Ha mede-tweakers,
Ik ben gestart met het mezelf bijbrengen van web scraping. met behulp van fora en allerlei tutorials heb ik al een mooi beginnetje kunnen maken.
De website die ik wil scrapen ziet er ongeveer zo uit:
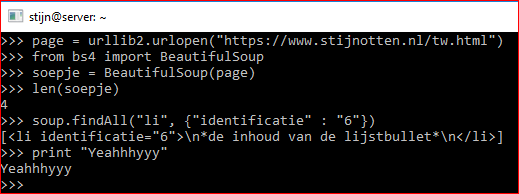
De ul heeft dus geen class of id, de li heeft het wel.
Wat ik wil doen is uiteindelijk een csv output genereren van alle data binnen de verschillende li's, met per regel uiteraard de data van 1 li.
Nu ben ik al de hele dag bezig aan de hand van deze website. Helaas is in dit voorbeeld het deel van de website waar "alles van 1 product" in staat een div class met class id/name. In mijn geval is de li het deel waar alles van 1 product in staat. In dit voorbeeld werkt dus de regel code:
my_page = page_soup.findAll('div", {"class"} : "class-name"}).
Ik heb (volgens mij) alle mogelijke opties geprobeerd, maar loop toch echt vast. Wat doe ik verkeerd in de findAll functie van beautiful soup?
Eeuwige credits voor het verlossende antwoord!
Ik ben gestart met het mezelf bijbrengen van web scraping. met behulp van fora en allerlei tutorials heb ik al een mooi beginnetje kunnen maken.
De website die ik wil scrapen ziet er ongeveer zo uit:
code:
1
2
3
4
5
6
7
8
9
10
11
12
| <section class="test"> <div id=nummer class=dag> <ul> <li identificatie=6> *de inhoud van de lijstbullet* </li> <li identificatie=7> *de inhoud van de lijstbullet* </li> </ul> </div> </section> |
De ul heeft dus geen class of id, de li heeft het wel.
Wat ik wil doen is uiteindelijk een csv output genereren van alle data binnen de verschillende li's, met per regel uiteraard de data van 1 li.
Nu ben ik al de hele dag bezig aan de hand van deze website. Helaas is in dit voorbeeld het deel van de website waar "alles van 1 product" in staat een div class met class id/name. In mijn geval is de li het deel waar alles van 1 product in staat. In dit voorbeeld werkt dus de regel code:
my_page = page_soup.findAll('div", {"class"} : "class-name"}).
Ik heb (volgens mij) alle mogelijke opties geprobeerd, maar loop toch echt vast. Wat doe ik verkeerd in de findAll functie van beautiful soup?
Eeuwige credits voor het verlossende antwoord!
:strip_exif()/u/664616/crop598d9b2802837_cropped.gif?f=community)

:strip_exif()/u/157466/shyguy.gif?f=community)