:strip_icc():strip_exif()/u/82975/crop633eccabd9275_cropped.jpg?f=community)
Heb een schema ingesteld dat er tussen bepaalde tijd 's nachts een Maintenance Window ingesteld staat.
Met als doel, dat wanneer er tijdens dat tijdsbestek een error zou komen, deze niet gemaild wordt.
Echter worden (wat opzich logisch is) er dan ook geen gegevens vastgelegd, welke wel handig zijn voor hisoritsch waardes.
Iemand hier al tegen aan gelopen?
- eagle00789
- Registratie: November 2005
- Laatst online: 11-06 10:31
Est. November 2005
:strip_exif()/u/161098/devil-pc.gif?f=community)
Ik zeg:
- Warning: een apparaat gaat een mankement vertonen waardoor het gewenst is nu een actie te vertonen
- Alert: Een apparaat heeft een mankement waardoor actie verplicht is.
Een device met een redundante voeding waarvan 1 voeding uitvalt: alert
Een device waarvan de schijf net onder de threshold is gevallen: Warning
Een device is geheel onbereikbaar: Alert
- Warning: een apparaat gaat een mankement vertonen waardoor het gewenst is nu een actie te vertonen
- Alert: Een apparaat heeft een mankement waardoor actie verplicht is.
Een voorbeeld van zijn bewering:
Een device met een redundante voeding waarvan 1 voeding uitvalt: Warning
Een device waarvan de schijf net onder de threshold is gevallen: Warning
Een device is geheel onbereikbaar: Alert
Je ziet, we hebben beide 2 verschillende opvattingen.
Nu wil ik graag eens van de community weten, wat denken zij dat de betere interpretatie is? (Andere opvattingen zijn natuurlijk ook welkom)
:strip_icc():strip_exif()/u/94769/horus.jpg?f=community)
Voorbeeldje: Hier is een Alert een melding die 24/7 op je mobiel binnenkomt, je wil niet wakker worden voor een device waar 1 van de 2 voedingen uitvalt, dan wil je dus een warning die je de volgende ochtend kan oppakken.
Any errors in spelling, tact, or fact are transmission errors.
- eagle00789
- Registratie: November 2005
- Laatst online: 11-06 10:31
Est. November 2005
Het probleem in het monitoringsysteem is dat beide voedingen apart worden gemonitord vie allebei 1 sensor. De sensoren weten van elkaar geen status en het systeem laat ze niet aan elkaar koppelen.Oogje schreef op woensdag 12 juni 2019 @ 09:34:
Wat mij betreft ligt het eraan welke acties aan een alert/warning hangen.
Voorbeeldje: Hier is een Alert een melding die 24/7 op je mobiel binnenkomt, je wil niet wakker worden voor een device waar 1 van de 2 voedingen uitvalt, dan wil je dus een warning die je de volgende ochtend kan oppakken.
Hierdoor wil je dus van beide voedingen altijd een alert hebben. Als je ze aan elkaar kunt koppelen, dan kun je dit wel realizeren.
We kunnen wel custom sensoren maken die dit scenario wel aankunnen.
Misschien is dat een alternatief voor mijn collega.
- paulhekje
- Registratie: Maart 2001
- Laatst online: 23-06 12:38
:strip_exif()/u/24090/hekje.gif?f=community)
Beetje onnodig; als 1 voeding kapot is doet het apparaat het nog; bij 2 zal de ping ook wel uitvallen, en daar zet je dan wel een alert op.eagle00789 schreef op woensdag 12 juni 2019 @ 13:11:
[...]
Het probleem in het monitoringsysteem is dat beide voedingen apart worden gemonitord vie allebei 1 sensor. De sensoren weten van elkaar geen status en het systeem laat ze niet aan elkaar koppelen.
Hierdoor wil je dus van beide voedingen altijd een alert hebben. Als je ze aan elkaar kunt koppelen, dan kun je dit wel realizeren.
We kunnen wel custom sensoren maken die dit scenario wel aankunnen.
Misschien is dat een alternatief voor mijn collega.
|=|=|=||=|=|=||=|=|=| http://www.vanwijck.com |=|=|=||=|=|=||=|=|=||=|=|=||=|=|=||=|=|=||=|=|=|
- unezra
- Registratie: Maart 2001
- Laatst online: 20-06 15:00
Ceci n'est pas un sous-titre.
In mijn beleving gebruik je 2 termen die alleen indirect iets elkaar te maken hebben.eagle00789 schreef op woensdag 12 juni 2019 @ 07:36:
Ik hoop dat iemand mij kan helpen. ik heb een discussie met een collega over het verschil tussen een alert en een warning als het gaat over sysops (Monitoring)
- Een alert is *alles* dat iets in je monitoring systeem triggert (Zabbix noemt dat een trigger)
- Een warning is een severity van een alert
Kijk je naar Zabbix, heb je de volgende severities:
- Not classified
- Information
- Warning
- Average
- High
- Disaster
Zie:
https://www.zabbix.com/do.../config/triggers/severity
Hun beschrijving zegt daarover dit:
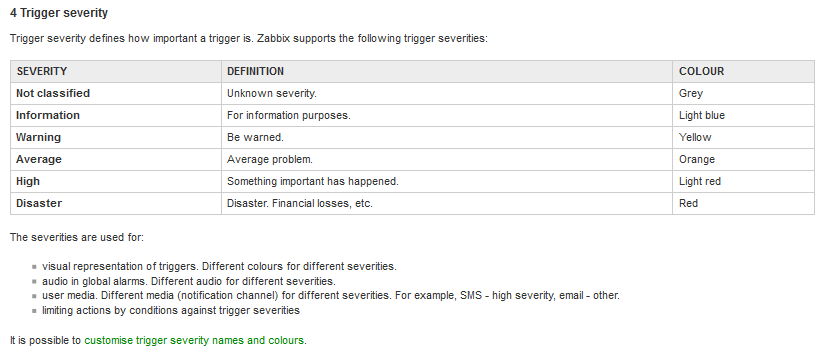
Ik vertaal het even naar Zabbix terminologie (severities van triggers) en wat ik er van vind.
- "Een device met een redundante voeding waarvan 1 voeding uitvalt: alert" --> High. Actie is noodzakelijk, zeker binnen 24 uur want je redundancy is aangetast maar je hoeft er in de regel niet voor uit je bed gebeld te worden.Ik zeg:Een voorbeeld van mijn bewering:
- Warning: een apparaat gaat een mankement vertonen waardoor het gewenst is nu een actie te vertonen
- Alert: Een apparaat heeft een mankement waardoor actie verplicht is.
Een device met een redundante voeding waarvan 1 voeding uitvalt: alert
Een device waarvan de schijf net onder de threshold is gevallen: Warning
Een device is geheel onbereikbaar: Alert
- "Een device waarvan de schijf net onder de threshold is gevallen: Warning" --> Warning, afhankelijk van je thresholds. (Wij hanteren in de regel 4 tresholds die beginnen op Warning, daarna Average, daarna High. Disaster is "disk 100% vol".
- "Een device is geheel onbereikbaar: Alert" --> Disaster (lijkt me geen verdere uitleg voor nodig, hiervoor moet je je bed uit gebeld worden *mits* het een mission critical systeem is. Niet kritieke systemen kunnen best een dag, soms dagen wachten. Daar zou je dus ook de severity van kunnen aanpassen of je werkproces.)
Ik denk dat het belangrijk is eerst de juiste terminologie te gebruiken hiervoor en niet te spreken over warnings en alerts, omdat dat compleet verschillende dingen binnen eenzelfde context (monitoring) zijn. Jullie monitoringsysteem zal denk ik ook niet de termen "warning" en "alert" gebruiken voor iets dat severities zijn.• Warning: een apparaat gaat een mankement vertonen waardoor het gewenst is nu een actie te vertonen
• Alert: Een apparaat heeft een mankement waardoor actie verplicht is.
[/list]
(ja dit is identiek aan dat wat ik beweer, echter interpreteert hij het anders)
Een voorbeeld van zijn bewering:
Een device met een redundante voeding waarvan 1 voeding uitvalt: Warning
Een device waarvan de schijf net onder de threshold is gevallen: Warning
Een device is geheel onbereikbaar: Alert
Je ziet, we hebben beide 2 verschillende opvattingen.
Nu wil ik graag eens van de community weten, wat denken zij dat de betere interpretatie is? (Andere opvattingen zijn natuurlijk ook welkom)
Ná Scaoll. - Don’t Panic.
- eagle00789
- Registratie: November 2005
- Laatst online: 11-06 10:31
Est. November 2005
Je hebt geheel gelijk, maar dat is mijn collega schuld die deze continu zo gebruikt en ik het langzaam overneem van hem op deze manier.unezra schreef op donderdag 13 juni 2019 @ 08:41:
[...]
In mijn beleving gebruik je 2 termen die alleen indirect iets elkaar te maken hebben.
- Een alert is *alles* dat iets in je monitoring systeem triggert (Zabbix noemt dat een trigger)
- Een warning is een severity van een alert
[...]
Ik denk dat het belangrijk is eerst de juiste terminologie te gebruiken hiervoor en niet te spreken over warnings en alerts, omdat dat compleet verschillende dingen binnen eenzelfde context (monitoring) zijn. Jullie monitoringsysteem zal denk ik ook niet de termen "warning" en "alert" gebruiken voor iets dat severities zijn.
De juiste terminologie voor ons monitoring pakket is als volgt:
| State | Critical Priority | Description | |
| Failed | 1 | The service is not functioning at the required level. | |
| Warning | 2 | The service is functioning but not at an optimal level. For example, the service thresholds could be set up to indicate a Warning state when a service is not meeting its SLA. | |
| Normal | 3 | The service is sending valid data and functioning at an optimal level according to the specified thresholds. | |
| Misconfigured | 4 | There is a setup error in the service thresholds. For example, if there is a gap between the threshold values and the service, the service changes to the Misconfigured state. | |
| Stale Data | 5 | The central server has not received an update during the specified time period and the data is out-of-date or unavailable. This occurs if the agent does not send an update or the connection between the Agent and the central server is down. The status of a service can change from the No Data to the Stale Data state if the data was not received during the expected period. For example, a local service can change to the Stale Data state if there is a delay in installing the appropriate agent on the device. Local services of a device can change from the No Data state to the Stale Data state if there is a delay in installing the appropriate agent on the device. | |
| No Data | 6 | The service has not yet sent any data. All newly added services start in the No Data state and can take several minutes before sending any data. The No Data state is displayed if the state of the service cannot be read or if the service changes to Indeterminate. | |
| 7 | The device is not connected to the network. This occurs when a device experiences a 'friendly' shut down or during a scheduled downtime. If a service is disabled, then its status changes to the Disconnected state. |
Het probleem zit hem er dus in dat de beide voedingen separaat gemonitord worden en dus niet van elkaar weten in het monitoring pakket of er al een andere service in warning state gaat. Hierdoor heb je dus de keuze om voor beide voedingen alleen een warning te kiezen of voor beide een failed.
Wel kan ik dus een custom service aanmaken zodat ik beide voedingen via 1 service monitor waar ik dan wel de logica aan kan hangen dat ze het van elkaar weten.
Ik hoop dat ik het zo iets duidelijker heb gemaakt voor je. (excuses voor de verkeerde terminologie)
- unezra
- Registratie: Maart 2001
- Laatst online: 20-06 15:00
Ceci n'est pas un sous-titre.
Top! Dat ziet er inderdaad een stuk logischer uit.eagle00789 schreef op donderdag 13 juni 2019 @ 11:06:
[...]
Je hebt geheel gelijk, maar dat is mijn collega schuld die deze continu zo gebruikt en ik het langzaam overneem van hem op deze manier.
De juiste terminologie voor ons monitoring pakket is als volgt:
State Critical Priority Description [Afbeelding] Failed 1 The service is not functioning at the required level. [Afbeelding] Warning 2 The service is functioning but not at an optimal level. For example, the service thresholds could be set up to indicate a Warning state when a service is not meeting its SLA. [Afbeelding] Normal 3 The service is sending valid data and functioning at an optimal level according to the specified thresholds. [Afbeelding] Misconfigured 4 There is a setup error in the service thresholds. For example, if there is a gap between the threshold values and the service, the service changes to the Misconfigured state. [Afbeelding] Stale Data 5 The central server has not received an update during the specified time period and the data is out-of-date or unavailable. This occurs if the agent does not send an update or the connection between the Agent and the central server is down. The status of a service can change from the No Data to the Stale Data state if the data was not received during the expected period. For example, a local service can change to the Stale Data state if there is a delay in installing the appropriate agent on the device. Local services of a device can change from the No Data state to the Stale Data state if there is a delay in installing the appropriate agent on the device. [Afbeelding] No Data 6 The service has not yet sent any data. All newly added services start in the No Data state and can take several minutes before sending any data. The No Data state is displayed if the state of the service cannot be read or if the service changes to Indeterminate. [Afbeelding] 7 The device is not connected to the network. This occurs when a device experiences a 'friendly' shut down or during a scheduled downtime. If a service is disabled, then its status changes to the Disconnected state.
Ik zou het zo doen:Het probleem zit hem er dus in dat de beide voedingen separaat gemonitord worden en dus niet van elkaar weten in het monitoring pakket of er al een andere service in warning state gaat. Hierdoor heb je dus de keuze om voor beide voedingen alleen een warning te kiezen of voor beide een failed.
Wel kan ik dus een custom service aanmaken zodat ik beide voedingen via 1 service monitor waar ik dan wel de logica aan kan hangen dat ze het van elkaar weten.
Ik hoop dat ik het zo iets duidelijker heb gemaakt voor je. (excuses voor de verkeerde terminologie)
- Voor beiden een Warning (Niet alleen bij uitval, maar ook bij andere issues met die voeding, ze kunnen dacht ik vaak ook partial failen. Dat heb ik gisteren gemerkt met een fan. De fan zelf geeft een warning in Zabbix, maar draait gewoon door. Hij is dus niet helemaal stuk maar ILO vind wel dat er iets mis is, dus geeft 'ie alsnog een warning af.)
- Een failed wanneer beiden een warning geven ("event correlation" is meestal de term hiervoor)
- Sowieso zorgen dat je een failed hebt op het apparaat waar die voedingen in zitten (beide voedingen down betekend 100% dat je apparaat weg is, maar dat kun je dus niet meer uit die PSU's halen, die monitoring valt dan immers helemaal weg).
Zijn beiden 100% kapot / uitgevallen, zul je geen warning krijgen op de PSU's, het apparaat staat immers uit, maar bij een partial failed (die zeker een warning rechtvaardigd), wil je absoluut meteen een failed hebben. (Wij zouden dat als "Disaster" in Zabbix classificeren, that is, als we aan event correlation zouden doen. Doen we alleen niet.)
De failed op het apparaat zelf is evident. Apparaat stuk. Die moet er óók zijn, je wil niet alleen triggeren op je PSU's.
Ná Scaoll. - Don’t Panic.
- Equator
- Registratie: April 2001
- Laatst online: 11:56
:strip_icc():strip_exif()/u/25852/bowmore_18k.jpg?f=community)
- Yariva
- Registratie: November 2012
- Laatst online: 24-06 14:18
:strip_icc():strip_exif()/u/480920/crop560beea971308_cropped.jpeg?f=community)
Om de boel nog even lastiger te maken.. Mochten je servers een HA paar zijn dan kan je jezelf ook afvragen of het uitmaakt dat 1 server kapot gaat. Wil je om 3 uur s'nachts worden wakker gebeld voor zo'n melding terwijl de 2de bak het alweer keurig heeft overgenomen?eagle00789 schreef op donderdag 13 juni 2019 @ 11:06:
[...]
Je hebt geheel gelijk, maar dat is mijn collega schuld die deze continu zo gebruikt en ik het langzaam overneem van hem op deze manier.
De juiste terminologie voor ons monitoring pakket is als volgt:
State Critical Priority Description [Afbeelding] Failed 1 The service is not functioning at the required level. [Afbeelding] Warning 2 The service is functioning but not at an optimal level. For example, the service thresholds could be set up to indicate a Warning state when a service is not meeting its SLA. [Afbeelding] Normal 3 The service is sending valid data and functioning at an optimal level according to the specified thresholds. [Afbeelding] Misconfigured 4 There is a setup error in the service thresholds. For example, if there is a gap between the threshold values and the service, the service changes to the Misconfigured state. [Afbeelding] Stale Data 5 The central server has not received an update during the specified time period and the data is out-of-date or unavailable. This occurs if the agent does not send an update or the connection between the Agent and the central server is down. The status of a service can change from the No Data to the Stale Data state if the data was not received during the expected period. For example, a local service can change to the Stale Data state if there is a delay in installing the appropriate agent on the device. Local services of a device can change from the No Data state to the Stale Data state if there is a delay in installing the appropriate agent on the device. [Afbeelding] No Data 6 The service has not yet sent any data. All newly added services start in the No Data state and can take several minutes before sending any data. The No Data state is displayed if the state of the service cannot be read or if the service changes to Indeterminate. [Afbeelding] 7 The device is not connected to the network. This occurs when a device experiences a 'friendly' shut down or during a scheduled downtime. If a service is disabled, then its status changes to the Disconnected state.
Het probleem zit hem er dus in dat de beide voedingen separaat gemonitord worden en dus niet van elkaar weten in het monitoring pakket of er al een andere service in warning state gaat. Hierdoor heb je dus de keuze om voor beide voedingen alleen een warning te kiezen of voor beide een failed.
Wel kan ik dus een custom service aanmaken zodat ik beide voedingen via 1 service monitor waar ik dan wel de logica aan kan hangen dat ze het van elkaar weten.
Ik hoop dat ik het zo iets duidelijker heb gemaakt voor je. (excuses voor de verkeerde terminologie)
Uiteraard is dat afhankelijk van de omgeving waar je in terecht komt. Maar bijvoorbeeld bij ons (met Zabbix) hebben wij de alerts als volgt:
- Informational: mogen vanzelf sprekend zijn. Dit zijn interfaces die iemand enabled bijvoorbeeld.
- Warning: Een interface dat up / down gaat. Een processor die wat hoger begint te draaien.
- Average: Hier komen de PSU's van jou binnen. Deze foutmelding is wat belangrijker dan een warning.
- High: Iets is onbereikbaar maar de service heeft (nog) geen impact
- Disaster: Service impacting. Een HA cluster valt uit, een VIP op de loadbalancer is down etc.
Mensen zijn gelijk, maar sommige zijn gelijker dan andere | Humans need not apply
- unezra
- Registratie: Maart 2001
- Laatst online: 20-06 15:00
Ceci n'est pas un sous-titre.
Het is niet multi-master (ook niet multi-proxy in de zin van HA proxies).
Wil je Zabbix zelf HA maken, moet je dat doen op je infra of op OS-niveau, Zabbix zelf kan het niet.
Het is een prima pakket, maar daar kan het toch nog iets leren van de grote (en gruwelijk dure) zuiver commerciële pakketten van HP en IBM. (Alleen zijn die weer dusdanig duur, dat ik me afvraag wat voor organisatiegrootte je anno 2019 nodig hebt om ze te rechtvaardigen.)
Ná Scaoll. - Don’t Panic.
/u/4024/burne.png?f=community)
Wij hebben nagios vervangen door shinken en thruk, en dat is triviaal HA te maken. En met de juiste skin lijkt het nog net (oude) nagios ook.unezra schreef op vrijdag 14 juni 2019 @ 20:48:
Overigens wel een ongelooflijk nadeel van Zabbix:
Het is niet multi-master (ook niet multi-proxy in de zin van HA proxies).
Wil je Zabbix zelf HA maken, moet je dat doen op je infra of op OS-niveau, Zabbix zelf kan het niet.
I don't like facts. They have a liberal bias.
:strip_icc():strip_exif()/u/403106/3868954827-1_60x60.jpg?f=community)
Ik denk dat dit ook compleet ligt aan de oplossing, ik vertrouw niet blindelings op HA failover bijvoorbeeld, als ik geen accurate applicatietests heb wil ik zelf wel even om 3u 's nachts kijken. Liever dan dat ik om 9u 's ochtends op werk met een high zit omdat de failover goed gegaan is maar de applicaties niet of half draaien voor inmiddels al een paar uur.Yariva schreef op vrijdag 14 juni 2019 @ 16:40:
Om de boel nog even lastiger te maken.. Mochten je servers een HA paar zijn dan kan je jezelf ook afvragen of het uitmaakt dat 1 server kapot gaat. Wil je om 3 uur s'nachts worden wakker gebeld voor zo'n melding terwijl de 2de bak het alweer keurig heeft overgenomen?
VW ID.7 Tourer Pro S | 5670 Wp JA Solar - 14x405 33° op zuid | Twente
- Freeaqingme
- Registratie: April 2006
- Laatst online: 13:08
/u/172597/crop5e1225c8b1011.png?f=community)
Zeg even dat 't om web servers gaat. Dan monitor je primair gewoon de website zelf natuurlijk of die het (nog) doet. Als dan 1 van je 3 web servers er uit ligt maakt dat niet uit, maar als 2 van de 3 web servers er uit liggen wil je dat vermoedelijk wel direct weten om 3 AM.True schreef op zaterdag 15 juni 2019 @ 00:38:
[...]
Ik denk dat dit ook compleet ligt aan de oplossing, ik vertrouw niet blindelings op HA failover bijvoorbeeld, als ik geen accurate applicatietests heb wil ik zelf wel even om 3u 's nachts kijken. Liever dan dat ik om 9u 's ochtends op werk met een high zit omdat de failover goed gegaan is maar de applicaties niet of half draaien voor inmiddels al een paar uur.
No trees were harmed in creating this message. However, a large number of electrons were terribly inconvenienced.
Quorum, in goed Nederlands. Met quorum (Latijn; letterlijk: van wie) wordt het minimumaantal personen of leden bedoeld dat aanwezig moet zijn om stemprocedure als geldig te kunnen beschouwen.Freeaqingme schreef op zaterdag 15 juni 2019 @ 00:50:
[...]
Zeg even dat 't om web servers gaat. Dan monitor je primair gewoon de website zelf natuurlijk of die het (nog) doet. Als dan 1 van je 3 web servers er uit ligt maakt dat niet uit, maar als 2 van de 3 web servers er uit liggen wil je dat vermoedelijk wel direct weten om 3 AM.
En je kunt je HA uitleggen wat het quorum is wat jij wilt hebben, en wat 'ie moet doen als 'ie daar onder komt. Als jij tien webservers hebt en er vallen er drie uit is er wellicht meer aan de hand dan gewoon pech en wil je dat er even een mens naar kijkt. En je kunt er dan voor kiezen om de site een storingsmelding te laten tonen.
I don't like facts. They have a liberal bias.
- Nergenss
- Registratie: Juni 2019
- Laatst online: 15-06 09:33
/u/1218402/crop6015d54db6b66_cropped.png?f=community)
[ Voor 94% gewijzigd door rens-br op 18-06-2019 16:05 ]
- raptorix
- Registratie: Februari 2000
- Laatst online: 17-02-2022
Overigens zie ik monitoring als sleutelonderdeel van devops, het signaleert niet alleen korte termijn problemen, maar geeft ook inzicht in verbeteringen tussen releases, als je dus bijvoorbeeld waarde aan een proces kan hangen, kun je ook aantonen dat een team dit verbeterd heeft.
[ Voor 32% gewijzigd door raptorix op 21-06-2019 10:31 ]
Verwijderd
Jij schrijft dat dit een nadeel is, zelf zie ik dit niet zo. Zabbix heeft een database backend en kan dus op dat front redundant gemaakt worden. Dit zelfde kun je doen met de "voorkant", je kunt het loadbalancen door een echte loadbalancer heen of je kunt er voor kiezen met active/failover te werken (vrrp/keepalived).unezra schreef op vrijdag 14 juni 2019 @ 20:48:
Overigens wel een ongelooflijk nadeel van Zabbix:
Het is niet multi-master (ook niet multi-proxy in de zin van HA proxies).
Wil je Zabbix zelf HA maken, moet je dat doen op je infra of op OS-niveau, Zabbix zelf kan het niet.
Het is een prima pakket, maar daar kan het toch nog iets leren van de grote (en gruwelijk dure) zuiver commerciële pakketten van HP en IBM. (Alleen zijn die weer dusdanig duur, dat ik me afvraag wat voor organisatiegrootte je anno 2019 nodig hebt om ze te rechtvaardigen.)
Dit is veel flexibeler dan de door jou genoemde hele dure oplossingen. In mijn optiek dus zelfs een voordeel.
- zjeeraar84
- Registratie: November 2011
- Laatst online: 12:48
Ik heb zelf ervaring met Nagios, Zabbix en Opmanager. Hier op de zaak zijn we bezig met de inrichting van een Nagios oplossing op basis van OMD-labs. Het gave hiervan is dat o.a. Thruk, Grafana en PNP4Nagios hier ook gelijk al in zit. PNP4Nagios heb ik al draaien, echter met Grafana heb ik een issue: de datasources Thruk en PNP zijn automatisch (door OMD-labs) toegevoegd maar geven een error:
pnp plugin failed
Error: Fetch error: 404 Not Found Instantiating http://nagios.bedrijf.nl/.../vendor/plugin-css/css.js Loading http://nagios.bedrijf.nl/.../vendor/plugin-css/css.js Instantiating http://nagios.bedrijf.nl/.../vendor/plugin-css/css.js Loading http://nagios.bedrijf.nl/...-datasource/query_ctrl.js Loading plugins/sni-pnp-datasource/module
pnp plugin failed
Error: Fetch error: 404 Not Found Instantiating http://nagios.bedrijf.nl/.../vendor/plugin-css/css.js Loading http://nagios.bedrijf.nl/.../vendor/plugin-css/css.js Instantiating http://nagios.bedrijf.nl/.../vendor/plugin-css/css.js Loading http://nagios.bedrijf.nl/...-datasource/query_ctrl.js Loading plugins/sni-pnp-datasource/module
Lijkt er op dat bepaalde files missen? Iemand enig idee?
Update 01-08: ik heb het maar opgelost door pnp4nagios helemaal uit te schakelen en alle performance data naar Influxdb te sturen, en alle plaatjes te maken d.m.v Grafana
[ Voor 6% gewijzigd door zjeeraar84 op 01-08-2019 08:20 ]
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
/u/125506/link-8bit.png?f=community)
Zat vandaag downloads: Zabbix 4.4.0 te lezen en zie een hoop mooie dingen. Een vraag die ik had is in de comments door Spro al beantwoord mbt nieuwe templates. Maar daarop aansluitend heb ik wel nog een vraag erover en een paar andere.
Bij een upgrade krijg je dus geen nieuwe templates. Ook eventuele aanpassingen krijg je niet. Maar, hoe krijg je die aanpassingen dan wel zonder je eigen aanpassingen te verliezen? Want vziw krijg je een foutmelding als je een template wilt inladen die reeds bestaat. Je zal dan de naam van de bestaande (of nieuwe) moeten aanpassen. Ik wil namelijk de 'fixes' voor de iLO, Windows en Linux templates hebben.
Ook ben ik benieuwd hoe feilloos een upgrade gaat. Momenteel draai ik nog 4.0.x. Op hun wiki staat het upgradetraject natuurlijk beschreven, maar zou ik ook zo naar 4.4 kunnen zonder 4.2 nodig te hebben? Dacht eerder eens gelezen te hebben dat je eerst naar de laatste tussenliggende release moet (dus 4.0.x > 4.2.y > 4.4.z). Uiteraard wel eerst even een backup maken van de database, voor het geval dat.
Is er ook ergens een optie oid waarmee je kan controleren of je bestaande triggers, configuratie, media types, etc. niet stuk gaan of wat er aangepast gaat worden alvorens de upgrade plaatsvind?
Commandline FTW
Je krijgt geen foutmelding als je een template dat reeds bestaat importeert, wel kan je tijdens de import 'update existing' uitzetten om je huidige wijzigingen niet verloren te laten gaan.Hero of Time schreef op woensdag 9 oktober 2019 @ 21:55:
* Hero of Time triggert een informational issue om dit topic weer tot leven te wekken.
Zat vandaag downloads: Zabbix 4.4.0 te lezen en zie een hoop mooie dingen. Een vraag die ik had is in de comments door Spro al beantwoord mbt nieuwe templates. Maar daarop aansluitend heb ik wel nog een vraag erover en een paar andere.
Bij een upgrade krijg je dus geen nieuwe templates. Ook eventuele aanpassingen krijg je niet. Maar, hoe krijg je die aanpassingen dan wel zonder je eigen aanpassingen te verliezen? Want vziw krijg je een foutmelding als je een template wilt inladen die reeds bestaat. Je zal dan de naam van de bestaande (of nieuwe) moeten aanpassen. Ik wil namelijk de 'fixes' voor de iLO, Windows en Linux templates hebben.
Ook ben ik benieuwd hoe feilloos een upgrade gaat. Momenteel draai ik nog 4.0.x. Op hun wiki staat het upgradetraject natuurlijk beschreven, maar zou ik ook zo naar 4.4 kunnen zonder 4.2 nodig te hebben? Dacht eerder eens gelezen te hebben dat je eerst naar de laatste tussenliggende release moet (dus 4.0.x > 4.2.y > 4.4.z). Uiteraard wel eerst even een backup maken van de database, voor het geval dat.
Is er ook ergens een optie oid waarmee je kan controleren of je bestaande triggers, configuratie, media types, etc. niet stuk gaan of wat er aangepast gaat worden alvorens de upgrade plaatsvind?
Upgrade gaat vlekkeloos vanaf 4.0 naar 4.4, qua foutmeldingen dan, in ieder geval op de 10 die ik vandaag gedaan heb ben ik geen problemen tegen gekomen. Je hoeft niet eerst de stap naar 4.2 te maken.
Vanaf 4.2 is de werking van proxies veranderd, waardoor daar nog wel een beetje hoofdpijn kan zitten; een proxy doet nu ook preprocessing en daarom moet die tegelijk met de server geupgrade worden. Doe je dat niet, praten ze niet meer met elkaar en wordt eea ineens heel rustig...
- unezra
- Registratie: Maart 2001
- Laatst online: 20-06 15:00
Ceci n'est pas un sous-titre.
Oh, da's hip!Spro schreef op woensdag 9 oktober 2019 @ 22:24:
[...]
Vanaf 4.2 is de werking van proxies veranderd, waardoor daar nog wel een beetje hoofdpijn kan zitten; een proxy doet nu ook preprocessing en daarom moet die tegelijk met de server geupgrade worden. Doe je dat niet, praten ze niet meer met elkaar en wordt eea ineens heel rustig...
Dus je master krijgt minder voor zijn kiezen op die manier?
Verder globale werking gelijk, as in, hij krijgt van zijn master te horen wat 'ie moet doen?
Ná Scaoll. - Don’t Panic.
Correct!unezra schreef op woensdag 9 oktober 2019 @ 23:20:
[...]
Oh, da's hip!
Dus je master krijgt minder voor zijn kiezen op die manier?
Verder globale werking gelijk, as in, hij krijgt van zijn master te horen wat 'ie moet doen?
Men is heel erg aan het zoeken om de performance verder op te schroeven, zonder de hardware belachelijk ver door te moeten schalen, de proxies wat taken over laten nemen is een resultaat daarvan.
verdere globale werking inderdaad gelijk, daar is niets veranderd.
- unezra
- Registratie: Maart 2001
- Laatst online: 20-06 15:00
Ceci n'est pas un sous-titre.
Nice!Spro schreef op donderdag 10 oktober 2019 @ 06:47:
[...]
Correct!
Men is heel erg aan het zoeken om de performance verder op te schroeven, zonder de hardware belachelijk ver door te moeten schalen, de proxies wat taken over laten nemen is een resultaat daarvan.
verdere globale werking inderdaad gelijk, daar is niets veranderd.
Ze zijn goed bezig daar.
Nu nog een keer een master/slave constructies voor de Zabbix master en proxies, zodat je redundancy op applicatieniveau kunt realiseren en onderhoud kunt plegen aan je master of proxy, zonder dat meteen je monitoring voor een periode weg valt. (Dat vind ik hier vrij irritant, als ik mijn master update en reboot, ben ik 15 minuten blind. Het loopt wel in, maar de eerste 15-20 minuten is 'ie redelijk onbruikbaar. Met periodiek onderhoud zijn de Zabbix servers daarom ook de machines die ik als eerste update.)
Ná Scaoll. - Don’t Panic.
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Leuk en aardig, maar het is juist de vernieuwingen die je wilt hebben. Dat betekend dat je de reeds bestaande die je niet hebt aangeraakt ook bijgewerkt wilt hebben.Spro schreef op woensdag 9 oktober 2019 @ 22:24:
[...]
Je krijgt geen foutmelding als je een template dat reeds bestaat importeert, wel kan je tijdens de import 'update existing' uitzetten om je huidige wijzigingen niet verloren te laten gaan.
Dat wordt dus de templates exporteren en vergelijken. Heb ik met wat mazzel ook gelijk al m'n laatste wijzigingen in kaart, want die ben ik een beetje uit 't oog verloren.
Gelukkig. Zal ik eens een dag plannen om dit te gaan doen. Want wat ik eerder nog eens bekeek, had 4.2 geen schokkende verbeteringen en vernieuwingen tov 4.0 waar wij wat aan hebben. Er was juist een issue dat met 4.0 was veroorzaakt, maar met 4.2 niet opgelost ging worden.Upgrade gaat vlekkeloos vanaf 4.0 naar 4.4, qua foutmeldingen dan, in ieder geval op de 10 die ik vandaag gedaan heb ben ik geen problemen tegen gekomen. Je hoeft niet eerst de stap naar 4.2 te maken.
Hoe lang duurt je onderhoud waarin de services niet draaien en hoe lang duurt een reboot dan? Waarom zou je met 2 minuten downtime gelijk 20 minuten blind zijn? Denk eerder dat je je onderhoud aan de machine efficiënter moet doen of het aantal taken die de machine doet verminderen zodat je downtime bij reboot minimaal is.unezra schreef op donderdag 10 oktober 2019 @ 07:55:
Nu nog een keer een master/slave constructies voor de Zabbix master en proxies, zodat je redundancy op applicatieniveau kunt realiseren en onderhoud kunt plegen aan je master of proxy, zonder dat meteen je monitoring voor een periode weg valt. (Dat vind ik hier vrij irritant, als ik mijn master update en reboot, ben ik 15 minuten blind. Het loopt wel in, maar de eerste 15-20 minuten is 'ie redelijk onbruikbaar. Met periodiek onderhoud zijn de Zabbix servers daarom ook de machines die ik als eerste update.)
Commandline FTW
- unezra
- Registratie: Maart 2001
- Laatst online: 20-06 15:00
Ceci n'est pas un sous-titre.
Mijn ervaring is dat de Zabbix master en proxies, ongeveer 15-20 minuten onbetrouwbare informatie geven na een reboot. Onderhoud zelf duurt 5 minuten, inclusief reboot.Hero of Time schreef op donderdag 10 oktober 2019 @ 08:34:
[...]
Hoe lang duurt je onderhoud waarin de services niet draaien en hoe lang duurt een reboot dan? Waarom zou je met 2 minuten downtime gelijk 20 minuten blind zijn? Denk eerder dat je je onderhoud aan de machine efficiënter moet doen of het aantal taken die de machine doet verminderen zodat je downtime bij reboot minimaal is.
Nu is het zeker zo dat mijn database te groot is en niet gepartitioneerd, maar los van dat vind ik een enkele, niet HA-uitvoering van zoiets belangrijks als monitoring, redelijk achterhaald. JUIST monitoring wil je ook op applicatieniveau dubbel hebben uitgevoerd.
Dat kan op dit moment niet. Agents kunnen maar met 1 master of proxy babbelen, redundant masters en proxies zijn niet mogelijk. Net iets dat de grote jongens wél goed doen. (Dat de agent maar met 1 kan connecten is geen probleem, master en proxies die niet redundant gemaakt kunnen worden wel.)
De grote jongens hebben veel nadelen en zijn zeker niet noodzakelijkerwijs in alle opzichten beter, maar dit doen ze wel beter dan Zabbix. Helaas. Want juist bij zoiets als Zabbix lijkt me het een feature die voor de developers relatief makkelijk te implementeren is en die het pakket naar een nog hoger niveau tilt.
Ná Scaoll. - Don’t Panic.
Gelukkig ben ik het niet helemaal met je eens, een agent kan met meerdere servers praten, geen enkel probleem: https://support.zabbix.com/browse/ZBXNEXT-584unezra schreef op donderdag 10 oktober 2019 @ 10:34:
[...]
Mijn ervaring is dat de Zabbix master en proxies, ongeveer 15-20 minuten onbetrouwbare informatie geven na een reboot. Onderhoud zelf duurt 5 minuten, inclusief reboot.
Nu is het zeker zo dat mijn database te groot is en niet gepartitioneerd, maar los van dat vind ik een enkele, niet HA-uitvoering van zoiets belangrijks als monitoring, redelijk achterhaald. JUIST monitoring wil je ook op applicatieniveau dubbel hebben uitgevoerd.
Dat kan op dit moment niet. Agents kunnen maar met 1 master of proxy babbelen, redundant masters en proxies zijn niet mogelijk. Net iets dat de grote jongens wél goed doen. (Dat de agent maar met 1 kan connecten is geen probleem, master en proxies die niet redundant gemaakt kunnen worden wel.)
De grote jongens hebben veel nadelen en zijn zeker niet noodzakelijkerwijs in alle opzichten beter, maar dit doen ze wel beter dan Zabbix. Helaas. Want juist bij zoiets als Zabbix lijkt me het een feature die voor de developers relatief makkelijk te implementeren is en die het pakket naar een nog hoger niveau tilt.
Dit geldt voor active en passive checks...
HA is prima supported: pacemaker, corosync en Galera(mysql). VIP tussen je Zabbix servers en je kan doen en laten wat je wil met de standby machine.
Daarnaast kan je natuurlijk je proxy ook HA uitvoeren met eenzelfde setup.
Hoewel Zabbix op de roadmap heeft staan om HA weer te implementeren, ben ik voorlopig tevreden met de manier waarop het nu werkt...
- mhofstra
- Registratie: September 2002
- Laatst online: 25-06 11:51
Wat voor issue was/is dat? Ik heb een update van 3.4 naar 4.2 gepland staan binnenkort maar misschien kan ik dan beter gelijk door naar 4.4?Hero of Time schreef op donderdag 10 oktober 2019 @ 08:34:
[...]
Gelukkig. Zal ik eens een dag plannen om dit te gaan doen. Want wat ik eerder nog eens bekeek, had 4.2 geen schokkende verbeteringen en vernieuwingen tov 4.0 waar wij wat aan hebben. Er was juist een issue dat met 4.0 was veroorzaakt, maar met 4.2 niet opgelost ging worden.
[...]
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Moest even goed nadenken, maar het is de waarde van het item als je die in je trigger tekst verwerkt. Bijvoorbeeld vrije schijfruimte. Trigger als deze <20% komt. Dan kan je als trigger tekst "Er is nog {item.lastvalue} vrij" gebruiken. Voor 4.0 werd dit op je dashboard bijgewerkt. Dus zou de laatste meting 18% zijn, zou je dashboard dus zeggen "Er is nog 18% vrij". Bij 4.0 zou er in alle gevallen "Er is 19,9% vrij" staan. Erg onhandig als je juist wilt weten hoeveel spoed een bepaald issue heeft om opgelost te worden.mhofstra schreef op donderdag 10 oktober 2019 @ 20:48:
[...]
Wat voor issue was/is dat? Ik heb een update van 3.4 naar 4.2 gepland staan binnenkort maar misschien kan ik dan beter gelijk door naar 4.4?
Men heeft het uiteindelijk een soort van opgelost in 4.0 door een extra kolom toe te voegen bij de widget met de waarde van de laatste meting, maar dat moest ik zelf inschakelen omdat het er later pas bij kwam. Ondertussen was 4.2 al wel uit. Wat er daar is gebeurt weet ik niet, daarvoor moet ik het issue weer naar voren halen, maar zou je zelf ook redelijk makkelijk moeten kunnen vinden met Google als je zoekt op 'zabbix trigger item.lastvalue' oid.
Ik kijk met 4.4 overigens eerst nog even de kat uit de boom. Als in, niet gelijk 4.4.0 pakken, maar straks als 4.4.1 of 4.4.2 uit is upgraden. Heb nog een project om af te maken en bij voorkeur voor het einde van de maand.
Commandline FTW
- DaRoot
- Registratie: Maart 2001
- Laatst online: 25-06 14:11
Some say...
:strip_icc():strip_exif()/u/25053/stig3got.jpg?f=community)
Ik heb mijn zabbix-server en zabbix-proxy beide ge-upgrade van 3.4.x naar 4.4.0.. ging tadellos.. had wel eerst backup gemaakt zoals in de manual/wiki beschreven staat, maar niet nodig gehad.Hero of Time schreef op woensdag 9 oktober 2019 @ 21:55:
* Hero of Time triggert een informational issue om dit topic weer tot leven te wekken.
Zat vandaag downloads: Zabbix 4.4.0 te lezen en zie een hoop mooie dingen. Een vraag die ik had is in de comments door Spro al beantwoord mbt nieuwe templates. Maar daarop aansluitend heb ik wel nog een vraag erover en een paar andere.
Bij een upgrade krijg je dus geen nieuwe templates. Ook eventuele aanpassingen krijg je niet. Maar, hoe krijg je die aanpassingen dan wel zonder je eigen aanpassingen te verliezen? Want vziw krijg je een foutmelding als je een template wilt inladen die reeds bestaat. Je zal dan de naam van de bestaande (of nieuwe) moeten aanpassen. Ik wil namelijk de 'fixes' voor de iLO, Windows en Linux templates hebben.
Ook ben ik benieuwd hoe feilloos een upgrade gaat. Momenteel draai ik nog 4.0.x. Op hun wiki staat het upgradetraject natuurlijk beschreven, maar zou ik ook zo naar 4.4 kunnen zonder 4.2 nodig te hebben? Dacht eerder eens gelezen te hebben dat je eerst naar de laatste tussenliggende release moet (dus 4.0.x > 4.2.y > 4.4.z). Uiteraard wel eerst even een backup maken van de database, voor het geval dat.
Is er ook ergens een optie oid waarmee je kan controleren of je bestaande triggers, configuratie, media types, etc. niet stuk gaan of wat er aangepast gaat worden alvorens de upgrade plaatsvind?
Alleen niet schrikken als je distro na het upgraden van de packages zegt dat ie klaar is, en je dan meteen naar de webinterface gaat.. je krijgt dan eerst een foutmelding dat de database versie niet klopt..
Als je ondertussen via top even meekijkt, zie je mysqld beetje druk doen, dat is de database upgrade..
zodra mysqld weer rustig is, werkt de webinterface ook weer.
Heb er tevens al enige tijd Grafana met de Zabbix plugin achter zitten, daarvoor hoefde ik niets aan te passen / upgraden, dat bleef gewoon werken.
Insured by MAFIA - You hit me, we hit you!!!
- Yariva
- Registratie: November 2012
- Laatst online: 24-06 14:18
Als je nog op een LTS versie draait zou ik daar lekker op blijven draaien (buiten non-productie omgevingen dan.) Met 5.0 over 8 maandjes in de aantocht waarmee je ook alle functionaliteit krijgt van 4.2 en 4.4 zou ik daar mijn geld op inzettenHero of Time schreef op donderdag 10 oktober 2019 @ 22:33:
[...]
Moest even goed nadenken, maar het is de waarde van het item als je die in je trigger tekst verwerkt. Bijvoorbeeld vrije schijfruimte. Trigger als deze <20% komt. Dan kan je als trigger tekst "Er is nog {item.lastvalue} vrij" gebruiken. Voor 4.0 werd dit op je dashboard bijgewerkt. Dus zou de laatste meting 18% zijn, zou je dashboard dus zeggen "Er is nog 18% vrij". Bij 4.0 zou er in alle gevallen "Er is 19,9% vrij" staan. Erg onhandig als je juist wilt weten hoeveel spoed een bepaald issue heeft om opgelost te worden.
Men heeft het uiteindelijk een soort van opgelost in 4.0 door een extra kolom toe te voegen bij de widget met de waarde van de laatste meting, maar dat moest ik zelf inschakelen omdat het er later pas bij kwam. Ondertussen was 4.2 al wel uit. Wat er daar is gebeurt weet ik niet, daarvoor moet ik het issue weer naar voren halen, maar zou je zelf ook redelijk makkelijk moeten kunnen vinden met Google als je zoekt op 'zabbix trigger item.lastvalue' oid.
Ik kijk met 4.4 overigens eerst nog even de kat uit de boom. Als in, niet gelijk 4.4.0 pakken, maar straks als 4.4.1 of 4.4.2 uit is upgraden. Heb nog een project om af te maken en bij voorkeur voor het einde van de maand.
Mensen zijn gelijk, maar sommige zijn gelijker dan andere | Humans need not apply
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Commandline FTW
- Yariva
- Registratie: November 2012
- Laatst online: 24-06 14:18
Nog wat hulp vanaf de wiki: https://www.zabbix.com/do...allation/upgrade/packages
Wat voornamelijk belangrijk is, en ook al is benoemd: Die proxy's gaan tegenstribbelen wanneer deze ook niet worden meegenomen met de upgrade. Deze moeten nu ook meteen mee.
Verder is het formaat voor LLD gewijzigd: Mocht je een script gebruiken voor LLD dan hoeft het "data" veld niet meer worden meegenomen. Enkel een lijst [ ] is voldoende. (source: https://www.zabbix.com/do...low-level_discovery_rules)
Mensen zijn gelijk, maar sommige zijn gelijker dan andere | Humans need not apply
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Commandline FTW
- Yarisken
- Registratie: Augustus 2010
- Laatst online: 08:45
Ik zou ssl certificaten willen monitoren. Thuis gebruik ik zabbix en op het werk gebruiken we prtg.
Weet iemand een tool die in een docker draait met een lichte footprint en dit out of the box kan monitoren ?
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Commandline FTW
- HKLM_
- Registratie: Februari 2009
- Laatst online: 11:47
:strip_exif()/u/290839/crop5b757283a589c_cropped.gif?f=community)
PRTG heeft een meerdere sensor voor het monitoren van certificaten.Yarisken schreef op zaterdag 22 februari 2020 @ 00:27:
Allen,
Ik zou ssl certificaten willen monitoren. Thuis gebruik ik zabbix en op het werk gebruiken we prtg.
Weet iemand een tool die in een docker draait met een lichte footprint en dit out of the box kan monitoren ?
[ Voor 69% gewijzigd door HKLM_ op 22-02-2020 12:38 ]
Cloud ☁️
- Yarisken
- Registratie: Augustus 2010
- Laatst online: 08:45
Inderdaad, mijn script in zabbix werkt ook zo. Ik ga er is over denken want ik ga het misschien idd wel kunnen toevoegen aan bestaande data en visualiseren.Hero of Time schreef op zaterdag 22 februari 2020 @ 00:48:
Hoe wil je de alerts krijgen? Want met het openssl commando kan je zo de informatie opvragen die je wilt en er wat omheen scripten om de geldigheid te parsen en mailen als het binnen je gedefinieerde criteria valt.
:strip_icc():strip_exif()/u/146731/crop562615a0aa64c.jpeg?f=community)
Kent iemand iets vergelijkbaars zoals PRTG wat in Docker op m'n Pi zou kunnen draaien? De belangrijkste checks die ik binnen PRTG gebruik zijn ping en HTTP(S). Vooral de mailnotificatie vind ik erg belangrijk, de webinterface kijk ik eigenlijk zelden in.
Heb al wel wat gezocht, maar de meeste dingen lijken zich juist weer op de Pi zelf te richten (CPU-temp, geheugen e.d.) en niet/minder op apparaten in het netwerk.
[ Voor 14% gewijzigd door ThinkPad op 27-02-2020 07:11 ]
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Commandline FTW
- Hipska
- Registratie: Mei 2008
- Laatst online: 23-06 14:35
/u/262016/crop64ed94e1a7757_cropped.png?f=community)
Ik kende Icinga nog niet, maar ziet er goed uit! Kan het op hun website niet goed vinden, maar is het een gratis product? (wil het thuis gebruiken voor m'n homelab).Hipska schreef op vrijdag 28 februari 2020 @ 13:50:
Icinga heeft packages voor op raspbian: http://packages.icinga.com/raspbian/
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Commandline FTW
- Yariva
- Registratie: November 2012
- Laatst online: 24-06 14:18
Zabbix heeft tegenwoordig officiele guides over hoe je de server installeert op Raspbian.ThinkPadd schreef op maandag 2 maart 2020 @ 13:57:
[...]
Ik kende Icinga nog niet, maar ziet er goed uit! Kan het op hun website niet goed vinden, maar is het een gratis product? (wil het thuis gebruiken voor m'n homelab).
Echter niet de database op een SD kaartje zetten, dan komt er binnen 2 weken rook uit
https://www.zabbix.com/do...buster&db=mysql&ws=apache
Monitoring op een Raspberry pi met alle voordelen van Zabbix erbij.
Mensen zijn gelijk, maar sommige zijn gelijker dan andere | Humans need not apply
- Turdie
- Registratie: Maart 2006
- Laatst online: 20-04 14:54
/u/169878/crop60f2c3c12a642_cropped.png?f=community)
En wat is Thruk dan?Hero of Time schreef op maandag 2 maart 2020 @ 17:09:
Icinga, die je niet moet verwarren met icinga2, is niets meer dan een fork van Nagios. Icinga2 is een complete rewrite en werkt significant anders qua opzet.
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Commandline FTW
- Turdie
- Registratie: Maart 2006
- Laatst online: 20-04 14:54
Of course ,maar wou even weten hoe jij als linux expert Thruk ziet,
[ Voor 3% gewijzigd door Turdie op 02-03-2020 17:21 ]
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Commandline FTW
- Hipska
- Registratie: Mei 2008
- Laatst online: 23-06 14:35
Ja het is gratis en zeker goed te gebruiken voor uw situatie.ThinkPadd schreef op maandag 2 maart 2020 @ 13:57:
[...]
Ik kende Icinga nog niet, maar ziet er goed uit! Kan het op hun website niet goed vinden, maar is het een gratis product? (wil het thuis gebruiken voor m'n homelab).
Ja uiteraard hebben we het dan over Icinga2, dacht dat de toevoeging ondertussen, na al die jaren, niet meer nodig was om verwarring te vermijden.Hero of Time schreef op maandag 2 maart 2020 @ 17:09:
Icinga, die je niet moet verwarren met icinga2, is niets meer dan een fork van Nagios. Icinga2 is een complete rewrite en werkt significant anders qua opzet.
- frut666
- Registratie: September 2005
- Laatst online: 08-11-2024
En mocht het er toevallig niet in zitten dan is er meestal wel een plugin voor te downloaden. Zo monitor ik onder andere puppet, fail2ban en status van een HP raid array.
Waar ik bij check_mk ook erg van gecharmeerd ben is het feit dat je heel makkelijk parent / child relaties kan leggen. Als b.v. mijn internet verbinding eruit ligt dan hoef ik geen notificaties te krijgen van mijn VPS servers die hij daardoor niet kan bereiken.
Verder is de performance goed. Weinig impact op de client systemen en de server zelf heeft ook niet zoveel nodig. En mocht die meer resources nodig gaan hebben dan kan ik hem heel eenvoudig distributed uitvoeren.
- Charlie_Root
- Registratie: November 2018
- Laatst online: 07:02
:strip_icc():strip_exif()/u/1134061/crop5ef734fe74e7c_cropped.jpeg?f=community)
Dan heb je het alléén over de front-end/webinterface.Hero of Time schreef op donderdag 27 februari 2020 @ 08:44:
Zabbix is gewoon een php applicatie, dus zou ook prima op een ARM architectuur moeten kunnen draaien. Misschien wat overkill, maar is iig een optie.
Ik ben zelf he-le-maal gek op Zabbix. Voor mensen die niet te veel configuratie willen doen werkt het out of the box prima, voor de basics. Voor mensen die (zoals ik) allemaal custom dingen willen is het nog mooier.
Kwestie van je triggers juist zetten met (bijv.) de nodata optie. Dat scheelt heel wat op loze meldingen na reboot of onderhoud.unezra schreef op donderdag 10 oktober 2019 @ 10:34:
[...]
Mijn ervaring is dat de Zabbix master en proxies, ongeveer 15-20 minuten onbetrouwbare informatie geven na een reboot. Onderhoud zelf duurt 5 minuten, inclusief reboot.
Dat is onjuist. Zabbix Agents kunnen met meerdere servers praten:unezra schreef op donderdag 10 oktober 2019 @ 10:34:
[...]
Dat kan op dit moment niet. Agents kunnen maar met 1 master of proxy babbelen, redundant masters en proxies zijn niet mogelijk. Net iets dat de grote jongens wél goed doen. (Dat de agent maar met 1 kan connecten is geen probleem, master en proxies die niet redundant gemaakt kunnen worden wel.)
Bron:List of comma delimited IP addresses, optionally in CIDR notation, or hostnames of Zabbix servers and Zabbix proxies.
https://www.zabbix.com/do...ndix/config/zabbix_agentd
Zoals je ziet is deze docu van versie 3.4, dus die optie bestaat al even. Alleen voor Active Checks bestaat die beperking, ik zou active uberhaupt niet adviseren voor de meeste zaken.
Het redundant uitvoeren van de server is ook ge-support en kan op meerdere manieren. Naar mijn mening doet zabbix het op dit front juist beter dan de grote jongens, ze laten het aan jou om te kiezen wat het beste bij je past.
[ Voor 73% gewijzigd door Charlie_Root op 27-06-2020 13:10 ]
The cause of the problem is: network down, IP packets delivered via UPS
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Correct, de server side/webinterface is php idd. Dat is vaak het belangrijkste, omdat Zabbix naast een agent ook gewoon SNMP snapt.Charlie_Root schreef op zaterdag 27 juni 2020 @ 13:04:
[...]
Dan heb je het alléén over de front-end/webinterface.
Commandline FTW
- Charlie_Root
- Registratie: November 2018
- Laatst online: 07:02
En het zabbix-server proces?Hero of Time schreef op zaterdag 27 juni 2020 @ 13:44:
[...]
Correct, de server side/webinterface is php idd. Dat is vaak het belangrijkste, omdat Zabbix naast een agent ook gewoon SNMP snapt.
The cause of the problem is: network down, IP packets delivered via UPS
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Kan ook gewoon op een Pi draaien, als dat je vraag is. Anders, niet zo muggenziften, het is daar veel te warm voor.
Commandline FTW
:strip_icc():strip_exif()/u/414086/crop5ed773b9784ba_cropped.jpeg?f=community)
- Equator
- Registratie: April 2001
- Laatst online: 11:56
Wij hebben bijna 40 locaties, sommigen met een eVPN, anderen met een IPsec of andere WAN verbinding.
Vanaf deze locaties worden diensten als SAP, en andere applicaties centraal benaderd. Ook SaaS diensten zoals Office 365.
Nu wil ik de kwaliteit van de verbinding naar deze diensten inzichtelijk hebben. Slechte kwaliteit (hoge latency etc.) kan dan input zijn voor het kiezen voor een betere en waarschijnlijk duurdere verbinding.
Ik heb in het verleden NetPath, nu van solarwinds, gezien. En ik ben ook al in contact met hun. Maar ik weet niet of dat voor mij de perfecte oplossing gaat zijn.
Iemand ervaringen met iets dergelijks?
- Ingegno
- Registratie: Oktober 2015
- Laatst online: 22-06-2025
Wij doen Zabbix.Equator schreef op maandag 17 augustus 2020 @ 21:35:
Ik ben zoekende naar een manier om de kwaliteit van diensten weer te geven vanuit verschillende locaties.
Wij hebben bijna 40 locaties, sommigen met een eVPN, anderen met een IPsec of andere WAN verbinding.
Vanaf deze locaties worden diensten als SAP, en andere applicaties centraal benaderd. Ook SaaS diensten zoals Office 365.
Nu wil ik de kwaliteit van de verbinding naar deze diensten inzichtelijk hebben. Slechte kwaliteit (hoge latency etc.) kan dan input zijn voor het kiezen voor een betere en waarschijnlijk duurdere verbinding.
Ik heb in het verleden NetPath, nu van solarwinds, gezien. En ik ben ook al in contact met hun. Maar ik weet niet of dat voor mij de perfecte oplossing gaat zijn.
Iemand ervaringen met iets dergelijks?
Je kunt de latency/drops/uptime/availability/noemmaarop monitoren. Vaak zijn hier al pre-built templates voor. Anders kun je zelf ook zo eentje in elkaar steken.
Je krijgt vervolgens de data in een mooi grafiekje te zien en mogelijk om een rapportage te exporteren.
- thieske1
- Registratie: Februari 2011
- Laatst online: 13:08
Voor office365 kan je eens kijken naar GSXEquator schreef op maandag 17 augustus 2020 @ 21:35:
Ik ben zoekende naar een manier om de kwaliteit van diensten weer te geven vanuit verschillende locaties.
Wij hebben bijna 40 locaties, sommigen met een eVPN, anderen met een IPsec of andere WAN verbinding.
Vanaf deze locaties worden diensten als SAP, en andere applicaties centraal benaderd. Ook SaaS diensten zoals Office 365.
Nu wil ik de kwaliteit van de verbinding naar deze diensten inzichtelijk hebben. Slechte kwaliteit (hoge latency etc.) kan dan input zijn voor het kiezen voor een betere en waarschijnlijk duurdere verbinding.
Ik heb in het verleden NetPath, nu van solarwinds, gezien. En ik ben ook al in contact met hun. Maar ik weet niet of dat voor mij de perfecte oplossing gaat zijn.
Iemand ervaringen met iets dergelijks?
- Equator
- Registratie: April 2001
- Laatst online: 11:56
Dank je wel voor je reply.Ingegno schreef op maandag 17 augustus 2020 @ 22:03:
[...]
Wij doen Zabbix.
Je kunt de latency/drops/uptime/availability/noemmaarop monitoren. Vaak zijn hier al pre-built templates voor. Anders kun je zelf ook zo eentje in elkaar steken.
Je krijgt vervolgens de data in een mooi grafiekje te zien en mogelijk om een rapportage te exporteren.
Zie je daarmee ook de verschillende hops in het netwerk? Ik zou graag zien vanaf waar in de keten het een issue wordt.
Zoals dit voorbeeld van NetPath:
Top, dank je wel. Zeer Office365 specifiek. Kun je daar ook andere zaken in meenemen?thieske1 schreef op maandag 17 augustus 2020 @ 22:39:
[...]
Voor office365 kan je eens kijken naar GSX
- thieske1
- Registratie: Februari 2011
- Laatst online: 13:08
Niet dat ik weer. wij gebruiken het alleen voor O365.Equator schreef op dinsdag 18 augustus 2020 @ 07:46:
[...]
Dank je wel voor je reply.
Zie je daarmee ook de verschillende hops in het netwerk? Ik zou graag zien vanaf waar in de keten het een issue wordt.
Zoals dit voorbeeld van NetPath:
[Afbeelding]
[...]
Top, dank je wel. Zeer Office365 specifiek. Kun je daar ook andere zaken in meenemen?
- Freeaqingme
- Registratie: April 2006
- Laatst online: 13:08
Kijk voor de grap ook even naar Smokeping. Het ziet er wellicht uit alsof het in het jaar 0 gemaakt is, maar het is in mijn beleving wel _de_ tool om kwaliteit van verbindingen te monitoren. Of je daar makkelijk eventueel automatische triggers aan kan hangen is weer een tweede (weet ik niet).Equator schreef op maandag 17 augustus 2020 @ 21:35:
Ik ben zoekende naar een manier om de kwaliteit van diensten weer te geven vanuit verschillende locaties.
Ik zie het vaak door netwerkafdelingen gebruikt worden zodat als er een klant klaagt over een bepaalde (WAN) verbinding, dat ze Smokeping in eerste instantie gebruiken als referentie om te kijken of er wellicht een transit/peeringclub rond dat tijdstip zat te kutten zodat ze niet verder hoeven te zoeken.
No trees were harmed in creating this message. However, a large number of electrons were terribly inconvenienced.
- Ingegno
- Registratie: Oktober 2015
- Laatst online: 22-06-2025
Zit er naar mijn weten niet default in (zeker niet in de default templates). Dat zou je dus eventueel moeten inbouwen mocht je die kant op gaan (wat dus best veel werk kan zijn). Probleem is dat je de intermediate devices niet onder controle hebt en je per intermediate device dus een soort simple check (ping/tracert) uitvoeren. En dat alles vervolgens weer in een soort autodiscovery gieten en een leuk plaatje van makenEquator schreef op dinsdag 18 augustus 2020 @ 07:46:
[...]
Dank je wel voor je reply.
Zie je daarmee ook de verschillende hops in het netwerk? Ik zou graag zien vanaf waar in de keten het een issue wordt.
Zoals dit voorbeeld van NetPath:
(lijkt me nu wel geinig om als sidegig op te pakken eigenlijk
Verwijderd
https://paessler.zoom.us/...qHtMEXCM__Y_pCyuSFptHlkiT
Verwijderd
Daar kan je precies zien welke sensoren eraan zitten te komen.
- Arfman
- Registratie: Januari 2000
- Laatst online: 25-06 15:08
Drome!
DRoME LAN Gaming | iRacing profiel | Kia e-Niro 64kWh | Hyundai Ioniq 28kWh | PV 5.760Wp |
- powerboat
- Registratie: December 2003
- Laatst online: 09:24
https://www.zabbix.com/do...ndix/config/zabbix_agentd
Zoals je ziet is deze docu van versie 3.4, dus die optie bestaat al even. Alleen voor Active Checks bestaat die beperking, ik zou active uberhaupt niet adviseren voor de meeste zaken.
Het redundant uitvoeren van de server is ook ge-support en kan op meerdere manieren. Naar mijn mening doet zabbix het op dit front juist beter dan de grote jongens, ze laten het aan jou om te kiezen wat het beste bij je past.
[/quote]
Volgens de trainer die ik gehad heb (Patrick Uyterhoeven) voor de Zabbix 2.2 training
- barrymossel
- Registratie: Juni 2003
- Laatst online: 25-06 09:21
Sinds kort heb ik een NUC met twee VM's. Eentje draait Home Assistant en de andere Ubuntu met verschillende docker containers. Nu wil ik monitoren of e.e.a. nog up is. Met name Home Assistant, MQTT en een website die als docker draait. Dus volgens mij redelijk simpel (intern en extern) monitoren of er verbinding mogelijk is.
Ik zie veel moeilijke uitgebreide monitors voorbij komen, maar bij voorkeur draai ik een simpele docker image die dit kan, met een simpele (fancy
Heeft iemand dé suggestie?
- powerboat
- Registratie: December 2003
- Laatst online: 09:24
Hahah nice ik heb toen ook de training van P gekregen. Mooie tijd toepowerboat schreef op woensdag 18 november 2020 @ 11:48:
Bron:
https://www.zabbix.com/do...ndix/config/zabbix_agentd
Zoals je ziet is deze docu van versie 3.4, dus die optie bestaat al even. Alleen voor Active Checks bestaat die beperking, ik zou active uberhaupt niet adviseren voor de meeste zaken.
Het redundant uitvoeren van de server is ook ge-support en kan op meerdere manieren. Naar mijn mening doet zabbix het op dit front juist beter dan de grote jongens, ze laten het aan jou om te kiezen wat het beste bij je past.
[/quote]
Volgens de trainer die ik gehad heb (Patrick Uyterhoeven) voor de Zabbix 2.2 training(Yeah, I know is al een tijdje geleden). Word het juist aangeraden (waar mogelijk) om Active Checks te doen zodat je de server minimaal belast.
:strip_exif()/u/22345/tweakers.gif?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
LibreNMS/OpenNMS iets voor je?barrymossel schreef op donderdag 22 april 2021 @ 18:17:
Ik zie door de bomen het bos niet meer...
Sinds kort heb ik een NUC met twee VM's. Eentje draait Home Assistant en de andere Ubuntu met verschillende docker containers. Nu wil ik monitoren of e.e.a. nog up is. Met name Home Assistant, MQTT en een website die als docker draait. Dus volgens mij redelijk simpel (intern en extern) monitoren of er verbinding mogelijk is.
Ik zie veel moeilijke uitgebreide monitors voorbij komen, maar bij voorkeur draai ik een simpele docker image die dit kan, met een simpele (fancy) webinterface en (email) alerts. Self hosted en gratiesch uiteraard.
Heeft iemand dé suggestie?
- 3DDude
- Registratie: November 2005
- Nu online
I void warranty's
is echt een Application Performance monitoring.
Is wel echt een enterprise tool.
https://www.dynatrace.com/
Be nice, You Assholes :)
- FlorianK
- Registratie: November 2022
- Laatst online: 02-10-2023
Is er iemand die me kan adviseren?
Ik huur een online server. Monitoring van infrastructuur is niet nodig; dat wordt middels SLA geregeld.
Wat ik wel nodig heb is het monitoren van geproduceerde logfiles en het gestart zijn van services.
Bij specifieke logregels wil ik graag dat er wat bestandsbewerkingen worden gedaan (verplaatsen van een bestand, pad naar dat bestand is te vinden in de log) en dat een service wordt herstart.
Daarnaast -als bonus- checken dat een service draait en zo niet; dat deze gestart wordt.
Bij problemen zou ik -naast de bovenstaande handelingen- graag een mail ontvangen.
Het mag wat kosten, maar dat hoeft niet.
Weet iemand iets dat hier goed bij zou passen?
....of weet iemand hoe ik zelf bij het juiste pakket uit zou kunnen komen? (iets met bomen en een bos...)
- Wiley99
- Registratie: Juni 2014
- Laatst online: 25-06 17:41
:strip_icc():strip_exif()/u/604788/crop5b6459a93ed01_cropped.jpeg?f=community)
Zabbix is met name gericht op de metrics maar je kan logbestanden lezen en heel goed signaleren op bepaalde regels of stukken tekst (via regex). Je kan acties laten uitvoeren op het OS, bijvoorbeeld het draaien van een script, dat de bestandsbewerkingen doet die je wil. E-mail bij 'problems' en herstarten van services (via scripts) is ook één van die acties. Ik zou evenwel nog niet kant-en-klaar weten hoe je die bestandsnaam uit Zabbix weer terugvoert aan het script dat de bewerkingen moet doen.
Een eenvoudiger monitoringtool die ik voor mijn raspberry's gebruik, maar dan met name voor het herstarten van pythonscripts, is Monit. Ik zit daar niet zo diep in, het is zeker veel beperkter maar misschien ook handzamer dan Zabbix, hoewel je misschien wat meer zelf moet scripten.
A polar bear is a rectangular bear after a coordinate transform - Never attribute to malice that which is adequately explained by stupidity
Gisteren mijn eerste eigen plugin gemaakt. Het haalt 2 waardes uit een tabel (aantal records en aantal records waar een veld leeg is). Er wordt mooi een grafiek aangemaakt, maar zit nu met het volgende. Als in de grafiek meer dan 100.000 als waarde staat, maakt checkmk er 1.00e+5 van, (1.20e+5 voor 120.000). Kan ik checkmk ergens aangeven dat de waardes vol uit geschreven moeten worden, zowel in de grafiek als in de "legenda".
:fill(white):strip_exif()/f/image/LkaZye6Y2mDu7LCm5oC1AO1n.png?f=user_large)
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Bedoel je dan de fork van Nagios, of de complete rewrite Icinga2?Hipska schreef op woensdag 2 november 2022 @ 15:21:
@HKLM_ @MrNGm Tot mijn grote verbazing staat er niets over icinga in de TS.
Zou met die weergave eerder denken dat er een beperkte ruimte is om een waarde te kunnen tonen en het daar zo breed is, dat het niet meer pas en daarom zo wordt getoond.ge-flopt schreef op woensdag 2 november 2022 @ 11:17:
Ik gebruik sinds enige tijd checkmk.
Gisteren mijn eerste eigen plugin gemaakt. Het haalt 2 waardes uit een tabel (aantal records en aantal records waar een veld leeg is). Er wordt mooi een grafiek aangemaakt, maar zit nu met het volgende. Als in de grafiek meer dan 100.000 als waarde staat, maakt checkmk er 1.00e+5 van, (1.20e+5 voor 120.000). Kan ik checkmk ergens aangeven dat de waardes vol uit geschreven moeten worden, zowel in de grafiek als in de "legenda".
[Afbeelding]
Maar als je schaal van 0 naar 1 miljoen gaat, is het wellicht een beter idee om je schaal zelf wat aan te passen, bijvoorbeeld door per duizend te tellen. Bij auto's zie je ook de toerenteller met 'x1000' in het midden en dan 1, 2, 3, etc bij de punten.
Commandline FTW
Misshien aan de linker kant heb je gelijk, maar zou verwachten dat je daan aan de onderkant wel de gehele aantallen te zien krijgt.Hero of Time schreef op woensdag 2 november 2022 @ 20:36:
[...]
Zou met die weergave eerder denken dat er een beperkte ruimte is om een waarde te kunnen tonen en het daar zo breed is, dat het niet meer pas en daarom zo wordt getoond.
Maar als je schaal van 0 naar 1 miljoen gaat, is het wellicht een beter idee om je schaal zelf wat aan te passen, bijvoorbeeld door per duizend te tellen. Bij auto's zie je ook de toerenteller met 'x1000' in het midden en dan 1, 2, 3, etc bij de punten.
- Douweegbertje
- Registratie: Mei 2008
- Laatst online: 24-04 02:02
Wat kinderachtig.. godverdomme
/u/262310/ava.png?f=community)
Mijn verbazing is nog groter dat we anno 2022 het nog over icinga en zabbix hebben. Beetje stoffige meuk allemaal als je het mij vraagt.Hipska schreef op woensdag 2 november 2022 @ 15:21:
@HKLM_ @MrNGm Tot mijn grote verbazing staat er niets over icinga in de TS.
Misschien ben ik wel biased maar is er misschien een reden dat heel het woord observability hier nog niet is gevallen?
Mooie standaard https://opentelemetry.io/ gebruiken en dan bewezen OSS tools zoals Prometheus met eventueel een laagje Thanos/Cortex/Mimir eroverheen. Traces met Jaeger/Tempo en logs via ES of beter nog via Loki. Visualiseren met Grafana en alerts via alertmanager.
IMO toch wel een beetje de standaard voor OSS voor als je het netjes/gangbaar wilt hebben.
- Wiley99
- Registratie: Juni 2014
- Laatst online: 25-06 17:41
Het zou inderdaad objectiever zijn als je jouw oplossingen gewoon als alternatieven zou noemen. Misschien met wat voordelen erbij om te nuanceren in welke use-cases heel veel verschillende componenten met allemaal hun eigen leercurves volgens jou de betere keuze is.Douweegbertje schreef op donderdag 3 november 2022 @ 03:03:
[...]
Mijn verbazing is nog groter dat we anno 2022 het nog over icinga en zabbix hebben. Beetje stoffige meuk allemaal als je het mij vraagt.
Misschien ben ik wel biased maar is er misschien een reden dat heel het woord observability hier nog niet is gevallen?
Jammer om andere producten, zoals Zabbix, dat actief ontwikkeld wordt en waar een grote gemeenschap en grote bedrijven al jaren goed mee werken, stoffig te noemen. Bijvoorbeeld omdat er maar één leercurve is, of omdat 'keep it simple' vaak kosteneffectiever is (uiteraard inclusief het effect van de monitoring) of omdat er nette LTS releases worden uitgegeven die jarenlang ondersteund worden.
A polar bear is a rectangular bear after a coordinate transform - Never attribute to malice that which is adequately explained by stupidity
- Freeaqingme
- Registratie: April 2006
- Laatst online: 13:08
Ik zou proven technology nou niet direct beschrijven als 'stoffig'. Het is software die wat mij betreft heel goed is in detecteren of iets wel of niet draait zoals het zou moeten. Daarnaast heeft een tool als Icinga nagenoeg geen dependencies, en daarmee tamelijk robuust (essentieel voor monitoring).Douweegbertje schreef op donderdag 3 november 2022 @ 03:03:
[...]
Mijn verbazing is nog groter dat we anno 2022 het nog over icinga en zabbix hebben. Beetje stoffige meuk allemaal als je het mij vraagt.
Toegegeven, er zijn zeker goede toepassingen voor OpenTelemetry, en dergelijke, maar dat is wat mij betreft eerder iets om /naast/ iets als Zabbix of Icinga te plaatsen in plaats van in plaats daarvan.
No trees were harmed in creating this message. However, a large number of electrons were terribly inconvenienced.
- Yarisken
- Registratie: Augustus 2010
- Laatst online: 08:45
In no-time ben je met zabbix aan het monitoren met de templates die ze standaard al voorzien. Dan zijn er nog een heel pak community made.Douweegbertje schreef op donderdag 3 november 2022 @ 03:03:
[...]
Mijn verbazing is nog groter dat we anno 2022 het nog over icinga en zabbix hebben. Beetje stoffige meuk allemaal als je het mij vraagt.
Misschien ben ik wel biased maar is er misschien een reden dat heel het woord observability hier nog niet is gevallen?
Mooie standaard https://opentelemetry.io/ gebruiken en dan bewezen OSS tools zoals Prometheus met eventueel een laagje Thanos/Cortex/Mimir eroverheen. Traces met Jaeger/Tempo en logs via ES of beter nog via Loki. Visualiseren met Grafana en alerts via alertmanager.
IMO toch wel een beetje de standaard voor OSS voor als je het netjes/gangbaar wilt hebben.
- Douweegbertje
- Registratie: Mei 2008
- Laatst online: 24-04 02:02
Wat kinderachtig.. godverdomme
Het is geen negativiteit of een aanval. Het is een mening. Niemand mag een tegenstrijdige mening hebben zonder dat het jammer is? Ik respecteer ook jouw beeld.Wiley99 schreef op donderdag 3 november 2022 @ 07:47:
[...]
Jammer om andere producten, zoals Zabbix, dat actief ontwikkeld wordt en waar een grote gemeenschap en grote bedrijven al jaren goed mee werken, stoffig te noemen.
Maar exact jouw quote is voor mij de definitie van waarom je eigenlijk blijft hangen in iets. Ze werken er al jaren goed mee, dus het is goed. Wellicht minder bewust over wat er allemaal mogelijk is en wat er benodigd is om stacks zoals K8s, cloudnative, microservices perfect te observeren.
Weten of iets up of down is, is voor mij de definitie van iets wat niet meer helemaal van toepassing is (om er maar niet in de term te blijven hangen). Je definieert SLA/SLO/SLI's en op basis daarvan doe je iets. Dat 'iets' down is, is niet relevant want het zou resilient /self healing moeten zijn en het is veel interessanter om te kijken wat het effect is voor de daadwerkelijke gebruiker. Gaat je latency omhoog? Dan net zo je burn rate op je SLO window.Freeaqingme schreef op donderdag 3 november 2022 @ 09:39:
[...]
Ik zou proven technology nou niet direct beschrijven als 'stoffig'. Het is software die wat mij betreft heel goed is in detecteren of iets wel of niet draait zoals het zou moeten. Daarnaast heeft een tool als Icinga nagenoeg geen dependencies, en daarmee tamelijk robuust (essentieel voor monitoring).
Toegegeven, er zijn zeker goede toepassingen voor OpenTelemetry, en dergelijke, maar dat is wat mij betreft eerder iets om /naast/ iets als Zabbix of Icinga te plaatsen in plaats van in plaats daarvan.
Dat is top natuurlijk, maar hoe snel je kan monitoren is 9 van de 10 keer irrelevant, het lijkt mij dat er belangrijkere dingen zijn. Daarnaast heb je het nog steeds over monitoring, en ik heb het over observability.Yarisken schreef op donderdag 3 november 2022 @ 16:30:
[...]
In no-time ben je met zabbix aan het monitoren met de templates die ze standaard al voorzien. Dan zijn er nog een heel pak community made.
----
Wat voor mij het grote verschil is, is dat je met Zabbix monitoring doet en met de tools wat ik aangaf meer richting observability gaat. In plaats van dat je een alert krijgt of iets ziet in Zabbix, waarna je daarna 'fysiek' gaat kijken _wat_ het probleem is, doe je dat met observability juist in de tools.
Ik kan beter misschien dit delen: https://github.com/cncf/t...y/blob/main/whitepaper.md in plaats van zelf een heel betoog te houden.
- Wiley99
- Registratie: Juni 2014
- Laatst online: 25-06 17:41
Naja, @FlorianK vroeg hoe hij één servertje kon monitoren. Daarop reageerde ik.
Misschien reageerde jij breder, over het hele topic (hoewel dat erg stil was tot @FlorianK zijn vraag stelde)
Waarschijnlijk praat jij ook over een heel andere doelgroep dan gewoon wat "thuisservertjes" monitoren. Doordat dat tweakers (daarom zitten we hier) het meestal leuk vinden om overal mee te experimenteren en allerlei nieuwigheden aan elkaar te knopen, betekent dat vaak ook een complete overdaad aan functionaliteit en software voor maar een heel kleine toepassing. Dan is het heel iets anders om een businesscase van een bedrijf rond te maken. De ene keer is dat Zabbix, Grafana en Graylog, de andere keer een ELK stack en weer een andere keer een van de vele alternatieven daarvoor. Gelukkig noem je al Kubernetes en microservices, misschien goed om je te realiseren dat een groot deel van de wereld daar niet op draait en daar niet op hoeft te draaien.
Gelukkig kunnen we kiezen en bij de juiste toepassing de juiste oplossingen kiezen. Ben uiteindelijk benieuwd of @FlorianK nog iets kan met al onze reacties. Wel fijn dat zoveel mensen input geven, lijkt me
A polar bear is a rectangular bear after a coordinate transform - Never attribute to malice that which is adequately explained by stupidity
- Douweegbertje
- Registratie: Mei 2008
- Laatst online: 24-04 02:02
Wat kinderachtig.. godverdomme
Sure, ik reageerde meer algemeen en deels op Hipska. Het hoeft ook allemaal niet zo'n gevecht te zijnWiley99 schreef op donderdag 3 november 2022 @ 19:53:
@Douweegbertje
Naja, @FlorianK vroeg hoe hij één servertje kon monitoren. Daarop reageerde ik.
Misschien reageerde jij breder, over het hele topic (hoewel dat erg stil was tot @FlorianK zijn vraag stelde)
Waarschijnlijk praat jij ook over een heel andere doelgroep dan gewoon wat "thuisservertjes" monitoren. Doordat dat tweakers (daarom zitten we hier) het meestal leuk vinden om overal mee te experimenteren en allerlei nieuwigheden aan elkaar te knopen, betekent dat vaak ook een complete overdaad aan functionaliteit en software voor maar een heel kleine toepassing. Dan is het heel iets anders om een businesscase van een bedrijf rond te maken. De ene keer is dat Zabbix, Grafana en Graylog, de andere keer een ELK stack en weer een andere keer een van de vele alternatieven daarvoor. Gelukkig noem je al Kubernetes en microservices, misschien goed om je te realiseren dat een groot deel van de wereld daar niet op draait en daar niet op hoeft te draaien.
Gelukkig kunnen we kiezen en bij de juiste toepassing de juiste oplossingen kiezen. Ben uiteindelijk benieuwd of @FlorianK nog iets kan met al onze reacties. Wel fijn dat zoveel mensen input geven, lijkt me
Verder probeerde ik, maar wellicht te straf, een discussie te starten om vanuit de origine wat oudere TS wat dingen op te gooien. Dat is inderdaad niet gebaseerd op 1 server maar net zo goed prima te gebruiken. Als ik nog dan op een tip mag wijzen: Persoonlijk vind ik het aanbod van Grafana cloud vrij genereus; https://grafana.com/products/cloud/ - zie voor de features hier: https://grafana.com/products/cloud/features/
Gratis 50GiB logs, 10k timeseries en een retentie van 14 dagen.
En ja ik ben wel een beetje biased. Ik zit al een lange tijd in dit wereldje en ik kom vaak setups tegen waarvan ik mijn twijfels heb. Uiteindelijk hebben mensen een 'probleem' of kun je met een bepaalde methode aantonen dat als je het net even anders zou doen, dat het je leven een stuk makkelijker maakt.
Om eerlijk te zijn had ik de reactie van FlorianK niet eens gezien. Persoonlijk denk ik dan dat dit allemaal op te lossen is met systemd voor de service en Restart=on-failure en een service die wat logica doet met een tail op de logs. Of het gewoon anders/beter maken van de applicatie in kwestie. Het gebruiken van een monitoring tool (welke is dan om het even) om structurele applicatie logica uit te voeren valt voor mij onder dezelfde noemer die bij aangaf; de juiste tool voor de job.
Eigenaardigheid die mij opvalt, als ik een 'threshold trigger' toevoeg (als X langer dan Y, dan Z), dan kan ik die alleen in seconden invullen. Sommige checks zijn niet zo heel kritisch en vind ik prima als hij bijv. 2 dagen een bepaalde waarde heeft voordat ik notificatie krijg (snapshots van een VM bijv.). Maar ik moet dan dus telkens de gewenste tijdtrigger omrekenen naar seconden. Ik kan nergens een optie vinden om die unit aan te passen van seconden naar uren bijv.
[ Voor 21% gewijzigd door ThinkPad op 19-12-2022 12:16 ]
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Ben op m'n werk lekker bezig met Zabbix. Auto-discover loopt, auto-registration van agents werkt mooi. Maar er is zeker 1 ding wat naar mijn idee niet goed gaat en dat is het monitoren van Veeam via HTTP API.
Ik krijg netjes de informatie binnen, of er een backup draait, hoe ver deze is, of deze is gefaald, etc. Maar! Er is een keer een backup mislukt, maar dat is meer dan een week geleden. De taken sindsdien zijn gewoon succesvol. Maar die ene faal blijft maar als trigger staan, ook als ik alle data clear, het probleem ack en sluit, het blijft terugkomen.
Mijn vermoeden is dat de backup jobs elke run nieuwe sessie IDs krijgen en om een of andere reden pakt Zabbix zowel de oudere als de huidige staat. Want er zijn ondertussen items die niet meer gevonden worden en pas weg zijn na de housekeeping periode (of ik gooi het handmatig weg, maar een dag later zijn er weer een paar niet meer beschikbaar, ik blijf dan bezig).
Iemand een idee hoe dit is op te lossen? Online kom ik niet veel verder, krijg voornamelijk hoe je het inricht of hoe het met de 3rd party powershell scripts geregeld moet worden. Zoals gezegd, het acknowledgen en sluiten van het issue loste het niet op, een discovery/check later was het weer een issue.
Commandline FTW
- het op een goedkope shared hosting al kan draaien
- ik makkelijk 'heartbeats' kan versturen náár het monitoring pakket (mijn primaire use case) Ik weet niet of dit dé juiste term is, een signaaltje zodra een proces of taak heeft gedraait om te laten weten dat het gebeurd is. Indien het signaaltje x periode uitblijft volgt een alarm.
- het makkelijker 'instappen' was dan Zabbix wat ik ook geprobeerd heb
- FastFred
- Registratie: Maart 2009
- Laatst online: 12:01
/u/296398/crop618d33cd3b82c_cropped.png?f=community)
We hebben nu PRTG (2500), onze licentie van 3 jaar loopt nog iets van 200 dagen. Maarrrr, Paessler is overgenomen en de nieuwe eigenaar wil geld verdienen. Dus zoals het er nu naar uitziet gaat de prijs met 445% omhoog voor ons
Wat monitoren wij nu met PRTG?
Hardware:
- Ping en/of uptime van, switches, routers, firewalls, accesspoints, fysieke (zowel ESX als Windows) en virtuele servers, CPU, RAM en disk load
- her en der een netflow sensor om netwerkload te zien.
Software:
- of bepaalde processen/batchtaken actief zijn op specifieke servers
- controle of Veeam backuptaken zonder errors gelopen hebben
[ Voor 4% gewijzigd door FastFred op 09-07-2024 11:12 ]
- tlpeter
- Registratie: Oktober 2005
- Laatst online: 11:51
Al het andere is ook in te stellen maar vergt wat meer werk.
- Wiley99
- Registratie: Juni 2014
- Laatst online: 25-06 17:41
A polar bear is a rectangular bear after a coordinate transform - Never attribute to malice that which is adequately explained by stupidity
- downtime
- Registratie: Januari 2000
- Niet online
Everybody lies
/u/1906/crop5dfd46928e003.png?f=community)
Je bedoelt: Eigendom van een bedrijf en kan dus ook elk moment overgenomen worden en verkloot worden?Wiley99 schreef op dinsdag 9 juli 2024 @ 12:53:
en het bedrijf doet zelf
- Wiley99
- Registratie: Juni 2014
- Laatst online: 25-06 17:41
Naja met die instelling moet je gewoon alles zelf doen. Het gaat hier om waardevolle ervaringen, niet om pessimistische doembeelden te delendowntime schreef op dinsdag 9 juli 2024 @ 13:40:
[...]
Je bedoelt: Eigendom van een bedrijf en kan dus ook elk moment overgenomen worden en verkloot worden?
A polar bear is a rectangular bear after a coordinate transform - Never attribute to malice that which is adequately explained by stupidity
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Het is open source en kan zo geforkt worden. Dit itt tools zoals eerder genoemde PRTG dat gewoon even de prijs verveelvoudigd. Dát is pas de boel verkloten! Dus kies je eigen gif maar, iets dat je nog kan blijven gebruiken zoals het nu is, of je helemaal krom moet gaan liggen door idiote licentiekosten.downtime schreef op dinsdag 9 juli 2024 @ 13:40:
[...]
Je bedoelt: Eigendom van een bedrijf en kan dus ook elk moment overgenomen worden en verkloot worden?
Onze MSP gebruikt het. Het is agentless omdat het via remote powershell en WMI de boel monitort in Windows, voor netwerkapparatuur is het SNMP, maar ondersteuning voor Linux is op z'n zachts gezegd slecht (of eigenlijk niet bestaand). Hun FAQ zegt wel leuk dit:ge-flopt schreef op dinsdag 9 juli 2024 @ 12:46:
Ik heb hier PIM+ nog niet voorbij zien komen. Ook een betaalde dienst, maar wij zijn er zeker te vreden mee alsook het Nederlandse bedrijf wat de ondersteuning doet.
Maar gaat niet in op hoe het z'n werk doet voor de andere besturingssystemen. Alleen dit:PIM+ ondersteunt Windows, Linux en andere besturingssystemen die de standaard internetprotocollen ondersteunen.
Leuk, maar zoals gezegd, WMI is een Windows ding, SNMP moet apart geïnstalleerd en geconfigureerd worden in je OS. Voor netwerkapparatuur is SNMP zo'n beetje de standaard en elk pakket ondersteund dit wel, daar is PIM+ niet uniek in.PIM+ gebruikt de standaardprotocollen zoals SNMP en WMI
Nog een dingetje waar PIM+ tekort schiet, is dat het opeens niet meer in staat was om onze iLO te monitoren zodra ik strengere cipher suites had afgedwongen. Men is moeten terugvallen op SNMP, ipv HTTP. Ik had zoiets niet verwacht, dat een pakket dat via API calls kan monitoren vast zit in de tijd van 10+ jaar terug. Hoezo snapt het TLS 1.2 niet?
Commandline FTW
- downtime
- Registratie: Januari 2000
- Niet online
Everybody lies
Ik kan me vergissen maar WMI heet tegenwoordig CIM en is een standaard die in Linux-land door SBLIM geimplementeerd wordt. Helaas kan ik zo snel niet vinden welke distro's het ondersteunen.Hero of Time schreef op dinsdag 9 juli 2024 @ 19:43:
[...]
Leuk, maar zoals gezegd, WMI is een Windows ding
- Hero of Time
- Registratie: Oktober 2004
- Laatst online: 25-06 22:32
Maar CIM staat niet op hun site genoemd.downtime schreef op dinsdag 9 juli 2024 @ 19:50:
[...]
Ik kan me vergissen maar WMI heet tegenwoordig CIM en is een standaard die in Linux-land door SBLIM geimplementeerd wordt. Helaas kan ik zo snel niet vinden welke distro's het ondersteunen.
Commandline FTW
Dat is vaak genoeg gebeurd met een positief resultaat:Hero of Time schreef op dinsdag 9 juli 2024 @ 19:43:
[...]
Het is open source en kan zo geforkt worden. Dit itt tools zoals eerder genoemde PRTG dat gewoon even de prijs verveelvoudigd. Dát is pas de boel verkloten! Dus kies je eigen gif maar, iets dat je nog kan blijven gebruiken zoals het nu is, of je helemaal krom moet gaan liggen door idiote licentiekosten.
pfSense --> OPNSense
ownCloud --> NextCloud
OpenOffice --> LibreOffice
MPC --> MPC-HC
Als Zabbix ooit Oracle/Adobe-achtige ambities krijgt, zal het niet lang duren. Het is namelijk grote delen van de community die veel werk verrichten in de achtergrond en voor support en ontwikkeling zorgen, die meteen naar het nieuwe platform gaan dat de open source missie verder zet.
- deHakkelaar
- Registratie: Februari 2015
- Laatst online: 27-07-2024
/u/658914/crop5f7a5ee826414_cropped.png?f=community)
Wat een verbetering was dat tov Nagios wat we voorheen draaiden met allemaal losse config bestandjes.
There are only 10 types of people in the world: those who understand binary, and those who don't
- Yarisken
- Registratie: Augustus 2010
- Laatst online: 08:45
Idd ook met Nagios begonnen en wat een miserie was dat. Dan test gedaan met Zabbix ... templates wat een zaligheid ... .deHakkelaar schreef op donderdag 11 juli 2024 @ 17:20:
Ik heb ook goede ervaringen met Zabbix in een enterprise omgeving al is dit weer een jaartje of tien geleden.
Wat een verbetering was dat tov Nagios wat we voorheen draaiden met allemaal losse config bestandjes.