:strip_exif()/u/4279/GoT_iZac.gif?f=community)
Ik ben al een tijdje met dit probleem zoet. Ik heb het eerst via Python geprobeerd en ben nu aan het kijken of ik het met Java kan oplossen.
Het uiteindelijke doel is om XML documenten met speciale karakters erin geparsed te krijgen. Probleem is dat de bestanden ANSI geencodeerd zijn.
Ik heb deze code al gevonden:
...maar die werkt niet omdat deze de speciale chars vervangt met blokjes.
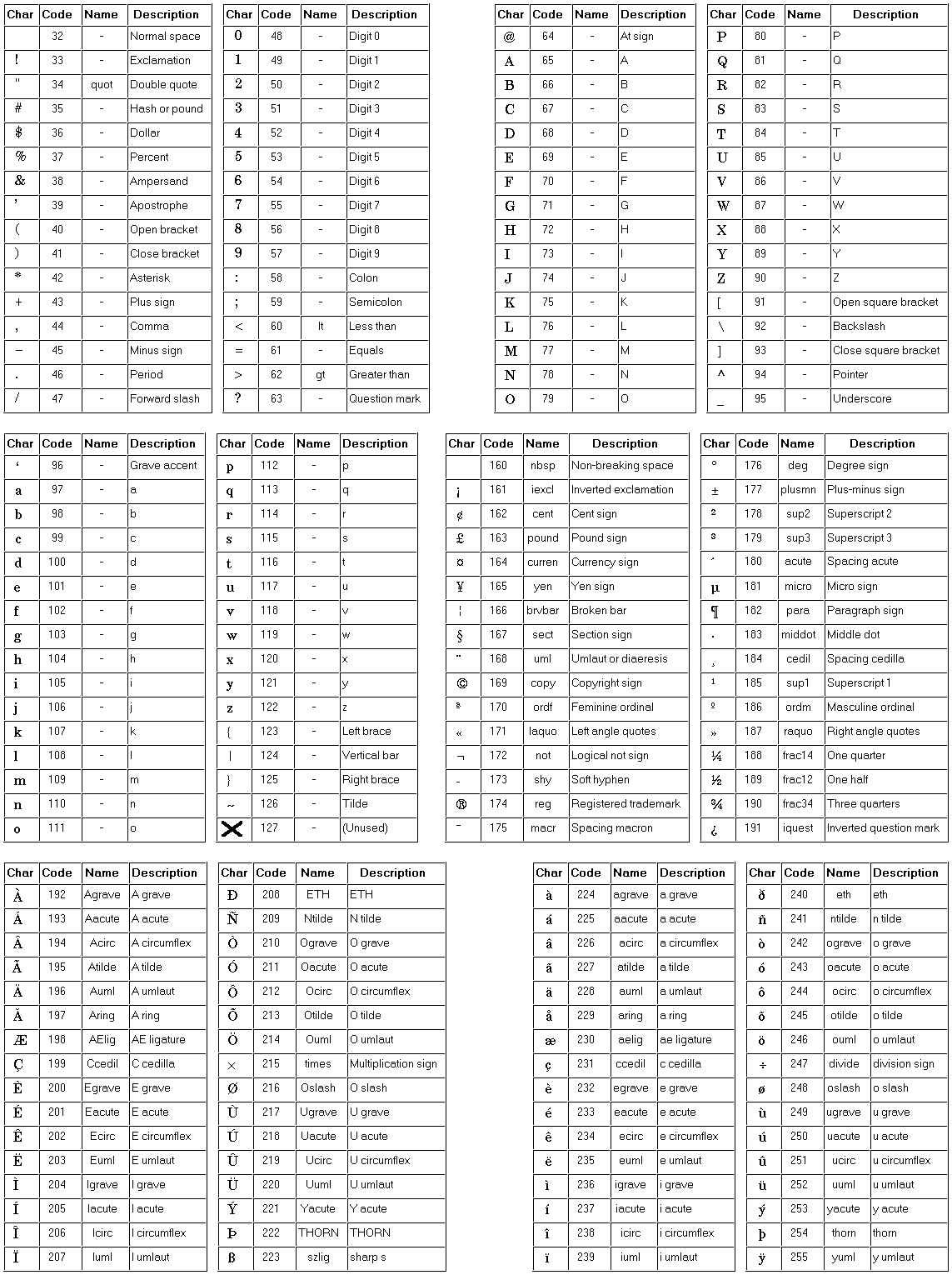
Wat ik nu aan het doen ben is om een ByteArray een voor een uit te lezen. Wat me hier opvalt is dat mijn speciale tekens een negatieve waarde hebben. Ik heb mijn bestand gemaakt door in kladblok de volgende unicode tekens toe te voegen:
€ - Alt+0128
- Alt+0129
‚ - Alt+0130
De negatieve byte waardes die ik nu krijg zijn -128, -127 en -126. Als ik deze nu van 256 aftrek krijg ik de precieze Unicode codes. Ik weet nu alleen niet hoe ik met deze codes nu weer tot de originele tekens kom. Verder heb ik ook het idee dat dit nu niet bepaald de beste oplossing is.
Iemand enig idee hoe ik dit kan aanpakken?
Het uiteindelijke doel is om XML documenten met speciale karakters erin geparsed te krijgen. Probleem is dat de bestanden ANSI geencodeerd zijn.
Ik heb deze code al gevonden:
code:
1
2
3
4
5
6
7
8
9
10
11
| public static byte[] convert(byte[] data, String srcEncoding, String targetEncoding) {
// First, decode the data using the source encoding.
// The String constructor does this (Javadoc).
String str = new String(data, srcEncoding);
// Next, encode the data using the target encoding.
// The String.getBytes() method does this.
byte[] result = str.getBytes(targetEncoding);
return result;
} |
...maar die werkt niet omdat deze de speciale chars vervangt met blokjes.
Wat ik nu aan het doen ben is om een ByteArray een voor een uit te lezen. Wat me hier opvalt is dat mijn speciale tekens een negatieve waarde hebben. Ik heb mijn bestand gemaakt door in kladblok de volgende unicode tekens toe te voegen:
€ - Alt+0128
- Alt+0129
‚ - Alt+0130
De negatieve byte waardes die ik nu krijg zijn -128, -127 en -126. Als ik deze nu van 256 aftrek krijg ik de precieze Unicode codes. Ik weet nu alleen niet hoe ik met deze codes nu weer tot de originele tekens kom. Verder heb ik ook het idee dat dit nu niet bepaald de beste oplossing is.
Iemand enig idee hoe ik dit kan aanpakken?
Verlanglijstje: Switch 2, PS5 Pro Most wanted: Switch 2
:strip_exif()/u/80759/monstermania_small.gif?f=community)
:strip_exif()/u/337/witcher_60x60.gif?f=community)
/u/27299/hoofd.png?f=community)
/u/17112/crop5862473fe8c51_cropped.png?f=community)
{kind=link}
{kind=link}