:fill(white):strip_exif()/i/2003943496.jpeg?f=thumbmini)
:strip_exif()/i/1321263566.png?f=thumbmini)
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
Even niets...
- iRReeL
- Registratie: Februari 2007
- Laatst online: 11-02-2025
Misschien had ik toch beter kunnen exporteren
Maar ik kan niet een losse VDEV importeren, dat is eigenlijk wat ik wil. Ik vraag me af of ik de huidige degraded pool kan exporteren en dan weer importeren en of dan de verplaatste disk wel meegenomen gaat worden.
Alternatief is het leegmaken van de disk of eventueel het label aanpassen?
Blijkbaar is er ook nog een "zpool labelclear <VDEV>" optie..
http://lists.freebsd.org/...-fs/2011-June/011767.html
Aan de andere kant begrijp ik dat het verplaatsen van de disk eigenlijk geen probleem zou mogen zijn
http://www.manpagez.com/man/8/zpool/If a device is removed from a system without running "zpool export" first, the device appears as potentially active. It cannot be determined if this was a failed export, or whether the device is really in use from another host. To import a pool in this state, the -f option is required.
Maar ik kan niet een losse VDEV importeren, dat is eigenlijk wat ik wil. Ik vraag me af of ik de huidige degraded pool kan exporteren en dan weer importeren en of dan de verplaatste disk wel meegenomen gaat worden.
Alternatief is het leegmaken van de disk of eventueel het label aanpassen?
Blijkbaar is er ook nog een "zpool labelclear <VDEV>" optie..
http://lists.freebsd.org/...-fs/2011-June/011767.html
Aan de andere kant begrijp ik dat het verplaatsen van de disk eigenlijk geen probleem zou mogen zijn
http://dlc.sun.com/osol/docs/content/ZFSADMIN/gbbvb.htmlOnce a device is reattached to the system, ZFS might or might not automatically detect its availability. If the pool was previously faulted, or the system was rebooted as part of the attach procedure, then ZFS automatically rescans all devices when it tries to open the pool. If the pool was degraded and the device was replaced while the system was up, you must notify ZFS that the device is now available and ready to be reopened by using the zpool online command.
Ik had nog geprobeerd de disk als spare toe te voegen in de hoop dat ie dan de UNAVAIL disk zou vervangen maar dat lukt ook nietzpool online Archive c5t50014EE6AADF2AA3d0
cannot online c5t50014EE6AADF2AA3d0: no such device in pool
# zpool online Archive c2t545d0
warning: device 'c2t545d0' onlined, but remains in faulted state
zpool add -f Archive spare c5t50014EE6AADF2AA3d0
invalid vdev specification
the following errors must be manually repaired:
/dev/dsk/c5t50014EE6AADF2AA3d0s0 is part of active ZFS pool Archive. Please see zpool(1M).
ZFS: FreeBSD10+ZFSguru, ASRock C2550D4I , 16GB, Nexus Value 430w
- DARKLORD
- Registratie: December 2000
- Laatst online: 04-07 10:24
heb je het al in het napp-it topic gevraagd ?
http://hardforum.com/showthread.php?t=1573272&page=93
http://hardforum.com/showthread.php?t=1573272&page=93
Fake omdat ze vaak onbekend bij de gebruiker geen onderdeel uitmaken van de chipset, die de hoogst mogelijke kwaliteit SATA poorten levert. Daarnaast zijn de extra chips vaak beperkt in bandbreedte, zoals geldt voor JMicron ("GigaByte SATA") of Marvell poorten, met een enkele uitzondering (Marvell 88SE9172).vso schreef op dinsdag 18 oktober 2011 @ 13:32:
paar dingen die ik me eigenlijk afvraag:
Hoe herken je "fake" en echte poorten op een MoBo? en waarom zijn ze "fake" ?
Daarnaast geldt dat onder non-Windows OS de Marvell chips toch erg veel bugs hebben gehad, mogelijk door gebrekkige documentatie. JMicron presteerd eigenlijk altijd al slecht, Silicon Image doet het daarintegen wel redelijk op non-Windows OS maar die heeft weer geen/beperkte chips met genoeg PCI-express bandbreedte. Zo gebruikte OCZ voor hun Revodrives een Silicon Image SiI-3124 wat een PCI-X chip is omdat de PCI-express 1.0 x1 te weinig bandbreedte levert, dan heb je wel weer een PCI-X naar PCI-express bridge chip nodig. De drivers van Silicon Image zijn echter weer ruk onder Windows.
Dus het is altijd gedoe met die extra chips; er bestaan simpelweg geen écht goede addon AHCI SATA chips. De enige écht goede SATA poorten zijn dus die afkomstig van AMD en Intel chipsets. Je kunt wel SAS controllers overwegen door het gebrek aan hoogwaardige SATA addon controllers, dat is dan ook wat veel ZFS gebruikers doen en zetten een LSI SAS controller in hun systeem. Marvell maakt ook SAS chips, maar die geven weer veel problemen dus die kun je beter vermijden.
Hetzelfde werkt met FreeBSD software RAID; wat zonder configuratie zou moeten werken op een volledig ander systeem met schijven op een andere controller of SATA kabel positie. Dat komt omdat de metadata op de schijven zelf staat aangesloten en FreeBSD een GEOM-framework heeft wat alle schijven kan 'proeven'. Echter dan heb je de RAID-layer actief, je zult dan nog handmatig een filesystem op die RAID-layer moeten mounten, dat gaat dan weer niet automatisch. ZFS is in dat opzicht wel beter ja.Ik vind ZFS met name goed omdat het "transporteerbaar" is, als ik me goed herrinner kan ik de disks eruit trekken .. fbsd opnieuw installaren, disks erin stoppen en met 1 of geen commando "importeer" ik de ZFS volume .. iets wat ik zover ik weet niet echt hoef te proberen met andere "volumes"
Kijk eens wat rond op fora als HardOCP daar vind je redelijk wat benchmarks. Met een goede setup kun je ver komen bij ZFS. Genoeg schijven, geneog geheugen en goede controllers zijn hierbij cruciaal.ik mis "cijfers" ik kan me echt geen beeld vormen van performance van zfs versus een RAID 5/10 etc ..
met name RAID Z dus .. ook al is het appels met peren vergelijken ..
De hoeveelheid RAM kun je direct merken in vrijwel alle I/O van ZFS, mits ook gebruikt (iets waarbij FreeBSD platforms tuning moeten verrichten in tegenstelling tot Solaris). Een SSD ga je alleen merken bij random reads (L2ARC) of sequential+random 'sync' writes (SLOG oftewel aparte LOG device). Een kleine SSD kan een hele grote array versnellen, door dingen waar hardeschijven heel slecht in zijn over te nemen en door de SSD te laten doen, zodat de hardeschijven zich op sequential I/O kunnen blijven richten, waar ze wél heel goed in zijn. Deze functie lijkt op SRT van Intel maar werkt 10x beter en is in tegenstelling tot SRT volkomen veilig; corruptie op de SSD wordt direct opgemerkt.Hoeveel impact heeft bv 1 gb extra RAM of een SSD waar ga ik dan de performance in terug zien ?
Pas zodra je alle schijven hebt vervangen door grotere capaciteit kun je de array/pool de extra capaciteit laten benutten, door de autoexpand property in te schakelen.Hoe gaat ZFS ermee om als je een HD vervangt door een groter model ? is het wijsheid het als je bv 6 "echte" controllers gebruikt" om tijdelijk een fake te gebruiken of gewoon disk eruit/erin en comando x.y.z
word de extra GB ook benut of niet ?
@iRReeL: je kunt ook even booten met een ZFSguru livecd, pool importeren en de disk daar vervangen, dan een export en weer terug naar Solaris.
- Aeogenia
- Registratie: Maart 2009
- Laatst online: 21-03-2024
Al een tijdje ben ik bezig mijn OS van mijn server over te zetten van Nexenta Core naar Openindiana maar het importeren van mijn pool lukt niet.
Openindiana herkend de pool maar ik krijg de foutmelding dat de pool is geformatteerd op een ander OS en niet geïmporteerd kan worden tegelijk staat de pool op unavail maar de disks online. De exacte error ben ik vergeten op te schrijven. Dit oorzaak van dit denk ik zelf al gelokaliseerd en ligt aan de formattering van Nexenta van 512 byte sectors ipv de normale 4K van Openindiana sectors. -f mount lukte ook niet, de pool is niet beschadigt aangezien hij nu nog goed werkt onder Nexenta.
Weet iemand een manier om mij een volledige herformatie in Openindiana van de pool te vermijden?
Als dit geen probleem zou moeten geven zou het dan ook aan kan liggen dat de pool op versie 26 is geformateerd? BvbD
Systeem:
inventaris: Nas
Openindiana herkend de pool maar ik krijg de foutmelding dat de pool is geformatteerd op een ander OS en niet geïmporteerd kan worden tegelijk staat de pool op unavail maar de disks online. De exacte error ben ik vergeten op te schrijven. Dit oorzaak van dit denk ik zelf al gelokaliseerd en ligt aan de formattering van Nexenta van 512 byte sectors ipv de normale 4K van Openindiana sectors. -f mount lukte ook niet, de pool is niet beschadigt aangezien hij nu nog goed werkt onder Nexenta.
Weet iemand een manier om mij een volledige herformatie in Openindiana van de pool te vermijden?
Als dit geen probleem zou moeten geven zou het dan ook aan kan liggen dat de pool op versie 26 is geformateerd? BvbD
Systeem:
inventaris: Nas
Je zult toch echt de exacte melding en output van zpool import moeten vermelden. Solaris gebruikt hardcoded 512-byte sectors dus een 4K pool zou het probleem niet mogen zijn; en al is dat het geval dan zou ZFS deze alsnog prima moeten kunnen herkennen (ashift=12).
Wellicht dat je pool een hogere versie is dan het systeem wat je draait? zpool import vertelt het je, paste hier de exacte output van dat commando.
Wellicht dat je pool een hogere versie is dan het systeem wat je draait? zpool import vertelt het je, paste hier de exacte output van dat commando.
- Aeogenia
- Registratie: Maart 2009
- Laatst online: 21-03-2024
Dat wil ik morgen wel even doen, dan hoor je nog van me. En mijn pool is versie 26 en boot schijf heeft versie 28.
- iRReeL
- Registratie: Februari 2007
- Laatst online: 11-02-2025
Ja ik heb toch het risico genomen en in Napp-it een export gedaan met de degraded array. Moest wel uiteindelijk de -f*** optie gebruiken. Daarna meteen weer een import gedaan in Napp-it en dat ging blijkbaar goed@iRReeL: je kunt ook even booten met een ZFSguru livecd, pool importeren en de disk daar vervangen, dan een export en weer terug naar Solaris.
Daarna zal ik de 4 disks op de JM322 op de M1015 zetten en dan ben ik 's benieuwd of ik wat betere perfformance ga krijgen
Ik heb nog een E-350 mITX bordje gekregen, ik had iets te laat gelezen dat die blijkbaar niet goed werkt met een PCI-E disk controller maar goe ik ga het toch 's proberen met de M1015.Pool
pool: Archive
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors using 'zpool clear' or replace the device with 'zpool replace'.
see: http://www.sun.com/msg/ZFS-8000-9P
scan: resilvered 13.5K in 0h0m with 0 errors on Thu Oct 20 10:57:38 2011
config:
NAME STATE READ WRITE CKSUM
Archive ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
c3t3d0 ONLINE 0 0 0
c3t5d0 ONLINE 0 0 0
c5t50014EE6AADF2AA3d0 ONLINE 0 0 2
c2t513d0 ONLINE 0 0 0
etc...
errors: No known data errors
ZFS: FreeBSD10+ZFSguru, ASRock C2550D4I , 16GB, Nexus Value 430w
- Aeogenia
- Registratie: Maart 2009
- Laatst online: 21-03-2024
Op vervolging van mijn post de import error:
pool: DT1
id: 31899993136497873155
status: UNAVAIL
action: The pool was last accessed by another system.
action: The pool cannot be imported due to damaged divices or data.
see: http://www.sun.com/msg/ZFS-8000-EY
config:
DT1 UNAVAIL insufficient replicas
mirror-0 UNAVAIL corrupted data
c2t1d0 ONLINE
c2t0d0 ONLINE
De error heeft iets te maken met een dropped data pool i.c.m. verschillende versies van ZFS. De enige oplossing die iemand gepost heeft is de pool te rewinden met:
zpool import -fFX DT1
Maar dit gaat (als het al lukt) heel lang duren 24h+ dus wil ik graag vermijden. Wat ik ook nog kan proberen is de pool up te upgraden naar versie 28 in Nexenta of de pool proberen te resilveren... Iemand een idee, wat ik het beste of nog meer kan proberen?
pool: DT1
id: 31899993136497873155
status: UNAVAIL
action: The pool was last accessed by another system.
action: The pool cannot be imported due to damaged divices or data.
see: http://www.sun.com/msg/ZFS-8000-EY
config:
DT1 UNAVAIL insufficient replicas
mirror-0 UNAVAIL corrupted data
c2t1d0 ONLINE
c2t0d0 ONLINE
De error heeft iets te maken met een dropped data pool i.c.m. verschillende versies van ZFS. De enige oplossing die iemand gepost heeft is de pool te rewinden met:
zpool import -fFX DT1
Maar dit gaat (als het al lukt) heel lang duren 24h+ dus wil ik graag vermijden. Wat ik ook nog kan proberen is de pool up te upgraden naar versie 28 in Nexenta of de pool proberen te resilveren... Iemand een idee, wat ik het beste of nog meer kan proberen?
- saiko223
- Registratie: Januari 2008
- Laatst online: 07-01 19:06
Wie van jullie gebruikt ecc ram voor de zfs (nas)? Aangezien ik tot nu toe geen mobo ben tegen gekomen die CPU onboard heeft en ecc ram ondersteuning op de PW.
Waarom wil je een onboard CPU? Ik heb zelf wel ECC (maar momenteel geen ZFS).
Ik ben ook nog niet echt veel integrated oplossingen tegengekomen waar ECC werkt...
Geen idee eigenlijk of de nieuwe E350 ECC ondersteund...
Ik ben ook nog niet echt veel integrated oplossingen tegengekomen waar ECC werkt...
Geen idee eigenlijk of de nieuwe E350 ECC ondersteund...
Even niets...
Brazos en Llano ondersteunen geen ECC, helaas. Vreemd wel, omdat de Athlon wel ECC ondersteunde, dus met name voor Llano is het vreemd dat er geen ECC wordt ondersteund omdat dat min of meer een moderne Athlon X4 CPU is met GPU onboard.
Moederbord doet ook niets met ECC ondersteuning; de geheugencontroller zit in de processor (IMC) - die moet ECC ondersteunen. Daarnaast moet het moederbord wellicht ondersteuning hebben om ECC daadwerkelijk te activeren, maar de hardware support is natuurlijk cruciaal.
Moederbord doet ook niets met ECC ondersteuning; de geheugencontroller zit in de processor (IMC) - die moet ECC ondersteunen. Daarnaast moet het moederbord wellicht ondersteuning hebben om ECC daadwerkelijk te activeren, maar de hardware support is natuurlijk cruciaal.
- saiko223
- Registratie: Januari 2008
- Laatst online: 07-01 19:06
Omdat ik ervan uit ga dat CPU onboard goedkoper in aankoop en stroomverbruik is. Maar als jij een mobo + cpu die 8gb ecc ram ondersteund + 6 sata poorten heeft rond de 100 euro kom ik daarop terug.FireDrunk schreef op vrijdag 21 oktober 2011 @ 14:00:
Waarom wil je een onboard CPU? Ik heb zelf wel ECC (maar momenteel geen ZFS).
Ik ben ook nog niet echt veel integrated oplossingen tegengekomen waar ECC werkt...
Geen idee eigenlijk of de nieuwe E350 ECC ondersteund...
Waarom kan ik in de PW niet zoeken op ecc ondersteuning?
[ Voor 5% gewijzigd door saiko223 op 21-10-2011 14:09 ]
Grappige is dan wel weer dat je zelf met de eis van 8GB komt... Atom ondersteunt dat niet eens (max 4GB) dan blijft er nog maar 1 andere over en dat is AMD Brazos (E350). Als je maar 100 euro uit wil geven, denk ik niet dat ECC voor jij een investering is waar je wat aan hebt.
Voor een beetje leuk ECC support zit je inderdaad aan een groter en duurder moederbord.
Goedkoopste oplossing die ik ken is een i3-2100. icm een MSI H61 bordje zou dat heel zuinig moeten zijn.
Voor een beetje leuk ECC support zit je inderdaad aan een groter en duurder moederbord.
Goedkoopste oplossing die ik ken is een i3-2100. icm een MSI H61 bordje zou dat heel zuinig moeten zijn.
Omdat fabrikanten daar meestal erg geheimzinnig over doen.Waarom kan ik in de PW niet zoeken op ecc ondersteuning?
[ Voor 38% gewijzigd door FireDrunk op 21-10-2011 14:11 ]
Even niets...
- saiko223
- Registratie: Januari 2008
- Laatst online: 07-01 19:06
De reden dat ik om die 100 euro mekker is dat ik dit lijstje in gedachte had. Maar die e35m1-l ondersteund dus geen eccFireDrunk schreef op vrijdag 21 oktober 2011 @ 14:10:
Grappige is dan wel weer dat je zelf met de eis van 8GB komt... Atom ondersteunt dat niet eens (max 4GB) dan blijft er nog maar 1 andere over en dat is AMD Brazos (E350). Als je maar 100 euro uit wil geven, denk ik niet dat ECC voor jij een investering is waar je wat aan hebt.
Voor een beetje leuk ECC support zit je inderdaad aan een groter en duurder moederbord.
Goedkoopste oplossing die ik ken is een i3-2100. icm een MSI H61 bordje zou dat heel zuinig moeten zijn.
En is het jullie ook opgevallen dat die 1tb van 30 euro naar 48 is gestegen. Misschien i.v.m. met overstroming in Korea maar dat is dan wel heel snel. (De reden dat ik voor 1 TB kies is omdat ik nog wat 1TB schijven over heb liggen waardoor ik dus makkelijk raidz2 kan draaien. En dan later mijn zpool upgraden naar 3tb )
Aan welk budget moet ik denken als ik voor ecc zou gaan?
| # | Product | Prijs | Subtotaal |
| 1 | Asus E35M1-I | € 96,16 | € 96,16 |
| 1 | Kingston DataTraveler G3 4GB Zwart | € 5,15 | € 5,15 |
| 1 | Samsung EcoGreen F3 HD105SI, 1TB | € 48,14 | € 48,14 |
| 1 | Lian Li PC-Q08B | € 92,13 | € 92,13 |
| 2 | € 2,45 | € 4,90 | |
| 1 | be quiet! Pure Power L7 300W | € 34,85 | € 34,85 |
| 1 | Kingston ValueRAM KVR1333D3E9SK2/8G | € 64,58 | € 64,58 |
| Bekijk collectie Importeer producten | Totaal | € 345,91 | |
Zoek op lijstjes met MSI en i3 in dit topic. Staan er genoeg.
Even niets...
- iRReeL
- Registratie: Februari 2007
- Laatst online: 11-02-2025
ZFS hoeft trouwens geen ECC ram, het vangt ook geheugen errors op (maar goed ik zelf geef ook de voorkeur aan ECC ram.
'Hdd-prijzen gaan stijgen door overstromingen Thailand' is van het nieuws van gister
Me dunkt dat een Asus Am3 bordje met een simpele CPU het goedkoopste zal zijn om ECC support te verkrijgen. (Ik kijk meestal in de handleiding of/welke er ECC opties zijn, dat is meestal bij ASUS en zelden bij andere merken).
'Hdd-prijzen gaan stijgen door overstromingen Thailand' is van het nieuws van gister
Me dunkt dat een Asus Am3 bordje met een simpele CPU het goedkoopste zal zijn om ECC support te verkrijgen. (Ik kijk meestal in de handleiding of/welke er ECC opties zijn, dat is meestal bij ASUS en zelden bij andere merken).
[ Voor 36% gewijzigd door iRReeL op 21-10-2011 15:25 ]
ZFS: FreeBSD10+ZFSguru, ASRock C2550D4I , 16GB, Nexus Value 430w
- Dadona
- Registratie: September 2007
- Laatst online: 17-07 23:16
/u/231803/ramdisk2.png?f=community)
Of een i3 aan ECC doet zou ik niet durven zeggen, mijn inschatting zou zijn dat het niet het geval is. Maar dat komt eigenlijk op de tweede plek. Consumenten moederborden van MSI doen niets met ECC dus die vlieger gaat sowieso al niet op. Als je op een consumentenbord wil gokken dan zou ik een Asus nemen. (MSI met een Athlon of een Phenom doet ook niet aan ECC, maar gelukkig werkt het bij Asus en Biostar wel.)
- saiko223
- Registratie: Januari 2008
- Laatst online: 07-01 19:06
Ik ben erg benieuwd naar de bron die claimt dat zfs ook geheugen errors opvangt. Dan ga ik lekker verder zoeken naar asus bordjes.iRReeL schreef op vrijdag 21 oktober 2011 @ 14:24:
ZFS hoeft trouwens geen ECC ram, het vangt ook geheugen errors op (maar goed ik zelf geef ook de voorkeur aan ECC ram.
'Hdd-prijzen gaan stijgen door overstromingen Thailand' is van het nieuws van gister
Me dunkt dat een Asus Am3 bordje met een simpele CPU het goedkoopste zal zijn om ECC support te verkrijgen. (Ik kijk meestal in de handleiding of/welke er ECC opties zijn, dat is meestal bij ASUS en zelden bij andere merken).
Of de i3 aan ECC doet is afhankelijk van het chipset. Er staat in een van de 20 topic waar we al deze meuk posten een verwijzing naar een gesprek met een SuperMicro engineer die verteld dat de i3 wel ECC kan, maar dat chipset en BIOS dat wel moeten ondersteunen/enablen.
Dat ging trouwens wel over de S1156 i3's... Geen idee of het ook geld voor de S1155
Dat ging trouwens wel over de S1156 i3's... Geen idee of het ook geld voor de S1155
[ Voor 13% gewijzigd door FireDrunk op 21-10-2011 15:34 ]
Even niets...
- saiko223
- Registratie: Januari 2008
- Laatst online: 07-01 19:06
Geen ecc
Met ecc. Ik ga ervan uit dat ecc hierop werkt.
De aankoop verschilt niet zoveel alleen hoe zit het met verbruik? Is zo'n e350 bordje veel zuiniger?
| # | Product | Prijs | Subtotaal |
| 1 | Asus E35M1-I | € 96,16 | € 96,16 |
| 1 | Kingston DataTraveler G3 4GB Zwart | € 5,40 | € 5,40 |
| 1 | Samsung EcoGreen F3 HD105SI, 1TB | € 48,71 | € 48,71 |
| 1 | Lian Li PC-Q08B | € 92,13 | € 92,13 |
| 2 | € 2,45 | € 4,90 | |
| 1 | be quiet! Pure Power L7 300W | € 34,85 | € 34,85 |
| 1 | Transcend 8GB DDR3 Dual/Triple Channel Kit | € 35,97 | € 35,97 |
| Bekijk collectie Importeer producten | Totaal | € 318,12 | |
Met ecc. Ik ga ervan uit dat ecc hierop werkt.
| # | Product | Prijs | Subtotaal |
| 1 | Kingston DataTraveler G3 4GB Zwart | € 5,40 | € 5,40 |
| 1 | Samsung EcoGreen F3 HD105SI, 1TB | € 48,71 | € 48,71 |
| 1 | Lian Li PC-Q08B | € 92,13 | € 92,13 |
| 2 | € 2,45 | € 4,90 | |
| 1 | AMD Athlon II X2 250 Boxed | € 47,90 | € 47,90 |
| 1 | be quiet! Pure Power L7 300W | € 34,85 | € 34,85 |
| 1 | ICIDU Value DDR3,1333-8GB KIT | € 46,80 | € 46,80 |
| 1 | Asus M4A88T-M | € 69,10 | € 69,10 |
| Bekijk collectie Importeer producten | Totaal | € 349,79 | |
De aankoop verschilt niet zoveel alleen hoe zit het met verbruik? Is zo'n e350 bordje veel zuiniger?
- iRReeL
- Registratie: Februari 2007
- Laatst online: 11-02-2025
Uiteraard kan ik de bron niet terugvinden waarin men aangaf dat 1 van de voordelen van ZFS is dat het ook ECC errors opvangt, ik weet dat het een podcast was van een van de developers. Voor mij was dit genoeg om alsnog voor een goedkopere oplossing te gaan zonder ECC.
Echter nu kom ik een studie/test tegen waarin staat dat ZFS RAM errors niet goed opvangt. Staat verder ook bij dat je dan ook CHIPKILL wil hebben als je het goed wil doen.
Dus ja ik persoonlijk zou dan toch weer voor ECC ram gaan.
Echter nu kom ik een studie/test tegen waarin staat dat ZFS RAM errors niet goed opvangt. Staat verder ook bij dat je dan ook CHIPKILL wil hebben als je het goed wil doen.
http://www.usenix.org/eve...ech/full_papers/zhang.pdfIn our analysis, we find that ZFS is indeed robust to a wide range of disk corruptions, thus partially confirming that many of its design goals have been met. However, we also find that ZFS often fails to maintain data integrity in the face of memory corruption. In many cases, ZFS is either unable to detect the corruption, returns bad data to the user, or simply crashes
Dus ja ik persoonlijk zou dan toch weer voor ECC ram gaan.
ZFS: FreeBSD10+ZFSguru, ASRock C2550D4I , 16GB, Nexus Value 430w
Dat heeft/had waarschijnlijk met disk ECC errors te maken... Ook een harddisk kan geheugen fouten maken (data leveren vanuit cache). Vanwege de Checksum achtergrond van ZFS ziet ZFS dit.
Wat ZFS (natuurlijk) niet kan zien is of er nadat de checksum controle gedaan is, de data ook daadwerkelijk zoals hij gecheckt is aan de gebruiker geleverd word. Simpelweg omdat moderne systemen zoiets nog niet kunnen.
Dit komt omdat geheugen nou eenmaal uit te lezen is wanneer een applicatie er om vraagt.
(The message above is purely based on experience and technological knowledge, and therefor, no rights can be acquired by accepting this post as truth.)
Wat ZFS (natuurlijk) niet kan zien is of er nadat de checksum controle gedaan is, de data ook daadwerkelijk zoals hij gecheckt is aan de gebruiker geleverd word. Simpelweg omdat moderne systemen zoiets nog niet kunnen.
Dit komt omdat geheugen nou eenmaal uit te lezen is wanneer een applicatie er om vraagt.
(The message above is purely based on experience and technological knowledge, and therefor, no rights can be acquired by accepting this post as truth.)
Even niets...
- donnervogel
- Registratie: Maart 2003
- Laatst online: 14-01-2023
Kijk ook eens naar deze vergelijking Asus E35M1-l met Asus M488T-M.saiko223 schreef op vrijdag 21 oktober 2011 @ 16:13:
Geen ecc
# Product Prijs Subtotaal 1 Asus E35M1-I € 96,16 € 96,16 1 Kingston DataTraveler G3 4GB Zwart € 5,40 € 5,40 1 Samsung EcoGreen F3 HD105SI, 1TB € 48,71 € 48,71 1 Lian Li PC-Q08B € 92,13 € 92,13 2 € 2,45 € 4,90 1 be quiet! Pure Power L7 300W € 34,85 € 34,85 1 Transcend 8GB DDR3 Dual/Triple Channel Kit € 35,97 € 35,97 Bekijk collectie
Importeer productenTotaal € 318,12
Met ecc. Ik ga ervan uit dat ecc hierop werkt.
# Product Prijs Subtotaal 1 Kingston DataTraveler G3 4GB Zwart € 5,40 € 5,40 1 Samsung EcoGreen F3 HD105SI, 1TB € 48,71 € 48,71 1 Lian Li PC-Q08B € 92,13 € 92,13 2 € 2,45 € 4,90 1 AMD Athlon II X2 250 Boxed € 47,90 € 47,90 1 be quiet! Pure Power L7 300W € 34,85 € 34,85 1 ICIDU Value DDR3,1333-8GB KIT € 46,80 € 46,80 1 Asus M4A88T-M € 69,10 € 69,10 Bekijk collectie
Importeer productenTotaal € 349,79
De aankoop verschilt niet zoveel alleen hoe zit het met verbruik? Is zo'n e350 bordje veel zuiniger?
Ik zou zelf voor de E35M1-l gaan, heeft meer mogelijkheden.
Hij wil ECC...
Even niets...
- donnervogel
- Registratie: Maart 2003
- Laatst online: 14-01-2023
My fault, het voorgaande niet goed doorgenomen.FireDrunk schreef op vrijdag 21 oktober 2011 @ 18:16:
Hij wil ECC...
http://www.swt.com/isf2.htmlFireDrunk schreef op vrijdag 21 oktober 2011 @ 15:33:
Of de i3 aan ECC doet is afhankelijk van het chipset. ...........
Dat ging trouwens wel over de S1156 i3's... Geen idee of het ook geld voor de S1155
These are our server systems based on Core i3 and Xeon 3400 series socket 1156 CPUs with up to 32GB memory.
The dual core CPUs here support ECC, unregistered memory only. Please choose the type of memory according to the CPU selected.
Maar kijk het nog even na...
Precies, maar of dat dus voor 1155 werkt, geen idee... Iemand?
Even niets...
Het staat ook in de datasheets van de cpu's, hieronder voor Socket 1156 resp 1155:
Intel® Core™ i5-600, i3-500 Desktop Processor Series and Intel® Pentium® Processor G6950 Series Datasheet, Volume 1
Intel® Core™ i5-600, i3-500 Desktop Processor Series and Intel® Pentium® Processor G6950 Series Datasheet, Volume 1
2nd Generation Intel® Core™ Processor Family Desktop Datasheet, Vol. 1The type of memory supported by the processor is dependent on the Intel 5 Series
Chipset SKU in the target platform:
— Desktop Intel 5 Series Chipset platforms only support non-ECC unbuffered
DIMMs and do not support any memory configuration that mixes non-ECC with
ECC unbuffered DIMMs
— Workstation Intel 3400 Series Chipset platforms support ECC and non-ECC
unbuffered DIMMs. The platforms do Not support any memory configuration
that mix non-ECC with ECC unbuffered DIMMs
The type of memory supported by the processor is dependent on the PCH SKU in
the target platform
— Desktop PCH platforms support non-ECC un-buffered DIMMs only
• Desktop PCH platform DDR3 DIMM Modules
— Raw Card A - Single Ranked x8 unbuffered non-ECC
— Raw Card B - Dual Ranked x8 unbuffered non-ECC
— Raw Card C - Single Ranked x16 unbuffered non-ECC
• Advanced Server/Workstation PCH platforms DDR3 DIMM Modules:
— Raw Card A - Single Ranked x8 unbuffered non-ECC
— Raw Card B - Dual Ranked x8 unbuffered non-ECC
— Raw Card C - Single Ranked x16 unbuffered non-ECC
— Raw Card D - Single Ranked x8 unbuffered ECC
— Raw Card E - Dual Ranked x8 unbuffered ECC
• Essential/Standard Server PCH platforms DDR3 DIMM Modules:
— Raw Card D - Single Ranked x8 unbuffered ECC
— Raw Card E - Dual Ranked x8 unbuffered ECC
Wel ECC dus.
Even niets...
- Waking_The_Dead
- Registratie: Januari 2010
- Laatst online: 04-07-2024
/u/342733/wtd_s.png?f=community)
Ik moet toegeven dat ik nog maar tot pagina 23 van deze topic gelezen heb, dus als een van mijn vragen al aan bod geweest is, mijn excuses.
Ik wil een dedicated video-NAS. Niets meer dan dat. Geen download managers, geen virtuele servers, geen fancy stuff. Gewoon pure opslag voor al mijn BD/DVD ISO's en divx bestanden. Momenteel heb ik een Synology DS211+ waar al mijn bestanden op staan. Die is echter vrij snel vol geraakt doordat ik begonnen ben met al mijn Blu Rays te rippen. Ik wil dus al mijn videomateriaal naar een dedicated NAS verhuizen.
De bedoeling is dat die NAS via WOL wordt wakker gemaakt door mijn mediaplayer en dat die na x aantal minuten inactiviteit gewoon weer uitschakelt. Mijn mediaplayer heeft een 100Mbit aansluiting, dus ik veronderstel dat als er een bottleneck zou zijn, de mediaplayer de bottleneck is en niet eender welk onderdeel van de toekomstige NAS.
Nu ben ik door dit topic overtuigd om ZFS te proberen en lijkt me dat sowieso een leuk projectje (jammer genoeg zijn de HDD prijzen net de lucht in geschoten maar dat geeft me meer tijd om wat extra onderzoek te doen).
Initieel had ik gedacht om zes schijven in RAID-Z2 te zetten. Maar toen dacht ik: 6 schijven die draaien om naar een film te kijken? Dat kan toch beter. Dus, waarom niet twee keer drie schijven in RAID-Z1... Dan moeten er maar drie schijven draaien als ik een film bekijk en dat scheelt weer wat stroomverbruik. Dan zet ik films en series gewoon op aparte volumes (of wat is de exacte benaming nu juist?). Dat is ook wat flexibeler als ik wil uitbreiden. Drie 2TB door 3TB modellen vervangen is een lagere drempel dan ineens zes schijven te moeten vervangen.
Nu ben ik mezelf ook de vraag gaan stellen: hoef ik eigenlijk wel redundantie? Als er een schijf crasht, dan zal ik wel eens luid vloeken, maar ik kan gerust alle verloren ISO's opnieuw rippen. Nu ja, in dat geval moet ik wel zo'n 50 schijfjes opnieuw rippen. Maar als in een RAID-Z1 twee van de drie schijven uitvallen, moet ik ook 100 schijfjes opnieuw rippen.... Bovendien heeft deze aanpak het voordeel dat ik gewoon een losse schijf kan bijplaatsen als ik plaats te kort kom.
Stel dat ik nu voor de niet-redundante oplossing ga, heeft het dan eigenlijk nog nut om voor ZFS te gaan?
En is het via ZFS ook mogelijk om een soort symbolic links naar directories te maken? Concreet zou ik dan een SSD gebruiken als bootschijf. Het zou handig zijn als ik daarop een folder "video" aanmaak en dan vanop mijn mediaplayer enkel die ene video-folder moet mappen. Die folder zou dan via symbolic links (of iets gelijkaardigs) moeten doorverwijzen naar de inhoud van alle andere schijven. Kan dit?
Ik wil een dedicated video-NAS. Niets meer dan dat. Geen download managers, geen virtuele servers, geen fancy stuff. Gewoon pure opslag voor al mijn BD/DVD ISO's en divx bestanden. Momenteel heb ik een Synology DS211+ waar al mijn bestanden op staan. Die is echter vrij snel vol geraakt doordat ik begonnen ben met al mijn Blu Rays te rippen. Ik wil dus al mijn videomateriaal naar een dedicated NAS verhuizen.
De bedoeling is dat die NAS via WOL wordt wakker gemaakt door mijn mediaplayer en dat die na x aantal minuten inactiviteit gewoon weer uitschakelt. Mijn mediaplayer heeft een 100Mbit aansluiting, dus ik veronderstel dat als er een bottleneck zou zijn, de mediaplayer de bottleneck is en niet eender welk onderdeel van de toekomstige NAS.
Nu ben ik door dit topic overtuigd om ZFS te proberen en lijkt me dat sowieso een leuk projectje (jammer genoeg zijn de HDD prijzen net de lucht in geschoten maar dat geeft me meer tijd om wat extra onderzoek te doen).
Initieel had ik gedacht om zes schijven in RAID-Z2 te zetten. Maar toen dacht ik: 6 schijven die draaien om naar een film te kijken? Dat kan toch beter. Dus, waarom niet twee keer drie schijven in RAID-Z1... Dan moeten er maar drie schijven draaien als ik een film bekijk en dat scheelt weer wat stroomverbruik. Dan zet ik films en series gewoon op aparte volumes (of wat is de exacte benaming nu juist?). Dat is ook wat flexibeler als ik wil uitbreiden. Drie 2TB door 3TB modellen vervangen is een lagere drempel dan ineens zes schijven te moeten vervangen.
Nu ben ik mezelf ook de vraag gaan stellen: hoef ik eigenlijk wel redundantie? Als er een schijf crasht, dan zal ik wel eens luid vloeken, maar ik kan gerust alle verloren ISO's opnieuw rippen. Nu ja, in dat geval moet ik wel zo'n 50 schijfjes opnieuw rippen. Maar als in een RAID-Z1 twee van de drie schijven uitvallen, moet ik ook 100 schijfjes opnieuw rippen.... Bovendien heeft deze aanpak het voordeel dat ik gewoon een losse schijf kan bijplaatsen als ik plaats te kort kom.
Stel dat ik nu voor de niet-redundante oplossing ga, heeft het dan eigenlijk nog nut om voor ZFS te gaan?
En is het via ZFS ook mogelijk om een soort symbolic links naar directories te maken? Concreet zou ik dan een SSD gebruiken als bootschijf. Het zou handig zijn als ik daarop een folder "video" aanmaak en dan vanop mijn mediaplayer enkel die ene video-folder moet mappen. Die folder zou dan via symbolic links (of iets gelijkaardigs) moeten doorverwijzen naar de inhoud van alle andere schijven. Kan dit?
26 pagina's maar? 
Dat Wake-on-LAN zal wel lukken, maar hoe wil je precies 'uitschakelen na x minuten inactiviteit' implementeren? Dat lijkt me toch wat lastiger. Waar gaat het je precies om, lawaai of stroomverbruik?
Dan je schijven, je kunt allerlei dingen overwegen. Als het je om stroomverbruik gaat, kun je ook notebookschijven overwegen, zoals de nieuwe Samsung M8 1TB schijf, die is 70 euro bij komplett en is niet gestegen in prijs. Dus kan een prima koop zijn met slechts 0.58W idle power. Dat is echt heel erg laag! Dan kun je prima 2 of 3 van die schijfjes in een RAID0 gebruiken voor je actieve data array die altijd draait. Eventueel grotere (en goedkoper-per-TB) desktopschijven gebruik je dan met spindown, die wel redundant zijn zoals een RAID-Z en dus als backup dienen. Wel iets duurder deze setup, maar wel lekker zuinig.
Dan je vraag, heeft ZFS wel zin. Nouja ZFS heeft natuurlijk heel veel voordelen. Een van die voordelen is dat je geen gezeik met RAID layers hebt en ZFS eigenlijk alle problemen automatisch oplost. Mocht er corruptie zijn en door je RAID0 kun je dat niet oplossen, dan weet je precies welke bestanden. Dus nooit meer 'silent corruption' is wel een groot voordeel vind ik. Gewoon iets wat werkt, zonder gezeik of rare dingen, zoals met traditioneel RAID nog vrij vaak voorkomt.
Symbolic links, ja je kunt gewoon symlinken. Weet niet precies wat je bedoelt maar bijvoorbeeld ik heb een HDD pool met Samba beschikbaar gemaakt en één folder wijst 'stiekem' naar mijn SSD pool, voor zaken als Virtual Machine images en andere dingen die ik extra snel wil hebben qua random access. Is dat wat je bedoelt? Symlinks werken eigenlijk op alle unices.
Weet je al wat voor hardware en software je wilt draaien? Als je low-power wilt, kun je kijken naar Brazos platform met PicoPSU. Ook geheel stil zonder fans, wat ook een groot voordeel is vind ik.
Dat Wake-on-LAN zal wel lukken, maar hoe wil je precies 'uitschakelen na x minuten inactiviteit' implementeren? Dat lijkt me toch wat lastiger. Waar gaat het je precies om, lawaai of stroomverbruik?
Dan je schijven, je kunt allerlei dingen overwegen. Als het je om stroomverbruik gaat, kun je ook notebookschijven overwegen, zoals de nieuwe Samsung M8 1TB schijf, die is 70 euro bij komplett en is niet gestegen in prijs. Dus kan een prima koop zijn met slechts 0.58W idle power. Dat is echt heel erg laag! Dan kun je prima 2 of 3 van die schijfjes in een RAID0 gebruiken voor je actieve data array die altijd draait. Eventueel grotere (en goedkoper-per-TB) desktopschijven gebruik je dan met spindown, die wel redundant zijn zoals een RAID-Z en dus als backup dienen. Wel iets duurder deze setup, maar wel lekker zuinig.
Dan je vraag, heeft ZFS wel zin. Nouja ZFS heeft natuurlijk heel veel voordelen. Een van die voordelen is dat je geen gezeik met RAID layers hebt en ZFS eigenlijk alle problemen automatisch oplost. Mocht er corruptie zijn en door je RAID0 kun je dat niet oplossen, dan weet je precies welke bestanden. Dus nooit meer 'silent corruption' is wel een groot voordeel vind ik. Gewoon iets wat werkt, zonder gezeik of rare dingen, zoals met traditioneel RAID nog vrij vaak voorkomt.
Symbolic links, ja je kunt gewoon symlinken. Weet niet precies wat je bedoelt maar bijvoorbeeld ik heb een HDD pool met Samba beschikbaar gemaakt en één folder wijst 'stiekem' naar mijn SSD pool, voor zaken als Virtual Machine images en andere dingen die ik extra snel wil hebben qua random access. Is dat wat je bedoelt? Symlinks werken eigenlijk op alle unices.
Weet je al wat voor hardware en software je wilt draaien? Als je low-power wilt, kun je kijken naar Brazos platform met PicoPSU. Ook geheel stil zonder fans, wat ook een groot voordeel is vind ik.
- Waking_The_Dead
- Registratie: Januari 2010
- Laatst online: 04-07-2024
Ik zit ondertussen aan pagina 40 
Het gaat mij vooral om stroomverbruik. De NAS zou echt enkel maar dienen om naar films of series te kijken. Dus als de film gedaan is, mag hij gewoon uit. De NAS komt in de berging, dus geluid is geen issue maar het zou dus wel handig zijn als hij gewoon automatisch uit gaat zodat ik niet naar de berging hoef.
Het moeten niet perse laptop schijven zijn, gewone desktop schijven volstaan voor mij wat stroomverbruik betreft. Maar ik vind het gewoon zonde dat er 6 schijven moeten draaien als ik gewoon een filmpje wil kijken.
Zie je een voordeel van een 6-disk RAID-Z2 configuratie t.o.v. een configuratie met twee 3-disk RAID-Z1 arrays?
Qua hardware weet ik het nog allemaal niet zo goed. Ik heb nog een oude Lian-Li kast waar ik een heel pak schijven in kwijt kan. Verder twijfel ik nog tussen een PicoPSU of een 80+ 300W PSU. Ik veronderstel dat theoretisch gezien een PicoPSU wel 6 schijven moet kunnen aansturen maar is dat ook zo in de praktijk?
Hoe zit het met RAM? Ik heb begrepen dat je daar nooit teveel kunt van hebben in een ZFS server, maar ga ik daar iets van merken als ik enkel maar films stream? Zou een atom CPU volstaan? Per slot van rekening moet die NAS eigenlijk helemaal niets doen behalve ISO's ter beschikking stellen (en ZFS aansturen uiteraard). Op mijn mediaplayer kan ik netwerkschijven mounten en het is de mediaplayer die alle decodeerwerk verricht.
Het enige wat mij nog een beetje tegenhoudt op ZFS gebied is de relatief beperkte uitbreidingsmogelijkheid wat schijven betreft.
Het gaat mij vooral om stroomverbruik. De NAS zou echt enkel maar dienen om naar films of series te kijken. Dus als de film gedaan is, mag hij gewoon uit. De NAS komt in de berging, dus geluid is geen issue maar het zou dus wel handig zijn als hij gewoon automatisch uit gaat zodat ik niet naar de berging hoef.
Het moeten niet perse laptop schijven zijn, gewone desktop schijven volstaan voor mij wat stroomverbruik betreft. Maar ik vind het gewoon zonde dat er 6 schijven moeten draaien als ik gewoon een filmpje wil kijken.
Zie je een voordeel van een 6-disk RAID-Z2 configuratie t.o.v. een configuratie met twee 3-disk RAID-Z1 arrays?
Qua hardware weet ik het nog allemaal niet zo goed. Ik heb nog een oude Lian-Li kast waar ik een heel pak schijven in kwijt kan. Verder twijfel ik nog tussen een PicoPSU of een 80+ 300W PSU. Ik veronderstel dat theoretisch gezien een PicoPSU wel 6 schijven moet kunnen aansturen maar is dat ook zo in de praktijk?
Hoe zit het met RAM? Ik heb begrepen dat je daar nooit teveel kunt van hebben in een ZFS server, maar ga ik daar iets van merken als ik enkel maar films stream? Zou een atom CPU volstaan? Per slot van rekening moet die NAS eigenlijk helemaal niets doen behalve ISO's ter beschikking stellen (en ZFS aansturen uiteraard). Op mijn mediaplayer kan ik netwerkschijven mounten en het is de mediaplayer die alle decodeerwerk verricht.
Het enige wat mij nog een beetje tegenhoudt op ZFS gebied is de relatief beperkte uitbreidingsmogelijkheid wat schijven betreft.
[ Voor 5% gewijzigd door Waking_The_Dead op 26-10-2011 20:15 ]
Automatisch uitschakelen zou ik niet weten hoe je dat zou moeten doen; dan zou je of netwerkverkeer of Samba-aanvragen in de gaten moeten houden. Ik heb hier nog nooit van gehoord; dus kan je hier niet bij helpen.
Je kunt natuurlijk wel een systeem zo zuinig maken dat hij eigenlijk niet uit hoeft. Als je begint met een heel zuinig Brazos systeem van rond de 10W dan hoef je ook niet verlegen te zitten om hem continu te laten draaien (20 euro stroomkosten per jaar bij 24/7 gebruik). Die 10W is dan wel excl. schijven en gebaseerd op het zuinige MSI bordje.
Maar je kunt ook meerdere arrays maken. Stel bijvoorbeeld je neemt twee notebookschijven van 1TB en zet die in een RAID0. Dan heb je 2TB onbeveiligde storage met notebookdisks maar wel heel zuinig (1,16W). Je kunt dan een hoofdarray maken met RAID-Z met 2TB desktopschijven: meer opslag maar hoeft niet altijd actief te zijn. Je kunt spindown automatisch instellen zodat de schijven automatisch na 15 minuten inactiviteit downspinnen, terwijl je je films en andere actieve data gewoon op je notebook HDD pool houdt.
Met zo'n setup heb je dus:
1) lage idle power
2) wel de opslag en prijs van desktopschijven
3) ook beveiliging (redundancy) op je desktop HDD pool
Een 6-disk RAID-Z2 is natuurlijk veel veiliger dan 2x 3 disks in RAID-Z, omdat je gegarandeerd twee disk failures kunt hebben. Of één failure + uBER (bad sectors).
PicoPSU kan prima met notebook disks, met desktopschijven moet je oppassen want dat wordt krap. Maar je kunt een eind komen hoor, met een 150W adapter zoals te koop bij Informatique voor rond de 75 euro (inclusief PicoPSU 150W). De Samsung F4EG verbruikt zo'n 16W spinup, notebook disks zo'n 4W. Dus je kunt:
Brazos systeem = 25W piek
2x notebook disks = 8W spinup (2x4)
6x Samsung F4EG disks = 96W spinup (6x16)
= totaal 129W piek vermogen.
Nu heeft de PicoPSU een beperkte +5V lijn, maar ik heb uitgerekend dat je daar lang niet aan komt met 6 schijven spinup.
Blijft wel de vraag hoe je 6+2 disks gaat inbouwen; je kunt wellicht een Silicon Image PCI-express x1 controller gebruiken, voor 2 extra poorten voor je notebook disks.
Oh en Intel Atom moet je niet doen; geen enkele reden voor. Hoog idle energieverbruik, geen goede PCI-express en SATA connectiviteit, max 4GB RAM en simpelweg een verouderd platform. Brazos = 10x sexier.
Je kunt natuurlijk wel een systeem zo zuinig maken dat hij eigenlijk niet uit hoeft. Als je begint met een heel zuinig Brazos systeem van rond de 10W dan hoef je ook niet verlegen te zitten om hem continu te laten draaien (20 euro stroomkosten per jaar bij 24/7 gebruik). Die 10W is dan wel excl. schijven en gebaseerd op het zuinige MSI bordje.
Desktopschijven op 5400rpm (green) verbruiken nog altijd bijna 8 keer zoveel stroom als notebookschijven. Samsung M8 1TB doet 0,58W idle en Samsung F4EG en andere groene desktopschijven zitten rond de 4W. Dus dat maakt wel verschil.Het moeten niet perse laptop schijven zijn, gewone desktop schijven volstaan voor mij wat stroomverbruik betreft. Maar ik vind het gewoon zonde dat er 6 schijven moeten draaien als ik gewoon een filmpje wil kijken.
Maar je kunt ook meerdere arrays maken. Stel bijvoorbeeld je neemt twee notebookschijven van 1TB en zet die in een RAID0. Dan heb je 2TB onbeveiligde storage met notebookdisks maar wel heel zuinig (1,16W). Je kunt dan een hoofdarray maken met RAID-Z met 2TB desktopschijven: meer opslag maar hoeft niet altijd actief te zijn. Je kunt spindown automatisch instellen zodat de schijven automatisch na 15 minuten inactiviteit downspinnen, terwijl je je films en andere actieve data gewoon op je notebook HDD pool houdt.
Met zo'n setup heb je dus:
1) lage idle power
2) wel de opslag en prijs van desktopschijven
3) ook beveiliging (redundancy) op je desktop HDD pool
Een 6-disk RAID-Z2 is natuurlijk veel veiliger dan 2x 3 disks in RAID-Z, omdat je gegarandeerd twee disk failures kunt hebben. Of één failure + uBER (bad sectors).
PicoPSU kan prima met notebook disks, met desktopschijven moet je oppassen want dat wordt krap. Maar je kunt een eind komen hoor, met een 150W adapter zoals te koop bij Informatique voor rond de 75 euro (inclusief PicoPSU 150W). De Samsung F4EG verbruikt zo'n 16W spinup, notebook disks zo'n 4W. Dus je kunt:
Brazos systeem = 25W piek
2x notebook disks = 8W spinup (2x4)
6x Samsung F4EG disks = 96W spinup (6x16)
= totaal 129W piek vermogen.
Nu heeft de PicoPSU een beperkte +5V lijn, maar ik heb uitgerekend dat je daar lang niet aan komt met 6 schijven spinup.
Blijft wel de vraag hoe je 6+2 disks gaat inbouwen; je kunt wellicht een Silicon Image PCI-express x1 controller gebruiken, voor 2 extra poorten voor je notebook disks.
Oh en Intel Atom moet je niet doen; geen enkele reden voor. Hoog idle energieverbruik, geen goede PCI-express en SATA connectiviteit, max 4GB RAM en simpelweg een verouderd platform. Brazos = 10x sexier.
[ Voor 3% gewijzigd door Verwijderd op 27-10-2011 09:25 ]
- Waking_The_Dead
- Registratie: Januari 2010
- Laatst online: 04-07-2024
Ondertussen volledig doorgelezen.... 
Bedankt voor de uitgebreide uitleg. Allen snap ik niet goed waarom je die extra notebookschijven in het verhaal blijft betrekken. Zou je die gebruiken om het OS op te zetten? En waarom 2 schijven? Als die crasht, kan ik dan niet gewoon het OS opnieuw installeren en klaar is Kees? Of zie ik het een beetje te simpel?
Ik had eerder gedacht om eventueel een 60 GiB Vertex 2 SSD te hergebruiken en daar het OS op te zetten. Die zit nu in mijn PC maar wordt wat krap dus ik wil die op termijn vervangen door een Crucial M4 128 of iets dergelijks.
De hoofdreden om voor de dubbele vdev configuratie te gaan, is grotere flexibiliteit naar uitbreiding toe. Als ik meer opslag nodig heb, dan zijn 3 schijven sneller vervangen door grotere modellen dan 6 schijven. Als ik dan nog meer opslag nodig heb, worden de 3 andere schijven vervangen en zijn de nieuwe schijven tegen die tijd (behoudens overstromingen en moesson regens) toch weer een pak gedaald in prijs.
Een bijkomende reden om voor de 2x3RAIDZ1 config te gaan, is verbruik. Maar goed, dat gaat in principe niet veel schelen als de schijven maar een paar uur per week actief zijn. Per slot van rekening zal ik wellicht meer stroom verbruiken als ik 100 BD schijfjes opnieuw moet rippen.
Maar even ter verificatie om te zien of ik alles wel goed begrepen heb: als ik het stroomverbruik als argument in rekening zou brengen, dan zou ik die twee vdev's ook in aparte pools moeten steken, juist? Als ze in dezelfde pool hangen, is het dan zo dat beide vdev's in gebruik zijn omdat ze gestriped worden? Dat is dan precies wat ik dan niet wil omdat er dan ook 6 schijven in gebruik zijn.
Ondertussen ga ik me eens in dat Brazos verhaal verdiepen
Bedankt voor de uitgebreide uitleg. Allen snap ik niet goed waarom je die extra notebookschijven in het verhaal blijft betrekken. Zou je die gebruiken om het OS op te zetten? En waarom 2 schijven? Als die crasht, kan ik dan niet gewoon het OS opnieuw installeren en klaar is Kees? Of zie ik het een beetje te simpel?
Ik had eerder gedacht om eventueel een 60 GiB Vertex 2 SSD te hergebruiken en daar het OS op te zetten. Die zit nu in mijn PC maar wordt wat krap dus ik wil die op termijn vervangen door een Crucial M4 128 of iets dergelijks.
De hoofdreden om voor de dubbele vdev configuratie te gaan, is grotere flexibiliteit naar uitbreiding toe. Als ik meer opslag nodig heb, dan zijn 3 schijven sneller vervangen door grotere modellen dan 6 schijven. Als ik dan nog meer opslag nodig heb, worden de 3 andere schijven vervangen en zijn de nieuwe schijven tegen die tijd (behoudens overstromingen en moesson regens) toch weer een pak gedaald in prijs.
Een bijkomende reden om voor de 2x3RAIDZ1 config te gaan, is verbruik. Maar goed, dat gaat in principe niet veel schelen als de schijven maar een paar uur per week actief zijn. Per slot van rekening zal ik wellicht meer stroom verbruiken als ik 100 BD schijfjes opnieuw moet rippen.
Maar even ter verificatie om te zien of ik alles wel goed begrepen heb: als ik het stroomverbruik als argument in rekening zou brengen, dan zou ik die twee vdev's ook in aparte pools moeten steken, juist? Als ze in dezelfde pool hangen, is het dan zo dat beide vdev's in gebruik zijn omdat ze gestriped worden? Dat is dan precies wat ik dan niet wil omdat er dan ook 6 schijven in gebruik zijn.
Ondertussen ga ik me eens in dat Brazos verhaal verdiepen
- Bierkameel
- Registratie: December 2000
- Niet online
I use Debian btw
:strip_exif()/u/16970/crop57cd1ef1eb0d0.gif?f=community)
Niet helemaal mee eens, ik heb zelf een Supermicro X7SPA-H-D525 met 2 x Intel GB, 6 x SATA en een PCIE 4x slot, en bovendien IPMI wat voor een servertje erg handig is, passief gekoelt en erg zuinig.Verwijderd schreef op donderdag 27 oktober 2011 @ 09:24:
Oh en Intel Atom moet je niet doen; geen enkele reden voor. Hoog idle energieverbruik, geen goede PCI-express en SATA connectiviteit, max 4GB RAM en simpelweg een verouderd platform. Brazos = 10x sexier.
Alle proemn in n drek
- Dadona
- Registratie: September 2007
- Laatst online: 17-07 23:16
Dat moederbord en de D945GSEJT waren naar mijn mening de enige interessante Atom borden. Maar de D945GSEJT is nu toch echt overklast door Brazos. De Supermicro blijft leuk vanwege de NICs en IPMI, maar is a ) niet goed leverbaar b ) te duur c ) qua energieverbruik toch de mindere.
Wil je de SATA poorten behouden dan is de Asus E35M1-I interessant. (Sowieso vanwege het mooie koelblok) Alleen jammer dat je waarschijnlijk ECC modules niet kunt benutten, ze draaien in non-ecc mode denk ik.
Wil je de SATA poorten behouden dan is de Asus E35M1-I interessant. (Sowieso vanwege het mooie koelblok) Alleen jammer dat je waarschijnlijk ECC modules niet kunt benutten, ze draaien in non-ecc mode denk ik.
SuperMicro maakt leuk spul, maar Intel Atom is expres gecastreerd door Intel en dat maakt het voor ZFS niet zo'n heel interessant platform.Bierkameel schreef op donderdag 27 oktober 2011 @ 10:28:
Niet helemaal mee eens, ik heb zelf een Supermicro X7SPA-H-D525 met 2 x Intel GB, 6 x SATA en een PCIE 4x slot, en bovendien IPMI wat voor een servertje erg handig is, passief gekoelt en erg zuinig.
Atom beperkingen:
- PCI-express 1.0 ipv 2.0
- maximaal 4GiB geheugen; terwijl ZFS op FreeBSD pas lekker werkt vanaf 8GiB; Brazos kan 16GiB (2x8GiB) aan
- met de US15W chipset beperkt aantal SATA poorten; dat SuperMicro bord gebruikt wel een ICH9R wat natuurlijk beter is
- lagere performance dan Brazos (hoeveel weet ik niet precies; maar mogelijk heeft Brazos meer geheugenbandbreedte wat voor ZFS wel uit kan maken)
- last but not least: bijna het dubbele idle power, alhoewel je een PicoPSU moet gebruiken om dat te zien; met een normale voeding is het verschil veel kleiner.


Bron: http://techreport.com/articles.x/20401/5
Met een zuinig Brazos bordje kun je mogelijk nog extremere verschillen zien. SuperMicro maakt overigens meestal wel zuinig spul, alleen jammer dat ze geen/nauwelijks AMD spul doen een Brazos-versie van dat mobo wat je noemt zou echt wel gaaf zijn.
Die heb ik ja; 8,9W is het laagste waar ik aan kwam onder Ubuntu. Wel zonder HDD, DVD, SATA, netwerk en CPU fan. Die fan alleen al verbruikt 0,9W!FireDrunk schreef op donderdag 27 oktober 2011 @ 10:39:
Bedoel je deze?
pricewatch: MSI E350IA-E45
Beetje jammer van het fannetje
MSI maakt wel zuinig spul dus dit kan best wel eens het meest zuinige bordje zijn. Nu draai ik met 2 HDDs en gigabit en fan en 8GiB RAM op zo'n 14,1W, nog steeds erg netjes vind ik.
Maar die fan wil ik wel vervangen. Het liefst door een groter heatsink met Arctic Thermal Adhesive, dus lijm die fixeert zodat je geen klemmetjes enzo nodig hebt. Hopelijk gaat dat werken, dan zou ik een heel zuinig passief gekoeld systeem hebben.
Overigens: een Core i3 2100T kan ook superzuinig zijn met het juiste moederbord en PicoPSU, dus dat kan ook een optie zijn. Wel iets hoger piekverbruik wat uitmaakt voor PicoPSU en de hoeveelheid schijven dat je erop kunt aansluiten, maar Core i3 heeft wel betere performance, meer PCIe uitbreidingsmogelijkheden en een moderner platform. Maar ook wel duurder natuurlijk.
[ Voor 6% gewijzigd door Verwijderd op 27-10-2011 11:06 ]
Is het fannetje wel nodig bij 14W idle verbruik?
Even niets...
- Dadona
- Registratie: September 2007
- Laatst online: 17-07 23:16
Je moet het platform vergelijken, niet alleen de processor. De Atom is nog niet zo slecht, het probleem is dat er vaak draken van chipsets naast zijn gezet. Ook de Supermicro lijkt mij niet de meest zuinige versie te hebben.
Zijn er uberhaupt moederborden die dan wel in de richting komen? (met Atom's)
Even niets...
Helaas wel ja, vooral omdat de heatsink voor de CPU echt heel erg klein is en volgens mij ook van goedkoop materiaal. Dat is wel jammer want Asus heeft Brazos bordjes met goede passieve koeling. Maar ik dacht dat kan ik altijd achteraf nog vervangen.FireDrunk schreef op donderdag 27 oktober 2011 @ 11:41:
Is het fannetje wel nodig bij 14W idle verbruik?
Met de fan disconnecten en helemaal idle loopt de temperatuur toch erg snel op. Logisch ook wel, 2W verbruik kan al oververhitting betekenen. De heatsink van de southbridge wordt totaal niet warm; volgens mij verbruikt de southbridge ook geen drol in idle. Ik schat zo'n 0,3 tot 0,5W. De heatsink van de CPU is niet veel groter dan de heatsink van de southbridge. Mooier was geweest als ze een gecombineerde heatsink voor zowel CPU als southbridge hadden gemaakt.
Maar daar heeft AMD dus vaak het voordeel door zuinige chipsets, iets waar Intel zeker in het verleden erg mee achterliep. Zo kun je je vast nog de oude atoms herinneren. 1W-2W verbruik maar de chipset verbruikte 25W ofzo.Dadona schreef op donderdag 27 oktober 2011 @ 11:53:
Je moet het platform vergelijken, niet alleen de processor. De Atom is nog niet zo slecht, het probleem is dat er vaak draken van chipsets naast zijn gezet. Ook de Supermicro lijkt mij niet de meest zuinige versie te hebben.
SuperMicro lijkt juist hele zuinige bordjes te maken; waarom denk je dat die juist niet zuinig zijn? Je moet uiteraard wel de extra functionaliteit meerekenen, bijvoorbeeld de ICH9R southbridge en dual gigabit en soms IPMI chip. Ook de H67 bordjes van SuperMicro hebben een hele kleine heatsink; dat betekent bijna automatisch al dat ze heel erg zuinig zijn. SuperMicro hoeft ook geen zware componenten voor overclocking te gebruiken enzo. Want vrijwel alle retailborden zijn gemaakt voor enthusiasts die niets geven om zuinigheid maar veel willen overclocken en wat niet al... voor mensen op zoek naar een zuinige thuisserver is er héél weinig keuze.
Verwijderd
Cipher wat ik een beetje vreemdt vind dat je een bordtje gebruikt zonder ecc. Is het een just for fun setup?
ECC wordt niet ondersteund door Brazos en Llano, dus je bent bij AMD op ouderwetse chips aangewezen. Voor bulldozer zijn geen zuinige bordjes beschikbaar. Dus dan kun je nog Intel overwegen.
Maar heb je wel echt ECC nodig? Het is leuk om het helemaal goed te doen en ook dat laatste beetje onveiligheid uit te sluiten met ECC geheugen. Maar voor mezelf: ik gebruik zfs send/receive dus ook geheugenfouten kunnen backups tussen servers niet corrumperen. Bij geheugenfouten merk je dat snel genoeg en ZFS kan meestal alle geheugenfouten corrigeren. Je ziet dan veel checksum errors op je disks voorbij komen, terwijl het in feite om memory corruption gaat.
In mijn geval: ik heb 2 ZFS servers één main en één backup. Dus ik ben niet zo bang voor gegevensverlies. Daarnaast nog écht belangrijke zaken op een off-site locatie. Dus mij kan niets gebeuren, wereldrampen uitgezonderd.
Ik ben voorstander van ECC, ook op de desktop voor consumenten. Geheugenfouten is gewoon iets wat je wilt uitsluiten omdat de gevolgen groot kunnen zijn en je vrijwel onmogelijk kunt aantonen dat het om geheugencorruptie ging tenzij je geheugen helemaal brak is met 1000 fouten per seconde in MemTest86+. Maar de vervelende realiteit is dat fabrikanten van moederborden en processors ECC graag voor hun serverproducten exclusief willen houden, om er zo flink aan te kunnen verdienen. De ECC support is zeker niet universeel.
Ook is het mij onduidelijk hoe de ECC support op consumentenprocessors van Intel nou werkt. Elke keer dat ik dacht dat ik het snapte, blijkt het toch weer anders te zijn. ECC supported kan betekenen dat je ECC geheugen wel werkt maar zonder de ECC bescherming. ECC unsupported kan betekenen dat geen ECC bescherming hebt, maar je ECC geheugen als normaal unbuffered non-ECC functioneert. Het is te onduidelijk en vaag om voor mij duidelijk te onthouden welke consumentenhardware nu ECC ondersteunen. Registered geheugen zit ik ook niet op te wachten; ik wil zuinige hardware met 1.25V geheugen en zie maar eens een combinatie te vinden van zuinig met ECC; het zijn twee verschillende werelden. Immers in een datacentrum betaal je vaak niet voor stroom met als gevolg dat serverhardware vaak niet erg zuinig is. Althans dat is mijn eigen indruk; Google enzo zal wel veel meer naar stroom(kosten) kijken.
Maar heb je wel echt ECC nodig? Het is leuk om het helemaal goed te doen en ook dat laatste beetje onveiligheid uit te sluiten met ECC geheugen. Maar voor mezelf: ik gebruik zfs send/receive dus ook geheugenfouten kunnen backups tussen servers niet corrumperen. Bij geheugenfouten merk je dat snel genoeg en ZFS kan meestal alle geheugenfouten corrigeren. Je ziet dan veel checksum errors op je disks voorbij komen, terwijl het in feite om memory corruption gaat.
In mijn geval: ik heb 2 ZFS servers één main en één backup. Dus ik ben niet zo bang voor gegevensverlies. Daarnaast nog écht belangrijke zaken op een off-site locatie. Dus mij kan niets gebeuren, wereldrampen uitgezonderd.
Ik ben voorstander van ECC, ook op de desktop voor consumenten. Geheugenfouten is gewoon iets wat je wilt uitsluiten omdat de gevolgen groot kunnen zijn en je vrijwel onmogelijk kunt aantonen dat het om geheugencorruptie ging tenzij je geheugen helemaal brak is met 1000 fouten per seconde in MemTest86+. Maar de vervelende realiteit is dat fabrikanten van moederborden en processors ECC graag voor hun serverproducten exclusief willen houden, om er zo flink aan te kunnen verdienen. De ECC support is zeker niet universeel.
Ook is het mij onduidelijk hoe de ECC support op consumentenprocessors van Intel nou werkt. Elke keer dat ik dacht dat ik het snapte, blijkt het toch weer anders te zijn. ECC supported kan betekenen dat je ECC geheugen wel werkt maar zonder de ECC bescherming. ECC unsupported kan betekenen dat geen ECC bescherming hebt, maar je ECC geheugen als normaal unbuffered non-ECC functioneert. Het is te onduidelijk en vaag om voor mij duidelijk te onthouden welke consumentenhardware nu ECC ondersteunen. Registered geheugen zit ik ook niet op te wachten; ik wil zuinige hardware met 1.25V geheugen en zie maar eens een combinatie te vinden van zuinig met ECC; het zijn twee verschillende werelden. Immers in een datacentrum betaal je vaak niet voor stroom met als gevolg dat serverhardware vaak niet erg zuinig is. Althans dat is mijn eigen indruk; Google enzo zal wel veel meer naar stroom(kosten) kijken.
- Waking_The_Dead
- Registratie: Januari 2010
- Laatst online: 04-07-2024
Ik denk dat ik hiermee maar eens aan de slag ga:
Ik heb nog een oude Lian-Li case waar alles in kan en nog wat oude schijven om eerst eens grondig te testen (in afwachting van een prijsdaling van grote HDD's).
CiPHER, kan je misschien nog eens uitleggen wat de bedoeling van die twee laptop schijven is? Nu ik je post herlees, zeg je dat ik daar mijn films kan opzetten. Dat is echter niet de bedoeling: ik heb momenteel 3,5TiB aan ISO's en mijn collectie is nog niet volledig geript, dus die wil ik echt wel op desktop schijven zetten.
| # | Product | Prijs | Subtotaal |
| 1 | Asus E35M1-I | € 94,95 | € 94,95 |
| 1 | Huntkey Jumper 300G | € 54,95 | € 54,95 |
| 1 | Transcend 8GB DDR3 Dual/Triple Channel Kit | € 35,06 | € 35,06 |
| Bekijk collectie Importeer producten | Totaal | € 184,96 | |
Ik heb nog een oude Lian-Li case waar alles in kan en nog wat oude schijven om eerst eens grondig te testen (in afwachting van een prijsdaling van grote HDD's).
CiPHER, kan je misschien nog eens uitleggen wat de bedoeling van die twee laptop schijven is? Nu ik je post herlees, zeg je dat ik daar mijn films kan opzetten. Dat is echter niet de bedoeling: ik heb momenteel 3,5TiB aan ISO's en mijn collectie is nog niet volledig geript, dus die wil ik echt wel op desktop schijven zetten.
Ik denk dat hij bedoeld dat je het OS op de twee gemirrorde schijven zet. En dan moet je iets slims verzinnen om films van je data pool (desktop HDD's) naar je laptop schijven te kopieëren, waarna je data pool kan gaan slapen en jij ondertussen je film kan gaan kijkenWaking_The_Dead schreef op vrijdag 28 oktober 2011 @ 21:12:
CiPHER, kan je misschien nog eens uitleggen wat de bedoeling van die twee laptop schijven is? Nu ik je post herlees, zeg je dat ik daar mijn films kan opzetten. Dat is echter niet de bedoeling: ik heb momenteel 3,5TiB aan ISO's en mijn collectie is nog niet volledig geript, dus die wil ik echt wel op desktop schijven zetten.
Kan je beide netwerkpoorten gebruiken? Of is 1 exclusief voor IPMI?Bierkameel schreef op donderdag 27 oktober 2011 @ 10:28:
[...]
Niet helemaal mee eens, ik heb zelf een Supermicro X7SPA-H-D525 met 2 x Intel GB, 6 x SATA en een PCIE 4x slot, en bovendien IPMI wat voor een servertje erg handig is, passief gekoelt en erg zuinig.
[ Voor 25% gewijzigd door onox op 28-10-2011 22:27 ]
Besloten heb ik nu al iig te gaan werken met 10 sata poorten onboard. ..
6 "echte" poorten word de storage en de fake poorten zet ik in
Misschien dat ik de fake voor zil/log SSD inzet ?
met de Transcend TS4GSSD25H-M 4GB met SATA-300-aansluiting op die 4 poorten .. kweet dat het niet
a 20,- per stuk
Hey weet iemand nu te zeggen wat nu meeste impact heeft .. ga ff uit van een 8gb Freebsd machine
met ZFS .. CPU heeft niet zoveel impact of toch stiekem wel ?
Wat heeft het meeste effect ? RAM, of SSD's voor cache/log .. en vooral belangrijk waar zie nu dan performance in terug ..
Wat ik vermoed is dat het geheel ssd/RAM erg invloed heeft in write verhaal ..
heb ik het nu mis of ???
Wat nu als mijn log"disk" omvalt ? hoe redundant is de zooi ?
6 "echte" poorten word de storage en de fake poorten zet ik in
Misschien dat ik de fake voor zil/log SSD inzet ?
met de Transcend TS4GSSD25H-M 4GB met SATA-300-aansluiting op die 4 poorten .. kweet dat het niet
a 20,- per stuk
Hey weet iemand nu te zeggen wat nu meeste impact heeft .. ga ff uit van een 8gb Freebsd machine
met ZFS .. CPU heeft niet zoveel impact of toch stiekem wel ?
Wat heeft het meeste effect ? RAM, of SSD's voor cache/log .. en vooral belangrijk waar zie nu dan performance in terug ..
Wat ik vermoed is dat het geheel ssd/RAM erg invloed heeft in write verhaal ..
heb ik het nu mis of ???
Wat nu als mijn log"disk" omvalt ? hoe redundant is de zooi ?
Tja vanalles
- Dadona
- Registratie: September 2007
- Laatst online: 17-07 23:16
Maar wat is er mis met een leuke Athlon II ? De basis kan uitkomen op 16W, natuurlijk meer dan Brazos, maar harde schijven ook tikken hard aan waardoor het relatieve verhaal een beetje meevalt. Daarnaast krijg je dan wel ECC, mits je het goede moederbord kiest.Verwijderd schreef op vrijdag 28 oktober 2011 @ 13:31:
ECC wordt niet ondersteund door Brazos en Llano, dus je bent bij AMD op ouderwetse chips aangewezen. Voor bulldozer zijn geen zuinige bordjes beschikbaar. Dus dan kun je nog Intel overwegen.
@vso, veel vragen, weinig aankopingspunten.
Als jij je pool met zware compressie wil inzetten dan gaat je CPU het meer voor de kiezen krijgen. Maar over het algemeen is geheugen het belangrijkste. RAM is erg sneller, SSD is groter waardoor je meer kunt cachen en overleeft (in principe een reboot). Of het echt fout kan gaan met een SSD hant van de ZFS versie af. Vanaf de standaard v28 (zo uit mijn hoofd) heb je geen risico meer dat je de pool verliest als de SSD faalt.
[ Voor 29% gewijzigd door Dadona op 29-10-2011 00:50 ]
- Snow_King
- Registratie: April 2001
- Laatst online: 23:36
Konijn is stoer!
:strip_exif()/u/26026/snowrabb.gif?f=community)
Op de X7SPA van SuperMicro kan je beide NIC's gebruiken.onox schreef op vrijdag 28 oktober 2011 @ 22:20:
Kan je beide netwerkpoorten gebruiken? Of is 1 exclusief voor IPMI?
De IPMI shared op de eerste NIC, maar die NIC is ook gewoon door het OS te gebruiken.
Leuk bordje, heb er aardig wat van draaien, geen klagen over!
- zzattack
- Registratie: Juli 2008
- Laatst online: 18:30
Op FreeBSD 9 RC-1 segfault smartctl wanneer ik schijven aan m'n SASUC8i probeer te queryen. Werkt dit bij iemand anders op 9 wel?
- Waking_The_Dead
- Registratie: Januari 2010
- Laatst online: 04-07-2024
Tenzij er een mediaplayer bestaat die degeljke functionaliteit voorziet, denk ik dat dit vrij onrealistisch is. Ik zou natuurlijk eerst kunnen inloggen, een ISO van 48GiB overzetten en dan mijn mediaplayer activeren. Maar dat doet een beetje afbreuk aan het gebruikersgemak van een mediaplayer, niet?onox schreef op vrijdag 28 oktober 2011 @ 22:20:
[...]
Ik denk dat hij bedoeld dat je het OS op de twee gemirrorde schijven zet. En dan moet je iets slims verzinnen om films van je data pool (desktop HDD's) naar je laptop schijven te kopieëren, waarna je data pool kan gaan slapen en jij ondertussen je film kan gaan kijken
Ik zou gewoon een Vertex 2 SSD willen gebruiken als bootschijf. Zijn er redenen om dat niet te doen?
Misschien ook wel handig om op de mailinglist van FreeBSD te vragen/vermelden, aangezien je een RC hebt.zzattack schreef op zaterdag 29 oktober 2011 @ 14:57:
Op FreeBSD 9 RC-1 segfault smartctl wanneer ik schijven aan m'n SASUC8i probeer te queryen. Werkt dit bij iemand anders op 9 wel?
Verwijderd
Beste mensen,
Ik zit er ook aan te denken om mijn servertje met ZFS te laten werken, ik heb alleen een aantal vragen.
Heb hier 5 schijven van 2tb liggen waarvan 3 de wd20ears en 2 de wd20earx (had ears besteld, kreeg earx).
Mijn idee is om deze in RAID-Z te zetten en weet dus niet of dit problemen kan opleveren (sata 300 en 600 mix).
Verder zit ik nog met het punt dat het ook als mediacenter moet kunnen dienen (iets dergelijks als xmbc).
Het idee is ook om iets van een wekelijkse backup te draaien naar een externe schijf (van een specifieke map), maar dat kan zo nodig ook wel handmatig.
Overige dingen zoals een simpele webserver etc lijkt me niet echt een probleempunt.
Ik weet niet of verder relevant is maar dit zijn de overige specs:
ASRock 880GMH/U3S3
8 gb dram 1600mhz non-ecc
athlon x3
Hij staat verder maar een paar uurtjes per dag aan (wanneer het nodig is eigenlijk) en zit verder verbonden met een aantal pc's en nog een extra mediacenter via gbit switches.
Ik zit nog te kijken of ik die 2 schijven nog kan omwisselen (had ze net voor de prijsstijgen gekocht dus opzich begrijpelijk dat ze een ander model sturen)
Mijn vraag is eigenlijk op welk os ik dit het beste kan doen?
EDIT:
Na het rond te kijken naar de verschillende alternatieven in dit topic denk ik dat freebsd wel een redelijke keuze is, ik zag dat er een port van xmbc is en ik denk eigenlijk dat een mix van sata 300 en 600 schijven niet eens zon gigantisch probleem zou vormen.
Ik kan deze neem ik aan gewoon vanaf cd op een usb installeren?
Ik zit er ook aan te denken om mijn servertje met ZFS te laten werken, ik heb alleen een aantal vragen.
Heb hier 5 schijven van 2tb liggen waarvan 3 de wd20ears en 2 de wd20earx (had ears besteld, kreeg earx).
Mijn idee is om deze in RAID-Z te zetten en weet dus niet of dit problemen kan opleveren (sata 300 en 600 mix).
Verder zit ik nog met het punt dat het ook als mediacenter moet kunnen dienen (iets dergelijks als xmbc).
Het idee is ook om iets van een wekelijkse backup te draaien naar een externe schijf (van een specifieke map), maar dat kan zo nodig ook wel handmatig.
Overige dingen zoals een simpele webserver etc lijkt me niet echt een probleempunt.
Ik weet niet of verder relevant is maar dit zijn de overige specs:
ASRock 880GMH/U3S3
8 gb dram 1600mhz non-ecc
athlon x3
Hij staat verder maar een paar uurtjes per dag aan (wanneer het nodig is eigenlijk) en zit verder verbonden met een aantal pc's en nog een extra mediacenter via gbit switches.
Ik zit nog te kijken of ik die 2 schijven nog kan omwisselen (had ze net voor de prijsstijgen gekocht dus opzich begrijpelijk dat ze een ander model sturen)
Mijn vraag is eigenlijk op welk os ik dit het beste kan doen?
EDIT:
Na het rond te kijken naar de verschillende alternatieven in dit topic denk ik dat freebsd wel een redelijke keuze is, ik zag dat er een port van xmbc is en ik denk eigenlijk dat een mix van sata 300 en 600 schijven niet eens zon gigantisch probleem zou vormen.
Ik kan deze neem ik aan gewoon vanaf cd op een usb installeren?
[ Voor 12% gewijzigd door Verwijderd op 01-11-2011 14:56 ]
- zzattack
- Registratie: Juli 2008
- Laatst online: 18:30
Is inmiddels gefixt, de port zal wel binnen een paar dagen geupdate zijn.zzattack schreef op zaterdag 29 oktober 2011 @ 14:57:
Op FreeBSD 9 RC-1 segfault smartctl wanneer ik schijven aan m'n SASUC8i probeer te queryen. Werkt dit bij iemand anders op 9 wel?
Hoeft geen probleem te zijn. Je zult geen winst halen uit de snellere schijven. Het enige probleem kan zijn dat EARX op sommige gebieden wat langzamer is door afwijkende firmware. De EARS worden dan op die momenten langzamer door EARX en andersom, de zwakste schakel dus. Dit geldt met name voor RAID-Z, waarbij het van belang is om gelijke schijven te gebruiken. Maar je hoeft het niet te overdrijven zal waarschijnlijk prima draaien.Verwijderd schreef op maandag 31 oktober 2011 @ 13:29:
Ik zit er ook aan te denken om mijn servertje met ZFS te laten werken, ik heb alleen een aantal vragen.
Heb hier 5 schijven van 2tb liggen waarvan 3 de wd20ears en 2 de wd20earx (had ears besteld, kreeg earx).
Mijn idee is om deze in RAID-Z te zetten en weet dus niet of dit problemen kan opleveren (sata 300 en 600 mix).
Als je voor FreeBSD wilt gaan kun je ook ZFSguru overwegen. Dan begin je met een ZFS-only installatie met automatische tuning en kun je rustig met ports verder uitbreiden. Zelf een ZFS-only systeem bouwen is erg omslachtig en dan moet je ook handmatig tuning uitvoeren om het meeste uit je systeem te krijgen. Wil je toch de handmatige FreeBSD route dan kun je mfsBSD livecd proberen.Verder zit ik nog met het punt dat het ook als mediacenter moet kunnen dienen (iets dergelijks als xmbc).
Het idee is ook om iets van een wekelijkse backup te draaien naar een externe schijf (van een specifieke map), maar dat kan zo nodig ook wel handmatig.
Overige dingen zoals een simpele webserver etc lijkt me niet echt een probleempunt.
Mijn vraag is eigenlijk op welk os ik dit het beste kan doen?
EDIT:
Na het rond te kijken naar de verschillende alternatieven in dit topic denk ik dat freebsd wel een redelijke keuze is
- Kriss1981
- Registratie: Februari 2008
- Laatst online: 01:26
@CiPHER
Las net dat je door Jason bent toegelaten bij de ontwikkeling van ZFSguru
Las net dat je door Jason bent toegelaten bij de ontwikkeling van ZFSguru
Verwijderd
Ik ben uiteindelijk voor ZFSguru gegaan en het werkt perfect tot nu toe, de snelheden hoeven van mij niet eens zo denderend te zijn aangezien het toch gelimiteerd wordt door de gigabit interface. Maar hij haalt een mooie 80 mb/s schrijven via samba. (een eerste benchmark via de web interface gaf een 180 lees, 230 schrijf aan)Verwijderd schreef op vrijdag 04 november 2011 @ 10:25:
[...]
Hoeft geen probleem te zijn. Je zult geen winst halen uit de snellere schijven. Het enige probleem kan zijn dat EARX op sommige gebieden wat langzamer is door afwijkende firmware. De EARS worden dan op die momenten langzamer door EARX en andersom, de zwakste schakel dus. Dit geldt met name voor RAID-Z, waarbij het van belang is om gelijke schijven te gebruiken. Maar je hoeft het niet te overdrijven zal waarschijnlijk prima draaien.
[...]
Als je voor FreeBSD wilt gaan kun je ook ZFSguru overwegen. Dan begin je met een ZFS-only installatie met automatische tuning en kun je rustig met ports verder uitbreiden. Zelf een ZFS-only systeem bouwen is erg omslachtig en dan moet je ook handmatig tuning uitvoeren om het meeste uit je systeem te krijgen. Wil je toch de handmatige FreeBSD route dan kun je mfsBSD livecd proberen.
Gefeliciteerd trouwens met je deelname aan het ZFSguru project
- Pantagruel
- Registratie: Februari 2000
- Laatst online: 19:48
Mijn 80486 was snel,....was!
:strip_icc():strip_exif()/u/3454/i486.jpg?f=community)
Ja, Jason heeft hem net een stok gegeven om nog harder mee te slaan hier in de ZFS gerelateerde fora @Tweakers.net.Kriss1981 schreef op vrijdag 04 november 2011 @ 20:56:
@CiPHER
Las net dat je door Jason bent toegelaten bij de ontwikkeling van ZFSguru
Ennuh, Jason da ge bedankt ben... da weetu ge ee
Asrock Z77 Extreme6, Intel i7-3770K, Corsair H100i, 32 GB DDR-3, 256 GB Samsung SSD + 2 x 3TB SATA, GeForce GTX 660 Ti, Onboard NIC and sound, SyncMaster 24"&22" Wide, Samsung DVD fikkertje, Corsair 500R
Losgelaten mag je ook wel zeggen, ben de laatste tijd wel wild geworden qua ideeën richting Jason. Kennelijk heeft het indruk gemaakt.Kriss1981 schreef op vrijdag 04 november 2011 @ 20:56:
@CiPHER
Las net dat je door Jason bent toegelaten bij de ontwikkeling van ZFSguru
Gelijk een nieuw GoT-gebod: Gij zult ZFSguru draaien!Pantagruel schreef op vrijdag 04 november 2011 @ 21:58:
Ja, Jason heeft hem net een stok gegeven om nog harder mee te slaan hier in de ZFS gerelateerde fora @Tweakers.net.
Serieus: ik vind ZFS hardstikke tof en hoop dat meer mensen hiervan gebruik zullen maken. Of dat nou middels ZFSguru is of een andere oplossing maakt niet zo superveel uit. Mijn interesse ligt wel bij ZFSguru omdat ik FreeBSD redelijk goed ken en het alternatieve FreeNAS te beperkt vind. Daarnaast heeft ZFSguru erg mooie features voor zo'n jong project en is het goed opgezet en ondanks het huidige ontwikkelstadium is het al heel gebruiksvriendelijk. Volgens mij kan ZFSguru dus een heel breed publiek aanspreken. Nu nog die laatste puntjes op de i zetten, daar hoop ik dan ook aan mee te kunnen werken.
Is er al VMXNET3 ondersteuning?
Even niets...
Dit topic op PfSense (gebaseerd op FreeBSD) doet vermoeden dat VMXNET3 ondersteuning nu aanwezig is:
http://forum.pfsense.org/index.php?topic=34043
Maar kan er niet zoveel over vinden eerlijk gezegd; benieuwd of je kunt uitproberen of je dat werkend kunt krijgen!
http://forum.pfsense.org/index.php?topic=34043
Maar kan er niet zoveel over vinden eerlijk gezegd; benieuwd of je kunt uitproberen of je dat werkend kunt krijgen!
- Dadona
- Registratie: September 2007
- Laatst online: 17-07 23:16
Ah zeer mooi CiPHER ! Geeft ook echt wat meer vertrouwen in de ontwikkeling en toekomst van ZFSGuru met twee ontwikkelaars.
Het is dat ik weinig tijd heb, anders zou ik graag mee willen helpen
Even niets...
- Pantagruel
- Registratie: Februari 2000
- Laatst online: 19:48
Mijn 80486 was snel,....was!
ZFS biedt inderdaad de nodige handige features mbt file serving, de combinatie met FreeBSD lijkt een gouden greep te zijn. Jason heeft er tenminste voldoende tijd ingestoken om met ZFSGuru van de meet af aan een makkelijke, goed werkende en uit te breiden distro samen te stellen.Verwijderd schreef op zaterdag 05 november 2011 @ 01:10:
[...]
Losgelaten mag je ook wel zeggen, ben de laatste tijd wel wild geworden qua ideeën richting Jason. Kennelijk heeft het indruk gemaakt.
[...]
Gelijk een nieuw GoT-gebod: Gij zult ZFSguru draaien!
Serieus: ik vind ZFS hardstikke tof en hoop dat meer mensen hiervan gebruik zullen maken. Of dat nou middels ZFSguru is of een andere oplossing maakt niet zo superveel uit. Mijn interesse ligt wel bij ZFSguru omdat ik FreeBSD redelijk goed ken en het alternatieve FreeNAS te beperkt vind. Daarnaast heeft ZFSguru erg mooie features voor zo'n jong project en is het goed opgezet en ondanks het huidige ontwikkelstadium is het al heel gebruiksvriendelijk. Volgens mij kan ZFSguru dus een heel breed publiek aanspreken. Nu nog die laatste puntjes op de i zetten, daar hoop ik dan ook aan mee te kunnen werken.
Asrock Z77 Extreme6, Intel i7-3770K, Corsair H100i, 32 GB DDR-3, 256 GB Samsung SSD + 2 x 3TB SATA, GeForce GTX 660 Ti, Onboard NIC and sound, SyncMaster 24"&22" Wide, Samsung DVD fikkertje, Corsair 500R
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
:strip_exif()/u/6647/Parhelia.gif?f=community)
Ik heb nu sinds 3 weken een ZFSGuru draaien op ESXi 5.
ZFSGuru draait zelf op een root-on-zfs install op een vmdisk op mijn esxi datastore (SSD). Ik heb 4 Samsungs F4 2TB via physical RDM gemapped en daar een raidz1 pool mee gemaakt. Deze pool is puur voor opslag en mediastreaming. Tot op heden werkte het wel ok. Voor mijn gevoel is de cpu usage een beetje hoog bij veel schrijven via nfs. Ik kan met zo'n 60Mb/s via netwerk schrijven, dat vind ik wel genoeg voor voornamelijk media streamen.
Nu zette ik vanmiddag een download aan op een andere vm die wegschreef op de pool en de performance donderde ineens in elkaar. Ik ben eens gaan kijken en zie in de console van ZFSGuru de volgende meldingen:

De smart status pagina geeft de volgende meldingen:
Wat ik sowieso raar vind is dat de power cycle count van die disk anders is dan de andere disks.
Is dit een doodgaande disk? Hij draait nu een scrub (76%, 200M/s) en heeft 4k repaired tot op heden.
ZFSGuru draait zelf op een root-on-zfs install op een vmdisk op mijn esxi datastore (SSD). Ik heb 4 Samsungs F4 2TB via physical RDM gemapped en daar een raidz1 pool mee gemaakt. Deze pool is puur voor opslag en mediastreaming. Tot op heden werkte het wel ok. Voor mijn gevoel is de cpu usage een beetje hoog bij veel schrijven via nfs. Ik kan met zo'n 60Mb/s via netwerk schrijven, dat vind ik wel genoeg voor voornamelijk media streamen.
Nu zette ik vanmiddag een download aan op een andere vm die wegschreef op de pool en de performance donderde ineens in elkaar. Ik ben eens gaan kijken en zie in de console van ZFSGuru de volgende meldingen:
De smart status pagina geeft de volgende meldingen:
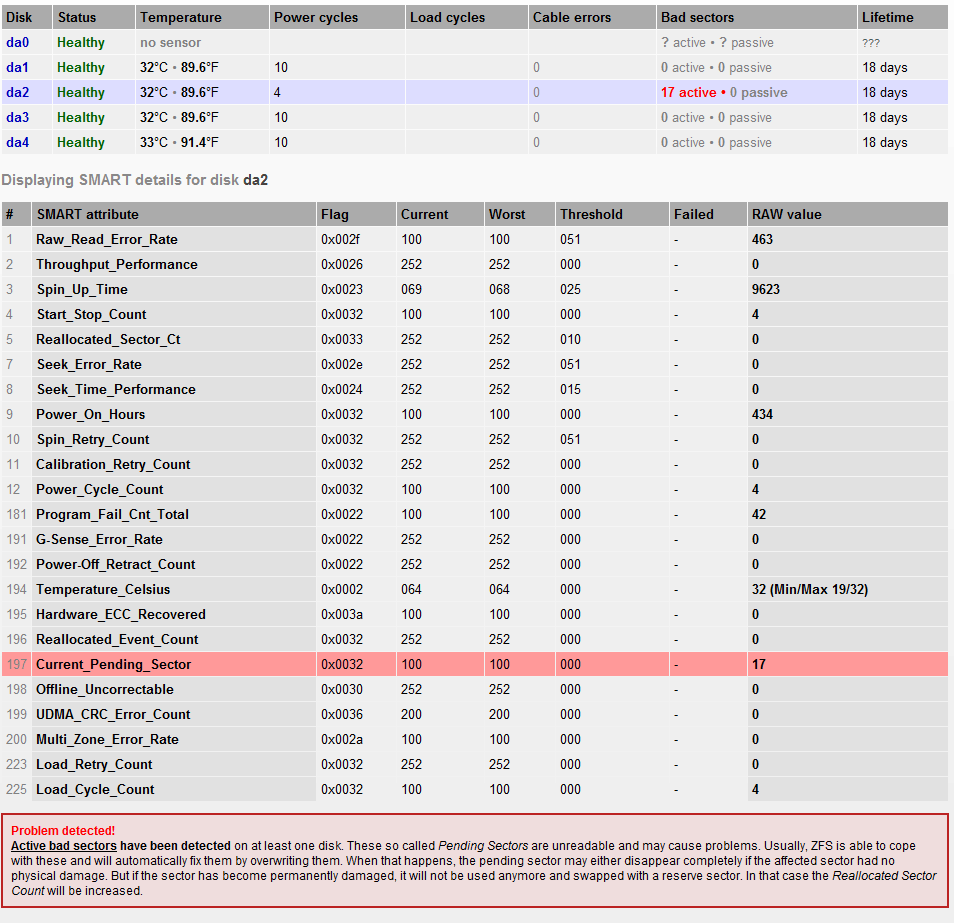
Wat ik sowieso raar vind is dat de power cycle count van die disk anders is dan de andere disks.
Is dit een doodgaande disk? Hij draait nu een scrub (76%, 200M/s) en heeft 4k repaired tot op heden.
Bedoel je 4000 sectoren? Das best veel...
Even niets...
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Nee bytes..
De scrub is nu klaar. Nu geeft zfs de volgende status:
De systemlog staat wel weer vol met dezelfde errors als eerder
De scrub is nu klaar. Nu geeft zfs de volgende status:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| [ssh@zfsguru ~]$ zpool status -v mediatank
pool: mediatank
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://www.sun.com/msg/ZFS-8000-9P
scan: resilvered 64.4M in 0h0m with 0 errors on Sat Nov 5 21:02:02 2011
config:
NAME STATE READ WRITE CKSUM
mediatank ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
gpt/samsung1 ONLINE 0 0 0
gpt/samsung2 ONLINE 118 263 0
gpt/samsung3 ONLINE 0 0 0
gpt/samsung4 ONLINE 0 0 0
errors: No known data errors |
De systemlog staat wel weer vol met dezelfde errors als eerder
code:
1
2
3
4
| Nov 5 21:01:53 zfsguru kernel: (da2:mpt0:0:2:0): READ(10). CDB: 28 0 41 d5 56 18 0 1 0 0 Nov 5 21:01:53 zfsguru kernel: (da2:mpt0:0:2:0): CAM status: SCSI Status Error Nov 5 21:01:53 zfsguru kernel: (da2:mpt0:0:2:0): SCSI status: Check Condition Nov 5 21:01:53 zfsguru kernel: (da2:mpt0:0:2:0): SCSI sense: MEDIUM ERROR asc:11,4 (Unrecovered read error - auto reallocate failed) |
Je hebt een redundante RAID-Z; pending sectors horen dus automatisch gerepareerd te worden. In jouw geval gebeurt dat niet. ZFS probeert het wel, maar krijgt write errors te zien aan je zpool status output.
Mijn vermoeden is dat dit komt door ESXi RDM mapping. Normaliter kan ZFS alle schade repareren door naar de getroffen sector te schrijven, maar kennelijk pikt de ESXi driver dit niet, en geeft een error bij write requests naar deze sector. Dit betekent dat ZFS niet meer bad sectors kan repareren op een RDM disk. Zou je ZFS directe controle geven over de disks, dan zou dit automatisch gerepareerd moeten worden. Datzelfde geldt wanneer je middels Vt-d de gehele controller aan het OS geeft, zodat er niets meer tussen de disk en het besturingssysteem inzit, zoals nu wel het geval is met RDM.
Wat je zou kunnen proberen: boot een ZFSguru livecd buiten ESXi om, dus zonder emulatie/virtualisatie. Importeer nu je pool en doe een scrub. Ga nu kijken naar je SMART informatie en naar de zpool status output. Zie je nu wel READ errors maar géén WRITE errors, en zijn de pending sectors nu weg? Zo ja, dan lijkt mijn analyse hierboven te kloppen dat je door gebruik van RDM dus de mogelijkheid om ZFS automatisch bad sectors te laten repareren wegneemt, en dat zou betekenen dat RDM een groot nadeel heeft.
Ik ben erg benieuwd of dit klopt, dus als je dit wilt testen, heel graag! Je kunt na het gebruik van die LiveCD gewoon weer exporteren en rebooten in je ESXi omgeving, dus in principe veilig. Doe wel een export van je pool na gebruik van die LiveCD, voordat je weer reboot naar je ESXi omgeving.
Mijn vermoeden is dat dit komt door ESXi RDM mapping. Normaliter kan ZFS alle schade repareren door naar de getroffen sector te schrijven, maar kennelijk pikt de ESXi driver dit niet, en geeft een error bij write requests naar deze sector. Dit betekent dat ZFS niet meer bad sectors kan repareren op een RDM disk. Zou je ZFS directe controle geven over de disks, dan zou dit automatisch gerepareerd moeten worden. Datzelfde geldt wanneer je middels Vt-d de gehele controller aan het OS geeft, zodat er niets meer tussen de disk en het besturingssysteem inzit, zoals nu wel het geval is met RDM.
Wat je zou kunnen proberen: boot een ZFSguru livecd buiten ESXi om, dus zonder emulatie/virtualisatie. Importeer nu je pool en doe een scrub. Ga nu kijken naar je SMART informatie en naar de zpool status output. Zie je nu wel READ errors maar géén WRITE errors, en zijn de pending sectors nu weg? Zo ja, dan lijkt mijn analyse hierboven te kloppen dat je door gebruik van RDM dus de mogelijkheid om ZFS automatisch bad sectors te laten repareren wegneemt, en dat zou betekenen dat RDM een groot nadeel heeft.
Ik ben erg benieuwd of dit klopt, dus als je dit wilt testen, heel graag! Je kunt na het gebruik van die LiveCD gewoon weer exporteren en rebooten in je ESXi omgeving, dus in principe veilig. Doe wel een export van je pool na gebruik van die LiveCD, voordat je weer reboot naar je ESXi omgeving.
[ Voor 7% gewijzigd door Verwijderd op 05-11-2011 21:46 ]
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Hmmz. Klinkt logisch alhoewel ik altijd dacht dat RDM echt directe physical toegang gaf tot de disks (smart werkt immers ook?). Dan zou een sector remap ook moeten werken toch? Dat doet de hdd toch zelf als je ernaartoe schrijft?
Ik heb ook een smartctl short test gedaan:
Ik kan je suggestie wel even testen. Kan ik gewoon 1.8 gebruiken? Ik draai nu 1.9RC2. Moet ik ook eerst een export doen voor het booten van de live-cd? Ik heb natuurlijk geen cd-speler in de server hangen, neem aan dat iso op bootable usb ook werkt?
Ik heb ook een smartctl short test gedaan:
code:
1
2
3
4
5
6
7
| smartctl 5.41 2011-06-09 r3365 [FreeBSD 8.2-STABLE amd64] (local build) Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net === START OF READ SMART DATA SECTION === SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed: read failure 90% 435 1101669160 |
Ik kan je suggestie wel even testen. Kan ik gewoon 1.8 gebruiken? Ik draai nu 1.9RC2. Moet ik ook eerst een export doen voor het booten van de live-cd? Ik heb natuurlijk geen cd-speler in de server hangen, neem aan dat iso op bootable usb ook werkt?
Nee niet exporteren, gewoon de LiveCD booten, daar eerst even updaten naar 0.1.9-rc2 en dan je pool importeren en een scrub draaien. En dan de SMART info opvragen en zpool status output bekijken (via ssh). Voordat je weer terug boot naar je ESXi omgeving eerst een export doen.
En over dat RDM directe disks doorstuurt, daar hadden FireDrunk en ik laatst nog een discussie over. Echter het feit dat een ATA disk opeens als SCSI wordt gepresenteerd betekent dat iets de commando's vertaalt, en dat betekent automatisch dat er een vertaallaag tussenzit. Dat kan ook de problemen veroorzaken waar je nu mee te maken hebt. Als dat klopt ben ik hier heel benieuwd naar, dus ik kijk erg uit naar je test met de LiveCD dat zou alles moeten verhelderen.
En over dat RDM directe disks doorstuurt, daar hadden FireDrunk en ik laatst nog een discussie over. Echter het feit dat een ATA disk opeens als SCSI wordt gepresenteerd betekent dat iets de commando's vertaalt, en dat betekent automatisch dat er een vertaallaag tussenzit. Dat kan ook de problemen veroorzaken waar je nu mee te maken hebt. Als dat klopt ben ik hier heel benieuwd naar, dus ik kijk erg uit naar je test met de LiveCD dat zou alles moeten verhelderen.
[ Voor 5% gewijzigd door Verwijderd op 05-11-2011 22:17 ]
Ik heb intussen een ESXi5 bakje gemaakt met 3 disks en een Intel SSD (om van te booten).
Nog geen tijd gehad om daadwerkelijk te testen. Komt binnenkort
Nog geen tijd gehad om daadwerkelijk te testen. Komt binnenkort
Even niets...
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Nou ik heb ZFSGuru inmiddels geboot vanaf een usb stick.
De pool is geïmporteerd (heerlijke feature dat dit zo makkelijk kan met zfs) en de scrub loopt nu. Hij zit op 17% nu.
Wat bepaalt eigenlijk de snelheid van de scrub? Nu zonder ESXi ertussen geeft hij 300M/s weer (was onder ESXi 200M/s). Direct op de hardware heeft ZFS nu natuurlijk wel wat meer power tot zijn beschikking (3cores-8Gb vs 2cores-2Gb op ESXi)
De pool is geïmporteerd (heerlijke feature dat dit zo makkelijk kan met zfs) en de scrub loopt nu. Hij zit op 17% nu.
Wat bepaalt eigenlijk de snelheid van de scrub? Nu zonder ESXi ertussen geeft hij 300M/s weer (was onder ESXi 200M/s). Direct op de hardware heeft ZFS nu natuurlijk wel wat meer power tot zijn beschikking (3cores-8Gb vs 2cores-2Gb op ESXi)
Ik kan niet zo snel zeggen wat de penalty onder ESXi is. Kan zijn latency van de disk access zelf, waar ZFS erg gevoelig voor is. Kan ook zijn wat CPU/geheugen overhead. Het is moeilijk te zeggen en ik heb niet echt goede vergelijkende benchmarks gezien voor het FreeBSD platform, waarbij ESXi met een normale install wordt vergeleken.
Ben benieuwd trouwens, hou je de zpool status output in de gaten evenals de SMART output (pending sectors) ?
Ben benieuwd trouwens, hou je de zpool status output in de gaten evenals de SMART output (pending sectors) ?
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Tussen stand:
De current pending sector staat op 10
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| [ssh@zfsguru ~]$ zpool status -v mediatank
pool: mediatank
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://www.sun.com/msg/ZFS-8000-9P
scan: scrub in progress since Sun Nov 6 00:14:55 2011
930G scanned out of 1.99T at 324M/s, 0h58m to go
2.45M repaired, 45.74% done
config:
NAME STATE READ WRITE CKSUM
mediatank ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
gpt/samsung1 ONLINE 0 0 0
gpt/samsung2 ONLINE 0 0 76 (repairing)
gpt/samsung3 ONLINE 0 0 0
gpt/samsung4 ONLINE 0 0 0
errors: No known data errors |
De current pending sector staat op 10
Hm dat is goed nieuws; ZFS lijkt nu wel de schade te repareren. Tegelijkertijd ook slecht nieuws voor ESXi + RDM + ZFS want die combinatie lijkt dus problemen te hebben waardoor ZFS geen bad sectors kan repareren.
Bij 100% zou je pending sectors 0 moeten zijn, technisch hoeft dat niet persé omdat er ook pending sectoren kunnen zijn op sectoren die ZFS niet in gebruik heeft en daar komt ZFS dan ook niet aan, maar daar ga ik even niet van uit.
Als bovenstaande klopt en RDM dus geen pending sectors kan fixen, dan hoeft het nog geen ramp te zijn als je op deze manier de schade alsnog kunt repareren. Maar dat betekent dan wel extra werk in plaats van dat ZFS automatisch dit soort dingen voor je doet zonder dat je er omkijken naar hebt.
Bij 100% zou je pending sectors 0 moeten zijn, technisch hoeft dat niet persé omdat er ook pending sectoren kunnen zijn op sectoren die ZFS niet in gebruik heeft en daar komt ZFS dan ook niet aan, maar daar ga ik even niet van uit.
Als bovenstaande klopt en RDM dus geen pending sectors kan fixen, dan hoeft het nog geen ramp te zijn als je op deze manier de schade alsnog kunt repareren. Maar dat betekent dan wel extra werk in plaats van dat ZFS automatisch dit soort dingen voor je doet zonder dat je er omkijken naar hebt.
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
De scrub is klaar. De pending sector staat echter nog steeds op 10. Lijkt dus geen verschil uit te maken alhoewel ik nu geen read of write errors zie. Ik zal morgen wat grote files heen en weer kopieren om te testen.
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| [ssh@zfsguru ~]$ zpool status -v mediatank
pool: mediatank
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://www.sun.com/msg/ZFS-8000-9P
scan: scrub repaired 2.45M in 1h47m with 0 errors on Sun Nov 6 02:02:33 2011
config:
NAME STATE READ WRITE CKSUM
mediatank ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
gpt/samsung1 ONLINE 0 0 0
gpt/samsung2 ONLINE 0 0 76
gpt/samsung3 ONLINE 0 0 0
gpt/samsung4 ONLINE 0 0 0
errors: No known data errors |
[ Voor 5% gewijzigd door Danfoss op 06-11-2011 02:21 ]
Mja dat is nog een lastig punt. Je pending sectors kunnen namelijk op gebieden zitten waar ZFS geen data opslaat; die fixt hij dan ook niet.
Wat je kunt doen is de hele nacht je pool volschrijven met nulletjes, zoals:
dd if=/dev/zero of=/mediatank/nulletjes.dat bs=1m
Dan schrijft hij hem helemaal vol. En kun je morgenochtend checken of die pending sectors dan allemaal weg zijn.
Wat je kunt doen is de hele nacht je pool volschrijven met nulletjes, zoals:
dd if=/dev/zero of=/mediatank/nulletjes.dat bs=1m
Dan schrijft hij hem helemaal vol. En kun je morgenochtend checken of die pending sectors dan allemaal weg zijn.
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Ik heb ongeveer 1 TB aan nullen geschreven op de pool en de pending-sector is gestegen naar 11. Echter ik krijg verder geen foutmeldingen en alles lijkt wel goed te werken. Is er niet een surface scan / bad sector check tool voor freebsd die ik op die disk zelf los kan laten?
Dus conclusie is denk ik inderdaad dat ESXi RDM met ZFS toch niet zo handig is op het moment dat je bad-sectors krijgt. Hmm. Misschien toch maar eens gaan nadenken over een Vt-d machine. Het is alleen een beetje zonde van de hardware die ik nu heb.
Dus conclusie is denk ik inderdaad dat ESXi RDM met ZFS toch niet zo handig is op het moment dat je bad-sectors krijgt. Hmm. Misschien toch maar eens gaan nadenken over een Vt-d machine. Het is alleen een beetje zonde van de hardware die ik nu heb.
Ik vind het wel een snelle conclusie. Want het correcten van een sector gebeurt niet echt op een speciale manier waardoor RDM in de weg zou moeten zitten...
ZFS stuurt toch geen commando naar de disk dat deze zijn kapotte sector moet repareren, ZFS alloceert toch gewoon een nieuwe sector en vermeld in de metadata dat de oude kapot is?
ZFS stuurt toch geen commando naar de disk dat deze zijn kapotte sector moet repareren, ZFS alloceert toch gewoon een nieuwe sector en vermeld in de metadata dat de oude kapot is?
Even niets...
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Voor zover ik het begrijp doet de harddisk het zelfs toch helemaal alleen? Bij een dubbele read-error markeert de hdd de sector als bad en re-alloceerd de boel naar een spare sector (de smart reallocated-sector-count word dan ook 1 hoger). Bij een enkele write error idem.
Hoe ZFS er mee omgaat weet ik niet precies. Is het niet dat zo ZFS zelf ook de bad sector detecteert en die sector dan voorgoed met rust laat?
In ieder geval kreeg ik onder ESXi RDM de foutmelding "SCSI sense: MEDIUM ERROR asc:11,4 (Unrecovered read error - auto reallocate failed" wat volgens mij aangeeft dat er iets in de communicatie met de disk niet goed gaat en het her-alloceren niet werkt. Nu ik even zonder ESXi ertussen draai lijkt alles gewoon goed te werken (afgezien dat de pending-sector niet minder lijkt te worden).
Ik denk dat ik sowieso de disk RMA stuur aangezien de eerste bad sectors na 18 dagen draaien geen goed teken kan zijn.
Hoe ZFS er mee omgaat weet ik niet precies. Is het niet dat zo ZFS zelf ook de bad sector detecteert en die sector dan voorgoed met rust laat?
In ieder geval kreeg ik onder ESXi RDM de foutmelding "SCSI sense: MEDIUM ERROR asc:11,4 (Unrecovered read error - auto reallocate failed" wat volgens mij aangeeft dat er iets in de communicatie met de disk niet goed gaat en het her-alloceren niet werkt. Nu ik even zonder ESXi ertussen draai lijkt alles gewoon goed te werken (afgezien dat de pending-sector niet minder lijkt te worden).
Ik denk dat ik sowieso de disk RMA stuur aangezien de eerste bad sectors na 18 dagen draaien geen goed teken kan zijn.
- Pantagruel
- Registratie: Februari 2000
- Laatst online: 19:48
Mijn 80486 was snel,....was!
Het is wellicht handig om de hdd uit de array te verwijderen en eerst met de software van de producent te scannen of er er daadwerkelijk media defecten zijn. Doorgaans wilt een producent/leverancier de erro rcode weten die de scan software uitspuugt. Samsung bijv. vertrouwt liever op hun eigen scan software dan op een hdd test progjes die mekkeren dat er een handvolle rotte sectoren zijn. Als de eigen software dan vervolgens roept dat er niets loos is accepteert Samsung de RMA aanvraag botweg niet.Danfoss schreef op zondag 06 november 2011 @ 16:06:
..snipz..
Ik denk dat ik sowieso de disk RMA stuur aangezien de eerste bad sectors na 18 dagen draaien geen goed teken kan zijn.
Asrock Z77 Extreme6, Intel i7-3770K, Corsair H100i, 32 GB DDR-3, 256 GB Samsung SSD + 2 x 3TB SATA, GeForce GTX 660 Ti, Onboard NIC and sound, SyncMaster 24"&22" Wide, Samsung DVD fikkertje, Corsair 500R
Hmm dat is best vreemd. Maar het kan zijn dat je schijf op dit moment gewoon meer pending sectoren aan het ontwikkelen is. Dat is opzich een slecht teken.Danfoss schreef op zondag 06 november 2011 @ 14:23:
Ik heb ongeveer 1 TB aan nullen geschreven op de pool en de pending-sector is gestegen naar 11.
Ja, dat kan ook zonder de disk uit de pool hoeven gooien. Je kunt dit uitvoeren:Is er niet een surface scan / bad sector check tool voor freebsd die ik op die disk zelf los kan laten?
dd if=/dev/gpt/samsung2 of=/dev/null conv=sync,noerror bs=512
Door de 512-byte blocksize (= 1 sector) gaat dit overigens wel redelijk traag, maar je krijgt dan precies te horen welke sectoren (LBA) problemen geven. Bewaar de output van dit dd-commando goed! Het vetgedrukte gedeelte is specifiek voor deze test, niet vergeten!
Dat laatste niet. Dat deed FAT en NTFS enzo in de tijd dat hardeschijven nog niet zelf bad sectors omwisselden. Tegenwoordig gebeurt dat door de schijf zelf. Maar de schijf gaat dat niet zomaar doen, daarmee zou het namelijk alle theoretische mogelijkheid om de inhoud van die onleesbare sector te recoveren overboord gooien. Dat zal de schijf nooit zelf doen; de host moet dat doen. En dat gebeurt door die sector te overschrijven met nieuwe data. De oude data is dan niet meer nodig en de schijf zal de sector dan direct omwisselen voor een nieuwe reservesector. De pending sector verdwijnt dan ook.FireDrunk schreef op zondag 06 november 2011 @ 15:02:
Ik vind het wel een snelle conclusie. Want het correcten van een sector gebeurt niet echt op een speciale manier waardoor RDM in de weg zou moeten zitten...
ZFS stuurt toch geen commando naar de disk dat deze zijn kapotte sector moet repareren, ZFS alloceert toch gewoon een nieuwe sector en vermeld in de metadata dat de oude kapot is?
Je hebt wel gelijk dat ZFS niets speciaals doet, het is en blijft een write-request die RDM mapped disk gewoon zou moeten accepteren. Maar het is wel een write request naar een bad sector, en dat gebeurt pas nadat die sector wordt gelezen maar een timeout geeft. ZFS zal direct van redundante bronnen (je andere schijven in een RAID-Z / mirror) de data lezen, maar probeert daarnaast ook de schade op de getroffen schijf direct te repareren door diezelfde - uit redundante bron-verkregen - data naar de bad sector te schrijven.
Het zou kunnen dat het met RDM niet lukt omdat die gaat stijgeren na het lezen van zo'n bad sector en dus ook de write request een timeout geeft. Dan werkt het truucje niet goed. Maar echt een sluitende theorie heb ik niet; dan zou ik precies moeten weten wat die RDM laag doet. Het is echter wel aannemelijk dat RDM verantwoordelijk is voor de timeouts en het feit dat het overschrijven van de bad sectors niet lukt.
Dit kunnen we uittesten, maar eerst heb ik de output nodig van het dd-commando hierboven. Als Danfoss tijd en zin heeft kunnen we dan wat testjes uitvoeren met RDM en direct via ZFSguru zonder ESXi.
Ik kan je helemaal volgen, goede beredenering, we wachten de output van Danfoss af.
Ik zal eens kijken of ik iets van RDM timeouts kan vinden in ESX.
Ik zal eens kijken of ik iets van RDM timeouts kan vinden in ESX.
[ Voor 28% gewijzigd door FireDrunk op 07-11-2011 10:00 ]
Even niets...
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Ik heb afgelopen nacht ESTOOL van Samsung losgelaten op de disk: http://pastebin.com/EdJ3bUSSVerwijderd schreef op zondag 06 november 2011 @ 22:37:
[...]
.....
Dit kunnen we uittesten, maar eerst heb ik de output nodig van het dd-commando hierboven. Als Danfoss tijd en zin heeft kunnen we dan wat testjes uitvoeren met RDM en direct via ZFSguru zonder ESXi.
Behoorlijk wat bad-sectors zo te zien.
Ik ben wel nieuwsgierig naar het verschil in wel/niet RDM in deze situatie aangezien ik het ook vreemd vind dat ik reallocated failures krijg in ZFS via RDM en niet als hij direct geconnect is. Ik las ook ergens op een forum van iemand dat hij fouten kreeg met physical RDM (wat ik heb) icm met ZFS en niet met virtual RDM. Zie ook hier voor het verschil.
Ik kan wel wat extra tests doen voor ik de disk terugstuur
dd if=/dev/gpt/samsung2 of=/dev/null conv=sync,noerror bs=512
Deze disk heeft toch 4k sectors? Moet de bs waarde dan niet anders zijn?
Physical en Virtual RDM is niet van echt toepassing op disks die je in het systeem doorgeeft. Het heeft te maken het het 'claimen' van de disk ten opzichte van de VMkernel. In Virtual Compatibility word het mogelijk om het volume over te failen binnen VM's. Bij Physical kan dat niet omdat er echt directe commando's doorgegeven worden.
Deze modus is normaal gesproken voor SAN tools om vanuit een VM bij je SAN config te komen.
Die directe access is voor de SAN tools nodig om fatsoenlijk te communiceren.
Vanuit die visie geloof ik ook wel dat RDM de commando's goed doorstuurt, maar wat CiPHER zegt over bad-sectors kan ik ook wel volgen. Omdat RDM voor SAN's is gemaakt en niet voor disks, zullen ze bad-sectors wel helemaal niet in het ontwerp meegenomen hebben.
Deze modus is normaal gesproken voor SAN tools om vanuit een VM bij je SAN config te komen.
Die directe access is voor de SAN tools nodig om fatsoenlijk te communiceren.
Vanuit die visie geloof ik ook wel dat RDM de commando's goed doorstuurt, maar wat CiPHER zegt over bad-sectors kan ik ook wel volgen. Omdat RDM voor SAN's is gemaakt en niet voor disks, zullen ze bad-sectors wel helemaal niet in het ontwerp meegenomen hebben.
Even niets...
Danfoss: ja inderdaad je zou ook bs=4096 kunnen doen, is waarschijnlijk ook stukken sneller.
En inderdaad die disk zou ik retourneren, maar het zou inderdaad interessant zijn wat testjes te doen.
Bewaar wel de output van dat commando heel goed! Daarin krijg je de exacte LBA (sectors) die onleesbaar zijn, I/O error krijg je dan enzo. Maar door de extra conv=sync,noerror gaat hij gewoon door en krijg je dus alle onleesbare sectoren te zien.
Met die kennis gaan we dan terug naar je ESXi+RDM configuratie, en proberen te lezen en te schrijven naar die locaties.
En inderdaad die disk zou ik retourneren, maar het zou inderdaad interessant zijn wat testjes te doen.
Bewaar wel de output van dat commando heel goed! Daarin krijg je de exacte LBA (sectors) die onleesbaar zijn, I/O error krijg je dan enzo. Maar door de extra conv=sync,noerror gaat hij gewoon door en krijg je dus alle onleesbare sectoren te zien.
Met die kennis gaan we dan terug naar je ESXi+RDM configuratie, en proberen te lezen en te schrijven naar die locaties.
[ Voor 12% gewijzigd door Verwijderd op 07-11-2011 10:37 ]
Goede test!
Even niets...
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
De exacte LBA heb ik nu toch ook al gekregen via de estool scan?
Inderdaad, had je link nog niet gezien. 
Dat is wel 512-byte LBA, dus voor elke bad sector krijg je 8 regels. Vandaar dat je denkt dat zijn heel veel bad sectors! Maar dat valt dus nog enigszins mee; het zou om 60 bad sectors gaan.
Wat nu? Ga eerst naar je livecd toe om te controleren dat je wat aan deze gegevens hebt, met iets als:
dd if=/dev/ada4 of=/dev/null bs=512 iseek=1074158600 count=1
Eigenlijk moet je alle LBA omrekenen, maar zo kan het wellicht ook. De goede manier is:
dd if=/dev/ada4 of=/dev/null bs=4096 iseek=134269825 count=1
Bovenste voorbeeld is de 512-byte LBA (1074158600) gedeeld door 8 zodat je 4K-LBA krijgt: 134269825.
Let erop dat je doordat je de gegevens van die utility hebt, geen /dev/gpt/samsung2 kunt gebruiken, maar nu de raw device moet aanspreken. Dus /dev/ada4 bijvoorbeeld, maar kijk even welke schijf dat is! Gebruik geen partities zoals /dev/ada4p2 ofzo.
Probeer wat LBA uit en als het goed is krijg je een I/O error. Kijk ook eens naar de console output (tail /var/log/messages) en daar zou je ook wat relevante output moeten zien.
Probeer nu te schrijven naar de LBA. Daarvoor moet je disk uit de array gegooid worden; FreeBSD staat niet toe dat je schrijft naar een device die in gebruik is. Maar wellicht kun je een (gevaarlijke!) omweg gebruiken:
sysctl kern.geom.debugflags=16
dd if=/dev/zero of=/dev/ada2 bs=4096 oseek=134269825 count=1
Waarschuwing: don't try this at home (without supervision)! Dit is een gevaarlijk commando, check het commando vier keer voordat je op enter drukt! Zorg dat je op de juiste disk werkt! Let op dat dit keer oseek in plaats van iseek wordt gebruikt!
Als je permission denied krijgt dan werkt de override niet, zie je gewoon wat output van:
dd if=/dev/ada4 of=/dev/null bs=4096 iseek=134269825 count=1
Dit zou moeten lukken dit keer. Geen I/O error meer. Zo ja: oke sector remap werkt! Zo nee: iets fout gedaan, ga niet door met de volgende stap.
Als bovenstaande is gelukt, kun je terug naar je ESXi+RDM booten en eigenlijk hetzelfde kunstje flikken. Let wel: je moet nu een andere sector pakken, want het voorbeeld hierboven heb je gefixed. Let erop dat je de sector door 8 deelt en bs=4096 gebruikt. Let ook op dat je device nu een andere naam kan hebben; dus geen /dev/ada2 maar /dev/ad4 bijvoorbeeld. Maak geen fouten, want met die override (debugflags) schakel je een cruciale beveiliging van GEOM uit!
Dat is wel 512-byte LBA, dus voor elke bad sector krijg je 8 regels. Vandaar dat je denkt dat zijn heel veel bad sectors! Maar dat valt dus nog enigszins mee; het zou om 60 bad sectors gaan.
Wat nu? Ga eerst naar je livecd toe om te controleren dat je wat aan deze gegevens hebt, met iets als:
dd if=/dev/ada4 of=/dev/null bs=512 iseek=1074158600 count=1
Eigenlijk moet je alle LBA omrekenen, maar zo kan het wellicht ook. De goede manier is:
dd if=/dev/ada4 of=/dev/null bs=4096 iseek=134269825 count=1
Bovenste voorbeeld is de 512-byte LBA (1074158600) gedeeld door 8 zodat je 4K-LBA krijgt: 134269825.
Let erop dat je doordat je de gegevens van die utility hebt, geen /dev/gpt/samsung2 kunt gebruiken, maar nu de raw device moet aanspreken. Dus /dev/ada4 bijvoorbeeld, maar kijk even welke schijf dat is! Gebruik geen partities zoals /dev/ada4p2 ofzo.
Probeer wat LBA uit en als het goed is krijg je een I/O error. Kijk ook eens naar de console output (tail /var/log/messages) en daar zou je ook wat relevante output moeten zien.
Probeer nu te schrijven naar de LBA. Daarvoor moet je disk uit de array gegooid worden; FreeBSD staat niet toe dat je schrijft naar een device die in gebruik is. Maar wellicht kun je een (gevaarlijke!) omweg gebruiken:
sysctl kern.geom.debugflags=16
dd if=/dev/zero of=/dev/ada2 bs=4096 oseek=134269825 count=1
Waarschuwing: don't try this at home (without supervision)! Dit is een gevaarlijk commando, check het commando vier keer voordat je op enter drukt! Zorg dat je op de juiste disk werkt! Let op dat dit keer oseek in plaats van iseek wordt gebruikt!
Als je permission denied krijgt dan werkt de override niet, zie je gewoon wat output van:
Dan heeft het gewerkt. Probeer dan de sector weer te lezen:1+0 records in
1+0 records out
dd if=/dev/ada4 of=/dev/null bs=4096 iseek=134269825 count=1
Dit zou moeten lukken dit keer. Geen I/O error meer. Zo ja: oke sector remap werkt! Zo nee: iets fout gedaan, ga niet door met de volgende stap.
Als bovenstaande is gelukt, kun je terug naar je ESXi+RDM booten en eigenlijk hetzelfde kunstje flikken. Let wel: je moet nu een andere sector pakken, want het voorbeeld hierboven heb je gefixed. Let erop dat je de sector door 8 deelt en bs=4096 gebruikt. Let ook op dat je device nu een andere naam kan hebben; dus geen /dev/ada2 maar /dev/ad4 bijvoorbeeld. Maak geen fouten, want met die override (debugflags) schakel je een cruciale beveiliging van GEOM uit!
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Ok. Hier ga ik vanavond mee aan de slag!
Nog even over deze commando's:
sysctl kern.geom.debugflags=16
dd if=/dev/zero of=/dev/ada2 bs=4096 oseek=134269825 count=1
Dat zijn dus 2 commando's toch? Is de "sysctl kern.geom.debugflags=16' een permanente setting?
Nog even over deze commando's:
sysctl kern.geom.debugflags=16
dd if=/dev/zero of=/dev/ada2 bs=4096 oseek=134269825 count=1
Dat zijn dus 2 commando's toch? Is de "sysctl kern.geom.debugflags=16' een permanente setting?
2 commando's ja, en nee na een reboot is die debugflags weer weg; je kunt beter direct rebooten nadat je klaar bent en geen andere dingen doen; om (menselijke) fouten te voorkomen!
debugflags=16 is potentiëel zeer gevaarlijk, omdat het write-access toestaat op tier-0 GEOM-providers die in gebruik zijn, iets wat normaliter strict verboden is.
debugflags=16 is potentiëel zeer gevaarlijk, omdat het write-access toestaat op tier-0 GEOM-providers die in gebruik zijn, iets wat normaliter strict verboden is.
Klinkt spannend
Even niets...
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Nou deel 1 is gedaan. Ik heb het volledig met 512b LBA adressen gedaan:
SMART status vooraf:
Current_Pending_Sector = 72
Reallocated_Sector_Ct = 0
Reallocated_Event_Count = 0
Direct access via ZFSGuru live-usb
Lezen:
dd if=/dev/ada3 of=/dev/null bs=512 iseek=1074158600 count=1
Resultaat:
dd: /dev/ada3: Input/output error
0+0 records in
0+0 records out
0 bytes transferred in 25.083684 secs (0 bytes/sec)
Schrijven:
sysctl kern.geom.debugflags=16
dd if=/dev/zero of=/dev/ada3 bs=512 oseek=1074158600 count=1
Resultaat:
1+0 records in
1+0 records out
512 bytes transferred in 0.001732 secs (295634 bytes/sec)
Opnieuw lezen:
dd if=/dev/ada3 of=/dev/null bs=512 iseek=1074158600 count=1
Resultaat:
1+0 records in
1+0 records out
512 bytes transferred in 0.001730 secs (295960 bytes/sec)
Dit lijkt dus te werken. Ik zie alleen geen verschil in smart status. Ik had verwacht dat ik een reallocation zou zien? Komt dit omdat ik 512b heb geschreven? Ik kan het ook nog wel even met 4k proberen?
Voor ik ESXi ertussen hang moet ik wel een pool export doen?
SMART status vooraf:
Current_Pending_Sector = 72
Reallocated_Sector_Ct = 0
Reallocated_Event_Count = 0
Direct access via ZFSGuru live-usb
Lezen:
dd if=/dev/ada3 of=/dev/null bs=512 iseek=1074158600 count=1
Resultaat:
dd: /dev/ada3: Input/output error
0+0 records in
0+0 records out
0 bytes transferred in 25.083684 secs (0 bytes/sec)
Schrijven:
sysctl kern.geom.debugflags=16
dd if=/dev/zero of=/dev/ada3 bs=512 oseek=1074158600 count=1
Resultaat:
1+0 records in
1+0 records out
512 bytes transferred in 0.001732 secs (295634 bytes/sec)
Opnieuw lezen:
dd if=/dev/ada3 of=/dev/null bs=512 iseek=1074158600 count=1
Resultaat:
1+0 records in
1+0 records out
512 bytes transferred in 0.001730 secs (295960 bytes/sec)
Dit lijkt dus te werken. Ik zie alleen geen verschil in smart status. Ik had verwacht dat ik een reallocation zou zien? Komt dit omdat ik 512b heb geschreven? Ik kan het ook nog wel even met 4k proberen?
Voor ik ESXi ertussen hang moet ik wel een pool export doen?
Ik zou het inderdaad met 4K doen, en dan kijken of je SMART status inderdaad verandering laat zien. Dan moet je wel alle LBA door 8 delen (4096 -> 512 bytes).
Voordat je terug naar ESXi gaat inderdaad je pool eerst exporteren, voor de zekerheid. Dan hoef je bij je ESXi-install geen import meer te doen.
Voordat je terug naar ESXi gaat inderdaad je pool eerst exporteren, voor de zekerheid. Dan hoef je bij je ESXi-install geen import meer te doen.
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Inderdaad met 4k wordt de current_pending_sector 1 lager. Gek genoeg stijgen de Reallocated_Sector_Ct en Reallocated_Event_Count niet. Staan nog steeds op 0.
Ik ga nu ESXi weer een slinger geven en hetzelfde proberen
Ik ga nu ESXi weer een slinger geven en hetzelfde proberen
Het hoeft niet altijd om fysieke schade te gaan, in dat geval wordt de sector niet omgewisseld. Ook wel een slecht teken hoor, maar het gaat nu even om de test met ESXi/RDM.
Dus stap 1 werkt goed, nu moet je een andere sector pakken en met ESXi proberen. Voordat je dat doet dus exporteren voordat je in ESXi boot.
Succes! Ben benieuwd.
Dus stap 1 werkt goed, nu moet je een andere sector pakken en met ESXi proberen. Voordat je dat doet dus exporteren voordat je in ESXi boot.
Succes! Ben benieuwd.
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Ok. dit is al intressant. Bij de eerste lees actie
dd if=/dev/da2 of=/dev/null bs=4096 iseek=134269826 count=1
Resultaat:
dd: /dev/da2: Input/output error
0+0 records in
0+0 records out
0 bytes transferred in 25.615408 secs (0 bytes/sec)
Echter in de kernel en system log van ZFSGuru regent het meldingen (5 keer voor 1 dd commando):
Schrijven werkt zonder problemen en zelfde smart resultaat als bij direct access. current_pending_sector is met 1 verlaagd.
Dus conclusie?: Er is geen verschil tussen wel of niet RDM alleen er komen een shitload aan errors in de logs van zfs terug (waarschijnlijk extra read errors die de RDM vertaling terug geeft?)
Vraag me nu alleen toch af of de disk nu echt stuk aan het gaan is of er iets anders aan de hand is. Ik vind het vaag dat smart geen re-allocated sector aangeeft na het opnieuw beschrijven van de sector. Dat betekent dat hij toch data kan schrijven en terug lezen op die sectoren?
Ik heb in zfsguru nu wel een melding na het booten in de system log staan:
GEOM: da2: the secondary GPT table is corrupt or invalid.
GEOM: da2: using the primary only -- recovery suggested.
dd if=/dev/da2 of=/dev/null bs=4096 iseek=134269826 count=1
Resultaat:
dd: /dev/da2: Input/output error
0+0 records in
0+0 records out
0 bytes transferred in 25.615408 secs (0 bytes/sec)
Echter in de kernel en system log van ZFSGuru regent het meldingen (5 keer voor 1 dd commando):
code:
1
2
3
4
| (da2:mpt0:0:2:0): READ(10). CDB: 28 0 40 6 5c 10 0 0 1 0 (da2:mpt0:0:2:0): CAM status: SCSI Status Error (da2:mpt0:0:2:0): SCSI status: Check Condition (da2:mpt0:0:2:0): SCSI sense: MEDIUM ERROR asc:11,4 (Unrecovered read error - auto reallocate failed) |
Schrijven werkt zonder problemen en zelfde smart resultaat als bij direct access. current_pending_sector is met 1 verlaagd.
Dus conclusie?: Er is geen verschil tussen wel of niet RDM alleen er komen een shitload aan errors in de logs van zfs terug (waarschijnlijk extra read errors die de RDM vertaling terug geeft?)
Vraag me nu alleen toch af of de disk nu echt stuk aan het gaan is of er iets anders aan de hand is. Ik vind het vaag dat smart geen re-allocated sector aangeeft na het opnieuw beschrijven van de sector. Dat betekent dat hij toch data kan schrijven en terug lezen op die sectoren?
Ik heb in zfsguru nu wel een melding na het booten in de system log staan:
GEOM: da2: the secondary GPT table is corrupt or invalid.
GEOM: da2: using the primary only -- recovery suggested.
[ Voor 39% gewijzigd door Danfoss op 07-11-2011 20:06 ]
Hmm vreemd. Als je nu een scrub start op je pool (terwjil je in ESXi zit) zie je dan write errors in de zpool status output?
Zo ja, kun je dan nog eens naar de LiveCD omgeving booten en daar hetzelfde doen?
Dat je reallocated sector count niet verhoogt wordt kan goed kloppen, dan is de sector zelf niet fysiek beschadigd maar kon hij toch niet gelezen worden. Hoe dit precies zit is me nog niet helemaal duidelijk, maar feit is wel dat dit met moderne schijven veel vaker voorkomt dan zeg met 320GB schijven, wat hoogstwaarschijnlijk met de toegenomen datadichtheid te maken heeft. Het gaat daarbij niet om fysieke schade waardoor de sector niet meer leesbaar is, maar het feit dat er onvoldoende CRC error correctie aanwezig is en dit steeds belangrijker wordt naarmate de datadichtheid toeneemt.
Hetzelfde geldt overigens bij NAND; bij verkleining van het NAND geheugen moet de hoeveelheid errorcorrectie worden verhoogd. Ik geloof dat voor 25nm-class NAND het zelfs al zover is dat 50% van de ruwe capaciteit voor errorcorrectie wordt gebruikt; hetgeen best wel veel is, veel meer dan de 56 bytes CRC op 4096 bytes die moderne hardeschijven hebben. Maar mijn verhaal hierboven is vast niet het complete verhaal, dus neem het met een korrel zout.
Zo ja, kun je dan nog eens naar de LiveCD omgeving booten en daar hetzelfde doen?
Dat je reallocated sector count niet verhoogt wordt kan goed kloppen, dan is de sector zelf niet fysiek beschadigd maar kon hij toch niet gelezen worden. Hoe dit precies zit is me nog niet helemaal duidelijk, maar feit is wel dat dit met moderne schijven veel vaker voorkomt dan zeg met 320GB schijven, wat hoogstwaarschijnlijk met de toegenomen datadichtheid te maken heeft. Het gaat daarbij niet om fysieke schade waardoor de sector niet meer leesbaar is, maar het feit dat er onvoldoende CRC error correctie aanwezig is en dit steeds belangrijker wordt naarmate de datadichtheid toeneemt.
Hetzelfde geldt overigens bij NAND; bij verkleining van het NAND geheugen moet de hoeveelheid errorcorrectie worden verhoogd. Ik geloof dat voor 25nm-class NAND het zelfs al zover is dat 50% van de ruwe capaciteit voor errorcorrectie wordt gebruikt; hetgeen best wel veel is, veel meer dan de 56 bytes CRC op 4096 bytes die moderne hardeschijven hebben. Maar mijn verhaal hierboven is vast niet het complete verhaal, dus neem het met een korrel zout.
- Danfoss
- Registratie: Mei 2000
- Laatst online: 00:40
Deze ruimte is te koop..
Schiet mij maar lek.
Scrub klaar:
Ik heb wel nog steeds 70 current pending sectors.
Scrub klaar:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [ssh@zfsguru ~]$ zpool status -v mediatank
pool: mediatank
state: ONLINE
scan: scrub repaired 0 in 2h39m with 0 errors on Mon Nov 7 23:03:29 2011
config:
NAME STATE READ WRITE CKSUM
mediatank ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
gpt/samsung1 ONLINE 0 0 0
gpt/samsung2 ONLINE 0 0 0
gpt/samsung3 ONLINE 0 0 0
gpt/samsung4 ONLINE 0 0 0
errors: No known data errors |
Ik heb wel nog steeds 70 current pending sectors.
Let op:
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.