The #1 programmer excuse for legitimately slacking off: "My code's compiling"
Firesphere: Sommige mensen verdienen gewoon een High Five. In the Face. With a chair.
- .Gertjan.
- Registratie: September 2006
- Laatst online: 25-04 15:06
Owl!
:strip_icc():strip_exif()/u/190884/dug.jpg?f=community)
- PiepPiep
- Registratie: Maart 2002
- Laatst online: 08-06 11:02
Ach, HoOftLeTtErS maken iig niet uitHaan schreef op donderdag 16 december 2010 @ 08:46:
Dit is ook een mooie:
http://ns.nl/actuele-vertrektijden/main.action
Voer dan een plaats in met spatie ervoor of -achter, dan vindt ie de plaats niet
/edit
Dat doet me gelijk denken aan het opbouwen van een sql query
sql = sql + " and ucase(id) = '" + ucase(id) + "'";
Waarom zou je een id case insensitive willen hebben
[ Voor 22% gewijzigd door PiepPiep op 16-12-2010 10:11 ]
486DX2-50 16MB ECC RAM 4x 500MB Drive array 1.44MB FDD MS-Dos 6.22
Verwijderd
er zal maar eens iemand een Id in kleine cijfers meegeven terwijl jij ze in hoofdcijfers opgeslagen had 
/me heeft tijdens zijn helpdeskperiode ooit de vraag "moet dat in hoofdletters?" gekregen toen hij een IP adres dicteerde.
/me heeft tijdens zijn helpdeskperiode ooit de vraag "moet dat in hoofdletters?" gekregen toen hij een IP adres dicteerde.
[ Voor 39% gewijzigd door Verwijderd op 16-12-2010 10:13 ]
- Alex)
- Registratie: Juni 2003
- Laatst online: 06-07 14:10
En het was geen IPv6-adres?Verwijderd schreef op donderdag 16 december 2010 @ 10:12:
* Alex) heeft tijdens zijn helpdeskperiode ooit de vraag "moet dat in hoofdletters?" gekregen toen hij een IP adres dicteerde.
We are shaping the future
/u/117810/cupcake2.png?f=community)
Vroeger ook eens gezien met een overzicht van patientdata. In het begin waren er denk ik nog niet zo veel patienten. Maar later welburne schreef op woensdag 15 december 2010 @ 23:48:
Hoe selecteer je een 'leeg' id voor een nieuwe customer?
Deze oplossing is van een klant:
code:
SELECT * FROM customer WHERE id_customer != '4' AND `id_customer` !='10' AND !='347' AND `id_customer` !='348' AND `id_customer` !='349' AND `id_customer` !='350' AND `id_customer` !='351' AND `iCL_BASECODE_CODEALIAS !='1339' AND `id_customer` !='1340' AND `id_customer` !='1341' AND `id_customer` !='1342' AND `id_customer` !='1343' AND `id_customer` !='1344'
*knip* 5000! regels
code:
Als jullie uitgelachen zijn zal ik 'm even verder inkorten
- farmertjes
- Registratie: Maart 2010
- Laatst online: 02-06-2025
Deze kwam ik gisteren tegen ... pijn aan m'n ogen
C#:
1
2
3
4
5
6
7
8
9
10
11
| for(i=0; i<5; i++) { try { text += arrayVanOnbekendeGrootte[i] +"<br>"; } catch { } } |
Verwijderd
Ja, mevrouw, shift ingedrukt houden.Verwijderd schreef op donderdag 16 december 2010 @ 10:12:
"moet dat in hoofdletters?"
- .oisyn
- Registratie: September 2000
- Laatst online: 10:13
:strip_icc():strip_exif()/u/12461/crop65b195553d948.jpg?f=community)
Lol. Áls je het dan zo op wil lossen, zet de try/catch dan iig om de for loop heenfarmertjes schreef op donderdag 16 december 2010 @ 10:35:
Deze kwam ik gisteren tegen ... pijn aan m'n ogen
C#:
.edit: oh nee wacht, een element kan natuurlijk ook null zijn.
[ Voor 9% gewijzigd door .oisyn op 16-12-2010 10:47 ]
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
Verwijderd
Deze zorgde ook voor een mooie bug:
De error werd in een andere functie gezet en werd gezet wanneer er een bepaalde file niet geopend kon worden. Het bovenstaande stukje code is een event handler voor HTTP requests...beetje jammer dat m'n microcontroller telkens vast liep toen ik een request deed...
C++:
1
2
3
4
5
| if (this->error) { this->close (); } // Hier kwam wat gekloot met files |
De error werd in een andere functie gezet en werd gezet wanneer er een bepaalde file niet geopend kon worden. Het bovenstaande stukje code is een event handler voor HTTP requests...beetje jammer dat m'n microcontroller telkens vast liep toen ik een request deed...
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
:strip_icc():strip_exif()/u/6143/rincewind.jpg?f=community)
Als er een element null is word er geen Exception gegooid.oisyn schreef op donderdag 16 december 2010 @ 10:46:
[...]
Lol. Áls je het dan zo op wil lossen, zet de try/catch dan iig om de for loop heen
.edit: oh nee wacht, een element kan natuurlijk ook null zijn.
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- .oisyn
- Registratie: September 2000
- Laatst online: 10:13
Je kunt gewoon ToString() aanroepen op null 
.edit: ah nee, dat niet, maar bij een impliciete ToString() mag het wel. Vaag
.edit: ah nee, dat niet, maar bij een impliciete ToString() mag het wel. Vaag
[ Voor 47% gewijzigd door .oisyn op 16-12-2010 11:10 ]
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Er word geen impliciete ToString gedaan volgens mij. Ik denk dat het gewoon in de operator+ van string is afgevangen.
edit:
Ik zie in System.String niet direct een operator+, maar uiteindelijk word natuurlijk gewoon Concat (of iets met vergelijkbaar gedrag ) aangeroepen.
edit:
Ik zie in System.String niet direct een operator+, maar uiteindelijk word natuurlijk gewoon Concat (of iets met vergelijkbaar gedrag ) aangeroepen.
C#:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public static string Concat(string str0, string str1) { if (IsNullOrEmpty(str0)) { if (IsNullOrEmpty(str1)) { return Empty; } return str1; } if (IsNullOrEmpty(str1)) { return str0; } int length = str0.Length; string dest = FastAllocateString(length + str1.Length); FillStringChecked(dest, 0, str0); FillStringChecked(dest, length, str1); return dest; } |
[ Voor 78% gewijzigd door Woy op 16-12-2010 11:23 ]
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
Verwijderd
Maar bij arrays gooit .net toch een IndexOutOfRangeException ipv null terug te geven?Woy schreef op donderdag 16 december 2010 @ 11:05:
[...]
Als er een element null is word er geen Exception gegooid
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Wel als je een element buiten de bounds van de array wil accessen. Maar er kan natuurlijk best een element null zijn, en .oisyn dacht dat dat ook een Exception triggerde, waardoor de try/catch om de for loop plaatsen ander gedrag zou opleveren.Verwijderd schreef op donderdag 16 december 2010 @ 11:22:
[...]
Maar bij arrays gooit .net toch een IndexOutOfRangeException ipv null terug te geven?
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- .oisyn
- Registratie: September 2000
- Laatst online: 10:13
^^^ what he says
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- TRON
- Registratie: September 2001
- Laatst online: 14-07 07:10
burne schreef op woensdag 15 december 2010 @ 23:48:
Hoe selecteer je een 'leeg' id voor een nieuwe customer?
Deze oplossing is van een klant:
code:
SELECT * FROM customer WHERE id_customer != '4' AND `id_customer` !='10' AND `id_customer` !='11' AND `id_customer` !='13' AND `id_customer` !='14' AND
*knip* 6000! regels
code:
Als jullie uitgelachen zijn zal ik 'm even verder inkorten
Dat doe je natuurlijk anders. Je vult je DB alvast met 100.000 ID's, vervolgens:
code:
1
2
3
4
5
| SELECT id_customer FROM customers WHERE naam_customer = "" ORDER BY id_customer ASC LIMIT 1 |
Doh
Leren door te strijden? Dat doe je op CTFSpel.nl. Vraag een gratis proefpakket aan t.w.v. EUR 50 (excl. BTW)
Verwijderd
Die laatste is toch niks mis mee?TRON schreef op donderdag 16 december 2010 @ 12:05:
[...]
Dat doe je natuurlijk anders. Je vult je DB alvast met 100.000 ID's, vervolgens:
code:
Doh
- !null
- Registratie: Maart 2008
- Laatst online: 13-07 10:58
Ik heb wel eens wat figuren bezig gezien die vonden dat je sowieso zelf altijd je key moest genereren in UUID vorm, de precieze motivatie wist ik niet meer, maar er is meestal wel een functie te vinden genereer_uuid() en het is een aardig brede key, dus je zult niet snel door je keys heen zijn.
Echter vraag ik me af, je hebt potentieel nog steeds een mogelijkheid (heeeele kleine kans) dat je een dubbele genereert. Dan verval je nog in simpele herkansingen? Weet niet hoe ze dat hadden opgelost eigenlijk.
Echter vraag ik me af, je hebt potentieel nog steeds een mogelijkheid (heeeele kleine kans) dat je een dubbele genereert. Dan verval je nog in simpele herkansingen? Weet niet hoe ze dat hadden opgelost eigenlijk.
Ampera-e (60kWh) -> (66kWh)
Elektrische camper (80kWh)
- Davio
- Registratie: November 2007
- Laatst online: 06-01-2025
:strip_exif()/u/240696/Darth%2520Stewie.gif?f=community)
Kan je de waarde van een auto_increment niet opvragen?
Ik zat eerst te denken om gewoon een insert te doen met default waarden en daarna de laatste regel op te vragen uit de tabel, maar dat gaat natuurlijk fout als er iemand anders ook snel een regel instopt.
Daarom is het beter om een insert in zijn geheel te doen met de ingevulde waarden en dan opvragen met een secundaire key, zoals een nickname ook maar één keer voor mag komen.
Ik zat eerst te denken om gewoon een insert te doen met default waarden en daarna de laatste regel op te vragen uit de tabel, maar dat gaat natuurlijk fout als er iemand anders ook snel een regel instopt.
Daarom is het beter om een insert in zijn geheel te doen met de ingevulde waarden en dan opvragen met een secundaire key, zoals een nickname ook maar één keer voor mag komen.
- !null
- Registratie: Maart 2008
- Laatst online: 13-07 10:58
Maar dan heb je dus een key bestaande uit 2 velden die allebei op zichzelf al uniek moeten zijn. Klopt ook niet echt qua database ontwerp.Davio schreef op donderdag 16 december 2010 @ 13:07:
Kan je de waarde van een auto_increment niet opvragen?
Ik zat eerst te denken om gewoon een insert te doen met default waarden en daarna de laatste regel op te vragen uit de tabel, maar dat gaat natuurlijk fout als er iemand anders ook snel een regel instopt.
Daarom is het beter om een insert in zijn geheel te doen met de ingevulde waarden en dan opvragen met een secundaire key, zoals een nickname ook maar één keer voor mag komen.
Ampera-e (60kWh) -> (66kWh)
Elektrische camper (80kWh)
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Een voordeel van GUID's gebruiken als keys, is dat je in meerdere systemen keys kan genereren, en die later kunt synchroniseren. Je zult alleen inderdaad altijd rekening moeten houden met collissions, hoe klein de kans daarop ook is.!null schreef op donderdag 16 december 2010 @ 13:06:
Ik heb wel eens wat figuren bezig gezien die vonden dat je sowieso zelf altijd je key moest genereren in UUID vorm, de precieze motivatie wist ik niet meer, maar er is meestal wel een functie te vinden genereer_uuid() en het is een aardig brede key, dus je zult niet snel door je keys heen zijn.
Echter vraag ik me af, je hebt potentieel nog steeds een mogelijkheid (heeeele kleine kans) dat je een dubbele genereert. Dan verval je nog in simpele herkansingen? Weet niet hoe ze dat hadden opgelost eigenlijk.
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- PiepPiep
- Registratie: Maart 2002
- Laatst online: 08-06 11:02
Is een UUID niet net als een GUID 128 bits?!null schreef op donderdag 16 december 2010 @ 13:06:
Ik heb wel eens wat figuren bezig gezien die vonden dat je sowieso zelf altijd je key moest genereren in UUID vorm, de precieze motivatie wist ik niet meer, maar er is meestal wel een functie te vinden genereer_uuid() en het is een aardig brede key, dus je zult niet snel door je keys heen zijn.
Echter vraag ik me af, je hebt potentieel nog steeds een mogelijkheid (heeeele kleine kans) dat je een dubbele genereert. Dan verval je nog in simpele herkansingen? Weet niet hoe ze dat hadden opgelost eigenlijk.
De kans dat er precies dan een meteoriet inslaat en de computer vernietigt is groter.
486DX2-50 16MB ECC RAM 4x 500MB Drive array 1.44MB FDD MS-Dos 6.22
- !null
- Registratie: Maart 2008
- Laatst online: 13-07 10:58
Ja GUID's inderdaad. Kans is astronomisch klein dat het niet lukt, maar wat ga je er aan doen? Ga je er overeen schrijven omdat je het niet checkt? Je doet er ook niet goed aan om een while loopje te schrijven denk ik.
De grotere databases hebben zelf functies om GUID's te genereren en kleine databases hebben er vaak op maat gesneden kolomtypes voor.
De grotere databases hebben zelf functies om GUID's te genereren en kleine databases hebben er vaak op maat gesneden kolomtypes voor.
Ampera-e (60kWh) -> (66kWh)
Elektrische camper (80kWh)
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Dan ga je er wel vanuit dat de algoritmes om GUID's te geneneren altijd echt Random en Uniform verdeelde waardes genereren. Je moet je vooral goed afvragen wat de consequenties zijn mocht het toch gebeuren. Als het enige effect is dat de gebruiker een foutmelding krijgt, en nogmaals zijn gegevens in moet voeren, dan is dat een risico wat je (waarschijnlijk) best kunt lopen. Loop je het risico dat je spaceshuttle ontploft als het gebeurt, dan wil je waarschijnlijk het risico wel uitsluiten.PiepPiep schreef op donderdag 16 december 2010 @ 13:11:
[...]
Is een UUID niet net als een GUID 128 bits?
De kans dat er precies dan een meteoriet inslaat en de computer vernietigt is groter.
Afhankelijk van wat voor systeem je hebt, kun je bij een eventuele collision de insert gewoon laten failen, om de gebruiker nogmaals te laten proberen.!null schreef op donderdag 16 december 2010 @ 13:32:
Ja GUID's inderdaad. Kans is astronomisch klein dat het niet lukt, maar wat ga je er aan doen? Ga je er overeen schrijven omdat je het niet checkt? Je doet er ook niet goed aan om een while loopje te schrijven denk ik.
Een ander voordeel van GUID's is dat je niet afhankelijk bent van de database om je key's te genereren, en je dus ook gewoon in je applicatie/datalaag de key kunt genereren.De grotere databases hebben zelf functies om GUID's te genereren en kleine databases hebben er vaak op maat gesneden kolomtypes voor.
Over het algemeen gebruik ik liever gewoon auto-incrementing fields, maar in sommige gevallen kunnen GUID's wel handig zijn.
[ Voor 28% gewijzigd door Woy op 16-12-2010 13:55 ]
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- Janoz
- Registratie: Oktober 2000
- Laatst online: 15-07 20:48
:strip_exif()/u/13818/episodebutler_60x60.gif?f=community)
Ik zou alleen GUID's gaan gebruiken wanneer de situatie het vereist. De enige situatie die dat vereist is wanneer er geen centrale (gesynchroniseerde) key uitgave mogelijk is. In alle andere gevallen zou ik gewoon gebruik maken van de beschikbare autoincrement of sequence (die weggeabstraheerd zit achter het door mij gebruikte ORM framework)
Ken Thompson's famous line from V6 UNIX is equaly applicable to this post:
'You are not expected to understand this'
- BM
- Registratie: September 2001
- Laatst online: 07:16
Admin Softe Goederen
Er word hier in het bedrijf wel gebruik gemaakt van GUIDs als PK's, maar de meerwaarde heb ik er hier nog niet van gevonden. Vind het voornamelijk irritant, bij autoincrement integer (oid) als PK staan je nieuwste waarden onderaan in de tabel. In een productieomgeving niet boeiend, maar tijdens het testen vind ik het wel handig, zeker in situaties (zoals hier) waar je geen created kolom in je tabel hebt
Xbox
Even the dark has a silver lining
- Sebazzz
- Registratie: September 2006
- Laatst online: 14-07 14:59
3dp
/u/189240/av70.png?f=community)
Wat een verassing, een 32-bit integer vs een 128bit integer.PolarBear schreef op donderdag 16 december 2010 @ 15:49:
GUIDs zijn ook nog eens trager als PK.
[Te koop: 3D printers] [Website] Agile tools: [Return: retrospectives] [Pokertime: planning poker]
:strip_icc():strip_exif()/u/5964/crop56503163e97a5.jpeg?f=community)
Ik weet niet wat ik een grotere fail vind; het maken van zo'n "beveiliging" of het daadwerkelijk implementeren ervan...
anders reageer ik even op een post op pagina 1
anders reageer ik even op een post op pagina 1
[ Voor 20% gewijzigd door Cartman! op 16-12-2010 15:59 ]
- kenneth
- Registratie: September 2001
- Niet online
achter de duinen
:strip_icc():strip_exif()/u/36003/crop584e9e5c223bd.jpeg?f=community)
Dit topic is een goed voorbeeld dat bepaalde zaken niet altijd zo voor de hand liggen als je zou denkenSebazzz schreef op donderdag 16 december 2010 @ 15:58:
[...]
Wat een verassing, een 32-bit integer vs een 128bit integer.
Look, runners deal in discomfort. After you get past a certain point, that’s all there really is. There is no finesse here.
- Jegorex
- Registratie: April 2004
- Laatst online: 20-06 00:55
:strip_icc():strip_exif()/u/111986/03042010122s.jpg?f=community)
Java + MySQL heeft StatementImpl.getLastInsertID() om dit te voorkomen.Davio schreef op donderdag 16 december 2010 @ 13:07:
Kan je de waarde van een auto_increment niet opvragen?
Ik zat eerst te denken om gewoon een insert te doen met default waarden en daarna de laatste regel op te vragen uit de tabel, maar dat gaat natuurlijk fout als er iemand anders ook snel een regel instopt.
javadocgetLastInsertID returns the value of the auto_incremented key after an executeQuery() or excute() call.
This gets around the un-threadsafe behavior of "select LAST_INSERT_ID()" which is tied to the Connection that created this Statement, and therefore could have had many INSERTS performed before one gets a chance to call "select LAST_INSERT_ID()".
[ Voor 36% gewijzigd door Jegorex op 16-12-2010 16:15 ]
- PiepPiep
- Registratie: Maart 2002
- Laatst online: 08-06 11:02
Tja, ik ga er ook stiekum vanuit dat bestanden goed weggeschreven worden als de write netjes het goede aantal terug geeft terwijl daar ook wel een bug in zou kunnen zitten.Woy schreef op donderdag 16 december 2010 @ 13:51:
Dan ga je er wel vanuit dat de algoritmes om GUID's te geneneren altijd echt Random en Uniform verdeelde waardes genereren.
Soms moet je van bepaalde dingen gewoon ervan uit gaan dat het goed werkt en GUID genereren door een os als windows of linux vertrouw ik eigenlijk wel.
486DX2-50 16MB ECC RAM 4x 500MB Drive array 1.44MB FDD MS-Dos 6.22
- .oisyn
- Registratie: September 2000
- Laatst online: 10:13
Dat er ergens een bug in zit is wat anders dan vertrouwen op een systeem wat de garantie per definitie niet kan geven.
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- Soultaker
- Registratie: September 2000
- Laatst online: 10-07 18:31
:strip_exif()/u/11775/SoulTaker.gif?f=community)
Hoe bedoel je dat Ik ben het met PiepPiep eens dat als je een OS functie hebt om een globally unique identifier te genereren dat je er dan ook vanuit mag gaan dat de gegenereerde identifiers uniek zijn. Als dat mis gaat is het klote, maar of dat nu komt door een OS bug (beetje à la Debian keygenfaal) of door toeval (gebrek aan entropie, of hardwarefalen bijvoorbeeld), in beide gevallen ben je er als applicatieprogrammeur niet verantwoordelijk voor de gevolgen, lijkt me.
Rekening houden met duplicaten bij het mergen van datasets lijkt me nog steeds een goede zaak, maar niet omdat de OS GUID functionaliteit wellicht kapot was, maar omdat er sprake kan zijn van gecorrumpeerde invoer. Het is een goed principe om fouten in de invoer (voor zover die redelijkerwijs te detecteren en niet te corrigeren zijn) niet zonder waarschuwing the propageren, om garbage in = garbage out te voorkomen. Dat is een kwestie van defensief programmeren, en dat is altijd een goed idee.
Rekening houden met duplicaten bij het mergen van datasets lijkt me nog steeds een goede zaak, maar niet omdat de OS GUID functionaliteit wellicht kapot was, maar omdat er sprake kan zijn van gecorrumpeerde invoer. Het is een goed principe om fouten in de invoer (voor zover die redelijkerwijs te detecteren en niet te corrigeren zijn) niet zonder waarschuwing the propageren, om garbage in = garbage out te voorkomen. Dat is een kwestie van defensief programmeren, en dat is altijd een goed idee.
[ Voor 4% gewijzigd door Soultaker op 16-12-2010 19:13 ]
- .oisyn
- Registratie: September 2000
- Laatst online: 10:13
Ik bedoel dat je een bug kunt fixen. Maar aan de uniciteit van een GUID valt weinig te fixen zonder een centrale authority
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- Davio
- Registratie: November 2007
- Laatst online: 06-01-2025
Ja, ook al is GUID ontworpen voor systemen die onderling geen gegevens uit kunnen wisselen, is het natuurlijk in theorie altijd mogelijk dat er een duplicate is. Ook al betwijfel ik of iemand van ons er in de praktijk een keer tegenaan loopt.
- FragFrog
- Registratie: September 2001
- Laatst online: 12:16
/u/35984/crop67a0be11e3453_cropped.png?f=community)
Hmmzja, maar PostgreSQL bijvoorbeeld kan het standaard niet zelf (handleiding) - moet je eerst een library voor installeren. Hadden een tijdje terug op werk een upgrade van PG8.1 naar 8.3 oid, werkte ineens die library niet meer!null schreef op donderdag 16 december 2010 @ 13:32:
De grotere databases hebben zelf functies om GUID's te genereren en kleine databases hebben er vaak op maat gesneden kolomtypes voor.
Then again, auto-increments gaan daar ook niet zo simpel mee..
- Crazy D
- Registratie: Augustus 2000
- Laatst online: 16-07 19:19
I think we should take a look.
:strip_icc():strip_exif()/u/10274/crop67712295188a6_cropped.jpg?f=community)
Dat heeft volgens mij meer te maken met de index. Een GUID is niet opvolgend. Als de GUID de clustered index is kan ie continue alles gaan lopen opschuiven. Als het geen clustered index is vraag ik me af of dat verschil in performance (32 bit vs 128 bit) daadwerkelijk merkbaar is in reguliere applicaties.Sebazzz schreef op donderdag 16 december 2010 @ 15:58:
[...]
Wat een verassing, een 32-bit integer vs een 128bit integer.
Exact expert nodig?
Verwijderd
Nu heb je natuurlijk wel zoiets als een UUID, die zou wel uniek moeten zijn zonder een overkoepelende instantie.
- .oisyn
- Registratie: September 2000
- Laatst online: 10:13
UUID is een standaard, GUID is Microsofts implementatie.
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- Dido
- Registratie: Maart 2002
- Laatst online: 12:10
heforshe
En daarvoor gebruiken we magie?Verwijderd schreef op donderdag 16 december 2010 @ 22:21:
Nu heb je natuurlijk wel zoiets als een UUID, die zou wel uniek moeten zijn zonder een overkoepelende instantie.
Dat je in sommige situaties maar aanneemt dat "with reasonable confidence" gelijk is aan "without a shadow of a doubt" of zelfs "with absolute certainty" is vaak aanvaardbaar, maar je moet je er natuurlijk ten alle tijden van bewust zijn dat dat een aanname is. En je weet wat er van aannames gezegd wordt ...anyone can create a UUID and use it to identify something with reasonable confidence that the identifier will never be unintentionally used by anyone for anything else.
- .oisyn
- Registratie: September 2000
- Laatst online: 10:13
v1 UUID gebruikte het MAC adres (waardoor de maker van de Melissa worm opgespoord kon worden ), maar zelfs die zijn niet uniek in de praktijk. Maar goed, dat zou je kunnen beschouwen als dat er dus wel een central authority is (namelijk degene die ranges uitdeelt aan de nic vendors en die vendor die intern weer zorgt dat zijn nummers uniek zijn).
Goed, de kans op een collision is dan wel klein (hou wel rekening met het birthday paradox), maar niet nonexistent.
Goed, de kans op een collision is dan wel klein (hou wel rekening met het birthday paradox), maar niet nonexistent.
[ Voor 14% gewijzigd door .oisyn op 16-12-2010 23:29 ]
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
Verwijderd
En wanneer je een int gebruikt of een bigint of whatever zul je op een gegeven moment met autonummering ook stuk lopen omdat de nummers op zijn. Het is altijd wat met PK's .
Grootste voordeel van een UUID is wel dat als je de streepjes er tussenuit haalt je een heel mooi lange order nummer hebt die toch niemand snapt (zoals een klant ooit zei).
(zoals een klant ooit zei).
Grootste voordeel van een UUID is wel dat als je de streepjes er tussenuit haalt je een heel mooi lange order nummer hebt die toch niemand snapt
- Janoz
- Registratie: Oktober 2000
- Laatst online: 15-07 20:48
Het moment waarop een autonummer fout gaat lopen is heel goed te voorspellen. GUID daarentegen is op elk mogelijk moment tussen nu en het moment dat een meteoor inslaat.
Ken Thompson's famous line from V6 UNIX is equaly applicable to this post:
'You are not expected to understand this'
Verwijderd
Klopt, dus wie laat er eens een mooie wiskundige analyse op los?Janoz schreef op vrijdag 17 december 2010 @ 11:40:
Het moment waarop een autonummer fout gaat lopen is heel goed te voorspellen. GUID daarentegen is op elk mogelijk moment tussen nu en het moment dat een meteoor inslaat.
- Davio
- Registratie: November 2007
- Laatst online: 06-01-2025
quote: WikipediaTo put these numbers into perspective, one's annual risk of being hit by a meteorite is estimated to be one chance in 17 billion,[25] that means the probability is about 0.00000000006 (6 × 10−11), equivalent to the odds of creating a few tens of trillions of UUIDs in a year and having one duplicate. In other words, only after generating 1 billion UUIDs every second for the next 100 years, the probability of creating just one duplicate would be about 50%. The probability of one duplicate would be about 50% if every person on earth owns 600 million UUIDs.
However, these probabilities only hold when the UUIDs are generated using sufficient entropy. Otherwise the probability of duplicates may be significantly higher, since the statistical dispersion may be lower.
- !null
- Registratie: Maart 2008
- Laatst online: 13-07 10:58
Ja maar er zijn dus constructies waarin men niet gebruik wil maken van autonummering. Als je die beslissing eenmaal genomen hebt valt er wel wat voor UUID's te zeggen.Janoz schreef op vrijdag 17 december 2010 @ 11:40:
Het moment waarop een autonummer fout gaat lopen is heel goed te voorspellen. GUID daarentegen is op elk mogelijk moment tussen nu en het moment dat een meteoor inslaat.
Nu ben ik niet heel erg op de hoogte van de professionele databases, maar als je een int als key hebt, dan is het niet ideaal als je van te voren een key moet krijgen, of van de ge-inserte sql statement daarna de key opvragen.
Ampera-e (60kWh) -> (66kWh)
Elektrische camper (80kWh)
Verwijderd
En nu nog afzetten tegen numerieke autonummering en je antwoord is compleet. Vooral dat afzetten is interessant.
- Soultaker
- Registratie: September 2000
- Laatst online: 10-07 18:31
Wat is daar "niet ideaal" aan? Als je van te voren een GUID genereert is dat toch hetzelfde als wanneer je een sequentieel nummertje trekt?!null schreef op vrijdag 17 december 2010 @ 13:44:
Nu ben ik niet heel erg op de hoogte van de professionele databases, maar als je een int als key hebt, dan is het niet ideaal als je van te voren een key moet krijgen, of van de ge-inserte sql statement daarna de key opvragen.
Maarja als je flink wil gaan joinen dan zijn geclusterde indexen toch wel handig.Crazy D schreef op donderdag 16 december 2010 @ 22:10:
[...]
Dat heeft volgens mij meer te maken met de index. Een GUID is niet opvolgend. Als de GUID de clustered index is kan ie continue alles gaan lopen opschuiven. Als het geen clustered index is vraag ik me af of dat verschil in performance (32 bit vs 128 bit) daadwerkelijk merkbaar is in reguliere applicaties.
- !null
- Registratie: Maart 2008
- Laatst online: 13-07 10:58
Als je eenmaal in dat bootje zit is het vervelend om te werken met 32 bit nummertje in een tabel met veel records. Dan verval je in een spelletje van random je key genereren en daarna kijken of hij niet al bezet is. En dan net zo lang proberen tot je een goeie hebt.Soultaker schreef op vrijdag 17 december 2010 @ 14:11:
[...]
Wat is daar "niet ideaal" aan? Als je van te voren een GUID genereert is dat toch hetzelfde als wanneer je een sequentieel nummertje trekt?
In principe is dat bij UUID's ook zo, alleen is de kans astronomisch klein, dus kun je er voor kiezen om er niet naar te kijken. (en je query dus laten falen, ervanuitgaande dat je daar prima carch mechanismes voor hebt met eventueel benodigde rollback)
Maar goed, ik zie ook niet snel in wanneer je dat allemaal nodig hebt hoor. Ik weet wel dat er wat fans bestaan die vrij snel, zo niet standaard, gebruik maken van UUID's en dat als vaste manier van werken met keys gebruiken.
Ik probeer te bedenken wat nou echt de grote voordelen zijn. Tot nu toe lijken de voordelen marginaal.
Ampera-e (60kWh) -> (66kWh)
Elektrische camper (80kWh)
- Soultaker
- Registratie: September 2000
- Laatst online: 10-07 18:31
Zo moet je het natuurlijk niet doen. Als je vooraf een nummertje trekt dan doe je dat uit een atomaire sequence (zoals bijvoorbeeld PostgreSQL die native biedt); als je het achteraf doet, dan vraag je de waarde van een autoincrement kolom op. In beide gevallen zorgt de databaseserver ervoor dat het gekozen nummer uniek is en hoef je dus nooit opnieuw te proberen. De kans op duplicaten is dan nul (wat technisch nog beter is dan "astronomisch klein" bij UUIDs hoewel het verschil praktisch nihil is).!null schreef op vrijdag 17 december 2010 @ 15:36:
Als je eenmaal in dat bootje zit is het vervelend om te werken met 32 bit nummertje in een tabel met veel records. Dan verval je in een spelletje van random je key genereren en daarna kijken of hij niet al bezet is.
Overigens zijn 32-bits getallen niet echt future-proof. Liever 64-bits integers gebruiken voor row identifiers.
[ Voor 6% gewijzigd door Soultaker op 17-12-2010 15:51 ]
- Crazy D
- Registratie: Augustus 2000
- Laatst online: 16-07 19:19
I think we should take a look.
Ja maar dan dus geen clustered op je guid veld, been there done that. Applicatie performde voor geen meter totdat de clustered index er vanaf werd gehaald. Toen werd ie opeens retesnel. Waarom? Heel veel inserts op een grote tabel met dus een clustered index op een GUI field. Je wil er wel een index op (idd voor het joinen), maar nieuwe records graag aan het eind toevoegen... clustered index op de identity column die ook in de tabel staat.PolarBear schreef op vrijdag 17 december 2010 @ 15:05:
[...]
Maarja als je flink wil gaan joinen dan zijn geclusterde indexen toch wel handig.
Exact expert nodig?
- Niemand_Anders
- Registratie: Juli 2006
- Laatst online: 09-07-2024
Dat was ik niet..
Omdat GUID van origine iets te random zijn zoals NewID() in T-SQL moet de database bij elke insert de indexen gaan bijwerken zodat de records in de juist volgorde blijven staan.
Lang leve de legacy applicaties. Guids in SQL Server 7 op NT4:
B3BFC6B3-05A2-11D6-9FBA-00C04FF317DF
B3BFC6B4-05A2-11D6-9FBA-00C04FF317DF
B3BFC6B5-05A2-11D6-9FBA-00C04FF317DF
Microsoft heeft het MAC adres uit de GUID gehaald waardoor je eigenlijk gewoon een random 128 bits getal overblijft.
Jimmy Nilsson kwam daarna op de proppen met een algoritme dat dat eerste 10 bytes van een GUID gebruikt, maar de laatste 6 bytes vervangt door een timestamp (resolutie 1/300 ms). Dit algoritme is bekend onder de naam GUID.Comb. Echter door de laatste 6 bytes zijn de GUIDS min of meer oplopend en hoeven de indexen (en pages) minder snel opnieuw opgebouwd te worden.
Zolang je niet te maken hebt databases welke met elkaar synchroniseren kun je meestal GUIDs vermijden. Zelf stap ik dan over naar het HiLo algoritme welke clients voorzien van een reeks. Vooral bij grote data hoeveelheden inserts kan HiLo voor extra performce zorgen omdat inserts in batches aangeboden kunnen worden. Echter moeten alle clients met HiLo gaan werken omdat het anders alsnog fout gaat..
Als je af en toe een importje hebt en daarbuiten vooral reads en updates, dan is de performance van de eigen database voldoende voor het toewijzen van een ID (autonummering/sequence).
Omdat dat erg lastig kan worden bij synchronisaties (foreign keys) kwam met met de GUID/UUID implementaties. GUID.Comb is momenteel voor databases de beste implementatie als je gebruik maakt van GUIDs.
Lang leve de legacy applicaties. Guids in SQL Server 7 op NT4:
B3BFC6B3-05A2-11D6-9FBA-00C04FF317DF
B3BFC6B4-05A2-11D6-9FBA-00C04FF317DF
B3BFC6B5-05A2-11D6-9FBA-00C04FF317DF
Microsoft heeft het MAC adres uit de GUID gehaald waardoor je eigenlijk gewoon een random 128 bits getal overblijft.
Jimmy Nilsson kwam daarna op de proppen met een algoritme dat dat eerste 10 bytes van een GUID gebruikt, maar de laatste 6 bytes vervangt door een timestamp (resolutie 1/300 ms). Dit algoritme is bekend onder de naam GUID.Comb. Echter door de laatste 6 bytes zijn de GUIDS min of meer oplopend en hoeven de indexen (en pages) minder snel opnieuw opgebouwd te worden.
Zolang je niet te maken hebt databases welke met elkaar synchroniseren kun je meestal GUIDs vermijden. Zelf stap ik dan over naar het HiLo algoritme welke clients voorzien van een reeks. Vooral bij grote data hoeveelheden inserts kan HiLo voor extra performce zorgen omdat inserts in batches aangeboden kunnen worden. Echter moeten alle clients met HiLo gaan werken omdat het anders alsnog fout gaat..
Als je af en toe een importje hebt en daarbuiten vooral reads en updates, dan is de performance van de eigen database voldoende voor het toewijzen van een ID (autonummering/sequence).
In een database wil je niet afhankelijk zijn van natuurlijke sleutels. Zeer weinig natuurlijke sleutels zijn permanent. Daarom kwam de database industrie met autonummering velden en sequences.clustered index op de identity column die ook in de tabel staat.
Omdat dat erg lastig kan worden bij synchronisaties (foreign keys) kwam met met de GUID/UUID implementaties. GUID.Comb is momenteel voor databases de beste implementatie als je gebruik maakt van GUIDs.
If it isn't broken, fix it until it is..
- roy-t
- Registratie: Oktober 2004
- Laatst online: 23-05 08:49
:strip_icc():strip_exif()/u/126096/crop580e4f8566fec_cropped.jpeg?f=community)
HiLo ken ik niet, is dat zoiets als.Niemand_Anders schreef op zaterdag 18 december 2010 @ 11:52:
worden. Echter moeten alle clients met HiLo gaan werken omdat het anders alsnog fout gaat..
Als je af en toe een importje hebt en daarbuiten vooral reads en updates, dan is de performance van de eigen database voldoende voor het toewijzen van een ID (autonummering/sequence).
DatabaseA vraagt aan KeyDatabase een range unique ids, maakt die op en vraagt dan weer een range?
- Janoz
- Registratie: Oktober 2000
- Laatst online: 15-07 20:48
Nee, niet helemaal. Het is meer dat een key wordt opgedeeld in twee delen en het meest significante deel wordt centraal beheert waardoor de client weet dat hij het minst significante deel helemaal voor zichzelf heeft.
Het lijkt wel op de ranges, maar echter is de server redelijk beperkt in het toekennen van de vorm van die ranges.
Het lijkt wel op de ranges, maar echter is de server redelijk beperkt in het toekennen van de vorm van die ranges.
Ken Thompson's famous line from V6 UNIX is equaly applicable to this post:
'You are not expected to understand this'
- CodeCaster
- Registratie: Juni 2003
- Niet online
Stop AI Slop
/u/86654/crop68d4ff30987a8.png?f=community)
Wens van klant: decimalen kunnen invoeren. Collega: prima, ik pas het mask van de MaskEdit even aan. Ik, als tester: FFFFFFFFFFUUUUUUUUUUUUUUUUUUUUUUUUUUUU.
Door het nieuwe mask bevat de .text nu altijd een waarde, bij geen invoer namelijk alsnog een punt (.). Leuke query krijg je dan
Delphi:
1
2
3
4
| if (Trim(foo.text) <> '') then sql.add(' foo = ' + foo.text + ',') else sql.add(' foo = 0,'); |
Door het nieuwe mask bevat de .text nu altijd een waarde, bij geen invoer namelijk alsnog een punt (.). Leuke query krijg je dan
Je moet niet dronken dat ik denken ben.
What seems to be the officer, problem?
Waar is de brand, meester?
- Grijze Vos
- Registratie: December 2002
- Laatst online: 21-02 23:50
Het eerste platform dat echt netjes met numerieke invoer omgaat moet ik nog vinden. Komma's en punten met localization zijn ook altijd geweldig.
Op zoek naar een nieuwe collega, .NET webdev, voornamelijk productontwikkeling. DM voor meer info
- Guldan
- Registratie: Juli 2002
- Laatst online: 08-07 19:49
Thee-Nerd
:strip_icc():strip_exif()/u/60219/guldan.jpg?f=community)
De enige manier om dat goed te krijgen is altijd te kijken naar de windows settings van de gebruiker en daarnaast de mogelijk om dit aan te passen als gebruiker. Maarja dat maakt het wel erg ingewikkeld..
/rant
ik bedoel wie heeft ooit verzonnen dat in een NL Excel een csv gescheiden is met een komma en in de rest van de landen (voorzover ik weet) met een punt komma.
M.b.t. de komma als scheidingsteken wordt pas leuk als je dit hebt (administratie pakket export)
Geloof mij het bestaat.. misschien niet een persoonlijke fuck-up maar wel die van iemand anders .
.
edit: Oisyn heeft gelijk, de landen door elkaar gehaald.
/rant
ik bedoel wie heeft ooit verzonnen dat in een NL Excel een csv gescheiden is met een komma en in de rest van de landen (voorzover ik weet) met een punt komma.
M.b.t. de komma als scheidingsteken wordt pas leuk als je dit hebt (administratie pakket export)
code:
1
2
| grootboeknr,omschrijving,bedrag,bedrag 1,test,5,00,0,00 |
Geloof mij het bestaat.. misschien niet een persoonlijke fuck-up maar wel die van iemand anders
edit: Oisyn heeft gelijk, de landen door elkaar gehaald.
[ Voor 4% gewijzigd door Guldan op 22-12-2010 11:35 ]
You know, I used to think it was awful that life was so unfair. Then I thought, wouldn't it be much worse if life were fair, and all the terrible things that happen to us come because we actually deserve them?
- .oisyn
- Registratie: September 2000
- Laatst online: 10:13
Volgens mij is het in het Engels juist met een komma, en in NL met een puntkomma. Dit juist omdat de decimale punt in NL een komma is. Maar sowieso, welke idioot heeft bedacht dat een csv bestand gelocalized moet worden 
[ Voor 25% gewijzigd door .oisyn op 22-12-2010 10:32 ]
Give a man a game and he'll have fun for a day. Teach a man to make games and he'll never have fun again.
- Matis
- Registratie: Januari 2007
- Laatst online: 15-07 21:35
Rubber Rocket
:strip_icc():strip_exif()/u/206968/325134.jpg?f=community)
@Guldan:
Voor zover ik heb weet, gaat (in ieder geval de Office Suites >= 2007) standaard uit van een ;. Ongeacht de locale-settings.
Dit is idd handiger om de reden die .oisyn al aangeeft
Voor meer duidelijkheid en/of manieren om er een ECHTE csv van te maken: [google=csv semicolon]
Voor zover ik heb weet, gaat (in ieder geval de Office Suites >= 2007) standaard uit van een ;. Ongeacht de locale-settings.
Dit is idd handiger om de reden die .oisyn al aangeeft
Voor meer duidelijkheid en/of manieren om er een ECHTE csv van te maken: [google=csv semicolon]
[ Voor 22% gewijzigd door Matis op 22-12-2010 10:34 ]
If money talks then I'm a mime
If time is money then I'm out of time
Verwijderd
Office kan standaard tegenwoordig alle seperators aan. Standaard kent hij tab, semicolon, space en comma + (others)Matis schreef op woensdag 22 december 2010 @ 10:33:
@Guldan:
Voor zover ik heb weet, gaat (in ieder geval de Office Suites >= 2007) standaard uit van een ;. Ongeacht de locale-settings.
Dit is idd handiger om de reden die .oisyn al aangeeft
Voor meer duidelijkheid en/of manieren om er een ECHTE csv van te maken: [google=csv semicolon]
- CodeCaster
- Registratie: Juni 2003
- Niet online
Stop AI Slop
Lokalisatie is inderdaad af en toe lastig, net ook weer ruzie met datums. Lastig als diverse mensen met voortschrijdend inzicht op een relatief grote codebase hebben gewerkt, waardoor je voor iedere handeling minstens drie truucjes kan vinden in de code.
Nu heb ik maar een nieuwe methode gemaakt die de invoer converteert naar ISO 8601-formaat middels FormatDateTime. En ja, dus eigenlijk een vierde truucje toegevoegd.
Waar ik het in mijn vorige post over had zorgde dus voor zo'n query:
Een leuke gimmick van SQL is trouwens het kunnen gebruiken van "select" in een insert in plaats van "values", dus zo:
Hierdoor zou in het project waaraan ik nu aan het werk ben het opbouwen van de queries een stuk efficiënter kunnen. Immers, regel 3 t/m 6 kunnen ook zó het update-statement in:
De vraag is sowieso of je dit in code wil doen, of je dit handmatig wil doen en waarom er in godesnaam geen O/R-mapper is gebruikt, maar goed. Dus ik open een form (businesslogica en presentatielogica scheiden, wasda?):
En dan heb ik echt een regel of honderd aan query-opbouw geknipt, die in allebei de blokken exact hetzelfde waren. Onderhoud is een bitch. De "find in files" op de tekst "sql.add" heb ik na tienduizenden hits maar afgebroken.
Onderhoud is een bitch. De "find in files" op de tekst "sql.add" heb ik na tienduizenden hits maar afgebroken.
Nu heb ik maar een nieuwe methode gemaakt die de invoer converteert naar ISO 8601-formaat middels FormatDateTime. En ja, dus eigenlijk een vierde truucje toegevoegd.
Waar ik het in mijn vorige post over had zorgde dus voor zo'n query:
SQL:
1
| update bar set foo = ., baz = 2 where x = y |
Een leuke gimmick van SQL is trouwens het kunnen gebruiken van "select" in een insert in plaats van "values", dus zo:
SQL:
1
2
3
4
5
6
| insert into foo (bar, col1, col2, col3) select bar = 'baz', col1 = 'val1', col2 = 'val2', col3 = 'val3' |
Hierdoor zou in het project waaraan ik nu aan het werk ben het opbouwen van de queries een stuk efficiënter kunnen. Immers, regel 3 t/m 6 kunnen ook zó het update-statement in:
SQL:
1
2
3
4
5
6
7
8
| update foo set bar = 'baz', col1 = 'val1', col2 = 'val2', col3 = 'val3' where id = 123 |
De vraag is sowieso of je dit in code wil doen, of je dit handmatig wil doen en waarom er in godesnaam geen O/R-mapper is gebruikt, maar goed. Dus ik open een form (businesslogica en presentatielogica scheiden, wasda?):
Delphi:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| procedure MyForm.Opslaan; begin if mode = 'new' then begin sql.add('insert into foo (bar, col1, col2, col3)'); sql.add('select '); sql.add('bar = "baz", '); sql.add('col1 = "val1", '); sql.add('col2 = "val2", '); sql.add('col3 = "val3", '); if (Trim(SomeTextbox.Text) <> '') then sql.add(' SomeText = "' + SomeTextbox.text + '",'); sql.add('col4 = "' + FormatDateTime('mm-dd-yyyy', StrToDate(DateTimeTextbox.Text) + '"'); sql.Execute(); end; if mode = 'edit' then begin sql.add('update foo (bar, col1, col2, col3)'); sql.add('set '); sql.add('bar = "baz", '); sql.add('col1 = "val1", '); sql.add('col2 = "val2", '); sql.add('col3 = "val3", '); if (Trim(SomeTextbox.Text) <> '') then sql.add(' SomeText = "' + SomeTextbox.text + '",'); sql.add('col4 = "' + FormatDateTime('mm-dd-yyyy', StrToDate(DateTimeTextbox.Text) + '"'); sql.add('where id = ' + id); sql.Execute(); end; end; |
En dan heb ik echt een regel of honderd aan query-opbouw geknipt, die in allebei de blokken exact hetzelfde waren.
[ Voor 5% gewijzigd door CodeCaster op 22-12-2010 11:48 ]
Je moet niet dronken dat ik denken ben.
What seems to be the officer, problem?
Waar is de brand, meester?
- Haan
- Registratie: Februari 2004
- Laatst online: 16-07 15:02
dotnetter
:strip_icc():strip_exif()/u/104670/66407.jpg?f=community)
Ze hebben het ook niet voor niets comma separated file genoemd hèGuldan schreef op woensdag 22 december 2010 @ 10:24:
De enige manier om dat goed te krijgen is altijd te kijken naar de windows settings van de gebruiker en daarnaast de mogelijk om dit aan te passen als gebruiker. Maarja dat maakt het wel erg ingewikkeld..
/rant
ik bedoel wie heeft ooit verzonnen dat in een NL Excel een csv gescheiden is met een komma en in de rest van de landen (voorzover ik weet) met een punt komma.
M.b.t. de komma als scheidingsteken wordt pas leuk als je dit hebt (administratie pakket export)
code:
Geloof mij het bestaat.. misschien niet een persoonlijke fuck-up maar wel die van iemand anders
edit: Oisyn heeft gelijk, de landen door elkaar gehaald.
Kater? Eerst water, de rest komt later
- Guldan
- Registratie: Juli 2002
- Laatst online: 08-07 19:49
Thee-Nerd
@Haan: Tab gescheiden heb ik altijd liever dan spatie gescheiden bestanden .
You know, I used to think it was awful that life was so unfair. Then I thought, wouldn't it be much worse if life were fair, and all the terrible things that happen to us come because we actually deserve them?
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
Lokalisatie/Globalistie kan sowieso soms een aardige bitch zijn. Je probeert het altijd zo veel mogelijk in de presentatie laag te doen, maar bij een project waar ik nu mee bezig ben is de logica ook gedeeltelijk afhankelijk van de Lokalisatie. Bij het vergelijken van dagen word dat lastig de definitie van een dag is afhankelijk van in welke tijdzone je zit, en het word zeker lastig als de ene dag 24 uur heeft, en de dag erna maar 23 uur. Het liefst zou je gewoon in UTC rekenen, maar dat komt dan weer niet overeen met de perceptie van de gebruiker.CodeCaster schreef op woensdag 22 december 2010 @ 11:22:
Lokalisatie is inderdaad af en toe lastig, net ook weer ruzie met datums. Lastig als diverse mensen met voortschrijdend inzicht op een relatief grote codebase hebben gewerkt, waardoor je voor iedere handeling minstens drie truucjes kan vinden in de code.
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- kenneth
- Registratie: September 2001
- Niet online
achter de duinen
Wat zo vervelend is aan i18n/L10n is dat veel ontwikkelaars het niet helemaal lijken te begrijpen. Hoeveel frustratie ik al niet gehad heb met erfenissen met slechte of onvolledige interpretaties van weeknummers (ISO: week 1 = first four days -- zo moeilijk is het niet!). Dan moet je het repareren maar dan dondert er weer van alles om waardoor het verleidelijk is om op oude voet verder te gaan ...
Of iemand heeft het idee wel gesnapt maar schrijft vervolgens een buggy implementatie van een omrekenmethode die al foutloos geimplementeerd is in .NET ... dat soort ellende.
Of iemand heeft het idee wel gesnapt maar schrijft vervolgens een buggy implementatie van een omrekenmethode die al foutloos geimplementeerd is in .NET ... dat soort ellende.
Look, runners deal in discomfort. After you get past a certain point, that’s all there really is. There is no finesse here.
Verwijderd
.NET probeert ISO 8601 te volgen, maar in een aantal scenarios zit deze er een week naast en Nederland werkt met NEN 2772 voor weeknummers, wat momenteel in de praktijk hetzelfde is als ISO 8601, maar feitelijk een andere standaard is die .NET niet kentkenneth schreef op woensdag 22 december 2010 @ 12:13:
Wat zo vervelend is aan i18n/L10n is dat veel ontwikkelaars het niet helemaal lijken te begrijpen. Hoeveel frustratie ik al niet gehad heb met erfenissen met slechte of onvolledige interpretaties van weeknummers (ISO: week 1 = first four days -- zo moeilijk is het niet!). Dan moet je het repareren maar dan dondert er weer van alles om waardoor het verleidelijk is om op oude voet verder te gaan ...
Of iemand heeft het idee wel gesnapt maar schrijft vervolgens een buggy implementatie van een omrekenmethode die al foutloos geimplementeerd is in .NET ... dat soort ellende.
- Davio
- Registratie: November 2007
- Laatst online: 06-01-2025
En dan noemen ze het nog standaard.Verwijderd schreef op woensdag 22 december 2010 @ 12:30:
[...]
.NET probeert ISO 8601 te volgen, maar in een aantal scenarios zit deze er een week naast en Nederland werkt met NEN 2772 voor weeknummers, wat momenteel in de praktijk hetzelfde is als ISO 8601, maar feitelijk een andere standaard is die .NET niet kent.
- kenneth
- Registratie: September 2001
- Niet online
achter de duinen
Aldus professor TanenbaumThe nice thing about standards is that you have so many to choose from.
Look, runners deal in discomfort. After you get past a certain point, that’s all there really is. There is no finesse here.
- remco_k
- Registratie: April 2002
- Laatst online: 11:53
een cassettebandje was genoeg
/u/53159/Isabelleicon6060.JPG?f=community)
Leg dat van die voorkeur op comma en puntcomma t.o.v. tab eens uit?Haan schreef op woensdag 22 december 2010 @ 11:47:
[...]
Helemaal vreselijk zijn tab-gescheiden files
Ik heb namelijk juist de voorkeur voor tab gescheiden.
In mijn optiek gaan daar minder snel dingen mee fout als bij comma en puntcomma gescheiden, die vaker voorkomen in de strings zelf - waardoor ze moeten worden quoted.
Dat moeten ze ook als er een tab in zit, maar dat komt (bij mij in ieder geval) vrijwel nooit / nooit voor.
Alles kan stuk.
- ShadowLord
- Registratie: Juli 2000
- Laatst online: 07:52
/u/8555/Shadow_60x60.png?f=community)
Helaas, in de US gebruiken ze de week waar 1 januari in valt. Dit om het helemaal gemakkelijk te maken natuurlijk. Zie ook: Wikipedia: Seven-day weekkenneth schreef op woensdag 22 december 2010 @ 12:13:
Wat zo vervelend is aan i18n/L10n is dat veel ontwikkelaars het niet helemaal lijken te begrijpen. Hoeveel frustratie ik al niet gehad heb met erfenissen met slechte of onvolledige interpretaties van weeknummers (ISO: week 1 = first four days -- zo moeilijk is het niet!). Dan moet je het repareren maar dan dondert er weer van alles om waardoor het verleidelijk is om op oude voet verder te gaan ...
Of iemand heeft het idee wel gesnapt maar schrijft vervolgens een buggy implementatie van een omrekenmethode die al foutloos geimplementeerd is in .NET ... dat soort ellende.
En dan is het nog de vraag of de 1e dag van de week maandag (ISO) of zondag (USA) is. Of zelfs zaterdag in sommige landen.
Werken met weeknummers is sowieso erg twijfelachtig. Bijna niemand weet wanneer iets plaatsvind als je roept 'in week 12 gaan we ... doen'. Datums zijn veel concreter voor 'normale' mensen.
En uiteraard gaat het helemaal fout als je weeknummers gaat gebruiken voor een rapportage o.i.d. die over meerdere jaren loopt. Immers, als ik roep 'week 1 2007', waar heb ik het dan over? Niet begin 2007 in dit geval! Als je namelijk het weeknummer met het jaartal van de datum combineert dan krijg je het bovenstaande geval: 31 2007 valt volgens die definitie in week 1 2007.
Oftewel je mag ook gelijk jaartallen gaan corrigeren om te matchen met het weeknummer. Maar dat is dan ook eer misleidend want aan aantal dagen viel in het andere jaar...
Ja, dit heb ik mogen doen en nee, ik was er niet blij mee. Weeknummers, bah
You see things; and you say, "Why?" But I dream things that never were; and I say, "Why not?"
- Davio
- Registratie: November 2007
- Laatst online: 06-01-2025
Datums zullen sowieso altijd een beperkt model van de realiteit vormen.
Doordat de aarde steeds langzamer draait duren dagen ook steeds langer. Miljoenen jaren geleden hadden we nog dagen van 20 uur. Had je minder vrije tijd en minder tijd om te slapen als je als dinosaurus 8 uur moest werken.
Maar dat is ook het mooie van onze datering, we begonnen met iets wat niet helemaal klopte en hebben het toen steeds uitgebreid en aangepast zodat het bleef kloppen in plaats van het systeem helemaal opnieuw ontworpen toen we er meer verstand van hadden. Dit gebeurt in de programmeerwereld natuurlijk ook constant, als je begint met buggy spaghetticode en de klant wil een of andere nieuwe functionaliteit.
Doordat de aarde steeds langzamer draait duren dagen ook steeds langer. Miljoenen jaren geleden hadden we nog dagen van 20 uur. Had je minder vrije tijd en minder tijd om te slapen als je als dinosaurus 8 uur moest werken.
Maar dat is ook het mooie van onze datering, we begonnen met iets wat niet helemaal klopte en hebben het toen steeds uitgebreid en aangepast zodat het bleef kloppen in plaats van het systeem helemaal opnieuw ontworpen toen we er meer verstand van hadden. Dit gebeurt in de programmeerwereld natuurlijk ook constant, als je begint met buggy spaghetticode en de klant wil een of andere nieuwe functionaliteit.
- Crazy D
- Registratie: Augustus 2000
- Laatst online: 16-07 19:19
I think we should take a look.
Dat denk ik ook altijd maar minstens de helft van onze klanten weet precies waar het over gaat als ze het hebben over iets dat in week 12 gaat gebeuren.ShadowLord schreef op woensdag 22 december 2010 @ 14:36:
Werken met weeknummers is sowieso erg twijfelachtig. Bijna niemand weet wanneer iets plaatsvind als je roept 'in week 12 jaan we ... doen'. Datums zijn veel concreter voor 'normale' mensen.
Dat is niet zo heel spannend. Als je een functie hebt die op basis van een datum je verteld welk weeknummer erbij hoort. Die zal altijd hetzelfde resultaat geven, dus week 1 - 2007 is alles waarbij die functie weeknr 1 teruggeeft en jaar 2007 is. Moet je uiteraard niet kijken naar year(datum) want dan kan idd 31 dec 2007 in week 1 vallen.En uiteraard gaat het helemaal fout als je weeknummers gaat gebruiken voor een rapportage o.i.d. die over meerdere jaren loopt. Immers, als ik roep 'week 1 2007', waar heb ik het dan over? Niet begin 2007 in dit geval! Als je namelijk het weeknummer met het jaartal van de datum combineert dan krijg je het bovenstaande geval: 31 2007 valt volgens die definitie in week 1 2007.
Maar ik heb ook een takke hekel aan weeknr's gelukkig kom ik er vrijwel altijd mee weg door de gebruiker een datum-traject te laten selecteren. Zoekt hij/zij zelf maar uit wat precies week 1 was
(en dan moet je niet een klant hebben met een gebroken boekjaar waarbij 1 augustus het begin van het boekjaar is, en zij bedoelen met week 1 de 1e week van augustus, en normale mensen bedoelen met week 1 wat in alle agenda's als week 1 wordt gezien
Exact expert nodig?
- RobIII
- Registratie: December 2001
- Niet online
Hoewel ik 't (deels) met je eens ben (ik heb zelf ook geen benul of we nou in week 49 of 51 zitten en dan zitten we nog tegen oud op nieuw aan; in augustus moet je 't me al helemaal niet vragen): het zal je verbazen hoeveel mensen met weeknummers werken. Complete volksstammen van projectplanners, bezorgdiensten, groothandels en ga zo maar door werken met weeknummers. Of ze dan allemaal dezelfde "standaard" hanteren weet ik niet (maar zolang de zaken binnen 'tzelfde land blijven is dat waarschijnlijk wel zo en zo niet merken ze 't snel genoegShadowLord schreef op woensdag 22 december 2010 @ 14:36:
Werken met weeknummers is sowieso erg twijfelachtig. Bijna niemand weet wanneer iets plaatsvind als je roept 'in week 12 jaan we ... doen'. Datums zijn veel concreter voor 'normale' mensen.
Onlangs zelf nog "last" van gehad:ShadowLord schreef op woensdag 22 december 2010 @ 14:36:
En uiteraard gaat het helemaal fout als je weeknummers gaat gebruiken voor een rapportage o.i.d. die over meerdere jaren loopt.
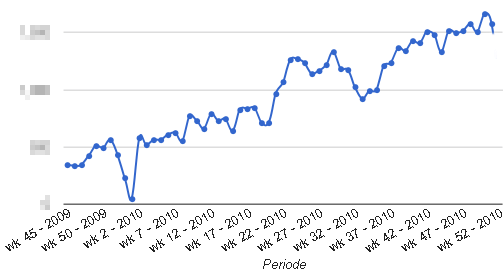
De eerste keer dat je 't ziet denk je: "WTF, waar komt die dip vandaan". En dan daagt 't ...
[ Voor 21% gewijzigd door RobIII op 22-12-2010 22:57 ]
There are only two hard problems in distributed systems: 2. Exactly-once delivery 1. Guaranteed order of messages 2. Exactly-once delivery.
Je eigen tweaker.me redirect
Over mij
- Woy
- Registratie: April 2000
- Niet online
Moderator Devschuur®
“Build a man a fire, and he'll be warm for a day. Set a man on fire, and he'll be warm for the rest of his life.”
- kenneth
- Registratie: September 2001
- Niet online
achter de duinen
C#:
1
| public class PrintDGV |
Als je een class maakt die een DataGridView print, noem hem dan PrintDataGridView. Als je schijfruimte tekort komt, koop een nieuwe schijf in plaats van met willekeurige afkortingen te komen
Look, runners deal in discomfort. After you get past a certain point, that’s all there really is. There is no finesse here.
- MBV
- Registratie: Februari 2002
- Laatst online: 10:34
tja, ik heb aan de andere kant een hekel aan OverlyDescriptiveCamelCasedClassNamesWithCapitalizedFirstLetter, ergens moet je een grens trekken. En dat 'ergens' is voor jouw collega wel erg ver naar korte namen
- Avalaxy
- Registratie: Juni 2006
- Laatst online: 12-03 15:40
:strip_icc():strip_exif()/u/180657/texacoiq2.jpg?f=community)
WithCapitalizedFirstLetter had je al weg kunnen laten
- Sebazzz
- Registratie: September 2006
- Laatst online: 14-07 14:59
3dp
Eerder nog DataGridViewPrinter, zelfstandig naamwoord. Het wordt aangeraden om classes te benoemen met een zelfstandig naamwoord.kenneth schreef op woensdag 29 december 2010 @ 21:33:
C#:
Als je een class maakt die een DataGridView print, noem hem dan PrintDataGridView. Als je schijfruimte tekort komt, koop een nieuwe schijf in plaats van met willekeurige afkortingen te komen
[Te koop: 3D printers] [Website] Agile tools: [Return: retrospectives] [Pokertime: planning poker]
- Alex)
- Registratie: Juni 2003
- Laatst online: 06-07 14:10
Of je maakt een class die overerft van de DataGridView-class (vooropgesteld dat deze niet sealed is) en maakt daarin een method 'Print' aan. Of je maakt een Extension Method.
Nog netter imo.
C#:
1
2
3
4
5
6
7
| public static class DataGridViewExtensions { public static void Print(this DataGridView dataGridView) { // hier gebeurt magie } } |
Nog netter imo.
We are shaping the future
Het afkorten om het afkorten is erg irritant. Helemaal met gode codecompletion is het onzin.
Lekker als je iemand anders' project overneemt met de wazigste afkortingen, of als je je eigen code terugleest en je het 'even' snel wou doen destijds
Lekker als je iemand anders' project overneemt met de wazigste afkortingen, of als je je eigen code terugleest en je het 'even' snel wou doen destijds
- Alex)
- Registratie: Juni 2003
- Laatst online: 06-07 14:10
Ik kort ook wel af hoor, ik typ gerust "DGV" in mijn code. Om vervolgens op <TAB> te drukken zodat ReSharper er toch meteen weer DataGridView van maakt. 
We are shaping the future
- kenneth
- Registratie: September 2001
- Niet online
achter de duinen
Een naam moet zo kort mogelijk zijn, zo lang als nodigMBV schreef op woensdag 29 december 2010 @ 22:26:
tja, ik heb aan de andere kant een hekel aan OverlyDescriptiveCamelCasedClassNamesWithCapitalizedFirstLetter, ergens moet je een grens trekken. En dat 'ergens' is voor jouw collega wel erg ver naar korte namen
Oeps, je hebt helemaal gelijk. Nouja, ik heb de naam maar gelaten zoals hij is, opruimen komt wel als ik een keer met die class zelf aan de slag ga. Opruimen om het opruimen vind ik namelijk ook een bad practiceSebazzz schreef op woensdag 29 december 2010 @ 22:36:
[...]
Eerder nog DataGridViewPrinter, zelfstandig naamwoord. Het wordt aangeraden om classes te benoemen met een zelfstandig naamwoord.
Look, runners deal in discomfort. After you get past a certain point, that’s all there really is. There is no finesse here.
- roy-t
- Registratie: Oktober 2004
- Laatst online: 23-05 08:49
Wijs! Hoewel ik daar wel eens last van hebkenneth schreef op donderdag 30 december 2010 @ 07:49:
[...]
Opruimen om het opruimen vind ik namelijk ook een bad practice
Klopt, maar als je aankomt met AchtrnmZndrTvgsl kan het lastig teruglezenkenneth schreef op donderdag 30 december 2010 @ 07:49:
[...]
Een naam moet zo kort mogelijk zijn, zo lang als nodig
- YopY
- Registratie: September 2003
- Laatst online: 01-05 10:25
Ik vindt het anders wel even rustgevend om zoiets aan het eind van de week te doen,kenneth schreef op donderdag 30 december 2010 @ 07:49:
Opruimen om het opruimen vind ik namelijk ook een bad practice
- kenneth
- Registratie: September 2001
- Niet online
achter de duinen
Uh, dat zeg ik toch418O2 schreef op donderdag 30 december 2010 @ 10:24:
[...]
Klopt, maar als je aankomt met AchtrnmZndrTvgsl kan het lastig teruglezen
Voordeel is trouwens niet alleen de leesbaarheid maar ook de voorspelbaarheid. 95% van de namen in een project/database gok ik in één keer goed (IntelliSense helpt je ook maar deels).
Look, runners deal in discomfort. After you get past a certain point, that’s all there really is. There is no finesse here.
- Haan
- Registratie: Februari 2004
- Laatst online: 16-07 15:02
dotnetter
Aan de andere kant wordt het weer afgeraden om extension methods te schrijven op classes uit de .NET library omdat je nooit weet wat er mee gebeurt in een nieuwe versie van het framework.Alex) schreef op woensdag 29 december 2010 @ 23:28:
Of je maakt een class die overerft van de DataGridView-class (vooropgesteld dat deze niet sealed is) en maakt daarin een method 'Print' aan. Of je maakt een Extension Method.
C#:
Nog netter imo.
Kater? Eerst water, de rest komt later
- FragFrog
- Registratie: September 2001
- Laatst online: 12:16
Laatste kwartier ~ halfuurtje van de dag wil ik er nog wel eens voor gebruiken; de code doornemen die je die dag geschreven hebt, rariteiten fixen, comments toevoegen waar die nog niet staan, etc. Even een moment van reflectie. Vooral als je net iets af hebt vlak voor het einde van de dag, het is nauwelijks de moeite waard om nog iets nieuws op te pakken, prima moment om op te gaan ruimenYopY schreef op donderdag 30 december 2010 @ 10:31:
Ik vindt het anders wel even rustgevend om zoiets aan het eind van de week te doen,
- kenneth
- Registratie: September 2001
- Niet online
achter de duinen
Hmm, inderdaad. Misschien ook maar invoeren
Look, runners deal in discomfort. After you get past a certain point, that’s all there really is. There is no finesse here.
/u/214894/crop5baaa31f9c4ff_cropped.png?f=community)
op stackoverflow kwam ik dit leuks tegen, vond het wel lachen
i_find_it_easier_to_read_text_with_underscores_separating_the_words, RatherThanHavingAnInitialCapitalLetterSeparatingTheWords.
Dude... camelcase or underscores the same, you should seriously work on reducing the length of your method names..
ButCamelCaseCausesProblemsWhenAcronymsLikeURLAreUsedAndAnywayHowOftenDoYouSeeVariableNamesThatOrThisLong
- Davio
- Registratie: November 2007
- Laatst online: 06-01-2025
Ik heb zelf het probleem dat ik voornamelijk alleen aan mijn eigen projecten werk en daarom niet al te consistent ben met comments en dergelijke. Ik denk dan vaak: "Ik heb het één keer verzonnen, ik kom daar nog wel een keer op."FragFrog schreef op donderdag 30 december 2010 @ 13:17:
[...]
Laatste kwartier ~ halfuurtje van de dag wil ik er nog wel eens voor gebruiken; de code doornemen die je die dag geschreven hebt, rariteiten fixen, comments toevoegen waar die nog niet staan, etc. Even een moment van reflectie. Vooral als je net iets af hebt vlak voor het einde van de dag, het is nauwelijks de moeite waard om nog iets nieuws op te pakken, prima moment om op te gaan ruimen
Tot die ene klant een jaar later belt dat iets het niet meer doet.
Mijn projecten zijn ook veelal proofs of concept ipv directe implementaties bij een klant, dat moedigt ook niet echt aan.
En ja, er zijn natuurlijk geen excuses om het niet netjes te doen, maar welke neuroot houdt zich daar nou aan?
- YopY
- Registratie: September 2003
- Laatst online: 01-05 10:25
Nee, dan zou ik ook niet netjes gaan programmeren. Project(je) waar ik nu mee bezig ben had ik eerst een prototype voor gemaakt om na te gaan wat er allemaal mogelijk was (samenvatting: webservice aanroepen, xml naar html, in een specifiek CMS met caching systeem en dergelijke) en op basis daarvan hebben we een aanpak gekozen die ik dan uitwerk - en dan netjes. Alle aparte functionaliteit netjes in aparte componenten / modules, beetje documentatie (moet nog globale documentatie schrijven, welke module doet wat en werkt hoe samen waarmee), wat unit tests waar ze logisch zijn, dat soort dingen. Met wat geluk is dit eindelijk een project dat netjes werkt, zonder aparte hacks, en zonder vaeghe bugs waar je nog weken op zit te hameren.quote: davioMijn projecten zijn ook veelal proofs of concept ipv directe implementaties bij een klant, dat moedigt ook niet echt aan.
Maar dat zal wel niet
- Sebazzz
- Registratie: September 2006
- Laatst online: 14-07 14:59
3dp
Het wordt sowieso aangeraden om als het kan te inheriten van een class in plaats van een extension ervoor te schrijven.Haan schreef op donderdag 30 december 2010 @ 12:18:
[...]
Aan de andere kant wordt het weer afgeraden om extension methods te schrijven op classes uit de .NET library omdat je nooit weet wat er mee gebeurt in een nieuwe versie van het framework.
[Te koop: 3D printers] [Website] Agile tools: [Return: retrospectives] [Pokertime: planning poker]
- Davio
- Registratie: November 2007
- Laatst online: 06-01-2025
Nou ja, ik bedoel met netjes eigenlijk meer de comments rond methoden en algehele documentatie, die schiet er nog wel eens bij in. Maar ja, dingen die voor mij logisch zijn, zijn dat voor klanten niet en dat vergeet ik wel eens.YopY schreef op donderdag 30 december 2010 @ 19:14:
[...]
Nee, dan zou ik ook niet netjes gaan programmeren. Project(je) waar ik nu mee bezig ben had ik eerst een prototype voor gemaakt om na te gaan wat er allemaal mogelijk was (samenvatting: webservice aanroepen, xml naar html, in een specifiek CMS met caching systeem en dergelijke) en op basis daarvan hebben we een aanpak gekozen die ik dan uitwerk - en dan netjes. Alle aparte functionaliteit netjes in aparte componenten / modules, beetje documentatie (moet nog globale documentatie schrijven, welke module doet wat en werkt hoe samen waarmee), wat unit tests waar ze logisch zijn, dat soort dingen. Met wat geluk is dit eindelijk een project dat netjes werkt, zonder aparte hacks, en zonder vaeghe bugs waar je nog weken op zit te hameren.
Maar dat zal wel niet
![]() Dit topic is gesloten.
Dit topic is gesloten.
![]()
Let op:
Uiteraard is het in dit topic niet de bedoeling dat andere users en/of topics aangehaald worden om ze voor gek te zetten. Lachen om je eigen code, of over dingen die je "wel eens tegengekomen bent" is prima, maar hou het onderling netjes.
Uiteraard is het in dit topic niet de bedoeling dat andere users en/of topics aangehaald worden om ze voor gek te zetten. Lachen om je eigen code, of over dingen die je "wel eens tegengekomen bent" is prima, maar hou het onderling netjes.