:fill(white):strip_exif()/i/2003943496.jpeg?f=thumbmini)
:strip_exif()/i/1321263566.png?f=thumbmini)
:strip_exif()/u/17028/ico_sphere.gif?f=community)
Wel opmerkelijk dat de Samsung 840 Pro je een veel betere 4K32 performance geven dan beide Intel types. Zeker aangezien de overige prestaties niet zo schokkend verschillen.FireDrunk schreef op zondag 23 februari 2014 @ 22:19:
Even flink aan het testen geweest:
ZIL = 2* 8GB Intel DC3700 SSD
:strip_icc():strip_exif()/u/6607/klootviool2.jpg?f=community)
Het verbaast met niet helemaal. De Intel DC SSD's zijn veel meer gericht op een consistente performance gedurende de hele levensduur van de SSD, waar de Samsungs gewoon het maximaal haalbare geven (wat dus naarmate de tijd vordert minder kan worden). Die consistentie telt in bedrijfsmatige server omgevingen zwaarder dan piek prestaties.Phuncz schreef op maandag 24 februari 2014 @ 09:10:
[...]
Wel opmerkelijk dat de Samsung 840 Pro je een veel betere 4K32 performance geven dan beide Intel types. Zeker aangezien de overige prestaties niet zo schokkend verschillen.
Zie ook de review van Tomshardware.
[ Voor 9% gewijzigd door Bigs op 24-02-2014 09:57 ]
- Afwezig
- Registratie: Maart 2002
- Laatst online: 20-05 16:25
Ik heb eens gekeken, maar volgens mij test firedrunk de dc s3700 helemaal niet tegen de samsung 840. Hij gebruikt zoals ik het lees de dc s3700 als slog in een 4 4tb raidz. De 840 staat er alleen maar in om het verschil tussen iscsi in een pure ssd setup tov een pool met normale schijven duidelijk te maken. En dan valt het verschil tussen de "oude" x25 en de nieuwe 840pro ineens reuze mee.
Volgens mij ging het hier vooral om iscsi met nfs vergelijken.
Volgens mij ging het hier vooral om iscsi met nfs vergelijken.
[ Voor 4% gewijzigd door Afwezig op 24-02-2014 10:08 ]
- Dadona
- Registratie: September 2007
- Laatst online: 27-07 22:01
/u/231803/ramdisk2.png?f=community)
De follow-up van het artikel op Arstechnica:
Step-by-step guide to ZFS on Ubuntu Precise Pangolin (LTS)
Step-by-step guide to ZFS on Ubuntu Precise Pangolin (LTS)
:strip_exif()/u/70909/BlueKachina_60x60.gif?f=community)
Inderdaad, het is wat Afwezig zegt. Die Intel SSD's onderin (x25's) staan natuurlijk helemaal niet in verhouding tot de Intel DC's.
Wat Afwezig terecht ziet, is dat het verschil tussen 2 mirrors van x25's net zo snel is als 1 mirror van 840 Pro's. Je zou verwachten dat meer SSD's het boeltje sneller maakt, maar dat valt dus wel mee.
Rare is wel, dat het lijkt alsof iSCSI keihard sync negeert omdat ik nog steeds dik 18000 iops haal ookal staat sync aan op 4*4TB zonder SLOG. Onder NFS zie je heel duidelijk dat de SYNC gehonoreerd wordt...
@jadjong, ik heb de Intel DC's zien pieken op 36MB/s elk tijdens de iSCSI tests met sync aan.
Wat Afwezig terecht ziet, is dat het verschil tussen 2 mirrors van x25's net zo snel is als 1 mirror van 840 Pro's. Je zou verwachten dat meer SSD's het boeltje sneller maakt, maar dat valt dus wel mee.
Rare is wel, dat het lijkt alsof iSCSI keihard sync negeert omdat ik nog steeds dik 18000 iops haal ookal staat sync aan op 4*4TB zonder SLOG. Onder NFS zie je heel duidelijk dat de SYNC gehonoreerd wordt...
@jadjong, ik heb de Intel DC's zien pieken op 36MB/s elk tijdens de iSCSI tests met sync aan.
Even niets...
- matty___
- Registratie: Augustus 2005
- Laatst online: 19-03 20:24
Zet je de sync niet op de client aan?FireDrunk schreef op maandag 24 februari 2014 @ 11:41:
Inderdaad, het is wat Afwezig zegt. Die Intel SSD's onderin (x25's) staan natuurlijk helemaal niet in verhouding tot de Intel DC's.
Wat Afwezig terecht ziet, is dat het verschil tussen 2 mirrors van x25's net zo snel is als 1 mirror van 840 Pro's. Je zou verwachten dat meer SSD's het boeltje sneller maakt, maar dat valt dus wel mee.
Rare is wel, dat het lijkt alsof iSCSI keihard sync negeert omdat ik nog steeds dik 18000 iops haal ookal staat sync aan op 4*4TB zonder SLOG. Onder NFS zie je heel duidelijk dat de SYNC gehonoreerd wordt...
@jadjong, ik heb de Intel DC's zien pieken op 36MB/s elk tijdens de iSCSI tests met sync aan.
Is ESXi, die regelt dat zelf. Ik zit wel te denken, misschien komt het door SCST.
Ik gebruik namelijk de fileio_handler ipv diskio_handler, misschien dat dat nog uitmaakt qua caching...
Ik gebruik namelijk de fileio_handler ipv diskio_handler, misschien dat dat nog uitmaakt qua caching...
[ Voor 73% gewijzigd door FireDrunk op 24-02-2014 13:13 ]
Even niets...
- - peter -
- Registratie: September 2002
- Laatst online: 16-07 12:59
/u/64204/crop5e333d1575fff.png?f=community)
Ik denk dat ik straks zelf gewoon moet gaan benchmarken, maar wat wordt er aangeraden qua compressie? Ik zie dat LZ4 aangeraden wordt tegenwoordig, omdat het uncompressable data snel skipt, maar gzip-9 is bijv. een stuk beter qua compressieverhouding volgens mij.
Ik ga een E8400 gebruiken met 3x 3TB WD Red.
--edit--
Hmm, gewone compressie benchmarks geven aan dat gzip9 2x beter compressed maar wel 30x zo langzaam is dan LZ4. Maar mogelijk dat ZFS iets meer multithreaded kan werken. Ik denk dat als ik 200MB/s write haal met GZIP-9 dat t verder niet echt uitmaakt. Gigabit is toch t limiterende, en de rest is dan mooi meegenomen.
Ik ga een E8400 gebruiken met 3x 3TB WD Red.
--edit--
Hmm, gewone compressie benchmarks geven aan dat gzip9 2x beter compressed maar wel 30x zo langzaam is dan LZ4. Maar mogelijk dat ZFS iets meer multithreaded kan werken. Ik denk dat als ik 200MB/s write haal met GZIP-9 dat t verder niet echt uitmaakt. Gigabit is toch t limiterende, en de rest is dan mooi meegenomen.
[ Voor 34% gewijzigd door - peter - op 24-02-2014 15:47 ]
LZ4 is eigenlijk altijd aan te raden als het kan (je hebt pool versie 5000 nodig), en kost inderdaad maar heel weinig CPU.
Over die ratios: Dat ligt volgens mij heel erg aan de content. GZIP-9 is geloof ik ook extreem traag en doet meerdere passes van je data, dus op zich begrijpelijk dat het beter compressed...
Compressie doe je vooral omdat je binary herhalingen wil compressen (ruwe images enzo), het verschil van een paar procent op een video file zal wel meevallen.
Bovendien gaat GZIP-9 altijd compressie doen, ook op bijvoorbeeld video files die al gecompressed zijn, wat je CPU echt onzinnig belast.
Over die ratios: Dat ligt volgens mij heel erg aan de content. GZIP-9 is geloof ik ook extreem traag en doet meerdere passes van je data, dus op zich begrijpelijk dat het beter compressed...
Compressie doe je vooral omdat je binary herhalingen wil compressen (ruwe images enzo), het verschil van een paar procent op een video file zal wel meevallen.
Bovendien gaat GZIP-9 altijd compressie doen, ook op bijvoorbeeld video files die al gecompressed zijn, wat je CPU echt onzinnig belast.
Even niets...
- - peter -
- Registratie: September 2002
- Laatst online: 16-07 12:59
Ok, ja, ik vind de skip functie van LZ4 wel aantrekkelijk idd. Hoef je daar zelf ook niet meer over na te denken.
(ik moet eerlijk bekennen dat ik nog bijna nergens compressie aan heb staan hoor  )
)
Ik moet daar binnenkort eens goed mee testen.
Ik moet daar binnenkort eens goed mee testen.
Even niets...
- fonsoy
- Registratie: Juli 2009
- Laatst online: 27-07 22:46
Ik ga binnenkort migreren van ZFSguru naar FreeNAS. De tweede controller is al binnen, alsmede voldoende harde schijven om alle data naar te kopiëren. Zo kunnen beide VM's naast elkaar draaien en kan ik performance testen. Nu werk ik met iSCSI, maar graag gebruik ik SMB om meer machines van de storage gebruik te laten maken. Hiervoor is AD integratie essentieel, en dus de reden van de migratie. Dan ga ik zeker ook even de compressie testen. Ik zal de prettige interface van ZFSguru zeker missen 
Zal dit zin hebben met 80% van de data aan muziek en films mp3/flac/blu-ray-rip kwaliteit?
Zal dit zin hebben met 80% van de data aan muziek en films mp3/flac/blu-ray-rip kwaliteit?
Lenovo W520 - i7 2720QM - 8GB DDR3 1333Mhz - 1080p - Nvidia 1000M - 9 cell accu
Wait, what? Waarom kan je niet gewoon SMB gebruiken? Heb je je hele pool geshared als 1 groot iSCSI volume?
Even niets...
- DXaroth
- Registratie: Maart 2011
- Laatst online: 10-07 21:16
Over het algemeen zal het weinig nut hebben om al compressed data op een compression-enabled volume te gooien.. je zal er een paar % mee besparen, maar niet veel meer dan dat.
- fonsoy
- Registratie: Juli 2009
- Laatst online: 27-07 22:46
Precies.FireDrunk schreef op maandag 24 februari 2014 @ 16:45:
Wait, what? Waarom kan je niet gewoon SMB gebruiken? Heb je je hele pool geshared als 1 groot iSCSI volume?
SMB had ook in eerste instantie gebruikt kunnen worden om deze pool te delen, toen heb ik voor iSCSI gekozen.
Nu wil ik toch graag over op SMB om meerdere machines toegang te geven. Maar om die meerdere machines toegang te geven, zou ik graag gebruik willen maken van Single Sign On, en is AD integratie vereist in verband met mijn windows omgeving
Lenovo W520 - i7 2720QM - 8GB DDR3 1333Mhz - 1080p - Nvidia 1000M - 9 cell accu
- - peter -
- Registratie: September 2002
- Laatst online: 16-07 12:59
Nou, mijn 3 WD Red 3TB schijven zijn binnen. En ik heb ze in mijn Ubuntu server gehangen met ZFS on Linux.
Ik dacht eerst even dat er iets mis was met mijn RaidZ1 pool, omdat de write maar op 70MB/S lag, maar dat was natuurlijk omdat ik de data van een enkele losse HD trok, die niet meer aankon.
Dit is met een E8400 en 4GB ram, met een hele desktop erop enzo (op een andere schijf).
Write
Read
Op zich niet heel erg hoog, maar ik kan wel leven met 200+ writespeeds, aangezien ik t gewoon met een enkele gigabit verbinding gebruik als storageserver. Samba trekt gewoon de volle 110MiB/S bij dus ik ben blij. Zeker ook omdat ik gewoon Ubuntu gewend ben en dat nu kan blijven gebruiken.
Ik heb ook nog even gzip vs LZ4 getest (bovenstaande is zonder compressie) en gzip-9 doet mijn server compleet hangen, veels te zwaar. Dus dan is de keus makkelijk gemaakt, aangezien LZ4 maar weinig CPU kost, en toch wel goed genoeg compressed (500 => 150) om bruikbaar te zijn.
Ik dacht eerst even dat er iets mis was met mijn RaidZ1 pool, omdat de write maar op 70MB/S lag, maar dat was natuurlijk omdat ik de data van een enkele losse HD trok, die niet meer aankon.
Dit is met een E8400 en 4GB ram, met een hele desktop erop enzo (op een andere schijf).
Write
code:
1
2
3
4
| dd if=/dev/zero of=/tank/zeroes2 bs=1M count=10000 10000+0 records gelezen 10000+0 records geschreven 10485760000 bytes (10 GB) gekopieerd, 49,1625 s, 213 MB/s |
Read
code:
1
2
3
4
| dd if=/tank/zeroes2 of=/dev/null bs=1M count=10000 10000+0 records gelezen 10000+0 records geschreven 10485760000 bytes (10 GB) gekopieerd, 44,1067 s, 238 MB/s |
Op zich niet heel erg hoog, maar ik kan wel leven met 200+ writespeeds, aangezien ik t gewoon met een enkele gigabit verbinding gebruik als storageserver. Samba trekt gewoon de volle 110MiB/S bij dus ik ben blij. Zeker ook omdat ik gewoon Ubuntu gewend ben en dat nu kan blijven gebruiken.
Ik heb ook nog even gzip vs LZ4 getest (bovenstaande is zonder compressie) en gzip-9 doet mijn server compleet hangen, veels te zwaar. Dus dan is de keus makkelijk gemaakt, aangezien LZ4 maar weinig CPU kost, en toch wel goed genoeg compressed (500 => 150) om bruikbaar te zijn.
- Ultraman
- Registratie: Februari 2002
- Nu online
:strip_icc():strip_exif()/u/48952/Ultraman-60x60-Ray-Animated.jpg?f=community)
Denk er wel aan dat:
1. dd absoluut geen benchmark is
2. allemaal nullen schrijven naar een intelligent filesystem als ZFS weinig zin heeft, zeker met compressie aan worden die vrolijk getruncate tot een enkele 0 en een tellertje.
1. dd absoluut geen benchmark is
2. allemaal nullen schrijven naar een intelligent filesystem als ZFS weinig zin heeft, zeker met compressie aan worden die vrolijk getruncate tot een enkele 0 en een tellertje.
Als je stil blijft staan, komt de hoek wel naar jou toe.
- - peter -
- Registratie: September 2002
- Laatst online: 16-07 12:59
Ja, ik snap idd dat t niet heel veel zegt, maar ik had uiteraard wel compressie uitstaan.
Ik kan op ZFS on Linux geen pool benchmark command vinden. En verder heb ik niet echt kaas gegeten van andere tools. Is er iets simpels aan te raden wat iets meer realistisch is?
Ik kan op ZFS on Linux geen pool benchmark command vinden. En verder heb ik niet echt kaas gegeten van andere tools. Is er iets simpels aan te raden wat iets meer realistisch is?
Pak IOMeter.. Werkt eigenlijk het best
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
:strip_icc():strip_exif()/u/200296/arch-dsotm_small.jpg?f=community)
Oke ik ben zo ver dat ik mijn eerste ZFS pool kan gaan maken. Ik heb die LSI MegaRAID controller vervangen voor een Areca ARC-1231ML welke wel goed JBOD ondersteunt.
Dit hangt er aan:
Vraag 1:
Ik lees dat er mogelijk iets gedaan moet worden met zgn. 4K schijven die zich voordoen alsof ze 512 zijn? Iets met een vdev instelling voor ZFS? Ik heb geprobeert hier meer over te vinden maar dit ontgaat me een beetje, hoe zie ik of dit nodig is en zo ja, wat moet ik doen? Ik zie bij het aanmaken van een nieuwe pool (zfs create etc) die parameter niet?
Vraag 2:
Zoals je ziet heb ik er dus 6 disks aanhangen. Ik heb een spare 2TB naast de server liggen (cold spare). Als ik nou een RAIDZ2 wil houd ik ongeveer 7,5TB over netto. In weze ben ik dan 2 disks kwijt aan parity.
Correctie graag als dit verkeerd is:
en dan:
Bovenstaande lijntjes werken en 'zpool status backup' geeft netjes alles online en 'no known data errors'. Echter, moet er niet ergens ext4 op komen of zo? En hoe mount ik het zodat ik het ook daadwerkelijk kan gebruiken?
Alvast bedankt!
Dit hangt er aan:
code:
1
2
3
4
5
6
7
| Ch01 JBOD 2000.4GB Hitachi HDS5C3020ALA632 Ch02 JBOD 2000.4GB ST2000DM001-9YN164 Ch03 JBOD 2000.4GB WDC WD20EARS-00MVWB0 Ch04 N.A. N.A. N.A. Ch05 JBOD 2000.4GB ST2000DM001-9YN164 Ch06 JBOD 2000.4GB ST2000DM001-9YN164 Ch07 JBOD 2000.4GB Hitachi HDS5C3020ALA632 |
Vraag 1:
Ik lees dat er mogelijk iets gedaan moet worden met zgn. 4K schijven die zich voordoen alsof ze 512 zijn? Iets met een vdev instelling voor ZFS? Ik heb geprobeert hier meer over te vinden maar dit ontgaat me een beetje, hoe zie ik of dit nodig is en zo ja, wat moet ik doen? Ik zie bij het aanmaken van een nieuwe pool (zfs create etc) die parameter niet?
Vraag 2:
Zoals je ziet heb ik er dus 6 disks aanhangen. Ik heb een spare 2TB naast de server liggen (cold spare). Als ik nou een RAIDZ2 wil houd ik ongeveer 7,5TB over netto. In weze ben ik dan 2 disks kwijt aan parity.
Correctie graag als dit verkeerd is:
code:
1
| zpool create backups raidz2 /dev/sda /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf |
en dan:
code:
1
2
3
| zfs create backups/Backups zfs create backups/Software zfs create backups/Whatever |
Bovenstaande lijntjes werken en 'zpool status backup' geeft netjes alles online en 'no known data errors'. Echter, moet er niet ergens ext4 op komen of zo? En hoe mount ik het zodat ik het ook daadwerkelijk kan gebruiken?
Alvast bedankt!
- DXaroth
- Registratie: Maart 2011
- Laatst online: 10-07 21:16
Tip: gebruik altijd de disk IDs ... mocht het systeem om de een of andere debiele reden je letter-assignments wijzigen, dan blijven je disk-by-id links werken..InflatableMouse schreef op maandag 24 februari 2014 @ 22:22:
Correctie graag als dit verkeerd is:
code:
EXT4 is ook een FS, net zoals ZFS, dus het is niet nodig om ze te formatten oid.. je array zal onder /<naam-van-array> beschikbaar zijn (/backups dus in dit geval , en /backups/Whatever , etc)
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Oke, dat is wel beter inderdaad.DXaroth schreef op maandag 24 februari 2014 @ 22:30:
[...]
Tip: gebruik altijd de disk IDs ... mocht het systeem om de een of andere debiele reden je letter-assignments wijzigen, dan blijven je disk-by-id links werken..
Ik zag inderdaad dat tie het automatisch mount. Ik ben nu aan het lezen hoe dat met forced mountpoints werkt want ik wil het onder /mnt/data hebben (data is dan het zfs volume).DXaroth schreef op maandag 24 februari 2014 @ 22:30:
EXT4 is ook een FS, net zoals ZFS, dus het is niet nodig om ze te formatten oid.. je array zal onder /<naam-van-array> beschikbaar zijn (/backups dus in dit geval , en /backups/Whatever , etc)
'set zfs mountpoint=/mnt/data backuppool/data' werkt handmatig, of is dit nu ook permanent? Hoe maak ik het anders permanent?
Het is trouwens goed snel ook. Na 186G ligt het gemiddelde op 334MB/s (gewoon een copieerslag in MC).
Als iemand nog iets kan roepen over dat 4K verhaal hoor ik het graag.
- Ultraman
- Registratie: Februari 2002
- Nu online
Dat is permanent reboot-vast, m.a.w.: het wordt onthouden.
Je zou het enkel voor het fs "backups" hoeven doen. Als je het mountpoint voor de kinderen daaronder nooit heb aangeraakt zijn die namelijk afhankelijk van het mountpoint van "backups" en zullen dan mee verhuizen.
Btw: Je kunt een mountpoint ook bij het aanmaken van een filesystem meegeven als optie.
Je zou het enkel voor het fs "backups" hoeven doen. Als je het mountpoint voor de kinderen daaronder nooit heb aangeraakt zijn die namelijk afhankelijk van het mountpoint van "backups" en zullen dan mee verhuizen.
Btw: Je kunt een mountpoint ook bij het aanmaken van een filesystem meegeven als optie.
[ Voor 6% gewijzigd door Ultraman op 25-02-2014 07:18 ]
Als je stil blijft staan, komt de hoek wel naar jou toe.
Volgens mij is Areca (ookal doet die aan JBOD) niet echt goed geschikt voor ZFS... CiPHER heeft daar geloof ik hele slechte ervaringen mee...
En wat wil je weten over 4K? Dat staat uitgebreid in de startpost of in de zoekfunctie... Zijn meerdere pagina's over geschreven.
En wat wil je weten over 4K? Dat staat uitgebreid in de startpost of in de zoekfunctie... Zijn meerdere pagina's over geschreven.
[ Voor 32% gewijzigd door FireDrunk op 25-02-2014 08:50 ]
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Hm dan ben ik niet zo goed bezig, hoe krijg ik het voor elkaar ....FireDrunk schreef op dinsdag 25 februari 2014 @ 08:50:
Volgens mij is Areca (ookal doet die aan JBOD) niet echt goed geschikt voor ZFS... CiPHER heeft daar geloof ik hele slechte ervaringen mee...
En wat wil je weten over 4K? Dat staat uitgebreid in de startpost of in de zoekfunctie... Zijn meerdere pagina's over geschreven.
[/quote]
Ja de theorie staat perfect uitgelegd en daarom stel ik ook de vraag, want wat ik niet goed kan vinden is
- hoe zie ik of ik 4K schijven heb (most 2TB+ is te generiek) en zo ja,
- hoe configureer ik dat?
Ik kan die pagina's waar jij het over hebt waar het in beschreven zou staan dus niet vinden. Wat ik wel vind als ik internet afstruin is bijvoorbeeld zoiets:
http://savagedlight.me/20...ebsd-zfs-advanced-format/
Maar het meeste is weer specifiek voor FreeBSD en mijn server draait Debian wheezy. Ik wil niet zomaar klakkeloos iets van het internet overnemen zonder dat dat geverifieerd te zien. Als hier namelijk iets verkeerd geroepen word zijn er tal van tweakers zoals jij en CiPHER die het corrigeren
Kort door de bocht:
4K optimalisatie is altijd handig, voor 4K schijven is het nodig, en voor 512byte schijven kan het amper kwaad. Andersom is erger (512byte sectoren gebruiken bij een 4K schijf).
4K schijven herken je bijvoorbeeld bij WD door het label Advanced Format.
Nadeel is dat (voor zover ik weet) nog geen enkele fabrikant ook daadwerkelijk 4K sectoren presenteert aan je operating system, en nog steeds liegt over de sectorgrootte.
Hierdoor moet je zelf sleutelen om je operating system te laten denken dat het toch 4K schijven zijn. Hoe dat bij linux werkt weet ik niet, onder BSD doe je dit met het GEOM framework (gnop commando).
Let wel op, als je een niet-efficient aantal schijven hebt (4 schijven in RAIDZ bijvoorbeeld) en je gebruikt 4K optimalisatie verlies je wat disk ruimte (paar procent). Bij 512byte sectoren is dit lager.
Bovendien moet je de 4K optimalisatie doen voordat je de pool aanmaakt, dus als je nu al een pool hebt, ben je te laat
4K optimalisatie is altijd handig, voor 4K schijven is het nodig, en voor 512byte schijven kan het amper kwaad. Andersom is erger (512byte sectoren gebruiken bij een 4K schijf).
4K schijven herken je bijvoorbeeld bij WD door het label Advanced Format.
Nadeel is dat (voor zover ik weet) nog geen enkele fabrikant ook daadwerkelijk 4K sectoren presenteert aan je operating system, en nog steeds liegt over de sectorgrootte.
Hierdoor moet je zelf sleutelen om je operating system te laten denken dat het toch 4K schijven zijn. Hoe dat bij linux werkt weet ik niet, onder BSD doe je dit met het GEOM framework (gnop commando).
Let wel op, als je een niet-efficient aantal schijven hebt (4 schijven in RAIDZ bijvoorbeeld) en je gebruikt 4K optimalisatie verlies je wat disk ruimte (paar procent). Bij 512byte sectoren is dit lager.
Bovendien moet je de 4K optimalisatie doen voordat je de pool aanmaakt, dus als je nu al een pool hebt, ben je te laat
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Bedankt voor je uitleg.
De pool is tijdelijk. Ik verwijder en maak het zo opnieuw aan dat is geen probleem. Ben nog druk aan het oefenen met de commando's, snapshotting, compressie, testen, etc. Wil me er goed mee thuis voelen voordat ik het daadwerkelijk in gebruik neem. Bovendien heb ik net die Areca maar weer te koop gezet om nu dus wel een echt goede controller in handen te krijgen. Drie maal scheepsrecht zullen we maar zeggen.
Om te weten of het 4K schijven zijn zal ik dus de typenummers een voor een moeten opzoeken en specifiek uit moeten zoeken hoe ik dat op Debian configureer.
Ik heb er overigens 6 schijven aan hangen van 2TB in RAIDZ2.
Het zit me niet echt mee ... maar goed, we komen er wel uiteindelijk.
De pool is tijdelijk. Ik verwijder en maak het zo opnieuw aan dat is geen probleem. Ben nog druk aan het oefenen met de commando's, snapshotting, compressie, testen, etc. Wil me er goed mee thuis voelen voordat ik het daadwerkelijk in gebruik neem. Bovendien heb ik net die Areca maar weer te koop gezet om nu dus wel een echt goede controller in handen te krijgen. Drie maal scheepsrecht zullen we maar zeggen
Om te weten of het 4K schijven zijn zal ik dus de typenummers een voor een moeten opzoeken en specifiek uit moeten zoeken hoe ik dat op Debian configureer.
Ik heb er overigens 6 schijven aan hangen van 2TB in RAIDZ2.
Het zit me niet echt mee ... maar goed, we komen er wel uiteindelijk.
[ Voor 3% gewijzigd door InflatableMouse op 25-02-2014 11:16 ]
- DXaroth
- Registratie: Maart 2011
- Laatst online: 10-07 21:16
4k schijven configureer je tijdens het aanmaken van je zpool:
Als je met debian bezig bent, deze is het wellicht waard om te lezen ook:
http://arstechnica.com/in...-gen-filesystem-on-linux/
redelijke basis dingen, maar laat ook genoeg dingen zien die je kan proberen om te leren etc.
code:
1
| zpool create -o ashift=12 <naam> <type> <disks> |
Als je met debian bezig bent, deze is het wellicht waard om te lezen ook:
http://arstechnica.com/in...-gen-filesystem-on-linux/
redelijke basis dingen, maar laat ook genoeg dingen zien die je kan proberen om te leren etc.
@InflatableMouse, enige eigenlijk goed gesupported controllers zijn:
*) Onboard AHCI poorten
*) ASMedia 1061 controller
*) LSI SAS2008 gebaseerde controllers (LSI, IBM, en Dell hebben er een paar.)
*) LSI SAS2308 gebaseerde controllers (idem)
Het LSI 1068E chipset is in principe ook gesupport, maar die ondersteund (bijna) geen 3TB schijven, dus is af te raden voor moderne setups. Ook heeft deze controller een bug als je hem bombardeert met SMART requests (dan locked de controller).
Bronnetje: http://www.servethehome.c...ntroller-hba-information/
*) Onboard AHCI poorten
*) ASMedia 1061 controller
*) LSI SAS2008 gebaseerde controllers (LSI, IBM, en Dell hebben er een paar.)
*) LSI SAS2308 gebaseerde controllers (idem)
Het LSI 1068E chipset is in principe ook gesupport, maar die ondersteund (bijna) geen 3TB schijven, dus is af te raden voor moderne setups. Ook heeft deze controller een bug als je hem bombardeert met SMART requests (dan locked de controller).
Bronnetje: http://www.servethehome.c...ntroller-hba-information/
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
@FireDrunk
Nogmaals dank. Het meest schandalige is dat me dat al eerder was verteld, ik was het alleen vergeten .
.
Zojuist de IBM M1015 besteld, is verdorie nieuw nog goedkoper dan die Areca 2de hands. Ach, ik verkoop het wel weer maar het is nog steeds vervelend.
Van de week komt tie binnen als het goed is.
@DXaroth,
Dank voor de link en de commandline.
Volgende vervelende is dat ik 2 schijven heb die niet 4K zijn, de rest wel. Beste is dan denk ik om het maar zo te laten zoals het is of niet?
Nogmaals dank. Het meest schandalige is dat me dat al eerder was verteld, ik was het alleen vergeten
Zojuist de IBM M1015 besteld, is verdorie nieuw nog goedkoper dan die Areca 2de hands. Ach, ik verkoop het wel weer maar het is nog steeds vervelend.
Van de week komt tie binnen als het goed is
@DXaroth,
Dank voor de link en de commandline.
Volgende vervelende is dat ik 2 schijven heb die niet 4K zijn, de rest wel. Beste is dan denk ik om het maar zo te laten zoals het is of niet?
Zoals ik al zei: 4K schijven als 512byte schijven gebruiken is vervelender dan 512byte schijven als 4K schijven.
4K optimalisatie is dus eigenlijk altijd aan te raden.
4K optimalisatie is dus eigenlijk altijd aan te raden.
Even niets...
- Pixeltje
- Registratie: November 2005
- Laatst online: 14:12
Woo-woohoo!
:strip_icc():strip_exif()/u/159609/caffeine_is_the_shit_60x60.shkl.jpg?f=community)
Even inhakend op het 4k vs 512b verhaal; ik heb sinds kort de nieuwste update van FreeNAS draaien en sindsdien krijg ik de dagelijks statusmail een mededeling dat mijn schijven niet optimaal zijn geconfigureerd (MAW; nu op 512b terwijl ze 4k kunnen zijn). Dit komt omdat ik oudere schijven stuk voor stuk heb vervangen door nieuwe.
Nu vraag ik me af of ik de blocksize alsnog kan aanpassen zonder mijn pool te vernietigen. Er staat nogal wat data op namelijk, en alleen de belangrijke zaken zijn in backup opgenomen. Weet iemand hoe ik, relatief veilig, de blocksize van 512b naar 4k krijg?
Nu vraag ik me af of ik de blocksize alsnog kan aanpassen zonder mijn pool te vernietigen. Er staat nogal wat data op namelijk, en alleen de belangrijke zaken zijn in backup opgenomen. Weet iemand hoe ik, relatief veilig, de blocksize van 512b naar 4k krijg?
And if this doesn't make us motionless, I do not know what can.
Niet, je moet je pool opnieuw aanmaken.
Even niets...
- Pixeltje
- Registratie: November 2005
- Laatst online: 14:12
Woo-woohoo!
Met als gevolg verlies van alle data.. das jammer. Enige optie is dan om een nieuwe pool te maken, daar de data heen te sturen en vervolgens de bestaande schijven in een nieuwe pool te mikken.FireDrunk schreef op dinsdag 25 februari 2014 @ 12:25:
Niet, je moet je pool opnieuw aanmaken.
Eens kijken wat die 2tb schijven nog kosten nu..
And if this doesn't make us motionless, I do not know what can.
Hoeveel data heb je? Misschien is er hier een tweaker waar je een middag koffie mag komen leuten en even zijn/haar storage mag lenen
Zojuist mijn tests op 4k afgerond:
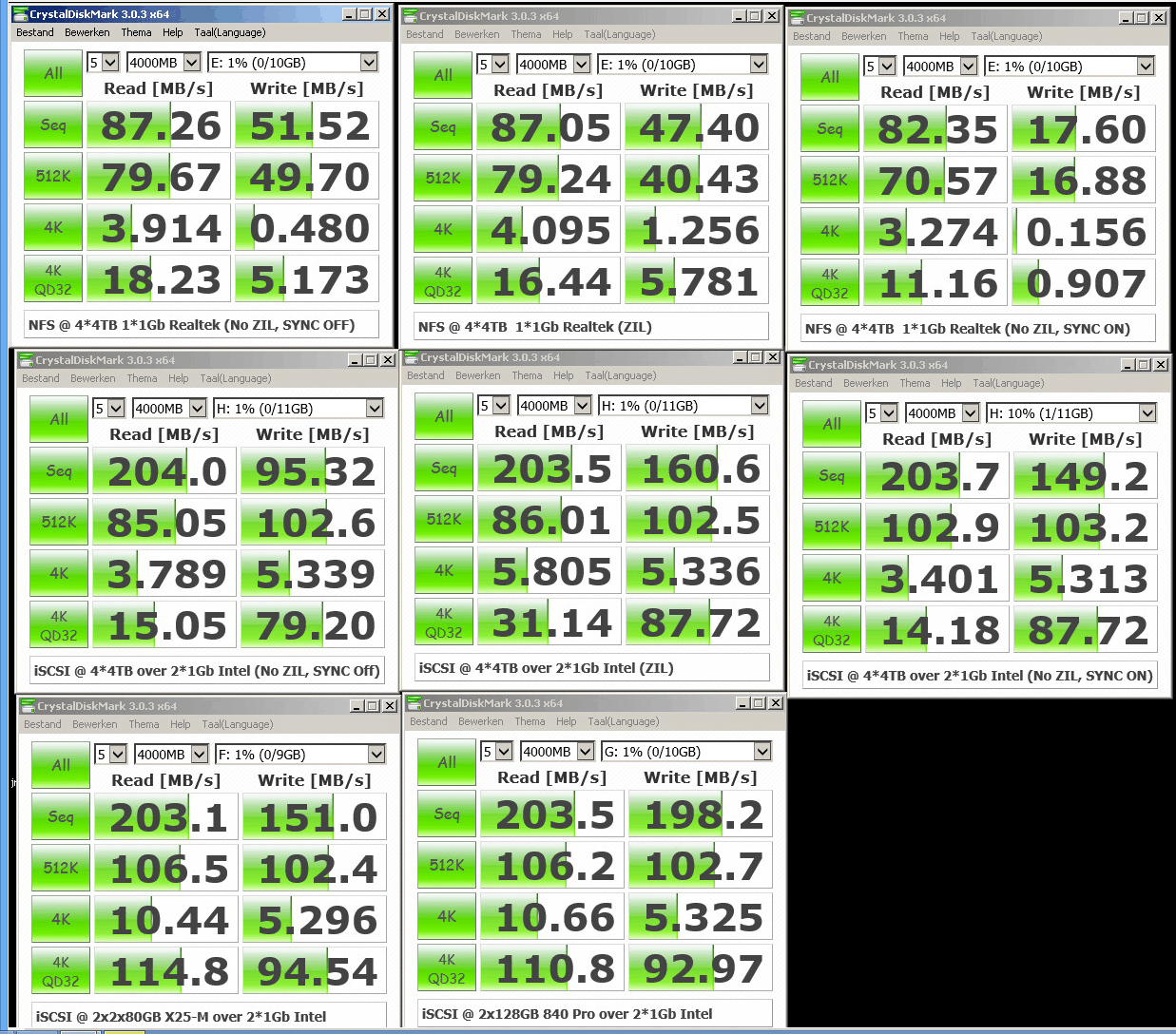
Maakt zo even uit de losse pols niet heel veel uit. Reads op de x25 lijken iets sneller, maar nfs en iSCSI op de HDD's zijn amper veranderd.
Zojuist mijn tests op 4k afgerond:
Maakt zo even uit de losse pols niet heel veel uit. Reads op de x25 lijken iets sneller, maar nfs en iSCSI op de HDD's zijn amper veranderd.
[ Voor 52% gewijzigd door FireDrunk op 25-02-2014 14:29 ]
Even niets...
- nwagenaar
- Registratie: Maart 2001
- Laatst online: 14:20
God, root. What's the differen
:strip_icc():strip_exif()/u/25115/hshUE4j.jpg?f=community)
Ik moet vanwege een hardware probleem/instabiliteit tijdelijk mijn huidige ZFS Pool (version 28) verhuizen naar een andere server. Echter, de andere server draait op Linux (mijn huidige ZFS-server draait op basis van ZFSGuru met FreeBSD 10) en ik vroeg mij af of het exporteren van de huidige pool binnen ZFSGuru en importeren onder Linux voldoende is om het werkend te krijgen.
Kan iemand bevestigen dat het importeren van een ZFS v28 Pool uit FreeBSD onder Linux gaat werken? En dat ik ook direct toegang heb tot mijn gegevens?
Ik zit niet echt te wachten om mijn Linux Server te vervangen voor FreeBSD/ZFSGuru ivm draaiende services. Dus ik hoop dat het (tijdelijk) importeren van mijn huidige pool een optie is.
Kan iemand bevestigen dat het importeren van een ZFS v28 Pool uit FreeBSD onder Linux gaat werken? En dat ik ook direct toegang heb tot mijn gegevens?
Ik zit niet echt te wachten om mijn Linux Server te vervangen voor FreeBSD/ZFSGuru ivm draaiende services. Dus ik hoop dat het (tijdelijk) importeren van mijn huidige pool een optie is.
Het is doodgewoon om storage en fileserver te scheiden. De storage biedt je dan middels iSCSI aan de fileserver aan. In veel gevallen betekent dit dat je een vergaande integratie met AD hebt en ook niet afhankelijk bent van storage leverancier (nu ZFS onder FreeBSD, straks een Nexenta oplossing of toch iets proprietair van bijv. EMC) wat dan ook de voornaamste redenen zijn waarom die scheiding wordt toegepast. Dit soort dingen kun je natuurlijk ook in het klein voor thuis toepassen en voor wie veel met AD wil werken zou ik het haast een must noemen. Scheelt ook weer gedoe met SambaFireDrunk schreef op maandag 24 februari 2014 @ 16:45:
Wait, what? Waarom kan je niet gewoon SMB gebruiken? Heb je je hele pool geshared als 1 groot iSCSI volume?
/u/11437/wandcontactdoos.png?f=community)
Het kan, maar in dat soort gevallen is je storage vaak een soort van black box die je van je leverancier binnen geschoven krijgt en die zelf geen NAS-functionaliteiten heeft, enkel fiber channel (of iSCSI) en het enige dat je (verder) via ethernet kunt doen een beetje managen is
De meeste mensen hier op GoT maken een all-in-one (ESXi + ZFS) of een fileserver (Samba + ZFS), juist met als doel zo goedkoop mogelijk zoveel mogelijk te doen. Extra hardware met extra stroomkosten is dan contraproductief, vandaar dat het redelijk ongebruikelijk is hier om alles als één target door te schuiven ergens anders heen (behalve uiteraard voor ESXi). En als 80% van je data muziek / films is denkt men hier al snel aan thuisgebruik
De meeste mensen hier op GoT maken een all-in-one (ESXi + ZFS) of een fileserver (Samba + ZFS), juist met als doel zo goedkoop mogelijk zoveel mogelijk te doen. Extra hardware met extra stroomkosten is dan contraproductief, vandaar dat het redelijk ongebruikelijk is hier om alles als één target door te schuiven ergens anders heen (behalve uiteraard voor ESXi). En als 80% van je data muziek / films is denkt men hier al snel aan thuisgebruik
"Your life is yours alone. Rise up and live it." - Richard Rahl
Rhàshan - Aditu Sunlock
Ik zie daarvoor geen problemen. Gewoon je pool exporteren (niet strict noodzakelijk) en in Linux weer importeren. Als je weer terug wilt naar ZFSguru doe je hetzelfde trucje: export en import.nwagenaar schreef op dinsdag 25 februari 2014 @ 16:42:
Kan iemand bevestigen dat het importeren van een ZFS v28 Pool uit FreeBSD onder Linux gaat werken? En dat ik ook direct toegang heb tot mijn gegevens?
Ik zit niet echt te wachten om mijn Linux Server te vervangen voor FreeBSD/ZFSGuru ivm draaiende services. Dus ik hoop dat het (tijdelijk) importeren van mijn huidige pool een optie is.
Jup, ik ben zelf recent overgestapt van BSD naar ZFSonLinux, en heb mijn 4*4TB pool meegenomen (niet eens ge-exporteerd, gewoon keihard geimporteerd).nwagenaar schreef op dinsdag 25 februari 2014 @ 16:42:
Ik moet vanwege een hardware probleem/instabiliteit tijdelijk mijn huidige ZFS Pool (version 28) verhuizen naar een andere server. Echter, de andere server draait op Linux (mijn huidige ZFS-server draait op basis van ZFSGuru met FreeBSD 10) en ik vroeg mij af of het exporteren van de huidige pool binnen ZFSGuru en importeren onder Linux voldoende is om het werkend te krijgen.
Kan iemand bevestigen dat het importeren van een ZFS v28 Pool uit FreeBSD onder Linux gaat werken? En dat ik ook direct toegang heb tot mijn gegevens?
Ik zit niet echt te wachten om mijn Linux Server te vervangen voor FreeBSD/ZFSGuru ivm draaiende services. Dus ik hoop dat het (tijdelijk) importeren van mijn huidige pool een optie is.
Even niets...
- Quindor
- Registratie: Augustus 2000
- Laatst online: 02:37
Switching the universe....
:strip_icc():strip_exif()/u/10414/crop5817c0657774d_cropped.jpeg?f=community)
Yes, ik heb hetzelfde gedaan, werkte perfect (5x4TB RaidZ1 van ZFSguru naar Ubuntu 13.10 server met ZoL).FireDrunk schreef op dinsdag 25 februari 2014 @ 18:18:
[...]
Jup, ik ben zelf recent overgestapt van BSD naar ZFSonLinux, en heb mijn 4*4TB pool meegenomen (niet eens ge-exporteerd, gewoon keihard geimporteerd).
Wel een TIP, verwijder in FreeBSD/ZFSguru nog eventjes je SLOG/ZIL en L2ARC devices. Dat kreeg ik onder Ubuntu niet meer voor elkaar en is een bekend probleem. Het is puur een cosmetisch probleem, maar toch.
- nwagenaar
- Registratie: Maart 2001
- Laatst online: 14:20
God, root. What's the differen
Ah, cool. Dank je voor de bevestiging; ik had al het één en ander gelezen maar ik wilde het gewoon zeker weten. Beter om RL bevestiging te hebben dan een theorie
@Quidor, draai jij een all-in-one of een losse ESX bak (ik zie in je Inventaris dat je een ESX machine hebt)
Zo ja, gebruik je iSCSI onder Ubuntu?
Zo ja, gebruik je iSCSI onder Ubuntu?
Even niets...
- Quindor
- Registratie: Augustus 2000
- Laatst online: 02:37
Switching the universe....
Aparte bak met een 2Gbit iSCSI koppeling. Ik heb een tijdje terug nog enkele benchmarks gepost met IETD benchmarks en ontdekte toen dan file based veel sneller was dan block based. Ook wat VMware iSCSI I/O tuning, etc. Heb je volgens mij wel voorbij zien komen.FireDrunk schreef op dinsdag 25 februari 2014 @ 19:00:
@Quidor, draai jij een all-in-one of een losse ESX bak (ik zie in je Inventaris dat je een ESX machine hebt)
Zo ja, gebruik je iSCSI onder Ubuntu?
Moet mijn configs op Tweakers.net nog eens updaten, is allemaal veranderd.
[ Voor 10% gewijzigd door Quindor op 25-02-2014 20:48 ]
- Borromini
- Registratie: Januari 2003
- Niet online
Mislukt misantroop
:strip_icc():strip_exif()/u/75828/sid.jpg?f=community)
Idem hier. ZFSGuru naar Debian GNU/kFreeBSD en daarna naar Debian GNU/Linux. Nooit geëxporteerd (niet netjes, ik weet het), gewoon zpool import -f elke keer gedaan. Geen vuiltje aan de lucht. Had wel backups min of meer.FireDrunk schreef op dinsdag 25 februari 2014 @ 18:18:
[...]
Jup, ik ben zelf recent overgestapt van BSD naar ZFSonLinux, en heb mijn 4*4TB pool meegenomen (niet eens ge-exporteerd, gewoon keihard geimporteerd).
Got Leenucks? | Debian Bookworm x86_64 / ARM | OpenWrt: Empower your router | Blogje
- Pixeltje
- Registratie: November 2005
- Laatst online: 14:12
Woo-woohoo!
Ik heb inderdaad een paar berichten gekregen daarover, vooralsnog niet op ingegaan omdat mijn pa voor een NAS in de markt is, als daar schijven voor komen kan ik die eerst even gebruiken om mijn data heen en weer te schuivenFireDrunk schreef op dinsdag 25 februari 2014 @ 14:27:
Hoeveel data heb je? Misschien is er hier een tweaker waar je een middag koffie mag komen leuten en even zijn/haar storage mag lenen
And if this doesn't make us motionless, I do not know what can.
Mja, dat zie ik ook met SCST, alleen vraag ik mij dan weer af of de fileio variant wel de SYNC's honoreerd van ESXi... Ik heb de vraag aan de scst-devel mailing lijst gesteld, maar die is nog niet goed aangekomen. Morgen nog maar eens proberen.Quindor schreef op dinsdag 25 februari 2014 @ 20:47:
[...]
Aparte bak met een 2Gbit iSCSI koppeling. Ik heb een tijdje terug nog enkele benchmarks gepost met IETD benchmarks en ontdekte toen dan file based veel sneller was dan block based. Ook wat VMware iSCSI I/O tuning, etc. Heb je volgens mij wel voorbij zien komen.
Moet mijn configs op Tweakers.net nog eens updaten, is allemaal veranderd.
Even niets...
Dat kan maar dat is niet de hoofdreden om het zo aan te pakken. Door de scheiding ben je niet zo sterk afhankelijk van de leverancier. Is je storage omgeving ruk, gooit de leverancier er met de pet naar, enz. dan is het switchen van storage omgeving een stuk eenvoudiger. Voor thuis is dat ook wel een voordeel: je kunt met verschillende systemen spelenPaul schreef op dinsdag 25 februari 2014 @ 17:08:
Het kan, maar in dat soort gevallen is je storage vaak een soort van black box die je van je leverancier binnen geschoven krijgt en die zelf geen NAS-functionaliteiten heeft, enkel fiber channel (of iSCSI) en het enige dat je (verder) via ethernet kunt doen een beetje managen is
In dit geval ging het om vm's, iets wat men hier ook zeer veelvuldig gebruikt. Als je echter kijkt wat mensen aan configs hebben is dat stroomkosten argument nou ook niet bepaald houdbaar meer. Maar daar zijn we tweakers voor niet waar?Extra hardware met extra stroomkosten is dan contraproductief, vandaar dat het redelijk ongebruikelijk is hier om alles als één target door te schuiven ergens anders heen (behalve uiteraard voor ESXi).
NAS-heads worden anders steeds populairder  En ook dingen als EMC Isilon wordt actief in de markt gezet. En natuurlijk is een NAS-head een appliance die block-based storage omzet naar file-based, maar eigenlijk altijd is dat een vendor-specific oplossing
En ook dingen als EMC Isilon wordt actief in de markt gezet. En natuurlijk is een NAS-head een appliance die block-based storage omzet naar file-based, maar eigenlijk altijd is dat een vendor-specific oplossing
Als je al een SAN hebt ga je natuurlijk niet zomaar local storage in een fileserver(cluster?) zetten, dat zet je op het SAN ivm backup, redundancy, support etc Begin je vanuit het niets dan is local storage veel gebruikelijker.
Als je al een SAN hebt ga je natuurlijk niet zomaar local storage in een fileserver(cluster?) zetten, dat zet je op het SAN ivm backup, redundancy, support etc
"Your life is yours alone. Rise up and live it." - Richard Rahl
Rhàshan - Aditu Sunlock
- Ibex
- Registratie: November 2002
- Laatst online: 27-07 21:12
^^ met stom.
Ik heb sinds enige tijd thuis ook overal ZFS in gebruik;
• NAS met single disk ZFS root en 8x2TB in RAID-Z2
• Laptop met single disk ZFS op SSD
• Offsite NAS met single disk ZFS
Wat werkt dit ongelofelijk heerlijk zeg. Zelf een service in elkaar gedraaid die op alle 3 de machines draait en die aan de hand van een configurationfile snapshots neemt, de snapshots na een bepaalde tijd terug gaat verwijderen (volgens een GFS principe) en de snapshots tussen de machines gaat repliceren.
Zo neemt mijn laptop elke avond een snapshot die richting NAS gaat, nemen de 2 NAS machines snapshots van hun belangrijke data en repliceren deze naar elkaar.
Mocht iemand intresse hebben om die service te gebruiken, geef maar een gil.
• NAS met single disk ZFS root en 8x2TB in RAID-Z2
• Laptop met single disk ZFS op SSD
• Offsite NAS met single disk ZFS
Wat werkt dit ongelofelijk heerlijk zeg. Zelf een service in elkaar gedraaid die op alle 3 de machines draait en die aan de hand van een configurationfile snapshots neemt, de snapshots na een bepaalde tijd terug gaat verwijderen (volgens een GFS principe) en de snapshots tussen de machines gaat repliceren.
Zo neemt mijn laptop elke avond een snapshot die richting NAS gaat, nemen de 2 NAS machines snapshots van hun belangrijke data en repliceren deze naar elkaar.
Mocht iemand intresse hebben om die service te gebruiken, geef maar een gil
Archlinux - Rode gronddingetjes zijn lekker - Komt uit .be
- Dadona
- Registratie: September 2007
- Laatst online: 27-07 22:01
gil !
(Niet voor mijzelf, maar dit zijn dingen waar iemand vast interesse in heeft. Al was het maar om erop verder te bouwen.)
(Niet voor mijzelf, maar dit zijn dingen waar iemand vast interesse in heeft. Al was het maar om erop verder te bouwen.)
- syl765
- Registratie: Juni 2004
- Laatst online: 27-07 21:32
/u/116403/crop64cfe7aeafeb6_cropped.png?f=community)
Bij deze ook een gil..
Altijd leuk om te kijken wat andere gebruiken.
Altijd leuk om te kijken wat andere gebruiken.
- Ibex
- Registratie: November 2002
- Laatst online: 27-07 21:12
^^ met stom.
Github project is te vinden op https://github.com/khenderick/zfs-snap-manager. Als je mogelijke problemen zou vinden, laat gerust iets weten of maak een ticket aan (of pull request ofzo). Feedback is altijd tof
[ Voor 4% gewijzigd door Ibex op 01-03-2014 16:01 ]
Archlinux - Rode gronddingetjes zijn lekker - Komt uit .be
- ikkeenjij36
- Registratie: Juli 2012
- Laatst online: 27-07 23:49
Hallo nou mijn server draait eindelijk stabiel zoals ik hem graag heb.
Alleen virtualbox wil niet meer starten/is uitgeschakeld vanzelf.
Raar maar niet erg belangrijk voor mij.
Nu ben ik op zoek naar een soort van script waarmee ik mijn server automatisch in standby/sleep modus kan krijgen en daarna weer op laten starten zodat hij bijvoorbeeld op zondag nacht om 3 uur am in standbye gaat en bijvoorbeeld om 7 uur am maandagochtend weer aangaat.
En dat je dat dan voor elke dag apart kunt instellen.
Ik heb zoiets wel al gezien bij omv maar weet niet of dit mogelijk is op zfsguru?
Graag reacties en tips.
Alleen virtualbox wil niet meer starten/is uitgeschakeld vanzelf.
Raar maar niet erg belangrijk voor mij.
Nu ben ik op zoek naar een soort van script waarmee ik mijn server automatisch in standby/sleep modus kan krijgen en daarna weer op laten starten zodat hij bijvoorbeeld op zondag nacht om 3 uur am in standbye gaat en bijvoorbeeld om 7 uur am maandagochtend weer aangaat.
En dat je dat dan voor elke dag apart kunt instellen.
Ik heb zoiets wel al gezien bij omv maar weet niet of dit mogelijk is op zfsguru?
Graag reacties en tips.
- FREAKJAM
- Registratie: Mei 2007
- Laatst online: 12:17
"MAXIMUM"
/u/217664/crop57a47149436c0_cropped.png?f=community)
Mensen die FreeNAS draaien, niet updaten naar de laatste versie (9.2.1.2).
fix mocht je toch 9.2.1.2 draaien:
of
code:
1
2
3
4
5
| 18:23:33 < alex-h2bsm> Hi guys, has the 9.2.1.2 release been recalled? 18:23:44 <+jpaetzel> yes 18:23:50 <+jpaetzel> it has a fatal flaw 18:23:55 <+jpaetzel> working on it now 18:24:25 <+jpaetzel> the auto importer and the firmware updater are broken |
fix mocht je toch 9.2.1.2 draaien:
code:
1
2
3
4
5
6
7
8
9
10
| 18:26:01 <+jpaetzel> # mountrw / 18:26:22 <+jpaetzel> # vi /usr/local/www/freenasUI/common/forms.py 18:27:14 <+jpaetzel> :160 18:27:23 <+jpaetzel> that will take you to a line that says: 18:27:31 <+jpaetzel> def done(self, request, events): 18:27:49 <+jpaetzel> change it to: 18:27:51 <+jpaetzel> def done(self, request=None, events=None, **kwargs): 18:28:24 <+jpaetzel> # mount -ur / 18:28:30 <+jpaetzel> # service django restart 18:28:36 <+jpaetzel> and you are back in business |
of
code:
1
2
3
4
| cd /tmp fetch 'http://download.freenas.org/errata/fix.sh' chmod 755 fix.sh sh ./fix.sh |
[ Voor 51% gewijzigd door FREAKJAM op 01-03-2014 19:26 ]
is everything cool?
Had het ook in esxi topic gepost maar misschien meer geschikt voor hier.
hmm, heb mijn asmedia 1061 handmatig geinstalleerd hier heb ik nu 2 datastores op (1 ssd en gewone hd ), vervolgens de panther intel ahci op passtrough gezet.
En deze heb ik nu aan de nas4free vm gehangen een pciconf -lvcb geeft mij het volgende:
Heb helaas nog geen disks hier om te testen, maar zoals ik het zie kan ik er nu gewoon disken op de SATA van de intel aansluiten moeten deze zichtbaar worden binnen Nas4free?
none2@pci0:3:0:0: class=0x010601 card=0x1e021849 chip=0x1e028086 rev=0x04 hdr=0x00
vendor = 'Intel Corporation'
device = 'Panther Point 6 port SATA AHCI Controller'
class = mass storage
subclass = SATA
bar [10] = type I/O Port, range 32, base 0x4038, size 8, enabled
bar [14] = type I/O Port, range 32, base 0x4030, size 4, enabled
bar [18] = type I/O Port, range 32, base 0x4028, size 8, enabled
bar [1c] = type I/O Port, range 32, base 0x4024, size 4, enabled
bar [20] = type I/O Port, range 32, base 0x4000, size 32, enabled
bar [24] = type Memory, range 32, base 0xfd4fe800, size 2048, enabled
cap 05[80] = MSI supports 1 message
cap 01[70] = powerspec 3 supports D0 D3 current D0
cap 12[a8] = SATA Index-Data Pair
cap 13[b0] = PCI Advanced Features: FLR TP
OK aan het testen geweest, oude disk gevonden word niet herkend.
zal een IBM M1015 gaan aanschaffen > it mode flashen > passtrough en dan zfs opbouwen.
hmm, heb mijn asmedia 1061 handmatig geinstalleerd hier heb ik nu 2 datastores op (1 ssd en gewone hd ), vervolgens de panther intel ahci op passtrough gezet.
En deze heb ik nu aan de nas4free vm gehangen een pciconf -lvcb geeft mij het volgende:
Heb helaas nog geen disks hier om te testen, maar zoals ik het zie kan ik er nu gewoon disken op de SATA van de intel aansluiten moeten deze zichtbaar worden binnen Nas4free?
none2@pci0:3:0:0: class=0x010601 card=0x1e021849 chip=0x1e028086 rev=0x04 hdr=0x00
vendor = 'Intel Corporation'
device = 'Panther Point 6 port SATA AHCI Controller'
class = mass storage
subclass = SATA
bar [10] = type I/O Port, range 32, base 0x4038, size 8, enabled
bar [14] = type I/O Port, range 32, base 0x4030, size 4, enabled
bar [18] = type I/O Port, range 32, base 0x4028, size 8, enabled
bar [1c] = type I/O Port, range 32, base 0x4024, size 4, enabled
bar [20] = type I/O Port, range 32, base 0x4000, size 32, enabled
bar [24] = type Memory, range 32, base 0xfd4fe800, size 2048, enabled
cap 05[80] = MSI supports 1 message
cap 01[70] = powerspec 3 supports D0 D3 current D0
cap 12[a8] = SATA Index-Data Pair
cap 13[b0] = PCI Advanced Features: FLR TP
OK aan het testen geweest, oude disk gevonden word niet herkend.
zal een IBM M1015 gaan aanschaffen > it mode flashen > passtrough en dan zfs opbouwen.
[ Voor 5% gewijzigd door Phyt_ op 01-03-2014 22:26 ]
You know you ve played warcraft III too much when.... Your sitting next to a guy at the busstop waiting for a bus, and he stands up before the bus gets there, and you claim that hes map hacking
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Zojuist installatie en configuratie afgerond van m'n nieuwe ZFS pool op de IBM M1015  maar na een reboot wordt er niets gemount.
maar na een reboot wordt er niets gemount.
Ik heb de pool aangemaakt met -m /mnt/data optie, met het idee dat onderliggende filesystems automatisch beschikbaar zijn. Na het aanmaken was dat ook zo.
Ik heb nu verschillende dingen gelezen over dat mounten en mountpoints e.d., maar ik vind even niet waarom ze niet na reboot mounten.
Iemand die me daar mee op weg kan helpen?
Dank!
Ik heb de pool aangemaakt met -m /mnt/data optie, met het idee dat onderliggende filesystems automatisch beschikbaar zijn. Na het aanmaken was dat ook zo.
Ik heb nu verschillende dingen gelezen over dat mounten en mountpoints e.d., maar ik vind even niet waarom ze niet na reboot mounten.
Iemand die me daar mee op weg kan helpen?
Dank!
-m is dacht ik tijdelijk. Als je het mountpoint permanent wil wijzigen doe je:
zfs set mountpoint=/mnt/data pool/filesystem
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Het mountpoint is wel goed, zfs mount -a mount alles netjes op de juiste plaats, alleen het was niet gemount na een reboot en dat zou volgens mij wel moeten (volgens wat ik begrepen heb tenminste).
Dan loop je waarschijnlijk tegen dezelfde bug aan waar ik ook tegenaan ben gelopen, namelijk dat de automount in Ubuntu (en dus waarschijnlijk ook Debian) stuk is voor ZFSonLinux.
The ZFS Storage Blog!: Tutorial: Ubuntu NAS/SAN All-in-one!
Zoek even op ZFS Sleep Fix
PS: Het is nog een ruwe draft
The ZFS Storage Blog!: Tutorial: Ubuntu NAS/SAN All-in-one!
Zoek even op ZFS Sleep Fix
PS: Het is nog een ruwe draft
[ Voor 3% gewijzigd door FireDrunk op 01-03-2014 20:32 ]
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Oke ik ben tegen een eigenaardigheidje aangelopen.
Ik heb zojuist m'n md raids verwijderd van m'n mediapool en op die 3 4TB schijven een zfs raidz pool gemaakt. Heb ik iets minder ruimte maar ik had nog 5TB vrij, dus voldoende om het redundant te maken.
Goed, ben nu alles aan het terug kopieren van m'n backup pool en tijdens de verificatie loop ik hier tegenaan:
Dus de grootte verschilt maar aantal bestanden + dirs is gelijk. cp -ruv doet ook niets (1ste regel). Het is dus blijkbaar goed, maar waarom verschillen die groottes?
Dat had ik voorheen niet met de "gewone" ext4 volumes ...
Edit:
Nog iets:
blkid geeft van de eerste pool (datapool) die ik heb aangemaakt netjes LABEL etc weer maar sdb/sdc/sdd hebben nog de info van mdadm. Kan dat nog makkelijk aangepast worden zodat die laastgenoemde er net zo uit zien als die onderste in de lijst?
Ik heb zojuist m'n md raids verwijderd van m'n mediapool en op die 3 4TB schijven een zfs raidz pool gemaakt. Heb ik iets minder ruimte maar ik had nog 5TB vrij, dus voldoende om het redundant te maken.
Goed, ben nu alles aan het terug kopieren van m'n backup pool en tijdens de verificatie loop ik hier tegenaan:
code:
1
2
3
4
5
6
7
8
9
10
| usertje@servertje:/mnt/data/Backups$ cp -ruv Concerts/ /mnt/media/ usertje@servertje:/mnt/data/Backups$ du -s Concerts/ 346494502 Concerts/ usertje@servertje:/mnt/data/Backups$ du -s /mnt/media/Concerts/ 345160368 /mnt/media/Concerts/ usertje@servertje:/mnt/data/Backups$ find Concerts/ | wc -l 355 usertje@servertje:/mnt/data/Backups$ find /mnt/media/Concerts/ | wc -l 355 usertje@servertje:/mnt/data/Backups$ |
Dus de grootte verschilt maar aantal bestanden + dirs is gelijk. cp -ruv doet ook niets (1ste regel). Het is dus blijkbaar goed, maar waarom verschillen die groottes?
Dat had ik voorheen niet met de "gewone" ext4 volumes ...
Edit:
Nog iets:
blkid geeft van de eerste pool (datapool) die ik heb aangemaakt netjes LABEL etc weer maar sdb/sdc/sdd hebben nog de info van mdadm. Kan dat nog makkelijk aangepast worden zodat die laastgenoemde er net zo uit zien als die onderste in de lijst?
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
| /dev/sda1: UUID="5877-CEEE" TYPE="vfat" /dev/sda2: LABEL="boot" UUID="3b9c5cb4-55f7-4809-825f-93fa274b6387" TYPE="ext4" /dev/sda3: UUID="f961aa89-7621-497a-a794-ad93d530899b" TYPE="swap" /dev/sda4: LABEL="root" UUID="25d94b5e-3803-4cfb-b7c1-27c3476261cb" TYPE="ext4" /dev/sdd1: UUID="92f9bcc7-9500-32c9-a8e0-cf30e40daa15" UUID_SUB="ebe1a27d-f6b3-51d8-66eb-286b944a2292" LABEL="servertje:0" TYPE="linux_raid_member" /dev/sdb1: UUID="92f9bcc7-9500-32c9-a8e0-cf30e40daa15" UUID_SUB="16884b2e-aa6a-c4ab-653f-f900e039cae8" LABEL="servertje:0" TYPE="linux_raid_member" /dev/sdc1: UUID="92f9bcc7-9500-32c9-a8e0-cf30e40daa15" UUID_SUB="29116de7-a763-b086-d4af-5e69033e8bd1" LABEL="servertje:0" TYPE="linux_raid_member" /dev/sdh1: LABEL="datapool" UUID="4136940606789809982" UUID_SUB="16486362791556719554" TYPE="zfs_member" /dev/sdg1: LABEL="datapool" UUID="4136940606789809982" UUID_SUB="5935007113664039638" TYPE="zfs_member" /dev/sdf1: LABEL="datapool" UUID="4136940606789809982" UUID_SUB="8905513856215458969" TYPE="zfs_member" /dev/sdi1: LABEL="datapool" UUID="4136940606789809982" UUID_SUB="5517633983283693819" TYPE="zfs_member" /dev/sde1: LABEL="datapool" UUID="4136940606789809982" UUID_SUB="1520761817449728646" TYPE="zfs_member" /dev/sdj1: LABEL="datapool" UUID="4136940606789809982" UUID_SUB="1035852609397734823" TYPE="zfs_member" |
[ Voor 44% gewijzigd door InflatableMouse op 01-03-2014 23:46 ]
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Zo dan ...
code:
1
2
3
4
5
6
7
8
9
| NAME STATE READ WRITE CKSUM
datapool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
ata-Hitachi_HDS5C3020ALA632_ML0220F30Z09GD ONLINE 0 0 0
ata-ST2000DM001-9YN164_W1E0L80S FAULTED 43 252 0 too many errors
ata-ST2000DM001-9YN164_W1E0KXJV ONLINE 0 0 0
ata-WDC_WD20EARS-00MVWB0_WD-WMAZA1448932 ONLINE 0 0 0
ata-ST2000DM001-9YN164_W1E0HYEX ONLINE 0 0 0
ata-Hitachi_HDS5C3020ALA632_ML0220F30Z0A1D ONLINE 0 0 0 |
code:
1
| Mar 2 10:52:49 servertje smartd[10006]: Device: /dev/sdf [SAT], open() failed: No such device |
[ Voor 7% gewijzigd door InflatableMouse op 02-03-2014 11:24 ]
Als je die disk weer online krijgt, zou ik je partities (mits je GPT gebruikt) een partitie label geven, en daar je pool op importeren.
Je kan dat doen door eerst je pool te exporteren
En daarnaa je pool weer te importeren met de -d optie:
Je kan dat doen door eerst je pool te exporteren
zpool export [poolnaam]
En daarnaa je pool weer te importeren met de -d optie:
zpool import -d /dev/disk/by-partlabel/
Even niets...
/u/8830/crop5df8eadcd55ca_cropped.png?f=community)
Even een andere vraag: in de ts staat wel het een en ander over monitoring, maar nog niet echt wat significants. Ik heb zelf nu de ZFS status in mijn nagios gehangen, dus ik weet als het echt niet goed gaat, maar graag zou ik in Zabbix wat leuke grafiekjes over disk i/o, usage, compression e.d. hebben. Ik kan hier op internet echter bar weinig over vinden.. hebben jullie nog suggesties?
Na betaling van een licentievergoeding van €1.000 verkrijgen bedrijven het recht om deze post te gebruiken voor het trainen van artificiële intelligentiesystemen.
BSD of Linux?
Even niets...
Ubuntu Linux
Na betaling van een licentievergoeding van €1.000 verkrijgen bedrijven het recht om deze post te gebruiken voor het trainen van artificiële intelligentiesystemen.
Hmm, geen idee. Ik weet dat er voor ZFS wel een hoop tempaltes zijn voor Zabbix, maar voor Nagios zou ik het zo niet weten.
Even niets...
Alle Zabbix ZFS templates die ik tot nu toe bekeken hebben zijn redelijk minimalistisch. (Doen meestal niets meer dan triggers per volume status instellen).
Na betaling van een licentievergoeding van €1.000 verkrijgen bedrijven het recht om deze post te gebruiken voor het trainen van artificiële intelligentiesystemen.
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Alles is GPT. Het leek me op ID juist het best omdat dat niet verandert, tenzij je een disk vervangt zoals ik nu heb gedaan. Die andere was inderdaad stuk, deed het nog wel maar self test klapte er op 10% al uit op unrecoverable read errors.FireDrunk schreef op zondag 02 maart 2014 @ 11:40:
Als je die disk weer online krijgt, zou ik je partities (mits je GPT gebruikt) een partitie label geven, en daar je pool op importeren.
Je kan dat doen door eerst je pool te exporteren
zpool export [poolnaam]
En daarnaa je pool weer te importeren met de -d optie:
zpool import -d /dev/disk/by-partlabel/
Ik was hier nog even niet op voorbereid (behalve dat ik een spare had liggen) maar nu begint het inlezen hoe ik verder moet. De nieuwe disk zit er in .. maar nu ...
- Xudonax
- Registratie: November 2010
- Laatst online: 22-07 11:43
code:
1
| zpool replace <pool> <device> <new-device> |
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
ja, had em al gevonden! Simpeler kan bijna niet.
# zpool replace datapool ata-ST2000DM001-9YN164_W1E0L80S /dev/disk/by-id/ata-WDC_WD20EADS-11R6B1_WD-WCAVY2473346
# zpool status
pool: datapool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Sun Mar 2 12:24:29 2014
183G scanned out of 8.45T at 317M/s, 7h35m to go
30.4G resilvered, 2.11% done
config:
NAME STATE READ WRITE CKSUM
datapool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
ata-Hitachi_HDS5C3020ALA632_ML0220F30Z09GD ONLINE 0 0 0
replacing-1 UNAVAIL 0 0 0
ata-ST2000DM001-9YN164_W1E0L80S UNAVAIL 0 0 0
ata-WDC_WD20EADS-11R6B1_WD-WCAVY2473346 ONLINE 0 0 0 (resilvering)
ata-ST2000DM001-9YN164_W1E0KXJV ONLINE 0 0 0
ata-WDC_WD20EARS-00MVWB0_WD-WMAZA1448932 ONLINE 0 0 0
ata-ST2000DM001-9YN164_W1E0HYEX ONLINE 0 0 0
ata-Hitachi_HDS5C3020ALA632_ML0220F30Z0A1D ONLINE 0 0 0
errors: No known data errors
Verwijderd
Kijk voor de grap eens naar SMART op je Seagate disks...
Daar wordt je pas niet vrolijk van.
Een vriend van mij heeft al een uitval van 140% (10 disks) over 17 maanden periode met Seagate disks.
na aanleiding van zijn ervaringen ben ik zelf ook eens gaan kijken...
Mijn 2 TB-disks (8 stuks in 2 QNAP's) heb ik tot op heden nog geen uitval gehad, maar de TRIM-waardes...
Schokkend!
80 miljoen raw-read_error_rate, 35-38 miljoen seek_error_rate en ga zo maar door.
En dat bij 28317 power_on_hours.
Om je een idee te geven met een 'referentiedisk' van WD...
Ruim 13000 power_on_hours, 2 raw_read_error_rate en 0 seek_error_rate.
Dat zet je wel even aan het denken.
Daar wordt je pas niet vrolijk van.
Een vriend van mij heeft al een uitval van 140% (10 disks) over 17 maanden periode met Seagate disks.
na aanleiding van zijn ervaringen ben ik zelf ook eens gaan kijken...
Mijn 2 TB-disks (8 stuks in 2 QNAP's) heb ik tot op heden nog geen uitval gehad, maar de TRIM-waardes...
Schokkend!
80 miljoen raw-read_error_rate, 35-38 miljoen seek_error_rate en ga zo maar door.
En dat bij 28317 power_on_hours.
Om je een idee te geven met een 'referentiedisk' van WD...
Ruim 13000 power_on_hours, 2 raw_read_error_rate en 0 seek_error_rate.
Dat zet je wel even aan het denken.
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ja, ik weet er alles van. Ik had dit ook wel verwacht alleen had ik gehoopt dat het iets langer zou duren. Ik wist dat het gebeuren stond iig en daarom heb ik er ook een RAIDZ2 van gemaakt, ik vertrouw die Seagates voor geen cent!
2 Seagates in mijn eigen pc zijn kort geleden vrijwel tegelijkertijd overleden (zat 3 dagen tussen). Twee van de 3 die in de server zitten (waarvan er nu 1 stuk is) waren al geRMA'd maar vertoonden direct na omruil weer problemen, alleen niet genoeg om ze opnieuw terug te sturen en ondertussen zijn ze ver uit garantie.
Had dus 4 Seagates in mijn server (nu nog 3) en allemaal hebben ze dezelfde problemen. Ik verwacht dat er binnenkort weer eentje sneuvelt maar ik heb nog 2 spares liggen. WD greens. De Seagate die net gesneuveld is is ook door een Seagate vervangen. Al mijn spares zijn al een paar jaartjes oud en vertonen geen van allen problemen.
Ik wil voorlopig nooit meer iets anders dan Hitachi (HGST). Mijn media pool zijn allemaal Hitachis/HGST's en er komen er volgende week 2 bij (allemaal 4TB). Mijn datapool hierboven wordt vervangen door WD's of ook Hitachis/HGST's als ze goedkoper worden.
2 Seagates in mijn eigen pc zijn kort geleden vrijwel tegelijkertijd overleden (zat 3 dagen tussen). Twee van de 3 die in de server zitten (waarvan er nu 1 stuk is) waren al geRMA'd maar vertoonden direct na omruil weer problemen, alleen niet genoeg om ze opnieuw terug te sturen en ondertussen zijn ze ver uit garantie.
Had dus 4 Seagates in mijn server (nu nog 3
Ik wil voorlopig nooit meer iets anders dan Hitachi (HGST). Mijn media pool zijn allemaal Hitachis/HGST's en er komen er volgende week 2 bij (allemaal 4TB). Mijn datapool hierboven wordt vervangen door WD's of ook Hitachis/HGST's als ze goedkoper worden.
Dat is geen getal van absoluut aantal errors; zoals bij UDMA CRC Error Count het geval is. Bij RRER en SER gaat het om 'rates' oftewel een verhouding tussen goed en slecht. Een hoog RAW-value betekent duus niets. Je kunt in feite alleen maar naar de Current/Worst/Threshold kijken.Verwijderd schreef op zondag 02 maart 2014 @ 16:45:
80 miljoen raw-read_error_rate, 35-38 miljoen seek_error_rate en ga zo maar door.
Hetzelfde geldt voor sommige schijven die temperatuur binary encoded opslaan. Dan heb je een getal van een paar miljoen; dat betekent niet dat je schijf zo heet is als de zon, maar dat dit getal een codering is van meerdere getallen.
Je kunt niet de SMART van twee schijven vergelijken. Omdat je appels met peren vergelijkt. Een raw-value van 0 voor schijf X kan overeen komen met een heel groot getal; daar kun je weinig zinnigs over zeggen. De genormaliseerde Current-waarde kun je het beste als uitgangspunt nemen.Om je een idee te geven met een 'referentiedisk' van WD...
Ruim 13000 power_on_hours, 2 raw_read_error_rate en 0 seek_error_rate.
Dat zet je wel even aan het denken.
Wat je wel kunt doen is schijven vergelijken met andere exemplaren van hetzelfde type; dan kun je de SMART inderdaad vergelijken.
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Da's wel interessant CiPHER, dat wist ik ook niet (over die verhouding).
Maar hier gaan de andere twee Seagates:
Mar 2 17:42:23 paradise smartd[6778]: Device: /dev/sde [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 119 to 111
Mar 2 17:42:25 paradise smartd[6778]: Device: /dev/sdg [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 117 to 119
M'n log staat weer vol.
Zpool resilveren moet nog 2,5 uur, het is RAIDZ2 dus fingers crossed. Het zal me toch niet gebeuren dat ik binnen een paar uur tijd 3 kapotte disks heb he ... ik wordt stiekum toch wel nerveus ...
En ja, ik heb backups.
Maar hier gaan de andere twee Seagates:
Mar 2 17:42:23 paradise smartd[6778]: Device: /dev/sde [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 119 to 111
Mar 2 17:42:25 paradise smartd[6778]: Device: /dev/sdg [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 117 to 119
M'n log staat weer vol.
Zpool resilveren moet nog 2,5 uur, het is RAIDZ2 dus fingers crossed. Het zal me toch niet gebeuren dat ik binnen een paar uur tijd 3 kapotte disks heb he ... ik wordt stiekum toch wel nerveus ...
En ja, ik heb backups
De Current waarde is een genormaliseerde waarde tussen 0 en 255; waarbij geldt: hoe hoger hoe beter. De meeste attributen beginnen bij 100 of 200; dat is de best mogelijke 'Current' waarde. Je kunt zien of RRER/SER een beetje normaal is door de Current met de Threshold te vergelijken. Zit de Current duidelijk boven de Threshold; dan is er weinig aan de hand; komt de Current beneden de Threshold, dan krijg je een officiële SMART failure.
Wat jij doet, InflatableMouse, met het in de gaten houden van SMART, is heel goed. Je kunt daardoor trends zien. Als je schijven nu boven de 100 doen met RRER en over een half jaar is dat gezakt tot 58; dan kun je daar wel een oordeel over vellen. Ook vergelijken met dezelfde schijven van hetzelfde type (en firmware) is mogelijk.
Maar wat maar al te vaak gebeurt is dat SMART verkeerd geïnterpreteerd wordt. Zelfs de makers van SMART-utilities (HDtune, CrystalDiskInfo) lijken SMART niet altijd goed te begrijpen, gezien het verkeerde advies wat ze geven. Wikipedia is ook niet behulpzaam als het gaat om SMART; dat is juridisch verwoord door iemand die niet begrijpt waar die attributen werkelijk over gaan. Overgetypt van een manual lijkt het wel.
Kortom, jammer, gemiste kans. SMART is namelijk zo nuttig om te zien of je schijf een beetje normaal functioneert. Maar helaas gaat het interpreteren van SMART vaker fout dan goed.
Wat jij doet, InflatableMouse, met het in de gaten houden van SMART, is heel goed. Je kunt daardoor trends zien. Als je schijven nu boven de 100 doen met RRER en over een half jaar is dat gezakt tot 58; dan kun je daar wel een oordeel over vellen. Ook vergelijken met dezelfde schijven van hetzelfde type (en firmware) is mogelijk.
Maar wat maar al te vaak gebeurt is dat SMART verkeerd geïnterpreteerd wordt. Zelfs de makers van SMART-utilities (HDtune, CrystalDiskInfo) lijken SMART niet altijd goed te begrijpen, gezien het verkeerde advies wat ze geven. Wikipedia is ook niet behulpzaam als het gaat om SMART; dat is juridisch verwoord door iemand die niet begrijpt waar die attributen werkelijk over gaan. Overgetypt van een manual lijkt het wel.
Kortom, jammer, gemiste kans. SMART is namelijk zo nuttig om te zien of je schijf een beetje normaal functioneert. Maar helaas gaat het interpreteren van SMART vaker fout dan goed.
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Het valt me nu pas op dat die ene dus is gezakt, van 119 naar 111. Blijkbaar las ik dit dus nooit goed want ik ging er altijd vanuit dat het de counters altijd stijgen. Dit zijn de laatste twee meldingen:
Als ik het goed begrijp is sde er dus slechter aan toe, omdat die waarde dus zakt. sdg doet het dus beter want die stijgt, wat betekent dat hij minder raw errors heeft en de verhouding daardoor hoger komt te liggen?
Zeg ik dat goed?
Mar 2 18:22:22 servertje smartd[6778]: Device: /dev/sde [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 119 to 108 Mar 2 18:22:24 servertje smartd[6778]: Device: /dev/sdg [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 117 to 118
Als ik het goed begrijp is sde er dus slechter aan toe, omdat die waarde dus zakt. sdg doet het dus beter want die stijgt, wat betekent dat hij minder raw errors heeft en de verhouding daardoor hoger komt te liggen?
Zeg ik dat goed?
Stijgen en of dalen is beide volgens mij niet goed. Volgens mij moet het gewoon gelijk blijven...
Maar goed, ik zie het hier ook, dus wat CiPHER zegt zal zeker waar zijn.
Maar goed, ik zie het hier ook, dus wat CiPHER zegt zal zeker waar zijn.
[ Voor 30% gewijzigd door FireDrunk op 02-03-2014 19:01 ]
Even niets...
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Mja, sde gaat op en neer. Ging net van 108 naar 118 en nu terug naar 107. sdg is nog een keertje naar 117 gegaan en is nu weer terug op 118.
Rebuild is compleet zonder extra problemen met sde of sdg, gelukkig.
Rebuild is compleet zonder extra problemen met sde of sdg, gelukkig
[ Voor 20% gewijzigd door InflatableMouse op 02-03-2014 22:09 ]
- Q
- Registratie: November 1999
- Laatst online: 13:04
Au Contraire Mon Capitan!
/u/1176/crop635f8931b2b68_cropped.png?f=community)
Dat soort dingen zie ik al 5 jaar lang in de logs van mijn server(s) en nog geen disk uitval gehad, ik denk dat dit gewoon wat fluctuaties zijn maar dat dit verder weinig kwaad kan.InflatableMouse schreef op zondag 02 maart 2014 @ 19:10:
Mja, sde gaat op en neer. Ging net van 108 naar 118 en nu terug naar 107. sdg is nog een keertje naar 117 gegaan en is nu weer terug op 118.
- Pixeltje
- Registratie: November 2005
- Laatst online: 14:12
Woo-woohoo!
Ik ben aan het kijken naar uitbreiding van mijn huidige NAS maar zit met een aantal vragen waar ik zelf niet zo snel uitkom;
Mijn NAS draait op Freenas (laatste stabiele versie, nummer weet ik even niet uit mijn hoofd) en is gebaseerd op een Sandy bridge systeem met een zuinige processor, 16 GB geheugen en 4 schijven van 2TB in een raidz2 array.
Mijn pa wil graag storage voor zijn belangrijkste bestanden, waardoor ik in eerste instantie een NAS voor hem aan het zoeken was (waarschijnlijk een Synology oid), maar nu mijn woonsituatie gewijzigd is en er meer mensen zijn die gebruik willen maken van centrale opslag leek het me een mooi moment om mijn kleine nasje te laten groeien.
Waar ik aan zit te denken is het volgende;
- Huidige 4 schijven laten voor wat ze zijn; inclusief de data.
- Extra schijven plaatsen (bijvoorbeeld 8*1TB via V&A) en configureren tot een raidz2; ik kan dan op die nieuwe array wat data backuppen van de bestaande array en ruimte maken voor nieuwe gebruikers, homeshares, etc etc.
Nu vraag ik me af of het verstandiger is om één nieuwe raidz2 te maken met 8 schijven, of twee arrays met 4 schijven. de netto opslagruimte wordt dan aanzienlijk minder maar de redundancy stijgt navenant.
Even los van de vraag of er backups gemaakt worden buiten mijn NAS (voor de echt belangrijke zaken wel), wat is met het oog op snelheid en betrouwbaarheid de beste oplossing? Of kijk ik niet ver genoeg en zijn er alternatieven die ik over het hoofd zie?
Mijn NAS draait op Freenas (laatste stabiele versie, nummer weet ik even niet uit mijn hoofd) en is gebaseerd op een Sandy bridge systeem met een zuinige processor, 16 GB geheugen en 4 schijven van 2TB in een raidz2 array.
Mijn pa wil graag storage voor zijn belangrijkste bestanden, waardoor ik in eerste instantie een NAS voor hem aan het zoeken was (waarschijnlijk een Synology oid), maar nu mijn woonsituatie gewijzigd is en er meer mensen zijn die gebruik willen maken van centrale opslag leek het me een mooi moment om mijn kleine nasje te laten groeien.
Waar ik aan zit te denken is het volgende;
- Huidige 4 schijven laten voor wat ze zijn; inclusief de data.
- Extra schijven plaatsen (bijvoorbeeld 8*1TB via V&A) en configureren tot een raidz2; ik kan dan op die nieuwe array wat data backuppen van de bestaande array en ruimte maken voor nieuwe gebruikers, homeshares, etc etc.
Nu vraag ik me af of het verstandiger is om één nieuwe raidz2 te maken met 8 schijven, of twee arrays met 4 schijven. de netto opslagruimte wordt dan aanzienlijk minder maar de redundancy stijgt navenant.
Even los van de vraag of er backups gemaakt worden buiten mijn NAS (voor de echt belangrijke zaken wel), wat is met het oog op snelheid en betrouwbaarheid de beste oplossing? Of kijk ik niet ver genoeg en zijn er alternatieven die ik over het hoofd zie?
And if this doesn't make us motionless, I do not know what can.
Het prijsverschil tussen 8x 1 TB 2e hands en 2x 4 TB nieuw lijkt me ruim op te wegen tegen het stroomgebruik en de garantie 3 Watt per schijf, 6 schijven verschil, 24/7 gebruik geeft (bij 25ct / KWh) 40 euro stroom per jaar.
Daarnaast zijn beide opties niet ideal, want je hebt geen macht van 2 als aantal dataschijven. 3, 5 of 9x 4TB in RaidZ (al zou ik bij 5 stoppen), 4, 6 of 10x in Z2.
Ik zou dus eerder 3x 4TB in RaidZ zetten dan een stapel 2e hands schijven van Marktplaats trekken en een bak stroom gebruiken zonder garantie
Daarnaast zijn beide opties niet ideal, want je hebt geen macht van 2 als aantal dataschijven. 3, 5 of 9x 4TB in RaidZ (al zou ik bij 5 stoppen), 4, 6 of 10x in Z2.
Ik zou dus eerder 3x 4TB in RaidZ zetten dan een stapel 2e hands schijven van Marktplaats trekken en een bak stroom gebruiken zonder garantie
[ Voor 10% gewijzigd door Paul op 03-03-2014 09:34 ]
"Your life is yours alone. Rise up and live it." - Richard Rahl
Rhàshan - Aditu Sunlock
- Pixeltje
- Registratie: November 2005
- Laatst online: 14:12
Woo-woohoo!
Oke das waar, of het er nu 8 worden of niet doet er niet toe, kan er ook 6 kopenPaul schreef op maandag 03 maart 2014 @ 09:31:
Het prijsverschil tussen 8x 1 TB 2e hands en 2x 4 TB nieuw lijkt me ruim op te wegen tegen het stroomgebruik en de garantie
Daarnaast zijn beide opties niet ideal, want je hebt geen macht van 2 als aantal dataschijven. 3, 5 of 9x 4TB in RaidZ (al zou ik bij 5 stoppen), 4, 6 of 10x in Z2.
Ik zou dus eerder 3x 4TB in RaidZ zetten dan een stapel 2e hands schijven van Marktplaats trekken en een bak stroom gebruiken zonder garantie
Klopt het verder wel dat ik in FreeNAS de ene array kan laten backuppen naar de andere? Heb hier nog geen ervaring mee omdat ik tot nog toe één array gebruik.
And if this doesn't make us motionless, I do not know what can.
- nwagenaar
- Registratie: Maart 2001
- Laatst online: 14:20
God, root. What's the differen
Ghe. Toevallig heb ik afgelopen vrijdagavond mijn schijven in mijn Ubuntu Server gehangen en eigenlijk komt het meeste bij mij zeer bekend voor. Binnen 5 minuten had ik alles werkend.FireDrunk schreef op zaterdag 01 maart 2014 @ 20:32:
Dan loop je waarschijnlijk tegen dezelfde bug aan waar ik ook tegenaan ben gelopen, namelijk dat de automount in Ubuntu (en dus waarschijnlijk ook Debian) stuk is voor ZFSonLinux.
The ZFS Storage Blog!: Tutorial: Ubuntu NAS/SAN All-in-one!
Zoek even op ZFS Sleep Fix
PS: Het is nog een ruwe draft
Alleen ik moet duidelijk toch nog wat gaan tweaken:
- Een rsync van een 20GB bestand op mijn ZFS-share naar /dev/shm geeft mij "maar" 40MB/s (dus op OS niveau)
- Een write van een 2GB bestand naar mijn ZFS-share middels samba/Windows8 geeft mij "maar" 25MB/s ~ 30MB/s
Hij is nu nog bezig met enkele benchmarks; maar ik moet duidelijk de samba-configuratie tweaken en daarbij is mijn cache ook nog niet actief. Maar zelfs zonder cache zou ie meer moeten halen en ik weet nagenoeg zeker dat mijn ZFSGuru configuratie het dubbele haalde (4x2TB Seagates in RAIDZ draaiende in een HP Microserver N40L met 16GB RAM).
Heeft iemand ervaringen met het tweaken van ZFS on Linux of wellicht enkele tips voor mij?
Wat was er twee keer zo snel? Samba of ZFS?
Even niets...
- nwagenaar
- Registratie: Maart 2001
- Laatst online: 14:20
God, root. What's the differen
Via samba haalde ik makkelijk 70MB/s; maar ik weet dat het één en ander nog getweaked moet worden. De snelheid binnen het OS was sowieso sneller. Ter indicatie, dit is de informatie middels dd:
Het is zo verdomd jammer dat Windows 8 Pro geen NFS client meer heeft zodat ik het één en ander beter kan benchmarken....
code:
1
2
3
4
| root@VDR01:/data# dd if=/dev/zero of=/data/zerofile.000 bs=1M count=20000 20000+0 records in 20000+0 records out 20971520000 bytes (21 GB) copied, 195.26 s, 107 MB/s |
code:
1
2
3
4
| root@VDR01:/data# dd if=/data/zerofile.000 of=/dev/null bs=1M 20000+0 records in 20000+0 records out 20971520000 bytes (21 GB) copied, 118.304 s, 177 MB/s |
Het is zo verdomd jammer dat Windows 8 Pro geen NFS client meer heeft zodat ik het één en ander beter kan benchmarken....
[ Voor 10% gewijzigd door nwagenaar op 03-03-2014 12:26 ]
socket options = TCP_NODELAY
in samba heeft vaak heel erg veel zin.
in samba heeft vaak heel erg veel zin.
Even niets...
- B2
- Registratie: April 2000
- Laatst online: 14:06
wa' seggie?
:strip_icc():strip_exif()/u/4824/i.jpeg?f=community)
Op zich zit ik nu een beetje voor eigen parochie te spreken, aangezien ik de verkoper van de schijven ben, maar ga je die schijven echt 24/7 laten draaien? Mijn eigen schijven laat ik al na een kwartier downspinnen. (Uberhaupt gaat mijn NAS in hibernate 's nachts) Die berekening die je maakt zal in dat geval niet opgaan en die 40 euro zal dus veel minder zijn.Paul schreef op maandag 03 maart 2014 @ 09:31:
Het prijsverschil tussen 8x 1 TB 2e hands en 2x 4 TB nieuw lijkt me ruim op te wegen tegen het stroomgebruik en de garantie
Daarnaast zijn beide opties niet ideal, want je hebt geen macht van 2 als aantal dataschijven. 3, 5 of 9x 4TB in RaidZ (al zou ik bij 5 stoppen), 4, 6 of 10x in Z2.
Ik zou dus eerder 3x 4TB in RaidZ zetten dan een stapel 2e hands schijven van Marktplaats trekken en een bak stroom gebruiken zonder garantie
Die 3 Watt was dan ook het idle-verbruik Al kan ik zo geen datasheets vinden van 1TB-schijven waarbij onderscheid wordt gemaakt tussen idle en sleep, mogelijk is sleep nog lager.
"Your life is yours alone. Rise up and live it." - Richard Rahl
Rhàshan - Aditu Sunlock
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Hoe monitoren jullie je pools?
Ik heb wel naar dingen als zabbix en nagios gekeken maar ik vind het een beetje overdreven, ik wil eigenlijk gewoon een mailtje krijgen als de status van een pool verandert, is dat makkelijk te doen?
Ik heb wel naar dingen als zabbix en nagios gekeken maar ik vind het een beetje overdreven, ik wil eigenlijk gewoon een mailtje krijgen als de status van een pool verandert, is dat makkelijk te doen?
- syl765
- Registratie: Juni 2004
- Laatst online: 27-07 21:32
kijk hier eens..
https://calomel.org/zfs_health_check_script.html
anders even googlen op zfs status scripts
https://calomel.org/zfs_health_check_script.html
anders even googlen op zfs status scripts
[ Voor 15% gewijzigd door syl765 op 03-03-2014 20:10 ]
- FREAKJAM
- Registratie: Mei 2007
- Laatst online: 12:17
"MAXIMUM"
Ik heb inmiddels een aantal weken flink getest/gespeeld met OMV, ZFSGuru, FreeNAS en NAS4Free en heb besloten om gewoon FreeNAS/ZFSGuru/NAS4Free whatsoever te gebruiken puur om ZFS hierop te regelen. Ik heb inmiddels Ubuntu server draaiende met sql, phpmyadin + lasi.sh. Installeren was echt easy peasy.
Ik stoei verder ook al een aantal dagen met spindown, maar dat krijg ik niet echt voor elkaar. Maar eigenlijk nog belangrijker, is het wel verstandig/raadzaam om disks te downspinnen die deel uitmaken van een zfs pool? Ik lees hier namelijk verschillende verhalen over. In mijn geval zal het ongeveer ~4x6 watt schelen (ik heb 6 wd reds die ik via esxi/passthrough (LSI 2308, X10SL7) doorgeef aan mijn VM).
Via de gui van FreeNAS/ZFSGuru/NAS4Free krijg ik het in ieder geval niet voor elkaar om de schijven te laten downspinnen. (Het staat allemaal netjes ingesteld, maar ze spinnen niet down) Handmatig lukt het dan weer wel, maar dat is ook niet echt wat ik zoek. Ik heb de posts gelezen van FireDrunk over de spindown utility en ik heb op het FreeNAS forum een scrippie gevonden. Hoe het scrippie precies werkt ben ik niet helemaal uit, maar ik heb eerder in dit topic CiPHER horen zeggen dat dat scrippie niet echt "netjes" is.
Ik heb geen Windows VM draaien op ESXi op dit moment (ben ook maar meteen voor ubuntu desktop gegaan als "testbak"). Ik zal binnenkort eens wat write benchmarks doen op mijn pool. Weet iemand toevallig een handig tooltje hiervoor? (aangezien dd benchmarking aka nullen wegschrijven op mijn pool niet echt hetgeen is wat ik zoek..)
Ik stoei verder ook al een aantal dagen met spindown, maar dat krijg ik niet echt voor elkaar. Maar eigenlijk nog belangrijker, is het wel verstandig/raadzaam om disks te downspinnen die deel uitmaken van een zfs pool? Ik lees hier namelijk verschillende verhalen over. In mijn geval zal het ongeveer ~4x6 watt schelen (ik heb 6 wd reds die ik via esxi/passthrough (LSI 2308, X10SL7) doorgeef aan mijn VM).
Via de gui van FreeNAS/ZFSGuru/NAS4Free krijg ik het in ieder geval niet voor elkaar om de schijven te laten downspinnen. (Het staat allemaal netjes ingesteld, maar ze spinnen niet down) Handmatig lukt het dan weer wel, maar dat is ook niet echt wat ik zoek. Ik heb de posts gelezen van FireDrunk over de spindown utility en ik heb op het FreeNAS forum een scrippie gevonden. Hoe het scrippie precies werkt ben ik niet helemaal uit, maar ik heb eerder in dit topic CiPHER horen zeggen dat dat scrippie niet echt "netjes" is.
Ik heb geen Windows VM draaien op ESXi op dit moment (ben ook maar meteen voor ubuntu desktop gegaan als "testbak"). Ik zal binnenkort eens wat write benchmarks doen op mijn pool. Weet iemand toevallig een handig tooltje hiervoor? (aangezien dd benchmarking aka nullen wegschrijven op mijn pool niet echt hetgeen is wat ik zoek..)
is everything cool?
Ik heb heel lang eenzelfde setup gehad, maar had toch relatief vaak problemen icm SabNZBd, SickBeard enzo over NFS op ZFS. Vage permissie problemen, of het terugvallen van de download directory van SabNZBd naar de default.
Pas heel goed op, en stel een ruime minimal free, want als SabNZBd je virtual disk vol plempt met downloads, ben je een poos bezig om dat weer op te schonen
Pas heel goed op, en stel een ruime minimal free, want als SabNZBd je virtual disk vol plempt met downloads, ben je een poos bezig om dat weer op te schonen
Even niets...
- FREAKJAM
- Registratie: Mei 2007
- Laatst online: 12:17
"MAXIMUM"
Ik ben nog niet aan het inrichten van NFS/ZFS gekomen plus ik heb Sab/Sick etc nog niet geconfigureerd, dus dat moet ik nog afwachten of dat gaat werken.
Anders kan ik nog altijd terug naar Windows + CIFS.
Anders kan ik nog altijd terug naar Windows + CIFS.
is everything cool?
Brrr... Vloeken in de kerk!
Even niets...
- FREAKJAM
- Registratie: Mei 2007
- Laatst online: 12:17
"MAXIMUM"
Je hebt nu ZoL toch? Ik zal je blog nog eens goed doorlezen
Wat een gedoe ook eigenlijk allemaal. Mijn HTPC is namelijk Windows dus dan moet ik NFS/CIFS regelen op wellicht dezelfde shares. (of voor CIFS read-only regelen, dan weet ik in ieder geval zeker dat het niet botst met elkaar).
edit:
Zucht, dit brengt me wel allemaal weer aan het twijfelen. Ik ben al 3 weken aan het spelen met FreeNAS, ZFSGuru, NAS4Free, noem maar op en ik kan maar niet de juiste keuze maken. Misschien ben ik wel te kieskeurig haha
Wat een gedoe ook eigenlijk allemaal. Mijn HTPC is namelijk Windows dus dan moet ik NFS/CIFS regelen op wellicht dezelfde shares. (of voor CIFS read-only regelen, dan weet ik in ieder geval zeker dat het niet botst met elkaar).
edit:
Zucht, dit brengt me wel allemaal weer aan het twijfelen. Ik ben al 3 weken aan het spelen met FreeNAS, ZFSGuru, NAS4Free, noem maar op en ik kan maar niet de juiste keuze maken. Misschien ben ik wel te kieskeurig haha
[ Voor 98% gewijzigd door FREAKJAM op 03-03-2014 23:27 ]
is everything cool?
- InflatableMouse
- Registratie: December 2006
- Laatst online: 15-06 17:00
Ik snap je probleem niet hoor. Mijn HTPC is ook Windows, mijn server draait Debian met ZoL. Ik heb zowel nfs shares voor mijn eigen pc, ook Debian en Samba voor de Windows 8 HTPC. Gewoon read/write, geen probleem. Wat zou daar botsen volgens jou?FREAKJAM schreef op maandag 03 maart 2014 @ 21:45:
Je hebt nu ZoL toch? Ik zal je blog nog eens goed doorlezen
Wat een gedoe ook eigenlijk allemaal. Mijn HTPC is namelijk Windows dus dan moet ik NFS/CIFS regelen op wellicht dezelfde shares. (of voor CIFS read-only regelen, dan weet ik in ieder geval zeker dat het niet botst met elkaar).
edit:
Zucht, dit brengt me wel allemaal weer aan het twijfelen. Ik ben al 3 weken aan het spelen met FreeNAS, ZFSGuru, NAS4Free, noem maar op en ik kan maar niet de juiste keuze maken. Misschien ben ik wel te kieskeurig haha
- FREAKJAM
- Registratie: Mei 2007
- Laatst online: 12:17
"MAXIMUM"
Ik bedoel zowel cifs/nfs regelen op exact dezelfde share. Kans op filelocking, hoewel die kans erg klein is i guess.
Ik wil zo simpel mogelijk vanaf mijn Windows 8 HTPC straks in ieder geval mijn mkv'tjes kunnen benaderen. Wellicht moet ik toch maar 1 doos maken in ESXi waar ik ZFS on Linux op ga doen en die tevens als downloadbak gaat fungeren. Uiteindelijk hoef ik dan alleen maar cifs shares te regelen, zodat mijn HTPC bij de data kan.
Ik wil zo simpel mogelijk vanaf mijn Windows 8 HTPC straks in ieder geval mijn mkv'tjes kunnen benaderen. Wellicht moet ik toch maar 1 doos maken in ESXi waar ik ZFS on Linux op ga doen en die tevens als downloadbak gaat fungeren. Uiteindelijk hoef ik dan alleen maar cifs shares te regelen, zodat mijn HTPC bij de data kan.
is everything cool?
Let op:
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.
Voor het bouwen van een ZFS NAS en andere hardwarevragen kun je beter terecht in Het grote DIY RAID NAS topic deel 3, zodat we dit topic reserveren voor ZFS-specifieke vragen en discussies.