:strip_icc():strip_exif()/u/39286/crop59ec5b33730d2_cropped.jpeg?f=community)
Ok, dan kom ik er ook even in, maar het is wellicht een vraag dat een eigen topic waardig is.
2 Coreswitches
Nah ja, plaatje ziet er niet zo heel mooi uit, maar goed, even beschrijving.
Core1/Core2 draaien alle Layer3 zaken voor Vlan10. Iedere ServerSw zit ob.v. STP aan 2 coreswitches, 1 actieve link dus.
Het blade enclosure hangt met een soort STP aan de beide serverswitches. Op de Hyper-V/ESX hosts zijn er 2 NIC's die via de MS/VMware software geteamed zijn, er vind dus para virtualisatie van de netwerkkaart plaats en het OS doet failover.
Apparatuur:
- HP 54xx switches met een van de laatste firmwares
- HP C7000 Blade Enclosures met Gen9 Blades. Netwerk met Virtual Connect
Ok, nou moeten dus de VDI's booten van hun image op de PVS server via PXE en dat werkt sinds afgelopen week vaker niet dan wel, heel soms werkt het ook wel. Dit alles zit dus Layer2 binnen 1 vlan! Dat is dan ook meteen het hele gekke aan het verhaal. De enige conclusie die wij kunnen trekken is dat er iets met ARP/Layer2 qua networking niet 100% in orde is.
Als we een VDI booten naast de PVS server (dus op VMware) is het bloedsnel en werkt het perfect, hence, het zit ergens in het netwerk, maar we hebben niets veranderd ... as per usual
Maar wat? Uiteraard hebben we al van alles lopen proberen, alle servers gereboot etc. Wat wel beter lijkt te gaan is als we de teaming op de Hyper-V er af halen en 1 NIC direct aan het VDI netwerk koppelen. Ook hier is de "oplossing" niet 100% water dicht, maar het werkt wel beter.
Ook hebben we de Layer3 VRRP tussen de core switches gewisseld, lijkt ook niet tot het gewenste resultaat te leiden.
Wij zijn even helemaal de weg kwijt, net als onze ARP pakketjes
Gevonden op internet (we gaan vandaag verder met testen overigens):
- Mogelijk broadcast limit? Zou een verklaring kunnen zijn waarom het normaal wat traag is
- Iets met STP? Is immers layer 2
Zijn er hier nog mensen met slimme ideeën? Bedankt alvast!
2 Coreswitches
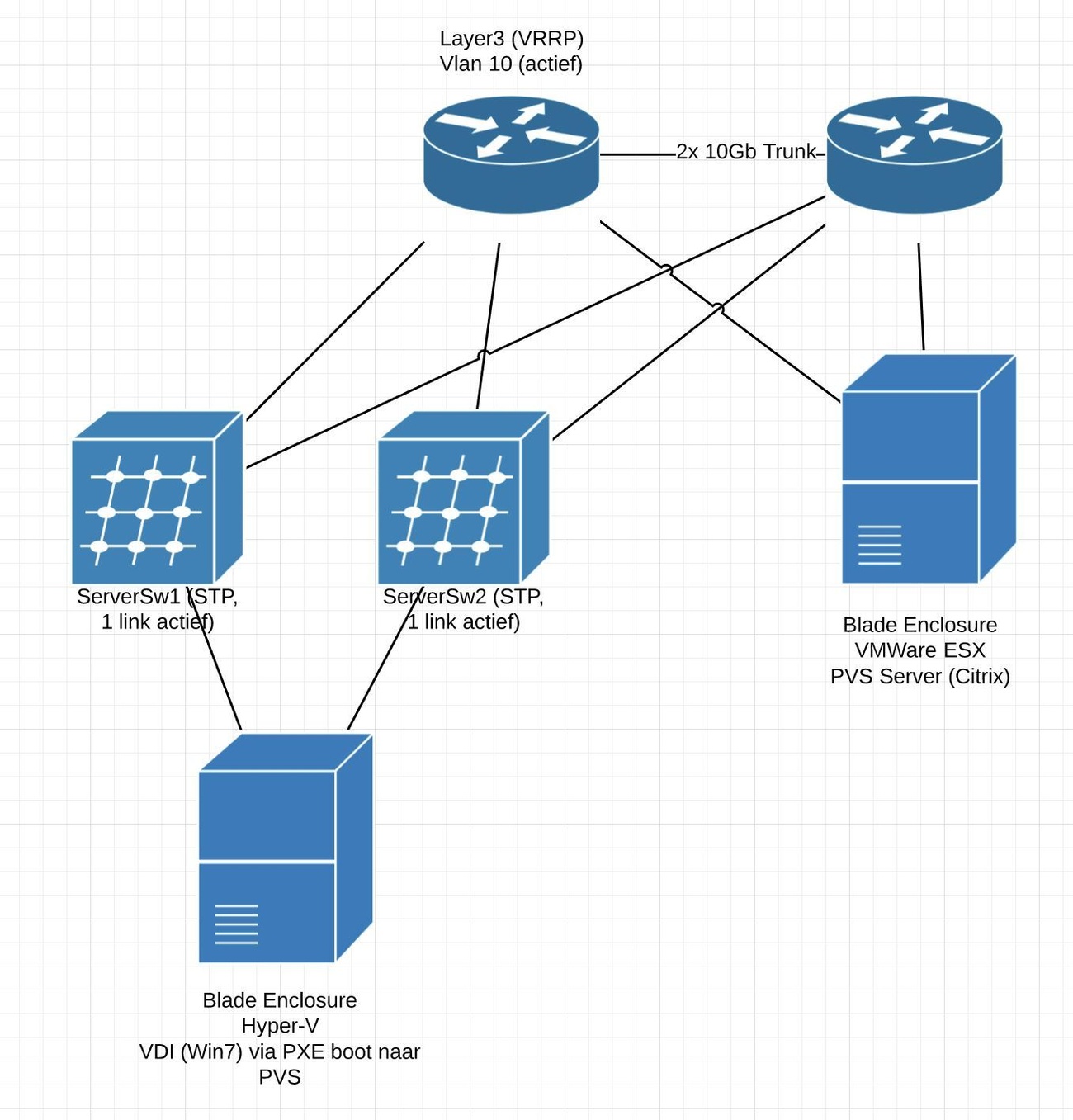
Nah ja, plaatje ziet er niet zo heel mooi uit, maar goed, even beschrijving.
Core1/Core2 draaien alle Layer3 zaken voor Vlan10. Iedere ServerSw zit ob.v. STP aan 2 coreswitches, 1 actieve link dus.
Het blade enclosure hangt met een soort STP aan de beide serverswitches. Op de Hyper-V/ESX hosts zijn er 2 NIC's die via de MS/VMware software geteamed zijn, er vind dus para virtualisatie van de netwerkkaart plaats en het OS doet failover.
Apparatuur:
- HP 54xx switches met een van de laatste firmwares
- HP C7000 Blade Enclosures met Gen9 Blades. Netwerk met Virtual Connect
Ok, nou moeten dus de VDI's booten van hun image op de PVS server via PXE en dat werkt sinds afgelopen week vaker niet dan wel, heel soms werkt het ook wel. Dit alles zit dus Layer2 binnen 1 vlan! Dat is dan ook meteen het hele gekke aan het verhaal. De enige conclusie die wij kunnen trekken is dat er iets met ARP/Layer2 qua networking niet 100% in orde is.
Als we een VDI booten naast de PVS server (dus op VMware) is het bloedsnel en werkt het perfect, hence, het zit ergens in het netwerk, maar we hebben niets veranderd ... as per usual
Maar wat? Uiteraard hebben we al van alles lopen proberen, alle servers gereboot etc. Wat wel beter lijkt te gaan is als we de teaming op de Hyper-V er af halen en 1 NIC direct aan het VDI netwerk koppelen. Ook hier is de "oplossing" niet 100% water dicht, maar het werkt wel beter.
Ook hebben we de Layer3 VRRP tussen de core switches gewisseld, lijkt ook niet tot het gewenste resultaat te leiden.
Wij zijn even helemaal de weg kwijt, net als onze ARP pakketjes
Gevonden op internet (we gaan vandaag verder met testen overigens):
- Mogelijk broadcast limit? Zou een verklaring kunnen zijn waarom het normaal wat traag is
- Iets met STP? Is immers layer 2
Zijn er hier nog mensen met slimme ideeën? Bedankt alvast!
Gezocht: netwerkbeheerder
Als je het niet aan een 6-jarige kan uitleggen, snap je er zelf ook niks van! - A. Einstein
/u/172597/crop5e1225c8b1011.png?f=community)
/u/35508/crop61e6aa7b579e2_cropped.png?f=community)
:strip_icc():strip_exif()/u/25852/bowmore_18k.jpg?f=community)
:strip_icc():strip_exif()/u/1604/60x60.jpg?f=community)
/u/11917/cheshirecat.png?f=community)
:strip_exif()/u/47664/afx_hax.gif?f=community)
:strip_icc():strip_exif()/u/84973/images.jpg?f=community)