed voorbeeld van schadebeperking is een UPS. Die zet je in om datacorruptie te voorkomen door de server(s) kans te geven om een clean shutdown te kunnen doen. Is het echt nodig? Nee
Het begon met iemand die voor het bedrijf waar hij werkzaam is een storage omgeving in elkaar wil zetten. Dat betekent echter niet dat de discussie dan maar niet over consumentenspul moet gaan want de discussie is ook handig voor de consument. Sterker nog, met de schijven van 2, 3 en 4TB in grote getallen begint het voor consumenten ook een must te worden.Dit topic gaat over consumenten spul, maar de popcorn discussie niet. Dus consumentenspul, ik wil het er niet over hebben.
Bedrijven als Google hebben een iets andere gedachte over servers: iedere server is vervangbaar. Ze creëren de redundantie dan niet in de server maar op serviceniveau. Dat werkt prima in grote omgevingen maar lang niet altijd in kleinere.Er schiet mij te binnen dat google servers met een accu uitrust zodat ze geen gecentraliseerde noodstroom hoeven te regelen. Maar de meeste bedrijven kunnen dat niet zomaar regelen.
Anyway, je kunt je beter voorbereiden op dat het stuk gaat ipv voorkomen dat het stuk gaat. Wie houdt er hier rekening mee en vervangt bijv. zijn schijven al preventief na een jaar of 3~4 (of juist de gehele machine)?
Xorg is geen compleet draaiende X omgeving, het is alleen een X11 server. Daar bovenop draai je nog wat meer zaken. Dit alles tezamen is wat je een compleet draaiende X omgeving noemt.FireDrunk schreef op dinsdag 11 maart 2014 @ 20:44:
Xorg is niet een complete draaiende X omgeving.
De headless server kan prima spullen bevatten die X11 nodig hebben. Je kunt dan een X11 server draaien op je eigen machine vanaf waar je dan een ssh connectie naar de headless server opent (het magische woord viel al: X11 Forwarding). Hij gebruikt dan de X11 server op je eigen machine en dat kan een groot voordeel zijn wanneer je iets als 3D acceleratie nodig hebt. Ook handig als je Ahsay als backup tool gebruikt. Die backupclient is grafisch. Met X11 Forwarding voorkom je dat je op alle servers een grafische omgeving moet gaan optuigen (wat dus meer beheer, meer kwetsbaarheid, etc. oplevert).
[ Voor 17% gewijzigd door ppl op 11-03-2014 23:44 ]
- Q
- Registratie: November 1999
- Laatst online: 09:01
@ppl, ik heb niets toe te voegen op je reactie behalve dan dat ik het met alle punten wel eens ben.
- TrsvK
- Registratie: September 2006
- Laatst online: 12-07 09:09
CONSENSUS! de popcorn kan de kast weer in
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
edit:
Nog even een offtopic vraag (gezien DIY):
Wat is, buiten ZFS/ OS, het grote verschil tussen een Synology RS2414+ en mijn laatstgenoemde zelfbouw oplossing? Zou de zelfbouw oplossing veel betere performance bieden? Gezien toegepast geheugen, SSDs en processor? Of ga ik dat over (gebonden) gigabit LAN niet merken?
[ Voor 50% gewijzigd door dreku88000 op 13-03-2014 17:35 . Reden: nog steeds laatste post.. ]
Lenovo Thinkpad Yoga X380
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Zijn er soort ILO alternatieven voor headless servertjes thuis in de meterkast eigenlijk? Ik probeer iets in de pricewatch te vinden maar kan maar moeilijk iets vinden.
Zijn er goedkope/betaalbare oplossingen voor thuisgebruik?
Zijn er goedkope/betaalbare oplossingen voor thuisgebruik?
Supermicro bordjes met IPMI wellicht? Als je wat in de Intel Avoton hoek zoekt kun je daar ook wel bij Asrock terecht (heb je ook IPMI). Maar wat noem jij betaalbaar/goedkoop?
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ik heb een Asrock bordje maar dat zal niet standaard op allemaal werken dan?
Ik zal es zoeken naar IPMI, nooit van gehoord namelijk.
Ik zal es zoeken naar IPMI, nooit van gehoord namelijk.
- dreku88000
- Registratie: Februari 2002
- Laatst online: 01-12-2025
Hier heb je een interessant/ leuk filmpje over de bouw van een DIY NAS met een Supermicro bodje inclusief configuratie van de NAS via IPMI interface. NAS draait op FreeNAS btw.
Lenovo Thinkpad Yoga X380
- Demo
- Registratie: Juni 2000
- Laatst online: 08:29
Probleemschietende Tovenaar
:strip_exif()/u/8077/jerney.gif?f=community)
Beter luisteren danInflatableMouse schreef op donderdag 13 maart 2014 @ 22:06:
Ik zal es zoeken naar IPMI, nooit van gehoord namelijk.
Unix doesn't prevent a user from doing stupid things, because that would necessarily prevent them from doing brilliant things.
while true ; do echo -n "bla" ; sleep 1 ; done
- Q
- Registratie: November 1999
- Laatst online: 09:01
Dat super micro bordje x-SCM-f is het goedkoopste bordje van SuperMicro met IPMI wat er zo'n beetje is, maar nog steeds 160 euro. Staat ook artikeltje over in mijn signature.dreku88000 schreef op donderdag 13 maart 2014 @ 22:09:
Hier heb je een interessant/ leuk filmpje over de bouw van een DIY NAS met een Supermicro bodje inclusief configuratie van de NAS via IPMI interface. NAS draait op FreeNAS btw.
- jacovn
- Registratie: Augustus 2001
- Laatst online: 08:08
Ooit een issue met een x9scm-f systeem en een x9scm-iif terug gekocht, maar die bevalt toch minder. Er zijn geen instellingen voor de pwm fans bijvoorbeeld. Dat slaat nergens op, want de fan pulst van langzaam naar snel om de paar seconden.
8x330 NO12.5°, 8x330 ZW12.5°, 8x350 ZW60°, 8x325 NO10°, SE8K, P500. 6x410 ZW10° Enphase
Let op:
In dit topic bespreken we de hardwarematige kant van het bouwen van een NAS. Vragen en discussies die betrekking hebben op de softwarematige kant, dien je elders te stellen. Zo is het ZFS topic de juiste plek voor vragen over ZFS maar ook over softwareplatformen zoals FreeNAS, NAS4Free, ZFSguru en andere softwareplatforms die met ZFS werken.
In dit topic bespreken we de hardwarematige kant van het bouwen van een NAS. Vragen en discussies die betrekking hebben op de softwarematige kant, dien je elders te stellen. Zo is het ZFS topic de juiste plek voor vragen over ZFS maar ook over softwareplatformen zoals FreeNAS, NAS4Free, ZFSguru en andere softwareplatforms die met ZFS werken.