BasieP schreef op woensdag 02 mei 2007 @ 15:05:
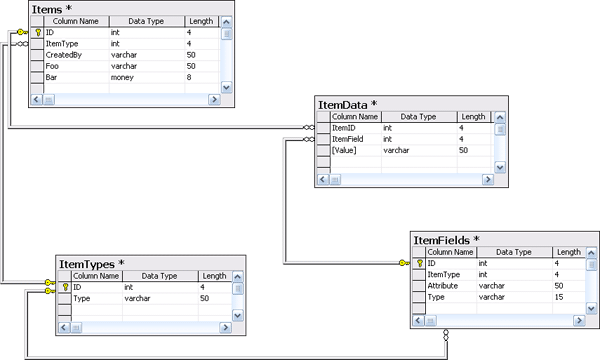
een tabel diepte is een tabel waarbij elke variable 1 record is. dus 1 record heeft dus de variable naam (als kolom) de waarde (als kolom) etc.
breedte is een doodnormale tabel zoals je die normaal maakt.
Precies, dat zei ik ook in mijn opmerking:
Hieronder ga ik er even van uit dat 'lengte' bij jou dus attributes in rows inhoudt en diepte / breedte attributes als columns
EfBe: Die tabel opzet [breedte] HEEFT geen voordeel. Ten eerste is het niet sneller (het is trager want je kunt geen queries uitschrijven zonder data interpretatie) en ten tweede is het niet onderhoudbaar. Hoe wil jij bv FK's gaan definieren? Veel plezier.
Daar prak je 'breedte' tussen in een quote van mij, terwijl ik dat dus NIET bedoel. Dat is de LENGTE quote. Als je me dingen gaat nadragen die ik niet beweerd heb dan houdt het op natuurlijk.
daar sla je de plank dus voledig mis. je hebt het hier over een doodnormale tabel. Die is ZEKER sneller dan een diepte tabel, en daar kan je prima FK's in defineren.
Beter lezen. En beter quoten!
op de rest van je verhaal ga ik neit eens reageren, aangezien je mijn post gewoon niet snapt

Tja, wie snapt wie nou niet? Ik had die opmerking wat ik onder breedte/diepte in jouw post verstond er niet voor niks boven gezet.
Hobbles schreef op woensdag 02 mei 2007 @ 09:26:
@EfBe: Probeer in het vervolg iets minder arrogant over te komen aub.
Ik stel mijn vraag hier om er ook iets van te leren, zodat ik mijn keuze in de toekomst kan onderbouwen. Ik kom hier niet iets vragen omdat ik iets niet snap, maar omdat ik de mening wou weten van andere (waarschijnlijk meer ervaren) personen.
Wellicht komt dit ook weer arrogant over, maar dat is dan maar zo: jij stelt hier een vraag. Mensen het onderwerp waarover ze een vraag stellen volledig begrijpen hoeven geen vragen te stellen, dus begrijp je iets niet. Dat is prima, maar maak jezelf wel een voorstelling in welke situatie jij zit: je bent op stage. Dat houdt dus in dat je per definitie niet alles weet en dus leert. Maar je hebt ook al een aantal jaren studie achter de rug. Dan met termen aankomen als lange/brede tabel en tabellen willen formuleren zonder theoretische basis... dan snap IK iets niet: wat heb je dan geleerd in de jaren voordat je op stage ging? (voordat je uit je vel springt: in erg veel gevallen kan de student hier geen reet aan doen, de opleiding is gewoon brak). Ik neem toch aan dat daar normale informatieanalyse aan bod is gekomen en normale vaktermen besproken zijn.
Oh, en als iemand het wel weet en jij niet betekent niet dat die persoon die het wel weet arrogant is. Iemand die arrogant is geeft nl. geen antwoord maar lacht je uit omdat je kennelijk iets niet snapt. Ik heb dacht ik wel degelijk antwoord gegeven. Het NARE is alleen dat dat niet het antwoord was wat je wilde horen, maar DAAR kan ik geen moer aan veranderen.
Trouwens, wat zegt jouw stagebegeleider hiervan? Of heeft die ook geen mening?
Ik zit dus met het probleem dat de attributen kunnen aangepast worden, dus er moeten attributen bijgemaakt of verwijdert kunnen worden. Daardoor is Optie 1 (veel kolommen) dus een iets minder goede oplossing voor mijn probleem naar mijn mening. Optie 1 kan ik alleen gebruiken voor de attributen die NOOIT veranderd kunnen worden.
Wat is de reden dat er attributen bijgemaakt moeten worden? Ik vraag dit omdat veel beginners nogal eens de fout maken dat ze data verwarren met table-layout.
Dat ik daardoor iets meer werk heb in het programmeren van de GUI neem ik er maar bij. Ook hier kan ik dan weer iets van leren. En bij deze kan ik dus ook besluiten dat Roblll al van in het begin de juiste oplossing voor mijn context heeft aangehaald.
[...]
Dit is een lookup tabel voor form elementen. Ik flans niet zomaar
[...]
Ah een lookup table. Dus je hebt voorgedefinieerde form elements en je hebt een tabel met instances van die elements? Waar heb je dan de nieuwe attributes nodig? De voorgedefinieerde form attributes zijn fixed, want ze representeren objects in code. De instances zijn gewoon rows in een table, dus ik zie het niet echt waar je speciale zaken nodig hebt, omdat dit gewoon een basic tabel opzet is.
/u/7685/ruinmytune-60x60.png?f=community)
:strip_exif()/u/13818/episodebutler_60x60.gif?f=community)
:strip_icc():strip_exif()/u/1857/crop5a4d06ced6afe_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/69009/eend.jpg?f=community)
:strip_icc():strip_exif()/u/5855/BDKAMZi.jpg?f=community)
:strip_icc():strip_exif()/u/222525/images.jpg?f=community)