Ik ben (voor het eerst) een database aan het opzetten om meetgegevens van ons product in op te slaan en makkelijk terug te vinden. Ik heb alleen moeite met het bepalen van een efficiënt design.
Ik zal eerst maar eens abstract proberen uit te uitleggen hoe het product opgebouwd is en wat voor een soort meetdata hier uit komt. Ons product is opgebouwd uit meerdere onderdelen en aan ieder onderdeel worden metingen verricht:
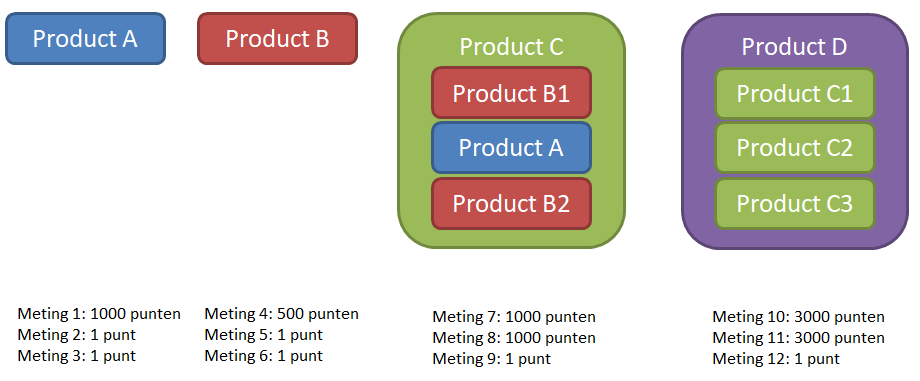
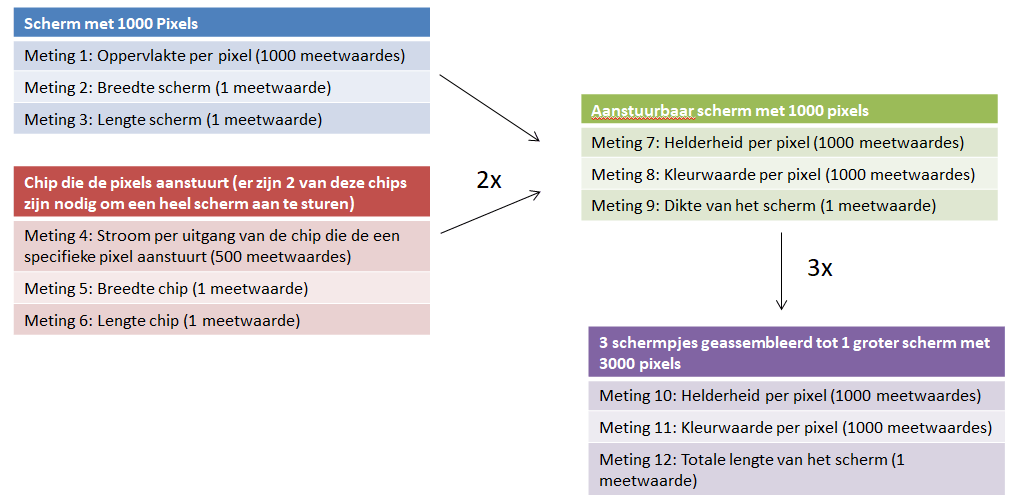
Product A en B zijn 2 losse onderdelen waar metingen aan verricht worden. Hier zit een meting bij die 1000 individuele meetpunten voor product A oplevert en 500 individuele meetpunten voor product B. Twee producten B en één product A worden geassembleerd tot product C waar ook weer metingen aan zitten die 1000 individuele meetpunten opleveren. Drie producten C worden geassembleerd tot het eindproduct D. Een bijkomend probleem is dat op het moment dat product A of B gemeten wordt nog niet bekend is welke gecombineerd worden tot product C. Het zelfde geld voor de drie producten C in het eindproduct D.
Daarnaast worden er per product nog individuele metingen gedaan die maar 1 meetpunt opleveren.
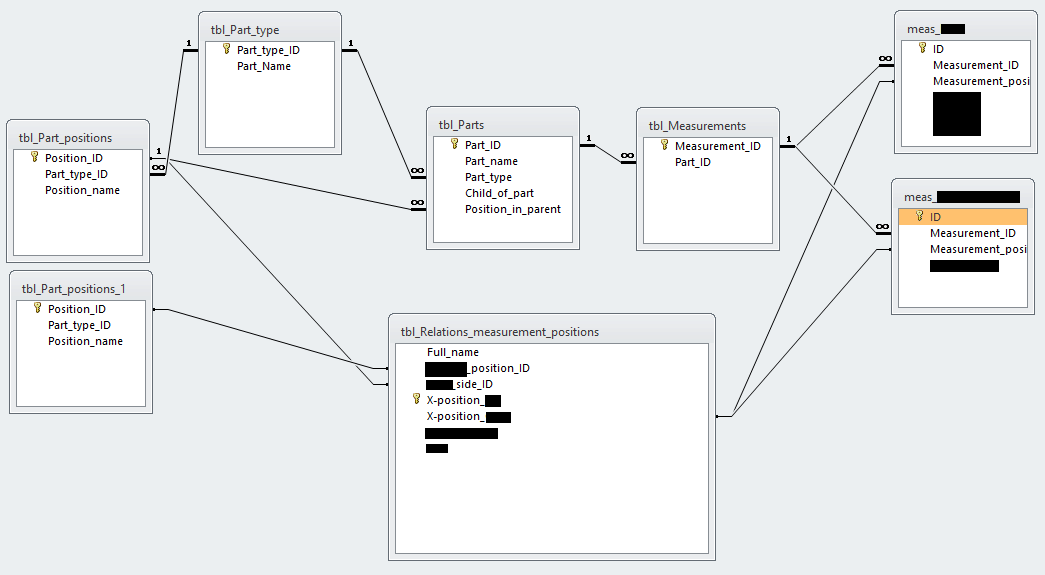
De metingen die gedaan worden hebben onderlinge relaties met elkaar. Deze heb ik proberen te weergeven in onderstaande tabel.
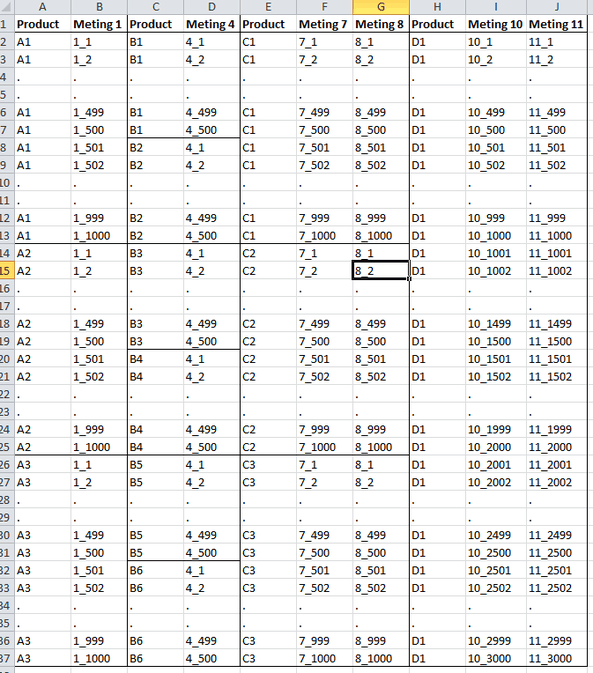
Nu vraag ik me af hoe ik de tabellen in de database zo kan inrichten zodat er efficiënt met query's nieuwe tabellen gegenereerd kunnen worden zoals, alle metingen die aan een eindproduct zijn uitgevoerd (voorbeeldtabel) of de meetwaarde van dezelfde meting over meerdere producten in de tijd.
Zelf had ik het idee om voor drie soorten tabellen te maken:
Al het advies, opmerkingen of vragen zijn welkom
Ik zal eerst maar eens abstract proberen uit te uitleggen hoe het product opgebouwd is en wat voor een soort meetdata hier uit komt. Ons product is opgebouwd uit meerdere onderdelen en aan ieder onderdeel worden metingen verricht:
Product A en B zijn 2 losse onderdelen waar metingen aan verricht worden. Hier zit een meting bij die 1000 individuele meetpunten voor product A oplevert en 500 individuele meetpunten voor product B. Twee producten B en één product A worden geassembleerd tot product C waar ook weer metingen aan zitten die 1000 individuele meetpunten opleveren. Drie producten C worden geassembleerd tot het eindproduct D. Een bijkomend probleem is dat op het moment dat product A of B gemeten wordt nog niet bekend is welke gecombineerd worden tot product C. Het zelfde geld voor de drie producten C in het eindproduct D.
Daarnaast worden er per product nog individuele metingen gedaan die maar 1 meetpunt opleveren.
De metingen die gedaan worden hebben onderlinge relaties met elkaar. Deze heb ik proberen te weergeven in onderstaande tabel.
Nu vraag ik me af hoe ik de tabellen in de database zo kan inrichten zodat er efficiënt met query's nieuwe tabellen gegenereerd kunnen worden zoals, alle metingen die aan een eindproduct zijn uitgevoerd (voorbeeldtabel) of de meetwaarde van dezelfde meting over meerdere producten in de tijd.
Zelf had ik het idee om voor drie soorten tabellen te maken:
- Tabellen met meetwaarden (voor iedere meting een eigen tabel). Maar hoe moet ik bijvoorbeeld de 3000 meetwaarden van bijvoorbeeld meting 10 opslaan? Iedere meetwaarde in een eigen kolom (dus uiteindelijke 3000+ kolommen) of voor iedere meting een eigen record, waardoor het aantal records uiteindelijk snel oploopt tot miljoenen?
- Eén tabel die de relaties tussen de verschillende producten vastlegd? Of 2 tabellen, één voor de koppelingen van product A en B tot C, en één voor de koppelingen tussen producten C en het eindproduct D?
- Één of meerdere tabellen die de relaties vastlegt tussen de meetpunten van de verschillende metingen?
Al het advies, opmerkingen of vragen zijn welkom

/u/3813/100_8985_ICON2.JPG?f=community)
/u/613048/crop5db7e8da13e77.png?f=community)
:strip_icc():strip_exif()/u/547196/crop5b5ecd5b528b3_cropped.jpeg?f=community)
:strip_exif()/u/396800/D-_3427da0a9c293b63f2a66dea2e642102.gif?f=community)

/u/26735/crop5b6e03049ac12.png?f=community)