:strip_icc():strip_exif()/u/273143/crop662a645733c16_cropped.jpg?f=community)
Hallo allemaal,
Ik ben bezig met een ERD in MySQL Workbench maar het is me niet echt duidelijk of er daadwerkelijk een functioneel verschil is tussen identifying en non-identifying relaties. Ik heb al rondgezocht maar ik stuit steeds op de volgende uitleg
An identifying relationship is when the existence of a row in a child table depends on a row in a parent table. This may be confusing because it's common practice these days to create a pseudokey for a child table, but not make the foreign key to the parent part of the child's primary key. Formally, the "right" way to do this is to make the foreign key part of the child's primary key. But the logical relationship is that the child cannot exist without the parent.
Example: A Person has one or more phone numbers. If they had just one phone number, we could simply store it in a column of Person. Since we want to support multiple phone numbers, we make a second table PhoneNumbers, whose primary key includes the person_id referencing the Person table.
We may think of the phone number(s) as belonging to a person, even though they are modeled as attributes of a separate table. This is a strong clue that this is an identifying relationship (even if we don't literally include person_id in the primary key of PhoneNumbers).
A non-identifying relationship is when the primary key attributes of the parent must not become primary key attributes of the child. A good example of this is a lookup table, such as a foreign key on Person.state referencing the primary key of States.state. Person is a child table with respect to States. But a row in Person is not identified by its state attribute. I.e. state is not part of the primary key of Person.
A non-identifying relationship can be optional or mandatory, which means the foreign key column allows NULL or disallows NULL, respectively.
bron: stackoverflow
Okee, deels is dat dus duidelijk. Iets dergelijks als een telefoonnummer is daadwerkelijk verbonden met een persoon en daarom wordt er voor een identifying relation gekozen. Een Staat is niet per se verbonden met een persoon (oftewel de tabel "Staten" kan Staten bevatten die niet per se zijn verbonden met een persoon).
Wat mij nu niet duidelijk is:
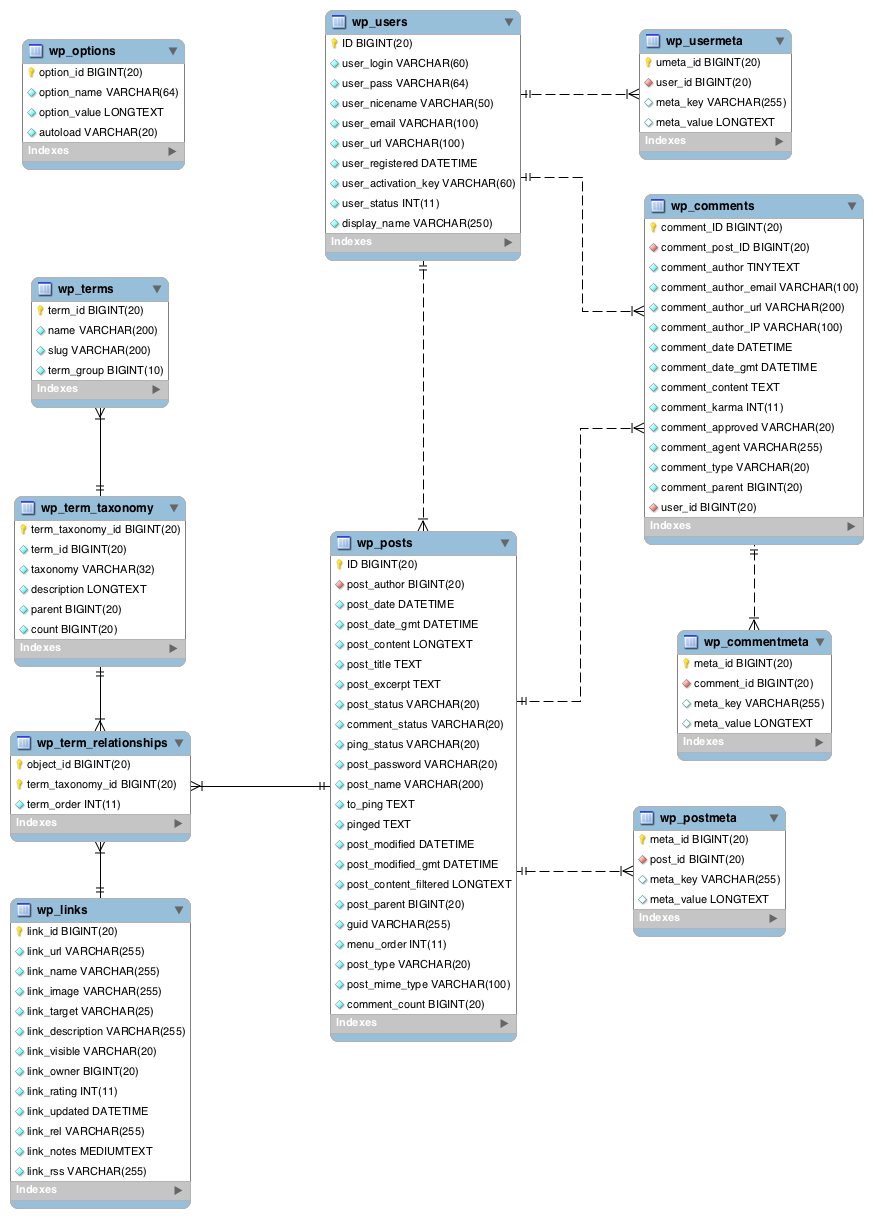
Als ik even een voorbeeld neem aan de Wordpress ERD, dan zie je dat daar zowel identifying relationships worden gebruikt als non-identifying. Maar de foreign-keys (rood-gekleurd ruitvormig icoon) bevatten een NOT NULL waarde. Oftewel het is nog verplicht dat een post gekoppeld is met een gebruiker, lijkt het hier op. Dat klopt toch? In dat geval kan er toch net zo goed gebruik gemaakt worden van een identifying-relationship? Of heb ik het mis?
Of is hier juist voor gekozen vanwege flexibiliteit? Dat een NOT NULL later alsnog eenvoudig naar NULL kan worden gewijzigd, indien gewenst?
Ik ben bezig met een ERD in MySQL Workbench maar het is me niet echt duidelijk of er daadwerkelijk een functioneel verschil is tussen identifying en non-identifying relaties. Ik heb al rondgezocht maar ik stuit steeds op de volgende uitleg
An identifying relationship is when the existence of a row in a child table depends on a row in a parent table. This may be confusing because it's common practice these days to create a pseudokey for a child table, but not make the foreign key to the parent part of the child's primary key. Formally, the "right" way to do this is to make the foreign key part of the child's primary key. But the logical relationship is that the child cannot exist without the parent.
Example: A Person has one or more phone numbers. If they had just one phone number, we could simply store it in a column of Person. Since we want to support multiple phone numbers, we make a second table PhoneNumbers, whose primary key includes the person_id referencing the Person table.
We may think of the phone number(s) as belonging to a person, even though they are modeled as attributes of a separate table. This is a strong clue that this is an identifying relationship (even if we don't literally include person_id in the primary key of PhoneNumbers).
A non-identifying relationship is when the primary key attributes of the parent must not become primary key attributes of the child. A good example of this is a lookup table, such as a foreign key on Person.state referencing the primary key of States.state. Person is a child table with respect to States. But a row in Person is not identified by its state attribute. I.e. state is not part of the primary key of Person.
A non-identifying relationship can be optional or mandatory, which means the foreign key column allows NULL or disallows NULL, respectively.
bron: stackoverflow
Okee, deels is dat dus duidelijk. Iets dergelijks als een telefoonnummer is daadwerkelijk verbonden met een persoon en daarom wordt er voor een identifying relation gekozen. Een Staat is niet per se verbonden met een persoon (oftewel de tabel "Staten" kan Staten bevatten die niet per se zijn verbonden met een persoon).
Wat mij nu niet duidelijk is:
Als ik even een voorbeeld neem aan de Wordpress ERD, dan zie je dat daar zowel identifying relationships worden gebruikt als non-identifying. Maar de foreign-keys (rood-gekleurd ruitvormig icoon) bevatten een NOT NULL waarde. Oftewel het is nog verplicht dat een post gekoppeld is met een gebruiker, lijkt het hier op. Dat klopt toch? In dat geval kan er toch net zo goed gebruik gemaakt worden van een identifying-relationship? Of heb ik het mis?
Of is hier juist voor gekozen vanwege flexibiliteit? Dat een NOT NULL later alsnog eenvoudig naar NULL kan worden gewijzigd, indien gewenst?
:strip_icc():strip_exif()/u/180657/texacoiq2.jpg?f=community)
:strip_exif()/u/22119/ch.gif?f=community)
:strip_icc():strip_exif()/u/1857/crop5a4d06ced6afe_cropped.jpeg?f=community)
{kind=link}