Een groot nadeel is dat je moet zoeken naar documentatie en een beginpunt, oftewel hetzelfde manco van veel OS projecten.
Het gaat ook meer om de interface dan hoe je dat voorelkaar krijgt - de reden dat dat goed werkt is voornamelijk dat je makkelijk verfijningen aan kunt klikken (en dat je te zien krijgt hoeveel resultaten je dan nog overhoudt). Het is een vrij intuitieve manier om een query samen te stellen, een query die de meeste gebruikers niet zelfstandig in een of andere syntax voorelkaar zouden krijgen.
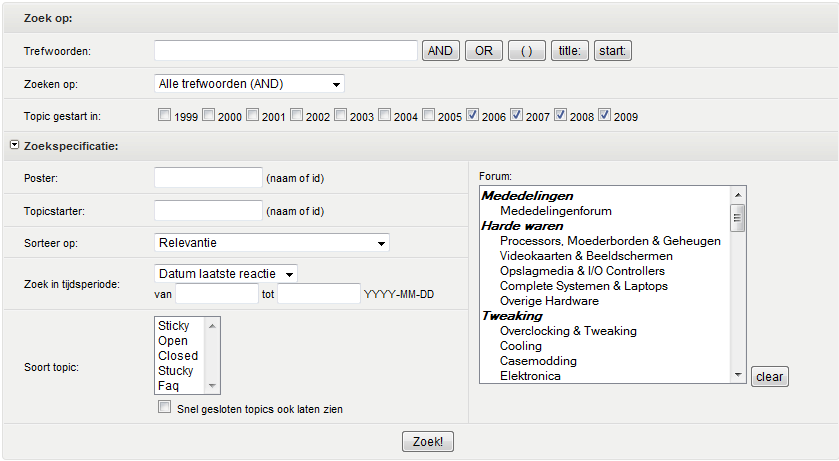
Dat snap ik, maar voor het forum wordt het pas echt behulpzaam als je nuttige beperkende criteria krijgt. De meeste mensen die informatie zoeken maakt het niet uit wie het schreef, maar wellicht wel wat voor additionele termen er bij passen.
Daar heb ik nog geen goed werkende open source voorbeelden van gezien, dus dan zit je al vrij snel vast aan een commercieel systeem.
Ik ook niet

Als je daar op zoekt krijg je vooral onderzoeksverhalen van mensen die het nauwelijks in de praktijk hebben toegepast of in ieder geval geen bruikbare omgeving hebben achtergelaten.
Ik denk dat de grootste slag die je kunt maken hem in de interface zit. En dat zou dus ook al bovenop Omega kunnen, als jullie daar beter mee uit de voeten kunnen.
Van omega weten we in ieder geval hoe het werkt en dat het de load die wij er op leggen aan kan. Puur als keyword-omgeving werkt het vrij goed, hoewel wat sturing van de relevantie met bijvoorbeeld de leeftijd van een topic nog wel nuttig zou zijn.
Dat is dan wel voor max 200,000 docs, maar geeft een indicatie.
Nouja, als wij alle topics willen indexeren komen we op 1,3 miljoen documenten en zes keer $700 is niet zo veel, maar zes keer $5800 wel... Als we alle reacties los willen nemen zitten we zelfs op dik in de 20 miljoen. De meeste van de commerciele omgevingen worden rap duurder boven een "beperkt" aantal documenten of hebben niet eens een prijsvermelding voor meer dan 1 miljoen en de echt geavanceerde systemen gaan er doorgaans van uit dat je documenten enorm veel waarde hebben en dat je dus zeer diep in de buidel wilt tasten om het doorzoekbaar te maken.
Maar het was maar een voorbeeld. Punt is meer dat er best veel (betaalbare) systemen zijn die specifiek sterk zijn in bepaalde functionaliteit (en die beter en goedkoper zijn dan Google). Het hangt er alleen enorm van af wat je zou willen doen.
Ze moeten dan dus vooral beter zijn in "meer dan een keyword retrieval engine", want dat doet Xapian vziw vrij goed, maar tegelijkertijd wel met dik een miljoen documenten overweg kunnen.
"Zelfbouw" op basis van Omega (of Lucene) is vaak verleidelijk, zeker voor een devver (hoe moeilijk kan het zijn?) maar is in de praktijk vaak een nogal tegenvallende klus (omdat het toch best wel lastig is). Het kan dus de moeite zijn bepaalde functionaliteit OTTB te hebben. Dat is ook typisch het voordeel van bijv. Solr boven sec Lucene (er zit al een heleboel in wat misschien niet al te lastig lijkt, maar waar je zo een paar maanden mee aan de slag bent om het zelf te doen).
Dat ben ik helemaal met je eens. Daarnaast missen we zelf nog wel een stukje document retrieval theorie, waardoor bepaalde zaken sowieso al minder kwaliteit zullen hebben.
Het gaat puur om performance (database off-loading), features (facetted search wordt al snel een CPU hog als je het niet al te handig doet, onzinnig voorbeeld maar als je bedenkt dat je zoiets in SQL zou moeten doen kun je je denk ik wel voorstellen dat een search engine daar ook specifiek goed in moet zijn), en interface. Als je dat allemaal zelf moet doen, is het de moeite niet. Maar er zijn dus alternatieven, alleen is het voor mij vanaf de zijlijn wat lastig te bedenken wat het handigste zou zijn

Dus ik laat maar wat ballonnetjes op. (Hope it helps).
De schaalgrootte, het feit dat relevantie bij ons verwatert met de leeftijd en dat er nagenoeg geen structuur in de tekst zit zijn de grootste punten inderdaad. En daarbij inderdaad nog het puntje security, wat we bij Xapian opgelost hebben door boolean-queries op de achtergrond toe te voegen.
Als je gerichter vragen wilt stellen is het waarschijnlijk handiger deze discussie naar e-mail te verhuizen. We zijn altijd benieuwd naar betere oplossingen, maar het moet dan niet alleen een ander systeem worden, vooral ook beter
:strip_exif()/u/40272/wim2.gif?f=community)
:strip_icc():strip_exif()/u/30094/gotstuur.jpg?f=community)
/u/145838/2095.PNG?f=community)
:strip_icc():strip_exif()/u/113929/Wolverine.jpg?f=community)
:strip_icc():strip_exif()/u/99521/Triviumsmall2.jpg?f=community)
:strip_icc():strip_exif()/u/136848/rsz_pure2.jpg?f=community)
/u/1830/acm.png?f=community)
:strip_exif()/u/26632/dosprompt2.gif?f=community)
:strip_icc():strip_exif()/u/43473/crop5e12eeae6a054_cropped.jpeg?f=community)
/u/3174/crop5f1e2a4facc1b.png?f=community)
:strip_icc():strip_exif()/u/47042/small.jpg?f=community)
:strip_icc():strip_exif()/u/93100/crop58a9d2a8b7692_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/11292/touchinverted.jpg?f=community)
:strip_icc():strip_exif()/u/11495/bombadilwince.jpg?f=community)
:strip_exif()/u/29321/crop6103ce90de63d_cropped.gif?f=community)
/u/100634/GoT.png?f=community)
{kind=link}
{kind=link}