:fill(white):strip_exif()/i/2003943496.jpeg?f=thumbmini)
:strip_exif()/i/1321263566.png?f=thumbmini)
- duiveltje666
- Registratie: Mei 2005
- Laatst online: 13-06-2022
Edit: je kunt ook Virtualbox gebruiken en de USB stick zo doorgeven, dan hoef je geen CD/DVD te branden. Of je koopt zo'n leuke Zalman 300 behuizing die .iso bestanden als virtuele CD/DVD/blueray kan presenteren via USB3. Die heb ik.
[ Voor 35% gewijzigd door Verwijderd op 07-12-2013 23:53 ]
- duiveltje666
- Registratie: Mei 2005
- Laatst online: 13-06-2022
- duiveltje666
- Registratie: Mei 2005
- Laatst online: 13-06-2022
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
/u/1176/crop635f8931b2b68_cropped.png?f=community)
Met mijn vorige server kocht ik gewoon even veel disks als in het chassis paste. Maar Als ik dat nu zou doen met een 24 bay chassis en 4 TB disks, dan wordt dat wel prijzig. Als ik met 12x4TB zou starten, zou ik al een heel eind komen.
Met Linux MDADM kun je een disk aan je array toevoegen om 'm groter te maken (grow). Dit kan nog steeds niet met ZFS zover ik weet.
Daarom bedacht ik dit: ik maak een RAID6 aan met MDADM en doe daar overheen ZFS. De enige reden voor mij om ZFS te kiezen is checksums: data integriteit.
Aangezien ZFS wel moet kunnen groeien (lijkt me) zou dit moeten werken, toch?
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
:strip_icc():strip_exif()/u/371379/zNcU5.jpg?f=community)
Daar hoor ik ook steeds meer goede verhalen over. Heb jij ervaring met ZFSonLinux als vm onder Windows?mkroes schreef op zaterdag 07 december 2013 @ 23:22:
[...]
zoals CiPHER al zegt: alles is mogelijk. Alleen is de ondersteuning nog steeds verre van voltooid.
Voornamelijk de scsi en network driver leveren nog wat problemen op (netwerk is er wel maar alleen legacy, 100mbit dus).
Vanwaar de noodzaak om Nas4free of ZFSguru te draaien? Als je graag ZFS wil gebruiken kan ik je ZFS on Linux wel aanraden.
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
ZFS op MDADM is nutteloos, je verliest je checksum mogelijkheden.Q schreef op zondag 08 december 2013 @ 10:54:
Mijn storage server zit vol en nu moest ik maar eens een nieuwe kopen.
Met mijn vorige server kocht ik gewoon even veel disks als in het chassis paste. Maar Als ik dat nu zou doen met een 24 bay chassis en 4 TB disks, dan wordt dat wel prijzig. Als ik met 12x4TB zou starten, zou ik al een heel eind komen.
Met Linux MDADM kun je een disk aan je array toevoegen om 'm groter te maken (grow). Dit kan nog steeds niet met ZFS zover ik weet.
Daarom bedacht ik dit: ik maak een RAID6 aan met MDADM en doe daar overheen ZFS. De enige reden voor mij om ZFS te kiezen is checksums: data integriteit.
Aangezien ZFS wel moet kunnen groeien (lijkt me) zou dit moeten werken, toch?
Je kan beter 10*4TB plaatsen en later een 2e vdev toevoegen van 10*4TB.
Dat werkt prima en is ook best practice in veel gevallen.
Of als je persé 24 disks wil, 4 setjes van 6 (maar dan verlies je heel veel schijven aan parity)
[ Voor 4% gewijzigd door FireDrunk op 08-12-2013 11:54 ]
Even niets...
- Mafketel
- Registratie: Maart 2000
- Laatst online: 05-07 06:36
En gaat ook niet gebeuren denk ik.Q schreef op zondag 08 december 2013 @ 10:54:
Met Linux MDADM kun je een disk aan je array toevoegen om 'm groter te maken (grow). Dit kan nog steeds niet met ZFS zover ik weet.
Met een disk uitbreiden is gewoon buiten zeer budget systemen niet aan de orde.
Je kunt op twee manieren uitbreiden. Een extra zpool toevoegen als stripe aan je bestaande zpool.
Je koopt nu 12 schijven die plaats je in 2 raid-z stripes (?) daar voeg je dan een derde raid-z stripe aan toe van 6 schijven.
Of je kunt alle schijven vervangen door een grotere versie, de extra ruimte kan daarna weer worden gebruikt.
Plaats de .iso op de USB stick, maar dan kun je er verder niets mee. Daarom vroeg ik wat je met de USB-stick wilde doen. Ik had je ook een DM gestuurd.duiveltje666 schreef op zondag 08 december 2013 @ 02:38:
nee , wil de livecd iso op usb "branden" , maar dan wel zodanig dat het op mn usb stick past
Bij ZFS kijk je even wat optimaal is en daar kun je het beste je configuratie op baseren. 10 disks in RAID-Z2 is min of meer de best mogelijke configuratie: goede redundancy tegen slechts 20% overhead. Bovendien is dit een configuratie die optimaal is voor 4K sector disks.Q schreef op zondag 08 december 2013 @ 10:54:
Mijn storage server zit vol en nu moest ik maar eens een nieuwe kopen.
Met mijn vorige server kocht ik gewoon even veel disks als in het chassis paste. Maar Als ik dat nu zou doen met een 24 bay chassis en 4 TB disks, dan wordt dat wel prijzig. Als ik met 12x4TB zou starten, zou ik al een heel eind komen.
En met reden. Het heralloceren van stripe blocks is een erg risicovolle operatie. Als tijdens het 'omspitten' van de data zich problemen voordoen zoals bad sectors en/of een crash/reset, dan is het maar de vraag of je data nog te recoveren is. ZFS expansion maakt dingen mogelijk die met traditioneel RAID niet mogelijk zijn, maar dan wel op een veilige manier. Bovendien binnen 1 seconde klaar. Het heeft voor thuisgebruikers inderdaad het nadeel dat je niet elke keer een schijfje bij kunt plaatsen. Het voordeel is dat dergelijke risicovolle operaties ook niet meer voor problemen kunnen zorgen. Alleen maar veilige expansion, of geen expansion.Met Linux MDADM kun je een disk aan je array toevoegen om 'm groter te maken (grow). Dit kan nog steeds niet met ZFS zover ik weet.
Dat gaat inderdaad werken. Je moet alleen weten dat je ZFS hiermee anaal neemt. Je verkracht op die manier de veiligheid van ZFS door de datastore op een onveilige legacy-RAID driver te draaien. Dé reden om ZFS te draaien is mijns inziens niet eens de checksums, maar een veilige betrouwbare RAID-laag die niet zomaar op zijn bek gaat. RAID-Z heeft geen write-hole, doet atomic writes (one-phase writes, dus ongeveer zoals RAID3) en heeft ook betere random write performance dan RAID5.Daarom bedacht ik dit: ik maak een RAID6 aan met MDADM en doe daar overheen ZFS. De enige reden voor mij om ZFS te kiezen is checksums: data integriteit.
Aangezien ZFS wel moet kunnen groeien (lijkt me) zou dit moeten werken, toch?
Dus je moet er rekening mee houden dat via deze route je een dag ziet:
FAULTED (corrupt metadata)
Hetzelfde geldt overigens als je ZFS (en RAID-Z) gebruikt op een hardware RAID volume. Dat zijn zowat de enige situaties waarin je ZFS kapot krijgt.
- Mystic Spirit
- Registratie: December 2003
- Laatst online: 12-07 20:58
PSN: mr_mysticspirit
/u/98763/MysticSpiritBlack.JPG?f=community)
Nu kreeg ik een Memscheduler error als ik op wilde starten. Iets met een invalid memory setting / memory reservation die gelijk moest zijn aan 8GB. Als ik de settings terug zet naar 6GB is er niks aan de hand.
Iemand enig idee waar dit probleem vandaan komt? Ik heb ook geen keuze voor het upgraden van virtual hardware, ik kan alleen de settings editten.
Heb je geheugentuning in /boot/loader.conf actief?
Even niets...
Verwijderd
Zowel RAID5 als RAIDZ 'died' in 2009. Het is dus niet verstandig om deze meer te gebruiken begrijp ik.RAIDZ1: ZFS software solution that is equivalent to RAID5. Its advantage over RAID 5 is that it avoids the write-hole and does not require any special hardware, meaning it can be used on commodity disks. If your FreeNAS® system will be used for steady writes, RAIDZ is a poor choice due to the slow write speed. CAUTION: RAIDZ1 "died" back in 2009 and should not be used if reliability of your data is important. Read Why RAID5 stopped working in 2009 for more information. Generally speaking, if you are using a RAIDZ1 pool and you have a single disk failure you can expect to be forced to destroy, recreate, and restore the pool from backup.
Bedoelen ze nu dat de code hiervoor niet meer wordt ontwikkeld en deze dus eigenlijk 'deprecated' is? Of gaat het om het feit dat zowel Raid5 en RaidZ1 een vals gevoel van veiligheid geven, omdat bij een HDD crash het waarschijnlijk niet meer lukt om de data te herstellen m.b.v. de parity disk. (als ik het goed begrijp is de som van de opslagcapaciteit van de schijven dan zo groot, dat de kans op een fout tijdens het herstellen van de pool zeer waarschijnlijk is, waardoor de poging faalt.)
Mocht het laatste geval de reden zijn, dan heeft RaidZ1 dus helemaal geen toegevoegde waarde t.o.v. Raid1 meer, klopt dat?
Ik wil graag een NAS gaan inrichten en dacht er aan om dan 3 harde schijven te kopen en in RAIDZ1 te gebruiken. Dan heb ik 3*3TB - 1*3TB = 6TB aan opslagcapaciteit en geen data verlies bij een diskcrash veronderstelde ik.
Als ik het nu begrijp kan ik dus beter 2 harde schijven kopen en deze in RAID1 zetten. Dan heb ik 'slechts' 3gb opslag capaciteit, maar wel de zekerheid dat ik de data kan herstellen na een crash.
Bij RaidZ1 zou ik iets meer opslagcapaciteit hebben, maar na een crash toch alles kwijt zijn door het 2009 probleem. Dan zou je net zo goed Raid0 kunnen doen met twee schijven, want dat geeft evenveel opslag capaciteit en zelfs betere prestaties? (je bent bij een diskcrash helaas wel de data kwijt, net zoals bij RaidZ1 blijkbaar het geval is?)
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Los van hoe groot de risico's van legacy (software) RAID nu werkelijk zijn: het kost me 2 disks: 300 euro. Als ik een storage monster 2.0 overweeg met 24 x 4 TB hou ik met twee vdevs RAIDZ2 alsnog netto 80 TB over. Dus waar praat ik over?Dat gaat inderdaad werken. Je moet alleen weten dat je ZFS hiermee anaal neemt. Je verkracht op die manier de veiligheid van ZFS door de datastore op een onveilige legacy-RAID driver te draaien. Dé reden om ZFS te draaien is mijns inziens niet eens de checksums, maar een veilige betrouwbare RAID-laag die niet zomaar op zijn bek gaat. RAID-Z heeft geen write-hole, doet atomic writes (one-phase writes, dus ongeveer zoals RAID3) en heeft ook betere random write performance dan RAID5.
Dus je moet er rekening mee houden dat via deze route je een dag ziet:
FAULTED (corrupt metadata)
Hetzelfde geldt overigens als je ZFS (en RAID-Z) gebruikt op een hardware RAID volume. Dat zijn zowat de enige situaties waarin je ZFS kapot krijgt.
Ik voel inderdaad eigenlijk meer voor een native ZFS-on-Linux oplossing, dat is netter.
Zou ZFS erg over de zeik gaan als je gewoon 24 disks in 1 RAIDz2 vdev gooit? Of kost dat alleen wat performance (maakt me niets uit, random performance al helemaal niet)?
- Mystic Spirit
- Registratie: December 2003
- Laatst online: 12-07 20:58
PSN: mr_mysticspirit
Het is inderdaad een ESXi melding:FireDrunk schreef op zondag 08 december 2013 @ 15:51:
Is het een melding van BSD of van ESXi? Want als je via VT-d werkt word al het geheugen keihard gealloceerd (dat moet voor VT-d). Het kan dus zijn dat je even bij de eigenschappen van de VM de reserveringen ook moet aanpassen. (Je kan niet 8GB geven en 6GB reserveren EN VT-d gebruiken...)
1
2
3
4
| Failed to start the virtual machine. Module MemSched power on failed. An error occured while parsing schduler-specific configuration parameters. Invalid memory setting: memory reservation (sched.mem.min) should be equal to memsize(8192). |
Wist niet dat dat een eigenschap was bij VT-D. ik zal bij resources het geheel ook even aanpassen en kijken wat er dan gebeurd. Ik kon namelijk wel makkelijk het aantal cores / sockets aanpassen.
edit:
Memory reservation is nu aangepast. Ik heb nu 8GB en het werkt
[ Voor 4% gewijzigd door Mystic Spirit op 08-12-2013 18:37 ]
Heel veel uitspraken van FreeNAS (inclusief die 'administrator' cyberjock) zijn discutabel op zijn best tot ronduit incorrect. Neem deze dus met een (behoorlijke) korrel zout.Verwijderd schreef op zondag 08 december 2013 @ 17:46:
Onderstaande passage kwam ik tegen toen ik de FreeNas documentatie aan het doorspitten was:
Zowel RAID5 als RAIDZ 'died' in 2009. Het is dus niet verstandig om deze meer te gebruiken begrijp ik.
Het artikel van Robin Harris dat RAID5 niet meer geschikt is in 2009 ken ik, daar link ik regelmatig naar. Maar de conclusies daarvan zijn zeker niet zomaar van toepassing op ZFS. Het maakt nogal verschil of je hooguit één bestand mist (en je kunt zien precies welk bestand dat is) of dat je je hele array en dus alle data kwijt bent. Nogal een verschil.
Hoe zit het nou? Ik heb geen zin in een turbolang verhaal, dus de korte versie:
Legacy RAID5 gaat erg binair om met disks. Een disk met een onleesbare sector wordt vaak uit de array getrapt. Stel je hebt een RAID5 die al een jaar prima werkt. Nu gaat er een schijf dood; oeps! Je koopt snel een nieuwe en de rebuild start je al heel snel. Maar nu - tijdens de rebuild - heeft tenminste één van de resterende member disks een read error. Dergelijke read errors duiden we aan met uBER; zeg maar bad sectors zonder fysieke schade. Nadat deze worden overschreven worden ze NIET omgewisseld met reserve sectoren maar worden ze gewoon weer in gebruik genomen. Ongeveer 90% van alle bad sectors bij moderne consumentenschijven is van dit type. Vroeger was dit nog maar iets van 5%, daarom is het 'Why RAID5 stops working in 2009' omdat 2009 grofweg het niveau is waarop het uBER ontoelaatbaar hoog is geworden. In de praktijk vanaf 666GB platters dat je grote problemen krijgt.
Dus kort gezegd, je hele RAID5 kan corrupt/defect/ontoegankelijk raken door één gefaalde disk en één klein bad sectortje. Dit geldt niet voor alle RAID5 engines, maar diegenen die niet tegen bad sectors en/of timeouts kunnen. De overgrote meerderheid dus van alle RAID-implementaties. Alleen LSI/3ware enzovoorts heb ik nog wat vertrouwen in dat zij het intelligenter doen.
Bij ZFS is het heel anders omdat ZFS geen disks uit de array gooit en corruptie direct herstelt. In het geval je een disk mist met RAID-Z en dus geen redundancy meer hebt, is er nog steeds niets aan de hand. Heb je dan read errors dan kunnen die ofwel ZFS metadata treffen of user data. ZFS zelf heeft nog extra ditto blocks (copies=2) voor metadata, dus ook op een RAID0 met bad sectors is ZFS nog beschermd. Alleen je data loopt dan risico. Bad sectors kunnen dan bestanden ontoegankelijk maken. Je krijgt dan een read error als je ze probeert te lezen, en de bestandsnamen worden in zpool status -v weergegeven. Zodra je schijf de data toch weer kan inlezen (recovery) worden de bestanden weer toegankelijk.
Hoe ZFS reageert en hoe legacy RAID5 reageert is toch een wereld van verschil. Dus kortom, dat verhaal van FreeNAS is een broodje aap, zoals wel meer onzin die op dat forum wordt uitgekermd.
RAID-Z is ook niet superieur aan een mirror; juist andersom. Maar een mirror heeft 50% overhead en beperkte (sequential) schrijfsnelheden. Daar doet RAID-Z het weer beter.Mocht het laatste geval de reden zijn, dan heeft RaidZ1 dus helemaal geen toegevoegde waarde t.o.v. Raid1 meer, klopt dat?
Lijkt mij een prima plan.Ik wil graag een NAS gaan inrichten en dacht er aan om dan 3 harde schijven te kopen en in RAIDZ1 te gebruiken. Dan heb ik 3*3TB - 1*3TB = 6TB aan opslagcapaciteit en geen data verlies bij een diskcrash veronderstelde ik.
Op de totale kosten van een 80TB monster is dat denk ik niet heel significant.Q schreef op zondag 08 december 2013 @ 18:15:
Los van hoe groot de risico's van legacy (software) RAID nu werkelijk zijn: het kost me 2 disks: 300 euro.
Ik weet niet wat je precies bedoelt hiermee. twee vdevs van 12 x 4TB is echter geen optimale configuratie voor 4K schijven. Ofwel je gaat optimaliseren met ashift=12 wat ook weer minder bruikbare opslag geeft door 'slack' oftewel verloren ruimte, of je houdt het lekker ashift=9 maar dan heb je brakke performance.Als ik een storage monster 2.0 overweeg met 24 x 4 TB hou ik met twee vdevs RAIDZ2 alsnog netto 80 TB over. Dus waar praat ik over?
Dan vind ik een enkele vdev met RAID-Z met 19 disks (16 data disks + 3 parity) nog leuker. Twee vdevs van 2x 10 disks in RAID-Z2 (dus 4 parity disks) lijkt mij de beste configuratie. Natuurlijk doe je daar ook SSDs bij om de IOps te pimpen dus zo kom je wel aan de 24 poorten.
Nog beter is een ZFS implementatie op het BSD platform, maar ZFS-on-Linux kun je zeker ook overwegen als je Linux fijner vindt werken.Ik voel inderdaad eigenlijk meer voor een native ZFS-on-Linux oplossing, dat is netter.
Je kunt zoveel disks in een vdev stoppen als je wilt. Maar je moet weten dat 100 disks in RAID-Z nooit hogere IOps performance heeft dan een enkele disk. Ook bij massaopslag zul je seeks krijgen dus het kan snel zijn dat je nauwelijks goede sequentiële snelheden haalt omdat je disks moeten seeken. Bovendien is het zo dat de langzaamste schakel alles bepaalt. De laatste disk over de streep is alsof alle disks met die snelheid gingen. Dit komt omdat bij RAID-Z alle disks bij een enkele I/O worden betrokken. Dit wijkt af van RAID5 die wel kan schalen met random reads. Bij RAID-Z geldt dat niet zo. Om die reden is RAID-Z meer verwant met RAID3 dan met RAID5. Staat tegenover dat RAID-Z betere random write kent dan RAID5. En veiliger vanwege atomicity.Zou ZFS erg over de zeik gaan als je gewoon 24 disks in 1 RAIDz2 vdev gooit? Of kost dat alleen wat performance (maakt me niets uit, random performance al helemaal niet)?
Dus stel je hebt 100 disks in een enkele vdev, dan kan het zijn dat alle disks maar op halve snelheid werken omdat er altijd wel EEN disk is die veel trager is. Met name disks met afwijkende firmware enzovoorts kan veel performance kosten. Dit is de reden dat in zijn algemeenheid wordt aangeraden niet meer dan 9 devices in een vdev te stoppen. Maar dat getal 9 komt ook maar uit de lucht vallen. De meest effectieve ('beste') configuratie is namelijk 10 disks in RAID-Z2: goede performance, goede redundancy en weinig overhead: slechts 20%.
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Maar IOPS en SSD en caching en random I/O al dat soort zaken maken mij niets uit. Het enige wat mij uitmaakt is sequentiële lees/schrijf performance.
Het streven is dat ik 400 MB/s moet kunnen halen tussen mijn machines (via 4x1GB bonding).
Het is me wel duidelijk dat ik me even beter moet verdiepen in ZFS wat betreft de performance, want het was mij niet duidelijk dat alle disks bij 1 I/O mee doen.
Het kan zomaar zijn dat ik tussen machines even 100+ GB heen-en-weer kopieer en ik zou graag zien dat de machines dan sustained 300-400MB/s aan kunnen.
Mocht ik alle spullen uiteindelijk binnen hebben dan ga ik eerst wel eens wat benchmarks draaien die ik ongetwijfeld ga delen. Ik sta open voor test-verzoeken
[ Voor 18% gewijzigd door Q op 08-12-2013 19:48 ]
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Ik heb vandaag een ri-vier case besteld met ruimte voor 24 disks. Daar moet ik wel een tijdje mee vooruit kunnen. Ik doe er gewoon 12 in en later misschien nog eens 12. Dan kom je toch uit op twee keer een RAIDZ2 vdev van 12 disks.
[ Voor 7% gewijzigd door Q op 08-12-2013 19:52 ]
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Ik zou er zelf zeker één SSD bij doen voor cache en SLOG dat helpt ook voor sequential doorvoer, althans het zorgt ervoor dat de disks meer sequential I/O kunnen doen zonder seeks tussendoor. Aangezien jij meer dan 1Gbps netwerk doet, wil je wel wat marge hebben. Het is namelijk niet zo dat als ZFS 400MB/s doet, je dat via je netwerk ook haalt.
ZFS is veel 'burstier' door de transaction groups. Het ene moment slurp je met RAM-snelheid I/O naarbinnen als een gek, het andere moment staat de I/O een tijd stil door de transaction commit; zoals barriers met Linux filesystems. Dat kun je allemaal tunen, maar mijn punt is dat je altijd marge wilt hebben en dat het niet zo werkt dat 400MB/s lokale performance ook 400MB/s netwerk performance betekent. Gedurende dat je minder I/O doet door een commit kun je dat namelijk niet inhalen omdat je netwerk ook bottleneck is. Zou je netwerk 100 gigabit zijn ofzo, dan is dit geen probleem omdat het qua doorvoer dan met RAM kan concurreren.
Dus wellicht een Intel 320 120GB erbij of een Crucial M500 120GB desnoods. Hartstikke leuk en kost geen drol relatief aan de totaalprijs. En dan rechtvaardig je ook dat je 'maar' 20 disks gebruikt, omdat je nog poorten nodig hebt.
Eventueel kun je ook nog 2x 11 disks in RAID-Z3 overwegen, dat is ook optimaal. Dan zit je aan 22 disks, maar de netto opslag verander natuurlijk niet. 22+1 SSD = 23. Lijkt me een prima config!
Kun je de SSD partitioneren voor gebruik van het operating system, L2ARC cache, SLOG en overprovisioning. Zou helemaal mooi zijn als je er twee zou nemen, dan kun je de SLOG in mirror doen en de cache in stripe. En OS ook in mirror dat kan leuk zijn.
Even niets...
- Mystic Spirit
- Registratie: December 2003
- Laatst online: 12-07 20:58
PSN: mr_mysticspirit
Ik heb momenteel ook een niet optimale pool van 5 data disks en 2 parity. Ik kan je melden dat er niet echt een vuistregel is. Het is afhankelijk van verschillende factoren, maar bij mij is het verlies momenteel ongeveer 7 a 8%.Q schreef op zondag 08 december 2013 @ 20:12:
Wat is de vuistregel / berekening? Ik kon het zo snel niet vinden met google. Kost me dit 1% of 10%?
Als je mijn posts nazooekt kun je zien hoe ik heb zitten worstelen met wat het verlies is / zou zijn en dat er dus eigenlijk geen goede berekening voor is.
[ Voor 15% gewijzigd door Mystic Spirit op 08-12-2013 20:26 ]
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Hoe meer ik snap van ZFS, hoe meer ik de neiging voel om gewoon ZFS anaal te nemen en alles op MDADM te gooien, als je met SSDs aan de slag moet om überhaupt er knappe sustained performance uit te slaan dan wordt ik eigenlijk niet zo heel blij. Voor een serieuze productie omgeving is dit een ander verhaal, maar het gaat hier om een uit de hand gelopen hobby.
Nu staat me bij dat er recent een patch was die de sustained read/write performance minder choppy/bursty zou maken, maar of dat al ergens in een release van zfs-on-linux is gekomen, .....
Ik denk ergens: fuck it, de data is niet dermate belangrijk dat als er een paar bitjes flippen er 100 mensen zonder baan zitten.
Met MDADM flikker ik gewoon een ouderwetse RAID6 neer met XFS en klaar is Q. Fuck checksums, fuck RAID write hole, het systeem hangt toch wel aan een vette UPS. Dat is wat ik nu heb en dat draait al 4.5 jaar prima met ongevraagde aso-vette en rock-stable performance.
Ik zou nog 2x10 en 1x4 disk RAIDZ2 vdev kunnen doen als ik 24 disks in het chassis kwijt wil. Maar dan gooi ik wel 300 euro extra aan disks weg. Tov een aso 24 disk RAID6 zou ik 600 euro aan disks weg gooien.
[ Voor 97% gewijzigd door Q op 08-12-2013 20:48 ]
- Mystic Spirit
- Registratie: December 2003
- Laatst online: 12-07 20:58
PSN: mr_mysticspirit
- Durandal
- Registratie: Juli 2002
- Laatst online: 29-04 16:35
Heb je daar ook je energieprijs in zitten, en eventuele uitbreidingen?Mystic Spirit schreef op zondag 08 december 2013 @ 20:33:
Het hangt er een beetje vanaf hoe je er naar kijkt. Als je onvoldoende ruimte hebt voor een optimale config en je wil wel de storage hebben is 10% misschien acceptabel. Ik heb ook doorgerekend dat een niet optimale config met 3TB harddrives momenteel goedkoper is dan een optimale met 4TB drives met dezelfde capaciteit. Dus ook of het verlies acceptabel is is weer afhankelijk van je situatie.
Ja, als ik me goed herinner was daar wat discussie over enige dagen geleden. ZoL zou pas een herstel doen tijdens een scrub, en BSD weten we eigenlijk niet.Verwijderd schreef op zondag 08 december 2013 @ 18:58:
Bij ZFS is het heel anders omdat ZFS geen disks uit de array gooit en corruptie direct herstelt.
Of heb ik de klok en klepel verkeerd?
[ Voor 42% gewijzigd door Durandal op 08-12-2013 20:43 ]
Ik weet niet precies hoe Mystic rekent maar behalve slack zit er natuurlijk ook ruimte in voor metadata. Dus qua percentage moet je met niet-optimale configuraties eerder denken aan 2 - 4%. Nog steeds veel.Q schreef op zondag 08 december 2013 @ 20:27:
Dan zou je al een paar TB verliezen op 40 TB, dat is wel zonde.
Daarom dat ik de 20 disks in 2x RAID-Z2 of 22 disks in 2x RAID-Z3 wel zo cool vind. Met twee SSDs.
Ik snap best je punt. Je verlaat je comfortzone waarbij dingen werken zoals je in je hoofd hebt. Maar ZFS kent wel beperkingen, maar ook veel vrijheden die je vaak pas ontdekt nadat je bent geswitched. Zeker voor iemand van jouw statuur zou ik ZFS zeker een kans geven.Hoe meer ik snap van ZFS, hoe meer ik de neiging voel om gewoon ZFS anaal te nemen en alles op MDADM te gooien (..)
Ik denk ergens: fuck it, de data is niet dermate belangrijk dat als er een paar bitjes flippen er 100 mensen zonder baan zitten.
Met al dat ruimteverlies heb je geen last van als je een optimale configuratie draait. Dus overweeg mijn setup eens. Dan heb je misschien niet ultra-veel bruikbare opslag, maar ook iets minder aanschafkosten en je doet geen concessies aan betrouwbaarheid.
Nou daar mag je blij mee zijn dan. Maar jij snapt natuurlijk net als ik dat in het verleden behaalde resultaten geen garantie voor doe toekomst zijn. Ga je zoveel disks - high density 4TB disks dus met hoge uBER - dan is de mogelijkheid tot bad sectors zeker aanwezig. Een rebuild gaat dan ook klerelang duren, en als er tijdens de rebuild meerdere bad sectors op meerdere disks komen, zit je met md-raid toch flink in de shit dacht ik zo. Die kans is in elk geval significant genoeg om er rekening mee te houden; het is natuurlijk niet allemaal onzin dat uBER en checksums enzo.Met MDADM flikker ik gewoon een ouderwetse RAID6 neer met XFS en klaar is Q. Fuck checksums, fuck RAID write hole, het systeem hangt toch wel aan een vette UPS. Dat is wat ik nu heb en dat draait al 4.5 jaar prima met ongevraagde aso-vette en rock-stable performance.
Dus de vraag is, wat lever je nu precies in? Dat je nieuwe build niet zoveel netto opslag heeft als je wilde? Dat is dan alles? Daar staat dan tegenover dat de ZFS route je andere voordelen geeft (snelle rebuilds, betrouwbare werking, checksums, krachtige snapshots, resistent tegen bad sectors en onderhoudsvrij - ZFS repareert zichzelf. Naast alle features enzo zijn dit best leuke eigenschappen die je niet zomaar overboord zou moeten gooien denk ik zelf.
En last but not least: van het Q continuum verwacht ik natuurlijk wel dat ze daar ook ZFS draaien.
- Mystic Spirit
- Registratie: December 2003
- Laatst online: 12-07 20:58
PSN: mr_mysticspirit
Geen uitbreidingen, want die kun je pas weer berekenen als je gaat uitbreiden met de prijzen die dan gelden.Durandal schreef op zondag 08 december 2013 @ 20:42:
[...]
Heb je daar ook je energieprijs in zitten, en eventuele uitbreidingen?
KNIP
Energie rekenen begint voor hdd's relatief onzinnig te worden in relatie tot de kosten van de hdd. In seek gebruikt een moderne schijf geen 10 watt meer. Dat betekent op jaarbasis als een hdd 24/7 staat te draaien dat je een berekening krijgt van 0,01KW x 8760 uur (= 87,6KWh ) x €0,23 = €20,15 op jaarbasis per HDD. Dat is ten opzichte van de aanschafprijs en afschrijving van een hdd niet echt relevant en al helemaal niet bij een schijf meer of minder als je het over arays van 10 tallen schijven hebt.
De metadata zit inderdaad ook in mijn percentage. Ik weet niet hoeveel ik voor metadata moet rekenen. Is er een commando dat laat zien hoeveel ruimte op gaat aan metadata? Dan wil ik het wel specifieker berekenen.Verwijderd schreef op zondag 08 december 2013 @ 20:57:
[...]
Ik weet niet precies hoe Mystic rekent maar behalve slack zit er natuurlijk ook ruimte in voor metadata. Dus qua percentage moet je met niet-optimale configuraties eerder denken aan 2 - 4%. Nog steeds veel.
Daarom dat ik de 20 disks in 2x RAID-Z2 of 22 disks in 2x RAID-Z3 wel zo cool vind. Met twee SSDs.
KNIP
[ Voor 3% gewijzigd door Mystic Spirit op 08-12-2013 21:13 ]
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Als ik 3 x 8 disk RAIDZ2 doe dan benut ik de 24 drive slots efficient (OS gaat op Mobo controller in RAID1 ergens in het chassis) maar dan verlies ik wel 6 disks aan parity.Verwijderd schreef op zondag 08 december 2013 @ 20:57:
Ik weet niet precies hoe Mystic rekent maar behalve slack zit er natuurlijk ook ruimte in voor metadata. Dus qua percentage moet je met niet-optimale configuraties eerder denken aan 2 - 4%. Nog steeds veel.
Daarom dat ik de 20 disks in 2x RAID-Z2 of 22 disks in 2x RAID-Z3 wel zo cool vind. Met twee SSDs.
Maar is 8 disk RAIDZ2 optimaal? Edit: volgens mij niet. Dus die vlieger gaat niet op. 2x10 en 1x4 disk wel maar dan krijg je belabberde performance.
Dat is een beetje onder de gordel, maar ach ik was ook anaal aan het ranten.Ik snap best je punt. Je verlaat je comfortzone waarbij dingen werken zoals je in je hoofd hebt. Maar ZFS kent wel beperkingen, maar ook veel vrijheden die je vaak pas ontdekt nadat je bent geswitched. Zeker voor iemand van jouw statuur zou ik ZFS zeker een kans geven.
Het probleem is dat ZFS een file system is dat bedoeld is voor zakelijk / professioneel gebruik en het houdt geen rekening met behoeften van zieke thuisgebruikers zoals ik.
Ik respecteer ZFS enorm maar je moet echt goed weten wat je aan het doen bent en alhoewel ik me een klein beetje had ingelezen had ik dit niet geheel verwacht.
Dat is een risico waar ik mij zeer terdege van bewust ben. Een rebuild met mijn huidige 1 TB disks duurt 5 uur. Met 4 TB disks zou dat bij gelijke performance dus 20 uur duren.Nou daar mag je blij mee zijn dan. Maar jij snapt natuurlijk net als ik dat in het verleden behaalde resultaten geen garantie voor doe toekomst zijn. Ga je zoveel disks - high density 4TB disks dus met hoge uBER - dan is de mogelijkheid tot bad sectors zeker aanwezig. Een rebuild gaat dan ook klerelang duren, en als er tijdens de rebuild meerdere bad sectors op meerdere disks komen, zit je met md-raid toch flink in de shit dacht ik zo. Die kans is in elk geval significant genoeg om er rekening mee te houden; het is natuurlijk niet allemaal onzin dat uBER en checksums enzo.
Wat ik met name inlever is verlies van netto opslag, maar dat is ook weer niet zo erg. Ik ga er nog even over nadenken.Dus de vraag is, wat lever je nu precies in? Dat je nieuwe build niet zoveel netto opslag heeft als je wilde? Dat is dan alles? Daar staat dan tegenover dat de ZFS route je andere voordelen geeft (snelle rebuilds, betrouwbare werking, checksums, krachtige snapshots, resistent tegen bad sectors en onderhoudsvrij - ZFS repareert zichzelf. Naast alle features enzo zijn dit best leuke eigenschappen die je niet zomaar overboord zou moeten gooien denk ik zelf.
En last but not least: van het Q continuum verwacht ik natuurlijk wel dat ze daar ook ZFS draaien.

[ Voor 5% gewijzigd door Q op 08-12-2013 21:43 ]
- Durandal
- Registratie: Juli 2002
- Laatst online: 29-04 16:35
Optimale configuratie is altijd n^2 disks, exclusief redundante disks (en spares).Q schreef op zondag 08 december 2013 @ 21:37:
[...]
Maar is 8 disk RAIDZ2 optimaal? Ik zie door de bomen het bos niet meer.
bijvoorbeeld (3, 4,) 6, 10 of 18 disks voor RaidZ2 dus. Eentje er af voor Z1 en 1 er bij voor Z3.
Per vdev, dus je kan ook 2x10 nemen.
[ Voor 7% gewijzigd door Durandal op 08-12-2013 21:49 ]
Mwa je mag je frustraties bij de overstap naar ZFS best uiten hoor. En ik kan dat ook redelijk begrijpen denk ik. Je komt uit een andere wereld waarin bepaalde zaken vanzelfsprekend zijn. Nu is dat allemaal anders. De truc is om niet alleen naar de beperkingen te kijken versus wat je nu hebt, maar ook naar de voordelen en vrijheden die je krijgt. Zaken die je niet automatisch als vanzelfsprekend acht.Q schreef op zondag 08 december 2013 @ 21:37:
Dat is een beetje onder de gordel, maar ach ik was ook anaal aan het ranten.
Een mooi voorbeeld is deze uitspraak van je:
Waarschijnlijk doel je op de 1x4 als derde vdev met 4 disks. Je denkt daarbij dat de snelheid omlaag gaat omdat er striping plaatsvindt met de grotere en snellere vdevs met elk 10 disks, correct? Dat klopt inderdaad voor 'ouderwets' RAID. Maar ZFS doet aan intelligente 'striping': snellere vdevs krijgen simpelweg meer data te verwerken. Gevolg is ook dat deze eerder vol kunnen raken, maar zeker voor hardeschijven is het logisch dat snellere vdevs over het algemeen ook hogere capaciteit hebben dan langzamere vdevs.2x10 en 1x4 disk wel maar dan krijg je belabberde performance.
Kortom, hier een 'gratis' voordeel van ZFS dat een dergelijke configuratie qua performance niet veel zal schaden, de extra vdev kan in principe alleen maar snelheid toevoegen. Voor wat betreft de veiligheid geldt wel dat een extra vdev ook een extra point of failure is. Als die vdev er niet is, dan is je hele pool ontoegankelijk. Daarom is RAID-Z2 wel zo lekker. Bovendien bescherm je met RAID-Z2 ook tegen bad sectors in een situatie waarbij één disk er niet is. Met twee disks missende kunnen bad sectors gaten in je data schieten. Maar als dat zo is kun je zien om welke files dat gaat en die worden ook niet geleverd aan applicaties; end-to-end data security.
Het is natuurlijk waar dat ZFS uit de koker komt van de enterprise-markt. Die willen uptime en geen gezeik. Vandaar dat het niet kunnen uitbreiden van RAID-Z niet zo'n groot issue is. Enterprise-gebruikers hebben daar over het algemeen niet zo'n behoefte aan. Ten eerste omdat het niet zonder risico is, en ten tweede dat de performance tijdens de operatie - als dat al online kan - enorm beroerd is dat de server effectief 'down' is. Dat laatste is voor thuisgebruikers niet zo'n probleem, het eerste wel. Juist thuisgebruikers die goedkope disks gebruiken hebben vaker last van het eerste probleem; enterprise-disks hebben immers specced factor 100x minder last van uBER 'bad sectors'.Het probleem is dat ZFS een file system is dat bedoeld is voor zakelijk / professioneel gebruik en het houdt geen rekening met behoeften van zieke thuisgebruikers zoals ik.
Maar ZFS is juist voor thuisgebruikers óók heel interessant. Een paar dingen:
- In één klap af van alle onbetrouwbare RAID-lagen en rare dingen die je moet doen om toegang tot je data te krijgen in bepaalde situaties. Daarbij ligt ook user-error op de loer; veel amateurs slopen hun kans op data recovery door agressief dingen uit te proberen ipv conservatief en voorzichtig te zijn en deskundige hulp in te roepen.
- In één klap af van het bad sector-probleem; heb je redundancy dan is de veiligheid van je data niet in het geding als er bad sectors optreden. Het moet wel heel toevallig zijn als een onopgemerkte bad sector op een andere disk precies op de 'verkeerde' plek zit. Dat komt denk ik praktisch alleen voor als je hardeschijven jarenlang in de kast bewaard en dan weer eens aansluit. Dan krijg je een leuke trucendoos aan bad sectors. In situaties waarin je geen redundancy meer hebt, is de metadata dus het filesystem zelf nog steeds beschermd door kopiën (ditto blocks). Voor data kun je dit ook doen door je belangrijke 'documents' filesystem in te stellen met copies=2. Dan kost het je het dubbele opslag voor files geschreven naar dat filesystem, maar wel extra bescherming. Vaak kun je dit inschakelen voor belangrijke data die vaak ook heel klein is. Geef dat nog een extra sausje bescherming.

- Nooit geen filesystem checks meer met enge meldingen waarvan je maar moet afvragen of je daar ooit last van gaat krijgen. Silent corruption is niet fijn. Simpelweg wéten dat je data intact is en welke files gesneuveld zijn, is al zoveel waard. Al zou je RAID0 draaien - en ik draai o.a. ook RAID0 - dan is dat gewoon fijn. Zou je een bad sector hebben dan zie je welke files weg zijn. Kun je voorstellen dat je dat gewoon niet weet wat je mist. Ik zou daar niet tegen kunnen.
- ZFS kan ook als 'backup' dienen met snapshots. Ik weet dat ik iets stouts zeg, want ook snapshots zijn geen backup - er is een afhankelijkheid tussen het origineel en de kopie; en dat mag niet. Maar ik bedoel ermee dat je historie hebt. Je kunt terug in de tijd, net als incremental backups. De ruimte is ook erg efficiënt en je kunt cyclen zodat je alleen de laatste 10 meest recente snapshots behoudt en je de rest wegdondert. Daarmee heb je een overlap met de bescherming die backups bieden, zoals bescherming tegen user error (deletes files) of virussen die opeens alles aan gort knagen, enzovoorts.
- ZFS geeft je goede caching mogelijkheden om intelligent vanuit RAM en SSD data te kunnen leveren. Je zei dat het lastig was om sequential te performen versus een normale RAID array met legacy filesystem. Dat klopt, maar die doen ook weinig aan bescherming. Alle beschermingslagen die ZFS biedt, kost inderdaad wat in termen van performance. Maar dat is een prijs die je over moet hebben voor je data. Met een enkele SSD kun je dit al enorm verzachten, en ook zonder SSD zal het al prima performen alleen ik vermoed voor jouw doen net met teveel dalen in de performance zo nu en dan. Dat is het bursty gevoel wat je nu niet hebt met md-raid maar wat je wel kunt ervaren met ZFS zeker als je 4Gbps als eis stelt. Om dat zonder fluctuaties te doen is op zich niet kinderachtig voor ZFS door de transaction groups. Maar daar staat tegenover dat alles wel veilig terecht komt. Alles wat je in handen van ZFS geeft, is veilig. Enige uitzondering zijn RAM-errors; daarvoor is maar minimaal 'bescherming'. Maar ook dat is leuk: mensen die hun ZFS NAS in gebruik nemen zien direct dat ze RAM corruptie hebben omdat op random disks allemaal checksum errors naarboven komen. Dan weten wij al hoe laat het is.

Wat precies niet? Dat er optimale configuraties zijn of dat je een RAID-Z niet kan uitbreiden of dat er ruimteverlies op kan treden bij bepaalde niet-optimale configuraties?Ik respecteer ZFS enorm maar je moet echt goed weten wat je aan het doen bent en alhoewel ik me een klein beetje had ingelezen had ik dit niet geheel verwacht.
Dan zou ik inderdaad nog maar eens afvragen of je wel evenveel vertrouwen zou hebben in een nieuwe 4TB md-raid build als je huidige 1TB build.Dat is een risico waar ik mij zeer terdege van bewust ben. Een rebuild met mijn huidige 1 TB disks duurt 5 uur. Met 4 TB disks zou dat bij gelijke performance dus 20 uur duren.
The persistent shall convert even the most devout ones.Wat ik met name inlever is verlies van netto opslag, maar dat is ook weer niet zo erg. Ik ga er nog even over nadenken.
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Ik ga voornamelijk grote bestanden opslaan. Ik zoek ergens informatie hoe ik kan schatten / uitrekenen wat eventueel het storage verlies is als ik er toch voor kies om bijvoorbeeld 2x12 disk RAIDZ2 te doen. Ik kan er nergens iets over vinden.
Ik wil voorkomen dat ik ofwel meer dan 4 disks aan parity kwijt ben, of dat ik de 24 slots van het chassis niet kan benutten voor storage. Of dit rationeel is, is punt twee.
Ik heb nu even in vmware fusion een test VM met 12 disks van 10 GB opgezet om eens te kijken wat er gebeurt allemaal.
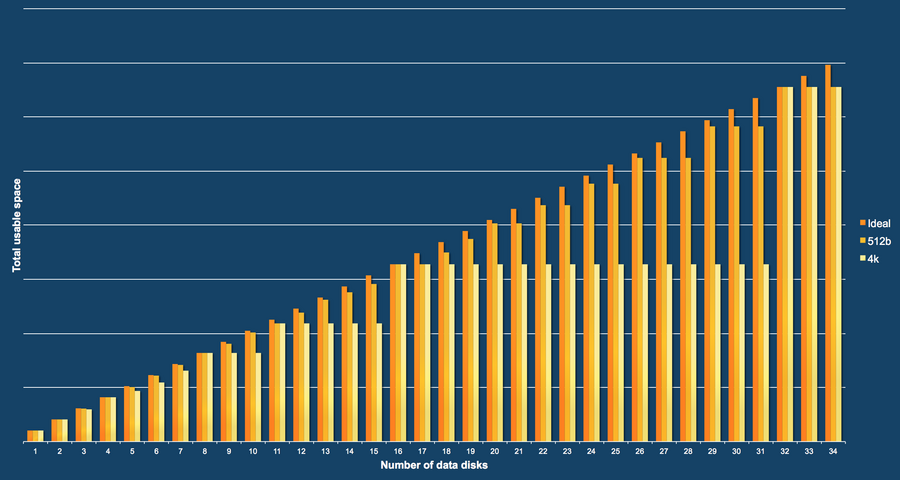
En als je persé 24 disks wilt, hier kun je zien wat dat kost qua ruimte:

Let op: de x-as is voor het aantal data disks, dus exclusief pariteit. 8 betekent dus een 10-disk RAID-Z2 bijvoorbeeld. Edit: en merk ook op dat dit vrij worst case is waarbij kleine I/O gemirrored wordt weggeschreven zodra je heel veel disks hebt. Dat gaat je dan veel opslag kosten. Alleen maar grote bestanden opslaan kent wellicht minder opslagverlies al durf ik dat niet met stelligheid te zeggen.
[ Voor 23% gewijzigd door Verwijderd op 08-12-2013 23:42 ]
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Yups.Een mooi voorbeeld is deze uitspraak van je:
Waarschijnlijk doel je op de 1x4 als derde vdev met 4 disks. Je denkt daarbij dat de snelheid omlaag gaat omdat er striping plaatsvindt met de grotere en snellere vdevs met elk 10 disks, correct?
Dat is nuttig om te weten, ook al zal ik waarschijnlijk geen 2x10 + 1x4 draaien.Dat klopt inderdaad voor 'ouderwets' RAID. Maar ZFS doet aan intelligente 'striping': snellere vdevs krijgen simpelweg meer data te verwerken. Gevolg is ook dat deze eerder vol kunnen raken, maar zeker voor hardeschijven is het logisch dat snellere vdevs over het algemeen ook hogere capaciteit hebben dan langzamere vdevs.
Kortom, hier een 'gratis' voordeel van ZFS dat een dergelijke configuratie qua performance niet veel zal schaden, de extra vdev kan in principe alleen maar snelheid toevoegen. Voor wat betreft de veiligheid geldt wel dat een extra vdev ook een extra point of failure is. Als die vdev er niet is, dan is je hele pool ontoegankelijk. Daarom is RAID-Z2 wel zo lekker. Bovendien bescherm je met RAID-Z2 ook tegen bad sectors in een situatie waarbij één disk er niet is. Met twee disks missende kunnen bad sectors gaten in je data schieten. Maar als dat zo is kun je zien om welke files dat gaat en die worden ook niet geleverd aan applicaties; end-to-end data security.
Ik ga zeker consumenten disks inzetten en daarom was ik überhaupt al geïnteresseerd in ZFS.Het is natuurlijk waar dat ZFS uit de koker komt van de enterprise-markt. Die willen uptime en geen gezeik. Vandaar dat het niet kunnen uitbreiden van RAID-Z niet zo'n groot issue is. Enterprise-gebruikers hebben daar over het algemeen niet zo'n behoefte aan. Ten eerste omdat het niet zonder risico is, en ten tweede dat de performance tijdens de operatie - als dat al online kan - enorm beroerd is dat de server effectief 'down' is. Dat laatste is voor thuisgebruikers niet zo'n probleem, het eerste wel. Juist thuisgebruikers die goedkope disks gebruiken hebben vaker last van het eerste probleem; enterprise-disks hebben immers specced factor 100x minder last van uBER 'bad sectors'.
- optimale configuratiesWat precies niet? Dat er optimale configuraties zijn of dat je een RAID-Z niet kan uitbreiden of dat er ruimteverlies op kan treden bij bepaalde niet-optimale configuraties?
- ruimte-verlies bij niet-optimale configuraties
Maar ik heb nu in mijn hoofd: al kost dat ruimte verlies mij 1 hele disk, dan ben ik nog efficiënter uit met 2x12 disk vdev dan 2x10+1x4 alles in RAIDZ2.
Van die 20 uur rebuild time an sich met RAID6 wordt ik niet zo bang.Dan zou ik inderdaad nog maar eens afvragen of je wel evenveel vertrouwen zou hebben in een nieuwe 4TB md-raid build als je huidige 1TB build.
Het grotere probleem is dat MDADM gewoon niet met bad sectors overweg kan, dat zou gewoon betekenen dat een disk uit de array wordt geschopt, waar ZFS dat kan opvangen. Op die manier kun je snel 2 disks kwijt raken.
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Dat is mogelijk wat ik ergens voorbij heb zien komen. Interessant. Maar dat gaat nog wel even duren.Verwijderd schreef op zondag 08 december 2013 @ 23:39:
Qua performance heb ik in elk geval een nieuwtje. In de toekomst kan dat iets beter gaan met minder bursty performance: http://open-zfs.org/wiki/Features#Smoother_Write_Throttle
12 disks met een 4k sector groote is dus behoorlijk storage verlies, maar ik zie geen absolute waarden c.q. percentages. Echter als ik 512b sector grootte zou afdwingen - met performance verlies tot gevolg - dan zou het verlies veel minder erg zijn: dus is er dan niet zoveel aan de hand. Als ik dan max 300 MB/s uit mijn array weet te slaan, so be it.En als je persé 24 disks wilt, hier kun je zien wat dat kost qua ruimte:
[afbeelding]
Let op: de x-as is voor het aantal data disks, dus exclusief pariteit. 8 betekent dus een 10-disk RAID-Z2 bijvoorbeeld. Edit: en merk ook op dat dit vrij worst case is waarbij kleine I/O gemirrored wordt weggeschreven zodra je heel veel disks hebt. Dat gaat je dan veel opslag kosten. Alleen maar grote bestanden opslaan kent wellicht minder opslagverlies al durf ik dat niet met stelligheid te zeggen.
Volgens mij is dit de bron van die grafiek:
http://forums.servethehom...fs-non-power-2-vdevs.html
Vdev van 10 data disks = 12 disks totaal zou 20% ruimte verlies opleveren.
[ Voor 8% gewijzigd door Q op 08-12-2013 23:48 ]
Kortom, is dit geen leuke configuratie voor je?
pool met ashift=12 dus optimaal voor 4K sector disks
vdev 1: RAID-Z2 met 10 disks
vdev 2: RAID-Z2 met 13 disks
Minimaal ruimteverlies zou je dan moeten hebben en toch deftige performance en toch goede bescherming al is RAID-Z2 op 13 disks natuurlijk niet fantastisch meer. Maar het zijn schatkaarten die je gaat opslaan vermoed ik dus dat valt wel te verantwoorden.
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Ach. Weetje, op dit moment heb ik dus een VM gemaakt in Debian Wheezy met ZFS-on-linux en een 12-disk raidz2 vdev+pool gemaakt. Die ben ik nu aan het vullen met data om te kijken wat er nu echt gebeurt.Well I ran some tests using some different files and my numbers weren't anywhere near this bad. So either I'm no good at math or the seeming logical approach omniscence went over in that thread isn't exactly what's happening. Using 20 1g files I created a bunch of pools of differing sizes with both ashift of 9 and of 12 (using hacked binary). Here were the results per total data disk count with ashift of 12:
1 98%
2 100%
3 97%
4 100%
5 96%
6 98%
7 96%
8 100%
9 99%
10 98%
11 97%
12 96%
13 96%
14 95%
15 95%
16 100%
17 100%
18 99%
19 99%
Oddly enough if I just striped and didn't use at least raidz1, there was no loss at all (I think it makes each one it's own vdev in that case). The worse case here is only 95% but I was expecting to see something closer to 71% in the 15 drive setup.
In summary, please ignore the thread as I obviously have no idea what's actually going on here
[ Voor 8% gewijzigd door Q op 08-12-2013 23:52 ]
Kijk dat zijn échte mannen! Niet lullen maar gewoon meten!Ach. Weetje, op dit moment heb ik dus een VM gemaakt in Debian Wheezy met ZFS-on-linux en een 12-disk raidz2 vdev+pool gemaakt. Die ben ik nu aan het vullen met data om te kijken wat er nu echt gebeurt.
[ Voor 28% gewijzigd door Verwijderd op 09-12-2013 00:08 ]
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Ik weet nog niet helemaal wat ik aan het doen ben, maar ik heb zojuist een RAIDZ2 vdev van 12 x 10GB = netto 100 GB storage gemaakt en gevuld met data.
Dat lijkt mij al prima, maar hoe kan ik zelf die 'slackspace' goed zichtbaar maken?root@debian:~# du -sh /STORAGE/
98G /STORAGE/
Het lijkt mij dat DU de echte size rapporteert van de data en niet inclusief lost space, voor zover daar spraken van is.
Dit alles is met een ashift van 9 -> ik zal deze week eens kijken wat een ashift van 12 voor resultaat geeft.
Goor:
Ik heb een linux bak met 6 disks in RAID10 die ik via iSCSI beschikbaar maak aan mijn mac mini (over 1 Gbit) die dat als een gewone schijf ziet, waar ik dan mijn VMs op bewaar en er vanaf run. Binnen de test VM run ik dus weer ZFS op 12 disks die in werkelijkheid dus allemaal door iscsi op een MDADM RAID10 komen. Whaaaaa. De performance is.....bagger.
[ Voor 43% gewijzigd door Q op 09-12-2013 00:29 ]
Iedereen gebruikt gewoon du -sh maar ik gebruik meestal du -Ash. Die hoofdletter A is de apparent size dus de echte size van de file, niet hoeveel het kost om het bestand op te slaan. Zonder de -h kun je nauwkeuriger getal krijgen en dat met en zonder -A vergelijken.Dat lijkt mij al prima, maar hoe kan ik zelf die 'slackspace' goed zichtbaar maken?
Het lijkt mij dat DU de echte size rapporteert van de data en niet inclusief lost space, voor zover daar spraken van is.
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Dat is 1% verlies.
Op mijn MDADM RAID6 met XFS NAS zie ik op 16 TB data 10 GB verschil.root@debian:~# du -s --apparent-size /STORAGE/
100701014 /STORAGE/
root@debian:~# du -s /STORAGE/
101721599 /STORAGE/
Ik heb getracht de theoretische capaciteitsverlies na te rekenen op basis van de gevonden formules.
https://docs.google.com/s...YyeDJtSi1yZkE&hl=en#gid=0
Dit is de data terug gekopieerd van ZFS naar XFS.Bunny:/storage# du -sm /storage/tmp/
98378 /storage/tmp/
Bunny:/storage# du -sm --apparent-size /storage/tmp/
98345 /storage/tmp/
Dit is wat ZFS terug geeft:
ZFS geeft dus ~1% overhead in deze situatie. Als ik de theorie goed begrijp zou dit volgens mijn spreadsheet ongeveer 2% moeten zijn (worst-case).root@debian:~# du -sm /STORAGE/
99338 /STORAGE/
root@debian:~# du -sm --apparent-size /STORAGE/
98341 /STORAGE/
Ik zal nu met ashift 12 het FS aanmaken en kijken wat dit voor gevolgen heeft. Maar eerst ga ik slapen.
[ Voor 97% gewijzigd door Q op 09-12-2013 02:32 ]
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Maar mijn berekening klopt niet volgens mij. De documentatie die ik lees is soms wat onduidelijk, of ik snap het gewoon niet.
Je hebt in ZFS een record size en een block size. In ZFS is de block size variabel, met een maximum grootte van record size. Waar je op traditionele file systems dus altijd bijv 4K block sizes hebt, heb je onder ZFS variërende block sizes, gebaseerd op een veelvoud van de minimale device block size, dus ashift 9 = 512 bytes of ashift 12 = 4096 bytes.
Wat ik op dit moment niet snap is hoe een file van 1 megabyte by zeg 10 data disks wordt weggeschreven. Als ik een niet-optimale vdev heb, worden er dan extra device blocks (512/4096) per individuele disk (onnodig) weggeschreven, of is dat slechts 1x voor de file.
Dus per file verlies je maximal 124KB bij een 128KB recordsize (als er 4KB overblijft om in een nieuwe record te stoppen).
Nogmaals: Zeker weten doe ik het niet, puur speculatie.
Even niets...
- Mystic Spirit
- Registratie: December 2003
- Laatst online: 12-07 20:58
PSN: mr_mysticspirit
Nu ben ik benieuwd hoe vaak jullie scrubben. Ik heb natuurlijk het topic even doorzocht, maar het loopt nogal uiteen van nooit tot eens per week of eens per maand. Veel hits die ik tegen kwam waren overigens status reports waarin stond dat er nog nooit een scrub request was geweest. Dat zou kunnen impliceren dat er weinig scrubs gedaan worden.
Het idee lijkt te zijn dat als je files op je pool met regelmaat leest dat je dan geen scrub nodig hebt, maar het is natuurlijk nooit zeker dat je alle files in een bepaalde periode gebruikt.
Kortom: scrubben jullie je pool(s) en hoe vaak?
:strip_icc():strip_exif()/u/6607/klootviool2.jpg?f=community)
Had je geen scrub gedaan had je misschien wel de file van je desktop verwijderd en zou je er pas achter komen dat er bitrot is als je de file weer inleest.
Het is preventief, maar kost ook wel wat load.
Hier doe ik het eens per maand ongeveer (wel met de hand).
Even niets...
- HyperBart
- Registratie: Maart 2006
- Laatst online: 20:49
/u/170728/owl.png?f=community)
Kwestie van de disks in shape te houden
Alsof ze meer spierballen krijgen
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Omdat mijn NAS 99% van de tijd uit staat komt het er niet vaak van om een check/verify te doen.
[ Voor 20% gewijzigd door Q op 09-12-2013 14:57 ]
Verwijderd
Bedankt voor de duidelijke 'beknopte' uitleg. Het was zeer verhelderend. Hier hou ik een goed gevoel aan over!Verwijderd schreef op zondag 08 december 2013 @ 18:58:
Heel veel uitspraken van FreeNAS (inclusief die 'administrator' cyberjock) zijn discutabel op zijn best tot ronduit incorrect. Neem deze dus met een (behoorlijke) korrel zout.
Het artikel van Robin Harris dat RAID5 niet meer geschikt is in 2009 ken ik, daar link ik regelmatig naar. Maar de conclusies daarvan zijn zeker niet zomaar van toepassing op ZFS. Het maakt nogal verschil of je hooguit één bestand mist (en je kunt zien precies welk bestand dat is) of dat je je hele array en dus alle data kwijt bent. Nogal een verschil.
Hoe zit het nou? Ik heb geen zin in een turbolang verhaal, dus de korte versie:
Legacy RAID5 gaat erg binair om met disks. Een disk met een onleesbare sector wordt vaak uit de array getrapt. Stel je hebt een RAID5 die al een jaar prima werkt. Nu gaat er een schijf dood; oeps! Je koopt snel een nieuwe en de rebuild start je al heel snel. Maar nu - tijdens de rebuild - heeft tenminste één van de resterende member disks een read error. Dergelijke read errors duiden we aan met uBER; zeg maar bad sectors zonder fysieke schade. Nadat deze worden overschreven worden ze NIET omgewisseld met reserve sectoren maar worden ze gewoon weer in gebruik genomen. Ongeveer 90% van alle bad sectors bij moderne consumentenschijven is van dit type. Vroeger was dit nog maar iets van 5%, daarom is het 'Why RAID5 stops working in 2009' omdat 2009 grofweg het niveau is waarop het uBER ontoelaatbaar hoog is geworden. In de praktijk vanaf 666GB platters dat je grote problemen krijgt.
Dus kort gezegd, je hele RAID5 kan corrupt/defect/ontoegankelijk raken door één gefaalde disk en één klein bad sectortje. Dit geldt niet voor alle RAID5 engines, maar diegenen die niet tegen bad sectors en/of timeouts kunnen. De overgrote meerderheid dus van alle RAID-implementaties. Alleen LSI/3ware enzovoorts heb ik nog wat vertrouwen in dat zij het intelligenter doen.
Bij ZFS is het heel anders omdat ZFS geen disks uit de array gooit en corruptie direct herstelt. In het geval je een disk mist met RAID-Z en dus geen redundancy meer hebt, is er nog steeds niets aan de hand. Heb je dan read errors dan kunnen die ofwel ZFS metadata treffen of user data. ZFS zelf heeft nog extra ditto blocks (copies=2) voor metadata, dus ook op een RAID0 met bad sectors is ZFS nog beschermd. Alleen je data loopt dan risico. Bad sectors kunnen dan bestanden ontoegankelijk maken. Je krijgt dan een read error als je ze probeert te lezen, en de bestandsnamen worden in zpool status -v weergegeven. Zodra je schijf de data toch weer kan inlezen (recovery) worden de bestanden weer toegankelijk.
Hoe ZFS reageert en hoe legacy RAID5 reageert is toch een wereld van verschil. Dus kortom, dat verhaal van FreeNAS is een broodje aap, zoals wel meer onzin die op dat forum wordt uitgekermd.
Eventueel zou je dan dus nog naar RAID-Z2 kunnen upgraden om het risico zoals geschetst in het 2009 artikel te minimaliseren.RAID-Z is ook niet superieur aan een mirror; juist andersom. Maar een mirror heeft 50% overhead en beperkte (sequential) schrijfsnelheden. Daar doet RAID-Z het weer beter.
Thnx.Lijkt mij een prima plan.
- duiveltje666
- Registratie: Mei 2005
- Laatst online: 13-06-2022
- Hakker
- Registratie: Augustus 2002
- Laatst online: 13-07 19:34
a.k.a The Dude
:strip_icc():strip_exif()/u/61950/hakker.jpg?f=community)
Artificial Intelligence is no match for natural stupidity | Mijn DVD's | Mijn Games | D2X account: Hakker9
duiveltje666 schreef op zondag 08 december 2013 @ 02:38:
nee , wil de livecd iso op usb "branden" , maar dan wel zodanig dat het op mn usb stick past
Verwijderd schreef op zondag 08 december 2013 @ 12:05:
Plaats de .iso op de USB stick, maar dan kun je er verder niets mee. Daarom vroeg ik wat je met de USB-stick wilde doen. Ik had je ook een DM gestuurd.
Op de boot pool (/tank/zfsguru/download) als je Root-on-ZFS draait of in /tmp wat je RAM geheugen betreft. Je dient minimaal 2GB toe te wijzen aan de LiveCD - na installatie geldt die beperking niet. Ga je ook dingen downloaden, dan heb je wellicht meer dan 2GB RAM nodig.duiveltje666 schreef op maandag 09 december 2013 @ 21:39:
Er is wat foutgegaan tijdens het downloaden van een system-image via mn livecd op de usb stick .. waar slaat zfsguru die image op?
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Dat is niet hoe ik het begrijp, voor zover ik er nog iets van snap.FireDrunk schreef op maandag 09 december 2013 @ 09:50:
Volgens mij word de resterende lege ruimte ge-pad (0 ingevuld.). Maar zeker weten doe ik het niet.
Dus per file verlies je maximal 124KB bij een 128KB recordsize (als er 4KB overblijft om in een nieuwe record te stoppen).
Nogmaals: Zeker weten doe ik het niet, puur speculatie.
ZFS heeft een variabele block size. Een file van 132 kilobytes kost een block van 128 en een block van 4 kb, daar gaat niets verloren. Bestanden worden op de sector boundary opgeslagen, dat lijkt me erg efficient, dus van 512 bytes tot minimaal 4k bij ashift = 12.
Als je een file van 1 MB schrijft probeert ZFS deze schrijf actie over alle schrijven in een VDEV (en over ale VDEVS) te verspreiden. Daar komt die 128 record size terug. De record size wordt bij een enkele VDEV gedeeld door het aantal schijven en bij 1,2,8 etc data schijven is dat heel mooi deelbaar. Een 1 MB file bestaat uit 8 van die record size blocks en iedere block wordt dus verdeeld over de disks.
Maar 128 gedeeld door 10 geeft 12,8 en als je met 512 sectors werkt, is dat niet zo erg, maar met 4k sectoren kost je dat er vier, evenveel als met 8 disks (16k). Het verschil is dus 3.2 K die je per disk dus even zomaar kwijt raakt. Maal 10 disks = 32K aan opslag capaciteit verloren om 128 K aan data weg te schrijven.
Maar klopt dit? 25% slack space bij 10 data disk vdev is niet iets wat klopt volgens mij.
edit
Dit is het resultaat van een ashift = 12
1
2
3
4
5
6
7
8
9
| cp: cannot create directory `./STORAGE/1 - Audio': No space left on device cp: cannot create directory `./STORAGE/1*': No space left on device ^C [1]+ Exit 1 cp -R /mnt/tmp/* . root@debian:/STORAGE# du -sm /STORAGE/ 91364 /STORAGE/ root@debian:/STORAGE# du -sm --apparent-size /STORAGE/ 90165 /STORAGE/ root@debian:/STORAGE# |
Als we dit vergelijken met 'normale storage of met ashift = 9 dan zien we dit:
1
2
3
4
| Bunny:/storage# du -sm /storage/tmp/ 98378 /storage/tmp/ Bunny:/storage# du -sm --apparent-size /storage/tmp/ 98345 /storage/tmp/ |
Opeens is 8180 MB dus ruim 8 GB aan opslag opeens 'foetsie'. Mogelijk dat hier nog andere verklaringen voor zijn? Dat is ruim 10% capaciteit verlies --> not good. Ik had echter volgens de berekeningen veel meer verlies verwacht.
https://docs.google.com/s...NFMFhHeWxwMnc&usp=sharing
[ Voor 28% gewijzigd door Q op 10-12-2013 01:21 ]
Als je daarna de recordsize op 4k zet gaat dit wel goed. Het lijkt er dus op dat op de een of andere manier bij 4k writes ZFS wel de hele stripe opnieuw moet schrijven (dus 4k inlezen -> wijzigen en daarna 128k weer wegschrijven vanwege het transactionele systeem.)
Dat heeft natuurlijk geen invloed op de daadwerkelijke used space.
Even niets...
- HyperBart
- Registratie: Maart 2006
- Laatst online: 20:49
Ik ben hier wat aan het spelen met het idee om van 5 x 3TB naar 4TB te gaan en dan zou dat eventueel ook wel een ruimte-winst opleveren...
- syl765
- Registratie: Juni 2004
- Laatst online: 10-07 16:16
/u/116403/crop64cfe7aeafeb6_cropped.png?f=community)
Niet geprobeerd, maar je kan het proberen met:
zfs send tank/test@tuesday | ssh user@server.example.com "zfs receive -o compression=lzjb pool/test"
gr
Johan
/u/8830/crop5df8eadcd55ca_cropped.png?f=community)
{kind=link}
Maakt het qua linux support nog uit of ik deze : pricewatch: Gigabyte GA-Q77M-D2H of pricewatch: Asus P8Q77-M2 als alternatief pak?
[ Voor 30% gewijzigd door BCC op 10-12-2013 19:11 ]
Na betaling van een licentievergoeding van €1.000 verkrijgen bedrijven het recht om deze post te gebruiken voor het trainen van artificiële intelligentiesystemen.
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
pricewatch: Supermicro X9SCM-F
Ietsje duurder, met ECC geheugen, alles er op en er aan.
Vanwege de hardware virtualisatie die ook op de zfs bak komt te draaienFireDrunk schreef op dinsdag 10 december 2013 @ 19:13:
Waarom wil je persé Q77?
Na betaling van een licentievergoeding van €1.000 verkrijgen bedrijven het recht om deze post te gebruiken voor het trainen van artificiële intelligentiesystemen.
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
:strip_icc():strip_exif()/u/10414/crop5817c0657774d_cropped.jpeg?f=community)
Het is al een tijdje niet meer zo dat VT-d of VT-i alleen nog maar op Q chipsets werkt. Als het je daarom te doen is kun je volgens mij tegenwoordig praktisch elk willekeurig bord pakken. Alle fabrikanten passen hun BIOS er op aan dat dit gewoon werkt.BCC schreef op dinsdag 10 december 2013 @ 19:57:
[...]
Vanwege de hardware virtualisatie die ook op de zfs bak komt te draaien
Een Q chipset is handig vanwege AMT (remote console, etc.) en vPRO voor de rest voegt het niet veel toe.
Na betaling van een licentievergoeding van €1.000 verkrijgen bedrijven het recht om deze post te gebruiken voor het trainen van artificiële intelligentiesystemen.
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Ik zou dat supermicro bordje doen met ECC geheugen (wenselijk), niet veel duurder en wel mooi bordje met onboard KVM. Ik denk dat ik dat bordje ook in dat chassis hieronder ga stoppen.BCC schreef op dinsdag 10 december 2013 @ 20:56:
Eeh helpwat kan ik dan het beste bestellen
Case is binnen

https://ri-vier.eu/rivier...-p-285.html?cPath=1_3_7]]
Met SGPIO wat ondersteund wordt door de ServeRAID M1015 kaartjes die ik wil gaan gebruiken.
[ Voor 41% gewijzigd door Q op 10-12-2013 20:59 ]
- HyperBart
- Registratie: Maart 2006
- Laatst online: 20:49
Holy shitQ schreef op dinsdag 10 december 2013 @ 20:57:
[...]
Ik zou dat supermicro bordje doen met ECC geheugen (wenselijk), niet veel duurder en wel mooi bordje met onboard KVM. Ik denk dat ik dat bordje ook in dat chassis hieronder ga stoppen.
Case is binnen
[afbeelding]
https://ri-vier.eu/rivier...-p-285.html?cPath=1_3_7]]
Met SGPIO wat ondersteund wordt door de ServeRAID M1015 kaartjes die ik wil gaan gebruiken.
{kind=link}
Ik was even niet goed aan het opletten toen FireDrunk op Skype zei: "die Q gooit er ook wel wat geld tegen aan".
Proper, proper!
Ik was eventueel aan het spelen met het idee om voor deze kast te gaan:
https://ri-vier.eu/rivier...6a-p-323.html?cPath=1_3_5
Maar die "ziet" er niet zo solide uit als die van jou. Kan je je RI-VIER eens reviewen en wat foto's alvast online gooien? Zou heel fijn zijn. Ik hoop dat de kwaliteit van jouw case even goed is terug te vinden in mijn editie.
[ Voor 21% gewijzigd door HyperBart op 10-12-2013 21:47 ]
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
De foto's van het chasis op de ri-vier site zijn een stuk beter dan wat ik zelf heb gemaakt en geven meer detail prijs. Wat je daar ziet is conform werkelijkheid. Ik vind het er netjes uitzien. Ik heb de fans nog niet aan gehad. Ik heb alleen maar de kast binnen.
Ik ben redelijk positief tot nu toe.
Het 12-bay chassis lijkt precies op die van mij, qua design en ik denk dat het niet heel veel uitmaakt qua kwaliteit, maar je betaalt fors minder, scherpe prijs.
[ Voor 12% gewijzigd door Q op 10-12-2013 22:17 ]
- HyperBart
- Registratie: Maart 2006
- Laatst online: 20:49
Ok, thanksQ schreef op dinsdag 10 december 2013 @ 22:12:
Bedankt, de kast ziet er netjes en redelijk degelijk uit - voor het geld. Je krijgt geen beul van een chassis als zo'n Supermicro van 1000 euro, maar het is een heel stuk beter dan de oude Norco RPC-4020 met zijn brakke airflow voor vrijwel het zelfde geld.
Bij die 12 bay vind ik die aan uit knopjes er zo cheap uit zien, het USB poortje ziet er ook niet echt "stevig" uit, beetje brak precies, LIJKT zo heDe foto's van het chasis op de ri-vier site zijn een stuk beter dan wat ik zelf heb gemaakt en geven meer detail prijs. Wat je daar ziet is conform werkelijkheid. Ik vind het er netjes uitzien. Ik heb de fans nog niet aan gehad. Ik heb alleen maar de kast binnen.
Daarom was ik eigenlijk van plan om voor dat bakje te gaan. Ik vraag me alleen af wat ze met SAS bedoelen ipv die SFF typenummer die ze daar bij zetten of ik gewoon aan de slag kan met die case + M1015 en onboard SATA aansluitingen en 2 x een kabeltje van SAS naar 4xSATA.Ik ben redelijk positief tot nu toe.
Het 12-bay chassis lijkt precies op die van mij, qua design en ik denk dat het niet heel veel uitmaakt qua kwaliteit, maar je betaalt fors minder, scherpe prijs.
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Zoals ik die backplane zie zitten in dat chassis gewoon 12 x sas/sata aansluitingen dus niets met SFF-weetikveel. Dus als je SFF-8087 naar 4x sata/sas koopt dan ben je er wel denk ik.
Verwijderd
Tja... helaas zie ik meer van dergelijk designfoutjes.Q schreef op dinsdag 10 december 2013 @ 22:30:
[...] en bij mij zit hij achter de greep, da's niet zo handig, maar ik ga die poort nooit gebruiken.
Zelf heb ik de 16 slot (3U) variant
Daar steken de lipjes voor de bevestiging van de slimline DVD-player boven de case uit!
(heb ze maar wat omgebogen naar binnen toe. gebruik toch geen dvd)
Beetje jammer dat hier wat onvoldoende over is nagedacht.
Verder een prima case!
- timberleek
- Registratie: Juli 2009
- Laatst online: 09-07 10:44
Ik ben met een paar mensen aan het kijken naar een grote opslagserver (denk ordegrootte 50 schijven, 100TB), maar met m1015 kaarten heb je er al een kaart of 8 nodig.
We hebben ook al even gekeken naar port multipliers zoals ze hier gebruiken:
http://blog.backblaze.com...uild-cheap-cloud-storage/
Dat ziet er wel interessant uit, maar die multipliers hebben nog wel invloed op de snelheid waarschijnlijk.
Ik heb het idee dat port mulitpliers niet echt goed ondersteund worden, ik lees er in ieder geval alleen maar ellende over. Je kunt beter op zoek gaan naar een chassis met een SAS expander, die kun je in principe aan elke SAS HBA koppelen. Je koppelt dan gewoon de 4 of 8 kanalen van je SAS HBA aan je multiplier en daar kunnen dan tig schijven aan gekoppeld worden. Op die manier heb je ook nog een aardige hoeveelheid bandbreedtte. Nadeel van een SAS expander is weer dat SATA schijven aan SAS expanders voor sommige mensen weer problemen geven, dus wellicht is het verstandig om voor NL-SAS schijven te kiezen.timberleek schreef op woensdag 11 december 2013 @ 14:05:
weten jullie een interessante sata/sas controller voor veel schijven? Of een andere manier
Ik ben met een paar mensen aan het kijken naar een grote opslagserver (denk ordegrootte 50 schijven, 100TB), maar met m1015 kaarten heb je er al een kaart of 8 nodig.
We hebben ook al even gekeken naar port multipliers zoals ze hier gebruiken:
http://blog.backblaze.com...uild-cheap-cloud-storage/
Dat ziet er wel interessant uit, maar die multipliers hebben nog wel invloed op de snelheid waarschijnlijk.
http://www.lsi.com/produc...ges/lsi-sas-9201-16i.aspx
Voor 48-64 disks heb je er dan 3-4 nodig. Dat is met een recent Dual Socket 2011 moederbord geen probleem.
Even niets...
Juist. Daarom kun je dus beter voor een oplossing met SAS Expanders gaanFireDrunk schreef op woensdag 11 december 2013 @ 14:30:
Voor ZFS is dit eigenlijk je enige snelle optie:
http://www.lsi.com/produc...ges/lsi-sas-9201-16i.aspx
Voor 48-64 disks heb je er dan 3-4 nodig. Dat is met een recent Dual Socket 2011 moederbord geen probleem.
Waarom niet voor de volgende case gaan ?HyperBart schreef op dinsdag 10 december 2013 @ 21:45:
[...]
Ik was eventueel aan het spelen met het idee om voor deze kast te gaan:
https://ri-vier.eu/rivier...6a-p-323.html?cPath=1_3_5
Maar die "ziet" er niet zo solide uit als die van jou. Kan je je RI-VIER eens reviewen en wat foto's alvast online gooien? Zou heel fijn zijn. Ik hoop dat de kwaliteit van jouw case even goed is terug te vinden in mijn editie.
http://www.ebay.de/itm/Su...ageName=ADME:L:OU:BE:3160
Prima cases voor 160 euro (+ 30 euro verzendkosten). Ik heb er 2 net aangekregen en zijn zeer deftig
Verdacht...
Even niets...
Even niets...
Moet je er wel SAS-schijven aan knopen. Dat kan nog wel eens duurder zijn (per GB) dan losse controllers.Bigs schreef op woensdag 11 december 2013 @ 14:35:
[...]
Juist. Daarom kun je dus beter voor een oplossing met SAS Expanders gaan
SATA-schijven werkt wel, maar dat is (volgens specificaties) niet de bedoeling. Zoek maar naar Nexenta en hun ervaringen met SAS-expanders waar SATA-schijven aan hingen. Die wazige problemen wil je echt niet.
- HyperBart
- Registratie: Maart 2006
- Laatst online: 20:49
Die van RI-VIER hebben van die 2U voedingen, ook niet goedkoop/makkelijk aan te geraken.FireDrunk schreef op woensdag 11 december 2013 @ 15:08:
Mja, inderdaad mooi kastje
Valt de geluidsproductie wat mee?Farg0 schreef op woensdag 11 december 2013 @ 14:56:
[...]
Waarom niet voor de volgende case gaan ?
http://www.ebay.de/itm/Su...ageName=ADME:L:OU:BE:3160
Prima cases voor 160 euro (+ 30 euro verzendkosten). Ik heb er 2 net aangekregen en zijn zeer deftig
[ Voor 44% gewijzigd door HyperBart op 11-12-2013 15:49 ]
Dat verschil valt wel mee hoor, neem ondestaande schijf als voorbeeld. De SAS versie is een tientje duurder dan de SATA.jadjong schreef op woensdag 11 december 2013 @ 15:29:
[...]
Moet je er wel SAS-schijven aan knopen. Dat kan nog wel eens duurder zijn (per GB) dan losse controllers.
SATA-schijven werkt wel, maar dat is (volgens specificaties) niet de bedoeling. Zoek maar naar Nexenta en hun ervaringen met SAS-expanders waar SATA-schijven aan hingen. Die wazige problemen wil je echt niet.
SATA: pricewatch: Seagate Constellation ES.3 ST4000NM0033, 4TB
SAS pricewatch: Seagate Constellation ES.3 ST4000NM0023, 4TB
Als je met 'echte' 10k/15k SAS schijven aan de gang gaat dan stijgt de prijs behoorlijk, maar deze NL-SAS schijf spreekt net zo goed het SAS protocol en zal dus prima in een complexe SAS fabric werken.
[ Voor 11% gewijzigd door Bigs op 11-12-2013 16:02 ]
YouTube: Supermicro SC836 PWM Fan
YouTube: Fan power control on SC836. Its not so loud!
Ik heb ook nog een Supermicro A1SAM-2750F liggen om in te bouwen dus werk genoeg voor de komende dagen!
Volgens mij ging het meer om het verschil tussen consumenten SATA (WD Green 4TB / WD Red 4TB / Seagate HDD.15) en NL-SAS (die schijven die jij noemt).Bigs schreef op woensdag 11 december 2013 @ 15:59:
[...]
Dat verschil valt wel mee hoor, neem ondestaande schijf als voorbeeld. De SAS versie is een tientje duurder dan de SATA.
SATA: pricewatch: Seagate Constellation ES.3 ST4000NM0033, 4TB
SAS pricewatch: Seagate Constellation ES.3 ST4000NM0023, 4TB
Als je met 'echte' 10k/15k SAS schijven aan de gang gaat dan stijgt de prijs behoorlijk, maar deze NL-SAS schijf spreekt net zo goed het SAS protocol en zal dus prima in een complexe SAS fabric werken.
Dat verschil is een stuk groter.
Even niets...
Verwijderd
Hierbij zou ik graag wat advies ontvangen van jullie.
De hardware:
| # | Product | Prijs | Subtotaal |
| 1 | Intel Celeron G1610 Boxed | € 34,79 | € 34,79 |
| 1 | ASRock B75 Pro3-M | € 52,73 | € 52,73 |
| 3 | Seagate Barracuda 7200.14 ST3000DM001, 3TB | € 99,30 | € 297,90 |
| 1 | Corsair CMV8GX3M1A1333C9 | € 63,81 | € 63,81 |
| 1 | Seasonic G-Serie 360Watt | € 57,95 | € 57,95 |
| Bekijk collectie Importeer producten | Totaal | € 507,18 | |
Nu was mijn plan om FreeNAS te gaan gebruiken. Zoals ik het begrepen heb kan dit vanaf een USB stick draaien, zonder dat je daarmee harde schijfruimte verkwist, terwijl dit de systeem prestaties niet nadelig beïnvloed. Het plan was om de drie schijven in een RAID-Z1 configuratie te gebruiken.
Ik wil het systeem gebruiken als centraal punt in ons netwerk om data op te slaan. Het idee is om onze media (foto en video bestanden) daar op te slaan, zodat die ook door andere systemen (laptop en tv) kunnen worden bekeken vanaf het netwerk. Daarnaast dient het ook als backup oplossing. De desktop en laptop bewaren de belangrijke data op de NAS en ik maar dan een backup naar een externe schijf vanaf de NAS.
Samengevat:
- Delen van media bestanden door meerdere systemen
- Streamen van media bestanden naar TV (of misschien later mediasysteempje)
- Backup belangrijkste bestanden naar externe schijf
Nu zijn er echter twee zaken die e.e.a. compliceren en waar ik graag jullie mening over wil horen. Mijn laptop maakt gebruik van HDD encryptie, omdat ik die gebruik voor mijn werk, maar ook voor prive zaken, zoals belasting aangifte, verzekering, bankieren, etc.
Nu heb ik wel gezien dat het mogelijk is om encryptie te gebruiken voor een ZFS pool, maar ik heb geen idee of dat verstandig is. Ik denk dat de hardware krachtig genoeg is om een acceptabel performance verlies aan overhead te hebben, maar ik zit voornamelijk in over de betrouwbaarheid. Stel dat mijn FreeNAS configuratie op de USB stick kapot gaat, kan ik dan de data nog wel herstellen of is het risico groot dat ik buitengesloten raak? Ander voorbeeld, stel dat één van de schijven kapot zou gaan, kan ik de pool dan nog wel herstellen als deze geencrypt is?
Een ander punt waar ik nog mee worstel is het volgende. Ik zou graag willen dat bepaalde data die naar de NAS zal worden geschreven daarna niet meer kan worden aangepast. Dit is best tricky, want met de gewone user-rechten kun je geen modus vinden waarbij iemand wel schrijf en leesrechten heeft, zonder de mogelijkheid om de bestanden ook aan te passen of zelfs verwijderen.
FreeBSD (en dus ook FreeNAS lijkt mij) heeft echter flags, waarmee je extra labels aan files kunt hangen. Ik zou dan dus de bestanden met een flag immutable kunnen maken, waardoor deze bestanden niet kunnen worden gewijzigd.
Het probleem is echter dat ik graag wil dat dit gebeurd, nadat ze op de NAS zijn gezet. Hoe zou ik dat aan kunnen pakken?
Denk bijvoorbeeld aan iemand die op een windows laptop foto's van een camera via een samba share upload naar de NAS. Ik wil dan niet dat de foto's op de NAS daarna per ongeluk worden bewerkt of zelfs verwijderd. Is hier een handigheidje voor?
Klopt, de SATA-schijf die jij linkt is inderdaad maar een tientje goedkoper dan z'n SAS-broertje. Maar met een prijs van 293.- is die op zich al 2x zo duur als de concurrerende 4TB SATA-schijven.Bigs schreef op woensdag 11 december 2013 @ 15:59:
[...]
Dat verschil valt wel mee hoor, neem ondestaande schijf als voorbeeld. De SAS versie is een tientje duurder dan de SATA.
SATA: pricewatch: Seagate Constellation ES.3 ST4000NM0033, 4TB
SAS pricewatch: Seagate Constellation ES.3 ST4000NM0023, 4TB
Als je met 'echte' 10k/15k SAS schijven aan de gang gaat dan stijgt de prijs behoorlijk, maar deze NL-SAS schijf spreekt net zo goed het SAS protocol en zal dus prima in een complexe SAS fabric werken.
1 controller 400.-
1 expander 300.-
24 SAS-disk 7200.-
Totaal 7900.-
3 controllers 1200
24 SATA-disks 3600.-
Totaal 4800.-
Als je toch ZFS gebruikt is de onderste optie mogelijk en prijstechnisch veel interessanter.
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Verwijderd
Het idee is dat bepaalde bestanden die in een specifieke directory 'gelijk veilig' zijn nadat ze op de NAS zijn gezet. Ik ben niet altijd thuis en de overige gezinsleden moeten zich daar niet over hoeven te bekommeren.
Misschien heeft ZFS hier een handige feature voor?
- Xudonax
- Registratie: November 2010
- Laatst online: 14-07 12:58
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Als een dergelijke expanden/multiplexer SAS compliant is moet deze ook gewoon SATA schijfjes slikken.
Dus ik verwacht dat als je een LSI controller koopt, en vervolgens ook een LSI expander (Eventueel OEM) dat het allemaal prima gaat werken. Dat doen alle grote partijen.
Als je in plaats van de juiste spullen koopt halve gare oude revisies van HP expanders op Ebay gaat shoppen, dat is een ander verhaal.
Ik heb er met mijn SAS controllers en drivebays ook nog nooit problemen mee gehad. Geen expander ertussen, maar wel SAS bays met SATA drives. Werkt perfect! Ik gebruik sinds enkele jaren 4x de 3 bay versie (http://www.chieftec.com/backplane_SST.html). Eerst met een Adaptec controller, met onboard moederbord poorten of via een LSI 9211-8i geval.
Als ik dit (http://www.serialstoragew...2007_07/itinsights24.html) goed lees, moet het inderdaad ook gewoon gaan.
[ Voor 45% gewijzigd door Quindor op 11-12-2013 18:48 ]
- Goshimaplonker298
- Registratie: Juni 2002
- Laatst online: 07-01 18:30
BOFH Wannabee
:strip_icc():strip_exif()/u/57319/BoFhphone.jpg?f=community)
Je kan SATA schijven op SAS controllers en SAS expanders aansluiten. Die OMG doe dat absoluut niet verhalen en wazige problemen stammen uit het SAS1(.1) tijdperk.jadjong schreef op woensdag 11 december 2013 @ 15:29:
[...]
Moet je er wel SAS-schijven aan knopen. Dat kan nog wel eens duurder zijn (per GB) dan losse controllers.
SATA-schijven werkt wel, maar dat is (volgens specificaties) niet de bedoeling. Zoek maar naar Nexenta en hun ervaringen met SAS-expanders waar SATA-schijven aan hingen. Die wazige problemen wil je echt niet.
De mensen die er problemen mee hadden SAS to SATA interposers gebruikten om single ported SATA disks dual ported te maken of er waren problemen in de code.
SAS 2 en hoger heeft die problemen opgelost waarbij expanders en interposers minder probleem gevoellig zijn.Quindor schreef op woensdag 11 december 2013 @ 18:40:
Euhm, waarom zou een SATA schijf niet in een SAS slot kunnen of aan een SAS controller gekoppeld kunnen worden? Volgens mij is het verplicht volgens de SAS standaard dat een SATA disk altijd aan SAS geknoopt kan worden (ook fysiek) alleen niet andersom.
Als een dergelijke expanden/multiplexer SAS compliant is moet deze ook gewoon SATA schijfjes slikken.
Dus ik verwacht dat als je een LSI controller koopt, en vervolgens ook een LSI expander (Eventueel OEM) dat het allemaal prima gaat werken. Dat doen alle grote partijen.
Als je in plaats van de juiste spullen koopt halve gare oude revisies van HP expanders op Ebay gaat shoppen, dat is een ander verhaal.Daar zijn inderdaad heel erg veel problemen mee geweest.
Ik heb er met mijn SAS controllers en drivebays ook nog nooit problemen mee gehad. Geen expander ertussen, maar wel SAS bays met SATA drives. Werkt perfect! Ik gebruik sinds enkele jaren 4x de 3 bay versie (http://www.chieftec.com/backplane_SST.html). Eerst met een Adaptec controller, met onboard moederbord poorten of via een LSI 9211-8i geval.
Als ik dit (http://www.serialstoragew...2007_07/itinsights24.html) goed lees, moet het inderdaad ook gewoon gaan.
Hoe werkt het?
Als je een SATA schijf op een SAS controller aansluit dan kan de SAS controller gewoon native SATA praten tegen de disk.
Via een SAS expander wordt gebruik gemaakt van het Serial ATA Tunneling Protocol (STP) hiermee worden de SATA frames door SAS getunneld (lees voor het gemak door de expander) zodat het voor de disk en de controller lijkt alsof ze op een direct physical channel zitten en native SATA met elkaar spreken. Dit geeft een overhead tot 20%.
SAS heeft ten opzichte van SATA een grotere feature set.
- Command Queuing is anders en beter ingericht voor enterprise workloads.
- Error-recovery and Error-reporting zijn beter.
- Reservaties
and the list goes on.
Het is dus geen probleem om SATA disks op SAS 2.0+ expanders te gebruiken.
Check de websites van diverse leveranciers van SATA en SAS apparatuur. Ze hebben allemaal Hardware Compatibility Lijsten. Deze staan vol van SATA drives die getest en goedbevonden zijn op hun SAS devices.
Als laatste daar nog een kanttekening bij. Dit zijn over het algemeen "enterprise class" HDD's en zo. Omdat de zakelijke markt hun target is met de Sata en SAS compabiliteit. SATA consumer drives werken ook. Je zal ze alleen niet op de HCL vinden.
[ Voor 23% gewijzigd door Goshimaplonker298 op 11-12-2013 21:55 ]
Pure-FTPd kun je vanuit de ports compilen met "UploadScript" support. Hiermee kun je een script aanroepen die uitgevoerd wordt zodra er iets is geupload. In dat script kun je dan iets met "chflags schg" doen zodat de geploade bestanden niet meer kunnen worden aangepast of verwijderd.Verwijderd schreef op woensdag 11 december 2013 @ 17:07:
....
Een ander punt waar ik nog mee worstel is het volgende. Ik zou graag willen dat bepaalde data die naar de NAS zal worden geschreven daarna niet meer kan worden aangepast. Dit is best tricky, want met de gewone user-rechten kun je geen modus vinden waarbij iemand wel schrijf en leesrechten heeft, zonder de mogelijkheid om de bestanden ook aan te passen of zelfs verwijderen.
....
Als je de securelevel verhoogt naar 1, dan kan zelfs root (of iemand met root rechten) deze bestanden niet meer aanpassen of verwijderen.
- Q
- Registratie: November 1999
- Laatst online: 04:43
Au Contraire Mon Capitan!
Verwijderd
Hoewel ik weinig ervaring heb met programmeren met systeem libraries heb ik wel even inotify gekeken. Het is inderdaad een interessante feature. De FreeBSD tegenhanger is niet helemaal equivalent, maar misschien dat je daar wel iets mee zou kunnen doen.Xudonax schreef op woensdag 11 december 2013 @ 18:32:
Ik zou haast zeggen, maak een daemon die via inotify (of hoe FreeBSD's variant erop heet) luistert naar wijzigingen in de map, en dan dat commando uitvoert. Maarja, ik kan goed begrijpen dat niet iedereen programmeerkennis heeft
Dat snapshotten is zeer interessant en ik was ook wel van plan om er gebruik van te gaan maken. Ik had er echter niet aan gedacht om het zo toe te passen.Verwijderd schreef op woensdag 11 december 2013 @ 18:32:
Gewoon regelmatig snapshotten. Desnoods iedere minuut, al vind ik dat wat overdreven. Maar qua efficiency zou het wel kunnen; snapshots werken heerlijk met ZFS.
d1ng schreef op woensdag 11 december 2013 @ 23:17:
Pure-FTPd kun je vanuit de ports compilen met "UploadScript" support. Hiermee kun je een script aanroepen die uitgevoerd wordt zodra er iets is geupload. In dat script kun je dan iets met "chflags schg" doen zodat de geploade bestanden niet meer kunnen worden aangepast of verwijderd.
Als je de securelevel verhoogt naar 1, dan kan zelfs root (of iemand met root rechten) deze bestanden niet meer aanpassen of verwijderen.
Een interessante invalshoek. FTP had ik dus ook niet aan gedacht, omdat ik er van uit ging samba (windows shares) te gaan gebruiken. Super handig dat je dergelijke scripts op een FTP server kunt draaien. Ik zal eens kijken hoe dat een beetje transparant op de windowssystemen kan worden geïmplementeerd.Q schreef op woensdag 11 december 2013 @ 23:55:
Zoiets kan ook met VSFTPD of te wel Very Secure FTP Daemon, geschreven door Crhis Evans, werkzaam voor Google. https://security.appspot.com/vsftpd.html
http://azerty.nl/0-1989-6...quad-msata-pcie-ssd-.html
Met 4* M500 120GB. Controller is AHCI, dus ik verwacht daar geen problemen.
Zou een badass ZIL maken
Edit: Het lijkt om een Marvell 91xx te gaan, iemand die weet of die goed met BSD / ZFS werken?
[ Voor 18% gewijzigd door FireDrunk op 12-12-2013 10:39 ]
Even niets...
Oeh gaaf ding voor weinig geld. Waarschijnlijk werkt het wel, FreeBSD ondersteunt een hele rits controllers uit die serie (zo niet alle):FireDrunk schreef op donderdag 12 december 2013 @ 10:36:
* FireDrunk heeft een stout idee:
http://azerty.nl/0-1989-6...quad-msata-pcie-ssd-.html
Met 4* M500 120GB. Controller is AHCI, dus ik verwacht daar geen problemen.
Zou een badass ZIL maken
Edit: Het lijkt om een Marvell 91xx te gaan, iemand die weet of die goed met BSD / ZFS werken?
http://svnweb.freebsd.org...i/ahci.c?view=markup#l259
Even niets...
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.