Twister336 schreef op vrijdag 08 april 2011 @ 16:59:
[...]
Een grotere queue diepte zorgt inderdaad voor een beter resultaat maar een grotere transfer grootte geeft doorgaans gelijkaardige resultaten. Het principe is dan eigenlijk hetzelfde. Je biedt de driver/controller een enorme hoeveelheid data tegelijk aan waardoor die de gegevens op de meest optimale manier kan lezen/schrijven.
Voor writes maakt queue depth niet zoveel uit; de QD32 zal maar iets hoger zijn dan de QD1, zeker bij hardeschijven. Bij SSDs hangt het af hoeveel data ze kunnen bufferen; sommigen niet zoveel en dus krijg je wel een redelijk verschil omdat dan de latency toeneemt en je niet alle beschikbare kanalen kunt 'vullen'.
Voor SSDs is queue depth enorm belangrijk met name voor random reads. In tegenstelling tot writes kunnen reads niet gebuffered worden. Bij qd=1 kun je maar één kanaal gebruiken, vergelijkbaar met single-threaded programma's/games die maar één CPU core gebruiken. Dat gebeurt vaak met blocking I/O, wat je veel ziet bij booting en application launch.
In de praktijk zal de queue depth sterk wisselen bij realistische workloads; sequential reads + random reads + een paar random writes. Dat maakt dat vaker meerdere NAND kanalen kunnen worden gebruikt, en je dus wel degelijk nut hebt van de RAID0-achtige structuur van meerdere NAND kanalen die parallel I/O kunnen verrichten. In benchmarks zijn de performance-effecten van meerdere kanalen nagenoeg gelijk aan wat een RAID0 driver met meerdere SSDs zou geven. 4 SSDs van 10 kanalen kun je dus zien als een SSD van 40 kanalen. Bij random reads is een hoge queue depth dan wel belangrijk; bij writes véél minder.
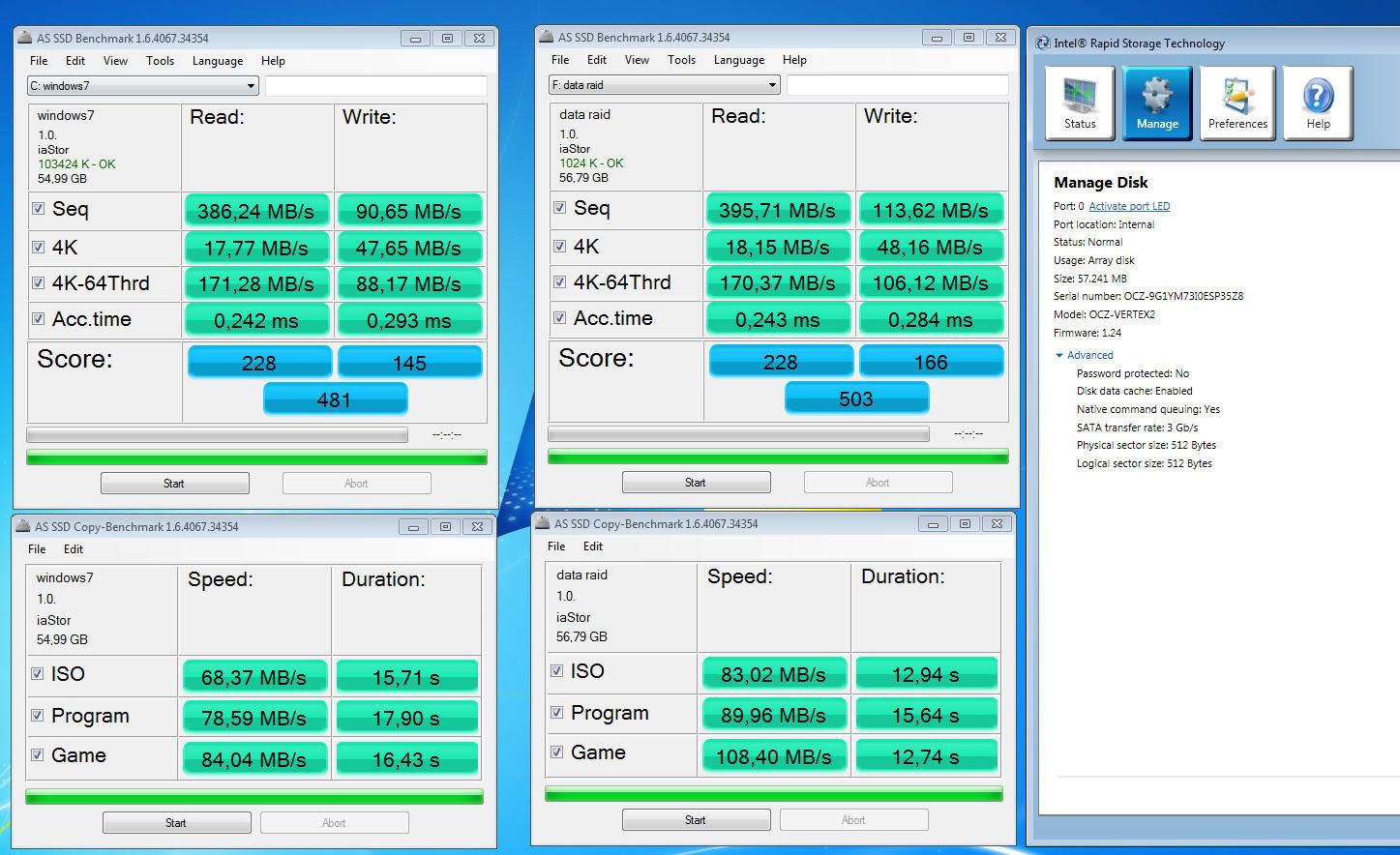
Ik heb als test 3x de benchmark in HD Tune opgestart, dan heb je dus een queue diepte van 3 (uiteraard moet je de resultaten dan wel optellen).
Maar niet contiguous, dus wordt dat een multistream sequential read benchmarks. De queued I/Os zijn dan namelijk niet contiguous; opeenvolgende LBA. Maar bij de meeste SSDs merk je dat geeneens; lezen is bloedje snel van een moderne SSD ook al doe je meerdere streams en wat random I/O tussendoor.
Bij sequentiële workloads (contiguous I/O) wordt door de driver of storage device zelf read-ahead toegepast. Als je LBA 0 leest en daarna 1, dan zal elke moderne HDD ook 2, 3, 4, 5, 6, 7, 8 alvast gaan lezen en in de cache chip zetten. Dan kan als daadwerkelijk 2 opgevraagd worden het mechanische gedeelte doorwerken. Als dat stil komt te liggen moet je wachten op een rotational delay, dus read-ahead is absoluut noodzakelijk en een primaire functie van elke moderne HDD.
Bij SSDs werkt het iets anders; Intel SSDs gebruiken de cache-chip niet om data op te slaan; alleen voor de mapping table. De data zelf staat in een 384KiB SRAM buffer geïntegreerd in de controller. Dit maakt dat de Intel controller erg lage latencies kent. Of SSDs read-ahead toepassen weet ik niet, want de latency van SSDs is zo laag dat je zelfs zonder read-ahead al goede leesprestaties krijgt, in tegenstelling tot hardeschijven.
Maar doordat read-ahead zo noodzakelijk was voor vele jaren, is dit geïntegreerd in ALLE filesystems (FAT16/32, NTFS, Ext2/3/4, XFS, JFS, UFS, ZFS). Zelfs DOS had een read-ahead en write buffer driver, ben de naam even vergeten. Zonder die driver was Windows 2000 installeren een 4-uur durende operatie door de trage disk I/O.
Dus als je HDTune gebruikt, doe je I/O die in de praktijk niet voorkomt. Dan kun je verschillen zien tussen drivers die dit intern al toepassen (Intel RST drivers, HDDs, hardware RAID) en storage die dat niet doet (vele RAID drivers, mogelijk ook SSDs).
Het verhaal over de queue depth als magische prestatieverhoger is voor mij heel onduidelijk.
Queue depth stelt de SSD in staat om meerdere kanalen te benutten, net zoals twee programma's tegelijkertijd twee CPU cores kunnen gebruiken. Als je dat niet doet gaat de extra potentiele performance dus naar de haaien. De overige channels krijg je gratis; de performance van de overige I/O wordt er niet door vertraagd.
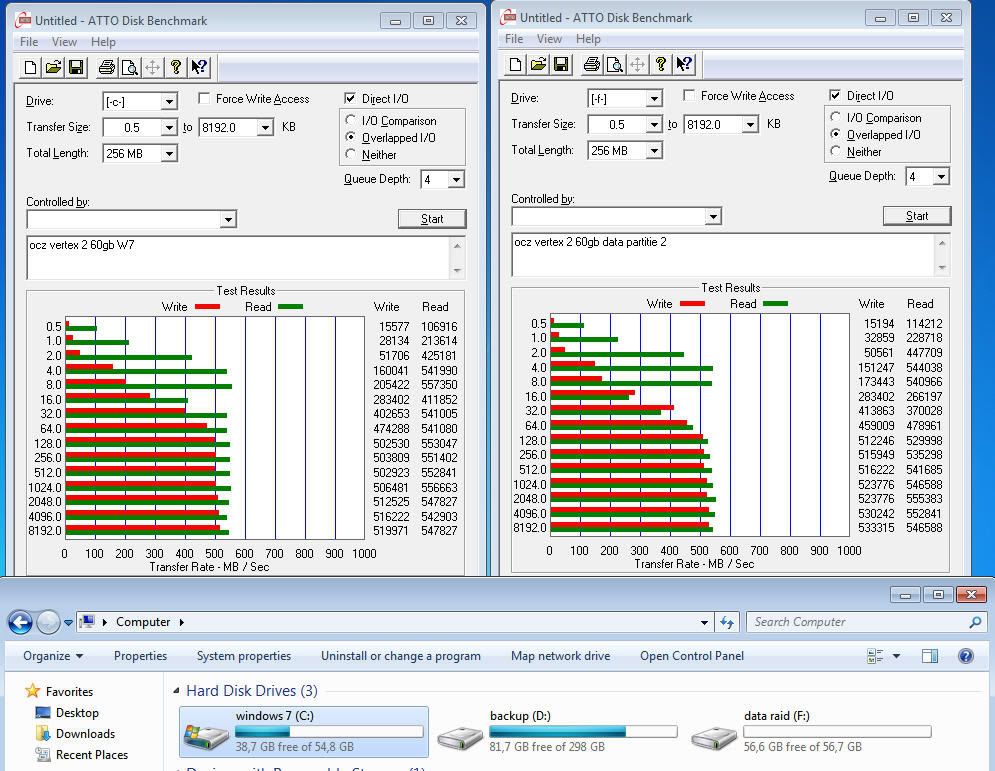
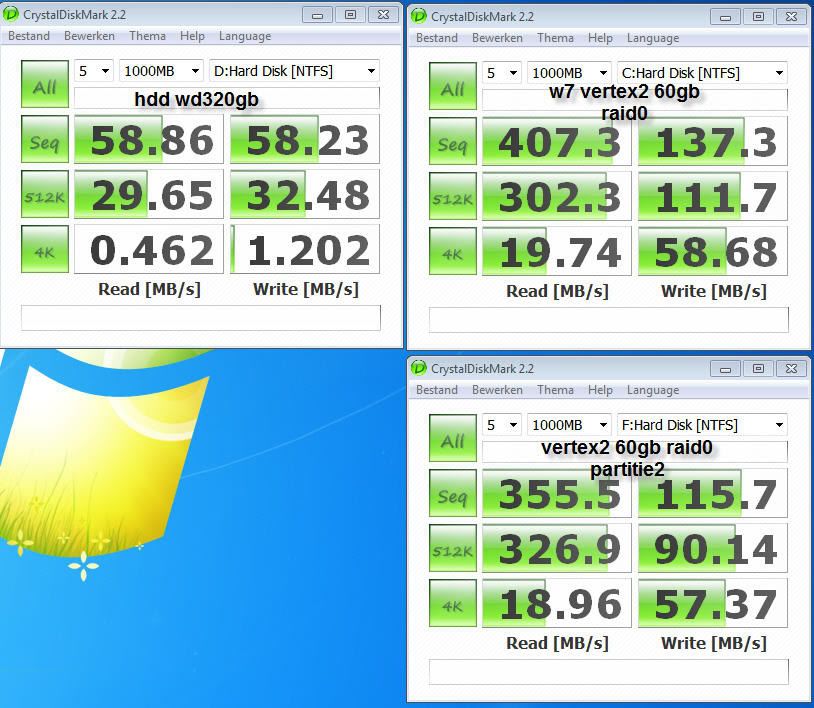
Bij qd=1 ofwel blocking reads zal de SSD maar één kanaal kunnen gebruiken van de totaal 10 bij Intel. Daarom dat het verschil tussen 4K en 4K32 max een factor 10 is voor Intel en 8 bij Sandforce. Sommige kleine capaciteit modellen hebben minder kanalen (4 bij sandforce, 5 bij intel) en daardoor schaalt de QD32 random reads ook veel minder goed.
Nu kun je de queue depth heel eenvoudig bestuderen met perfmon (zit gewoon bij Windows). Als je dan de test in HD Tune uitvoert krijg je een queue depth van ongeveer 1, doe je de (file) test in CDM dan krijg je eveneens een queue depth van 1.
Omdat de controller de I/O ook even hard weer wegtrekt, heb je geen directe indicatie hoeveel I/Os er gemiddeld gelijktijdig naar de SSD gaan; de effectieve queue depth.
Die QD32 test in CDM is onzin. Als er constant 32 I/O operaties in de wachtrij staan is er iets grondig mis met de systeemconfiguratie.
Als ik mijn VMs opstart op mijn ZFS machine zie ik voor al mijn 4 SSDs een queue depth van 255; de max. Hoe meer queue depth je kunt veroorzaken; des te beter je systeemconfiguratie. Vergelijkbaar met een programma wat multithreaded geschreven is om optimaal gebruik te maken van meerdere CPU cores. Deze vergelijking is wel een beetje kort door de bocht; maar de essentie dat je overige kanalen hebt die je gratis kunt benutten is zeker gelijkwaardig aan het verhaal met CPU cores.
Queue depth veroorzaken is echter een stuk eenvoudiger. Je zult wel zien dat desktop OSen veel minder queue depth veroorzaken dan server-achtige I/O. Blocking reads komen vaak voor op een desktop, en dus zit je voor een deel vast aan de 4K qd=1 performance. Maar dat is nog steeds heel erg goed als je daar 20MB/s kan doen; daarom starten applicaties ook zo snel op vergelijken met HDDs die moeite hebben om 1MB/s te halen en in extreme situaties nog veel minder.
:strip_icc():strip_exif()/u/193806/22.jpg?f=community)
/u/34200/crop6554f56fe2075_cropped.png?f=community)
:strip_exif()/u/348540/crop5aa8ff353c2a9_cropped.gif?f=community)


/u/5360/crop65d3c045ca48f_cropped.png?f=community)

/u/1/femme.png?f=community)
:strip_exif()/u/9676/12.gif?f=community)
/u/400/defember100.png?f=community)
:strip_icc():strip_exif()/u/30381/Monion_Driver60x60.jpg?f=community)

/u/189240/av70.png?f=community)
")




:strip_exif()/u/118818/icon2.gif?f=community)
/u/16847/crop64e4572a34bf1_cropped.png?f=community)

:strip_icc():strip_exif()/u/80269/adriaan2_60.jpg?f=community)
:strip_icc():strip_exif()/u/269773/profielfoto.jpg?f=community)
:strip_exif()/u/120076/crop662cc528d7e2f_cropped.webp?f=community)
/u/4501/crop5bdb35c450e89.png?f=community)
/u/271383/crop5e6b72d2a673b_cropped.png?f=community)
:strip_icc():strip_exif()/u/4167/bacall8.jpg?f=community)
:strip_exif()/u/17028/ico_sphere.gif?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}