:fill(white):strip_exif()/i/2003943496.jpeg?f=thumbmini)
:strip_exif()/i/1321263566.png?f=thumbmini)
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
Even niets...
- syl765
- Registratie: Juni 2004
- Laatst online: 15-07 11:15
/u/116403/crop64cfe7aeafeb6_cropped.png?f=community)
@Q
In het bestand showdisks staat op regel 65 het volgelde
Get all network interfaces.
Er verwijst nog meer commentaar naar interfaces in het script.
Komt denk ik uit een ander script
In het bestand showdisks staat op regel 65 het volgelde
Get all network interfaces.
Er verwijst nog meer commentaar naar interfaces in het script.
Komt denk ik uit een ander script
[ Voor 19% gewijzigd door syl765 op 01-02-2014 23:27 ]
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
:strip_icc():strip_exif()/u/10414/crop5817c0657774d_cropped.jpeg?f=community)
Leuke tooltjes Q!
Zo te zien gaat er bij 'showsmart' bij mij iets mis en vergeet hij 2 disks. Ook kan hij de temperatuur van mijn Vertex2 niet lezen terwijl bijvoorbeeld ZFSguru onder FreeBSD dat wel lukte.
Ook apart om te zien dan mijn Intel i350 Quad een firmware heeft van 0,93. Da's niet handig?
Verder over de SSD's. Ik vind het leuk om met SLOG/ZIL en L2ARC te prutsen. Vooral voor mijn iSCSI en NFS zaken voor VMware kan ik de invloed daarvan zeker merken. Ik zit er zelfs aan te twijfelen om overal SYNC op de forceren zodat alle I/O voortaan via de SSD's loopt. Iig als test eens proberen zodra ik een paar nieuwe heb.
Levensduur van die dingen maak ik me niet zo'n zorgen over. Over 5 jaar koop ik toch weer nieuwe en is een SSD van ~250GB eigenlijk niet meer zo interessant, zo ook met de vertex'en nu. Trouwens, dit is mijn eerste Vertex(2) die echt de geest lijkt te geven. Ik heb 1xVertex1 en 3xVertex2 en zo lang je ze netjes over-provisioned en zo nu en dan een keertje met een secure erase leeg haalt (na een 1,5 jaar in gebruik bijvoorbeeld) doen ze het perfect. Ik weet prima dat de gebruikte controller problemen heeft gehad met van alles, maar alleen al over-provisioning helpt echt een hele hoop.
Ik heb in mijn ESXi server ook een 500GB 840 en 500GB 840EVO zitten, wederom met een redelijke overprovision maak ik me daar echt niet druk meer om. 10j+ verwacht ik.
Maar ach, mijn Vertex 1 is uit 2008 volgens mij. Die is al lang lang afgeschreven. En de Vertex 2's zijn van omstreeks 2010 verwacht ik. Ook minimaal ~3.5 jaar oud dus. Tijd gaat hard in IT land!
Die M500's zien er leuk uit maar de schrijf snelheid staat me tegen. Nog eens verder kijken en bepalen over zo'n write buffer voor mij echt interessant is. Want....eventjes kijken of ik het goed heb. SLOG flushed met de huidige versie van ZFS standaard elke 5 seconden volgens mij. Dus in theorie, met een SSD met powercaps kun je niets verliezen omdat ze SYNC write doen en dus alles op de SSD staat, maar zonder powercaps kun je 5 seconden aan writes verliezen omdat in theorie de SLOG nooit verder achterloopt? Misschien dat er nog wat verloren gaat in de onboard cache van je disks.
Conclusie, geld niet uitgeven aan dure SSD's maar aan een UPS?

Zo te zien gaat er bij 'showsmart' bij mij iets mis en vergeet hij 2 disks. Ook kan hij de temperatuur van mijn Vertex2 niet lezen terwijl bijvoorbeeld ZFSguru onder FreeBSD dat wel lukte.
Ook apart om te zien dan mijn Intel i350 Quad een firmware heeft van 0,93. Da's niet handig?
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| root@quinnas:/tmp/showtools# ls LICENSE README.md showdisks showifs showsmart root@quinnas:/tmp/showtools# ./showdisks --------------------------------- | DEVICE | MODEL | --------------------------------- | sda | SAMSUNG HD203WI | | sdb | OCZ-VERTEX2 | | sdc | WDC WD40EZRX-00SPEB0 | | sdd | WDC WD40EZRX-00SPEB0 | | sde | WDC WD40EZRX-00SPEB0 | | sdf | WDC WD40EZRX-00SPEB0 | | sdg | OCZ-VERTEX | | sdh | SAMSUNG HD203WI | | sdi | WDC WD40EZRX-00SPEB0 | --------------------------------- root@quinnas:/tmp/showtools# ./showsmart --------------------------------------------------------------------------- | DEVICE | TEMP | POWERON | REALLOC. | REALLOC. EVNT | PENDING | CRC ERR. | --------------------------------------------------------------------------- | sdc | 35 | 2051 | 0 | 0 | 0 | 0 | | sdd | 34 | 2051 | 0 | 0 | 0 | 0 | | sde | 33 | 2051 | 0 | 0 | 0 | 0 | | sdf | 33 | 2051 | 0 | 0 | 0 | 0 | | sdg | ? | 11252 | ? | ? | ? | ? | | sdh | 30 | 30209 | 0 | 0 | 0 | 4 | | sdi | 36 | 2051 | 0 | 0 | 0 | 0 | --------------------------------------------------------------------------- root@quinnas:/tmp/showtools# ./showifs --------------------------------------------------------------------------------------- | INTERFACE | LINK | IP ADDRESS | MAC ADDRESS | TYPE | DRIVER | FIRMWARE | --------------------------------------------------------------------------------------- | eth1 | yes | 10.10.128.254 | a0:36:9f:02:e7:08 | Ethernet | igb | 0.93, | | eth2 | no | | a0:36:9f:02:e7:09 | Ethernet | igb | 0.93, | | eth3 | no | | a0:36:9f:02:e7:0a | Ethernet | igb | 0.93, | | eth4 | no | | a0:36:9f:02:e7:0b | Ethernet | igb | 0.93, | | lo | yes | 127.0.0.1 | | Local | | | | p5p1 | no | | c8:60:00:e1:43:ca | Ethernet | r8169 | | --------------------------------------------------------------------------------------- |
Verder over de SSD's. Ik vind het leuk om met SLOG/ZIL en L2ARC te prutsen. Vooral voor mijn iSCSI en NFS zaken voor VMware kan ik de invloed daarvan zeker merken. Ik zit er zelfs aan te twijfelen om overal SYNC op de forceren zodat alle I/O voortaan via de SSD's loopt. Iig als test eens proberen zodra ik een paar nieuwe heb.
Levensduur van die dingen maak ik me niet zo'n zorgen over. Over 5 jaar koop ik toch weer nieuwe en is een SSD van ~250GB eigenlijk niet meer zo interessant, zo ook met de vertex'en nu. Trouwens, dit is mijn eerste Vertex(2) die echt de geest lijkt te geven. Ik heb 1xVertex1 en 3xVertex2 en zo lang je ze netjes over-provisioned en zo nu en dan een keertje met een secure erase leeg haalt (na een 1,5 jaar in gebruik bijvoorbeeld) doen ze het perfect. Ik weet prima dat de gebruikte controller problemen heeft gehad met van alles, maar alleen al over-provisioning helpt echt een hele hoop.
Ik heb in mijn ESXi server ook een 500GB 840 en 500GB 840EVO zitten, wederom met een redelijke overprovision maak ik me daar echt niet druk meer om. 10j+ verwacht ik.
Maar ach, mijn Vertex 1 is uit 2008 volgens mij. Die is al lang lang afgeschreven. En de Vertex 2's zijn van omstreeks 2010 verwacht ik. Ook minimaal ~3.5 jaar oud dus. Tijd gaat hard in IT land!
Die M500's zien er leuk uit maar de schrijf snelheid staat me tegen. Nog eens verder kijken en bepalen over zo'n write buffer voor mij echt interessant is. Want....eventjes kijken of ik het goed heb. SLOG flushed met de huidige versie van ZFS standaard elke 5 seconden volgens mij. Dus in theorie, met een SSD met powercaps kun je niets verliezen omdat ze SYNC write doen en dus alles op de SSD staat, maar zonder powercaps kun je 5 seconden aan writes verliezen omdat in theorie de SLOG nooit verder achterloopt? Misschien dat er nog wat verloren gaat in de onboard cache van je disks.
Conclusie, geld niet uitgeven aan dure SSD's maar aan een UPS?
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Performance impact door de move van ZFSguru naar Ubuntu lijkt wel mee te vallen. Een scrub in ZFSguru was volgens mij altijd zo'n 6 uur bezig. Nu in Ubuntu 13.10 server duurt het ook exact 6h met een gemiddelde snelheid van 430MB/sec.
Uiteraard zegt dat niet zoveel over alle andere performance zaken, maar toch.
Nog maar eens wat tuning doen, zoals dat hij na een boot alle metadata automatisch naar mijn L2ARC trekt enzo.
Uiteraard zegt dat niet zoveel over alle andere performance zaken, maar toch.
Nog maar eens wat tuning doen, zoals dat hij na een boot alle metadata automatisch naar mijn L2ARC trekt enzo.
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
/u/1176/crop635f8931b2b68_cropped.png?f=community)
Ik misbruik gewoon smartctl voor de smart waarden, maar waar ik de devices vandaan haal is Linux specifiek hard-coded. Ik heb geen BSD op hardware om mee testen momenteel.FireDrunk schreef op zaterdag 01 februari 2014 @ 23:19:
Werkt die tweede gewoon op smartmontools? Want dan doet hij het waarschijnlijk ook wel op BSD als je alleen de devicepaden aanpast?
Dankjewel! Zou je de output van smartctl -A /dev/sdg willen geven? en die van smartctl -A -d ata /dev/sdg ?Quindor schreef op zaterdag 01 februari 2014 @ 23:50:
Leuke tooltjes Q!
Zo te zien gaat er bij 'showsmart' bij mij iets mis en vergeet hij 2 disks. Ook kan hij de temperatuur van mijn Vertex2 niet lezen terwijl bijvoorbeeld ZFSguru onder FreeBSD dat wel lukte.
Ook apart om te zien dan mijn Intel i350 Quad een firmware heeft van 0,93. Da's niet handig?
Mag ik je output van ls -alh /sys/block en /dev/disk/by-path ?
Misschien even via pastebin of dm als je zou willen, zodat dit topic niet teveel wordt vervuild.
De tooltjes zijn op elkaar gebaseerd inderdaad dus er zal nog wel wat vuil in zitten, wat ik moet opruimen. De showdisks tool is het meest mature met cmd line argument parsing enzo. Dat wil ik ook in de andere tools stoppen.
Wat betreft de firmware output met comma: mag ik de ruwe output hebben van ethtool -i <interface> ?
Ik denk dat ZIL uitzetten het zelfde effect geeft. En meer RAM = meer caching.Verder over de SSD's. Ik vind het leuk om met SLOG/ZIL en L2ARC te prutsen. Vooral voor mijn iSCSI en NFS zaken voor VMware kan ik de invloed daarvan zeker merken. Ik zit er zelfs aan te twijfelen om overal SYNC op de forceren zodat alle I/O voortaan via de SSD's loopt. Iig als test eens proberen zodra ik een paar nieuwe heb.
ZIL / Sync writes uitzetten en gewoon machine aan UPS hangen, waar hij toch al aan hoortConclusie, geld niet uitgeven aan dure SSD's maar aan een UPS?
[ Voor 72% gewijzigd door Q op 02-02-2014 10:15 ]
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Ik ken Brian Ewell niet, maar hij liet een zeer uitgebreid commentaar achter op mijn blog op een artikel over ZFS op je home NAS.
Ik denk dat er veel dingen in staan die erg interessant zijn voor de meesten hierzo.
www.brianewell.com
Ik denk dat er veel dingen in staan die erg interessant zijn voor de meesten hierzo.
www.brianewell.com
Ik denk dat ook hier de boodschap is: Geen SSDs nodig voor een NAS. SSD kan wel handig zijn als je al voldoende RAM hebt en met VMs loopt te klooien en dus random I/O hebt. Anders niet.First, I have to laugh at how different this article is from the only other article of yours I've read: "Why I do not use ZFS..." I'm glad you changed your mind. I use ZFS on Illumos exclusively (SmartOS) at work and at home. My workload at home includes several zones, one of which serves as a NAS appliance. My apologies if the commands I reference aren't available on your system.
Memory (ARC):
The 1G Memory/1T (Formatted) Pool is a good rule of thumb for all installations, even home ones. At minimum, you're going to want enough RAM to properly stage your TXGs for good write performance. That would be upto 10 seconds of your pool's write capacity (regardless of TXGs flushing every 5 seconds.)
Beyond that, you're going to want to see as much memory as you can get into your ARC. At minimum, caching all of your pool's metadata will give you reasonable performance across the board. It's great when your filesystem doesn't have to read from disk to figure out where to read from disk to figure out where to read from disk to figure out where your data is.
At best, you'll have enough memory to take advantage of ZFS' prefetching mechanisms which is basically where ZFS recognizes an access pattern and requests the data from the disk before your application does. It has to have a place to put that data. I use an N54L at home (it's based on an AMD Turion II) and the first thing I did was spend the extra $200 USD to fill it to capacity with 16G of ECC RAM (about $10 more than non-ECC). The 2G that the N54L shipped with it wouldn't have lasted it the night.
You can tell if your system isn't able to cache all of it's metadata under the ARC by looking at zfs::arcstats:arc_meta_* under kstat. If your arc_meta_max exceeds arc_meta_limit, that's very bad for read performance. You either need more RAM, or you need to tweak the ARC data/metadata ratio: something that's not worth $200 to think about.
Additionally, you can use kstat to check your hit and miss counters and determine just how effective your ARC (and L2ARC) is over time by checking under zfs::arcstats:*hits and zfs::arcstats:*misses and doing some math. If your metadata hit rates are high (>99%) you probably have enough RAM for a home fileserver. If your data hit rates are low, you just barely have enough. In short, more RAM is (usually) always a good thing (unless we're talking about +192GB in a SAN environment, but we're not.)
L2ARC:
If you don't have enough memory for a healthy ARC, don't even bother with L2ARC. The L2ARC collects ARC cache data that is about to expire (to the MFU/MRU ghost lists) and instead stores it in secondary storage, most popularly, one or more SSD drives. The header information for the cached data stays in the ARC for faster access.
This storage tier was intended for "warm" data, not "hot" data that should stay in the ARC, or "cold" data that should stay on the disks, but data that was accessed frequently enough to justify the cost of extra performance. It really shines with random data access, and really doesn't with streaming data access ... Given the usage patterns of the normal home user, (the heatmap of their data) it really has no place in a home NAS.
The best way to know for certain is to actually use one for a few months and check kstat. The data under zfs::arcstats:*l2* is relevant. A few specifics follow:
l2_hdr_size: The amount of memory being used to store headers for data stored in the L2ARC. AKA, the RAM cost of using an L2ARC.
l2_hits, l2_misses: Useful for calculating the hit ratio of your L2ARC. Remember that L2ARC won't be considered if there was an ARC hit.
l2_read_bytes, l2_write_bytes: The total volume of data read from or written to your L2ARC devices.
I use SmartOS at home (hosting a handful of zones providing routing, NAS, and hosting several applications, all on that N54L) and decided I wanted to experiment with an L2ARC. I used an 80G SSD in front of 1T of data for a few months before removing it based on the following:
l2_hdr_size: ~450M. 450M of ARC to support 80G of L2ARC seems like a no brainer at first, but just wait till you see the other statistics.
l2_hits/(l2_hits+l2_misses) =~ 45%. In contrast, my ARC hit rate was ~99.4% (data and metadata). So 0.6% of the time (when I'd miss the ARC), it would only hit the L2ARC 45% of the time. My data was cooling off way too fast to justify keeping it in the caches.
l2_read_bytes = 20GB, l2_write_bytes = 1600GB. I had read just 20GB of data from the cache over 4 months while writing it's capacity 20 times over in the same period of time.
L2ARC really works well when dealing with that "warm" data I mentioned earlier. If your data is really polar (like mine), save your RAM and save your money.
SLOG:
If you can get away with asynchronous writes, don't bother. If you MUST have synchronous writes, this is required for any reasonable performance. Since most all writes in a home NAS can be done asynchronously, don't bother. In my own experience running VMs at home, as long as you don't have something forcing all of your writes to be synchronous (like ESXi,) you should be good without one.
Deduplication:
Is the fastest way to make yourself wish you had more RAM. It works by maintaining DeDuplication Tables (DDT) within your pool which keep track of the sha256 checksum of each allocated block. With a DDT, you never write a block that already exists in your pool, you just make another reference to it instead. Great idea in theory, but it's way before it's time. A DDT entry exists for every deduplicated block in your pool, which means it can get very large. DDT data must be consulted prior to every write, which means you pay a huge performance penalty if it isn't already in the ARC. Considering that, it's easy to see how this could go very wrong. The L2ARC doesn't really help either, since the DDT isn't "warm", it's quite hot. Reading it from the L2ARC will give you sub-optimal performance, reading it from disks will give you sub-bedrock performance.
On top of that, most pools wouldn't really benefit from deduplication anyways. You can easily check your own pool by using: zdb -S <pool>
My own pool: dedup = 1.02, compress = 1.02, copies = 1.00, dedup * compress / copies = 1.04 So basically I would get the same benefit that I currently do from compression, except I'd have to use an obscene amount of RAM to do it. In short, not worth it for home use, and honestly it's really not worth it for enterprise use either.
Compression:
Usually Improves performance. Using lz4 always* improves performance. Disk IO is orders of magnitude slower than your CPU is, and if disk access is happening, it likely means one or more programs are waiting for a read to return: CPU time is available. If you can reduce the amount of time the IO subsystem is accessing the data at a slight cost to CPU time, which would have just been wasted waiting for the IO to complete anyways, you come out ahead.
The only time this doesn't work well is usually when you're doing something crazy, like using gzip-9 on incompressible data. lz4 works so well because it's very cheap to compress incompressible data (it recognizes it very early and quits while it's ahead) and very cheap to decompress data. *Unless you're chronically CPU bound, lz4 compression on ZFS is always a good move.
Drives in a RAIDZ vdev:
I could easily make a blog post about this alone. Short version: You really shouldn't exceed 10 drives in a RAIDZ2 vdev. If you do, make it 18 drives, and if you exceed that, make it 34 drives.</pool>
Ik vind dat stukje van Aaron Toponce over Sync en Async wel interessant, want wat nou als ik ESXi gebruik (wat veel Sync writes doet, maar ook niet 100%). Betekend dat dat ik echt om de 10-100 iops een TXG flush heb? Want dat zou natuurlijk wel funest zijn voor je performance, los van het feit dat je sync=disabled hebt.
Er mogen volgens mij nog steeds niet meerdere TXG's lopen tegelijkertijd, dat zou dus betekenen, dat sync=disabled maar een heel beperkt effect heeft, omdat de TXG sowieso geflushed moet zijn voor er weer async geschreven kan worden.
In een 1.000.000 iops systeem van Oracle / Sun kan ik mij zulk soort scenario's niet voorstellen, want dan zouden je writes veel te veel vertraging opleveren... Juist in hele grote systemen, zet je de TXG timeout hoog, omdat je zoveel mogelijk writes in 1 TXG groep wil verzamelen...
Misschien heb ik het verkeerd hoor, maar ik ben heel benieuwd of hier nog meer zinnigs over te zeggen valt
Er mogen volgens mij nog steeds niet meerdere TXG's lopen tegelijkertijd, dat zou dus betekenen, dat sync=disabled maar een heel beperkt effect heeft, omdat de TXG sowieso geflushed moet zijn voor er weer async geschreven kan worden.
In een 1.000.000 iops systeem van Oracle / Sun kan ik mij zulk soort scenario's niet voorstellen, want dan zouden je writes veel te veel vertraging opleveren... Juist in hele grote systemen, zet je de TXG timeout hoog, omdat je zoveel mogelijk writes in 1 TXG groep wil verzamelen...
Misschien heb ik het verkeerd hoor, maar ik ben heel benieuwd of hier nog meer zinnigs over te zeggen valt
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Als je sync=disabled doet, dan negeert ZFS gewoon sync write requests. Volgens mij worden die gewoon als async in txgs periodiek naar disk geflushed en niet om de 10-100 iops ofzo. Met NFS heb ik het zelf gezien, van 20 MB/s naar 400 MB/s is nogal een verschil. Edit: moet zeggen dat ik even twijfel over random IO. Maar volgens mij maakt dat niet uit.
Er zijn zoals ik het begreep 3 txgs: eentje die wordt gevuld met nieuwe data, eentje in rust en eentje die data naar de vdevs toe schrijft. Waarschijnlijk is dat de reden waarom je 2x5 is 10 seconden aan RAM buffer moet hebben, maar ik zal dat eens beter nalezen.
Aaron Toponce's blog is ook erg goed leesvoer https://pthree.org/category/zfs/
Er zijn zoals ik het begreep 3 txgs: eentje die wordt gevuld met nieuwe data, eentje in rust en eentje die data naar de vdevs toe schrijft. Waarschijnlijk is dat de reden waarom je 2x5 is 10 seconden aan RAM buffer moet hebben, maar ik zal dat eens beter nalezen.
Aaron Toponce's blog is ook erg goed leesvoer https://pthree.org/category/zfs/
[ Voor 14% gewijzigd door Q op 02-02-2014 13:00 ]
Och natuurlijk, sync writes worden async met sync=disabled, dus komen ze allemaal in dezelfde Transaction Group. Je hebt dus bij sync=disabled gewoon de normale flow van TXG's.
Even niets...
- Kortfragje
- Registratie: December 2000
- Laatst online: 25-06 18:28
......
Q, ik heb je scriptjes gedownload, idd erg leuk (voor snelle check). Ik heb alleen een probleem met de showsmart :
Zoals je ziet vind showdisks wel alle disks maar showsmart niet.
Ik heb mijn zpool via /dev/disk/by-id/ (dmv een alias in /etc/zfs/vdev_id.conf) aangemaakt. In /dev/disk/by-path staan ook alleen de drie disks die hij vindt. Zou je jouw scriptje ook via /dev/disk/by-id kunnen laten lopen zoals in showdisks ?
De pastebin met de door jou gevraagde output staat hier : http://pastebin.com/fAFz3TcM
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| root@gertdus-server:~/Desktop# ./showsmart.py --------------------------------------------------------------------------- | DEVICE | TEMP | POWERON | REALLOC. | REALLOC. EVNT | PENDING | CRC ERR. | --------------------------------------------------------------------------- | sdc | 29 | 1899 | 0 | 0 | 0 | 0 | | sdf | 29 | 4348 | 0 | 0 | 0 | 0 | | sdg | 27 | 2200 | 0 | 0 | 0 | 0 | --------------------------------------------------------------------------- root@gertdus-server:~/Desktop# ./showdisks.py ----------------------------------- | DEVICE | MODEL | ----------------------------------- | sda | WDC WD20EZRX-00DC0B0 | | sdb | WDC WD20EFRX-68AX9N0 | | sdc | WDC WD20EFRX-68AX9N0 | | sdd | WDC WD20EARX-00PASB0 | | sde | WDC WD20EFRX-68AX9N0 | | sdf | WDC WD20EARX-00PASB0 | | sdg | WDC WD5000BPVT-22HXZT3 | ----------------------------------- root@gertdus-server:~/Desktop# ./showifs.py ---------------------------------------------------------------------------------------------- | INTERFACE | LINK | IP ADDRESS | MAC ADDRESS | TYPE | DRIVER | FIRMWARE | ---------------------------------------------------------------------------------------------- | eth0 | yes | | ac:22:0b:82:ca:7f | Ethernet | r8169 | rtl8168f-1_0.0.5 | | eth1 | yes | 192.168.10.3 | 00:1b:21:40:45:88 | Ethernet | igb | 1.112, | | eth2 | no | | 00:1b:21:40:45:89 | Ethernet | igb | 1.112, | | eth3 | yes | | 00:1b:21:40:45:8c | Ethernet | igb | 1.112, | | eth4 | no | | 00:1b:21:40:45:8d | Ethernet | igb | 1.112, | | lo | yes | 127.0.0.1 | | Local | | | ---------------------------------------------------------------------------------------------- |
Zoals je ziet vind showdisks wel alle disks maar showsmart niet.
Ik heb mijn zpool via /dev/disk/by-id/ (dmv een alias in /etc/zfs/vdev_id.conf) aangemaakt. In /dev/disk/by-path staan ook alleen de drie disks die hij vindt. Zou je jouw scriptje ook via /dev/disk/by-id kunnen laten lopen zoals in showdisks ?
De pastebin met de door jou gevraagde output staat hier : http://pastebin.com/fAFz3TcM
[ Voor 25% gewijzigd door Kortfragje op 02-02-2014 18:40 ]
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Bedankt, ik zal er even naar gaan kijken.
- Dr_Hell
- Registratie: Juni 2002
- Laatst online: 20-05 20:40
Q, ik mis een aantal disks in /dev/disk/by-path die er wel staan in /dev/disk/by-id.
Dit is op Ubuntu 12.04 met kernel 3.11.0-15.
Volgens https://bugs.launchpad.ne...urce/systemd/+bug/1193705 is dit een bewuste keuze van upstream en zou je altijd by-id moeten gaan gebruiken.
Voor anderen die ZFS on Linux gebruiken is het ook wel handig om dit te weten.
http://pastebin.com/vqp8xqsA
Dit is op Ubuntu 12.04 met kernel 3.11.0-15.
Volgens https://bugs.launchpad.ne...urce/systemd/+bug/1193705 is dit een bewuste keuze van upstream en zou je altijd by-id moeten gaan gebruiken.
Voor anderen die ZFS on Linux gebruiken is het ook wel handig om dit te weten.
http://pastebin.com/vqp8xqsA
[ Voor 4% gewijzigd door Dr_Hell op 02-02-2014 19:39 ]
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Bedankt voor de tip, ik zal showdisk en showsmart hier op aanpassen waar nodig. Ik wil niet teveel het ZFS topic kapen om deze tools te debuggen, schiet gerust github issues in of DM mij. Bedankt voor de feedback so far.
Ik heb een geupdatede versie van showsmart net gepushed, ik ben benieuwd of die wel alle devices ziet.
Misschien ga ik showdisks en showsmart met elkaar integreren (showdisk blijft over), maar dat moet ik nog even uitzoeken.
Ik heb een geupdatede versie van showsmart net gepushed, ik ben benieuwd of die wel alle devices ziet.
Misschien ga ik showdisks en showsmart met elkaar integreren (showdisk blijft over), maar dat moet ik nog even uitzoeken.
[ Voor 16% gewijzigd door Q op 02-02-2014 20:36 ]
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
BAM! Kogel door de kerk, ik neem 3x 840 EVO's van 250GB over van iemand. Hoe ik ze precies ga inzetten ga ik nog een beetje mee testen (I know, super grote ZIL en super grote L2ARC kost veel memory dus ARC, etc. etc.) Iig leuk om mee te prusten, worst case bouw ik ze in mijn ESXi server in als datastores! Met 3 stuks (En de 240GB Vertex2) zullen de writes per dag ook allemaal wel mee vallen. 
Voor Q heb ik een pastebin: http://pastebin.com/0BhFUXLs
Ik heb ook eindelijk gevonden hoe je bepaalde ZFS settings in ZoL kunt veranderen. Dat was binnen FreeBSD/ZFSguru dan weer een stuk makkelijker!
root@quinnas:/etc/modprobe.d# more zfs.conf
options zfs l2arc_write_boost=104857600
options zfs l2arc_write_max=52428800
options zfs l2arc_noprefetch=0
Ook heb ik in mijn '/etc/rc.local' de volgende regel gezet:
screen -d -m find /
Op die manier word mijn directory en file metadata tijdens het opstarten in ieder geval 1x gelezen zodat deze alvast in het geheugen zit. ZFSguru had daar een optie voor ingebouwd (die volgens mij ongeveer hetzelfde doet).
Voor Q heb ik een pastebin: http://pastebin.com/0BhFUXLs
Ik heb ook eindelijk gevonden hoe je bepaalde ZFS settings in ZoL kunt veranderen. Dat was binnen FreeBSD/ZFSguru dan weer een stuk makkelijker!
root@quinnas:/etc/modprobe.d# more zfs.conf
options zfs l2arc_write_boost=104857600
options zfs l2arc_write_max=52428800
options zfs l2arc_noprefetch=0
Ook heb ik in mijn '/etc/rc.local' de volgende regel gezet:
screen -d -m find /
Op die manier word mijn directory en file metadata tijdens het opstarten in ieder geval 1x gelezen zodat deze alvast in het geheugen zit. ZFSguru had daar een optie voor ingebouwd (die volgens mij ongeveer hetzelfde doet).
- Kortfragje
- Registratie: December 2000
- Laatst online: 25-06 18:28
......
Briljant Q, hij pakt nu inderdaad alle disks..
Dank voor je hulp.
Niet alle smart parameters komen mee, maar ik neem aan dat dat 'work in progress' is?
(omdat in de vorige versie de volgende parameters by default meekwamen ( DEVICE | TEMP | POWERON | REALLOC. | REALLOC. EVNT | PENDING | CRC ERR. |))
Nogmaals dank.
Dank voor je hulp.
Niet alle smart parameters komen mee, maar ik neem aan dat dat 'work in progress' is?
(omdat in de vorige versie de volgende parameters by default meekwamen ( DEVICE | TEMP | POWERON | REALLOC. | REALLOC. EVNT | PENDING | CRC ERR. |))
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| root@gertdus-server:~/Desktop# ./showsmart.py ------------------------------- | Dev | Temp | Pending Sector | ------------------------------- | sda | 29 | 0 | | sdb | 28 | 0 | | sdc | 29 | 0 | | sdd | 29 | 0 | | sde | 28 | 0 | | sdf | 29 | 0 | | sdg | 28 | 0 | ------------------------------- root@gertdus-server:~/Desktop# ./showdisks.py -------------------------------- | DEV | MODEL | -------------------------------- | sda | WDC WD20EZRX-00DC0B0 | | sdb | WDC WD20EFRX-68AX9N0 | | sdc | WDC WD20EFRX-68AX9N0 | | sdd | WDC WD20EARX-00PASB0 | | sde | WDC WD20EFRX-68AX9N0 | | sdf | WDC WD20EARX-00PASB0 | | sdg | WDC WD5000BPVT-22HXZT3 | -------------------------------- root@gertdus-server:~/Desktop# |
Nogmaals dank.
[ Voor 6% gewijzigd door Kortfragje op 02-02-2014 23:10 ]
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Bedankt voor de feedback.Kortfragje schreef op zondag 02 februari 2014 @ 21:39:
Briljant Q, hij pakt nu inderdaad alle disks..
Dank voor je hulp.
Probeer eens de help op te vragen? -hNiet alle smart parameters komen mee, maar ik neem aan dat dat 'work in progress' is?
Ik moet standaard als output misschien -h doen en alleen output geven als er opties worden mee gegeven.
Edit: dit is nu standaard: geen argumenten = help weergeven.
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| root@nano:~/gold/showtools# ./showsmart
usage: showsmart [-h] [-t] [-H] [-p] [-r] [-R] [-c]
Show detailed SMART device information in ASCII table format
optional arguments:
-h, --help show this help message and exit
-t, --temp Temperature in Celcius
-H, --hours Power On Hours
-p, --pending Pending Sector Count
-r, --reallocated Reallocated Sector Count
-R, --reallocatedevent
Reallocated Sector Event Count
-c, --crc CRC Error |
Gaaf, goed voor L2ARC, misschien l2arc stripen en ZIL mirroren. Voor ZIL heb je aan 1 a 2 GB al zat trouwens, dus als je SLOG 4 GB is heb je meer dan zat.Quindor schreef op zondag 02 februari 2014 @ 21:15:
BAM! Kogel door de kerk, ik neem 3x 840 EVO's van 250GB over van iemand. Hoe ik ze precies ga inzetten ga ik nog een beetje mee testen (I know, super grote ZIL en super grote L2ARC kost veel memory dus ARC, etc. etc.) Iig leuk om mee te prusten, worst case bouw ik ze in mijn ESXi server in als datastores! Met 3 stuks (En de 240GB Vertex2) zullen de writes per dag ook allemaal wel mee vallen.
De nieuwste versie zou beter moeten werken, bedankt.Voor Q heb ik een pastebin: http://pastebin.com/0BhFUXLs
Die comma + hex waarde bij de ethtool -i output lijkt bijna een bug in ethtool of firmware ....
Goed om te weten, had dit nog niet uitgezocht.Ik heb ook eindelijk gevonden hoe je bepaalde ZFS settings in ZoL kunt veranderen. Dat was binnen FreeBSD/ZFSguru dan weer een stuk makkelijker!
root@quinnas:/etc/modprobe.d# more zfs.conf
options zfs l2arc_write_boost=104857600
options zfs l2arc_write_max=52428800
options zfs l2arc_noprefetch=0
[ Voor 73% gewijzigd door Q op 02-02-2014 23:38 ]
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
iSCSI aan de gang prutsen op Ubuntu is ook kinderspel!
Ik had mijn volumes nog vanuit ZFSguru en die waren ook netjes automatisch bekend geworden onder "/dev/zvol/"
Dus vervolgens het volgende in "/etc/iet/ietd.conf" gegooid:
Target iqn.2012-03.com.example:ESXi-2TB
IncomingUser Quindor PasswordHere(min 12chars)
OutgoingUser
Lun 0 Path=/dev/zvol/Mirror-2TB/2TB-iSCSI-VMware,Type=blockio
Alias ESXi-2TB
MaxConnections 4
FirstBurstLength 262144
MaxBurstLength 1048576
Target iqn.2012-03.com.example:ESXi-4TB
IncomingUser Quindor PasswordHere(min 12chars)
OutgoingUser
Lun 0 Path=/dev/zvol/RAIDz1-4TB/4TB-iSCSI-VMware,Type=blockio
Alias ESXi-2TB
MaxConnections 4
FirstBurstLength 262144
MaxBurstLength 1048576
De extra Burst zaken zijn de instellingen die ESXi standaard hanteert voor iSCSI connecties. Na een "service iscsitarget restart" werkt het als een trein!
In ESXi moet je de 'dynamic discovery' toevoegen (bij meerdere netwerk kaarten, verschillende subnets gebruiken en all IP's opgeven, CHAP authenticatie ingeven, daarna scannen, volume toevoegen en niet vergeten al je volumes (in mijn geval 2) eventjes op round-robin balancing te zetten als je meerdere netwerk kaarten gebruikt!
Er zijn betere guides op internet te vinden uiteraard. Zo te zien klap ik nu wel tegen de SYNC I/O snelheid van mijn SSD's aan, maar dat is als het goed is binnenkort gefixed.
update:
Voor de volledigheid, ook nog eventjes een stukje uit "/etc/network/interfaces
auto eth3
iface eth3 inet static
address 172.16.32.1
netmask 255.255.255.0
network 172.16.32.0
broadcast 172.16.32.255
mtu 9000
auto eth4
iface eth4 inet static
address 172.16.16.1
netmask 255.255.255.0
network 172.16.16.0
broadcast 172.16.16.255
mtu 9000
Niet vergeten op alle plekken in ESXi ook de MTU size te vergroten en ook netjes 2 vSwitches aan te maken, etc.
update:
Well that's odd, ik heb eventjes een "zfs set sync=disabled RAIDz1-4TB/4TB-iSCSI-VMware" gegeven waardoor er dus niets meer in de weg zou moeten staan en ik haal EXACT 102MB/sec verdeelt over 2 netwerk kaarten. Shut ik 1 kaart down dan haal ik ook 100MB/sec, maar dan over 1 netwerk kaart. Hu?
Ik had mijn volumes nog vanuit ZFSguru en die waren ook netjes automatisch bekend geworden onder "/dev/zvol/"
Dus vervolgens het volgende in "/etc/iet/ietd.conf" gegooid:
Target iqn.2012-03.com.example:ESXi-2TB
IncomingUser Quindor PasswordHere(min 12chars)
OutgoingUser
Lun 0 Path=/dev/zvol/Mirror-2TB/2TB-iSCSI-VMware,Type=blockio
Alias ESXi-2TB
MaxConnections 4
FirstBurstLength 262144
MaxBurstLength 1048576
Target iqn.2012-03.com.example:ESXi-4TB
IncomingUser Quindor PasswordHere(min 12chars)
OutgoingUser
Lun 0 Path=/dev/zvol/RAIDz1-4TB/4TB-iSCSI-VMware,Type=blockio
Alias ESXi-2TB
MaxConnections 4
FirstBurstLength 262144
MaxBurstLength 1048576
De extra Burst zaken zijn de instellingen die ESXi standaard hanteert voor iSCSI connecties. Na een "service iscsitarget restart" werkt het als een trein!
In ESXi moet je de 'dynamic discovery' toevoegen (bij meerdere netwerk kaarten, verschillende subnets gebruiken en all IP's opgeven, CHAP authenticatie ingeven, daarna scannen, volume toevoegen en niet vergeten al je volumes (in mijn geval 2) eventjes op round-robin balancing te zetten als je meerdere netwerk kaarten gebruikt!
Er zijn betere guides op internet te vinden uiteraard. Zo te zien klap ik nu wel tegen de SYNC I/O snelheid van mijn SSD's aan, maar dat is als het goed is binnenkort gefixed.
update:
Voor de volledigheid, ook nog eventjes een stukje uit "/etc/network/interfaces
auto eth3
iface eth3 inet static
address 172.16.32.1
netmask 255.255.255.0
network 172.16.32.0
broadcast 172.16.32.255
mtu 9000
auto eth4
iface eth4 inet static
address 172.16.16.1
netmask 255.255.255.0
network 172.16.16.0
broadcast 172.16.16.255
mtu 9000
Niet vergeten op alle plekken in ESXi ook de MTU size te vergroten en ook netjes 2 vSwitches aan te maken, etc.
update:
Well that's odd, ik heb eventjes een "zfs set sync=disabled RAIDz1-4TB/4TB-iSCSI-VMware" gegeven waardoor er dus niets meer in de weg zou moeten staan en ik haal EXACT 102MB/sec verdeelt over 2 netwerk kaarten. Shut ik 1 kaart down dan haal ik ook 100MB/sec, maar dan over 1 netwerk kaart. Hu?
[ Voor 25% gewijzigd door Quindor op 02-02-2014 23:40 ]
Verwijderd
Op mijn 10.0-002 install heb ik de "Note: no voltage sensors are available on your system." melding.
Moet ik nog ergens iets doen om ze wel zichtbaar te krijgen?
Moet ik nog ergens iets doen om ze wel zichtbaar te krijgen?
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Precies, valt best mee, zie nog wat leuke details die ik niet wist over ESXi.Quindor schreef op zondag 02 februari 2014 @ 23:32:
iSCSI aan de gang prutsen op Ubuntu is ook kinderspel!
2 x Lun 0, gaat dat wel goed?Lun 0 Path=/dev/zvol/Mirror-2TB/2TB-iSCSI-VMware,Type=blockio
Lun 0 Path=/dev/zvol/RAIDz1-4TB/4TB-iSCSI-VMware,Type=blockio
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Yes, volgens mij bepaald dat wat er op die connectie mee gegeven moet worden als LUN niet zozeer als welke Host LUN ID het aangeboden moet worden.Q schreef op zondag 02 februari 2014 @ 23:42:
[...]
Precies, valt best mee, zie nog wat leuke details die ik niet wist over ESXi.
[...]
2 x Lun 0, gaat dat wel goed?
Nu je dat zo zegt had ik natuurlijk ook beide in dezelfde target kunnen duwen.
Over de performance, die is alweer wat omhoog. Ik was eventjes vergeten dat voor ESXi dit nieuwe LUN's waren en dat ik daarvoor dus de round-robin policy moet aanpassen. Standaard doet hij round-robin per 1000 IO's wat veel te veel is voor mijn situatie (en sequential transfers) met deze nu op 1 te zetten zit ik rond de 130MB/sec..... Nog niet helemaal wat ik wil, maar goed, ruimte voor verbetering.
Op de CLI (Via SSH bijvoorbeeld) van ESXi doe je het volgende
[code]
~ # esxcli storage nmp device list (Hiermee kun je je devicename's vinden)
~ # esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=1 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
~ # esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=1 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
[/code]
Ok, ik wist dat ik het eerder anders had gedaan dus dat heb ik eventjes opgezocht. Omdat ik jumbo frames gebruik kan ik beter elk frame proberen te vullen en dan over te schakelen naar een nieuw frame op een andere adapter. Daarvoor gebruik je de volgende waarden:
code:
1
2
| ~ # esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=16 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88 ~ # esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes 8320 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88 |
Het is belangrijk om het in die volgorde uit te voeren. Balancing gebeurt dan om de 16 IO's of 8320 bytes. Wat je als laatste ingeeft word in principe gebruikt in mijn geval dus de 8320 bytes. Dat geeft mij binnen een VM de volgende waardes:

Makes me a happy camper!
*Ik gebruik wel in beiden mijn ESXi server en mijn Ubuntu 13.10 ZFS NAS Intel server i350 dual en quad netwerk kaarten. You milage may vary (oh, en ebay is your friend voor die kaarten
Hopelijk hebben andere mensen er ook wat aan, ik zal verder mijn spam weer een beetje stoppen.
[ Voor 39% gewijzigd door Quindor op 03-02-2014 00:47 ]
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Ik heb nog wat Linux OS netwerk tuning en 'igb' (netwerk kaart die ik gebruik) tuning gedaan om de performance net nog een beetje te verbeteren.....en..... Ik heb de theoretische grens doorbroken! 

Nah, ik weet niet waarom het mis gaat, misschien dat het net tussen 2 frames in zit ofzo? Hoe dan ook is er weer een paar percent bij gekomen en kunnen we iig stellen dat iSCSI , VMware en ZFS prima kan werken.
(Overigens is naast de benchmarks bijvoorbeeld een storage vmotion ook een stukje sneller geworden).
Ik zal morgen wat in elkaar trachten te typen om de netwerk veranderingen te laten zien. Gaat vooral om buffers, en queues, etc.
Nah, ik weet niet waarom het mis gaat, misschien dat het net tussen 2 frames in zit ofzo? Hoe dan ook is er weer een paar percent bij gekomen en kunnen we iig stellen dat iSCSI , VMware en ZFS prima kan werken.
(Overigens is naast de benchmarks bijvoorbeeld een storage vmotion ook een stukje sneller geworden).
Ik zal morgen wat in elkaar trachten te typen om de netwerk veranderingen te laten zien. Gaat vooral om buffers, en queues, etc.
Verwijderd
Heb je misschien ook al eens getest met iSCSI voor ESX op een dedup-volume?Quindor schreef op maandag 03 februari 2014 @ 01:36:
[...] kunnen we iig stellen dat iSCSI , VMware en ZFS prima kan werken.
ESXi buffered reads in RAM, dus als het zeker weet dat de data niet gewijzigd is, kan de data gewoon lokaal geleverd worden door je ESXi host ipv door je storage (voor zover ik weet).
Bovendien moet je VEEL grotere test sizes nemen. 500MB past veel te makkelijk in RAM (icm ZFS al helemaal).
Pak het liefst 4GB test size in CDM.
Persoonlijk gebruik ik liever IOMeter, daar kan je veel langere en grotere (uitgebreidere) tests mee doen.
Mocht je niet weten hoe dat moet, kan ik wel een keer een tutorial maken.
Bovendien moet je VEEL grotere test sizes nemen. 500MB past veel te makkelijk in RAM (icm ZFS al helemaal).
Pak het liefst 4GB test size in CDM.
Persoonlijk gebruik ik liever IOMeter, daar kan je veel langere en grotere (uitgebreidere) tests mee doen.
Mocht je niet weten hoe dat moet, kan ik wel een keer een tutorial maken.
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Ik vind dit wel interessant, iSCSI + ZFS + VMware werkt dus ook (erg) goed, aangenomen dat de transfers via iSCSI lopen en niet uit RAM van de VMware server komenQuindor schreef op zondag 02 februari 2014 @ 23:49:
Hopelijk hebben andere mensen er ook wat aan, ik zal verder mijn spam weer een beetje stoppen.
De grap is dat ik precies deze setup wil instellen voor een niet-critisch systeem op mijn werk, dus bedankt
Ik draai ook al een poosje (paar weken) ESXi icm iSCSI, zal zometeen ook eens benchen met CDM en ATTO.
Even niets...
Verwijderd
Ik doe het al een aantal jaren.
Maar ik ga 'm nu toch echt omzetten van m'n 2*1 Gb van de QNAP naar 20 Gb via IB op ZFSguru.
Maar vooral opletten dat je de I/O roundrobin in ESX zo laag mogelijk zet. (ik heb 'm op 1 staan)
Maar ik ga 'm nu toch echt omzetten van m'n 2*1 Gb van de QNAP naar 20 Gb via IB op ZFSguru.
Maar vooral opletten dat je de I/O roundrobin in ESX zo laag mogelijk zet. (ik heb 'm op 1 staan)
Als ik dezelfde test run als jij bekom ik deze resultaten. (win7 en freenas zijn beide vm's op dezelfde host)Quindor schreef op maandag 03 februari 2014 @ 01:36:
Ik heb nog wat Linux OS netwerk tuning en 'igb' (netwerk kaart die ik gebruik) tuning gedaan om de performance net nog een beetje te verbeteren.....en..... Ik heb de theoretische grens doorbroken!
[afbeelding]
Nah, ik weet niet waarom het mis gaat, misschien dat het net tussen 2 frames in zit ofzo? Hoe dan ook is er weer een paar percent bij gekomen en kunnen we iig stellen dat iSCSI , VMware en ZFS prima kan werken.
(Overigens is naast de benchmarks bijvoorbeeld een storage vmotion ook een stukje sneller geworden).
Ik zal morgen wat in elkaar trachten te typen om de netwerk veranderingen te laten zien. Gaat vooral om buffers, en queues, etc.
{kind=link}

- Deze advertentie is geblokkeerd door Pi-Hole -
Verwijderd
Jij gebruikt een shortcut van de ene VM naar de andere.
Het klopt dat je dan zonder problemen boven de 1 Gb uit kan komen.
Het klopt dat je dan zonder problemen boven de 1 Gb uit kan komen.
Inderdaad, ik dacht: nu dat we toch met benchmarks aan het gooien zijn.Verwijderd schreef op maandag 03 februari 2014 @ 13:39:
Jij gebruikt een shortcut van de ene VM naar de andere.
Het klopt dat je dan zonder problemen boven de 1 Gb uit kan komen.
- Deze advertentie is geblokkeerd door Pi-Hole -
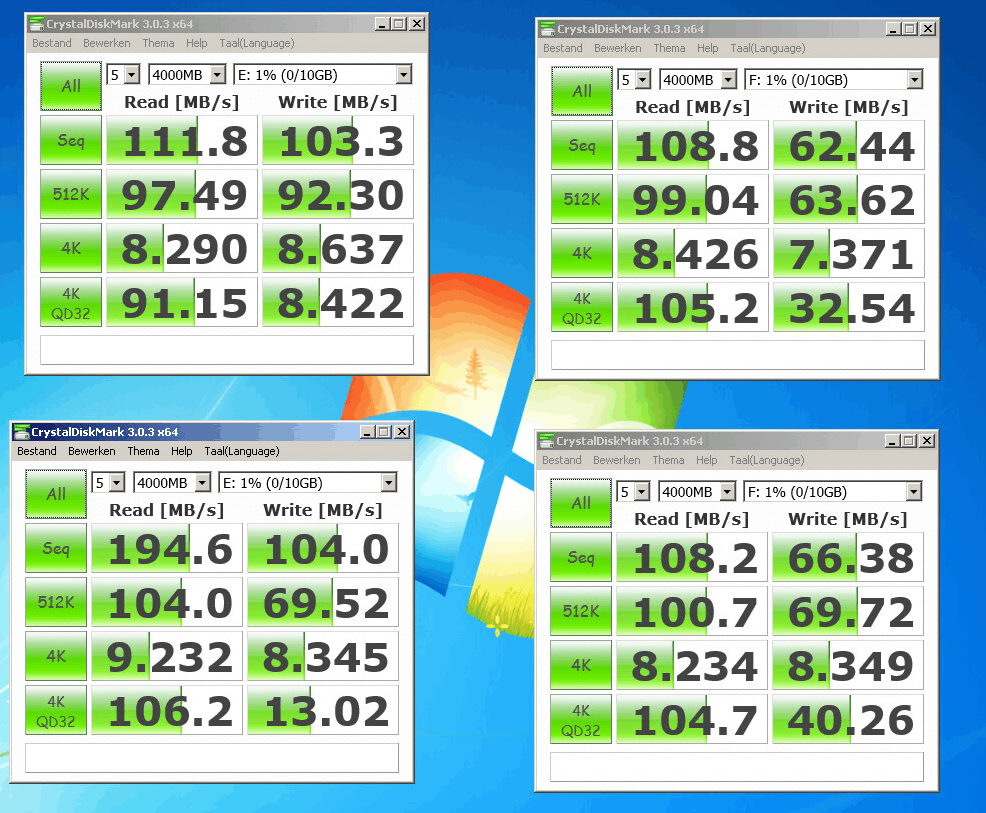
E: = 2* 840 Pro 128GB in Mirror
F: = 4*4TB in RAIDZ
Host is aangesloten via 2*1Gbit met Jumbo Frames aan
Boven is met default Round Robin instellingen,
Onder is met getunede Round Robin instellingen zoals hierboven aangegven.
Sync staat overal uit. (UPS
Ben nog niet zo overtuigd.
Even niets...
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Waar precies ben je niet van overtuigd?
Je read met de andere instellingen is toch ~1.8x zo hoog als daarvoor? Al mijn tests gaan overigens naar 5x4TB in RAIDz1 dus waarom jou test lager is naar je disken dan SSD snap ik ook niet helemaal. Ik heb sync nu op default staan wat volgens mij disabled is.
Verder is atto wat makkelijker om sequential transfers te testen aangezien die ook verschillende blok groottes laat zien.
De aanpassingen binnen ESXi en de netwerk kaarten in mijn Ubuntu bakje zorgen er iig voor dat ik nu ~140MB/sec storage vMotion doe in plaats van ~90MB/sec ervoor. Geen verdubbelen, maar toch.
Verder vind ik de snelheid van de iSCSI koppeling interessant, de storage daar achter en cached of niet boeit me in dit geval niet zo. Ik draai bijvoorbeeld LZ4 compressie, dus dat is sowieso al niet eerlijk.
ESXi doet verder geen IO caching of andere fratsen zover ik weet, is je storage traag, dan zie je dat ook. Daarnaast meet ik altijd op de storage machine dus zie ik het daadwerkelijke verkeer voorbij komen.

Wat ik dan wel weer maf vind is dat mijn writes vele malen meer zijn dan wat er binnenkomt, maar ik verwacht dat daarbij wellicht het verkeer naar de SSD's word meegerekend aangezien ik prefetch van streaming aan heb gezet. Maar dat ga ik wel eens onderzoeken.
update:
Hier een plaatje als de grotere blokken van ATTO bezig zijn. Dat verteld mij dat mijn 2Gbit iSCSI link iig met grote blokken helemaal dicht word geduwd en dus dat de setup in principe in orde is.

Ik heb bij ATTO alleen wel een raar gat bij 8K blokken (zie plaatjes hierboven) en ik heb het vermoeden dat dat wellicht komt door de 8230 bytes instelling binnen ESXi, daar ga ik eens wat mee prutsen.
Je read met de andere instellingen is toch ~1.8x zo hoog als daarvoor? Al mijn tests gaan overigens naar 5x4TB in RAIDz1 dus waarom jou test lager is naar je disken dan SSD snap ik ook niet helemaal. Ik heb sync nu op default staan wat volgens mij disabled is.
Verder is atto wat makkelijker om sequential transfers te testen aangezien die ook verschillende blok groottes laat zien.
De aanpassingen binnen ESXi en de netwerk kaarten in mijn Ubuntu bakje zorgen er iig voor dat ik nu ~140MB/sec storage vMotion doe in plaats van ~90MB/sec ervoor. Geen verdubbelen, maar toch.
Verder vind ik de snelheid van de iSCSI koppeling interessant, de storage daar achter en cached of niet boeit me in dit geval niet zo. Ik draai bijvoorbeeld LZ4 compressie, dus dat is sowieso al niet eerlijk.
ESXi doet verder geen IO caching of andere fratsen zover ik weet, is je storage traag, dan zie je dat ook. Daarnaast meet ik altijd op de storage machine dus zie ik het daadwerkelijke verkeer voorbij komen.
Wat ik dan wel weer maf vind is dat mijn writes vele malen meer zijn dan wat er binnenkomt, maar ik verwacht dat daarbij wellicht het verkeer naar de SSD's word meegerekend aangezien ik prefetch van streaming aan heb gezet. Maar dat ga ik wel eens onderzoeken.
update:
Hier een plaatje als de grotere blokken van ATTO bezig zijn. Dat verteld mij dat mijn 2Gbit iSCSI link iig met grote blokken helemaal dicht word geduwd en dus dat de setup in principe in orde is.
Ik heb bij ATTO alleen wel een raar gat bij 8K blokken (zie plaatjes hierboven) en ik heb het vermoeden dat dat wellicht komt door de 8230 bytes instelling binnen ESXi, daar ga ik eens wat mee prutsen.
[ Voor 24% gewijzigd door Quindor op 03-02-2014 19:04 ]
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Zo, klaar met tuning, ik heb besloten uit de vele settings die ik geprobeerd heb het volgende te gebruiken:
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=7800 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=7800 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
esxcli storage nmp device list
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=262144 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=262144 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
Met deze waarden had ik iig geen gat bij bijvoorbeeld 4KB of 8KB zoals ik eerder wel had en zijn de transfer waardes goed. Reads kan nog net een beetje hoger lijkt het (222000KB/sec) maar 212000KB/sec vind ik meer dan prima om als compromis te nemen.

Wat me wel opvalt is dat toen ik ZFSguru draaide mijn 4K QD32 rond de 100MB/sec was en nu een heel stuk lager. Firedrunk, draai jij ZFS on Linux of een BSD variant?
Verder ben ik zoals ik al vermelde bezig geweest met het bij-tunen van mijn Ubuntu netwerk stack zoals ik dat ook binnen ZFSguru/FreeBSD had gedaan. Ik heb de 'indruk' dat het daar zeker beter van is geworden maar ik heb voor en na niet per setting getest. Alle bovenstaande waardes zijn MET de tuning aanwezig getest.
Ik heb de volgende waardes in /etc/sysctl.conf opgenomen. Dit vergroot voornamelijk maximale blok groottes en buffers:
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Daarnaast heb ik met ethtool gekeken waarop de queues van mijn netwerk kaart stond en deze naar het maximale vergroot om zo de doorvoer hoger en constanter te maken:
root@quinnas:/etc# ethtool -g eth3
Ring parameters for eth3:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
oot@quinnas:/etc# ethtool -G eth3 rx 4096 tx 4096
De waardes zijn volgens mij default wat conservatief om in alle sitauties gemiddeld gezien een acceptable performance te realizeren. Aangezien mijn server vooral storage server is zal deze voornamelijk grote blokken verwerken en daarvoor is het beter dat deze dan zo groot mogelijk zijn. Een langere queue is daarbij ook geen probleem.
Heb je bijvoorbeeld een firewall die heel snel kleine pakketjes moet kunnen verwerken dan zijn deze settings waarschijnlijk NIET de juiste.
Overigens haal ik sinds de netwerk veranderingen altijd vrij strak 110MB/sec als het van de SSD's (L2ARC) afkomt. Vanaf disk fluctueert het vaak tussen de 80MB/sec en 110MB/sec.
Vanaf disk fluctueert het vaak tussen de 80MB/sec en 110MB/sec.
Sowieso met alle bovenstaande settings, gebruik ze als een richtlijn. Dit is wat voor mij werkt met mijn hardware, etc. etc. Dus test zelf wat voor jou goed werkt en wat niet!
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=7800 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=7800 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
esxcli storage nmp device list
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=262144 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=262144 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
Met deze waarden had ik iig geen gat bij bijvoorbeeld 4KB of 8KB zoals ik eerder wel had en zijn de transfer waardes goed. Reads kan nog net een beetje hoger lijkt het (222000KB/sec) maar 212000KB/sec vind ik meer dan prima om als compromis te nemen.
Wat me wel opvalt is dat toen ik ZFSguru draaide mijn 4K QD32 rond de 100MB/sec was en nu een heel stuk lager. Firedrunk, draai jij ZFS on Linux of een BSD variant?
Verder ben ik zoals ik al vermelde bezig geweest met het bij-tunen van mijn Ubuntu netwerk stack zoals ik dat ook binnen ZFSguru/FreeBSD had gedaan. Ik heb de 'indruk' dat het daar zeker beter van is geworden maar ik heb voor en na niet per setting getest. Alle bovenstaande waardes zijn MET de tuning aanwezig getest.
Ik heb de volgende waardes in /etc/sysctl.conf opgenomen. Dit vergroot voornamelijk maximale blok groottes en buffers:
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Daarnaast heb ik met ethtool gekeken waarop de queues van mijn netwerk kaart stond en deze naar het maximale vergroot om zo de doorvoer hoger en constanter te maken:
root@quinnas:/etc# ethtool -g eth3
Ring parameters for eth3:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
oot@quinnas:/etc# ethtool -G eth3 rx 4096 tx 4096
De waardes zijn volgens mij default wat conservatief om in alle sitauties gemiddeld gezien een acceptable performance te realizeren. Aangezien mijn server vooral storage server is zal deze voornamelijk grote blokken verwerken en daarvoor is het beter dat deze dan zo groot mogelijk zijn. Een langere queue is daarbij ook geen probleem.
Heb je bijvoorbeeld een firewall die heel snel kleine pakketjes moet kunnen verwerken dan zijn deze settings waarschijnlijk NIET de juiste.
Overigens haal ik sinds de netwerk veranderingen altijd vrij strak 110MB/sec als het van de SSD's (L2ARC) afkomt.
Sowieso met alle bovenstaande settings, gebruik ze als een richtlijn. Dit is wat voor mij werkt met mijn hardware, etc. etc. Dus test zelf wat voor jou goed werkt en wat niet!
[ Voor 11% gewijzigd door Quindor op 05-02-2014 23:38 ]
Ik zit op Vanilla FreeBSD 10.0-RELEASE.
Wat ik bedoelde met niet overtuigd was inderdaad het verschil tussen mijn Disks en mijn SSD's. Die performance verhoudingen kloppen niet helemaal. De caching van de Diskpool lijkt in verhouding veel aggressiever dan die van de SSD's. Misschien word het ARC cache ook verdeeld in verhouding tot de grootte van de pools (dat er dus eigenlijk veel meer ARC is voor de datapool dan voor de SSD pool).
Dit en het feit dat ik 'maar' 8GB geheugen in de bak heb, zal vast allemaal niet meehelpen
Ik zal morgen nog eens uitgebreider naar jouw tuning instellingen kijken.
PS: Heb je je netwerksettings nog die je in BSD hebt aangepast? Ik heb heel wat blog posts gelezen, maar die verwijzen allemaal naar instellingen die vanaf FreeBSD 9.2 en 10 default zijn (zoals hogere vnodes, tcp windowsizes, receive side scaling)
Enige wat ik nog zou kunnen tuning zijn de transaction group timeouts en de vdev cache settings.
PPS: Mijn ESXi nodes bevatten beide 16GB RAM, dus ik zou uit beide 8GB kunnen halen en dat erbij steken en eens testen of het zoveel verschil maakt.
Wat ik bedoelde met niet overtuigd was inderdaad het verschil tussen mijn Disks en mijn SSD's. Die performance verhoudingen kloppen niet helemaal. De caching van de Diskpool lijkt in verhouding veel aggressiever dan die van de SSD's. Misschien word het ARC cache ook verdeeld in verhouding tot de grootte van de pools (dat er dus eigenlijk veel meer ARC is voor de datapool dan voor de SSD pool).
Dit en het feit dat ik 'maar' 8GB geheugen in de bak heb, zal vast allemaal niet meehelpen
Ik zal morgen nog eens uitgebreider naar jouw tuning instellingen kijken.
PS: Heb je je netwerksettings nog die je in BSD hebt aangepast? Ik heb heel wat blog posts gelezen, maar die verwijzen allemaal naar instellingen die vanaf FreeBSD 9.2 en 10 default zijn (zoals hogere vnodes, tcp windowsizes, receive side scaling)
Enige wat ik nog zou kunnen tuning zijn de transaction group timeouts en de vdev cache settings.
PPS: Mijn ESXi nodes bevatten beide 16GB RAM, dus ik zou uit beide 8GB kunnen halen en dat erbij steken en eens testen of het zoveel verschil maakt.
[ Voor 7% gewijzigd door FireDrunk op 03-02-2014 21:03 ]
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Disk-total van dstat geeft alle IO weer van alle disks, inclusief overhead van parity en eventueel data die van/naar ssd cache wordt geschreven. Met -D sda,sdb,sdc etc kun je het per disk visualiseren net zoals je voor het netwerk deed.Quindor schreef op maandag 03 februari 2014 @ 18:55:
Wat ik dan wel weer maf vind is dat mijn writes vele malen meer zijn dan wat er binnenkomt, maar ik verwacht dat daarbij wellicht het verkeer naar de SSD's word meegerekend aangezien ik prefetch van streaming aan heb gezet. Maar dat ga ik wel eens onderzoeken.
[ Voor 8% gewijzigd door Q op 03-02-2014 21:12 ]
Ik heb ook gemerkt, dat de recordsize van ZFS ernstig veel uitmaakt (als je NFS gebruikt) voor het aantal writes wat daadwerkelijk gebeurt naar je disks. Bij een recordsize van 4k of 8k zag ik bij het gebruik van ZFS substantieel minder overhead dan bij de default van 128k.
(Bij iSCSI geld dat niet, want daar bepaalt VMFS de recordsize).
Hoewel ik mij nu net bedenk dat het bovenliggende filesystem (waar je ZVOL in zit) wel een recordsize heeft.
Ik weet eerlijk gezegd niet of een ZVOL alleen een logische locatie heeft in een filesystem of ook echt hier op staat... morgen eens opzoeken...
Met jouw laatste Round Robin settings:
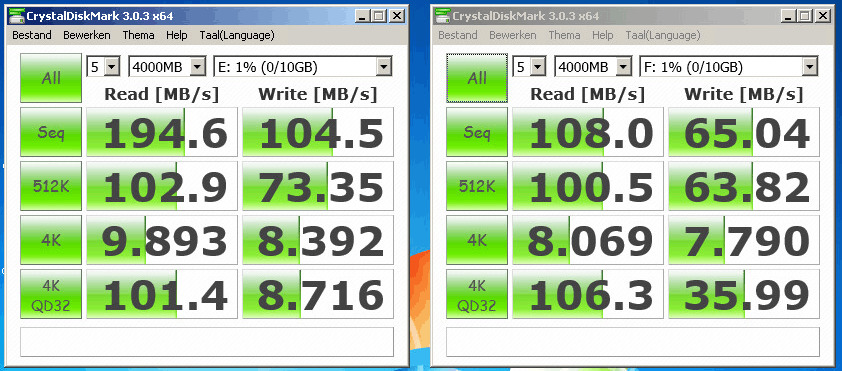
Ik heb overigens wel Jumbo Frames aan. (9000)
(Bij iSCSI geld dat niet, want daar bepaalt VMFS de recordsize).
Hoewel ik mij nu net bedenk dat het bovenliggende filesystem (waar je ZVOL in zit) wel een recordsize heeft.
Ik weet eerlijk gezegd niet of een ZVOL alleen een logische locatie heeft in een filesystem of ook echt hier op staat... morgen eens opzoeken...
Met jouw laatste Round Robin settings:
Ik heb overigens wel Jumbo Frames aan. (9000)
[ Voor 49% gewijzigd door FireDrunk op 03-02-2014 21:43 ]
Even niets...
- Micr0mega
- Registratie: Februari 2004
- Laatst online: 24-11-2025
:strip_icc():strip_exif()/u/105956/lill.jpg?f=community)
Ik heb een aantal weken geleden de twee USB 3.0 stickjes van mijn mirrored rpool vervangen omdat deze om de een of andere reden er af en toe gewoon uit vlogen (niet letterlijk). Nu heeft dat probleem zich niet meer voorgedaan, maar daar zijn sinds kort checksum en data errors voor in de plaats gekomen:
Met -v krijg ik inderdaad een mooi lijstje met de corrupte bestanden. Gelukkig geen essentiële dingen, maar ik wil ze toch graag repareren. Dus ik dacht, laat ik een van die USB 3.0 stickjes er weer in steken en weer attachen aan de pool; er zijn immers niet veel bestanden veranderd sindsdien en mogelijk kunnen er zo wat blocks gerepareerd worden.
Zo gezegd zo gedaan, met het volgende resultaat:
Ohja ik draai (nog) OpenIndiana, vandaar de slices. Maar goed, bijzondere foutmelding dus, want:
Daarnaast zijn er ook geen mounts 'ro' te bekennen en de volumes op de pool zijn inderdaad gewoon schrijfbaar. Ik heb natuurlijk even 'zpool set readonly=off potion' geprobeerd, maar krijg dan terecht de melding dat dit alleen tijdens het importeren van een pool kan. En even exporteren en her-importeren gaat nogal lastig met m'n root pool
Ik heb ook nog niet durven rebooten, straks zit ik écht met een read-only rpool en daar zit ik niet op te wachten. De Google biedt helaas weinig resultaat, voornamelijk pagina's over hoe een pool read-only te importeren...
Iemand een idee wat hier gaande is?
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # zpool status potion
pool: potion
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://illumos.org/msg/ZFS-8000-8A
scan: scrub repaired 2.39M in 0h15m with 159 errors on Mon Feb 3 19:00:28 2014
config:
NAME STATE READ WRITE CKSUM
potion ONLINE 0 0 159
mirror-0 ONLINE 0 0 318
c2t0d0s0 ONLINE 0 0 318
c6t0d0s0 ONLINE 0 0 414
errors: 159 data errors, use '-v' for a list |
Met -v krijg ik inderdaad een mooi lijstje met de corrupte bestanden. Gelukkig geen essentiële dingen, maar ik wil ze toch graag repareren. Dus ik dacht, laat ik een van die USB 3.0 stickjes er weer in steken en weer attachen aan de pool; er zijn immers niet veel bestanden veranderd sindsdien en mogelijk kunnen er zo wat blocks gerepareerd worden.
Zo gezegd zo gedaan, met het volgende resultaat:
code:
1
2
| # zpool attach -f potion c2t0d0s0 c8t0d0s0 cannot attach c8t0d0s0 to c2t0d0s0: pool is read-only |
Ohja ik draai (nog) OpenIndiana, vandaar de slices. Maar goed, bijzondere foutmelding dus, want:
code:
1
2
3
| # zpool get readonly potion NAME PROPERTY VALUE SOURCE potion readonly off - |
Daarnaast zijn er ook geen mounts 'ro' te bekennen en de volumes op de pool zijn inderdaad gewoon schrijfbaar. Ik heb natuurlijk even 'zpool set readonly=off potion' geprobeerd, maar krijg dan terecht de melding dat dit alleen tijdens het importeren van een pool kan. En even exporteren en her-importeren gaat nogal lastig met m'n root pool
Ik heb ook nog niet durven rebooten, straks zit ik écht met een read-only rpool en daar zit ik niet op te wachten. De Google biedt helaas weinig resultaat, voornamelijk pagina's over hoe een pool read-only te importeren...
Iemand een idee wat hier gaande is?
Ik heb je post drie keer gelezen, maar ik snap echt niet wat je nu probeert? Je hebt 3 USB sticks waarvan er 1 niet in je systeem zat. Je hebt corruptie op je online root pool (bestaande uit c2t0d0s0 en c6t0d0s0), en je wil aan 1 van de members van de mirror een 3e USB stick attachen en je verwacht dan dat je op magische wijze bij de oude files kan?
Ik volg je niet?
Ik volg je niet?
Even niets...
- Micr0mega
- Registratie: Februari 2004
- Laatst online: 24-11-2025
Hah en ik probeerde het nog wel zo duidelijk op te schrijven
De 3e USB stick (c8t0d0s0) die ik probeer toe te voegen aan de pool is één van de sticks die eerst deel uitmaakte van de pool, maar is dus een aantal weken geleden uit de pool gehaald. Het is dus geen lege of nieuwe stick, partities (of slices) zijn dan ook nog hetzelfde en de files zouden er op moeten staan.
De 3e USB stick (c8t0d0s0) die ik probeer toe te voegen aan de pool is één van de sticks die eerst deel uitmaakte van de pool, maar is dus een aantal weken geleden uit de pool gehaald. Het is dus geen lege of nieuwe stick, partities (of slices) zijn dan ook nog hetzelfde en de files zouden er op moeten staan.
- syl765
- Registratie: Juni 2004
- Laatst online: 15-07 11:15
Dat gaat niet lukken.
Er is al te veel data verandert.
Wat je misschien wel kan doen is die derde usb disk importeren als een tweede pool onder een andere naam.
Het was tenslotte een mirror, dus dat zou moeten kunnen.
zpool import potion oldpotion
Er is al te veel data verandert.
Wat je misschien wel kan doen is die derde usb disk importeren als een tweede pool onder een andere naam.
Het was tenslotte een mirror, dus dat zou moeten kunnen.
zpool import potion oldpotion
[ Voor 4% gewijzigd door syl765 op 04-02-2014 09:01 ]
Precies, dat was precies wat ik dacht. Je kan niet zomaar een oude versie van een disk bijprikken bij een nieuwe pool en verwachten dat de data gemerged wordt.
Ik denk dat dat ook de reden is dat ZFS de pool als read-only bestempeld, het is namelijk een oude versie van een reeds bestaande pool (dus is het misschien een backup denkt ZFS), en dus wordt hij als read-only geforceerd (gok ik).
Ik denk dat dat ook de reden is dat ZFS de pool als read-only bestempeld, het is namelijk een oude versie van een reeds bestaande pool (dus is het misschien een backup denkt ZFS), en dus wordt hij als read-only geforceerd (gok ik).
[ Voor 42% gewijzigd door FireDrunk op 04-02-2014 09:02 ]
Even niets...
- HyperBart
- Registratie: Maart 2006
- Laatst online: 22:33
/u/170728/owl.png?f=community)
Voor diegenen die eens willen experimenteren met iets anders, zonet met FD op dit pareltje gestoten:
http://ajenti.org/
http://support.ajenti.org...-on-freebsd-experimental/
http://ajenti.org/
http://support.ajenti.org...-on-freebsd-experimental/
[ Voor 24% gewijzigd door HyperBart op 04-02-2014 09:18 ]
De installatie is echt peanuts, BSD support is wel echt expirimenteel. Veel dingen werken nog niet, maar de meeste wel!
(Het heeft ook (nog) geen ZFS support, en Samba support is kapot atm, maar wel zeer veelbelovend!)
(Het heeft ook (nog) geen ZFS support, en Samba support is kapot atm, maar wel zeer veelbelovend!)
[ Voor 30% gewijzigd door FireDrunk op 04-02-2014 09:45 ]
Even niets...
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Wat is jouw ervaring tot nu toe met 10 icm ZFS? Ik heb het idee dat hij op eens veel meer gebruik maakt van de swap terwijl dat met 9 nooit een probleem was. Na het stream van aantal 4gb mkvtjes wordt alles super traag en wordt er lekker geswapt. Met als topper gisteren een vastloper omdat er geen swap meer wasFireDrunk schreef op maandag 03 februari 2014 @ 21:02:
Ik zit op Vanilla FreeBSD 10.0-RELEASE.
Hmm, daar heb ik geen last van. Wel heb ik ARC keihard gelimiteerd (6G van de 8G ).
Ik heb juist weer problemen met CTL(d). Ik vind de nieuwe Kernel iSCSI implementatie erg instabiel. heb al diverse kernel lockups gehad (CTL blijft hangen met Aborting Task, ik kan wel switchen tussen TTY's, maar een keyboard aanslag word niet eens meer geregisteerd. Met andere woorden, de hele server hangt, maar dan zonder kernel panic).
[root@NAS ~]# cat /boot/loader.conf zfs_load="YES" #Kernel Tuning kern.maxvnodes=250000 #ZFS Tuning vfs.zfs.arc_min="6G" vfs.zfs.arc_max="6G" vfs.zfs.prefetch_disable="1" vfs.zfs.txg.timeout="1" vfs.zfs.no_write_throttle="1" vfs.zfs.write_limit_override="1073741824"
Ik heb juist weer problemen met CTL(d). Ik vind de nieuwe Kernel iSCSI implementatie erg instabiel. heb al diverse kernel lockups gehad (CTL blijft hangen met Aborting Task, ik kan wel switchen tussen TTY's, maar een keyboard aanslag word niet eens meer geregisteerd. Met andere woorden, de hele server hangt, maar dan zonder kernel panic).
Even niets...
- Micr0mega
- Registratie: Februari 2004
- Laatst online: 24-11-2025
Het was het proberen waard Ik had er niet aan gedacht dat de melding dat de pool read-only is, misschien wel slaat op de stick die ik attach. Foutmelding is daar iets te vaag voor.
Helaas lijkt het er op dat het wel aan het stickje zelf ligt, want '# zpool import' levert geen enkel resultaat op. Hij kan de pool dus niet meer vinden, ook niet met -D. Ook een volledig import commando geprobeerd, maar:
Ik denk dat dit een mooi moment is om van OpenIndiana over te stappen naar ZFSonLinux. Was een mooi avontuurtje en best wat leuke dingen geleerd over Solaris, maar ben toch meer thuis in Linux. Vooral de packages is wat meer up-to-date; zelf compilen is wel leuk, maar gaat meer tijd in zitten om te onderhouden. Maar het heeft toch aardig gedraaid
Helaas lijkt het er op dat het wel aan het stickje zelf ligt, want '# zpool import' levert geen enkel resultaat op. Hij kan de pool dus niet meer vinden, ook niet met -D. Ook een volledig import commando geprobeerd, maar:
code:
1
2
3
| # zpool import -f -R /mnt/ potion oldpotion cannot import 'potion': a pool with that name is already created/imported, and no additional pools with that name were found |
Ik denk dat dit een mooi moment is om van OpenIndiana over te stappen naar ZFSonLinux. Was een mooi avontuurtje en best wat leuke dingen geleerd over Solaris, maar ben toch meer thuis in Linux. Vooral de packages is wat meer up-to-date; zelf compilen is wel leuk, maar gaat meer tijd in zitten om te onderhouden. Maar het heeft toch aardig gedraaid
code:
1
2
| # uptime 11:39am up 387 day(s), 15:42, 1 user, load average: 0.11, 0.11, 0.10 |
- syl765
- Registratie: Juni 2004
- Laatst online: 15-07 11:15
Je kan het eens met de CD van FreeBSD 10 proberen om de pool te importeren.
Nu gaat het blijkbaar niet doordat de huidige pool dezelfde naam heeft.
gr
Nu gaat het blijkbaar niet doordat de huidige pool dezelfde naam heeft.
gr
- Micr0mega
- Registratie: Februari 2004
- Laatst online: 24-11-2025
Denk niet dat dat zin heeft; regel 3 in het code-blok van mijn vorige post is het belangrijkst. Een pool met die naam wordt dus überhaupt niet gedetecteerd. Zoals ik even daarvoor ook zeg: '# zpool import' levert geen enkel resultaat op.
De 'disk tasting' is totaal anders op BSD versus Solaris versus Linux in combinatie met ZFS, dus switchen van platform zou zeker andere resultaten kunnen opleveren.
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Updated versie van showtools (Linux only)
Ik heb showdisk, shownet en showsmart samengesmolten tot 1 tool 'show'.Ik zou het waarderen als mensen ervaringen willen delen over:
1. of het werkt
2. of dit handig is
Misschien dat er handige smart waarden missen? Of andere info?
Als je het wil proberen:
code:
1
| git clonehttps://github.com/louwrentius/showtools.git |
Voorbeeld van output:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| root@nano:~/gold/showtools# ./show
usage: show [-h] [-a] [-m] [-S] [-s] [-f] [-c] [-p] [-w] [-o] [-t] [-H] [-P]
[-r] [-R] [-C] [-l] [-4] [-6] [-M] [-T] [-d] [-F]
{disk,net}
show: error: too few arguments
usage: show [-h] [-a] [-m] [-S] [-s] [-f] [-c] [-p] [-w] [-o] [-t] [-H] [-P]
[-r] [-R] [-C] [-l] [-4] [-6] [-M] [-T] [-d] [-F]
{disk,net}
Show detailed disk|net device information in ASCII table format
positional arguments:
{disk,net} Show disk information
optional arguments:
-h, --help show this help message and exit
Storage (generic):
Generic options for storage devices
-a, --all-opts show all information
-m, --model device model
-S, --serial device serial number
-s, --size device size in Gigabytes
-f, --firmware device firmware version
-c, --controller controller to which device is connected
-p, --pcipath /dev/disk/by-path/ ID of the device
-w, --wwn device World Wide Name
-o, --scsi /dev/by-id/scsi
Storage (SMART):
Options based on SMART values of storage devices
-t, --temp temperature in Celcius
-H, --hours power on hours
-P, --pending pending sector count
-r, --reallocated reallocated sector count
-R, --reallocatedevent
reallocated sector event count
-C, --crc CRC error
Network:
Available options for network devices
-l, --link network card link status
-4, --ipv4 IPv4 address
-6, --ipv6 IPv6 address
-M, --mac hardware / MAC address
-T, --show-type network card type
-d, --driver driver module
-F, --firmware-version
firmware version
root@nano:~/gold/showtools# ./show disk -mSsftHrRP
--------------------------------------------------------------------------------------------------
| DEV | MODEL | SERIAL NUMBER | GB | FIRMWARE | Temp | Hours | PS | RS | RSE |
--------------------------------------------------------------------------------------------------
| sda | SAMSUNG HD103UJ | S13PJ1EQ506364 | 1000 | 1AA01112 | 24 | 6981 | 0 | 1 | 0 |
| sdb | HGST HDS724040ALE640 | PK1301PAKB0H1X | 4000 | MJAOA580 | 32 | 186 | 0 | 0 | 0 |
| sdc | SAMSUNG HD501LJ | S0MUJ1FPB80741 | 500 | CR100-12 | 27 | 29819 | 0 | 0 | 0 |
| sdd | SAMSUNG HD103UJ | S13PJ1CQ608460 | 1000 | 1AA01112 | 25 | 9520 | 0 | 39 | 38 |
| sde | SAMSUNG HD501LJ | S0MUJ1FPB80735 | 500 | CR100-12 | 26 | 29808 | 0 | 2 | 2 |
| sdf | WDC WD3200JS-00PDB0 | WD-WCAPD1564619 | 320 | 21.00M21 | 32 | 50864 | 0 | 0 | 0 |
| sdg | WDC WD740GD-75FLA1 | WD-WMAKE1494401 | 74 | 27.08D27 | 28 | 28414 | 0 | 0 | 0 |
| sdh | SAMSUNG HD501LJ | S0MUJ1NPB30457 | 500 | CR100-12 | 24 | 29813 | 0 | 0 | 0 |
| sdi | WDC WD5000AAKS-00V1A0 | WD-WCAWF0023425 | 500 | 05.01D05 | 26 | 13764 | 0 | 0 | 0 |
| sdj | HGST HDS724040ALE640 | PK1381PAKGPLBS | 4000 | MJAOA580 | 31 | 187 | 0 | 0 | 0 |
| sdk | WDC WD5000AAKS-00V1A0 | WD-WCAWF0038211 | 500 | 05.01D05 | 26 | 15244 | 0 | 0 | 0 |
| sdl | SAMSUNG HD501LJ | S0MUJ1KPB33125 | 500 | CR100-12 | 26 | 29806 | 0 | 0 | 0 |
| sdm | Crucial_CT120M500SSD1 | 132909550C6B | 120 | MU03 | 25 | 141 | 0 | 0 | 16 |
| sdn | Crucial_CT120M500SSD1 | 13430955E39F | 120 | MU03 | 24 | 141 | 0 | 0 | 16 |
--------------------------------------------------------------------------------------------------
root@nano:~/gold/showtools# ./show net -lm4MTdF
--------------------------------------------------------------------------------
| DEV | Link | IPv4 | MAC | Type | Driver | Firmware |
--------------------------------------------------------------------------------
| bond0 | yes | 10.0.2.3 | 00:26:55:d7:a6:d1 | Ethernet | bonding | 2 |
| eth0 | yes | 10.0.1.12 | 00:25:90:d6:5a:3b | Ethernet | e1000e | 0.13-4 |
| eth1 | yes | | 00:26:55:d7:a6:d1 | Ethernet | e1000e | 5.12-2 |
| eth2 | yes | | 00:26:55:d7:a6:d1 | Ethernet | e1000e | 5.12-2 |
| eth3 | yes | | 00:26:55:d7:a6:d1 | Ethernet | e1000e | 5.12-2 |
| eth4 | yes | | 00:26:55:d7:a6:d1 | Ethernet | e1000e | 5.12-2 |
| eth5 | no | | 00:25:90:d6:5a:3a | Ethernet | e1000e | 2.1-2 |
| lo | yes | 127.0.0.1 | | Local | | |
-------------------------------------------------------------------------------- |
Wauw! Keurig hoor! Ziet er netjes uit! (En netjes een -h 
 )
)
Even niets...
- Micr0mega
- Registratie: Februari 2004
- Laatst online: 24-11-2025
Bedankt voor de suggesties, ik heb FreeBSD 10.0-ALPHA5 en Debian Wheezy even in een VM geprobeerd met passthrough van de USB. FreeBSD wil net zoals OpenIndiana geen pool zien om te importeren. Linux daarentegen wel:
Maar helaas:
Ook met numerieke id geprobeerd, en met -F -n opties, met hetzelfde resultaat. Wordt dus niks meer denk ik, zeker niet met een aantal van deze berichten in /var/log/syslog:
Met 'disk' kom ik dus even niet verder.
Ook lijkt het in de help message of disk,net optioneel is, maar je moet wel 1 van de 2 kiezen. Misschien naar 'man zpool' kijken als voorbeeld, en dus beide subcommando's uitschrijven met ieder hun argumenten?
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| root@wheezy-zfs:~# zpool import
pool: potion
id: 3065292287302787017
state: DEGRADED
status: The pool was last accessed by another system.
action: The pool can be imported despite missing or damaged devices. The
fault tolerance of the pool may be compromised if imported.
see: http://zfsonlinux.org/msg/ZFS-8000-EY
config:
potion DEGRADED
mirror-0 DEGRADED
usb-JetFlash_Transcend_16GB_L67NTI1A-0:0-part5 ONLINE
c6t0d0s0 UNAVAIL |
Maar helaas:
code:
1
2
3
4
| root@wheezy-zfs:~# zpool import -f -R /mnt/potion/ potion
cannot import 'potion': no such pool or dataset
Destroy and re-create the pool from
a backup source. |
Ook met numerieke id geprobeerd, en met -F -n opties, met hetzelfde resultaat. Wordt dus niks meer denk ik, zeker niet met een aantal van deze berichten in /var/log/syslog:
end_request: critical target error, dev sdb, sector 32658
Ziet er netjes uit, meteen even op m'n verse Wheezy VM geprobeerd. Eerste melding was netjes dat hdparm ontbrak. Daarna de volgende resultaten als feedback:Q schreef op dinsdag 04 februari 2014 @ 20:49:Updated versie van showtools (Linux only)
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| root@wheezy-zfs:~/showtools# ./show disk -mSsftHrRP
Traceback (most recent call last):
File "./show", line 647, in <module>
devicedata = process_device(device)
File "./show", line 448, in process_device
disksmart = get_smart_data(fullpath)
File "./show", line 311, in get_smart_data
child = subprocess.Popen(['smartctl', '-a', '-d', 'ata', device], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
File "/usr/lib/python2.7/subprocess.py", line 679, in __init__
errread, errwrite)
File "/usr/lib/python2.7/subprocess.py", line 1259, in _execute_child
raise child_exception
OSError: [Errno 2] No such file or directory
root@wheezy-zfs:~/showtools# apt-get install smartmontools
root@wheezy-zfs:~/showtools# ./show disk -mSsftHrRP
Traceback (most recent call last):
File "./show", line 647, in <module>
devicedata = process_device(device)
File "./show", line 462, in process_device
disksize = get_disk_size(diskdata)
File "./show", line 271, in get_disk_size
sizeingb = int(sizeinmb) / 1000
ValueError: invalid literal for int() with base 10: ''
root@wheezy-zfs:~/showtools# ./show net -lm4MTdF
------------------------------------------------------------------------------------
| DEV | Link | IPv4 | MAC | Type | Driver | Firmware |
------------------------------------------------------------------------------------
| eth0 | | 192.168.153.128 | 00:0c:29:be:1f:30 | Ethernet | | |
| lo | | 127.0.0.1 | | Local | | |
------------------------------------------------------------------------------------ |
Met 'disk' kom ik dus even niet verder.
Ook lijkt het in de help message of disk,net optioneel is, maar je moet wel 1 van de 2 kiezen. Misschien naar 'man zpool' kijken als voorbeeld, en dus beide subcommando's uitschrijven met ieder hun argumenten?
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Bedankt voor de feedback, ik moet de error afhandeling verbeteren. SMART werkt niet op een VM tenzij de hardware via passthrough is doorgegeven. ik zie dat hdparm -i ook faalt op je disk device. Mogelijk moet ik dit toch maar met fdisk uitlezen als hdparm faalt.
Ik heb een HP server op mijn werk met 22 x 300 GB disks + 2 x SSD INTEL SLC 250 GB & 64 GB RAM voorzien van ZFS.
Ik heb een 100 GB volume aangemaakt en met XFS geformatteerd. Daar een fio benchmark met 4K requests en IODEPTH van 16 op los gelaten. Hele mooie getallen:
Met IODEPTH van 32:
Gaaf hoor 6800 IOPS met uitstekende latency dankzij sloot aan RAM en SSD.
Maar even rekenen: 22 x 10K RPM = 22 x 120 IOPS = 2640 IOPS puur random READ voor de 22 disks.
Alle extra IOPS komen door RAM en SSD cache denk ik dan. Zeker ook als je naar de latency kijkt.
Als je de benchmark een paar keer gaat draaien, wordt de cache warm en krijg je waanzinnige 150000 IOPS op momenten
Als je dit vergelijkt met een normale consumenten SSD is deze performance allemaal niet zo hoog, dat besef ik. Maar dit hangt allemaal aan een hardware raid controller P410i ofzo en volgens mij is dat ook allemaal niet zo optimaal voor de SSDs.
Ik heb een HP server op mijn werk met 22 x 300 GB disks + 2 x SSD INTEL SLC 250 GB & 64 GB RAM voorzien van ZFS.
Ik heb een 100 GB volume aangemaakt en met XFS geformatteerd. Daar een fio benchmark met 4K requests en IODEPTH van 16 op los gelaten. Hele mooie getallen:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| random-read: (g=0): rw=randread, bs=4K-4K/4K-4K, ioengine=libaio, iodepth=16
2.0.8
Starting 1 process
Jobs: 1 (f=1): [r] [100.0% done] [9640K/0K /s] [2410 /0 iops] [eta 00m:00s]
random-read: (groupid=0, jobs=1): err= 0: pid=19653
read : io=740264KB, bw=12335KB/s, iops=3083 , runt= 60015msec
slat (usec): min=3 , max=164 , avg= 9.23, stdev= 4.91
clat (usec): min=0 , max=225850 , avg=5175.98, stdev=7755.24
lat (usec): min=14 , max=225855 , avg=5185.70, stdev=7755.58
clat percentiles (usec):
| 1.00th=[ 16], 5.00th=[ 20], 10.00th=[ 24], 20.00th=[ 41],
| 30.00th=[ 102], 40.00th=[ 1816], 50.00th=[ 3824], 60.00th=[ 5472],
| 70.00th=[ 6880], 80.00th=[ 8896], 90.00th=[12352], 95.00th=[15552],
| 99.00th=[24448], 99.50th=[30336], 99.90th=[112128], 99.95th=[140288],
| 99.99th=[189440]
bw (KB/s) : min= 8272, max=150928, per=100.00%, avg=12352.76, stdev=12918.33
lat (usec) : 2=0.01%, 10=0.01%, 20=4.39%, 50=16.59%, 100=8.03%
lat (usec) : 250=6.45%, 500=2.62%, 750=0.29%, 1000=0.14%
lat (msec) : 2=2.22%, 4=10.33%, 10=32.45%, 20=14.31%, 50=1.91%
lat (msec) : 100=0.12%, 250=0.13%
cpu : usr=1.80%, sys=3.45%, ctx=148043, majf=0, minf=47
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=185066/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=740264KB, aggrb=12334KB/s, minb=12334KB/s, maxb=12334KB/s, mint=60015msec, maxt=60015msec |
Met IODEPTH van 32:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| random-read: (g=0): rw=randread, bs=4K-4K/4K-4K, ioengine=libaio, iodepth=32
2.0.8
Starting 1 process
Jobs: 1 (f=1): [r] [100.0% done] [27336K/0K /s] [6834 /0 iops] [eta 00m:00s]
random-read: (groupid=0, jobs=1): err= 0: pid=19679
read : io=2713.3MB, bw=46298KB/s, iops=11574 , runt= 60010msec
slat (usec): min=3 , max=149 , avg= 6.43, stdev= 3.01
clat (usec): min=0 , max=238189 , avg=2755.98, stdev=4642.06
lat (usec): min=14 , max=238195 , avg=2762.77, stdev=4642.77
clat percentiles (usec):
| 1.00th=[ 13], 5.00th=[ 16], 10.00th=[ 23], 20.00th=[ 199],
| 30.00th=[ 209], 40.00th=[ 215], 50.00th=[ 223], 60.00th=[ 326],
| 70.00th=[ 3472], 80.00th=[ 5792], 90.00th=[ 8256], 95.00th=[11584],
| 99.00th=[19072], 99.50th=[22912], 99.90th=[33024], 99.95th=[39168],
| 99.99th=[95744]
bw (KB/s) : min=21576, max=573040, per=100.00%, avg=46474.88, stdev=99757.67
lat (usec) : 2=0.01%, 4=0.01%, 10=0.01%, 20=6.95%, 50=7.81%
lat (usec) : 100=0.10%, 250=43.07%, 500=5.21%, 750=0.11%, 1000=0.05%
lat (msec) : 2=1.42%, 4=7.33%, 10=20.99%, 20=6.14%, 50=0.78%
lat (msec) : 100=0.02%, 250=0.01%
cpu : usr=4.72%, sys=8.00%, ctx=327546, majf=0, minf=63
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued : total=r=694588/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=2713.3MB, aggrb=46298KB/s, minb=46298KB/s, maxb=46298KB/s, mint=60010msec, maxt=60010msec |
Gaaf hoor 6800 IOPS met uitstekende latency dankzij sloot aan RAM en SSD.
Maar even rekenen: 22 x 10K RPM = 22 x 120 IOPS = 2640 IOPS puur random READ voor de 22 disks.
Alle extra IOPS komen door RAM en SSD cache denk ik dan. Zeker ook als je naar de latency kijkt.
Als je de benchmark een paar keer gaat draaien, wordt de cache warm en krijg je waanzinnige 150000 IOPS op momenten
Als je dit vergelijkt met een normale consumenten SSD is deze performance allemaal niet zo hoog, dat besef ik. Maar dit hangt allemaal aan een hardware raid controller P410i ofzo en volgens mij is dat ook allemaal niet zo optimaal voor de SSDs.
[ Voor 34% gewijzigd door Q op 05-02-2014 00:39 ]
Verwijderd
Ik ben wel benieuwd wat de getallen zijn op een RAIDZ1/2-array.
Nog even tav de P410i... Ik heb getallen gezien van 35000 tot 60000 iops afhankelijk van welke generatie controller.
Wat dat betreft zou ik al vanuit de basis al wel hogere getallen verwacht dan de initiële 6800.
Is dit lokaal getest of over ethernet?
Nog even tav de P410i... Ik heb getallen gezien van 35000 tot 60000 iops afhankelijk van welke generatie controller.
Wat dat betreft zou ik al vanuit de basis al wel hogere getallen verwacht dan de initiële 6800.
Is dit lokaal getest of over ethernet?
God*****ju, voor de 5e keer is mijn FreeBSD 10.0-RELEASE server gecrasht.
De nieuwe in-kernel iSCSI Target daemon lijkt niet echt stabiel te zijn.
Op de console vliegen een aantal CTL foutmeldingen voorbij over het aborten van tasks.
En ESXi hangt ook als een gieter op de iSCSI verbinding.
Bagger...
Even niets...
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Update naar stable al overwogen?FireDrunk schreef op woensdag 05 februari 2014 @ 10:05:

God*****ju, voor de 5e keer is mijn FreeBSD 10.0-RELEASE server gecrasht.
De nieuwe in-kernel iSCSI Target daemon lijkt niet echt stabiel te zijn.
Op de console vliegen een aantal CTL foutmeldingen voorbij over het aborten van tasks.
En ESXi hangt ook als een gieter op de iSCSI verbinding.
Bagger...
- Ultraman
- Registratie: Februari 2002
- Laatst online: 14:26
:strip_icc():strip_exif()/u/48952/Ultraman-60x60-Ray-Animated.jpg?f=community)
Als je met dergelijke nieuwe features aan de slag wilt lijkt het mij inderdaad verstandig om ipv 10.0-RELEASE over te stappen naar de 10.0-STABLE tree, dan heb je sneller wat nuttige patches.
Ik neem aan dat de problemen al bekend zijn of dat je ze rapporteert via de mailing list?
Of wacht op 10.1-RELEASE, wellicht is die beter. Daar wacht ik op alvorens ik van versie 9.x naar de 10.x ga springen. Al heb ik 10.0-R wel getest voor mijn doeleinden op mijn testmachientje en alle functionaliteit die ik nu gebruik lijkt goed te werken. De nieuwe iSCSI is bij mij ook wisselvallend.
Ik neem aan dat de problemen al bekend zijn of dat je ze rapporteert via de mailing list?
Of wacht op 10.1-RELEASE, wellicht is die beter. Daar wacht ik op alvorens ik van versie 9.x naar de 10.x ga springen. Al heb ik 10.0-R wel getest voor mijn doeleinden op mijn testmachientje en alle functionaliteit die ik nu gebruik lijkt goed te werken. De nieuwe iSCSI is bij mij ook wisselvallend.
Als je stil blijft staan, komt de hoek wel naar jou toe.
Ik zou niet weten wat ik zou moeten melden. Algehele malaise is zo lastig te melden, en omdat de kernel niet crasht, heb ik ook geen dump logs.
Maar upgraden naar 10.0-STABLE is inderdaad misschien een goed idee.
https://bugs.freenas.org/issues/3221
Dit is ongeveer het probleem wat ik ook heb. Hier blijkt dat updaten naar 9.2.1 zin had, dus 10.0-STABLE zal inderdaad misschien helpen.
Even kijken hoe ik dat moet doen (volgens de officiele manieren)...
Iemand een goede handleiding?
Maar upgraden naar 10.0-STABLE is inderdaad misschien een goed idee.
https://bugs.freenas.org/issues/3221
Dit is ongeveer het probleem wat ik ook heb. Hier blijkt dat updaten naar 9.2.1 zin had, dus 10.0-STABLE zal inderdaad misschien helpen.
Even kijken hoe ik dat moet doen (volgens de officiele manieren)...
Iemand een goede handleiding?
[ Voor 39% gewijzigd door FireDrunk op 05-02-2014 11:09 ]
Even niets...
- Pantagruel
- Registratie: Februari 2000
- Laatst online: 20:34
Mijn 80486 was snel,....was!
:strip_icc():strip_exif()/u/3454/i486.jpg?f=community)
Voor hen die ZFS on Linux links hebben laten liggen i.v.m. het gebrek aan een gemakkelijke beheeroppervlakte, sinds de 0.9e2l preview ondersteund Napp-it ook Linux
napp-it 0.9e2L preview, universal release fpr OI, OmniOS, S11.1 and Linux (Debian7, Ubuntu 12 LTS)
STH heeft inmiddels een posting mbt ZoL+Napp-it op basis van Hyper-V.
Maar weest gewaarschuwd, het is en blijf een preview.
napp-it 0.9e2L preview, universal release fpr OI, OmniOS, S11.1 and Linux (Debian7, Ubuntu 12 LTS)
STH heeft inmiddels een posting mbt ZoL+Napp-it op basis van Hyper-V.
Maar weest gewaarschuwd, het is en blijf een preview.
[ Voor 32% gewijzigd door Pantagruel op 05-02-2014 11:39 ]
Asrock Z77 Extreme6, Intel i7-3770K, Corsair H100i, 32 GB DDR-3, 256 GB Samsung SSD + 2 x 3TB SATA, GeForce GTX 660 Ti, Onboard NIC and sound, SyncMaster 24"&22" Wide, Samsung DVD fikkertje, Corsair 500R
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Kwestie van de juist svn repo (svn://svn.freebsd.org/base/stable/10/) uitchecken, world en kernel builden, mergemaster, reboot.FireDrunk schreef op woensdag 05 februari 2014 @ 10:23:
Ik zou niet weten wat ik zou moeten melden. Algehele malaise is zo lastig te melden, en omdat de kernel niet crasht, heb ik ook geen dump logs.
Maar upgraden naar 10.0-STABLE is inderdaad misschien een goed idee.
https://bugs.freenas.org/issues/3221
Dit is ongeveer het probleem wat ik ook heb. Hier blijkt dat updaten naar 9.2.1 zin had, dus 10.0-STABLE zal inderdaad misschien helpen.
Even kijken hoe ik dat moet doen (volgens de officiele manieren)...
Iemand een goede handleiding?
Verschilt niet met normale buildworld behalve dat je een andere repo gebruikt
[ Voor 5% gewijzigd door matty___ op 05-02-2014 12:05 ]
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Lokaal getest, maar dit is fors oude hardware (DL370 G6), wel met de laatste firmware.Verwijderd schreef op woensdag 05 februari 2014 @ 09:13:
Ik ben wel benieuwd wat de getallen zijn op een RAIDZ1/2-array.
Nog even tav de P410i... Ik heb getallen gezien van 35000 tot 60000 iops afhankelijk van welke generatie controller.
Wat dat betreft zou ik al vanuit de basis al wel hogere getallen verwacht dan de initiële 6800.
Is dit lokaal getest of over ethernet?
- syl765
- Registratie: Juni 2004
- Laatst online: 15-07 11:15
De stappen voor een upgrade naar stable zijn vrij makkelijk.
Update de source tree naar 10 stable.
# cd /usr/src
# make cleanworld && make builworld && make kernel kernconf=GENERIC
# mergemaster -p
# make installworld
# mergemaster -iU
# shutdown -r now
Gr
Update de source tree naar 10 stable.
# cd /usr/src
# make cleanworld && make builworld && make kernel kernconf=GENERIC
# mergemaster -p
# make installworld
# mergemaster -iU
# shutdown -r now
Gr
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Dat tunen met iSCSI blijft lastig. Omdat ik toch niet helemaal tevreden was met de waardes die ik via ESXi krijg ben ik nog een beetje aan het finetunen geweest. Daar is naar mijn mening een wat gelijkmatigere setting uitgekomen dan eerst.
esxcli storage nmp device list
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=262144 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=262144 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
4 IO's en verdelen op 256KByte per pad. Geen benchmark piek winnaar maar gemiddeld genomen wel het beste lijkt het. Maar, zoals altijd, your results may vary.
esxcli storage nmp device list
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=iops --iops=4 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=262144 --device=t10.94544500000000003C9171F709287C63AACFB5DE08482F88
esxcli storage nmp psp roundrobin deviceconfig set --cfgfile --type=bytes --bytes=262144 --device=t10.9454450000000000836329A6984353BAFB9DC0F4155B10BE
4 IO's en verdelen op 256KByte per pad. Geen benchmark piek winnaar maar gemiddeld genomen wel het beste lijkt het. Maar, zoals altijd, your results may vary.
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
@Quindor: ik heb op bovengenoemde oude storage machine met SSDs jouw benchmarks met genoemde settings kunnen repliceren. Voor ruwe doorvoer lijkt IOPS=1 toch het beste. bytes lijken niet heel veel te doen.
Ik ga morgen met quad-nics testen.
Dit vind ik een Bug in de default instellingen van ZFS:
Standaard maakt ZFS een volume aan met 8K (volumeblock)
Dan kun je met RAIDZ2 krijgen dat 10GB aan data in werkelijkheid 20 GB gebruikt:
Dat is op te lossen door het volume met 16K blocks of groter te maken.
Ik ga morgen met quad-nics testen.
Dit vind ik een Bug in de default instellingen van ZFS:
Standaard maakt ZFS een volume aan met 8K (volumeblock)
Dan kun je met RAIDZ2 krijgen dat 10GB aan data in werkelijkheid 20 GB gebruikt:
https://github.com/zfsonlinux/zfs/issues/1807So here's the thing. Each 8k volume block has its own parity disks. That's how RAID-Z works. If you have 4k AF disks (zdb shows "ashift: 12") then what happens is each 8k block consists of 2x disks of data, and 2x disks of parity. You're expecting that generally there's 4x disks of data and 2x disks of parity all the way across the pool. There isn't.
Switch to using a block size of 16k or larger and you should be in better shape for space usage, at the expense of having a worse read-copy-write cycle for when smaller writes occur on the volume. With a filesystem's default of 128k you're already covered there.
Dat is op te lossen door het volume met 16K blocks of groter te maken.
- michelstreurman
- Registratie: September 2012
- Laatst online: 10-04-2024
gewoon even een gekke vraag: Ik heb de volgende diskopstelling op dit moment in mijn setup zitten:
1x OCZ Solid v2 32GB SSD, 1x Samsung 840 120GB SSD, 2x Maxtor en 1x Western Digital 320GB HDD 8MB cache schijven (op dit moment mijn raid0) en 1x Samsung Spinpoint F1 1TB HDD
zou ik hier een leuk werkend freeBSD of andersoortig (mijn voorkeur gaat uit naar standaard linux / ubuntu) ZFS setup mee kunnen opzetten? Ik ben zelf niet zo zeer voor redundantie maar meer voor snelheid maar als ik via dit systeem een klein stukje veiligheid kan inbouwen zou dat ontzettend tof zijn! Ik heb op dit moment trouwens de volgende specs:
Specs:
Mainboard: Gigabyte EP35-DS3P
Proc: Intel Core2Quad Q9550 @ 2.83GHz
Geheugen: 4x2GB Kingston HyperX KHX6400D2/2G (5-5-5-18)
GFX: Sparkle nVidia Geforce GTX470 1280MB
Sound: PCI Soundblaster XFI XtremeMusic
NIC: Intel PRO/1000GT Desktop Adapter
1x OCZ Solid v2 32GB SSD, 1x Samsung 840 120GB SSD, 2x Maxtor en 1x Western Digital 320GB HDD 8MB cache schijven (op dit moment mijn raid0) en 1x Samsung Spinpoint F1 1TB HDD
zou ik hier een leuk werkend freeBSD of andersoortig (mijn voorkeur gaat uit naar standaard linux / ubuntu) ZFS setup mee kunnen opzetten? Ik ben zelf niet zo zeer voor redundantie maar meer voor snelheid maar als ik via dit systeem een klein stukje veiligheid kan inbouwen zou dat ontzettend tof zijn! Ik heb op dit moment trouwens de volgende specs:
Specs:
Mainboard: Gigabyte EP35-DS3P
Proc: Intel Core2Quad Q9550 @ 2.83GHz
Geheugen: 4x2GB Kingston HyperX KHX6400D2/2G (5-5-5-18)
GFX: Sparkle nVidia Geforce GTX470 1280MB
Sound: PCI Soundblaster XFI XtremeMusic
NIC: Intel PRO/1000GT Desktop Adapter
[ Voor 6% gewijzigd door michelstreurman op 06-02-2014 00:44 ]
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
@Q hmm, interessant voor de mensen die RAIDz2 draaien inderdaad! Ik draai zelf RAIDz1 dus voor mij niet van toepassing, phew!
Verder ben ik benieuwd naar de tests! Het ligt natuurlijk ook heel erg aan je hardware welke setting voor jou setup het beste werkt. Ik zag een raar 8KB gat in mijn grafieken en dat is niet heel wenselijk!
@michelstreurman
Ik denk dat de hardware die je hebt en de wensen die je hebt helemaal compatibel zijn met elkaar. ZFS is gecreëerd voor data veiligheid en secundair daarvan performance middels bepaalde caching mogelijkheden. Als ik kijk naar de spullen die je hebt dan sluit dat allemaal niet helemaal op elkaar aan (naar mijn mening). Je hebt al RAID0 over je 'gelijke' disks, sneller dan dat gaat het niet worden! Stel nou dat je 5x2TB disks had of iets in die richting dan kan het interessant zijn met de SSD's en het oog op veiligheid, maar verder denk ik niet dat het is wat je zoekt.
Ik heb nu weer wat mafs wat ik me niet kan herinneren van mijn FreeBSD installatie. Ik heb nu 1xVertex2 en 3x840EVO ingebouwd zitten en voor de L2ARC werkt dat top (30% over-provision allemaal, etc.) maar mijn ZIL lijkt gelimiteerd te zijn op 70MB/sec of ik nou 1 SSD gebruik of 4! Met 4 word het gewoon verdeelt over de beschikbare devices. Ik test dat overigens met mijn iSCSI VMware koppeling en sync=always. Maar dat heb ik volgens mij in ZFSguru/FreeBSD ook altijd gedaan en dit niet gezien. Nog maar eens verder onderzoeken.
Ik heb zelf nog een vraagje voor de mensen hier. Gebruiken jullie ashift=12 als jullie een SSD toevoegen als SLOG of L2ARC device? Ik heb vandaag alles maar eens opnieuw aangemaakt middels de volgende regel:
"zpool add -o ashift=12 Mirror-2TB cache /dev/disk/by-id/ata-Samsung_SSD_840_EVO_250GB_S1DBNSADXXXXXXX-part3"
Daarmee worden dus 4KB sectors gebruikt op je SSD inplaats van 512 bytes en aangezien SSD's getuned zijn op 4KB read/write over het algemeen lijkt me dat dus gunstiger. Maar ik lees er verder vrij weinig over op internet. Heeft iemand hier daar een mening over?
Verder ben ik benieuwd naar de tests! Het ligt natuurlijk ook heel erg aan je hardware welke setting voor jou setup het beste werkt. Ik zag een raar 8KB gat in mijn grafieken en dat is niet heel wenselijk!
@michelstreurman
Ik denk dat de hardware die je hebt en de wensen die je hebt helemaal compatibel zijn met elkaar. ZFS is gecreëerd voor data veiligheid en secundair daarvan performance middels bepaalde caching mogelijkheden. Als ik kijk naar de spullen die je hebt dan sluit dat allemaal niet helemaal op elkaar aan (naar mijn mening). Je hebt al RAID0 over je 'gelijke' disks, sneller dan dat gaat het niet worden! Stel nou dat je 5x2TB disks had of iets in die richting dan kan het interessant zijn met de SSD's en het oog op veiligheid, maar verder denk ik niet dat het is wat je zoekt.
Ik heb nu weer wat mafs wat ik me niet kan herinneren van mijn FreeBSD installatie. Ik heb nu 1xVertex2 en 3x840EVO ingebouwd zitten en voor de L2ARC werkt dat top (30% over-provision allemaal, etc.) maar mijn ZIL lijkt gelimiteerd te zijn op 70MB/sec of ik nou 1 SSD gebruik of 4! Met 4 word het gewoon verdeelt over de beschikbare devices. Ik test dat overigens met mijn iSCSI VMware koppeling en sync=always. Maar dat heb ik volgens mij in ZFSguru/FreeBSD ook altijd gedaan en dit niet gezien. Nog maar eens verder onderzoeken.
Ik heb zelf nog een vraagje voor de mensen hier. Gebruiken jullie ashift=12 als jullie een SSD toevoegen als SLOG of L2ARC device? Ik heb vandaag alles maar eens opnieuw aangemaakt middels de volgende regel:
"zpool add -o ashift=12 Mirror-2TB cache /dev/disk/by-id/ata-Samsung_SSD_840_EVO_250GB_S1DBNSADXXXXXXX-part3"
Daarmee worden dus 4KB sectors gebruikt op je SSD inplaats van 512 bytes en aangezien SSD's getuned zijn op 4KB read/write over het algemeen lijkt me dat dus gunstiger. Maar ik lees er verder vrij weinig over op internet. Heeft iemand hier daar een mening over?
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Zo te zien heb ik een probleem opgelost wat ik had met de IETD iSCSI initiator in Ubuntu 13.10.
Ik vond het maar raar dat mijn 4K reads and writes zo laag waren sinds ik de overstap van FreeBSD naar Ubuntu had gemaakt.
Zojuist heb ik een iSCSI volume target gemaakt maar dan inplaats van blockio heb ik fileio gebruikt. Zie het resultaat!

244MB/sec! Nou, dat is dichterbij het theoretische maximum van 2Gbps dan ik ooit gezien heb.
update--
Ook nog eventjes een AS-SSD gedaan en die laat helemaal het verschil zien. Damn! "fileio" it is!

config in ietd.conf:
Target iqn.2012-03.com.example:ESXi-fileIOtest
IncomingUser Quindor Quindor123456
OutgoingUser
Lun 0 Path=/RAIDz1-4TB/Other/iSCSI/test1.vol,Type=fileio
Alias ESXi-fileIOtest
MaxConnections 4
QueuedCommands 32
Wthreads 8
FirstBurstLength 262144
MaxBurstLength 1048576
Vervolgens moet je de file wel eventjes aanmaken/vullen met data tot de grootte dat het betreffende volume mag worden.
dd if=/dev/zero of=/RAIDz1-4TB/Other/iSCSI/test1.vol bs=1MB count=8192
Dit zorgt ervoor dat er een file van 8GB ontstaat en het volume is dan dus ook 8GB. Aangezien ik LZ4 compressie aan heb staat op dit volume verliep dat mat 3,6GB/s!
Ik vond het maar raar dat mijn 4K reads and writes zo laag waren sinds ik de overstap van FreeBSD naar Ubuntu had gemaakt.
Zojuist heb ik een iSCSI volume target gemaakt maar dan inplaats van blockio heb ik fileio gebruikt. Zie het resultaat!
244MB/sec! Nou, dat is dichterbij het theoretische maximum van 2Gbps dan ik ooit gezien heb.
update--
Ook nog eventjes een AS-SSD gedaan en die laat helemaal het verschil zien. Damn! "fileio" it is!
config in ietd.conf:
Target iqn.2012-03.com.example:ESXi-fileIOtest
IncomingUser Quindor Quindor123456
OutgoingUser
Lun 0 Path=/RAIDz1-4TB/Other/iSCSI/test1.vol,Type=fileio
Alias ESXi-fileIOtest
MaxConnections 4
QueuedCommands 32
Wthreads 8
FirstBurstLength 262144
MaxBurstLength 1048576
Vervolgens moet je de file wel eventjes aanmaken/vullen met data tot de grootte dat het betreffende volume mag worden.
dd if=/dev/zero of=/RAIDz1-4TB/Other/iSCSI/test1.vol bs=1MB count=8192
Dit zorgt ervoor dat er een file van 8GB ontstaat en het volume is dan dus ook 8GB. Aangezien ik LZ4 compressie aan heb staat op dit volume verliep dat mat 3,6GB/s!
[ Voor 54% gewijzigd door Quindor op 06-02-2014 03:10 ]
Verwijderd
Klopt helemaal!Q schreef op donderdag 06 februari 2014 @ 00:03:
[...]Voor ruwe doorvoer lijkt IOPS=1 toch het beste.
Als ik bij een klant kom die performance-problemen ondervinden in hun SAN-omgeving, is dit ook altijd het eerste punt waar ik naar kijk.
Teveel mensen laten dit op default waardes staan, of verhogen ze zelfs. (vraag mij niet waarom...)
Helemaal binnen Citrix- en gevirtualiseerde omgevingen zijn de I/O's killing.
Voor degene die wat minder goed bekend met dit fenomeen zijn:
Stel je hebt je I/O's op 1000 staan (=default dacht ik) binnen ESX...
Er worden dus 1000 I/O's op 1 pad gezet voordat ie gaat switchen naar het andere pad.
Als er dus 1 I/O om wat voor reden dan ook lang duurt, staan er nog 999 te wachten op de completion van die ene I/O.
I/O-nr 1001 gaat vervolgens weer naar het andere pad.
Als je de roundrobin op 1 I/O zet, zal ie dus per I/O switchen per pad.
Hoe meer paden je hebt, hoe minder de kans op 'opstoppingen' door blocking I/O's, en daarmee hogere doorvoersnelheden.
Verwijderd
Lol...Quindor schreef op donderdag 06 februari 2014 @ 02:45:
[...]
dd if=/dev/zero of=/RAIDz1-4TB/Other/iSCSI/test1.vol bs=1MB count=8192
Dit zorgt ervoor dat er een file van 8GB ontstaat en het volume is dan dus ook 8GB. Aangezien ik LZ4 compressie aan heb staat op dit volume verliep dat mat 3,6GB/s!
/dev/zero en compressie... Daar gaan je disken het niet warm van krijgen.
De 'beperkende factor' is je CPU in dit geval.
@]Byte[, Dat is niet helemaal waar, want er kunnen ook verstoppingen op LUN niveau zijn... Iets als reservation conflicts enzo (vooral bij iSCSI)
Even niets...
Verwijderd
Ik had het kunnen verwachten... (ik zat al tijdje te denken... Waar blijft ie nu toch? )
JA, klopt ook. Vooral als je maar 1 LUN hebt... Maar dat kan je weer 'afvangen' door meerdere LUN's aan te maken
En JA, er zijn altijd nog wel meer bottle-necks te vinden.... Maarja, we hebben het hier ook niet over een paar honderd k-euro-systeem... (die evengoed tegen "Iets als reservation conflicts enzo" aan kunnen lopen... )
Iets 100% donkey-proof maken is een utopie. Maar met ZFS komen wel wel heel kort in de buurt, en dat tegen een fractie van de prijs van de grote commerciële dozenschuivers...
JA, klopt ook. Vooral als je maar 1 LUN hebt... Maar dat kan je weer 'afvangen' door meerdere LUN's aan te maken
En JA, er zijn altijd nog wel meer bottle-necks te vinden.... Maarja, we hebben het hier ook niet over een paar honderd k-euro-systeem... (die evengoed tegen "Iets als reservation conflicts enzo" aan kunnen lopen...
Iets 100% donkey-proof maken is een utopie. Maar met ZFS komen wel wel heel kort in de buurt, en dat tegen een fractie van de prijs van de grote commerciële dozenschuivers...
Oh zeker weten. Ik haal hier met mijn el-cheapo opstelling al 7000 IOPS ofzo, en een maat van mij heeft recentelijk nog een complete NAS/SAN gekocht voor dik 40.000 die hetzelfde doet...
Dus ach..
Dus ach..
Even niets...
Verwijderd
I rest my case...FireDrunk schreef op donderdag 06 februari 2014 @ 11:51:
[...] nog een complete NAS/SAN gekocht voor dik 40.000 die hetzelfde doet...
- sphere
- Registratie: Juli 2003
- Laatst online: 15:19
Debian abuser
/u/87795/voetje.png?f=community)
Voor 40k koop je in ieder geval NetApp, die tenminste zo slim is dat hij files tegelijkertijd read/write kan delen onder CIFS en NFS.
Dat kan toch met bijna elk OS?
(Ik doe het zelf ook gewoon met BSD)
(Ik doe het zelf ook gewoon met BSD)
[ Voor 38% gewijzigd door FireDrunk op 06-02-2014 15:32 ]
Even niets...
- Quindor
- Registratie: Augustus 2000
- Laatst online: 17-04 00:24
Switching the universe....
Klopt, hoewel er duidelijk overal waarschuwingen staan dat je dit NIET moet doen. Hoe dan ook werkt het naar mijn mening in beperkte schaal ok. Iets met file locking, etc.FireDrunk schreef op donderdag 06 februari 2014 @ 15:32:
Dat kan toch met bijna elk OS?
(Ik doe het zelf ook gewoon met BSD)
NetApp is een voorverchter voor iets wat in de Enterprise wereld "Unified Storage" heet. Een SAN wat naast block storage (FC en iSCSI) ook andere protocollen aanbied zoals een NAS (NFS en CIFS/SMB).
Ik ben er persoonlijk geen voorstander van (Ik heb liever een geweldig block storage SAN en als ik CIFS nodig heb, dan zet ik er wel een windows servertje voor, etc.) maar helaas is het sinds enkele jaren een hit. Netapp is de meest bekende maar ook EMC met hun VNX(e) serie, etc. doen er ook aan.
Hoe dan ook, het beschikbaar stellen over NFS en CIFS en ook eventueel nog eens een iSCSI volume hebben dat ook als file gepresenteerd is word daarbij vaak als waardevol gezien. Persoonlijk snap ik nooit zo goed waarom, maar goed.
Netapp heeft wel enkele handige functies zoals dat je een snapshot als directory kunt benaderen, etc. maar persoonlijk ben ik er geen voorstander van, deels door het gebruikte filesystem wat eronder zit en de performance dat een dergelijke apparaat levert wat naar mijn mening vrij dramatisch is. Het is dan ook echt een array wat je koopt voor de feature list, dat dat betekend dat je het lang niet allemaal tegelijk moet/kan gebruiken en dat het array alles maar matig verricht word daarbij helaas onder de tafel geveegd aangezien managers over het algemeen naar features kijken en niet zozeer IOps, latency, etc.
(Excuses voor de rant, ik kom door mijn werk met veel verschillende array's in aanraking en ook de performance dat een dergelijke array kan leveren, Netapp ben ik nooit zo tevreden over)
[ Voor 5% gewijzigd door Quindor op 06-02-2014 15:50 ]
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
File I/O geeft bij mij 8500 random read 4K IOPs via Iometer + 4 workers + queue depth = 4.Quindor schreef op donderdag 06 februari 2014 @ 02:45:
Zojuist heb ik een iSCSI volume target gemaakt maar dan inplaats van blockio heb ik fileio gebruikt. Zie het resultaat!
Block I/O geeft ~3500 raondom read 4K IOPs met dezelfde instellingen.
dit komt omdat FileIO door het OS gecached wordt en Block I/O niet. Blockio zou dan in de cache van ZFS terecht moeten komen maar ik zie dan erg veel misses. Bij fileio zie ik gewoon nul iops op de zfs stack, alles komt puur uit de 64 GB RAM van de bak.
Wat dat aan gaat is 8500 random IOPS nog best mager. Maar heb jumbo frames nog niet aan staan en 1500 bytes vs 9000 bytes bji 4000 bytes requests zou 3 requests moeten schelen...
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Dat is een goede vraag maar die kan ik niet beantwoorden.
Via een andere VMware host haal ik over iSCSI zelfs 12000 random iops. Grappig. Kan dat niet goed verklaren, oudere hardware, alleen meer cpu mhz.
Via een andere VMware host haal ik over iSCSI zelfs 12000 random iops. Grappig. Kan dat niet goed verklaren, oudere hardware, alleen meer cpu mhz.
Betere NIC? Lagere latency? Bedenk dat 0.01ms verschil in latency op 6000 iops veel scheelt...
Even niets...
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Zit op 10Gbit nic, maar netwerk is 1 gbit. Het zou kunnen. Goed punt.FireDrunk schreef op donderdag 06 februari 2014 @ 17:05:
Betere NIC? Lagere latency? Bedenk dat 0.01ms verschil in latency op 6000 iops veel scheelt...
- Nindustries
- Registratie: Januari 2012
- Laatst online: 07-07 17:18
Heeft iemand hier toevalig zfs performance cijfers met de Intel Avoton C2750 Octa-Core CPU?
Ben eens benieuwd wat de cijfers zijn met onder andere CIFS.
Ben eens benieuwd wat de cijfers zijn met onder andere CIFS.
~ beware of misinformation.
- Q
- Registratie: November 1999
- Laatst online: 16:51
Au Contraire Mon Capitan!
Interessante processor, kende die nog niet. Atom met 2.4ghz en 8 cores.
- Nindustries
- Registratie: Januari 2012
- Laatst online: 07-07 17:18
Exactly my toughts. Ben zeer benieuwd hoe ZFS omgaat met het hoge aantal kernen, en of er een aantal Gb lijnen kunnen volgepompt worden.Q schreef op donderdag 06 februari 2014 @ 18:44:
Interessante processor, kende die nog niet. Atom met 2.4ghz en 8 cores.
~ beware of misinformation.
Dat sowieso wel, het ligt vooral aan het protocol... NFS is veel minder zwaar dan SMB.
Even niets...
Ik ben meer geïnteresseerd in het kleine broertjeNindustries schreef op donderdag 06 februari 2014 @ 17:48:
Heeft iemand hier toevalig zfs performance cijfers met de Intel Avoton C2750 Octa-Core CPU?
Ben eens benieuwd wat de cijfers zijn met onder andere CIFS.
Verwijderd
WAUW.... scheelt dat zoveel??FireDrunk schreef op donderdag 06 februari 2014 @ 17:05:
Betere NIC? Lagere latency? Bedenk dat 0.01ms verschil in latency op 6000 iops veel scheelt...
Waar komt die wetenschap / berekening vandaan? (altijd handig voor later
Gelukkig zijn m'n IB-kabels eindelijk onderweg. Zodra ik ze binnen heb kan ik die meuk gelijk over IB omzetten.
[oeps]
Beter leren lezen...
Dacht even te lezen dat 0.01 ms verschil 6000 IOPS zou kosten.
[ Voor 11% gewijzigd door Verwijderd op 06-02-2014 19:41 ]
Nee, je kan de berekening vrij simpel maken. Een iSCSI pakketje via TCP heeft 3 keer heen en weer tijd, (Request, Receive, Acknowledge) icm delayed acknowledge. (volgens mij)
1Gb = 1000Mb = 1.000.000 Kb = 125.000 KB/s = 31250 4K IOPS zonder enige latency en protocol overhead
[1Gb = 1000Mb = 1.000.000 Kb = 1.000.000.000 b/s = = 30517 4K IOPS met Jumbo Frames aan (er van uitgaande dat het restant van protocol overhead in de jumbo frame past. Als je 2IOPS in 1 frame kwijt kan, zou je dit dus zelfs nog kunnen verdubbelen.
Mijn iSCSI verbinding thuis (server -> swtich -> cluster-node) heeft een latency van ~0.220 ms
Dat is dus 4545 IOPS maximaal als er elke round-tripe 1 IOP gedaan kan worden.
(Of 9000 als er 2 IOPS in een frame gaan)
Je waardes liggen dus altijd ergens tussen de 4545 en 60000 (afhankelijk van bursting, delayed acknowledgements en queue depth)
(Eigenlijk nog steeds best vaag dus)
1Gb = 1000Mb = 1.000.000 Kb = 125.000 KB/s = 31250 4K IOPS zonder enige latency en protocol overhead
[1Gb = 1000Mb = 1.000.000 Kb = 1.000.000.000 b/s = = 30517 4K IOPS met Jumbo Frames aan (er van uitgaande dat het restant van protocol overhead in de jumbo frame past. Als je 2IOPS in 1 frame kwijt kan, zou je dit dus zelfs nog kunnen verdubbelen.
Mijn iSCSI verbinding thuis (server -> swtich -> cluster-node) heeft een latency van ~0.220 ms
Dat is dus 4545 IOPS maximaal als er elke round-tripe 1 IOP gedaan kan worden.
(Of 9000 als er 2 IOPS in een frame gaan)
Je waardes liggen dus altijd ergens tussen de 4545 en 60000 (afhankelijk van bursting, delayed acknowledgements en queue depth)
(Eigenlijk nog steeds best vaag dus
[ Voor 24% gewijzigd door FireDrunk op 06-02-2014 19:57 ]
Even niets...
Verwijderd
Okay. Ik snap het. (moest het wel even een paar keer doorlezen en zelf berekenen...)
En dat zeggende kan je op die manier wel weer de maximale doorvoersnelheid berekenen icm de max MTU-size.
Maar om jou bovenstaande berekening lineair door te trekken, zou ik over 20 Gb IB theoretisch tussen de 90900 en 625000 kunnen komen...
/me maakt zich geen enkele illusie... maar wil wel straks eens serieus testen met o.a. een ramdisk.
En dat zeggende kan je op die manier wel weer de maximale doorvoersnelheid berekenen icm de max MTU-size.
Maar om jou bovenstaande berekening lineair door te trekken, zou ik over 20 Gb IB theoretisch tussen de 90900 en 625000 kunnen komen...
/me maakt zich geen enkele illusie... maar wil wel straks eens serieus testen met o.a. een ramdisk.
[ Voor 7% gewijzigd door Verwijderd op 06-02-2014 20:44 ]
- Xudonax
- Registratie: November 2010
- Laatst online: 14-07 12:58
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| pool: tank
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Thu Feb 6 18:55:26 2014
1,27T scanned out of 4,03T at 131M/s, 6h9m to go
216G resilvered, 31,47% done
config:
NAME STATE READ WRITE CKSUM
tank DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
replacing-0 UNAVAIL 0 0 0
ata-HGST_HTS541010A9E680_JB100013J2RP1A UNAVAIL 0 0 0
ata-HGST_HTS541010A9E680_J810001VJ1Y3XA ONLINE 0 0 0 (resilvering)
ata-HGST_HTS541010A9E680_JB100013J3ST5B ONLINE 0 0 0
ata-HGST_HTS541010A9E680_JB100013J3TXGB ONLINE 0 0 0
ata-HGST_HTS541010A9E680_JB40001MGG3MJC ONLINE 0 0 0
ata-HGST_HTS541010A9E680_JB100013J4HGNB ONLINE 0 0 0
ata-HGST_HTS541010A9E680_JB100013J4J15B ONLINE 0 0 0
logs
ata-INTEL_SSDSA2CW120G3_CVPR126608BS120LGN-part1 ONLINE 0 0 0
cache
ata-SanDisk_SDSSDRC032G_131172400266 ONLINE 0 0 0
errors: No known data errors |
Waarom duurt een rebuild toch zo lang... Het heeft er vast niets mee te maken dat het volume ondertussen ook nog een aantal VMs host en dat ik er een film vanaf stream, toch?
Anyway, ik heb weer een vervangende schijf terug van MaxICT. Al met al tevreden over de RMA service, hoewel het wel verdraaid lang duurt voordat de vervangende schijf arriveerde. Maar goed, RAIDZ2 kan best met een dooie schijf lopen voor ~1.5 weken
- HyperBart
- Registratie: Maart 2006
- Laatst online: 22:33
Gaat toch prima snel, niet? Die disk doet maximum wat, 130MB/s? Zit toch netjes tegen zijn maximum?Xudonax schreef op donderdag 06 februari 2014 @ 21:48:
code:
pool: tank state: DEGRADED status: One or more devices is currently being resilvered. The pool will continue to function, possibly in a degraded state. action: Wait for the resilver to complete. scan: resilver in progress since Thu Feb 6 18:55:26 2014 1,27T scanned out of 4,03T at 131M/s, 6h9m to go 216G resilvered, 31,47% done config: NAME STATE READ WRITE CKSUM tank DEGRADED 0 0 0 raidz2-0 DEGRADED 0 0 0 replacing-0 UNAVAIL 0 0 0 ata-HGST_HTS541010A9E680_JB100013J2RP1A UNAVAIL 0 0 0 ata-HGST_HTS541010A9E680_J810001VJ1Y3XA ONLINE 0 0 0 (resilvering) ata-HGST_HTS541010A9E680_JB100013J3ST5B ONLINE 0 0 0 ata-HGST_HTS541010A9E680_JB100013J3TXGB ONLINE 0 0 0 ata-HGST_HTS541010A9E680_JB40001MGG3MJC ONLINE 0 0 0 ata-HGST_HTS541010A9E680_JB100013J4HGNB ONLINE 0 0 0 ata-HGST_HTS541010A9E680_JB100013J4J15B ONLINE 0 0 0 logs ata-INTEL_SSDSA2CW120G3_CVPR126608BS120LGN-part1 ONLINE 0 0 0 cache ata-SanDisk_SDSSDRC032G_131172400266 ONLINE 0 0 0 errors: No known data errors
Waarom duurt een rebuild toch zo lang... Het heeft er vast niets mee te maken dat het volume ondertussen ook nog een aantal VMs host en dat ik er een film vanaf stream, toch?
Anyway, ik heb weer een vervangende schijf terug van MaxICT. Al met al tevreden over de RMA service, hoewel het wel verdraaid lang duurt voordat de vervangende schijf arriveerde. Maar goed, RAIDZ2 kan best met een dooie schijf lopen voor ~1.5 weken
Tenzij de speed daar weer gegeven is zoals de scrub snelheid wordt gerekend, dan valt het tegen. Wat doet iedere disk afzonderlijk?
VM's en films hebben wel impact ja, daarom dat ik twijfel of het niet moet zijn zoals bij scrub snelheden...
- fluppie007
- Registratie: April 2005
- Laatst online: 17-07 16:27
In ZFSguru zit een rename pool functie. Kan ik deze veilig gebruiken? Wat zijn de eventuele consequenties? Bij één van de twee te renamen pools zit er een iSCSI target & een Samba share op.
- Remcor2000
- Registratie: Augustus 2002
- Laatst online: 16-07 09:19
:strip_icc():strip_exif()/u/62294/Copy%2520of%2520sq-qotsa-go-flow-vid-int.jpg?f=community)
Ik zit met een vreemd probleem. Ik heb een Ubuntu server gemaakt in Virtualbox waarin ik een installatie aan het opzetten was van Owncloud. Tijdens de installatie kreeg ik een rare foutmelding waardoor ik geprobeerd heb de (virtuele) server te rebooten, waar de (virtuele) server in bleef hangen in status powering off.
Omdat ik na 15 minuten wachten toch wel door wilde heb ik de service van Virtualbox gestopt, en daarna weer gestart in de hoop dat de virtuele server weer te starten was.
Maar het vervelende is nu, de Virtualbox service werkt niet meer. Ik kom niet meer op het service panel.
Ik heb de service gedeinstalleerd, en daarna weer geinstalleerd. Verder nog via command line proberen te starten maar dat geeft ook geen resultaat.
Hebben jullie adviezen voor ik de boel verder sloop?
Omdat ik na 15 minuten wachten toch wel door wilde heb ik de service van Virtualbox gestopt, en daarna weer gestart in de hoop dat de virtuele server weer te starten was.
Maar het vervelende is nu, de Virtualbox service werkt niet meer. Ik kom niet meer op het service panel.
Ik heb de service gedeinstalleerd, en daarna weer geinstalleerd. Verder nog via command line proberen te starten maar dat geeft ook geen resultaat.
Hebben jullie adviezen voor ik de boel verder sloop?
| root@zfsguru /ZFS1/zfsguru/services/10.0-001/virtualbox]# ./service_start.sh * starting service virtualbox * executing manual start script * service register script - version 2 * AUTOSTART_RUNCONTROL file found! Yes, this service is registered in that file! * AUTOSTART_LOADER file found! Yes, this service is registered in that file! * this service has no AUTOSTART_SCRIPT file * service is registered! * activating kernel modules kldload: can't load vboxdrv.ko: File exists * manually starting virtualbox Starting vboxwebsrv. * disabling authentication for VirtualBox webservice API * done executing manual start script |
- Xudonax
- Registratie: November 2010
- Laatst online: 14-07 12:58
Totale leessnelheid van de pool was ~130MB/s, en dat vind ik toch wel een ietwat tegenvallen gezien het een (degraded) RAIDZ2 volume van 6 schijven betreft. Maar, het zijn wel weer laptop schijfjes, welke op ~100MB elk toppen. Naja, het werkt nu in ieder geval weerHyperBart schreef op vrijdag 07 februari 2014 @ 08:56:
[...]
Gaat toch prima snel, niet? Die disk doet maximum wat, 130MB/s? Zit toch netjes tegen zijn maximum?
Tenzij de speed daar weer gegeven is zoals de scrub snelheid wordt gerekend, dan valt het tegen. Wat doet iedere disk afzonderlijk?
VM's en films hebben wel impact ja, daarom dat ik twijfel of het niet moet zijn zoals bij scrub snelheden...
- ikkeenjij36
- Registratie: Juli 2012
- Laatst online: 17-07 05:32
Hallo mijn dochter heeft waarschijnlijk wat gedaan in/op mijn server en daardoor wil het niet meer werken
Als ik reboot dan zegt ie op de terminal Php warning exec() has been disabled for security reasons in etc/zfsguru-login.sh on line 156.
In de webgui van zfsguru kan ik dus ook niks meer.
Wel toegang via de commandline.
Ook weet ik zeker dat er nog een snapshot van gisteren opstaat toen alles werkte.
Kan ik dat snapshot gebruiken om te herstellen?
En hoe doe ik dat precies dan?
Gaat dat lukken via de livecd van zfsguru?
Alle advies is welkom want ik heb nu een server paniek crisis hier thuis:)
Als ik reboot dan zegt ie op de terminal Php warning exec() has been disabled for security reasons in etc/zfsguru-login.sh on line 156.
In de webgui van zfsguru kan ik dus ook niks meer.
Wel toegang via de commandline.
Ook weet ik zeker dat er nog een snapshot van gisteren opstaat toen alles werkte.
Kan ik dat snapshot gebruiken om te herstellen?
En hoe doe ik dat precies dan?
Gaat dat lukken via de livecd van zfsguru?
Alle advies is welkom want ik heb nu een server paniek crisis hier thuis:)
Even de PHP.ini wijzigen. safe mode staat waarschijnlijk aan.
Even niets...
- ikkeenjij36
- Registratie: Juli 2012
- Laatst online: 17-07 05:32
Beste firedunk,kan je misschien kleine aanwijzing geven welke command ik moet gebruiken?FireDrunk schreef op zaterdag 08 februari 2014 @ 09:31:
Even de PHP.ini wijzigen. safe mode staat waarschijnlijk aan.
Sorry linux noob.
Verwijderd
nano /usr/local/etc/php.iniikkeenjij36 schreef op zaterdag 08 februari 2014 @ 09:44:
[...]
Beste firedunk,kan je misschien kleine aanwijzing geven welke command ik moet gebruiken?
Sorry linux noob.
En zoek even naar de regel:
safe_mode = Off
Zo zou ie moeten staan.
Zoeken kan je doen met:
[Ctrl] w safe_mode [Enter]
[ Voor 25% gewijzigd door Verwijderd op 08-02-2014 09:50 ]
Wat hij zegt
Even niets...
- ikkeenjij36
- Registratie: Juli 2012
- Laatst online: 17-07 05:32
Geprobeerd gezocht en niet gevonden?Verwijderd schreef op zaterdag 08 februari 2014 @ 09:45:
[...]
nano /usr/local/etc/php.ini
En zoek even naar de regel:
safe_mode = Off
Zo zou ie moeten staan.
Zoeken kan je doen met:
[Ctrl] w safe_mode [Enter]
Wat nu?
Als ik de webgui van zfsguru open krijg ik dit als melding:ERROR: Command execution test failed; aborting
en de vorige natuurlijk op de terminal als ik die erop aansluit
Let op:
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.