Dag 6 deel 2 was na deel 1 idd wel makkelijk. Ik zat alleen te klooien met de inifinite delen en was vergeten dat de Locations zelf ook meetellen. Dus hij was idd niet zo moeilijk, zat gewoon zelf te kutten 
/u/341393/zandloper2.png?f=community)
Woy schreef op vrijdag 7 december 2018 @ 11:46:
[...]
Dan doe jij 6 verkeerd of ik 7, maar zeker 6 part 2 was erg eenvoudig IMHO
spoiler:[code=c#]
var result = (from x in Enumerable.Range(0, input.Max(p=>p.x))
from y in Enumerable.Range(0, input.Max(p=>p.y))
where input.Sum(point=>Dist((x,y), point)) < 10000
select (x,y)).Count();
[/code]
Lye schreef op donderdag 6 december 2018 @ 22:51:
[...]
Jouw deel 2 gaat mank op de volgende input:
1, 1
zou als output 199980001 moeten hebben. Hetzelfde probleem had ik dus ook
spoiler:
Het probleem zit m in de grootte van je bounding box. Het is heel goed mogelijk dat er punten "safe" zijn die buiten de gegeven coordinaten liggen. Met bovenstaande input zou jouw oplossing een bounding box van 1x1 bekijken en beslissen dat dit de "safe" area is, echter is de daadwerkelijke safe space een ruit binnen een bounding box van 20001x20001. Dit maakt het wel een stuk lastiger als je het een beetje snel wil houden.
Een ander voorbeeld waarbij de bounding box ook groter moet zijn dan min*max:
Een ander voorbeeld waarbij de bounding box ook groter moet zijn dan min*max:
2, 2 4, 5 1, 4
spoiler:
Waarbij de maximale manhattan distance < 15. In dit geval ga je aan alle kanten 2 punten buiten de min*max bounding box ('0' is hierbij de gegeven coördinaten, '-' is de veilige oppervlakte):
- ---- --0--- ------- --0----- -----0- ----- ---
[ Voor 13% gewijzigd door Lye op 07-12-2018 13:05 ]
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
:strip_icc():strip_exif()/u/6143/rincewind.jpg?f=community)
@Lye ja daar was ik mij bewust van, maar voor mijn input was het ieder geval geen probleem. ( Het is ook waarom ik de coordinaten selecteer. Ik had ook gechecked of er geen coordinaten op de rand van het grid aan de voorwaarden voldeden. )
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
:strip_icc():strip_exif()/u/481839/e-resized.jpg?f=community)
Ik ben vandaag echt enorm aan het klooien geweest. Na het weggelegd te hebben ging het opeens wel 
Soms zit ik zo vast om te proberen om iets stoms op te lossen terwijl het op een andere manier 10x makkelijker gaat
Hij doet het in 1ms
Soms zit ik zo vast om te proberen om iets stoms op te lossen terwijl het op een andere manier 10x makkelijker gaat
Hij doet het in 1ms
- veldsla
- Registratie: April 2000
- Laatst online: 18-07 12:11
:strip_icc():strip_exif()/u/5080/veldsla.jpg?f=community)
Argh damn. Lang geprutst op deel 2. Meestal lees ik het forum pas als ik de boel af heb, maar kwam toch maar even kijken. Zie ik de opmerkingen over slecht lezen al staan. En ja hoor  LEZEN!
LEZEN!
- Daanoz
- Registratie: Oktober 2007
- Laatst online: 29-06 16:24
:strip_icc():strip_exif()/u/237526/crop5e05c1d265781_cropped.jpeg?f=community)
Ja, lezen is zo belangrijk bij deze puzzels, klein leesfoutje is zo gemaakt... Meestal dan uiteindelijk een facepalm momentje.
- Soultaker
- Registratie: September 2000
- Laatst online: 10-07 18:31
:strip_exif()/u/11775/SoulTaker.gif?f=community)
Wat deden jullie verkeerd?
Qua algoritme ging het bij mij wel goed, maar bij deel 2 was ik eerst vergeten de 60 seconde toe te voegen (die in het voorbeeld niet meetelde) en daarna printte ik de letters (zoals bij deel 1) in plaats van de totale tijd. Maar beide fouten waren natuurlijk eenvoudig op te lossen.
Qua algoritme ging het bij mij wel goed, maar bij deel 2 was ik eerst vergeten de 60 seconde toe te voegen (die in het voorbeeld niet meetelde) en daarna printte ik de letters (zoals bij deel 1) in plaats van de totale tijd. Maar beide fouten waren natuurlijk eenvoudig op te lossen.
- Nilltris
- Registratie: Mei 2011
- Laatst online: 14-06-2023
/u/407977/crop5c8f648279d1b.png?f=community)
Voor het tweede deel van dag 1 moet je net zo lang de input loopen tot je twee keer dezelfde frequentie bent tegen gekomen. Met een extra loop ga je dat, denk ik, niet redden. Met een andere loop welheuveltje schreef op vrijdag 7 december 2018 @ 11:32:
[...]
Dat verklaart
Thuis eens opnieuw draaien met een extra loop erin
- veldsla
- Registratie: April 2000
- Laatst online: 18-07 12:11
Soultaker schreef op vrijdag 7 december 2018 @ 15:29:
Wat deden jullie verkeerd?
spoiler:
If multiple steps are available, workers should still begin them in alphabetical order.
- ElkeBxl
- Registratie: Oktober 2014
- Laatst online: 12-07 20:30
Tassendraagster
:strip_exif()/u/627282/charmander-kerst.gif?f=community)
Ik had ook verkeerd naar het voorbeeld gekeken. Eerst met die 60 seconden en daarna met 2 vs 5 workersSoultaker schreef op vrijdag 7 december 2018 @ 15:29:
Wat deden jullie verkeerd?
Note to self: beter lezen
Without nipples, boobs are pointless - 365 project - In mijn hoofd is het alle dagen Kerstmis - What type of bees make milk? Boobies! - What type of bees are scary? BoooOOOOOooobeees! - Cactusliefhebster
- veldsla
- Registratie: April 2000
- Laatst online: 18-07 12:11
Oh no
AoC problemen zijn meestal best klein dus ruzie met de borrow-checker lijkt niet echt een issue of wel?
- Radiant
- Registratie: Juli 2003
- Niet online
Certified MS Bob Administrator
:strip_exif()/u/88216/Goomba-animated.gif?f=community)
- 60s vergeten eerst..Soultaker schreef op vrijdag 7 december 2018 @ 15:29:
Wat deden jullie verkeerd?
Qua algoritme ging het bij mij wel goed, maar bij deel 2 was ik eerst vergeten de 60 seconde toe te voegen (die in het voorbeeld niet meetelde) en daarna printte ik de letters (zoals bij deel 1) in plaats van de totale tijd. Maar beide fouten waren natuurlijk eenvoudig op te lossen.
- Daarna ging mijn code vrolijk het hele pad af omdat een stap al werd 'klaargemeld' terwijl deze pas net begon bij een worker (copy/paste van deel 1). Duurde even voordat ik die door had; tot het opviel dat alle workers altijd bezig waren.
Vandaag en gister waren leuke opdrachten, niet te moeilijk, niet te simpel
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
/u/12668/hydra.png?f=community)
Blij dat ik niet de enige ben.
https://niels.nu
- Boudewijn
- Registratie: Februari 2004
- Niet online
omdat het kan
:strip_icc():strip_exif()/u/105199/crop5cb76c6d18020_cropped.jpeg?f=community)
Kan iemand me vertellen hoe je de regex-matching voor 5 doet? Ik zoek dan specifiek de matching tussen <willekeurige letter klein><willekeurige letter groot> , en omgedraaid. Mijn huidige oplossing in spoiler tags:
Niet echt charmant, dus een regex is wel beter dan een forloop. Hier staat de code voor de liefhebber:
https://pastebin.com/z2Bfw7mU
Het is prima leesbaar, maar de performance is niet heel best .
.
spoiler:
Ik heb het nu met een parser opgelost in python die de hele string afloopt op zoek naar kleine-x + grote-x danwel omgedraaid. Die worden verwijderd en de functie stopt. Geeft dan de string terug en een boolean of er iets is aangepast is. Die functie roep ik telkens aan tot er niets meer aangepast is, dan is de boel klaar.
Niet echt charmant, dus een regex is wel beter dan een forloop. Hier staat de code voor de liefhebber:
https://pastebin.com/z2Bfw7mU
Het is prima leesbaar, maar de performance is niet heel best
[ Voor 3% gewijzigd door Boudewijn op 07-12-2018 17:59 ]
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Een Regex zal vast mogelijk zijn, maar lijkt mij in dit geval zeker niet de beste oplossing. Al zou je een juiste match kunnen vinden is het nog steeds suboptimaal omdat je meerdere keren over dezelfde string heen moet lopen om hem te reduceren.Boudewijn schreef op vrijdag 7 december 2018 @ 17:59:
Kan iemand me vertellen hoe je de regex-matching voor 5 doet? Ik zoek dan specifiek de matching tussen <willekeurige letter klein><willekeurige letter groot> , en omgedraaid. Mijn huidige oplossing in spoiler tags:
spoiler:Ik heb het nu met een parser opgelost in python die de hele string afloopt op zoek naar kleine-x + grote-x danwel omgedraaid. Die worden verwijderd en de functie stopt. Geeft dan de string terug en een boolean of er iets is aangepast is. Die functie roep ik telkens aan tot er niets meer aangepast is, dan is de boel klaar.
Niet echt charmant, dus een regex is wel beter dan een forloop. Hier staat de code voor de liefhebber:
https://pastebin.com/z2Bfw7mU
Het is prima leesbaar, maar de performance is niet heel best
Een optie is natuurlijk gewoon iets met een loopje genereren ala ( \aA|Aa|bB|Bb........\ ), er zullen vast nog kortere manieren zijn om het op te schrijven, maar ik verwacht niet perse dat dat sneller is.
spoiler:
hiermee hoef je maximaal 1 maal door de string te lopen.
[code=c#]
var stack = new Stack<char>();
foreach(char c in input)
{
if(stack.Count == 0 || (stack.Peek() ^ c) != 32)
stack.Push(c);
else
stack.Pop();
}
[/code]
voor Part2 voer ik deze code 26* uit en skip ik die letters van het alphabet.
[code=c#]
var stack = new Stack<char>();
foreach(char c in input)
{
if(stack.Count == 0 || (stack.Peek() ^ c) != 32)
stack.Push(c);
else
stack.Pop();
}
[/code]
voor Part2 voer ik deze code 26* uit en skip ik die letters van het alphabet.
[ Voor 6% gewijzigd door Woy op 07-12-2018 19:08 ]
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- ZieglerNichols
- Registratie: Mei 2015
- Niet online
Ik vind Rust wel een mooie taal, maar ik doe er nu geen AOC mee. Veel te frustrerend omdat ik nog niet vloeiend genoeg ben. Misschien dat ik over een paar maanden nog eens alles in Rust over doe.
:strip_icc():strip_exif()/u/1007893/crop5f84470ecb79a.jpeg?f=community)
Dag 5 is voor mij ondertussen ook gelukt in c#.
https://github.com/ydderfBackwards/AdventOfCode2018
Alleen voor deel 2 van dag 5, is voor mij de programmatijd eerder uit te drukken in minuten ipv msec...
Maar hij doet wel wat hij moet doen, dus als hobby-ist ben ik blij
(maar dat komt denk ik ook wel weer overeen met de programmeertijd in verhouding met de experts
https://github.com/ydderfBackwards/AdventOfCode2018
Alleen voor deel 2 van dag 5, is voor mij de programmatijd eerder uit te drukken in minuten ipv msec...
Maar hij doet wel wat hij moet doen, dus als hobby-ist ben ik blij
(maar dat komt denk ik ook wel weer overeen met de programmeertijd in verhouding met de experts
[ Voor 14% gewijzigd door ydderf op 07-12-2018 20:42 ]
Soms gaat het niet zoals het moet, maar moet het maar zoals het gaat
- Osxy
- Registratie: Januari 2005
- Laatst online: 26-07 11:47
Holy crap on a cracker
:strip_icc():strip_exif()/u/133678/133963684346bda9327d0a6-1.jpg?f=community)
Her en der in de loop van mijn carrière verschillende talen gebruikt. Nooit echt ergens expert in geworden, heb nooit formeel functie als programmeur vervult (tester, informatieanalyst, applicatiebeheerder)
Sinds kort begonnen met C# en om mijzelf uit te dagen gezellig aan knutselen aan de AoC.
Gaat relatief langzaam maar haal er veel lol uit en tot nu toe nog niet ECHT vast gezeten.
Net dag 3 klaar.
https://github.com/osxy/A...ee/master/AoC2018/AoC2018
Dag 1, deel 1: 0,1197ms
Dag 1, deel 2: 5,7017ms
Dag 2, deel 1: 0,0533ms
Dag 2, deel 2: 0,065ms
Dag 3, deel 1: 377,3239ms
Dag 3, deel 2: 19,7853ms
Sinds kort begonnen met C# en om mijzelf uit te dagen gezellig aan knutselen aan de AoC.
Gaat relatief langzaam maar haal er veel lol uit en tot nu toe nog niet ECHT vast gezeten.
Net dag 3 klaar.
https://github.com/osxy/A...ee/master/AoC2018/AoC2018
Dag 1, deel 1: 0,1197ms
Dag 1, deel 2: 5,7017ms
Dag 2, deel 1: 0,0533ms
Dag 2, deel 2: 0,065ms
Dag 3, deel 1: 377,3239ms
Dag 3, deel 2: 19,7853ms
[ Voor 31% gewijzigd door Osxy op 07-12-2018 21:49 ]
"Divine Shields and Hearthstones do not make a hero heroic."
Gisteren geen tijd gehad, dus vandaag begonnen met dag 6. Alleen kom ik er niet uit Nog geen slimme manier kunnen bedenken om te bepalen tot waar ik moet zoeken. Iemand een hint voor een Google term / algoritme?
Eerst nu mar dag 7 gedaan die wel in 1 keer lukte in 30 ms.
Eerst nu mar dag 7 gedaan die wel in 1 keer lukte in 30 ms.
C# Day 07
Leuke uitdaging, had wel even nodig om te begrijpen wat nu precies de bedoeling was. Maar wel tevreden hoe snel het runt. Beiden doen er 0.22ms over. Ik gebruik voor beiden dezelfde implementatie.
2.
Leuke uitdaging, had wel even nodig om te begrijpen wat nu precies de bedoeling was. Maar wel tevreden hoe snel het runt. Beiden doen er 0.22ms over. Ik gebruik voor beiden dezelfde implementatie.
1.diabolofan schreef op vrijdag 7 december 2018 @ 21:52:
Iemand een hint voor een Google term / algoritme?
spoiler:
Makkelijkste is om gewoon een grid te maken, je kan zelf wel bedenk wat de dimensies moeten zijn.
2.
spoiler:
Vervolgens groei je als het ware naar buiten. (Breadth-first search)
[ Voor 43% gewijzigd door DRaakje op 07-12-2018 22:29 ]
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
Leuk maar ik had de instructie voor deel 2 verkeerd begrepen
voor de mensen die PHP gebruiken:
spoiler:
Node C has one metadata entry, 2. Because node C has only one child node, 2 references a child node which does not exist, and so the value of node C is 0.
Ik ging er dus vanuit dat als max(metadata)>count(children) de value 0 was maar als een child niet bestaat dan telt alleen die waarde als 0
Ik ging er dus vanuit dat als max(metadata)>count(children) de value 0 was maar als een child niet bestaat dan telt alleen die waarde als 0
voor de mensen die PHP gebruiken:
spoiler:
Ik deed het eerst met een array, dat duurde 500ms, ik heb het nu omgebouwd naar een SplStack en nu doet ie het in 7ms
[ Voor 18% gewijzigd door emnich op 08-12-2018 07:54 ]
- ppx17
- Registratie: December 2007
- Laatst online: 24-10-2025
@Hydra Dat is een stuk vlotter dan het hier gaat.
Day 8 in PHP
spoiler:
In principe geen gekkigheden gebruikt, gewoon een boom van nodes gebouwd en daar 2x overheen gelopen, maar het opbouwen van de boom uit data kost php hier al 10 ms. Het traversen is in 2x 2ms gedaan.
Day 8 in PHP
[ Voor 3% gewijzigd door ppx17 op 13-12-2018 11:11 ]
40D | 8 | 50 | 100 | 300
C# Day 08
2ms en .14ms
Makkelijk dagje. Voorgaande dagen waren de doordeweekse dagen makkelijk, dit jaar omgekeerd?
2ms en .14ms
Makkelijk dagje. Voorgaande dagen waren de doordeweekse dagen makkelijk, dit jaar omgekeerd?
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
/u/243953/crop56f55a7bcf291.png?f=community)
Hij was inderdaad prima te doen. Maar vind ik wel prima, had de afgelopen 2 dagen niet echt tijd om er mee aan de slag te gaan, dus kan ik nu even bij trekken
Benches voor dag 8:
1: 50595 ns => 0.051ms
2: 4925 ns => 0.005ms (en dat is nog trager omdat de benchmark for some reason niet stopt als ik geen output binnen de timers plak)
Benches voor dag 8:
1: 50595 ns => 0.051ms
2: 4925 ns => 0.005ms (en dat is nog trager omdat de benchmark for some reason niet stopt als ik geen output binnen de timers plak)
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Mijn oplossing voor dag 8 in PHP: https://pastebin.com/qY5gtzsx
[ Voor 9% gewijzigd door BernardV op 08-12-2018 10:17 ]
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
Het kan in ieder geval een aardig stuk simpeler.emnich schreef op zaterdag 8 december 2018 @ 09:09:
@Hydra mijn code staat hier
Het is overigens niet gebouwd op pure snelheid maar ik was wel verrast over het verschil tussen een Stack en een array in PHP.
Als ik snel kijk weet ik niet precies waar ik veel sneller zou kunnen.
spoiler:
Ik zou beginnen me alles in 1 keer naar een lijst/queue/stack/whatever van integers te parsen.
Daarnaast; je hebt aardig wat uitzonderingssituaties die eigenlijk niet nodig zijn. Je 'root' node is gewoon de hele input. Je leest van de queue het aantal kinderen en aantal metadata, deze kun je voor een 'for-loop' recursief lezen. Je zit kwa aanpak wel dicht in de buurt, dus ik kan niet inschatten of dat iets uit gaat maken.
Daarnaast; je hebt aardig wat uitzonderingssituaties die eigenlijk niet nodig zijn. Je 'root' node is gewoon de hele input. Je leest van de queue het aantal kinderen en aantal metadata, deze kun je voor een 'for-loop' recursief lezen. Je zit kwa aanpak wel dicht in de buurt, dus ik kan niet inschatten of dat iets uit gaat maken.
https://niels.nu
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
spoiler:
. Erg jammer voor mijn stats ik een 0 was vergeten bij de maximum distance waardoor het antwoord verkeerd was
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Part 8 heb ik uiteindelijk op 2 manieren opgelost, de nette en de snellere.
spoiler:
Voor de nette heb ik ook netjes naar een boom structuur geparsed. Maar de opdracht is zo eenvoudig dat je ook gewoon in place binnen de array de oplossing kunt vinden zonder er een andere datastructuur omheen te bouwen.
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Ik heb nog nooit iets in Rust gedaan, lijkt me leuk. Ik ga proberen dag 8 in Rust te maken.
- veldsla
- Registratie: April 2000
- Laatst online: 18-07 12:11
Leuk recursief probleempje. Vooral leuk als je in probleem 2 recursief de functie van probleem 1 aanroept .
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
Leuk dat je kijkt, bedankt.Hydra schreef op zaterdag 8 december 2018 @ 10:35:
[...]
Het kan in ieder geval een aardig stuk simpeler.
spoiler:Ik zou beginnen me alles in 1 keer naar een lijst/queue/stack/whatever van integers te parsen.
Daarnaast; je hebt aardig wat uitzonderingssituaties die eigenlijk niet nodig zijn. Je 'root' node is gewoon de hele input. Je leest van de queue het aantal kinderen en aantal metadata, deze kun je voor een 'for-loop' recursief lezen. Je zit kwa aanpak wel dicht in de buurt, dus ik kan niet inschatten of dat iets uit gaat maken.
Welke uitzonderingssituaties zijn niet nodig? Ik zie 1 overbodige `if` en het is gebouwd dat er meerdere roots kunnen zijn. Dat zou er inderdaad nog uit kunnen maar dat maakt voor de performance niet echt uit. Verder doe ik volgens mij precies wat je voorschrijft maar PHP is gewoon langzaam (net als mijn machine). Ik ben benieuwd of het echt sneller kan.
Alleen het omzetten van de string naar een stack duurt al 3ms in PHP
Als je het puur op performance bouwt zou het misschien nog sneller kunnen dan gebruik je verder geen classes maar mij lukt het niet om het sneller te krijgen.
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Hier is hij dan, mijn eerste Rust projectje: https://pastebin.com/HPkKHT3ebernardV schreef op zaterdag 8 december 2018 @ 11:00:
Ik heb nog nooit iets in Rust gedaan, lijkt me leuk. Ik ga proberen dag 8 in Rust te maken.
Dag 8 in Rust. IntelliJ heeft me wel geholpen door de code completion, anders had ik niet alles "zo snel" kunnen vinden.
Het kan waarschijnlijk veel beter in Rust, dus alle tips van Rust gebruikers zijn welkom.
- veldsla
- Registratie: April 2000
- Laatst online: 18-07 12:11
Ziet er best ok uit. Je maakt nogal wat kopieën van je data, dus dat is een performance dingetje. Dit kan waarschijnlijk ook met slices (ik gebruikte een iterator)
De Clippy linter is ook een leuk tooltje om je te helpen. Die vind bv .split(" ") niet ok en zal misschien split(' ') (char ipv string) voorstellen, maar er is ook split_whitespace() in de stdlib.
Returns zijn impliciet en schrijf je alleen uit als het een early return is.
Verder zijn voor veel van de for loopjes iterators en adaptors beschikbaar (sum-en (sum), pushen naar een vector (extend)). (Bijna) Alle index operaties zullen in de uiteindelijke binary een bounds check doen wat bij iterators niet nodig is en dus snellere code kan opleveren.
De Clippy linter is ook een leuk tooltje om je te helpen. Die vind bv .split(" ") niet ok en zal misschien split(' ') (char ipv string) voorstellen, maar er is ook split_whitespace() in de stdlib.
Returns zijn impliciet en schrijf je alleen uit als het een early return is.
Verder zijn voor veel van de for loopjes iterators en adaptors beschikbaar (sum-en (sum), pushen naar een vector (extend)). (Bijna) Alle index operaties zullen in de uiteindelijke binary een bounds check doen wat bij iterators niet nodig is en dus snellere code kan opleveren.
Je hebt een vergelijkbare oplossing als ik:
https://pastebin.com/Pjg5r96a
Enige (voor deze input nutteloze) optimalisatie die ik nog kon bedenken:
spoiler:
Is om bij deel 2 de gecalculeerde child node waarde op te slaan mocht deze meerdere malen in de meta data worden genoemd.
Leverde helaas niet echt veel performance winst op.
Leverde helaas niet echt veel performance winst op.
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
@veldsla Dank je voor je feedback.
Looptijd van de huidige versie (getimed met time::PreciseTime) is voor beide parts samen 2.1ms
Door de data in de constructor te wijzigen van Vec<i32> naar &[i32] en alle clones te vervangen door as_slice() gaat de looptijd naar 1.03ms. Toch een verdubbeling van de snelheid!
Ik moet me meer verdiepen in de mogelijkheden van Rust en wat de do's en don'ts zijn.
Ik zal nu verder gaan met de rest van je opmerkingen.
Looptijd van de huidige versie (getimed met time::PreciseTime) is voor beide parts samen 2.1ms
Door de data in de constructor te wijzigen van Vec<i32> naar &[i32] en alle clones te vervangen door as_slice() gaat de looptijd naar 1.03ms. Toch een verdubbeling van de snelheid!
Ik moet me meer verdiepen in de mogelijkheden van Rust en wat de do's en don'ts zijn.
Ik zal nu verder gaan met de rest van je opmerkingen.
Verwijderd
part 1: 227.95µs
part 2: 320.394µs
https://github.com/DutchG.../master/day08/src/main.rs
https://github.com/DutchG...aster/day08_2/src/main.rs
Ik maak geen stack aan, geen Tree structure met Nodes...De input zelf is al een soort van Tree structure, dus ik maak gebruik van alleen Iterators en recursion!
part 2: 320.394µs
https://github.com/DutchG.../master/day08/src/main.rs
https://github.com/DutchG...aster/day08_2/src/main.rs
Ik maak geen stack aan, geen Tree structure met Nodes...De input zelf is al een soort van Tree structure, dus ik maak gebruik van alleen Iterators en recursion!
Dag 8 was goed te doen gelukkig.
Thanks, ga dag 6 weer eens proberenDRaakje schreef op vrijdag 7 december 2018 @ 22:01:
1.
spoiler:Makkelijkste is om gewoon een grid te maken, je kan zelf wel bedenk wat de dimensies moeten zijn.
2.
spoiler:Vervolgens groei je als het ware naar buiten. (Breadth-first search)
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
Geïnspireerd op anderen een snellere versie in PHP.
Nu 3.5ms ipv de 7ms van vanochtend keer. Iemand die nog ziet waar het veel sneller kan?
Nu 3.5ms ipv de 7ms van vanochtend keer. Iemand die nog ziet waar het veel sneller kan?
Hehe, dag 6 ook klaar. Brute-force in 10 sec, maar vind het wel even best. Uiteindelijk zelfs maar geprint wat er in m'n gridje stond aangezien ik het niet helemaal meer kon volgen. Levert wel mooie plaatjes op:

Ook al heb ik nu de juiste antwoorden, alsnog vind ik de vraagstelling en uitleg een beetje vaag, maarja.
Ook al heb ik nu de juiste antwoorden, alsnog vind ik de vraagstelling en uitleg een beetje vaag, maarja.
[ Voor 8% gewijzigd door diabolofan op 08-12-2018 17:44 ]
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
Euh, is m'n dag 9 submission verwijderd?
https://niels.nu
- ElkeBxl
- Registratie: Oktober 2014
- Laatst online: 12-07 20:30
Tassendraagster
Hier geen problemen met dag 9. Net deel 1 gedaan. Maar als ik deel 2 goed begrijp, kan ik nu rustig douche gaan nemen want voor deel 1 was mijn algoritme al bijna halve minuut bezig... 
Without nipples, boobs are pointless - 365 project - In mijn hoofd is het alle dagen Kerstmis - What type of bees make milk? Boobies! - What type of bees are scary? BoooOOOOOooobeees! - Cactusliefhebster
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
Er zijn op dit moment wat problemen met de database volgens mij. Daarnet lagen de notifications er ook al uit. Er zijn ook al topics over in SB. Even afwachten denk ik. Waarschijnlijk komt hij nog wel terug,Hydra schreef op zondag 9 december 2018 @ 10:39:
Euh, is m'n dag 9 submission verwijderd?
Ben zelf net klaar. Viel mij alles mee. Na mijn eerste keer lezen had ik nog niet helemaal door van hoe en wat, maar ben gewoon begonnen en gaande weg kwam ik er wel achter (zonder dat ik te veel werk had gedaan).
spoiler:
Heb zelf een doublelinkedlist gemaakt waarbij de laatste naar de eerste verwees en viceverse. Schrijf een paar update functies en voila
Performance viel mij ook alles mee, waarschijnlijk ook door pointer gebruik
part 1: 4004787 ns => 4,005 ms
part 2: 543225500 ns => 543,226 ms
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
Dag 9 in Kotlin
spoiler:
Weer een tijdje vast gezeten omdat ik het score deel verkeerd gelezen had. Ik telde altijd 23 op i.p.v. de waarde van de knikker die deelbaar was door 23. En dan kom je iedere keer te laag uit.
[ Voor 6% gewijzigd door Hydra op 09-12-2018 14:44 ]
https://niels.nu
- H!GHGuY
- Registratie: December 2002
- Niet online
Try and take over the world...
:strip_exif()/u/72391/Pinky_and_the_Brain_-_Brain.gif?f=community)
Ik ben ook maar een (laattijdig) begonnen. Geen score dus, maar wel eens leuk.
Aangezien ik op het werk al enkele jaren OCaml doe, wou ik wel eens zien hoe die zich leent voor dit soort oefeningetjes... Voorlopig al een 8-tal opdrachtjes gedaan en de conclusie is positief.
Het meest interessante is dat met uitzondering van 1 opdracht, waarbij ik op een bug in een library ben gestoten, ze stuk voor stuk "write+compile+run=right answer" waren. Behalve die ene uitzondering (waar na de bug te fixen, mijn code ook meteen correct was) dus behoorlijk productief en expressief.
Voor geinteresseerden, linkje naar repo
Aangezien ik op het werk al enkele jaren OCaml doe, wou ik wel eens zien hoe die zich leent voor dit soort oefeningetjes... Voorlopig al een 8-tal opdrachtjes gedaan en de conclusie is positief.
Het meest interessante is dat met uitzondering van 1 opdracht, waarbij ik op een bug in een library ben gestoten, ze stuk voor stuk "write+compile+run=right answer" waren. Behalve die ene uitzondering (waar na de bug te fixen, mijn code ook meteen correct was) dus behoorlijk productief en expressief.
Voor geinteresseerden, linkje naar repo
spoiler:
ASSUME makes an ASS out of U and ME
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
Zeg dat wel. M'n reply die ik eerder gepost heb staat op dit moment onder jouw postGropah schreef op zondag 9 december 2018 @ 10:44:
Er zijn op dit moment wat problemen met de database volgens mij.
Grappig dat er gesorteerd wordt op reactie ID in plaats van gewoon op reactie tijd. Weer zo'n typische aanname dat die altijd netjes oplopend zijn
[ Voor 22% gewijzigd door Hydra op 09-12-2018 14:46 ]
https://niels.nu
- Soultaker
- Registratie: September 2000
- Laatst online: 10-07 18:31
Voor dag 9: een nette, objectgeorienteerde oplossing (Python code) doet er helaas 10x zo lang over als de ad hoc implementatie (Python code). De laatste runt in ~120 ms met PyPy.
- Radiant
- Registratie: Juli 2003
- Niet online
Certified MS Bob Administrator
Dag 9 part 1 in Python gemaakt, runde best een tijdje maargoed, kwam het goede antwoord uit. Toen kwam part 2
spoiler:
Ga het maar opnieuw schrijven in C met een linked list
- H!GHGuY
- Registratie: December 2002
- Niet online
Try and take over the world...
Wat me hier wel opvalt is dat iedereen wel over runtimes loopt op te scheppen, maar dat er geen uniforme manier is om te meten...
met of zonder inlezen van data uit file (of stdin)?
met of zonder uitschrijven van antwoord op stdout?
met of zonder opstart van applicatie?
ik neem aan dat iedereen een andere input-set krijgt; af en toe kun je stoppen van het moment er een oplossing gevonden is, dus dat kan verschillen.
Ik schep graag mee op () dus als we het lekker eens kunnen zijn wil ik ook best eens tijden lopen posten. OCaml is over het algemeen best een snelle taal en komt goed mee. Voorlopig zijn mijn tijden iets hoger dan sommige andere talen, maar ik time mijn volledige main loop, inclusief inlezen + parsen.
met of zonder inlezen van data uit file (of stdin)?
met of zonder uitschrijven van antwoord op stdout?
met of zonder opstart van applicatie?
ik neem aan dat iedereen een andere input-set krijgt; af en toe kun je stoppen van het moment er een oplossing gevonden is, dus dat kan verschillen.
Ik schep graag mee op (
ASSUME makes an ASS out of U and ME
- Radiant
- Registratie: Juli 2003
- Niet online
Certified MS Bob Administrator
veldsla schreef op zondag 9 december 2018 @ 20:04:
Geen LL gebruikt
-edit- Kunt wel zien dat ik een beetje brak ben. Netjes gedaan @Verwijderd
spoiler:
Zag ook iemand die in Python een deque gebruikt (intern is dat een linked list). Is een deque nou by design de manier om zoiets op te lossen, of werkt het toevallig goed in Python en Rust?
- ZieglerNichols
- Registratie: Mei 2015
- Niet online
Dag 10 was leuke mix tussen puur programmeren en een beetje menselijke input. Mijn oplossing in Matlab: https://pastebin.com/gkLg44YU
spoiler:
Zou wel gaaf zijn als iemand deze zonder menselijke input kan oplossen. Er zijn vast wel text/charachter recognition libraries hiervoor te vinden
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
Ik krijg gewoon letters te zien maar mijn antwoord wordt niet geaccepteerd? Iedereen heeft een andere code dus ik kan het antwoord gewoon plaatsen volgens mij.
Kan iemand me een andere input geven dan kan ik kijken of het daarmee werkt.
code:
1
2
3
4
5
6
7
8
9
| ###### # # ##### #### ##### ##### # # #####
# ## # # # # # # # # # # # # #
# ## # # # # # # # # # # # #
# # # # # # # # # # # # # # #
##### # # # ##### # ##### ##### ###### #####
# # # # # # # ### # # # # # # #
# # # # # # # # # # # # # # #
# # ## # # # # # # # # # # #
# # ## # # # ## # # # # # # # |
Kan iemand me een andere input geven dan kan ik kijken of het daarmee werkt.
[ Voor 86% gewijzigd door emnich op 10-12-2018 08:01 ]
- Daanoz
- Registratie: Oktober 2007
- Laatst online: 29-06 16:24
Hmm, ik had een soort gelijke output... Zou moeten werken zou ik zeggen.
Wel leuk voor de afwisseling inderdaad.
Wel leuk voor de afwisseling inderdaad.
spoiler:
De juist 'tick' uiteindelijk gevonden door een aanname te doen dat alle sterren binnen 200 x 50 zouden vallen, als er grote characters zouden uitkomen was er waarschijnlijk wel een andere tactiek nodig...
- ElkeBxl
- Registratie: Oktober 2014
- Laatst online: 12-07 20:30
Tassendraagster
Je bent zeker dat die eerste geen E is ipv een F? Volgens mij mis je de onderste rij nog? En je 6e letter lijkt op een R maar zal een B zijn.emnich schreef op maandag 10 december 2018 @ 07:51:
Ik krijg gewoon letters te zien maar mijn antwoord wordt niet geaccepteerd? Iedereen heeft een andere code dus ik kan het antwoord gewoon plaatsen volgens mij.
Without nipples, boobs are pointless - 365 project - In mijn hoofd is het alle dagen Kerstmis - What type of bees make milk? Boobies! - What type of bees are scary? BoooOOOOOooobeees! - Cactusliefhebster
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
@ElkeBxl dat was het inderdaad, de R was een B  Ik zag het toen ik de input van Daanoz probeerde
Ik zag het toen ik de input van Daanoz probeerde
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
Okay, ik heb de oplossing voor dag 10, ik kan alleen deel 1 niet automatisch 'uit' de oplossing halen... Hmm. Dat gaat nog ff duren 
[ Voor 4% gewijzigd door Hydra op 10-12-2018 08:26 ]
https://niels.nu
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Dag 10 is goed te doen.
spoiler:
Ik had deel 2 al opgelost om deel 1 te doen. Ik heb de punten laten loopen tot de initiele max(xmax,ymax) en de kleinste bounding box bepaald en dan die printen.
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
Implementatie verspreid over 2 files vandaag:
[Day 10 in Kotlin]
[Day 10 in Kotlin]
spoiler:
OCR helper
Hij doet vooralsnog alleen de karakters in mijn outputs, ga het later wel ombouwen zodat 'ie 'alle' karakters' kan.
Hij doet vooralsnog alleen de karakters in mijn outputs, ga het later wel ombouwen zodat 'ie 'alle' karakters' kan.
[ Voor 5% gewijzigd door Hydra op 10-12-2018 09:48 ]
https://niels.nu
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Even een testje met OCR: http://bernardv.xs4all.nl/day10/
Je kunt je input plaatsen, standaard staat er de test-input.
//EDIT: De server is niet snel, dus kan even duren voordat je resultaat hebt. Draait op een oude single core pentium
Je kunt je input plaatsen, standaard staat er de test-input.
//EDIT: De server is niet snel, dus kan even duren voordat je resultaat hebt. Draait op een oude single core pentium
[ Voor 34% gewijzigd door BernardV op 10-12-2018 10:54 ]
Leuk, maar je OCR werkt nog niet optimaal. bij mij vind ie XECXBPZB, maar jij vindt AECKBEPZBbernardV schreef op maandag 10 december 2018 @ 10:48:
Even een testje met OCR: http://bernardv.xs4all.nl/day10/
Je kunt je input plaatsen, standaard staat er de test-input.
//EDIT: De server is niet snel, dus kan even duren voordat je resultaat hebt. Draait op een oude single core pentium
- ElkeBxl
- Registratie: Oktober 2014
- Laatst online: 12-07 20:30
Tassendraagster
Bij mijn input is het wel correct
Without nipples, boobs are pointless - 365 project - In mijn hoofd is het alle dagen Kerstmis - What type of bees make milk? Boobies! - What type of bees are scary? BoooOOOOOooobeees! - Cactusliefhebster
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Zou je me je input eens kunnen sturen?DRaakje schreef op maandag 10 december 2018 @ 10:56:
[...]
Leuk, maar je OCR werkt nog niet optimaal. bij mij vind ie XECXBPZB, maar jij vindt AECKBEPZB
- ZieglerNichols
- Registratie: Mei 2015
- Niet online
Bij mijn input werkt het ook niet helemaal lekker (zie: https://imgur.com/MFGQLyB ), maar wel gaaf dat je dit met OCR probeert te doen!bernardV schreef op maandag 10 december 2018 @ 10:48:
Even een testje met OCR: http://bernardv.xs4all.nl/day10/
Je kunt je input plaatsen, standaard staat er de test-input.
//EDIT: De server is niet snel, dus kan even duren voordat je resultaat hebt. Draait op een oude single core pentium
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
@emnich Ja dit is in PHP. Met GD de input naar een image schrijven en daarna OCR.
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
GeweldigbernardV schreef op maandag 10 december 2018 @ 11:05:
@emnich Ja dit is in PHP. Met GD de input naar een image schrijven en daarna OCR.
Heb m'n eigen OCR implementatie gemaakt, was leuk om te doen
https://niels.nu
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Ik heb wat tweaks aangebracht in de OCR herkenning, hoop dat hij nu beter werkt met verschillende input.
https://gist.github.com/u...8ad7b4b0594b3b8b029bc47b4emnich schreef op maandag 10 december 2018 @ 11:01:
@DRaakje wil je hem mij ook sturen, ik ben ook bezig met de OCR.
https://pastebin.com/N3Rkw1YL
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
@DRaakje Hij werkt nu ook met jouw input. Was even spelen met de grootte van de "pixels" en de ruimte tussen de letters.
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
Echt tof deze vandaag. Ik heb ook een eigen OCR gebouwd. Alleen de S,O,Q,M,V,W missen nog om te testen. Heeft iemand die toevallig?
- sjakie02
- Registratie: November 2011
- Laatst online: 22-07 17:46
/u/434683/crop5df38445a586d_cropped.png?f=community)
Ik kwam een leuke Chrome extension tegen die allerlei grafieken aan de private leaderboards toevoegt: https://chrome.google.com...bokofodhhjpipflmdplipblbe
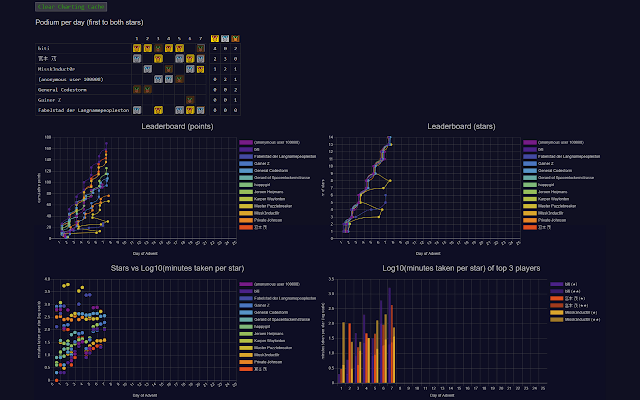
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
Ben ik de enige die dus echt totaal geen zin heeft in OCR en aanverwanten? Ik laat hem voor nu even voor wat hij is. Ben ook veels te moe om er mee aan de slag te gaan
[ Voor 4% gewijzigd door Gropah op 10-12-2018 14:39 ]
Verwijderd
Radiant schreef op zondag 9 december 2018 @ 21:36:
[...]
spoiler:Zag ook iemand die in Python een deque gebruikt (intern is dat een linked list). Is een deque nou by design de manier om zoiets op te lossen, of werkt het toevallig goed in Python en Rust?
spoiler:
In Rust is een Deque een circular buffer, en geen Linked List. het is echter wel een hele goed oplossing, omdat je vrij gemakkelijk de Deque 'rond kan draaien', door items van de front te poppen, en ze in de back the pushen, of andersom om de andere kant op te draaien. pop en push zijn hier constant?? (verbeter me als het fout is) time, dus dat is lekker snel!
- woutertje
- Registratie: Maart 2002
- Laatst online: 24-07 23:09
:strip_exif()/u/51994/radiaton.gif?f=community)
Van dag 10 een animatie gemaakt, met verschillende kleuren voor elke letter. Programmeertaal is Rust.
Vond hem vandaag best wel weer leuk :-).

Vond hem vandaag best wel weer leuk :-).
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
Je hoeft helemaal geen OCR te doen, je kan het gewoon zelf lezen van het scherm.Gropah schreef op maandag 10 december 2018 @ 14:39:
Ben ik de enige die dus echt totaal geen zin heeft in OCR en aanverwanten? Ik laat hem voor nu even voor wat hij is. Ben ook veels te moe om er mee aan de slag te gaan
Voor de fun heb ik een OCR gemaakt maar dat heb je helemaal niet nodig voor de opdracht.
Verwijderd
vandaag was vergelijkbaar met https://adventofcode.com/2017/day/20 gecombineerd met https://adventofcode.com/2016/day/8 . Vond het...meh, niet mijn favoriet
[ Voor 6% gewijzigd door Verwijderd op 10-12-2018 15:08 ]
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Voor mij was het een redelijk makkelijke aanpassing of je nu een char schrijft naar je scherm of een "pixel" in een afbeelding. Ik heb ook geen OCR zelf geschreven, alleen tesseract gepakt.Gropah schreef op maandag 10 december 2018 @ 14:39:
Ben ik de enige die dus echt totaal geen zin heeft in OCR en aanverwanten? Ik laat hem voor nu even voor wat hij is. Ben ook veels te moe om er mee aan de slag te gaan
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
Als in deze tesseract? Das niet "alleen maar" imobernardV schreef op maandag 10 december 2018 @ 15:47:
[...]
Voor mij was het een redelijk makkelijke aanpassing of je nu een char schrijft naar je scherm of een "pixel" in een afbeelding. Ik heb ook geen OCR zelf geschreven, alleen tesseract gepakt.
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Ik heb het gewoon door de Azure OCR API gegooid. https://azure.microsoft.c...services/computer-vision/Gropah schreef op maandag 10 december 2018 @ 15:59:
[...]
Als in deze tesseract? Das niet "alleen maar" imo
Maar in eerste instantie gewoon zelf het antwoord uitgelezen.
AWS en Google hebben vergelijkbaar APIs
[ Voor 4% gewijzigd door Woy op 10-12-2018 16:04 ]
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- Hydra
- Registratie: September 2000
- Laatst online: 26-04 10:16
Zoals anderen zeiden; het is niet nodig. Alleen heb ik zelf een runnertje gemaakt om alle antwoorden van alle dagen netjes in een tabel te printen, en dan past de output van deel 1 daar natuurlijk niet echt in. Dus ik had de keuze om het antwoord te hard-coden of een OCR implementatie te maken. TjaGropah schreef op maandag 10 december 2018 @ 14:39:
Ben ik de enige die dus echt totaal geen zin heeft in OCR en aanverwanten? Ik laat hem voor nu even voor wat hij is. Ben ook veels te moe om er mee aan de slag te gaan
https://niels.nu
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Ja die, maar "apt-get" doet wonderenGropah schreef op maandag 10 december 2018 @ 15:59:
[...]
Als in deze tesseract? Das niet "alleen maar" imo
//EDIT: Dit is trouwens de implementatie waarmee ik het opgelost heb: https://pastebin.com/FC5RHyWB
spoiler:
Enige wat later toegevoegd is is de smin/smax om te bepalen in welke range je gaat zoeken.
[ Voor 28% gewijzigd door BernardV op 10-12-2018 16:55 ]
- ppx17
- Registratie: December 2007
- Laatst online: 24-10-2025
Vond vandaag juist wel een leuke vanwege de mogelijkheden tot optimalisatie. Van m'n eerste implementatie (+- 450ms) naar de laatste (2.8ms) in een iteratie of 5. (Zonder OCR overigens, daar zag ik dan weer geen noodzaak voor)
[ Voor 11% gewijzigd door ppx17 op 10-12-2018 17:11 ]
40D | 8 | 50 | 100 | 300
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Nette oplossing @ppx17 mooi ook om te zien dat je de stapgrootte aanpast. Doet me denken aan “raad het getal onder xxx”
Wat ik me wel afvraag is de while < 10 dat is een aanname op de gegevens die je hebt, maar als de afmeting anders zou zijn.. maar al met al, nette oplossing.
Wat ik me wel afvraag is de while < 10 dat is een aanname op de gegevens die je hebt, maar als de afmeting anders zou zijn.. maar al met al, nette oplossing.
- Soultaker
- Registratie: September 2000
- Laatst online: 10-07 18:31
Re efficient het tijdstip zoeken voor dag 17:
spoiler:
ppx17's oplossing een soort ad-hoc implementatie van dat idee, die iets meer evaluaties doet dan strict noodzakelijk (maar ook O(log N) is).
je kunt er vanuit gaan dat de bounding box van de punten minimaal is op het doeltijdstip, dus kun je een ternary search uitvoeren om dat tijdstip te vinden (Python code)
[ Voor 9% gewijzigd door Soultaker op 10-12-2018 22:02 ]
- ZieglerNichols
- Registratie: Mei 2015
- Niet online
Dag 11 in Matlab: https://pastebin.com/pQebVwp3
Niet bepaald snel met 135.711ms (als in 135 duizend milliseconde )
Niet bepaald snel met 135.711ms (als in 135 duizend milliseconde
- ppx17
- Registratie: December 2007
- Laatst online: 24-10-2025
Dag 11 in php. Draait in 2,5 seconde op m'n pc. Nog even verder dubben hoe ik dit sneller ga krijgen...
spoiler:
Grootste probleem zijn de squares van size 11 en 13, die zijn groot / traag en worden niet versneld door de 2x2 of 3x3 caches.
[ Voor 25% gewijzigd door ppx17 op 11-12-2018 08:35 ]
40D | 8 | 50 | 100 | 300
Verwijderd
Helemaal niets gecached in python. Deel 1 was snel genoeg zo, maar deel twee red je niet voor alle size.
spoiler: niet zo elegant
tenzij je aanneemt dat het maximum square niet al te groot is
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
Totaal ongeoptimaliseerd doet deel 2 er bij mij 1min17 over het is te doen, maar niet om over naar huis te schrijven.
spoiler:
Zit er over na te denken om de vorige grid te cachen en daar dan bij behorende boundries elke keer bij op te tellen. Maar heb atm nog niet echt zin om er aan te beginnen
Gropah schreef op dinsdag 11 december 2018 @ 09:47:
spoiler:Zit er over na te denken om de vorige grid te cachen en daar dan bij behorende boundries elke keer bij op te tellen. Maar heb atm nog niet echt zin om er aan te beginnen
spoiler:
Cachen is hier nogal ingewikkeld. Er is een veel elegantere oplossing, waarmee je een voorberekening doet op je grid, en hierna de som van elke willekeurige rectangle daar uit kan halen in een O(1) operatie.
- BernardV
- Registratie: December 2003
- Laatst online: 16:05
Hij werkt niet goed bij mijn input '5468'.ppx17 schreef op dinsdag 11 december 2018 @ 08:33:
Dag 11 in php. Draait in 2,5 seconde op m'n pc. Nog even verder dubben hoe ik dit sneller ga krijgen...
spoiler:Grootste probleem zijn de squares van size 11 en 13, die zijn groot / traag en worden niet versneld door de 2x2 of 3x3 caches.
spoiler:
Part 1 is goed, part 2 niet, dat moet zijn: 90,101,15 en je code geeft 237,249,11
spoiler:
Ik heb een aanname gedaan dat het grootste powergrid niet groter kan zijn dan de wortel van de gridsize (300), tot nu toe lijkt dat goed, maar ik kan het niet wiskundig onderbouwen.
- Gropah
- Registratie: December 2007
- Niet online
Oompa-Loompa 💩
kokx schreef op dinsdag 11 december 2018 @ 10:26:
[...]
spoiler:Cachen is hier nogal ingewikkeld. Er is een veel elegantere oplossing, waarmee je een voorberekening doet op je grid, en hierna de som van elke willekeurige rectangle daar uit kan halen in een O(1) operatie.
spoiler:
cachen is misschien het verkeerde woord. Op dit moment bereken ik voor elke positie de waarde. Voor part 1 maak je dan squares met size = 3, en somt hij dus 9 waarden. Voor part 2 varieert dat dus maar doet hij 1,4,9,16, etc waarde optellen.
Ik zat er over na te denken om een grid te maken waar de waarden van n in komen, en voor n+1 dan de waarde uit dat grid te halen en dan de boundaries er van de box die er nog niet in zit bij op te tellen. Scheelt al een boel berekeningen.
Ik heb ook summed area tables voorbij zien komen, misschien dat ik dat ook nog op een manier ga implementeren, maar ben atm ook benieuwd wat de eerste methode die ik omschrijf aan performance oplevert.
Ik zat er over na te denken om een grid te maken waar de waarden van n in komen, en voor n+1 dan de waarde uit dat grid te halen en dan de boundaries er van de box die er nog niet in zit bij op te tellen. Scheelt al een boel berekeningen.
Ik heb ook summed area tables voorbij zien komen, misschien dat ik dat ook nog op een manier ga implementeren, maar ben atm ook benieuwd wat de eerste methode die ik omschrijf aan performance oplevert.
Gropah schreef op dinsdag 11 december 2018 @ 10:30:
[...]
spoiler:cachen is misschien het verkeerde woord. Op dit moment bereken ik voor elke positie de waarde. Voor part 1 maak je dan squares met size = 3, en somt hij dus 9 waarden. Voor part 2 varieert dat dus maar doet hij 1,4,9,16, etc waarde optellen.
Ik zat er over na te denken om een grid te maken waar de waarden van n in komen, en voor n+1 dan de waarde uit dat grid te halen en dan de boundaries er van de box die er nog niet in zit bij op te tellen. Scheelt al een boel berekeningen.
Ik heb ook summed area tables voorbij zien komen, misschien dat ik dat ook nog op een manier ga implementeren, maar ben atm ook benieuwd wat de eerste methode die ik omschrijf aan performance oplevert.
spoiler:
Summed area tables is dus wat ik heb gedaan. Is ontzettend simpel te implementeren, als je de sommen van wikipedia volgt. En geeft niet alle vervelende edge-cases die caching oplevert.
25ms en 1.5sec Zo nog eens kijken naar die ...
spoiler:
summed area table. Dat zit er inderdaad simpel uit, en ook logisch.
spoiler:
Mijn oplossing was om voor elk positie, een loop te hebben steeds de grid 1 maatje groter maakt. Dan hoef je alleen de Rij en Column ernaast erbij op te tellen.
[ Voor 12% gewijzigd door DRaakje op 11-12-2018 11:11 ]
- heuveltje
- Registratie: Februari 2000
- Laatst online: 24-07 17:04
KoelkastFilosoof
:strip_exif()/u/3287/crop6274f828ec8f4.gif?f=community)
Even zeker weten dat ik vraag 11. deel 1 goed begrijp.
puzzel input is dus een 5 cijferig getal.
Dus eerst genereer je uit dat getal , een array van 300*300 met de individuele celwaardes.
En dan ga je binnen dat array zoeken naar het 3x3 blok met de hoogste totaal som ?
puzzel input is dus een 5 cijferig getal.
Dus eerst genereer je uit dat getal , een array van 300*300 met de individuele celwaardes.
En dan ga je binnen dat array zoeken naar het 3x3 blok met de hoogste totaal som ?
Heuveltjes CPU geschiedenis door de jaren heen : AMD 486dx4 100, Cyrix PR166+, Intel P233MMX, Intel Celeron 366Mhz, AMD K6-450, AMD duron 600, AMD Thunderbird 1200mhz, AMD Athlon 64 x2 5600, AMD Phenom X3 720, Intel i5 4460, AMD Ryzen 5 3600 5800x3d
- emnich
- Registratie: November 2012
- Niet online
kom je hier vaker?
1816 1343ms in PHP, het kan vast sneller maar ik vind het vandaag wel goed geloof ik.
@heuveltje In principe klopt dat (de input hoeft overigens niet 5 lang te zijn).
spoiler:
Ik heb gewoon een bruteforce waarbij ik alle squares bereken. Als het totaal van de square lager wordt dan break ik eruit en heb ik hem gevonden. In theorie kan het vast dat er nog een hogere komt na eerst een lagere maar in alle test scenario's was dat niet het geval.
@heuveltje In principe klopt dat (de input hoeft overigens niet 5 lang te zijn).
[ Voor 18% gewijzigd door emnich op 11-12-2018 11:57 ]