:fill(white):strip_exif()/i/2003943496.jpeg?f=thumbmini)
:strip_exif()/i/1321263566.png?f=thumbmini)
Dan is dit inmiddels bij FreeBSD aangepast; 1/4e van de ARC lijkt mij een goede default setting. Beter dan een fixed 128MiB wat het volgens mij vroeger was.
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
:strip_exif()/u/396800/D-_3427da0a9c293b63f2a66dea2e642102.gif?f=community)
Voor de geïnterreseerden. Ik heb vorige week deze NAS samengesteld:
Bij normaal gebruik zoals een beetje downloaden e.d. verbruikt hij zo'n 36 watt. Gemeten met een Cresta energiemeter. Hoogst gemeten piek was 90 watt.
| # | Product | Prijs | Subtotaal |
| 1 | Intel Pentium G3220 Boxed | € 45,50 | € 45,50 |
| 1 | ASRock Z87E-ITX | € 121,50 | € 121,50 |
| 4 | WD Red SATA 6 Gb/s WD20EFRX, 2TB | € 82,77 | € 331,08 |
| 1 | Fractal Design Node 304 Zwart | € 64,95 | € 64,95 |
| 1 | Cooler Master Hyper 212 EVO | € 24,50 | € 24,50 |
| 1 | Crucial CT102464BA160B | € 62,95 | € 62,95 |
| 1 | Seasonic G-Serie 360Watt | € 50,- | € 50,- |
| Bekijk collectie Importeer producten | Totaal | € 795,47 | |
Bij normaal gebruik zoals een beetje downloaden e.d. verbruikt hij zo'n 36 watt. Gemeten met een Cresta energiemeter. Hoogst gemeten piek was 90 watt.
Sinds de 2 dagen regel reageer ik hier niet meer
- Kortfragje
- Registratie: December 2000
- Laatst online: 25-06 18:28
......
Aangezien er een hoop gezegd werd over hoeveel netto ruimte er beschikbaar is bij bepaalde RaidZ configuraties heb ik vanmiddag een virtuele oefening gehouden.
In virtualbox heb ik 20 drives aangemaakt (4,000,000,000 bytes, 3.64 GB) en een hoop verschillende arrays aangemaakt.
Lang verhaal kort (in ZoL, ubuntu 14.04 LTS) kreeg ik de volgende resultaten (fractie is "grootte gerapporteerd door zfs list" / "(disks - parity disks) * diskgrootte" :
ashift=9

ashift=12

Ik hoop dat iemand er wat aan heeft!
In virtualbox heb ik 20 drives aangemaakt (4,000,000,000 bytes, 3.64 GB) en een hoop verschillende arrays aangemaakt.
Lang verhaal kort (in ZoL, ubuntu 14.04 LTS) kreeg ik de volgende resultaten (fractie is "grootte gerapporteerd door zfs list" / "(disks - parity disks) * diskgrootte" :
ashift=9
ashift=12
Voor meer details zien mijn blog: http://blog.gjpvanwesten....ace-do-you-lose-with.htmlThat means that your RaidZ3 does not cost you 3 drives but 3 + an additional 2.1 drives. So you place 18 * 3.64 TB = 65.52 TB in your chassis and get only 12.9 * 3.64 TB = 46.96 TB storage....
Ik hoop dat iemand er wat aan heeft!
[ Voor 4% gewijzigd door Kortfragje op 24-08-2014 23:25 ]
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Mooie verhaal 
@Kortfragje. Je schrijft op een gegeven moment over 37*512 en 5*4096. Waar komen die 37 en 5 vandaag?
@Iedereen. Heeft iemand een verklaring waarom 4 schijven in alle configuraties 99% oplevert terwijl je bij de RAIDZ1 dit bij 3 schijven zou verwachten en bij RAIDZ3 bij 5 schijven. Of zie ik iets vanzelfsprekends over het hoofd?
@Kortfragje. Je schrijft op een gegeven moment over 37*512 en 5*4096. Waar komen die 37 en 5 vandaag?
@Iedereen. Heeft iemand een verklaring waarom 4 schijven in alle configuraties 99% oplevert terwijl je bij de RAIDZ1 dit bij 3 schijven zou verwachten en bij RAIDZ3 bij 5 schijven. Of zie ik iets vanzelfsprekends over het hoofd?
Sinds de 2 dagen regel reageer ik hier niet meer
- dcm360
- Registratie: December 2006
- Niet online
/u/200133/artemis_square_e_60-60.png?f=community)
Als ik dit goed begrijp, heb je n data-disks (onderaan de grafiek), plus de parity disk(s). Wat jij dus leest als 4 schijven, zijn dus eigenlijk 5, 6 en 7 schijven in respectievelijk Raid-Z1, Z2 en Z3.
Het valt wellicht ook op dat de grafiek begint bij 1 schijf, terwijl het minimum voor Z1 2 schijven is, en voor Z3 4. Aan het einde heeft Z1 ook hooguit 19 schijven (plus 1 maakt 20), en Z3 heeft er 17 (plus 3 maakt ook 20).
*kuch* dit staat uiteraard ook bij de testmethode achter de link in de post van Kortfragje.
Met wat rekenen op de achterkant van een envelop haalt mijn Z1-array met 3x3TB (alsin: 3x3=6) een score van 0,980. Nu nog het geklooi met Proxmox/iSCSI/LVM/ZOL oplossen en ik kan het ook daadwerkelijk eens gaan gebruiken.
Het valt wellicht ook op dat de grafiek begint bij 1 schijf, terwijl het minimum voor Z1 2 schijven is, en voor Z3 4. Aan het einde heeft Z1 ook hooguit 19 schijven (plus 1 maakt 20), en Z3 heeft er 17 (plus 3 maakt ook 20).
*kuch* dit staat uiteraard ook bij de testmethode achter de link in de post van Kortfragje.
Met wat rekenen op de achterkant van een envelop haalt mijn Z1-array met 3x3TB (alsin: 3x3=6) een score van 0,980. Nu nog het geklooi met Proxmox/iSCSI/LVM/ZOL oplossen en ik kan het ook daadwerkelijk eens gaan gebruiken.
[ Voor 62% gewijzigd door dcm360 op 25-08-2014 01:18 ]
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
Wat voor geklooi?
Even niets...
- dcm360
- Registratie: December 2006
- Niet online
Het hele verhaaltje dan maar even
Op de ZoL-machine heb ik een ZVOL aangemaakt, deze exporteer ik met iSCSI. Proxmox pakt deze export op, en daarin heb ik deze geïnitialiseerd met LVM. Dit gaat prima allemaal.
Vervolgens herstart ik de ZoL-machine, en blijkt Proxmox er niet meer bij te kunnen. Sterker nog, de iscsitarget-service op de ZoL-machine kan niet meer een lock krijgen op de ZVOL: deze is opgepakt door LVM en ik heb een mooie /dev/export-n erbij (waarbij die n een foutje van Proxmox is, ik had een NFS-mount met de naam export-n, en vervolgens heeft ie de LVM-storage niet de naam export-l maar ook export-n genoemd. Maargoed, dit is het probleem niet).
De situatie krijg ik tijdelijk zoals het moet door 'vgchange -a n export-n' uit te voeren gevolgd door een 'service iscsitarget restart'. Na een reboot is /dev/export-n echter weer terug en kan ik de volgende melding terugvinden in /var/log/messages:
iscsi_trgt: blockio_open_path(167) Can't open device /dev/tank/proxmox2, error -16
Op de ZoL-machine heb ik een ZVOL aangemaakt, deze exporteer ik met iSCSI. Proxmox pakt deze export op, en daarin heb ik deze geïnitialiseerd met LVM. Dit gaat prima allemaal.
Vervolgens herstart ik de ZoL-machine, en blijkt Proxmox er niet meer bij te kunnen. Sterker nog, de iscsitarget-service op de ZoL-machine kan niet meer een lock krijgen op de ZVOL: deze is opgepakt door LVM en ik heb een mooie /dev/export-n erbij (waarbij die n een foutje van Proxmox is, ik had een NFS-mount met de naam export-n, en vervolgens heeft ie de LVM-storage niet de naam export-l maar ook export-n genoemd. Maargoed, dit is het probleem niet).
De situatie krijg ik tijdelijk zoals het moet door 'vgchange -a n export-n' uit te voeren gevolgd door een 'service iscsitarget restart'. Na een reboot is /dev/export-n echter weer terug en kan ik de volgende melding terugvinden in /var/log/messages:
iscsi_trgt: blockio_open_path(167) Can't open device /dev/tank/proxmox2, error -16
Je moet ervoor zorgen dat je lokale LVM dus niet meer scant naar nieuwe volumes, omdat het ZVOL device door LVM gewoon gescant word en in gebruik genomen wordt...
https://www.centos.org/do..._Manager/lvm_filters.html
Filtertje maken op /dev/zvol of /dev/zfs (weet even niet meer welke het was).
https://www.centos.org/do..._Manager/lvm_filters.html
Filtertje maken op /dev/zvol of /dev/zfs (weet even niet meer welke het was).
[ Voor 13% gewijzigd door FireDrunk op 25-08-2014 09:44 ]
Even niets...
- dcm360
- Registratie: December 2006
- Niet online
Daar was ik al een klein beetje mee aan het spelen. Nu maar het filter "a/.*/" weggehaald en het lijkt te werken.
Mooi, weer een blije ZFS gebruiker 
Hoe bevalt je ZVOL performance? Ik lees hele wisselende verhalen op internet. Hier is het op zich prima qua sequentiële performance, maar qua IOPS zou ik nog wel graag wat meer zien...
Hoe bevalt je ZVOL performance? Ik lees hele wisselende verhalen op internet. Hier is het op zich prima qua sequentiële performance, maar qua IOPS zou ik nog wel graag wat meer zien...
Even niets...
- dcm360
- Registratie: December 2006
- Niet online
Ik heb er (via iSCSI en Proxmox dus) Windows Server 2012 op geïnstalleerd, en daarin CrystalDiskMark draaien levert het volgende plaatje op:

Nu is dit natuurlijk wel mooi en aardig, maar de daadwerkelijke performance is uiteraard lager (want dit is zoals je misschien al doorhad meer een benchmark van de doorvoersnelheid naar het geheugen van de ZoL-machine). Ik zou echter zeggen dat deze virtuele Windows 2012 net zo snel aanvoelt als de fysieke Windows 7-machine die er door vervangen gaat worden (die draait vanaf een oude 750GB SpinPoint). Meer IOPS heb ik naar mijn idee overigens ook niet echt veel aan: er moeten wat VM's van opstarten en dat is het dan wel.
Nu is dit natuurlijk wel mooi en aardig, maar de daadwerkelijke performance is uiteraard lager (want dit is zoals je misschien al doorhad meer een benchmark van de doorvoersnelheid naar het geheugen van de ZoL-machine). Ik zou echter zeggen dat deze virtuele Windows 2012 net zo snel aanvoelt als de fysieke Windows 7-machine die er door vervangen gaat worden (die draait vanaf een oude 750GB SpinPoint). Meer IOPS heb ik naar mijn idee overigens ook niet echt veel aan: er moeten wat VM's van opstarten en dat is het dan wel.
Dat ziet er inderdaad netjes uit, ik ga ervan uit dat dit localhost iSCSi is, en niet 10Gb?
Even niets...
- dcm360
- Registratie: December 2006
- Niet online
Dat zou interessant zijn, een berg budget-hardware en dan wel 10Gb netwerk  Localhost is het overigens strikt genomen ook niet, het gaat door de software-switch in Proxmox (ZFS in een KVM-machine).
Localhost is het overigens strikt genomen ook niet, het gaat door de software-switch in Proxmox (ZFS in een KVM-machine).
Ja ok, maar dan gaat het niet over een fysiek netwerk heen, alleen maar in-memory troep
10Gb is best betaalbaar hoor, als je het point-to-point doet, kan je met Infiniband of de wat oudere 10Gb netwerkkaarten al voor 200,- klaar zijn.
10Gb is best betaalbaar hoor, als je het point-to-point doet, kan je met Infiniband of de wat oudere 10Gb netwerkkaarten al voor 200,- klaar zijn.
Even niets...
- dcm360
- Registratie: December 2006
- Niet online
200,- is nog wel een aardig bedrag op een server die me nu 800,- heeft gekost  Iets snellers dan Gb voor tussen mijn server en workstation heb ik al eens naar gekeken, en de conclusie was toen dat het niet haalbaar was. De pc's staan weliswaar op dezelfde verdieping, maar dan wel net niet in de uiterste 2 hoeken. De verbinding loopt nu door ~15 meter kabel en 3 switches, en op sommige plaatsen past er niet nog een kabel bij.
Iets snellers dan Gb voor tussen mijn server en workstation heb ik al eens naar gekeken, en de conclusie was toen dat het niet haalbaar was. De pc's staan weliswaar op dezelfde verdieping, maar dan wel net niet in de uiterste 2 hoeken. De verbinding loopt nu door ~15 meter kabel en 3 switches, en op sommige plaatsen past er niet nog een kabel bij.
- Extera
- Registratie: Augustus 2004
- Laatst online: 22-06 02:20
Ik gebruik al een tijdje een point-2-point 10Gb verbinding tussen mijn NAS en ESX host. Dit werkt perfect.
Ik gebruik 2 Myricom 10G-PCIE-8A-C CX4 10GbE 10Gb 10G Ethernet NICs met een CX4 kabel er tussen.
even een vraag:
Ik heb 2 120GB SSD's voor L2ARC / SLOG besteld. (M500's).
Op welke manier zou ik deze het best kunnen indelen?
Ik heb 2 pools, 1 voor media (5x4TB zRaid) en 1 voor VMware (8x1TB, 4x2disk mirror)
Voor de media pool is SLOG / L2ARC niet echt van toepassing denk ik.
SLOG zeker niet, en L2ARC zou hooguit metadata gaan bevatten welke nu al in ARC zouden moeten staan.
SLOG voor de VMware pool is om synced writes (NFS) een boost te geven.
10 GB als SLOG lijkt me meer dan voldoende voor deze pool?
2 10GB partities van de SSDs mirrored dan.
De rest kan ik dan striped als L2ARC gebruiken, of voor de VMware pool, of verdelen over beide pools?
Ik gebruik 2 Myricom 10G-PCIE-8A-C CX4 10GbE 10Gb 10G Ethernet NICs met een CX4 kabel er tussen.
even een vraag:
Ik heb 2 120GB SSD's voor L2ARC / SLOG besteld. (M500's).
Op welke manier zou ik deze het best kunnen indelen?
Ik heb 2 pools, 1 voor media (5x4TB zRaid) en 1 voor VMware (8x1TB, 4x2disk mirror)
Voor de media pool is SLOG / L2ARC niet echt van toepassing denk ik.
SLOG zeker niet, en L2ARC zou hooguit metadata gaan bevatten welke nu al in ARC zouden moeten staan.
code:
1
2
3
4
5
6
7
| [root@claustofobia] ~# top last pid: 349; load averages: 0.00, 0.01, 0.00 up 17+19:18:20 12:42:49 44 processes: 1 running, 43 sleeping CPU: 0.4% user, 0.0% nice, 0.0% system, 0.0% interrupt, 99.6% idle Mem: 195M Active, 152M Inact, 18G Wired, 585M Buf, 4379M Free ARC: 17G Total, 4807M MFU, 12G MRU, 2612K Anon, 228M Header, 127M Other Swap: 28G Total, 28G Free |
SLOG voor de VMware pool is om synced writes (NFS) een boost te geven.
10 GB als SLOG lijkt me meer dan voldoende voor deze pool?
2 10GB partities van de SSDs mirrored dan.
De rest kan ik dan striped als L2ARC gebruiken, of voor de VMware pool, of verdelen over beide pools?
[ Voor 9% gewijzigd door Extera op 25-08-2014 12:57 ]
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
@Extera, zie eerste post van dit topic onder "Handige tutorials"
Sinds de 2 dagen regel reageer ik hier niet meer
Wat CurlyMo zegt, daar staat een handleiding gelinkt die ik gemaakt heb.
Mirroren van je SLOG is inderdaad goed, stripen van je L2ARC hoeft niet, dat doet ZFS zelf al.
Je kan dus gewoon beide L2ARC partities individueel toevoegen.
(voordeel is dan dat de helft van je L2ARC nog gewoon werkt als 1 van de SSD's uitvalt, als je ze striped, valt gelijk je hele L2ARC uit, en performance technisch maakt het niets uit.)
Mirroren van je SLOG is inderdaad goed, stripen van je L2ARC hoeft niet, dat doet ZFS zelf al.
Je kan dus gewoon beide L2ARC partities individueel toevoegen.
(voordeel is dan dat de helft van je L2ARC nog gewoon werkt als 1 van de SSD's uitvalt, als je ze striped, valt gelijk je hele L2ARC uit, en performance technisch maakt het niets uit.)
Even niets...
- Extera
- Registratie: Augustus 2004
- Laatst online: 22-06 02:20
Ik gebruik FreeNAS, ik kom er wel uit hoe ik de SLOG en L2ARC toevoeg aan de pools.
Mijn vraag is hoeveel nut het heeft op een pool welke 90% media bevat.
metadata kan ook uit ARC komen, en een grote L2ARC zal bij media files welke 1x gelezen worden er ook niet voor zorgen dat de pool minder op spint.
Ik ga wel een SLOG aan de media pool toevoegen, deze wil ik nog wel eens misbruiken om tijdelijk een VM op te zetten
Mijn vraag is hoeveel nut het heeft op een pool welke 90% media bevat.
metadata kan ook uit ARC komen, en een grote L2ARC zal bij media files welke 1x gelezen worden er ook niet voor zorgen dat de pool minder op spint.
Ik ga wel een SLOG aan de media pool toevoegen, deze wil ik nog wel eens misbruiken om tijdelijk een VM op te zetten
L2ARC op een grote mediapool zou ik inderdaad ook niet doen, als je 1 grote pool hebt voor zowel media als vm images zou ik van je mediafilesystem de secondarycache property op metadata zetten.
Dan word er alleen metadata op L2ARC gezet.
* FireDrunk heeft dat ook.
Dan word er alleen metadata op L2ARC gezet.
* FireDrunk heeft dat ook.
Even niets...
- KennieNL
- Registratie: Mei 2007
- Laatst online: 01-07 18:50
Weet iemand hoe memory hungry ZFS tegenwoordig is op Linux? Zonder fancy features zoals dedup e.d.
Op dit moment draai ik thuis op mn servertje MDADM+Ext4 met 2x2TB WD green diskjes. Destijds ook naar ZFS gekeken maar BSD is niet mijn ding en ZFS on Linux vond ik nog teveel in kinderschoentjes staan.
Ik overweeg nog een extra 4TB disk (nog even kijken welke) erin te zetten welke gewoon als single disk ZFS gaat functioneren... als die data weg is, tjah jammer dan. Huidige array uitbreiden (en eventueel omzetten naar ZFS) vind ik met 2TB diskjes te duur worden.
Eventueel overweeg ik nog de huidige array om te zetten, maar waarschijnlijk pas op een later moment.
Heb nu 8GB RAM in de machine zitten, waarvan 3.5GB op dit moment cache is. Volgens mij moet ik hier wel ruim voldoende aan hebben... enige wat het ding doet is wat non intensieve VMs hosten en wat downlaaien.
Op dit moment draai ik thuis op mn servertje MDADM+Ext4 met 2x2TB WD green diskjes. Destijds ook naar ZFS gekeken maar BSD is niet mijn ding en ZFS on Linux vond ik nog teveel in kinderschoentjes staan
Ik overweeg nog een extra 4TB disk (nog even kijken welke) erin te zetten welke gewoon als single disk ZFS gaat functioneren... als die data weg is, tjah jammer dan. Huidige array uitbreiden (en eventueel omzetten naar ZFS) vind ik met 2TB diskjes te duur worden.
Eventueel overweeg ik nog de huidige array om te zetten, maar waarschijnlijk pas op een later moment.
Heb nu 8GB RAM in de machine zitten, waarvan 3.5GB op dit moment cache is. Volgens mij moet ik hier wel ruim voldoende aan hebben... enige wat het ding doet is wat non intensieve VMs hosten en wat downlaaien
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Dat het redelijk werkt op een Raspberry Pi (512MB) zegt genoeg.
Om een volwaarde ZFS array te bouwen kan je een aantal dingen doen:
Optie 1.
1x4TB + 2x2TB Stripe = 1 ZFS mirror van 4TB.
Optie 2.
4TB opdelen in 2TB partities. 1 partitie samen met de 2x2TB in een RAIDZ array stoppen. Die andere 2TB kan je dan als single disk ZFS pool gebruiken.
Om een volwaarde ZFS array te bouwen kan je een aantal dingen doen:
Optie 1.
1x4TB + 2x2TB Stripe = 1 ZFS mirror van 4TB.
Optie 2.
4TB opdelen in 2TB partities. 1 partitie samen met de 2x2TB in een RAIDZ array stoppen. Die andere 2TB kan je dan als single disk ZFS pool gebruiken.
Sinds de 2 dagen regel reageer ik hier niet meer
- Contagion
- Registratie: Maart 2000
- Laatst online: 20:42
@Curlymo; die heb ik even gemist; is er inmiddels een ARM implementatie van ZFS on Linux?? Ik dacht dat het alleen x64 was (tenzij je ZFS-FUSE gebruikt, dan kan het ook op x64 met echt weinig RAM). Voor ARM gebruik ik tot nu toe altijd maar BTRFS met al z'n makken.
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Besef je dat ZFS niet geschikt is als hoofd bestandssysteem. Daarvoor kan je beter BTRFS blijven gebruiken.CurlyMo schreef op woensdag 30 juli 2014 @ 17:38:
Afgelopen dagen een beetje lopen klooien met een Raspberry Pi met als doel om als offsite backup te fungeren.
Snelheden zijn best ok.
Sinds de 2 dagen regel reageer ik hier niet meer
- KennieNL
- Registratie: Mei 2007
- Laatst online: 01-07 18:50
Hmm, optie 2 is eigenlijk nog niet zo slecht... Optie 1 valt af omdat ik toch echt meer dan 4TB nodig heb (heb nog 2x1TB in mn desktop die zowat vol zitten).CurlyMo schreef op maandag 25 augustus 2014 @ 17:14:
Dat het redelijk werkt op een Raspberry Pi (512MB) zegt genoeg.
Om een volwaarde ZFS array te bouwen kan je een aantal dingen doen:
Optie 1.
1x4TB + 2x2TB Stripe = 1 ZFS mirror van 4TB.
Optie 2.
4TB opdelen in 2TB partities. 1 partitie samen met de 2x2TB in een RAIDZ array stoppen. Die andere 2TB kan je dan als single disk ZFS pool gebruiken.
- Contagion
- Registratie: Maart 2000
- Laatst online: 20:42
@curlyMo Ik denk dat we langs elkaar heen praten. Ik kreeg uit jouw opmerking het idee dat de RPi ZFS kan draaien, maar uit je eerdere post niet (BTRFS). BTRFS als root filesysteem is aardig, maar ik heb echt al ZO veel gezeik gehad met BTRFS dat ik er een beetje moedeloos van wordt. Data loss, ENOSPC errors, resilver problemen (balancing), alleen het feit dat het op ARM werkt en je on the fly kan expanden en defraggen maakt het dat ik het steeds weer probeer.
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Zoals ik dus aangaf, kan de RPi ZFS draaien, maar is het niet geschikt als root on zfs. Wel voor je externe schijf.
Sinds de 2 dagen regel reageer ik hier niet meer
- Kortfragje
- Registratie: December 2000
- Laatst online: 25-06 18:28
......
Het ging over 128Kb verdeeld over 7 data disks, dat is 18,29 Kb per disk. Bij sector grootte van 512 bytes is dat 37 sectoren (18.5 Kb) om de data weg te schrijven. 36 sectoren ~ 18 Kb ( te weinig). Als je disk 4Kb sector size gebruikt heb je 5 sectoren van 4 Kb (4096 bytes), totaal 20 Kb nodig. Hier zou 4 sectoren 16 Kb opleveren (wat te weinig is).CurlyMo schreef op maandag 25 augustus 2014 @ 00:34:
Mooie verhaal
@Kortfragje. Je schrijft op een gegeven moment over 37*512 en 5*4096. Waar komen die 37 en 5 vandaag?
@Iedereen. Heeft iemand een verklaring waarom 4 schijven in alle configuraties 99% oplevert terwijl je bij de RAIDZ1 dit bij 3 schijven zou verwachten en bij RAIDZ3 bij 5 schijven. Of zie ik iets vanzelfsprekends over het hoofd?
Wat betreft je vraag over de 99 %, dcm360 heeft gelijk, ik heb in de plot alleen data schijven gebruikt, dus 4 schijven = 4 dataschijven. Dat is 5 schijven bij RaidZ1, 6 schijven bij RaidZ2 en 7 schijven bij RaidZ3.
Wat ik niet snap is waarom dit ook 99 & 99 % is voor Z1 en Z3 bij 8 data schijven maar ogenschijnlijk voor Z3 slechts 94%. Misschien heeft iemand anders een antwoord?
Ik was wel van plan het geheel nog is met andere virtuele hard disk groottes te proberen als ik weer zin heb
Hoe heb je dan precies getest; heb je daadwerkelijk data gevuld of enkel naar de free space gekeken bij een lege pool? Indien dat laatste dan kloppen je metingen niet; dan zijn dit enkel schattingen. Je zult echt moeten meten met het vullen van de pool met data.
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Reden genoeg om dan wel voor FreeBSD te gaan waar dit geen probleem isCurlyMo schreef op maandag 25 augustus 2014 @ 17:30:
[...]
Besef je dat ZFS niet geschikt is als hoofd bestandssysteem. Daarvoor kan je beter BTRFS blijven gebruiken.
:strip_icc():strip_exif()/u/6607/klootviool2.jpg?f=community)
Of je kiest voor je root schijf een bestandssysteem wat compleet en stabiel is, zoals ext4 of XFSCurlyMo schreef op maandag 25 augustus 2014 @ 17:30:
[...]
Besef je dat ZFS niet geschikt is als hoofd bestandssysteem. Daarvoor kan je beter BTRFS blijven gebruiken.
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Ik heb toen ook aangegeven dat mijn doel niet is om ZFS on root te gebruiken, maar de RPi te gebruiken voor een offsite ZFS backup.
Sinds de 2 dagen regel reageer ik hier niet meer
- Remcor2000
- Registratie: Augustus 2002
- Laatst online: 06-07 16:39
:strip_icc():strip_exif()/u/62294/Copy%2520of%2520sq-qotsa-go-flow-vid-int.jpg?f=community)
Ik heb helaas een probleem gekregen met mijn ZFSguru setup.
Er is een defecte schijf die piept en een crash veroorzaakt. Ik kan niet meer bij de webgui komen. En zodra ik de defecte schijf loskoppel (machine staat dan uit), dan boot de machine niet meer.
Er blijft dat een cursor en sterretje knipperen.
Mijn idee is nu om met de livecd te booten, maar kan ik dan een herstel doen van de installatie en daarna de nieuwe schijf netjes plaatsen en herstellen?
Er is een defecte schijf die piept en een crash veroorzaakt. Ik kan niet meer bij de webgui komen. En zodra ik de defecte schijf loskoppel (machine staat dan uit), dan boot de machine niet meer.
Er blijft dat een cursor en sterretje knipperen.
Mijn idee is nu om met de livecd te booten, maar kan ik dan een herstel doen van de installatie en daarna de nieuwe schijf netjes plaatsen en herstellen?
Ja dat kan; je kunt je pool importeren zodra je van de LiveCD bent geboot. Wat voor pool configuratie gebruik je trouwens?
- Remcor2000
- Registratie: Augustus 2002
- Laatst online: 06-07 16:39
Ok goed om te horen. Het gaat om een raidz configuratie van 3 Seagate st2000dm001 waarvan nu 1 dood is.
Ik heb de livecd nu draaien en de degraded pool geimporteerd. Moet ik nu nog een installatie root on ZFS doen? Of moet ik nu eerst wachten tot ik de nieuwe schijf binnen heb en die plaats. En daarna pas de install doen?
Ik heb de livecd nu draaien en de degraded pool geimporteerd. Moet ik nu nog een installatie root on ZFS doen? Of moet ik nu eerst wachten tot ik de nieuwe schijf binnen heb en die plaats. En daarna pas de install doen?
[ Voor 51% gewijzigd door Remcor2000 op 25-08-2014 21:39 ]
- Kortfragje
- Registratie: December 2000
- Laatst online: 25-06 18:28
......
Ik heb de zfs list output gebruikt (die naar mijn weten nauwkeuriger is dan zpool list). Ik heb vandaag echte data geschreven (met dd) en het lijkt iig voor 7 en 8 disk RaidZ1 /Z2/Z3 arrays te kloppen. Ik zal morgen nog wat meer steekproeven doen en het eea wat netter in een post vermelden.Verwijderd schreef op maandag 25 augustus 2014 @ 18:48:
Hoe heb je dan precies getest; heb je daadwerkelijk data gevuld of enkel naar de free space gekeken bij een lege pool? Indien dat laatste dan kloppen je metingen niet; dan zijn dit enkel schattingen. Je zult echt moeten meten met het vullen van de pool met data.
Ik heb vandaag wat tests gedaan (4, 7, 8, 15 datadisks 4k sector in Z1 , Z2, and Z3). I heb dd gebruikt om een test dataset op het volume te vullen met data uit /dev/zero (blocks of 1M).
eigenlijk nagenoeg geen verschil tussen zfs list en de echte data(4/12 was 100% correct, 6/12 was 0.1% kleiner, 1/16 was 0.1% groter, en 1/16 was 0.4% groter). hieruit concludeer ik dat zfs list in ieder geval nauwkeurig genoeg is om een schatting te doen.

Daarnaast, ik gebruik de output van zfs list / zpool list ook om te bepalen wanneer mn storage een upgrade nodig heeft. Ik doe dat niet pas als de pool echt vol is, dus de oefening van hierboven is wellicht sowieso academisch
[ Voor 37% gewijzigd door Kortfragje op 26-08-2014 22:04 ]
- Remcor2000
- Registratie: Augustus 2002
- Laatst online: 06-07 16:39
Het is me gelukt! Waarvoor dank
Ik heb uiteindelijk de harde schijf vervangen. Daarna van de LiveCD gestart en de pool geimporteerd.
Daar werd de pool als degraded aangegeven, en heb ik nieuwe disk GPT geformatteerd. Hij werd daarna beschikbaar voor replacement van de oude disk. Dat heb ik gedaan, en na een uurtje of 4 a 5 resilveren was de pool weer online.
Helaas kon ik onder de boot pagina niet meer mijn oude installatie terug vinden. (wel een oudere FreeBSD versie 9) maar de recentere 10.1 die in gebruikte was weg. Dat verklaard waarschijnlijk dan waarom hij niet meer wilde booten van de overige twee disks.
Ik heb nu een nieuwe 10.1 installatie gemaakt via Root on ZFS en alles werkt weer. Nu nog de virtualbox service weer opnieuw instellen en de virtuele machines importeren en ben ik terug waar ik was.
Maar nu blijf ik me afvragen wat ik nu fout heb gedaan waardoor mijn vorige installatie ineens weg is. Want was dat wel goed gegaan, had ik mijn services ook weer netjes terug gehad. Iemand een idee?
Ik heb uiteindelijk de harde schijf vervangen. Daarna van de LiveCD gestart en de pool geimporteerd.
Daar werd de pool als degraded aangegeven, en heb ik nieuwe disk GPT geformatteerd. Hij werd daarna beschikbaar voor replacement van de oude disk. Dat heb ik gedaan, en na een uurtje of 4 a 5 resilveren was de pool weer online.
Helaas kon ik onder de boot pagina niet meer mijn oude installatie terug vinden. (wel een oudere FreeBSD versie 9) maar de recentere 10.1 die in gebruikte was weg. Dat verklaard waarschijnlijk dan waarom hij niet meer wilde booten van de overige twee disks.
Ik heb nu een nieuwe 10.1 installatie gemaakt via Root on ZFS en alles werkt weer. Nu nog de virtualbox service weer opnieuw instellen en de virtuele machines importeren en ben ik terug waar ik was.
Maar nu blijf ik me afvragen wat ik nu fout heb gedaan waardoor mijn vorige installatie ineens weg is. Want was dat wel goed gegaan, had ik mijn services ook weer netjes terug gehad. Iemand een idee?
Verwijderd
Hmm, Sinds mijn rebuild/upgrade zomaar wat random CKSUM fouten op willekeurige disks hier en daar.
Voeding (CX600M 600watt) of geheugen in de fout (Kingston Hyper-X geen ecc met aleen jaar of 2/3 draaiuren)
Dat wordt maar weer trial en error vervangen ben ik bang.
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://illumos.org/msg/ZFS-8000-9P
scan: scrub repaired 0 in 8h20m with 0 errors on Sun Aug 24 03:36:11 2014
config:
NAME STATE READ WRITE CKSUM
storage ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
diskid/DISK-Z300TM ONLINE 0 0 0
diskid/DISK-Z300V6 ONLINE 0 0 0
diskid/DISK-Z300V6 ONLINE 0 0 0
diskid/DISK-Z300V5 ONLINE 0 0 0
diskid/DISK-Z300H4 ONLINE 0 0 0
raidz1-1 ONLINE 0 0 0
diskid/DISK-Z3011N ONLINE 0 0 0
diskid/DISK-Z301GR ONLINE 0 0 0
diskid/DISK-Z300TM ONLINE 0 0 1
diskid/DISK-Z300V5 ONLINE 0 0 0
diskid/DISK-Z300V4 ONLINE 0 0 0
raidz1-2 ONLINE 0 0 0
diskid/DISK-Z300TN ONLINE 0 0 0
diskid/DISK-Z300H4 ONLINE 0 0 0
diskid/DISK-Z301LM ONLINE 0 0 0
diskid/DISK-Z300H4 ONLINE 0 0 0
diskid/DISK-Z301LM ONLINE 0 0 0
logs
ada0 ONLINE 0 0 0
cache
ada1 ONLINE 0 0 0 |
Voeding (CX600M 600watt) of geheugen in de fout (Kingston Hyper-X geen ecc met aleen jaar of 2/3 draaiuren)
Dat wordt maar weer trial en error vervangen ben ik bang.
- Q
- Registratie: November 1999
- Laatst online: 00:25
Au Contraire Mon Capitan!
/u/1176/crop635f8931b2b68_cropped.png?f=community)
Het kan zeker de voeding zijn, maar het klinkt typisch als brak RAM geheugen, gok ik zo. Draaiuren op RAM maakt niets uit. Alles gaat stuk, geheugen ook.Verwijderd schreef op woensdag 27 augustus 2014 @ 17:18:
Hmm, Sinds mijn rebuild/upgrade zomaar wat random CKSUM fouten op willekeurige disks hier en daar.
Voeding (CX600M 600watt) of geheugen in de fout (Kingston Hyper-X geen ecc met aleen jaar of 2/3 draaiuren)
Dat wordt maar weer trial en error vervangen ben ik bang.
Als het brak RAM is, (test even met memtest en laat een tijdje draaien), dan zou ik de machine niet meer booten in het OS totdat je het geheugen hebt vervangen. Het kan (hoeft niet) serieus mis gaan met ZFS en rot geheugen al beweren mensen soms anders. Uiteindelijk maakt het mij niet uit, het is jouw data tenslotte.
http://louwrentius.com/please-use-zfs-with-ecc-memory.html
[ Voor 30% gewijzigd door Q op 27-08-2014 21:41 ]
Checksum errors op willekeurige disks is vrijwel zeker RAM bitflips. Dat kun je met MemTest86+ voor 12+ uur wel uitsluiten. Schade voor je pool is maar een kleine kans; eigen tests met tienduizenden fouten heeft geen corrupte pool opgeleverd. Dat dat bij jou wel zou gebeuren met enkele bitflips is dus een zeer geringe kans. Natuurlijk wel fijn als je niet lang rondloopt met dit probleem.
Maar dit komt heel vaak voor; veel mensen hebben door dat een RAM-reepje brak is doordat ZFS fouten corrigeert. Als je een legacy filesystem had gebruikt, had je dit helemaal niet doorgehad en dan had het wel veel problemen/corruptie kunnen veroorzaken.
Maar dit komt heel vaak voor; veel mensen hebben door dat een RAM-reepje brak is doordat ZFS fouten corrigeert. Als je een legacy filesystem had gebruikt, had je dit helemaal niet doorgehad en dan had het wel veel problemen/corruptie kunnen veroorzaken.
Verwijderd
Toch twijfel ik. Is een checksum niet een controle van wat er naar disk weggeschreven is?
Dus een vergelijking van wat er in RAM staat/stond en wat er naar disk geschreven is.
Dus een vergelijking van wat er in RAM staat/stond en wat er naar disk geschreven is.
Checksum error betekent dat ZFS andere data op de disk aantreft dan het verwacht, afgaande op de checksum. Dat betekent:
1) dat er verkeerde (corrupte) data op de disk stond; wat door RAM corruptie in het verleden kan zijn gebeurd
2) er goede data op de disk staat, maar tijdens het uitlezen een bitflip is opgetreden waardoor het als corrupt gezien wordt
Er is geen permanente corruptie; het wordt automatisch weer hersteld. In theorie is er de mogelijkheid dat wel blijvende schade optreedt als je door blijft gaan met fout RAM geheugen. Ik heb dat niet kunnen produceren met een defect geheugenreepje wat vele tienduizenden bitflips per seconde produceert. Dus dat van een paar bitflips je pool op zijn bek gaat hoef je denk ik niet zo bang te zijn.
Je hoeft ook niets te doen verder; nadat je het RAM geheugen hebt vervangen is je pool prima in orde. Alle corruptie wordt weer herstelt uit redundante bron. Het grootste gevaar van RAM corruptie is dat je file wordt afgekeurd omdat de checksum zelf verkeerd is aangemaakt. Dan kan deze ook niet worden herstelt en zie je in de zpool status -v output dat je file corrupt is. In feite is er geen corruptie maar ZFS denkt door de foutieve checksum dat alle redundante bronnen corrupt zijn. Ook dat heb ik niet kunnen produceren met mijn tests met defect RAM geheugen.
1) dat er verkeerde (corrupte) data op de disk stond; wat door RAM corruptie in het verleden kan zijn gebeurd
2) er goede data op de disk staat, maar tijdens het uitlezen een bitflip is opgetreden waardoor het als corrupt gezien wordt
Er is geen permanente corruptie; het wordt automatisch weer hersteld. In theorie is er de mogelijkheid dat wel blijvende schade optreedt als je door blijft gaan met fout RAM geheugen. Ik heb dat niet kunnen produceren met een defect geheugenreepje wat vele tienduizenden bitflips per seconde produceert. Dus dat van een paar bitflips je pool op zijn bek gaat hoef je denk ik niet zo bang te zijn.
Je hoeft ook niets te doen verder; nadat je het RAM geheugen hebt vervangen is je pool prima in orde. Alle corruptie wordt weer herstelt uit redundante bron. Het grootste gevaar van RAM corruptie is dat je file wordt afgekeurd omdat de checksum zelf verkeerd is aangemaakt. Dan kan deze ook niet worden herstelt en zie je in de zpool status -v output dat je file corrupt is. In feite is er geen corruptie maar ZFS denkt door de foutieve checksum dat alle redundante bronnen corrupt zijn. Ook dat heb ik niet kunnen produceren met mijn tests met defect RAM geheugen.
Verwijderd
Aha! Bedankt voor de informatie.
Deze kwam ik ook nog tegen. Gloednieuwe Crucial MX100 256GB.
Er is al wel ~32TB naar de pool geschreven. Maar toch. Dit lijkt me dan toch wel op een geheugen probleem lijken en geen voeding/kabel probleem. De SSD zit namelijk op een compleet andere (onboard) sata controller.
Deze kwam ik ook nog tegen. Gloednieuwe Crucial MX100 256GB.
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| root@storage:/usr/home/frank # zfs-stats -L
------------------------------------------------------------------------
ZFS Subsystem Report Wed Aug 27 23:16:15 2014
------------------------------------------------------------------------
L2 ARC Summary: (DEGRADED)
Passed Headroom: 8.74m
Tried Lock Failures: 269.48k
IO In Progress: 2.56k
Low Memory Aborts: 40
Free on Write: 16.83k
Writes While Full: 103.02k
R/W Clashes: 91
Bad Checksums: 455.10k
IO Errors: 10
SPA Mismatch: 0 |
Er is al wel ~32TB naar de pool geschreven. Maar toch. Dit lijkt me dan toch wel op een geheugen probleem lijken en geen voeding/kabel probleem. De SSD zit namelijk op een compleet andere (onboard) sata controller.
- Q
- Registratie: November 1999
- Laatst online: 00:25
Au Contraire Mon Capitan!
Nuttige info:
http://nex7.blogspot.nl/2...showComment=1396212538095
Ik raad je aan om de machine niet meer in het OS te booten en de pool niet te importen totdat je de oorzaak weet en hebt opgelost.
http://nex7.blogspot.nl/2...showComment=1396212538095
Ik raad je aan om de machine niet meer in het OS te booten en de pool niet te importen totdat je de oorzaak weet en hebt opgelost.
if you get a bit flip in memory related to incoming writes that haven't hit disk yet, probably the best-case scenario is it affects a single block of data, and that block of data is part of a single file on a filesystem dataset, and the file is either unimportant, easily recovered, or in some way internally redundant such that you can still read the file. Obviously, the chance this is what happens is proportional to how much of your pool is such datasets and such files.
The next worse scenario would be the corrupt block is within a file again, and that file is unreadable, lost, but everything else is OK.
The next worse scenario would be the corrupt block is within a file, but that file is huge, and that file is responsible for something elsewhere that now fails -- for instance, that file was a .vmdk for some VM in your infrastructure. That VM either dies, or becomes a risk, as it is unable to read/write to that disk anymore.
The next worse scenario is the same as above, but that VM was critical to your environment and just went offline.
The next worse scenario is the same as the above, but instead of a file, it was an iSCSI zvol and one or more of your VM's are now having disk issues.
The next worse scenario is the same as the above, but the corruption must have hit something critical to the VMFS layer, as ALL your VM's just started having problems/dying.
The next worse scenario is the corrupt block ends up in critical metadata for ZFS itself. The system panics, and upon reboot you are unable to import the pool through any sane means, and have to either restore the entire thing from backup or engage a data recovery expert because you didn't have backups.
Samenvatting van het bovenstaande:
Als er corruptie plaatsvindt binnen een file, kan die file stukgaan in het ergste geval. In de meeste gevallen is de schade beperkt tot een enkele redundante kopie en wordt de schade dus gewoon gecorrigeerd. Als de file een belangrijke file is zoals een VM-container (.vmdk) kan dat wel erg vervelend zijn als die zomaar stuk is. Maar natuurlijk heb je voor dergelijk belangrijke bestanden goede backups zoals gebruiker Q zovaak op hamert.
Als er corruptie plaatsvindt op de metadata, heeft ZFS de beschikking over ditto blocks + de normale redundantie, waardoor corruptie op metadata niveau extreem zeldzaam is. Ook een enkele disk zonder redundantie heeft dergelijke bescherming.
Wat niet genoemd wordt in bovenstaande beschrijving, is de kans dat een checksum verkeerd wordt berekend, en derhalve een bestand direct corrupt is onafhankelijk van het niveau van redundantie.
In alle gevallen kun je zien om welke bestanden het gaat, in de zpool status -v output. Corruptie merk je dus altijd op, en voor ècht belangrijke zaken heb je natuurlijk altijd een backup.
Als er corruptie plaatsvindt binnen een file, kan die file stukgaan in het ergste geval. In de meeste gevallen is de schade beperkt tot een enkele redundante kopie en wordt de schade dus gewoon gecorrigeerd. Als de file een belangrijke file is zoals een VM-container (.vmdk) kan dat wel erg vervelend zijn als die zomaar stuk is. Maar natuurlijk heb je voor dergelijk belangrijke bestanden goede backups zoals gebruiker Q zovaak op hamert.
Als er corruptie plaatsvindt op de metadata, heeft ZFS de beschikking over ditto blocks + de normale redundantie, waardoor corruptie op metadata niveau extreem zeldzaam is. Ook een enkele disk zonder redundantie heeft dergelijke bescherming.
Wat niet genoemd wordt in bovenstaande beschrijving, is de kans dat een checksum verkeerd wordt berekend, en derhalve een bestand direct corrupt is onafhankelijk van het niveau van redundantie.
In alle gevallen kun je zien om welke bestanden het gaat, in de zpool status -v output. Corruptie merk je dus altijd op, en voor ècht belangrijke zaken heb je natuurlijk altijd een backup.
- Q
- Registratie: November 1999
- Laatst online: 00:25
Au Contraire Mon Capitan!
Met legacy file systems heb je het risico op bitrot. Maar als je legacy file system verkloot wordt kun je meestal nog een hoop data redden, mede omdat er ook tools voor zijn. Met ZFS is het over en sluiten als je pool corrupt raakt en de enige manier waarop dat eigenlijk kan gebeuren is rot geheugen.
http://research.cs.wisc.e...zfs-corruption-fast10.pdf
Het zou goed kunnen gaan. Hee ik probeer positief te blijven
http://research.cs.wisc.e...zfs-corruption-fast10.pdf
Observation5: For most metadata blocks in the page cache, checksums are not valid and thus useless in de- tecting memory corruptions.
Lig je lekker 's nachts rustig te slapen terwijl je machine een scrub over al je data doet met rot geheugen.Observation 9: There is no recovery for corrupted metadata. In the cases where no apparent error happened (as indicated by a dot or not shown) and the operation was not meant to update the corrupted field, the corrup- tion remained in the metadata block in the page cache.
In summary, ZFS fails to detect and recover from many corruptions. Checksums in the page cache are not used to protect the integrity of blocks. Therefore, bad data blocks are returned to the user or written to disk. Moreover, corrupted metadata blocks are accessed by ZFS and lead to operation failure and system crashes.
Het zou goed kunnen gaan. Hee ik probeer positief te blijven
[ Voor 7% gewijzigd door Q op 28-08-2014 01:02 ]
Nee hoor; je merkt namelijk vanzelf dat je checksum errors krijgt bij brak RAM geheugen. En dan weet je dat het tijd is om Memtest te draaien en de foute RAM module te vervangen. En daarna doe je een scrub op je ZFS pool en zie je dat er corruptie is geconstateerd en gecorrigeerd en werkt alles weer naar behoren. Geen enkele reden tot paniekvoetbal. Om je data tegen extreem kleine risico's te beschermen, waaronder een corrupte pool bij geheugencorruptie, een dode pool door een meteorietinslag enzovoorts, heb je natuurlijk backups voor de meest belangrijke data. Voor minder belangrijke data is het voldoende dat voor extreem kleine risico's je weet om welke bestanden het gaan; dan kun je die opnieuw downloaden. Probleem opgelost.
Los van de hele geheugendiscussie, vergelijk wel even appels met appels...
Als je een Ext4 systeem draait en daarbovenop bcache (zowel read als write), en LVM met 100 snapshots, en je gaat dan die 'simpele' recovery tooltjes draaien, ben je waarschijnlijk net zo ver van huis als met ZFS.
Bedenk goed dat ZFS niet 'alleen' maar een simpel filesystem is, het is zoveel meer.
Ja het is soms zeker complex om ZFS te recoveren, dat hoor je mij niet zeggen.
MAAR, bedenk je wel goed, dat er soms veel meer mogelijk is dan je online leest... Dat zpool import niet meer werkt betekend 99 van de 100 keer dat ZFS een keuze moet maken om data te droppen (transacties terugdraaien).
ZFS zal deze beslissing *NOOIT* zelf nemen, dit zul je altijd expliciet moeten doen (zdb commando).
In dat opzicht lees je veel gejammer op internet, maar als je bijvoorbeeld zoekt op "ZFS War stories" krijg je vaak wat verhalen van echt goede ZFS guru's die pools wel gefixed krijgen.
(Verhalen van ixSystems mensen die met 100TB aan disks op de achterbank naar een klant rijden om daar een pool die alleen maar read only is, te kopieren om deze writable te maken)
Als je een Ext4 systeem draait en daarbovenop bcache (zowel read als write), en LVM met 100 snapshots, en je gaat dan die 'simpele' recovery tooltjes draaien, ben je waarschijnlijk net zo ver van huis als met ZFS.
Bedenk goed dat ZFS niet 'alleen' maar een simpel filesystem is, het is zoveel meer.
Ja het is soms zeker complex om ZFS te recoveren, dat hoor je mij niet zeggen.
MAAR, bedenk je wel goed, dat er soms veel meer mogelijk is dan je online leest... Dat zpool import niet meer werkt betekend 99 van de 100 keer dat ZFS een keuze moet maken om data te droppen (transacties terugdraaien).
ZFS zal deze beslissing *NOOIT* zelf nemen, dit zul je altijd expliciet moeten doen (zdb commando).
In dat opzicht lees je veel gejammer op internet, maar als je bijvoorbeeld zoekt op "ZFS War stories" krijg je vaak wat verhalen van echt goede ZFS guru's die pools wel gefixed krijgen.
(Verhalen van ixSystems mensen die met 100TB aan disks op de achterbank naar een klant rijden om daar een pool die alleen maar read only is, te kopieren om deze writable te maken
Even niets...
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Eigenlijk is dat precies de reden dat ik zo nu en dan een tutorial schrijf over bepaalde ZFS functies. Het is een beetje zoals ik mijn familie vaak vertel: "Denk je echt dat er in computerland geen makkelijkere manier zal zijn dan X helemaal handmatig te doen?" Dat is in hun geval vaak wel zo. Datzelfde vraag ik mezelf ook regelmatig af bij ZFS. Het resultaat is hetzelfde
Sinds de 2 dagen regel reageer ik hier niet meer
Exact! Ik zou zelf ook wel wat meer tijd willen spenderen in het echt 'eigen' maken van ZFS' zdb commando, maar ik heb er gewoon de tijd niet voor.
Het liefst zou ik gewoon een pool maken van 10 disks, en dan flink er in gaan hakken met DD en kijken hoe goed ik de pool nog kan restoren
Het liefst zou ik gewoon een pool maken van 10 disks, en dan flink er in gaan hakken met DD en kijken hoe goed ik de pool nog kan restoren
Even niets...
- Mezz0
- Registratie: Februari 2001
- Laatst online: 03-07 08:22
ESXi-ZFS-NAS
:strip_exif()/u/22470/preloader-w8-cycle-black.gif?f=community)
Probleem lijkt opgelost. Ik heb de pool gedelete en een nieuwe opgebouwd met 5 identieke/zeflde merk schijven in Raidz1 en nu heb ik weer een performance van 900 read en 350 writeFireDrunk schreef op donderdag 21 augustus 2014 @ 12:48:
[...]
Ligt ook een beetje aan de manier van storage teruggeven aan je Host (ESXi). NFS is niet zo snel, iSCSI is in veel gevallen sneller. Bovendien is een L2ARC toevoegen in sommige gevallen funest voor de write performance (ZFS gaat de data cachen op de L2ARC SSD en als dat erg lang duurt, bottlenecked dat in zeldzame gevallen de algehele write speed van de pool).
Bovendien moet je gebruik maken van PVSCSI in de VM, daar word alles een stuk sneller van
Ik zal later mn screenshot nog even dumpen
http://esxilab.wordpress.com If all is virtual then what is real?
Bedenk ook dat een ZFS Pool altijd trager wordt naarmate deze voller loopt. Geen idee hoe vol je oude pool was, maar een 50% vulling scheelt al snel 20-30% in snelheid.
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 00:25
Au Contraire Mon Capitan!
Je downplayed de risico's (metheoriet inslag) maar je verwijst wel snel naar backups om je in te dekken.Nee hoor; je merkt namelijk vanzelf dat je checksum errors krijgt bij brak RAM geheugen. En dan weet je dat het tijd is om Memtest te draaien en de foute RAM module te vervangen. En daarna doe je een scrub op je ZFS pool en zie je dat er corruptie is geconstateerd en gecorrigeerd en werkt alles weer naar behoren. Geen enkele reden tot paniekvoetbal. Om je data tegen extreem kleine risico's te beschermen, waaronder een corrupte pool bij geheugencorruptie, een dode pool door een meteorietinslag enzovoorts, heb je natuurlijk backups voor de meest belangrijke data. Voor minder belangrijke data is het voldoende dat voor extreem kleine risico's je weet om welke bestanden het gaan; dan kun je die opnieuw downloaden. Probleem opgelost.
Het enige wat ik thelightning87 aanraadt, en dat geldt net zo hard met andere file systems alleen met ZFS nog meer ivm gebrek aan recovery tools is:
Boot je systeem niet in het OS zolang je RAM stuk is (of dat je hier niet zeker over bent). Zet je systeem ook zo snel mogelijk uit.
Het kan helemaal mis gaan.
Die kans dat het helemaal mist gaat wordt hier enorm gebagatelliseerd. Mensen beginnen weer de analogie met meteorieten en bliksem inslagen aan te halen. Maar het gaat niet alleen om jullie eigen data.
Dit is een stroman argument. De meeste mensen in dit forum draaien geen EXT4 + LVM met 100 snapshots. Die draaien met een hardware kaart + FS of misschien een simpele MDADM RAID + FS als ze geen ZFS gebruiken. Maar daar gaat het niet om.Los van de hele geheugendiscussie, vergelijk wel even appels met appels...
Als je een Ext4 systeem draait en daarbovenop bcache (zowel read als write), en LVM met 100 snapshots, en je gaat dan die 'simpele' recovery tooltjes draaien, ben je waarschijnlijk net zo ver van huis als met ZFS.
Het enige wat je met DD simuleert is data corruptie op disk of een totaal gefaalde drive. En ZFS is gemaakt om juist daar tegen te kunnen. Toch?Het liefst zou ik gewoon een pool maken van 10 disks, en dan flink er in gaan hakken met DD en kijken hoe goed ik de pool nog kan restoren
[ Voor 13% gewijzigd door Q op 28-08-2014 12:14 ]
Oh, die discussie mag je zonder mij voeren hoor, je weet mijn exacte standpunten daar wel van. Het ging mij alleen om de complexiteit van de tools. Niet meer en niet minder.
Kern:
Ja de (recovery) tools van ZFS zijn (vaak) complexer dan die van Ext4, *maar* je krijgt met ZFS er een bak functionaliteit bij.
Dat is alles wat ik bedoelde Voor de rest: Heb je helemaal gelijk.
BTW: Tof linkje! Zeer leerzaam!
Kern:
Ja de (recovery) tools van ZFS zijn (vaak) complexer dan die van Ext4, *maar* je krijgt met ZFS er een bak functionaliteit bij.
Dat is alles wat ik bedoelde
BTW: Tof linkje! Zeer leerzaam!
[ Voor 4% gewijzigd door FireDrunk op 28-08-2014 12:14 ]
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 00:25
Au Contraire Mon Capitan!
Oh ik zou mensen nooit ZFS afraden omdat recoveren een probleem kan zijn. Er zijn inderdaad teveel voordelen aan ZFS tov legacy om niet met ZFS te gaan.
BTW: graag gedaan Je BSD podcast staat in de queue tnx.
BTW: graag gedaan
[ Voor 16% gewijzigd door Q op 28-08-2014 12:25 ]
Zo klinkt dat anders niet...Q schreef op donderdag 28 augustus 2014 @ 00:51:
Met legacy file systems heb je het risico op bitrot. Maar als je legacy file system verkloot wordt kun je meestal nog een hoop data redden, mede omdat er ook tools voor zijn. Met ZFS is het over en sluiten als je pool corrupt raakt en de enige manier waarop dat eigenlijk kan gebeuren is rot geheugen.
Even niets...
Over het gebrek aan recoverytools in ZFS... ZFS heeft veel manieren om zelf al automatisch te recoveren. Dat is natuurlijk veel beter dan handmatig met tools aan de slag gaan. Als het theoretisch mogelijk is je data te recoveren via tools, dan zou dat ook geautomatiseerd kunnen. Dus waarom dan losse tools als je het in het filesystem zelf kunt stoppen. In theorie kun je alle potentie om je data terug te krijgen in het filesystem zelf proppen en dan worden handmatige recoverytools overbodig. Zo ver is ZFS nou ook weer niet, maar zeker een heel eind. Transaction groups terugdraaien kan trouwens met een forced import (zpool import -F) en je hebt ook een Extreme Rewind Forced import, zpool import -XF.
En Q, je zegt dat het beter is om de pool niet te blijven gebruiken; dat onderschrijf ik ook wel. Alleen denk ik juist dat je de risico's van je pool kwijtraken wel ernstig overschat. Waarop baseer je deze stelling? Heb je zelf tests gedaan en daarmee ZFS op zijn bek gekregen? Hoe verklaar je dat ik met vele tienduizenden RAM bitflips ZFS niet op zijn bek krijg? Dat een gebruiker dan extreem veel risico loopt met enkele bitflips lijkt me enigszins overdreven. En voor het mitigeren van dergelijke kleine risico's heb je natuurlijk altijd backups. Voor minder belangrijke data is het lopen van een klein risico veelal acceptabel.
Ik kan me ook niet herinneren dat iemand hier met een corrupte pool zat. Enige wat ik op ZFSguru forum heb meegemaakt is iemand die hardware RAID gebruikte en derhalve met een corrupte pool zat; maar dat is een ander verhaal natuurlijk als je een dergelijke unsupported configuratie draait. Een corrupte pool door RAM bitflips lijkt me extreem zeldzaam. Terwijl er al zoveel mensen een brak RAM reepje hadden en toch hun pool al in gebruik. Als het risico zo groot was als jij suggereert, zouden er dan inmiddels ook al een paar slachtoffers moeten zijn.
En Q, je zegt dat het beter is om de pool niet te blijven gebruiken; dat onderschrijf ik ook wel. Alleen denk ik juist dat je de risico's van je pool kwijtraken wel ernstig overschat. Waarop baseer je deze stelling? Heb je zelf tests gedaan en daarmee ZFS op zijn bek gekregen? Hoe verklaar je dat ik met vele tienduizenden RAM bitflips ZFS niet op zijn bek krijg? Dat een gebruiker dan extreem veel risico loopt met enkele bitflips lijkt me enigszins overdreven. En voor het mitigeren van dergelijke kleine risico's heb je natuurlijk altijd backups. Voor minder belangrijke data is het lopen van een klein risico veelal acceptabel.
Ik kan me ook niet herinneren dat iemand hier met een corrupte pool zat. Enige wat ik op ZFSguru forum heb meegemaakt is iemand die hardware RAID gebruikte en derhalve met een corrupte pool zat; maar dat is een ander verhaal natuurlijk als je een dergelijke unsupported configuratie draait. Een corrupte pool door RAM bitflips lijkt me extreem zeldzaam. Terwijl er al zoveel mensen een brak RAM reepje hadden en toch hun pool al in gebruik. Als het risico zo groot was als jij suggereert, zouden er dan inmiddels ook al een paar slachtoffers moeten zijn.
Enige scenario's die ik gehoord heb, zijn problemen tijdens het uitbreiden met extra VDEV's en tegelijkertijd het upgrade van ZFS pool versies. En dan gaat er op DAT moment iets fout in de kernel
Das onhandig
Das onhandig
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 00:25
Au Contraire Mon Capitan!
Er worden er niet veel genoemd maar de gevallen zijn gedocumenteerd op het FreeNAS forum. Wat daar precies is gebeurd is altijd gissen.Verwijderd schreef op donderdag 28 augustus 2014 @ 14:06:
Als het risico zo groot was als jij suggereert, zouden er dan inmiddels ook al een paar slachtoffers moeten zijn.
Met alle respect CiPHER, maar ik zou mijn keuzes niet willen baseren omdat iemand ooit een keer met wat brak geheugen een test deed en geen problemen had. Dat kan zeker leerzaam zijn maar dan zoek ik meer informatie zoals of de rotte geheugen locaties random over de chip waren verdeeld of zich concentreerden op een plek?
Lijkt me een mooie blogpost waard!
@Firedrunk, was leuke podcast over zfs war stories. Dat was een gevalletje van de pool niet upgraden maar wel je tools oid. Maar ~100 TB kopieren. Man. Met 1 GB/s duurt dat al meer dan een dag
[ Voor 18% gewijzigd door Q op 28-08-2014 14:29 ]
- Extera
- Registratie: Augustus 2004
- Laatst online: 22-06 02:20
Het toevoegen van 2 M500's als SLOG heeft niet echt gewenste resultaat 
ik heb de diks op de volgende manier opgedeeld:
Die andere 8GB's zijn voor een andere pool, maar dat zou later pas komen...
dit geeft (1TB Samsung F1's)
Dit geeft de volgende resultaten met Sync Standard
.
.
Referentie met sync=disabled
Ik ben een beetje aan het eind van mijn latijn om Vmware icm NFS goed performant te krijgen @ ZFS.
Jullie nog ideeën?
ik heb de diks op de volgende manier opgedeeld:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| [root@claustofobia] ~# gpart create -s gpt da6 da6 created [root@claustofobia] ~# gpart create -s gpt da8 da8 created [root@claustofobia] ~# gpart add -t freebsd-zfs -b 2048 -a 4k -l log0 -s 8G da6 da6p1 added [root@claustofobia] ~# gpart add -t freebsd-zfs -b 2048 -a 4k -l log2 -s 8G da6 da6p2 added [root@claustofobia] ~# gpart add -t freebsd-zfs -b 2048 -a 4k -l cache0 -s 90G da6 da6p3 added [root@claustofobia] ~# gpart add -t freebsd-zfs -b 2048 -a 4k -l log1 -s 8G da8 da8p1 added [root@claustofobia] ~# gpart add -t freebsd-zfs -b 2048 -a 4k -l log3 -s 8G da8 da8p2 added [root@claustofobia] ~# gpart add -t freebsd-zfs -b 2048 -a 4k -l cache1 -s 90G da8 da8p3 added [root@claustofobia] ~# zpool add SAN log mirror gpt/log0 gpt/log1 [root@claustofobia] ~# zpool add SAN cache gpt/cache0 gpt/cache1 |
Die andere 8GB's zijn voor een andere pool, maar dat zou later pas komen...
dit geeft (1TB Samsung F1's)
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| [root@claustofobia] ~# zpool status
pool: SAN
state: ONLINE
scan: scrub repaired 0 in 3h43m with 0 errors on Sun Aug 17 03:43:04 2014
config:
NAME STATE READ WRITE CKSUM
SAN ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gptid/10f7bbfb-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0
gptid/11523654-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/11f92775-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0
gptid/126ce3fe-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
gptid/12cdaa49-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0
gptid/133878f0-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0
mirror-3 ONLINE 0 0 0
gptid/6d3d8cb4-f57a-11e3-86a4-0060dd47d1cb ONLINE 0 0 0
gptid/7079a32c-f57a-11e3-86a4-0060dd47d1cb ONLINE 0 0 0
logs
mirror-4 ONLINE 0 0 0
gpt/log0 ONLINE 0 0 0
gpt/log1 ONLINE 0 0 0
cache
gpt/cache0 ONLINE 0 0 0
gpt/cache1 ONLINE 0 0 0 |
Dit geeft de volgende resultaten met Sync Standard
code:
1
2
3
4
| [root@claustofobia] /mnt/SAN/VMware# zfs get sync NAME PROPERTY VALUE SOURCE SAN sync standard default SAN/VMware sync standard local |
.
.
Referentie met sync=disabled
Ik ben een beetje aan het eind van mijn latijn om Vmware icm NFS goed performant te krijgen @ ZFS.
Jullie nog ideeën?
Al je writes zijn sync writes; dat is niet hoe het hoort. Sync writes horen enkel bij FLUSH CACHE commando's te gebeuren. Als alle writes sync writes zijn, is je performance met of zonder sLOG bijzonder slecht. Is er een mogelijkheid om VMware normaal te laten omgaan met sync writes? Alles maar op de sync zetten is wat er bij 1e generatie filesystems gebeurde; in de jaren 80 en 90. Dat zou 2014 niet meer mogen gebeuren.
Daarnaast vraag ik me af of je je SSDs wel juist hebt gepartitioneerd zodat je tenminste 25 tot 40 procent van de SSD vrijhoud voor overprovisioning. Dat is nodig als je de SSD voor L2ARC cache gebruikt. Een dergelijk gebruik vereist veel meer spare space dan een normaal filesystem. sLOG zelf heeft niet bijzonder behoefte aan spare space; omdat dezelfde ruimte continu wordt overschreven. Je hebt 8GiB gebruikt; dat is vrij veel. 4GiB zou wellicht beter zijn; dat is fijner voor je SSD aangezien een minder groot stuk LBA elke keer wordt overschreven.
De oplossing voor je performanceprobleem licht aan de client-zijde: die moet niet zoveel sync writes veroorzaken. Want aan ZFS zijde heb je dan enkel de mogelijkheid tot het eerbiedigen van al die sync writes; of het als async behandelen van sync writes. Dat is wat de instelling sync=disabled doet. Dat betekent echter dat je ook voor metadata writes geen sync writes hebt. Normaliter zijn alleen dergelijke writes sync en zijn alle normale writes async. Dat is hoe het hoort.
Daarnaast vraag ik me af of je je SSDs wel juist hebt gepartitioneerd zodat je tenminste 25 tot 40 procent van de SSD vrijhoud voor overprovisioning. Dat is nodig als je de SSD voor L2ARC cache gebruikt. Een dergelijk gebruik vereist veel meer spare space dan een normaal filesystem. sLOG zelf heeft niet bijzonder behoefte aan spare space; omdat dezelfde ruimte continu wordt overschreven. Je hebt 8GiB gebruikt; dat is vrij veel. 4GiB zou wellicht beter zijn; dat is fijner voor je SSD aangezien een minder groot stuk LBA elke keer wordt overschreven.
De oplossing voor je performanceprobleem licht aan de client-zijde: die moet niet zoveel sync writes veroorzaken. Want aan ZFS zijde heb je dan enkel de mogelijkheid tot het eerbiedigen van al die sync writes; of het als async behandelen van sync writes. Dat is wat de instelling sync=disabled doet. Dat betekent echter dat je ook voor metadata writes geen sync writes hebt. Normaliter zijn alleen dergelijke writes sync en zijn alle normale writes async. Dat is hoe het hoort.
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Zojuist kreeg ik bij een upgrade van ZFSGuru oftewel FreeBSD een paar vervelende gasten :
plexmediaserver-plexpass en compat9x-amd64
Oplossing? Een force pkg update:
En we zijn weer op de rit.
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| New packages to be INSTALLED:
db5: 5.3.28_1
plexmediaserver-plexpass: 0.9.9.16.555
compat9x-amd64: 9.2.902000.201310
jpeg-turbo: 1.3.0_2
Installed packages to be UPGRADED:
pcre: 8.34_2 -> 8.35
php55-gd: 5.5.15 -> 5.5.15_1
php55: 5.5.15 -> 5.5.15_1
mod_php55: 5.5.15 -> 5.5.15_1
apr: 1.5.1.1.5.3_3 -> 1.5.1.1.5.3_4
sqlite3: 3.8.5_1 -> 3.8.6
py27-six: 1.5.2 -> 1.7.3_1
py27-cryptography: 0.4 -> 0.5.4
git: 2.0.2_1 -> 2.1.0
php55-dom: 5.5.15 -> 5.5.15_1
php55-session: 5.5.15 -> 5.5.15_1
php55-mysqli: 5.5.15 -> 5.5.15_1
php55-json: 5.5.15 -> 5.5.15_1
php55-mysql: 5.5.15 -> 5.5.15_1
php55-mcrypt: 5.5.15 -> 5.5.15_1
openldap-server: 2.4.39_2 -> 2.4.39_3
php55-hash: 5.5.15 -> 5.5.15_1
php55-openssl: 5.5.15 -> 5.5.15_1
cdialog: 1.2.20140219,1 -> 1.2.20140219,2
Installed packages to be REINSTALLED:
glib-2.36.3_3 (needed shared library changed)
ldb-1.1.17 (needed shared library changed)
tevent-0.9.21 (needed shared library changed)
gobject-introspection-1.36.0_2 (needed shared library changed)
dbus-glib-0.100.2_1 (needed shared library changed)
apache24-2.4.10_1 (needed shared library changed)
avahi-app-0.6.31_2 (needed shared library changed)
py27-cffi-0.8.6 (needed shared library changed)
denyhosts-2.6_5 (direct dependency changed)
rdiff-backup-1.2.8_1,1 (needed shared library changed)
py27-cheetah-2.4.4_1 (needed shared library changed)
py27-sqlite3-2.7.8_5 (needed shared library changed)
py27-yenc-0.3 (needed shared library changed)
lighttpd-1.4.35_5 (needed shared library changed)
The process will require 36 MB more space.
79 MB to be downloaded. |
plexmediaserver-plexpass en compat9x-amd64
Oplossing? Een force pkg update:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # pkg update -f
Updating FreeBSD repository catalogue...
Fetching meta.txz: 100% 944 B 0.9k/s 00:01
Fetching digests.txz: 100% 2 MB 2.0M/s 00:01
Fetching packagesite.txz: 100% 5 MB 1.1M/s 00:05
Processing new repository entries: 100%
FreeBSD repository update completed. 23409 packages processed:
0 updated, 0 removed and 23409 added.
# pkg autoremove
Checking integrity... done (0 conflicting)
Deinstallation has been requested for the following 9 packages:
Installed packages to be REMOVED:
compat9x-amd64-9.2.902000.201310
plexmediaserver-plexpass-0.9.9.16.555
db46-4.6.21.4
db48-4.8.30.0_2
libassuan-2.1.1_1
libgcrypt-1.6.1_3
libgpg-error-1.13_1
libksba-1.3.0_1
pth-2.0.7
The operation will free 196 MB. |
En we zijn weer op de rit.
Sinds de 2 dagen regel reageer ik hier niet meer
Wat voor pkg commando geef je dan op? Want TO BE INSTALLED betekent dat plex-plexpass op dit moment niet is geïnstalleerd, maar dat het pkg-commando dit wilt gaan installeren. Dus hoe zit dat dan?
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Een normale pkg upgrade. Er was dus iets flink mis met de pkg database. Of een promotieactie van plex
Sinds de 2 dagen regel reageer ik hier niet meer
Lijkt me een bug aan de zijde van pkg inderdaad. Er wordt overigens nog flink gesleuteld aan pkgNG - er komen regelmatig nieuwe versies uit van 'pkg'. De paar versies terug kreeg ik nog elke keer een melding dat ik 'pkg-static' moest draaien, terwijl dat onzin was en het draaien ervan de melding ook niet wegkreeg. Kortom, het moet nog stabiliseren. Ook op andere gebieden is FreeBSD nog druk bezig; waaronder de native iSCSI implementatie, waar zeer regelmatig commits binnenkomen. En ook bhyve krijgt vrij regelmatig commits. Die volg ik een beetje. De indruk die ik heb is dat het nog een tijd moet rijpen voordat het echt volwassen is.
NFS is altijd kut, en CrystalDiskMark is zelf ook niet zo'n goede bencmark tool ben ik achter gekomen... Probeer eens AS-SSD of IOMeter, dan krijg je hele andere resultaten.Extera schreef op vrijdag 29 augustus 2014 @ 00:28:
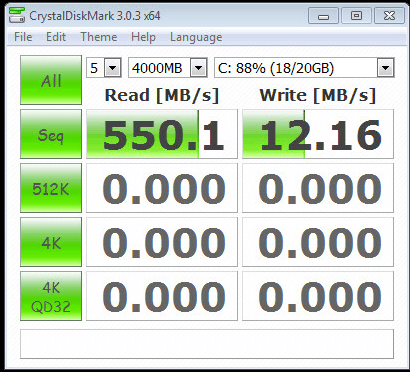
Het toevoegen van 2 M500's als SLOG heeft niet echt gewenste resultaat
ik heb de diks op de volgende manier opgedeeld:
code:
Die andere 8GB's zijn voor een andere pool, maar dat zou later pas komen...
dit geeft (1TB Samsung F1's)
code:
[root@claustofobia] ~# zpool status pool: SAN state: ONLINE scan: scrub repaired 0 in 3h43m with 0 errors on Sun Aug 17 03:43:04 2014 config: NAME STATE READ WRITE CKSUM SAN ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 gptid/10f7bbfb-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0 gptid/11523654-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0 mirror-1 ONLINE 0 0 0 gptid/11f92775-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0 gptid/126ce3fe-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0 mirror-2 ONLINE 0 0 0 gptid/12cdaa49-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0 gptid/133878f0-efc8-11e3-8dd5-0060dd47d1cb ONLINE 0 0 0 mirror-3 ONLINE 0 0 0 gptid/6d3d8cb4-f57a-11e3-86a4-0060dd47d1cb ONLINE 0 0 0 gptid/7079a32c-f57a-11e3-86a4-0060dd47d1cb ONLINE 0 0 0 logs mirror-4 ONLINE 0 0 0 gpt/log0 ONLINE 0 0 0 gpt/log1 ONLINE 0 0 0 cache gpt/cache0 ONLINE 0 0 0 gpt/cache1 ONLINE 0 0 0
Dit geeft de volgende resultaten met Sync Standard
code:
.
[afbeelding]
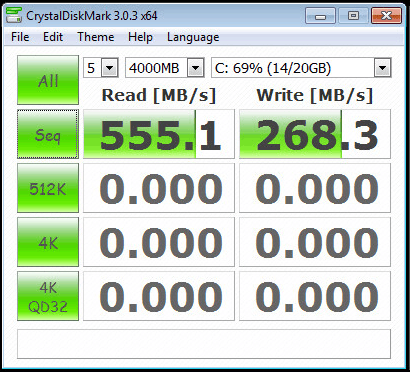
.
Referentie met sync=disabled
[afbeelding]
Ik ben een beetje aan het eind van mijn latijn om Vmware icm NFS goed performant te krijgen @ ZFS.
Jullie nog ideeën?
Ik ben om exact jouw reden naar iSCSI overgestapt, zelfs met 2 * Intel DC S3700 200GB als SLOG was NFS hier nog traag...
Even niets...
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Mbt PKG: Er is iets veranderd in 1.3.7 waardoor je eerst pkg update -f moest doen.
Kan de mailing nu zo snel niet vinden
Kan de mailing nu zo snel niet vinden
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Handig dat dat niet even in een post installatie bericht wordt verteld.
Sinds de 2 dagen regel reageer ik hier niet meer
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Het levert niet altijd problemen op en hoe had je dit bericht willen zien? Volgens mij kun je geen berichten tonen na installatie zoals met ports wel het geval is.CurlyMo schreef op vrijdag 29 augustus 2014 @ 10:03:
Handig dat dat niet even in een post installatie bericht wordt verteld.
Hebbes:
Pkg 1.3.7 is now released. The port is updated. pkg.FreeBSD.org packages
are now published with fixed shared libraries.
It was found that 'pkg update -f' may be required as well.
Here are the updated instructions:
- Binary package users should run 'pkg update -f' and 'pkg check -Ba'
after upgrading to pkg-1.3.7 and before updating any other packages.
This avoids needing to reinstall anything not needed due to changed
shared libraries.
For binary package users:
# pkg install ports-mgmt/pkg
# pkg update -f
# pkg check -Ba
# pkg upgrade
For port users:
# portsnap fetch update
# make -C /usr/ports/ports-mgmt/pkg build deinstall install clean
# pkg check -Ba
- People building packages for serving to other systems need to rebuild
all packages with 1.3.7.
[ Voor 55% gewijzigd door matty___ op 29-08-2014 10:17 ]
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Zag laatst een presentatie met benchmarks tussen vmware en byhve en vmware was nog wel sneller maar het gat is niet zo groot als je denkt.Verwijderd schreef op vrijdag 29 augustus 2014 @ 00:57:
En ook bhyve krijgt vrij regelmatig commits. Die volg ik een beetje. De indruk die ik heb is dat het nog een tijd moet rijpen voordat het echt volwassen is.
Als je dan bedenkt dat bhyve met super weinig loc is gemaakt en dit beetje de eerste iteratie is, is het best wel indrukwekkend. Want hoe lang is vmware al op de markt?
Let wel dit is 10.0 Release:
http://andrea.brancatelli...ware-esxi-5-5-comparison/
http://andrea.brancatelli...xi-5-5-comparison-part-2/
Interessant artikeltje!
Even niets...
- toelie
- Registratie: December 2006
- Laatst online: 05-06 09:03
Klopt iSCSI is over het algemeen een stukje sneller, maar 12 mb/s sequential writes met dubbel M500 als SLOG is echt niet normaal te noemen.FireDrunk schreef op vrijdag 29 augustus 2014 @ 08:17:
[...]
NFS is altijd kut, en CrystalDiskMark is zelf ook niet zo'n goede bencmark tool ben ik achter gekomen... Probeer eens AS-SSD of IOMeter, dan krijg je hele andere resultaten.
Ik ben om exact jouw reden naar iSCSI overgestapt, zelfs met 2 * Intel DC S3700 200GB als SLOG was NFS hier nog traag...
Net even crystal disk mark gedraait. Hier haal ik 143 mb/s synced sequential writes in een windows 7 vm die op NFS datastore draait met een 100GB DC S3700 als SLOG terwijl er ook nog 8 andere vm's draaien.
- Berkeley
- Registratie: Juli 2013
- Laatst online: 08-11-2025
/u/527806/freebsd_black.png?f=community)
Hallo mensen! Ik export een ZVOL via iSCSI naar mijn virtualisatie server(FreeBSD). Nu wil ik graag aan de virtualisatie kant gebruik maken van snapshots om die vervolgens te verplaatsen/op te slaan op een aparte pool op mijn storage server. Is dit mogelijk, of is dit te omslachtig en zijn er betere oplossingen?
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Gewoon je zvol benaderen als elk ander ZFS bestandsysteem. Werkt prima.
Sinds de 2 dagen regel reageer ik hier niet meer
- Berkeley
- Registratie: Juli 2013
- Laatst online: 08-11-2025
Of ik begrijp jou niet helemaal of net andersom, maar het geen waarom ik dit graag wil is omdat als ik bijvoorbeeld een verkeerde directory verwijder ik hem via de snapshots op de storage server zo terug kan halen, of worden snapshots niet in dezelfde directory opgeslagen oid?CurlyMo schreef op zaterdag 30 augustus 2014 @ 21:00:
Gewoon je zvol benaderen als elk ander ZFS bestandsysteem. Werkt prima.
En ook vooral, als je pool bijvoorbeeld toch kappot gaat oid, je alle snapshots nog wel hebt.
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Een zvol heeft exact dezelfde eigenschappen als een zfs bestandssysteem en kan dus ook vrijwel hetzelfde:
Overtuigd Ik zou je trouwens adviseren om het zelf ook een zo te testen met een dummy zvol.
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| # zfs create -V 100M data/test # newfs /dev/zvol/data/test # mkdir /tmp/test # mount /dev/zvol/data/test /tmp/test # df -h /dev/zvol/data/test 96M 8.0K 89M 0% /tmp/test # cd /tmp/test # dd if=/dev/random of=test.txt bs=50M count=1 # ls .snap test.txt # md5 test.txt MD5 (test.txt) = 41edb0c4be3dfad8c51a030c65532bf1 # zfs snapshot data/test@foo01 data/test@foo01 0 - 74.2M - # zfs list -t snapshot -r data/test NAME USED AVAIL REFER MOUNTPOINT data/test@foo01 0 - 74.2M - # rm test.txt # ls .snap # zfs rollback data/test@foo01 cannot rollback 'data/test': dataset is busy # cd .. # umount /tmp/test # zfs rollback data/test@foo01 # mount /dev/zvol/data/test /tmp/test/ mount: /dev/zvol/data/test: R/W mount of /tmp/test denied. Filesystem is not clean - run fsck.: Operation not permitted # fsck_ufs /dev/zvol/data/test ** /dev/zvol/data/test ** Last Mounted on /tmp/test ** Phase 1 - Check Blocks and Sizes ** Phase 2 - Check Pathnames ** Phase 3 - Check Connectivity ** Phase 4 - Check Reference Counts ** Phase 5 - Check Cyl groups 3 files, 12810 used, 11869 free (21 frags, 1481 blocks, 0.1% fragmentation) ***** FILE SYSTEM MARKED CLEAN ***** # mount /dev/zvol/data/test /tmp/test/ # cd /tmp/test/ # ls .snap test.txt MD5 (test.txt) = 41edb0c4be3dfad8c51a030c65532bf1 |
Overtuigd
Sinds de 2 dagen regel reageer ik hier niet meer
- nero355
- Registratie: Februari 2002
- Laatst online: 22-02 18:06
:strip_exif()/u/49248/DPCkoeienUD.gif?f=community)
Dat jij stout bent geweest is geen excuus om FreeBSD te gaan zitten beschuldigenCurlyMo schreef op vrijdag 29 augustus 2014 @ 10:03:
Handig dat dat niet even in een post installatie bericht wordt verteld.
http://svnweb.freebsd.org/ports/head/UPDATING?view=markup <= ALTIJD LEZEN voordat je gaat UPGRADEN!!!
Maar door het niet te doen leer je opzich ook wel van : Je leert dan namelijk hoeveel tijd je verspilt door geen instructies op te volgen
|| Stem op mooiere Topic Search linkjes! :) " || Pi-Hole : Geen advertenties meer voor je hele netwerk! >:) ||
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Dat is maar deels waar. FreeBSD packages hebben de mogelijkheid om de gebruiker van informatie te voorzien nadat een pakket is geïnstalleerd. In het geval van Samba ziet dat er zo uit (in de +MANIFEST):
Ik zou het dus vanzelfsprekend vinden als die informatie over het geforceerd updaten van je database dus ook gewoon in die message wordt gestopt. Dan wordt je op de plek waar je die informatie wilt hebben geïnformeerd; tijdens je upgrade.
code:
1
2
3
4
5
6
7
8
| message: |- =============================================================================== Samba3 *package* now doesn't include ADS support due the portability problems with Kerberos5 libraries on different installations. You need to compile the port yourself to get this functionality. For additional hints and directions, please, look into the README.FreeBSD file. =============================================================================== |
Ik zou het dus vanzelfsprekend vinden als die informatie over het geforceerd updaten van je database dus ook gewoon in die message wordt gestopt. Dan wordt je op de plek waar je die informatie wilt hebben geïnformeerd; tijdens je upgrade.
Sinds de 2 dagen regel reageer ik hier niet meer
- GoVegan
- Registratie: Juni 2002
- Laatst online: 19-06 07:45
Graag advies gevraagd,
ik zit hier momenteel met een ch3snas met 2 hdd in raid 1 waar op een paar mysql databasen draaien en een ruimte waar via smb en ftp backups neer worden gezet.
met name de snelheid van de nas is niet meer toereikend voor de mysql databasen.
met die reden op zoek naar wat nieuws.
Vooral Software matig vind ik het beetje lastig. Lees veel positiefs over zfs, OS word dus waarschijnlijk zfsguru of nas4free.
Belangrijkste voor mij is dat het een continue systeem word. met name mysql moet door blijven draaien.
backup opslag zit nu rond de 1 tb dus max 2 tb aan ruimte hiervoor nodig. msyql niet meer dan paar 100 mb.
Als ik het goed begrijp zit ik dan met raid1 (met 2 3tb schijven) al safe?
En heb ik de nog de mogelijkheid om later extra schijven toe te voegen als extra mirrors?
eventueel een kleine ssd voor l2arc en zil voor wat extra snelheid?
zat te denken om 3 pools te maken voor system, backup en mysql (dit is toch mogelijk wanneer je de schijf 3 losse partitions maakt)
Wat hardware betreft zit ik momenteel de denken aan het onderstaande.
Iemand nog tips of adviezen?
ik zit hier momenteel met een ch3snas met 2 hdd in raid 1 waar op een paar mysql databasen draaien en een ruimte waar via smb en ftp backups neer worden gezet.
met name de snelheid van de nas is niet meer toereikend voor de mysql databasen.
met die reden op zoek naar wat nieuws.
Vooral Software matig vind ik het beetje lastig. Lees veel positiefs over zfs, OS word dus waarschijnlijk zfsguru of nas4free.
Belangrijkste voor mij is dat het een continue systeem word. met name mysql moet door blijven draaien.
backup opslag zit nu rond de 1 tb dus max 2 tb aan ruimte hiervoor nodig. msyql niet meer dan paar 100 mb.
Als ik het goed begrijp zit ik dan met raid1 (met 2 3tb schijven) al safe?
En heb ik de nog de mogelijkheid om later extra schijven toe te voegen als extra mirrors?
eventueel een kleine ssd voor l2arc en zil voor wat extra snelheid?
zat te denken om 3 pools te maken voor system, backup en mysql (dit is toch mogelijk wanneer je de schijf 3 losse partitions maakt)
Wat hardware betreft zit ik momenteel de denken aan het onderstaande.
Iemand nog tips of adviezen?
| # | Product | Prijs | Subtotaal |
| 1 | Intel Pentium G3220 Boxed | € 45,50 | € 45,50 |
| 1 | ASRock B85M Pro4 | € 55,- | € 55,- |
| 2 | WD Red SATA 6 Gb/s WD30EFRX, 3TB | € 100,96 | € 201,92 |
| 1 | Kingston KVR1333D3N9/8G | € 70,- | € 70,- |
| 1 | Seasonic G-Serie 360Watt | € 50,- | € 50,- |
| 1 | Crucial MX100 256GB | € 89,99 | € 89,99 |
| Bekijk collectie Importeer producten | Totaal | € 512,41 | |
- Beninho
- Registratie: April 2011
- Laatst online: 04-07 15:07
Ik heb een vraag of ZFS-snapshots.
Mijn systeem in de afgelopen jaren gigantisch veel snapshots gemaakt, veelal van data waarvan er nu geen snapshots meer noodzakelijk zijn. Ik heb het commando gevonden waarmee ik individuele snapshots kan verwijderen, maar bestaat er ook een mogelijkheid / commando om alle snapshots collectief te verwijderen?
Mijn systeem in de afgelopen jaren gigantisch veel snapshots gemaakt, veelal van data waarvan er nu geen snapshots meer noodzakelijk zijn. Ik heb het commando gevonden waarmee ik individuele snapshots kan verwijderen, maar bestaat er ook een mogelijkheid / commando om alle snapshots collectief te verwijderen?
panasonic 5KW L-serie | 300L SWW | 3700+3200 Wp oost-west
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Zelf even een loopje maken die dat doet. Je kan op internet voldoende voorbeelden vinden. Je kan ook het scriptje zfs-auto-snapshot gebruiken.
Sinds de 2 dagen regel reageer ik hier niet meer
- lord4163
- Registratie: Oktober 2010
- Laatst online: 11-01 21:30
Ik gebruik zelf zfs-periodic (als ik me dat juist herinner). Kun je zelf regels maken, bijvoorbeeld kun je zeggen elke dag een snapshot maken, na een week alleen een snapshot van de week behouden, na een maand slechts een van die maand behouden en hetzelfde voor een jaar. (zo heb ik het)Beninho schreef op zondag 31 augustus 2014 @ 13:46:
Ik heb een vraag of ZFS-snapshots.
Mijn systeem in de afgelopen jaren gigantisch veel snapshots gemaakt, veelal van data waarvan er nu geen snapshots meer noodzakelijk zijn. Ik heb het commando gevonden waarmee ik individuele snapshots kan verwijderen, maar bestaat er ook een mogelijkheid / commando om alle snapshots collectief te verwijderen?
- Extera
- Registratie: Augustus 2004
- Laatst online: 22-06 02:20
Klopt, VMware gaat nogal geforceerd om met writes door alles maar synced te willen.Verwijderd schreef op vrijdag 29 augustus 2014 @ 00:39:
Al je writes zijn sync writes; dat is niet hoe het hoort. Sync writes horen enkel bij FLUSH CACHE commando's te gebeuren. Als alle writes sync writes zijn, is je performance met of zonder sLOG bijzonder slecht. Is er een mogelijkheid om VMware normaal te laten omgaan met sync writes? Alles maar op de sync zetten is wat er bij 1e generatie filesystems gebeurde; in de jaren 80 en 90. Dat zou 2014 niet meer mogen gebeuren.
Wat mij betreft niet geheel zonder reden, VMware wil gewoon zeker weten dat de data veilig is weggeschreven.
Ik vraag mij af hoe dit in professionele omgevingen wordt opgelost. In een Cisco Flexpod design worden in professionele ook NFS shares gebruik in VMware. Dit performed gewoon prima (10Gbit voltrekken is een eitje).
Dat is een forse over provisoning. Bedankt voor de tips. Ik zal de SLOGs verkleinen naar 4GB, en 40% vrijhouden (L2ARC dus verkleinen).Verwijderd schreef op vrijdag 29 augustus 2014 @ 00:39:
Daarnaast vraag ik me af of je je SSDs wel juist hebt gepartitioneerd zodat je tenminste 25 tot 40 procent van de SSD vrijhoud voor overprovisioning. Dat is nodig als je de SSD voor L2ARC cache gebruikt. Een dergelijk gebruik vereist veel meer spare space dan een normaal filesystem. sLOG zelf heeft niet bijzonder behoefte aan spare space; omdat dezelfde ruimte continu wordt overschreven. Je hebt 8GiB gebruikt; dat is vrij veel. 4GiB zou wellicht beter zijn; dat is fijner voor je SSD aangezien een minder groot stuk LBA elke keer wordt overschreven.
Klopt, alleen VMware zal dit met een reden doen, en die respecteer ik liever dan dat ik sync ga disablen.Verwijderd schreef op vrijdag 29 augustus 2014 @ 00:39:
De oplossing voor je performance probleem licht aan de client-zijde: die moet niet zoveel sync writes veroorzaken. Want aan ZFS zijde heb je dan enkel de mogelijkheid tot het eerbiedigen van al die sync writes; of het als async behandelen van sync writes. Dat is wat de instelling sync=disabled doet. Dat betekent echter dat je ook voor metadata writes geen sync writes hebt. Normaliter zijn alleen dergelijke writes sync en zijn alle normale writes async. Dat is hoe het hoort.
Dus, of de performance omhoog met NFS, of ik blijf iSCSI draaien.
Dat eerste is mislukt
Ik zal eens naar AS-SSD kijken. IOMeter is op zoveel manieren in te stellen dat het lastig is om een bench te draaien welke mooi vergelijkingsmateriaal oplevert, of het moet gaan om benches puur om de performance verschillen tussen de technieken naar boven te halenFireDrunk schreef op vrijdag 29 augustus 2014 @ 08:17:
NFS is altijd kut, en CrystalDiskMark is zelf ook niet zo'n goede bencmark tool ben ik achter gekomen... Probeer eens AS-SSD of IOMeter, dan krijg je hele andere resultaten.
Ik ben om exact jouw reden naar iSCSI overgestapt, zelfs met 2 * Intel DC S3700 200GB als SLOG was NFS hier nog traag...
Dat is interessant, dat zou toch betekenen dat er bij mij iets verkeerd gaat...toelie schreef op vrijdag 29 augustus 2014 @ 10:47:
Klopt iSCSI is over het algemeen een stukje sneller, maar 12 mb/s sequential writes met dubbel M500 als SLOG is echt niet normaal te noemen.
Net even crystal disk mark gedraait. Hier haal ik 143 mb/s synced sequential writes in een windows 7 vm die op NFS datastore draait met een 100GB DC S3700 als SLOG terwijl er ook nog 8 andere vm's draaien.
HELD!RobHaz schreef op zaterdag 30 augustus 2014 @ 20:59:
Hallo mensen! Ik export een ZVOL via iSCSI naar mijn virtualisatie server(FreeBSD). Nu wil ik graag aan de virtualisatie kant gebruik maken van snapshots om die vervolgens te verplaatsen/op te slaan op een aparte pool op mijn storage server. Is dit mogelijk, of is dit te omslachtig en zijn er betere oplossingen?
Je brengt mij op een idee, ik ga het ook op deze manier oplossen.
Geen NFS, wel iSCSI, alleen geen file extend maar een ZVOL.
Ik wist niet dat je die kan mounten en inzien, wat met een iSCSI file extend niet kan.
Dit is de gulden middenweg wat mij betreft, het ZVOL kan ik snapshotten repliceren naar een aparte dataset en mocht ik een backup terug willen zetten kan ik een rollback doen op de backup dataset en de files van de VM eruit plukken.
Met een iSCSI file extend was dit veel te omslachtig.
- Extera
- Registratie: Augustus 2004
- Laatst online: 22-06 02:20
huh? ik krijg mijn ZVOL niet gemount
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| [root@claustofobia] ~# zfs create -V 100M SAN/test
[root@claustofobia] ~# newfs /dev/zvol/SAN/test
/dev/zvol/SAN/test: 100.0MB (204800 sectors) block size 32768, fragment size 4096
using 4 cylinder groups of 25.03MB, 801 blks, 3328 inodes.
super-block backups (for fsck_ffs -b #) at:
192, 51456, 102720, 153984
[root@claustofobia] ~# mount /dev/zvol/SAN/test /tmp/test/
mount: /dev/zvol/SAN/test: No such file or directory
[root@claustofobia] ~# cd /dev/zvol/SAN/
[root@claustofobia] /dev/zvol/SAN# ls
./ ../ test
[root@claustofobia] /dev/zvol/SAN# ls -lah
total 1
dr-xr-xr-x 2 root wheel 512B Sep 1 12:28 ./
dr-xr-xr-x 3 root wheel 512B Sep 1 12:28 ../
crw-r----- 1 root operator 0x103 Sep 1 12:28 test |
Wat voor FS is newfs?
Even niets...
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
UFS.
@Extera, welk besturingssysteem?
@Extera, welk besturingssysteem?
Sinds de 2 dagen regel reageer ik hier niet meer
- Extera
- Registratie: Augustus 2004
- Laatst online: 22-06 02:20
ik heb die commando's ook maar overgenomen van CurlyMo 
Ik draai FreeNAS, FreeBSD 9.2-RELEASE-p9
Ik draai FreeNAS, FreeBSD 9.2-RELEASE-p9
Staat er nog iets in dmesg of je kernel log?
Even niets...
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 22:16
Zojuist hier nogmaal geprobeerd en het werkt zonder problemen
FreeBSD server 10.0-STABLE FreeBSD 10.0-STABLE #0: Sun Apr 20 21:20:08 UTC 2014 jason@zfsguru:/usr/obj/tmpfs/2-source/sys/NEWCONS-OFED-POLLING-ALTQ amd64
FreeBSD server 10.0-STABLE FreeBSD 10.0-STABLE #0: Sun Apr 20 21:20:08 UTC 2014 jason@zfsguru:/usr/obj/tmpfs/2-source/sys/NEWCONS-OFED-POLLING-ALTQ amd64
Sinds de 2 dagen regel reageer ik hier niet meer
/u/116403/crop64cfe7aeafeb6_cropped.png?f=community)
@Govegan
Tevens is een l2arc misschien ook wat overbodig, maar dat hangt een beetje af wat je NAS verder doet. Maar een l2arc voor een smb share die af en toe gebruikt word is niet de moeite.
Een tweede partitie voor backup, die kan ik niet helemaal plaatsen in het geheel.
Is dit de backup van de andere datasets, of is dit een backup share voor een andere machine?
Als dit als backup is voor de lokale data dan zou ik deze gewoon weglaten aangezien je dan beter copies=2 op de zfs dataset kan zetten met af en toe een snapshot.
Voor mysql kun je misschien een tweede ssd aanschaffen en een aparte ssd pool aanmaken voor mysql.
Als ik het goed begrijp is dat het belangrijkste onderdeel van de NAS. Voor deze dataset kun je gezien de grote van de mysql database dan ook twee kleinere ssd's nemen. tevens kun je dan de snapshots nog kopieren naar de twee hdd's. Je kan zelfs een aparte jail draaien op de ssd dataset met een aparte mysql server.
Maar zorg er zeker voor dat er een echte backup aanwezig is voor je data.!!! Offsite of op een externe USB of esata disk.
gr
Ik denk niet dat een SLOG device zoden aan de dijk gaat zetten aangezien je hoogstwaarschijnlijk geen sync writes hebt.Als ik het goed begrijp zit ik dan met raid1 (met 2 3tb schijven) al safe?
En heb ik de nog de mogelijkheid om later extra schijven toe te voegen als extra mirrors?
eventueel een kleine ssd voor l2arc en zil voor wat extra snelheid?
zat te denken om 3 pools te maken voor system, backup en mysql (dit is toch mogelijk wanneer je de schijf 3 losse partitions maakt)
Tevens is een l2arc misschien ook wat overbodig, maar dat hangt een beetje af wat je NAS verder doet. Maar een l2arc voor een smb share die af en toe gebruikt word is niet de moeite.
Een tweede partitie voor backup, die kan ik niet helemaal plaatsen in het geheel.
Is dit de backup van de andere datasets, of is dit een backup share voor een andere machine?
Als dit als backup is voor de lokale data dan zou ik deze gewoon weglaten aangezien je dan beter copies=2 op de zfs dataset kan zetten met af en toe een snapshot.
Voor mysql kun je misschien een tweede ssd aanschaffen en een aparte ssd pool aanmaken voor mysql.
Als ik het goed begrijp is dat het belangrijkste onderdeel van de NAS. Voor deze dataset kun je gezien de grote van de mysql database dan ook twee kleinere ssd's nemen. tevens kun je dan de snapshots nog kopieren naar de twee hdd's. Je kan zelfs een aparte jail draaien op de ssd dataset met een aparte mysql server.
Maar zorg er zeker voor dat er een echte backup aanwezig is voor je data.!!! Offsite of op een externe USB of esata disk.
gr
Ach, zelfs casual MySQL kan prima op een harddisk hoor... Voordat je echt aan het limiet van een Harddisk zit met MySQL moet je al goed je best doen hoor... Een beetje websites op MySQL jeukt een HDD echt niet...
Even niets...
- Extera
- Registratie: Augustus 2004
- Laatst online: 22-06 02:20
Nope!FireDrunk schreef op maandag 01 september 2014 @ 13:32:
Staat er nog iets in dmesg of je kernel log?
Vreemd!CurlyMo schreef op maandag 01 september 2014 @ 13:35:
Zojuist hier nogmaal geprobeerd en het werkt zonder problemen
FreeBSD server 10.0-STABLE FreeBSD 10.0-STABLE #0: Sun Apr 20 21:20:08 UTC 2014 jason@zfsguru:/usr/obj/tmpfs/2-source/sys/NEWCONS-OFED-POLLING-ALTQ amd64
Ik krijg het niet voor elkaar.
Ik zal het nog eens proberen in een test VM vanavond, en anders een topic openen @ FreeNAS forums.
- Berkeley
- Registratie: Juli 2013
- Laatst online: 08-11-2025
Het geen hoe ik het altijd doe op FreeBSD:Extera schreef op maandag 01 september 2014 @ 14:26:
[...]
Nope!
[...]
Vreemd!
Ik krijg het niet voor elkaar.
Ik zal het nog eens proberen in een test VM vanavond, en anders een topic openen @ FreeNAS forums.
Je maakt de zvol( zfs create -v xxxG pool/zvolname of iets dergelijks)
en daarna gooi je in je /etc/ctl.conf (FreeBSD 10.0) bijvoorbeeld:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| auth-group ag0 {
chap username1 secretsecret
}
portal-group pg0 {
discovery-auth-group no-authentication
listen 0.0.0.0
listen [::]
}
target iqn.tweakers.com:target0 {
auth-group ag0
portal-group pg0
lun 0 {
path /dev/zvol/pool/zvol
size 100G
}
} |
Dat is _alles_ dat je doet op de iSCSI server. En natuurlijk even de service starten enzo(zie: https://www.freebsd.org/doc/handbook/network-iscsi.html voor een betere uitleg)
Wat je doet aan de kankt waar je hem wil mounten, in mijn geval FreeBSD is ook niet zo moeilijk, je maakt /etc/iscsi.conf aan en daar plaats je iets in als:
code:
1
2
3
4
5
6
7
| t0 {
TargetAddress = xxxx
TargetName = iqn.tweakers.net:target0
AuthMethod = CHAP
chapIName = username1
chapSecret = secretsecret
} |
zorg vantevoren dat je iscsid hebt draaien(service iscsid onestart <- aan te bevelen om in rc.conf te zetten als: iscsid_enable="YES") en voer dan
code:
uit, dit zorgt er voor dat je zvol gemount wordt.1
| iscsictl -An t0 |
Nu moet je er nog even achterkomen hoe de disk heet die je via iSCSI '''binnenkrijgt"''' dit is erg makelijk te doen door [code] tail /var/log/messages [\code] uit te voeren als het goed is krijg je iets als
code:
als output.1
2
3
4
| Aug 31 12:20:22 theslik kernel: da0 at iscsi1 bus 0 scbus2 target 0 lun 0 Aug 31 12:20:22 theslik kernel: da0: <FREEBSD CTLDISK 0001> Fixed Direct Access SCSI-5 device Aug 31 12:20:22 theslik kernel: da0: Serial Number MYSERIAL 1 Aug 31 12:20:22 theslik kernel: da0: 256000MB (524288000 512 byte sectors: 255H 63S/T 32635C) |
Dit betekend dus dat /dev/da0 de schijf is die je via iSCSI krijgt. Wat je nu dus wilt doen is er een filesystem op zetten, bijvoorbeeld via newfs, dit kan je zelf wel uitvinden denk ik.
Handige links die ik gebruik:
https://www.freebsd.org/d...andbook/disks-adding.html (<- het toevoegen van disks)
https://www.freebsd.org/doc/handbook/network-iscsi.html (<- iscsi op FreeBSD)
Als het goed is zou het hier allemaal mee moeten lukken.
- Extera
- Registratie: Augustus 2004
- Laatst online: 22-06 02:20
RobHaz, bedankt.
Een ZVOL via iSCSI aanbieden lukt me wel, ik wil de ZVOL echter (ook) mounten in FreeBSD.
De uiteindelijke setup wordt dan:
- ZVOL (3TB) op pool 'SAN' (4x2disk mirror).
- Snapshot's en replicatie naar pool 'backup' (1disk).
- ZVOL / snapshots op pool 'backup' wil ik dan kunnen mounten en kunnen browsen om gemakkelijk een restore te doen van een VM.
Het mounten van een ZVOL lukt niet op mijn FreeNAS doos.
Onder ZFSguru lukt het wel:
Ik heb een topic gemaakt @ FreeNAS forum.
Een ZVOL via iSCSI aanbieden lukt me wel, ik wil de ZVOL echter (ook) mounten in FreeBSD.
De uiteindelijke setup wordt dan:
- ZVOL (3TB) op pool 'SAN' (4x2disk mirror).
- Snapshot's en replicatie naar pool 'backup' (1disk).
- ZVOL / snapshots op pool 'backup' wil ik dan kunnen mounten en kunnen browsen om gemakkelijk een restore te doen van een VM.
Het mounten van een ZVOL lukt niet op mijn FreeNAS doos.
Onder ZFSguru lukt het wel:
code:
1
2
3
4
5
6
7
8
9
10
11
12
| [root@zfsguru /home/ssh]# zfs create -V 100M tank/test
newfs /dev/zvol/tank/test[root@zfsguru /home/ssh]# newfs /dev/zvol/tank/test
/dev/zvol/tank/test: 100.0MB (204800 sectors) block size 32768, fragment size 4096
using 4 cylinder groups of 25.03MB, 801 blks, 3328 inodes.
super-block backups (for fsck_ffs -b #) at:
192, 51456, 102720, 153984
[root@zfsguru /home/ssh]# mkdir /tmp/test
[root@zfsguru /tmp]# mount -r /dev/zvol/tank/test /tmp/test
[root@zfsguru /tmp]# df -h
Filesystem Size Used Avail Capacity Mounted on
/dev/zvol/tank/test 96M 8.0K 89M 0% /tmp/test |
Ik heb een topic gemaakt @ FreeNAS forum.
- Berkeley
- Registratie: Juli 2013
- Laatst online: 08-11-2025
welke versie van FreeBSD gebruikt ZFSguru? Misschien dat het daar aan ligt, aangezien ctl e.d pas in 10.0 gemaakt zijn, en in 9.2 dus misschien problemen veroorzaakt.
- erikdeperik
- Registratie: Juni 2001
- Laatst online: 25-07-2024
is het mogelijk om bv freenass, op de een of andere manier, op een vm te draaien zodat je toch zfs hebt onder windows?
ik zeg maar zo "zeg maar niks"
Met Virtualbox kan dat ja. Heeft enkel nut als je ruwe disks of partities doorgeeft aan de VM; dit moet met command line commando's. Een .vmdk bestand als hardeschijf container gebruiken heeft weinig nut; dan heb je een ZFS filesystem op een NTFS filesystem opgeslagen en de zwakste schakel telt natuurlijk. Maar bij ruwe disks zou het prima kunnen.
- erikdeperik
- Registratie: Juni 2001
- Laatst online: 25-07-2024
tnx cypher.
ik heb bv nog een areca kaart die windows alleen kent als ik de drivers instaleer .
maargoed ik moet nog veel lezen eer ik eraan begin.
ik heb bv nog een areca kaart die windows alleen kent als ik de drivers instaleer .
maargoed ik moet nog veel lezen eer ik eraan begin.
ik zeg maar zo "zeg maar niks"
Areca en ZFS zijn incompatible. Als je ZFS wilt gebruiken, dient ZFS zo dicht mogelijk bij de disks te zitten. Alles wat er tussen zit, kan voor problemen zorgen. Met name hardware RAID zoals Areca is één van de weinige manieren om ZFS op zijn bek te krijgen. Als ZFS 'A' zegt, kan Areca gewoon 'B' doen, en dat gaat niet goed.
Het bouwen van een NAS is natuurlijk de beste methode; maar als je wilt beginnen kan het met Virtualbox wel. Maar als je vervolgens Disk -> Areca -> Windows -> NTFS -> Virtualbox -> AHCI emulatie -> ZFS als storage-chain hebt, moet je wel begrijpen dat dit geen goede/veilige setup is. Hooguit om te testen. Dan kun je nog beter gewoon NTFS gebruiken.
Het bouwen van een NAS is natuurlijk de beste methode; maar als je wilt beginnen kan het met Virtualbox wel. Maar als je vervolgens Disk -> Areca -> Windows -> NTFS -> Virtualbox -> AHCI emulatie -> ZFS als storage-chain hebt, moet je wel begrijpen dat dit geen goede/veilige setup is. Hooguit om te testen. Dan kun je nog beter gewoon NTFS gebruiken.
Let op:
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.