:fill(white):strip_exif()/i/2003943496.jpeg?f=thumbmini)
:strip_exif()/i/1321263566.png?f=thumbmini)
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
Even niets...
- Jaap-Jan
- Registratie: Februari 2001
- Laatst online: 08:05
:strip_icc():strip_exif()/u/22092/crop5fa8360e95568_cropped.jpeg?f=community)
En waarom per sé RAID-Z1 en niet gewoon een mirror?
| Last.fm | "Mr Bent liked counting. You could trust numbers, except perhaps for pi, but he was working on that in his spare time and it was bound to give in sooner or later." -Terry Pratchett
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
:strip_icc():strip_exif()/u/286431/crop680f6b95743ca_cropped.jpg?f=community)
OK, top, dan ga ik die bestellen. Dan heb ik hem morgen binnen (hoop ik) en is m'n pool tenminste niet meer degraded.FireDrunk schreef op dinsdag 19 maart 2013 @ 18:33:
Zeker, nieuwe schijven doen al snelheden boven 1Gb netwerk, dus tenzij je trunks maakt of met 10Gb aan de slag gaat, heb je niet veel spindels of snelle schijven nodig.
Sequentieel maakt het inderdaad überhaupt niets uit, maar ik vroeg me dus vooral af wat de performance hit in de random reads/writes was.
Hogere write performance en netto meer opslagruimte (dus goedkoper). Met mirroring ben je namelijk 50% van je schijven kwijt aan redundancy, bij RAID-Z1 met 3 schijven maar 33,3%.Jaap-Jan schreef op dinsdag 19 maart 2013 @ 18:38:
En waarom per sé RAID-Z1 en niet gewoon een mirror?
Daarnaast draai ik nu dus ook al RAID-Z1 (nu dus degraded) en was het plan om ivm geld de 3 schijven geleidelijk te vervangen door nieuwe exemplaren.
De eerste bestel ik vandaag, zodat m'n pool morgen (als het goed is) tenminste niet meer degraded is.
Over een paar maanden koop ik de overige 2 exemplaren wel en dan kan ik m'n pool expanden.
Als ik over zou gaan naar mirroring zou dat niet kunnen
[ Voor 5% gewijzigd door Compizfox op 19-03-2013 18:45 ]
Gewoon een heel grote verzameling snoertjes
Zoals gezegd, je test cycles zijn 5, dus je test begint met 5 * 4 kilobyte = 20 kilobyte. Dat moet minimaal 8 keer je RAM zijn, dus minimaal 64 gigabyte in plaats van 20 kilobyte. De hele test die je doet is fout; wat je test is gewoon doorvoer ofwel sequential I/O naar je server. L2ARC kun je het beste testen met realistische scenario's. Zoals: installeer een spel op je NAS met en zonder L2ARC en ga de opstarttijd testen of level load of wat dan ook.Xudonax schreef op vrijdag 15 maart 2013 @ 15:23:
En als "laatste stukje" van mijn benchmarks de resultaten met een SSD als cache:
Juist andersom: vrijwel niks sneller (alleen SMP is iets sneller) maar idle power zou een factor 10 tot 20 afgenomen zijn. Dat geldt echter enkel voor de mobiele tak, waarbij ook de VRM nu op de package wordt geïntegreerd. Deze zuinige Haswell chips zullen enkel in BGA versie uitkomen. Dat betekent dus dat je ze niet kunt kopen (stel zeg! dat we zouden kunnen kopen wat we willen...)EnerQi schreef op zaterdag 16 maart 2013 @ 09:36:
Intel processor 'Haswell' komt binnenkort uit (opvolger Ivy bridge). Voor zover ik het begrepen heb, zou het weer sneller moeten zijn maar het idle gebruik gaat zeer weinig omlaag.
Kennelijk is europa geen markt; azië en amerika geven weinig om stroomkosten. De enige reden voor Intel om de idle power terug te dringen is omdat ze mee willen dingen naar tablets en andere lage TDP mobiele devices. De enige hoop die ik heb is dat er bordjes komen waar de CPU al opzit, zoals de AMD C60/E350 maar dan met de nieuwe Intel Haswell. Dan zou je misschien bordjes met 4W idle kunnen krijgen ofzo. Intel kennende gaat dat niet gebeuren: veel T model processors mogen wij consumenten ook niet kopen van Intel.
Sneller RAM scheelt bijna nooit iets in de prestaties. Echter, dat zijn standaardapplicaties. Taken waarbij de RAM flink wordt gebruikt, zien we wel grote verschillen. Denk hierbij aan AMD met IGP; ander geheugen kan hierbij de prestaties met 50% doen toenemen versus het langzaamste geheugen. Dat is wat anders dan de gebruikelijke 1-2%.FireDrunk schreef op zaterdag 16 maart 2013 @ 09:37:
Alleen 1600Mhz CL9 of CL10 is eigenlijk een upgrade t.o.v. 1333Mhz geheugen. Maar voor een standaard NAS boeit het allemaal vrij weinig, dus neem dan gewoon het goedkoopste.
Ik vraag me af in hoeverre dit ook voor ZFS geldt. ZFS zou zeer geheugenintensief moeten zijn en waarschijnlijk ook RAM bottlenecked.
Je gaat het vooral voelen in de opslagruimte die beperkt wordt door extra slack. Aangenomen dat je ashift=12 draait (optimaal voor 4K disks) - met standaard ashift ben je geen extra ruimte kwijt maar dan lever je dus wel in qua prestaties. Optimale configuraties zijn optimaal voor zowel prestaties als opslagruimte.Jormungandr schreef op zaterdag 16 maart 2013 @ 21:47:
In hoeverre ga je de performance hit voelen als je een niet-conform disk aantal gebruikt voor raidz/raidz2?
ZFSguru wel, maar ZFS biedt die ondersteuning niet. Ook niet onder Solaris platform. De feitelijke support gebeurt door een userland binary (een normale applicatie) die 'zfsd' wordt genoemd. Dit is nu ook naar BSD geport en zou in FreeBSD 10 moeten zitten. Maar in de meeste situaties wil je RAID-Z2 draaien in plaats van hot-spare.Bigs schreef op maandag 18 maart 2013 @ 10:14:
Biedt ZFSguru eigenlijk ondersteuning voor hotspares?
Sendmail is een van de dingen (net als BIND) die standaard geïnstalleerd zijn op FreeBSD en je ook expliciet moet disablen anders gaat die elke nacht mailqueue herkauwen. Ik vind het een ramp, dus schakel sendmail ook gelijk uit. Sendmail is verder berucht om security vulnerabilities. Vieze zooi vind ik het. Maar als je simpelweg mail wilt kunnen versturen, is dit wel wat je wilt.Mafketel schreef op maandag 18 maart 2013 @ 21:36:
Ik ben een beetje in de war....
portmaster -l vind dat sendmail niet is geinstallerd en postfix wel....
Even in een nieuw bericht, voor de overzichtelijkheid:
Enige mogelijkheid die ik zie is dat er toch een vorm van RAM corruptie is ontstaan. Heb je al scrub gestart en wat gebeurt er dan met de corruptie? Ennuhh.. niet zomaar op knopjes drukken hè.


Tijd om KVM + FreeBSD + ZFS als incompatible of experimenteel aan te duiden? Want dit probleem had je niet met ESXi op dezelfde hardware, correct?FireDrunk schreef op dinsdag 19 maart 2013 @ 16:51:
Warning: some files on your pool are inaccessible due to unrecoverable corruption! The files affected, are:
Godverdomme, nog heel even en ik flikker mijn server het raam uit...
Afgelopen 4 dagen, geen enkele kernel log melding wat ook maar iets met problemen te maken heeft...
Zowel in de host niet, als in de ZFSguru VM.
Enige mogelijkheid die ik zie is dat er toch een vorm van RAM corruptie is ontstaan. Heb je al scrub gestart en wat gebeurt er dan met de corruptie? Ennuhh.. niet zomaar op knopjes drukken hè.
Wat doen jullie toch met jullie servers?Compizfox schreef op dinsdag 19 maart 2013 @ 16:57:
Verdomme, weer een schijf gesneuveld....
Dat betekent dus 1,5 core gemiddeld over de laatste 60 seconden; althans als je dat ziet in ZFSguru op de status pagina. Dat is gewoon de average load van de laatste minuut maal honderd. 150% is dus niet heel hoog ofzo. Je kunt het met top -P in een terminal beter zien. Dan zie je ook de interrupt usage bijvoorbeeld.
Kun je de output van 'ifconfig' eens geven? Ik heb hetzelfde bord en dat werkt prima. Heb je DHCP op je netwerk?ilovebrewski schreef op dinsdag 19 maart 2013 @ 17:59:
Blijkt aan de pc te liggen waar ik in eerste instantie de bootable usb heb gemaakt. USB aansluiting werkt niet naar behoren.
Nu in de server en hij boot iig op
Maar hij vind alleen geen ip adres. Staat http://0.0.0.0 (loop)
Het is bedraad GB netwerk en ik heb het volgende moederbord.
Ja, maar ik durf echt geen schuldige aan te wijzen, want ik kan echt NERGENS een foutmelding vinden. Enige wat ik kan verzinnen is dat het met tijd (of clockskew voor de nerds) te maken heeft, en dat ZFS zijn checksums berekend afhankelijk van tijd ofzo.Verwijderd schreef op dinsdag 19 maart 2013 @ 19:37:
Even in een nieuw bericht, voor de overzichtelijkheid:
[...]
Tijd om KVM + FreeBSD + ZFS als incompatible of experimenteel aan te duiden? Want dit probleem had je niet met ESXi op dezelfde hardware, correct?
Enige mogelijkheid die ik zie is dat er toch een vorm van RAM corruptie is ontstaan. Heb je al scrub gestart en wat gebeurt er dan met de corruptie? Ennuhh.. niet zomaar op knopjes drukken hè.
Verder kan ik NIETS verzinnen...
Overigens ben ik niet de enige die onder KVM draait hoor, er zijn al anderen die het wel gewoon werkend hebben... Misschien doe ik wel iets verkeerd...
Wat ik ABSOLUUT niet begrijp, is hoe oude files corrupt kunnen raken.
Ik kan er echt met geen mogelijkheid bij dat ik nu dus corrupte files heb van wel een jaar oud. Die files heb ik gewoon niet eens gelezen... Het is dus uberhaupt vreemd dat ZFS ziet dat ze corrupt zijn zonder dat er een disk failure of iets geweest is.
(nu met een scrub heb ik 6.5G kaduuk, in 83 files...)
EDIT:
hmm, ik druk net op enter in mijn VM, en ik krijg ineens:
vm_fault: pager read error, pid 19989 (smbd) vm_fault: pager read error, pid 21203 (smbd)
Toch maar even memtesten...
[ Voor 31% gewijzigd door FireDrunk op 19-03-2013 20:02 ]
Even niets...
Standaard gebruikt ZFSguru swap op ZVOLs. Als er corruptie ontstaat in die ZVOL door RAM (kan eigenlijk alleen maar RAM zijn) dan kan dat grote gevolgen hebben. Die melding die je net krijgt is in elk geval een grote waarschuwing IMO. Een extra keer memtesten kan denk ik geen kwaad.
Mocht je inderdaad corrupt RAM hebben, is dat een hele opluchting. Je kunt dan je RAM corruptievrij maken door het reepje te verwijderen en te hertesten. Daarna in ZFSguru weer een scrub draaien. Als je redundancy hebt, wordt de disk-corruptie aangericht door RAM-corruptie ook net zo hard weer gecorrigeerd. Dat is in elk geval mijn ervaring.
Hoe dan ook, dit is wel een smet op het draaien van een gevirtualiseerde ZFS storage box; als dit soort geintjes echt aan KVM zou liggen of in elk geval de combinatie KVM met FreeBSD/ZFS, dan lijkt me dat een waarschuwing waard op diverse fora waar actieve ZFS gebruikers aanwezig zijn.
Mocht je inderdaad corrupt RAM hebben, is dat een hele opluchting. Je kunt dan je RAM corruptievrij maken door het reepje te verwijderen en te hertesten. Daarna in ZFSguru weer een scrub draaien. Als je redundancy hebt, wordt de disk-corruptie aangericht door RAM-corruptie ook net zo hard weer gecorrigeerd. Dat is in elk geval mijn ervaring.
Hoe dan ook, dit is wel een smet op het draaien van een gevirtualiseerde ZFS storage box; als dit soort geintjes echt aan KVM zou liggen of in elk geval de combinatie KVM met FreeBSD/ZFS, dan lijkt me dat een waarschuwing waard op diverse fora waar actieve ZFS gebruikers aanwezig zijn.
Enige wat ik ook nog kan verzinnen is dat ik onder KVM mijn CPU type doorgeef aan de VM (SandyBridge omdat IvyBridge nog niet 100% gesupport is in het lijstje staat...). Dit zorgt er dus ook voor dat de Hardware matige AES instructie zichtbaar is in de VM.
Misschien hebben ze bij Intel of KVM wel zitten slapen en die instructie niet VT-x proof gemaakt... Maar dat is allemaal far fetched...
(memtest loopt, nog geen fouten).
WTF, ik zie net dat mijn ram sowieso verkeerd zit
Het draait op 1333Mhz cas 6-6-6-20 ipv 1600Mhz 10-10-10-27, en in Single channel mode
En fixed
Woopsie
Misschien hebben ze bij Intel of KVM wel zitten slapen en die instructie niet VT-x proof gemaakt... Maar dat is allemaal far fetched...
(memtest loopt, nog geen fouten).
WTF, ik zie net dat mijn ram sowieso verkeerd zit
Het draait op 1333Mhz cas 6-6-6-20 ipv 1600Mhz 10-10-10-27, en in Single channel mode
En fixed
Woopsie
[ Voor 19% gewijzigd door FireDrunk op 19-03-2013 20:23 ]
Even niets...
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
:strip_icc():strip_exif()/u/371379/zNcU5.jpg?f=community)
Hieronder de output. Ik heb gewoon DHCP. Live-cd via virtual box op mijn laptop pakt hij wel gewoon.Verwijderd schreef op dinsdag 19 maart 2013 @ 19:37:
Kun je de output van 'ifconfig' eens geven? Ik heb hetzelfde bord en dat werkt prima. Heb je DHCP op je netwerk?
http://imageshack.us/photo/my-images/856/20130319200409.jpg/
[ Voor 14% gewijzigd door ilovebrewski op 19-03-2013 20:26 ]
Dat venstertje van ZFS geeft niet altijd goed je IP weer. Je server zit nu op 192.168.1.12.ilovebrewski schreef op dinsdag 19 maart 2013 @ 20:22:
[...]
Kun je de output van 'ifconfig' eens geven? Ik heb hetzelfde bord en dat werkt prima. Heb je DHCP op je netwerk?
[/quote]
Hieronder de output. Ik heb gewoon DHCP. Live-cd via virtual box op mijn laptop pakt hij wel gewoon.
http://imageshack.us/photo/my-images/856/20130319200409.jpg/
Even niets...
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
Sjeezz wat een noob ben ik. nja we leren iedere dag weer bijFireDrunk schreef op dinsdag 19 maart 2013 @ 20:24:
[...]
Dat venstertje van ZFS geeft niet altijd goed je IP weer. Je server zit nu op 192.168.1.12.
TOP THNX!!
Dat je 0.0.0.0 zag komt inderdaad omdat de detectie fout gaat. Maar opzich heeft ZFSguru gelijk; je hebt ook een IP adres 0.0.0.0 omdat je de parallelle poort niet hebt uitgeschakeld. Dit is iets van het jaar 1990 wat nu natuurlijk alleen meer problemen kan veroorzaken. Lekker uitschakelen dus, dan heb je geen plip0 netwerk interface meer (IP over parallelle poort; wie verzint het).
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
OK ga ik uitschakelen!Verwijderd schreef op dinsdag 19 maart 2013 @ 20:36:
Dat je 0.0.0.0 zag komt inderdaad omdat de detectie fout gaat. Maar opzich heeft ZFSguru gelijk; je hebt ook een IP adres 0.0.0.0 omdat je de parallelle poort niet hebt uitgeschakeld. Dit is iets van het jaar 1990 wat nu natuurlijk alleen meer problemen kan veroorzaken. Lekker uitschakelen dus, dan heb je geen plip0 netwerk interface meer (IP over parallelle poort; wie verzint het).
En rommelen met ZFSGURU!
1e memtest pass is er door...
Even niets...
Staat ergens verborgen in de bios. Ik had een tijdje terug precies het zelfde. De oplossing van CiPHER lost het direct opilovebrewski schreef op dinsdag 19 maart 2013 @ 20:42:
[...]
OK ga ik uitschakelen!
En rommelen met ZFSGURU!
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Tweedehands HDDs erin pleuren. Dat ga ik dus vanaf nu nooit meer doen.
Gewoon een heel grote verzameling snoertjes
Tja alles kan kapot...
Even niets...
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Bij mij geeft ie anders ook niet het goede IP aan:Verwijderd schreef op dinsdag 19 maart 2013 @ 20:36:
Dat je 0.0.0.0 zag komt inderdaad omdat de detectie fout gaat. Maar opzich heeft ZFSguru gelijk; je hebt ook een IP adres 0.0.0.0 omdat je de parallelle poort niet hebt uitgeschakeld. Dit is iets van het jaar 1990 wat nu natuurlijk alleen meer problemen kan veroorzaken. Lekker uitschakelen dus, dan heb je geen plip0 netwerk interface meer (IP over parallelle poort; wie verzint het).
code:
1
| Web-interface is running at http://0.0.0.0 (loop) |
Ik heb echter geen plip0:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| $ ifconfig
vmx3f0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 4000
options=403bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,TSO4,TSO6,VLAN_HWTSO>
ether 00:0c:29:39:02:c7
inet6 fe80::20c:29ff:fe39:2c7%vmx3f0 prefixlen 64 scopeid 0x1
inet 192.168.2.5 netmask 0xffffff00 broadcast 192.168.2.255
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
media: Ethernet 10Gbase-T
status: active
pflog0: flags=41<UP,RUNNING> metric 0 mtu 33152
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
pfsync0: flags=41<UP,RUNNING> metric 0 mtu 1500
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
syncpeer: 0.0.0.0 maxupd: 128
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> metric 0 mtu 4000
options=600003<RXCSUM,TXCSUM,RXCSUM_IPV6,TXCSUM_IPV6>
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x4
inet 127.0.0.1 netmask 0xff000000
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL> |
Gewoon een heel grote verzameling snoertjes
Dat komt omdat jij een beetje rare naam hebt voor je netwerkadapter: vmx3f0. De regular expression detectiecode is zo geschreven dat hij een naam met als laatste een getal verwacht; geen getallen in de naam zelf. Dat geldt voor alle adapters, behalve deze zo lijkt het. Misschien omdat de ontwikkelaars van ESXi niet op de hoogte waren (of lak hadden aan) de conventies binnen FreeBSD, maar dat is maar speculatie.
offtopic:
je kan natuurlijk ook gewoon RegExxen op inet [0-9^3.0-9^3.0-9^3]
*uit de losse pols...*
je kan natuurlijk ook gewoon RegExxen op inet [0-9^3.0-9^3.0-9^3]
*uit de losse pols...*
Even niets...
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Aha, dat klinkt wel logisch. 
Gewoon een heel grote verzameling snoertjes
- HyperBart
- Registratie: Maart 2006
- Laatst online: 09:22
/u/170728/owl.png?f=community)
Compizfox schreef op dinsdag 19 maart 2013 @ 16:57:
Verdomme, weer een schijf gesneuveld....
Maakt ook gekke geluiden. Het probleem is ook dat heel FreeBSD er unresponsive van wordt...
Nou nouCompizfox schreef op dinsdag 19 maart 2013 @ 22:31:
[...]
Tweedehands HDDs erin pleuren. Dat ga ik dus vanaf nu nooit meer doen.
Doet er mij aan denken dat ik ECHT nog eens een backupje extra moet trekken...
Wat dat betreft had ik het volgende idee:
Ik heb 5 x 3TB als pool "hulk" in RAIDZ en 2 x 2TB in mirror als pool "SPIEGELTJE". Onder hulk heb ik voor iedere share een filesystem: Bart, Documenten, Video, Beeldmateriaal Gezin, Muziek etc...
Uiteindelijk is de own made data alleen van belang. Dus wou ik die senden/receiven met snapshots naar de pool SPIEGELTJE. Bedoeling is dan om de mirror het merendeel van de tijd degraded te laten draaien en regelmatig de tweede disk er eens terug in te steken en een resilver van de mirror te doen...
Ik heb me wat ingelezen in de snapshots en zfs send receive, op zich heel leuk met optie -i , maar ik ga alleen wat intelligentie moeten inbouwen dat hij altijd de naam van de voorlaatste en laatste snapshot ergens wegzet om met de optie -i altijd netjes te syncen naar SPIEGELTJE, en daar wringt het nog wat
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Samsung HD753LJ's, 3x. Er zijn ondertussen al 2 van defect gegaan, waarvan ik er 1 heb vervangen door een andere (2e handse) van hetzelfde type.HyperBart schreef op woensdag 20 maart 2013 @ 00:08:
[...]
[...]
Nou nou
Dat is iets anders. Als een RAID-controller een HDD (of meer) eruit tieft tijdens een rebuild, ben je fucked, maar is dat op zich geen defecte schijf. Die schijf zal namelijk vast geen fysieke schade hebben, los van die URE.Vandaag had ik een klant aan de lijn die zijn DPM-backups naar een Thecus NAS deed van 7 x 2TB. Eentje was er uit geflikkerd wegens SMART errors, en tijdens de rebuild waren er nog 2 die moeilijk deden (ik vermoed een URE) en dat was dan al met RAID6 en WD Black RE schijven... Om maar even aan te tonen dat nieuwkoop ook geen garantie is op eeuwig blijvend werkend.
UREs komen namelijk tegenwoordig nou eenmaal veel voor en zijn dus te beschouwen als "normaal". Dat hardware-RAID5 hier niet mee om kan gaan laat zien dat het een gedateerde techniek is. Maar daarom gebruik ik juist ZFS
De eerste schijf (paar maanden geleden) die defect raakte, had een heleboel bad sectors (iets van 2000 dacht ik), en dat werden er rap meer. Die was aan het overlijden dus, en heb ik daarom vervangen.
De schijf die vandaag is overleden kapte er plotseling mee met een hele hoop ATA timeouts en read errors. Toen ik even IRL een kijkje nam bij de servert in kwestie hoorde ik dan ook een hoop gekke geluiden en gekraak. Lijkt me obvious: Die schijf is ook fysiek defect.
[ Voor 6% gewijzigd door Compizfox op 20-03-2013 00:14 ]
Gewoon een heel grote verzameling snoertjes
Bad sectors of echt schijffalen zou ik inderdaad wel gescheiden houden. Zeker met consumentenschijven moet je bad sectors gewoon incalculeren. In veel builds zie ik dat meerdere disks allemaal pending sectoren hebben. Dat is met ZFS, waar ZFS die sectoren dus niet gebruikt. Maar dat is al wel een indicatie dat je mocht je hardware RAID hebben gebruikt dus een probleem had gehad.
Niet helemaal, omdat je dan de loopback adapter kunt krijgen, of bridged verbindingen, of alias adressen of bijvoorbeeld die parallelle poort. Om die reden wordt ook naar de naam van de adapter gekeken, en daar zit dus nog een bugje in; die alleen voorkomt met de netwerkinterface die 'third party' is en derhalve een afwijkende naam heeft.FireDrunk schreef op dinsdag 19 maart 2013 @ 22:51:
offtopic:
je kan natuurlijk ook gewoon RegExxen op inet [0-9^3.0-9^3.0-9^3]
*uit de losse pols...*
- Jaap-Jan
- Registratie: Februari 2001
- Laatst online: 08:05
Uiteraard ben je relatief gezien meer ruimte kwijt, maar je aanschafkosten zijn lager (2x WD20EZRX kost €168,- inclusief verzenden, 3x WD10EZRX kost €178,- inclusief verzenden) en het verbruik zal ook lager zijn.Compizfox schreef op dinsdag 19 maart 2013 @ 18:44:
[...]
Hogere write performance en netto meer opslagruimte (dus goedkoper).Met mirroring ben je namelijk 50% van je schijven kwijt aan redundancy, bij RAID-Z1 met 3 schijven maar 33,3%.
Qua write performance lijk je wel gelijk te hebben, wel tegen mijn verwachting in, overigens.
Ik zie wel een upgrade- pad. Maak een mirror van de (degraded) RAID-Z array en je nieuwe disk en vervang later die RAID-Z array voor een nieuwe disk. Klaar.Daarnaast draai ik nu dus ook al RAID-Z1 (nu dus degraded) en was het plan om ivm geld de 3 schijven geleidelijk te vervangen door nieuwe exemplaren.
De eerste bestel ik vandaag, zodat m'n pool morgen (als het goed is) tenminste niet meer degraded is.
Over een paar maanden koop ik de overige 2 exemplaren wel en dan kan ik m'n pool expanden.
Als ik over zou gaan naar mirroring zou dat niet kunnen
Als je later toch weer een RAID-Z array wilt draaien mik je één van die schijven uit je mirror, maak je een nieuwe (in eerste instantie) degraded RAID-Z array aan, kopiëer je alle data over en voeg je de laatst overgebleven schijf uit je mirror toe aan de array. Voorbeeldje van een tutorial. Oke, dit is voor FreeNAS, maar het ging me er even om om de stappen te laten zien.
[ Voor 10% gewijzigd door Jaap-Jan op 20-03-2013 00:58 ]
| Last.fm | "Mr Bent liked counting. You could trust numbers, except perhaps for pi, but he was working on that in his spare time and it was bound to give in sooner or later." -Terry Pratchett
Vanochtend geen RAM errors te zien om mijn server. Nu maar eens dat CPU type wijzigen in KVM.
Na het terugzetten van het CPU type naar Westmere zijn alle checksum errors weg.
Ik heb een FreeBSD topic gevonden waar iemand een probleem had met het doorgeven van bepaalde instructies aan FreeBSD 9.1 icm een AMD Opteron, het terugvoeren van het aantal instructies hielp daar ook.
Schijnt iets in de FreeBSD loader te zijn dat moeilijk doet.
Toch een vreemde zaak...
Na het terugzetten van het CPU type naar Westmere zijn alle checksum errors weg.
Ik heb een FreeBSD topic gevonden waar iemand een probleem had met het doorgeven van bepaalde instructies aan FreeBSD 9.1 icm een AMD Opteron, het terugvoeren van het aantal instructies hielp daar ook.
Schijnt iets in de FreeBSD loader te zijn dat moeilijk doet.
Toch een vreemde zaak...
[ Voor 67% gewijzigd door FireDrunk op 20-03-2013 08:40 ]
Even niets...
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Ja, maar met 2x WD20EZRX in mirror heb ik netto maar 1 TB opslagruimte (50% kwijt), en met 3x in RAID-Z1 heb ik 2 TB (33,3% kwijt).Jaap-Jan schreef op woensdag 20 maart 2013 @ 00:25:
[...]
Uiteraard ben je relatief gezien meer ruimte kwijt, maar je aanschafkosten zijn lager (2x WD20EZRX kost €168,- inclusief verzenden, 3x WD10EZRX kost €178,- inclusief verzenden) en het verbruik zal ook lager zijn.
Bij mirroring zou je write-snelheid even hoog moeten zijn als ie zou zijn met 1 schijf. Met RAID-Z1 is het 2x zo snel (3 schijven tegelijk - 1 parity = 2)Qua write performance lijk je wel gelijk te hebben, wel tegen mijn verwachting in, overigens.
Gewoon een heel grote verzameling snoertjes
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Volgens mij is dat niet zo. Met Raidz1 heb je schrijfsnelheid van 1 disk.Compizfox schreef op woensdag 20 maart 2013 @ 10:27:
oring zou je write-snelheid even hoog moeten zijn als ie zou zijn met 1 schijf. Met RAID-Z1 is het 2x zo snel (3 schijven tegelijk - 1 parity = 2)
"RAID-Z: Similarly to RAID-5, you get n-1 disks worth of space, and spend 1 parity disk for fault tolerance. One disk breaks, you still get to your data. Performance is more complicated: Writes are spread across all disks, so essentially, per I/O, you'll always get the performance of a single disk. Same for reads. If you're lucky and the stars align and you read a lot of data at once, you may get more than that. I'll let the zpool(1M) man page explain the rest"
http://constantin.glez.de...-why-mirroring-still-best
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Die redenering snap ik niet, en volgens mij is het ook niet zo. Writes zijn inderdaad verspreid over meerdere disks, maar juist daarom is het sneller dan 1 disk.
Ook Wikipedia geeft dat aan:
RAID5 write speed = (n−1)X
Met n het aantal schijven en X de snelheid van een enkele disk.
Bij RAID1 is het 1X, en met RAID0 is het nX.
Wikipedia: RAID
Ook Wikipedia geeft dat aan:
RAID5 write speed = (n−1)X
Met n het aantal schijven en X de snelheid van een enkele disk.
Bij RAID1 is het 1X, en met RAID0 is het nX.
Wikipedia: RAID
[ Voor 10% gewijzigd door Compizfox op 20-03-2013 11:02 ]
Gewoon een heel grote verzameling snoertjes
- HyperBart
- Registratie: Maart 2006
- Laatst online: 09:22
matty___ schreef op woensdag 20 maart 2013 @ 10:51:
[...]
Volgens mij is dat niet zo. Met Raidz1 heb je schrijfsnelheid van 1 disk.
"RAID-Z: Similarly to RAID-5, you get n-1 disks worth of space, and spend 1 parity disk for fault tolerance. One disk breaks, you still get to your data. Performance is more complicated: Writes are spread across all disks, so essentially, per I/O, you'll always get the performance of a single disk. Same for reads. If you're lucky and the stars align and you read a lot of data at once, you may get more than that. I'll let the zpool(1M) man page explain the rest"
http://constantin.glez.de...-why-mirroring-still-best
Jullie verwisselen IOPS met throughput. IOPS zijn gelijk met iedere spindle, maar de bandbreedte verhoogt met iedere spindle die er bij komt...Compizfox schreef op woensdag 20 maart 2013 @ 11:01:
Die redenering snap ik niet, en volgens mij is het ook niet zo. Writes zijn inderdaad verspreid over meerdere disks, maar juist daarom is het sneller dan 1 disk.
Ook Wikipedia geeft dat aan:
RAID5 write speed = (n−1)X
Met n het aantal schijven en X de snelheid van een enkele disk.
Bij RAID1 is het 1X, en met RAID0 is het nX.
Wikipedia: RAID
[ Voor 28% gewijzigd door HyperBart op 20-03-2013 11:20 ]
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
raidz1 != raid5 in dat opzichtCompizfox schreef op woensdag 20 maart 2013 @ 11:01:
Die redenering snap ik niet, en volgens mij is het ook niet zo. Writes zijn inderdaad verspreid over meerdere disks, maar juist daarom is het sneller dan 1 disk.
Ook Wikipedia geeft dat aan:
RAID5 write speed = (n−1)X
Met n het aantal schijven en X de snelheid van een enkele disk.
Bij RAID1 is het 1X, en met RAID0 is het nX.
Wikipedia: RAID
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
hmm zo had ik er nog niet naar gekekenHyperBart schreef op woensdag 20 maart 2013 @ 11:19:
[...]
[...]
Jullie verwisselen IOPS met throughput. IOPS zijn gelijk met iedere spindle, maar de bandbreedte verhoogt met iedere spindle die er bij komt...
- Jaap-Jan
- Registratie: Februari 2001
- Laatst online: 08:05
De WD20EZRX is 2 TB, dus met 2x in mirror houdt je netto 2 TB over. De €/GB van 2TB- schijven zijn veel beter dan die van 1 TB schijven. Die 50% verlies houdt je nog steeds, maar dat verschil zit tussen de oren.Compizfox schreef op woensdag 20 maart 2013 @ 10:27:
[...]
Ja, maar met 2x WD20EZRX in mirror heb ik netto maar 1 TB opslagruimte (50% kwijt), en met 3x in RAID-Z1 heb ik 2 TB (33,3% kwijt).
Aha. Sequential write speeds worden dus wel beter, maar random write speeds niet.HyperBart schreef op woensdag 20 maart 2013 @ 11:19:
[...]
[...]
Jullie verwisselen IOPS met throughput. IOPS zijn gelijk met iedere spindle, maar de bandbreedte verhoogt met iedere spindle die er bij komt...
| Last.fm | "Mr Bent liked counting. You could trust numbers, except perhaps for pi, but he was working on that in his spare time and it was bound to give in sooner or later." -Terry Pratchett
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
Nu zijn ze ook bezig met zfsonlinux.
Is er te verwachten dat ik kan overstappen vanaf zfsguru naar zfsonlinus zonder dataverlies?
Tot nu toe niks tegenover zfsguru. Ik heb echter zelf wat meer ervaring met Linux.
Is er te verwachten dat ik kan overstappen vanaf zfsguru naar zfsonlinus zonder dataverlies?
Tot nu toe niks tegenover zfsguru. Ik heb echter zelf wat meer ervaring met Linux.
- Jaap-Jan
- Registratie: Februari 2001
- Laatst online: 08:05
Het zou kunnen volgens mij. ZFSGuru ondersteund (via FreeBSD) maximaal zpool versie 28 en ZFS on Linux ondersteund versie 28 ook.
| Last.fm | "Mr Bent liked counting. You could trust numbers, except perhaps for pi, but he was working on that in his spare time and it was bound to give in sooner or later." -Terry Pratchett
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
code:
1
2
3
| ada0 GPT: Storage4 750.2 GB 698.6 GiB 512 B <SAMSUNG HD753LJ 1AA01107> ATA-7 SATA 2.x device ada1 GPT: Storage5 1 TB 931.5 GiB 512 B <SAMSUNG HD753LJ 1AA01118> ATA-7 SATA 2.x device ada2 GPT: Storage1 750.2 GB 698.6 GiB 512 B <SAMSUNG HD753LJ 1AA01118> ATA-7 SATA 2.x device |
Mogelijk bugje in ZFSGuru? Op ada1 zat eerst inderdaad altijd een Samsung HD753LJ, maar die heb ik nu vervangen door een WDC WD10EZRX.
Gewoon een heel grote verzameling snoertjes
Inderdaad. RAID-Z heeft door zijn RAID3-achtige structuur geen voordeel uit random I/O. Daar staat tegenover dat de random write snelheid even groot is als een enkele disk zonder RAID (net iets langzamer). Dat klinkt misschien niet goed, maar RAID5 is daarintegen juist heel traag met random write (je moet eerst lezen om te kunnen schrijven). Bij RAID-Z is dat niet zo, maar zijn random reads juist weer veel trager dan RAID5.Jaap-Jan schreef op woensdag 20 maart 2013 @ 13:03:
Aha. Sequential write speeds worden dus wel beter, maar random write speeds niet.
Dus:
Bij RAID-Z geldt dat per vdev dit de random I/O prestaties biedt van één disk. Dus twee vdevs van elk 10 disks in RAID-Z2 zou dezelfde IOps prestaties moeten hebben als twee disks in RAID0. Om die reden wordt RAID-Z vaak afgeraden in server workloads. Daar valt wat voor te zeggen. Weet wel dat RAID-Z eigenlijk alleen random read als nadeel heeft, en juist dat kun je uitstekend oplossen met goede RAM caching (ARC level 1) en SSD caching (ARC level 2). Netto is RAID-Z dus qua prestaties heel geschikt juist voor ons thuisgebruikers die massaopslag doen maar ook wel wat IOps.
ZFS in Solaris heeft voor metadata de Hybrid allocator geschreven. Die zorgt ervoor dat RAID-Z op sommige momenten even een RAID1 mirror wordt, en de metadata op die manier geschreven wordt. Dit zorgt voor veel snellere IOps bij directory searches enzovoorts, wanneer men geen L2ARC SSD cache heeft. Helaas is dit proprietary en zullen we dus nooit zien in écht ZFS (open source ZFS).
Is het zo dat ZFS bepaalde data op de disks leest/schrijft als het krapjes wordt met geheugen? Ik heb soms wel eens dat het geheugen behoorlijk vol loopt (door programma's of tmpfs) en dan gaat het systeem hangen en gaat het hard disk lampje druk knipperen. Dit terwijl ik geen swap support heb in m'n kernel (swappen is uitstel van executie en zo jaren 90).
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
ik denk dat die eerder de arc leeg begint te maken en aan het verkleinen is. Weet je trouwens zeker dat die aan het schrijven is?onox schreef op woensdag 20 maart 2013 @ 19:00:
Is het zo dat ZFS bepaalde data op de disks leest/schrijft als het krapjes wordt met geheugen? Ik heb soms wel eens dat het geheugen behoorlijk vol loopt (door programma's of tmpfs) en dan gaat het systeem hangen en gaat het hard disk lampje druk knipperen. Dit terwijl ik geen swap support heb in m'n kernel (swappen is uitstel van executie en zo jaren 90).
Dat lijkt mij ook het meest logische (dat je ARC 'geflushed' word). Programma geheugen gaat (als het goed is) boven 'wired' geheugen van ZFS. ZFS word dus verplicht om zijn ARC te legen, waardoor je meer reads krijgt direct van disk.
Even niets...
Zojuist weer checksum errors, vm uitgezet, CPU nog verder teruggeschroeft en nu zijn ze weer weg... Geen idee of het CPU type verlagen helpt, of dat het simpelweg rebooten van de VM alles al oplost...
Er loopt nu weer een scrub...
Er loopt nu weer een scrub...
Even niets...
- B2
- Registratie: April 2000
- Laatst online: 10-07 10:29
wa' seggie?
:strip_icc():strip_exif()/u/4824/i.jpeg?f=community)
Ik loop ook telkens tegen checksum errors aan. (met dezelfde combi KVM+ZFSGuru en het via vt-d doorgeven van M1015's).FireDrunk schreef op donderdag 21 maart 2013 @ 11:41:
Zojuist weer checksum errors, vm uitgezet, CPU nog verder teruggeschroeft en nu zijn ze weer weg... Geen idee of het CPU type verlagen helpt, of dat het simpelweg rebooten van de VM alles al oplost...
Er loopt nu weer een scrub...
ZFSGuru geeft geen cable errors.
Ik verdenk toch sterk de combi KVM+FreeBSD+ZFS. Ook zijn disken bij mij soms weg, en zijn ze na een powercycle weer te zien. Het lijkt me sterk dat dat aan de kabels kan liggen.
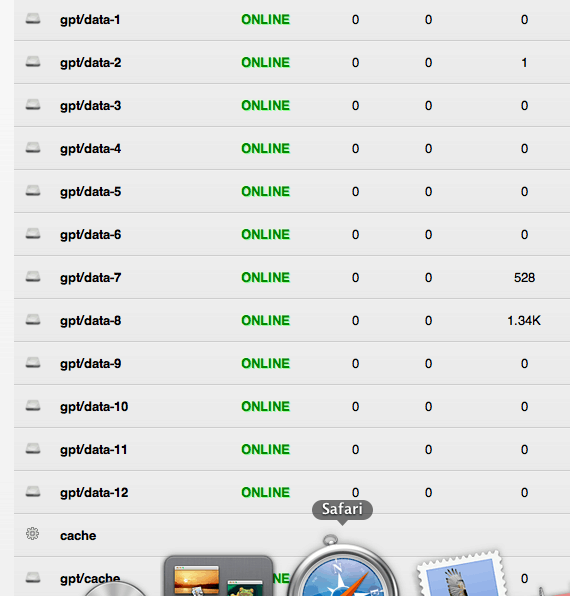
[ Voor 20% gewijzigd door B2 op 21-03-2013 12:19 ]
Mja, ik begin KVM ook te verdenken... Eigenlijk moet een KVM Developer hier eens naar kijken...
Het liefst een met verstand van ZFS
Het liefst een met verstand van ZFS
Even niets...
- B2
- Registratie: April 2000
- Laatst online: 10-07 10:29
wa' seggie?
Inderdaad. Ik overweeg om het hele virtualisatie verhaal maar te schrappen en ZFSonLinux te gaan gebruiken. Ik heb Linux nodig voor Plex Media Server, vandaar geen native BSD.FireDrunk schreef op donderdag 21 maart 2013 @ 12:20:
Mja, ik begin KVM ook te verdenken... Eigenlijk moet een KVM Developer hier eens naar kijken...
Het liefst een met verstand van ZFS
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
Ik wil graag jullie reactie horen over de volgende configuratie en hoe ik mijn overige schijven het beste kan gebruiken.
OS ZFSGURU
1st Kingston SSDNow V300 120GB
- partitie 1 voor systeem/boot pool: 50GB
- partitie 2 voor L2ARC cache: 70GB
4st Western Digital Red WD30EFRX, 3TB in RAIDZ
Nu heb ik nog 2 schijven 2TB en 2 van 1,5TB over. Ben er nog niet uit wat ik hiermee wil.
Eerst wilde ik de 4 schijven ook in RAIDZ zetten maar dan hou ik toch maar 4,5TB over? Of is dit anders als met het OUDE RAID?
OS ZFSGURU
1st Kingston SSDNow V300 120GB
- partitie 1 voor systeem/boot pool: 50GB
- partitie 2 voor L2ARC cache: 70GB
4st Western Digital Red WD30EFRX, 3TB in RAIDZ
Nu heb ik nog 2 schijven 2TB en 2 van 1,5TB over. Ben er nog niet uit wat ik hiermee wil.
Eerst wilde ik de 4 schijven ook in RAIDZ zetten maar dan hou ik toch maar 4,5TB over? Of is dit anders als met het OUDE RAID?
Ik zou je SSD wel onderprovisionen (partitie kleiner maken dan de SSD), Kingston SSD's staan er niet echt bekend om dat ze lang mee gaan.
Verder is 50GB voor boot heel erg ruim bemeten... ZFSguru neemt een kleine 1GB in beslag... Niet echt veel...
Verder is 50GB voor boot heel erg ruim bemeten... ZFSguru neemt een kleine 1GB in beslag... Niet echt veel...
Even niets...
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
OK, wist niet dat Kingston daar bekend om stond anders had ik een andere genomen. Nja we zien het wel.
Hoeveel GB is verstandig om aan te houden voor ZFSguru?
En helpt het dan de levensduur te bevorderen als ik de partities kleiner maak als de SSD?
Hoeveel GB is verstandig om aan te houden voor ZFSguru?
En helpt het dan de levensduur te bevorderen als ik de partities kleiner maak als de SSD?
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Niet voor de levensduur, maar het helpt wel tegen performance degradation als je OS geen TRIM ondersteunt.ilovebrewski schreef op donderdag 21 maart 2013 @ 14:31:
En helpt het dan de levensduur te bevorderen als ik de partities kleiner maak als de SSD?
Zo dan... Dat zijn flink wat disks
Gewoon een heel grote verzameling snoertjes
- Contagion
- Registratie: Maart 2000
- Laatst online: 00:04
@ilovebrewski Ik zou je 2TB en 1.5TB schijven aan elkaar knopen tot 3.5TB schijven en die dan opnemen in de array (FreeBSD: geom, Linux: mdadm). Dan heb je dus 6x3TB RAID-Z1 (of veiliger: Z2) effectief (want die laatste 0,5 TB is niet de grootste gemene deler van disks,). Netto houdt je dus 15 TB (RAIDZ1 5+1) of 12 TB (RAIDZ2) over.
@compizfox: maakt dat iets uit? Hoe groot de partities zijn? Een SSD zal toch zelf wel iets van wear-leveling in zich hebben en uiteindelijk de sectoren op een totaal andere fysieke plek zetten? Ik zou juist denken dat een grotere partities minder noodzaak tot wear-leveling heeft omdat er in die partitie genoeg ruimte is voor het FS om files op een andere sector te zetten ipv een sector te hergebruiken.
@compizfox: maakt dat iets uit? Hoe groot de partities zijn? Een SSD zal toch zelf wel iets van wear-leveling in zich hebben en uiteindelijk de sectoren op een totaal andere fysieke plek zetten? Ik zou juist denken dat een grotere partities minder noodzaak tot wear-leveling heeft omdat er in die partitie genoeg ruimte is voor het FS om files op een andere sector te zetten ipv een sector te hergebruiken.
[ Voor 38% gewijzigd door Contagion op 21-03-2013 17:59 ]
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Lees je eens in in hoe SSDs werken, dat gaat sneller dan dat ik het hier compleet uit ga zitten leggenContagion schreef op donderdag 21 maart 2013 @ 17:57:
@compizfox: maakt dat iets uit? Hoe groot de partities zijn? Een SSD zal toch zelf wel iets van wear-leveling in zich hebben en uiteindelijk de sectoren op een totaal andere fysieke plek zetten? Ik zou juist denken dat een grotere partities minder noodzaak tot wear-leveling heeft omdat er in die partitie genoeg ruimte is voor het FS om files op een andere sector te zetten ipv een sector te hergebruiken.
Een SSD weet niet dat een page leeg is als je OS een bestand verwijdert. Het TRIM-commando is bedoeld om dit duidelijk te maken aan de firmware van de SSD, maar als je OS/controller dat niet ondersteunt werkt dat dus niet. Na een tijdje fanatiek gebruik denkt je SSD dan dat de partitie compleet beschreven is, en dan valt er nog weinig meer te doen aan garbage collection...
Gewoon een heel grote verzameling snoertjes
- Contagion
- Registratie: Maart 2000
- Laatst online: 00:04
Ok, een CF kaart of SD kaart doet dat dan dus anders. Het leek me voor de hand dat een SSD dat ook van zichzelf doet. Overigens is het TRIMmen eigenlijk een machanisme wat daar bovenop ligt dus misschien hebben we beide gelijk: het filesysteem bepaalt dat een sector leeg is maar de drive weet dat niet. Het TRIM command vertelt juist DAT tegen de SSD zodat zijn wear leveling mechanisme ook weet dat die sector leeg is ipv zelf de slimmerik uit te hangen.
Edit: Wikipedia vindt dat een SSD ook aan wear leveling doet. Ik vermoed dat het dus misschien toch niet uit maakt of je een hele drive alloceert of een partitie van 1 GB. De overige zeg 79 GB bij een 80 GB drive komen toch wel vol alleen weet jij daar niks van, dat doet de SSD al voor je met zijn eigen wear leveling technieken. Trim kan wel helpen dat efficienter te doen.
Edit: Wikipedia vindt dat een SSD ook aan wear leveling doet. Ik vermoed dat het dus misschien toch niet uit maakt of je een hele drive alloceert of een partitie van 1 GB. De overige zeg 79 GB bij een 80 GB drive komen toch wel vol alleen weet jij daar niks van, dat doet de SSD al voor je met zijn eigen wear leveling technieken. Trim kan wel helpen dat efficienter te doen.
[ Voor 29% gewijzigd door Contagion op 21-03-2013 18:40 ]
Wear levelling != write redirection. Een CF kaart heeft geen echte controller waardoor het heel traag is met random write. Dat maakt het verschil met een SSD. Wear levelling is enkel om de writes te spreiden. Write redirection - wat alleen SSDs hebben - is om de SSD snel te maken. De SSD schrijft dan niet naar de plek die het normaliter zou kiezen gebaseerd op de logische LBA die de host aangeeft. In normaal Nederlands: een CF kaart schrijft naar sector 23858 als de host dat vraagt; een SSD zegt wel dat hij dat heeft gedaan, maar die write kan ook heel ergens anders zijn opgeslagen.
Door de write redirection is de random write een factor 1000 tot 100000 (dus 10 miljoen procent) sneller: van 0,001MB/s naar boven de 100MB/s voor een SSD. Deze feature vereist dan wel TRIM of althans de SSD heeft continu extra ruimte nodig; meer ruimte dan de host kan zien.
Concreet betekent dit dat je SSDs altijd wilt overprovisionen. 70 gigabyte aan L2ARC is ook enorm veel; ik zou het met 40GiB eens proberen dat is al een shitload die je toch nooit vol krijgt. Partitioneren doe je in ZFSguru op de Disks pagina met de partition map editor die ik heb ontworpen. Dan kun je zelf netjes partities maken zoals je wilt, en de lege ruimtes kun je TRIMen (als je SSD als 'ada' wordt herkend).
Door de write redirection is de random write een factor 1000 tot 100000 (dus 10 miljoen procent) sneller: van 0,001MB/s naar boven de 100MB/s voor een SSD. Deze feature vereist dan wel TRIM of althans de SSD heeft continu extra ruimte nodig; meer ruimte dan de host kan zien.
Concreet betekent dit dat je SSDs altijd wilt overprovisionen. 70 gigabyte aan L2ARC is ook enorm veel; ik zou het met 40GiB eens proberen dat is al een shitload die je toch nooit vol krijgt. Partitioneren doe je in ZFSguru op de Disks pagina met de partition map editor die ik heb ontworpen. Dan kun je zelf netjes partities maken zoals je wilt, en de lege ruimtes kun je TRIMen (als je SSD als 'ada' wordt herkend).
- HyperBart
- Registratie: Maart 2006
- Laatst online: 09:22
Ik wil eigenlijk mijn "main" pool zo snapshot vrij mogelijk houden op ieder punt in de tijd (met uitzondering wanneer hij natuurlijk aan het senden is naar mijn backup pool).
Mijn idee was dus:
Zoals je kan zien heb ik 2 snapshots van Bart, @1 heb ik naar spiegeltje gestuurd met:
Prima, dan krijg je dat ook te zien zoals hierboven. Maar ik heb daarna een @2 genomen en ik wil die nu terug syncen naar spiegeltje/Bart met behoud van @1 op spiegeltje, dus ik dacht:
Maar ik wil niet overwriten, ik wel net op hulk geen snapshots open (of eentje dan max) en op SPIEGELTJE wil ik ze a volonté opstapelen als backup.
Wat doe ik fout?
Dit is uiteraard op een test systeempje
Mijn idee was dus:
[root@zfsguru /home/ssh]# zfs list -t snapshot NAME USED AVAIL REFER MOUNTPOINT SPIEGELTJE/Bart@1 0 - 31K - hulk/Bart@1 0 - 31K - hulk/Bart@2 0 - 31K -
Zoals je kan zien heb ik 2 snapshots van Bart, @1 heb ik naar spiegeltje gestuurd met:
[root@zfsguru /home/ssh]# zfs send hulk/Bart@1 | zfs receive SPIEGELTJE/Bart@1
Prima, dan krijg je dat ook te zien zoals hierboven. Maar ik heb daarna een @2 genomen en ik wil die nu terug syncen naar spiegeltje/Bart met behoud van @1 op spiegeltje, dus ik dacht:
[root@zfsguru /home/ssh]# zfs send hulk/Bart@3 | zfs recv SPIEGELTJE/Bart@3 cannot receive new filesystem stream: destination 'SPIEGELTJE/Bart' exists must specify -F to overwrite it
Maar ik wil niet overwriten, ik wel net op hulk geen snapshots open (of eentje dan max) en op SPIEGELTJE wil ik ze a volonté opstapelen als backup.
Wat doe ik fout?
Dit is uiteraard op een test systeempje
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Jep.Contagion schreef op donderdag 21 maart 2013 @ 18:37:
Ok, een CF kaart of SD kaart doet dat dan dus anders. Het leek me voor de hand dat een SSD dat ook van zichzelf doet. Overigens is het TRIMmen eigenlijk een machanisme wat daar bovenop ligt dus misschien hebben we beide gelijk: het filesysteem bepaalt dat een sector leeg is maar de drive weet dat niet.
Hoe bedoel je dat? Een SSD kán simpelweg niet zelf de slimmerik uithangen, want dat zou betekent dat de SSD een random sector moet kiezen om te overwriten, waarmee de kans groot is dat hij data overwrite die in gebruik is.Het TRIM command vertelt juist DAT tegen de SSD zodat zijn wear leveling mechanisme ook weet dat die sector leeg is ipv zelf de slimmerik uit te hangen.
Zoals ik al zei kan ik je hiervoor veel beter doorverwijzen naar het SSD-topic: Het grote SSD topic ~ Deel 9Edit: Wikipedia vindt dat een SSD ook aan wear leveling doet. Ik vermoed dat het dus misschien toch niet uit maakt of je een hele drive alloceert of een partitie van 1 GB. De overige zeg 79 GB bij een 80 GB drive komen toch wel vol alleen weet jij daar niks van, dat doet de SSD al voor je met zijn eigen wear leveling technieken. Trim kan wel helpen dat efficienter te doen.
Punt is dat SSD's graag elke random write naar een aparte block schrijven, omdat ze anders read-modify-write moeten doen op een bestaande block. (Een SSD kan schrijven per page, maar wissen per block, en een block is dus groter dan een page)
Om dit te kunnen doen, moet een SSD weten welke pages niet beschreven zijn. Na een tijdje gebruik zullen al die blocks uiteindelijk beschreven zijn met kleine beetjes data, waardoor de hij bij random writes hele blocks moet wissen om bij 1 page iets op te schrijven. Maar als je op filesystem-level bestanden verwijdert weet je SSD dat niet, en daardoor gaat ie onnodig (al reeds verwijderde) data zitten moven naar blocks die nog niet helemaal vol zitten, en dat kost enorm veel performance vanwege de read-modify-write die hij steeds moet uitvoeren.
Hiervoor is dus TRIM uitgevonden, zodat je SSD op de hoogte is welke pages ongebruikt zijn.
Over provisioning kan hiervoor ook, omdat de SSD daardoor een stukje reserved space heeft waarnaar hij random writes kan schrijven, en waarvan hij weet dat hij nooit echt vol zit omdat het OS dit niet kan gebruiken.
Niet mee eens. Zolang je TRIM gebruikt, en je zorgt dat je partitie niet helemaal vol zit, is dat overbodig.Verwijderd schreef op donderdag 21 maart 2013 @ 18:51:
Concreet betekent dit dat je SSDs altijd wilt overprovisionen.
Gewoon een heel grote verzameling snoertjes
L2ARC en SLOG ondersteunen geen TRIM hoor. Zelfs ZFS zelf ondersteunt enkel TRIM onder BSD platform voor zover ik weet. Maar al zou je TRIM ondersteuning hebben, dan nog wil je extra overprovisioning instellen. Speciale cache SSDs hebben dit van nature, die zijn vaak kleiner omdat veel meer dan de standaard 6,8% als spare space wordt gebruikt. Dat is hét verschil tussen een normale SSD en een 'cache' SSD die vaak als Intel SRT caching wordt ingezet (vaak mSATA).
Je hebt meer spare space nodig als je veel random writes doet. Voor licht consumentengebruik (Windows/Linux) is 6,8% genoeg omdat de SSD niet enkel gebruikt gaat worden voor random writes. Maar als je een SSD als cache SSD gebruikt is dat hoofdzakelijk wel zo. Het is dan jammer als je weinig overprovisioning gebruikt. Je write amplification kan dan flink gaan oplopen.
Een SSD van 80GB zou ik als volgt gebruiken:
- 20GB partitie voor systeem/boot (zeker als je services enzo wilt gebruiken kun je beter hier wat extra ruimte aan besteden)
- 36GB partitie voor L2ARC
- 4GB partitie voor SLOG (optioneel)
- 20GB ruimte vrijgelaten voor overprovisioning
Je hebt meer spare space nodig als je veel random writes doet. Voor licht consumentengebruik (Windows/Linux) is 6,8% genoeg omdat de SSD niet enkel gebruikt gaat worden voor random writes. Maar als je een SSD als cache SSD gebruikt is dat hoofdzakelijk wel zo. Het is dan jammer als je weinig overprovisioning gebruikt. Je write amplification kan dan flink gaan oplopen.
Een SSD van 80GB zou ik als volgt gebruiken:
- 20GB partitie voor systeem/boot (zeker als je services enzo wilt gebruiken kun je beter hier wat extra ruimte aan besteden)
- 36GB partitie voor L2ARC
- 4GB partitie voor SLOG (optioneel)
- 20GB ruimte vrijgelaten voor overprovisioning
[ Voor 5% gewijzigd door Verwijderd op 21-03-2013 19:29 ]
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
In dat geval is overprovisioning wel handig ja.Verwijderd schreef op donderdag 21 maart 2013 @ 19:29:
L2ARC en SLOG ondersteunen geen TRIM hoor. Zelfs ZFS zelf ondersteunt enkel TRIM onder BSD platform voor zover ik weet.
Dat begrijp ik niet echt... Wat is het verschil met zorgen dat je partitie niet vol raakt + TRIM?Maar al zou je TRIM ondersteuning hebben, dan nog wil je extra overprovisioning instellen.
Gewoon een heel grote verzameling snoertjes
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
Ik ga ermee aan de slag! Dacht heb toch 120GB dus deel het op.Verwijderd schreef op donderdag 21 maart 2013 @ 18:51:
Wear levelling != write redirection. Een CF kaart heeft geen echte controller waardoor het heel traag is met random write. Dat maakt het verschil met een SSD. Wear levelling is enkel om de writes te spreiden. Write redirection - wat alleen SSDs hebben - is om de SSD snel te maken. De SSD schrijft dan niet naar de plek die het normaliter zou kiezen gebaseerd op de logische LBA die de host aangeeft. In normaal Nederlands: een CF kaart schrijft naar sector 23858 als de host dat vraagt; een SSD zegt wel dat hij dat heeft gedaan, maar die write kan ook heel ergens anders zijn opgeslagen.
Door de write redirection is de random write een factor 1000 tot 100000 (dus 10 miljoen procent) sneller: van 0,001MB/s naar boven de 100MB/s voor een SSD. Deze feature vereist dan wel TRIM of althans de SSD heeft continu extra ruimte nodig; meer ruimte dan de host kan zien.
Concreet betekent dit dat je SSDs altijd wilt overprovisionen. 70 gigabyte aan L2ARC is ook enorm veel; ik zou het met 40GiB eens proberen dat is al een shitload die je toch nooit vol krijgt. Partitioneren doe je in ZFSguru op de Disks pagina met de partition map editor die ik heb ontworpen. Dan kun je zelf netjes partities maken zoals je wilt, en de lege ruimtes kun je TRIMen (als je SSD als 'ada' wordt herkend).
Ik ga het als volgt doen
- 40GB L2ARC
- 40GB boot
- 40GB TRIMen
Kijken hoe het bevalt.
Wat vind jij trouwens van het idee van Contagion?
@ilovebrewski Ik zou je 2TB en 1.5TB schijven aan elkaar knopen tot 3.5TB schijven en die dan opnemen in de array (FreeBSD: geom, Linux: mdadm). Dan heb je dus 6x3TB RAID-Z1 (of veiliger: Z2) effectief (want die laatste 0,5 TB is niet de grootste gemene deler van disks,). Netto houdt je dus 15 TB (RAIDZ1 5+1) of 12 TB (RAIDZ2) over.
- HyperBart
- Registratie: Maart 2006
- Laatst online: 09:22
Een van de wijzen hier nog een ideetje over? CiPHER?HyperBart schreef op donderdag 21 maart 2013 @ 19:12:
Ik wil eigenlijk mijn "main" pool zo snapshot vrij mogelijk houden op ieder punt in de tijd (met uitzondering wanneer hij natuurlijk aan het senden is naar mijn backup pool).
Mijn idee was dus:
[root@zfsguru /home/ssh]# zfs list -t snapshot NAME USED AVAIL REFER MOUNTPOINT SPIEGELTJE/Bart@1 0 - 31K - hulk/Bart@1 0 - 31K - hulk/Bart@2 0 - 31K -
Zoals je kan zien heb ik 2 snapshots van Bart, @1 heb ik naar spiegeltje gestuurd met:
[root@zfsguru /home/ssh]# zfs send hulk/Bart@1 | zfs receive SPIEGELTJE/Bart@1
Prima, dan krijg je dat ook te zien zoals hierboven. Maar ik heb daarna een @2 genomen en ik wil die nu terug syncen naar spiegeltje/Bart met behoud van @1 op spiegeltje, dus ik dacht:
[root@zfsguru /home/ssh]# zfs send hulk/Bart@3 | zfs recv SPIEGELTJE/Bart@3 cannot receive new filesystem stream: destination 'SPIEGELTJE/Bart' exists must specify -F to overwrite it
Maar ik wil niet overwriten, ik wel net op hulk geen snapshots open (of eentje dan max) en op SPIEGELTJE wil ik ze a volonté opstapelen als backup.
Wat doe ik fout?
Dit is uiteraard op een test systeempje
Ok, de kogel is door de kerk (of door de storage, hoe je het ook wil zien).
KVM is niet stabiel genoeg, en ik ga het verwijderen. Ik kan niet vinden waarom, maar ik heb om onverklaarbare wijze checksum errors.
Ik ga weer terug naar FreeBSD native draaien, met een Ubuntu VM in VirtualBox.
Helaas kan ik dan wat minder testen en spelen met VM's aangezien VirtualBox daar niet echt geschikt voor is, maar dat neem ik dan maar voor lief. Ik heb nog een 1U Opteron bakje liggen welke daar wel goed geschikt voor is, dus dan moet ik die maar aansluiten.
KVM is exit
KVM is niet stabiel genoeg, en ik ga het verwijderen. Ik kan niet vinden waarom, maar ik heb om onverklaarbare wijze checksum errors.
Ik ga weer terug naar FreeBSD native draaien, met een Ubuntu VM in VirtualBox.
Helaas kan ik dan wat minder testen en spelen met VM's aangezien VirtualBox daar niet echt geschikt voor is, maar dat neem ik dan maar voor lief. Ik heb nog een 1U Opteron bakje liggen welke daar wel goed geschikt voor is, dus dan moet ik die maar aansluiten.
KVM is exit
Even niets...
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Laat dat nou net gisteren in de current zijn toegevoegd (voor de l2arc) cq verbeterdVerwijderd schreef op donderdag 21 maart 2013 @ 19:29:
L2ARC en SLOG ondersteunen geen TRIM hoor. Zelfs ZFS zelf ondersteunt enkel TRIM onder BSD platform voor zover ik weet.
http://svnweb.freebsd.org...=revision&revision=248575 en
http://svnweb.freebsd.org...=revision&revision=248577
[ Voor 7% gewijzigd door matty___ op 22-03-2013 09:47 ]
- B2
- Registratie: April 2000
- Laatst online: 10-07 10:29
wa' seggie?
Hier ook, ik ga alleen naar Ubuntu + ZFS ppa. Normaal gesproken gebruik ik altijd een RedHat afgeleide distro, maar het simpel kunnen gebruiken van een ppa ipv de source vind ik voor dit geval wel handig.FireDrunk schreef op vrijdag 22 maart 2013 @ 09:42:
Ok, de kogel is door de kerk (of door de storage, hoe je het ook wil zien).
KVM is niet stabiel genoeg, en ik ga het verwijderen. Ik kan niet vinden waarom, maar ik heb om onverklaarbare wijze checksum errors.
Dat zou ik ook nog kunnen doen inderdaad... Maar ik ben een beetje bang om ZIL + L2ARC te gebruiken in Linux ZFS. Voor de snelheid hoef ik het ook niet te doen, want die is momenteel toch gelimiteerd op mijn Areca.
[ Voor 30% gewijzigd door FireDrunk op 22-03-2013 10:12 ]
Even niets...
- Contagion
- Registratie: Maart 2000
- Laatst online: 00:04
Ik heb hier dus ook ZFs On Linux draaien en ik ben er uitermate tevreden over. Nog geen gekke dingen gehad en voor zover ze er waren (drives die net niet genoeg prik hebben en daardoor af en toe uit- en aanschakelen) wordt dit (zoals verwacht) zonder morren opgelost door ZFS. ZIL + L2ARC heb ik geen ervaring mee, Als je Pool V28 gebruikt kan je het toch gewoon proberen en evt. alsnog terug naar FreeBSD met Ubuntu in VM?
Interessante discussie over SSD en wear leveling. Cipher , jij zegt 'Wear levelling != write redirection' maar op welke manier wordt wear leveling dan opgelost (in SD / CF kaarten)? Ik heb altijd veronderstelt dat een SD controller een soort lijst met blokken bijhoudt (niet sectoren maar iets groters) en dat die blokken wel over de disk 'verplaatst worden' zoals het het beste uitkomt. Bijv. een fotocamera zal altijd veel in de eerste paar % van de disk schrijven. Daar staan immers de eerstgemaakte foto's na het wissen van een kaart EN de FAT. Voor die plekken is een dergelijk wear-leveling mechanisme genoeg.
Interessante discussie over SSD en wear leveling. Cipher , jij zegt 'Wear levelling != write redirection' maar op welke manier wordt wear leveling dan opgelost (in SD / CF kaarten)? Ik heb altijd veronderstelt dat een SD controller een soort lijst met blokken bijhoudt (niet sectoren maar iets groters) en dat die blokken wel over de disk 'verplaatst worden' zoals het het beste uitkomt. Bijv. een fotocamera zal altijd veel in de eerste paar % van de disk schrijven. Daar staan immers de eerstgemaakte foto's na het wissen van een kaart EN de FAT. Voor die plekken is een dergelijk wear-leveling mechanisme genoeg.
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
Als je zo overschakelt tussen Ubuntu en ZFSguru detecteert het andere OS dan automatisch je pools? Of moet je nog speciale handelingen verrichten?Contagion schreef op vrijdag 22 maart 2013 @ 10:41:
Ik heb hier dus ook ZFs On Linux draaien en ik ben er uitermate tevreden over. Nog geen gekke dingen gehad en voor zover ze er waren (drives die net niet genoeg prik hebben en daardoor af en toe uit- en aanschakelen) wordt dit (zoals verwacht) zonder morren opgelost door ZFS. ZIL + L2ARC heb ik geen ervaring mee, Als je Pool V28 gebruikt kan je het toch gewoon proberen en evt. alsnog terug naar FreeBSD met Ubuntu in VM?
- B2
- Registratie: April 2000
- Laatst online: 10-07 10:29
wa' seggie?
export import zou moeten werken volgens mij. Eventueel zelfs zonder export en een import -f doen.ilovebrewski schreef op vrijdag 22 maart 2013 @ 11:06:
[...]
Als je zo overschakelt tussen Ubuntu en ZFSguru detecteert het andere OS dan automatisch je pools? Of moet je nog speciale handelingen verrichten?
- Xudonax
- Registratie: November 2010
- Laatst online: 08-07 13:06
export/import werkt in ieder gewoon vanaf ZFSGuru naar ZFS on Linux. En ook ik heb nergens last van met ZFS on Linux, doe ~350MB/s sequential op m'n RAIDZ2 pool. Mijn mirror pool is trager, maar dat komt door de schijven zelf natuurlijk
Dan blijf ik nog steeds bij ZIL en L2ARC, die vind ik toch wel fijn.. ZFSonLinux geloof ik inderdaad wel...
Even niets...
Je hebt gewoon veel meer spare space nodig dan normaal. Neem dit plaatje eens:Compizfox schreef op donderdag 21 maart 2013 @ 20:14:
Dat begrijp ik niet echt... Wat is het verschil met zorgen dat je partitie niet vol raakt + TRIM?

Hier zie je verschillende kleuren lijnen die aangeven hoe je de SSD gebruikt. Een SSD die als caching (SRT of L2ARC) wordt gebruikt, zal veel meer random writes en dynamische data veroorzaken dan het typisch gebruik van een SSD in desktops waarbij tot 80% van de data niet meer wordt aangepast na te zijn geschreven.
Het eigenlijke probleem is fragmentatie van de vrije ruimte. Als je dus alleen maar 4K writes gaat doen naar je SSD dan heb je meer spare space nodig om dezelfde write amplification te behalen. Dat kun je in bovenstaande grafiek wel aardig zien. Bedenk hierbij dat de grafiek begint bij 0.1 spare factor dus 10% spare space; consumenten SSDs hebben standaard slechts 6,8% spare space.
Kort antwoord is dus omdat L2ARC zwaarder is voor je SSD, mits het ook actief gebruikt wordt. Bovendien kun je altijd achteraf de partities nog groter maken (met ZFSguru is dat vrij makkelijk via de partition editor).
Ik raad aan dat je de eerste partitie de systeempartitie maakt. Dit vanwege de BSD bootcode. Je mag je pool overigens geen 'boot' noemen - die naam is gereserveerd. Je kunt 'systeem' ofzo gebruiken.ilovebrewski schreef op donderdag 21 maart 2013 @ 20:22:
Ik ga ermee aan de slag! Dacht heb toch 120GB dus deel het op.
Ik ga het als volgt doen
- 40GB L2ARC
- 40GB boot
- 40GB TRIMen
Ja kan prima. geom_stripe (RAID0) of geom_concat (JBOD/spanning) kun je gebruiken. Ik raad geom_stripe aan. Dat maakt het iets sneller omdat je oudere schijven langzamer zijn dan nieuwe 3TB schijven. Nadeel is dat je 2*1.5TB krijgt en de 0.5TB verdwijnt. Maar dat is dus helemaal niet zo erg want je wilt hem juist als 3TB disk gebruiken. Bovendien kun je die 0.5TB nog wel gebruiken als je partities gebruikt.Wat vind jij trouwens van het idee van Contagion?
@ilovebrewski Ik zou je 2TB en 1.5TB schijven aan elkaar knopen tot 3.5TB schijven en die dan opnemen in de array (FreeBSD: geom, Linux: mdadm). Dan heb je dus 6x3TB RAID-Z1 (of veiliger: Z2) effectief (want die laatste 0,5 TB is niet de grootste gemene deler van disks,). Netto houdt je dus 15 TB (RAIDZ1 5+1) of 12 TB (RAIDZ2) over.
geom_stripe kun je niet via de ZFSguru web-interface bedienen (wellicht in de toekomst). Maar de command line is best makkelijk:
gstripe label -s 131072 stripe3tb /dev/gpt/disk1-partitievoorstripe /dev/gpt/disk2-partitievoorstripe
Die partities moet je dan eerst aanmaken via ZFSguru en een labelnaam geven. Dan het gstripe commando hierboven als root uitvoeren. Verder moet je geom_stripe RAID0 kernel module laten starten tijdens de boot:
echo "geom_stripe_load=\"YES\"" >> /boot/loader.conf
(maak geen fout met dit commando, de dubbele >> is heel belangrijk)
- Xudonax
- Registratie: November 2010
- Laatst online: 08-07 13:06
L2ARC heb ik lopen over 2 lullige USB stickies. Goed genoeg voor het bijhouden van stuff als de directory lijsten enzo, maar ik gebruik ZFS niet op een manier dat ik er verder echt iets aan heb. Een ZIL/SLOG SSD heb ik nog niet geprobeerd tbho, maar de disks zijn snel genoeg om 1GbE bij te houden
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
@CiPHER, duidelijk verhaal!
Heb iig wat te hobbyen van het weekend.
TOF al die hulp van iedereen.
Heb iig wat te hobbyen van het weekend.
TOF al die hulp van iedereen.
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
Ik moet zeggen dat ik het toch moeilijk vind om te beslissen of ik ga beginnen in ZFSguru of ZFSonLINUX.Xudonax schreef op vrijdag 22 maart 2013 @ 11:11:
export/import werkt in ieder gewoon vanaf ZFSGuru naar ZFS on Linux. En ook ik heb nergens last van met ZFS on Linux, doe ~350MB/s sequential op m'n RAIDZ2 pool. Mijn mirror pool is trager, maar dat komt door de schijven zelf natuurlijk
Wat is jullie mening voor een noob? Heb wel wat ervaring, maar ben toch maar een krutselaar
Wat ik belangrijk vind is dat als het straks draait het weinig onderhoud moet hebben.
- Xudonax
- Registratie: November 2010
- Laatst online: 08-07 13:06
Bij weinig onderhoud zou ik toch de voorkeur geven aan ZFSGuru. Dit is een systeem wat volledig rond ZFS gebouwd is met een mooie webinterface en alles. Als je ZFS on Linux wilt gaan doen moet je toch al snel naar de commandline grijpen omdat er nog geen/weinig GUI tooltjes voor zijn.
Plus dat je bij ZFSGuru alles mooi op één plaats kunt beheren
Plus dat je bij ZFSGuru alles mooi op één plaats kunt beheren
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
Thnx voor je adviesXudonax schreef op vrijdag 22 maart 2013 @ 12:07:
Bij weinig onderhoud zou ik toch de voorkeur geven aan ZFSGuru. Dit is een systeem wat volledig rond ZFS gebouwd is met een mooie webinterface en alles. Als je ZFS on Linux wilt gaan doen moet je toch al snel naar de commandline grijpen omdat er nog geen/weinig GUI tooltjes voor zijn.
Plus dat je bij ZFSGuru alles mooi op één plaats kunt beheren
We gaan dus voor ZFSguru (wel jammer dat AjaXplorer het nog niet doet in de laatste versie)
- Contagion
- Registratie: Maart 2000
- Laatst online: 00:04
FreeNAS of NAS4Free kunnen ook, maar dan zit je aan een oudere FreeBSD versie (toch? ik heb er al tijden niet naar gekeken). Voor hulp kun je hier wel het best terecht met ZFSGuru want Cipher zit daar bovenop
Nas4free is prima bij, alleen hebben ze in mijn ogen een rare manier om services te gebruiken. Je moet ze perse in een jail draaien... best vervelend...
Even niets...
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
Ja, dat snap ik.Verwijderd schreef op vrijdag 22 maart 2013 @ 11:41:
[...]
Je hebt gewoon veel meer spare space nodig dan normaal. Neem dit plaatje eens:
[afbeelding]
Hier zie je verschillende kleuren lijnen die aangeven hoe je de SSD gebruikt. Een SSD die als caching (SRT of L2ARC) wordt gebruikt, zal veel meer random writes en dynamische data veroorzaken dan het typisch gebruik van een SSD in desktops waarbij tot 80% van de data niet meer wordt aangepast na te zijn geschreven.
Het eigenlijke probleem is fragmentatie van de vrije ruimte. Als je dus alleen maar 4K writes gaat doen naar je SSD dan heb je meer spare space nodig om dezelfde write amplification te behalen. Dat kun je in bovenstaande grafiek wel aardig zien. Bedenk hierbij dat de grafiek begint bij 0.1 spare factor dus 10% spare space; consumenten SSDs hebben standaard slechts 6,8% spare space.
Kort antwoord is dus omdat L2ARC zwaarder is voor je SSD, mits het ook actief gebruikt wordt. Bovendien kun je altijd achteraf de partities nog groter maken (met ZFSguru is dat vrij makkelijk via de partition editor).
[...]
Maar vrije, gepartitioneerde ruimte (waarvan de SSD door het gebruik van TRIM ook wéét dat het vrij is) heeft toch hetzelfde effect als ongepartitioneerde ruimte?
Gewoon een heel grote verzameling snoertjes
misschien is het al een keer gevraagd, en misschien is het geen ZFS issue maar.
ik heb zfsguru met 6x 2TB raid6 draaien met verschillende "filesystems" mijn hoofd filesystem is tank en daaronder een stuk of 10 filesystems bijv.
tank/VMware
tank/backup
tank/iso
deze share ik via samba (VMware alleen nfs) maar alle filesystems geven een verschillende grootte aan. zie hier:

kan dat op een of andere manier aangepast worden? Heb al beetje zitten zoeken maar dacht eerst dat het een Samba issue is maar niks gevonden.
ik heb zfsguru met 6x 2TB raid6 draaien met verschillende "filesystems" mijn hoofd filesystem is tank en daaronder een stuk of 10 filesystems bijv.
tank/VMware
tank/backup
tank/iso
deze share ik via samba (VMware alleen nfs) maar alle filesystems geven een verschillende grootte aan. zie hier:
kan dat op een of andere manier aangepast worden? Heb al beetje zitten zoeken maar dacht eerst dat het een Samba issue is maar niks gevonden.
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
- Zijn het wel filesystems, en geen volumes?
- In het eerste geval, heb je een quota ingesteld?
- In het eerste geval, heb je een quota ingesteld?
Gewoon een heel grote verzameling snoertjes

{kind=link}
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
maar ze geven wel allemaal even veel vrije ruimte weer dus dat klopt dan weer wel.Oid schreef op vrijdag 22 maart 2013 @ 14:45:
misschien is het al een keer gevraagd, en misschien is het geen ZFS issue maar.
ik heb zfsguru met 6x 2TB raid6 draaien met verschillende "filesystems" mijn hoofd filesystem is tank en daaronder een stuk of 10 filesystems bijv.
tank/VMware
tank/backup
tank/iso
deze share ik via samba (VMware alleen nfs) maar alle filesystems geven een verschillende grootte aan. zie hier:
[afbeelding]
kan dat op een of andere manier aangepast worden? Heb al beetje zitten zoeken maar dacht eerst dat het een Samba issue is maar niks gevonden.
Daar zit het hem in volgens mij. Als een filesystem ruimte 'tekort' komt vraagt hij dat aan de pool. Zolang er nog geen tekort is, zie je volgens mij dus alleen maar hoeveel ruimte van de pool geallocceerd is aan een filesystem.
Maar 100% weten doe ik het niet.
Maar 100% weten doe ik het niet.
Even niets...
Ja dat klopt wel inderdaad, iets om over na te denken als je zfs implementeert, verschillende filesystems kunnen verschillende groottes weergeven.matty___ schreef op vrijdag 22 maart 2013 @ 16:03:
[...]
maar ze geven wel allemaal even veel vrije ruimte weer dus dat klopt dan weer wel.
wat heb ik daar nou aanFireDrunk schreef op vrijdag 22 maart 2013 @ 16:15:
Daar zit het hem in volgens mij. Als een filesystem ruimte 'tekort' komt vraagt hij dat aan de pool. Zolang er nog geen tekort is, zie je volgens mij dus alleen maar hoeveel ruimte van de pool geallocceerd is aan een filesystem.
Maar 100% weten doe ik het niet.
nee hoor geintje, thanks ik dacht misschien simpel commandotje afvuren en klaar, maar echt storend is het niet. als het filesystem vol zit, zou de pool ook vol zitten in dit geval
- Mafketel
- Registratie: Maart 2000
- Laatst online: 05-07 06:36
kweenie waarom niemand nog een antwoord heb gegeven maar...HyperBart schreef op donderdag 21 maart 2013 @ 20:38:
[...]
Een van de wijzen hier nog een ideetje over? CiPHER?
Het staat gewoon in de beschrijving van zfs send van oracle
You can send incremental data by using the zfs send -i option. For example:
host1# zfs send -i tank/dana@snap1 tank/dana@snap2 | ssh host2 zfs recv newtank/dana
aangepast naar jouw voorbeeldje, waar je overigens dat 3 tje vandaan haalt is me ook niet helemaal duidelijk.
zfs send -i hulk/Bart@1 hulk/Bart@2 | zfs recv SPIEGELTJE/Bart
Ik zou zeggen lees nog wat meer documentatie van zfs, het is in iedergeval goed dat je dingen uitprobeert.
Dat kan dus niet. Dan stuur je de verschillen tussen @1 en @2 naar /Bart.
Maar omdat dat snapshot nog niet bestaat, kan je niet alleen de verschillen sturen, omdat hij niet weet welke data het verschil is tussen de pool en @1...
(Ik heb het er ook al met HyperBart over gehad )
Maar omdat dat snapshot nog niet bestaat, kan je niet alleen de verschillen sturen, omdat hij niet weet welke data het verschil is tussen de pool en @1...
(Ik heb het er ook al met HyperBart over gehad
Even niets...
Niet helemaal hetzelfde. Met TRIM kun je zeker bij L2ARC veel 'snippertjes' aan vrije ruimte krijgen. Maar daar heeft je controller niets aan; die wil vrije erase blocks van 128K tot 512K. Je zult heel veel TRIMed space nodig hebben om van nature vrije erase blocks te krijgen. Als je je SSD heel intensief gebruikt zoals L2ARC 24/7 dan zal je write amplification flink oplopen als je enkel op TRIM vertrouwt om de SSD spare space te geven. Je SSD heeft dan driemiljoen snippers van 4K blocks bijvoorbeeld; maar daar kan het nog niets mee. Mocht er dan ruimte vrij moet worden gemaakt, dan moet de SSD met garbage collection aan de slag om een deels beschreven erase block te lezen, de gegevens elders onder te breken en daarna te erasen. Daarna kan het de write request uitvoeren. Als dit regelmatig gebeurt heb je een hoge write amplification.Compizfox schreef op vrijdag 22 maart 2013 @ 14:39:
Maar vrije, gepartitioneerde ruimte (waarvan de SSD door het gebruik van TRIM ook wéét dat het vrij is) heeft toch hetzelfde effect als ongepartitioneerde ruimte?
Dedicated spare space wordt als één groot blok gegeven aan de SSD. Hierdoor zou het makkelijker moeten zijn om van nature vrije erase blocks te krijgen. Het is voor de SSD altijd handiger spare space te gebruiken die als groot blok niet in gebruik is. Dus één groot blok van 20GiB is perfect, als dat allemaal verdeeld is over 4K snippertjes over het LBA-bereik en dus ook fysiek NAND adres, is dat helemaal niet zo gunstig.
Maar echt concrete cijfers heb ik hier niet van. Wel dat bedrijven die serieus SSDs gebruiken vaak 50% overprovisioning gebruiken en TRIM geheel uitschakelen. TRIM kan namelijk van zichzelf enorm veel vertraging opleveren en met genoeg spare space heb je geen TRIM nodig. Dus puur naar prestaties/levensduur gekeken is 50% OP dé juiste keuze. Consumenten zijn een uitzondering omdat voor hen een SSD een heel duur product is, wat ze ten volle willen kunnen benutten. De prioriteiten liggen hier dus heel anders.
- Wouter.S
- Registratie: Maart 2009
- Laatst online: 02-01 09:15
e^(i*pi ) +1 = 0
:strip_exif()/u/294322/64-floyd.gif?f=community)
Er zijn zo van die momenten dat je toch echt blij bent dan je ZFS draait in plaats van hardware RAID
Ik draai al ZFS sinds een drietal jaar, naar volle tevredenheid zonder ooit echt noemenswaardige problemen. De array (6*1.5TB Samsung HD154UI)) is nog gebouwd met de eerste FreeNas (0.7 dacht ik?), dan eventjes overgegaan op die nieuwe FreeNas maar bijna onmiddellijk overgestapt op ZFSGuru.
De problemen begonnen 2 weken geleden. Eén disk vertoonde in de plots 15 active bad sectors.
Een scrub leverde geen fouten op dus alles nog goed en wel. Ik ging rustig op zoek naar een replacement disk. Nu begin deze week start ik mijn NAS op en word ik getrakteerd op het krakende/tikkende geluid van een mechanisch failende disk. Ik dacht dat het diezelfde disk ging zijn maar toen ik ging kijken bleek het een totaal andere disk te zijn die gewoon zonder waarschuwing de geest had gegeven. ZFS had de disk zelfs al uit de array gekegeld en de array was nu dus degraded. Bij hardware RAID zou de array nu naar alle waarschijnlijkheid gefailed zijn, lang leve ZFS
Ondertussen heb ik al enkele vervangende exemplaren op de kop kunnen tikken en momenteel is de boel aan het resilveren.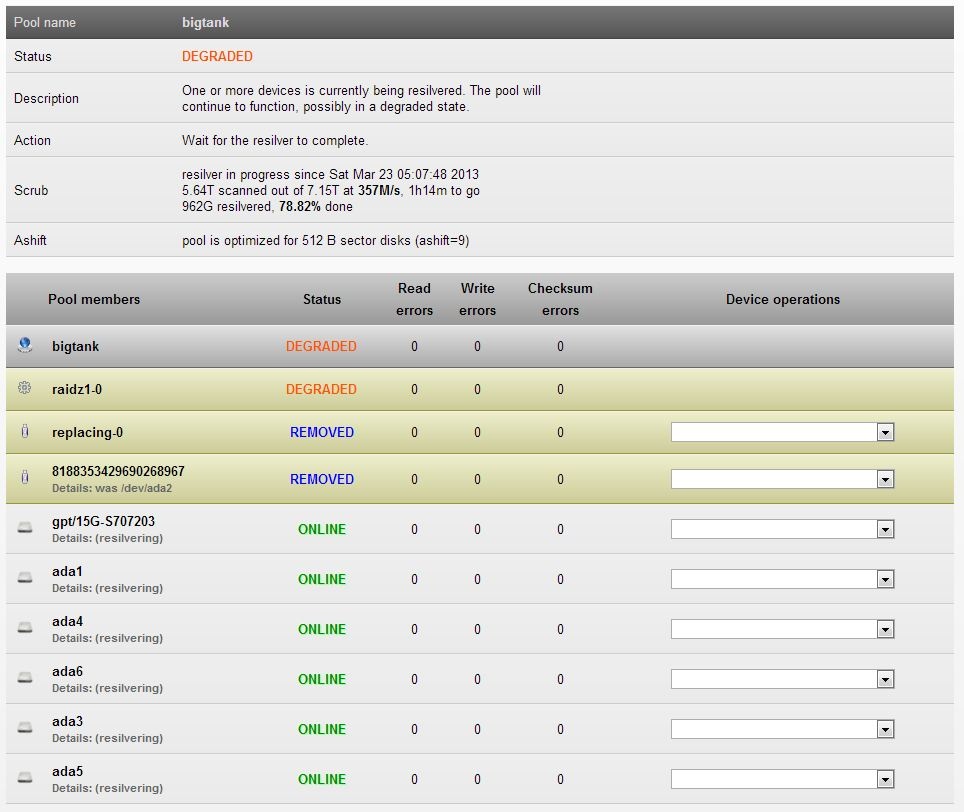
Het plan is de disk met bad sectoren ook te vervangen en dan eens grondig te formatteren, misschien is deze nog wel bruikbaar. Moesten er tijdens het resilveren nog onherstelbare fouten optreden dan zal ZFS aangeven dewelke en dan kan ik deze eenvoudig herstellen vanuit mijn offline backup.
Moral of the story, dankjewel ZFS
Ik draai al ZFS sinds een drietal jaar, naar volle tevredenheid zonder ooit echt noemenswaardige problemen. De array (6*1.5TB Samsung HD154UI)) is nog gebouwd met de eerste FreeNas (0.7 dacht ik?), dan eventjes overgegaan op die nieuwe FreeNas maar bijna onmiddellijk overgestapt op ZFSGuru.
De problemen begonnen 2 weken geleden. Eén disk vertoonde in de plots 15 active bad sectors.
Een scrub leverde geen fouten op dus alles nog goed en wel. Ik ging rustig op zoek naar een replacement disk. Nu begin deze week start ik mijn NAS op en word ik getrakteerd op het krakende/tikkende geluid van een mechanisch failende disk. Ik dacht dat het diezelfde disk ging zijn maar toen ik ging kijken bleek het een totaal andere disk te zijn die gewoon zonder waarschuwing de geest had gegeven. ZFS had de disk zelfs al uit de array gekegeld en de array was nu dus degraded. Bij hardware RAID zou de array nu naar alle waarschijnlijkheid gefailed zijn, lang leve ZFS
Ondertussen heb ik al enkele vervangende exemplaren op de kop kunnen tikken en momenteel is de boel aan het resilveren.
Het plan is de disk met bad sectoren ook te vervangen en dan eens grondig te formatteren, misschien is deze nog wel bruikbaar. Moesten er tijdens het resilveren nog onherstelbare fouten optreden dan zal ZFS aangeven dewelke en dan kan ik deze eenvoudig herstellen vanuit mijn offline backup.
Moral of the story, dankjewel ZFS
Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius -- and a lot of courage -- to move in the opposite direction.
- Mafketel
- Registratie: Maart 2000
- Laatst online: 05-07 06:36
Sorry ik ben niet duidelijk genoeg geweest.Verwijderd schreef op dinsdag 19 maart 2013 @ 19:31:
[...]
Sendmail is een van de dingen (net als BIND) die standaard geïnstalleerd zijn op FreeBSD en je ook expliciet moet disablen anders gaat die elke nacht mailqueue herkauwen. Ik vind het een ramp, dus schakel sendmail ook gelijk uit. Sendmail is verder berucht om security vulnerabilities. Vieze zooi vind ik het. Maar als je simpelweg mail wilt kunnen versturen, is dit wel wat je wilt.
In de standaard zfsguru installatie(0.2.0-bet8-9.1-005) is postfix geinstalleerd ipv sendmail.
In de webgui en in d rc.conf is dit daarentegen niet aangepast vandaar mijn verwarring.
Nu wilde ik eigenlijk alleen weten of dit idd verwarrend is en in de webgui onder services internal, postfix ipv sendmail zou moeten staan
En zo ook de rc.conf zo aangepast moet worden zoals in http://www.freebsd.org/do...ook/mail-changingmta.html word vermeld.
postfix_enable=“YES” en sendmail allemaal op "NO"
Dit natuurlijk alleen als je mail op je nas wil hebben
Ik begrijp niet helemaal wat je zegt. snapshot 1 bestaat omdat je die in eerste instantie hebt overgepompt met je eerste zfs send en receive, als je daarna de recente gegevens erbij wil stoppen doe je dat van het verschil van 1 en 2. Tenminste zo lees ik de documentatie en heb ik het geloof ik anderhalf jaar geleden bij een migratie ook al toegepast.FireDrunk schreef op vrijdag 22 maart 2013 @ 17:34:
Dat kan dus niet. Dan stuur je de verschillen tussen @1 en @2 naar /Bart.
Maar omdat dat snapshot nog niet bestaat, kan je niet alleen de verschillen sturen, omdat hij niet weet welke data het verschil is tussen de pool en @1...
(Ik heb het er ook al met HyperBart over gehad
[ Voor 24% gewijzigd door Mafketel op 23-03-2013 10:48 ]
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
@CiPHER
Gaat Ajaxplorer weer functioneel worden? (of een soortgelijke file manager)
Ik zou het zelf namelijk erg handig vinden
Gaat Ajaxplorer weer functioneel worden? (of een soortgelijke file manager)
Ik zou het zelf namelijk erg handig vinden
[ Voor 15% gewijzigd door ilovebrewski op 23-03-2013 13:19 ]
- Jonny55
- Registratie: Maart 2012
- Laatst online: 15-01-2021
Ik heb momenteel MySQLgeinstaleerd in zfsguru.
alleen kan ik niet inloggen in php admin ik heb de standaard inlog gegevens al geprobeerd maar helaas zonder succes.
weet iemand het log in en wachtwoord of hoe ik en nieuw wachtwoord kan aanmaken???
alleen kan ik niet inloggen in php admin ik heb de standaard inlog gegevens al geprobeerd maar helaas zonder succes.
weet iemand het log in en wachtwoord of hoe ik en nieuw wachtwoord kan aanmaken???
Dat is je default wachtwoord van MySQL, als je die nog niet ingesteld hebt, moet je even de handleiding van MySQL erbij pakken hoe je het root ww reset.
Even niets...
- Jonny55
- Registratie: Maart 2012
- Laatst online: 15-01-2021
Had al gekeken op de MySQL website maar kon zo snel niet vinden...FireDrunk schreef op zaterdag 23 maart 2013 @ 18:24:
Dat is je default wachtwoord van MySQL, als je die nog niet ingesteld hebt, moet je even de handleiding van MySQL erbij pakken hoe je het root ww reset.
Kan iemand even duidelijk uitleggen wat nu de procedure is om in PHP admin in te kunnen loggen?
Ik wil graag PureFTPd werkend hebben maar het vereist MySQL database,want ik mis echt FTP op zfsguru dat is echt en misser!
- Compizfox
- Registratie: Januari 2009
- Laatst online: 08-07 18:12
15 bad sectors zijn nou niet bepaald een reden om de disk te vervangen hoor, sterker nog, dit komt heel vaak voor bij grote schijven (met grote datadichtheid).Wouter.S schreef op zaterdag 23 maart 2013 @ 10:07:
De problemen begonnen 2 weken geleden. Eén disk vertoonde in de plots 15 active bad sectors.[afbeelding]
Een scrub leverde geen fouten op dus alles nog goed en wel. Ik ging rustig op zoek naar een replacement disk.
Waarschijnlijk verdwijnen ze vanzelf weer.
Gewoon een heel grote verzameling snoertjes
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
Heb een nieuwe instal gedaan naar 9.0-004. Dan werkt de Ajaxplorer
Heb nu direct op mijn server mijn externe HD (NTFS) aangesloten. Deze zie ik echter niet in mijn filebrowser. Kan dit niet of doe ik iets verkeerd?
Heb nu direct op mijn server mijn externe HD (NTFS) aangesloten. Deze zie ik echter niet in mijn filebrowser. Kan dit niet of doe ik iets verkeerd?
- Wouter.S
- Registratie: Maart 2009
- Laatst online: 02-01 09:15
e^(i*pi ) +1 = 0
Ondertussen zijn beide disks vervangen en de array is weer netjes ONLINE.Compizfox schreef op zaterdag 23 maart 2013 @ 20:33:
[...]
15 bad sectors zijn nou niet bepaald een reden om de disk te vervangen hoor, sterker nog, dit komt heel vaak voor bij grote schijven (met grote datadichtheid).
Waarschijnlijk verdwijnen ze vanzelf weer.
De nieuwe disks heb ik geformatteerd GPT en een labeltje meegegeven. Bij de disk die REMOVED was uit de array was gewoon eenvoudig 'replace' in de GUI en het resilveren startte. De disk met de bad sectors kon ik echter niet gewoon replacen. Deze heb ik eerst offline moeten halen en dan pas slaagde een replace. Ik kreeg de foutmelding dat de nieuwe disk kleiner was dan de oude. Waarschijnlijk komt dit door de format (boot+reserved space). Kan dit kwaad voor de gehele array in de toekomst als deze nog voller geraakt?
De disk met bad sectoren straks maar even met nulletjes vullen
Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius -- and a lot of courage -- to move in the opposite direction.
Kun je niet gewoon ftp/vsftpd proberen? Heb je geen lompe externe database voor nodigJonny55 schreef op zaterdag 23 maart 2013 @ 19:14:
[...]
Had al gekeken op de MySQL website maar kon zo snel niet vinden...
Kan iemand even duidelijk uitleggen wat nu de procedure is om in PHP admin in te kunnen loggen?
Ik wil graag PureFTPd werkend hebben maar het vereist MySQL database,want ik mis echt FTP op zfsguru dat is echt en misser!
- ilovebrewski
- Registratie: Augustus 2010
- Laatst online: 02-04-2025
hoe maak ik een L2ARC partitie? Moet ik een bepaalde GPT type invoeren? Of moet dit later bij het maken van een pool?
Gevonden
Gevonden
[ Voor 17% gewijzigd door ilovebrewski op 24-03-2013 13:05 ]
- thomasie
- Registratie: Januari 2010
- Laatst online: 26-06-2024
Ik ben een beetje bezig met het overgaan van een linux NAS naar ZFSguru, vooral omdat ik me een stuk veiliger voel bij ZFS. Alleen het lukt me gewoon niet een werkende AMP config draaiend te krijgen. Ik heb geprobeerd het via de web interface van ZFSguru en ook via ports maar ik heb de hele tijd problemen. Is er iemand hier die AMP config draaiend heeft?
De fouten die ik heb bij het installeren via de web interface is dat php bij het installeren van mySQL zeurt over mysqli:
De fouten die ik heb bij het installeren via de web interface is dat php bij het installeren van mySQL zeurt over mysqli:
En bij het zelf installeren werkt php ook niet lekker.The mysqli extension is missing. Please check your PHP configuration. <a href="Documentation.html#faqmysql" target="documentation"><img src="themes/dot.gif" title="Documentation" alt="Documentation" class="icon ic_b_help" /></a>
- Jaap-Jan
- Registratie: Februari 2001
- Laatst online: 08:05
Dat betekent dat je de mysqli- extension niet geïnstalleerd hebt, of hij is niet geenabled in je php.ini- configfile.
En wat zijn de problemen met php? Met 'werkt php ook niet lekker' kunnen we niet veel.
Overigens is dit best wel off- topic in deze thread.
En wat zijn de problemen met php? Met 'werkt php ook niet lekker' kunnen we niet veel.
Overigens is dit best wel off- topic in deze thread.
| Last.fm | "Mr Bent liked counting. You could trust numbers, except perhaps for pi, but he was working on that in his spare time and it was bound to give in sooner or later." -Terry Pratchett
- thomasie
- Registratie: Januari 2010
- Laatst online: 26-06-2024
Oh sorry. Ik zal anders wel even in de ZFSguru irc wat gaan vragen.
Ik was helemaal vergeten dat ik mysql misschien nog moest enabelen in php.ini. Maar misschien toch wel interessant voor CiPHER dat bij mysql installeren phpMyAdmin wat ook direct wordt gedownload niet echt werkt.
Ik was helemaal vergeten dat ik mysql misschien nog moest enabelen in php.ini. Maar misschien toch wel interessant voor CiPHER dat bij mysql installeren phpMyAdmin wat ook direct wordt gedownload niet echt werkt.
- Jaap-Jan
- Registratie: Februari 2001
- Laatst online: 08:05
Let op: mysqli is wat anders dan mysql. De eerste is een verbeterde versie van de tweede, maar kunnen naast elkaar worden geïnstalleerd en bieden beiden een andere interface. Dus software die er gebruik van maakt moet zelf kiezen of ze mysql of mysqli gebruiken.
Maar als ik het zo zie dan zouden in ZFSGuru modules automatisch worden toegevoegd in php.ini als ze worden geïnstalleerd.
Maar als ik het zo zie dan zouden in ZFSGuru modules automatisch worden toegevoegd in php.ini als ze worden geïnstalleerd.
| Last.fm | "Mr Bent liked counting. You could trust numbers, except perhaps for pi, but he was working on that in his spare time and it was bound to give in sooner or later." -Terry Pratchett
Let op:
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.