:fill(white):strip_exif()/i/2003943496.jpeg?f=thumbmini)
:strip_exif()/i/1321263566.png?f=thumbmini)
Bij een scrub wordt de 'ruwe' data weergeven: ook de parity-data wordt dus meegerekend in dit getal.Keiichi schreef op donderdag 08 september 2016 @ 08:03:
[...]
Ik heb waarschijnlijk ergens iets over het hoofd gezien, maar hoe kun je hier 19.8T aan data op hebben? Ik dacht dat hier maar 16T maximaal op kon
:strip_icc():strip_exif()/u/6607/klootviool2.jpg?f=community)
Scrubs kunnen wel even duren. HIer loopt er momenteel een op een array van zes 7200rpm schijven:
Deze server wordt ook wel druk gebruikt terwijl dit loopt.
code:
1
2
3
| scan: scrub in progress since Wed Sep 7 09:55:29 2016
6.66T scanned out of 23.3T at 85.2M/s, 56h57m to go
0 repaired, 28.57% done |
Deze server wordt ook wel druk gebruikt terwijl dit loopt.
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
:strip_exif()/u/396800/D-_3427da0a9c293b63f2a66dea2e642102.gif?f=community)
Wat mij trouwens opvalt aan je plaatje is dat de oude disk die je nu aan het vervangen bent niet meer aanwezig is in je pool. Was deze compleet dood of is er een andere reden waarom je hem eruit hebt getrokken? Het vervangen van een falende disk terwijl die falende disk nog aanwezig is aan te raden. Alleen als je disk echt dood is dan haal je hem helemaal uit je pool.MikeVM schreef op donderdag 08 september 2016 @ 00:30:
2de disk is blijkbaar ook aan het stukgaan
[afbeelding]
gelukkige heb ineens 2 disks besteld..
Sinds de 2 dagen regel reageer ik hier niet meer
- HyperBart
- Registratie: Maart 2006
- Laatst online: 10:09
/u/170728/owl.png?f=community)
Mja die discussie is al eens gevoerd hoor, ik val daar CiPHER wel in bij dat ik liefst heb dat ZFS zo dicht mogelijk bij de disk zit. Dan kan je wel pRDM's gebruiken, maar ik vind het nog altijd wat riskanter. Zoals eerder gezegd, ieder moet de voordelen en nadelen afzetten tegen zijn usecase. Ik doe het bv. niet meer, ik wil graag zo safe mogelijk spelen. Dat dat geen garantie is van vage fouten is een ander verhaalCompizfox schreef op dinsdag 06 september 2016 @ 20:48:
[...]
Zoals je al zegt, dat is maar net de vraag.
Bij ESXi heb je bijvoorbeeld "virtual RDM" en "physical RDM". In het eerste geval wordt een HDD niet 'raw' doorgegeven, maar als block device. Je hebt dan binnen je VM geen SMART e.d., en de schijf wordt niet gezien als schijf, maar als een generiek block device. Dat moet je niet hebben met ZFS.
Maar met "physical RDM" is dat niet het geval en wordt de schijf echt als schijf doorgegeven. In dit geval is de schijf "niet van echt te onderscheiden" (je kunt dan via de VM bij SMART, camcontrol herkent het merk/type/serienummer van de schijf, enz). Dit is geen probleem voor ZFS.
En dat is precies de vraag waarin ik geïnteresseerd ben. Uit de Proxmox wiki maak ik op dat het om dat tweede geval gaat, maar ik zoek nog bevestiging (vandaar dat ik het hier vraag).
[...]
Dit verhaal ken ikHet doorgeven van een complete controller is niet praktisch, alleen al om het feit dat je een 2e (dure) controller nodig hebt. Die heb ik niet, en die ben ik niet bereid aan te schaffen als het niet nodig is.
Momenteel draait deze fileserver niet gevirtualiseerd, en ik ben nu aan het bekijken of virtualisatie mogelijk is.
Dan ga ik het hierbij ook houdenCompizfox schreef op dinsdag 06 september 2016 @ 21:49:
Maar goed, het was niet echt mijn bedoeling om een discussie te beginnen over disk passthrough vs controller passthrough
Dat is echt wel bizar traag zeg, dat zou normaal niet langer als een paar minuten in het begin traag mogen zijn...MikeVM schreef op woensdag 07 september 2016 @ 02:13:
mn server is al sinds 19h bezig met "currently being resilvered"
maar het schiet niet echt op.
[afbeelding]
server spec:
Raidz2 10 disks of 3TB
intel Core i5 2400u
16GB DDR3
Akkoord, maar vind je niet dat dit HEEL lang blijft duren? Als ik begin te scrubben (vergelijkbaar niet hetzelfde, I know) dan is dat slechts een paar minuten traag en dan gaat ie al vlotjes richten de xxx MB/s, hier spreken we ocharmpjes nog over KB/sVerwijderd schreef op woensdag 07 september 2016 @ 13:53:
In het begin is een sync altijd heel langzaam omdat metadata wordt gesynced. Pas na een tijd gaat de scrub op een redelijke snelheid. In het begin zie je dan ook: "scan is slow, no estimated time' ofzoiets staan.
Ik vind dat je resilver echt belabberd traag gaat. Nu weet ik niet of dat ligt aan het feit dat ik een resilver snelheid verwar met een scrub en dat een resilver de snelheid is van de disk(s) zelf die hij aan het repareren is of de hele array I/O die hij samentelt. Als het dat eerste is dan lijkt het mij prima, als het dat laatste is vind ik het traag...MikeVM schreef op woensdag 07 september 2016 @ 13:27:
oh, ik was vergeten te melden dat een disk vervangen heb, en daarna deze handmatig heb toegevoegd.
ondertussen staat ie op 26%
[afbeelding]
[quote]FireDrunk schreef op woensdag 07 september 2016 @ 18:35:
Tja, als je nog 17TB (17.825.792MB), en het gaat met 90MB/s, dan is dat niet zo gek.
90MB/s is best wel traag voor een RAIDZ2 array van 10 schijven, na 51h, mag je ervan uitgaan dat de metadata wel gesynced is (meestal gaat de snelheid na 20min-2h wel echt hard omhoog.
Is je array altijd zo traag geweest?
Zo gaat het hier (een scrub is zeer vergelijkbaar, maar niet 100%):
Start:
[pre]
scan: scrub in progress since Wed Sep 7 18:36:03 2016
86.6M scanned out of 19.8T at 4.33M/s, (scan is slow, no estimated time)
0 repaired, 0.00% done
[/pre]
Na 20 minuten:
[pre]
scan: scrub in progress since Wed Sep 7 18:36:03 2016
286G scanned out of 19.8T at 225M/s, 25h19m to go
0 repaired, 1.41% done
[/pre]
6*4TB RAIDZ2 array btw.
[/quote]
Dat bedoel ik dus, die snelheid die hij ziet tijdens zijn resilver, is dat van die ene disk die aan het schrijven is of is dat getal de gecumuleerde snelheid die je normaal ook ziet bij een scrub?
Zie je wel, het is gewoon heel traag, dit is bij mij (vergelijkbaar) ooit als volgt geweest:
HyperBart in "Het grote ZFS topic"
WoohooowMikeVM schreef op donderdag 08 september 2016 @ 00:30:
[...]
is de bottleneck niet de schrijfsnelheid van die ene HDD? (WD RED)
zou het helpen als ik even 32GB ram erin plaats in plaats van 16GB?
kan ik het silverproces pauzeren?
2de disk is blijkbaar ook aan het stukgaan
[afbeelding]
gelukkige heb ineens 2 disks besteld..
Wat ik even niet begrijp (post eens een zpool status aub) is dat je een kapotte disk had, die gereplaced hebt maar dat die vervangende disk nu ook op unavailable staat?
Komt er nog eens bij dat je die FAULTED disk hebt. Als ik jou was zou ik die netjes laten steken tot die eerste defecte disk (die weg is) geresilvered is met zijn vervanger en dan pas de volgende doen.
En hou het volgende advies zeker in de toekomst heel hard in gedachten: Altijd een disk proberen te vervangen terwijl de oude nog opgekoppeld is. Als ie door het OS niet meer zichtbaar is desnoods even rebooten zodat hij er terug bij is en dan replacen, ook al is het maar even, je hebt op dat moment misschien nog even je kapotte disk ter beschikking en het risico op dataloss verkleint weer een stukje omdat je nog volledige redundantie hebt zolang alle disks er nog zijn waar als je de disk er uit knikkert die pariteit niet meer beschikbaar is.
HyperBart in "Het grote ZFS topic"
HyperBart schreef op zaterdag 18 april 2015 @ 21:48:
[...]
ZFS Replace
ZFS gaat nu de data die disk 5 bevat aan de hand van 1 2 3 4 5 wegschrijven naar disk 6 om 'm zo maar even te noemen.
Het voordeel is nu dat tijdens dat "berekenen van de weg te schrijven data", als er toevallig op dat moment op disk 3 een gek foutje voorkomt, dat hij (hopelijk) disk 5 op dat moment nog kan bereiken om de data on the fly te reconstrueren en goed weg te schrijven naar disk 6... Heb je disk 5 op dat moment niet, dan zegt ZFS "woeps, die data kon ik niet meer goed wegschrijven, oh ja aangezien ik ook weet heb van het filesystem wat op je pool draait kan ik je nu ineens ook vertellen dat de data die ik niet kon reconstrueren deel uitmaakte van het volgende bestandje, en dat bestandje is nu kapot!"
[ Voor 4% gewijzigd door HyperBart op 08-09-2016 09:22 ]
- MikeVM
- Registratie: Mei 2007
- Laatst online: 17-06 09:21
- Baloo -
okay, dat is misschien wel een goed idee,HyperBart schreef op donderdag 08 september 2016 @ 09:11:
En hou het volgende advies zeker in de toekomst heel hard in gedachten: Altijd een disk proberen te vervangen terwijl de oude nog opgekoppeld is. Als ie door het OS niet meer zichtbaar is desnoods even rebooten zodat hij er terug bij is en dan replacen, ook al is het maar even, je hebt op dat moment misschien nog even je kapotte disk ter beschikking en het risico op dataloss verkleint weer een stukje omdat je nog volledige redundantie hebt zolang alle disks er nog zijn waar als je de disk er uit knikkert die pariteit niet meer beschikbaar is.
ik had de disk eruit gehaald omdat zfsguru heel traag bootte omdat hij de kapotte disk wou aanspreken en heel de tijd errors kreeg,
zpool status
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| [root@zfsguru /home/ssh]# zpool status
pool: Data
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Tue Sep 6 19:09:47 2016
21.2T scanned out of 21.5T at 143M/s, 0h42m to go
2.02T resilvered, 98.38% done
config:
NAME STATE READ WRITE CKSUM
Data DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/A_Z2_24TB-disk1 ONLINE 0 0 0
gpt/A_Z2_24TB-disk2 ONLINE 0 0 0
gpt/A_Z2_24TB-disk3 ONLINE 0 0 0
replacing-3 UNAVAIL 0 0 0
12813854006524053520 UNAVAIL 0 0 0 was /dev/gpt/A_Z2_24TB-disk4
gpt/RED1 ONLINE 0 0 0 (resilvering)
gpt/A_Z2_24TB-disk5 ONLINE 0 0 0
gpt/A_Z2_24TB-disk6 ONLINE 0 0 0
gpt/A_Z2_24TB-disk7 ONLINE 0 0 19 (resilvering)
gpt/A_Z2_24TB-disk8 ONLINE 0 0 0
gpt/A_Z2_24TB-disk9 FAULTED 28 78 1 too many errors (resilvering)
gpt/A_Z2_24TB-disk10 ONLINE 0 0 0
cache
gpt/SSD_L2ARC ONLINE 0 0 0
errors: No known data errors
pool: OS
state: ONLINE
status: The pool is formatted using a legacy on-disk format. The pool can
still be used, but some features are unavailable.
action: Upgrade the pool using 'zpool upgrade'. Once this is done, the
pool will no longer be accessible on software that does not support feature
flags.
scan: none requested
config:
NAME STATE READ WRITE CKSUM
OS ONLINE 0 0 0
gpt/SSD_BOOT ONLINE 0 0 0
errors: No known data errors
[root@zfsguru /home/ssh]# |
[ Voor 56% gewijzigd door MikeVM op 08-09-2016 14:24 ]
\\ Baloo \\ Mijn iRacing profiel
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
Die 143MB/s is al beter, maar nog niet uitmuntend.
Wel eng dat hij dus aangeeft dat er 3 disks resilvering zijn
Disk 9 heeft dus ook gebokt, en op disk7 heb je silent corruptie gehad
Ik zou hierna even een memtestje draaien.
Wel eng dat hij dus aangeeft dat er 3 disks resilvering zijn
Disk 9 heeft dus ook gebokt, en op disk7 heb je silent corruptie gehad
Ik zou hierna even een memtestje draaien.
Even niets...
- HyperBart
- Registratie: Maart 2006
- Laatst online: 10:09
Inderdaad, het is nog erger dan ik eerst dacht. Je hebt dus 3 disks die aan het bokken zijn. Als je nu die disk niet verwijderd had dan kon je daar nog af en toe op "rekenen" om in het geval dat nu de andere 2 disks op hetzelfde moment een fout geven de stripe toch nog te herstellen op basis van de data die beschikbaar was op die falende disk. Nu ja, dat is te laat, fingers crossed dat er nu niets misgaat, maar ik zou met de piepers zitten... 
Anyway, die traagheid is nu volgens mij ook wel te verklaren owv het feit dat het nu over 3 disks gaat ipv maar ééntje die hij moet repareren en dat dit zo een gevalletje is waarbij ZFS niet supersnel is, maar FireDrunk die weet daar misschien nog wat meer over te vertellen.
Naar de toekomst dus het volgende doen:
Doe jezelf een plezier en verwijder ZEKER geen disks.
EDIT: zie nu pas dat je al op 98% zit. Komt wel goed.
Anyway, die traagheid is nu volgens mij ook wel te verklaren owv het feit dat het nu over 3 disks gaat ipv maar ééntje die hij moet repareren en dat dit zo een gevalletje is waarbij ZFS niet supersnel is, maar FireDrunk die weet daar misschien nog wat meer over te vertellen.
Naar de toekomst dus het volgende doen:
zpool replace Data /pad/naar/je/gpt/partitie/van/gpt/A_Z2_24TB-disk9 /pad/naar/je/gpt/partitie/gpt-devervangendedisk
Doe jezelf een plezier en verwijder ZEKER geen disks.
EDIT: zie nu pas dat je al op 98% zit. Komt wel goed.
- MikeVM
- Registratie: Mei 2007
- Laatst online: 17-06 09:21
- Baloo -
eerst memtest en dan pas die 2de disk vervangen? of eerst de disk vervangen?FireDrunk schreef op donderdag 08 september 2016 @ 14:27:
Ik zou hierna even een memtestje draaien.
\\ Baloo \\ Mijn iRacing profiel
Ik zou deze resilver af maken, daarna memtesten.
Even niets...
- MikeVM
- Registratie: Mei 2007
- Laatst online: 17-06 09:21
- Baloo -
Dit zal wel genoeg zijn denk ik?

\\ Baloo \\ Mijn iRacing profiel
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Na 24 uurtjes laten draaien wel ja.
Sinds de 2 dagen regel reageer ik hier niet meer
- MikeVM
- Registratie: Mei 2007
- Laatst online: 17-06 09:21
- Baloo -
Disk 2 vervangen is wel sneller denk ik.

Server time is incorrect (replacement start was om 2u49)
de screenshot was 15 na start resilvering.
Server time is incorrect (replacement start was om 2u49)
de screenshot was 15 na start resilvering.
[ Voor 34% gewijzigd door MikeVM op 09-09-2016 03:09 ]
\\ Baloo \\ Mijn iRacing profiel
Dat gaat een stuk beter. Zat de vorige disk op een andere, misschien tragere controller?
Even niets...
- HyperBart
- Registratie: Maart 2006
- Laatst online: 10:09
Post nog eens een zpool status?MikeVM schreef op vrijdag 09 september 2016 @ 03:06:
Disk 2 vervangen is wel sneller denk ik.
[afbeelding]
Server time is incorrect (replacement start was om 2u49)
de screenshot was 15 na start resilvering.
- MikeVM
- Registratie: Mei 2007
- Laatst online: 17-06 09:21
- Baloo -
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| [root@zfsguru /home/ssh]# zpool status
pool: Data
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Fri Sep 9 00:49:33 2016
11.8T scanned out of 21.5T at 296M/s, 9h36m to go
1.12T resilvered, 54.70% done
config:
NAME STATE READ WRITE CKSUM
Data DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gpt/A_Z2_24TB-disk1 ONLINE 0 0 0
gpt/A_Z2_24TB-disk2 ONLINE 0 0 0
gpt/A_Z2_24TB-disk3 ONLINE 0 0 0
gpt/RED1 ONLINE 0 0 0
gpt/A_Z2_24TB-disk5 ONLINE 0 0 0
gpt/A_Z2_24TB-disk6 ONLINE 0 0 0
gpt/A_Z2_24TB-disk7 ONLINE 0 0 0
gpt/A_Z2_24TB-disk8 ONLINE 0 0 0
replacing-8 UNAVAIL 0 0 0
15509199086037054745 UNAVAIL 0 0 0 was /dev/gpt/A_Z 2_24TB-disk9/old
gpt/A_Z2_24TB-disk9 ONLINE 0 0 0 (resilvering)
gpt/A_Z2_24TB-disk10 ONLINE 0 0 0
cache
gpt/SSD_L2ARC ONLINE 0 0 0
errors: No known data errors
[root@zfsguru /home/ssh]# |
ik had de oude faulty drive er weer uitgehaald, omdat de server(webgui) hierdoor heel traag werd.
[ Voor 3% gewijzigd door MikeVM op 09-09-2016 17:58 ]
\\ Baloo \\ Mijn iRacing profiel
- Geckx
- Registratie: November 2008
- Laatst online: 24-05 15:29
Even een theoretische vraag alvorens ik dit zou toepassen in de praktijk:
Voor een kennis zou ik op zijn vraag ook een ZFS based home nas systeem willen samenstellen.
Voor 2 doeleinden:
- media server
- opslag belangrijke documenten/foto's
Hij heeft 5 schijven van 3TB
Nu zou ik hem een RAIDZ1 config aanraden voor zijn media bestanden (niet zeer kritisch)
Maar voor zijn documenten en foto's vind ik single parity wat magertjes..
Nu is mijn vraag of het mogelijk is om bijvoorbeeld elke schijf te partitioneren (met correcte 4K alignment) in 500GB + 2500GB (uiteraard niet exact correct, maar doet er niet toe als vb)
Dan een 5-way mirror te doen met de 500GB partitie (zeer veilig dus voor zijn foto's en documenten) en een raidz1 met het resterende.
Dan zou hij 2 pools hebben, eentje met grote data veiligheid en eentje met matige bescherming.
Maar de vraag is dus of dit aan te raden is om partities ipv raw devices aan ZFS te voeren? Heeft dit nadelen naar stabiliteit en kan ZFS hier vreemd op reageren op lange termijn?
Ik heb ook al aangeraden op eventueel schijven bij te kopen, maar liever niet. Zou ook nieuw mobo + case betekenen.
Voor een kennis zou ik op zijn vraag ook een ZFS based home nas systeem willen samenstellen.
Voor 2 doeleinden:
- media server
- opslag belangrijke documenten/foto's
Hij heeft 5 schijven van 3TB
Nu zou ik hem een RAIDZ1 config aanraden voor zijn media bestanden (niet zeer kritisch)
Maar voor zijn documenten en foto's vind ik single parity wat magertjes..
Nu is mijn vraag of het mogelijk is om bijvoorbeeld elke schijf te partitioneren (met correcte 4K alignment) in 500GB + 2500GB (uiteraard niet exact correct, maar doet er niet toe als vb)
Dan een 5-way mirror te doen met de 500GB partitie (zeer veilig dus voor zijn foto's en documenten) en een raidz1 met het resterende.
Dan zou hij 2 pools hebben, eentje met grote data veiligheid en eentje met matige bescherming.
Maar de vraag is dus of dit aan te raden is om partities ipv raw devices aan ZFS te voeren? Heeft dit nadelen naar stabiliteit en kan ZFS hier vreemd op reageren op lange termijn?
Ik heb ook al aangeraden op eventueel schijven bij te kopen, maar liever niet. Zou ook nieuw mobo + case betekenen.
[ Voor 3% gewijzigd door Geckx op 11-09-2016 12:00 ]
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Waarom niet een RAIDZ2 voor alles?
Sinds de 2 dagen regel reageer ik hier niet meer
- Geckx
- Registratie: November 2008
- Laatst online: 24-05 15:29
Dan zou hij ofwel 1 schijf moeten opgeven of 1 moeten bijplaatsen (geen optie).CurlyMo schreef op zondag 11 september 2016 @ 12:29:
Waarom niet een RAIDZ2 voor alles?
Volgens de best practice (ook hier in dit topic) neem je toch best 4 of 6 schijven voor RAID-Z2?
Dus ik vroeg me af of je verschillende vdevs en pools kan maken met dezelfde schijven, maar andere partities..
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Best practice is nog iets anders dan enige optie. Het is dus beter om, maar andere configuraties werken ook prima. Helemaal als je gaat stoeien met niet ideale configuraties zoals in jouw voorstel meerdere pools op verschillende partities.Geckx schreef op zondag 11 september 2016 @ 13:22:
Dan zou hij ofwel 1 schijf moeten opgeven of 1 moeten bijplaatsen (geen optie).
Volgens de best practice (ook hier in dit topic) neem je toch best 4 of 6 schijven voor RAID-Z2?
Wat ook helpt is even een uitdraai van de hardware geven. Dan is er ook makkelijker advies te geven.
Sinds de 2 dagen regel reageer ik hier niet meer
5 schijven inRAIDZ2 kan prima, Wat jij wil met partities kan ook prima. Ik heb nog nooit hele devices aan ZFS gegeven, juist altijd partities. ZFSOnLinux maakt zelfs zelf partities voor je aan als je ZFS een hele disk geeft.
Raw devices doorgeven is iets van wat in het Solaris tijdperk belangrijk was, maar tegenwoordig eerder bad practice is.
Raw devices doorgeven is iets van wat in het Solaris tijdperk belangrijk was, maar tegenwoordig eerder bad practice is.
Even niets...
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Het doel daarvan is wel wezenlijk anders. Daar gaat het om het afvangen van mogelijk verschillend aantal bytes per HDD merk voor dezelfde theoretische capaciteit. @Geckx wil juist meerdere pools bouwen over verschillende partities. Dat lijkt me minder ideaal dan gewoon RAIDZ2 met 5 disks.FireDrunk schreef op zondag 11 september 2016 @ 14:08:
Ik heb nog nooit hele devices aan ZFS gegeven, juist altijd partities. ZFSOnLinux maakt zelfs zelf partities voor je aan als je ZFS een hele disk geeft.
Sinds de 2 dagen regel reageer ik hier niet meer
- Geckx
- Registratie: November 2008
- Laatst online: 24-05 15:29
Klopt inderdaad dat mijn doel anders is dan wat ZFSOnLinux default doet.
Niet dat er geweldig veel I/O's zullen opgezet worden maar ik was niet zeker of dit voor extra overhead zou zorgen bij ZFS of niet. Ook bij het vervangen van 1 drive, impliceert dit dat 2 pools tegelijk moeten resilveren op dezelfde hdd's.
Ik heb zelf atijd gewoon volledige disks gebruikt voor mijn pools, dus mijn vraag was vooral naar ervaringen van jullie.
Wat betreft RAIDZ2 met 5 disks, zijn er bepaalde tweaks die dan moeten gebeuren om toch zo optimaal mogelijk te werken? Schijven zijn 3x WD Red 3TB + 2x WD Black 3TB (inderdaad ook niet optimaal door verschillende rpm)
Niet dat er geweldig veel I/O's zullen opgezet worden maar ik was niet zeker of dit voor extra overhead zou zorgen bij ZFS of niet. Ook bij het vervangen van 1 drive, impliceert dit dat 2 pools tegelijk moeten resilveren op dezelfde hdd's.
Ik heb zelf atijd gewoon volledige disks gebruikt voor mijn pools, dus mijn vraag was vooral naar ervaringen van jullie.
Wat betreft RAIDZ2 met 5 disks, zijn er bepaalde tweaks die dan moeten gebeuren om toch zo optimaal mogelijk te werken? Schijven zijn 3x WD Red 3TB + 2x WD Black 3TB (inderdaad ook niet optimaal door verschillende rpm)
[ Voor 14% gewijzigd door Geckx op 11-09-2016 14:27 ]
Ik vermoed dat de I/O scheduler van ZFS is geschreven met de aanname dat het de enige gebruiker van een fysieke schijf is. Bij acties als scrubs en resilvers zou je dus wel eens tegen prestatieproblemen kunnen aanlopen als je de schijven deelt tussen twee pools. Dat is overigens eenvoudig te voorkomen door de pools een voor een te herstellen na het vervangen van een schijf. Voor het dagelijkse thuisgebruik zou de voorgestelde aanpak naar mijn idee geen problemen mogen geven, maar ik heb het zelf nooit geprobeerd.
Compressie aanzetten (ookal heeft het minder zin op de media files). En je kan eventueel 1MB Blocksize gebruiken. Maar dat is een vrij recente feature.Geckx schreef op zondag 11 september 2016 @ 14:22:
Klopt inderdaad dat mijn doel anders is dan wat ZFSOnLinux default doet.
Niet dat er geweldig veel I/O's zullen opgezet worden maar ik was niet zeker of dit voor extra overhead zou zorgen bij ZFS of niet. Ook bij het vervangen van 1 drive, impliceert dit dat 2 pools tegelijk moeten resilveren op dezelfde hdd's.
Ik heb zelf atijd gewoon volledige disks gebruikt voor mijn pools, dus mijn vraag was vooral naar ervaringen van jullie.
Wat betreft RAIDZ2 met 5 disks, zijn er bepaalde tweaks die dan moeten gebeuren om toch zo optimaal mogelijk te werken? Schijven zijn 3x WD Red 3TB + 2x WD Black 3TB (inderdaad ook niet optimaal door verschillende rpm)
Even niets...
Tip voor de mensen die Fedora (of iets anders wat recente kernels bevat) draaien.
Niet upgraden naar 4.7.2, ZFS breekt dan
Niet upgraden naar 4.7.2, ZFS breekt dan
Even niets...
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Misschien een suffe vraag waarvan ik het antwoord niet zo snel kan vinden. Als ik een GELI versleutelde pool wil migreren naar een ander systeem, welke GELI data dien ik dan mee te migreren? Alleen de sleutels of ook de metadata? Of nog andere dingen?
Sinds de 2 dagen regel reageer ik hier niet meer
- dcm360
- Registratie: December 2006
- Niet online
/u/200133/artemis_square_e_60-60.png?f=community)
Specifiek .2 of 4.7.x? Want volgens mij moet er even gewacht worden op ZoL 6.5.8 voordat het überhaupt met kernel 4.7.x gaat werkenFireDrunk schreef op maandag 12 september 2016 @ 11:13:
Tip voor de mensen die Fedora (of iets anders wat recente kernels bevat) draaien.
Niet upgraden naar 4.7.2, ZFS breekt dan
Ik weet heel eerlijk gezegd niet of ik 4.7.1 heb gehad. De vorige "stable" kernel die op mijn systeem stond is 4.6.7, en dat is nu mijn actieve kernel.
Volgens de GitHub issue is het specifiek 4.7.2.
Volgens de GitHub issue is het specifiek 4.7.2.
Even niets...
- MikeVM
- Registratie: Mei 2007
- Laatst online: 17-06 09:21
- Baloo -
Server draait nu wel weer vrolijk. sneller als voorheen denk ik zelfs, het lijkt zelfs dat de cpu meer kracht heeft op de nieuwe zfsguru versie. Rar bestanden uitpakken gaat veel sneller in ieder geval.
nu heb ik nog een probleem wat ik niet zelf krijg opgelost.
Sabnzbd kan bestanden in mijn watched folder niet uitlezen omdat deze niet de juiste chmod rechten heeft. deze kan ik dan telkens wel handmatig veranderen met [ chmod -R 777 /blabla/watched ], maar dat is niet echt wenselijk.
ik heb geprobeerd de rechten van de gebruiker _sabnzbd en de groep _sabnzbd te veranderen, maar dat heeft geen invloed.
de file in de watched folder wordt aangemaakt via samba (user Michiel)
nu heb ik nog een probleem wat ik niet zelf krijg opgelost.
Sabnzbd kan bestanden in mijn watched folder niet uitlezen omdat deze niet de juiste chmod rechten heeft. deze kan ik dan telkens wel handmatig veranderen met [ chmod -R 777 /blabla/watched ], maar dat is niet echt wenselijk.
ik heb geprobeerd de rechten van de gebruiker _sabnzbd en de groep _sabnzbd te veranderen, maar dat heeft geen invloed.
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| [root@zfsguru /]# cat etc/group # $FreeBSD: releng/10.3/etc/group 256366 2013-10-12 06:08:18Z rpaulo $ # wheel:*:0:root,ssh daemon:*:1: kmem:*:2: sys:*:3: tty:*:4: operator:*:5:root mail:*:6: bin:*:7: news:*:8: man:*:9: games:*:13: ftp:*:14: staff:*:20: sshd:*:22: smmsp:*:25: mailnull:*:26: guest:*:31: bind:*:53: unbound:*:59: proxy:*:62: authpf:*:63: _pflogd:*:64: _dhcp:*:65: uucp:*:66: dialer:*:68: network:*:69: audit:*:77: www:*:80: hast:*:845: nogroup:*:65533: nobody:*:65534: zfsguru-web:*:888: share:*:1000: ssh:*:44: _tss:*:601: _sabnzbd:*:0: messagebus:*:556: avahi:*:558: cups:*:193: polkit:*:562: polkitd:*:565: haldaemon:*:560: colord:*:970: pulse:*:563: pulse-access:*:564: pulse-rt:*:557: vboxusers:*:920: |
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| [root@zfsguru /]# cat /etc/passwd # $FreeBSD: releng/10.3/etc/master.passwd 256366 2013-10-12 06:08:18Z rpaulo $ # root:*:0:0:Charlie &:/root:/usr/local/bin/bash toor:*:0:0:Bourne-again Superuser:/root: daemon:*:1:1:Owner of many system processes:/root:/usr/sbin/nologin operator:*:2:5:System &:/:/usr/sbin/nologin bin:*:3:7:Binaries Commands and Source:/:/usr/sbin/nologin tty:*:4:65533:Tty Sandbox:/:/usr/sbin/nologin kmem:*:5:65533:KMem Sandbox:/:/usr/sbin/nologin games:*:7:13:Games pseudo-user:/usr/games:/usr/sbin/nologin news:*:8:8:News Subsystem:/:/usr/sbin/nologin man:*:9:9:Mister Man Pages:/usr/share/man:/usr/sbin/nologin sshd:*:22:22:Secure Shell Daemon:/var/empty:/usr/sbin/nologin smmsp:*:25:25:Sendmail Submission User:/var/spool/clientmqueue:/usr/sbin/nologin mailnull:*:26:26:Sendmail Default User:/var/spool/mqueue:/usr/sbin/nologin bind:*:53:53:Bind Sandbox:/:/usr/sbin/nologin unbound:*:59:59:Unbound DNS Resolver:/var/unbound:/usr/sbin/nologin proxy:*:62:62:Packet Filter pseudo-user:/nonexistent:/usr/sbin/nologin _pflogd:*:64:64:pflogd privsep user:/var/empty:/usr/sbin/nologin _dhcp:*:65:65:dhcp programs:/var/empty:/usr/sbin/nologin uucp:*:66:66:UUCP pseudo-user:/var/spool/uucppublic:/usr/local/libexec/uucp/uucico pop:*:68:6:Post Office Owner:/nonexistent:/usr/sbin/nologin auditdistd:*:78:77:Auditdistd unprivileged user:/var/empty:/usr/sbin/nologin www:*:80:80:World Wide Web Owner:/nonexistent:/usr/sbin/nologin hast:*:845:845:HAST unprivileged user:/var/empty:/usr/sbin/nologin nobody:*:65534:65534:Unprivileged user:/nonexistent:/usr/sbin/nologin zfsguru-web:*:888:888:ZFSguru web-interface user:/nonexistent:/sbin/nologin share:*:1000:1000:ZFSguru share user:/nonexistent:/sbin/nologin ssh:*:44:44:ZFSguru SSH user:/home/ssh:/usr/local/bin/bash michiel:*:1001:1000:Samba user:/nonexistent:/sbin/nologin _tss:*:601:601:TrouSerS user:/var/empty:/usr/sbin/nologin _sabnzbd:*:0:0:User &:/services/sabnzbdplus/data:/usr/sbin/nologin messagebus:*:556:556:D-BUS Daemon User:/nonexistent:/usr/sbin/nologin avahi:*:558:558:Avahi Daemon User:/nonexistent:/usr/sbin/nologin cups:*:193:193:Cups Owner:/nonexistent:/usr/sbin/nologin polkit:*:562:562:PolicyKit User:/nonexistent:/usr/sbin/nologin polkitd:*:565:565:Polkit Daemon User:/var/empty:/usr/sbin/nologin haldaemon:*:560:560:HAL Daemon User:/nonexistent:/usr/sbin/nologin colord:*:970:970:colord color management daemon:/nonexistent:/usr/sbin/nologin pulse:*:563:563:PulseAudio System User:/nonexistent:/usr/sbin/nologin vboxusers:*:920:920:Virtualbox user:/nonexistent:/usr/sbin/nologin |
de file in de watched folder wordt aangemaakt via samba (user Michiel)
\\ Baloo \\ Mijn iRacing profiel
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Niet echt een vraag die iets te maken heeft met ZFS naar mijn idee.
Sinds de 2 dagen regel reageer ik hier niet meer
ZoL 0.6.5.8 is beschikbaar sinds een paar dagen: https://github.com/zfsonlinux/zfs/releases/tag/zfs-0.6.5.8 met compatibility voor 4.7 + 4.8dcm360 schreef op maandag 12 september 2016 @ 14:04:
[...]
Specifiek .2 of 4.7.x? Want volgens mij moet er even gewacht worden op ZoL 6.5.8 voordat het überhaupt met kernel 4.7.x gaat werken
[ Voor 0% gewijzigd door smesjz op 13-09-2016 12:40 . Reden: typo ]
- dcm360
- Registratie: December 2006
- Niet online
Dat had ik dan even gemist Zou ik eigenlijk ook weer terug kunnen naar een 4.7 kernel nu.
- MikeVM
- Registratie: Mei 2007
- Laatst online: 17-06 09:21
- Baloo -
ik zou de topicstarter willen vragen om een klein stukje te willen toevoegen over Spindown...FireDrunk schreef op woensdag 14 november 2012 @ 16:01:
Voor de mensen met een M1015:
Prerequisite: ZFSguru / FreeBSD portstree (of de gewone ports tree gebruiken uiteraard...)
cd /usr/ports/sysutils/spindown make && make install
nano /etc/rc.conf
-b voor background, -d per device, -t voor timeout in seconden#Enable Spindown spindown_enable="YES" spindown_flags="-b -d da0 -d da1 -d da2 -d da3 -d da4 -d da5 -d da6 -d da7 -t 300"
Onderaan toevoegen.
offtopic:
@CiPHER, misschien iets om automatisch te enablen als er da* devices gevonden worden?
ik heb hier al zelf enkele dingen opgelijst die ik zelf ondervonden heb, correct me if im wrong..
HDD SPINDOWN TIPS
WD Greens : disable intellipark met wdiddle3.exe (uitvoeren onder dos, google: wdidle3 disable intellipark)
door intellipark (een functie die in windows wel werkt) kan freebsd de hdd's niet in spindown laten gaan.
M1015 controllers: gebruik commando Spindown voor deze harde schijven
voorbeeldcode
code:
1
| spindown -D -d da1 -d da2 -d da3 |
rc.conf
[code]
andere controllers (onboard)cd /usr/ports/sysutils/spindown make && make install
nano /etc/rc.conf
-b voor background, -d per device, -t voor timeout in seconden#Enable Spindown spindown_enable="YES" spindown_flags="-b -d da0 -d da1 -d da2 -d da3 -d da4 -d da5 -d da6 -d da7 -t 300"
gebruik atacontrol of camcontrol
ik snap dit zelf niet zo goed, dus misschien kunnen jullie dit zelf beter schrijven
\\ Baloo \\ Mijn iRacing profiel
- Compizfox
- Registratie: Januari 2009
- Laatst online: 23:57
:strip_icc():strip_exif()/u/286431/crop680f6b95743ca_cropped.jpg?f=community)
Hier even op terugkomend en ter documentatie:Compizfox schreef op dinsdag 06 september 2016 @ 21:49:
[...]
Sure, er vindt een vertaalslag plaats van SATA naar SCSI. Maar de schijf wordt door het guest OS wel gezien als schijf, en dat is het belangrijkste. Ik heb dit zelf onder Hyper-V en ESXi geprobeerd met ZFS en dat werkt prima.
Maar goed, het was niet echt mijn bedoeling om een discussie te beginnen over disk passthrough vs controller passthrough
Ik heb deze thread gevonden waarin iemand deze setup gebruikt ("physical disk to kvm" zoals beschreven in de Proxmox wiki). De TS heeft problemen met het weergeven van SMART-data in de OMV webinterface, maar meldt dat het weergeven van SMART-data via smartctl direct over SSH wel werkt. Dat laatste zou dus betekenen dat het inderdaad over 'raw' disk passthrough gaat, waarbij de schijf niet als block device maar als schijf maar wordt doorgegeven.
Nee, deze methode is geen 'raw' passthrough. De schijven worden gezien als "QEMU device" en dingen als SMART werken niet. Helaas.
In het geval van de virtio-controller wordt de schijf niet herkend via camcontrol devlist, maar wel weer via geom disk list. In het geval van de sata-controller staat hij wel in camcontrol devlist. Ik heb ook de scsi-controller geprobeerd, maar daarmee wilde FreeBSD helemaal niet booten (ik kreeg een error die ik niet meer weet).
[ Voor 12% gewijzigd door Compizfox op 16-09-2016 20:01 ]
Gewoon een heel grote verzameling snoertjes
- Wiebeltje
- Registratie: Maart 2013
- Laatst online: 03-07 19:14
Ik heb al een tijd een NAS met ZoL (Debian) in mirror draaien (2x 3TB) + SSD. Hier gebruik ik een Asrock B845m-ITX voor. Dit draait prima maar ik heb ondertussen ook aardig wat software geinstalleerd staan en ik zou dat graag willen gaan splitsen over een aantal VM's.
Nu was mijn idee om een ASRock H110M-ITX icm een G4400 te kopen zodat ik de beschikking heb over VT-d. Om mijn bestaande data te behouden had ik het volgende verzonnen:
Op de SSD installeer ik proxmox. Vervolgens maak een VM (KVM?) met Debian / Ubuntu ZoL. Deze krijgt dan via VT-d direct toegang tot de twee disks. Op die manier kan ik de disks evengoed in spindown zetten, staan alle VM's op mijn SSD (lekker snel) en zou ZFS het zonder problemen moeten doen. De data kan ik dan evt met andere VM's delen via NFS / Samba.
Ik heb nog niet heel veel ervaring met VM's en ik ben dus benieuwd of dit zo gaat werken. Sowieso kom ik VT-d veel tegen icm PCI (controllers). Werkt dit uberhaubt met onboard SATA poorten? Ook de bovenstaande post geeft me wat twijfels. Ik dacht altijd dat VT-d er voor zorgde dat er totaal geen virtualisatielaag tussen de disks en de VM zit maar blijkbaar is dit niet zo? Gaat dit voor problemen zorgen icm met ZFS?
Het alternatief zou natuurlijk zijn dat ik VM's ga draaien bovenop mijn huidige OS met bijv. Virtualbox maar dat vind ik toch minder. Proxmox doet zelf tegenwoordig ook ZFS maar ik wil mijn VM's dus niet op mijn HDD's hebben staan dus daar heb ik verder niet zo veel aan vrees ik.
De extra kosten van een nieuw mobo is overigens geen issue, de oude wil ik inzetten als mediacenter.
Nu was mijn idee om een ASRock H110M-ITX icm een G4400 te kopen zodat ik de beschikking heb over VT-d. Om mijn bestaande data te behouden had ik het volgende verzonnen:
Op de SSD installeer ik proxmox. Vervolgens maak een VM (KVM?) met Debian / Ubuntu ZoL. Deze krijgt dan via VT-d direct toegang tot de twee disks. Op die manier kan ik de disks evengoed in spindown zetten, staan alle VM's op mijn SSD (lekker snel) en zou ZFS het zonder problemen moeten doen. De data kan ik dan evt met andere VM's delen via NFS / Samba.
Ik heb nog niet heel veel ervaring met VM's en ik ben dus benieuwd of dit zo gaat werken. Sowieso kom ik VT-d veel tegen icm PCI (controllers). Werkt dit uberhaubt met onboard SATA poorten? Ook de bovenstaande post geeft me wat twijfels. Ik dacht altijd dat VT-d er voor zorgde dat er totaal geen virtualisatielaag tussen de disks en de VM zit maar blijkbaar is dit niet zo? Gaat dit voor problemen zorgen icm met ZFS?
Het alternatief zou natuurlijk zijn dat ik VM's ga draaien bovenop mijn huidige OS met bijv. Virtualbox maar dat vind ik toch minder. Proxmox doet zelf tegenwoordig ook ZFS maar ik wil mijn VM's dus niet op mijn HDD's hebben staan dus daar heb ik verder niet zo veel aan vrees ik.
De extra kosten van een nieuw mobo is overigens geen issue, de oude wil ik inzetten als mediacenter.
VT-d werkt met PCIe Devices in zijn geheel. Niet met afzonderlijke disks. Je kan dus niet "2 schijven"doorgeven. Je kan wel de controller waar de schijven aan hangen doorgeven.
Als je dus 2 disks onboard hebt, en daarnaast nog een SSD, gaat het niet werken.
Momenteel is de beste optie om een NVMe SSD te kopen, deze zitten direct op de PCIe bus, en hebben een eigen controller, waardoor ze niet afhankelijk zijn van je onboard controller.
Als je dus 2 disks onboard hebt, en daarnaast nog een SSD, gaat het niet werken.
Momenteel is de beste optie om een NVMe SSD te kopen, deze zitten direct op de PCIe bus, en hebben een eigen controller, waardoor ze niet afhankelijk zijn van je onboard controller.
Even niets...
- Compizfox
- Registratie: Januari 2009
- Laatst online: 23:57
Zoals FireDrunk al aangeeft, is VT-d (IOMMU) het doorgeven van een hele controller (HBA). Je kunt geen losse schijven doorgeven.Wiebeltje schreef op zaterdag 17 september 2016 @ 16:35:
Ik heb nog niet heel veel ervaring met VM's en ik ben dus benieuwd of dit zo gaat werken. Sowieso kom ik VT-d veel tegen icm PCI (controllers). Werkt dit uberhaubt met onboard SATA poorten? Ook de bovenstaande post geeft me wat twijfels. Ik dacht altijd dat VT-d er voor zorgde dat er totaal geen virtualisatielaag tussen de disks en de VM zit maar blijkbaar is dit niet zo? Gaat dit voor problemen zorgen icm met ZFS?
Bovenstaande post gaat wel over het doorgeven van losse schijven, en heeft dus niets met VT-d te maken.
Het doorgeven van een controller met VT-d gaat dus werken en zal geen problemen opleveren met ZFS. Het doorgeven van losse disks met Proxmox is niet 'raw' (zoals beschreven in mijn vorige post) en is dus niet aan te raden voor ZFS.
Dat is best een slim idee! Jammer dat die PCI-e SSDs nog zo duur zijn.FireDrunk schreef op zaterdag 17 september 2016 @ 16:38:
Momenteel is de beste optie om een NVMe SSD te kopen, deze zitten direct op de PCIe bus, en hebben een eigen controller, waardoor ze niet afhankelijk zijn van je onboard controller.
[ Voor 28% gewijzigd door Compizfox op 17-09-2016 16:50 ]
Gewoon een heel grote verzameling snoertjes
Samsungs eerste NVMe ssd (De sm951) is voor 128GB anders prima betaalbaar.
pricewatch: Samsung SM951 (NVMe) 128GB
pricewatch: Samsung SM951 (NVMe) 128GB
[ Voor 45% gewijzigd door FireDrunk op 17-09-2016 18:25 ]
Even niets...
- Wiebeltje
- Registratie: Maart 2013
- Laatst online: 03-07 19:14
Bedankt voor de info! Dit maakt alles een stuk helderder. Er blijven dus waarschijnlijk twee opties over.
Zo'n 128GB NVMe is inderdaad wel te doen en zou genoeg moeten zijn. Dan kan daar Promox en de VM's op. Mijn huidige SSD (256GB) kan dan nog bij de onboard controller voor BT downloads / ZFS cache.
- Een NVMe SSD kopen en de onboard controller via VT-d doorgeven
- Een losse (RAID) controller aanschaffen en daar de disks of SSD op zetten.
Zo'n 128GB NVMe is inderdaad wel te doen en zou genoeg moeten zijn. Dan kan daar Promox en de VM's op. Mijn huidige SSD (256GB) kan dan nog bij de onboard controller voor BT downloads / ZFS cache.
Op zich zijn de controllers met op ASMedia 1061 en 1062 gebaseerde chipsets prima controllers voor een lage prijs. De 1061 is PCIe 1.0, en kan dus maximaal 250MB/s verstoken. 2 moderne snelle schijven trekken dat wel dicht, maar of je er echt last van hebt.
De 1062 is PCIe 2.0 en kan dus 500MB/s aan, wat ruim genoeg is voor 2 schijven.
EDIT:
Voor de mensen die echt een goedkope "extra" controller zoeken. Deze is ook goedkoop, en is ook een volwaardige NVMe controller.
pricewatch: Intel 600p 128GB
Helaas wel een stukje langzamer dan de concurrentie, maar daar is de prijs dan ook naar.
De 1062 is PCIe 2.0 en kan dus 500MB/s aan, wat ruim genoeg is voor 2 schijven.
EDIT:
Voor de mensen die echt een goedkope "extra" controller zoeken. Deze is ook goedkoop, en is ook een volwaardige NVMe controller.
pricewatch: Intel 600p 128GB
Helaas wel een stukje langzamer dan de concurrentie, maar daar is de prijs dan ook naar.
[ Voor 39% gewijzigd door FireDrunk op 19-09-2016 10:23 ]
Even niets...
- Wiebeltje
- Registratie: Maart 2013
- Laatst online: 03-07 19:14
Ik heb gister alles besteld en het is de Samsung sm951 geworden! Groot genoeg voor mijn VM's en dan kan ik mijn huidige SSD ook nog inzetten voor caching en downloads.
Het enige nadeel is dat de sm951 niet super goed leverbaar is.
Het enige nadeel is dat de sm951 niet super goed leverbaar is.
Hooow wacht eens even. Proxmox heeft native ZoL ter zijne beschikking, niets VT-d'en nodig met Proxmox.Wiebeltje schreef op zaterdag 17 september 2016 @ 16:35:
Ik heb al een tijd een NAS met ZoL (Debian) in mirror draaien (2x 3TB) + SSD. Hier gebruik ik een Asrock B845m-ITX voor. Dit draait prima maar ik heb ondertussen ook aardig wat software geinstalleerd staan en ik zou dat graag willen gaan splitsen over een aantal VM's.
Nu was mijn idee om een ASRock H110M-ITX icm een G4400 te kopen zodat ik de beschikking heb over VT-d. Om mijn bestaande data te behouden had ik het volgende verzonnen:
Op de SSD installeer ik proxmox. Vervolgens maak een VM (KVM?) met Debian / Ubuntu ZoL. Deze krijgt dan via VT-d direct toegang tot de twee disks. Op die manier kan ik de disks evengoed in spindown zetten, staan alle VM's op mijn SSD (lekker snel) en zou ZFS het zonder problemen moeten doen. De data kan ik dan evt met andere VM's delen via NFS / Samba.
Ik heb nog niet heel veel ervaring met VM's en ik ben dus benieuwd of dit zo gaat werken. Sowieso kom ik VT-d veel tegen icm PCI (controllers). Werkt dit uberhaubt met onboard SATA poorten? Ook de bovenstaande post geeft me wat twijfels. Ik dacht altijd dat VT-d er voor zorgde dat er totaal geen virtualisatielaag tussen de disks en de VM zit maar blijkbaar is dit niet zo? Gaat dit voor problemen zorgen icm met ZFS?
Het alternatief zou natuurlijk zijn dat ik VM's ga draaien bovenop mijn huidige OS met bijv. Virtualbox maar dat vind ik toch minder. Proxmox doet zelf tegenwoordig ook ZFS maar ik wil mijn VM's dus niet op mijn HDD's hebben staan dus daar heb ik verder niet zo veel aan vrees ik.
De extra kosten van een nieuw mobo is overigens geen issue, de oude wil ik inzetten als mediacenter.
Mijn Proxmox setup is als volgt:
2*SSD in ZFS Mirror als Rpool, aangemaakt door Proxmox installer < dient enkel als rpool.
1*Samsung EVO als single ZFS (LUKS) disk < dient enkel als datastore
5*4TB RaidZ2 (LUKS) disks < dient als "NAS" storage en backup voor de VM's van de Samsung SSD
De 2 extra ZFS pools zijn manueel aangemaakt op de Proxmox host zelf.
Als "NAS" heb ik een LXC container aangemaakt die enkele bind mounts van de storage pool doorkrijgt. Deze container neemt alle SAMBA configuratie voor zijn rekening. Lekker efficiënt en ontkoppeld van de Proxmox host.
Je data "delen" met andere containers kan heel eenvoudig met die bind mounts (dus zonder NFS, vt-d of whatever).
Sorry voor de korte uitleg, momenteel druk hier
PM me maar indien je meer uitleg wenst.
edit: Niet vergeten je ARC geheugen te limiteren op de host zelf (default=50%); in /etc/modprobe.d/zfs.conf de waarde: options zfs zfs_arc_max=4299967296 aanpassen.
[ Voor 3% gewijzigd door A1AD op 20-09-2016 11:02 ]
- Deze advertentie is geblokkeerd door Pi-Hole -
- Geckx
- Registratie: November 2008
- Laatst online: 24-05 15:29
Korte vraag:
Dat je geen virtuele diks (vhd, vmk, qemu,...) moet gebruiken voor ZFS pools is logisch.
Maar hoe zit het met L2ARC en ZIL?
Ik heb hier namelijk een FreeNAS draaien die gevoed wordt met spinning rust door een LSI 9220-8i d.m.v. pcie passthrough.
op de host (proxmox) heb ik verschillende mirrors aan SSD's. Voornamelijk voor de OS schijven van de VM's..
Kan ik hiervan een deel doorgeven om als ZIL en/of L2ARC te gebruiken? of is dit ook af te raden?
Dat je geen virtuele diks (vhd, vmk, qemu,...) moet gebruiken voor ZFS pools is logisch.
Maar hoe zit het met L2ARC en ZIL?
Ik heb hier namelijk een FreeNAS draaien die gevoed wordt met spinning rust door een LSI 9220-8i d.m.v. pcie passthrough.
op de host (proxmox) heb ik verschillende mirrors aan SSD's. Voornamelijk voor de OS schijven van de VM's..
Kan ik hiervan een deel doorgeven om als ZIL en/of L2ARC te gebruiken? of is dit ook af te raden?
SLOG en L2ARC schijven maken net zo goed onderdeel uit van je pool, dus waarom zou je daar andere regels voor hanteren? Even los van of die regel juist is of niet, die discussie ga ik liever niet aan.
Voor sLOG is het cruciaal dat hij FLUSH requests ondersteunt en dat als het een SSD is deze de data sinds de laatste FLUSH ook onthoudt (dus geen Samsung SSDs).
Voor L2ARC gelden die regels niet. De L2ARC device mag ook heleboel corruptie vertonen; allemaal geen probleem. Voor sLOG mag er absoluut geen corruptie zijn.
Kortom; er zit zeker verschil tussen L2ARC en sLOG qua eisen die gesteld worden aan de (virtuele) disk.
Voor L2ARC gelden die regels niet. De L2ARC device mag ook heleboel corruptie vertonen; allemaal geen probleem. Voor sLOG mag er absoluut geen corruptie zijn.
Kortom; er zit zeker verschil tussen L2ARC en sLOG qua eisen die gesteld worden aan de (virtuele) disk.
- Geckx
- Registratie: November 2008
- Laatst online: 24-05 15:29
OK dus als ik heb goed begrijp is het best om, indien ik een sLOG wil toevoegen aan mijn pool, een extra paar SSD's aan de SAS controller hang en op die manier rechtstreeks doorgeef.
Voor de L2ARC zou ik evengoed een virtuele disk kunnen gebruiken, maar als ik toch SSD's rechtstreeks beschikbaar heb kan ik die net zo goed gebruiken.
Bedankt voor de reacties.
Voor de L2ARC zou ik evengoed een virtuele disk kunnen gebruiken, maar als ik toch SSD's rechtstreeks beschikbaar heb kan ik die net zo goed gebruiken.
Bedankt voor de reacties.
- Compizfox
- Registratie: Januari 2009
- Laatst online: 23:57
Dat klopt, maar dan moet je die fileserver dus op de host doen. Meestal is het net zo handig om dat in een VM te doen, zodat je bijvoorbeeld FreeNAS kunt draaien.A1AD schreef op dinsdag 20 september 2016 @ 10:55:
[...]
Hooow wacht eens even. Proxmox heeft native ZoL ter zijne beschikking, niets VT-d'en nodig met Proxmox.
Heeft de LXC guest dan 'direct' toegang tot die ZFS pool? Of moet je dan een ander filesystem (zoals ext4) binnen die VHD gebruiken?Als "NAS" heb ik een LXC container aangemaakt die enkele bind mounts van de storage pool doorkrijgt. Deze container neemt alle SAMBA configuratie voor zijn rekening. Lekker efficiënt en ontkoppeld van de Proxmox host.
Je data "delen" met andere containers kan heel eenvoudig met die bind mounts (dus zonder NFS, vt-d of whatever).
Dat laatste vind ik geen mooie oplossing. Je hebt dan je data in een ext4 (of iets anders) partitie staan, wat weer als VHD op een ZFS-pool staat.
Gewoon een heel grote verzameling snoertjes
Directe toegang! Echt wat een systeemCompizfox schreef op dinsdag 20 september 2016 @ 20:32:
[...]
Dat klopt, maar dan moet je die fileserver dus op de host doen. Meestal is het net zo handig om dat in een VM te doen, zodat je bijvoorbeeld FreeNAS kunt draaien.
[...]
Heeft de LXC guest dan 'direct' toegang tot die ZFS pool? Of moet je dan een ander filesystem (zoals ext4) binnen die VHD gebruiken?
Dat laatste vind ik geen mooie oplossing. Je hebt dan je data in een ext4 (of iets anders) partitie staan, wat weer als VHD op een ZFS-pool staat.
Je mount een path van het host filesystem aan je LXC guests, je kan eenvoudig vb:
(host) /pool/media/films aan je download LXC koppelen als een je Plex LXC
Je kan dit zelfs met oa. dvb-d adaptors doen, geen vt-d nodig. ++ voor efficiëntie.
(ik begrijp niet dat hier geen: "Het grote Proxmox topic" is op tweakers)
[ Voor 19% gewijzigd door A1AD op 20-09-2016 23:08 ]
- Deze advertentie is geblokkeerd door Pi-Hole -
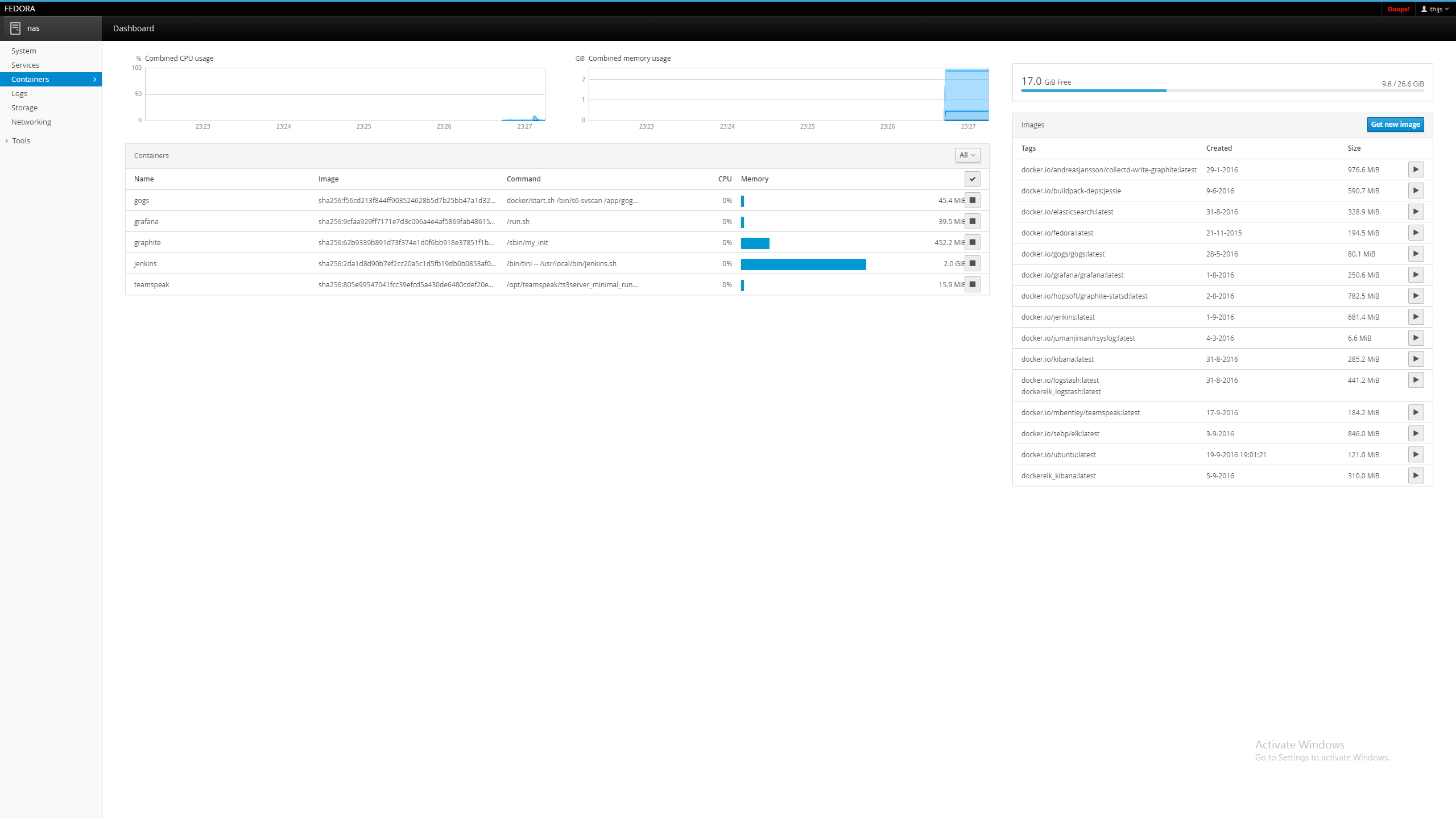
Containers zijn lief 
Helaas zijn mijn Docker images alles behalve klein
Helaas zijn mijn Docker images alles behalve klein
Even niets...
- Compizfox
- Registratie: Januari 2009
- Laatst online: 23:57
Thanks! Dit is zeker interessant...A1AD schreef op dinsdag 20 september 2016 @ 22:59:
[...]
Directe toegang! Echt wat een systeem
Je mount een path van het host filesystem aan je LXC guests, je kan eenvoudig vb:
(host) /pool/media/films aan je download LXC koppelen als een je Plex LXC
Je kan dit zelfs met oa. dvb-d adaptors doen, geen vt-d nodig. ++ voor efficiëntie.
Gewoon een heel grote verzameling snoertjes
Heeeel liefFireDrunk schreef op dinsdag 20 september 2016 @ 23:28:
Containers zijn lief
Helaas zijn mijn Docker images alles behalve klein
[afbeelding]
Je hebt het voordeel van gescheiden te werken en toch dicht op "het metaal" te zitten.
Docker is ook best hip geworden. Het heeft zo elk zijn doel (LXC - Docker). Ik denk dat mijn lxc template (Debian Jessie) niet veel groter is
Debian, freenas, ESX gebruikt in het verleden en Proxmox is voor mij de ultieme thuis (AIO) server.
(Web interface incl. HTML5 console en mobile ui, onboard backup, ZFS, opensource, geen domme beperkingen, lxc, kvm, active ontwikkeling, vol waardig os en updaten met apt, ...)
Dat wil ik toch ook nog even kwijt: LXC > mate > x2goserver en je hebt en volwaardige container desktop
... Maar we wijken af, excuses CiPHER
- Deze advertentie is geblokkeerd door Pi-Hole -
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Is het geen idee om eens een Proxmox topic te openen? Ben net over op ESXi en nou dit weer 
Sinds de 2 dagen regel reageer ik hier niet meer
Groot nadeel van Proxmox is dat ze een Debian achtergrond hebben, waardoor ze qua Kernel echt ver 3.16, i stand corrected, het valt wel mee achter blijven. ZFS en oude kernels is een beetje... meh... Het gaat, maar liever niet.
Dat geldt voor BTRFS voor veel sterker.
Dat geldt voor BTRFS voor veel sterker.
[ Voor 11% gewijzigd door FireDrunk op 21-09-2016 10:53 ]
Even niets...
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Het draait ook op CentOS las ik.
Sinds de 2 dagen regel reageer ik hier niet meer
Mja, persoonlijk vind ik (beide) kernels erg oud. Maar dat is mijn persoonlijke mening
Even niets...
- dcm360
- Registratie: December 2006
- Niet online
Ach, ze hadden ook ZFS voor kernel 2.6.32, dus een 3.x kernel valt nog wel redelijk mee wat dat betreft. Overigens weet ik niet precies waar ze bij Proxmox tegenwoordig de kernel vandaan halen, maar de 2.6.x-kernel was een RHEL-kernel (en niet Debian, ook al is het systeem verder Debian-based).
Overigens zou ik een Proxmox-topic ook wel gaaf vinden Ik zou er ook best wel graag aan willen bijdragen (al heb ik er vermoedelijk vrij weinig tijd voor momenteel).
Overigens zou ik een Proxmox-topic ook wel gaaf vinden
[ Voor 22% gewijzigd door dcm360 op 21-09-2016 11:37 ]
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Volgens deze wiki is de kernel van Proxmox gewoon versie 4:
https://pve.proxmox.com/w..._VE_Kernel#Proxmox_VE_4.x
Dat zou dus prima moeten zijn.
https://pve.proxmox.com/w..._VE_Kernel#Proxmox_VE_4.x
Dat zou dus prima moeten zijn.
Sinds de 2 dagen regel reageer ik hier niet meer
- dcm360
- Registratie: December 2006
- Niet online
Juistem, ik kwam in mijn zoektocht uit op https://pve.proxmox.com/wiki/Linux_Kernel, welke overduidelijk nog gaat over de oude Proxmox met OpenVZ. Maar tegenwoordig is het dus Debian met een kernel van Ubuntu
Fout fout en nog eens foutFireDrunk schreef op woensdag 21 september 2016 @ 10:52:
Groot nadeel van Proxmox is dat ze een Debian achtergrond hebben, waardoor ze qua Kernel echt ver 3.16, i stand corrected, het valt wel mee achter blijven. ZFS en oude kernels is een beetje... meh... Het gaat, maar liever niet.
Dat geldt voor BTRFS voor veel sterker.
> Ze gebruiken de laatste LTS kernel!
uname -a
> Linux pve 4.4.16-1-pve #1 SMP Wed Aug 31 15:14:37 CEST 2016 x86_64 GNU/Linux
edit: oeps, andere reacties niet gelezen
Dat lijkt mij een goed plan, iemand met teveel tijd?CurlyMo schreef op woensdag 21 september 2016 @ 09:33:
Is het geen idee om eens een Proxmox topic te openen? Ben net over op ESXi en nou dit weer
[ Voor 30% gewijzigd door A1AD op 21-09-2016 12:17 ]
- Deze advertentie is geblokkeerd door Pi-Hole -
WHUT, 4.4.6??? 

* FireDrunk gaat ProxMox serieus overwegen....
Hebben ze de "Ik moet rebooten voor elke netwerk wijziging" "bug" al opgelost?
* FireDrunk gaat ProxMox serieus overwegen....
Hebben ze de "Ik moet rebooten voor elke netwerk wijziging" "bug" al opgelost?
[ Voor 40% gewijzigd door FireDrunk op 21-09-2016 12:45 ]
Even niets...
4.4.16 *FireDrunk schreef op woensdag 21 september 2016 @ 12:45:
WHUT, 4.4.6???
* FireDrunk gaat ProxMox serieus overwegen....
Hebben ze de "Ik moet rebooten voor elke netwerk wijziging" "bug" al opgelost?
Host / KVM / LXC netwerk wijziging? Dan test ik het eens. Nu ja een LXC herstarten duurt 5 seconden ofzo
- Deze advertentie is geblokkeerd door Pi-Hole -
Toevoegen van een Bridge op een NIC. Vorige keer moest ik daarvoor rebooten... Ik bedoel... dat kan al sinds windows 98 zonder reboot
Even niets...
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Dat werkt in Ubuntu/Debian en FreeBSD ook prima zonder rebooten, kan me niet goed voorstellen dat dit niet (desnoods via de CLI) zou werken in Proxmox.FireDrunk schreef op woensdag 21 september 2016 @ 12:54:
Toevoegen van een Bridge op een NIC. Vorige keer moest ik daarvoor rebooten... Ik bedoel... dat kan al sinds windows 98 zonder reboot
Sinds de 2 dagen regel reageer ik hier niet meer
Dat begrijp ik, alleen de vorige keer dat ik dat dus instelde in Proxmox (3.1 ofzo?) moest dat dus wel.
Even niets...
- Compizfox
- Registratie: Januari 2009
- Laatst online: 23:57
Jep. Proxmox 3.x had oude kernels, maar dat was vanwege OpenVZ. OpenVZ vereist een speciale gemodificeerde kernel, en die was vaak erg out-of-date.
Met LXC bestaat dit probleem niet meer.
Gewoon een heel grote verzameling snoertjes
- idef1x
- Registratie: Januari 2004
- Laatst online: 03-07 09:39
:strip_icc():strip_exif()/u/101865/crop5e04c97889698_cropped.jpeg?f=community)
Hmm ja inderdaad de 16.04 LTS Ubuntu kernel zie ik. Zouden ze dan ook LXD draaien? (Ben ik net aan gewend geraaktdcm360 schreef op woensdag 21 september 2016 @ 11:57:
Juistem, ik kwam in mijn zoektocht uit op https://pve.proxmox.com/wiki/Linux_Kernel, welke overduidelijk nog gaat over de oude Proxmox met OpenVZ. Maar tegenwoordig is het dus Debian met een kernel van Ubuntu
"LXD and Docker are not needed for ProxMox VE as the latter manages all it's LXC instances from within itself"idef1x schreef op woensdag 21 september 2016 @ 13:59:
[...]
Hmm ja inderdaad de 16.04 LTS Ubuntu kernel zie ik. Zouden ze dan ook LXD draaien? (Ben ik net aan gewend geraakt
bron
edit: er zijn ook topics over te vinden op het Proxmox forum
[ Voor 6% gewijzigd door A1AD op 21-09-2016 14:12 ]
- Deze advertentie is geblokkeerd door Pi-Hole -
- ikke26
- Registratie: Juli 2009
- Laatst online: 03-07 19:48
Rebooten is niet meer nodig na een handmatige netwerkwijziging direct in /etc/network/interfaces op de host is mijn ervaring.FireDrunk schreef op woensdag 21 september 2016 @ 12:45:
WHUT, 4.4.6???
* FireDrunk gaat ProxMox serieus overwegen....
Hebben ze de "Ik moet rebooten voor elke netwerk wijziging" "bug" al opgelost?
Een simpele "service networking restart" was laatst voldoende om nieuwe instellingen door te voeren, waarbij het na F5'en ook in de webinterface klopte.
[ Voor 4% gewijzigd door ikke26 op 24-10-2016 04:36 ]
- Geckx
- Registratie: November 2008
- Laatst online: 24-05 15:29
Hier ook heel tevreden van Proxmox, doet wat het moet (en meer) voor 0 euro.
Je kan wel niet alles via de GUI (zoals bij klassieke hyper-v en vSphere), wat misschien sommigen nog kan afschrikken, maar voor een linux amateur (wat ik toch ook eigenlijk ben) voldoende tutorials te vinden.
In combinatie met ceph kun je zelf je eigen hyperconverged server infra opzetten.
Open source concurrentie voor Nutanix
Je kan wel niet alles via de GUI (zoals bij klassieke hyper-v en vSphere), wat misschien sommigen nog kan afschrikken, maar voor een linux amateur (wat ik toch ook eigenlijk ben) voldoende tutorials te vinden.
In combinatie met ceph kun je zelf je eigen hyperconverged server infra opzetten.
Open source concurrentie voor Nutanix
[ Voor 34% gewijzigd door Geckx op 21-09-2016 18:04 ]
Dat klopt wel een beetje, het configureren van je bind mounts voor lxc containers moet je aanpassen in de /etc/pve/lxc/vmid.conf file. Maar dat zijn ze aan het aanpassen naar de gui.Geckx schreef op woensdag 21 september 2016 @ 18:01:
Je kan wel niet alles via de GUI (zoals bij klassieke hyper-v en vSphere), wat misschien sommigen nog kan afschrikken, maar voor een linux amateur (wat ik toch ook eigenlijk ben) voldoende tutorials te vinden.
En verder wat ZFS commando's, maar niets wat ze hier niet met hun ogen toe kunnen.
De standaard zaken zitten toch wel echt allemaal in de web interface, of mis ik iets?
Er zijn zeker zaken die beter kunnen, de ingebouwde backups ondersteunen enkel full backup. Er is online wel een patch voor (voordeel van opensource) incrementele maar de devs weigeren dit in te bouwen met excuus: het moet een eenvoudiger backup mechanisme blijven.
Voor offsite backup is er nieuw speelgoed: pve-zsync welke standaard om het kwartier een ZFS send en receive doet van een bepaalde dataset (os disk) naar een remote zpool. Nog cli only.
- Deze advertentie is geblokkeerd door Pi-Hole -
Oeh, dat klinkt echt allemaal wel netjes
Hoe zit het met de script API om nieuwe VM's aan te maken? Ik neem aan dat het gewoon libvirtd is?
Hoe zit het met de script API om nieuwe VM's aan te maken? Ik neem aan dat het gewoon libvirtd is?
Even niets...
https://forum.proxmox.com/threads/proxmox-and-libvirt.3813/FireDrunk schreef op donderdag 22 september 2016 @ 08:18:
Oeh, dat klinkt echt allemaal wel netjes
Hoe zit het met de script API om nieuwe VM's aan te maken? Ik neem aan dat het gewoon libvirtd is?
Proxmox heeft zijn eigen tools (zowel command line (pct, qm) als een REST API)
- Deze advertentie is geblokkeerd door Pi-Hole -
- idef1x
- Registratie: Januari 2004
- Laatst online: 03-07 09:39
Wat dan weer gelijk een nadeel is, want vendor lock-in...A1AD schreef op donderdag 22 september 2016 @ 12:34:
[...]
https://forum.proxmox.com/threads/proxmox-and-libvirt.3813/
Proxmox heeft zijn eigen tools (zowel command line (pct, qm) als een REST API)
Ik hou het maar gewoon even lekker op commandline voor thuis...kan ik nog sneller een container mee aanslingeren dan met proxmox merk ik (best wel wat doorclicken zag ik gisteren)..
Maarre is dat proxmox topic al aangemaakt? Of wordt dit topic eerdaags hernoemd naar het grote proxmox topic
Ik wil SmartOS nog maar weer even noemen, zones/kvm/native ZFS/netwerk virtualizatie (dit heb ik nog niet fatsoenlijk onder linux gezien, zo ja suggesties?)/andere advanced zaken waar ik zelf nog niet wat mee heb gedaan (Service Management SMF, Dtrace, etc).
Enige wat je wel moet hebben is doorzettingsvermogen. Als je eenmaal de basis voorbij bent vind ik de tooling die Joyent vanuit SmartOS biedt echt super.
Ik boot via pxe-boot mn server (zo kan ik makkelijk upgraden, hoef ik geen usb-stick naar de schuur te brengen, booten/reboot gaat via ILO/IPMI bij mij)
Installatie gaat via een commandline wizzard die wat vragen over ip-settings/dns/user/pass vraagt, hierna maak je je pool aan en kan je beginnen.
middels imgadm (image administrator) kun je van Joyent of third-party kan en klare images binnen trekken welke je als basis gaat gebruiken voor een zone/vm (denk aan een user-omgeving met default set aan packages zoals een Apache2/MySQL/PHP -zone). Je kunt ze ook zelf maken.
middels vmadm (virtual machine administrator maak je zones of vm's aan. Je gebruikt hiervoor manifests, dit zijn een soort recepten die je zone/vm beschrijven (gewoon een tekstfile in .json structuur), je geeft hierin aan cpu's/ram/diskspace/nic's/hostname/etc waaruit je vm bestaat. Na het maken van deze file valideer ik deze (je maakt snel typo's) en daarna creeer je je zone/vm (vmadm create -f <path to file>) en klaar, je kunt op deze manier erg snel meerdere zone's uitrollen.
middels dladm (datalink administrator) kun je je netwerk virtualiseren. Dit gaat van geïsoleerde netwerken die puur virtueel zijn tot vlan-trunking tot link-bonding tot het zetten van speed-limits voor vm/zone -x of -y of qos (quality of service) voor het verlenen van voorrang qua netwerkverkeer voor bepaalde vm's.
En met name deze laatste zie ik in linux/vsphere land weinig terug. Ik denk dat openflow als basis dit moet kunnen, echter vind ik de uitwerking die ik tot nu toe in SmartOS zie erg eenduidig en duidelijk (waarschijnlijk door de uitgebreide documentatie). Kennen jullie misschien hier alternatieven voor (vergelijkbaar met Crossbow onder Illumos)?
Enige wat je wel moet hebben is doorzettingsvermogen
Ik boot via pxe-boot mn server (zo kan ik makkelijk upgraden, hoef ik geen usb-stick naar de schuur te brengen, booten/reboot gaat via ILO/IPMI bij mij)
Installatie gaat via een commandline wizzard die wat vragen over ip-settings/dns/user/pass vraagt, hierna maak je je pool aan en kan je beginnen.
middels imgadm (image administrator) kun je van Joyent of third-party kan en klare images binnen trekken welke je als basis gaat gebruiken voor een zone/vm (denk aan een user-omgeving met default set aan packages zoals een Apache2/MySQL/PHP -zone). Je kunt ze ook zelf maken.
middels vmadm (virtual machine administrator maak je zones of vm's aan. Je gebruikt hiervoor manifests, dit zijn een soort recepten die je zone/vm beschrijven (gewoon een tekstfile in .json structuur), je geeft hierin aan cpu's/ram/diskspace/nic's/hostname/etc waaruit je vm bestaat. Na het maken van deze file valideer ik deze (je maakt snel typo's) en daarna creeer je je zone/vm (vmadm create -f <path to file>) en klaar, je kunt op deze manier erg snel meerdere zone's uitrollen.
middels dladm (datalink administrator) kun je je netwerk virtualiseren. Dit gaat van geïsoleerde netwerken die puur virtueel zijn tot vlan-trunking tot link-bonding tot het zetten van speed-limits voor vm/zone -x of -y of qos (quality of service) voor het verlenen van voorrang qua netwerkverkeer voor bepaalde vm's.
En met name deze laatste zie ik in linux/vsphere land weinig terug. Ik denk dat openflow als basis dit moet kunnen, echter vind ik de uitwerking die ik tot nu toe in SmartOS zie erg eenduidig en duidelijk (waarschijnlijk door de uitgebreide documentatie). Kennen jullie misschien hier alternatieven voor (vergelijkbaar met Crossbow onder Illumos)?
Bedoel je dan Multi tenancy netwerken? Want vSphere doet ook vxlan's?
Even niets...
Belangrijk:
Voor mensen die net als ik, zonder de release notes te lezen, upgraden naar ZFSonLinux 0.6.5.8 op een SystemD platform (Ubuntu 16.0.4, CentOS 7, Fedora > 18).
https://github.com/zfsonlinux/zfs/releases/tag/zfs-0.6.5.8 (zoals ik )
Voor mensen die net als ik, zonder de release notes te lezen, upgraden naar ZFSonLinux 0.6.5.8 op een SystemD platform (Ubuntu 16.0.4, CentOS 7, Fedora > 18).
https://github.com/zfsonlinux/zfs/releases/tag/zfs-0.6.5.8
Anders zit je zonder ZFS poolsChanges
This release contains updates to the systemd service files. In order to ensure the services are started properly it's recommended that after updating the systemd presets be reset to the defaults.
systemctl preset zfs-import-cache zfs-import-scan zfs-mount zfs-share zfs-zed zfs.target
Even niets...
- idef1x
- Registratie: Januari 2004
- Laatst online: 03-07 09:39
Bedankt voor de tip, maar als je de standaard Ubuntu 16.0.4 packages gebruikt zullen ze dat er toch wel in meenemen lijkt me?FireDrunk schreef op vrijdag 23 september 2016 @ 17:53:
Belangrijk:
Voor mensen die net als ik, zonder de release notes te lezen, upgraden naar ZFSonLinux 0.6.5.8 op een SystemD platform (Ubuntu 16.0.4, CentOS 7, Fedora > 18).
https://github.com/zfsonlinux/zfs/releases/tag/zfs-0.6.5.8
[...]
Anders zit je zonder ZFS pools
Ik weet het ik weet het: assumption is the mother...
Dat zou je verwachten, maar bij mij was het iig niet zo (Fedora 23).
Even niets...
- Freeaqingme
- Registratie: April 2006
- Laatst online: 01:55
/u/172597/crop5e1225c8b1011.png?f=community)
Dat is dan alleen relevant als je handmatig die service definities aangepast hebt? Ben wel blij dat ik je bericht zie. Had al een nieuwe kernel gebakken, om die op een random moment in vol vertrouwen op productie te deployenFireDrunk schreef op vrijdag 23 september 2016 @ 17:53:
Belangrijk:
Voor mensen die net als ik, zonder de release notes te lezen, upgraden naar ZFSonLinux 0.6.5.8 op een SystemD platform (Ubuntu 16.0.4, CentOS 7, Fedora > 18).
https://github.com/zfsonlinux/zfs/releases/tag/zfs-0.6.5.8
[...]
Anders zit je zonder ZFS pools
No trees were harmed in creating this message. However, a large number of electrons were terribly inconvenienced.
Nope, ik had mijn service files niet aangeraakt, en toch werden de pools (3) niet automatisch geïmporteerd en gemount.
Even niets...
- idef1x
- Registratie: Januari 2004
- Laatst online: 03-07 09:39
Ik had het dan ook over UbuntuFireDrunk schreef op vrijdag 23 september 2016 @ 19:19:
Dat zou je verwachten, maar bij mij was het iig niet zo (Fedora 23).
Ik hou de standaard ubuntu zfs packages maar aan sinds ik eens de kernel opnieuw compileerde (weet niet meer waarom ik dat wilde overigens) en toen ging er van alles mis met zfs....nou ja ik moest opeens weer zfs-dkms installeren en wat fratsen, dus dacht laat maar ik hou het wel standaard ubuntu .. Dus wanneer Ubuntu update, hoop ik dat ze er rekening mee houden
:strip_icc():strip_exif()/u/14822/crop5db582e94f03d_cropped.jpeg?f=community)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
recent ook aan de slag gegaan met ZFSguru onder ESX6met een IBM1015 in pass-through, en so far so good!
Ik ben zelfs wat wantrouwend aangezien de pool meteen beschikbaar en online is. Ik ben Intel raids gewend welke dagen nodig had om alle disks te verify'en. Het klopt toch wel dat ik direct aan de slag kan?
ik heb wel een vraag:
via de webinterface heb ik nu een RAIDZ aangemaakt met 4 disks maar wil eigenlijk nog korte tijd de optie hebben om deze om te zetten naar RAIDZ2 met 5 disks.
Ik heb ooit gelezen dat je dan een Z2 met 5 disks aan moet maken in een degraded mode, echter via de webinterface lukt dit niet.
Is het nog steeds mogelijk en kan het via de CLI ?
Ik ben zelfs wat wantrouwend aangezien de pool meteen beschikbaar en online is. Ik ben Intel raids gewend welke dagen nodig had om alle disks te verify'en. Het klopt toch wel dat ik direct aan de slag kan?
ik heb wel een vraag:
via de webinterface heb ik nu een RAIDZ aangemaakt met 4 disks maar wil eigenlijk nog korte tijd de optie hebben om deze om te zetten naar RAIDZ2 met 5 disks.
Ik heb ooit gelezen dat je dan een Z2 met 5 disks aan moet maken in een degraded mode, echter via de webinterface lukt dit niet.
Is het nog steeds mogelijk en kan het via de CLI ?
ZFS is natuurlijk een stukje slimmer dan legacy RAID. Waarom data rebuilden die niet bestaat? Pas als je bestanden opslaat, dienen die beschermd te worden. Lege ongebruikte ruimte niet. Een pool aanmaken is dus <0.1 seconden klaar en er hoeft niets gerebuild te worden.R1 schreef op zaterdag 24 september 2016 @ 09:54:
recent ook aan de slag gegaan met ZFSguru onder ESX6met een IBM1015 in pass-through, en so far so good!
Ik ben zelfs wat wantrouwend aangezien de pool meteen beschikbaar en online is. Ik ben Intel raids gewend welke dagen nodig had om alle disks te verify'en. Het klopt toch wel dat ik direct aan de slag kan?
Jawel hoor. Gewoon bij Disks->Memory pagina een memdisk maken. Enige wat je hoeft te veranderen is de grootte; maak daar maar van 10 terabyte bijvoorbeeld. De RAM is pas nodig naarmate de ramdisk gevuld wordt, dus het kost je geen RAM.ik heb wel een vraag:
via de webinterface heb ik nu een RAIDZ aangemaakt met 4 disks maar wil eigenlijk nog korte tijd de optie hebben om deze om te zetten naar RAIDZ2 met 5 disks.
Ik heb ooit gelezen dat je dan een Z2 met 5 disks aan moet maken in een degraded mode, echter via de webinterface lukt dit niet.
Nadat je een memory disk hebt, kun je hem formatteren net als een normale disk op de Disks pagina. Dan kun je op de Pools pagina een RAID-Z2 maken van 5 disks met de memory disk geselecteerd.
Let wel op: je mag de pool niet gaan vullen met data, want dan wordt de memory disk ook gebruikt. Na het aanmaken van de pool even rebooten dan is hij degraded en kun je hem in gebruik nemen.
Succes!
- duiveltje666
- Registratie: Mei 2005
- Laatst online: 13-06-2022
Ehm .. draai hier de latest proxmox : 4.4.19 als kernelversie.FireDrunk schreef op woensdag 21 september 2016 @ 10:52:
Groot nadeel van Proxmox is dat ze een Debian achtergrond hebben, waardoor ze qua Kernel echt ver 3.16, i stand corrected, het valt wel mee achter blijven. ZFS en oude kernels is een beetje... meh... Het gaat, maar liever niet.
Dat geldt voor BTRFS voor veel sterker.
- ComTech
- Registratie: November 2002
- Laatst online: 28-06 19:14
:strip_icc():strip_exif()/u/71319/crop63827a2053b9b_cropped.jpg?f=community)
Ik wil mijn backup server eigenlijk omzetten naar Ubuntu (staat nu freenas op).
Maar wil wel met zfs door blijven gaan.
Kan ik m'n zfs pool gewoon weer importeren ?
Is het echt zo makkelijk als
Moet ik in freenas ook nog de pool exporteren?
Maar wil wel met zfs door blijven gaan.
Kan ik m'n zfs pool gewoon weer importeren ?
Is het echt zo makkelijk als
code:
1
| zfs import pool |
Moet ik in freenas ook nog de pool exporteren?
- dcm360
- Registratie: December 2006
- Niet online
Daar waren we al achter jaduiveltje666 schreef op zaterdag 24 september 2016 @ 17:34:
[...]
Ehm .. draai hier de latest proxmox : 4.4.19 als kernelversie.
- duiveltje666
- Registratie: Mei 2005
- Laatst online: 13-06-2022
Overigens ben ik bezig met een startpost te bakken voor een Proxmox topic..
dat is een truc die ik zelf niet kon bedenkenVerwijderd schreef op zaterdag 24 september 2016 @ 11:44:
[...]
ZFS is natuurlijk een stukje slimmer dan legacy RAID. Waarom data rebuilden die niet bestaat? Pas als je bestanden opslaat, dienen die beschermd te worden. Lege ongebruikte ruimte niet. Een pool aanmaken is dus <0.1 seconden klaar en er hoeft niets gerebuild te worden.
[...]
Jawel hoor. Gewoon bij Disks->Memory pagina een memdisk maken. Enige wat je hoeft te veranderen is de grootte; maak daar maar van 10 terabyte bijvoorbeeld. De RAM is pas nodig naarmate de ramdisk gevuld wordt, dus het kost je geen RAM.
Nadat je een memory disk hebt, kun je hem formatteren net als een normale disk op de Disks pagina. Dan kun je op de Pools pagina een RAID-Z2 maken van 5 disks met de memory disk geselecteerd.
Let wel op: je mag de pool niet gaan vullen met data, want dan wordt de memory disk ook gebruikt. Na het aanmaken van de pool even rebooten dan is hij degraded en kun je hem in gebruik nemen.
Succes!
zo gezegd zo gedaan, maar dan is de size niet exact gelijk, dus probeer ik de force optie, maar dan blijft de webinterface minutenlang hangen. Heb het ook op de CLI geprobeerd (feature bpobj bestaat dan niet overigens), maar dan blijft hij ook minutenlang hangen en dus reboot ik maar.... het zou niet minutenlang moeten duren toch? Ik kan nog proberen te achterhalen hoe groot de spinning disks zijn om een exacte match te maken qua memdisk
nog een andere vraag: is de pool nu portable voor andere distro's zoals een nas4free, freenas etc? niet dat ik weg wil, maar vroeg t mij wel af of je nu zo kunt importeren op een andere.
Post eens wat je op de command line hebt gedaan dan?
Dat minutenlang hangen klopt in elk geval niet; misschien één van je disks die aan het bokken is ofzo? Heb je de kernel logs bekeken?
Dat minutenlang hangen klopt in elk geval niet; misschien één van je disks die aan het bokken is ofzo? Heb je de kernel logs bekeken?
een Z1 staat er zo met 5 seconden, de Z2 heb ik aangemaakt op 14.38.
14:50 was t klaar na heel veel geduld
ik kan weinig vinden in de var/log/messages. Nog een andere plek waar ik zou moeten kijken?
onderstaand is ook het cmd dat op de CLI heel lang duurt (zonder bpobj).
2016-09-25 14:50:37 zpool create -f -d -o feature@async_destroy=enabled -o feature@empty_bpobj=enabled -o feature@lz4_compress=enabled -O atime=off DenZ2 raidz2 gpt/WD1 gpt/WD2 gpt/WD3 gpt/WD4 gpt/memdisk1
14:50 was t klaar na heel veel geduld
ik kan weinig vinden in de var/log/messages. Nog een andere plek waar ik zou moeten kijken?
onderstaand is ook het cmd dat op de CLI heel lang duurt (zonder bpobj).
2016-09-25 14:50:37 zpool create -f -d -o feature@async_destroy=enabled -o feature@empty_bpobj=enabled -o feature@lz4_compress=enabled -O atime=off DenZ2 raidz2 gpt/WD1 gpt/WD2 gpt/WD3 gpt/WD4 gpt/memdisk1
Hm, dan zou ik willen zien of er disk I/O is. Ik zou niet goed weten waarom het lang zou moeten duren.
Maar het werkt wel? Doe eens een zpool list? Heb je al gereboot? Zo nee, eerst de zpool list doen.
Maar het werkt wel? Doe eens een zpool list? Heb je al gereboot? Zo nee, eerst de zpool list doen.
het werkt wel, t duurt alleen even. Geeft nu netjes de unavailable memdisk aan. Deze kan ik later replacen met de toekomstige spinning disk hoop ik.
maar had al gereboot, dit is de list.
Kan t wel opnieuw doen zonder reboot als t helpt?
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
DenZ2 36.2T 3.06M 36.2T 10.2G - 0% 1.00x DEGRADED -
ZFSbootVMw 95.5G 3.03G 92.5G - - 3% 1.00x ONLINE -
maar had al gereboot, dit is de list.
Kan t wel opnieuw doen zonder reboot als t helpt?
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
DenZ2 36.2T 3.06M 36.2T 10.2G - 0% 1.00x DEGRADED -
ZFSbootVMw 95.5G 3.03G 92.5G - - 3% 1.00x ONLINE -
- ComTech
- Registratie: November 2002
- Laatst online: 28-06 19:14
Het is gelukt.ComTech schreef op zaterdag 24 september 2016 @ 18:27:
Ik wil mijn backup server eigenlijk omzetten naar Ubuntu (staat nu freenas op).
Maar wil wel met zfs door blijven gaan.
Kan ik m'n zfs pool gewoon weer importeren ?
Is het echt zo makkelijk als
code:
Moet ik in freenas ook nog de pool exporteren?
code:
1
| sudo zpool import -a -f |
De pool was gelockt of zoiets maar met de code -f ging hij hem importeren.
Alles goed en wel behalve de totale ruimte die is nu maar 1.5 TB terwijl er 2x2 TB schijven in mirror staan voorheen had ik =- 1.8 TB.
Hoe kan ik dat oplossen?
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Wat ik me afvroeg. Ik zit met het idee om een Samsung SM961 256GB NVME SSD als SLOG en L2ARC in te zetten. Reviews geven aan dat het om een OEM model gaat met in extreme situaties data corruptie. Is het nu zo dat ZFS in een RAIDZ2 situatie mogelijke corruptie van een SLOG automatisch zal repareren?
Sinds de 2 dagen regel reageer ik hier niet meer
Nee, je kan potentieel een paar transaction groups verliezen. Je array zal niet compleet onleesbaar worden.
Het maximale wat je kwijt kan raken is ongeveer een paar seconden tot een paar minuten (afhankelijk van de load).
Het maximale wat je kwijt kan raken is ongeveer een paar seconden tot een paar minuten (afhankelijk van de load).
Even niets...
- CurlyMo
- Registratie: Februari 2011
- Laatst online: 08:15
Dus of zich vrij veilig te gebruiken als je die risico's als aanvaardbaar beschouwd. Het is dus niet zo als bij het risico van niet-ECC RAM. Dat de disks corrupte data uit het geheugen krijgen en dat ZFS niet beter weet dan dat dit de data is zoals hij het had moeten krijgen, en het dus ook niet kan repareren.
[ Voor 57% gewijzigd door CurlyMo op 28-09-2016 08:32 ]
Sinds de 2 dagen regel reageer ik hier niet meer
Zijn er nog mensen die automatisch ZFS snapshots maken met intelligente tooling? Ik kan best wat scripten, maar heb geen zin om het wiel opnieuw uit te vinden.
Ik wil een bepaald ZFS Filesystem automatisch snapshotten in de trant van 4 snapshots per dag, 1 dag bewaren, 1 snapshot per dag een week bewaren, 1 snapshot per maand een jaar bewaren. (dus in totaal 5+1+7+12 snapshots steeds roeleren.)
OS: Fedora 23 (RPM/YUM repo is een pre).
Ik wil een bepaald ZFS Filesystem automatisch snapshotten in de trant van 4 snapshots per dag, 1 dag bewaren, 1 snapshot per dag een week bewaren, 1 snapshot per maand een jaar bewaren. (dus in totaal 5+1+7+12 snapshots steeds roeleren.)
OS: Fedora 23 (RPM/YUM repo is een pre).
Even niets...
- Compizfox
- Registratie: Januari 2009
- Laatst online: 23:57
Zeker. Ik gebruik zfSnap. Geen idee of er een repo voor is.FireDrunk schreef op woensdag 12 oktober 2016 @ 21:39:
Zijn er nog mensen die automatisch ZFS snapshots maken met intelligente tooling? Ik kan best wat scripten, maar heb geen zin om het wiel opnieuw uit te vinden.
Ik wil een bepaald ZFS Filesystem automatisch snapshotten in de trant van 4 snapshots per dag, 1 dag bewaren, 1 snapshot per dag een week bewaren, 1 snapshot per maand een jaar bewaren. (dus in totaal 5+1+7+12 snapshots steeds roeleren.)
OS: Fedora 23 (RPM/YUM repo is een pre).
Gewoon een heel grote verzameling snoertjes
- VorCha
- Registratie: November 2004
- Laatst online: 03-02 09:16
Ik heb zoiets zelf opgetuigd voor wat directories, ik kan je de scripts eerst wel DM'en, misschien heb je daar wat aan?FireDrunk schreef op woensdag 12 oktober 2016 @ 21:39:
Zijn er nog mensen die automatisch ZFS snapshots maken met intelligente tooling? Ik kan best wat scripten, maar heb geen zin om het wiel opnieuw uit te vinden.
Ik wil een bepaald ZFS Filesystem automatisch snapshotten in de trant van 4 snapshots per dag, 1 dag bewaren, 1 snapshot per dag een week bewaren, 1 snapshot per maand een jaar bewaren. (dus in totaal 5+1+7+12 snapshots steeds roeleren.)
OS: Fedora 23 (RPM/YUM repo is een pre).
Mja, ik zoek toch eerlijk gezegd iets van een breed geteste aard Ik zal eens naar zfSnap kijken, ziet er prima uit.
Toch bedankt voor het aanbod
Toch bedankt voor het aanbod
[ Voor 16% gewijzigd door FireDrunk op 12-10-2016 22:58 ]
Even niets...
Let op:
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.