Je laat nu net het belangrijkste weg:

Perhaps, this is why some have begun inventing more benign names for monads.
Zelfs Simon Peyton-Jones (GHC developer; MS Research) is van mening dat monad een slechte naam is:
Simon Peyton Jones:
Okay. The worst thing about monad is the name.
Richard Campbell:
They sound far worse than they are.
Simon Peyton Jones:
Yeah, that's why. The name is very off-putting because it comes from something mathematical. I'm on record as saying we should have called them warm, fuzzy things.
Het zal dus nog wel even duren (of zelfs nooit gebeuren) voordat we hier grootse toevoegingen kunnen verwachten. Je ziet het ook al hoe hier op 'var' gereageerd wordt: veel programmeurs zijn tamelijk conservatief, zeker bij serieuzere code.
Mjah, conservatisme zie je helaas in de gehele geschiedenis van de informatica terug.
Ik kan me nog herinneren dat generics in beta waren en ik voorstelde om ze in een subproject te gaan gebruiken: 'waarom zou je dat willen?'

Als een bepaalde feature nog in beta was, dan zou ik me wel kunnen voorstellen dat je het nog niet zou toepassen in een (sub)project.
In
2008, toen R3 vroeg 'Even iets compleet anders: waarom is alles "var" bij jou?' dacht ik precies hetzelfde. Inmiddels begin ik dus meer in dezelfde richting als de
R#-ontwikkelaars te denken als het om var gaat.
Dat was dus een probleem van gewenning. Als je gewend bent om bij elke variabele een expliciete typeannotatie te zien, dan moet je leren die gewenning ongedaan te maken.
Het nut van 'higher-kinded generics' bij praktische toepassingen ontgaat me nu nog steeds, maar bij var ben ik om.

Misschien zijn er twee dingen nodig om 't nut te kunnen inzien van higher-kinded generics. Ten eerste is de notatie. Je moet jezelf wel makkelijk kunnen uitdrukken in een taal en ook ermee kunnen spelen (i.e., uitvoerbare code). Relevant stukje conversatie op IRC een tijdje terug:
quote: IRC
<RayNbow> <luite> geeft trouwens wel aan hoeveel notatie uitmaakt <-- hoe bedoel je precies?
<RayNbow> als de notatie te lastig wordt... dat mensen dan minder geneigd zijn om 't als bruikbaar te zien?
<luite> ja idd, als notatie 'natuurlijk' is ben je veel sneller geneigd een abstractie te accepteren en als bruikbaar te zien
Ten tweede is het belangrijk om de juiste patronen te kennen en kunnen herkennen. Als je bijvoorbeeld inziet dat iets zich gedraagt als een monad, dan weet je dat je in C# de LINQ syntax kunt gebruiken.
Ter illustratie, probabilistische netwerken vormen een monad en we kunnen dus de LINQ syntax gebruiken. Het voorbeeld dat ik ga bespreken heb ik uit
deze (redelijk toegankelijke) talk, die het op zijn beurt van Wikipedia heeft:
Suppose that there are two events which could cause grass to be wet: either the sprinkler is on or it's raining. Also, suppose that the rain has a direct effect on the use of the sprinkler (namely that when it rains, the sprinkler is usually not turned on). Then the situation can be modeled with Bayesian network. All three variables have two possible values T (for true) and F (for false).
De kans dat het gras nat is kan met het volgende diagram worden weergegeven:
 (klikbaar voor iets grotere versie)
(klikbaar voor iets grotere versie)
De pijlen in dit diagram laten zien hoe de informatie stroomt. Uit de stochast "Rain" vloeit de informatie of het wel of niet regent en draagt in het diagram het label
r. Zoals je kunt zien bereikt deze informatie de stochasten "Sprinkler" en "Grass wet". Op dezelfde wijze stroomt er informatie van "Sprinkler" naar "Grass wet". De informatie of het gras nat is vloeit van "Grass wet" uit het gehele diagram.
We kunnen ook de vraag stellen: "wat is de kans dat het regent, gegeven het feit dat gras nat is?". Deze vraag wordt in het volgende diagram worden weergegeven:
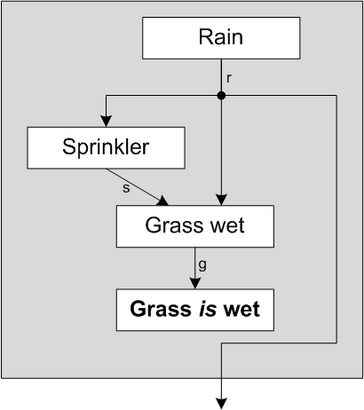
Het diagram is vrijwel hetzelfde als voorheen, alleen nu voegen we een bewering toe dat de informatie van "Grass wet" waar moet zijn (="
Grass is wet") en i.p.v. of het gras nat is laten we de informatie uit "Rain" naar buiten vloeien.
Deze diagrammen kun je 1-op-1 vertalen naar code. We liften eerst de booleans true en false naar een rijker type. Dit scheelt namelijk straks wat typwerk:
C#:
1
2
| static Prob PFalse = new Prob(false);
static Prob PTrue = new Prob(true); |
Vervolgens implementeren we de kanstabellen:
C#:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| static Prob Rain()
{
return 0.2 * PTrue + 0.8 * PFalse;
}
static Prob Sprinkler(bool raining)
{
return
!raining ? 0.40 * PTrue + 0.60 * PFalse :
raining ? 0.01 * PTrue + 0.99 * PFalse :
null;
}
static Prob GrassWet(bool sprinkler, bool raining)
{
return
!sprinkler && !raining ? PFalse :
!sprinkler && raining ? 0.80 * PTrue + 0.20 * PFalse :
sprinkler && !raining ? 0.90 * PTrue + 0.10 * PFalse :
sprinkler && raining ? 0.99 * PTrue + 0.01 * PFalse :
null;
} |
Uiteindelijk kun je elk van de twee diagrammen beschrijven met een LINQ query:
C#:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| static void Main(string[] args)
{
var grasswet = from r in Rain()
from s in Sprinkler(r)
from g in GrassWet(s, r)
select g;
var diditrain = from r in Rain()
from s in Sprinkler(r)
from g in GrassWet(s, r)
where g
select r;
Console.WriteLine(grasswet); // <0,44838:True, 0,55162:False>
Console.WriteLine(diditrain); // <0,16038:True, 0,288:False>
Console.WriteLine(diditrain / diditrain.Norm1()); // <0,357687675632276:True, 0,642312324367724:False>
Console.ReadKey();
} |
De from-clauses labelen de informatie die uit een stochast stroomt, zodat we deze informatie aan andere stochasten kunnen doorgeven. Met een where-clause kunnen we "gegeven het feit dat..." modeleren en met select-clause kunnen we opgeven welke informatie uit het diagram vloeit.
[
Voor 0% gewijzigd door
RayNbow op 28-03-2011 18:16
. Reden: link fix ]
/u/81985/crop566b00b43645a.png?f=community)
:strip_icc():strip_exif()/u/148505/31bb5b263ef71bb4d5751e9a89035105.jpeg.jpg?f=community)
:strip_icc():strip_exif()/u/6143/rincewind.jpg?f=community)
:strip_icc():strip_exif()/u/12461/crop65b195553d948.jpg?f=community)
/u/112490/crop5821eafeac2b9_cropped.png?f=community)
/u/320875/OK.png?f=community)
/u/596198/crop57b76f39423d0_cropped.png?f=community)
:strip_icc():strip_exif()/u/14853/bluepiSW.jpg?f=community)
:strip_icc():strip_exif()/u/80211/crop625154a54bd09_cropped.jpg?f=community)
/u/218480/crop67d969f5402ed_cropped.png?f=community)
/u/86654/crop68d4ff30987a8.png?f=community)
/u/12668/hydra.png?f=community)
:strip_icc():strip_exif()/u/145751/check-in-minion-small2.jpg?f=community)
:strip_icc():strip_exif()/u/23872/Y2.jpg?f=community)
/u/3813/100_8985_ICON2.JPG?f=community)
/u/179024/crop6582083e7ab8e_cropped.png?f=community)
:strip_icc():strip_exif()/u/104670/66407.jpg?f=community)
:fill(white):strip_exif()/f/image/qNc2zoeRzX5wolZtIyb7vp3y.png?f=user_large){kind=link}