Wel apart dat een bedrijf wat geen fatsoenlijke servers meer verkoopt nu wel vindt dat ze containers in hun client OS moeten ondersteunen. Is dit puur als service naar developers of heeft de doorsnee desktop user er ook wat aan?ThomasG schreef op dinsdag 10 juni 2025 @ 10:07:
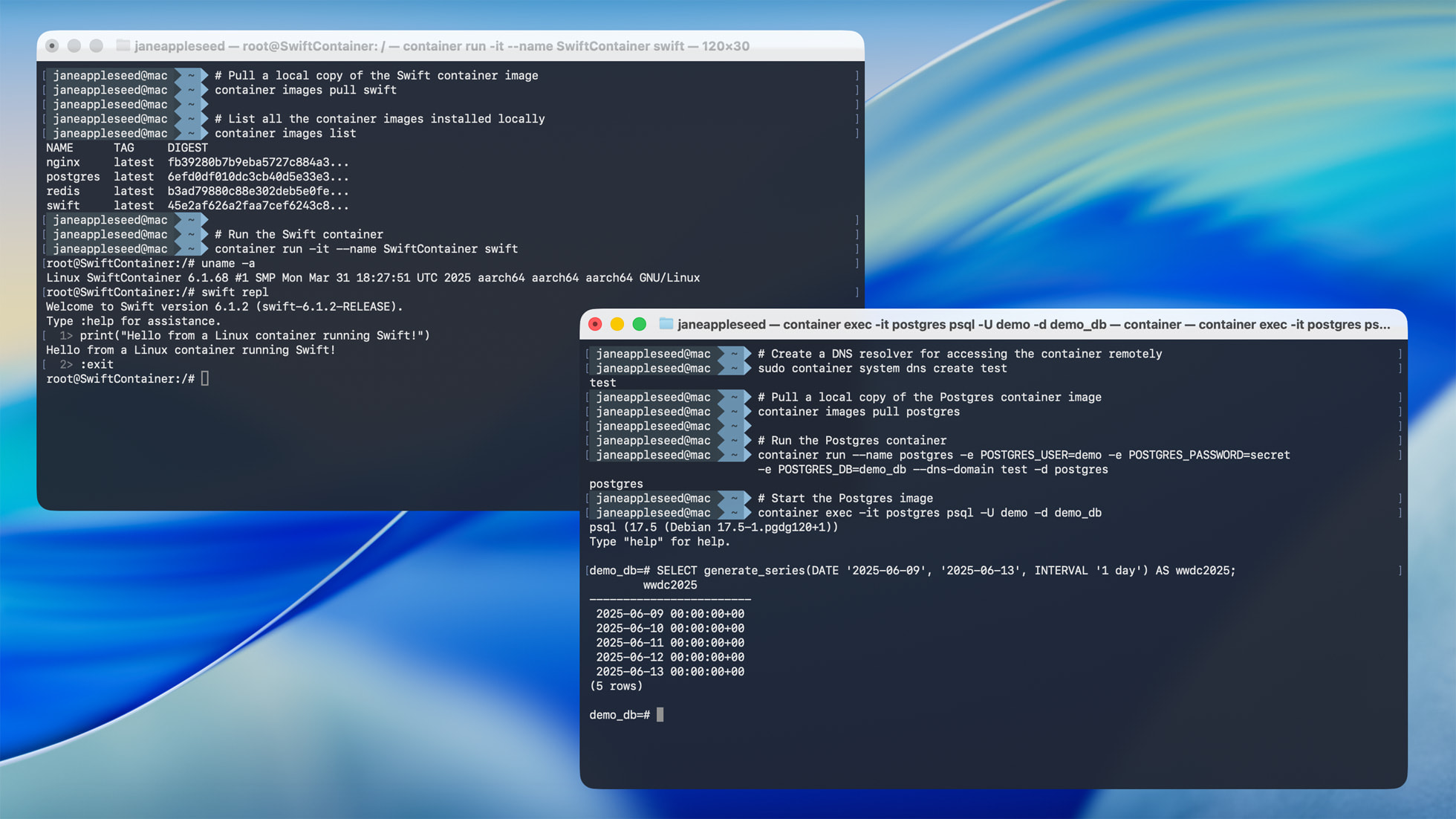
macOS Tahoe krijgt Containerization Framework
[Afbeelding]
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
:strip_icc():strip_exif()/u/6143/rincewind.jpg?f=community)
Developers zijn natuulijk wel gewoon een redelijk grote groep gebruikers waar je voor wilt cateren, ik zie inderdaad niet hoe dit iets toevoegt voor normale desktop gebruikers, hooguit voor de wat meer tech-savy users die apps als containers willen draaien.downtime schreef op dinsdag 10 juni 2025 @ 10:51:
[...]
Wel apart dat een bedrijf wat geen fatsoenlijke servers meer verkoopt nu wel vindt dat ze containers in hun client OS moeten ondersteunen. Is dit puur als service naar developers of heeft de doorsnee desktop user er ook wat aan?
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- DevWouter
- Registratie: Februari 2016
- Laatst online: 17:43
Werkt aan Todo2d.com
:strip_icc():strip_exif()/u/734655/crop69fb2d19b907a_cropped.jpg?f=community)
Omdat veel developers werken op MacOs. En er zijn meer virtualisatie systemen dan alleen Docker. Verder kunnen de images ook gewoon uitgewisseld worden. Je bent alleen niet meer verplicht tot Docker.downtime schreef op dinsdag 10 juni 2025 @ 10:51:
[...]
Wel apart dat een bedrijf wat geen fatsoenlijke servers meer verkoopt nu wel vindt dat ze containers in hun client OS moeten ondersteunen. Is dit puur als service naar developers of heeft de doorsnee desktop user er ook wat aan?
"Doubt—the concern that my views may not be entirely correct—is the true friend of wisdom and (along with empathy, to which it’s related) the greatest enemy of polarization." -- David Blankenhorn
- RobertMe
- Registratie: Maart 2009
- Laatst online: 15:26
Maar was je dat dan, verplicht tot Docker? Want "Docker" is al jaren gestandaardiseerd binnen het Open Container Initiative (dat is gebaseerd op de formaten van Docker) en heeft, in ieder geval onder Linux, ook al meerdere runtimes (met K8s uiteraard als bekenste, maar ook Podman bv). En toevallig (of nouja, vast niet) kwamen dit weekend op HN ook wat "links" voorbij van container runtimes voor Mac wat mij ook liet denken aan "Docker alternatief" (/"de OCI container variant").DevWouter schreef op dinsdag 10 juni 2025 @ 12:06:
Verder kunnen de images ook gewoon uitgewisseld worden. Je bent alleen niet meer verplicht tot Docker.
- DevWouter
- Registratie: Februari 2016
- Laatst online: 17:43
Werkt aan Todo2d.com
Nee, en Docker is van ver gekomen. Maar om even aan te geven hoe ingewikkeld is: K8s is geen runtime, maar een orchestation, meestal gebruikt het containerd. En er zijn allerlei verschillen tussen containerd, CRI-O, Docker of Mirantis die vaak toch erg relevant zijn qua performance.RobertMe schreef op dinsdag 10 juni 2025 @ 12:57:
[...]
Maar was je dat dan, verplicht tot Docker? Want "Docker" is al jaren gestandaardiseerd binnen het Open Container Initiative (dat is gebaseerd op de formaten van Docker) en heeft, in ieder geval onder Linux, ook al meerdere runtimes (met K8s uiteraard als bekenste, maar ook Podman bv). En toevallig (of nouja, vast niet) kwamen dit weekend op HN ook wat "links" voorbij van container runtimes voor Mac wat mij ook liet denken aan "Docker alternatief" (/"de OCI container variant").
Ik denk dat we mogen aannemen dat Apple spul vergelijkbaar of beter werkt dan Docker.
"Doubt—the concern that my views may not be entirely correct—is the true friend of wisdom and (along with empathy, to which it’s related) the greatest enemy of polarization." -- David Blankenhorn
- Creepy
- Registratie: Juni 2001
- Laatst online: 30-06 20:15
Tactical Espionage Splatterer
:strip_exif()/u/26373/anim4.gif?f=community)
Dan heb jij meer vertrouwen in Apple dan ikDevWouter schreef op dinsdag 10 juni 2025 @ 13:40:
[...]
Ik denk dat we mogen aannemen dat Apple spul vergelijkbaar of beter werkt dan Docker.
"I had a problem, I solved it with regular expressions. Now I have two problems". That's shows a lack of appreciation for regular expressions: "I know have _star_ problems" --Kevlin Henney
- Kriekel
- Registratie: Maart 2017
- Laatst online: 30-06 22:38
/u/900065/crop65b3839879b1c_cropped.png?f=community)
Stackoverflow heeft storing, drie jaar geleden was dat een probleem geweest, vandaag is dat een "oeps, ach ja, chatGPT waar waren we gebleven?"
- .oisyn
- Registratie: September 2000
- Laatst online: 15:38
:strip_icc():strip_exif()/u/12461/crop65b195553d948.jpg?f=community)
Allejezus wat een godganze klotetool is de git command line ook. /rant
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- Rhapsody
- Registratie: Oktober 2002
- Laatst online: 30-06 22:42
In Metal We Trust
:strip_exif()/u/69039/MetallicA.gif?f=community)
Heb je hier wat aan? https://github.com/nvbn/thefuck.oisyn schreef op woensdag 11 juni 2025 @ 10:40:
Allejezus wat een godganze klotetool is de git command line ook. /rant
🇪🇺 pro Europa!
- .oisyn
- Registratie: September 2000
- Laatst online: 15:38
Not really. Ik heb een rebase gedaan met merge conflicts, maar een van de files is een binary file en ik wil gewoon "ours" pakken. mergetool heb ik niets aan want het is een binary file. git merge of git rebase met een merge strategy is het blijkbaar al te laat voor want ik zit al in een rebase. git status zegt "first resolve conflicts". JA HOE DAN ACHTELIJKE TORVALDS DEMON SPAWNRhapsody schreef op woensdag 11 juni 2025 @ 10:44:
[...]
Heb je hier wat aan? https://github.com/nvbn/thefuck
.edit: oh, git checkout --ours dus. Ja, heel logisch
.edit2: oh en dán nog eens een git add.
[ Voor 8% gewijzigd door .oisyn op 11-06-2025 10:57 ]
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- RobertMe
- Registratie: Maart 2009
- Laatst online: 15:26
git checkout --ours, of theirs dus. En uiteraard niet vergeten dat bij een rebase ours en theirs soort van "omgedraaid" zijn. Ours is immers de branch die je hebt opgegeven bij git rebase. (Terwijl bij een merge theirs juist de opgegeven branch is)..oisyn schreef op woensdag 11 juni 2025 @ 10:53:
[...]
Not really. Ik heb een rebase gedaan met merge conflicts, maar een van de files is een binary file en ik wil gewoon "ours" pakken. mergetool heb ik niets aan want het is een binary file. git merge of git rebase met een merge strategy is het blijkbaar al te laat voor want ik zit al in een rebase. git status zegt "first resolve conflicts". JA HOE DAN ACHTELIJKE TORVALDS DEMON SPAWN
Edit:
Ja logisch. Want als je wijzigingen doet moet je die ook adden aan de staging area. En checkout is natuurlijk ook gewoon een wijziging en dat je een checkout --ours/theirs doet betekent niet dat die wijziging definitief is. Misschien wil je die file als basis nemen en vervolgens toch nog met de hand wat wijzigingen doen (of bv een tool over de file draaien die wijzigingen doet)..edit2: oh en dán nog eens een git add.
[ Voor 22% gewijzigd door RobertMe op 11-06-2025 11:01 ]
- RayNbow
- Registratie: Maart 2003
- Laatst online: 18:56
Kirika <3
/u/81985/crop566b00b43645a.png?f=community)
Of je schrijft gewoon in 1x goede code en bestaat je repository uit één enkele commit..oisyn schreef op woensdag 11 juni 2025 @ 10:40:
Allejezus wat een godganze klotetool is de git command line ook. /rant
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
Soms wil je je probeersels wel bewaren. Dat lukt niet als je steeds --amend gebruikt.
let the past be the past.
- RayNbow
- Registratie: Maart 2003
- Laatst online: 18:56
Kirika <3
Maar dan schrijf je dus niet in 1x goede code.SPee schreef op woensdag 11 juni 2025 @ 11:47:
Dat lukt niet als je steeds --amend gebruikt.
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- MueR
- Registratie: Januari 2004
- Laatst online: 15:13
/u/102105/crop56f481fe1f74f.png?f=community)
Ik word altijd zenuwachtig als code in een keer doet wat het moet doen. Dan zit ik langer te debuggen om er achter te komen wat ik gemist heb.RayNbow schreef op woensdag 11 juni 2025 @ 11:32:
[...]
Of je schrijft gewoon in 1x goede code en bestaat je repository uit één enkele commit.
Anyone who gets in between me and my morning coffee should be insecure.
- RobertMe
- Registratie: Maart 2009
- Laatst online: 15:26
Daarvoor heb je het reflog, en zolang de vuilnisman nog niet langs is geweest kun je die commits nog gewoon inzienSPee schreef op woensdag 11 juni 2025 @ 11:47:
Soms wil je je probeersels wel bewaren. Dat lukt niet als je steeds --amend gebruikt.
- .oisyn
- Registratie: September 2000
- Laatst online: 15:38
Dat doe ík wel maar dan blijkt dat ik weer moet mergen met de inferieure code van anderenRayNbow schreef op woensdag 11 juni 2025 @ 11:32:
[...]
Of je schrijft gewoon in 1x goede code en bestaat je repository uit één enkele commit.
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- RobertMe
- Registratie: Maart 2009
- Laatst online: 15:26
Dan had je dus toch --theirs moeten gebruiken en niet ours. Want nu heb je juist de code binary file van die anderen behouden..oisyn schreef op woensdag 11 juni 2025 @ 13:06:
[...]
Dat doe ík wel maar dan blijkt dat ik weer moet mergen met de inferieure code van anderen
Of dat het framework dat je gebruikt toch niet voldoet en je alles herschrijft naar een ander framework..oisyn schreef op woensdag 11 juni 2025 @ 13:06:
[...]
Dat doe ík wel maar dan blijkt dat ik weer moet mergen met de inferieure code van anderen
Dezelfde perfecte code, maar dan op andere manier.
Of gewoon gewoon meer perfecte code toevoegen.
let the past be the past.
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Nu we het toch over git en command-line hebben. Wisten jullie dat je meerdere branches tegelijk checked out kunt hebben binnen dezelfde repository? En dat je bij mergen/rebasen niet steeds hetzelfde opnieuw hoeft te doen?
- .oisyn
- Registratie: September 2000
- Laatst online: 15:38
In dit geval was die binary een screenshot van een test-situatie, waarbij ik de test sowieso opnieuw moet runnen nadat de code gemerged is, waar mogelijk een verandering uit komt, en dan wil ik die verandering comparen met wat er in de repo staat en niet wat ik eerder heb gegenereerdRobertMe schreef op woensdag 11 juni 2025 @ 13:09:
[...]
Dan had je dus toch --theirs moeten gebruiken en niet ours. Want nu heb je juist de code binary file van die anderen behouden.
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- ZaZ
- Registratie: Oktober 2002
- Laatst online: 19-06 00:18
Tweakers abonnee
:strip_icc():strip_exif()/u/68028/crop5c0ef8207f712_cropped.jpeg?f=community)
Mijn werkgever is helemaal hoteldebotel van Claude in combinatie met MCP servers. Hij heeft in 3 dagen zelf een repository de grond uit gestampt met een project waar hij normaal maanden over zou doen (naar eigen zeggen).
Enfin, iedereen wordt dus geënthousiasmeerd om het ook eens te gaan proberen, dat 'vibe-coden'.
Iedereen is natuurlijk wel bekend met hoe LLM's helemaal los lijken te gaan als je ze teveel ruimte geeft daarom werden er uitgebreide tips gegeven. Hier een beetje in het kort:
Laat de LLM eerst de code documenteren. Alle libraries afzonderlijk.
Maak een project binnen Claude en een standaard prompt waarin je vertelt om de docs eerst te lezen.
Dan vragen om een plan te maken met wat je voor mekaar probeert te krijgen en dat plan op laten schrijven in kleine stappen en dat dan ook weer op te slaan op disk.
Vervolgens binnen het project steeds nieuwe 'chats' beginnen en 'm steeds 1 stap laten uitvoeren en controleren.
Rinse and repeat.
Nou, ik heb het een week een kans gegeven en ik kan nou niet echt zeggen dat ik het gevoel heb dat ik sneller ga. Ja, er wordt zeker meer code geproduceerd, maar ik ben godganse tijd bezig om dat kreng terug te fluiten. Ik krijg het gewoon niet goed werkend. Je moet echt goed op blijven letten wat de code precies doet. Als ik het niet zelf schrijf verlies ik het overzicht een beetje en voor ik het weet heb ik weer een bak overengineered bende die verder eigenlijk niet eens echt goed is.
Ik geloof het allemaal wel. Ik ga gewoon weer verder zoals ik het altijd al deed.
Tenslotte ook maar eens een blik geworpen op die wonder repo van hem en man man man....
Heel veel onzin code die vooral andere onzin code bezighoudt en daarom niet echt meteen duidelijk te detecteren als dode code, maar het zit vol met dat soort 'eilandjes'.
Talloze onnodige vistors en adapters, implementatiedetails gedupliceerd all over the place en ga zo maar door. Minimal api's en controllers dwars door elkaar. Het is zo'n grote troep dat ik zelf het gewoon opnieuw zou schrijven.
Alle unit tests harken zelfs in de database.
Maar goed, hij is er heel blij mee. Het doet functioneel wat hij heeft gevraagd en daarmee is het dus geweldig. Ik kreeg dus de vraag of ik er toch niet nog een keer verder mee wilde experimenteren.
Neen was mijn antwoord. Ik ben echt niet zo'n oude lul die niet mee wil gaan met de laatste dingen hoor, maar het is er gewoon nog lang niet. Het is leuk om snel snippet te laten schrijven als je heel specifiek bent of een wat 'grotere' vraag te stellen en dat dan wel of niet gebruiken ter inspiratie, maar daar houdt het op het moment voor mij wel een beetje op.
Enfin, iedereen wordt dus geënthousiasmeerd om het ook eens te gaan proberen, dat 'vibe-coden'.
Iedereen is natuurlijk wel bekend met hoe LLM's helemaal los lijken te gaan als je ze teveel ruimte geeft daarom werden er uitgebreide tips gegeven. Hier een beetje in het kort:
Laat de LLM eerst de code documenteren. Alle libraries afzonderlijk.
Maak een project binnen Claude en een standaard prompt waarin je vertelt om de docs eerst te lezen.
Dan vragen om een plan te maken met wat je voor mekaar probeert te krijgen en dat plan op laten schrijven in kleine stappen en dat dan ook weer op te slaan op disk.
Vervolgens binnen het project steeds nieuwe 'chats' beginnen en 'm steeds 1 stap laten uitvoeren en controleren.
Rinse and repeat.
Nou, ik heb het een week een kans gegeven en ik kan nou niet echt zeggen dat ik het gevoel heb dat ik sneller ga. Ja, er wordt zeker meer code geproduceerd, maar ik ben godganse tijd bezig om dat kreng terug te fluiten. Ik krijg het gewoon niet goed werkend. Je moet echt goed op blijven letten wat de code precies doet. Als ik het niet zelf schrijf verlies ik het overzicht een beetje en voor ik het weet heb ik weer een bak overengineered bende die verder eigenlijk niet eens echt goed is.
Ik geloof het allemaal wel. Ik ga gewoon weer verder zoals ik het altijd al deed.
Tenslotte ook maar eens een blik geworpen op die wonder repo van hem en man man man....
Heel veel onzin code die vooral andere onzin code bezighoudt en daarom niet echt meteen duidelijk te detecteren als dode code, maar het zit vol met dat soort 'eilandjes'.
Talloze onnodige vistors en adapters, implementatiedetails gedupliceerd all over the place en ga zo maar door. Minimal api's en controllers dwars door elkaar. Het is zo'n grote troep dat ik zelf het gewoon opnieuw zou schrijven.
Alle unit tests harken zelfs in de database.
Maar goed, hij is er heel blij mee. Het doet functioneel wat hij heeft gevraagd en daarmee is het dus geweldig. Ik kreeg dus de vraag of ik er toch niet nog een keer verder mee wilde experimenteren.
Neen was mijn antwoord. Ik ben echt niet zo'n oude lul die niet mee wil gaan met de laatste dingen hoor, maar het is er gewoon nog lang niet. Het is leuk om snel snippet te laten schrijven als je heel specifiek bent of een wat 'grotere' vraag te stellen en dat dan wel of niet gebruiken ter inspiratie, maar daar houdt het op het moment voor mij wel een beetje op.
Lekker op de bank
- Styxxy
- Registratie: Augustus 2009
- Laatst online: 30-06 14:10
/u/313216/crop679f937b7f4c1_cropped.png?f=community)
Ik vond volgend artikel ook erg goed beschrijvend wat de limieten zijn van AI assistents, en hoe je met die beperkingen goed omgaat om er optimaal gebruik van te maken. https://blog.thepete.net/...-wrong-and-how-to-fix-it/
tl;dr Hoe vager de requirements, hoe meer je het gevoel krijgt dat de AI er niets van kan .
.
tl;dr Hoe vager de requirements, hoe meer je het gevoel krijgt dat de AI er niets van kan
- Haan
- Registratie: Februari 2004
- Laatst online: 15:35
dotnetter
:strip_icc():strip_exif()/u/104670/66407.jpg?f=community)
@ZaZ er is naar mijn mening wel een groot verschil tussen 'vibe-coden' en zelf programmeren mbv een AI tool. Bij vibe-coden kijk je puur functioneel en moet je vooral niet naar de code gaan kijken. Ideaal voor prototypen of iets van een hobby projectje maar niet iets wat je live op productie moet willen zetten. Als ik zie wat een van onze product owners in een paar minuten tevoorschijn tovert met een tool als v0 is dat heel indrukwekkend. Je hebt letterlijk met een prompt van een paar zinnen in een minuut een volledig functionerende applicatie. En dat werkt toch fijner dan een paar screenshotjes in een user story 
Ik heb zelf de laatste weken/maanden veel getest met de verschillende GitHub Copilot opties icm VS Code en het is een nieuwe techniek die je je eigen moet maken, maar als je het een beetje in de vingers hebt kan je er veel winst mee boeken. En dat zit dan voornamelijk in de simpele, saaie dingen zoals documenteren van code, boilerplate code, unit tests. Als je dat een beetje slim inzet heb je zelf meer tijd voor de leuke dingen. En de ontwikkeling gaat nog steeds snel, iedere maand worden de tools en modellen beter dus ik ben er van overtuigd dat iedereen vroeg of laat mee zal gaan.
AI tools zullen developers niet snel vervangen, maar als je als developer niet met de tools om leert gaan, zul je op een gegeven moment wel vervangen worden door schoolverlaters die je aan alle kanten voorbij rennen en een stuk goedkoper zijn. Vergelijk het met code schrijven in notepad versus een fatsoenlijke IDE gebruiken.
Ik heb zelf de laatste weken/maanden veel getest met de verschillende GitHub Copilot opties icm VS Code en het is een nieuwe techniek die je je eigen moet maken, maar als je het een beetje in de vingers hebt kan je er veel winst mee boeken. En dat zit dan voornamelijk in de simpele, saaie dingen zoals documenteren van code, boilerplate code, unit tests. Als je dat een beetje slim inzet heb je zelf meer tijd voor de leuke dingen. En de ontwikkeling gaat nog steeds snel, iedere maand worden de tools en modellen beter dus ik ben er van overtuigd dat iedereen vroeg of laat mee zal gaan.
AI tools zullen developers niet snel vervangen, maar als je als developer niet met de tools om leert gaan, zul je op een gegeven moment wel vervangen worden door schoolverlaters die je aan alle kanten voorbij rennen en een stuk goedkoper zijn. Vergelijk het met code schrijven in notepad versus een fatsoenlijke IDE gebruiken.
Kater? Eerst water, de rest komt later
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
/u/373849/cowava2.png?f=community)
Van "shit, ik moet weer op jacht", naar 2 aanbiedingen...
Veel nadenken en voor en nadelen afwegen volgende week
Veel nadenken en voor en nadelen afwegen volgende week
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
Ik heb voor mijn privé projecten ook Copilot aan staan. Maar als ik een regel zonder wil typen, maar eerst wil uitlijnen, moet ik elke tab die suggestie weer wegklikken. Zeer vervelend dat ze die tab als activator hebben gebruikt. Blijkbaar kun je dat wel in een verborgen setting aanpassen, dus dat ga ik nog doen.Haan schreef op vrijdag 13 juni 2025 @ 09:15:
@ZaZ er is naar mijn mening wel een groot verschil tussen 'vibe-coden' en zelf programmeren mbv een AI tool. Bij vibe-coden kijk je puur functioneel en moet je vooral niet naar de code gaan kijken. Ideaal voor prototypen of iets van een hobby projectje maar niet iets wat je live op productie moet willen zetten. Als ik zie wat een van onze product owners in een paar minuten tevoorschijn tovert met een tool als v0 is dat heel indrukwekkend. Je hebt letterlijk met een prompt van een paar zinnen in een minuut een volledig functionerende applicatie. En dat werkt toch fijner dan een paar screenshotjes in een user story
Ik heb zelf de laatste weken/maanden veel getest met de verschillende GitHub Copilot opties icm VS Code en het is een nieuwe techniek die je je eigen moet maken, maar als je het een beetje in de vingers hebt kan je er veel winst mee boeken. En dat zit dan voornamelijk in de simpele, saaie dingen zoals documenteren van code, boilerplate code, unit tests. Als je dat een beetje slim inzet heb je zelf meer tijd voor de leuke dingen. En de ontwikkeling gaat nog steeds snel, iedere maand worden de tools en modellen beter dus ik ben er van overtuigd dat iedereen vroeg of laat mee zal gaan.
AI tools zullen developers niet snel vervangen, maar als je als developer niet met de tools om leert gaan, zul je op een gegeven moment wel vervangen worden door schoolverlaters die je aan alle kanten voorbij rennen en een stuk goedkoper zijn. Vergelijk het met code schrijven in notepad versus een fatsoenlijke IDE gebruiken.
let the past be the past.
- .oisyn
- Registratie: September 2000
- Laatst online: 15:38
Klopt ik heb daarvoor het pijltje naar rechts geconfigureerd. Andersom is het ook irritant, dan wil je de suggestie wél, maar staat er ondertussen ook een standaard autocompleet-dingetje open en dan gebruikt hij dat ipv de copilot suggestie, die je dan vervolgens kwijt bentSPee schreef op vrijdag 13 juni 2025 @ 11:23:
[...]
Ik heb voor mijn privé projecten ook Copilot aan staan. Maar als ik een regel zonder wil typen, maar eerst wil uitlijnen, moet ik elke tab die suggestie weer wegklikken. Zeer vervelend dat ze die tab als activator hebben gebruikt. Blijkbaar kun je dat wel in een verborgen setting aanpassen, dus dat ga ik nog doen.
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Als je zelf een stukje typt komt de suggestie (vaak) weer terug. Ik vind dat je sowieso betere suggesties krijgt als je zelf het begin typt, dan wordt het aangevuld in de zelfde stijl..oisyn schreef op vrijdag 13 juni 2025 @ 14:10:
[...]
Klopt ik heb daarvoor het pijltje naar rechts geconfigureerd. Andersom is het ook irritant, dan wil je de suggestie wél, maar staat er ondertussen ook een standaard autocompleet-dingetje open en dan gebruikt hij dat ipv de copilot suggestie, die je dan vervolgens kwijt bent
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
Gewoon CoPilot niet gebruiken...?
A real copilot, on a commercial airline? They know the plane. The systems. They’ve done the simulations. They go through recertification. When they speak, it’s to enhance the pilot... Not to shotgun random advice into the cockpit and eject themselves mid-flight.
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
:strip_icc():strip_exif()/u/269054/crop6064049cee9ab_cropped.jpg?f=community)
Zo is het met het stenenbijl ook gegaan. Destijds "state of the art" gereedschap.....
Wie du mir, so ich dir.
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
Niet helemaal.eheijnen schreef op dinsdag 17 juni 2025 @ 09:04:
[...]
Zo is het met het stenenbijl ook gegaan. Destijds "state of the art" gereedschap.....
Of, preciezer, helemaal niet.
Alle zinloze "AI" en "LLM" systemen hebben alleen maar bewezen dat hun gebruikers minder zelfstandig kunnen denken.
Het dichtste bij een vergelijking zou zijn IDE versus Kate. En zelfs dan, komt het nog niet in de buurt van het weghalen van zelfstandig denken.
Als dit geblaat over AI echt zo geweldig was als sommigen mij willen laten geloven, dan zou ik niet zo veel AI code hoven te debuggen en problemen op te lossen die volledig ontstaan zijn door blind copy-pasten van foutieve, door bugs omringde code.
Een blinde copy-paste van StackOverflow bevat tenminste nog een gedachtengang van de schrijver.
De horror-verhalen over de ecologische rampen die sommigen "LLM" noemen, of de vergelijking met een (steen)bijl, maken mij niet meer enthousiast.
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- Haan
- Registratie: Februari 2004
- Laatst online: 15:35
dotnetter
AI-assisted programmeren is een nieuwe tool die je moet leren / leren waarderen. Het is geen magie, gewoon een (bijzonder krachtig) hulpmiddel dat op de juiste manier ingezet moet worden.
Om te vergelijken met normaal gereedschap kan een elektrische multi-tool in de handen van een onervaren klusser ook vreselijk veel schade aanrichten, maar in de handen van een klusjesman die weet wat hij doet enorm veel tijd besparen tov de klusjesman die met handzaag en beitels aan de slag gaat.
Om te vergelijken met normaal gereedschap kan een elektrische multi-tool in de handen van een onervaren klusser ook vreselijk veel schade aanrichten, maar in de handen van een klusjesman die weet wat hij doet enorm veel tijd besparen tov de klusjesman die met handzaag en beitels aan de slag gaat.
Kater? Eerst water, de rest komt later
De tijd gaat vooruit (windmolen, stoommachine, zo maken ze op vandaag niet meer, etc.)...Firesphere schreef op dinsdag 17 juni 2025 @ 13:25:
[...]
Niet helemaal.
Of, preciezer, helemaal niet.
Alle zinloze "AI" en "LLM" systemen hebben alleen maar bewezen dat hun gebruikers minder zelfstandig kunnen denken.
Het dichtste bij een vergelijking zou zijn IDE versus Kate. En zelfs dan, komt het nog niet in de buurt van het weghalen van zelfstandig denken.
Als dit geblaat over AI echt zo geweldig was als sommigen mij willen laten geloven, dan zou ik niet zo veel AI code hoven te debuggen en problemen op te lossen die volledig ontstaan zijn door blind copy-pasten van foutieve, door bugs omringde code.
Een blinde copy-paste van StackOverflow bevat tenminste nog een gedachtengang van de schrijver.
De horror-verhalen over de ecologische rampen die sommigen "LLM" noemen, of de vergelijking met een (steen)bijl, maken mij niet meer enthousiast.
En ook al is dit niet de heilige graal zoals het aangekondigd werd, is dit zeker een blijvertje en zullen we er nog wel meer van zien.
Zoals meerdere mensen al aangeven kan dit een handige aanvulling zijn maar ook weer geen vervanging voor hoger geschoolde expertise.
Wie du mir, so ich dir.
- Haan
- Registratie: Februari 2004
- Laatst online: 15:35
dotnetter
Hier nog een aardig artikel dat een aantal voor- en nadelen benoemt: https://engineering.leani...99t-grow-great-engineers/
Kater? Eerst water, de rest komt later
/u/161671/269e4805d60917f22c3872de8f8fcd0e-d33ige3__1__360.png?f=community)
Ik wacht op het moment dat we een LLM niet meer op nieuwe, menselijke, data kunnen trainen. Want als al die data die een LLM nu uitspuugt (al dan niet aangepast) op het internet komt, gaat het uiteindelijk geen betere gebruikerservaring(en) geven: een LLM wordt dan gedeeltelijk getrained door eigen data. Dat zal vast goed gaan.
Ik sluit me dan ook gedeeltelijk aan bij @Firesphere. Een LLM als techniek kan veel toffe dingen (een soort verlengde van NLP), maar het kan ook heel veel niet. Intelligent zijn bijvoorbeeld. Het hele gedoe dat een LLM veel meer stroom verbruikt landt nog niet bij het gros van de mensen, maar dat gaat na deze hele hype nog wel komen. Dan is de storm voorbij en zal het wel mee gaan vallen.
“AI” ontkom je niet aan, denk ik, maar het er mee om gaan, of slim kunnen ontwijken van, is veel belangrijker. Ik snap de hype van vibe coding ed ook niet, want het voelt voor mij alsof ik een incompetente dev naast mij heb zitten die ik beetje bij beetje de goede kant op duw, laat mij het dan maar zelf doen.
Ik sluit me dan ook gedeeltelijk aan bij @Firesphere. Een LLM als techniek kan veel toffe dingen (een soort verlengde van NLP), maar het kan ook heel veel niet. Intelligent zijn bijvoorbeeld. Het hele gedoe dat een LLM veel meer stroom verbruikt landt nog niet bij het gros van de mensen, maar dat gaat na deze hele hype nog wel komen. Dan is de storm voorbij en zal het wel mee gaan vallen.
“AI” ontkom je niet aan, denk ik, maar het er mee om gaan, of slim kunnen ontwijken van, is veel belangrijker. Ik snap de hype van vibe coding ed ook niet, want het voelt voor mij alsof ik een incompetente dev naast mij heb zitten die ik beetje bij beetje de goede kant op duw, laat mij het dan maar zelf doen.
[ Voor 17% gewijzigd door sky- op 17-06-2025 17:22 ]
don't be afraid of machines, be afraid of the people who build and train them.
- Crazy D
- Registratie: Augustus 2000
- Laatst online: 14:42
I think we should take a look.
:strip_icc():strip_exif()/u/10274/crop67712295188a6_cropped.jpg?f=community)
AI helpt soms, geen complete rocket science maar het scheelt me wel typen. Dat is lekker. Maar te vaak zitten er nog fouten in. En aanpassen van bestaande functies gaat ook nog niet altijd even lekker. Of hij (?) komt met een oplossing, zeg ik: dat mag niet, zegt ie vrolijk: ja klopt, dat mag niet. Stel het dan niet voor 

Ben het wel eens met @sky- dat het wel zorgelijk is dat ze straks getraind worden met hun eigen output, waardoor je eigenlijk alleen maar meer fouten gaan genereren.
Ben het wel eens met @sky- dat het wel zorgelijk is dat ze straks getraind worden met hun eigen output, waardoor je eigenlijk alleen maar meer fouten gaan genereren.
Exact expert nodig?
- RobertMe
- Registratie: Maart 2009
- Laatst online: 15:26
Het probleem is toch dat die LLM helemaal niks snapt en ook niks valideert? Hij lult gewoon met je mee. Jij zegt "mag niet" waaroo de LLM antwoordt met "inderdaad", omdat zoiets nu eenmaal vaak voor komt in "opvolging van woorden".Crazy D schreef op dinsdag 17 juni 2025 @ 20:35:
AI helpt soms, geen complete rocket science maar het scheelt me wel typen. Dat is lekker. Maar te vaak zitten er nog fouten in. En aanpassen van bestaande functies gaat ook nog niet altijd even lekker. Of hij (?) komt met een oplossing, zeg ik: dat mag niet, zegt ie vrolijk: ja klopt, dat mag niet. Stel het dan niet voor
Dat is gewoon hetzelfde als wat hier een paar weken terug langs kwam. Link naar Reddit draadje dat weer linkte naar .NET GitHub waarbij MS aan Copilot vraagt om tickets op te lossen. En Copilot keer op keer komt aanzetten met "oplossingen" waarbij de unit tests falen (of die zelfs nieuwe unit tests files maakte, maar niet in de project file toevoegde en dus niet eens werd uitgevoerd). En elke keer als iemand antwoordde met "de tests mislukken, kun je het oplossen?" volgde een "Je hebt gelijk. Ik heb het nu opgelost" en werkte de tests nog steeds niet (al dan niet andere fouten). Ergo: het ding heeft geen enkel begrip van wat gevraagd wordt en gooit gewoon nieuwe / andere code over de schutting heen ("in de hoop dat die de vraag beantwoordt").
:strip_exif()/u/47168/loop.gif?f=community)
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
Ik hoop van harte dat het een gruwelijke dood sterft, en indien mogelijk, sleep Google, Microsoft, OpenAI et. al. mee.eheijnen schreef op dinsdag 17 juni 2025 @ 15:35:
[...]
De tijd gaat vooruit (windmolen, stoommachine, zo maken ze op vandaag niet meer, etc.)...
En ook al is dit niet de heilige graal zoals het aangekondigd werd, is dit zeker een blijvertje en zullen we er nog wel meer van zien.
Zoals meerdere mensen al aangeven kan dit een handige aanvulling zijn maar ook weer geen vervanging voor hoger geschoolde expertise.
Mijn opinie van deze Laagopgeleide Leugen Machines wordt alleen maar ondersteund door onderzoek zoals dit: https://arxiv.org/abs/2506.08872
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
LLM/AI heeft zeker nut. Het is gewoon een volgende ontwikkeling. Het probleem is dat veel mensen het verkeerd gebruiken. Maar dat betekend niet meteen dat LLM als geheel niet deugd. Dat we van een telraam naar een rekenmachine gingen en daarna naar een computer waren er ook veel mensen op tegen. Nu zijn er maar weinig die liever geen computer hebben. Als de hype van LLM af is, krijgen we een beter beeld van de mogelijkheden.Firesphere schreef op woensdag 18 juni 2025 @ 09:23:
[...]
Ik hoop van harte dat het een gruwelijke dood sterft, en indien mogelijk, sleep Google, Microsoft, OpenAI et. al. mee.
Mijn opinie van deze Laagopgeleide Leugen Machines wordt alleen maar ondersteund door onderzoek zoals dit: https://arxiv.org/abs/2506.08872
Het "probleem" van LLM is dat de kwaliteit van de output sterk afhangt van de kwaliteit van je input. Bullshit in = bullshit out. We hebben hier op kantoor wel eens wat testjes gedaan. Dan zijn er een paar collega's bij die vinden dat LLM niet deugd omdat ze slechte resultaten krijgen. Maar als we het dan vergelijken met de output die ik en andere collega's krijgen, is die van ons wél goed of heel dicht in de buurt. Het verschil zit in de invoer. Mijn prompts zijn veel specifieker en duidelijker, en dan krijg ik heel vaak precies wat ik vroeg en hoe ik het wilde hebben.
Dit betekent trouwens niet dat ik een voorstander ben van bijvoorbeeld lukraak copy-paste ChatGPT code of programmeurs vervangen door AI.
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Als de LLM getraind is op dat soort data, gezet het goede resultaten. Het probleem is dat Copilot en ChatGPT dat niet zijn, en die willen nog wel eens dingen verzinnen. Dat moet je dan dus ook niet aan een LLM vragen, tenzij het je eigen dataset is.RobertMe schreef op dinsdag 17 juni 2025 @ 21:19:
[...]
Het probleem is toch dat die LLM helemaal niks snapt en ook niks valideert? Hij lult gewoon met je mee. Jij zegt "mag niet" waaroo de LLM antwoordt met "inderdaad", omdat zoiets nu eenmaal vaak voor komt in "opvolging van woorden".
Dat is gewoon hetzelfde als wat hier een paar weken terug langs kwam. Link naar Reddit draadje dat weer linkte naar .NET GitHub waarbij MS aan Copilot vraagt om tickets op te lossen. En Copilot keer op keer komt aanzetten met "oplossingen" waarbij de unit tests falen (of die zelfs nieuwe unit tests files maakte, maar niet in de project file toevoegde en dus niet eens werd uitgevoerd). En elke keer als iemand antwoordde met "de tests mislukken, kun je het oplossen?" volgde een "Je hebt gelijk. Ik heb het nu opgelost" en werkte de tests nog steeds niet (al dan niet andere fouten). Ergo: het ding heeft geen enkel begrip van wat gevraagd wordt en gooit gewoon nieuwe / andere code over de schutting heen ("in de hoop dat die de vraag beantwoordt").
Je kunt lokaal eigen LLMs trainen op bijvoorbeeld gigabytes aan PDF bestanden, en dat werkt fantastisch zolang je binnen die context blijft. Maar je moet het model dat daarop getraind is niet vragen wat de hoofdstad van Parijs is, want dan zegt het doodleuk Amsterdam. Net zoals altijd: zelf controleren!
- RobertMe
- Registratie: Maart 2009
- Laatst online: 15:26
Telraam naar rekenmachine is natuurlijk een slecht voorbeeld. Een rekenmachine (en telraam) werken puur op basis van feiten. Het is dus puur het vervangen van het een door het ander.ThomasG schreef op woensdag 18 juni 2025 @ 10:48:
Dat we van een telraam naar een rekenmachine gingen en daarna naar een computer waren er ook veel mensen op tegen.
Ga je vervolgens een LLM om een berekening vragen dan blijkt een LLM ineens geen wiskunde te kennen (en hebben 10 olifanten waarvan er 2 geen poten hebben ineens 80 poten want iedereen weer toch dat olifanten 10 poten hebben en voor de olifanten zonder poten moet je 0 poten er af trekken want ze hebben 0 poten).
Een LLM geeft meer een "mening" of "verzint" zijn eigen antwoord. Dat antwoord kan goed zijn, maar kan ook fout zijn. En zeker zolang het antwoord vaker fout dan goed is heeft het weinig IMO weinig nut om het te gebruiken.
En als ik lees "je moet de juiste vragen stellen", dan ben je dus gewoon aan het programmeren, alleen dan in een andere taal? I.p.v. dat je programmeert in Java / C# / PHP / ... zit je te programmeren in "natuurlijke taal" waarbij je ook de juiste termen en structuren moet gebruiken om ervoor te zorgen dat het doet wat het moet doen. Effectief maak je daarmee van de LLM een transpiler, die het van de ene naar de andere taal om zet.
Edit:
Want als jij een rekenmachine gebruikt ga je daarna dezelfde berekening nog eens op een andere rekenmachine doen?ThomasG schreef op woensdag 18 juni 2025 @ 10:55:
Net zoals altijd: zelf controleren!
[ Voor 8% gewijzigd door RobertMe op 18-06-2025 11:08 ]
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Dat ligt er aan hoe je er naar kijkt. Als je een AI vraagt "Schrijf functie dat X doet" krijg je zeer waarschijnlijk iets wat je niet bedoelde. Terwijl als vraagt "Schrijf een functie met ... als invoer, daar .. mee doet, en .. als uitvoer geeft. met dat dit, dat, zus, zo. etc." kom je heel dicht in de buurt. En ja, je bent inderdaad min of meer zelf aan het programmeren. Het is ook geen vervanging, maar een ondersteuning. Als je blind kunt typen is een lange invoer geen probleem, en kan bij sommige code flink tijd besparen.RobertMe schreef op woensdag 18 juni 2025 @ 11:01:
[...]
En als ik lees "je moet de juiste vragen stellen", dan ben je dus gewoon aan het programmeren, alleen dan in een andere taal? I.p.v. dat je programmeert in Java / C# / PHP / ... zit je te programmeren in "natuurlijke taal" waarbij je ook de juiste termen en structuren moet gebruiken om ervoor te zorgen dat het doet wat het moet doen. Effectief maak je daarmee van de LLM een transpiler, die het van de ene naar de andere taal om zet.
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Het is inderdaad een slecht voorbeeld, omdat een LLM geen rekenmachine is. Je moet een LLM ook niet vragen om wiskunde te doen, want dát kan het niet. Er zijn trouwels wel AI modellen die specifiek op wiskunde gericht zijn, en die schijnen dat wel goed te kunnen.RobertMe schreef op woensdag 18 juni 2025 @ 11:01:
[...]
Telraam naar rekenmachine is natuurlijk een slecht voorbeeld. Een rekenmachine (en telraam) werken puur op basis van feiten. Het is dus puur het vervangen van het een door het ander.
- RobertMe
- Registratie: Maart 2009
- Laatst online: 15:26
Maar als je zo specifiek alles moet uitschrijven is het toch gewoon sneller om daadwerkelijk code te typen? Tenzij je onervaren in de programmeertaal bent en het wel in natuurlijke taal kunt uitschrijven maar niet kunt programmeren. Want als je vervolgens de params, de return, en de logica (/"algoritme") moet uitschrijven is de code / syntax ook het probleem niet meer. Immers bestaat ook veel tijd van programmeren over het nadenken over hoe je iets gaat oplossen. En als je de "hoe" weet is de syntax peanuts (als je bekend bent met de taal).ThomasG schreef op woensdag 18 juni 2025 @ 11:11:
[...]
Dat ligt er aan hoe je er naar kijkt. Als je een AI vraagt "Schrijf functie dat X doet" krijg je zeer waarschijnlijk iets wat je niet bedoelde. Terwijl als vraagt "Schrijf een functie met ... als invoer, daar .. mee doet, en .. als uitvoer geeft. met dat dit, dat, zus, zo. etc." kom je heel dicht in de buurt. En ja, je bent inderdaad min of meer zelf aan het programmeren. Het is ook geen vervanging, maar een ondersteuning. Als je blind kunt typen is een lange invoer geen probleem, en kan bij sommige code flink tijd besparen.
Want "maak een functie optellen met 2 integer parameters en die een int returned door de twee integers bij elkaar op te tellen" is toch echt meer werk dan "int optellen(int a, int b) { return a+b; }".
En nee, de reactie daarop is niet "maar dat is ook een heel simpel voorbeeld". Want je onderstreept zelf dat je bij de LLM ook heel expliciet / uitgebreid moet zijn in wat die moet doen. Dus als het lange / complexe code oplevert moet je ook een lange / complexe prompt opstellen. Waarbij je net zo goed tijd kwijt bent in het bedenken hoe je die prompt goed en gestructureerd opstelt zodat de LLM deze ook " het beste" begrijpt.
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Het ligt er aan. Sommige dingen zijn inderdaad sneller zelf te typen. Vooral eenvoudige code. Een functie als optellen is sneller te typen, in de huidige vorm. Als is het in de huidige vorm weer geen production-ready code, afhankelijk van de context. Integer overflow, wat als er bepaalde constraints op zitten, etc. etc. Je moet dat per case bekijken.RobertMe schreef op woensdag 18 juni 2025 @ 11:23:
[...]
Maar als je zo specifiek alles moet uitschrijven is het toch gewoon sneller om daadwerkelijk code te typen? Tenzij je onervaren in de programmeertaal bent en het wel in natuurlijke taal kunt uitschrijven maar niet kunt programmeren. Want als je vervolgens de params, de return, en de logica (/"algoritme") moet uitschrijven is de code / syntax ook het probleem niet meer. Immers bestaat ook veel tijd van programmeren over het nadenken over hoe je iets gaat oplossen. En als je de "hoe" weet is de syntax peanuts (als je bekend bent met de taal).
Want "maak een functie optellen met 2 integer parameters en die een int returned door de twee integers bij elkaar op te tellen" is toch echt meer werk dan "int optellen(int a, int b) { return a+b; }".
En nee, de reactie daarop is niet "maar dat is ook een heel simpel voorbeeld". Want je onderstreept zelf dat je bij de LLM ook heel expliciet / uitgebreid moet zijn in wat die moet doen. Dus als het lange / complexe code oplevert moet je ook een lange / complexe prompt opstellen. Waarbij je net zo goed tijd kwijt bent in het bedenken hoe je die prompt goed en gestructureerd opstelt zodat de LLM deze ook " het beste" begrijpt.
- RobertMe
- Registratie: Maart 2009
- Laatst online: 15:26
Maar ook die exta cases zal een LLM niet automatisch rekening mee houden. Dus ook die zaken moet je expliciet naar vragen om daar rekening mee te houden. En dan ben je dus weer terug bij af. (Het kost meer / net zoveel werk om een prompt uit te schrijven met alle edge cases als dat het kost om de functie zelf te programmeren incl alle edge cases).ThomasG schreef op woensdag 18 juni 2025 @ 11:32:
[...]
Het ligt er aan. Sommige dingen zijn inderdaad sneller zelf te typen. Vooral eenvoudige code. Een functie als optellen is sneller te typen, in de huidige vorm. Als is het in de huidige vorm weer geen production-ready code, afhankelijk van de context. Integer overflow, wat als er bepaalde constraints op zitten, etc. etc. Je moet dat per case bekijken.
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Dat moet je inderdaad zelf vragen. Toch kan het via LLM sneller zijn, helemaal als je handig wordt in de prompts. Vooral als er ook nog wat documentatie en tests bij wilt hebben. Ja, je moet het zelf nalezen en controleren. Maar dat moet sowieso. Als je het slim inzet kun je je productiviteit verhogen. Gebruik ik het altijd? Nee. Zit het er wel eens naast? Ja. Zorgt het er voor dat ik meer tijd heb voor andere zaken? Ja.RobertMe schreef op woensdag 18 juni 2025 @ 11:37:
[...]
Maar ook die exta cases zal een LLM niet automatisch rekening mee houden. Dus ook die zaken moet je expliciet naar vragen om daar rekening mee te houden. En dan ben je dus weer terug bij af. (Het kost meer / net zoveel werk om een prompt uit te schrijven met alle edge cases als dat het kost om de functie zelf te programmeren incl alle edge cases).
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
Large Lying Machines "denken" niet. Het is geen biologisch "wezen"
Anyhoe, als je geinteresseerd bent in mijn mening, kun je die op mijn website lezen
Anyhoe, als je geinteresseerd bent in mijn mening, kun je die op mijn website lezen
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- RayNbow
- Registratie: Maart 2003
- Laatst online: 18:56
Kirika <3
Hoera, ik hoef het verliezen van mijn baan niet te vrezen. Er is namelijk weinig trainingsdata voor het werkgebied waar ik me in bevind te vinden.ThomasG schreef op woensdag 18 juni 2025 @ 10:55:
Als de LLM getraind is op dat soort data[...]
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
Nou, precies dat. Een LLM gaat je nooit dingen vertellen die het niet geleerd is. Het zal dus - by design - altijd achter lopen op de werkelijkheid. Dat maakt het voor bepaalde vakgebieden minder interessant. En inderdaad, een LLM denkt niet en gaat dat ook niet doen.
don't be afraid of machines, be afraid of the people who build and train them.
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Zelfs als dat wel zo is ben je niet meteen je baan kwijt. Althans niet als je er een beetje goed in bentRayNbow schreef op woensdag 18 juni 2025 @ 13:06:
[...]
Hoera, ik hoef het verliezen van mijn baan niet te vrezen. Er is namelijk weinig trainingsdata voor het werkgebied waar ik me in bevind te vinden.
Ik loop er voor de aardigheid steeds wel wat mee te spelen, maar het resultaat valt me toch echt behoorlijk tegen in de hele breedte van wat proberen te 'vibe coden' van de basis van een stukje datavergelijking die ik letterlijk zelf met een uurtje in elkaar heb geknutseld tot vragen over hoe ik bepaalde dingen ook alweer doe met versie zus van frameworkje A en versie zo van frameworkje B. Krijg je allemaal hallucinante bij elkaar geraapte antwoorden, terwijl je als je weet wat je ongeveer zoekt binnen 1 minuut een antwoord hebt gevonden via docs of Stackoverflow.
Heel af en toe stel ik eens een vraag die wel eens wat nuttigs oplevert, maar al met al voelt het echt totaal niet als een productiviteitsverbetering.
Hetzelfde geldt eigenlijk een beetje voor de tab completion. Daar heb je zo vaak net sneaky bugs inzitten waar je overeen leest omdat het bijna correct is dat je uiteindelijk meer tijd kwijt bent dan wanneer je het zelf had geschreven evt. met wat ouderwetse LSP-based code completion.
Heel af en toe stel ik eens een vraag die wel eens wat nuttigs oplevert, maar al met al voelt het echt totaal niet als een productiviteitsverbetering.
Hetzelfde geldt eigenlijk een beetje voor de tab completion. Daar heb je zo vaak net sneaky bugs inzitten waar je overeen leest omdat het bijna correct is dat je uiteindelijk meer tijd kwijt bent dan wanneer je het zelf had geschreven evt. met wat ouderwetse LSP-based code completion.
"The question of whether a computer can think is no more interesting than the question of whether a submarine can swim" - Edsger Dijkstra
- farlane
- Registratie: Maart 2000
- Laatst online: 30-06 23:35
/u/3813/100_8985_ICON2.JPG?f=community)
Ok, Framework 12 wordt mn nieuwe tablet.
Laptops met namen inside zijn dope
Laptops met namen inside zijn dope
Somniferous whisperings of scarlet fields. Sleep calling me and in my dreams i wander. My reality is abandoned (I traverse afar). Not a care if I never everwake.
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
Net als Apple zei "You're holding it wrong" toen ze de antenne van hun nieuwe iPhone een beetje onhandig hadden geplaatst?ThomasG schreef op woensdag 18 juni 2025 @ 10:48:
[...]
LLM/AI heeft zeker nut. Het is gewoon een volgende ontwikkeling. Het probleem is dat veel mensen het verkeerd gebruiken. Maar dat betekend niet meteen dat LLM als geheel niet deugd. Dat we van een telraam naar een rekenmachine gingen en daarna naar een computer waren er ook veel mensen op tegen. Nu zijn er maar weinig die liever geen computer hebben. Als de hype van LLM af is, krijgen we een beter beeld van de mogelijkheden.
Het "probleem" van LLM is dat de kwaliteit van de output sterk afhangt van de kwaliteit van je input. Bullshit in = bullshit out. We hebben hier op kantoor wel eens wat testjes gedaan. Dan zijn er een paar collega's bij die vinden dat LLM niet deugd omdat ze slechte resultaten krijgen. Maar als we het dan vergelijken met de output die ik en andere collega's krijgen, is die van ons wél goed of heel dicht in de buurt. Het verschil zit in de invoer. Mijn prompts zijn veel specifieker en duidelijker, en dan krijg ik heel vaak precies wat ik vroeg en hoe ik het wilde hebben.
Dit betekent trouwens niet dat ik een voorstander ben van bijvoorbeeld lukraak copy-paste ChatGPT code of programmeurs vervangen door AI.
Als ik kilometers aan prompt moet schrijven om een bruikbaar antwoord te krijgen, schrijf ik liever de code zelf en weet ik wat er in zit.
En tot slot, I don't want a robot that does art so I can do the laundry, I want a robot that does the laundry so I can do art.
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
/u/56000/neuken.png?f=community)
Ik heb github copilot meedraaien in visual studio, en het is heel erg hit or miss. En speelt vals (volgens mij). Volgens mij claimen ze dat ze niet meekijken. Maar ik was wat enum waardes aan het copy pasten uit een api (custom made voor ons, documentatie is niet publiek toegankelijk) en na de tweede vulde hij 'm volledig aan. Hoe dan? Scheelt wel een hoop saai werk.
Andere keren type ik twee letters en vult ie precies in wat ik wilde doen. Prima!
Maar vaak ook complete kots. Verkeerd hoofdlettergebruik, functies verzinnen die niet bestaan. Ik denk dan als je dan toch ook m'n scherm leest kan je op z'n minst de codebase even analyseren wat er wel en niet bestaat toch?
Andere keren type ik twee letters en vult ie precies in wat ik wilde doen. Prima!
Maar vaak ook complete kots. Verkeerd hoofdlettergebruik, functies verzinnen die niet bestaan. Ik denk dan als je dan toch ook m'n scherm leest kan je op z'n minst de codebase even analyseren wat er wel en niet bestaat toch?
- DevWouter
- Registratie: Februari 2016
- Laatst online: 17:43
Werkt aan Todo2d.com
Ik blijf het toch wel zorgelijk vinden dat men overtuigt blijft dat een LLM “denkt” en “leert”. Het is gewoon een complex gok automaat.
Maar het mooie van mensen die nu veel LLMs gebruiken is dat ze hun vaardigheden verliezen en bagger produceren.
Dus… dat probleem lost zich zelf op. We zijn die mensen over een paar jaar kwijt en we hebben genoeg brown field projects dat we steeds makkelijker over onze salaris kunnen handelen.

Maar het mooie van mensen die nu veel LLMs gebruiken is dat ze hun vaardigheden verliezen en bagger produceren.
Dus… dat probleem lost zich zelf op. We zijn die mensen over een paar jaar kwijt en we hebben genoeg brown field projects dat we steeds makkelijker over onze salaris kunnen handelen.
"Doubt—the concern that my views may not be entirely correct—is the true friend of wisdom and (along with empathy, to which it’s related) the greatest enemy of polarization." -- David Blankenhorn
Dat is precies een groot struikelblok of beter minpunt. Dat die dingen niet gewoon zeggen dat ze niets gevonden hebben.sig69 schreef op donderdag 19 juni 2025 @ 00:49:
Andere keren type ik twee letters en vult ie precies in wat ik wilde doen. Prima!
Maar vaak ook complete kots. Verkeerd hoofdlettergebruik, functies verzinnen die niet bestaan. Ik denk dan als je dan toch ook m'n scherm leest kan je op z'n minst de codebase even analyseren wat er wel en niet bestaat toch?
In het begin met ChatGPT heb ik dat ding eens gevraagd naar de songtekst van een bestaand nummer van een bestaande artiest. En dat werd niet gevonden. In plaats van dat als antwoord te geven begint dat ding zelf wat te "verzinnen". Antwoord ik dat het niet klopt begint ie wat anders te verzinnen...
En zo krijg je op een vraag een fout antwoord, waarop op je dat aangeeft. Zegt ie klopt en komt met een volgend antwoord. Weer fout!. Dat geef je dan weer aan, zegt ie klopt en komt vervolgens weer met het eerste foute antwoord. Zoveel voor kunstmatig bewustzijn....
Dat kan ook op de lange termijn "interessant" worden als die dingen dynamisch content/bagger gaan produceren die vrij toegankelijk is op internet. Die meuk komt dan weer terecht in die machines waarmee een negatieve feedbackloop ontstaat....
Wie du mir, so ich dir.
:strip_icc():strip_exif()/u/5964/crop56503163e97a5.jpeg?f=community)
Wees gewoon bewust van je tooling. Ik heb gisteren in n uurtje iets zitten knutselen wat niet m'n expertise is met ChatGPT waar ik anders zeker 2 dagen aan kwijt was geweest en dan was t resultaat ook minder geweest. Is het nu perfect? Vast niet maar het is meer dan goed genoeg voor wat t moet doen, dan ben ik toch een heel stuk productiever geweest dan zonder.
Het enige waar ik inderdaad heb gemerkt dat het kan helpen is als je iets doet waar je zelf niet heel erg bekend mee bent, maar wat wel heel veel gebruikt wordt, waardoor er heel veel trainingsdata over beschikbaar is.Cartman! schreef op donderdag 19 juni 2025 @ 08:36:
Wees gewoon bewust van je tooling. Ik heb gisteren in n uurtje iets zitten knutselen wat niet m'n expertise is met ChatGPT waar ik anders zeker 2 dagen aan kwijt was geweest en dan was t resultaat ook minder geweest. Is het nu perfect? Vast niet maar het is meer dan goed genoeg voor wat t moet doen, dan ben ik toch een heel stuk productiever geweest dan zonder.
"The question of whether a computer can think is no more interesting than the question of whether a submarine can swim" - Edsger Dijkstra
- Kheos
- Registratie: Juni 2011
- Laatst online: 15:43
FP ProMod
Maar is het dan niet handiger om jezelf te informeren en bij te leren zodat je het de volgende keer zonder ai kunt? Iets met jezelf leren vissen in plaats van een hoop 1en en 0en te vragen om een vis te hallucinerenMugwump schreef op donderdag 19 juni 2025 @ 09:13:
[...]
Het enige waar ik inderdaad heb gemerkt dat het kan helpen is als je iets doet waar je zelf niet heel erg bekend mee bent, maar wat wel heel veel gebruikt wordt, waardoor er heel veel trainingsdata over beschikbaar is.
En bijkomend is dat je er nu veel minder van geleerd hebt dan wanneer je er wel 2 dagen over had gedaan. Waar zit de toegevoegde waarde? Dat je iets snel in elkaar hebt gezet?Mugwump schreef op donderdag 19 juni 2025 @ 09:13:
[...]
Het enige waar ik inderdaad heb gemerkt dat het kan helpen is als je iets doet waar je zelf niet heel erg bekend mee bent, maar wat wel heel veel gebruikt wordt, waardoor er heel veel trainingsdata over beschikbaar is.
don't be afraid of machines, be afraid of the people who build and train them.
Ik doel ook niet op het gebruik van LLMs om een kant en klaar stuk software te genereren. Ik doel b.v. op het feit dat ik iets in Python moet doen waar ik zelf niet heel diep in zit. In zo'n geval helpt de LLM-autocomplete die Jetbrains me vaak om de syntax sneller op te pakken of suggesties te krijgen die me attenderen op bepaalde language features die ik niet kende of waar ik niet aan gedacht had.Kheos schreef op donderdag 19 juni 2025 @ 10:50:
[...]
Maar is het dan niet handiger om jezelf te informeren en bij te leren zodat je het de volgende keer zonder ai kunt? Iets met jezelf leren vissen in plaats van een hoop 1en en 0en te vragen om een vis te hallucineren
"The question of whether a computer can think is no more interesting than the question of whether a submarine can swim" - Edsger Dijkstra
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
Kheos schreef op donderdag 19 juni 2025 @ 10:50:
[...]
Maar is het dan niet handiger om jezelf te informeren en bij te leren zodat je het de volgende keer zonder ai kunt? Iets met jezelf leren vissen in plaats van een hoop 1en en 0en te vragen om een vis te hallucineren
Deze neem ik even over in mijn verhaal. Vrij vertaald, en met bron vermelding, uiteraard.
Mocht u dat liever niet hebben, laat't me even weten en ik haal'm weer weg
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
/u/224026/crop5a1c1a6fcf1b1.png?f=community)
{kind=link}
Dat ligt er maar aan natuurlijk. Soms heb je van die dingen die 1x fire&forget zijn en buiten je normale taken vallen.Kheos schreef op donderdag 19 juni 2025 @ 10:50:
[...]
Maar is het dan niet handiger om jezelf te informeren en bij te leren zodat je het de volgende keer zonder ai kunt? Iets met jezelf leren vissen in plaats van een hoop 1en en 0en te vragen om een vis te hallucineren
Simply put: ik ben best een handige klusser, maar voor de elektra aanpassingen voor de nieuwe keuken huur ik een elektricien in. Ik kijk dan wel hoe en wat en waarom hij dingen doet (op een afstandje, soms achteraf, soms bij de koffiepauze met hem) zodat ik er iets van meekrijg.
Het aantal keukens wat ik heb laten plaatsen in mijn leven is 2, in 2 verschillende huizen (dus environments) met heel wat jaren er tussen. Mijn kennis van episode 1 was ten tijde van episode 2 al verouderd. Ik had het dus sowieso niet veilig kunnen doen zelf die tweede keer, althans niet conform industry standards.
Ik weet dat we op Tweakers zitten, maar het is niet alleen maar 1 of 0. LLM's hebben hun nut. Ze zijn geen perfecte vervanger.
Tjolk is lekker. overal en altijd.
Die AI op internet wordt met van alles gevoerd om zoveel mogelijk mensen wat aan te bieden.
Ter vergelijking zou je er een uitsluitend op een specifiek project en de daarvoor gebruikte programmeertaal en misschien aanverwante theorie / technieken kunnen trainen....
Ter vergelijking zou je er een uitsluitend op een specifiek project en de daarvoor gebruikte programmeertaal en misschien aanverwante theorie / technieken kunnen trainen....
Wie du mir, so ich dir.
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
Het lijkt er op dat ik het weer ga aansturen op de vliegvelden hier 
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
Je wordt professioneel regendanser?Firesphere schreef op donderdag 19 juni 2025 @ 13:33:
Het lijkt er op dat ik het weer ga aansturen op de vliegvelden hier
"The question of whether a computer can think is no more interesting than the question of whether a submarine can swim" - Edsger Dijkstra
Dat ik snel iets eenmaligs nodig heb waarvan ik weet dat ik het kan maar er niet snel mee ben en veel moet opzoeken. Nu heb ik iets wat werkt en het heeft me maar weinig tijd gekost. Minder van geleerd, ik ben geen 16 jarige op school meersky- schreef op donderdag 19 juni 2025 @ 10:57:
[...]
En bijkomend is dat je er nu veel minder van geleerd hebt dan wanneer je er wel 2 dagen over had gedaan. Waar zit de toegevoegde waarde? Dat je iets snel in elkaar hebt gezet?
En het is ook wat overdreven om elk hulpmiddel maar te zien als desastreus voor leren. IDEs en LSPs maken je leven gewoon heel veel makkelijker, maar daar zeuren we niet dat ze je niet uiterst nauwkeurig leren typen of leren de APIs van 3 miljoen miljard libraries uit je hoofd kunnen opdreunen.
"The question of whether a computer can think is no more interesting than the question of whether a submarine can swim" - Edsger Dijkstra
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Laat Torvalds je maar niet horen. Hij gebruikt nog steeds Emacs omdat een (andere) IDE leren gebruiken te veel tijd kost en/of moeite isMugwump schreef op donderdag 19 juni 2025 @ 16:16:
En het is ook wat overdreven om elk hulpmiddel maar te zien als desastreus voor leren. IDEs en LSPs maken je leven gewoon heel veel makkelijker, maar daar zeuren we niet dat ze je niet uiterst nauwkeurig leren typen of leren de APIs van 3 miljoen miljard libraries uit je hoofd kunnen opdreunen.
Ik ken ze hoor, de hippe developers die VIM of Emacs en split keyboards gebruiken, vinden dat een developer 120+ woorden per minuut kunnen typen en ga zo maar door. Niet aan mij besteed. Al moet ik zeggen dat van die collega's die vinden dat keyboard shortcuts het werk van de duivel zijn en weigeren een toetsenbord te gebruiken voor alles behalve het typen van tekst weer het andere uiterste zijn.ThomasG schreef op donderdag 19 juni 2025 @ 16:20:
[...]
Laat Torvalds je maar niet horen. Hij gebruikt nog steeds Emacs omdat een (andere) IDE leren gebruiken te veel tijd kost en/of moeite is
"The question of whether a computer can think is no more interesting than the question of whether a submarine can swim" - Edsger Dijkstra
- Kalentum
- Registratie: Juni 2004
- Laatst online: 17:20
:strip_icc():strip_exif()/u/116726/crop5e3ee297a8a03_cropped.jpeg?f=community)
Met Dvorak Colemak toetsenbordindelingMugwump schreef op donderdag 19 juni 2025 @ 16:47:
[...]
Ik ken ze hoor, de hippe developers die VIM of Emacs en split keyboards gebruiken, vinden dat een developer 120+ woorden per minuut kunnen typen en ga zo maar door. Niet aan mij besteed. Al moet ik zeggen dat van die collega's die vinden dat keyboard shortcuts het werk van de duivel zijn en weigeren een toetsenbord te gebruiken voor alles behalve het typen van tekst weer het andere uiterste zijn.
- downtime
- Registratie: Januari 2000
- Niet online
Everybody lies
/u/1906/crop5dfd46928e003.png?f=community)
Erger nog... Het is MicroEmacs. Wikipedia: MicroEMACSThomasG schreef op donderdag 19 juni 2025 @ 16:20:
[...]
Laat Torvalds je maar niet horen. Hij gebruikt nog steeds Emacs omdat een (andere) IDE leren gebruiken te veel tijd kost en/of moeite is
- dusty
- Registratie: Mei 2000
- Laatst online: 21-02 00:06
Celebrate Life!
LLMs gebruiken is in principe hetzelfde als stackoverflow gebruiken; Als de programmeur copy-paste en het niet probeert te begrijpen wat de code doet, leert de programmeur niets. Als hij/zij echter de code probeert te begrijpen dan zal de programmeur het wel leren.Kheos schreef op donderdag 19 juni 2025 @ 10:50:
[...]
Maar is het dan niet handiger om jezelf te informeren en bij te leren zodat je het de volgende keer zonder ai kunt? Iets met jezelf leren vissen in plaats van een hoop 1en en 0en te vragen om een vis te hallucineren
Op het moment is het mijn ervaring dat code door AI gemaakt is, hetzelfde qualiteit is als een junior programmeur; Er is een kans dat het werkt, maar er zijn vaak dingen fout die een fix nodig hebben voordat je het echt kan gebruiken. ( voor prototyping kan het okay zijn om het niet te veranderen, echter niet voor een eind product.)
Back In Black!
"Je moet haar alleen aan de ketting leggen" - MueR
- RayNbow
- Registratie: Maart 2003
- Laatst online: 18:56
Kirika <3
Ware het niet dat je op Stackoverflow extra signalen hebt om een antwoord op waarde te schatten: een score op basis van votes en discussies onder de antwoorden zelf.dusty schreef op zaterdag 21 juni 2025 @ 14:41:
[...]
LLMs gebruiken is in principe hetzelfde als stackoverflow gebruiken;
Wat heb je met LLM's? Een stukje plausibel lijkende tekst zonder enkele toetsing.
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- ThomasG
- Registratie: Juni 2006
- Laatst online: 29-06 19:07
Stackoverflow staat vol met cowboy antwoorden. Die zijn ronduit slecht maar krijgen wel veel votes, want: als je het copy-pasted werkt het. (Zoals bijv SElinux geheel uitschakelen, omdat je PHP file upload niet werkt.) Ook, of misschien wel juist, bij Stackoverflow moet je zelf goed opletten en nadenken. De comments met een beter antwoord of waarschuwingen staan vaak verscholen.RayNbow schreef op zaterdag 21 juni 2025 @ 18:06:
[...]
Ware het niet dat je op Stackoverflow extra signalen hebt om een antwoord op waarde te schatten: een score op basis van votes en discussies onder de antwoorden zelf.
Wat heb je met LLM's? Een stukje plausibel lijkende tekst zonder enkele toetsing.
- dcm360
- Registratie: December 2006
- Niet online
/u/200133/artemis_square_e_60-60.png?f=community)
En dan heb je LLM's, getraind op StackoverflowThomasG schreef op zondag 22 juni 2025 @ 15:54:
[...]
Stackoverflow staat vol met cowboy antwoorden. Die zijn ronduit slecht maar krijgen wel veel votes, want: als je het copy-pasted werkt het. (Zoals bijv SElinux geheel uitschakelen, omdat je PHP file upload niet werkt.) Ook, of misschien wel juist, bij Stackoverflow moet je zelf goed opletten en nadenken. De comments met een beter antwoord of waarschuwingen staan vaak verscholen.
- RayNbow
- Registratie: Maart 2003
- Laatst online: 18:56
Kirika <3
Als je PHP gebruikt, heb je een groter probleem.ThomasG schreef op zondag 22 juni 2025 @ 15:54:
(Zoals bijv SElinux geheel uitschakelen, omdat je PHP file upload niet werkt.)
Kwam afgelopen week bijv. dit tegen.
:strip_exif()/f/image/pFWOeDax1zhhY0B67zSG9tTE.png?f=user_large)
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- Marc3l
- Registratie: December 2005
- Laatst online: 17:41
Het ligt er ook net aan wat je wilt bereiken. HTML / CSS(Tailwind) gaat prima.dusty schreef op zaterdag 21 juni 2025 @ 14:41:
[...]
LLMs gebruiken is in principe hetzelfde als stackoverflow gebruiken; Als de programmeur copy-paste en het niet probeert te begrijpen wat de code doet, leert de programmeur niets. Als hij/zij echter de code probeert te begrijpen dan zal de programmeur het wel leren.
Op het moment is het mijn ervaring dat code door AI gemaakt is, hetzelfde qualiteit is als een junior programmeur; Er is een kans dat het werkt, maar er zijn vaak dingen fout die een fix nodig hebben voordat je het echt kan gebruiken. ( voor prototyping kan het okay zijn om het niet te veranderen, echter niet voor een eind product.)
Filament (package voor Laravel) slechte ervaring mee, Laravel core werkt vaak ook prima.
Ik hoef er ook niet van te leren maar merk nu al, de simpele dingen die toch tijd kosten om zelf te schrijven doet Junie toch een stuk sneller.
Uiteraard controleer ik de output wel, en werk stapje voor stapje en als het resultaat goed is, dan commit en anders reset ik de boel weer.
- Firesphere
- Registratie: September 2010
- Laatst online: 12:47
Yoshis before Hoshis
https://mastodon.social/@jessie/114743379402097019


Dat moet ik echt even in de vleesopslag plaatsen!
Dat moet ik echt even in de vleesopslag plaatsen!
I'm not a complete idiot. Some parts are missing.
.Gertjan.: Ik ben een zelfstandige alcoholist, dus ik bepaal zelf wel wanneer ik aan het bier ga!
- Jolijter
- Registratie: Januari 2015
- Laatst online: 16:08
Ik heb weinig vertrouwen in mijn vleesopslag.Firesphere schreef op woensdag 25 juni 2025 @ 12:16:
https://mastodon.social/@jessie/114743379402097019
Dat moet ik echt even in de vleesopslag plaatsen!
- DevWouter
- Registratie: Februari 2016
- Laatst online: 17:43
Werkt aan Todo2d.com
Nou… Tweakers Dev Summit heeft mijn talk afgewezen. Had ik eigenlijk wel verwacht gezien het gebrek aan sleutel woorden (vanwege interesse), hippe dingen (want sponsors) en het feit dat ik er amper energie in gestopt had (ik had privé veel op mijn bord).
Dat gezegd te hebben, als dit de zoveelste conferentie is waar de lineup mij tegen zal vallen dan ga ik eens poging doen om iets te bedenken waar iedereen zijn/haar afgewezen talks kan publiceren zodat er weer eens iets interessants te kiezen valt.
Voor degene die wel gekozen zijn/worden: Gefeliciteerd alvast tenzij het over AI gaat, dan hoop ik dat een auto over je laptop rijdt en je geen backups hebt 
Dat gezegd te hebben, als dit de zoveelste conferentie is waar de lineup mij tegen zal vallen dan ga ik eens poging doen om iets te bedenken waar iedereen zijn/haar afgewezen talks kan publiceren zodat er weer eens iets interessants te kiezen valt.
Voor degene die wel gekozen zijn/worden: Gefeliciteerd alvast tenzij het over AI gaat, dan hoop ik dat een auto over je laptop rijdt en je geen backups hebt
"Doubt—the concern that my views may not be entirely correct—is the true friend of wisdom and (along with empathy, to which it’s related) the greatest enemy of polarization." -- David Blankenhorn
- wackmaniac
- Registratie: Februari 2004
- Laatst online: 29-06 09:36
/u/105842/Homer_60x60.png?f=community)
Je ziet dat een boel conferenties zich wel heel erg uitspreken over nieuwe sprekers kansen geven in de CFP, maar dat de lijst met uiteindelijke sprekers toch vaak voornamelijk gevuld is met bekende namen. Heeft er waarschijnlijk ook mee te maken dat de kaartjes verkocht moeten worden. Maakt wel dat ik vaak bij de uncon-track te vinden ben
Read the code, write the code, be the code!
- gekkie
- Registratie: April 2000
- Laatst online: 28-06 00:46
Achja dan maar kijken of er nog een uni is die een hok ter beschikking wil stellen .. eigen bammetjes mee en wie weet is er een nieuwe conferentie geboren
Tenzij het open-source gerelateerd is .. dan kun je al terecht bij FOSDEM en co (al hoe wel daar ook de keuze soms niet altijd geheel onbeinvloed lijkt door de toko van de organizer van het hok).
Dan wel pluggen bij meetups her en der in den landen die er ook genoeg zijn (naast de praatjes van de sponsor zijn er dan meestal ook wel 1 of 2 andere per avond).
Tenzij het open-source gerelateerd is .. dan kun je al terecht bij FOSDEM en co (al hoe wel daar ook de keuze soms niet altijd geheel onbeinvloed lijkt door de toko van de organizer van het hok).
Dan wel pluggen bij meetups her en der in den landen die er ook genoeg zijn (naast de praatjes van de sponsor zijn er dan meestal ook wel 1 of 2 andere per avond).
[ Voor 18% gewijzigd door gekkie op 30-06-2025 19:13 ]
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Hoewel ik het met je eens ben dat veel conferenties vooral de voorspelbare hippe dingen doen.DevWouter schreef op maandag 30 juni 2025 @ 15:36:
Nou… Tweakers Dev Summit heeft mijn talk afgewezen. Had ik eigenlijk wel verwacht gezien het gebrek aan sleutel woorden (vanwege interesse), hippe dingen (want sponsors)
Is dit toch al genoeg om het af te wijzen? Als je er niet veel tijd in wil stoppen, hoe verwacht je dan dat je uitgenodigd wordt?En het feit dat ik er amper energie in gestopt had (ik had privé veel op mijn bord).
Dat ben ik ook volledig met je eens, ik snap dat het op het moment lastig is om een conferentie volledig zonder AI te doen, maar het is nu alleen nog maar AI.....Voor degene die wel gekozen zijn/worden: Gefeliciteerd alvast tenzij het over AI gaat, dan hoop ik dat een auto over je laptop rijdt en je geen backups hebt
Wil je overigens je idee hier delen?
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- DevWouter
- Registratie: Februari 2016
- Laatst online: 17:43
Werkt aan Todo2d.com
Er wordt namelijk (extreem veel) geld verdiend aan conferenties. Je moet namelijk de organisatoren verleiden en dus rekening houden met wat zij nodig hebben (of je het nou leuk vind of niet). Dus een naïef idee insturen is nooit voldoende.Woy schreef op maandag 30 juni 2025 @ 20:22:
[...]
Hoewel ik het met je eens ben dat veel conferenties vooral de voorspelbare hippe dingen doen.
[...]
Is dit toch al genoeg om het af te wijzen? Als je er niet veel tijd in wil stoppen, hoe verwacht je dan dat je uitgenodigd wordt?
Bedenk ook dat ze veel inzendingen krijgen (waaronder wat ik “verkooppraatjes” die een stuk beter uitgewerkt zijn door sales) en je minder ruimte hebt om mensen te overtuigen dan een gemiddelde review in een krant.
Overigens die talks die een soort verkooppraatje zijn worden meestal door mensen gedaan zodat ze een eerste conferentie op hun naam hebben
Het idee dat het een soort loterij is ongelooflijk naïef.
Even de achtergrond: Ik had collega’s die al jaren regelmatig uitgenodigd werden (o.a. door Microsoft zelf) en die exact wisten hoe het systeem werkt.
Oprecht, waarom zou dat moeilijk zijn? De meeste talks over dat onderwerp zijn “wij hebben een magische doos die soort van werkt en dit werkt voor ons”. Inhoudelijk is het compleet nutteloos tenzij je exact dezelfde data hebt met dezelfde doelstelling. De paar die wel interessant zijn vereisen een expertise die niet in 50 minuten te doen is. Los van de inspiratie factor en de pols-factor heb ik nog geen een goede gezien.[...]
Dat ben ik ook volledig met je eens, ik snap dat het op het moment lastig is om een conferentie volledig zonder AI te doen, maar het is nu alleen nog maar AI.....
Sure, website waar mensen afgewezen talks kunnen uploaden. Inclusief mogelijkheid tot feedback en vragen, beide met handmatige moderatie (dit zodat sociale media amper invloed heeft). Voorpagina kent een wekelijkse selectie (zoals YouTube in de allereerste jaren).Wil je overigens je idee hier delen?
De eis is wel dat je talk op het moment van indienen niet ergens anders gepubliceerd is (dit is trouwens gebruikelijk bij meeste conferenties), omdat we vooral de afgewezen talks willen. Talks moeten vooral afwijkend van de norm zijn die dus eigenlijk geen kans hebben bij de grote conferenties.
Voordeel van gebruikers is dat ze vooral in een veilige omgeving ervaring op kunnen doen en op die manier naamsbekendheid kunnen opbouwen.
Denk een beetje longform content van impopulaire onderwerpen die ontzettend interessant zijn en waar bij je als content creator vooral garanties wil hebben dat je content met respect behandeld wordt. En waar je ook nuttige feedback kan krijgen.
Uiteraard is het bovenstaande een zaadje.
"Doubt—the concern that my views may not be entirely correct—is the true friend of wisdom and (along with empathy, to which it’s related) the greatest enemy of polarization." -- David Blankenhorn
- MueR
- Registratie: Januari 2004
- Laatst online: 15:13
Hmm.. misschien moet ik volgend jaar maar eens een proposal voor een talk insturen. Als ik de deadline niet weer mis. Heb wel een mooie case stiekem.
Anyone who gets in between me and my morning coffee should be insecure.
Ik heb net mijn vakantie besteed met tallks bekijken op yt. Mijn "to view" lijst afgewerkt. Maar het valt me steeds vaker op dat het mij weinig nieuws brengt.
Ook bv een talk/vlogcast over een boek publiceren en dat die onder een paar onderwerpen valt. Viel me daarna bij talks ook op.
Ik speel wel met een idee over een talk, maar kan daar ook een uitgebreid curriculum van maken. Dat valt overigens onder het onderwerp "lessons learned". Een van die onderwerpen.
Geen idee of dat iets wordt, want ik ben niet zo van (publiek) spreken.
Ook bv een talk/vlogcast over een boek publiceren en dat die onder een paar onderwerpen valt. Viel me daarna bij talks ook op.
Ik speel wel met een idee over een talk, maar kan daar ook een uitgebreid curriculum van maken. Dat valt overigens onder het onderwerp "lessons learned".
Geen idee of dat iets wordt, want ik ben niet zo van (publiek) spreken.
let the past be the past.
- RayNbow
- Registratie: Maart 2003
- Laatst online: 18:56
Kirika <3
Ik dacht, laat ik de ochtend beginnen met het testen van ChatGPT en welke antwoorden het kan verzinnen... Mijn prompt:
Op een schaal van 1-10, hoe dichtbij denken jullie dat het antwoord van ChatGPT bij de waarheid zat?Can you help me with understanding with a piece of code? It's about this file: https://raw.githubusercon...ompressed_GPSTIME11_v2.cs
In this file, the method `decompress` is called on the `IntegerCompressor` object `ic_gpstime` various times. Magic constants are used as the second argument for these method calls. I have found out that the constants range from 0 up to and including 8. Could you explain for each of these constants (0-8) what these constants mean?
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- Ealanrian
- Registratie: Februari 2009
- Laatst online: 15:36
Ik denk dat ie er 1 goed heeftRayNbow schreef op dinsdag 1 juli 2025 @ 06:33:
Ik dacht, laat ik de ochtend beginnen met het testen van ChatGPT en welke antwoorden het kan verzinnen... Mijn prompt:
[...]
Op een schaal van 1-10, hoe dichtbij denken jullie dat het antwoord van ChatGPT bij de waarheid zat?
- DaFeliX
- Registratie: December 2002
- Laatst online: 14:36
Tnet Devver
/u/74211/crop5db297afbbd2b_cropped.png?f=community)
Ik kan mij voorstellen dat dit enorm balen is! ik ben onderdeel van het team dat bezig is met de selectie van sprekers voor de devsummit, dus misschien ligt het wel aan mij dat ie afgewezen is. Mocht je er behoefte aan hebben, mijn DM staat open voor je.DevWouter schreef op maandag 30 juni 2025 @ 15:36:
Nou… Tweakers Dev Summit heeft mijn talk afgewezen. Had ik eigenlijk wel verwacht gezien het gebrek aan sleutel woorden (vanwege interesse), hippe dingen (want sponsors) en het feit dat ik er amper energie in gestopt had (ik had privé veel op mijn bord).
Dat gezegd te hebben, als dit de zoveelste conferentie is waar de lineup mij tegen zal vallen dan ga ik eens poging doen om iets te bedenken waar iedereen zijn/haar afgewezen talks kan publiceren zodat er weer eens iets interessants te kiezen valt.
[...]
Ik kan dit alleen maar beamen, maar dat komt (voor wat betreft de DevSummit) niet doordat we niet willen. Wij sturen zelf juist actief op sprekers die je normaal niet op 't podium ziet. Als er twee sprekers 'tzelfde onderwerp zouden doen, gunnen we het sneller iemand die je normaal niet gezien hebt op een podium.wackmaniac schreef op maandag 30 juni 2025 @ 15:49:
Je ziet dat een boel conferenties zich wel heel erg uitspreken over nieuwe sprekers kansen geven in de CFP, maar dat de lijst met uiteindelijke sprekers toch vaak voornamelijk gevuld is met bekende namen. Heeft er waarschijnlijk ook mee te maken dat de kaartjes verkocht moeten worden. Maakt wel dat ik vaak bij de uncon-track te vinden ben
Maar wij zijn geen opleidingsprogramma voor 't geven van een talk, dat zal de spreker toch echt zelf moeten doen. We hebben een sprekerscoach die we aanbieden en zullen een spreker in een interview tips en tops geven over de talk. Dit doen we met 1 persoon die commercieel betrokken is bij de devsummit ("weet wat men wil zien") en 1 persoon die inhoudelijke kennis heeft over het onderwerp (bijvoorbeeld een developer). Maar we kunnen niet samen met een spreker van begin tot eind een presentatie in elkaar zetten; dat zal de spreker toch echt zelf moeten doen. We kijken dus ook naar óf iemand een presentatie zou kunnen geven, en helaas zie je dan dat mensen die 't zouden kunnen vaker hebben gesproken.
We hebben in 't verleden gekeken of we iets als lightning talks of zeepkisttalks kunnen aanbieden, misschien kan dit mensen helpen met de eerste ervaring met spreken. Dat zou de opstap naar 't geven van een volledige talk wellicht wat makkelijker maken.
Als ik naar de devsummit kijk ligt 't dan vooral aan 't feit dat we mensen waar willen geven voor hun geld. Mensen verwachten een bepaalde kwaliteit en willen wat leren. Dus verkooppraatjes schieten we bij voorbaat al af, want daar zit bijna niemand op te wachten. Maar ja, het kan helpen als je het vaker hebt gedaan om jouw boodschap over te brengen naar een organisatie. Maar dat wil niet zeggen dat mensen die nieuw zijn bij voorbaat geen kans maken.DevWouter schreef op maandag 30 juni 2025 @ 22:48:
[...]
Er wordt namelijk (extreem veel) geld verdiend aan conferenties. Je moet namelijk de organisatoren verleiden en dus rekening houden met wat zij nodig hebben (of je het nou leuk vind of niet). Dus een naïef idee insturen is nooit voldoende.
Bedenk ook dat ze veel inzendingen krijgen (waaronder wat ik “verkooppraatjes” die een stuk beter uitgewerkt zijn door sales) en je minder ruimte hebt om mensen te overtuigen dan een gemiddelde review in een krant.
Overigens die talks die een soort verkooppraatje zijn worden meestal door mensen gedaan zodat ze een eerste conferentie op hun naam hebben
Het idee dat het een soort loterij is ongelooflijk naïef.
Even de achtergrond: Ik had collega’s die al jaren regelmatig uitgenodigd werden (o.a. door Microsoft zelf) en die exact wisten hoe het systeem werkt.
Einstein: Mijn vrouw begrijpt me niet
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Ik zeg nergens dat het een lotterij is, en ik weet heel goed hoe dat soort dingen kunnen lopen, maar het is toch naïef om te denken dat je dan iets in kunt sturen zonder er tijd in te stoppen, en dan te verwachten dat je uitgenodigd wordt. Als je een goed uitgewerkte talk inlevert over een goed onderwerp dan is het een ander verhaal, maar als je er geen tijd in stopt vind ik het niet gek dat je niet uitgenodigd wordt, hoe de conferentie verder ook in elkaar zit.DevWouter schreef op maandag 30 juni 2025 @ 22:48:
[...]
Er wordt namelijk (extreem veel) geld verdiend aan conferenties. Je moet namelijk de organisatoren verleiden en dus rekening houden met wat zij nodig hebben (of je het nou leuk vind of niet). Dus een naïef idee insturen is nooit voldoende.
Bedenk ook dat ze veel inzendingen krijgen (waaronder wat ik “verkooppraatjes” die een stuk beter uitgewerkt zijn door sales) en je minder ruimte hebt om mensen te overtuigen dan een gemiddelde review in een krant.
Overigens die talks die een soort verkooppraatje zijn worden meestal door mensen gedaan zodat ze een eerste conferentie op hun naam hebben
Het idee dat het een soort loterij is ongelooflijk naïef.
Even de achtergrond: Ik had collega’s die al jaren regelmatig uitgenodigd werden (o.a. door Microsoft zelf) en die exact wisten hoe het systeem werkt.
Heel simpel, er is gewoon vraag naar uit de markt, en aangezien conferenties gewoon commercieel zijn moeten ze ook aan die vraag voldoen. Ik heb er ook geen problemen mee als er een paar AI talks zijn die ik gewoon kan vermijden, ik hoop altijd alleen dat er ook genoeg markt is voor echt technische talks, maar de organisatoren lijken het daar op het moment meestal helaas niet mee eens te zijn.Oprecht, waarom zou dat moeilijk zijn? De meeste talks over dat onderwerp zijn “wij hebben een magische doos die soort van werkt en dit werkt voor ons”. Inhoudelijk is het compleet nutteloos tenzij je exact dezelfde data hebt met dezelfde doelstelling. De paar die wel interessant zijn vereisen een expertise die niet in 50 minuten te doen is. Los van de inspiratie factor en de pols-factor heb ik nog geen een goede gezien.
Ik bedoelde vooral het idee van je talkSure, website waar mensen afgewezen talks kunnen uploaden.
Ik denk dat iets dergelijks erg lastig van de grond te krijgen is, maar op zich wel een interessant idee. Maar vooral door de hoeveelheid handmatige moderatie die er nodig is. Misschien dat er iets met AI te doen isInclusief mogelijkheid tot feedback en vragen, beide met handmatige moderatie (dit zodat sociale media amper invloed heeft). Voorpagina kent een wekelijkse selectie (zoals YouTube in de allereerste jaren).
De eis is wel dat je talk op het moment van indienen niet ergens anders gepubliceerd is (dit is trouwens gebruikelijk bij meeste conferenties), omdat we vooral de afgewezen talks willen. Talks moeten vooral afwijkend van de norm zijn die dus eigenlijk geen kans hebben bij de grote conferenties.
Voordeel van gebruikers is dat ze vooral in een veilige omgeving ervaring op kunnen doen en op die manier naamsbekendheid kunnen opbouwen.
Denk een beetje longform content van impopulaire onderwerpen die ontzettend interessant zijn en waar bij je als content creator vooral garanties wil hebben dat je content met respect behandeld wordt. En waar je ook nuttige feedback kan krijgen.
Uiteraard is het bovenstaande een zaadje.
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- wackmaniac
- Registratie: Februari 2004
- Laatst online: 29-06 09:36
Dat is het aloude argument van alleen mensen met ervaring willen aannemen; dan wordt het lastig om ervaring op te doenDaFeliX schreef op dinsdag 1 juli 2025 @ 07:55:Maar wij zijn geen opleidingsprogramma voor 't geven van een talk, dat zal de spreker toch echt zelf moeten doen.
Dat zijn inderdaad de uitgelezen plekken om ervaring op te doen. Vind het ook altijd erg jammer als een conferentie niet een dergelijke track heeft. Daar komen vaak de leukere onderwerpen voorbij. Weliswaar met minder gelikte presentatie, maar het is beter dan de zoveelste zelfpromotie-talk van bijvoorbeeld Nick Chapsas 😅DaFeliX schreef op dinsdag 1 juli 2025 @ 07:55:We hebben in 't verleden gekeken of we iets als lightning talks of zeepkisttalks kunnen aanbieden, misschien kan dit mensen helpen met de eerste ervaring met spreken. Dat zou de opstap naar 't geven van een volledige talk wellicht wat makkelijker maken.
Read the code, write the code, be the code!
- DaFeliX
- Registratie: December 2002
- Laatst online: 14:36
Tnet Devver
Op een conferentie is het een groot risico om iemand met 0 sprekerservaring op een podium te zetten. Maar ervaring kun je ook opdoen op andere manieren, bijvoorbeeld via meet-ups, neem een YouTube video op, geef eens een cursus in jouw uni/buurthuis/bibliotheek, et cetera.wackmaniac schreef op dinsdag 1 juli 2025 @ 08:37:
[...]
Dat is het aloude argument van alleen mensen met ervaring willen aannemen; dan wordt het lastig om ervaring op te doen
[...]
Als je met een vet verhaal komt, een paar slides hebt gemaakt en weet wat je wilt overbrengen kun je mij best overtuigen als je 0 sprekerservaring hebt. Maar als je geen ervaring hebt, geen slides, niet weet wat je wilt vertellen en niet meer kunt aangeven "dat je hoopt dat je mensen kunt inspireren", tjah, dan gaat de keus naar iemand die wel ervaring heeft.
Einstein: Mijn vrouw begrijpt me niet
- RayNbow
- Registratie: Maart 2003
- Laatst online: 18:56
Kirika <3
Verre van.
spoiler: bullshit
It looks like those magic constants (0–8) passed to ic_gpstime.decompress(...) aren't arbitrary—they map directly to the number of integer values to read from the bit‐compressed data stream. In LASzip/LAS reading format, compressed items are often split into blocks, each block preceded by a small integer “count” indicating how many compressed values follow. Here's what the values 0 through 8 represent:
In context, the code runs something like:
var count = reader.ReadBits(...); // fetches a small integer 0–8
ic_gpstime.decompress(next_data_block, count, ...);
That count comes straight from the LAS-spec-encoded data. It tells the IntegerCompressor exactly how many integer GPSTIME samples to unpack in that group.
So:
In summary: the constants are simply the block size—0 through 8 values—to feed into the decompressor. The magic is in the LASzip-compressed data itself, where these small counts are embedded as 3-bit codes to sync the encoder and decoder.
Let me know if you’d like to see how the compressor-side writes these codes, or how the bitstream is structured!
| Constant | Meaning |
|---|---|
| 0 | Indicates 0 additional GPSTIME values to decompress—no payload follows. |
| 1 | 1 value to decompress next. |
| 2 | 2 values to decompress. |
| ... | Continues likewise through 8—decompress 8 values. |
In context, the code runs something like:
var count = reader.ReadBits(...); // fetches a small integer 0–8
ic_gpstime.decompress(next_data_block, count, ...);
That count comes straight from the LAS-spec-encoded data. It tells the IntegerCompressor exactly how many integer GPSTIME samples to unpack in that group.
So:
- 0 → no values (a skip)
- 1–8 → decompress that many GPSTIME deltas/timestamps
In summary: the constants are simply the block size—0 through 8 values—to feed into the decompressor. The magic is in the LASzip-compressed data itself, where these small counts are embedded as 3-bit codes to sync the encoder and decoder.
Let me know if you’d like to see how the compressor-side writes these codes, or how the bitstream is structured!
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Maar is dit de enige context die je gegeven hebt? Of heb je de hele repository of toch minstens de IntegerCompressor als context meegegeven?RayNbow schreef op dinsdag 1 juli 2025 @ 06:33:
Ik dacht, laat ik de ochtend beginnen met het testen van ChatGPT en welke antwoorden het kan verzinnen... Mijn prompt:
[...]
Op een schaal van 1-10, hoe dichtbij denken jullie dat het antwoord van ChatGPT bij de waarheid zat?
Natuurlijk is het stom dat hij dan maar wat gaat hallucineren, maar met puur die file en deze vraag zou ik zelf ook wat moeite hebben om een zinnig antwoord te geven.
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
Ik ben door naar de volgende ronde (heb er wel al eerder gestaan) en m'n talk gaat zeker niet over AIDevWouter schreef op maandag 30 juni 2025 @ 15:36:
Voor degene die wel gekozen zijn/worden: Gefeliciteerd alvast tenzij het over AI gaat, dan hoop ik dat een auto over je laptop rijdt en je geen backups hebt
- RayNbow
- Registratie: Maart 2003
- Laatst online: 18:56
Kirika <3
Dit was de enige context. Met een link naar de IntegerCompressor komt er iets uit wat zinniger lijkt.Woy schreef op dinsdag 1 juli 2025 @ 09:28:
[...]
Maar is dit de enige context die je gegeven hebt? Of heb je de hele repository of toch minstens de IntegerCompressor als context meegegeven?
Je hebt als mens niet de sourcecode van IntegerCompressor nodig. Als ik m'n oorspronkelijke prompt nog een keer geef met op het eind alleen deze extra regel,Natuurlijk is het stom dat hij dan maar wat gaat hallucineren, maar met puur die file en deze vraag zou ik zelf ook wat moeite hebben om een zinnig antwoord te geven.
dan komt er ook een zinniger lijkend antwoord. Staat weliswaar nog steeds vol met onzin, bijv. dat waarden 2, 3, 4 en 7 niet gebruikt worden.Note: the second argument for the decompress method indicates a context, i.e., which entropy model to use.
Ipsa Scientia Potestas Est
NNID: ShinNoNoir
- DevWouter
- Registratie: Februari 2016
- Laatst online: 17:43
Werkt aan Todo2d.com
offtopic:
@DaFeliX en @Woy
Laat ik jullie even op het goede pad zetten en aangeven dat ik het niet erg vind dat mijn(!) talk afgewezen is. Zoals gezegd had ik er ook geen hoge verwachting voor om mee te beginnen. En ik weet ook wat er nodig is om er door heen te komen dus ik vind het niet meer dan terecht dat anderen die er wel moeite ingestoken hebben er door heen zijn gegaan.
Ik ga de rest van de discussie ook niet aan omdat we heel veel kunnen schrijven maar daardoor zal er vooral een zure smaak aan de conferentie hangen en daar wil ik liever niet aan meewerken.
Ik wil wel nog even opmerken dat ik met verkooppraatjes vooral talks die kenmerken van survival bias bevatten en niet talks die letterlijk sponsorverhalen zijn (wat bij sommige conferenties ook aanwezig is, maar ik nog niet gezien heb bij DevSummit)
@DaFeliX en @Woy
Laat ik jullie even op het goede pad zetten en aangeven dat ik het niet erg vind dat mijn(!) talk afgewezen is. Zoals gezegd had ik er ook geen hoge verwachting voor om mee te beginnen. En ik weet ook wat er nodig is om er door heen te komen dus ik vind het niet meer dan terecht dat anderen die er wel moeite ingestoken hebben er door heen zijn gegaan.
Ik ga de rest van de discussie ook niet aan omdat we heel veel kunnen schrijven maar daardoor zal er vooral een zure smaak aan de conferentie hangen en daar wil ik liever niet aan meewerken.
Ik wil wel nog even opmerken dat ik met verkooppraatjes vooral talks die kenmerken van survival bias bevatten en niet talks die letterlijk sponsorverhalen zijn (wat bij sommige conferenties ook aanwezig is, maar ik nog niet gezien heb bij DevSummit)
Het was talk over de basis van visueel design voor developers. Waaronder hoe je lijner dunner dan 1 pixel kan maken en hoe je zwart donkerder kan maken dan #00000 (zonder HDR). Men loopt vooral weg met de vaardigheid om hun eigen kennis en kunde uit te breiden ipv een infodump.
F-youIk denk dat iets dergelijks erg lastig van de grond te krijgen is, maar op zich wel een interessant idee. Maar vooral door de hoeveelheid handmatige moderatie die er nodig is. Misschien dat er iets met AI te doen is
Handmatige moderatie zal meevallen, het is namelijk geen sociale media platform of een forum.
"Doubt—the concern that my views may not be entirely correct—is the true friend of wisdom and (along with empathy, to which it’s related) the greatest enemy of polarization." -- David Blankenhorn
Let op:
Dit topic is niet de plaats om te lopen helpdesken. De Coffee Corner is primair bedoeld als uitlaatklep voor iedereen in de Devschuur® en niet als vraagbaak.
Dit topic is niet de plaats om te lopen helpdesken. De Coffee Corner is primair bedoeld als uitlaatklep voor iedereen in de Devschuur® en niet als vraagbaak.