Binnen ons bedrijf zijn we bezig met een voorstel voor herinrichting van ons netwerk zowel in software alswel hardware. Over de softwarekant zijn we redelijk uit. Voor hardware kunnen we kiezen voor weer fysieke servers of een virtualisatie oplossing waarbij VMWare de beste papieren heeft (KVM als lowbudget alternatief)
Het 1e voorstel wat ik naar de directie wil doen is een Dell ps4100 SAN en daarbij 2 of 3 VMware servers met de VMware Essentials kit.
Een alternatief voorstel is 3 VMware servers met een stapeltje SAS schijven, maar qua totaalprijs scheelt dat nog niet eens zoveel tov de aparte SAN.
Het laatste alternatief is 6 fsyieke servers met een paar SAS schijven, al dan niet met een 7e gelijke server op reserve.
(in alle gevallen gaan nachtelijke backups gaan een aparte, grote NAS)
Wat ik echter niet duidelijk krijg is of ik in de eerste optie het beste voor 2 dikke servers kan kiezen of voor 3 'normaal dikke' servers, Dell heeft daar ook geen echt antwoord op.
Mijn overweging: met 2 servers kan er later nog een 3e bij onder de VMware essentials kit (met toekomstpad voor Essentials Plus kit of Acceleration kit) en het scheelt een licentie voor Veeam (nog aan te schaffen backuppakket). Qua aanschafkosten scheelt het net genoeg om interessant te kunnen zijn, zeker omdat het totaal aan hardware en licentiekosten toch al niet leuk is...
Maar bij storing van 1 server moet de andere server wel alle VMs kunnen draaien, ook als er in de nabije toekomst 1 of 2 VMs bij komen. Wanneer dat twijfelachtig wordt, dan moet er alsnog een 3e server bij komen, liefst een ongeveer gelijke als we al hebben wat dan dus weer een forse aanschafprijs heeft.
Hoe reëel is het dus om al onze VMs in geval van storing op 1 server te kunnen draaien? kan het, kan het nog net of is het echt te veel van het goede?
Er komen de volgende VM's op:
Windows 2008 R2 (AD)
Windows 2008 R2 (Exchange 2010 - 100 users)
Windows 2003 64bit (SQL en applicatieserver)
Windows 2008 R2 (lichte applicatieserver)
Windows 2008 (virtueel werkstation voor specifiek gebruik, hebben we nu ook al)
Ubuntu 12.04 (webserver)
CentOS 6.3 (VOIP)
In totaal 20 cores en 88 GB RAM
Ik zit te twijfelen tussen:
2x Dell R620 met 2x 8core 2,3 Ghz CPU en 128 GB RAM
3x Dell R420 met 2x 6core 2,3 Ghz CPU en 96 GB RAM
We hebben nu overigens nog 3 fysieke HP ML350 G6 servers met daarop SBS2008 (AD en Exchange), Windows 2003 64bit (SQL en applicatieserver) en Ubuntu 12.04 (webserver), deze servers zin 3 - 5 jaar oud.
Een meting liet zien dat we voor storage 750 IOPS nodig zijn op 95% percentiel en 1300 IOPS op 99% percentiel
Het 1e voorstel wat ik naar de directie wil doen is een Dell ps4100 SAN en daarbij 2 of 3 VMware servers met de VMware Essentials kit.
Een alternatief voorstel is 3 VMware servers met een stapeltje SAS schijven, maar qua totaalprijs scheelt dat nog niet eens zoveel tov de aparte SAN.
Het laatste alternatief is 6 fsyieke servers met een paar SAS schijven, al dan niet met een 7e gelijke server op reserve.
(in alle gevallen gaan nachtelijke backups gaan een aparte, grote NAS)
Wat ik echter niet duidelijk krijg is of ik in de eerste optie het beste voor 2 dikke servers kan kiezen of voor 3 'normaal dikke' servers, Dell heeft daar ook geen echt antwoord op.
Mijn overweging: met 2 servers kan er later nog een 3e bij onder de VMware essentials kit (met toekomstpad voor Essentials Plus kit of Acceleration kit) en het scheelt een licentie voor Veeam (nog aan te schaffen backuppakket). Qua aanschafkosten scheelt het net genoeg om interessant te kunnen zijn, zeker omdat het totaal aan hardware en licentiekosten toch al niet leuk is...
Maar bij storing van 1 server moet de andere server wel alle VMs kunnen draaien, ook als er in de nabije toekomst 1 of 2 VMs bij komen. Wanneer dat twijfelachtig wordt, dan moet er alsnog een 3e server bij komen, liefst een ongeveer gelijke als we al hebben wat dan dus weer een forse aanschafprijs heeft.
Hoe reëel is het dus om al onze VMs in geval van storing op 1 server te kunnen draaien? kan het, kan het nog net of is het echt te veel van het goede?
Er komen de volgende VM's op:
Windows 2008 R2 (AD)
Windows 2008 R2 (Exchange 2010 - 100 users)
Windows 2003 64bit (SQL en applicatieserver)
Windows 2008 R2 (lichte applicatieserver)
Windows 2008 (virtueel werkstation voor specifiek gebruik, hebben we nu ook al)
Ubuntu 12.04 (webserver)
CentOS 6.3 (VOIP)
In totaal 20 cores en 88 GB RAM
Ik zit te twijfelen tussen:
2x Dell R620 met 2x 8core 2,3 Ghz CPU en 128 GB RAM
3x Dell R420 met 2x 6core 2,3 Ghz CPU en 96 GB RAM
We hebben nu overigens nog 3 fysieke HP ML350 G6 servers met daarop SBS2008 (AD en Exchange), Windows 2003 64bit (SQL en applicatieserver) en Ubuntu 12.04 (webserver), deze servers zin 3 - 5 jaar oud.
Een meting liet zien dat we voor storage 750 IOPS nodig zijn op 95% percentiel en 1300 IOPS op 99% percentiel
:strip_icc():strip_exif()/u/84973/images.jpg?f=community)
:strip_exif()/u/535/fan.gif?f=community)
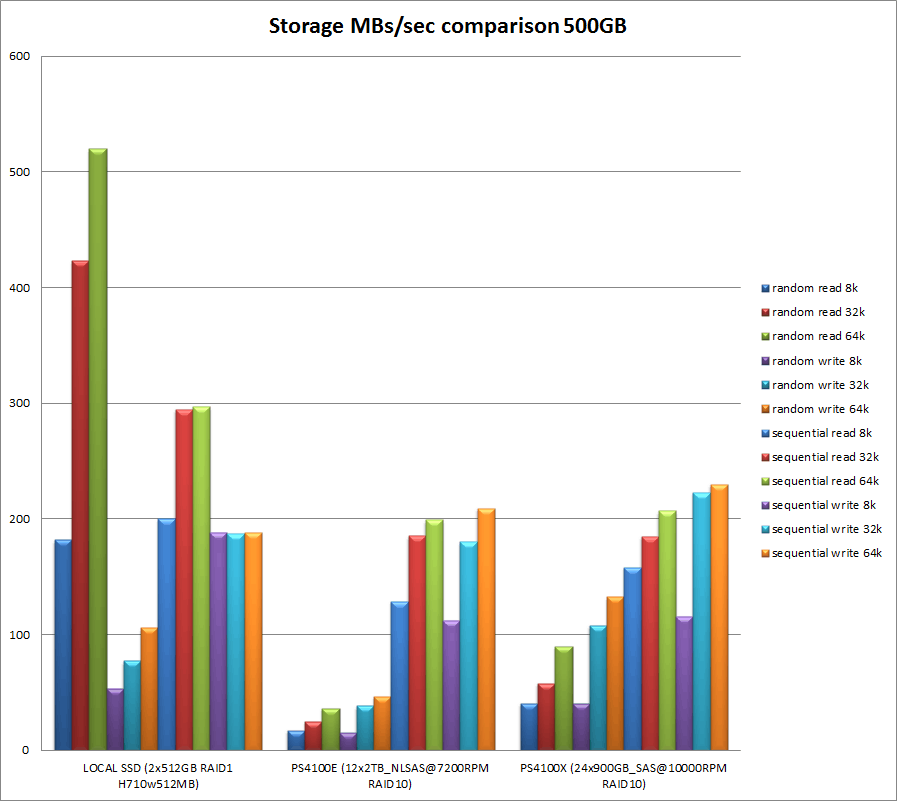

/u/113601/crop5e3f183d640f8_cropped.png?f=community)
:strip_icc():strip_exif()/u/25852/bowmore_18k.jpg?f=community)