Hoi allemaal,
ik heb een zelfbouw NAS die Ubuntu 18.10 draait. De NAS wordt gebruikt om media op te slaan die ik via Kodi afspeel en er draait Hassio met Home-assistant op. Om de ongeveer anderhalve week is de NAS niet meer bereikbaar via SSH en het enige wat helpt is rebooten.
Dit is de HW die ik gebruik:
Verder heb ik temperatuur, cpu load, memory load etc gedaan. Zie hier bijvoorbeeld van de CPU load:
als ik naar de temperaturen kijken zie ik niets boven de 45 graden voorbij komen.
Ik heb memtest gedaan met de resultaten onderaan de post. Passed met 0 fouten. Ik heb wel maar 4 uur gedraaid omdat ik geen licentie heb.
Hier is de kernel log waar een crash om 02:08 op 18-03 gebeurt:
kernel log
Laatste regels voor de crash:
Ik heb de condensators gecontroleerd op bol staan maar daar vond ik eigenlijk ook niets.
Ik heb hiervoor Openmediavault gedraaid en daar had ik hetzelfde probleem. Ik vermoed daarom dat het probleem in de HW zit maar ik weet dus niet in welke component.
Ik hoopte dat iemand hier misschien een idee heeft waar te zoeken of hoe een diagnose te stellen door bijvoorbeeld en andere log uit te lezen of een loggingtool aan te zetten?
Ik snap dat het een heel erg open vraag is maar ik zit een beetje met de handen in het haar. Ik heb veel mooie automations draaien, pihole en nog wat andere zaken maar als het onverwachts crasht is het wel vervelend, vooral als er mensen op bezoek zijn oid..
Memtest output:
Edit: het syslog lijkt wel door te lopen: syslog
ik heb een zelfbouw NAS die Ubuntu 18.10 draait. De NAS wordt gebruikt om media op te slaan die ik via Kodi afspeel en er draait Hassio met Home-assistant op. Om de ongeveer anderhalve week is de NAS niet meer bereikbaar via SSH en het enige wat helpt is rebooten.
Dit is de HW die ik gebruik:
- Intel Celeron G1820 Boxed
- ASRock H81M-DGS R2.0
- 2x WD Green HDD, 3TB
- Fractal Design Core 1000 USB 3.0
- Kingston KVR16N11S8/4
- be quiet! System Power 7 300W
- Kingston SSDNow V300 60GB (draait het OS)
- Ubuntu 18.10
- Hassio Home assistant
- Sonarr
- Radarr
- Transmission
- Sabnzbd
Verder heb ik temperatuur, cpu load, memory load etc gedaan. Zie hier bijvoorbeeld van de CPU load:
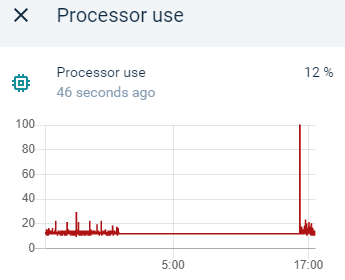
als ik naar de temperaturen kijken zie ik niets boven de 45 graden voorbij komen.
Ik heb memtest gedaan met de resultaten onderaan de post. Passed met 0 fouten. Ik heb wel maar 4 uur gedraaid omdat ik geen licentie heb.
Hier is de kernel log waar een crash om 02:08 op 18-03 gebeurt:
kernel log
Laatste regels voor de crash:
code:
1
2
3
| Mar 18 00:00:06 Server kernel: [11770.104536] hassio: port 9(veth7f1d42f) entered disabled state Mar 18 00:24:27 Server kernel: [13231.032544] perf: interrupt took too long (3969 > 3943), lowering kernel.perf_event_max_sample_rate to 50250 Mar 18 02:08:00 Server kernel: [19443.940252] perf: interrupt took too long (4975 > 4961), lowering kernel.perf_event_max_sample_rate to 40000 |
Ik heb de condensators gecontroleerd op bol staan maar daar vond ik eigenlijk ook niets.
Ik heb hiervoor Openmediavault gedraaid en daar had ik hetzelfde probleem. Ik vermoed daarom dat het probleem in de HW zit maar ik weet dus niet in welke component.
Ik hoopte dat iemand hier misschien een idee heeft waar te zoeken of hoe een diagnose te stellen door bijvoorbeeld en andere log uit te lezen of een loggingtool aan te zetten?
Ik snap dat het een heel erg open vraag is maar ik zit een beetje met de handen in het haar. Ik heb veel mooie automations draaien, pihole en nog wat andere zaken maar als het onverwachts crasht is het wel vervelend, vooral als er mensen op bezoek zijn oid..
Memtest output:
code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| Summary Report Date 2019-04-26 15:03:43 Generated by MemTest86 V8.1 Free (64-bit) Result PASS System Information EFI Specifications 2.31 System Manufacturer To Be Filled By O.E.M. Product Name To Be Filled By O.E.M. Version To Be Filled By O.E.M. Serial Number To Be Filled By O.E.M. BIOS Vendor American Megatrends Inc. Version P1.20 Release Date 12/06/2013 Baseboard Manufacturer ASRock Product Name H81M-DGS R2.0 Version Serial Number E80-46041502717 CPU Type Intel Celeron G1820 @ 2.70GHz CPU Clock 2699 MHz # Logical Processors 2 L1 Cache 4 x 64K (138868 MB/s) L2 Cache 4 x 256K (42019 MB/s) L3 Cache 2048K (29188 MB/s) Memory 3778M (8281 MB/s) DIMM Slot #0 4GB DDR3 PC3-12800 Kingston / 9905584-014.A00LF / AD0E07FF 11-11-11-28 / 1600 MHz / 1.5V Result summary Test Start Time 2019-04-26 04:51:25 Elapsed Time 1:53:31 Memory Range Tested 0x0 - 11F600000 (4598MB) CPU Selection Mode Parallel (All CPUs) ECC Polling Enabled # Tests Passed 48/48 (100%) Test # Tests Passed Errors Test 0 [Address test, walking ones, 1 CPU] 4/4 (100%) 0 Test 1 [Address test, own address, 1 CPU] 4/4 (100%) 0 Test 2 [Address test, own address] 4/4 (100%) 0 Test 3 [Moving inversions, ones & zeroes] 4/4 (100%) 0 Test 4 [Moving inversions, 8-bit pattern] 4/4 (100%) 0 Test 5 [Moving inversions, random pattern] 4/4 (100%) 0 Test 6 [Block move, 64-byte blocks] 4/4 (100%) 0 Test 7 [Moving inversions, 32-bit pattern] 4/4 (100%) 0 Test 8 [Random number sequence] 4/4 (100%) 0 Test 9 [Modulo 20, ones & zeros] 4/4 (100%) 0 Test 10 [Bit fade test, 2 patterns, 1 CPU] 4/4 (100%) 0 Test 13 [Hammer test] 4/4 (100%) 0 Certification This document certifies that the Tests described above have been carried out by a suitably qualified technician on the System described above. Signed ___________________________ Put your company name here: Level 5, 63 Foveaux St, Surry Hills, 2010, Sydney, Australia Phone + 61 2 9690 0444 Fax + 61 2 9690 0445 E-Mail: info@passmark.com |
Edit: het syslog lijkt wel door te lopen: syslog
[ Voor 31% gewijzigd door Jlo88 op 25-06-2019 13:35 . Reden: syslog toegevoegd ]
:strip_icc():strip_exif()/u/91018/dgtw.jpg?f=community)
:strip_icc():strip_exif()/u/85308/mirko.jpg?f=community)
/u/78932/Jewel3GoT.png?f=community)
:strip_exif()/u/389747/iconcroppedresizedsmallercroppedcroppedresized.gif?f=community)
:strip_icc():strip_exif()/u/204552/crop5f061f1e94305.jpeg?f=community)
:strip_icc():strip_exif()/u/146731/crop562615a0aa64c.jpeg?f=community)
/u/286685/crop58fcf863c48a5.png?f=community)
:strip_exif()/u/52746/eric-cartman_small.gif?f=community)
/u/38159/DirkJan.png?f=community)

/u/125506/link-8bit.png?f=community)